1. Introduction
Simulation analysis is playing an increasingly prominent role in resolving real-world problems that cannot be solved with numerical and analytical methods [
1]. For example, in the system-on-chip field, distributed cosimulation is a practical approach to unify and analyze abstracted hardware resources [
2]. In the social systems, simulations have been utilized to evaluate passenger flow organization and facility layout at metro stations [
3] or to find an optimal condition for the growth of crops in greenhouse control systems [
4]. Generally, such a simulation analysis requires one to perform simulation evaluations of all possible input combinations as a ‘‘what-if’’ analysis [
5]; thus, it consumes too much simulation execution time due to many repeated experiments. To reduce the execution time, various studies have been conducted: the distributed execution of simulators using hardware resources [
6], parallel event scheduling using the graphics processing units [
7], a flattening simulation algorithm for hierarchical models [
8], and simulation-based optimization integrating a meta-model and a meta-heuristic method [
9], etc.
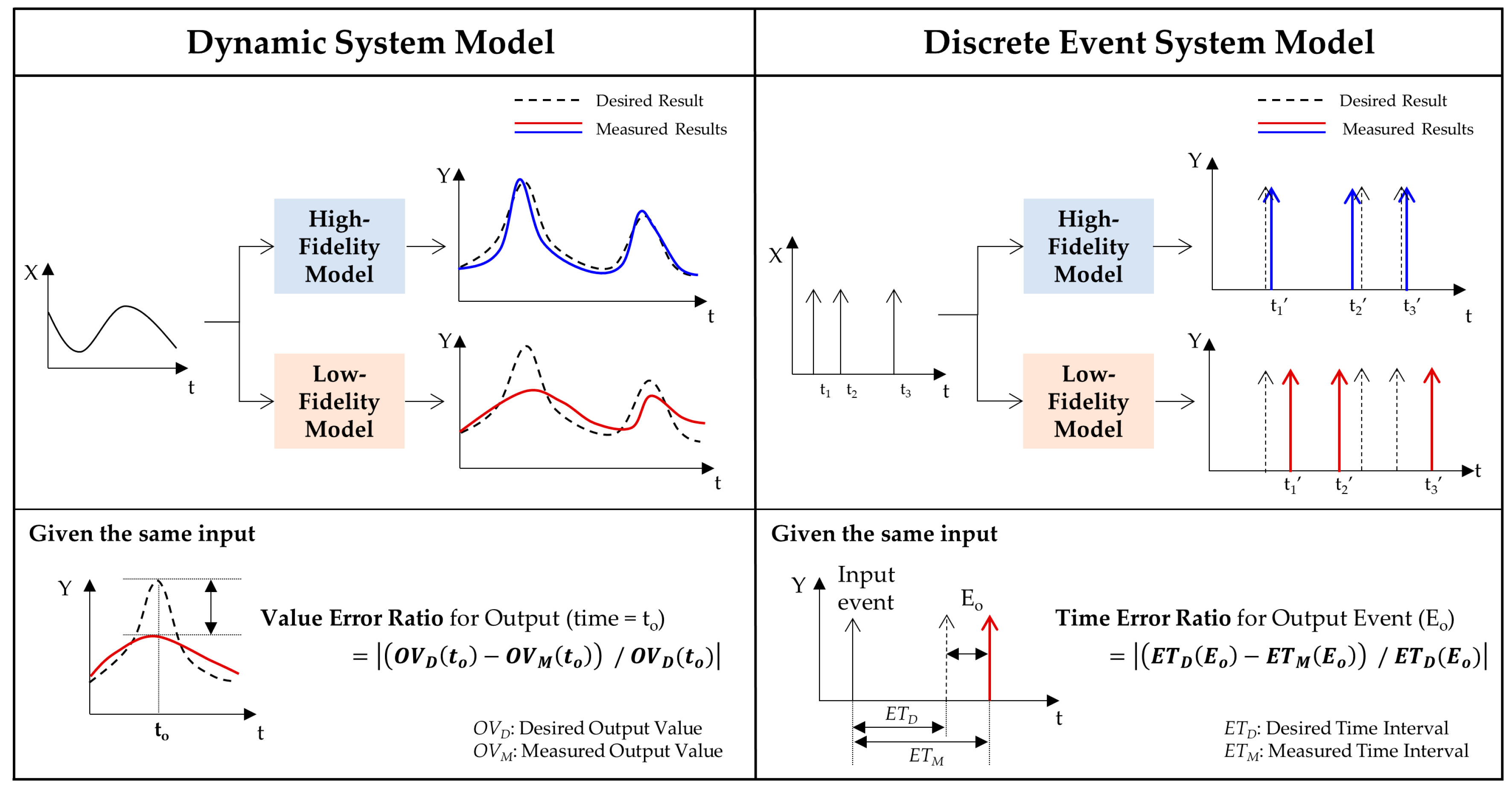
This paper focuses on a multi-fidelity modeling scheme to achieve simulation speedup for simulation analysis. In the simulation world, the most common use of the term “fidelity” refers to the faithfulness with which model behavior reflects modeled system behavior [
10,
11]. For the models that represent the same reference system, fidelity is compared by their outputs for the same input. In other words, a high-fidelity model has a high accuracy in model output compared to the reference system, whereas a low-fidelity model has a relatively less accurate output. Because the high-fidelity simulation is very time-consuming due to the high computational load, an appropriate portion of a simulation scenario requires simulating with high-fidelity models.
To decrease the simulation time without significant loss in respect to simulation accuracy, we propose a multi-fidelity modeling framework. The proposed framework consists of a dynamical conversion process between high- and lower-fidelity models. It employs a fidelity change approach to select a suitable model from a pool of models with variable fidelities. Within a single simulation scenario (i.e., a simulation design point), all the time frames need not be simulated with high-fidelity models [
12]. Therefore, the high-fidelity models are primarily used for important regions of the scenario, whereas the lower-fidelity models are used for marginal parts. In this context, the point of our framework is to decide which model needs to change its level of fidelity and to know when to change the fidelity within the simulation scenario.
To this end, we define three concepts in the framework: (1) an interest region where the model output has a serious effect on the overall simulation analysis, (2) a fidelity change condition (FCC) to check whether the fidelity of the model needs to be changed based on the defined interest region, and (3) a selection model to choose a model with the proper fidelity when the FCC is satisfied. The proposed framework, based on these concepts, allows the achievement of a condition-based transformation between high- and low-fidelity simulations within a scenario, reducing the overall computational cost and ensuring the accuracy of the simulation analysis.
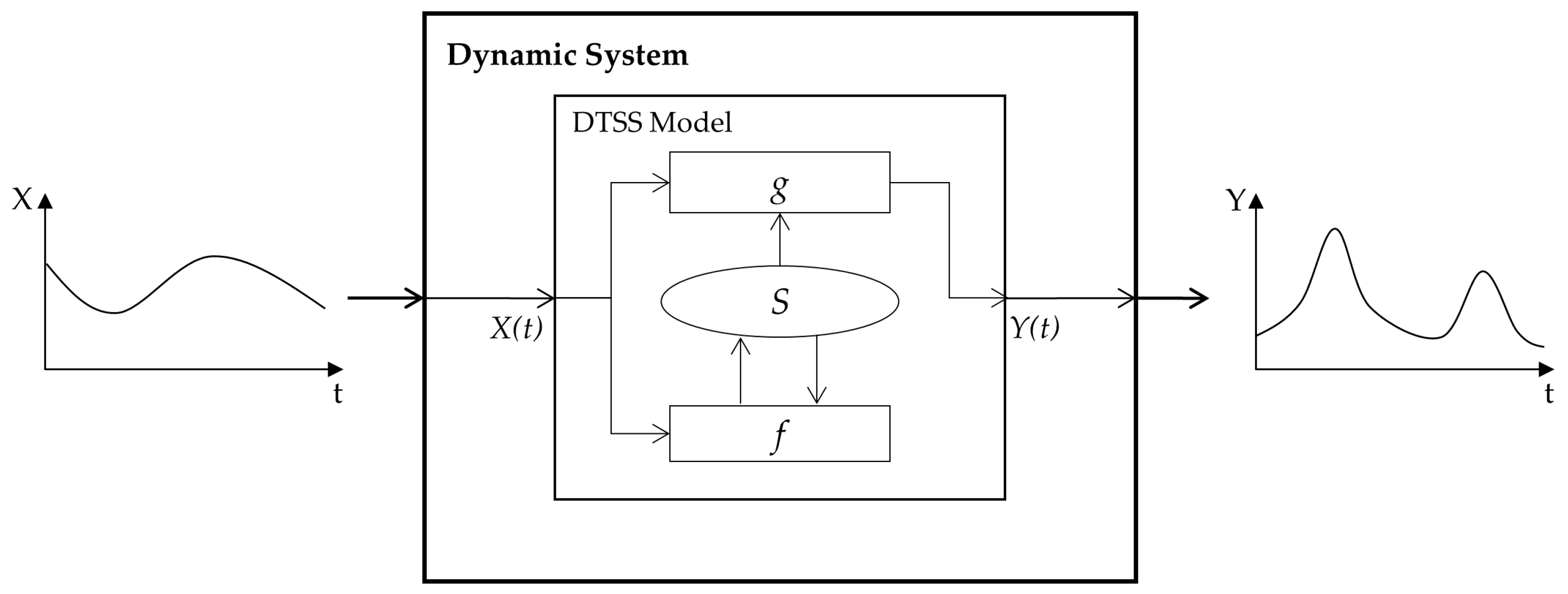
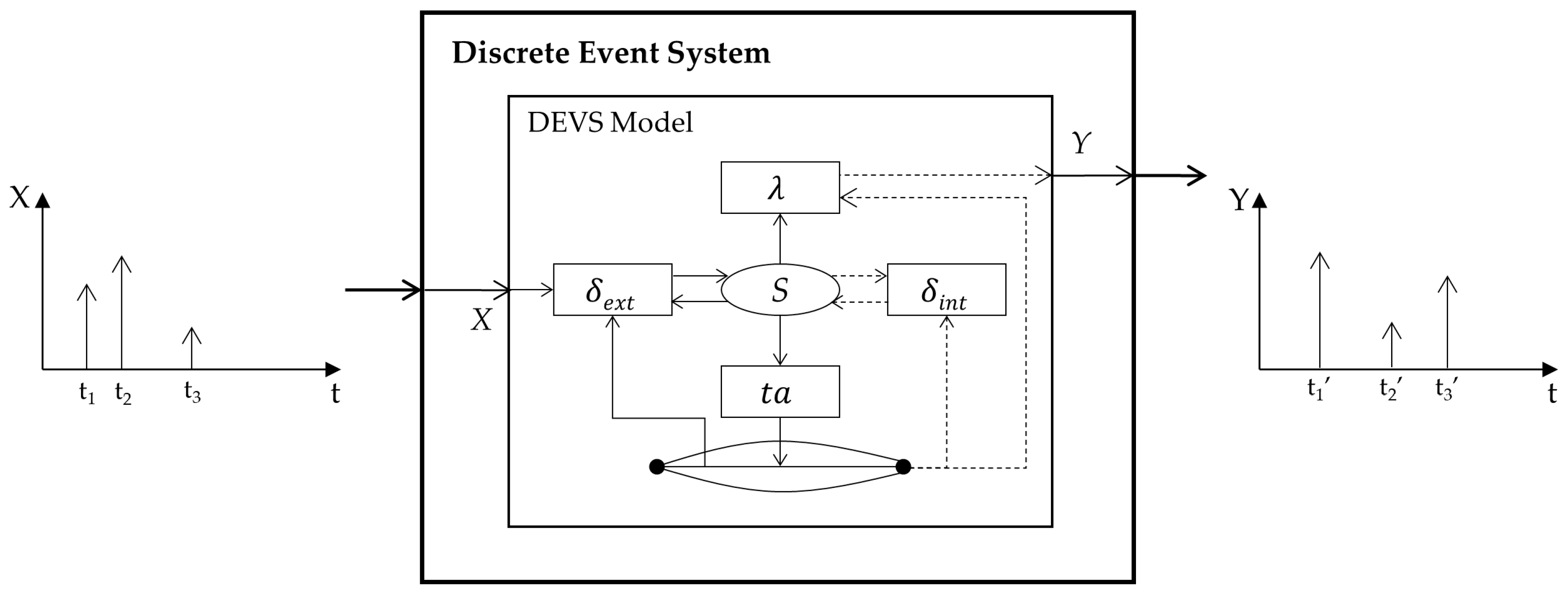
The targeted system of this paper is a discrete event dynamic system. It exhibits hybrid behaviors characterized by a set of continuous laws that are switched by discrete events [
13]. The dynamic property facilitates the development of apparent high- and low-fidelity models for a target system, and the discrete event property allows one to know when the level of fidelity is changed with discrete events. In our framework, these concepts are proposed with formal modeling specifications. In particular, this paper uses the discrete time system specification (DTSS) for the dynamic system model and the discrete event system specification (DEVS) for the discrete event system [
14]. Such a formal modeling approach facilitates maximizing the reusability of existing models and simulation algorithms.
In recent years, multi-fidelity modeling and simulation (M&S) have been studied in many application fields such as aerospace engineering [
15], submarine systems [
16], computational fluid dynamics [
17], and supply chain systems [
18], etc. A common point of these studies is to drive the preliminary design process using low-fidelity models as surrogates for expensive high-fidelity simulations. High-fidelity models are then used in the final design stages to refine the design. This means that the fidelity change has not occurred during the same simulation scenario. In addition, these studies focused on application-oriented methods, which have key differences from our study.
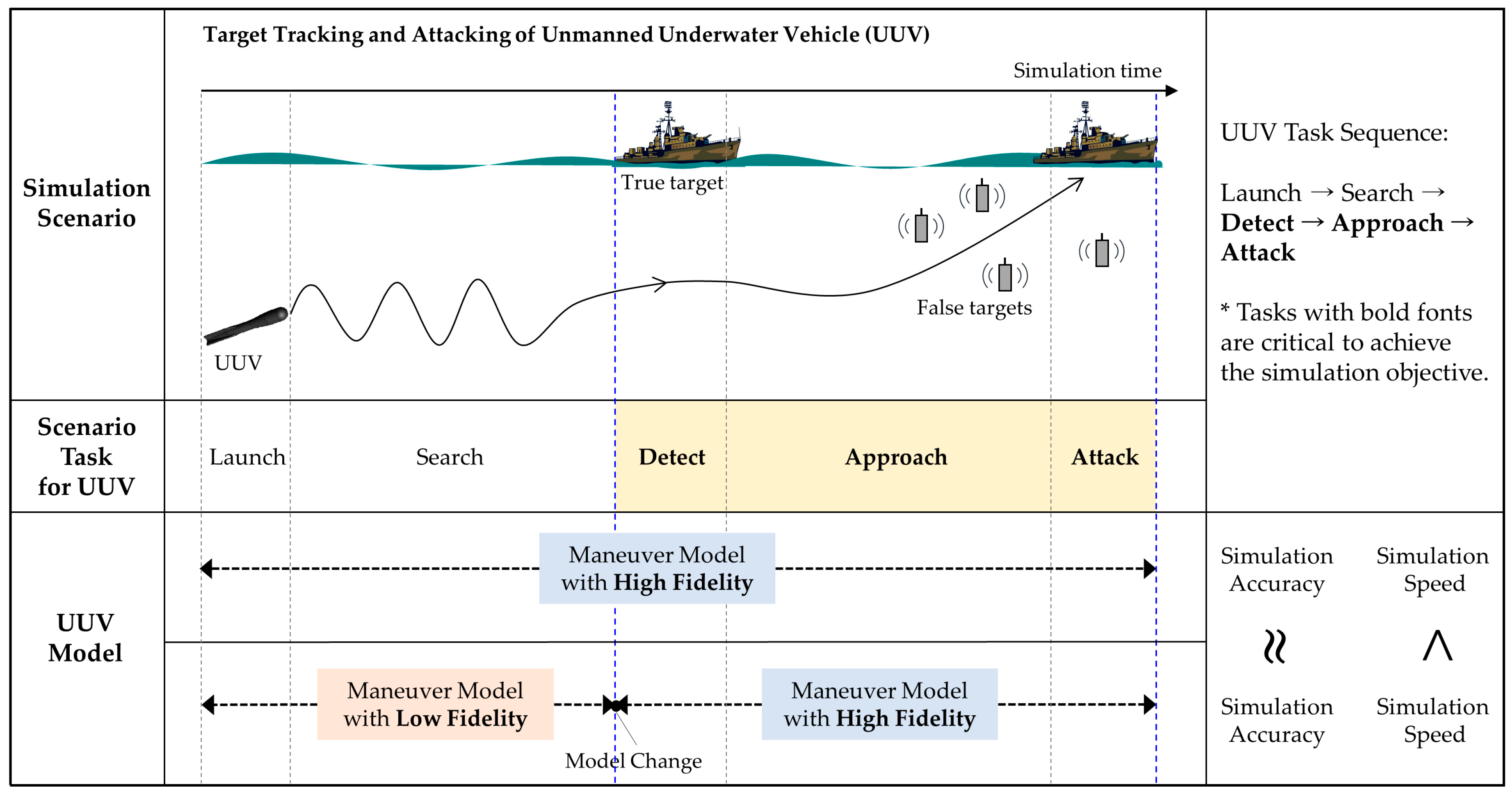
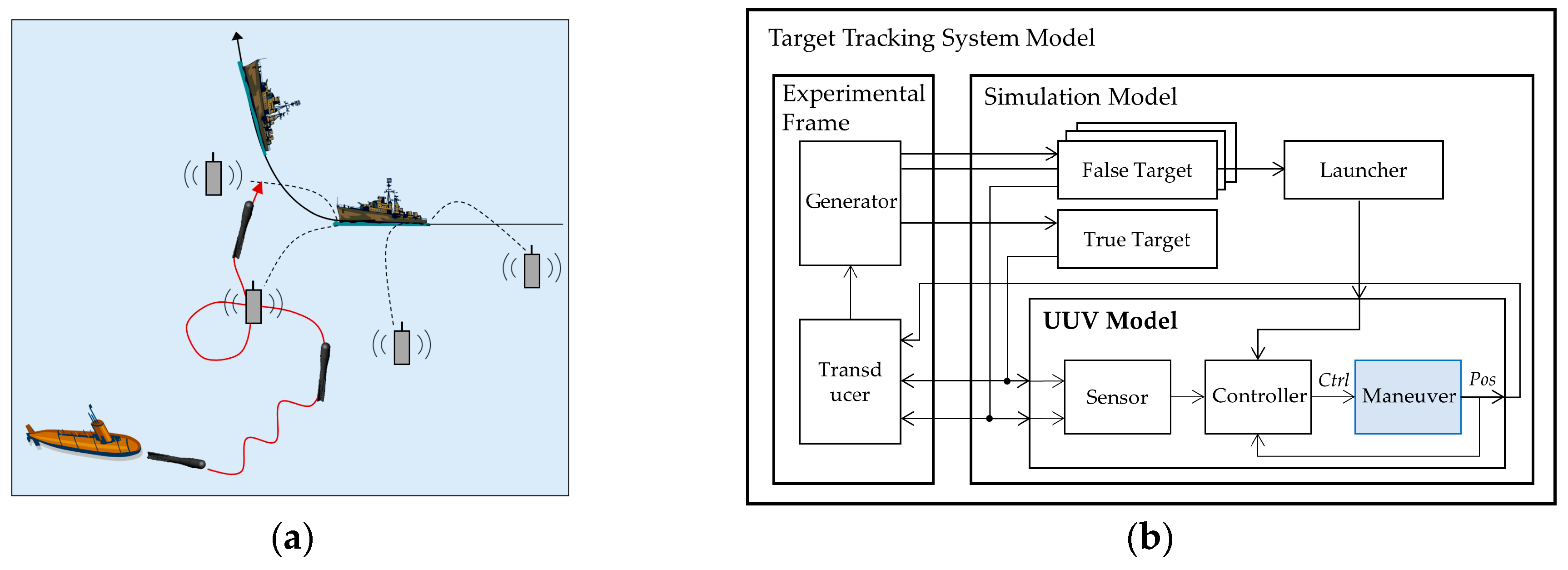
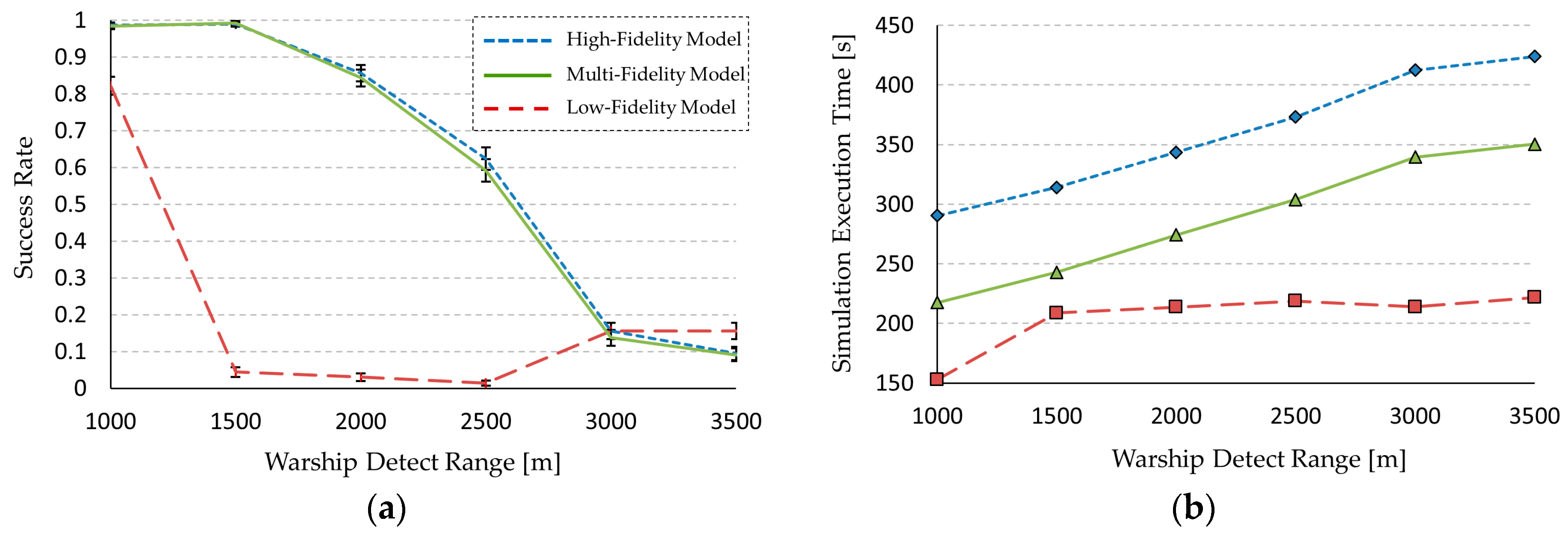
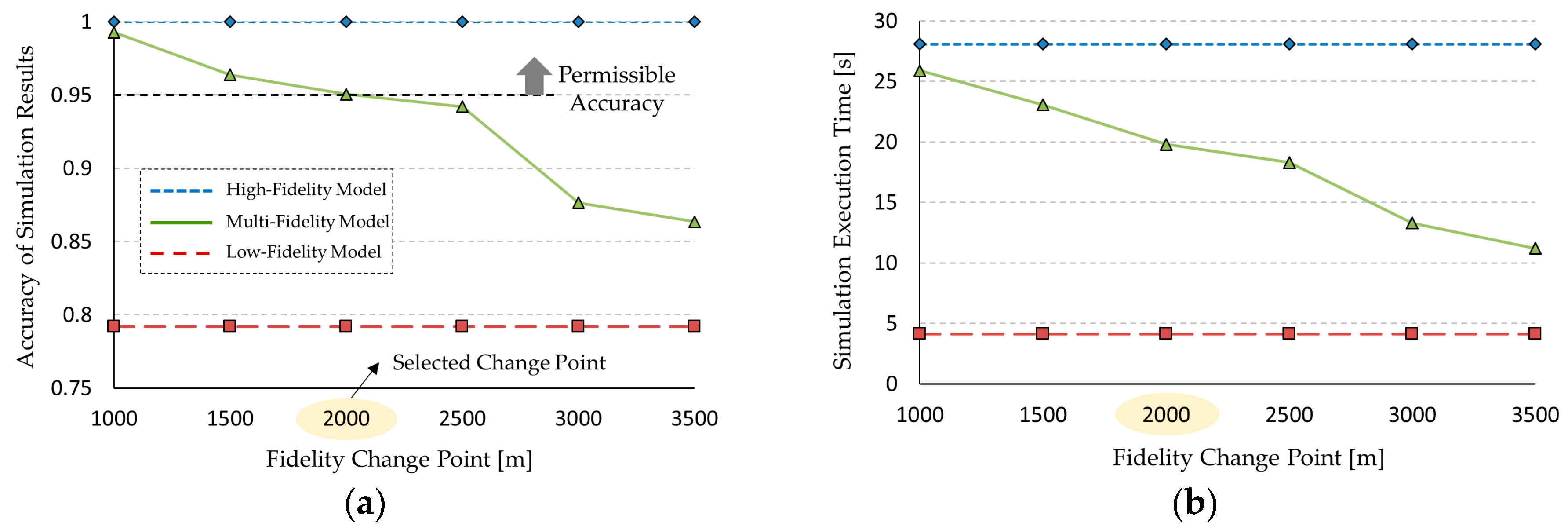
For experimentation, we performed two practical applications that show the effectiveness of the proposed framework in simulation speedup and accuracy. An unmanned underwater vehicle (UUV) was modeled for the dynamic system, and urban transportation vehicles (UTVs) were modeled for the discrete event system. For empirical evaluations, we define two measurements (i.e., an output error and a speedup ratio). The proposed modeling framework enhances the simulation speed about 1.25 times and 1.21 times for each application with an accuracy loss of about 5%. Additionally, due to the use of formal representation, most existing models and simulation engines were reused without any modifications.
This paper is organized as follows.
Section 2 explains the target system, model fidelity, and simulation region, and
Section 3 introduces the literature review.
Section 4 describes the proposed multi-fidelity modeling framework. The two case studies are described in
Section 5, and a conclusion is given in
Section 6.
3. Literature Review
Over the last decade, several studies have sought to use multi-fidelity M&S to speed up simulations. The fundamental concept for these studies is multi-fidelity optimization, where lower-fidelity simulations are used to approximate the behavior of the high-fidelity simulation.
For example, Viana et al. [
30] used multi-fidelity approximations combined with heuristic methods for the optimal design of aircraft pressure bulkheads. They coupled nonlinear high-fidelity analysis and linear low-fidelity analysis with four methods (i.e., ant colony optimization, genetic algorithm, particle swarm optimization, and life cycle model). Zheng et al. [
31] introduced several applications, such as an airfoil wing simulation, car crash simulation, and an artificial neural network, etc., which were achieved with multi-fidelity modeling and an approximation management framework.
Sun et al. [
32] proposed a two-stage multi-fidelity procedure for solving crashworthiness design for cellular structures and materials. In the first stage of their proposed work, a correction response surface was constructed based on the ratio between high-fidelity and low-fidelity analyses at a few sample points. In the second stage, low-fidelity analysis is replaced with a radial bias function approximation. Xu et al. [
33] presented an ordinal transformation approach to transform the original solution space into a one-dimensional space based on the rankings of solutions using the low-fidelity model. After that, they used an optimal sampling approach to search solutions in the transformed one-dimensional space for optimal solutions using high-fidelity simulations.
One of the common points of the above-mentioned studies is to drive the preliminary design process using low-fidelity models as surrogates for expensive high-fidelity simulations. Then, high-fidelity models are employed in the final design stages to refine the design. In this case, the multi-fidelity technique is to utilize initial design points determined from a low-fidelity simulation to correct the simulation at other design points. This means that the fidelity did not change dynamically during the same simulation scenario. In addition, because these studies have focused on application-based approaches to resolve practical issues, there has been no formal representation of the multi-fidelity model and no model reusability of existing simulation models.
Williams and Alleyne [
34] presented a modeling framework for dynamically changing the fidelity of component models throughout a single scenario–the approach most similar to our own. For a dynamic change of fidelity, they proposed the following design concepts: (1) a supervisor filter to analyze and determine which inputs trigger a switch to low- and high-fidelity models and (2) a dwell time that provides a buffer during fidelity switching. The proposed framework was demonstrated for a finite-volume model of a vapor compression system where the model fidelity is based on the number of volumes used for the evaporator. Although the authors regarded dynamic changes of the fidelity, this study also suffers from an insufficient representation of behaviors of the event-based system. For example, the authors did not consider internal discrete events of the model but focused on exogenous signals; thus, the modeling form used in Williams and Alleyne’s study also makes it difficult to directly apply it to the discrete event dynamic system.
In common with most M&S methods, multi-fidelity M&S inevitably involves behavioral errors of the developed models due to their approximations. Cassettari et al. [
35] classified them into two types. The first error is directly connected to the translation of the real system into a simulation model; the second one is related to the transformation of the simulation models. In multi-fidelity M&S, the high-fidelity model facilitates reducing the first error, whereas the lower-fidelity models make the second error in place of enhancing simulation speedup. To minimize the second error, in this paper, we only use lower-fidelity models for the marginal parts of a single scenario. As we explained in the introduction, the single simulation scenario does not need to be simulated with high-fidelity models. For example, if a simulation analysis for one-day traffic is carried out, it is highly effective to focus on analyzing traffic during rush hour. Therefore, the high-fidelity models are primarily used for important regions of the scenario, whereas the lower-fidelity models are used for marginal parts. With this concept, this paper proposes a general framework for multi-fidelity modeling for enhancing simulation speed while minimizing accuracy loss and maximizing model reusability. We will show these points with empirical simulation results in
Section 5.
4. Proposed Framework
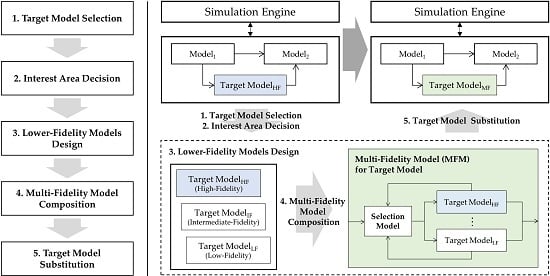
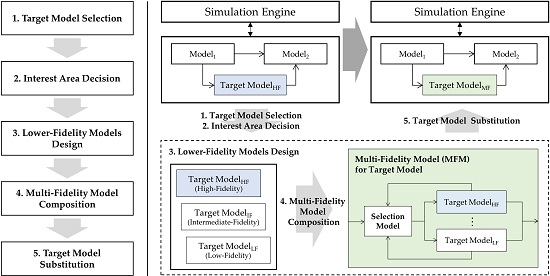
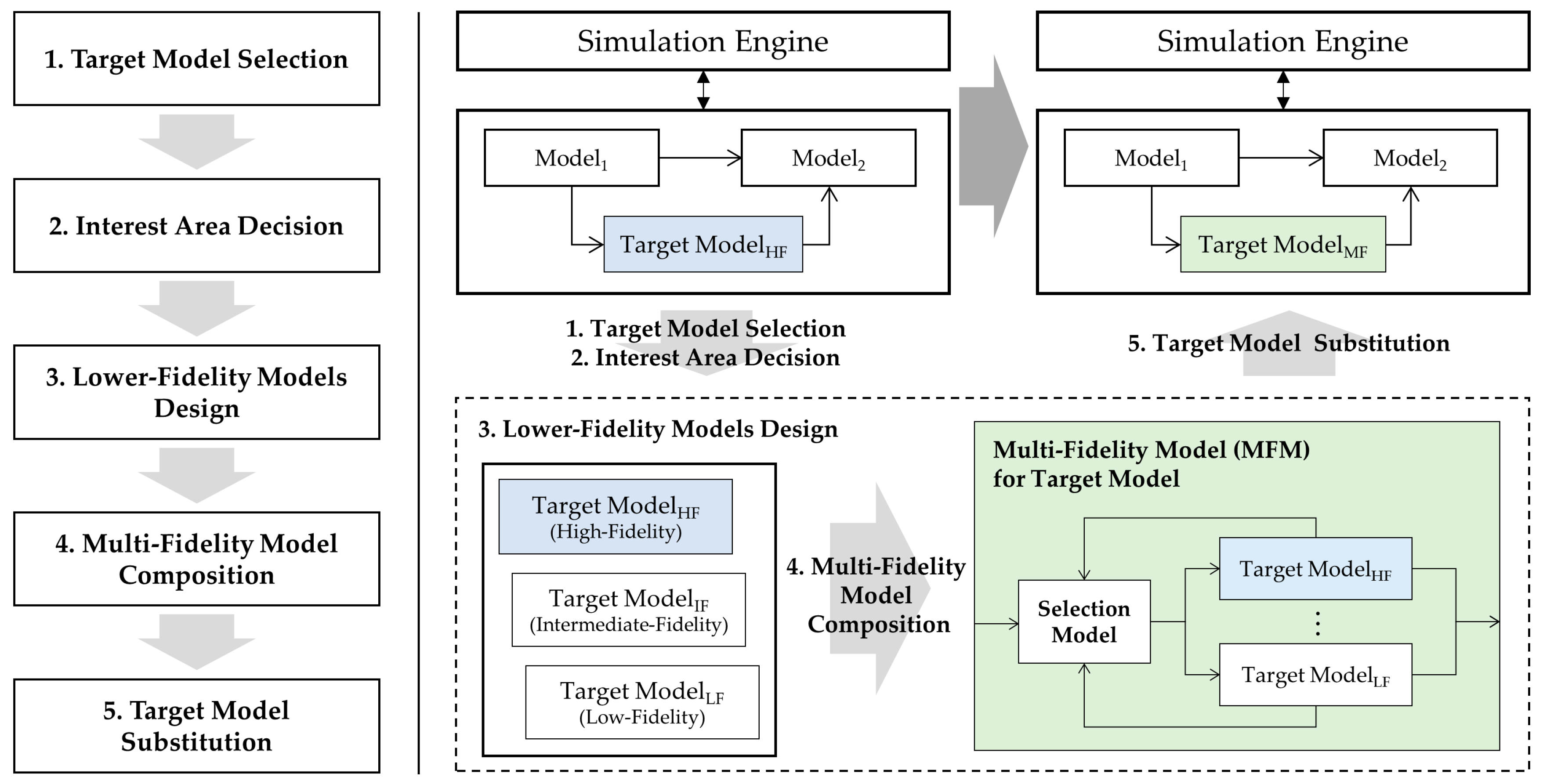
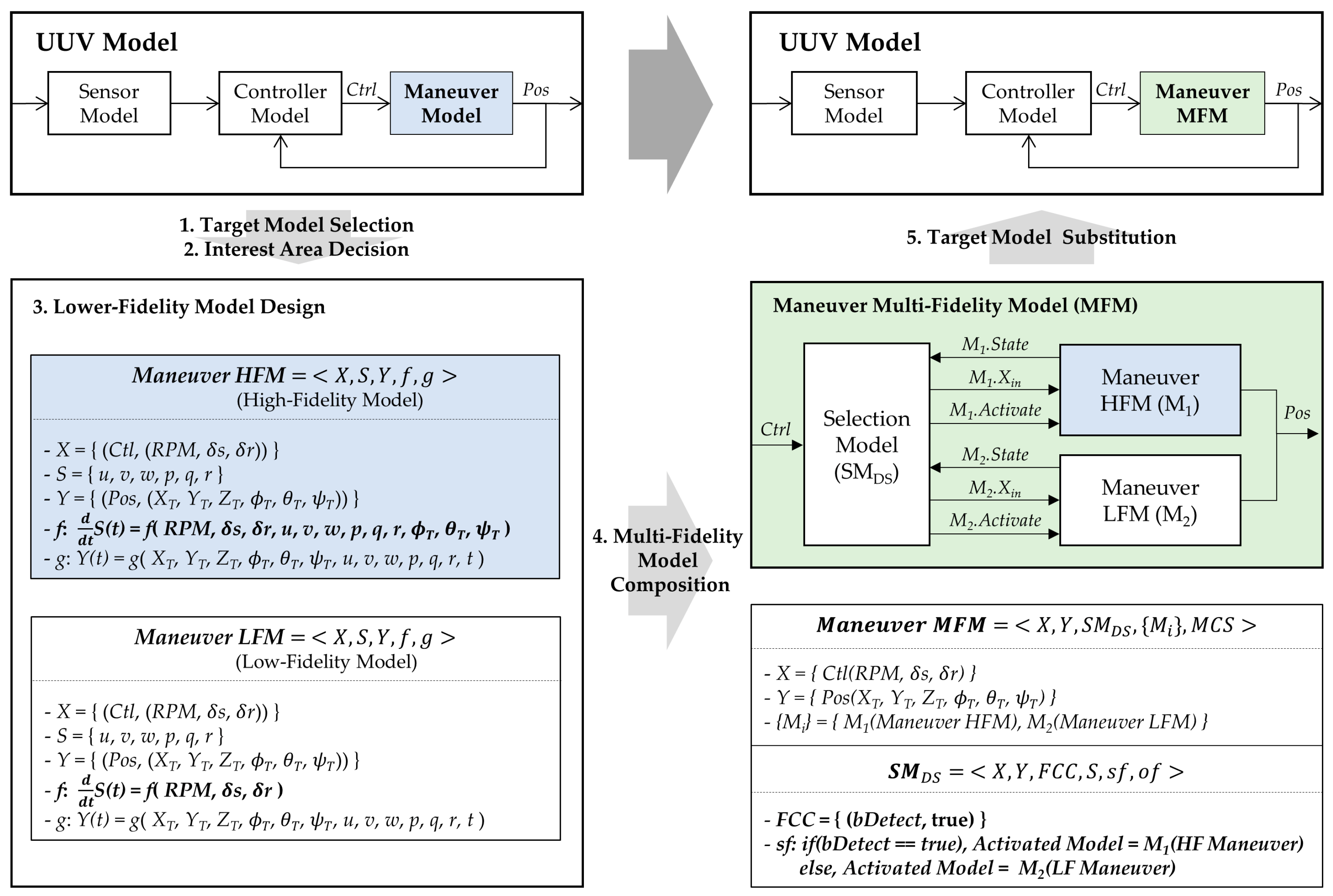
This section proposes the overall procedure for the multi-fidelity modeling framework. As depicted in the left diagram of
Figure 5, the framework consists of the following five steps: (1) target model selection, (2) interest region definition, (3) lower-fidelity model design, (4) multi-fidelity model composition, and (5) selected target model substitution. In this framework, we assume that the target model already has a high fidelity (Target Model
HF in
Figure 5 are relevant here). Based on the high-fidelity model, lower-fidelity models for the target model (e.g., Target Model
IF and Target Model
LF) are additionally developed for simulations in non-interest regions. A multi-fidelity model (e.g., Target Model
MF) contains a selection model to choose a proper model from among the models with variable fidelities. With regard to a systemic aspect, the input and output variables of the existing target model are equal to those of the multi-fidelity model that is substituted for the model (see Target Model
HF and Target Model
MF in
Figure 5). This guarantees the reuse of other existing models and the simulation engine minimizing modifications.
In the following subsections, we will explain the steps in detail and describe the evaluation index for simulation speedup.
4.1. Target Model Selection and Interest Region Definition
The first step of the proposed framework is to choose a target sub-model from the entire simulation model. The selected model should satisfy the following two prerequisites: (1) it is modeled by the DTSS or DEVS formalism and (2) it fundamentally has high fidelity with computational complexity and is executed frequently during the simulation.
Next, we define an interest region of the target model. As we explained in
Section 2.3, the interest region is a part of the whole simulation scenario where the model output has a serious effect on the overall simulation analysis. The definition of the interest region simplifies how the framework achieves multi-fidelity modeling: the high-fidelity model is exclusively simulated within the interest region of the whole scenario. If the overall scenario is designated as a large interest region, the high-fidelity model is fully simulated without using lower-fidelity models, which means that changes of the model’s fidelity do not occur within the scenario.
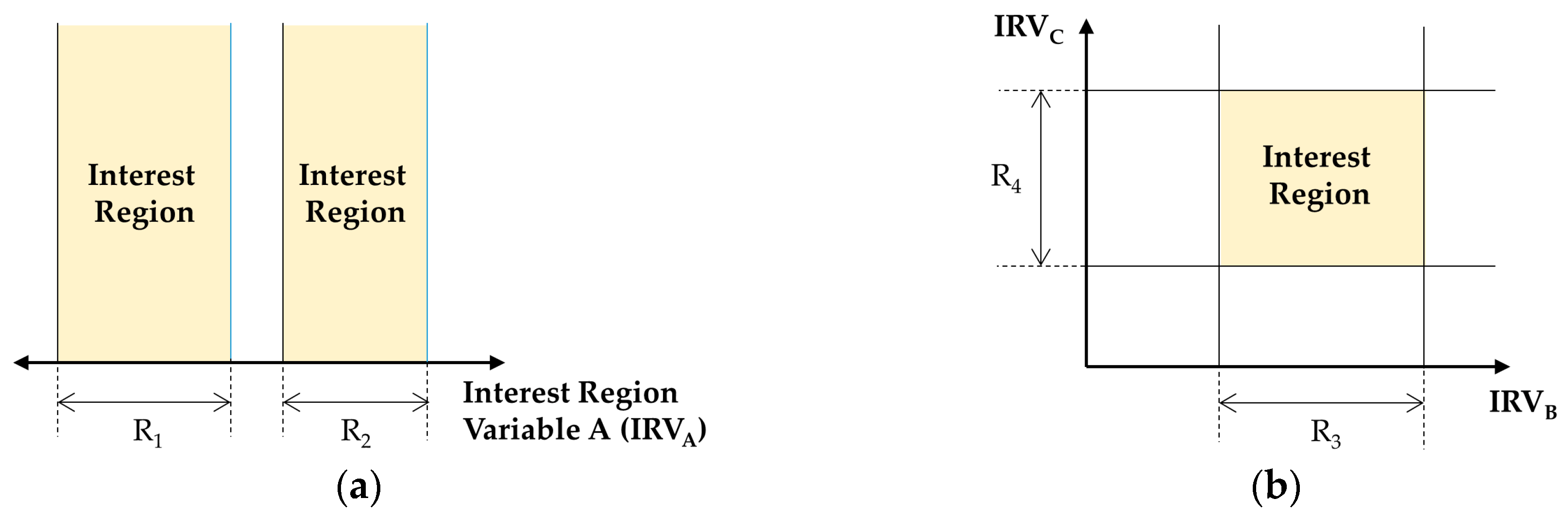
Figure 6 shows two examples for setting up the interest region. Because our target system is a discrete event dynamic system, which is represented with either the DEVS or DTSS model, the simulation is a process of updating input, state, and output variables as time progresses. In this context, the interest region is an acceptable range of the input and state variables of the target model.
Figure 6a shows that two regions are set up with two ranges (i.e., R
1 and R
2) for one interest region variable (IRV
A);
Figure 6b represents just one region to intersect two ranges for two variables (i.e., R
3 for IRV
B and R
4 for IRV
C).
4.2. Lower-Fidelity Model Design
The third step is to develop lower-fidelity models for the selected target model. We will explain this step by distinguishing between dynamic and discrete event system models.
4.2.1. Lower-Fidelity Models Design for the Dynamic System
As mentioned in
Section 2, the fidelity of the DTSS model is determined by the state transition function. Therefore, lower-fidelity models are designed to simplify this function of the current target model that already has a high fidelity. For simplification of the function, this paper suggests two methods: elimination and projection. The elimination method deletes the terms that have little effect on the accuracy of output in the state transition function and the projection method fixes the values of variables in the state transition function.
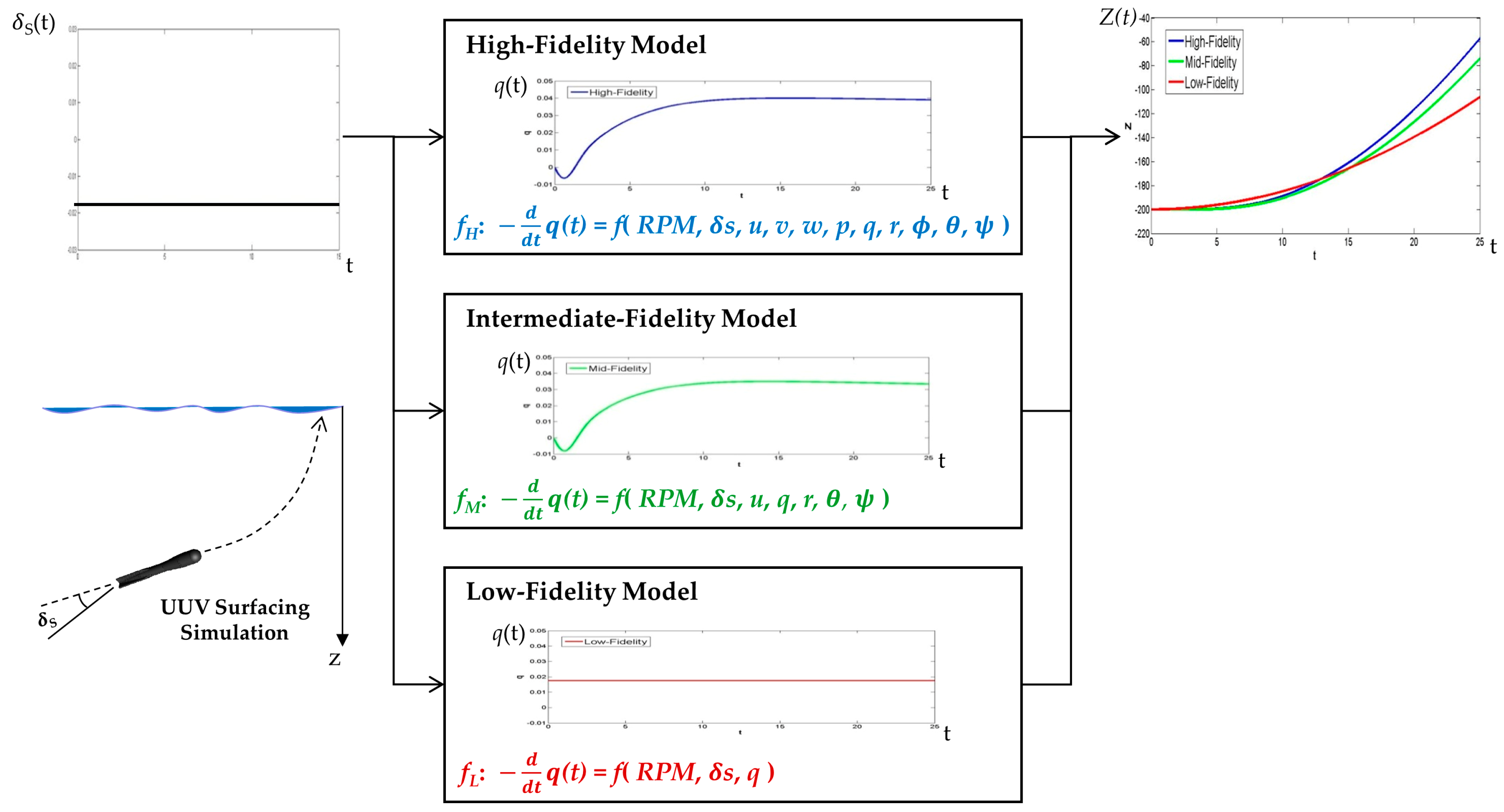
Figure 7 shows an example of lower-fidelity model design for a UUV surfacing simulation. The target model is the maneuver model for UUV motion in six degrees of freedom. We assume that the input of the UUV maneuver model is an elevator
S(
t), the output is a depth
Z(
t), and one of the state variables is a pitch
q(
t). The state transition function of the model is a differential equation, which consists of many terms. Further explanations for the maneuver equation are found in [
36]. Depending on the level of eliminating terms, an intermediate-fidelity model and a low-fidelity model can be developed by using the elimination method, which is used to derive
fM and
fL from
fH and
fM, respectively. The more terms that are eliminated, the more the accuracy of the state and out variables decreases.
Table 1 shows empirical results regarding the simulation execution time and simulation accuracy for the above example. We first measured the elapsed time for a single simulation. The simulation of the high-fidelity model took about twice as much execution time as the low-fidelity model. For example, if the number of iterations of this simulation is more than 500,000, the high-fidelity model’s simulation takes twenty-three more days than that of the low-fidelity model. We next calculated ϵ derived from Equation (1). In this experiment, the desired result is obtained from the high-fidelity model (this means that the reference model is the high-fidelity model
fH). For simulation accuracy, the high-fidelity and the intermediate-fidelity models had similar ϵ values; however, the low-fidelity model had an
value with a significant difference.
4.2.2. Lower-Fidelity Models Design for the Discrete Event System
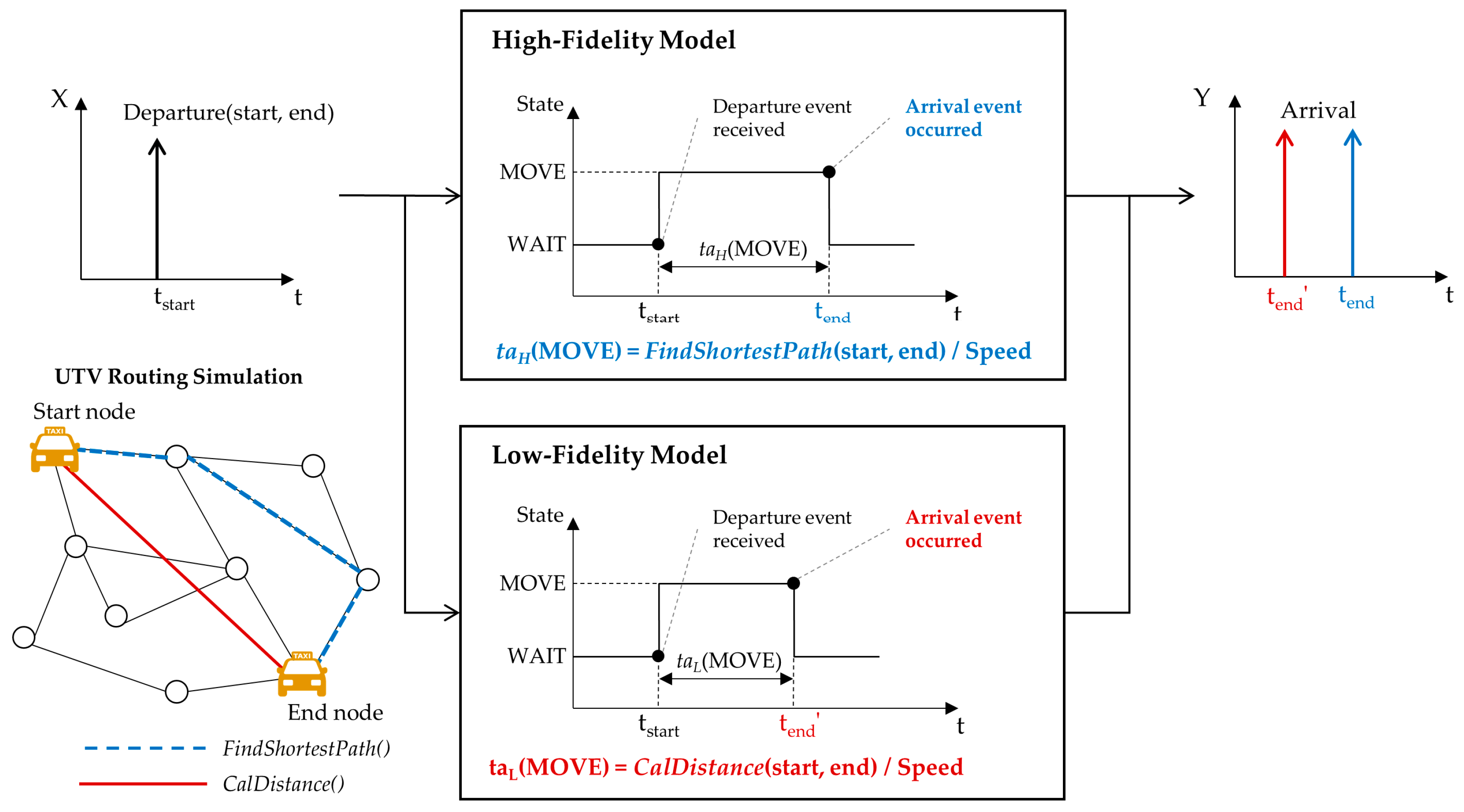
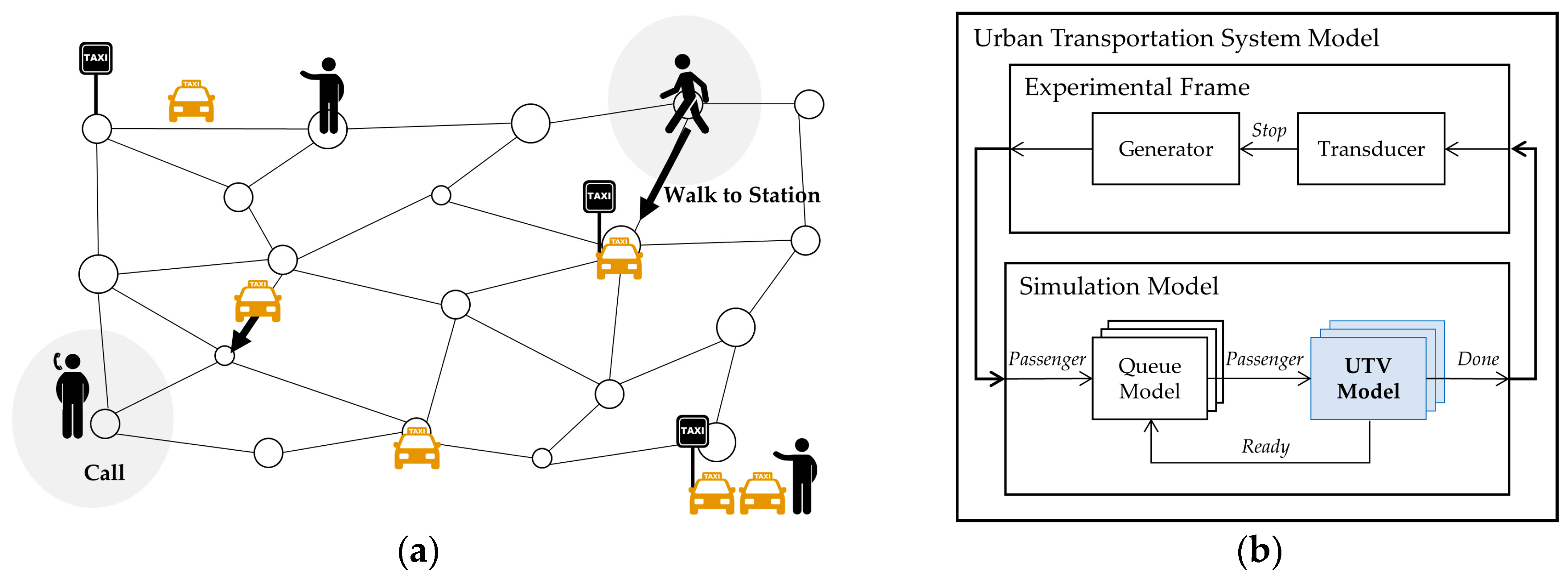
In the discrete event system, lower-fidelity models are designed to simplify the time advance function of the DEVS model. We explained high- and low-fidelity models for the UTV, which is shown in
Figure 8. The UTV brings passengers to their destinations via the fastest route; thus, its DEVS model computes the duration time from pickup to drop-off, which is carried out by the time advance function. In
Figure 8, when the UTV model receives an input event,
Departure, the model changes the state to
MOVE from
WAIT. Then, the model computes the time of the state,
MOVE, to generate the output event. The high-fidelity model calculates it by using the Dijkstra algorithm [
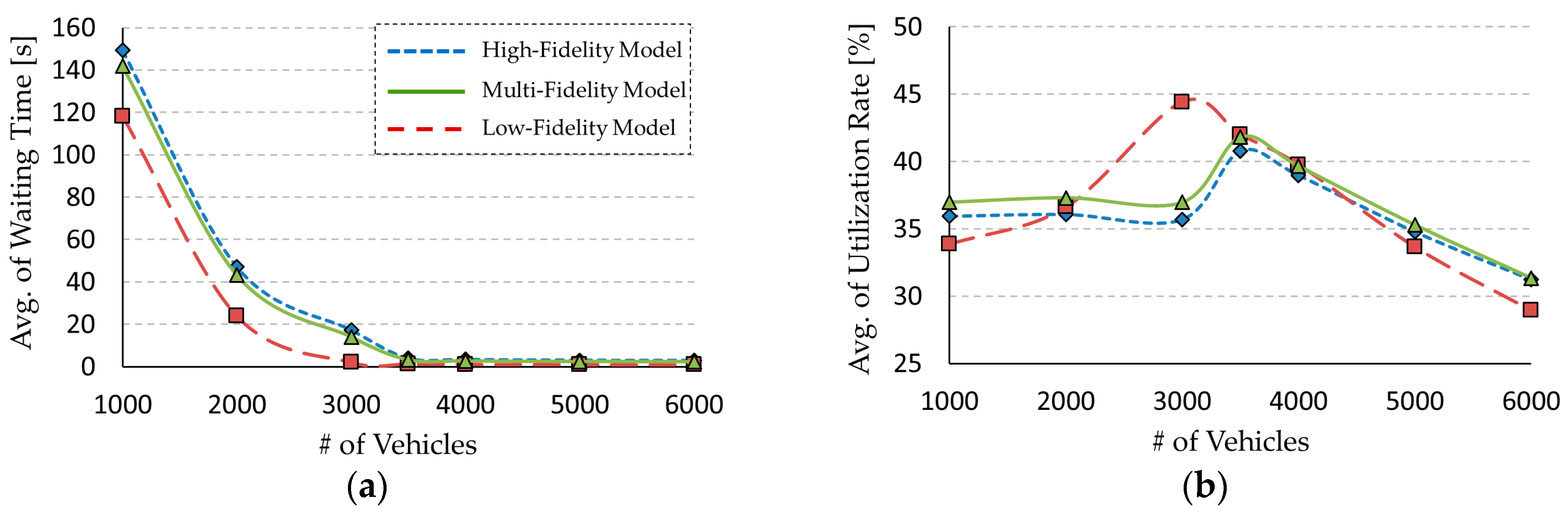
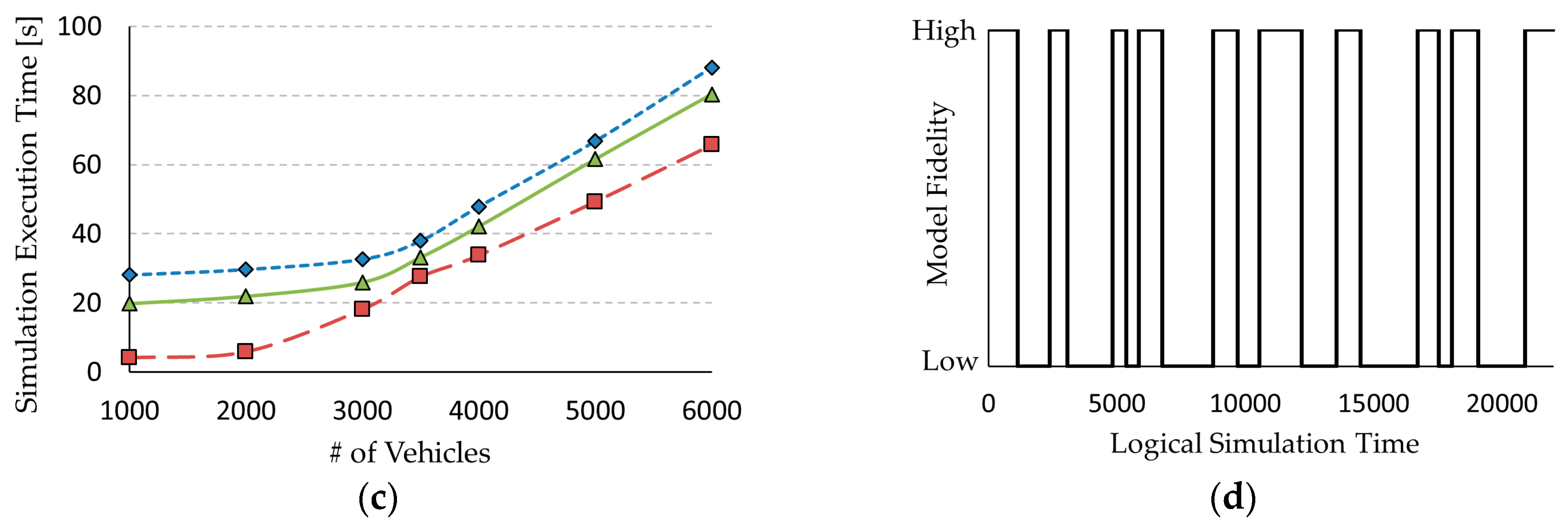
37], which finds the shortest path from a start node to an end node in a map with several nodes and their connections. However, the Dijkstra algorithm has computational complexity and the increase in computational cost is exponentially related to the number of nodes. The low-fidelity model uses a simple algorithm that just calculates the travel time of the straight-line distance between the start and end nodes. The accuracy of this simple algorithm is lower than that of the Dijkstra algorithm, though its calculation speed is much faster than that of the Dijkstra algorith.
We measured the execution time and
for 2000 input events, as shown in
Table 2. The simulation of the low-fidelity model was approximately seven times faster than the case of the high-fidelity model; however,
for the low-fidelity model was 0.21 higher than that of the high-fidelity model.
, which was measured in these two simple examples, is a theoretical measurement focusing on the target model itself, not the overall simulation model. Because the target model is a sub-model of the whole model, we will evaluate the simulation accuracy from the view of the overall simulation objective in
Section 5.
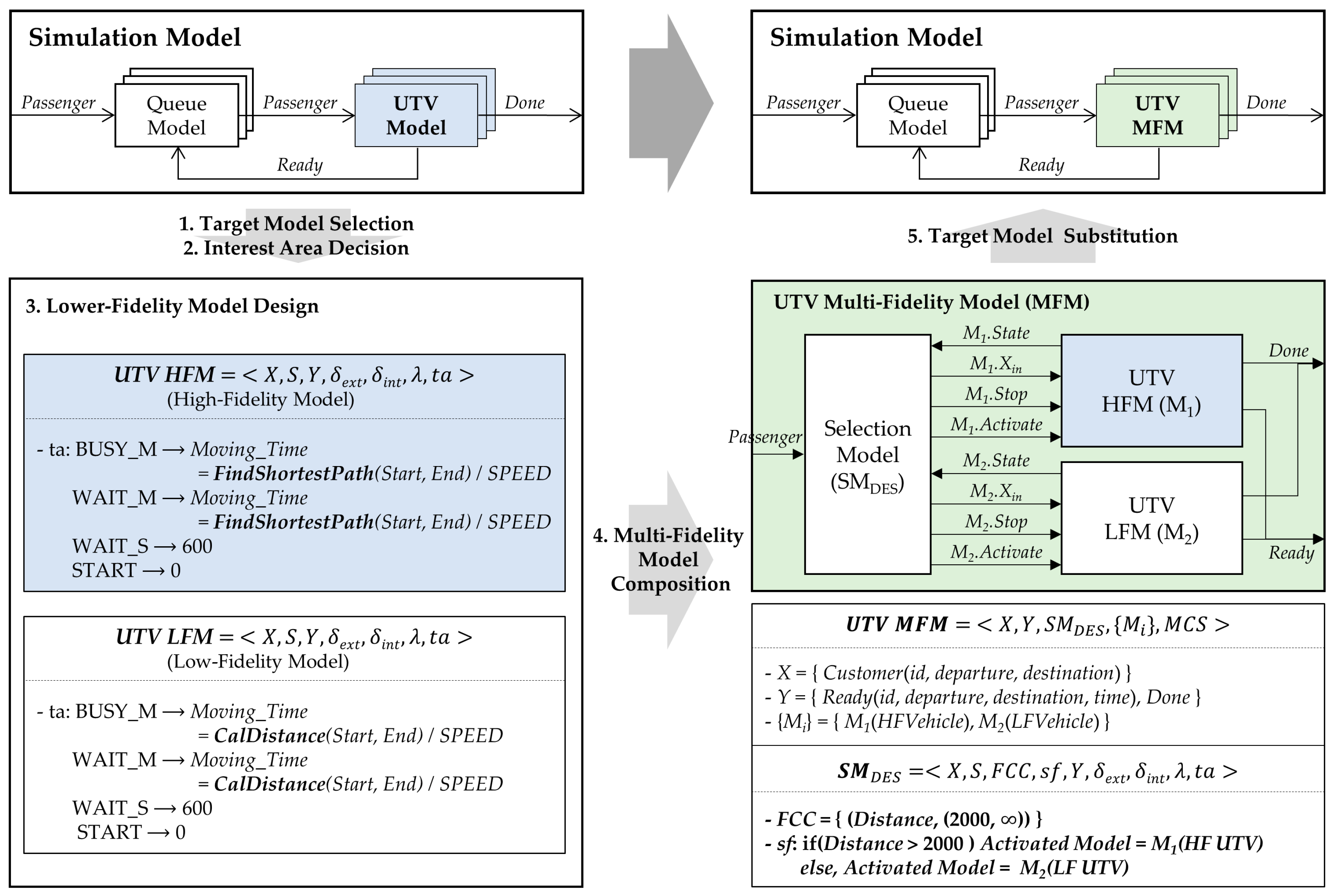
4.3. Multi-Fidelity Model Composition and Target Model Substitution
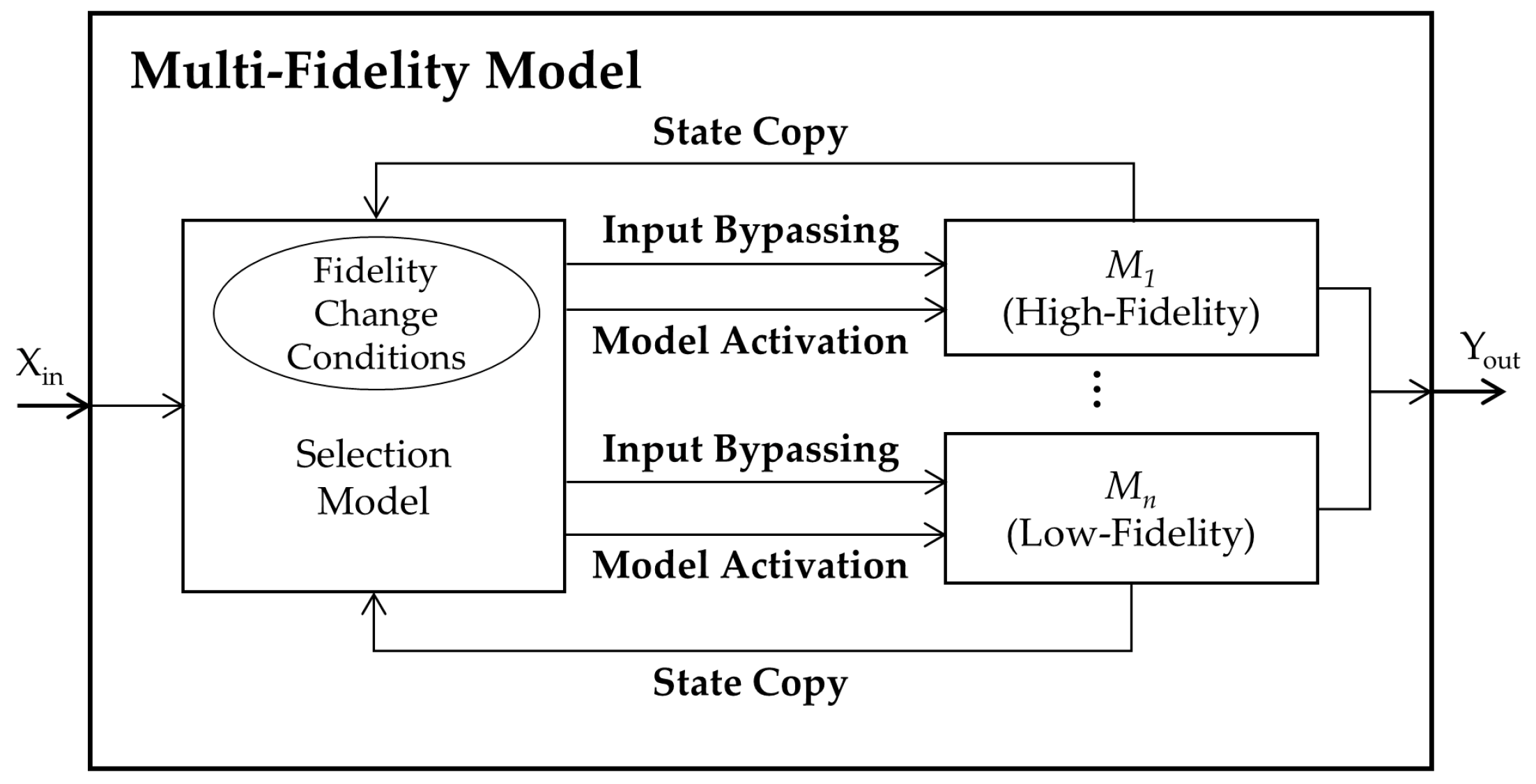
After the development of lower-fidelity models for the target model, we needed to composite a multi-fidelity model (MFM). For composition, the formal structure of the MFM is illustrated in
Figure 9. The MFM consists of two types of models: internal target models and a selection model. The original target model and its derived models with lower-fidelity correspond to the internal target models. A selection model determines an appropriate internal model for each predefined region, which implies that, among the several internal models, only one model is activated for each simulation time.
To be specific, the selection model has two important roles. When the selection model receives an input (
Xin in
Figure 9) from outside of the MFM, it decides whether the current internal model needs to be changed based on the FCC. First, if the model requires no change, the selection model sends the input to the model. The internal model carries out its own actions and generates two outputs: an actual model result for the input (
Yout) and its current state. The current state is transferred to the selection model. These are the cases of the input bypassing and the state copy, as shown in
Figure 9. Otherwise, if a model change is required, the selection model activates the other model by sending the input
Xin with the copied state for continued simulation. This is relevant to the model activation in
Figure 9. In this way, the selection model will manage the trade-off between the computational resources and the accuracy of the simulation results. Specifically, it will decrease the computational burden in noncritical regions while increasing the simulation accuracy in critical regions. The specification for the MFM is described as follows.
is the set of inputs;
is the set of outputs;
is the set of models with variable fidelities;
is the selection model;
is the model coupling scheme;
is the external input coupling;
is the external output coupling;
is the internal coupling.
4.3.1. Multi-Fidelity Model Composition for Dynamic System
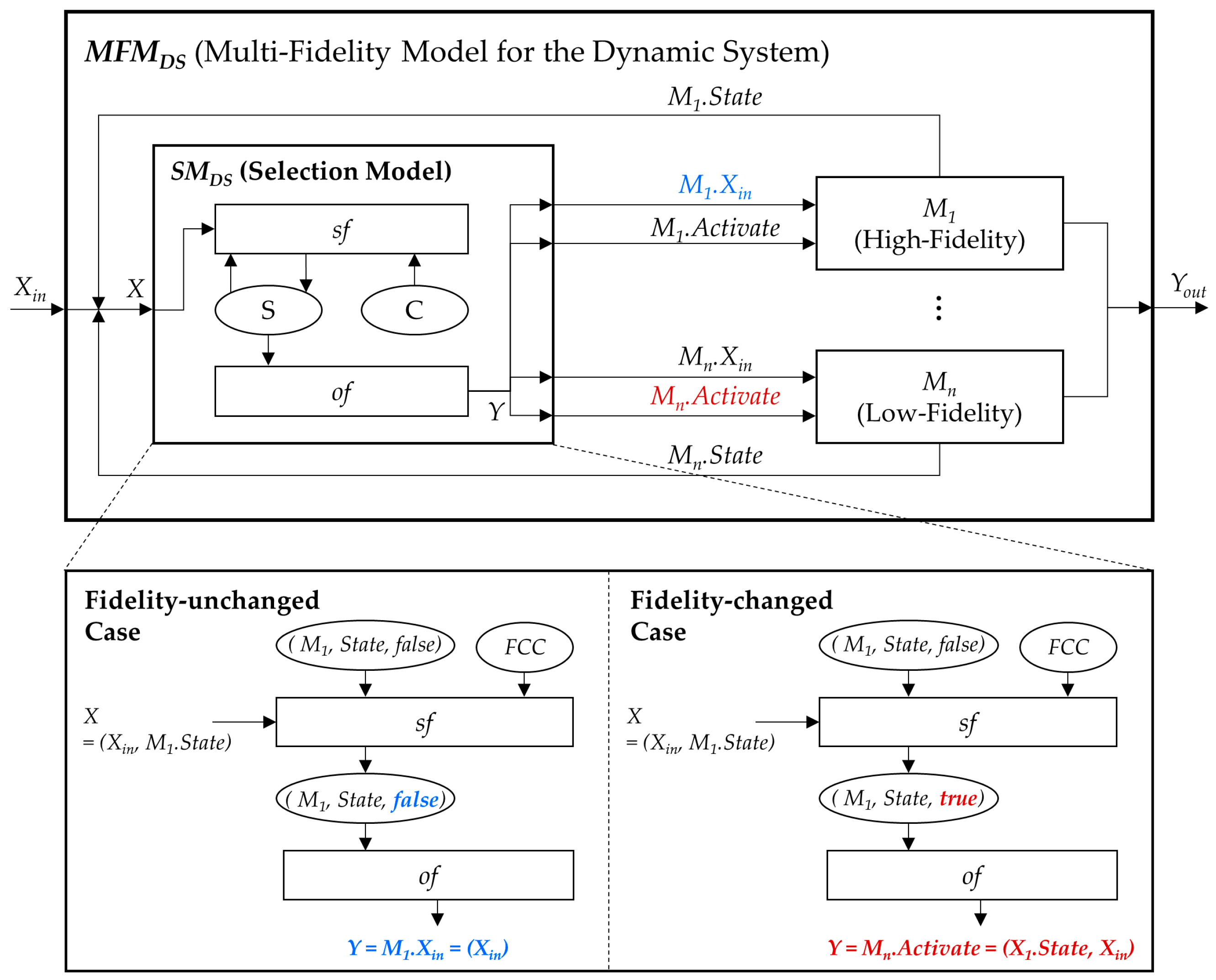
Figure 10 shows the structure of the multi-fidelity model of the dynamic system. The internal models (i.e.,
M1 to
Mn) are expressed with the DTSS formalism mentioned in
Section 2; the
SMDS has a similar form to the DTSS so that overall models can be simulated with the existing simulation engine.
is the set of inputs;
is the current state input of internal model ;
is the set of outputs;
is the set of bypassing outputs to ;
is the set of activating outputs to ;
is the set of internal model states;
is the set of fidelity change conditions;
is the selection function;
is the output function.
The specification of the
SMDS is given after
Figure 10. The
SMDS has two types of input sets: an external input set from outside of the
MFMDS and a state input set. The two types of output sets for input bypassing and model activation are allowed by the
SMDS. Fundamentally, the
SMDS receives the external input
Xin, and sends it to a current internal model
Mi in the form of the output
Mi.Xin. The
SMDS receives the state input
Xi.State from the
Mi and checks whether a model change is needed. If a change is required, the
SMDS sends the output for model activation
Mj.Activate to the altered model
Mj. The
SMDS has two sets of states: (1) a set of internal model states including the current internal model, the state variable of the model, and the Boolean variable to check whether there has been a model change; and (2) a set of fidelity change conditions. Finally, the
SMDS employs two functions: a selection function
sf and an output function
of. The
sf, which is mapped to the state transition function of the DTSS model, decides whether the current internal model is changed with the
FCC when the
SMDS receives an external input. If the current internal model does not need to be changed, the
of sends the external input to the model. Otherwise, the
of sends the state of the current internal model and the external input to the altered internal model (blue fonts are relevant to the fidelity-unchanged case and red ones correspond to the fidelity-changed case in
Figure 10).
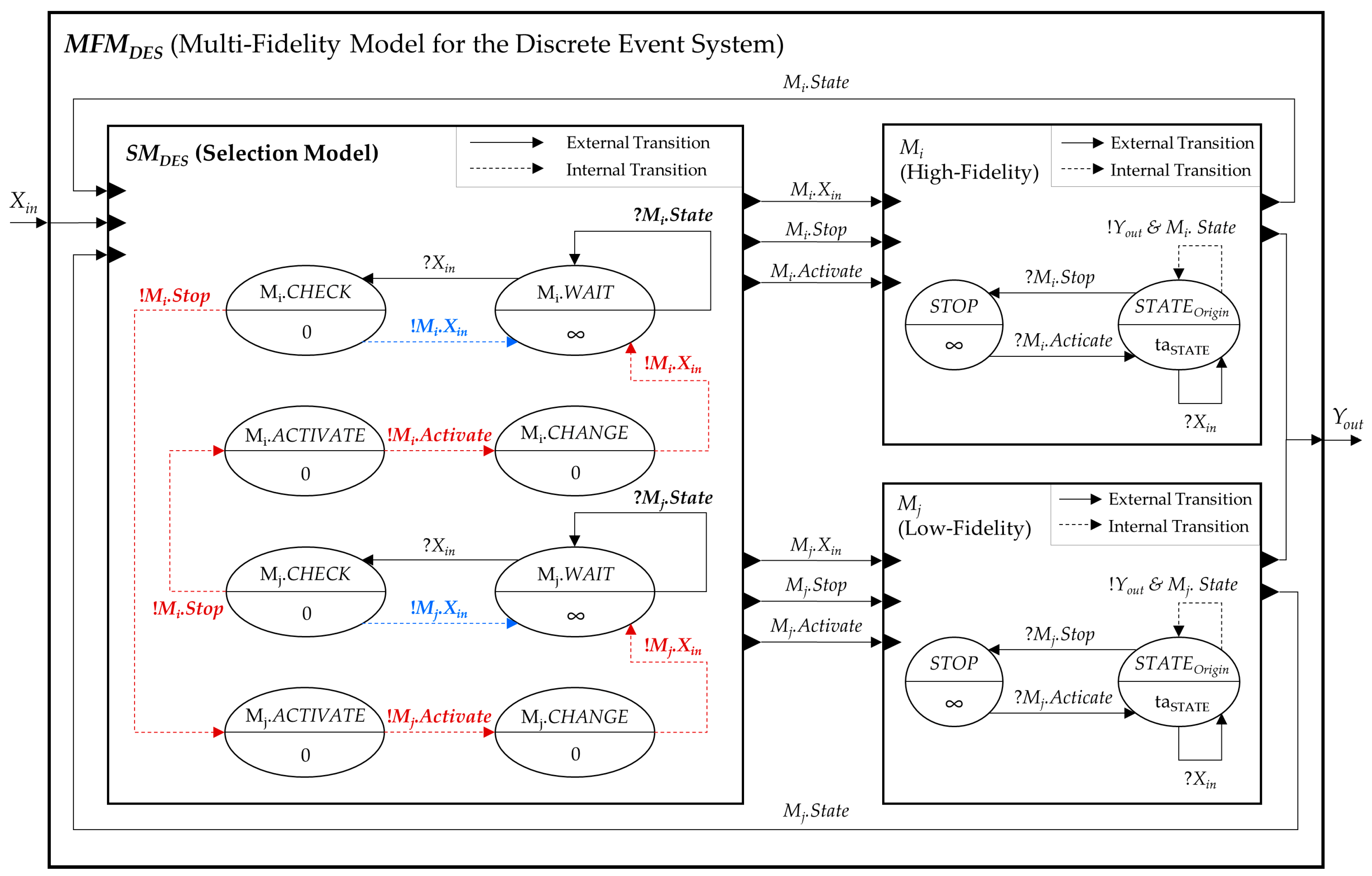
4.3.2. Multi-Fidelity Model Composition for Discrete Event System
The structure of the multi-fidelity model of the discrete event system is shown in
Figure 11. All the models in the
MFMDES are designed with the DEVS formalism [
18]. Unlike the DTSS model, the DEVS model can be executed regardless of whether it receives an input event or not. Thus, the
MFMDES has an additional output event
Mi.Stop to stop the execution of the current internal model
Mi when another internal model needs to be activated. If the current model receives the input event
Mi.Stop, it enters the STOP state, which is an additional state in which the state time is infinite, and waits for the next activation. When the
Mi receives the activate event afterward
Mi.Activate, the
Mi returns to the previous state before it is deactivated
StateOrigin. The specification is a formal representation of the selection model
SMDES.
is the set of inputs;
is the current state input of internal model ;
is the set of outputs;
is the bypassing output of ;
is the activate output of ;
is the stop output of .
is the set of fidelity change conditions.
;
;
;
;
;
;
;
;
;
;
;
Except for the stop event, the input and output sets of the
SMDES are identical to those of the
SMDS. The
SMDES has two sets of states (i.e.,
FCC and
S). The
FCC is the same as that of
SMDS, whereas the
S is slightly different. In the
SMDES, the
S is mapped to four phase sets—
Mi.WAIT,
Mi.CHECK,
Mi.ACTIVE, and
Mi.CHANGE. Unlike the
SMDS, two important roles of
SMDES are conducted by a series of phase transitions. The basic phase is
Mi.WAIT, assuming that the current internal model is
Mi. When the
SMDES receives the input event
Xin from the
Mi, it moves the phase into
Mi.CHECK and checks whether the activated model is changed to the
Mj based on the
sf and the
FCC. As in the first case, if the current internal model
Mi needs to remain active, the
SMDES changes its phase to
Mi.WAIT and forwards the received input
Xin to the
Mi. In another case, if the
Mi needs to be changed, the
SMDES moves the phase to
Mj.ACTIVE—according to the next activation model,
Mj—and sends the stop event
Mi.Stop to the
Mi. Then, the
SMDES moves the phase to
Mj.CHANGE to send the activation event
Mj.Activate to the
Mj. Finally, the phase of the
SMDES changes to
Mj.WAIT, and
SMDES sends the
Xin to the current internal model
Mj. In either case, the
SMDES receives the state information from the current activated model and waits until another input
Xin arrives. A sequence of transitions of the phase, the input, and the output for input bypassing is as follows (parentheses contain the output message, ⟹ means the external transition, and ⟶ means the internal transition):
Additionally, a series of phase transitions for the model change is as follows (inputs and outputs in red fonts in
Figure 11 are relevant to this sequence):
Finally, the MFM substitutes the target model with minimal modifications of the other models. Small modifications used to add more messages—and the STOP state, in the case of the DEVS model—are unrelated to model logic, as they are just subsidiary functions.
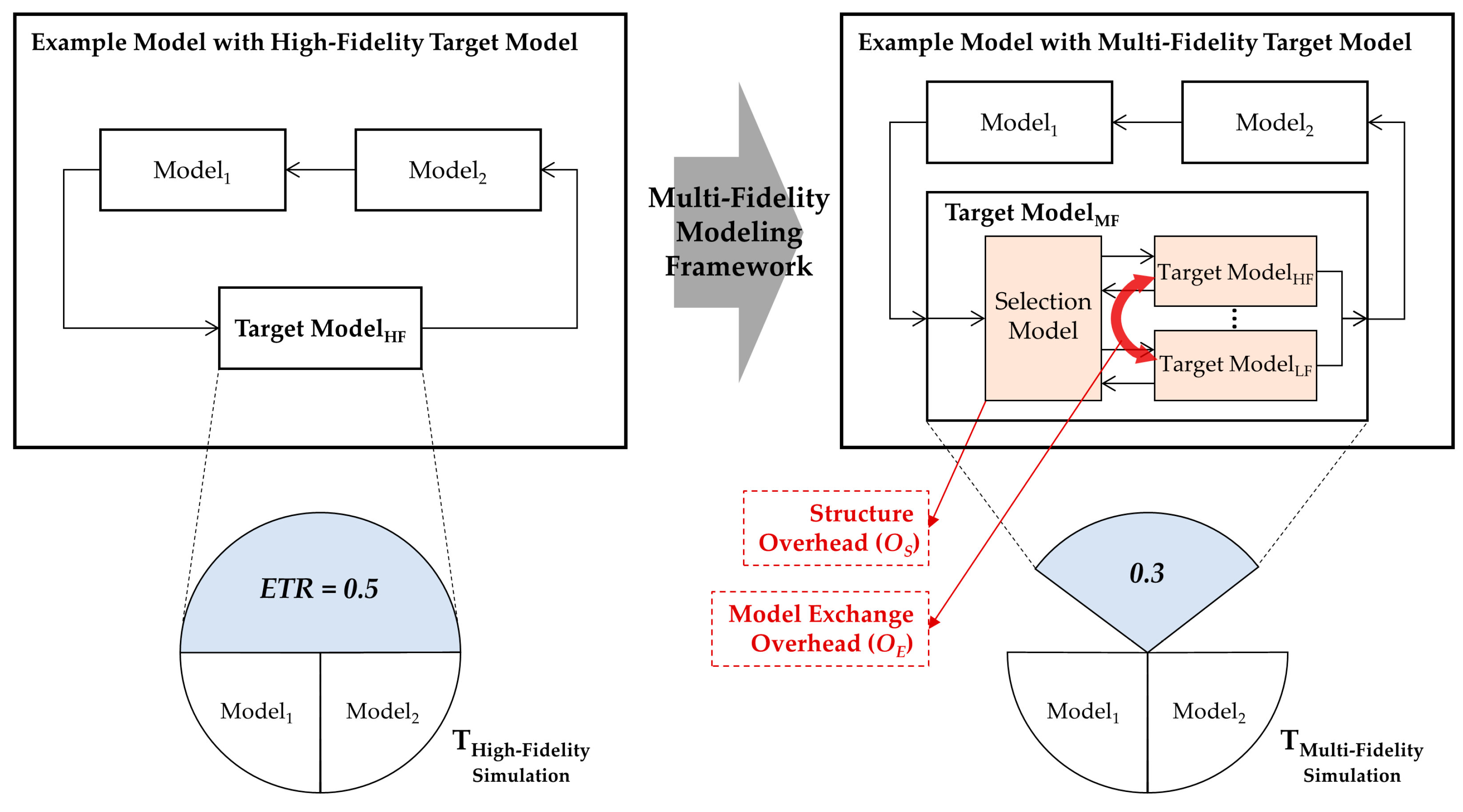
4.4. Evaluation Index for Simulation Speedup
The simulation speed improvement obtained by applying the proposed multi-fidelity framework is defined as follows:
ETR is the percentage of execution time of the target model in the overall simulation execution time.
and
are the coefficients for the structure overhead and model exchange overhead in the selection model, respectively. The value of
is greater than 1, and
has a value between 0 and 1. For each model
in the multi-fidelity model,
is the ratio of execution time of
to the execution time of the target model, and
is the percentage at which
is simulated in the entire simulation scenario (
). That is,
implies the actual ratio of execution time of
in the multi-fidelity model. When
is the same as the target model, the value of
is 1, and
is the percentage of the interest region in the scenario.
Figure 12 illustrates the speedup of the proposed framework and the notations in (2). In order to apply the proposed framework more effectively based on (2) (i.e., to maximize the speedup), we first have to select a model with a large
ETR as a target model. This corresponds to the second of the two prerequisites in the first step of the target model selection in our framework. Using a variety of fidelity models through appropriate scenario partitioning can minimize
, but can lead to increasing the structure overhead
; thus, we have to reduce the overhead by simplifying the selection function
sf. In addition, minimizing the frequency of model exchange can increase the speedup by reducing the overhead
.
6. Conclusions
In this paper, for a discrete event dynamic system, we proposed a multi-fidelity modeling framework to increase the simulation speed without a significant loss in the accuracy of the simulation results. To this end, we defined a concept of interest region and a fidelity change condition. The proposed framework including the defined concepts consists of the following five steps: (1) target model selection, (2) interest region definition, (3) lower-fidelity models design, (4) multi-fidelity model composition, and (5) selected target model substitution. Because the multi-fidelity model in the framework was designed with the DEVS and DTSS formalism, it can substitute the selected target model without the modification of other models and the simulation engine.
The two case studies demonstrated the effectiveness of the proposed framework. We applied the framework to a UUV simulation for the dynamic system and a UTV simulation for the discrete event system. As a result, the simulation speed of these simulations increased about 1.25 and 1.21 times, respectively, without a significant loss in the accuracy of the simulation results. We expect that this framework will be effectively applied to various analyzes of discrete event dynamic systems by increasing the simulation speed.
As discussed in
Section 4.4, we theoretically explained several factors to improve the performance of the framework. Above all, the most important point is how to develop good lower-fidelity models from the high-fidelity models. The development of the lower-fidelity models is dependent on the high-fidelity models. We proposed two transformation methods (i.e., the elimination and projection) that were generalized from our years of M&S studies. Nevertheless, in this paper, we centered on proposing the framework and discussed relatively little about the development of the lower-fidelity models. Thus, the transformation methods could be open to being more formalized, which will be our first focus in future work. Additionally, in many engineering fields, practical lower-fidelity models have already been developed that are not based on our formalism. To better utilize these existing models, we will extend our framework, which will decrease the cost of the redundant development of the models.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}