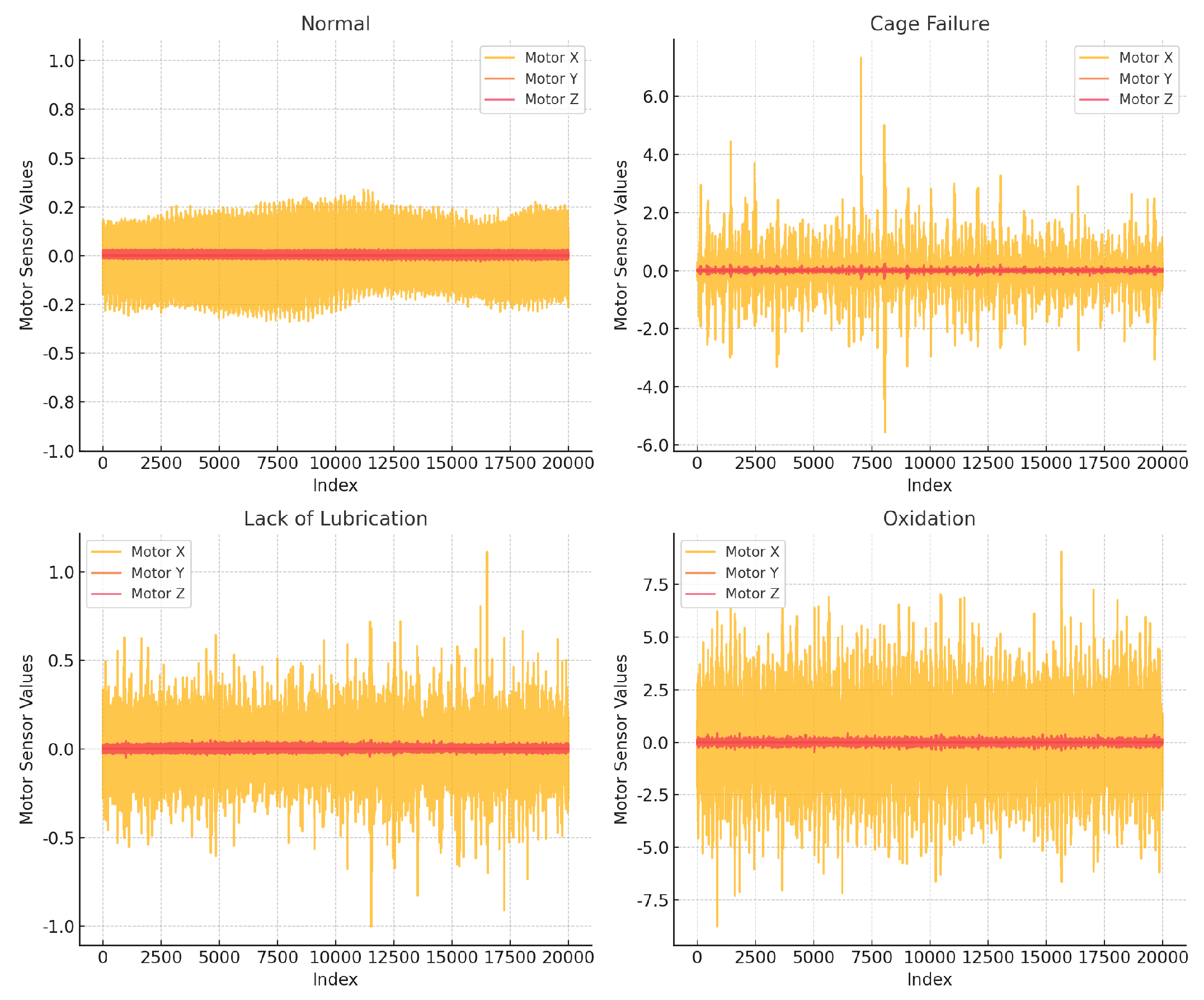
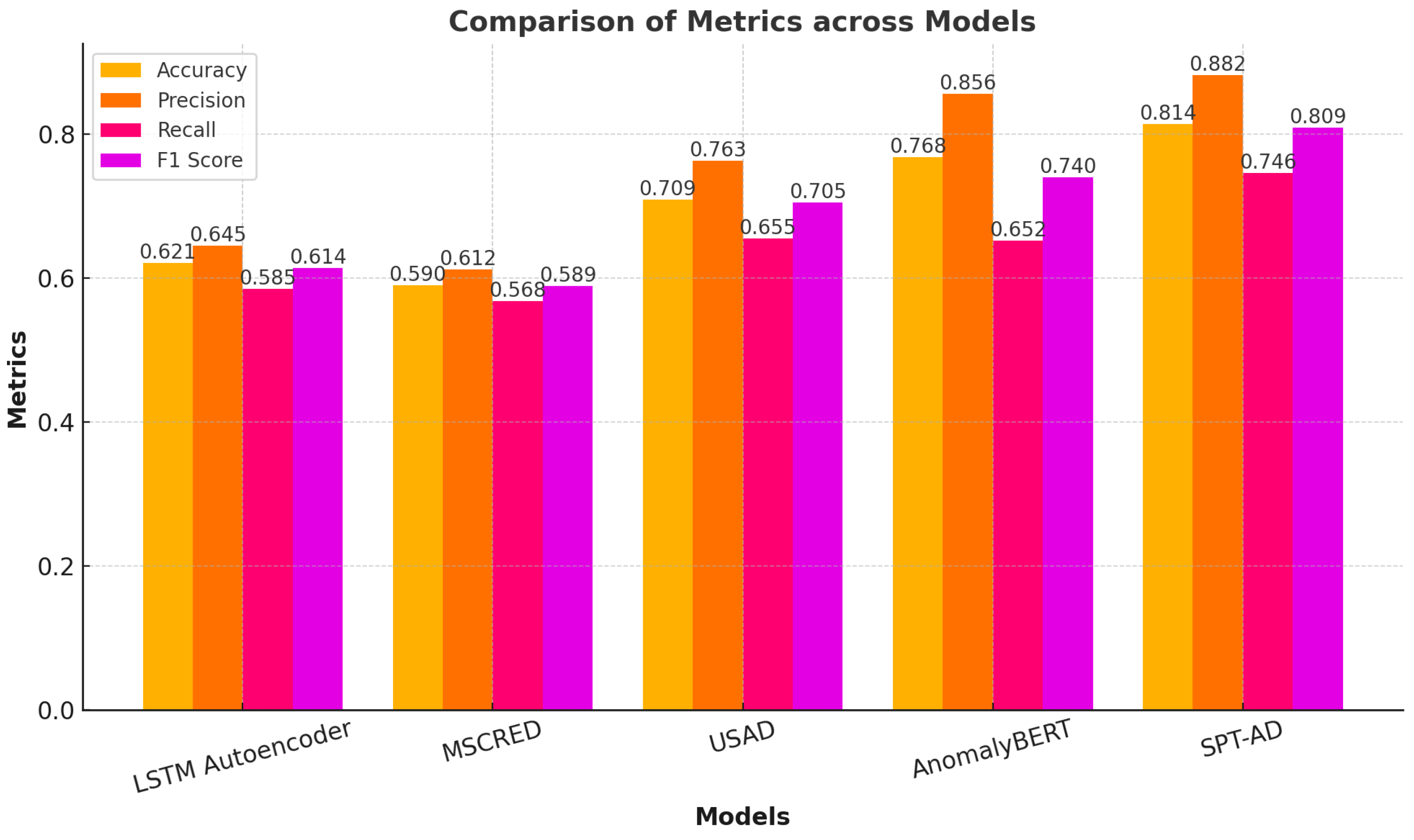
3.1. Model Framework
Self-Supervised Pyramidal Transformer Network-Based Anomaly Detection (SPT-AD) is a transformer-based algorithm that performs time series anomaly detection by generating anomaly data through self-supervised learning. An algorithm called AnomalyBERT was proposed based on the motif of BERT, which uses only the encoder structure of the transformer [
46]. In this paper, we propose a new architecture SPT-AD based on the AnomalyBERT architecture, which replaces the core component of the multi-head self attention (MSA) with the Pyramidal Attention Module (PAM) of Pyraformer and adds a Coarse-Scale Construction Module (CSCM) to improve the anomaly detection performance and computational efficiency of time series data [
47]. The proposed model overcomes data imbalance while maintaining synthesis outliers through a data degradation method and effectively learns temporal and inter-variable correlations utilizing multi-resolution representation through the Pyramidal Attention Module. This section describes the proposed model structure and algorithms in detail. The overall structure of the model is shown in
Figure 1.
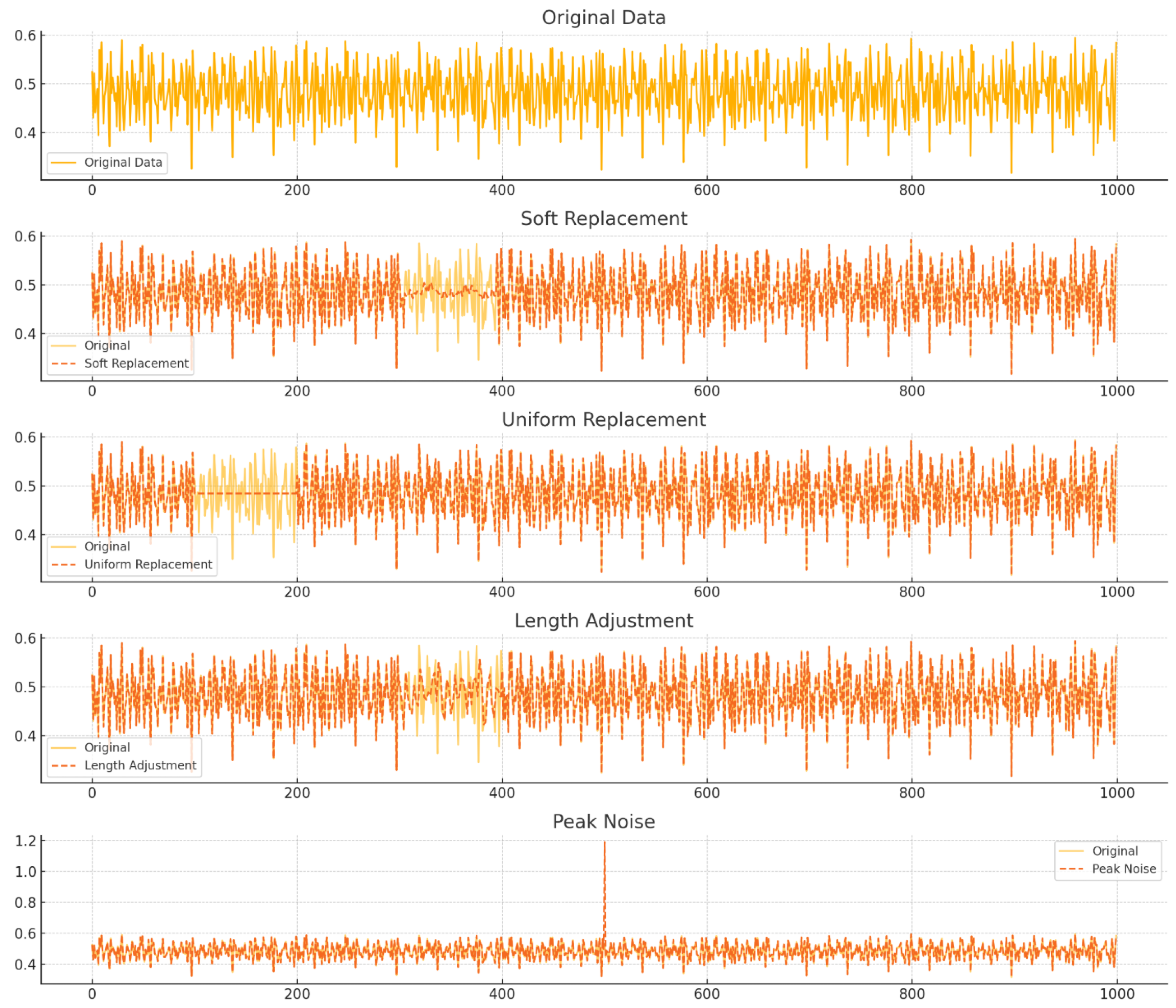
SPT-AD uses four synthesis outlier methods proposed in AnomalyBERT to generate outlier data and learn outlier patterns by comparing the original data with the degraded data when training the model. The four types of synthesis outliers used are as follows. They can also be seen in
Figure 2.
Our approach to data degradation methods include the following elements:
Soft Replacement: Soft replacement is a method of replacing missing values or outliers in time series data utilizing a specific combination of weights for values outside a window that contains data around those values.
Uniform Replacement: Uniform replacement is a method of replacing missing values or outliers with a single, fixed, constant value. This value can be chosen as a logical default for the data, or it can be the mean, median, or a specific reference value.
Length Adjustment: Length adjustment is a technique for adjusting the length of time series data, stretching or shrinking the data to make them the right length when they do not meet your analysis needs.
Peak Noise: Peak noise is a technique for inserting unusually high peak values at specific points in time series data; it is useful for testing the noisy nature of data or observing the response of a system.
In the Linear Embedding Layer Map, each point in the time series data is embedded into a high-dimensional space to create an initial embedding vector as input for the transformer model. Input data are denoted as , where N is the length of the time series, and D is the dimension of each data point. Output data are denoted as .
The Coarse-Scale Construction Module (CSCM) is a module that converts time series data into multi-resolution layers, compressing the information in the time series at each resolution and passing it on to higher layers. Each resolution is generated by 1D convolution using a kernel and stride of
C-Scale. If the input time series data are
, the CSCM reduces the data length to
N/
C at each layer. The final output consists of a feature vector
of multi-resolution layers.
(S: number of resolution layers, C: convolution stride).
The transformer body is composed of multiple layers of Pyramidal Attention Module (PAM) and Feed Forward (Multilayer Perceptron, MLP) blocks. The Pyramidal Attention Module is used to learn temporal patterns and interactions between variables in time series data. The final output of the transformer body is a latent feature vector, . where A is the length of the time series window. N is the length of the time series window (number of data points), and is the feature dimensionality generated by the transformer body.
The Pyramidal Attention Module is a multi-resolution-based attention mechanism proposed in Pyraformer, which is used as an alternative to multi-head self attention (MSA).
Our approach’s attention module includes the following elements:
Inter-scale Attention: Soft replacement replaces missing values or outliers in time series data utilizing a specific combination of weights for values outside a window containing data around those values.
Intra-scale Attention: This learns the interactions between neighboring nodes within each resolution, exchanging information between neighboring nodes in the same resolution succession.
The Pyramidal Attention Module synthesizes multi-resolution information to generate a potential feature vector, . Combining inter-scale and intra-scale attention reduces the computational complexity of the transformer from to and enables efficient learning while maintaining temporal dependencies even on long time series data.
The Prediction Block is the final step in APT-AD, which calculates an outlier score (0 to 1) for each time series point from the output of the transformer body. The model is trained by comparing it to the outlier bins generated by applying synthesis outliers. The potential feature vector
, which is the output of the transformer body, is input into the Prediction Block, which outputs the anomaly score
. Each feature vector
is transformed into a single value
through a linear transformation and normalization function.
Here,
W is the trainable weight matrix,
b is the bias value,
is the anomaly score before normalization, and
is the normalization function (Sigmoid), and the final output
A is expressed as the anomaly score for each time series point, where the closer the value of
is to 1, the more likely the data point is to be an anomaly. As a result, the overall behavior of the Prediction Block can be expressed as follows:
The Prediction Block is trained with Binary Cross Entropy Loss by comparing the predicted outlier scores with the outlier data labels generated by the synthesis outliers. The loss function is defined as follows:
(
: degraded data labels: 0 (normal), 1 (anomaly);
: anomaly scores output from the Prediction Block).
3.2. SPT-AD Algorithm
As shown in Algorithm 1, the given input data
consist of time series data, where
N data points are arranged along the time axis, and each data point is represented as a
-dimensional vector. These input data are projected into a high-dimensional latent space through a linear transformation defined as
where
is the weight matrix used to project the input data into the latent space, and
is the bias vector added to the projected vector. This allows the input data to gain richer representation in the high-dimensional space. Then, the initial latent representation is set as
where
denotes the normalized or further transformed
.
For scales
, multi-scale convolution is performed iteratively. In this process, the convolution operation is applied using
where kernel size and stride are utilized. The features extracted at different scales are then combined as
The dimensionality of this combined scale feature is defined as
where
L represents the extended length of the time series data through multi-scale convolution.
For each attention layer
, inter-scale attention and intra-scale attention are computed. The inter-scale attention is defined as
and the intra-scale attention is defined as
All the attention results extracted from different scales are combined to form the multi-resolution feature representation
Subsequently, for each time series point
, a linear transformation is computed as
This value is transformed through sigmoid normalization as
Finally, the anomaly scores are returned as
where each
represents the anomaly score for the corresponding time step.
| Algorithm 1 SPT-AD Algorithm |
Require: Input time series data - 1:
Step 1: Project Input to Latent Space - 2:
▷Linear transformation using weights and bias - 3:
▷Normalization or further transformation of - 4:
Step 2: Apply Multi-Scale Convolution - 5:
for to S do - 6:
▷Apply convolution at scale s - 7:
end for - 8:
Combine features: - 9:
Compute dimensionality: , where - 10:
Step 3: Compute Attention Scores - 11:
for to do - 12:
for to S do - 13:
Compute inter-scale attention: - 14:
Compute intra-scale attention: - 15:
end for - 16:
end for - 17:
Combine attention results: - 18:
Step 4: Compute Anomaly Scores - 19:
for each time series point do - 20:
▷Linear transformation - 21:
▷Sigmoid normalization - 22:
end for - 23:
Output: ▷Anomaly scores for each time step
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}