
Panoptic Segmentation Method Based on Feature Fusion and Edge Guidance


Abstract
1. Introduction
- (1)
- A dynamic multi-scale feature fusion module is proposed, which adaptively captures contextual information through cascaded deformable convolutional kernels and dual-dimensional attention in both channel and spatial domains.
- (2)
- An explicit edge feature guidance module is introduced, establishing a bidirectional enhancement mechanism between pixel features and edge gradients.
- (3)
- A dual-path Transformer decoder architecture is designed, enabling collaborative optimization of global semantics and local features through cross-attention mechanisms.
2. Related Work
2.1. Panoptic Segmentation Methods
2.2. Feature Fusion Techniques
2.3. Edge-Guided Segmentation
3. Method
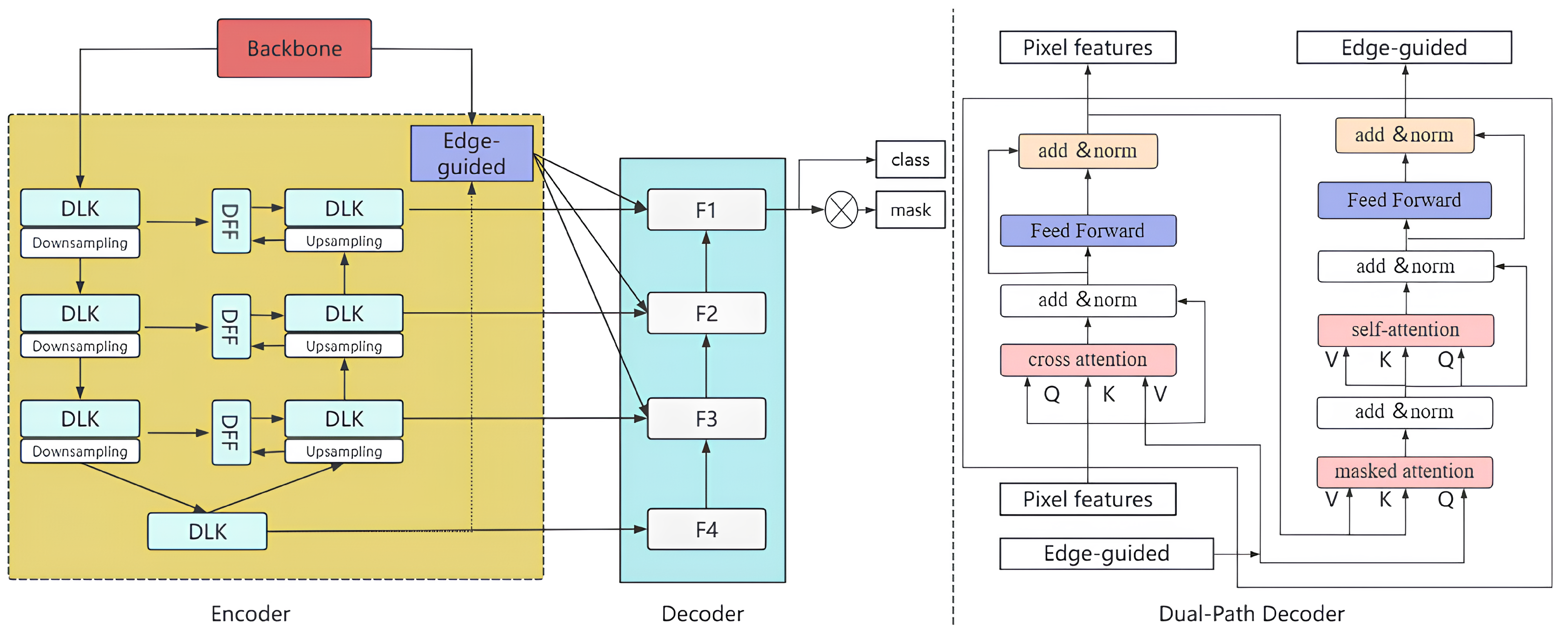
3.1. Network Infrastructure Overview
- Dynamic Large Kernel (DLK) Modules: Applied sequentially to the backbone features C1, C2, C3, C4 with intermediate downsampling, producing initial multi-scale features E1, E2, E3, E4 with enhanced receptive fields.
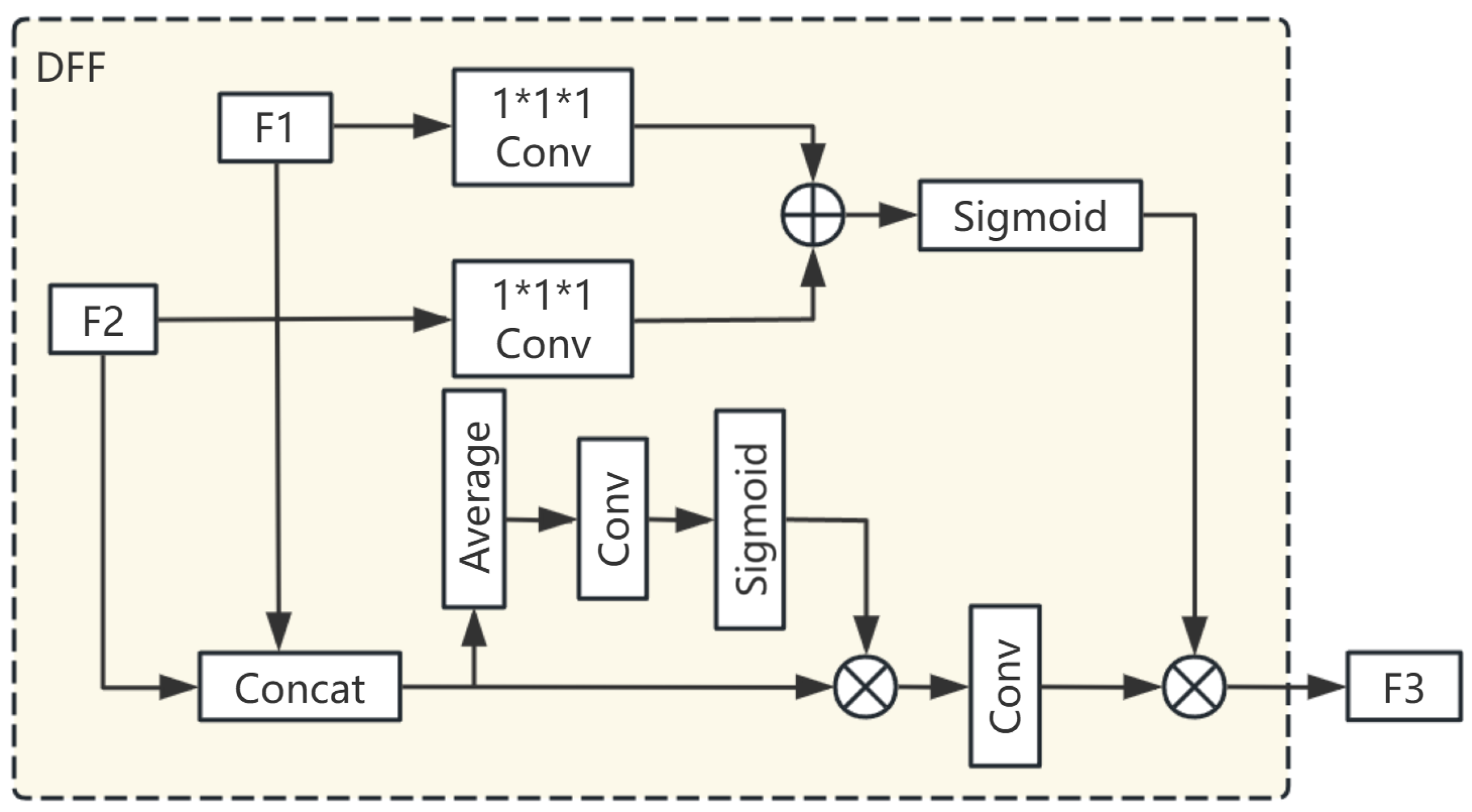
- Dynamic Feature Fusion (DFF) Modules: These modules perform adaptive cross-scale fusion between adjacent features from the DLK modules (e.g., fusing E1 and E2, E2 and E3, etc.) to produce refined features E1’, E2’, E3’. The deepest feature E4 (renamed E4’ for consistency notation later) doesn’t undergo DFF fusion at this stage but provides deep semantic context. The output E1’, E2’, E3’, E4’ captures richer context than the original backbone features.
- Edge Guidance Fusion (EGF) Module: It takes the shallow, high-resolution C1 feature from the backbone and the deep feature from the encoder. It fuses them to generate an edge-enhanced feature map, , guided by an auxiliary edge loss during training.
- Multi-scale Edge Injection: The learned edge feature is then downsampled to match the resolutions of and integrated with them using a gating mechanism. This process yields the final multi-scale feature pyramid . These features , spanning resolutions to , serve as the input to the decoder.
3.2. Dynamic Multi-Scale Feature Fusion Module
3.2.1. Dynamic Large Kernel Module
3.2.2. Dynamic Feature Fusion Module
3.3. Edge Guidance Module
3.4. Dual-Path Decoder
3.5. Loss Function
4. Experiments
4.1. Specific Realizations
4.1.1. Datasets and Evaluation Indicators
4.1.2. Implementation Details
4.2. Experimental Results and Analysis
- 1.
- Enhanced recognition of small objects and details: Whether it is a long-distance traffic light, pedestrian, or traffic sign on a city street, or an animal, distant object, or background in the COCO dataset, PSM-FFEG shows stronger recognition and accurate segmentation capabilities. The red box area highlights the obvious omission or ambiguity of Mask2Former on these small targets or details, while PSM-FFEG can capture and outline them more effectively. This is due to the better use of multi-scale information by the dynamic feature fusion module.
- 2.
- Improved accuracy in boundary and edge processing: Improved accuracy of boundary and edge processing: Across the two datasets, PSM-FFEG shows significant advantages in processing object edges. Whether it is the boundary between vehicles and roads/backgrounds, the outlines of buildings and the sky, or the boundaries between animals and grass, athletes, etc., the edges generated by PSM-FFEG are clearer, smoother, and closer to the real contours. In contrast, the edges of Mask2Former sometimes appear fuzzy, jagged, or have slight penetration. This directly confirms the effectiveness of the edge guidance module (EGF) in optimizing boundary representation. While these qualitative results focus on comparing the final segmentation masks, visualizing confidence scores or uncertainty maps could offer further insights into model behavior. Generating and analyzing such maps was considered outside the scope of the current comparative analysis but represents a potential direction for future work.
- 3.
- Robustness and consistency in complex scenes: In the crowded baseball scene or animal scene as shown in Figure 6, as well as the complex urban intersection (Figure 5), PSM-FFEG appears to perform better in dealing with object occlusion, dense instances, and complex backgrounds. It seems better able to distinguish adjacent instances (e.g., players in Figure 6), reducing mis-segmentation and category confusion compared to the baseline. We hypothesize that the richer features from the dynamic fusion modules and the enhanced pixel-query interaction in the dual-path decoder contribute to this improved robustness. The interactive optimization mechanism of the dual-path decoder likely plays a key role. However, we note that this assessment is primarily qualitative, as we did not employ specific datasets or metrics designed to quantitatively measure performance under varying levels of occlusion.
4.3. Ablation Study
5. Conclusions
- Computational Complexity: The introduction of the cascaded convolutions and attention mechanisms within the DLK modules, the cross-scale fusion in DFF, and particularly the iterative nature of the Dual-Path Transformer Decoder contribute to increased computational complexity (FLOPs and parameters) compared to simpler baseline models like Mask2Former with a standard decoder. This might pose challenges for deployment in real-time applications or on resource-constrained hardware without further optimization or model compression.
- Hyperparameter Sensitivity: The performance of PSM-FFEG can be sensitive to the setting of certain hyperparameters. This includes the loss weights balancing the main panoptic loss terms (, , ) and the auxiliary edge loss (), as well as potential internal parameters within the attention or fusion modules. Achieving optimal performance currently requires careful empirical tuning for each dataset, which can be time-consuming.
- Long-range Dependency Modeling: While the DLK module increases the effective receptive field and attention mechanisms capture context, the model’s ability to explicitly model very long-range spatial dependencies across the entire image might still be limited compared to architectures employing global self-attention across all pixels, which are often computationally prohibitive at high resolutions. The attention mechanisms used are primarily focused within local windows or feature channels.
- Potential Failure Cases: While demonstrating overall improvement, the model might still struggle in certain scenarios. These could include: objects belonging to extremely rare categories not well represented in the training data; images with severe weather, lighting, or blur exceeding training conditions; objects with highly atypical appearances; or instances where the auxiliary edge supervision was noisy or inaccurate, potentially providing misleading guidance. A systematic analysis of such failure modes was not conducted but is important for understanding robustness.
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kirillov, A.; He, K.; Girshick, R.; Dollár, P.; Russakovsky, O. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 9404–9413. [Google Scholar]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2018, 7, 87–93. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Xiong, Y.; Liao, R.; Zhao, H.; Hu, R.; Bai, M.; Yumer, E.; Urtasun, R. UPSNet: A unified panoptic segmentation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–21 June 2019; pp. 8818–8826. [Google Scholar]
- Cheng, B.; Collins, M.D.; Zhu, Y.; Liu, T.; Huang, T.S.; Adam, H.; Chen, L.C. Panoptic-DeepLab: A simple, strong, and fast baseline for bottom-up panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12475–12485. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Shazeer, N.; Kaiser, L.; Ku, A.; Tran, D. Image transformer. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1290–1299. [Google Scholar]
- Yao, Z.; Wang, X.; Bao, Y. K-Query: Panoptic segmentation method based on keypoint query. J. Comput. 2023, 46, 1693–1708. [Google Scholar] [CrossRef]
- Kirillov, A.; Girshick, R.; He, K.; Dollár, P. Panoptic feature pyramid networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 6399–6408. [Google Scholar]
- Azad, R.; Niggemeier, L.; Hüttemann, M.; Antoine, E.; Baumgartner, M. Beyond self-attention: Deformable large kernel attention for medical image segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2024; pp. 1287–1297. [Google Scholar]
- Wang, Z.; Lin, X.; Wu, N.; Zhuang, Y.; Wang, J. DTMFormer: Dynamic Token Merging for Boosting Transformer-Based Medical Image Segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 5814–5822. [Google Scholar]
- Moon, T.K. The expectation-maximization algorithm. IEEE Signal Process. Mag. 1996, 13, 47–60. [Google Scholar] [CrossRef]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: New York, NY, USA, 2009; pp. 248–255. [Google Scholar]
- Hou, R.; Li, J.; Bhargava, A.; Raventos, A.; Guizilini, V.; Fang, C.; Lynch, J.; Gaidon, A. Real-time panoptic segmentation from dense detections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8523–8532. [Google Scholar]
- Chang, S.E.; Chen, Y.; Yang, Y.C.; Lin, E.T.; Hsiao, P.Y.; Fu, L.C. SE-PSNet: Silhouette-based enhancement feature for panoptic segmentation network. J. Vis. Commun. Image Represent. 2023, 90, 103736. [Google Scholar] [CrossRef]
- Mohan, R.; Valada, A. EfficientPS: Efficient panoptic segmentation. Int. J. Comput. Vis. 2021, 129, 1551–1579. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, R.; Zhu, D.; Wang, W.; Wu, J.; Liu, L.; Wang, S.; Zhao, B. Cascade contour-enhanced panoptic segmentation for robotic vision perception. Front. Neurorobotics 2024, 18, 1489021. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zhao, H.; Qi, X.; Wang, L.; Li, Z.; Sun, J.; Jia, J. Fully convolutional networks for panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021; pp. 214–223. [Google Scholar]
- Jain, J.; Li, J.; Chiu, M.; Hassani, A.; Tulyakov, S.; Minaee, S. OneFormer: One transformer to rule universal image segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 2989–2998. [Google Scholar]
- Li, Q.; Qi, X.; Torr, P.H. Unifying training and inference for panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 14–19 June 2020; pp. 13320–13328. [Google Scholar]
- Lin, G.; Li, S.; Chen, Y.; Li, X. IDNet: Information decomposition network for fast panoptic segmentation. IEEE Trans. Image Process. 2023, 33, 1487–1496. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Pang, J.; Chen, K.; Loy, C.C. K-Net: Towards unified image segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 10326–10338. [Google Scholar]
- Wang, H.; Zhu, Y.; Adam, H.; Yuille, A.; Chen, L.C. MaX-DeepLab: End-to-end panoptic segmentation with mask transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual Event, 19–25 June 2021; pp. 5463–5474. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | PQ | PQth | PQst |
|---|---|---|---|---|
| RT Panoptics [17] | Res50 | 58.8 | 52.1 | 63.7 |
| UPSNet [6] | Res50 | 59.3 | 54.6 | 62.7 |
| SE-PSNet [18] | Res50 | 60.0 | 55.9 | 62.9 |
| EfficientPS [19] | Res50 | 60.3 | 55.3 | 53.9 |
| CCPSNet [20] | Res50 | 60.5 | 56.9 | 63.1 |
| PanopticFCN [21] | Res50 | 61.4 | 54.8 | 66.6 |
| Mask2Former [9] | Res50 | 62.1 | 54.8 | 67.3 |
| OneFormer [22] | Res50 | 62.7 | 55.8 | 68.4 |
| K-Query [10] | Res50 | 63.2 | 56.2 | 68.3 |
| Ours | Res50 | 64.7 | 59.4 | 69.1 |
| Method | Backbone | PQ | PQth | PQst |
|---|---|---|---|---|
| UPSNet [6] | Res50 | 42.5 | 48.6 | 33.4 |
| Unilying [23] | Res50 | 43.4 | 48.6 | 35.5 |
| IDNet [24] | Res50 | 42.1 | 47.5 | 33.9 |
| CCPSNet [20] | Res50 | 43.0 | 49.2 | 33.6 |
| PanopticFCN [21] | Res50 | 44.3 | 50.0 | 35.6 |
| K-Net [25] | Res50 | 47.1 | 51.7 | 40.3 |
| Max-DeepLab [26] | Max-X | 48.4 | 53.0 | 41.5 |
| Mask2Former [9] | Res50 | 51.9 | 57.7 | 43.0 |
| OneFormer [22] | Res50 | 52.2 | 57.9 | 43.5 |
| K-Query [10] | Res50 | 52.9 | 58.9 | 43.8 |
| Ours | Res50 | 54.3 | 61.4 | 44.3 |
| Category | Mask2Former | PSM-FFEG | Improvement |
|---|---|---|---|
| Road | 98.5 | 99.1 | 0.6 |
| Sidewalk | 86.7 | 88.9 | 2.2 |
| Building | 92.3 | 94.2 | 1.9 |
| Wall | 58.4 | 63.8 | 5.4 |
| Fence | 62.1 | 65.7 | 3.6 |
| Poles | 65.3 | 68.9 | 3.6 |
| Traffic Light | 70.2 | 74.5 | 4.3 |
| Traffic Sign | 79.8 | 83.2 | 3.4 |
| Vegetation | 92.4 | 93.8 | 1.4 |
| Terrain | 62.8 | 65.9 | 3.1 |
| Sky | 94.9 | 95.7 | 0.8 |
| Person | 82.6 | 85.4 | 2.8 |
| Rider | 65.1 | 68.8 | 3.7 |
| Car | 94.3 | 95.9 | 1.6 |
| Truck | 68.7 | 74.3 | 5.6 |
| Bus | 78.9 | 83.6 | 4.7 |
| Train | 71.2 | 75.8 | 4.6 |
| Motorcycle | 65.4 | 72.2 | 6.8 |
| Bicycle | 77.2 | 80.5 | 3.3 |
| Network | DLK+DFF | Edge-Guided | Dual-Path | PQ | PQth | PQst | AP | IoU |
|---|---|---|---|---|---|---|---|---|
| Mask2Former | - | - | - | 62.1 | 54.8 | 67.3 | 37.3 | 77.5 |
| PSM-FFEG | ✔ | - | - | 63.4 | 56.8 | 68.2 | 38.5 | 79.3 |
| ✔ | ✔ | - | 64.1 | 58.6 | 68.8 | 39.6 | 79.8 | |
| ✔ | ✔ | ✔ | 64.7 | 59.4 | 69.1 | 40.7 | 80.3 |
| Model | PQ (%) | FLOPs (G) | Parameters (M) | FPS | Inference (ms) |
|---|---|---|---|---|---|
| Mask2Former | 62.1 | 74.3 | 43.8 | 36.1 | 27.7 |
| PSM-FFEG | 64.7 | 89.6 | 46.5 | 29.3 | 34.1 |
| Difference | +2.6 | +15.3 | +2.7 | −6.8 | +6.4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, L.; Wang, S.; Teng, S. Panoptic Segmentation Method Based on Feature Fusion and Edge Guidance. Appl. Sci. 2025, 15, 5152. https://doi.org/10.3390/app15095152
Yang L, Wang S, Teng S. Panoptic Segmentation Method Based on Feature Fusion and Edge Guidance. Applied Sciences. 2025; 15(9):5152. https://doi.org/10.3390/app15095152
Chicago/Turabian StyleYang, Lanshi, Shiguo Wang, and Shuhua Teng. 2025. "Panoptic Segmentation Method Based on Feature Fusion and Edge Guidance" Applied Sciences 15, no. 9: 5152. https://doi.org/10.3390/app15095152
APA StyleYang, L., Wang, S., & Teng, S. (2025). Panoptic Segmentation Method Based on Feature Fusion and Edge Guidance. Applied Sciences, 15(9), 5152. https://doi.org/10.3390/app15095152