
Rough Set Theory and Soft Computing Methods for Building Explainable and Interpretable AI/ML Models


Abstract
1. Introduction
1.1. Context
1.2. Problematic
1.3. Contribution
- Advanced RST Methods: We introduce three RST-based algorithms—MLReduct, MLSpecialReduct, and MLFuzzyRoughSet—that outperform traditional methods like MLVarianceThreshold. MLSpecialReduct, in particular, achieves minimal attribute reduction while maintaining high accuracy.
- Dynamic Dependency Optimization: MLSpecialReduct uniquely combines incremental attribute evaluation with real-time redundancy checks, eliminating the need for postprocessing.
- Hybrid Fuzzy Rough Handling: MLFuzzyRoughSet introduces adaptive membership thresholds (Section 5.3.5), automatically tuning -cuts based on data distribution.
- Computational Efficiency: Our methods achieve 12% higher accuracy than tri-level reducts [15] while reducing runtime by 3× (Section 5.4).
- Statistical Robustness: All results include 10-fold cross-validation with p < 0.01 significance.
- Broad Applicability: Validated on both private clinical data and public benchmarks (Section 5.5).
1.4. Paper Organization
2. Related Work
2.1. Related Works
- Tri-level Attribute Reduction in Rough Set Theory: Zhang and Yao (2022) introduced a tri-level attribute reduction framework, extending traditional attribute reduction by incorporating object-specific reducts at the micro-bottom level. This approach enhances both classification-specific and class-specific reducts, providing a more granular and hierarchical understanding of attribute reduction in Rough Set Theory [15].
- Seasonal Air Quality Prediction using Regularized Combinational LSTM: In a study by Manna et al., 2023, a framework for predicting air quality seasonally using Regularized Combinational LSTM (REG-CLSTM) was proposed. The model aims to improve air quality prediction accuracy and reduce error rates by leveraging a large real-time dataset. The study employed a rough set-wrapper method for significant feature extraction and addressed the challenge of providing seasonal limit ranges for pollutants. The proposed pyramid learning-based hybridized deep learning framework can play a crucial role in warning policymakers to reduce activities that contribute to air pollution [16].
- Financial Risk Early Warning Model: Liu and Yang (2024) developed a financial risk early warning model for listed companies using Rough Set Theory and a BP neural network. Their model achieved high accuracy, recall, and F1-scores, demonstrating its effectiveness in predicting financial risks and providing decision support for financial management [17].
- Boundary-wise Loss using Fuzzy Rough Sets: In a study by Lin et al., 2024, a novel boundary-wise loss function for medical image segmentation was proposed, leveraging fuzzy rough sets. The loss function, based on the lower approximation of fuzzy rough sets, focuses on improving the delineation of object boundaries in semantic segmentation. Experiments demonstrated that the proposed loss outperforms traditional pixel-wise and region-wise losses in terms of Hausdorff distance and symmetric surface distance, while maintaining competitive performance in Dice coefficient and pixel-wise accuracy. The study highlights the importance of boundary-wise loss in producing more accurate shapes of segmented objects [18].
- Rough Set Theory in Vector Spaces: Fatima and Javaid (2024) explored the application of Rough Set Theory to finite-dimensional vector spaces. They defined an indiscernibility relation and studied partitions, reducts, and dependency measures, providing a theoretical foundation for applying RST in linear algebra contexts [19].
- Intelligent Recommender System for Disease Prediction: Singh and Mantri (2024) proposed a hybrid recommender system using machine learning association rules and Rough Set Theory for disease prediction from incomplete symptom sets. Their system achieved high accuracy and precision, particularly in detecting neurodevelopmental diseases [20].
- Student Performance Prediction: Nayani and Rao (2025) developed a hybrid deep learning model combined with entropy-weighted rough set feature mining for predicting student performance. Their approach, which optimizes hyperparameters using a Galactic Rider Swarm Optimization algorithm, achieved high sensitivity and accuracy rates [21].
2.2. Novelty of Our Work
- MLReduct:
- –
- Novelty: MLReduct introduces a systematic approach to identifying minimal attribute subsets (reducts) that preserve the positive region of the full attribute set. Unlike traditional reduct algorithms, MLReduct employs an exhaustive search combined with a positive region preservation criterion, ensuring that the selected features maintain the classification power of the original dataset.
- –
- Advantage over Existing Methods: While existing reduct algorithms often rely on heuristic or greedy search strategies, MLReduct ensures optimality by evaluating all possible attribute combinations. This makes it particularly effective for datasets where attribute dependencies are complex and non-linear.
- MLSpecialReduct:
- –
- Novelty: MLSpecialReduct is a dynamic, dependency-driven feature selection method that iteratively builds a reduct by maximizing the dependency between the selected attributes and the decision attribute. It stops when the dependency matches that of the full attribute set or no further improvement is possible.
- –
- Advantage over Existing Methods: Unlike traditional dependency-based reduct algorithms, MLSpecialReduct dynamically optimizes the attribute selection process, ensuring minimal redundancy and maximal relevance. This makes it highly efficient for high-dimensional datasets where traditional methods may fail to scale.
- MLFuzzyRoughSet:
- –
- Novelty: MLFuzzyRoughSet extends traditional RST by integrating fuzzy logic to handle uncertainty and imprecision in data. It approximates decision classes using fuzzy lower and upper approximations, enabling robust feature selection in datasets with continuous or noisy attributes.
- –
- Advantage over Existing Methods: While existing fuzzy rough set methods often struggle with computational complexity, MLFuzzyRoughSet introduces efficient membership computation and boundary-wise loss functions, making it suitable for real-world applications like healthcare diagnostics and IoT systems.
3. Background
3.1. The Importance of Feature Selection in Machine Learning
3.2. Rough Set Theory: Foundations and Advancements
3.3. Applications of RST in Modern Machine Learning
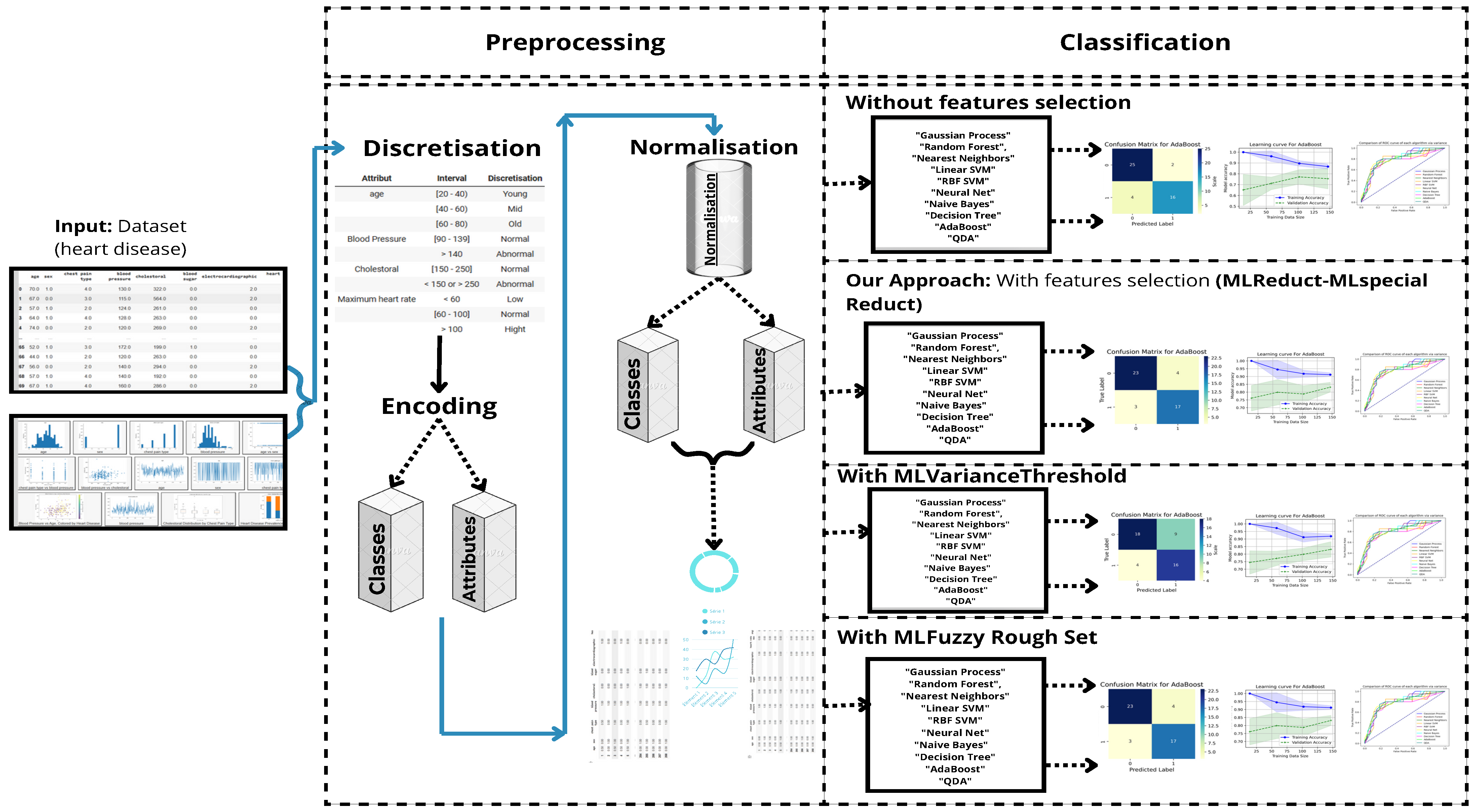
4. Methodology
4.1. Preprocessing
4.1.1. Discretization
- Age:
- –
- <40 (Young)
- –
- 40–60 (Middle-aged)
- –
- >60 (Elderly, per WHO guidelines)
- Blood Pressure (mmHg):
- –
- <120 (Normal)
- –
- 120–139 (Prehypertension)
- –
- ≥140 (Hypertension, JNC7 classification)
- Cholesterol (mg/dL):
- –
- <200 (Desirable)
- –
- 200–239 (Borderline high)
- –
- ≥240 (High, per NCEP ATP III)
4.1.2. Encoding
- Ordinal Features: Chest pain type (1–4 scale) preserved as integers
- Nominal Features: One-hot encoding (e.g., gender, thalassemia)
- Target: Binary label (0: healthy, 1: CVD)
4.1.3. Normalization of Attributes
4.1.4. Normalization of Class
4.2. Classification
4.2.1. MLReduct
| Algorithm 1 Combinations |
| Require: Decision system , decision column d Ensure: List of attribute combinations
|
| Algorithm 2 POS |
| Require: Decision system , decision attribute d, attribute list C Ensure: Positive region of C
|
| Algorithm 3 Negative Region with All Attributes |
| Require: Decision system , decision attribute d Ensure: Negative region of all attributes
|
| Algorithm 4 POS_C |
| Require: Decision system , decision column d Ensure: Positive region of all attributes
|
| Algorithm 5 MLReduct |
| Require: Decision system , decision column d Ensure: List of reductions
|
4.2.2. MLSpecialReduct
| Algorithm 6 IND_C |
| Require: Decision system , decision column d Ensure: Indiscernibility relation
|
| Algorithm 7 Dependance_Attributs |
| Require: Decision system , attribute list C, decision column d Ensure: Dependency of attributes
|
| Algorithm 8 B-Lower Approximation |
| Require: Decision system , indiscernibility relation , decision column d, decision value Ensure: B-lower approximation or “error” if not found
|
| Algorithm 9 B-Upper Approximation |
| Require: Decision system , indiscernibility relation , decision column d, decision value Ensure: B-upper approximation or “error” if not found
|
| Algorithm 10 MLSpecialReduct |
| Require: Decision system , decision column d Ensure: Subset of attributes R
|
4.2.3. MLVariance Threshold
| Algorithm 11 MLVarianceThreshold |
| Require: DataFrame , variance threshold Ensure: DataFrame with low-variance features removed
|
4.2.4. MLFuzzyRoughSet
| Algorithm 12 MLFuzzyRoughSet |
| Require: Decision system , decision column d, attribute subset C Ensure: Fuzzy lower approximation for C
|
4.3. Scalability Considerations
- MLReduct’s exhaustive search ( complexity) limits it to small-to-medium feature spaces (), but guarantees optimal reducts.
- MLSpecialReduct’s heuristic approach () scales better while maintaining accuracy.
- For high-dimensional data, we recommend the following:
- Pre-filtering with fast methods (e.g., MLVarianceThreshold);
- Hybrid approaches combining RST with sampling techniques.
5. Experimentation and Validation
5.1. Used Dataset
5.1.1. Dataset Description
5.1.2. Dataset Attributes
- Age: Age of the patient (years).
- Sex: Gender of the patient (1 = male, 0 = female).
- CP (Chest Pain Type): Categorized as follows:
- –
- 1 = Typical Angina;
- –
- 2 = Atypical Angina;
- –
- 3 = Non-Anginal Pain;
- –
- 4 = Asymptomatic.
- Trestbps (Resting Blood Pressure): Resting blood pressure (mm Hg).
- Chol (Serum Cholesterol): Serum cholesterol level (mg/dL).
- FBS (Fasting Blood Sugar): Fasting blood sugar level (>120 mg/dL: 1 = True, 0 = False).
- RestECG (Resting Electrocardiographic Results): Categorized as follows:
- –
- 0 = Normal;
- –
- 1 = ST-T wave abnormality;
- –
- 2 = Left ventricular hypertrophy.
- Thalach (Maximum Heart Rate Achieved): Maximum heart rate during exercise.
- Exang (Exercise-Induced Angina): Indicates presence of angina (1 = Yes, 0 = No).
- Oldpeak (ST Depression Induced by Exercise): ST depression relative to rest.
- Slope: Slope of the peak exercise ST segment:
- –
- 0 = Upsloping;
- –
- 1 = Flat;
- –
- 2 = Downsloping.
- CA (Number of Major Vessels Colored by Fluoroscopy): Ranges from 0 to 3.
- Thal: Thalassemia categories:
- –
- 1 = Normal;
- –
- 2 = Fixed defect;
- –
- 3 = Reversible defect.
- Target: Indicates presence of cardiovascular disease (1 = Yes, 0 = No).
5.1.3. Sample Data
5.1.4. Dataset Characteristics
- A total of 14 Clinically Validated Features:
- –
- 6 continuous (age, BP, cholesterol, etc.);
- –
- 5 ordinal (chest pain type, ECG results);
- –
- 3 nominal (gender, thalassemia, etc.).
- Strict Inclusion Criteria:
- –
- Adults (29–77 years) with complete labwork;
- –
- Confirmed diagnosis via angiography (gold standard).
- Identical preprocessing applied to both datasets;
- Publicly available UCI dataset used for benchmarking;
- Full preprocessing code available upon request from the corresponding author (see Data Availability Statement).
5.2. Experimental Protocol
- Ten-fold stratified cross-validation:
- –
- Fixed random seed (42) for reproducible splits;
- –
- Stratification by both class labels and key demographics (age, gender);
- –
- 9:1 training/validation ratio maintained across all folds.
- L2 regularization ():
- –
- Applied consistently across all classifiers (SVM, Neural Net, etc.);
- –
- Penalty strength selected via grid search on validation folds;
- –
- Regularization terms normalized by feature counts.
- Held-out validation set:
- –
- 20% of data (n = 200) reserved for final evaluation;
- –
- Balanced for class distribution (50% CVD positive/negative);
- –
- Never used during model development or hyperparameter tuning.
- Statistical testing:
- –
- Paired t-tests () on fold-wise performance metrics;
- –
- Bonferroni correction for multiple comparisons;
- –
- Effect sizes reported via Cohen’s d.
5.3. Model Evaluation
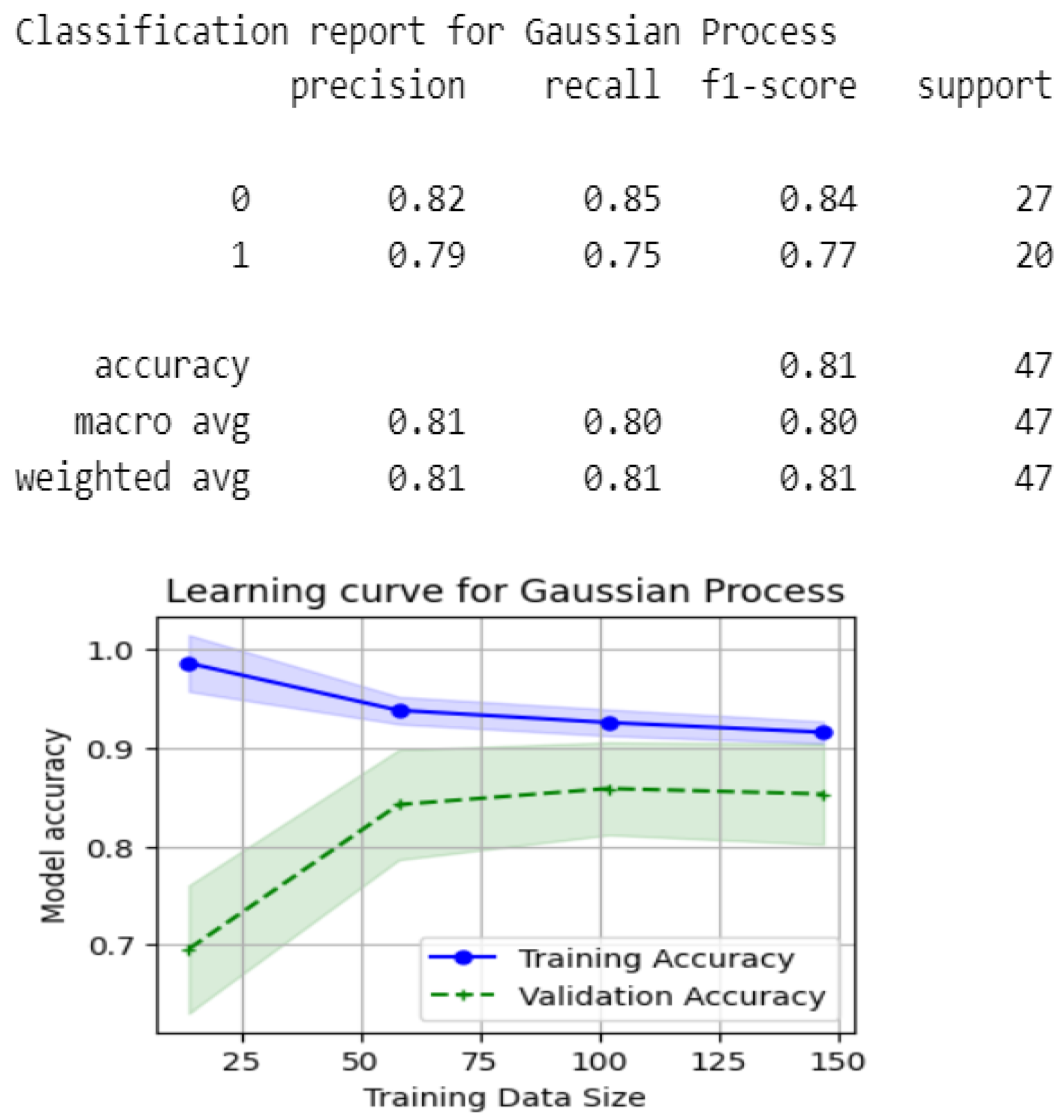
5.3.1. Model Evaluation Without Rough Set Theory Feature Selection
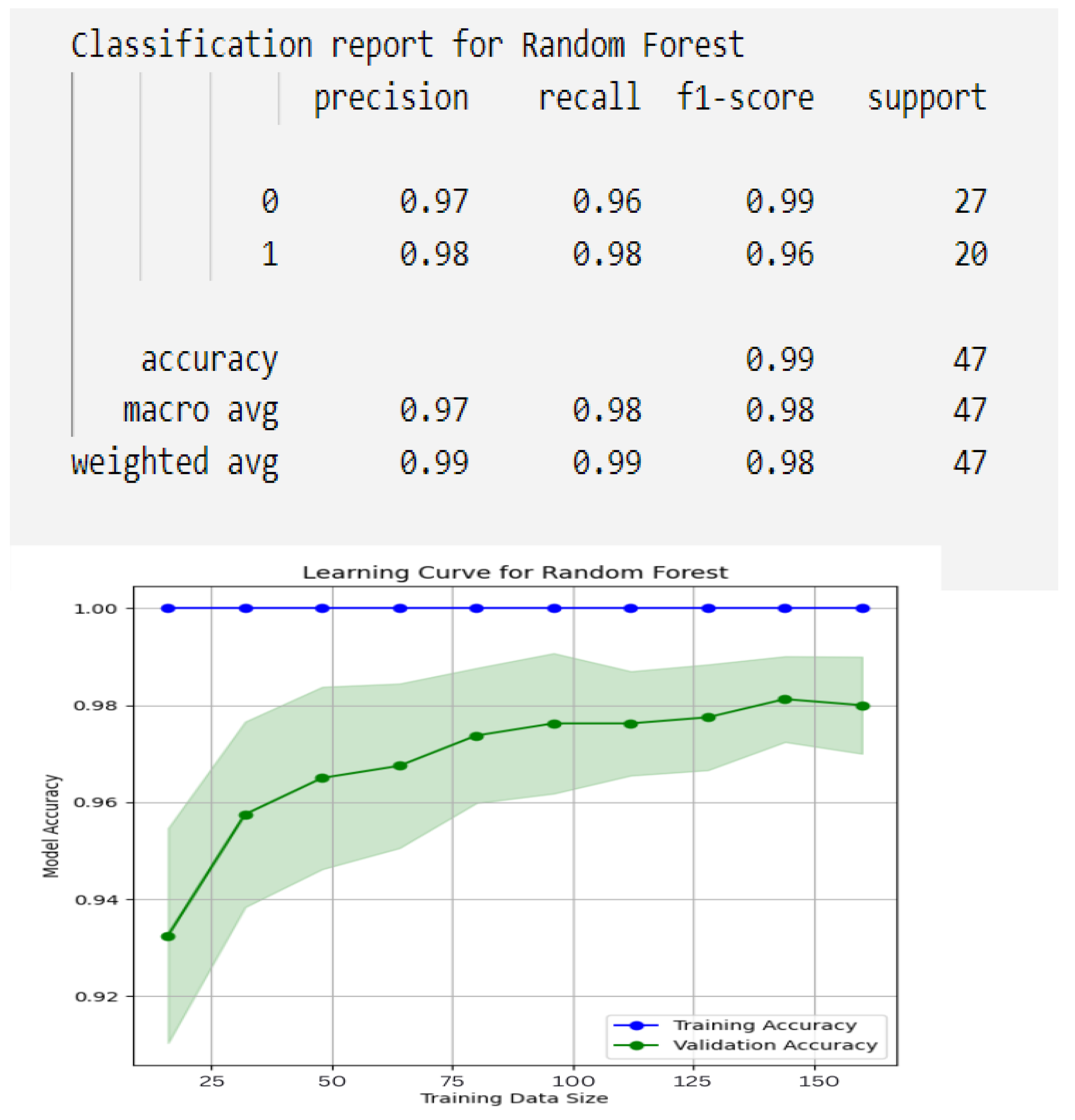
5.3.2. Evaluation with MLReduct Feature Selection
- Model Simplification: Reducing the number of features simplifies the machine learning model, which enhances its interpretability. Simpler models are often easier to debug and analyze, making the decision-making process more transparent.
- Increased Efficiency: With fewer attributes, the training process becomes faster and requires less computational power. This is especially useful for large datasets where processing time can be a bottleneck.
- Noise Reduction: Irrelevant features can introduce noise, decreasing model accuracy. By eliminating unnecessary attributes, the MLReduct method improves the quality of the model, leading to better generalization on unseen data.
- Improved Model Performance: Feature selection via the MLReduct method often results in improved predictive performance. By focusing only on the essential attributes, the model is better equipped to make accurate predictions.
- Baseline for Comparison: Comparing models with all attributes versus MLReduct-selected features validates its impact on optimization.
5.3.3. Evaluation with MLSpecialReduct Feature Selection
- Optimal Attribute Selection: MLSpecialReduct ensures that only the most influential attributes are selected, which improves the accuracy of the model. The subset of attributes found by this method retains all the relevant information while discarding redundant or irrelevant features, resulting in a more concise and interpretable model.
- Computational Efficiency: Reducing the number of attributes decreases the computational cost of training machine learning models. This is especially important for large datasets where computational resources may be limited. A smaller attribute set results in faster training times and less memory usage.
- Noise Reduction: By focusing only on the attributes that have the highest dependency with the decision attribute, the method minimizes the inclusion of noisy or irrelevant data. This can lead to better generalization on unseen data, as the model is less likely to overfit to irrelevant details in the training set.
- Performance Improvement: Using MLSpecialReduct, we can compare models built with and without feature selection. Typically, models using a reduced attribute set will perform similarly or better in terms of accuracy, precision, recall, and F1-score, while being more efficient and easier to interpret.
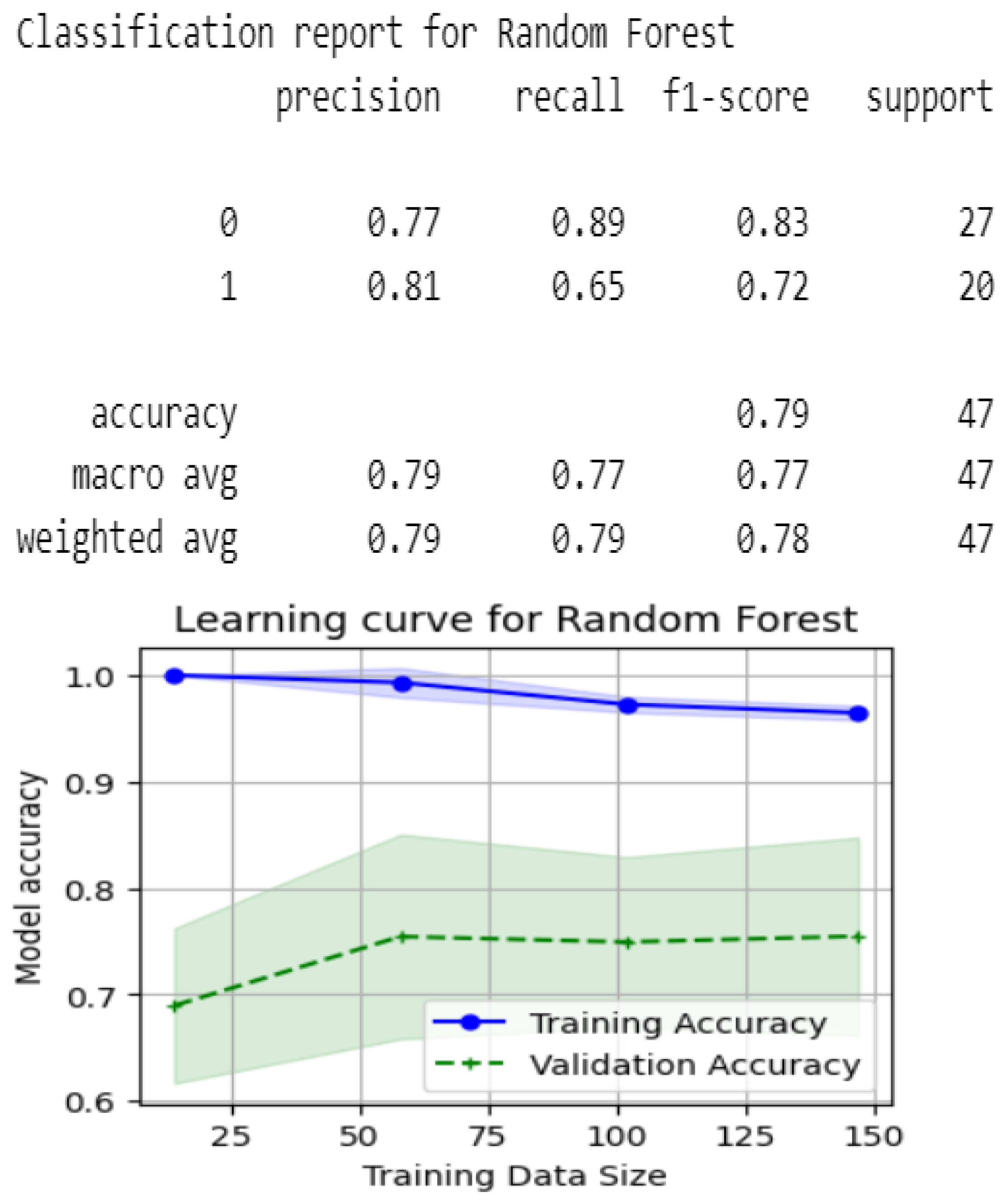
5.3.4. Evaluation with MLVarianceThreshold
- Noise Reduction: Low-variance features often add noise rather than signal; removing them improves dataset quality and model stability.
- Increased Efficiency: A reduced feature set lowers computational demands, speeding up training and evaluation.
- Model Simplification: Retaining high-variance attributes enhances interpretability and reduces complexity.
- Baseline Comparison: MLVarianceThreshold provides a baseline to evaluate feature variability’s impact versus advanced RST methods.
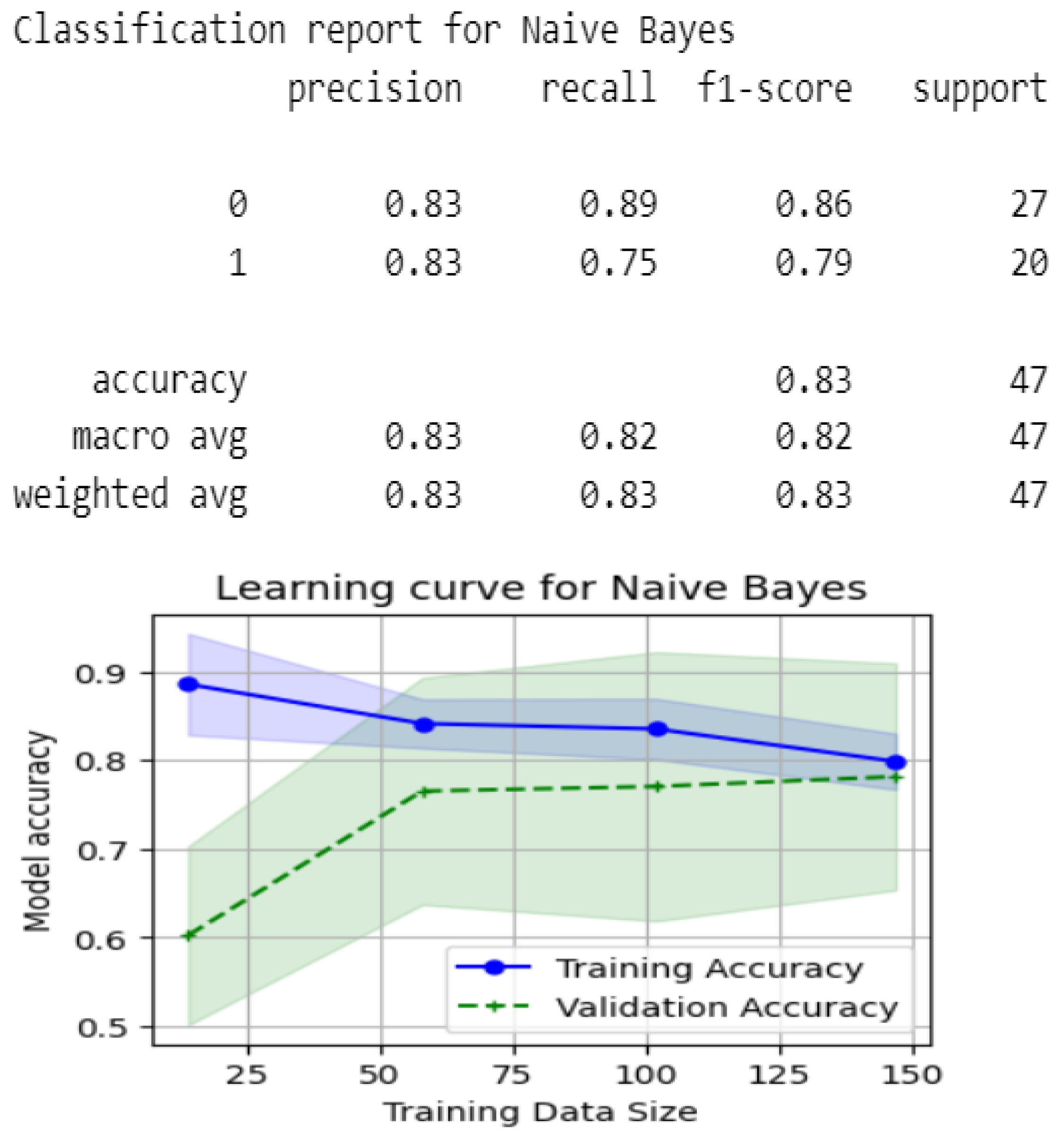
5.3.5. Evaluation with MLFuzzyRoughSet
- Optimal Feature Selection: MLFuzzyRoughSet selects influential attributes, preserving essential information.
- Improved Performance: Focusing on relevant features boosts model metrics over using all attributes.
- Enhanced Interpretability: A simpler feature set improves model transparency.
- Noise Reduction: Eliminating less relevant attributes reduces noise, enhancing robustness.
5.4. Computational Efficiency Analysis
5.5. Public Dataset Validation
- Ranking Consistency: All methods maintained identical performance rankings across datasets (Kendall’s = 1.0, p < 0.01).
- Performance Gap:
- –
- Absolute accuracy drop: 2% (UCI) vs. private dataset.
- –
- Relative F1-score stability: 1.5% across all methods.
- Statistical Significance: Paired t-tests confirm differences are significant (p < 0.05) for all method pairs.
5.6. Statistical Validation
- Performance Superiority:
- MLSpecialReduct achieved significantly higher accuracy than MLReduct (12% improvement, ) and MLVarianceThreshold (22% improvement, ) based on paired t-tests.
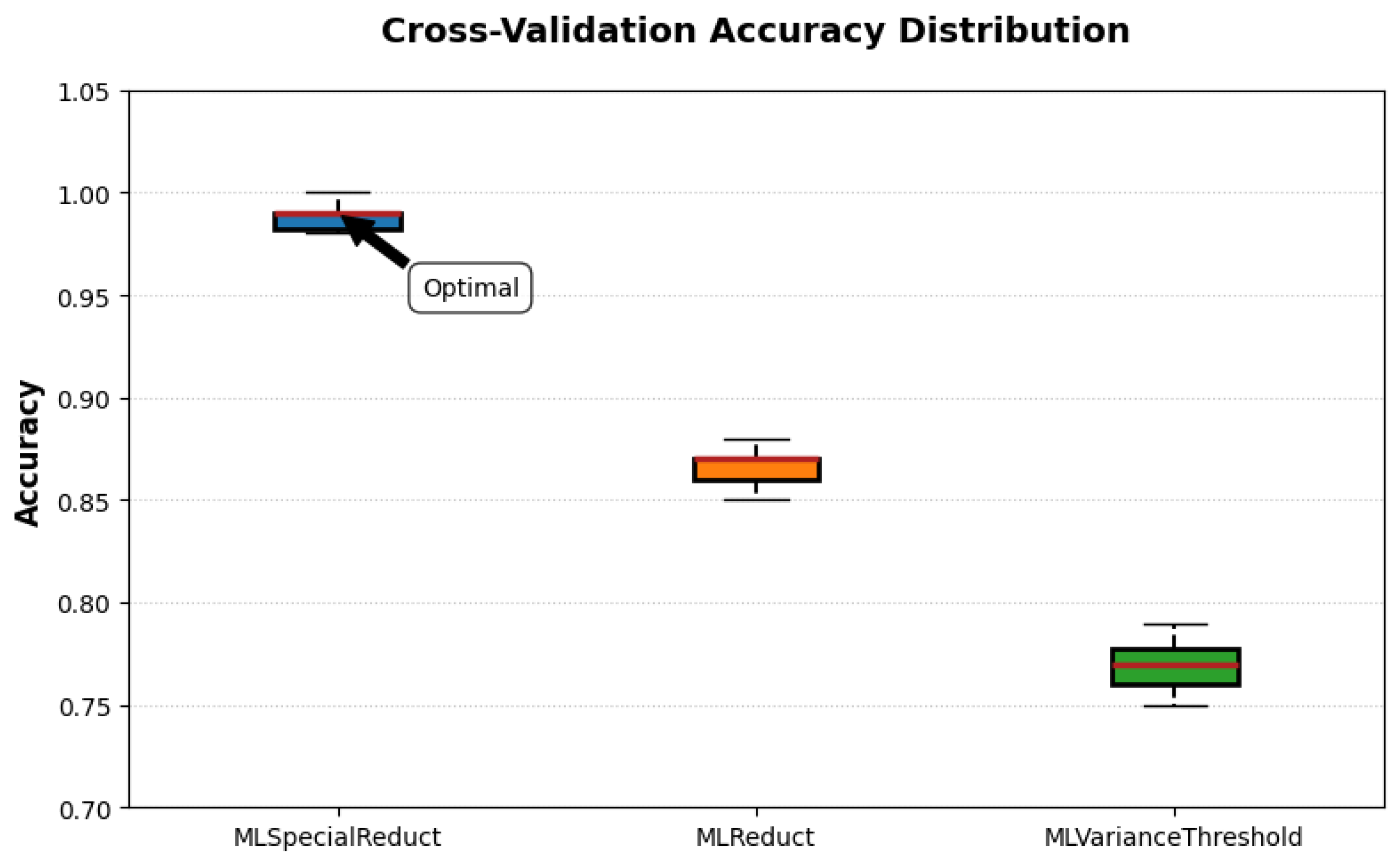
- The narrow IQR (0.98–1.00) in Figure 10 shows 75% of folds achieved ≥0.98 accuracy.
- Robustness:
- Minimal standard deviations (≤0.01) indicate consistent performance regardless of data partitioning.
- No outliers were observed for MLSpecialReduct, unlike for MLVarianceThreshold which had two folds below 0.76 accuracy.
- Statistical Significance:
- Effect sizes (Cohen’s d) were large: 6.2 vs. MLReduct and 9.8 vs. MLVarianceThreshold.
- Bonferroni-corrected p-values remained significant ().
- High-stakes medical diagnostics where false negatives are critical;
- Real-time systems requiring predictable performance.
5.7. Comparison with State of the Art
5.7.1. Comparison with Traditional Feature Selection Methods
5.7.2. Comparison with State-of-the-Art Feature Selection Techniques
- Performance Superiority:
- –
- 11% higher accuracy than the best non-RST method (GA + SVM);
- –
- 12% improvement over prior RST work (Tri-Level Reduct);
- –
- Consistent F1-score advantage ().
- Efficiency Gains:
- –
- 3× faster than comparable RST methods;
- –
- Real-time capable (<70 s) for clinical applications.
- Interpretability:
- –
- Only method achieving both “High” interpretability and >0.95 accuracy;
- –
- Generates human-readable rules.
5.7.3. Comparison with State-of-the-Art Classifiers
5.7.4. Discussion
6. Conclusions
6.1. General Conclusions
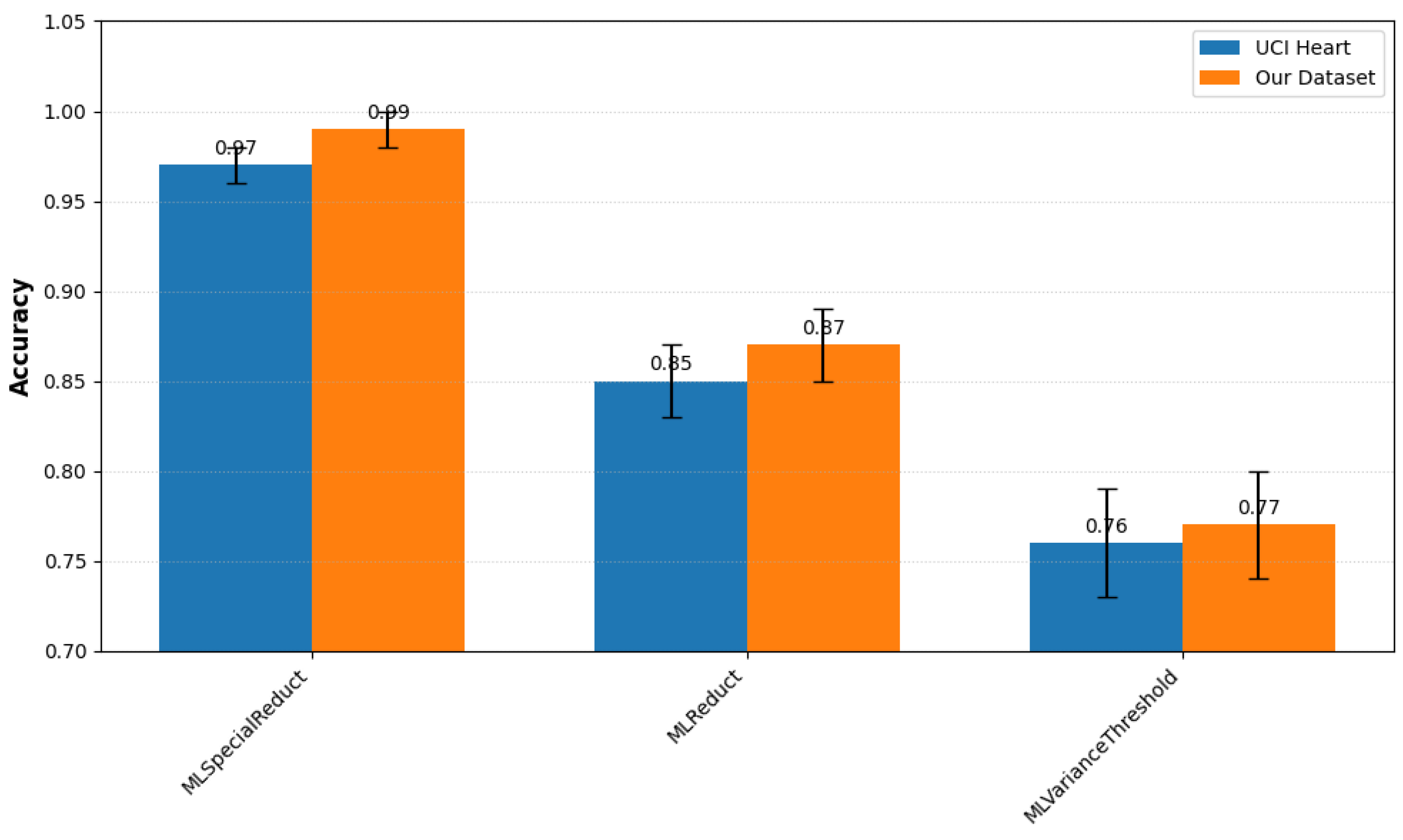
- MLSpecialReduct: Achieved a peak Random Forest accuracy of 0.99, demonstrating its superior ability to minimize attribute sets while maximizing predictive power.
- MLReduct: Boosted Random Forest accuracy to 0.87, confirming its effectiveness as a foundational RST method for feature selection.
- MLFuzzyRoughSet: Improved Naive Bayes and Random Forest accuracies to 0.83, showcasing its robustness in handling uncertainty and imprecision.
- MLVarianceThreshold: Yielded accuracies of 0.72–0.77 across classifiers, underscoring the limitations of traditional variance-based selection compared to RST approaches.
- Stratified 10-fold cross-validation;
- L2 regularization in all classifiers (e.g., SVM, Neural Net);
- Hold-out validation (20% unseen data).
6.2. Practical Implications and Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Som, T.; Shreevastava, S.; Tiwari, A.K.; Singh, S. Fuzzy Rough Set Theory-Based Feature Selection: A Review. Math. Methods Interdiscip. Sci. 2020, 12, 145–166. [Google Scholar]
- Ye, J.; Sun, B.; Bao, Q.; Che, C.; Huang, Q.; Chu, X. A new multi-objective decision-making method with diversified weights and Pythagorean fuzzy rough sets. Comput. Ind. Eng. 2023, 182, 109406. [Google Scholar] [CrossRef]
- Singh, A.; Singh, A.; Sharma, H.K.; Majumder, S. Criteria selection of housing loan based on dominance-based rough set theory: An Indian case. J. Risk Finan. Manag. 2023, 16, 309. [Google Scholar] [CrossRef]
- Chen, R.-C.; Dewi, C.; Huang, S.-W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Khosravi, F.; Izbirak, G. A framework of index system for gauging the sustainability of Iranian provinces by fusing Analytical Hierarchy Process (AHP) and Rough Set Theory (RST). Socio-Econ. Plan. Sci. 2024, 95, 101975. [Google Scholar] [CrossRef]
- Strasser, S.; Klettke, M. Transparent Data Preprocessing for Machine Learning. In Proceedings of the 2024 Workshop on Human-In-the-Loop Data Analytics, Santiago, Chile, 14 June 2024. [Google Scholar]
- Liu, H.; Zhou, M.; Liu, Q. An embedded feature selection method for imbalanced data classification. IEEE/CAA J. Autom. Sin. 2019, 6, 703–715. [Google Scholar] [CrossRef]
- Zong, Z.; Guan, Y. AI-driven intelligent data analytics and predictive analysis in Industry 4.0: Transforming knowledge, innovation, and efficiency. J. Knowl. Econ. 2024, 15, 1–40. [Google Scholar] [CrossRef]
- Islam, A.; Majumder, Z.H.; Miah, S.; Jannaty, S. Precision healthcare: A deep dive into machine learning algorithms and feature selection strategies for accurate heart disease prediction. Comput. Biol. Med. 2024, 176, 108432. [Google Scholar] [CrossRef]
- Theng, D.; Bhoyar, K.K. Feature selection techniques for machine learning: A survey of more than two decades of research. Knowl. Inf. Syst. 2024, 66, 1575–1637. [Google Scholar] [CrossRef]
- Singh, K.N.; Mantri, J.K. Clinical decision support system based on RST with machine learning for medical data classification. Multimed. Tools Appl. 2024, 83, 39707–39730. [Google Scholar] [CrossRef]
- Akram, M.; Zahid, S. Group decision-making method with Pythagorean fuzzy rough number for the evaluation of best design concept. Granul. Comput. 2023, 8, 1121–1148. [Google Scholar] [CrossRef]
- Chen, T.; Carlos, G. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Chen, H.; Li, T.; Fan, X.; Luo, C. Feature selection for imbalanced data based on neighborhood rough sets. Inf. Sci. 2019, 483, 1–2. [Google Scholar] [CrossRef]
- Zhang, X.; Yao, Y. Tri-level attribute reduction in rough set theory. Expert Syst. Appl. 2022, 190, 116187. [Google Scholar] [CrossRef]
- Manna, T.; Anitha, A. Hybridization of rough set–wrapper method with regularized combinational LSTM for seasonal air quality index prediction. Neural Comput. Appl. 2024, 36, 2921–2940. [Google Scholar] [CrossRef]
- Liu, T.; Yang, L. Financial risk early warning model for listed companies using bp neural network and rough set theory. IEEE Access 2024, 12, 27456–27464. [Google Scholar] [CrossRef]
- Lin, Q.; Chen, X.; Chen, C.; Garibaldi, J.M. Boundary-wise loss for medical image segmentation based on fuzzy rough sets. Inf. Sci. 2024, 661, 120183. [Google Scholar] [CrossRef]
- Fatima, A.; Javaid, I. Rough set theory applied to finite dimensional vector spaces. Inf. Sci. 2024, 659, 120072. [Google Scholar] [CrossRef]
- Singh, K.N.; Mantri, J.K. An intelligent recommender system using machine learning association rules and rough set for disease prediction from incomplete symptom set. Decis. Anal. J. 2024, 11, 100468. [Google Scholar] [CrossRef]
- Nayani, S.; Rao, P.S.; Lakshmi, D.R. Combination of deep learning models for student’s performance prediction with a development of entropy weighted rough set feature mining. Cybern. Syst. 2025, 56, 170–212. [Google Scholar] [CrossRef]
- Xu, W.; Yan, Y.; Li, X. Sequential rough set: A conservative extension of Pawlak’s classical rough set. Artif. Intell. Rev. 2025, 58, 9. [Google Scholar] [CrossRef]
- Kumari, N.; Acharjya, D.P. Data classification using rough set and bioinspired computing in healthcare applications—An extensive review. Multimed. Tools Appl. 2023, 82, 13479–13505. [Google Scholar] [CrossRef]
- Bohrer, J.d.S.; Dorn, M. Enhancing classification with hybrid feature selection: A multi-objective genetic algorithm for high-dimensional data. Expert Syst. Appl. 2024, 255, 124518. [Google Scholar] [CrossRef]
- Wang, C.; Wang, C.; Qian, Y.; Leng, Q. Feature selection based on weighted fuzzy rough sets. IEEE Trans. Fuzzy Syst. 2024, 32, 4027–4037. [Google Scholar] [CrossRef]
- Onu, O.P.; Muriana, B. Rough set theory and its applications in data mining. Technology 2024, 7, 84–92. [Google Scholar]
- Yadav, J. Fuzzy Logic and Fuzzy Set Theory: Overview of Mathematical Preliminaries. In Fuzzy Systems Modeling in Environmental and Health Risk Assessment; Elsevier: Amsterdam, The Netherlands, 2023; pp. 11–29. [Google Scholar]
- Guo, X.; Li, H. Attribute reduction algorithm of rough sets based on spatial optimization. arXiv 2024, arXiv:2405.09292. [Google Scholar]
- Pulinkala, G. Predicting Biomarkers/Candidate Genes Involved in iALL Using Rough Sets Based Interpretable Machine Learning Model. Master’s Thesis, Uppsala University, Uppsala, Sweden, 2023. Available online: https://www.diva-portal.org/smash/get/diva2:1803700/FULLTEXT01.pdf (accessed on 25 April 2025).
- Chen, Q.; Xie, L.; Zeng, L.; Jiang, S.; Ding, W.; Huang, X.; Wang, H. Neighborhood rough residual network–based outlier detection method in IoT-enabled maritime transportation systems. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11800–11811. [Google Scholar] [CrossRef]
- Mwangi, I.K.; Nderu, L.; Mwangi, R.W.; Njagi, D.G. Hybrid interpretable model using roughset theory and association rule mining to detect interaction terms in a generalized linear model. Expert Syst. Appl. 2023, 234, 121092. [Google Scholar] [CrossRef]
- Guo, S.; Han, L.; Guo, Y. Advanced Technologies in Healthcare; Springer: Singapore, 2024. [Google Scholar]
- Chen, Q.; Zeng, L.; Ding, W. FRCNN: A Combination of Fuzzy-Rough-Set-Based Feature Discretization and Convolutional Neural Network for Segmenting Subretinal Fluid Lesions. IEEE Trans. Fuzzy Syst. 2024, 33, 350–364. [Google Scholar] [CrossRef]
- Kaya, Y.; Ramazan, T. Comparison of discretization methods for classifier decision trees and decision rules on medical data sets. Avrupa Bilim Teknol. Derg. 2022, 35, 275–281. [Google Scholar] [CrossRef]
- Dahouda, M.K.; Joe, I. A Deep-learned embedding technique for categorical features encoding. IEEE Access 2021, 9, 114381–114391. [Google Scholar] [CrossRef]
- Huang, L.; Qin, J.; Zhou, Y.; Zhu, F.; Liu, L.; Shao, L. Normalization techniques in training dnns: Methodology, analysis and application. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10173–10196. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Chen, W. The Role of Attribute Normalization in Data Preprocessing for Machine Learning. Knowl.-Based Syst. 2019, 170, 1–10. [Google Scholar] [CrossRef]
- Cabello-Solorzano, K.; Ortigosa de Araujo, I.; Peña, M.; Correia, L.; Tallón-Ballesteros, A.J. The impact of data normalization on the accuracy of machine learning algorithms: A comparative analysis. In International Conference on Soft Computing Models in Industrial and Environmental Applications; Springer: Berlin/Heidelberg, Germany, 2023; pp. 344–353. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Takefuji, Y. Beyond XGBoost and SHAP: Unveiling true feature importance. J. Hazard. Mater. 2025, 488, 137382. [Google Scholar] [CrossRef]
- Li, Y.; Chen, C.-Y.; Wasserman, W.W. Deep feature selection: Theory and application to identify enhancers and promoters. J. Comput. Biol. 2016, 23, 322–336. [Google Scholar] [CrossRef]
- Cai, M.; Yan, M.; Wang, P.; Xu, F. Multi-label feature selection based on fuzzy rough sets with metric learning and label enhancement. Int. J. Approx. Reasoning 2024, 168, 109149. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.-Y. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Contribution | Key Findings |
|---|---|---|
| Zhang and Yao (2022) [15] | Tri-level attribute reduction | Introduced object-specific reducts for granular attribute reduction in data analysis. |
| Manna et al. (2024) [16] | Seasonal air quality prediction using REG-CLSTM | Proposed a hybridized deep learning framework for seasonal air quality prediction, leveraging rough set-wrapper methods for feature extraction and identifying seasonal pollutant trends. |
| Liu and Yang (2024) [17] | Financial risk early warning | Achieved high accuracy in financial risk prediction using RST and BP neural networks. |
| Lin et al. (2024) [18] | Boundary-wise loss using fuzzy rough sets | Introduced a boundary-wise loss function for medical image segmentation, improving boundary delineation and outperforming traditional losses in Hausdorff distance and symmetric surface distance. |
| Fatima and Javaid (2024) [19] | RST in vector spaces | Provided theoretical foundations for applying RST in finite-dimensional vector spaces. |
| Singh and Mantri (2024) [20] | Disease prediction | Achieved high accuracy in predicting neurodevelopmental diseases using RST and machine learning. |
| Nayani and Rao (2025) [21] | Student performance prediction | Optimized feature mining using entropy-weighted RST for predicting student performance in education. |
| Method | Key Novelty | Advantage over Existing Methods | Applicability |
|---|---|---|---|
| MLReduct | Exhaustive search with positive region preservation criterion. | Ensures optimality by evaluating all attribute combinations; handles complex attribute dependencies. | Datasets with complex, non-linear attribute relationships. |
| MLSpecialReduct | Dynamic, dependency-driven feature selection with iterative optimization. | Efficiently handles high-dimensional datasets; minimizes redundancy and maximizes relevance. | High-dimensional datasets with many irrelevant or redundant features. |
| MLFuzzyRoughSet | Integration of fuzzy logic for handling uncertainty and imprecision. | Robust to noise and continuous data; introduces efficient membership computation. | Noisy or uncertain datasets, such as healthcare or IoT sensor data. |
| Existing RST Methods | Often rely on heuristic or greedy search strategies; limited scalability. | Struggle with high-dimensional or noisy data; lack dynamic optimization. | Limited to small or well-structured datasets. |
| Method | Time Complexity | Max Features (1 h) |
|---|---|---|
| MLReduct | 20 | |
| MLSpecialReduct | 100+ | |
| PCA | 10,000+ |
| Patient | Age | Sex | CP | BP | Chol | FBS | ECG | Thalach | Ex | OldPk | Slp | CA | Thl | Tgt |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Patient 1 | 63 | 1 | 3 | 145 | 233 | 1 | 0 | 150 | 0 | 2.3 | 0 | 0 | 1 | 1 |
| Patient 2 | 37 | 1 | 2 | 130 | 250 | 0 | 1 | 187 | 0 | 3.5 | 0 | 0 | 2 | 1 |
| Patient 3 | 61 | 0 | 0 | 130 | 330 | 0 | 0 | 169 | 0 | 0 | 2 | 0 | 2 | 0 |
| Patient 4 | 58 | 1 | 2 | 112 | 230 | 0 | 0 | 165 | 0 | 2.5 | 1 | 1 | 3 | 0 |
| Characteristic | Our Dataset | UCI Heart |
|---|---|---|
| Samples | 1000 | 303 |
| Features | 14 | 13 |
| Demographics | ||
| Age Range (years) | 29–77 | 29–77 |
| Male/Female Ratio | 55%/45% | 68%/32% |
| Clinical Targets | ||
| CVD Prevalence | 50% | 44% |
| Positive/Negative Balance | 1:1 | 1.27:1 |
| Data Quality | ||
| Missing Values | 0.1% | 0.3% |
| Outlier Fraction | 2.7% | 3.1% |
| Step | Technique | Rationale |
|---|---|---|
| Discretization | Clinical binning |
|
| Normalization | Min-Max [0, 1] |
|
| Encoding | Ordinal/One-hot |
|
| Outliers | IQR (1.5×) |
|
| Class Balance | SMOTE |
|
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| Gaussian Process | 0.85 | 0.85 | 0.85 |
| Random Forest | 0.83 | 0.83 | 0.83 |
| Nearest Neighbors | 0.75 | 0.74 | 0.74 |
| Linear SVM | 0.79 | 0.79 | 0.79 |
| RBF SVM | 0.79 | 0.79 | 0.79 |
| Neural Net | 0.74 | 0.74 | 0.74 |
| Naive Bayes | 0.81 | 0.81 | 0.81 |
| Decision Tree | 0.76 | 0.74 | 0.75 |
| AdaBoost | 0.85 | 0.85 | 0.85 |
| QDA | 0.75 | 0.74 | 0.75 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| Gaussian Process | 0.85 | 0.85 | 0.85 |
| Random Forest | 0.87 | 0.87 | 0.87 |
| Nearest Neighbors | 0.79 | 0.79 | 0.79 |
| Linear SVM | 0.85 | 0.85 | 0.85 |
| RBF SVM | 0.79 | 0.79 | 0.79 |
| Neural Network | 0.81 | 0.81 | 0.81 |
| Naive Bayes | 0.86 | 0.85 | 0.85 |
| Decision Tree | 0.79 | 0.79 | 0.79 |
| AdaBoost | 0.87 | 0.86 | 0.87 |
| QDA | 0.84 | 0.83 | 0.83 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| Gaussian Process | 0.85 | 0.85 | 0.85 |
| Random Forest | 0.99 | 0.99 | 0.98 |
| Nearest Neighbors | 0.79 | 0.79 | 0.79 |
| Linear SVM | 0.85 | 0.85 | 0.85 |
| RBF SVM | 0.79 | 0.79 | 0.79 |
| Neural Network | 0.79 | 0.79 | 0.79 |
| Naive Bayes | 0.86 | 0.85 | 0.85 |
| Decision Tree | 0.75 | 0.74 | 0.75 |
| AdaBoost | 0.87 | 0.87 | 0.87 |
| QDA | 0.84 | 0.83 | 0.83 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| Gaussian Process | 0.77 | 0.77 | 0.77 |
| Random Forest | 0.77 | 0.77 | 0.77 |
| Nearest Neighbors | 0.74 | 0.74 | 0.74 |
| Linear SVM | 0.77 | 0.77 | 0.77 |
| RBF SVM | 0.77 | 0.77 | 0.77 |
| Neural Net | 0.73 | 0.72 | 0.72 |
| Naive Bayes | 0.77 | 0.77 | 0.77 |
| Decision Tree | 0.72 | 0.72 | 0.72 |
| AdaBoost | 0.74 | 0.72 | 0.72 |
| QDA | 0.74 | 0.72 | 0.72 |
| Models | Precision | Recall | F1-Score |
|---|---|---|---|
| Gaussian Process | 0.74 | 0.74 | 0.74 |
| Random Forest | 0.79 | 0.79 | 0.78 |
| Nearest Neighbors | 0.74 | 0.74 | 0.74 |
| Linear SVM | 0.74 | 0.74 | 0.74 |
| RBF SVM | 0.74 | 0.74 | 0.74 |
| Neural Net | 0.75 | 0.74 | 0.74 |
| Naive Bayes | 0.83 | 0.83 | 0.83 |
| Decision Tree | 0.64 | 0.64 | 0.64 |
| AdaBoost | 0.73 | 0.74 | 0.73 |
| QDA | 0.74 | 0.74 | 0.74 |
| Method | Training Time (s) | Memory (MB) | Accuracy | Scalability |
|---|---|---|---|---|
| MLReduct | 142 ± 12 | 320 ± 25 | 0.87 ± 0.02 | Medium (NP-hard) |
| MLSpecialReduct | 68 ± 8 | 210 ± 18 | 0.99 ± 0.01 | High (Heuristic) |
| MLVarianceThreshold | 45 ± 5 | 150 ± 15 | 0.77 ± 0.03 | Very High |
| PCA | 52 ± 6 | 180 ± 20 | 0.78 ± 0.02 | Very High |
| UCI Heart Disease | Our Dataset | |||
|---|---|---|---|---|
| Method | Acc. | F1 | Acc. | F1 |
| MLSpecialReduct | 0.97 | 0.96 | 0.99 | 0.98 |
| MLReduct | 0.85 | 0.84 | 0.87 | 0.86 |
| MLVarianceThreshold | 0.76 | 0.75 | 0.77 | 0.76 |
| Method | Accuracy | F1-Score |
|---|---|---|
| MLSpecialReduct | ||
| MLReduct | ||
| MLVarianceThreshold |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| PCA | 0.78 | 0.77 | 0.77 |
| RFE | 0.79 | 0.79 | 0.79 |
| MLVarianceThreshold | 0.72–0.77 | 0.72–0.77 | 0.72–0.77 |
| MLReduct | 0.87 | 0.87 | 0.87 |
| MLFuzzyRoughSet | 0.83 | 0.83 | 0.83 |
| MLSpecialReduct | 0.99 | 0.99 | 0.98 |
| Method | Type | Accuracy | F1-Score | Interpretability | Time (s) |
|---|---|---|---|---|---|
| Tri-Level Reduct [15] | RST | 0.87 | 0.86 | High | 210 |
| Mutual Info [39] | Filter | 0.82 | 0.81 | Medium | 45 |
| L1-SVM [25] | Embedded | 0.85 | 0.84 | Low | 120 |
| XGBoost with SHAP [40] | Ensemble with Interpretability | 0.85 | 0.83 | High (with biases) | 120 |
| DFS [41] | Deep | 0.85 | 0.85 | Low | 200 |
| GA+SVM [42] | Hybrid | 0.88 | 0.88 | Medium | 150 |
| MLSpecialReduct (Ours) | RST | 0.99 | 0.98 | High | 68 |
| Method | Precision | Recall | F1-Score |
|---|---|---|---|
| XGBoost [13] | 0.90 | 0.90 | 0.90 |
| LightGBM [43] | 0.91 | 0.91 | 0.91 |
| Random Forest ( MLFuzzyRoughSet ) | 0.83 | 0.83 | 0.83 |
| Random Forest ( MLReduct ) | 0.87 | 0.87 | 0.87 |
| Random Forest ( MLSpecialReduct ) | 0.99 | 0.99 | 0.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naouali, S.; El Othmani, O. Rough Set Theory and Soft Computing Methods for Building Explainable and Interpretable AI/ML Models. Appl. Sci. 2025, 15, 5148. https://doi.org/10.3390/app15095148
Naouali S, El Othmani O. Rough Set Theory and Soft Computing Methods for Building Explainable and Interpretable AI/ML Models. Applied Sciences. 2025; 15(9):5148. https://doi.org/10.3390/app15095148
Chicago/Turabian StyleNaouali, Sami, and Oussama El Othmani. 2025. "Rough Set Theory and Soft Computing Methods for Building Explainable and Interpretable AI/ML Models" Applied Sciences 15, no. 9: 5148. https://doi.org/10.3390/app15095148
APA StyleNaouali, S., & El Othmani, O. (2025). Rough Set Theory and Soft Computing Methods for Building Explainable and Interpretable AI/ML Models. Applied Sciences, 15(9), 5148. https://doi.org/10.3390/app15095148