
ECE-TTS: A Zero-Shot Emotion Text-to-Speech Model with Simplified and Precise Control


Abstract
1. Introduction
2. ECE-TTS
2.1. Modeling Principles
2.1.1. Flow Matching-Based TTS
2.1.2. Classifier-Guided and Classifier-Free Guidance
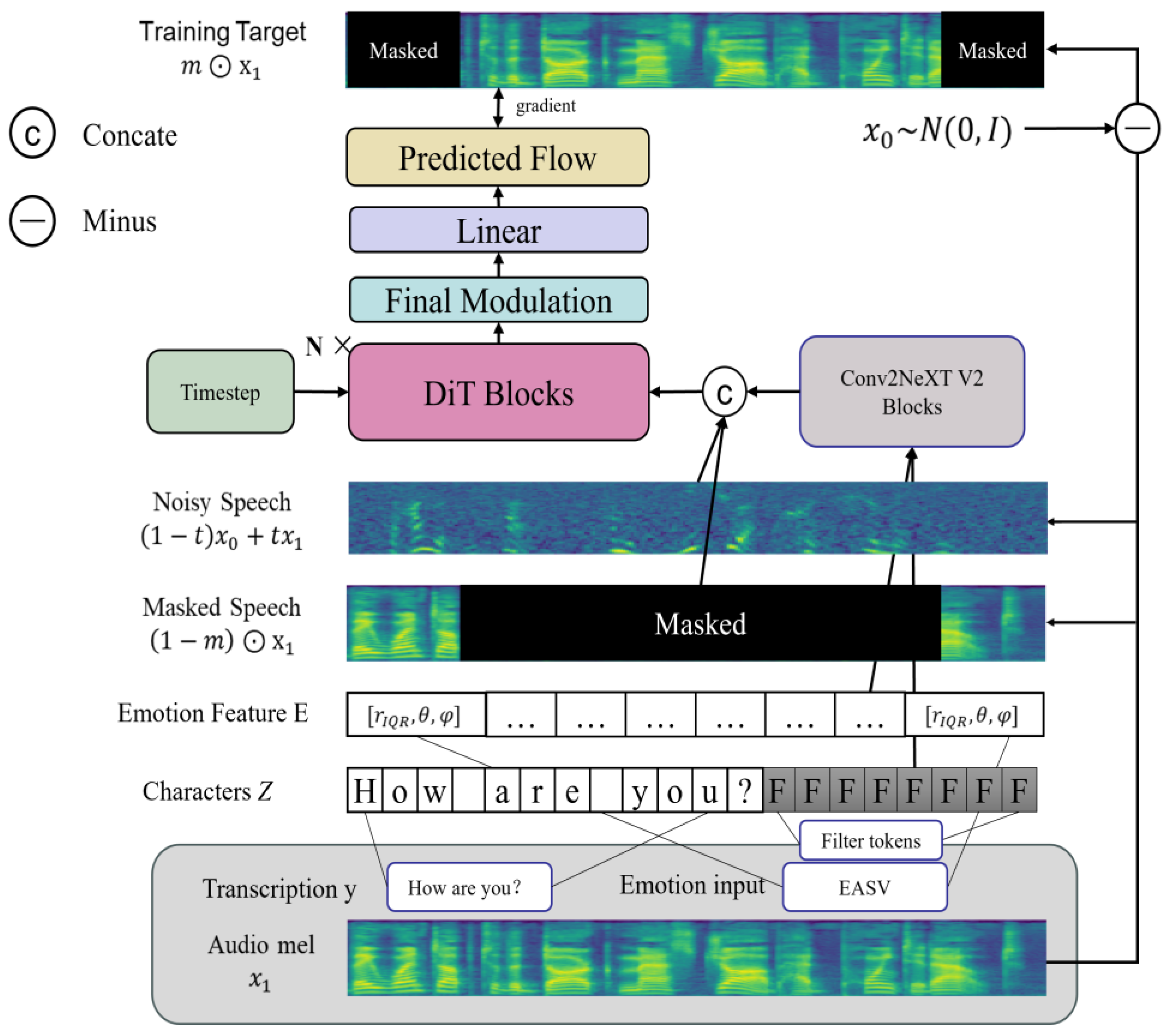
2.2. Model Architecture
2.2.1. Model Training
2.2.2. Model Inference
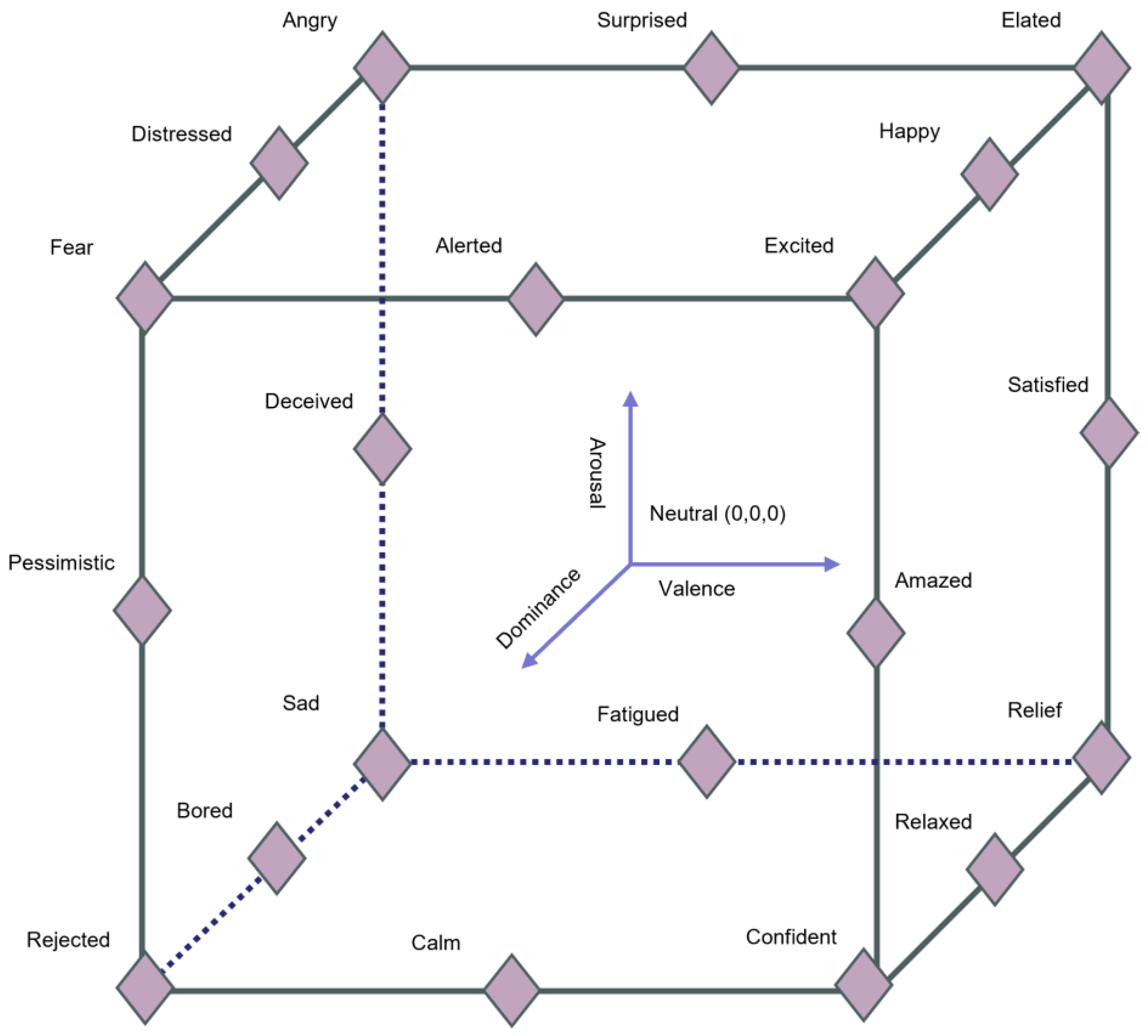
2.3. Emotion Control Strategy
2.3.1. Emotion Style Adjustment Through Adaptive Coordinate Transformation
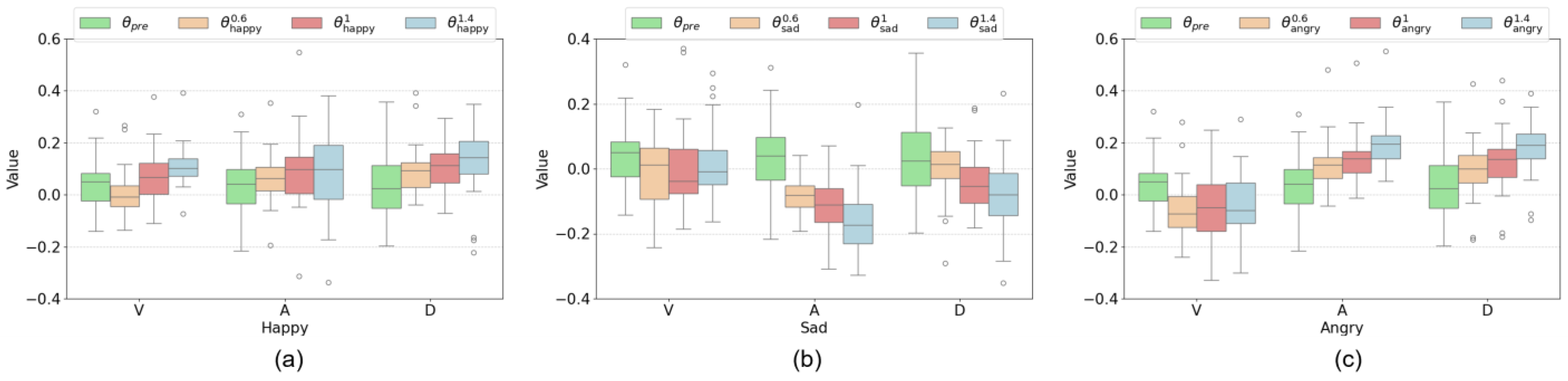
2.3.2. Emotion Intensity Modulation via Emotion Arithmetic
3. Experiments
3.1. Data
3.1.1. Training Data
3.1.2. Evaluation Data
3.2. Experimental Setup
3.2.1. Model Configuration
3.2.2. Hardware and Software Setup
3.3. Evaluation Metrics
3.3.1. Objective Metrics
3.3.2. Subjective Metrics
3.4. Results and Analyze
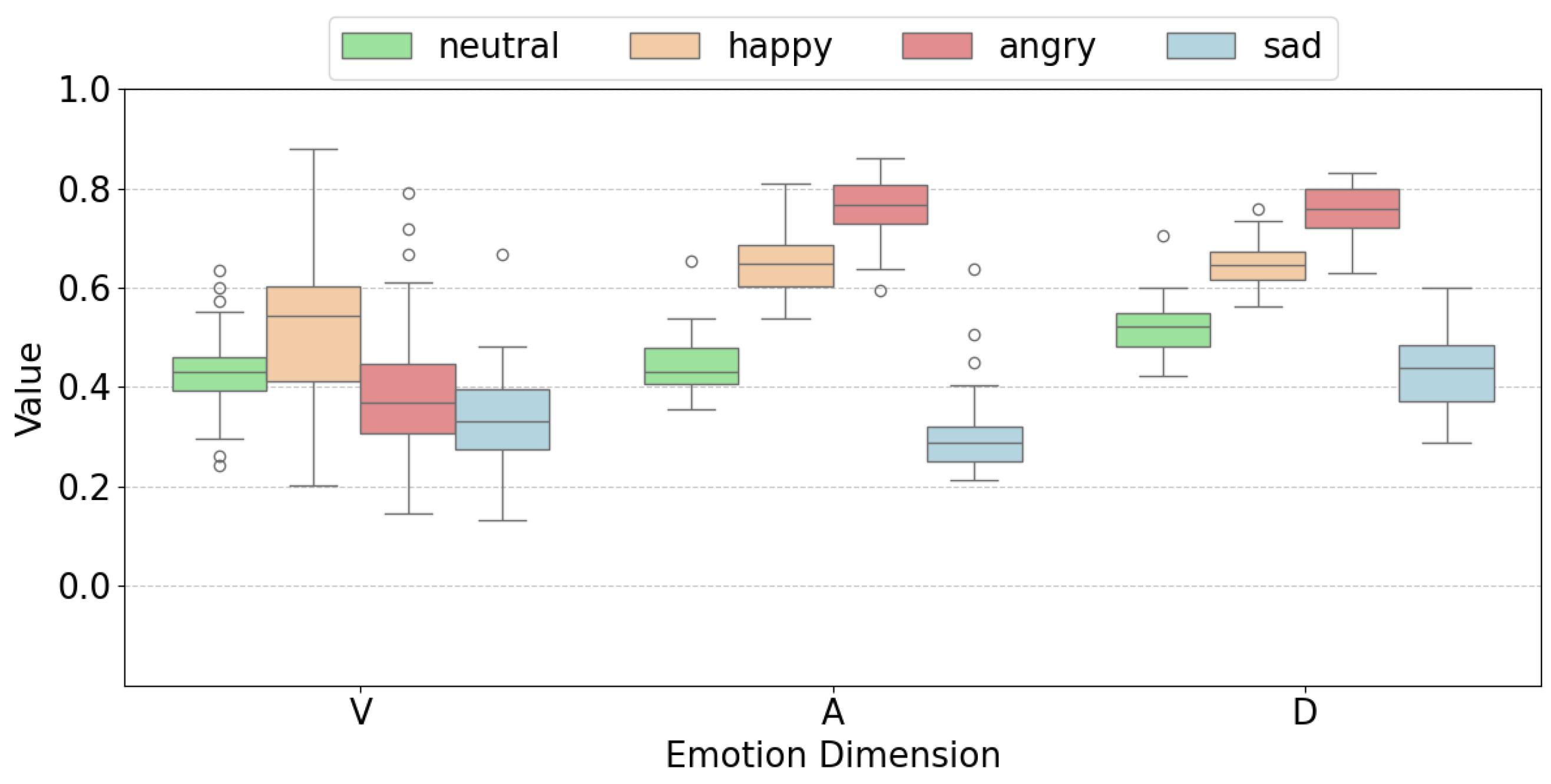
3.4.1. Results of Emotion Style Control Experiment
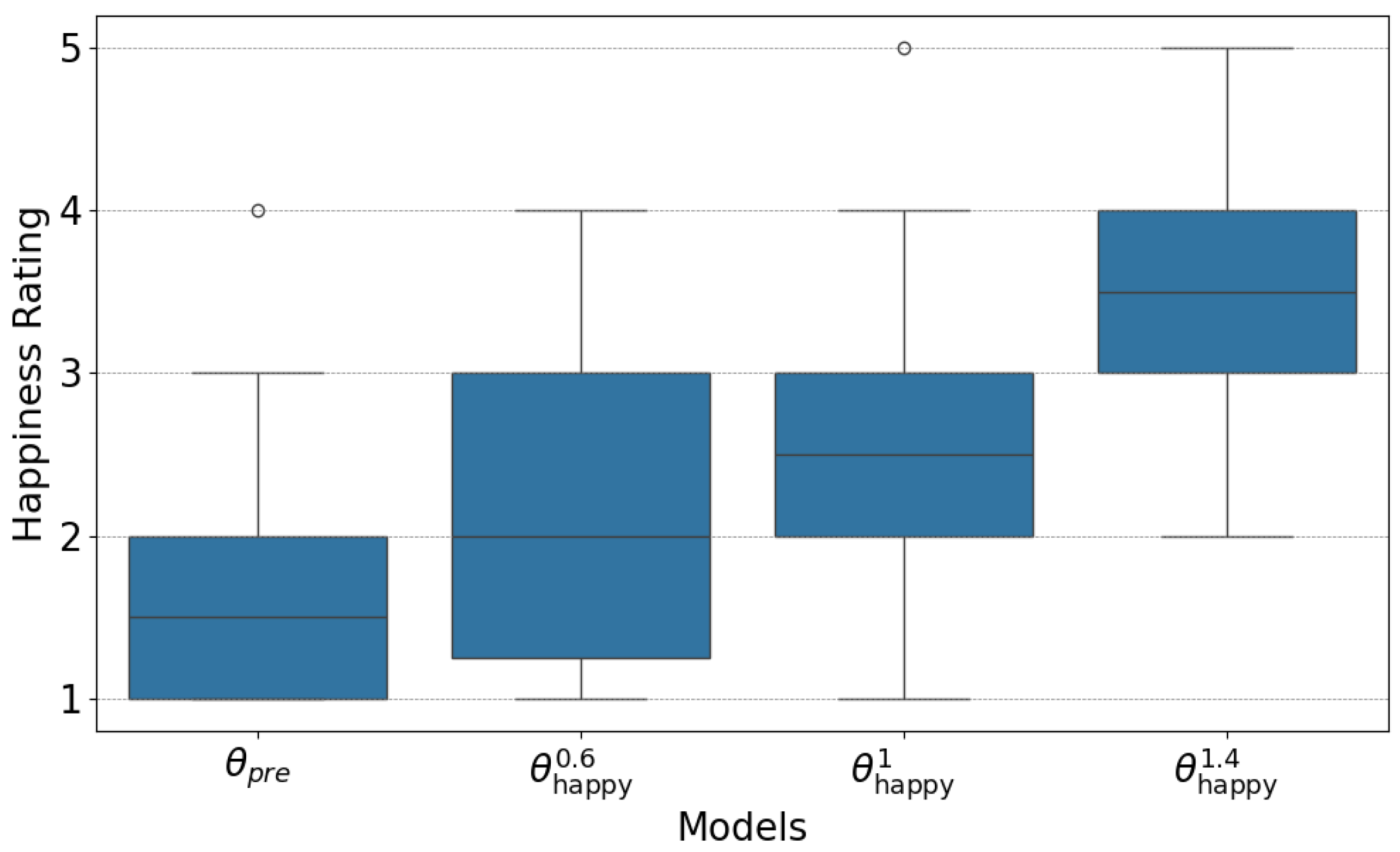
3.4.2. Results of Emotion Intensity Control Experiment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Shen, K.; Ju, Z.; Tan, X.; Liu, Y.; Leng, Y.; He, L.; Qin, T.; Zhao, S.; Bian, J. Naturalspeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers. arXiv 2023, arXiv:2304.09116. [Google Scholar]
- Ju, Z.; Wang, Y.; Shen, K.; Tan, X.; Xin, D.; Yang, D.; Liu, Y.; Leng, Y.; Song, K.; Tang, S.; et al. Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models. arXiv 2024, arXiv:2403.03100. [Google Scholar]
- Lee, S.H.; Choi, H.Y.; Kim, S.B.; Lee, S.W. Hierspeech++: Bridging the gap between semantic and acoustic representation of speech by hierarchical variational inference for zero-shot speech synthesis. arXiv 2023, arXiv:2311.12454. [Google Scholar]
- Mehta, S.; Tu, R.; Beskow, J.; Székely, É.; Henter, G.E. Matcha-TTS: A fast TTS architecture with conditional flow matching. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 11341–11345. [Google Scholar]
- Wang, Y.; Zhan, H.; Liu, L.; Zeng, R.; Guo, H.; Zheng, J.; Zhang, Q.; Zhang, X.; Zhang, S.; Wu, Z. Maskgct: Zero-shot text-to-speech with masked generative codec transformer. arXiv 2024, arXiv:2409.00750. [Google Scholar]
- Anastassiou, P.; Chen, J.; Chen, J.; Chen, Y.; Chen, Z.; Chen, Z.; Cong, J.; Deng, L.; Ding, C.; Gao, L.; et al. Seed-tts: A family of high-quality versatile speech generation models. arXiv 2024, arXiv:2406.02430. [Google Scholar]
- Chen, Y.; Niu, Z.; Ma, Z.; Deng, K.; Wang, C.; Zhao, J.; Yu, K.; Chen, X. F5-tts: A fairytale that fakes fluent and faithful speech with flow matching. arXiv 2024, arXiv:2410.06885. [Google Scholar]
- Triantafyllopoulos, A.; Schuller, B.W. Expressivity and speech synthesis. arXiv 2024, arXiv:2404.19363. [Google Scholar]
- Zhao, W.; Yang, Z. An emotion speech synthesis method based on vits. Appl. Sci. 2023, 13, 2225. [Google Scholar] [CrossRef]
- Jung, W.; Lee, J. E3-VITS: Emotional End-to-End TTS with Cross-Speaker Style Transfer. Available online: https://openreview.net/pdf?id=qL47xtuEuv (accessed on 27 April 2025).
- Casanova, E.; Weber, J.; Shulby, C.D.; Junior, A.C.; Gölge, E.; Ponti, M.A. Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone. In Proceedings of the International Conference on Machine Learning, PMLR, Baltimore, MD, USA, 17–23 July 2022; pp. 2709–2720. [Google Scholar]
- Kim, J.; Kong, J.; Son, J. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech. In Proceedings of the International Conference on Machine Learning, PMLR, Online, 18–24 July 2021; pp. 5530–5540. [Google Scholar]
- Huang, R.; Ren, Y.; Liu, J.; Cui, C.; Zhao, Z. Generspeech: Towards style transfer for generalizable out-of-domain text-to-speech. Adv. Neural Inf. Process. Syst. 2022, 35, 10970–10983. [Google Scholar]
- Cho, D.H.; Oh, H.S.; Kim, S.B.; Lee, S.H. EmoSphere-TTS: Emotional style and intensity modeling via spherical emotion vector for controllable emotional text-to-speech. arXiv 2024, arXiv:2406.07803. [Google Scholar]
- Ren, Y.; Hu, C.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.Y. Fastspeech 2: Fast and high-quality end-to-end text to speech. arXiv 2020, arXiv:2006.04558. [Google Scholar]
- Peebles, W.; Xie, S. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4195–4205. [Google Scholar]
- Lee, K.; Kim, D.W.; Kim, J.; Cho, J. Ditto-tts: Efficient and scalable zero-shot text-to-speech with diffusion transformer. arXiv 2024, arXiv:2406.11427. [Google Scholar]
- Eskimez, S.E.; Wang, X.; Thakker, M.; Li, C.; Tsai, C.H.; Xiao, Z.; Yang, H.; Zhu, Z.; Tang, M.; Tan, X.; et al. E2 tts: Embarrassingly easy fully non-autoregressive zero-shot tts. In Proceedings of the 2024 IEEE Spoken Language Technology Workshop (SLT), Macao, China, 2–5 December 2024; pp. 682–689. [Google Scholar]
- Liu, Z.; Wang, S.; Zhu, P.; Bi, M.; Li, H. E1 tts: Simple and fast non-autoregressive tts. arXiv 2024, arXiv:2409.09351. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.S.; Xie, S. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16133–16142. [Google Scholar]
- Lee, Y.; Rabiee, A.; Lee, S.Y. Emotional end-to-end neural speech synthesizer. arXiv 2017, arXiv:1711.05447. [Google Scholar]
- Tits, N.; El Haddad, K.; Dutoit, T. Exploring transfer learning for low resource emotional tts. In Intelligent Systems and Applications, Proceedings of the 2019 Intelligent Systems Conference (IntelliSys), London, UK, 5–6 September 2019; Springer: Berlin/Heidelberg, Germany, 2020; Volume 1, pp. 52–60. [Google Scholar]
- Tits, N.; Wang, F.; Haddad, K.E.; Pagel, V.; Dutoit, T. Visualization and interpretation of latent spaces for controlling expressive speech synthesis through audio analysis. arXiv 2019, arXiv:1903.11570. [Google Scholar]
- Wang, Y.; Skerry-Ryan, R.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards end-to-end speech synthesis. arXiv 2017, arXiv:1703.10135. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerry-Ryan, R.; et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 4779–4783. [Google Scholar]
- Skerry-Ryan, R.; Battenberg, E.; Xiao, Y.; Wang, Y.; Stanton, D.; Shor, J.; Weiss, R.; Clark, R.; Saurous, R.A. Towards end-to-end prosody transfer for expressive speech synthesis with tacotron. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4693–4702. [Google Scholar]
- Triantafyllopoulos, A.; Schuller, B.W.; İyimen, G.; Sezgin, M.; He, X.; Yang, Z.; Tzirakis, P.; Liu, S.; Mertes, S.; André, E.; et al. An overview of affective speech synthesis and conversion in the deep learning era. Proc. IEEE 2023, 111, 1355–1381. [Google Scholar] [CrossRef]
- Jing, Y.; Yang, Y.; Feng, Z.; Ye, J.; Yu, Y.; Song, M. Neural style transfer: A review. IEEE Trans. Vis. Comput. Graph. 2019, 26, 3365–3385. [Google Scholar] [CrossRef]
- Wang, Y.; Stanton, D.; Zhang, Y.; Ryan, R.S.; Battenberg, E.; Shor, J.; Xiao, Y.; Jia, Y.; Ren, F.; Saurous, R.A. Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 5180–5189. [Google Scholar]
- Wu, H.; Wang, X.; Eskimez, S.E.; Thakker, M.; Tompkins, D.; Tsai, C.H.; Li, C.; Xiao, Z.; Zhao, S.; Li, J.; et al. Laugh Now Cry Later: Controlling Time-Varying Emotional States of Flow-Matching-Based Zero-Shot Text-To-Speech. In Proceedings of the 2024 IEEE Spoken Language Technology Workshop (SLT), Macao, China, 2–5 December 2024; pp. 690–697. [Google Scholar]
- Inoue, S.; Zhou, K.; Wang, S.; Li, H. Hierarchical emotion prediction and control in text-to-speech synthesis. In Proceedings of the ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 10601–10605. [Google Scholar]
- Inoue, S.; Zhou, K.; Wang, S.; Li, H. Fine-grained quantitative emotion editing for speech generation. In Proceedings of the 2024 Asia Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Macao, China, 3–6 December 2024; pp. 1–6. [Google Scholar]
- Russell, J.A. A circumplex model of affect. J. Personal. Soc. Psychol. 1980, 39, 1161. [Google Scholar] [CrossRef]
- Wagner, J.; Triantafyllopoulos, A.; Wierstorf, H.; Schmitt, M.; Burkhardt, F.; Eyben, F.; Schuller, B.W. Dawn of the transformer era in speech emotion recognition: Closing the valence gap. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10745–10759. [Google Scholar] [CrossRef]
- Cho, D.H.; Oh, H.S.; Kim, S.B.; Lee, S.W. EmoSphere++: Emotion-Controllable Zero-Shot Text-to-Speech via Emotion-Adaptive Spherical Vector. arXiv 2024, arXiv:2411.02625. [Google Scholar] [CrossRef]
- Zhou, K.; Sisman, B.; Rana, R.; Schuller, B.W.; Li, H. Emotion intensity and its control for emotional voice conversion. IEEE Trans. Affect. Comput. 2022, 14, 31–48. [Google Scholar] [CrossRef]
- Parikh, D.; Grauman, K. Relative attributes. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 503–510. [Google Scholar]
- Zhu, X.; Yang, S.; Yang, G.; Xie, L. Controlling emotion strength with relative attribute for end-to-end speech synthesis. In Proceedings of the 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Singapore, 14–18 December 2019; pp. 192–199. [Google Scholar]
- Lei, Y.; Yang, S.; Xie, L. Fine-grained emotion strength transfer, control and prediction for emotional speech synthesis. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; pp. 423–430. [Google Scholar]
- Schnell, B.; Garner, P.N. Improving emotional TTS with an emotion intensity input from unsupervised extraction. In Proceedings of the 11th ISCA Speech Synthesis Workshop, Budapest, Hungary, 26–28 August 2021; pp. 60–65. [Google Scholar]
- Lei, Y.; Yang, S.; Wang, X.; Xie, L. Msemotts: Multi-scale emotion transfer, prediction, and control for emotional speech synthesis. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 30, 853–864. [Google Scholar] [CrossRef]
- Zhou, K.; Sisman, B.; Rana, R.; Schuller, B.W.; Li, H. Speech synthesis with mixed emotions. IEEE Trans. Affect. Comput. 2022, 14, 3120–3134. [Google Scholar] [CrossRef]
- Um, S.Y.; Oh, S.; Byun, K.; Jang, I.; Ahn, C.; Kang, H.G. Emotional speech synthesis with rich and granularized control. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7254–7258. [Google Scholar]
- Im, C.B.; Lee, S.H.; Kim, S.B.; Lee, S.W. Emoq-tts: Emotion intensity quantization for fine-grained controllable emotional text-to-speech. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Online, 7–13 May 2022; pp. 6317–6321. [Google Scholar]
- Guo, Y.; Du, C.; Chen, X.; Yu, K. Emodiff: Intensity controllable emotional text-to-speech with soft-label guidance. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Kalyan, P.; Rao, P.; Jyothi, P.; Bhattacharyya, P. Emotion arithmetic: Emotional speech synthesis via weight space interpolation. In Proceedings of the Interspeech 2024, Kos Island, Greece, 1–5 September 2024; pp. 1805–1809. [Google Scholar]
- Ekman, P.; Friesen, W.V. Constants across cultures in the face and emotion. J. Personal. Soc. Psychol. 1971, 17, 124–129. [Google Scholar] [CrossRef]
- Zhou, K.; Sisman, B.; Liu, R.; Li, H. Emotional voice conversion: Theory, databases and esd. Speech Commun. 2022, 137, 1–18. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Nguyen, T.A.; Hsu, W.N.; d’Avirro, A.; Shi, B.; Gat, I.; Fazel-Zarani, M.; Remez, T.; Copet, J.; Synnaeve, G.; Hassid, M.; et al. Expresso: A benchmark and analysis of discrete expressive speech resynthesis. arXiv 2023, arXiv:2308.05725. [Google Scholar]
- Plutchik, R. The nature of emotions: Human emotions have deep evolutionary roots, a fact that may explain their complexity and provide tools for clinical practice. Am. Sci. 2001, 89, 344–350. [Google Scholar] [CrossRef]
- Ho, J.; Salimans, T. Classifier-free diffusion guidance. arXiv 2023, arXiv:2207.12598. [Google Scholar]
- Lipman, Y.; Chen, R.T.; Ben-Hamu, H.; Nickel, M.; Le, M. Flow matching for generative modeling. arXiv 2022, arXiv:2210.02747. [Google Scholar]
- Le, M.; Vyas, A.; Shi, B.; Bakhturina, E.; Kim, M.; Min, S.; Lee, J.; Mustafa, B.; Pang, R.; Tur, G.; et al. Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale. Adv. Neural Inf. Process. Syst. 2023, 36, 14005–14034. [Google Scholar]
- Chen, R.T.; Rubanova, Y.; Bettencourt, J.; Duvenaud, D.K. Neural ordinary differential equations. Adv. Neural Inf. Process. Syst. 2018, 31, 1–13. [Google Scholar] [CrossRef]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Liu, S.; Su, D.; Yu, D. Diffgan-tts: High-fidelity and efficient text-to-speech with denoising diffusion gans. arXiv 2022, arXiv:2201.11972. [Google Scholar]
- Li, W.; Minematsu, N.; Saito, D. WET: A Wav2vec 2.0-Based Emotion Transfer Method for Improving the Expressiveness of Text-to-Speech. In Proceedings of the Speech Prosody 2024, Leiden, The Netherlands, 2–5 July 2024; pp. 1235–1239. [Google Scholar]
- Ma, Z.; Zheng, Z.; Ye, J.; Li, J.; Gao, Z.; Zhang, S.; Chen, X. emotion2vec: Self-supervised pre-training for speech emotion representation. arXiv 2023, arXiv:2312.15185. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 28492–28518. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Voice Quality | Specification |
|---|---|
| Data Size | 200 h |
| Language | English |
| Emotion Classes | Neutral, Happy, Angry, Sad, Disgusted, Excited, Fearful |
| Emotion Annotation Model | Emo2vec |
| Transcription Model | Whisper-Large |
| Component | Configuration |
|---|---|
| Processor | AMD EPYC 7F72 24-Core Processor |
| GPU | NVIDIA A100 80 GB |
| Operating System | Ubuntu 20.04 LTS (64-bit) |
| CUDA Version | 12.2 |
| PyTorch Version | 2.5.1 + cu124 |
| Programming Language | Python 3.10 |
| Voice Quality | MOS Evaluation Criteria | Score |
|---|---|---|
| Very Good | Clear, natural voice with smooth communication. | 5 |
| Good | Mostly clear, slight difficulty due to mild noise. | 4 |
| Medium | Somewhat unclear, but communication is possible. | 3 |
| Bad | Unclear, requires repetition, with noticeable delay. | 2 |
| Very Bad | Unintelligible, very difficult to understand. | 1 |
| Method | SMOS | NMOS | EMOS |
|---|---|---|---|
| GT | 4.02 ± 0.06 | 4.07 ± 0.06 | 4.10 ± 0.06 |
| Generspeech [13] | 3.84 ± 0.07 | 3.96 ± 0.07 | 3.85 ± 0.08 |
| EmoSphere++ [35] | 3.91 ± 0.08 | 3.98 ± 0.07 | 3.86 ± 0.07 |
| ECE-TTS | 3.93 ± 0.07 | 3.98 ± 0.07 | 3.94 ± 0.06 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, S.; Zhou, R.; Yuan, Q. ECE-TTS: A Zero-Shot Emotion Text-to-Speech Model with Simplified and Precise Control. Appl. Sci. 2025, 15, 5108. https://doi.org/10.3390/app15095108
Liang S, Zhou R, Yuan Q. ECE-TTS: A Zero-Shot Emotion Text-to-Speech Model with Simplified and Precise Control. Applied Sciences. 2025; 15(9):5108. https://doi.org/10.3390/app15095108
Chicago/Turabian StyleLiang, Shixiong, Ruohua Zhou, and Qingsheng Yuan. 2025. "ECE-TTS: A Zero-Shot Emotion Text-to-Speech Model with Simplified and Precise Control" Applied Sciences 15, no. 9: 5108. https://doi.org/10.3390/app15095108
APA StyleLiang, S., Zhou, R., & Yuan, Q. (2025). ECE-TTS: A Zero-Shot Emotion Text-to-Speech Model with Simplified and Precise Control. Applied Sciences, 15(9), 5108. https://doi.org/10.3390/app15095108