

CLSTM-MT (a Combination of 2-Conv CNN and BiLSTM Under the Mean Teacher Collaborative Learning Framework): Encryption Traffic Classification Based on CLSTM (a Combination of 2-Conv CNN and BiLSTM) and Mean Teacher Collaborative Learning



Abstract
1. Introduction
2. Related Work
2.1. Rule-Based Methods
2.2. Statistical-Feature-Based Methods
2.3. Machine-Learning-Based Methods
2.4. Deep-Learning-Based Methods
2.5. Semi-Supervised Learning Methods
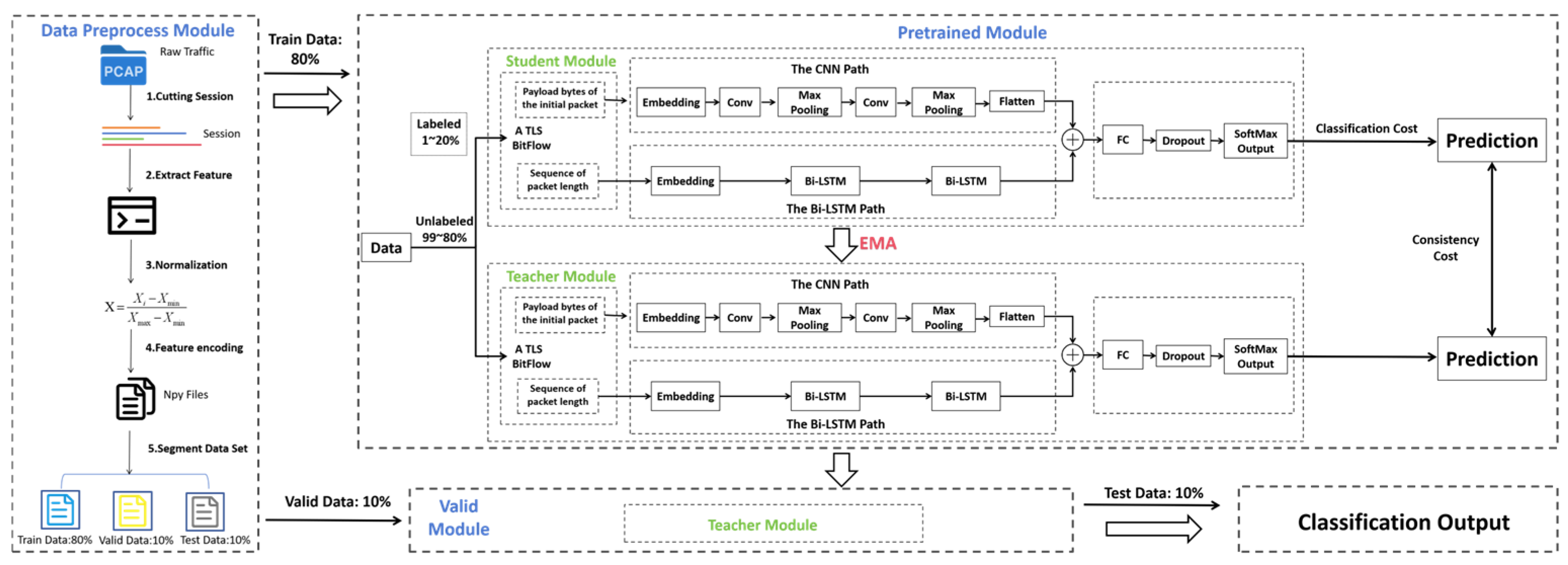
3. Methodology
3.1. System Architecture of CLSTM-MT
3.2. Data Preprocessing Module
- Session Segmentation: The purpose of segmentation is to reduce continuous PCAP streams based on sessions. The two common types of traffic representation are sessions and flows. A session is a stream divided into five tuples (source IP address, source port, destination IP address, destination port, and protocol). Flows are very similar to sessions but only contain traffic in a single direction, meaning that the source IP/port and destination IP/port cannot be swapped. In this study, continuous PCAP files are segmented based on sessions, converting incoming traffic files into PCAP format data. Each session is limited to a maximum of 100,000 packets and 100,000 bytes to facilitate subsequent uniform processing.
- Feature Extraction: Before extracting features, we anonymize the packets and select the most useful features for traffic identification.
- Packet Anonymization: To ensure the normal use of traffic data, we anonymize the IP and MAC addresses of every packet in each session to prevent user’s privacy from being divulged and to protect the usability of the traffic data.
- Feature Selection: We extract the following features: Sequence Length Feature (Sequence), the length of the sequence; Payload Feature (Payload), the first Byte_Num bytes of the payload from the first Packet_Num packets; and Statistical Feature (Statistic), 26-dimensional statistical features of the traffic (e.g., flag features, packet size features, protocol distribution features, etc.).
- 3.
- Data Normalization: To enable the model to better learn the underlying relationships in the data, we normalize packet payload data, sequence data, and statistical data to the [0, 1] range using the normalization formula shown in the formula below.
- 4.
- Feature Encoding: The processed features are converted into numerical form and saved as npy files to facilitate model processing.
- 5.
- Dataset Splitting: Finally, the preprocessed data are divided into training and validation sets according to the required proportions.
3.3. Model Design
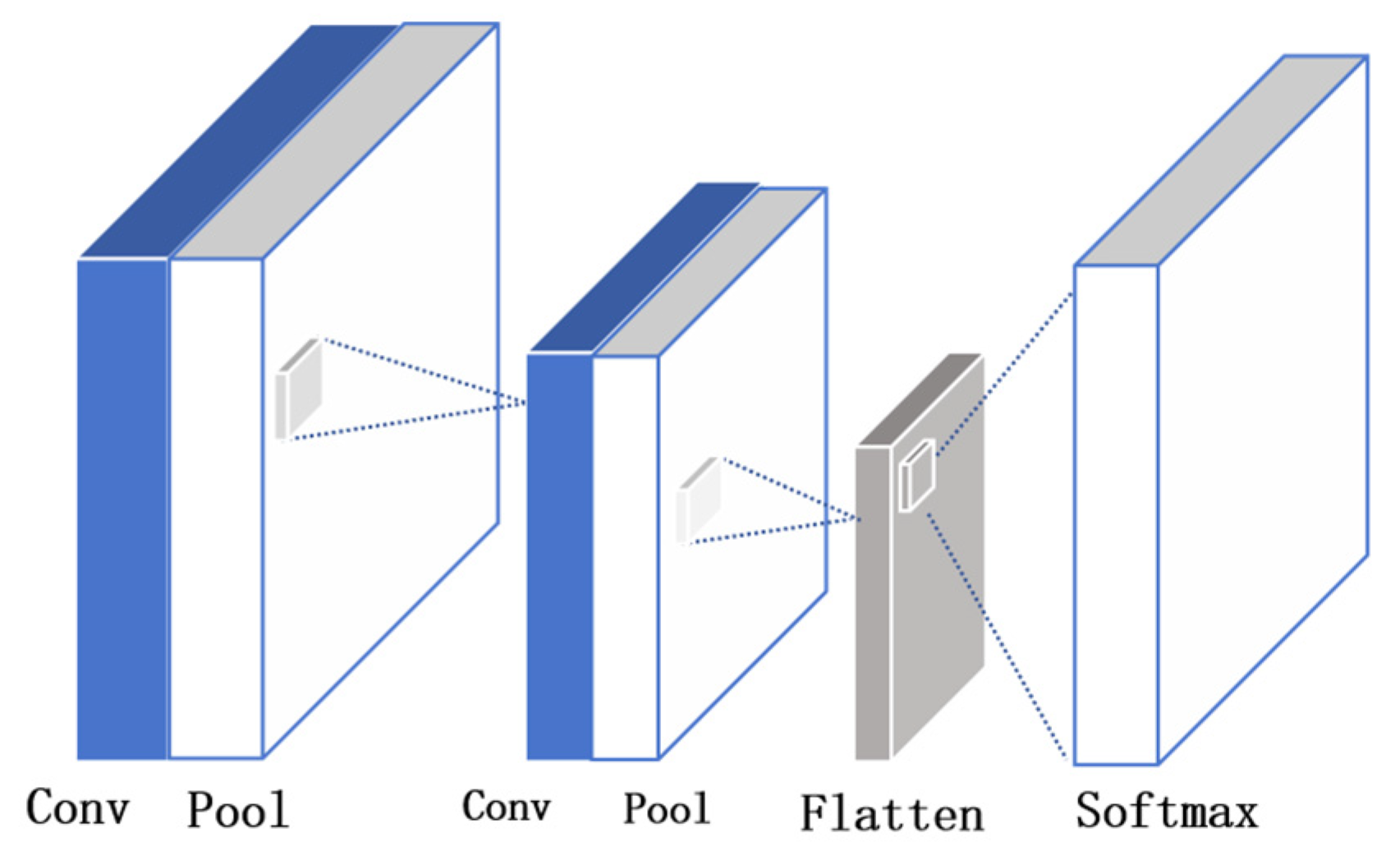
- (1)
- CNN architecture and its role in encryption application traffic identification
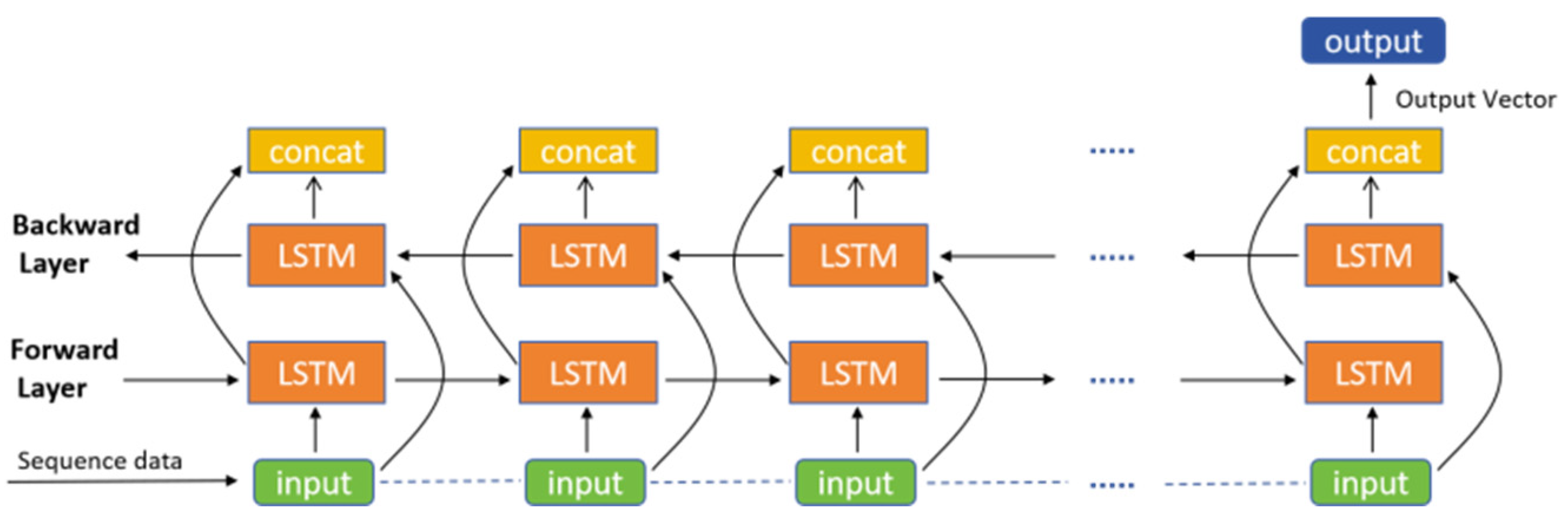
- (2)
- BiLSTM Architecture and Its Role in Encrypted Application Traffic Identification
3.4. Mean Teacher Framework Integration
4. Experimental Evaluation
4.1. Experimental Setup
4.1.1. Data Preparation
4.1.2. Equipment Requirements
4.1.3. Evaluation Metrics
- Accuracy (AC): The proportion of correctly classified samples out of the total number of samples.
- Precision (PC): The proportion of correctly classified positive samples out of all predicted-positive samples.
- Recall (RC): The proportion of correctly classified positive samples out of all actual positive samples.
- F1 Score (F1): The harmonic mean of precision and recall.
4.2. Experimental Results Compared to Baseline Models
4.3. Compared with the Experimental Results of Other Advanced Models
- Rule-Based Method: FlowPrint [28];
- Statistical-Feature-Based Method: APPScanner [5];
- Machine-Learning-Based Method: SVM [11];
- Semi-Supervised and Deep Learning-Based Method: MT-CNN [24].
4.4. Ablation Experiments and Results
- Without 2-conv CNN: If the CNN model is removed and only BiLSTM and the Mean Teacher architecture are used, the model accuracy drops to 85.6% and 80.4%. This indicates that the local information captured during the feature extraction phase by CNN is critical to the overall performance of the model.
- Without BiLSTM: When BiLSTM is removed and only CNN and the Mean Teacher architecture are used, the model accuracy is 91.2% and 82.2%. This shows that BiLSTM plays an important role in modeling the traffic sequence information.
- Without the Mean Teacher architecture: Without the Mean Teacher semi-supervised learning architecture, the model accuracy significantly decreases to 62.7% and 56.6%. This suggests that the Mean Teacher architecture can effectively leverage unlabeled data for learning, thus significantly improving model performance.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | ISCXVPN2016 | ISCXTOR2016 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1% | 5% | 10% | 15% | 20% | 1% | 5% | 10% | 15% | 20% | |
| Ours | 62.1% | 80.3% | 85.4% | 93.4% | 97.8% | 41.0% | 61.5% | 73.4% | 81.2% | 86.3% |
| Ours w/o 2-conv CNN | 51.1% | 54.6% | 69.4% | 73.5% | 85.6% | 43.2% | 51.8% | 62.7% | 71.5% | 80.4% |
| Ours w/o LSTM | 53.2% | 62.3% | 75.3% | 81.1% | 91.2% | 41.4% | 52.9% | 65.3% | 73.2% | 82.2% |
| Ours w/o MT | 32.4% | 40.3% | 52.9% | 55.2% | 62.7% | 31.3% | 37.6% | 43.9% | 51.0% | 56.6% |
4.5. Analysis of Visual Experiment Results
5. Discussion
5.1. Key Findings and Contributions
- Combining CNN and BiLSTM: By integrating the powerful feature extraction capabilities of CNN and BiLSTM with the advantages of Mean Teacher in semi-supervised learning, the accuracy of encrypted traffic identification is significantly improved. This integration reduces the model’s reliance on labeled data, making it more practical for real-world applications where labeled data are scarce.
- Consistency Constraint: The use of consistency loss ensures that the student model’s predictions are closely aligned with those of the teacher model. This constraint enhances the robustness and adaptability of the model, enabling effective identification and classification of encrypted traffic even when dealing with complex or anomalous patterns.
- Theoretical and Practical Significance: Our approach has important theoretical significance and practical value for network security, traffic management, quality of service assurance, and other fields. It provides a reliable solution for recognizing and classifying encrypted traffic, which is critical for maintaining the integrity and security of network systems.
5.2. Limitations and Future Work
- computational Overhead:
- 2.
- Data Requirements:
- 3.
- Generalization Across Different Traffic Types:
- 4.
- Real-Time Deployment Strategies:
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, L.; Gao, S.; Liu, B.; Lu, Z. Research Status and Development Trends on Network Encrypted Traffic Identification. Netinfo Secur. 2019, 19, 19–25. [Google Scholar]
- Rezaei, S.; Liu, X. Deep learning for encrypted traffic classification: An overview. IEEE Commun. Mag. 2019, 57, 76–81. [Google Scholar] [CrossRef]
- Madhukar, A.; Williamson, C. A longitudinal study of P2P traffic classification. In Proceedings of the 14th IEEE International Symposium on Modeling, Analysis, and Simulation, Monterey, CA, USA, 11–14 September 2006. [Google Scholar]
- Yeganeh, S.H.; Eftekhar, M.; Ganjali, Y.; Keralapura, R.; Nucci, A. Cute: Traffic classification using terms. In Proceedings of the 2012 21st International Conference on Computer Communications and Networks (ICCCN), Munich, Germany, 30 July–2 August 2012; pp. 1–9. [Google Scholar]
- Taylor, V.F.; Spolaor, R.; Conti, M.; Martinovic, I. AppScanner: Automatic Fingerprinting of Smartphone Apps from Encrypted Network Traffic. In Proceedings of the 2016 IEEE European Symposium on Security and Privacy (EuroS&P), Saarbruecken, Germany, 21–24 March 2016; pp. 439–454. [Google Scholar]
- Huang, S.; Chen, K.; Liu, C.; Liang, A.; Guan, H. A statistical-feature-based approach to internet traffic classification using Machine Learning. In Proceedings of the 2009 International Conference on Ultra Modern Telecommunications & Workshops, St. Petersburg, Russia, 12–14 October 2009; pp. 1–6. [Google Scholar]
- Perdisci, R.; Lee, W.; Jajodia, S. A deep-learning approach to detecting encrypted malicious web traffic. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 1271–1280. [Google Scholar]
- Chen, L.; Li, Y.; Jiang, X. A deep convolutional neural network approach for encrypted traffic classification. Comput. Commun. 2020, 155, 151–161. [Google Scholar]
- Abbasi, M.; Shahraki, A.; Taherkordi, A. Deep Learning for Network Traffic Monitoring and Analysis(NTMA): A Survey. Comput. Commun. 2021, 170, 19–41. [Google Scholar] [CrossRef]
- Mirsky, Y.; Doitshman, T.; Elovici, Y.; Shabtai, A. Kitsune: An ensemble of autoencoders for online network intrusion detection. In Proceedings of the Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Hao, S.; Hu, J.; Liu, S.; Song, T.; Guo, J.; Liu, S. Improved SVM method for internet traffic classification based on feature weight learning. In Proceedings of the 2015 International Conference on Control, Automation and Information Sciences (ICCAIS), Changshu, China, 29–31 October 2015; pp. 102–106. [Google Scholar]
- Wang, M.; Zheng, K.; Luo, D.; Yang, Y.; Wang, X. An Encrypted Traffic Classification Framework Based on Convolutional Neural Networks and Stacked Autoencoders. In Proceedings of the 2020 IEEE 6th International Conference on Computer and Communications (ICCC), Chengdu, China, 11–14 December 2020; pp. 634–641. [Google Scholar]
- Yang, Y.; Kang, C.; Gou, G.; Li, Z.; Xiong, G. TLS/SSL Encrypted Traffic Classification with Autoencoder and Convolutional Neural Network. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications, Exeter, UK, 28–30 June 2018; pp. 362–369. [Google Scholar]
- Hang, Z.; Lu, Y.; Wang, Y.; Xie, Y. Flow-MAE: Leveraging Masked AutoEncoder for Accurate, Efficient and Robust Malicious Traffic Classification. In Proceedings of the 26th International Symposium on Research in Attacks, Intrusions and Defenses (RAID ’23), Hong Kong, China, 16–18 October 2023; Association for Computing Machinery: New York, NY, USA, 2023; pp. 297–314. [Google Scholar]
- He, K.; Chen, X.; Xie, S.; Li, Y.; Dollár, P.; Girshick, R. Masked Autoencoders Are Scalable Vision Learners. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 15979–15988. [Google Scholar]
- Liu, C.; He, L.; Xiong, G.; Cao, Z.; Li, Z. FS-Net: A flow sequence network for encrypted traffic classification. In Proceedings of the IEEE International Conference on Computer Communications (INFOCOM), Paris, France, 29 April–2 May 2019; pp. 1171–1179. [Google Scholar]
- Yao, H.; Liu, C.; Zhang, P.; Wu, S.; Jiang, C.; Yu, S. Identification of Encrypted Traffic Through Attention Mechanism Based Long Short Term Memory. IEEE Trans. Big Data 2019, 8, 241–252. [Google Scholar] [CrossRef]
- Lin, X.; Xiong, G.; Gou, G.; Li, Z.; Shi, J.; Yu, J. ET-BERT: A contextualized datagram representation with pre-training transformers for encrypted traffic classification. In Proceedings of the WWW‘22: The ACM Web Conference 2022, Lyon, France, 25–29 April 2022. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 6000–6010. [Google Scholar]
- Fahad, A.; Almalawi, A.; Tari, Z.; Alharthi, K.; Al Qahtani, F.S.; Cheriet, M. SemTra: A semi-supervised approach to traffic flow labeling with minimal human effort. Pattern Recognit. 2019, 91, 1–12. [Google Scholar] [CrossRef]
- Zhao, R.; Zhan, M.; Deng, X.; Wang, Y.; Wang, Y.; Gui, G.; Xue, Z. Yet another traffic classifier: A masked autoencoder based traffic transformer with multi-level flow representation. Proc. AAAI Conf. Artif. Intell. 2023, 37, 5420–5427. [Google Scholar] [CrossRef]
- Zhou, G.; Guo, X.; Liu, Z.; Li, T.; Li, Q.; Xu, K. TrafficFormer: An Efficient Pre-trained Model for Traffic Data. In Proceedings of the 2025 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 12–14 May 2025; p. 101. [Google Scholar]
- Tarvainen, A.; Valpola, H. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17), Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 1195–1204. [Google Scholar]
- Shi, K.; Zeng, Y.; Ma, B.; Liu, Z.; Ma, J. MT-CNN: A Classification Method of Encrypted Traffic Based on Semi-Supervised Learning. In Proceedings of the GLOBECOM 2023—2023 IEEE Global Communications Conference, Kuala Lumpur, Malaysia, 4–8 December 2003; pp. 7538–7543. [Google Scholar]
- Alam, S.; Alam, Y.; Cui, S.; Akujuobi, C.M. Unsupervised network intrusion detection using convolutional neural networks. In Proceedings of the 2023 IEEE 13th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 8–11 March 2023; pp. 712–717. [Google Scholar]
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of encrypted and VPN traffic using time-related features. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy, Rome, Italy, 19–21 February 2016; pp. 407–414. [Google Scholar]
- Lashkari, A.H.; Gil, G.D.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of Tor Traffic using Time based Features. In Proceedings of the International Conference on Information Systems Security and Privacy, Porto, Portugal, 19–21 February 2017. [Google Scholar]
- van Ede, T.; Bortolameotti, R.; Continella, A.; Ren, J.; Dubois, D.J.; Lindorfer, M.; Choffnes, D.; van Steen, M.; Peter, A. FlowPrint: Semi-Supervised Mobile-App Fingerprinting on Encrypted Network Traffic. In Proceedings of the Network and Distributed System Security Symposium, San Diego, CA, USA, 23–26 February 2020. [Google Scholar]



| Label | Class | Count |
|---|---|---|
| 1 | Aim_Chat | 1340 |
| 2 | 5000 | |
| 3 | 5000 | |
| 4 | FTPS | 5000 |
| 5 | Hangout | 5000 |
| 6 | ICQ | 823 |
| 7 | Netflix | 5000 |
| 8 | SFTP | 5000 |
| 9 | Skype | 5000 |
| 10 | Spotify | 5000 |
| 11 | Torrent | 5000 |
| 12 | Vimeo | 5000 |
| 13 | VoipBuster | 5000 |
| 14 | Youtube | 5000 |
| Label | Class | Count |
|---|---|---|
| 1 | Traffic | 5000 |
| 2 | Web Browsing | 5000 |
| 3 | 5000 | |
| 4 | Chat | 5000 |
| 5 | Streaming | 5000 |
| 6 | File Transfer | 5000 |
| 7 | VoIP | 5000 |
| 8 | P2P | 5000 |
| Model | ISCXVPN2016 | ISCXTOR2016 | FLOPs (106) | Params (106) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1% | 5% | 10% | 15% | 20% | 1% | 5% | 10% | 15% | 20% | |||
| 1-conv CNN | 16.8% | 31.5% | 47.6% | 49.8% | 52.9% | 23.2% | 27.1% | 35.7% | 41.3% | 51.2% | 285.7 | 5.7 |
| 2-conv CNN | 27.2% | 33.6% | 50.8% | 52.6% | 54.1% | 26.7% | 30.3% | 42.9% | 47.5% | 53.8% | 65.3 | 5.2 |
| 3-conv CNN | 26.7% | 33.9% | 46.6% | 50.4% | 53.2% | 21.8% | 31.2% | 33.2% | 45.6% | 51.7% | 93.2 | 8.5 |
| BiLSTM | 30.3% | 41.2% | 50.7% | 51.1% | 58.2% | 24.2% | 34.4% | 38.8% | 42.7% | 55.4% | 63.8 | 4.7 |
| 2-conv CNN + BiLSTM | 32.4% | 43.3% | 52.9% | 55.2% | 62.7% | 31.3% | 37.6% | 43.9% | 51.0% | 56.6% | 71.9 | 10.9 |
| CLSTM-MT | 62.1% | 80.3% | 83.9% | 93.4% | 97.8% | 41.0% | 61.5% | 73.4% | 81.2% | 86.3% | 34.9 | 4.1 |
| Method | ISCXVPN2016 | ISCXTOR2016 | ||||||
|---|---|---|---|---|---|---|---|---|
| Accuary | Precision | Recall | F1-Score | Accuary | Precision | Recall | F1-Score | |
| FlowPrint | 0.6163 | 0.6697 | 0.6651 | 0.6673 | 0.5155 | 0.6778 | 0.6120 | 0.6337 |
| AppScanner | 0.6266 | 0.4864 | 0.5198 | 0.5030 | 0.5369 | 0.6920 | 0.6276 | 0.6582 |
| SVM | 0.6767 | 0.5152 | 0.5153 | 0.5150 | 0.6097 | 0.7190 | 0.5898 | 0.6480 |
| MT-CNN | 0.9329 | 0.9492 | 0.9173 | 0.9330 | 0.8124 | 0.9108 | 0.7538 | 0.8099 |
| CLSTM-MT | 0.9784 | 0.9788 | 0.9784 | 0.9783 | 0.8633 | 0.6778 | 0.7684 | 0.8336 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiu, X.; Yan, G.; Yin, L. CLSTM-MT (a Combination of 2-Conv CNN and BiLSTM Under the Mean Teacher Collaborative Learning Framework): Encryption Traffic Classification Based on CLSTM (a Combination of 2-Conv CNN and BiLSTM) and Mean Teacher Collaborative Learning. Appl. Sci. 2025, 15, 5089. https://doi.org/10.3390/app15095089
Qiu X, Yan G, Yin L. CLSTM-MT (a Combination of 2-Conv CNN and BiLSTM Under the Mean Teacher Collaborative Learning Framework): Encryption Traffic Classification Based on CLSTM (a Combination of 2-Conv CNN and BiLSTM) and Mean Teacher Collaborative Learning. Applied Sciences. 2025; 15(9):5089. https://doi.org/10.3390/app15095089
Chicago/Turabian StyleQiu, Xiaozong, Guohua Yan, and Lihua Yin. 2025. "CLSTM-MT (a Combination of 2-Conv CNN and BiLSTM Under the Mean Teacher Collaborative Learning Framework): Encryption Traffic Classification Based on CLSTM (a Combination of 2-Conv CNN and BiLSTM) and Mean Teacher Collaborative Learning" Applied Sciences 15, no. 9: 5089. https://doi.org/10.3390/app15095089
APA StyleQiu, X., Yan, G., & Yin, L. (2025). CLSTM-MT (a Combination of 2-Conv CNN and BiLSTM Under the Mean Teacher Collaborative Learning Framework): Encryption Traffic Classification Based on CLSTM (a Combination of 2-Conv CNN and BiLSTM) and Mean Teacher Collaborative Learning. Applied Sciences, 15(9), 5089. https://doi.org/10.3390/app15095089