
Graph-Level Label-Only Membership Inference Attack Against Graph Neural Networks


Abstract
1. Introduction
- We propose GLO-MIA, which, to the best of our knowledge, is the first label-only membership inference attack against graph neural networks in graph classification tasks, revealing the vulnerability of GNNs to such threats.
- We propose a general perturbation method to implement GLO-MIA, which infers membership by leveraging the robustness of graph samples to the perturbations.
- We evaluate GLO-MIA using four representative GNN methods on three real-world datasets and analyze the factors that influence attack performance. Experimental results show that GLO-MIA can achieve an attack accuracy of up to 0.825, outperforming baselines by up to 8.5%. Even in the most restrictive black-box scenario, GLO-MIA achieves performance comparable to that of probability-based MIAs that utilize prediction probability vectors of the model.
2. Background
2.1. Notations
2.2. Graph Neural Networks
3. Related Work
4. Graph-Level Label-Only Membership Inference Attack
4.1. Threat Model
4.1.1. Formalization of the Problem
4.1.2. Adversary’s Knowledge and Capability
4.2. Attack Methodology
4.2.1. Attack Intuition
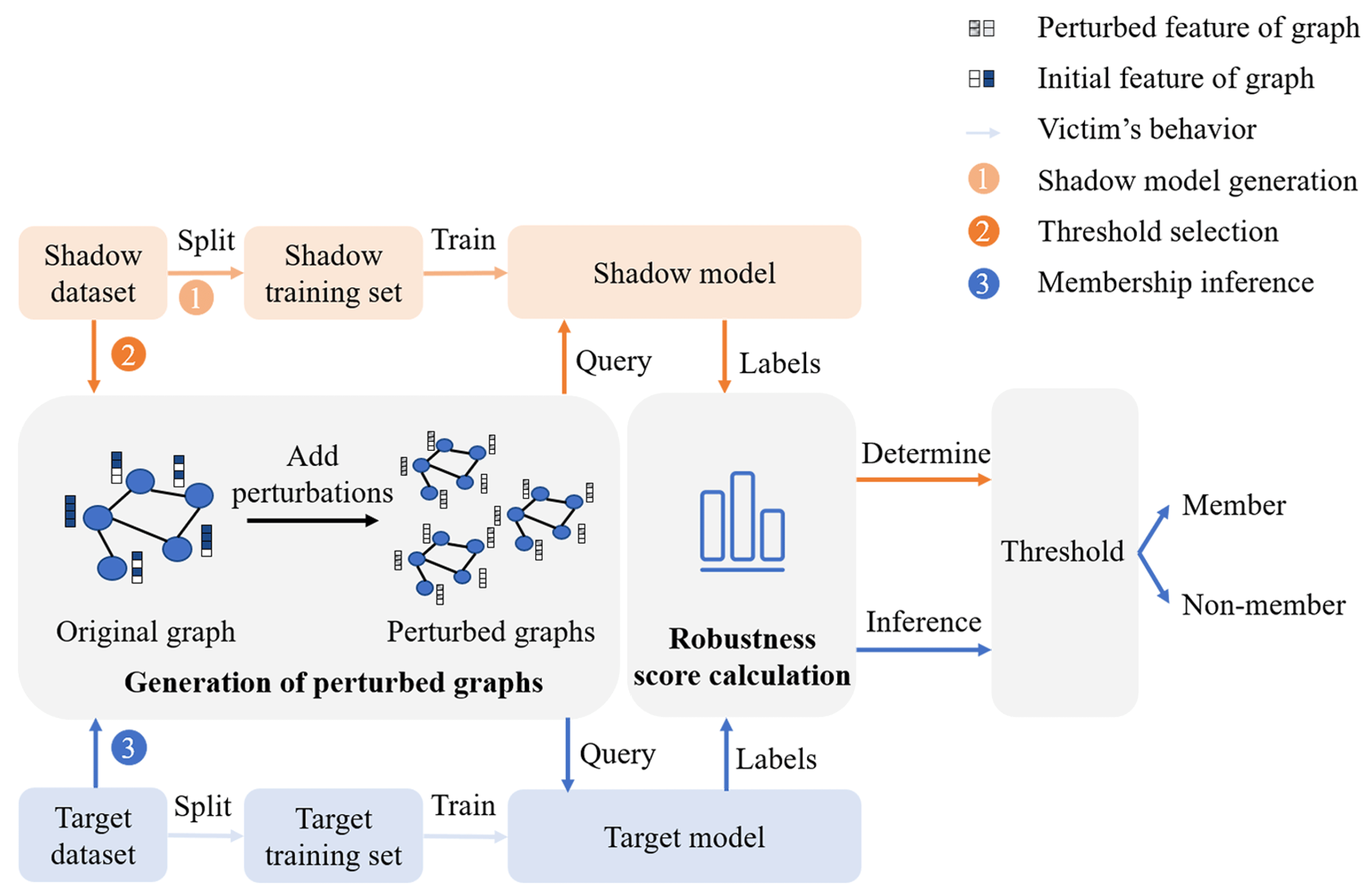
4.2.2. Attack Overview
- (a)
- The adversary generates a set of perturbed graphs for each shadow graph using Algorithm 1, as introduced in Section 4.2.3.
- (b)
- The adversary calculates robustness scores using the prediction labels via Equation (8), as introduced in Section 4.2.1.
- (c)
- The adversary labels the robustness scores of the shadow training data as “member” and those of the shadow testing data as “non-member” to construct the attack dataset, by which a threshold for the robustness score can be selected.
- (a)
- The adversary perturbs the target graph to generate a set of perturbed graphs.
- (b)
- The adversary calculates the robustness score of the target graph.
- (c)
- The adversary compares the robustness score of the target graph with the selected threshold. If the score is above the threshold, the graph is a member; otherwise, it is a non-member.
4.2.3. Generation of Perturbed Graphs
- (a)
- Create a copy of the input graph as to ensure that the perturbations are applied to without affecting (line 6).
- (b)
- Initialize the perturbation matrix (denoted by ) as a zero matrix of shape , where n and d represent the number of nodes and the feature dimension of the input graph, respectively. It stores perturbation values, which are calculated as follows (line 7):where is a random perturbation value uniformly sampled from the perturbation range that is adjusted by the scaler s.
- (c)
- Initialize the operator matrix (denoted by ) as a zero matrix of shape , and store the arithmetic operators at the non-zero feature positions indicated by . The arithmetic operators are generated according to the following equation (line 8):where is an integer randomly sampled between 0 and 1. The values of elements of the matrix can only be or , representing the addition or subtraction of a perturbation value.
- (d)
- Perform element-wise multiplication of perturbation values by their corresponding operators and add them to the features of , ensuring that perturbations are added only to non-zero features, while the others remain unchanged (lines 9–10).
- (e)
- Finally, add to the set , which is the set of perturbed graphs (line 11).
| Algorithm 1 Generation_of_Perturbed_Graphs () |
|
4.2.4. Perturbation Magnitude Estimation and Threshold Selection
5. Experiments
5.1. Experimental Setup
5.1.1. Datasets
5.1.2. Model Architectures and Training Settings
5.1.3. Metrics
5.1.4. Baselines
5.2. Experimental Results
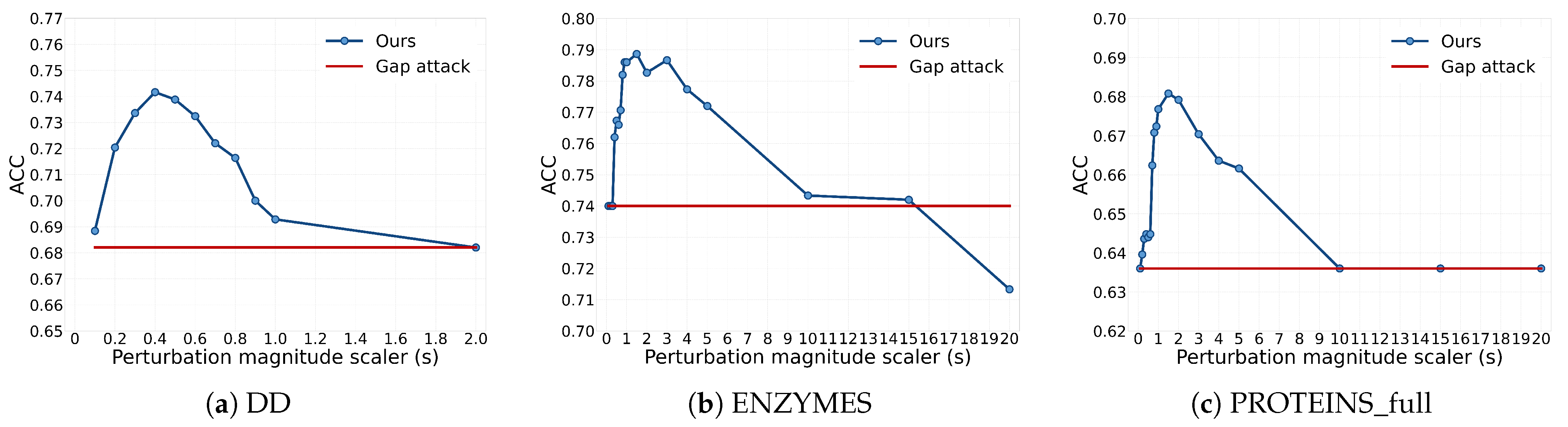
5.3. The Impact of Perturbation Magnitude
5.4. The Impact of the Number of Perturbed Graphs
5.5. Possible Defense
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hirst, J.D.; Sternberg, M.J. Prediction of Structural and Functional Features of Protein and Nucleic Acid Sequences by Artificial Neural Networks. Biochemistry 1992, 31, 7211–7218. [Google Scholar] [CrossRef] [PubMed]
- Borgatti, S.P.; Mehra, A.; Brass, D.J.; Labianca, G. Network Analysis in the Social Sciences. Science 2009, 323, 892–895. [Google Scholar] [CrossRef] [PubMed]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Kipf, T.N.; Welling, M. Variational Graph Auto-Encoders. arXiv 2016, arXiv:1611.07308. [Google Scholar]
- Pan, S.; Hu, R.; Long, G.; Jiang, J.; Yao, L.; Zhang, C. Adversarially Regularized Graph Autoencoder for Graph Embedding. arXiv 2018, arXiv:1802.04407. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How Powerful Are Graph Neural Networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- He, X.; Wen, R.; Wu, Y.; Backes, M.; Shen, Y.; Zhang, Y. Node-Level Membership Inference Attacks against Graph Neural Networks. arXiv 2021, arXiv:2102.05429. [Google Scholar]
- Olatunji, I.E.; Nejdl, W.; Khosla, M. Membership Inference Attack on Graph Neural Networks. In Proceedings of the 2021 Third IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Atlanta, GA, USA, 13–15 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 11–20. [Google Scholar]
- Wu, B.; Yang, X.; Pan, S.; Yuan, X. Adapting Membership Inference Attacks to GNN for Graph Classification: Approaches and Implications. In Proceedings of the 2021 IEEE International Conference on Data Mining (ICDM), Auckland, New Zealand, 7–10 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1421–1426. [Google Scholar]
- Yang, J.; Li, H.; Fan, W.; Zhang, X.; Hao, M. Membership Inference Attacks Against the Graph Classification. In Proceedings of the GLOBECOM 2023–2023 IEEE Global Communications Conference, Kuala Lumpur, Malaysia, 4–8 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 6729–6734. [Google Scholar]
- Conti, M.; Li, J.; Picek, S.; Xu, J. Label-Only Membership Inference Attack against Node-Level Graph Neural Networks. In Proceedings of the 15th ACM Workshop on Artificial Intelligence and Security, Los Angeles, CA, USA, 7–11 November 2022; pp. 1–12. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive Representation Learning on Large Graphs. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wu, B.; Yang, X.; Pan, S.; Yuan, X. Model Extraction Attacks on Graph Neural Networks: Taxonomy and Realisation. In Proceedings of the 2022 ACM on Asia Conference on Computer and Communications Security; Association for Computing Machinery: New York, NY, USA, 2022; pp. 337–350. [Google Scholar]
- Shen, Y.; He, X.; Han, Y.; Zhang, Y. Model Stealing Attacks Against Inductive Graph Neural Networks. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 22–26 May 2022; pp. 1175–1192. [Google Scholar]
- Zhang, Z.; Chen, M.; Backes, M.; Shen, Y.; Zhang, Y. Inference attacks against graph neural networks. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 4543–4560. [Google Scholar]
- Wang, X.; Wang, W.H. Group Property Inference Attacks Against Graph Neural Networks. In Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, Los Angeles, CA, USA, 7–11 November 2022; pp. 2871–2884. [Google Scholar]
- Duddu, V.; Boutet, A.; Shejwalkar, V. Quantifying Privacy Leakage in Graph Embedding. In Proceedings of the MobiQuitous 2020-17th EAI International Conference on Mobile and Ubiquitous Systems: Computing, Networking and Services, Darmstadt, Germany, 7–9 December 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 76–85. [Google Scholar]
- Zhang, Z.; Liu, Q.; Huang, Z.; Wang, H.; Lee, C.K.; Chen, E. Model Inversion Attacks Against Graph Neural Networks. IEEE Trans. Knowl. Data Eng. 2022, 35, 8729–8741. [Google Scholar] [CrossRef]
- Shokri, R.; Stronati, M.; Song, C.; Shmatikov, V. Membership Inference Attacks against Machine Learning Models. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 3–18. [Google Scholar]
- Yeom, S.; Giacomelli, I.; Fredrikson, M.; Jha, S. Privacy Risk in Machine Learning: Analyzing the Connection to Overfitting. In Proceedings of the 2018 IEEE 31st Computer Security Foundations Symposium (CSF), Oxford, UK, 9–12 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 268–282. [Google Scholar]
- Salem, A.; Zhang, Y.; Humbert, M.; Berrang, P.; Fritz, M.; Backes, M. ML-Leaks: Model and Data Independent Membership Inference Attacks and Defenses on Machine Learning Models. arXiv 2018, arXiv:1806.01246. [Google Scholar]
- Li, Z.; Zhang, Y. Membership Leakage in Label-Only Exposures. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 15–19 November 2021; pp. 880–895. [Google Scholar]
- Choquette-Choo, C.A.; Tramer, F.; Carlini, N.; Papernot, N. Label-Only Membership Inference Attacks. In Proceedings of the 38th International Conference on Machine Learning (PMLR), Virtual, 18–24 July 2021; PMLR; pp. 1964–1974. [Google Scholar]
- Song, C.; Shmatikov, V. Auditing Data Provenance in Text-Generation Models. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 196–206. [Google Scholar]
- He, X.; Jia, J.; Backes, M.; Gong, N.Z.; Zhang, Y. Stealing Links from Graph Neural Networks. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Online, 11–13 August 2021; pp. 2669–2686. [Google Scholar]
- Zhang, G.; Liu, B.; Zhu, T.; Ding, M.; Zhou, W. Label-Only Membership Inference Attacks and Defenses in Semantic Segmentation Models. IEEE Trans. Dependable Secur. Comput. 2022, 20, 1435–1449. [Google Scholar] [CrossRef]
- Lu, Z.; Liang, H.; Zhao, M.; Lv, Q.; Liang, T.; Wang, Y. Label-Only Membership Inference Attacks on Machine Unlearning without Dependence of Posteriors. Int. J. Intell. Syst. 2022, 37, 9424–9441. [Google Scholar] [CrossRef]
- He, Y.; Li, B.; Liu, L.; Ba, Z.; Dong, W.; Li, Y.; Qin, Z.; Ren, K.; Chen, C. Towards Label-Only Membership Inference Attack Against Pre-Trained Large Language Models. arXiv 2025, arXiv:2502.18943. [Google Scholar]
- Morris, C.; Kriege, N.M.; Bause, F.; Kersting, K.; Mutzel, P.; Neumann, M. TUDataset: A Collection of Benchmark Datasets for Learning with Graphs. arXiv 2020, arXiv:2007.08663. [Google Scholar]
- Dobson, P.D.; Doig, A.J. Distinguishing Enzyme Structures from Non-Enzymes without Alignments. J. Mol. Biol. 2003, 330, 771–783. [Google Scholar] [CrossRef] [PubMed]
- Borgwardt, K.M.; Ong, C.S.; Schoenauer, S.; Vishwanathan, S.V.N.; Smola, A.J.; Kriegel, H.P. Protein Function Prediction via Graph Kernels. Bioinformatics 2005, 21, i47–i56. [Google Scholar] [CrossRef] [PubMed]
- Schomburg, I.; Chang, A.; Ebeling, C.; Gremse, M.; Heldt, C.; Huhn, G.; Schomburg, D. BRENDA, the enzyme database: Updates and major new developments. Nucleic Acids Res. 2004, 32, D431–D433. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Type | Graphs | Classes | Avg. Nodes | Avg. Edges | Features |
|---|---|---|---|---|---|---|
| DD | Bioinformatics | 1178 | 2 | 284.32 | 715.66 | 89 |
| PROTEINS_full | Bioinformatics | 1113 | 2 | 39.06 | 72.82 | 32 |
| ENZYMES | Bioinformatics | 600 | 6 | 32.63 | 62.14 | 21 |
| Dataset | Model | Train–Test Gap | Ours | Gap Attack |
|---|---|---|---|---|
| DD | GAT | 0.360 | 0.728 | 0.680 |
| GraphSAGE | 0.364 | 0.738 | 0.682 | |
| GCN | 0.352 | 0.722 | 0.676 | |
| GIN | 0.376 | 0.713 | 0.688 | |
| ENZYMES | GAT | 0.480 | 0.789 | 0.740 |
| GraphSAGE | 0.480 | 0.825 | 0.740 | |
| GCN | 0.520 | 0.800 | 0.760 | |
| GIN | 0.547 | 0.786 | 0.773 | |
| PROTEINS_full | GAT | 0.272 | 0.676 | 0.636 |
| GraphSAGE | 0.292 | 0.670 | 0.646 | |
| GCN | 0.312 | 0.674 | 0.656 | |
| GIN | 0.340 | 0.697 | 0.670 |
| Dataset | Model | Ours | CELoss | Mentr |
|---|---|---|---|---|
| DD | GAT | 0.717 | 0.595 | 0.721 |
| GraphSAGE | 0.746 | 0.682 | 0.785 | |
| GCN | 0.728 | 0.606 | 0.731 | |
| GIN | 0.736 | 0.629 | 0.751 | |
| ENZYMES | GAT | 0.798 | 0.816 | 0.877 |
| GraphSAGE | 0.845 | 0.725 | 0.844 | |
| GCN | 0.809 | 0.685 | 0.829 | |
| GIN | 0.832 | 0.701 | 0.834 | |
| PROTEINS_full | GAT | 0.688 | 0.621 | 0.678 |
| GraphSAGE | 0.677 | 0.540 | 0.656 | |
| GCN | 0.679 | 0.516 | 0.641 | |
| GIN | 0.697 | 0.548 | 0.672 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, J.; Lu, Y. Graph-Level Label-Only Membership Inference Attack Against Graph Neural Networks. Appl. Sci. 2025, 15, 5086. https://doi.org/10.3390/app15095086
Dai J, Lu Y. Graph-Level Label-Only Membership Inference Attack Against Graph Neural Networks. Applied Sciences. 2025; 15(9):5086. https://doi.org/10.3390/app15095086
Chicago/Turabian StyleDai, Jiazhu, and Yubing Lu. 2025. "Graph-Level Label-Only Membership Inference Attack Against Graph Neural Networks" Applied Sciences 15, no. 9: 5086. https://doi.org/10.3390/app15095086
APA StyleDai, J., & Lu, Y. (2025). Graph-Level Label-Only Membership Inference Attack Against Graph Neural Networks. Applied Sciences, 15(9), 5086. https://doi.org/10.3390/app15095086