
A Convolutional Neural Network as a Potential Tool for Camouflage Assessment



Abstract
1. Introduction
1.1. Observer Camouflage Metrics
1.2. Computational Camouflage Metrics
1.3. YOLO Camouflage Metric
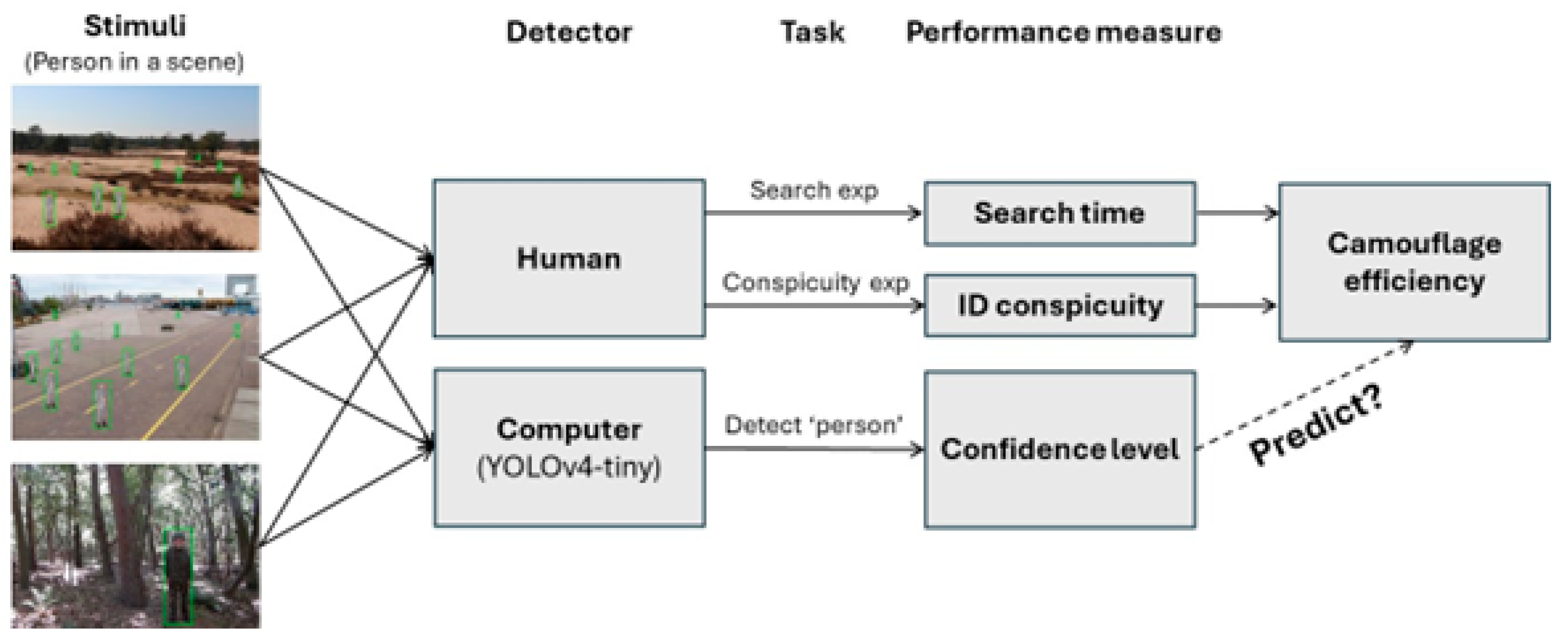
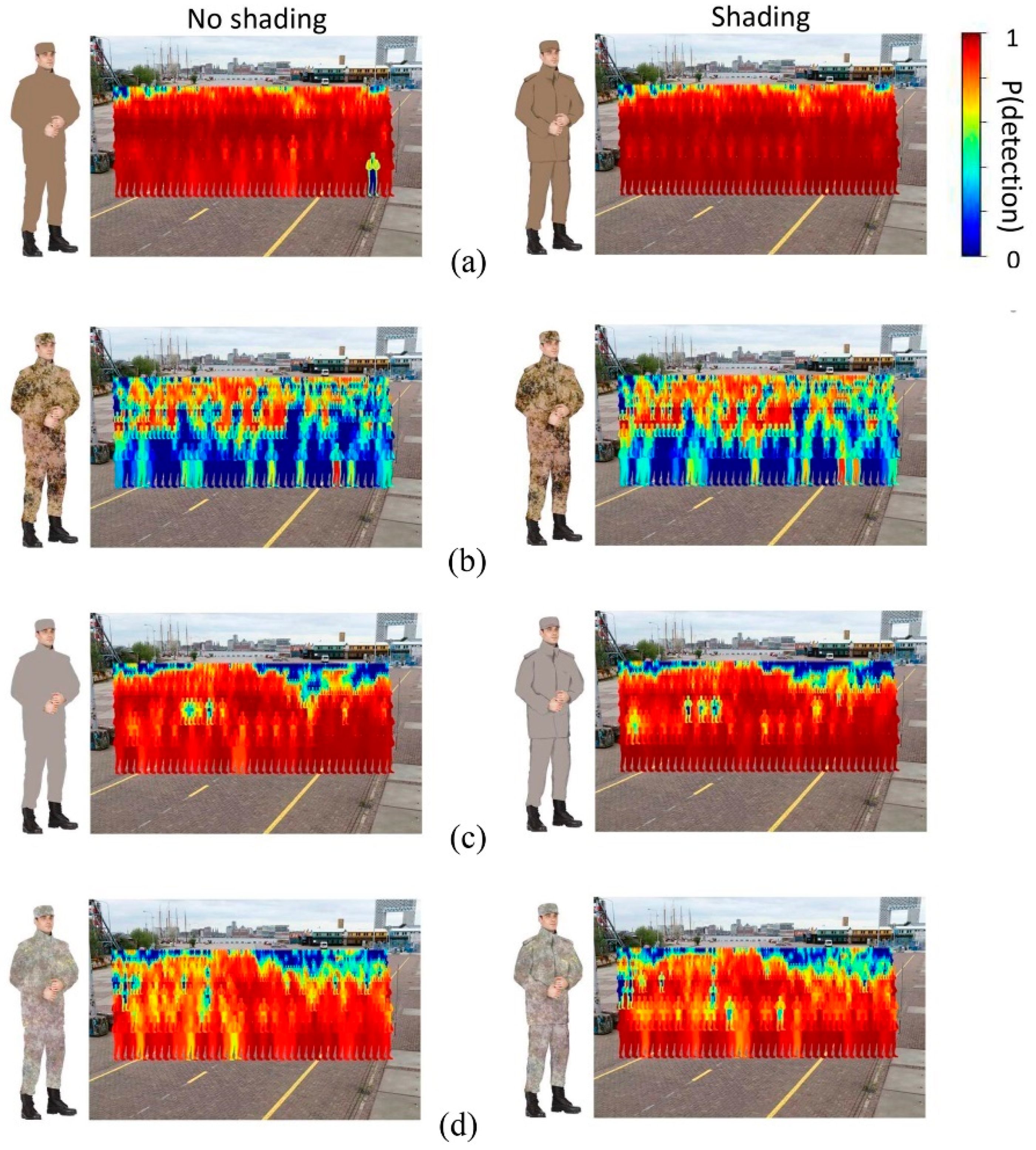
2. Experiment 1: YOLO Detection Performance for Camouflaged Persons
2.1. Methods
2.2. Results
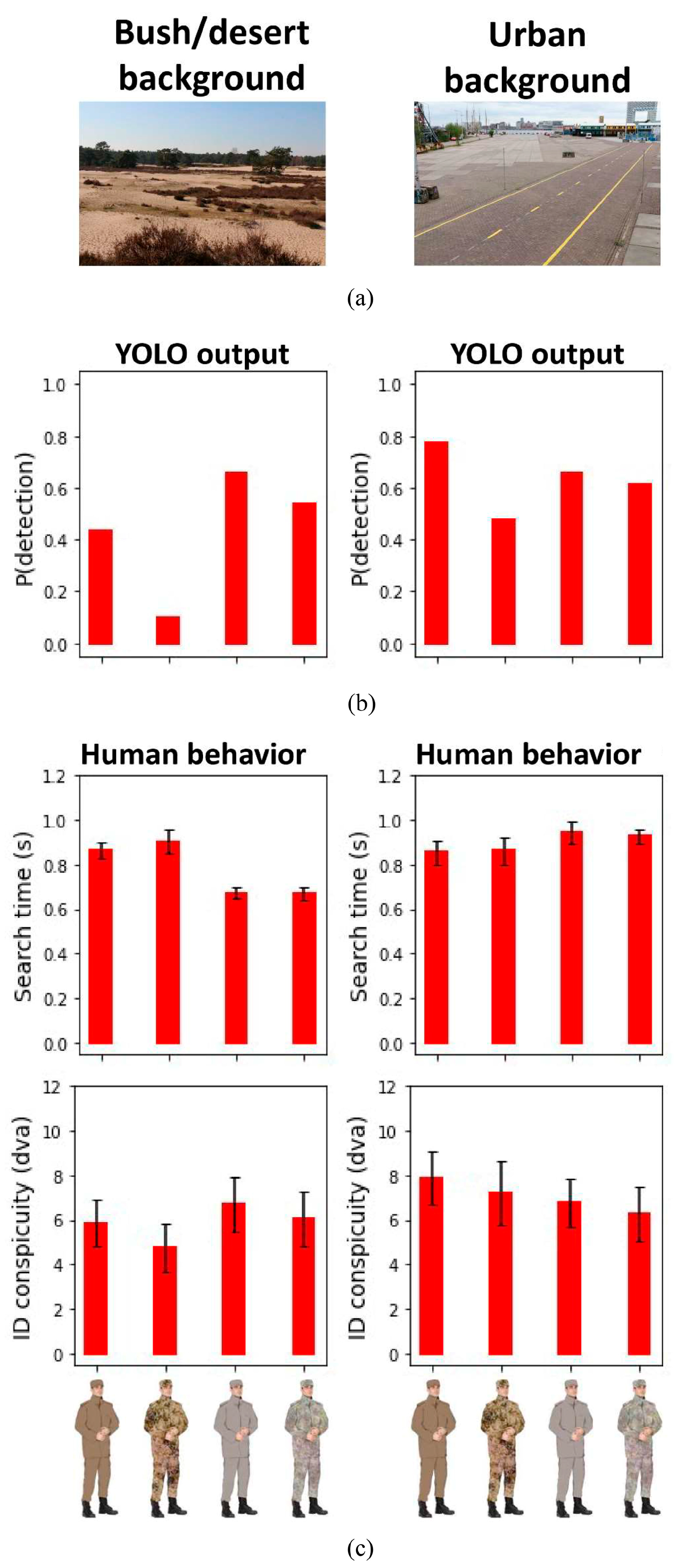
3. Experiment 2: YOLO vs. Human Camouflaged Person Detection on Photosimulations
3.1. Methods Experiment 2a
3.2. Methods Experiment 2b
3.2.1. Participants
3.2.2. Stimuli and Apparatus
3.2.3. Design and Procedure
3.3. Results
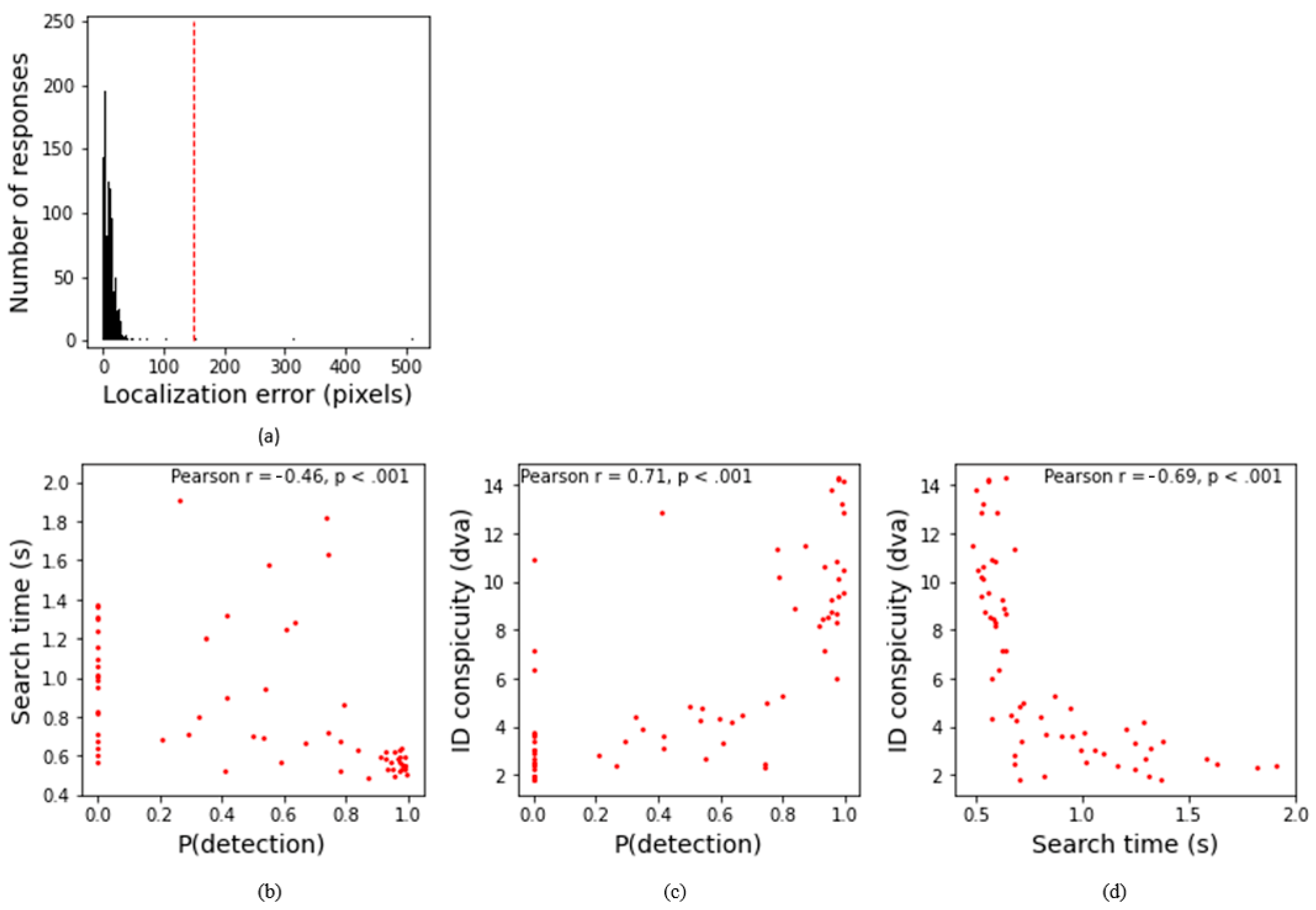
4. Experiment 3: YOLO vs. Human Camouflaged Person Detection on Naturalistic Images
4.1. Methods Experiment 3a
4.2. Methods Experiment 3b
4.3. Results
5. Discussion
5.1. Limitations
5.2. Future Directions
5.3. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Toet, A. Computational versus psychophysical image saliency: A comparative evaluation study. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2131–2146. [Google Scholar] [CrossRef] [PubMed]
- Toet, A.; Hogervorst, M. Review of camouflage assessment techniques. In Proceedings of the Target and Background Signatures VI, Orlando, FL, USA, 20 September 2020; pp. 1–29. [Google Scholar] [CrossRef]
- Mondal, A. Camouflage design, assessment and breaking techniques: A survey. Multimed. Syst. 2022, 28, 141–160. [Google Scholar] [CrossRef]
- Li, N.; Li, L.; Jiao, J.; Xu, W.; Qi, W.; Yan, X. Research status and development trend of image camouflage effect evaluation. Multimed. Tools Appl. 2022, 81, 29939–29953. [Google Scholar] [CrossRef]
- Li, Y.; Liao, N.; Deng, C.; Li, Y.; Fan, Q. Assessment method for camouflage performance based on visual perception. Opt. Lasers Eng. 2022, 158, 107152. [Google Scholar] [CrossRef]
- Ramsey, S.; Mayo, T.; Howells, C.; Shabaev, A.; Lambrakos, S.G. Modeling apparent camouflage patterns for visual evaluation. In Proceedings of the Algorithms and Technologies for Multispectral, Hyperspectral, and Ultraspectral Imagery XXIV, Orlando, FL, USA, 8 May 2018; p. 1064428. [Google Scholar] [CrossRef]
- Ramsey, S.; Mayo, T.; Shabaev, A.; Lambrakos, S. Modeling apparent color for visual evaluation of camouflage fabrics. In Proceedings of the Optics and Photonics for Information Processing XI, San Diego, CA, USA, 7–8 August 2017; p. 103950. [Google Scholar] [CrossRef]
- Cass, J.; Van der Burg, E.; Alais, D. Finding flicker: Critical differences in temporal frequency capture attention. Front. Psychol. 2011, 2, 1–7. [Google Scholar] [CrossRef]
- Van der Burg, E.; Cass, J.; Olivers, C.N.L.; Theeuwes, J.; Alais, D. Efficient visual search from synchronized auditory signals requires transient audiovisual events. PLoS ONE 2010, 5, e10664. [Google Scholar] [CrossRef]
- Van der Burg, E.; Cass, J.; Theeuwes, J. Changes (but not differences) in motion direction fail to capture attention. Vis. Res. 2019, 165, 54–63. [Google Scholar] [CrossRef]
- Toet, A.; Bijl, P. Visual conspicuity. In Encyclopedia of Optical Engineering; Driggers, R.G., Ed.; Marcel Dekker Inc.: New York, NY, USA, 2003; pp. 2929–2935. [Google Scholar]
- Toet, A.; Kooi, F.L.; Bijl, P.; Valeton, J.M. Visual conspicuity determines human target acquisition performance. Opt. Eng. 1998, 37, 1969–1975. [Google Scholar] [CrossRef]
- van der Burg, E.; Ju, J.; Hogervorst, M.A.; Lee, B.; Culpepper, J.; Toet, A. The relation between visual search and visual conspicuity for moving targets. In Proceedings of the Target and Background Signatures VII, Online, 12 September 2021; pp. 92–101. [Google Scholar] [CrossRef]
- Beintema, J.A.; Toet, A. Conspicuity of moving soldiers. In Proceedings of the Infrared Imaging Systems: Design, Analysis, Modeling, and Testing XXII, Orlando, FL, USA, 26–28 April 2011; pp. 1–12. [Google Scholar] [CrossRef]
- Toet, A. Visual conspicuity of targets in synthetic IR imagery. In Camouflage, Concealment and Deception Evaluation Techniques; Toet, A., Ed.; North Atlantic Treaty Organization: Neuilly-sur-Seine Cedex, France, 2001; Volume RTO-TM-017 AC/323(SCI-012)TP/32, pp. 137–152. [Google Scholar]
- Toet, A.; Kooi, F.L.; Kuijper, F.; Smeenk, R.J.M. Objective assessment of simulated daytime and NVG image fidelity. In Proceedings of the Enhanced and Synthetic Vision 2005, Orlando, FL, USA, 28 March–1 April 2005; pp. 1–10. [Google Scholar] [CrossRef]
- Bai, X.; Liao, N.; Wu, W. Assessment of camouflage effectiveness based on perceived color difference and gradient magnitude. Sensors 2020, 20, 4672. [Google Scholar] [CrossRef]
- Yang, X.; Xu, W.-d.; Jia, Q.; Liu, J. MF-CFI: A fused evaluation index for camouflage patterns based on human visual perception. Def. Technol. 2021, 17, 1602–1608. [Google Scholar] [CrossRef]
- Kriegeskorte, N. Deep Neural Networks: A new framework for modeling biological vision and brain information processing. Annu. Rev. Vis. Sci. 2015, 1, 417–446. [Google Scholar] [CrossRef]
- den Hollander, R.; Adhikari, A.; Tolios, I.; van Bekkum, M.; Bal, A.; Hendriks, S.; Kruithof, M.; Gross, D.; Jansen, N.; Perez, G.; et al. Adversarial patch camouflage against aerial detection. In Proceedings of the Artificial Intelligence and Machine Learning in Defense Applications II, Orlando, FL, USA, 21–25 September 2020. [Google Scholar] [CrossRef]
- Lapuschkin, S.; Wäldchen, S.; Binder, A.; Montavon, G.; Samek, W.; Müller, K.-R. Unmasking Clever Hans predictors and assessing what machines really learn. Nat. Commun. 2019, 10, 1096. [Google Scholar] [CrossRef] [PubMed]
- Talas, L.; Fennell, J.G.; Kjernsmo, K.; Cuthill, I.C.; Scott-Samuel, N.E.; Baddeley, R.J. CamoGAN: Evolving optimum camouflage with Generative Adversarial Networks. Methods Ecol. Evol. 2020, 11, 240–247. [Google Scholar] [CrossRef]
- Fennell, J.G.; Talas, L.; Baddeley, R.J.; Cuthill, I.C.; Scott-Samuel, N.E. The Camouflage Machine: Optimizing protective coloration using deep learning with genetic algorithms. Evolution 2021, 75, 614–624. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Van der Burg, E.; Hogervorst, M.A.; Toet, A. Measuring the dynamics of camouflage in natural scenes using convolutional neural networks. In Proceedings of the Target and Background Signatures VIII, Berlin, Germany, 5 December 2022. [Google Scholar] [CrossRef]
- Hall, J.R.; Cuthill, I.C.; Baddeley, R.B.; Shohet, A.J.; Scott-Samuel, N.E. Camouflage, detection and identification of moving targets. Proc. R. Soc. B Biol. Sci. 2013, 280, 20130064. [Google Scholar] [CrossRef]
- Troscianko, T.; Benton, C.P.; Lovell, P.G.; Tolhurst, D.J.; Pizlo, Z. Camouflage and visual perception. Philos. Trans. R. Soc. B Biol. Sci. 2009, 364, 449–461. [Google Scholar] [CrossRef]
- Safaldin, M.; Zaghden, N.; Mejdoub, M. An Improved YOLOv8 to Detect Moving Objects. IEEE Access 2024, 12, 59782–59806. [Google Scholar] [CrossRef]
- Van der Burg, E.; Hogervorst, M.A.; Toet, A. Adaptive camouflage for moving objects. J. Percept. Imaging 2021, 4, 020502-1–020502-15. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/cvf conference on computer vision and pattern recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tambunan, I.H.; Silaen, D.; Michael, F.; Sihotang, B.A.; Sitanggang, K.G. Performance comparison of YOLOv4 and YOLOv4-Tiny algorithm for object detection on wheeled soccer robot. In Proceedings of the 2022 IEEE International Conference of Computer Science and Information Technology (ICOSNIKOM), Laguboti, Indonesia, 19–21 October 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Duncan, J.; Humphreys, G.W. Visual search and stimulus similarity. Psychol. Rev. 1989, 96, 433–458. [Google Scholar] [CrossRef]
- Selj, G.K.; Heinrich, D.H. Disruptive coloration in woodland camouflage: Evaluation of camouflage effectiveness due to minor disruptive patches. In Proceedings of the Target and Background Signatures II, Edinburgh, UK, 26–27 September 2016; pp. 83–97. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, W.; Yu, J.; He, L.; Chen, J.; He, Y. Complete and accurate holly fruits counting using YOLOX object detection. Comput. Electron. Agric. 2022, 198, 107062. [Google Scholar] [CrossRef]
- Sun, H.; Wang, B.; Xue, J. YOLO-P: An efficient method for pear fast detection in complex orchard picking environment. Front. Plant Sci. 2023, 13, 1089454. [Google Scholar] [CrossRef] [PubMed]
- Billock, V.A. Neural acclimation to 1/f spatial frequency spectra in natural images transduced by the human visual system. Phys. D Nonlinear Phenom. 2000, 137, 379–391. [Google Scholar] [CrossRef]
- Chapeau-Blondeau, F.; Chauveau, J.; Rousseau, D.; Richard, P. Fractal structure in the color distribution of natural images. Chaos Solitons Fractals 2009, 42, 472–482. [Google Scholar] [CrossRef]
- Chauveau, J.; Rousseau, D.; Chapeau-Blondeau, F. Fractal capacity dimension of three-dimensional histogram from color images. Multidimens. Syst. Signal Process. 2010, 21, 197–211. [Google Scholar] [CrossRef]
- Chauveau, J.; Rousseau, D.; Richard, P.; Chapeau-Blondeau, F. Multifractal analysis of three-dimensional histogram from color images. Chaos Solitons Fractals 2010, 43, 57–67. [Google Scholar] [CrossRef]
- Field, D.J. Relations between the statistics of natural images and the response properties of cortical cells. J. Opt. Soc. Am. A 1987, 4, 2379–2394. [Google Scholar] [CrossRef]
- Torralba, A.; Oliva, A. Statistics of natural images categories. Netw. Comput. Neural Syst. 2003, 14, 391–412. [Google Scholar] [CrossRef]
- Toet, A.; Hogervorst, M.A. Urban camouflage assessment through visual search and computational saliency. Opt. Eng. 2013, 52, 1–8. [Google Scholar] [CrossRef]
- Pitié, F.; Kokaram, A.C.; Dahyot, R. Automated colour grading using colour distribution transfer. Comput. Vis. Image Underst. 2007, 107, 123–137. [Google Scholar] [CrossRef]
- World Medical Association. World Medical Association declaration of Helsinki: Ethical principles for medical research involving human subjects. J. Am. Med. Assoc. 2013, 310, 2191–2194. [Google Scholar] [CrossRef] [PubMed]
- Peirce, J.W. PsychoPy—Psychophysics software in Python. J. Neurosci. Methods 2007, 162, 8–13. [Google Scholar] [CrossRef] [PubMed]
- Peirce, J.W. Generating stimuli for neuroscience using PsychoPy. Front. Neuroinformatics 2009, 2, 10–18. [Google Scholar] [CrossRef]
- Toet, A.; Bijl, P. Visual search. In Encyclopedia of Optical Engineering; Driggers, R.G., Ed.; Marcel Dekker Inc.: New York, USA, 2003; pp. 2949–2954. [Google Scholar]
- Li, M.-L.; Sun, G.-B.; Yu, J.-X. A Pedestrian Detection Network Model Based on Improved YOLOv5. Entropy 2023, 25, 381. [Google Scholar] [CrossRef]
- Ramdas, K.V.; Gumaste, S. Detection of Camouflaged Objects Using Convolutional Neural Network. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 798–810. [Google Scholar]
- Zhang, W.; Zhou, Q.; Li, R.; Niu, F. Research on camouflaged human target detection based on deep learning. Comput. Intell. Neurosci. 2022, 2022. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Horowitz, T.S. Five factors that guide attention in visual search. Nat. Hum. Behav. 2017, 1, 58. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Horowitz, T.S. What attributes guide the deployment of visual attention and how do they do it? Nat. Rev. Neurosci. 2004, 5, 495–501. [Google Scholar] [CrossRef]
- Van der Burg, E.; Olivers, C.N.; Bronkhorst, A.W.; Theeuwes, J. Pip and pop: Nonspatial auditory signals improve spatial visual search. J. Exp. Psychol. Hum. Percept. Perform. 2008, 34, 1053–1065. [Google Scholar] [CrossRef]
- Van der Burg, E.; Olivers, C.N.; Bronkhorst, A.W.; Theeuwes, J. Poke and pop: Tactile-visual synchrony increases visual saliency. Neurosci. Lett. 2009, 450, 60–64. [Google Scholar] [CrossRef] [PubMed]
- Johansson, G. Visual perception of biological motion and a model for its analysis. Percept. Psychophys. 1973, 14, 201–211. [Google Scholar] [CrossRef]
- Ullman, S.; Vidal-Naquet, M.; Sali, E. Visual features of intermediate complexity and their use in classification. Nat. Neurosci. 2002, 5, 682–687. [Google Scholar] [CrossRef]
- Merilaita, S.; Scott-Samuel, N.E.; Cuthill, I.C. How camouflage works. Philos. Trans. R. Soc. B Biol. Sci. 2017, 372, 20160341. [Google Scholar] [CrossRef]
- Terven, J.; Cordova-Esparza, D. A comprehensive review of YOLO: From YOLOv1 to YOLOv8 and beyond. arXiv 2023, arXiv:2304.00501. [Google Scholar] [CrossRef]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhu, H.; Ren, Q.; Luo, R.; Lan, H. Improved YOLO-based Pedestrian Detection Algorithm. In Proceedings of the 2023 6th International Conference on Image and Graphics Processing, Chongqing, China, 6–8 January 2023; pp. 135–141. [Google Scholar] [CrossRef]
- Li, M.; Chen, S.; Sun, C.; Fang, S.; Han, J.; Wang, X.; Yun, H. An Improved Lightweight Dense Pedestrian Detection Algorithm. Appl. Sci. 2023, 13, 8757. [Google Scholar] [CrossRef]
- Maya-Martínez, S.-U.; Argüelles-Cruz, A.-J.; Guzmán-Zavaleta, Z.-J.; Ramírez-Cadena, M.-d.-J. Pedestrian detection model based on Tiny-Yolov3 architecture for wearable devices to visually impaired assistance. Front. Robot. AI 2023, 10, 1052509. [Google Scholar] [CrossRef]
- Mishra, S.; Jabin, S. Real-Time Pedestrian Detection using YOLO. In Proceedings of the 2023 International Conference on Recent Advances in Electrical, Electronics & Digital Healthcare Technologies (REEDCON), New Delhi, India, 1–3 May 2023; pp. 84–88. [Google Scholar] [CrossRef]
- Razzok, M.; Badri, A.; El Mourabit, I.; Ruichek, Y.; Sahel, A. Pedestrian Detection and Tracking System Based on Deep-SORT, YOLOv5, and New Data Association Metrics. Information 2023, 14, 218. [Google Scholar] [CrossRef]
- Tang, F.; Yang, F.; Tian, X. Long-Distance Person Detection Based on YOLOv7. Electronics 2023, 12, 1502. [Google Scholar] [CrossRef]
- Xiang, N.; Wang, L.; Jia, C.; Jian, Y.; Ma, X. Simulation of Occluded Pedestrian Detection Based on Improved YOLO. J. Syst. Simul. 2023, 35, 286–299. [Google Scholar] [CrossRef]
- Zou, G.; Zhang, Z. Pedestrian target detection algorithm based on improved YOLO v5. In Proceedings of the International Conference on Internet of Things and Machine Learning (IoTML 2023), Singapore, 15–17 September 2023; p. 1293719. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, X.; Hu, E.; Wang, A.; Shiri, B.; Lin, W. VNDHR: Variational Single Nighttime Image Dehazing for Enhancing Visibility in Intelligent Transportation Systems via Hybrid Regularization. IEEE Trans. Intell. Transp. Syst. 2025, 1–15. [Google Scholar] [CrossRef]
- Kong, L.; Wang, J.; Zhao, P. YOLO-G: A Lightweight Network Model for Improving the Performance of Military Targets Detection. IEEE Access 2022, 10, 55546–55564. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Schwegmann, A. Evaluation of dual attribute adversarial camouflage and counter-AI reconnaissance methods in terms of more realistic spatial alignment. In Proceedings of the Target and Background Signatures IX, Amsterdam, The Netherlands, 3–7 September 2023. [Google Scholar] [CrossRef]
- Schwegmann, A. Camouflage methods to counter artificial intelligence recognition (Conference Presentation). In Proceedings of the Target and Background Signatures VIII, Berlin, Germany, 5 September 2022; p. 1227005. [Google Scholar]
- Meyes, R.; Lu, M.; de Puiseau, C.W.; Meisen, T. Ablation studies in artificial neural networks. arXiv 2019, arXiv:1901.08644. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. In Proceedings of the Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Wang, Y.; Fang, Z.; Zheng, Y.-f.; Yang, Z.; Tong, W.; Cao, T.-y. Dual Attribute Adversarial Camouflage toward camouflaged object detection. Def. Technol. 2023, 22, 166–175. [Google Scholar] [CrossRef]
- Abrams, R.A.; Christ, S.E. Motion onset captures attention. Psychol. Sci. 2003, 14, 427–432. [Google Scholar] [CrossRef]
- Abrams, R.A.; Christ, S.E. The onset of receding motion captures attention: Comment on Franconeri and Simons (2003). Percept. Psychophys. 2005, 67, 219–223. [Google Scholar] [CrossRef]
- Howard, C.J.; Holcombe, A.O. Unexpected changes in direction of motion attract attention. Atten Percept Psychophys 2010, 72, 2087–2095. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
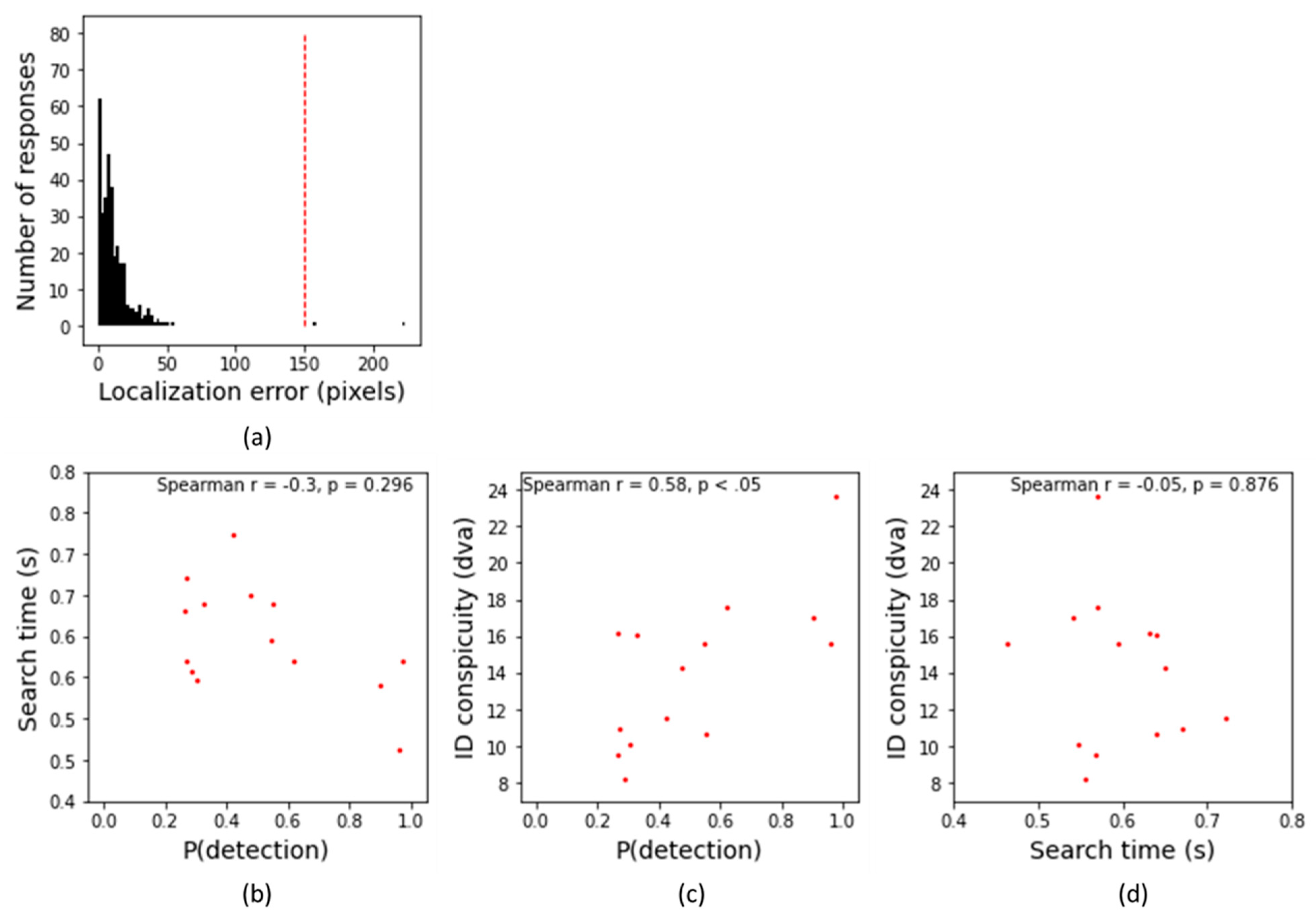
| p(Detection) × Search | p(Detection) × Conspicuity | Search × Conspicuity | ||||
|---|---|---|---|---|---|---|
| Subject | Spearman r | p | Spearman r | p | Spearman r | p |
| 1 | −0.61 | <0.01 | 0.75 | <0.001 | −0.77 | <0.001 |
| 2 | −0.55 | <0.001 | 0.77 | <0.001 | −0.75 | <0.001 |
| 3 | −0.56 | <0.001 | 0.75 | <0.001 | −0.80 | <0.001 |
| 4 | −0.59 | <0.001 | 0.72 | <0.001 | −0.73 | <0.001 |
| 5 | −0.47 | <0.001 | 0.67 | <0.001 | −0.48 | <0.001 |
| 6 | −0.67 | <0.001 | 0.72 | <0.001 | −0.84 | <0.001 |
| mean | −0.65 | <0.001 | 0.76 | <0.001 | −0.84 | <0.001 |
| Search × p(Detection) | Conspicuity × p(Detection) | Conspicuity × Search | ||||
|---|---|---|---|---|---|---|
| Subject | Spearman r | p | Spearman r | p | Spearman r | p |
| 1 | −0.11 | 0.70 | 0.71 | <0.01 | −0.20 | 0.49 |
| 2 | −0.10 | 0.73 | 0.48 | 0.08 | −0.42 | 0.13 |
| 3 | −0.42 | 0.13 | 0.55 | <0.05 | 0.09 | 0.75 |
| 4 | −0.24 | 0.42 | 0.66 | <0.01 | −0.02 | 0.95 |
| 5 | −0.24 | 0.42 | 0.10 | 0.74 | 0.16 | 0.59 |
| 6 | −0.17 | 0.56 | 0.55 | <0.05 | −0.20 | 0.50 |
| mean | −0.30 | 0.30 | 0.58 | <0.05 | −0.05 | 0.88 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Van der Burg, E.; Toet, A.; Perone, P.; Hogervorst, M.A. A Convolutional Neural Network as a Potential Tool for Camouflage Assessment. Appl. Sci. 2025, 15, 5066. https://doi.org/10.3390/app15095066
Van der Burg E, Toet A, Perone P, Hogervorst MA. A Convolutional Neural Network as a Potential Tool for Camouflage Assessment. Applied Sciences. 2025; 15(9):5066. https://doi.org/10.3390/app15095066
Chicago/Turabian StyleVan der Burg, Erik, Alexander Toet, Paola Perone, and Maarten A. Hogervorst. 2025. "A Convolutional Neural Network as a Potential Tool for Camouflage Assessment" Applied Sciences 15, no. 9: 5066. https://doi.org/10.3390/app15095066
APA StyleVan der Burg, E., Toet, A., Perone, P., & Hogervorst, M. A. (2025). A Convolutional Neural Network as a Potential Tool for Camouflage Assessment. Applied Sciences, 15(9), 5066. https://doi.org/10.3390/app15095066