1. Introduction
Consensus algorithms are protocols allowing an agent network to agree on certain quantities of interest. Early work on consensus in social systems was introduced by DeGroot [
1], who modeled individuals iteratively updating their opinions to the average of their neighbors’ opinions. However, it is known that other individuals who are not neighbors are also influential in people’s opinions [
2] and behaviour [
3,
4]. In control theory, consensus gained prominence for coordinating multi-agent systems (e.g., fleets of autonomous vehicles or sensor networks) [
5,
6]. How this consensus is reached heavily depends on the initial state and network structure.
Let
be a network with
V as the set of nodes and
E as the set of nodes. If
A is the adjacency matrix of
G and
D is its degree matrix (a diagonal matrix with the degree of the node
in the position
), the
Laplacian matrix is defined as
. Laplacian matrices and their spectral properties have been extensively studied due to their appeal when studying graph connectivity, spreading, and community detection [
7,
8]. This facilitates measuring robustness, spectral clustering, and partition of networks.
While a Laplacian matrix captures direct (one-hop) connections connecting adjacent nodes by an edge, Estrada extended the notion of adjacency to include paths of length
k between nodes generalized to incorporate longer path-based connections, rather than only immediate neighbors by introducing
k-path Laplacian matrices [
9]. These matrices are constructed from
k-path adjacency matrices that count the shortest paths of length
k between any pair of nodes, providing a multi-hop representation of the network connectivity. We recall that the case of
returns classical Laplacian matrices. If the multiplicity of the zero eigenvalue of
is one, then the network is
k-path connected (analogous to one-hop connectivity for the standard Laplacian matrix). These path-based extensions provide a more global view of connectivity beyond immediate neighbors.
The introduction of path-based Laplacians permits the incorporation of long-range connections and the study of how they impact dynamic network processes. This connectivity extension is particularly relevant for complex networks such as social [
10] or transportation systems [
11], where indirect connections (friends-of-friends in a social network or multi-hop routes in a transportation network) significantly influence network behavior.
For example, considering
, we can accelerate synchronization and consensus in networks by effectively reducing distances between nodes [
12,
13]. Additionally, by weighting connections along paths, path-Laplacian matrices generalize a foundational graph-theoretic concept and provide a richer framework to study connectivity and diffusion processes on networks.
In this work, we introduce several machine learning methods for estimating the consensus in networks comprising long-range interactions through
k-path-Laplacian matrices instead of using numerical methods. We study three different types of networks: Erdös–Renyi [
14], Watts–Strogatz [
15], and Barabási–Albert [
16]. We also test several machine learning methods to estimate the consensus finally obtained in these networks as time passes.
The manuscript is organized as follows: In
Section 2, we review some aspects on mechanisms on multi-agent systems modeled as networks. Useful machine learning models to study dynamics on networks, mainly based on recurrent neural networks, are described in
Section 3. The mathematical formalism of consensus through path-Laplacian matrices for directed and undirected networks is shown in
Section 4. In
Section 5, we describe the data generation for the process which will be used for training, validation, and testing the models. We describe the performance of the models in
Section 6 and we outline the conclusions in
Section 7.
2. Consensus Mechanisms in Multi-Agent Systems
Multi-agent systems can be modeled through a network in which agents interacting with each other are directly connected by an edge. Connectivity is a crucial property for reaching a consensus in a network [
6,
17,
18,
19]. These foundational works lay on the idea that graph connectivity (often quantified by properties of the Laplacian matrix
L) is a crucial condition for consensus. For instance, if the agents’ communication graph has a spanning tree across time, the agents’ states will converge to a common value. Connectivity can also be linked to spectral theory. The second-smallest eigenvalue of
L, known as the Fiedler value or algebraic connectivity, relates to how well the graph is connected [
20]. In addition, continuous or, at least, frequent enough connectivity is also required to reach the consensus state. For static (fixed-topology) networks, consensus algorithms can be analyzed directly using Laplacian matrices. The standard first-order consensus update is given by
where
L is the Laplacian matrix of the network, which drives all agent states
to the agreement (consensus) on an average initial value when the graph is connected.
The Fiedler value also provides the convergence rate to consensus; that is, a larger Fiedler eigenvalue yields faster consensus [
21].
Beyond one-hop (nearest-neighbor) interactions, recent studies consider whether leveraging multi-hop information can improve consensus speed or resilience. Traditional consensus uses only direct neighbor states; however, nodes in many real networks can also be indirectly influenced by more distant nodes (e.g., a friend-of-a-friend in a social network). Path-based Laplacians have been applied to consensus dynamics to capture such influences. Estrada [
9] showed that allowing agents to utilize not only their immediate neighbors’ states but also the states of nodes at a distance
k (via the
k-path Laplacian) can accelerate agreement; see also [
12,
13,
22].
Long-range interactions provide additional communication “shortcuts” in the network, speeding up information spread and consensus formation. This concept has been extended in control protocols [
23]. Such approaches are particularly relevant in systems where influence extends beyond immediate contacts. In opinion dynamics, models incorporating second- or third-neighborhood influences (sometimes called “social power” or indirect influence) help explain how global consensus or polarization can emerge [
24].Therefore, as network connectivity drives consensus, it is natural to consider how modern data-driven methods can further capture and predict such complex dynamics.
3. Machine Learning Models for Studying Dynamics on Networks
Modeling the dynamics of processes on networks often requires capturing both temporal patterns and network structure. In the past decade, researchers have increasingly turned to machine learning—and particularly deep learning models—to model and predict network dynamics. Recurrent neural networks (RNNs), especially Long Short-Term Memory (LSTM) networks [
25], have shown notable success in forecasting traffic flow and travel speeds by effectively learning long-range temporal dependencies [
26]. Similarly, LSTMs have been applied to social networks to predict the evolution of user engagement and information diffusion over time, leveraging their strength in sequence modeling to anticipate bursts of activity or link formations. Complementary methods such as eXtreme Gradient Boosting (e.g., XGBoost [
27]), consisting of the use of ensembles of decision trees to model nonlinear relationships, have been applied either as standalone models or in hybrid schemes with LSTMs to refine predictions.
More recently, the Transformer architecture [
28] has revolutionized sequence modeling by leveraging self-attention to capture both local and global interactions—yielding improved performance in traffic forecasting and social-interaction modeling [
29]. Transformers rely on self-attention mechanisms to capture relationships in sequential data, either temporal patterns or correlations between locations, and they are highly parallelizable, enabling very large models. In social-network analysis, Transformers (and their variant, graph Transformers) have been employed to model sequences of interactions or events (like sequences of posts or the evolution of relationships), benefiting from attention to identify critical earlier interactions that influence later outcomes [
30].
Hybrid approaches combine spatial feature extraction with temporal dynamics, including convolutional Transformers [
31,
32] and convolutional LSTM networks [
33,
34,
35]. The idea behind them is to use convolutional layers to capture local spatial structure (for example, nearby roads on a map or local clusters in a network) and Transformer/LSTM layers to capture broader contextual or temporal patterns. Variants like graph-structured LSTMs (applying ConvLSTM, also known as CNN-LSTM, ideas to graph adjacency instead of image grids) have been developed to handle network data more directly [
36]. Similarly, for social networks, one could imagine using CNNs on graph-structured data (via graph convolution operations) combined with Transformers for temporal sequences to model phenomena like epidemic spreading or information cascades with high fidelity [
37].
Finally, emerging models such as Extended LSTM (xLSTM) [
38] push the limits of recurrent architectures by introducing modifications such as exponential memory gating or parallelizable memory units. Early experiments in sequence modeling (primarily language modeling benchmarks) suggest that, with proper scaling and gating enhancements, xLSTMs can achieve competitive performance to Transformers [
38] without the training difficulties that vanilla LSTMs face. Robust synthetic data generation becomes indispensable to effectively evaluate and validate these machine learning methods, as detailed in the following section.
4. Mathematical Formalism of Consensus Through Path-Laplacian Matrices
Consider a simple undirected network
with
nodes (vertices) and
edges. Two nodes
are said to be
adjacent if an edge
is connecting them. The
adjacency matrix A of
G is the
matrix with entries
if
(and
otherwise). Let
denote the degree of node
i (number of neighbors). The diagonal
degree matrix is
. We recall that the
Laplacian matrix is defined as
which is a symmetric positive semi-definite matrix of size
that has real, non-negative eigenvalues
[
39,
40]. When modeling, we assume that a node represents an agent, and its adjacent nodes will be connected to it with edges. Classical consensus models assume that each agent is influenced only by its nearest neighbors (direct connections). In what follows, we introduce a generalized Laplacian formalism that allows for incorporating longer-range interactions beyond immediate neighbors. This generalization is based on graph paths and will lead to an extended family of Laplacian matrices capturing
k-hop relationships in the network.
4.1. Path-Based Laplacian Matrices
A
path of length
k in
G is a sequence of
distinct vertices
such that each consecutive pair
is an edge in
E. The
distance between two nodes
i and
j is defined as the length of the shortest path connecting
i to
j. Let
denote the graph’s diameter (the maximum distance over all node pairs). For each integer
k with
, we define the
k-path adjacency matrix, denoted
, as the
(symmetric) matrix with entries
In other words,
if and only if there exists at least one shortest length path
k between node
i and node
j. This matrix generalizes the ordinary adjacency matrix (
) to connections via longer paths. We also define the
k-path degree of node
i as
i.e., the number of nodes at distance exactly
k from
i in the network [
9]. By construction,
is the usual degree. We introduce the
k-path Laplacian matrix of the network
G as follows [
9]:
Equivalently, we can write
, where
is the diagonal matrix of
k-path degrees. For
,
, which is exactly the classical Laplacian
L. Each
is symmetric and positive semi-definite. In fact, one can verify that for any real vector
,
confirming that all eigenvalues of
are non-negative. Moreover,
shares the zero-eigenvalue property of the standard Laplacian: since each off-diagonal
in row
i of
is balanced by the contribution to the diagonal entry
, it follows that
. Thus, 0 is an eigenvalue of
with eigenvector
for every
k. The multiplicity of this zero eigenvalue reflects the number of disconnected components in the graph when considering only
k-distance connections. In particular, if the network
G is such that any node can reach any other node through a sequence of hops of length
(sometimes said to be
k-path connected’, then
has a unique zero eigenvalue. In general,
m zero eigenvalues of
indicate that the graph can be partitioned into
m disjoint subgraphs that are not linked by any
k-length path. This is a natural generalization of the connectivity interpretation of the ordinary Laplacian (
). The family
thus provides a spectrum of Laplacian-like operators, each capturing network connectivity at a different path-length scale. Importantly, higher values of
k account for more “long-range” links in the network, and as we will see, incorporating such long-range interactions can significantly impact dynamic processes like consensus.
4.2. Consensus Dynamics on Undirected Networks
We start reviewing the standard consensus process on an undirected network and then describe its extension using the multi-hop Laplacians introduced above. Consider an undirected network of n agents (nodes) whose goal is to reach agreement on some vector . Let denote the state (value of ) held by agent i at time t. In a consensus algorithm, each agent updates its state by interacting with its neighbors, gradually reducing differences between agents’ values. We distinguish two common frameworks: continuous-time and discrete-time consensus dynamics. Later, we will see how to introduce multi-hop interactions.
4.2.1. Continuous-Time Consensus
In the first-order continuous-time model, each agent
i adjusts its state with a rate proportional to the discrepancies with its neighbors’ states. This is described by the following system of ordinary differential equations
where
denotes the set of neighbors of node
i (all
,
, such that
). Equivalently, in vector form, one can write
where
and
L is the Laplacian of the network [
21]. Equation (
8) is a linear system whose solution is
. For a connected graph,
L has a single zero eigenvalue and all other eigenvalues
. In this case, the system (
8) drives the agents to a consensus:
converges to
as
for all
i. Indeed, one can show
, where
c is a constant equal to the average of the initial states
[
21,
41]. This average is an invariant of (
8) because
, so
. The eigenvalues of
L govern the convergence rate of continuous consensus; in particular, the algebraic connectivity) determines the slowest decay mode and hence the asymptotic convergence speed [
7,
21].
4.2.2. Discrete-Time Consensus
In discrete time, consensus is achieved by iterative averaging. At each time step,
, every agent
updates its state as a convex combination of its own and its neighbors’ previous states (
). A common discrete model can be formulated as
where
is a small step size, also interpreted as an interaction weight [
21]. In matrix form, this update can be expressed as
where
I is the identity of order
n. Let
denote the update’s weight matrix. Other generalizations of diffusion that include subdiffusion and super diffusion in networks were stated in [
42].
By construction, each row of
W sums to 1 and
if
(with
as well). If
, where
is the maximum degree in the network, then
W has all non-negative entries and no entry exceeds 1, meaning that
W is a stochastic matrix. In such a matrix, only the rows are normalized to sum to 1. On the one hand, if
W is
doubly stochastic, that is, both its rows and its columns sum to 1, then the average of the states is invariant under the update, that is
for all
, and the consensus is reached at
with
, with
c equalling the initial average
. On the other hand, if
W is only row-stochastic, then the limiting consensus state will be a weighted average determined by the left eigenvector of
W corresponding to eigenvalue 1 [
43]. The convergence of (
10) is again related to the spectrum of
L analogously to the continuous case.
4.2.3. Multi-Hop Consensus Dynamics
The previous models can be extended to incorporate
long-range interactions using the
k-path Laplacians
. To model such phenomena, we introduce additional coupling terms that account for neighbors at distances
, etc. Suppose we fix an integer
and assign a weight coefficient
to interactions via
k-hop neighbors (where
). It is natural to assume
, reflecting that closer neighbors exert a stronger influence than far neighbors. In some cases, the weights are considered as
, with
, representing an exponential decay of the influence concerning distance. These transformations do not qualitatively transform the diffusion dynamics, i.e., for any parameter, the dynamics remain standard diffusion. However, the Mellin transformation (power law) transforms from normal diffusion to superdiffusion for certain values of the exponent [
22,
44]. In a continuous-time setting, generalized consensus dynamics can be written as
We recall that the standard nearest-neighbor model is obtained from (
8) when
and
). The matrix
from (
11) acts as an effective Laplacian matrix for the multi-hop coupling. Like each
, the combined matrix
is symmetric, positive, and semi-definite, and
. Analogously, a multi-hop consensus update can be formulated for the discrete case shown in (
10):
where
denotes the combined update matrix
, which generalizes the Perron matrix of the standard model. As before, for
to define a proper consensus update, it should have non-negative entries, and each row should sum to 1. Sufficient conditions can be derived from the step-size
and the network’s
k-path degrees. For instance, if we take
for all
k, a suitable choice of the step size would be
4.3. Consensus Dynamics on Directed Networks
Suppose that
is now a directed network with
A as an adjacency matrix. For each node
, the
out-degree of
is defined as
and the
in-degree as
. Then, the
directed Laplacian is given by
where
. Note that
satisfies
, but, in general, it is not symmetric, so its spectral properties differ from those of the undirected case [
45]. We recall that a directed network is
weight-balanced if
for all
. In this case, we can show that
is symmetric. Consequently,
has real eigenvalues and a simple zero eigenvalue with the eigenvector
(on both left and right) [
46]. In the continuous-time case, this guarantees that the total sum of states remains invariant, so the final consensus state is exactly the arithmetic mean of the initial conditions. In contrast, if the network is not balanced, the consensus state will be a weighted average determined by the stationary distribution of the row-stochastic matrix
[
43]. The discrete-time case is similar to the continuous one. The case of multi-hop interactions is expressed through the
k-hop Laplacian defined as
with
as the diagonal matrix of
k-hop out-degrees and
.
5. Synthetic Data Generation for Network-Based Analyses
Synthetic data generation is essential for developing and testing network algorithms under controlled conditions. Traditional random graph models have long generated synthetic networks with controlled properties. The Erdős–Rényi model produces random graphs by independently connecting nodes with a fixed probability, yielding networks that serve as null models for graph algorithms [
47]. Watts and Strogatz’s small-world networks interpolate between regular lattices and random graphs, capturing the high clustering and short path lengths already observed in real-life examples [
15]. Barabási and Albert’s scale-free model introduced preferential attachment, producing graphs with a power-law degree distribution capturing nature’s essence in forming networks [
16]. These foundational models allow researchers to synthetically create social or transportation network topologies with desired global properties (randomness, small-world characteristics, heavy-tailed connectivity), which are helpful in testing network behavior theories and algorithms’ robustness (e.g., community detection or consensus). It is worth mentioning that other techniques, such as Stochastic Block Models (SBMs) [
48] and the Lancichinetti–Fortunato–Radicchi (LFR) [
49], can capture community structure and realistic degree heterogeneity. In addition, deep generative models enable us to improve synthetic graph generation by incorporating structural patterns from a set of training graphs (e.g., real social networks or road networks) as GraphRNN [
50], NetGAN [
51], or GraphVAE [
52] do. However, we will restrict ourselves to the aforementioned three seminal network models in this work.
Below, we present two distinct procedures for synthetic data generation based on the consensus dynamics outlined previously. The first scenario considers a local (one-hop) interaction model, while the second scenario extends interactions through an exponential (multi-hop) model. Both approaches begin to generate a network and are subsequently converted into directed networks by assigning orientations to edges, allowing bidirectional connections with a given probability.
5.1. Base Case: Local (One-Hop) Interactions
In the local interaction scenario, the synthetic network generation process begins by sampling an undirected random graph with n nodes according to the chosen random model (Erdös–Renyi, Watts–Strogatz, or Barabàsi–Albert). Each undirected network acts as the structural backbone for the subsequent directed network construction.
Let
be an undirected network and
be the new directed network. Here,
. We assign a direction to each edge
, creating an initial directed edge
. Additionally, the reverse edge (
) is introduced probabilistically (e.g., with probability 0.3), thus resulting in a directed network
. The rest of the calculations are performed over
. We compute its adjacency matrix
A and the diagonal out-degree matrix
, from which the directed Laplacian matrix is derived as
Consistent with the previously described consensus dynamics, we introduce the auxiliary matrix
and determine the iterative update matrix
P as:
with
c typically chosen around 100 to ensure numerical stability. The initial state vector
is constructed from the diagonal elements of
K (i.e.,
). The consensus evolution then iterates according to:
until the state convergence reaches a predefined tolerance
or until the maximum allowed iterations are performed. Only the first ten state vectors and the final convergent mean state are retained to ensure computational efficiency and manageable data volume.
5.2. Exponential Case: Extended (Multi-Hop) Interactions
The exponential (multi-hop) interaction scenario generalizes the one-hop procedure by explicitly considering higher-order node interactions. The network diameter
of
(defined on the underlying undirected topology) is calculated, determining the maximum interaction range. For each interaction distance
k from 1 to
, the corresponding
k-hop adjacency matrix
is computed through repeated matrix multiplication. Each
leads to the associated
k-path Laplacian matrix:
where
is a diagonal matrix containing the out-degree sums of
. The interactions across longer paths are weighted by an exponentially decaying factor
, where
, which controls the influence decay rate. Thus, the multi-hop consensus iterative update matrix
is defined as:
where the parameter
is carefully chosen to maintain non-negative matrix entries and row normalization, ensuring stochastic-like behavior.
The iterative consensus evolution begins from an initial state
constructed from the diagonal entries of the one-hop matrix
. The state vector is then updated iteratively according to:
and the procedure continues until convergence (within tolerance
) or the maximum iteration limit is reached. As before, only the initial ten states and the final mean consensus state are recorded, ensuring computational tractability while capturing essential dynamic features.
5.3. Pseudocode of the Data Generation
Algorithm 1 summarizes the synthetic data generation steps for local and exponential consensus cases, explicitly detailing graph construction, edge orientation, Laplacian calculations, iterative consensus procedures, and data storage considerations.
| Algorithm 1 Synthetic data generation with base (one-hop) and exponential (multi-hop) consensus |
Require: Number of nodes n; random graph model ; case type ; bidirectional probability ; tolerance ; maximum iterations ; decay parameter (for multi-hop); record length Ensure: Time-series states ; final consensus value
- 1:
Generate random undirected graph (BA, WS, or ER). - 2:
Create directed graph G from , orienting edges and adding reverse edges with probability . - 3:
Compute adjacency matrix A and out-degree diagonal matrix from G. - 4:
Form directed Laplacian ; set , . - 5:
if case type = base then - 6:
Set . - 7:
else - 8:
Compute . - 9:
Calculate matrices and Laplacians for . - 10:
Set . - 11:
end if - 12:
Initialize . - 13:
for to do - 14:
- 15:
if then - 16:
break - 17:
end if - 18:
end for - 19:
Record and .
|
6. Results
In this section, we present the performance assessment of our proposed models under different directed graph configurations, focusing on accurately predicting the final consensus value while accommodating the extended connectivity provided by
k-path Laplacian matrices. We generated, for every graph type (Erdős–Rényi, Watts–Strogatz, and Barabási–Albert), node size (25, 50, 100, 200, and 300), and case (base and exponential), a fixed-size training set of 2400 samples and a test set of 600 samples. Each model—XGBoost, LSTM, Extended LSTM, Transformer, and ConvLSTM—was exposed to identical training and test data to allow fair comparisons. Unless otherwise stated, we reserve 20% of the training data for validation, leading to an 80/20 train–validation split. Al the models and training data are accessible at
https://github.com/yusef320/AI-Driven-Consensus (accessed on 30 March 2025).
We systematically tuned hyperparameters through predefined search grids tailored to each approach. We also performed some preliminary experiments to fine-tune these ranges and ensure robust performance across different model types. For instance, maximum tree depth, number of estimators, and learning rate were explored for XGBoost; hidden layer sizes, projection sizes, and multiple LSTM layers were considered for the recurrent-based architectures; and varying numbers of heads, hidden dimensions, and layers were tested for the Transformer models. A mean-squared-error objective-guided training, combined with early stopping triggered after 30 consecutive epochs (or boosting rounds for XGBoost) without validation loss improvement. The 30-epoch threshold was specifically selected based on our observation that during the first epoch, with our chosen hyperparameters, the model did not demonstrate a stable learning trend.
Final evaluations were performed on the 600-sample holdout test set. The main performance metrics include Root Mean Squared Error (RMSE) and Mean Absolute Percentage Error (MAPE).
Post training, predictive performance was evaluated primarily using the RMSE and the MAPE. RMSE provides a clear representation of the typical magnitude of prediction errors in the original units of the target variable. At the same time, MAPE offers a normalized error measure by expressing the average absolute error as a percentage of the true values.
In the following subsections, we compare predictive accuracy and computational overhead for each candidate model, emphasizing how long-range interactions (via higher-order path-Laplacian matrices) influence the quality of the consensus estimation. As discussed previously, larger values of k allow greater leverage of indirect connectivity, potentially strengthening information flow in highly sparse or disconnected graphs. The empirical findings highlight the importance of carefully chosen hyperparameters and how each architecture scales in the presence of multi-hop influences.
6.1. Validation
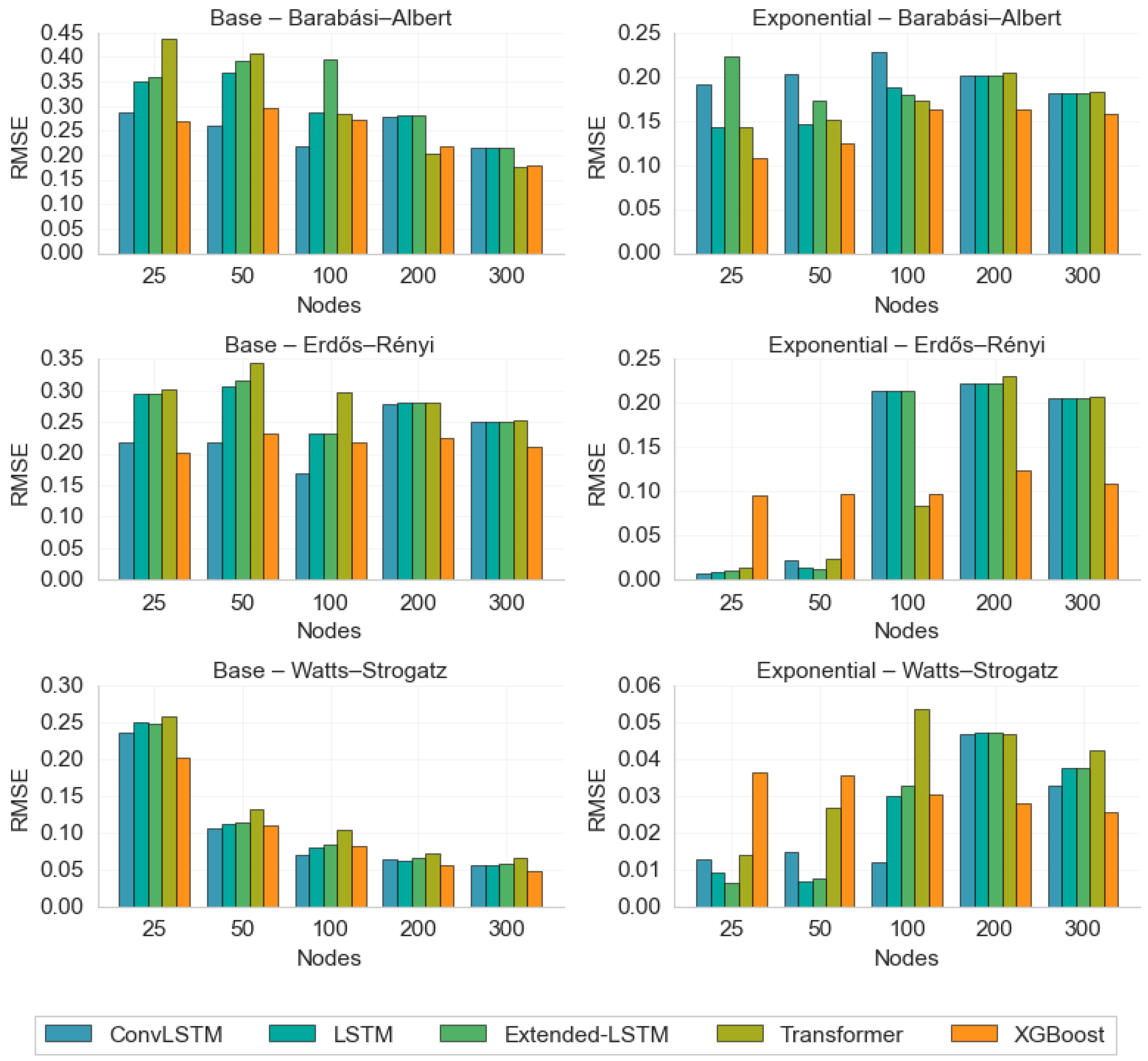
Figure 1 presents the RMSE achieved by five predictive models—ConvLSTM, LSTM, Extended LSTM, Transformer, and XGBoost—for both the base (left column) and exponential (right column) scenarios in three network types: Barabási–Albert (top row), Erdős–Rényi (middle row), and Watts–Strogatz (bottom row). Each chart compares the models’ RMSE for increasing node sizes (25, 50, 100, 200, 300). Overall, the exponential scenario reduces the RMSE relative to the base scenario, suggesting that multi-hop interactions improve predictive accuracy. These patterns highlight how network topology, including long-range interactions and model architecture, each influence consensus prediction accuracy.
In
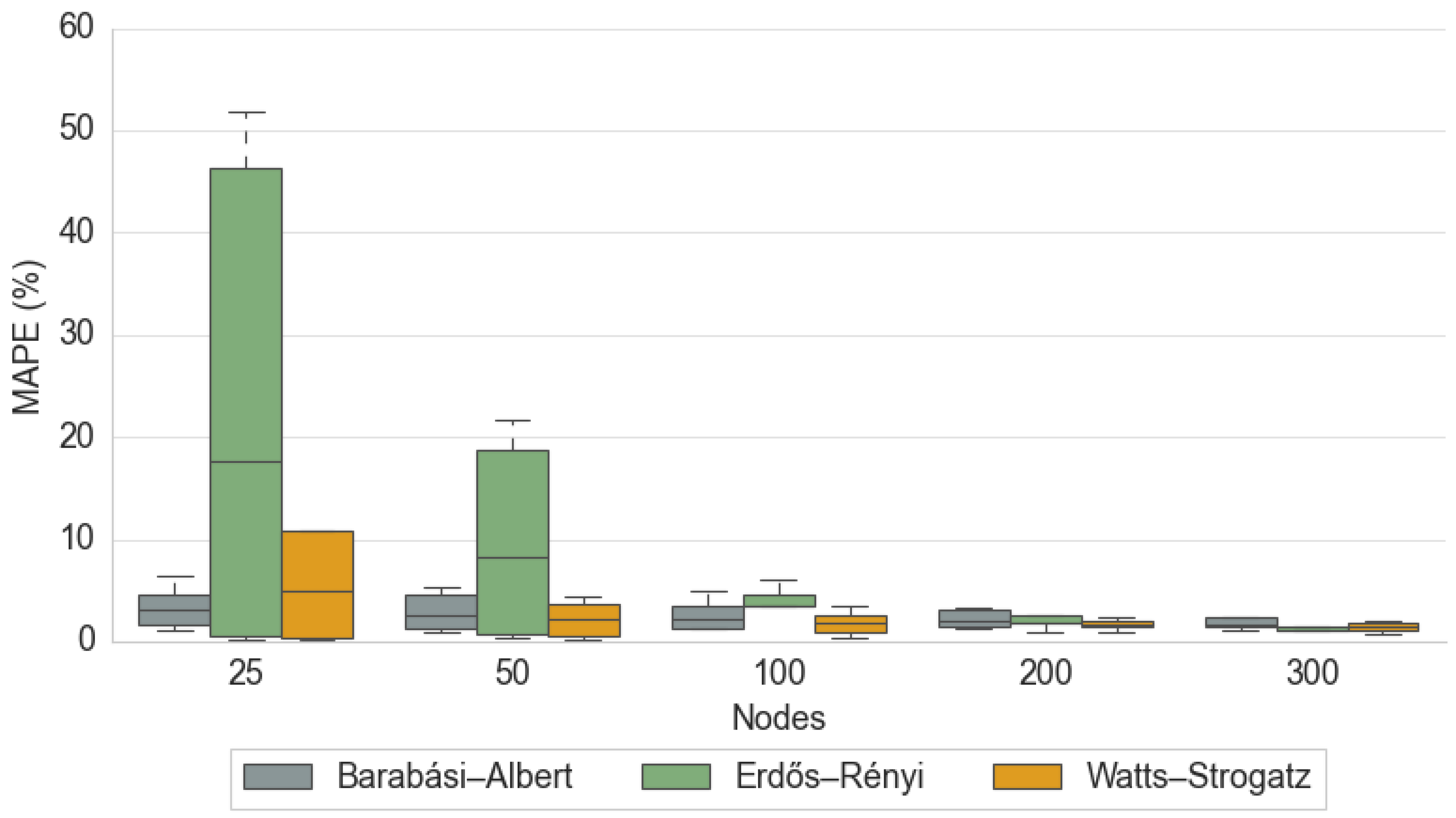
Figure 2, we show the Mean Absolute Percentage Error (MAPE) across different network sizes (25, 50, 100, 200, 300 nodes) for three topologies: Barabási–Albert, Erdős–Rényi, and Watts–Strogatz. The bars indicate that at smaller scales (25 and 50 nodes), Erdős–Rényi networks exhibit substantially higher MAPE values, suggesting more variability or unpredictability in their consensus dynamics. Watts–Strogatz networks present intermediate error levels, while Barabási–Albert remains comparatively lower even for smaller node counts. As the number of nodes increases, the MAPE for all three topologies converges to very low values, implying that larger networks become easier to predict regardless of their underlying structure. This pattern highlights the strong influence of network topology—especially the randomness in Erdős–Rényi—on predictability at small scales, whereas scale-free (Barabási–Albert) and small-world (Watts–Strogatz) networks remain more stable in smaller configurations. In addition, the higher MAPE variability at smaller scales, particularly for models like Extended LSTM, Transformer, and XGBoost, is likely due to the models’ sensitivity to network sparsity at smaller node sizes. These models have a greater capacity to capture complex relationships, but at smaller scales, they may overfit to the specific realizations of the network, leading to higher variability in predictions.
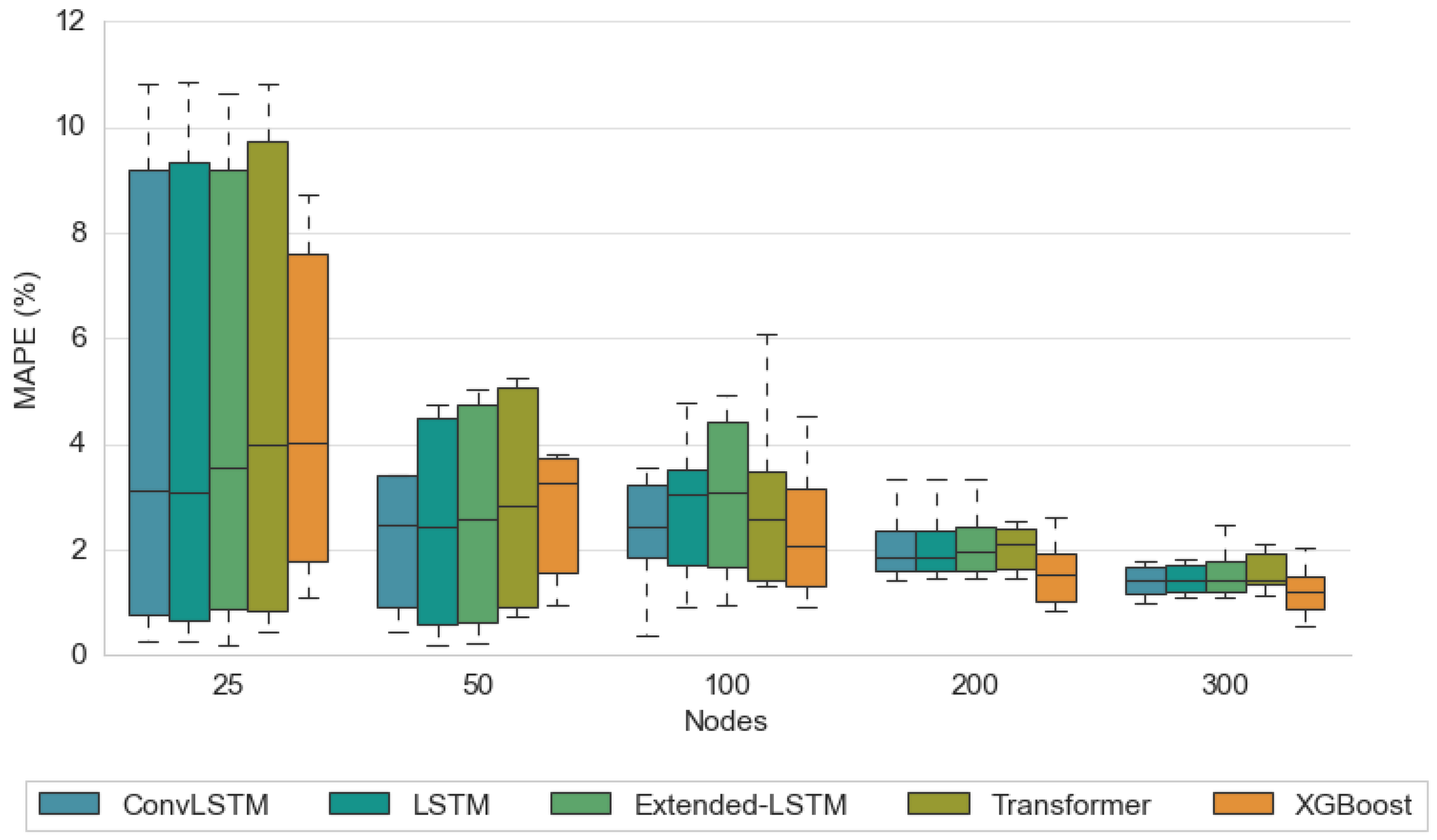
Figure 3 displays box-and-whisker plots of the Mean Absolute Percentage Error (MAPE) for five predictive models—ConvLSTM, LSTM, Extended LSTM, Transformer, and XGBoost—across varying network sizes (25, 50, 100, 200, 300). Each box illustrates the distribution of prediction errors, with taller boxes and whiskers indicating more considerable variability. At small network sizes (25–50 nodes), specific methods (e.g., Extended LSTM, Transformer, and XGBoost) seem to produce slightly higher median MAPEs than ConvLSTM and LSTM. When you get to 200–300 nodes, the boxes for most methods become narrower and cluster closer together. In other words, as the network size increases, all models tend to converge toward lower MAPE values, reflecting improved stability and predictability. It is worth mentioning that the lack of hubs and strong clustering in Erdös–Renyi networks results in more uniform and homogeneous structures, where most nodes have similar degrees. This reduces the presence of highly connected nodes or local communities that can accelerate or concentrate the spreading in the network, resulting in a more variable and unpredictable diffusion.
Overall, the results emphasize that both model architecture and mostly network size significantly affect prediction accuracy.
6.2. Computational Efficiency
Figure 4 illustrates the average prediction time (in milliseconds) for five models—ConvLSTM, LSTM, Extended LSTM, Transformer, and XGBoost—across networks of increasing size (25, 50, 100, 200, 300 nodes). The graph shows that ConvLSTM’s prediction time scales significantly as the number of nodes grows, surpassing 0.25 ms at 300 nodes. In contrast, LSTM, Extended LSTM, Transformer, and XGBoost remain relatively stable and low in prediction time, indicating they handle larger networks more efficiently. This highlights the importance of computational overhead when selecting a model for real-time or large-scale scenarios.
7. Conclusions
Our study introduces a novel framework that significantly advances the modeling of consensus dynamics in multi-agent networks by incorporating machine learning methods to include the effect of long-range interactions through path-Laplacian matrices. By extending the classical one-hop Laplacian formulation to account for k-hop connections, we have demonstrated that capturing extended connectivity not only estimates the final consensus state, but also enhances the robustness of consensus protocols. Such an approach results in particular interest in directed networks, when the consensus is not just the average of components and depends on the inner structure of the network.
The experimental analysis—conducted on synthetic networks generated using Erdös–Rényi, Watts–Strogatz, and Barabási–Albert models—underscores the pivotal role of multi-hop interactions. In the base case of local interactions, traditional consensus mechanisms perform adequately; however, the exponential (multi-hop) approach reveals a marked improvement in consensus speed and accuracy. This suggests that considering indirect, long-range influences provides additional communication “shortcuts”, thereby effectively reducing the distance between nodes and promoting faster agreement.
Moreover, our comparative study of various machine learning techniques—including LSTM, xLSTM, Transformer, XGBoost, and ConvLSTM—highlights the considerable potential of data-driven methods in predicting the final consensus state. Notably, these advanced architectures excel in capturing both local and global temporal dynamics inherent in complex networks. Integrating deep learning with advanced graph-theoretic constructs paves the way for more efficient and adaptive consensus algorithms, particularly relevant in applications such as autonomous systems and distributed sensor networks. We also point out that the extension of this approach to larger scales of nodes have to be carefully addressed due to (linear) complexity growth, the vanishing gradient problem that makes the training unstable, and the batch-size reduction that makes the training slower.
In summary, the most compelling outcomes of our work are the successful extension of the Laplacian framework to encapsulate long-range interactions and the demonstrated efficacy of state-of-the-art machine learning models in predicting consensus dynamics. These insights enrich our theoretical understanding and offer practical avenues for enhancing consensus mechanisms in real-world multi-agent systems.
Author Contributions
Conceptualization, Y.A., B.R. and J.A.C.; investigation, Y.A., B.R. and J.A.C.; software, Y.A. and J.A.C.; validation, Y.A.; visualization, Y.A.; formal analysis, B.R. and J.A.C.; writing—original draft preparation, Y.A., B.R. and J.A.C.; writing—review and editing, Y.A., B.R. and J.A.C.; supervision, J.A.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the European Union - NextGenerationEU, ANDHI project CPP2021-008994 and PID2021-124618NB-C21, by MCIN/AEI/10.13039/501100011033 and by “ERDF A way of making Europe”, from the European Union.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
References
- DeGroot, M.H. Reaching a Consensus. J. Am. Statist. Assoc. 1974, 69, 118–121. [Google Scholar] [CrossRef]
- Garofalo, J.; Lippiello, E.; Rippa, F. Competition between long-range and short-range interactions in the voter model for opinion dynamics. Eur. Phys. J. B 2025, 98, 49. [Google Scholar] [CrossRef]
- Christakis, N.; Fowler, J. Connected: The Surprising Power of Our Social Networks and How They Shape Our Lives; Hachette UK: London, UK, 2009. [Google Scholar]
- Christakis, N.; Fowler, J. Social contagion theory: Examining dynamic social networks and human behavior. Stat. Med. 2013, 32, 556–577. [Google Scholar] [CrossRef]
- Li, Y.; Tan, C. A survey of the consensus for multi-agent systems. Syst. Sci. Control Eng. 2019, 7, 468–482. [Google Scholar] [CrossRef]
- Amirkhani, A.; Barshooi, A. Consensus in multi-agent systems: A review. Artif. Intell. Rev. 2022, 55, 3897–3935. [Google Scholar] [CrossRef]
- Mohar, B. The Laplacian Spectrum of Graphs. In Graph Theory, Combinatorics, and Applications; Alavi, Y.E.A., Ed.; Wiley: Hoboken, NJ, USA, 1991; pp. 871–898. [Google Scholar]
- Merris, R. Laplacian Matrices of Graphs: A Survey. Linear Algebra Appl. 1994, 197–198, 143–176. [Google Scholar] [CrossRef]
- Estrada, E. Path Laplacian matrices: Introduction and application to the analysis of consensus in networks. Linear Algebra Appl. 2012, 436, 3373–3391. [Google Scholar] [CrossRef]
- Park, P.; Blumenstock, J.; Macy, M. The strength of long-range ties in population-scale social networks. Science 2018, 362, 1410–1413. [Google Scholar] [CrossRef]
- Viana, M.; da Fontoura Costa, L. Fast long-range connections in transportation networks. Phys. Lett. A 2011, 375, 1626–1629. [Google Scholar] [CrossRef]
- Estrada, E.; Gambuzza, L.V.; Frasca, M. Long-Range Interactions and Network Synchronization. SIAM J. Appl. Dyn. Syst. 2018, 17, 427–453. [Google Scholar] [CrossRef]
- Estrada, E. Path Laplacians versus fractional Laplacians as nonlocal operators on networks. New J. Phys. 2021, 23, 073049. [Google Scholar] [CrossRef]
- Van Der Hofstad, R. Random Graphs and Complex Networks; Cambridge University Press: Cambridge, UK, 2014; Volume I. [Google Scholar]
- Watts, D.; Strogatz, S. Collective dynamics of ‘small-world’ networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef]
- Barabási, A.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [PubMed]
- Jadbabaie, A.; Lin, J.; Morse, A.S. Coordination of Groups of Mobile Autonomous Agents Using Nearest Neighbor Rules. IEEE Trans. Autom. Control 2003, 48, 988–1001. [Google Scholar] [CrossRef]
- Moreau, L. Stability of Multiagent Systems with Time-Dependent Communication Links. IEEE Trans. Autom. Control 2005, 50, 169–182. [Google Scholar] [CrossRef]
- Ren, W.; Beard, R.W. Consensus Seeking in Multi-Agent Systems under Dynamically Changing Interaction Topologies. IEEE Trans. Autom. Control 2005, 50, 655–661. [Google Scholar] [CrossRef]
- Fiedler, M. Algebraic Connectivity of Graphs. Czechoslovak Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- Olfati-Saber, R.; Fax, J.A.; Murray, R.M. Consensus and Cooperation in Networked Multi-Agent Systems. Proc. IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef]
- Estrada, E.; Hameed, E.; Hatano, N.; Langer, M. Path Laplacian operators and superdiffusive processes on graphs. I. One-dimensional case. Linear Algebra Appl. 2017, 523, 307–334. [Google Scholar] [CrossRef]
- Ma, C.; Wang, X.; Fang, R. Consensus of Networked Multi-Agent Systems via Transformed d-Path Laplacian. Neurocomputing 2020, 386, 181–190. [Google Scholar]
- Proskurnikov, A.; Cao, M. Consensus in Multi-Agent Systems. In Wiley Encyclopedia of Electrical and Electronics Engineering; Wiley & Sons: Hoboken, NJ, USA, 2016; Volume 2, p. 14. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Polson, N.; Sokolov, V. Deep learning for short-term traffic flow prediction. Transp. Res. Part C Emerg. Technol. 2017, 79, 1–17. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD, San Francisco, CA, USA, 13–17 August 2016; Volume 79, pp. 785–794. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; IOP Publishing: Bristol, UK, 2017; pp. 5998–6008. [Google Scholar]
- Lan, X.; Wang, Z.; Song, G. Traffic flow prediction with transformer neural network. IEEE Access 2021, 9, 91242–91252. [Google Scholar]
- Kreuzer, D.; Beaini, D.; Hamilton, W.; Létourneau, V.; Tossou, P. Rethinking graph transformers with spectral attention. Adv. Neural Inf. Process. Syst. 2021, 34, 21618–21629. [Google Scholar]
- Khan, A.; Rauf, Z.; Sohail, A.; Khan, A.; Asif, H.; Asif, A.; Farooq, U. A survey of the vision transformers and their CNN-transformer based variants. Artif. Intell. Rev. 2023, 56, 2917–2970. [Google Scholar] [CrossRef]
- Firbas, N.; Garibo-i Orts, Ò.; Garcia-March, M.; Conejero, J. Characterization of anomalous diffusion through convolutional transformers. J. Phys. A Math. Theor. 2023, 56, 014001. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Zha, W.; Liu, Y.; Wan, Y.; Luo, R.; Li, D.; Yang, S.; Xu, Y. Forecasting monthly gas field production based on the CNN-LSTM model. Energy 2022, 260, 124889. [Google Scholar] [CrossRef]
- Lozano, M.; Garibo-i Orts, Ò.; Piñol, E.; Rebollo, M.; Polotskaya, K.; Garcia-March, M.; Conejero, J.; Escolano, F.; Oliver, N. Open data science to fight COVID-19: Winning the 500k XPRIZE Pandemic Response Challenge. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Bilbao, Spain, 13–17 September 2021; Springer: Cham, Switzerland, 2021; pp. 384–399. [Google Scholar]
- Zayats, V.; Ostendorf, M. Conversation modeling on reddit using a graph-structured LSTM. Trans. Assoc. Comput. Linguist. 2018, 6, 121–132. [Google Scholar] [CrossRef]
- Hechtlinger, Y.; Chakravarti, P.; Qin, J. A generalization of convolutional neural networks to graph-structured data. arXiv 2017, arXiv:1704.08165. [Google Scholar]
- Beck, M.; Pöppel, K.; Spanring, M.; Auer, A.; Prudnikova, O.; Kopp, M.K.; Klambauer, G.; Brandstetter, J.; Hochreiter, S. xLSTM: Extended Long Short-Term Memory. arXiv 2024, arXiv:2405.04517. [Google Scholar]
- Godsil, C.; Royle, G. Algebraic Graph Theory; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Chung, F.R.K. Spectral Graph Theory; American Mathematical Society: Providence, RI, USA, 1996. [Google Scholar]
- Mesbahi, M.; Egerstedt, M. Graph Theoretic Methods in Multiagent Networks; Princeton University Press: Princeton, NJ, USA, 2010. [Google Scholar]
- Diaz-Diaz, F.; Estrada, E. Time and space generalized diffusion equation on graph/networks. Chaos Solitons Fractals 2022, 156, 111791. [Google Scholar] [CrossRef]
- Xu, L.; Zhao, P. Exponential Convergence of Directed Consensus under Time-Varying Topologies. IEEE Control Syst. Lett. 2022, 10, 156–161. [Google Scholar]
- Estrada, E.; Hameed, E.; Langer, M.; Puchalska, A. Path Laplacian operators and superdiffusive processes on graphs. II. Two-dimensional lattice. Linear Algebra Appl. 2018, 555, 373–397. [Google Scholar] [CrossRef]
- Wang, X.; Liu, Y.; Chen, Z. Consensus on Directed and Weighted Graphs: A Survey. IEEE Trans. Netw. Sci. Eng. 2021, 8, 3147–3160. [Google Scholar]
- Park, J.; Kim, S. Directed Graph Balancing and Consensus in Multi-Agent Systems. Automatica 2023, 152, 110995. [Google Scholar]
- Erdos, P.; Rényi, A. On random graphs. Publ. Math. Debr. 1959, 6, 290–297. [Google Scholar] [CrossRef]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic blockmodels: First steps. Soc. Netw. 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Lancichinetti, A.; Fortunato, S.; Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 2008, 78, 046110. [Google Scholar] [CrossRef]
- You, J.; Ying, R.; Ren, X.; Hamilton, W.; Leskovec, J. GraphRNN: Generating realistic graphs with deep auto-regressive models. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; pp. 5708–5717. [Google Scholar]
- Bojchevski, A.; Shchur, O.; Zügner, D.; Günnemann, S. NetGAN: Generating graphs via random walks. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholm, Sweden, 10–15 July 2018; pp. 610–619. [Google Scholar]
- Simonovsky, M.; Komodakis, N. GraphVAE: Towards generation of small graphs using variational autoencoders. In Proceedings of the 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 412–422. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).




{kind=link}
{kind=link}
{kind=link}
{kind=link}