
Enhancing Federated Intrusion Detection with Class-Specific Dynamic Sampling


Abstract
1. Introduction
2. Related Works on Federated Personalization
- A set of shared layers, typically the earlier layers (feature extractors), which are aggregated across all clients to capture global knowledge.
- A set of personal layers, often the latter or task-specific layers, which remain local to each client, thus allowing them to adapt to idiosyncratic features or data distributions.
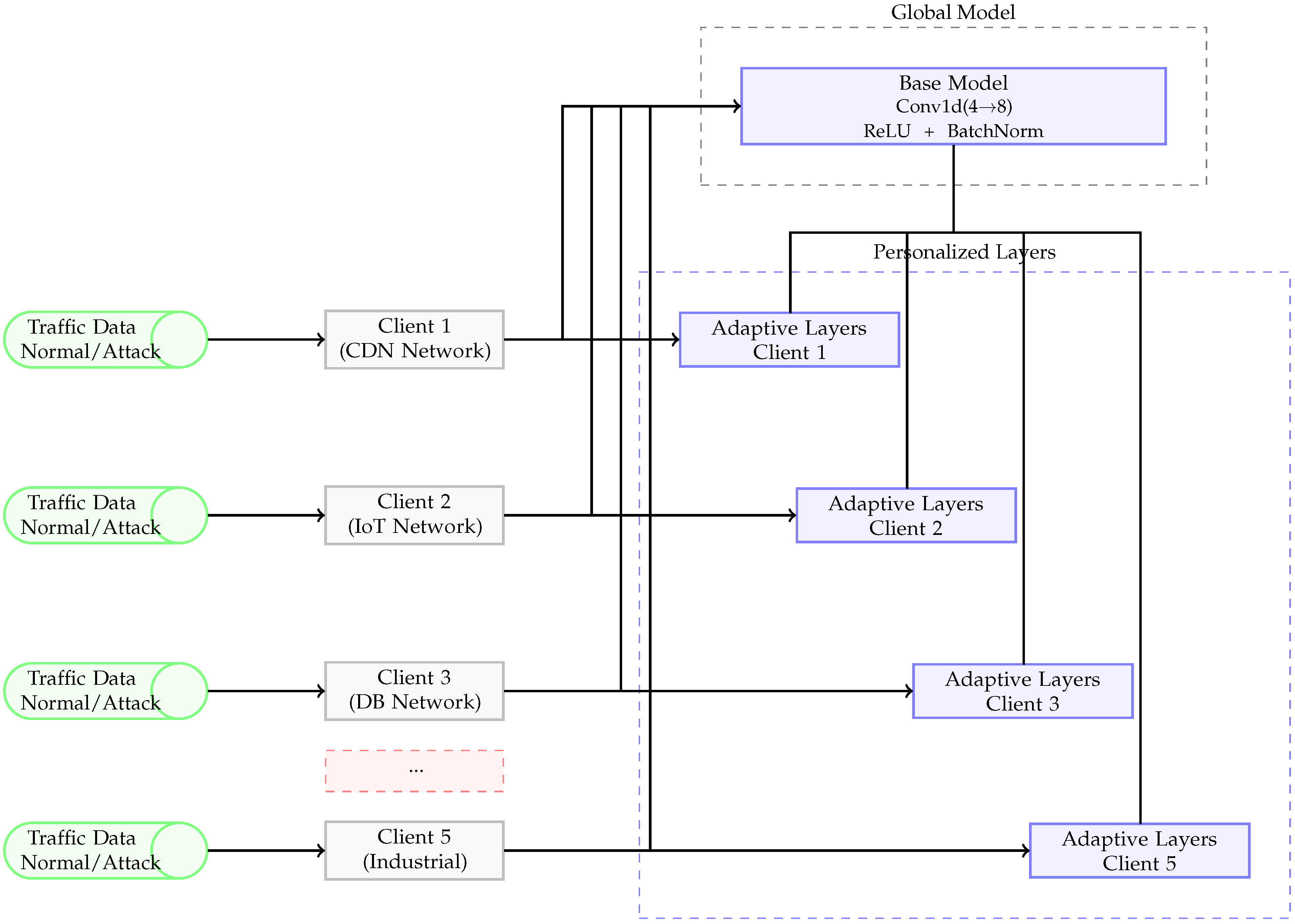
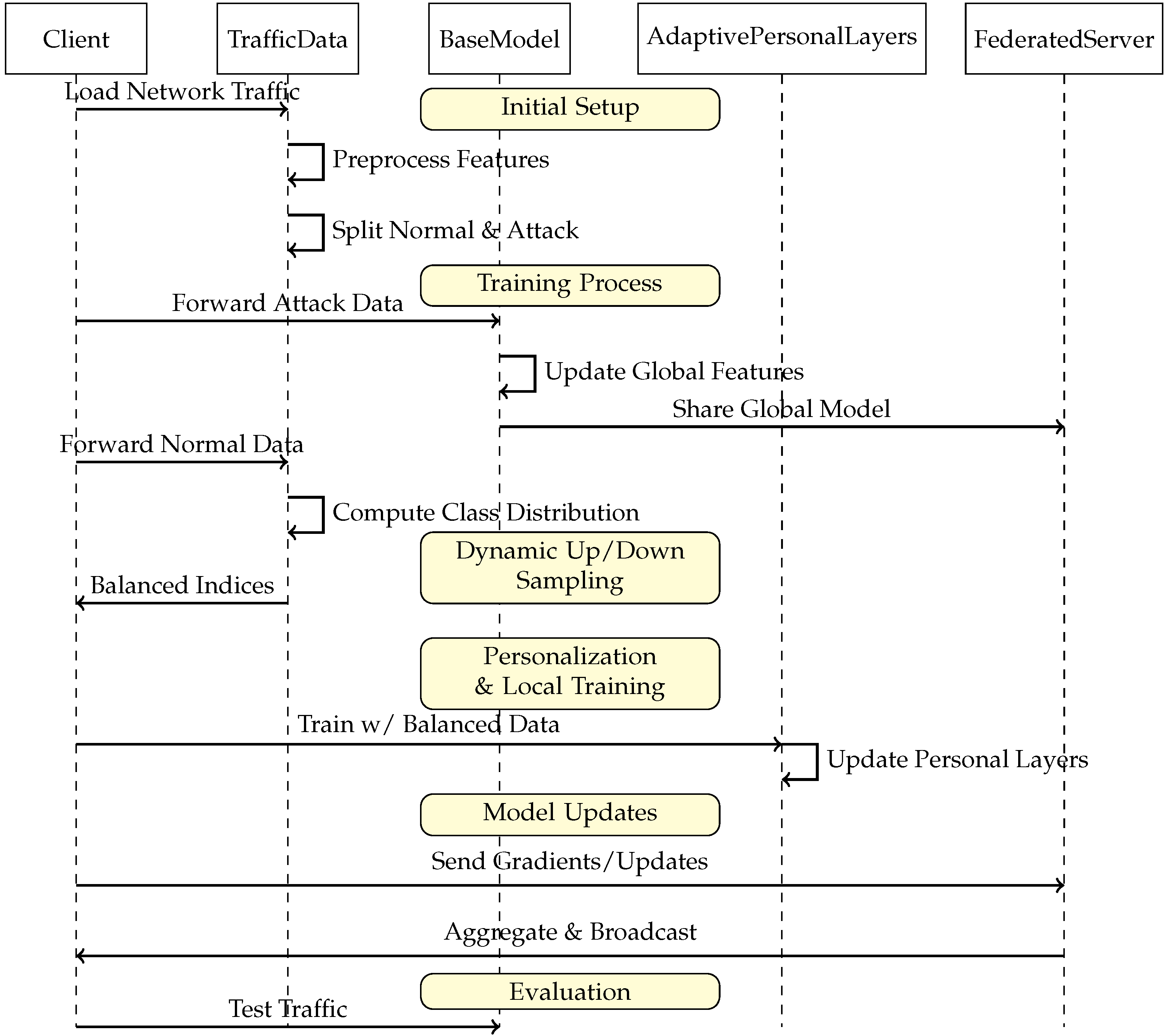
3. DS-FedIDS
3.1. Dynamic Sampling-FedIDS Approach
- Forward Attack Data: The client updates global parameters, promoting a consistent malicious-signature repository across all clients.
- Dynamic Up/Down Sampling: The client inspects local class distributions (normal sub-classes or minority attacks) and rebalances data.
- Local Training: The now-balanced normal data are used to refine each client’s personal layers. Attack patterns remain in the global portion.
- Model Updates: Gradients or parameter deltas are sent to the federated server for aggregation, culminating in a shared global model distributed back to the clients.
3.2. Dynamic Sampling Formulations
Dynamic Sampling Logic
| Algorithm 1 Dynamic Up/Down Sampling for Balancing Local Classes |
| Require: Local dataset , class set , target threshold (e.g., mean or fraction of max) Ensure: Balanced dataset (with up/down sampling applied)
|
3.3. Experimental Setup
3.4. Dataset Description and Preprocessing
3.5. Non-IID Data Characteristics
- CDN: Primarily HTTP(S) flows and large-volume data transfers, with a prevalence of tcp connections.
- IoT: Often dominated by DNS, MQTT, or lightweight request-response traffic; smaller packet sizes and frequent connections.
- Database: Fewer protocols in use (often tcp only), with specialized services (e.g., SQL-based).
- Office: Balanced among web, mail, and file-sharing services. Attack types vary widely but are generally less frequent than in high-exposure networks.
- Industrial: Typically large or specialized data bursts, sometimes with older or proprietary protocols, and medium-sized packets.
3.6. Feature Distributions by Network Type
3.6.1. Service Distribution Analysis
3.6.2. Attack Distribution Analysis
3.6.3. Protocol Distribution Analysis
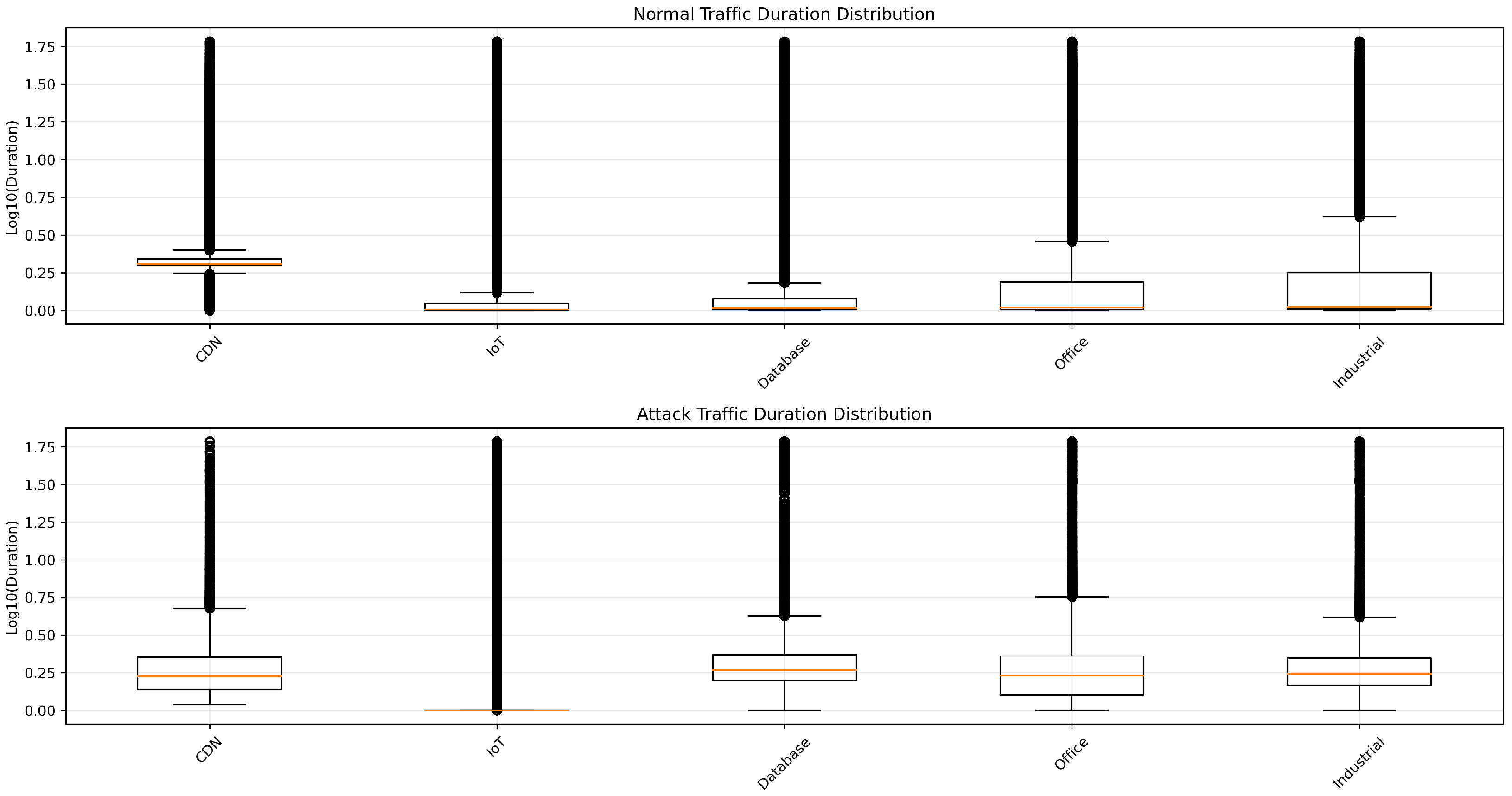
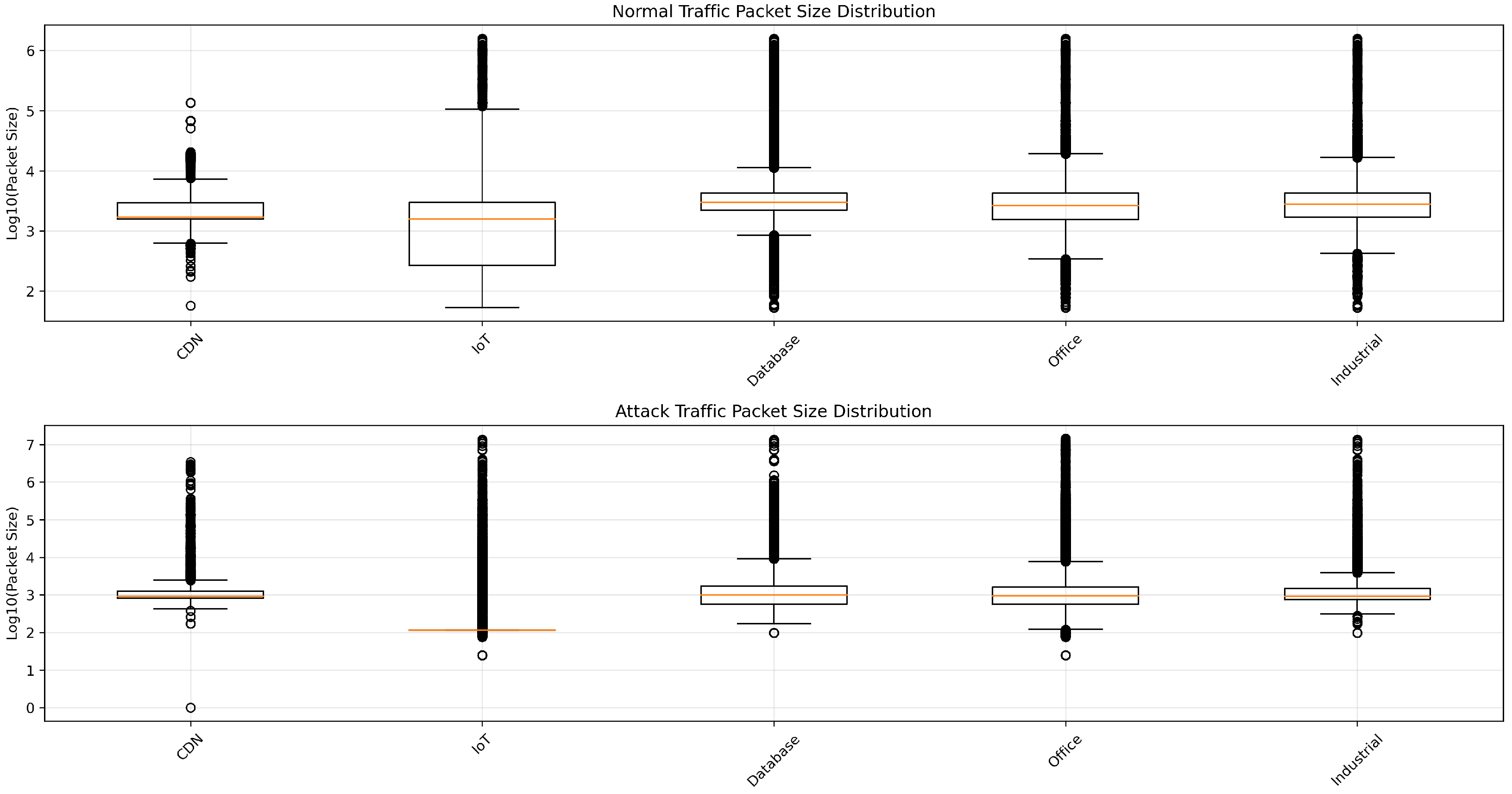
3.7. Visual Analysis of Traffic Patterns
3.8. Experimental Evaluation and Analysis
- 1.
- Accuracy and Class-Wise Performance: Measured as the global accuracy across all clients, along with detailed per-class accuracy trends.
- 2.
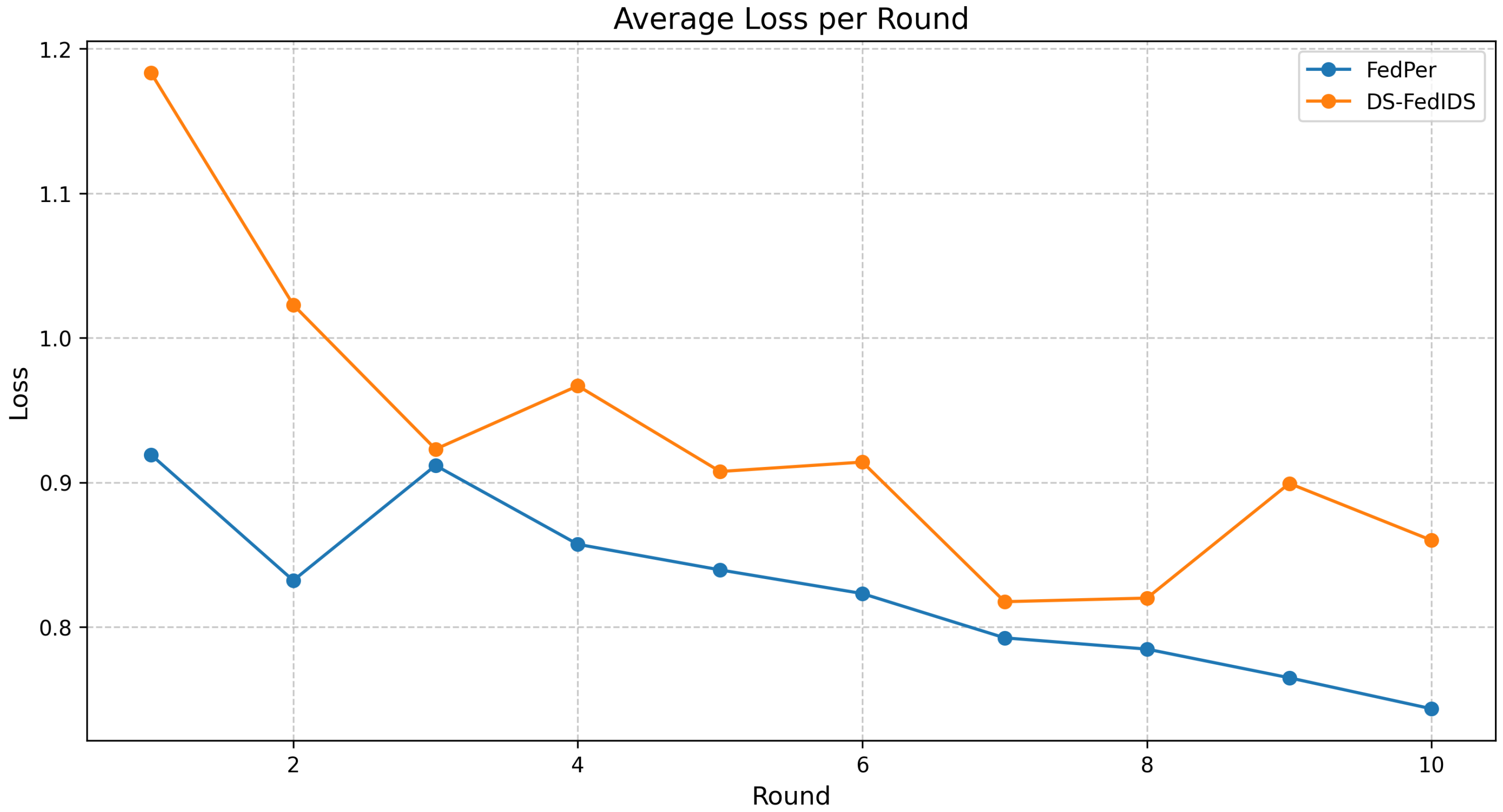
- Efficiency and Training Overheads: Captured via the average training time per round and the overall loss trajectory.
3.9. Comparison with Other Personalized FL Frameworks
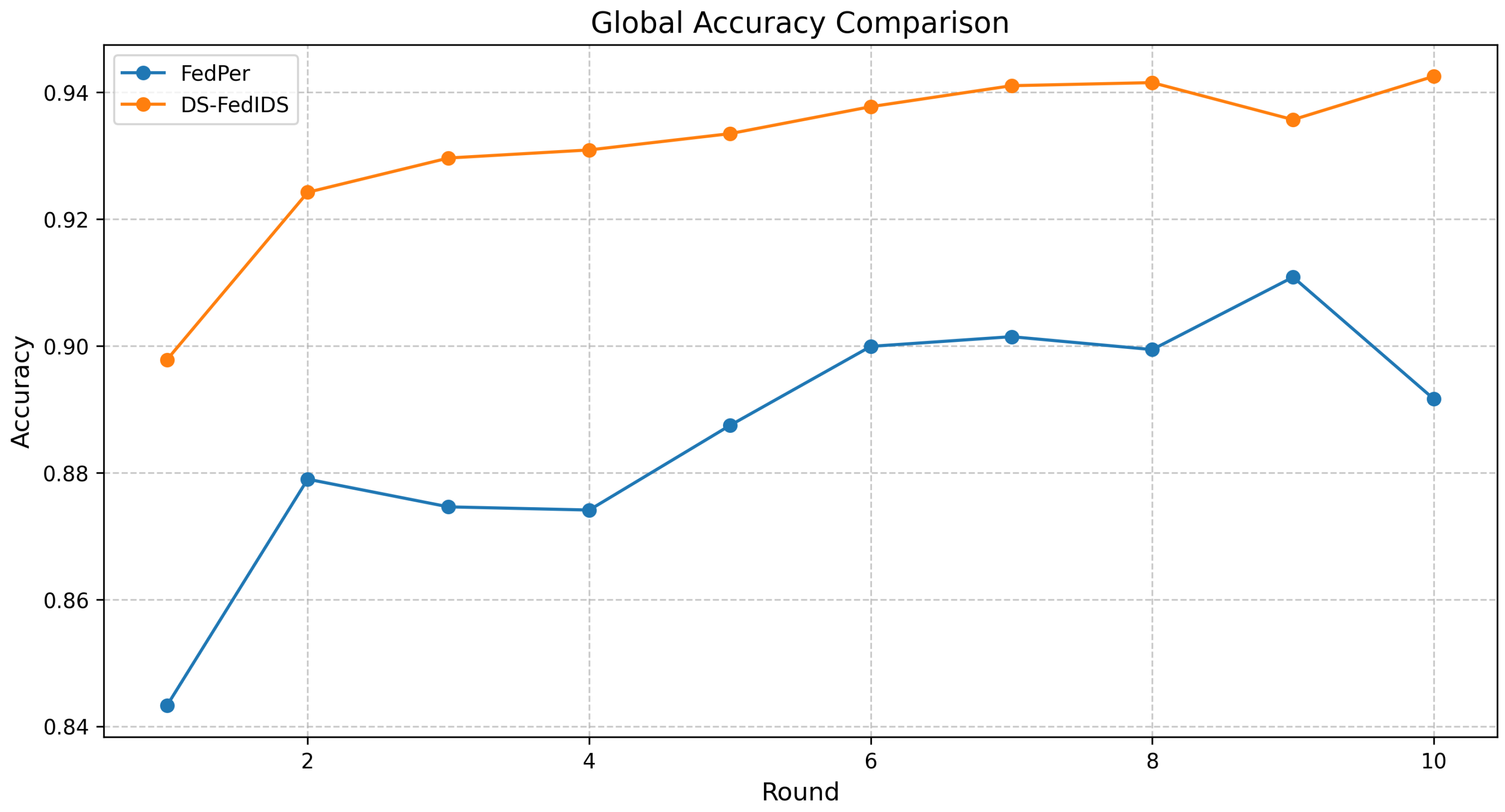
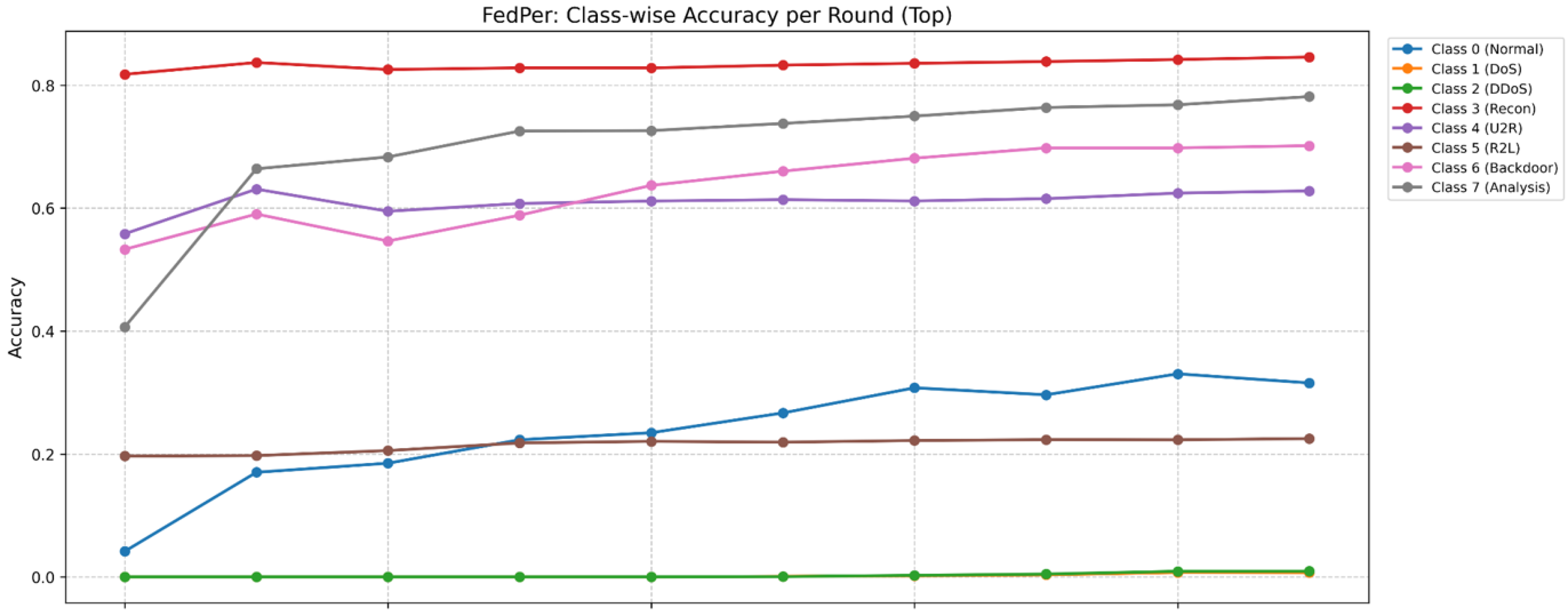
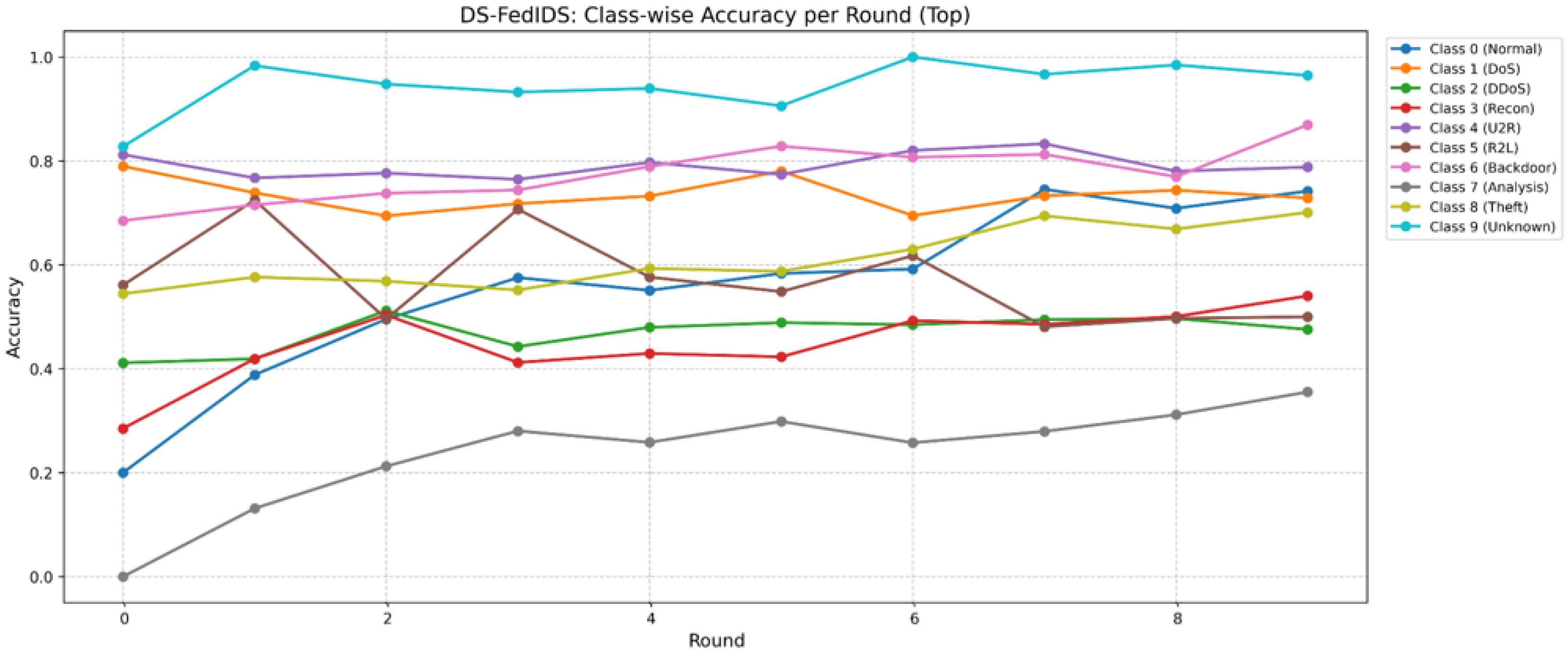
3.10. Experimental Results
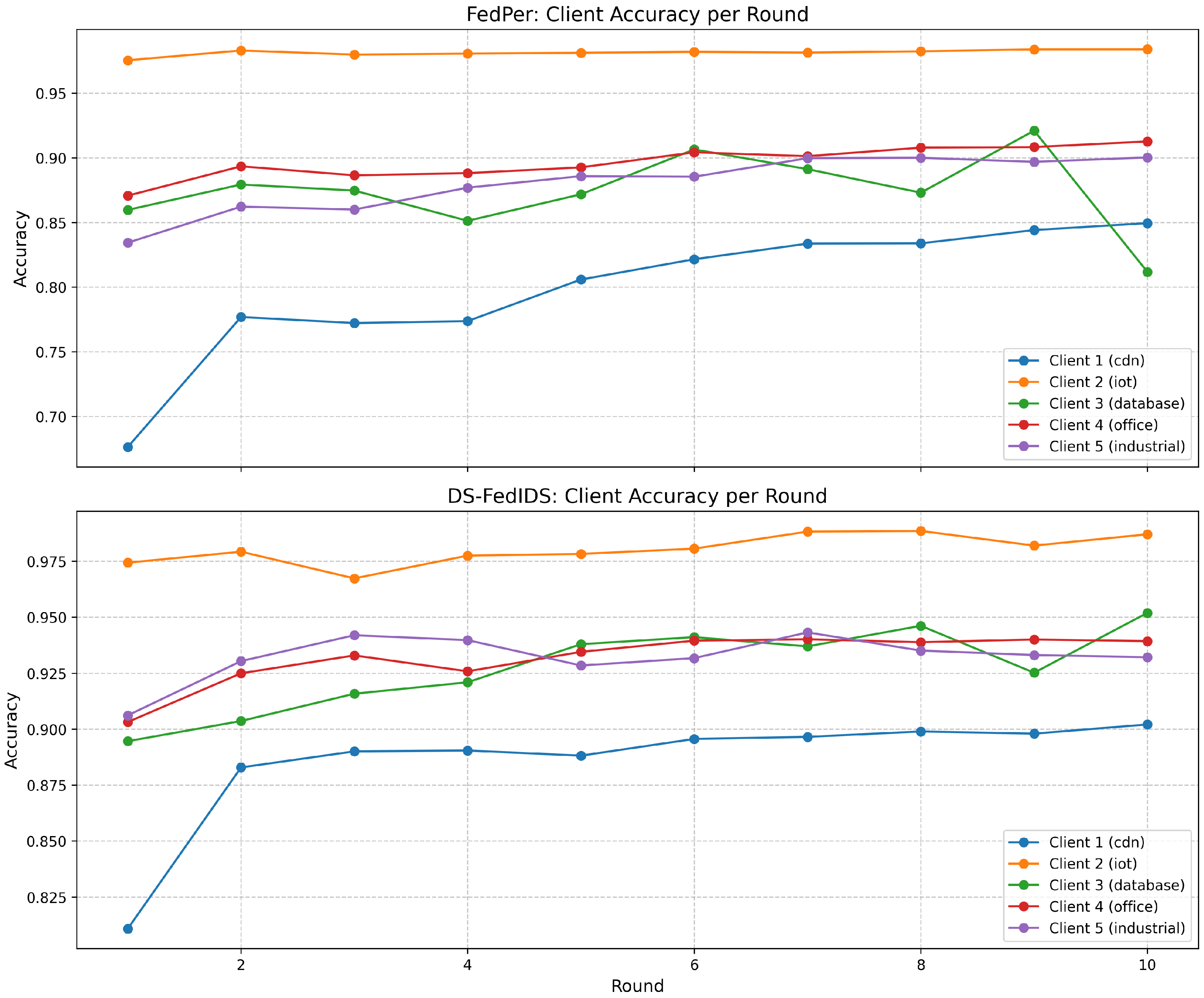
- DS-FedIDS consistently outperforms the baseline FedPer in global accuracy, particularly after the initial training rounds, indicating effective personalization and knowledge sharing.
- Dynamic sampling significantly enhances the detection of minority attack classes, such as Theft and R2L attacks, overcoming a common limitation in traditional intrusion detection systems.
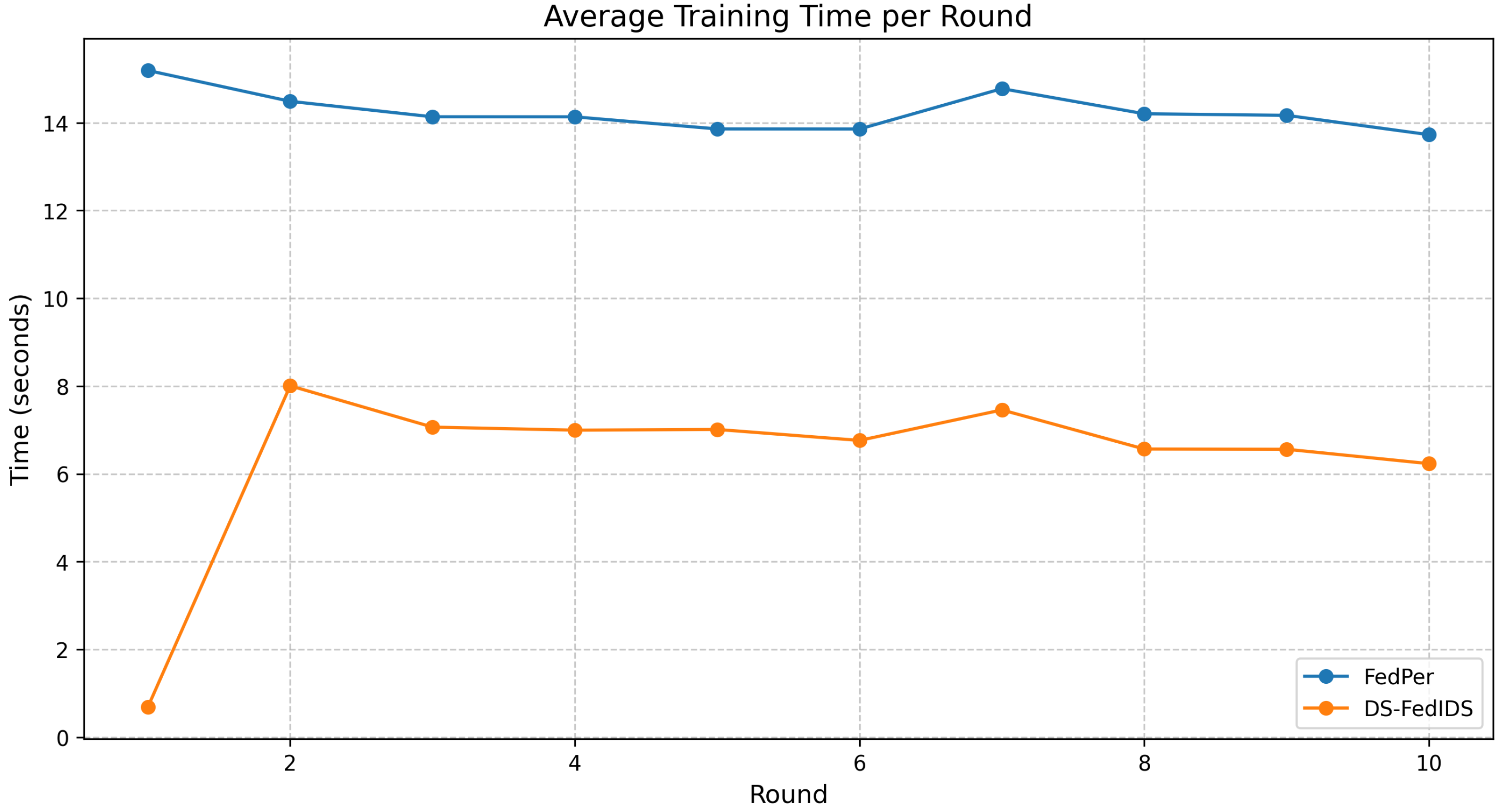
- Despite the added complexity of sampling and personalization, DS-FedIDS maintains efficient training overhead, which is particularly beneficial for resource-constrained environments like edge devices.
- Client-specific analysis reveals stable improvements across diverse network types, with notable gains in edge-based scenarios where data distributions vary significantly.
- Exploration of stratified sampling techniques enhances the preservation of traffic distribution characteristics when applying dynamic sampling thresholds.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McMahan, H.B.; Moore, E.; Ramage, D.; Hampson, S. Communication-efficient learning of deep networks from decentralized data. arXiv 2016, arXiv:1602.05629. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Alazab, M.; Khan, S.; Krishnan, S.S.R.; Pham, Q.-V.; Reddy, M.P.K.; Gadekallu, T.R. Federated Learning for Cybersecurity: Concepts, Challenges and Future Directions. IEEE Trans. Ind. Inform. 2021, 18, 3501–3509. [Google Scholar] [CrossRef]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2019, arXiv:1811.03604. [Google Scholar]
- Fan, L.; Jin, H. A Practical Framework for Privacy-Preserving Data Analytics. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 311–321. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated Learning with Non-IID Data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Reddi, S.J.; Charles, Z.; Zaheer, M.; Garrett, Z.; Rush, K.; Konečný, J.; Kumar, S.; McMahan, H.B. Adaptive Federated Optimization. arXiv 2020, arXiv:2003.00295. [Google Scholar]
- Li, T.; Hu, S.; Beirami, A.; Smith, V. Ditto: Fair and Robust Federated Learning Through Personalization. arXiv 2020, arXiv:2012.04221. [Google Scholar]
- Neyigapula, B.S. Federated Learning for Collaborative Network Security in Decentralized Environments. J. Sens. Netw. Data Commun. 2023, 3, 81–92. [Google Scholar]
- Hanzely, F.; Richtárik, P. Federated learning of a mixture of global and local models. arXiv 2021, arXiv:2002.05516. [Google Scholar]
- Tharaphe, T.T.; Yoshiaki, S.; Masakatu, M. Personalized federated learning-based intrusion detection system: Poisoning attack and defense. Future Gener. Comput. Syst. 2024, 149, 44–58. [Google Scholar]
- Chakraborty, S.; Sharma, N.; Mondal, T.; Khatri, S.K.; Biswas, B. Machine Learning for Automated Industrial IoT Attack Detection: An Efficiency-Complexity Trade-off. ACM Trans. Manag. Inf. Syst. 2021, 12, 1–26. [Google Scholar] [CrossRef]
- Hsu, T.-M.H.; Qi, H.; Brown, M. Measuring the effects of non-identical data distribution for federated visual classification. arXiv 2019, arXiv:1909.06335. [Google Scholar]
- Khodak, M.; Balcan, M.-F.; Talwalkar, A. Adaptive gradient-based meta-learning methods. arXiv 2019, arXiv:1906.02717. [Google Scholar]
- Arivazhagan, M.G.; Aggarwal, V.; Singh, A.K.; Choudhary, S. Federated learning with personalization layers. arXiv 2019, arXiv:1912.00818. [Google Scholar]
- Dinh, C.T.; Tran, N.H.; Nguyen, T.D. Personalized Federated Learning with Moreau Envelopes. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual Conference, 6–12 December 2020; pp. 21394–21405. [Google Scholar]
- Shamsian, A.; Navon, A.; Fetaya, E.; Chechik, G. Personalized Federated Learning using Hypernetworks. arXiv 2021, arXiv:2103.04628. [Google Scholar]
- Shibly, K.H.; Roy, S.K.; Hossain, M.A.; Bhuiyan, M.Z.A.; Hossain, M.S. Personalized Federated Learning for Automotive Intrusion Detection Systems. In Proceedings of the 2022 IEEE Future Networks World Forum, Montreal, QC, Canada, 12–14 October 2022; pp. 544–549. [Google Scholar]
- He, C.; Annavaram, M.; Avestimehr, S. Group Knowledge Transfer: Federated Learning of Large CNNs at the Edge. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual Conference, 6–12 December 2020; pp. 14068–14080. [Google Scholar]
- Lin, T.; Stich, S.U.; Patel, K.K.; Jaggi, M. Don’t Use Large Mini-Batches, Use Local SGD. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Sengupta, S.; Chowdhary, A.; Sabur, A.; Alshamrani, A.; Huang, D.; Kang, S. Privacy-Preserving Cyber-Security Information Exchange Mechanism. In Proceedings of the Performance Evaluation of Computer and Telecommunication Systems, Montreal, QC, Canada, 24–27 July 2016. [Google Scholar]
- Alkhamisi, A.; Katib, I.; Buhari, S.M. Federated Learning-Based Security Attack Detection for Multi-Controller Software-Defined Networks. Algorithms 2024, 17, 290. [Google Scholar] [CrossRef]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009; Available online: https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf (accessed on 29 April 2025).
- Fallah, A.; Mokhtari, A.; Ozdaglar, A. Personalized Federated Learning with Theoretical Guarantees: A Model-Agnostic Meta-Learning Approach. In Proceedings of the Advances in Neural Information Processing Systems 33 (NeurIPS 2020), Virtual Conference, 6–12 December 2020; pp. 3557–3568. [Google Scholar]
- Li, T.; Sanjabi, M.; Beirami, A.; Smith, V. Fair Resource Allocation in Federated Learning. In Proceedings of the 8th International Conference on Learning Representations (ICLR 2020), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- He, H.; Ma, Y. Imbalanced Learning: Foundations, Algorithms, and Applications; Wiley-IEEE Press: Hoboken, NJ, USA, 2013. [Google Scholar]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef]
- Chen, C.; Liu, X.; Qiu, T.; Sangaiah, A.K. Dynamic oversampling strategy for imbalanced big data in intrusion detection. IEEE Access 2021, 9, 99362–99375. [Google Scholar]
- Collins, L.; Hassani, H.; Mokhtari, A.; Shakkottai, S. Exploiting shared representations for personalized federated learning. arXiv 2023, arXiv:2102.07078. [Google Scholar]
- Wu, D.; Xia, S.-T.; Wang, Y. Adversarial Weight Perturbation Helps Robust Generalization. Adv. Neural Inf. Process. Syst. 2020, 33, 11964–11976. [Google Scholar]
- Smith, V.; Chiang, C.-K.; Sanjabi, M.; Talwalkar, A.S. Federated Multi-Task Learning. In Proceedings of the Advances in Neural Information Processing Systems 30 (NeurIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 4424–4434. [Google Scholar]
- Caldas, S.; Wu, P.; Li, T.; Konečný, J.; McMahan, H.B.; Smith, V.; Talwalkar, A. LEAF: A benchmark for federated settings. arXiv 2019, arXiv:1812.01097. [Google Scholar]
- Moustafa, N.; Slay, J. UNSW-NB15: A Comprehensive Data Set for Network Intrusion Detection Systems (UNSW-NB15 Network Data Set). In Proceedings of the Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. Available online: https://research.unsw.edu.au/projects/unsw-nb15-dataset (accessed on 19 March 2025).

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Number of Clients | 5 |
| Federated Rounds | 10 |
| Local Epochs | 5 |
| Batch Size | 64 |
| Learning Rate | 0.001 (decay 0.95 per round) |
| Optimizer | Adam |
| Loss Function | Negative Log Likelihood |
| Dynamic Sampling Threshold () | |
| Pruning Start Round | 5 |
| Service | CDN | IoT | DB | Office | Industrial |
|---|---|---|---|---|---|
| http | 80.71 | 9.46 | 0.00 | 13.48 | 17.34 |
| dns | 0.03 | 35.86 | 0.00 | 0.00 | 0.00 |
| ftp | 19.21 | 0.00 | 0.00 | 3.21 | 0.00 |
| ssl | 0.06 | 0.00 | 0.00 | 0.00 | 0.00 |
| smtp | 0.00 | 0.00 | 0.00 | 5.33 | 0.00 |
| pop3 | 0.00 | 0.00 | 0.00 | 0.10 | 0.00 |
| dhcp | 0.00 | 0.01 | 0.00 | 0.00 | 0.00 |
| other | 0.00 | 54.67 | 100.00 | 77.88 | 82.66 |
| Attack Cat. | CDN | IoT | DB | Office | Industrial |
|---|---|---|---|---|---|
| Exploits | 61.87 | 6.90 | 22.74 | 37.78 | 38.21 |
| DoS | 8.25 | 1.20 | 3.63 | 5.26 | 5.84 |
| Reconnaissance | 9.48 | 4.36 | 17.59 | 17.02 | 14.92 |
| Generic | 8.17 | 78.90 | 3.22 | 5.41 | 5.57 |
| Fuzzers | 8.57 | 7.67 | 49.11 | 30.68 | 31.54 |
| Analysis | 2.53 | 0.23 | 0.21 | 0.90 | 1.32 |
| Backdoor | 0.45 | 0.13 | 0.77 | 0.50 | 0.66 |
| Shellcode | 0.00 | 0.56 | 2.71 | 2.19 | 1.61 |
| Worms | 0.67 | 0.06 | 0.02 | 0.25 | 0.33 |
| Protocol | CDN | IoT | DB | Office | Industrial |
|---|---|---|---|---|---|
| tcp | 100.00 | 54.57 | 100.00 | 86.38 | 100.00 |
| udp | 0.00 | 45.43 | 0.00 | 13.62 | 0.00 |
| Framework | Average Accuracy | Avg. Inference Time (s) | Total Training Time (s) |
|---|---|---|---|
| FedPer | 0.8787 | 0.1440 | 661.72 |
| PFedMe | 0.5089 | 0.6591 | 2252.51 |
| PerFedAvg | 0.4811 | 0.6870 | 588.85 |
| LG-FedAvg | 0.7941 | 0.5868 | 449.30 |
| DS-FedIDS | 0.9266 | 0.1307 | 20.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Youm, S.; Kim, T. Enhancing Federated Intrusion Detection with Class-Specific Dynamic Sampling. Appl. Sci. 2025, 15, 5067. https://doi.org/10.3390/app15095067
Youm S, Kim T. Enhancing Federated Intrusion Detection with Class-Specific Dynamic Sampling. Applied Sciences. 2025; 15(9):5067. https://doi.org/10.3390/app15095067
Chicago/Turabian StyleYoum, Sungkwan, and Taeyoon Kim. 2025. "Enhancing Federated Intrusion Detection with Class-Specific Dynamic Sampling" Applied Sciences 15, no. 9: 5067. https://doi.org/10.3390/app15095067
APA StyleYoum, S., & Kim, T. (2025). Enhancing Federated Intrusion Detection with Class-Specific Dynamic Sampling. Applied Sciences, 15(9), 5067. https://doi.org/10.3390/app15095067