
Online Prediction of Concrete Temperature During the Construction of an Arch Dam Based on a Sparrow Search Algorithm–Incremental Support Vector Regression Model


Abstract
1. Introduction
2. Methodology
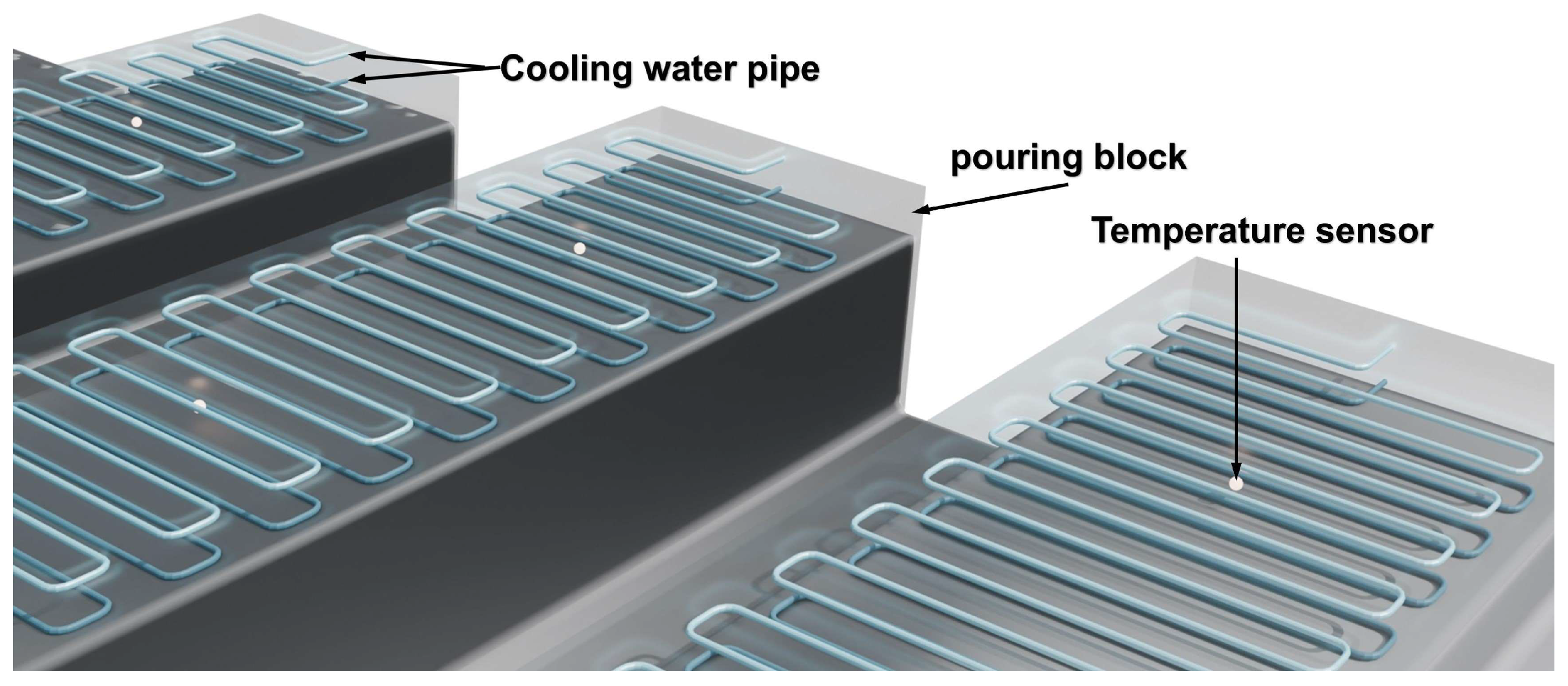
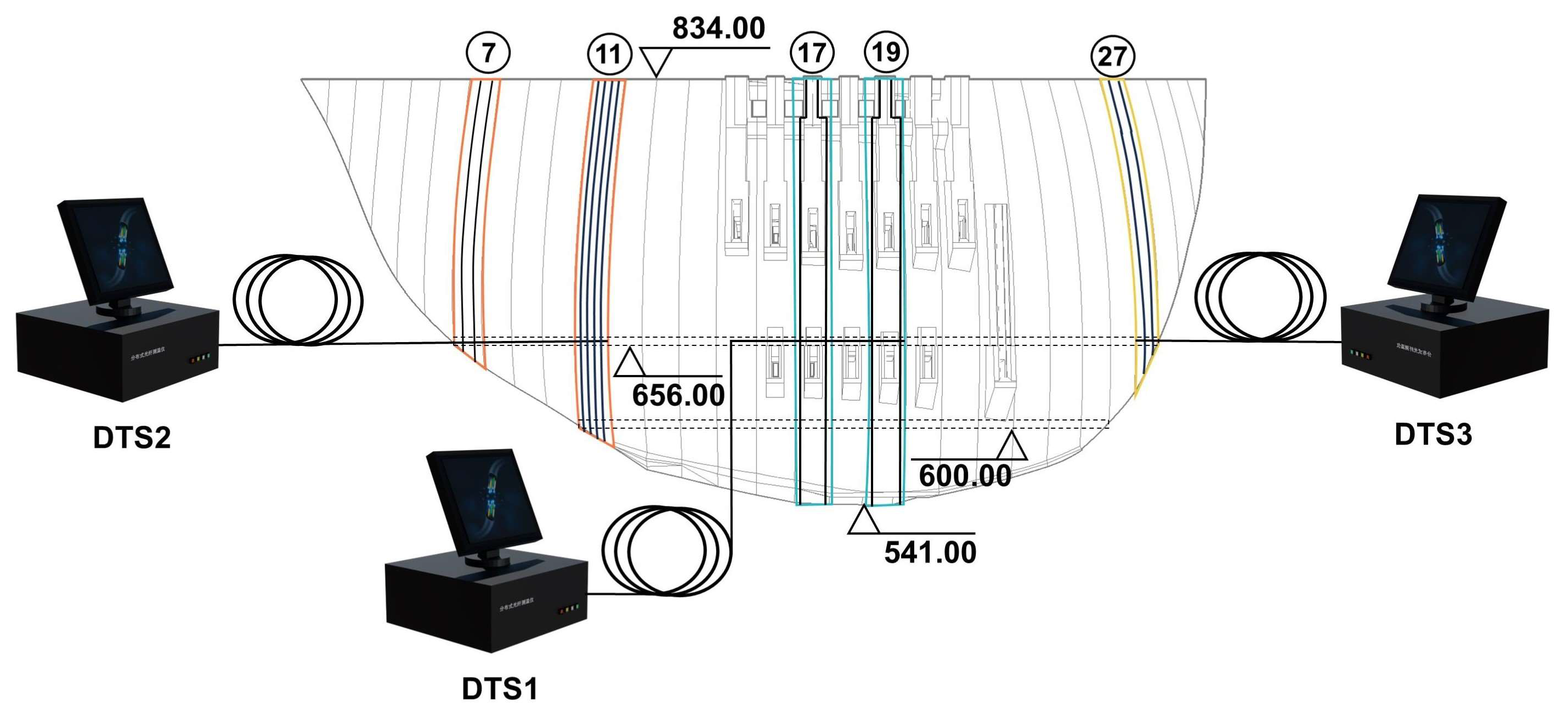
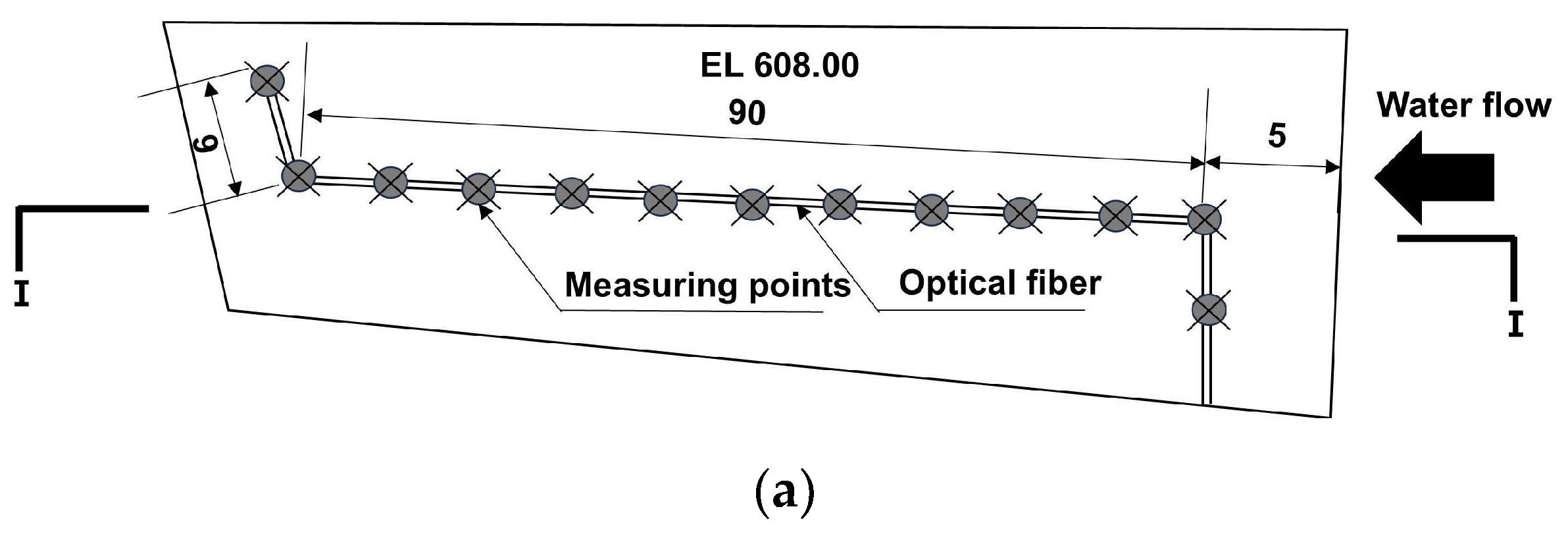
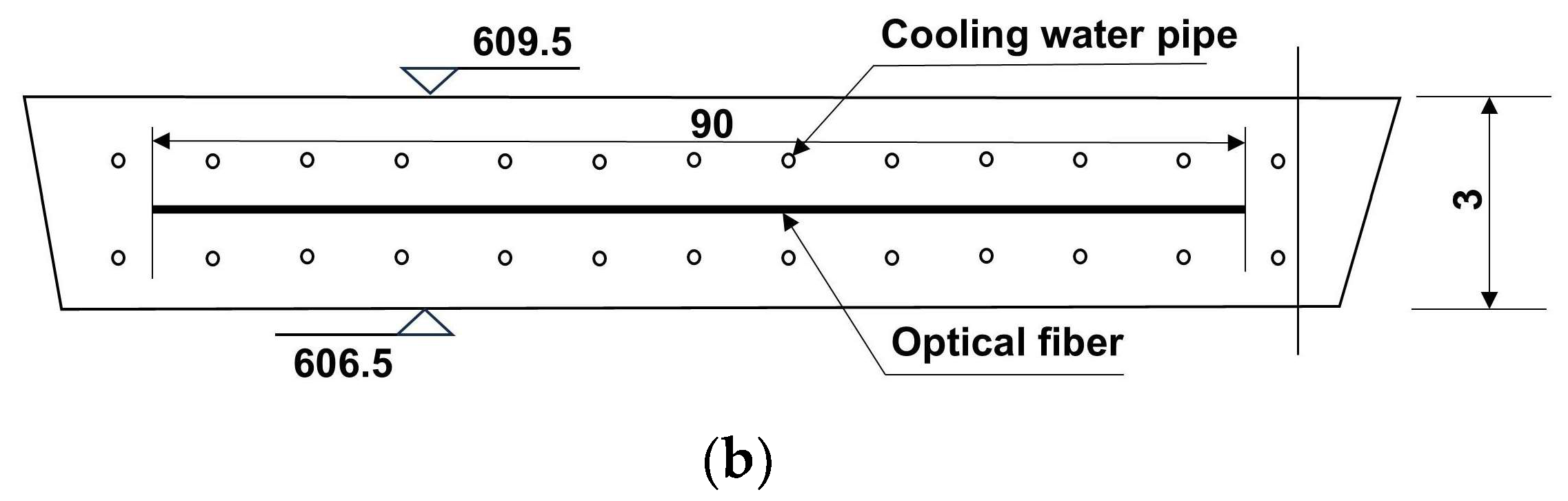
2.1. Data Collection Method
2.2. A Concrete Temperature Prediction Model Based on SSA-ISVR
2.2.1. Feature Selection for Model Inputs
2.2.2. SVR Theory
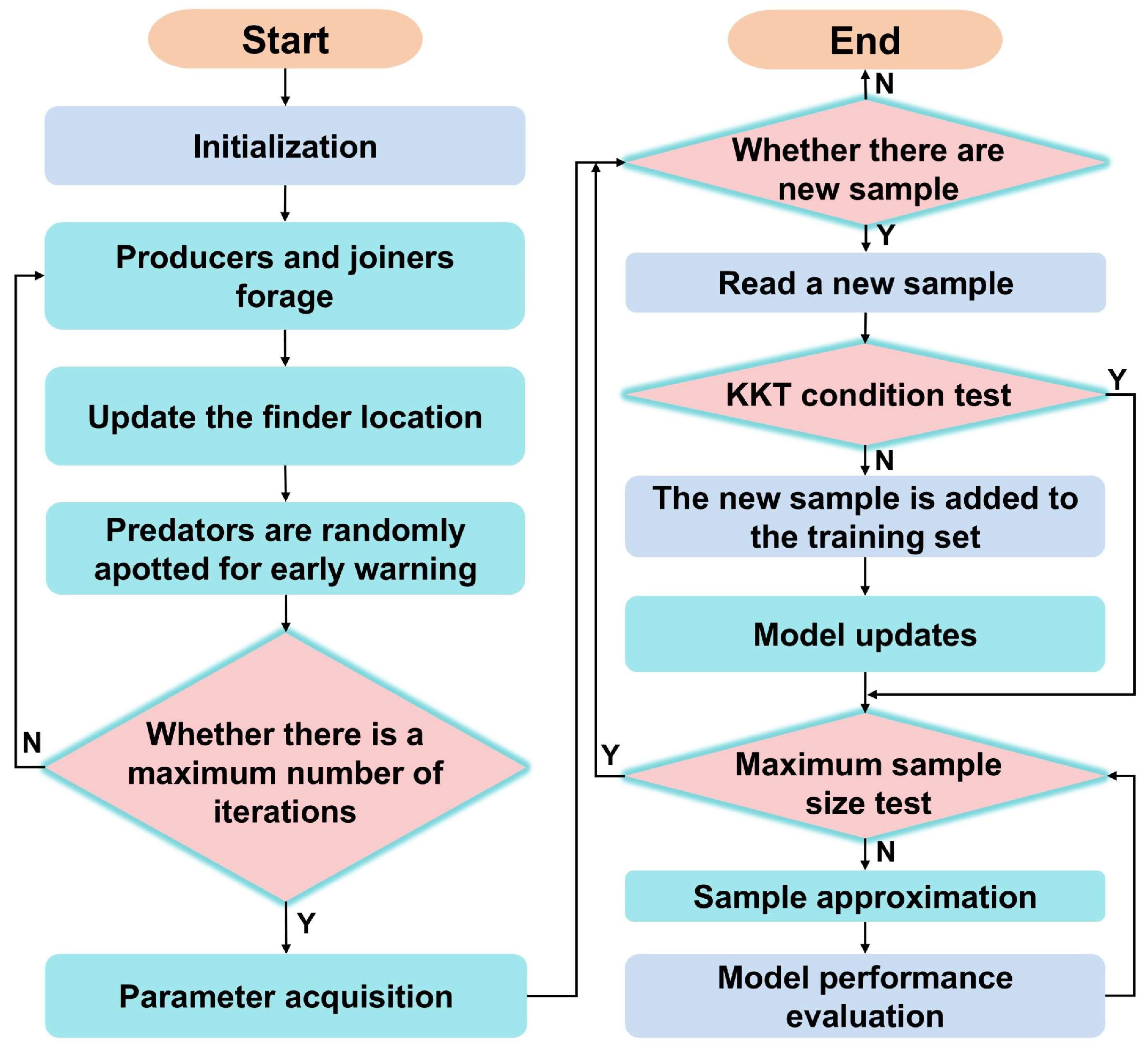
2.2.3. SSA Optimization Algorithm Theory
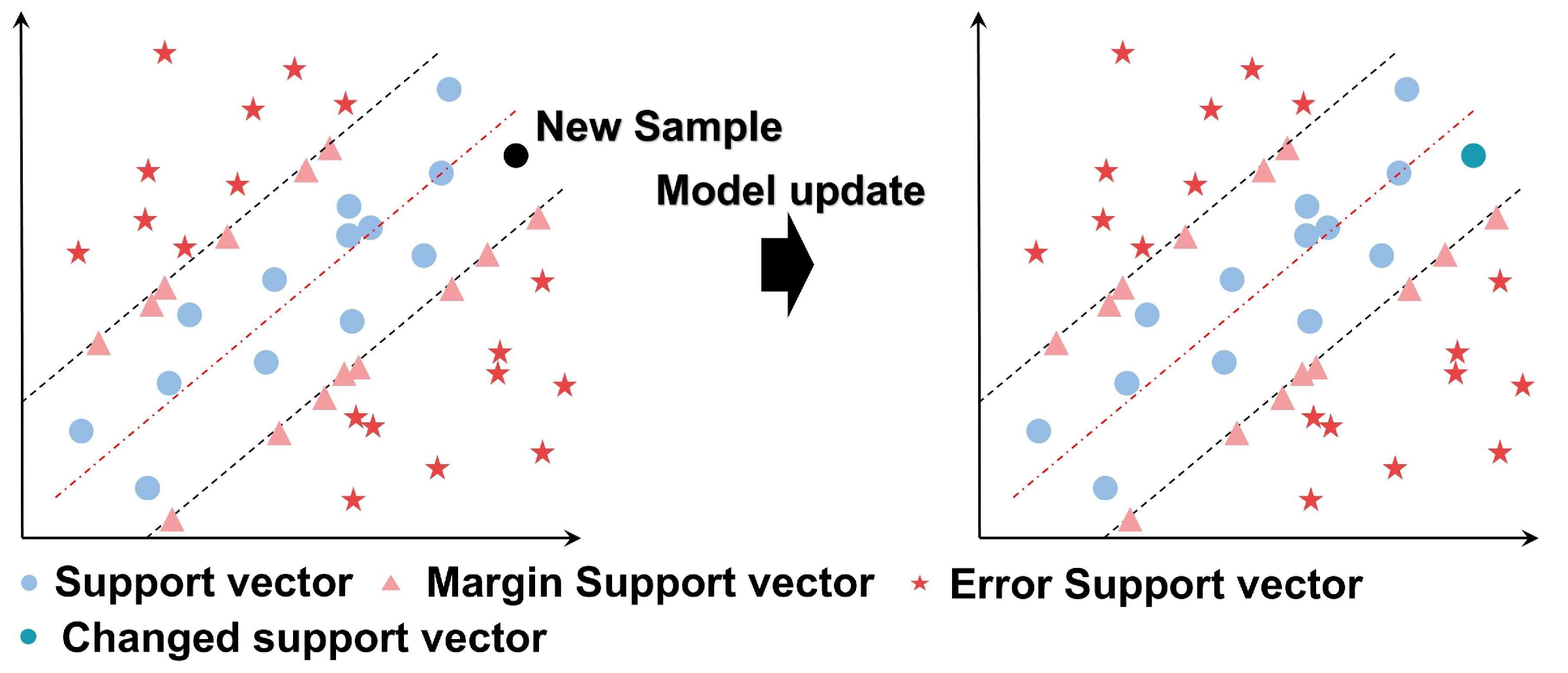
2.3. Sample Augmentation and Reduction Methods
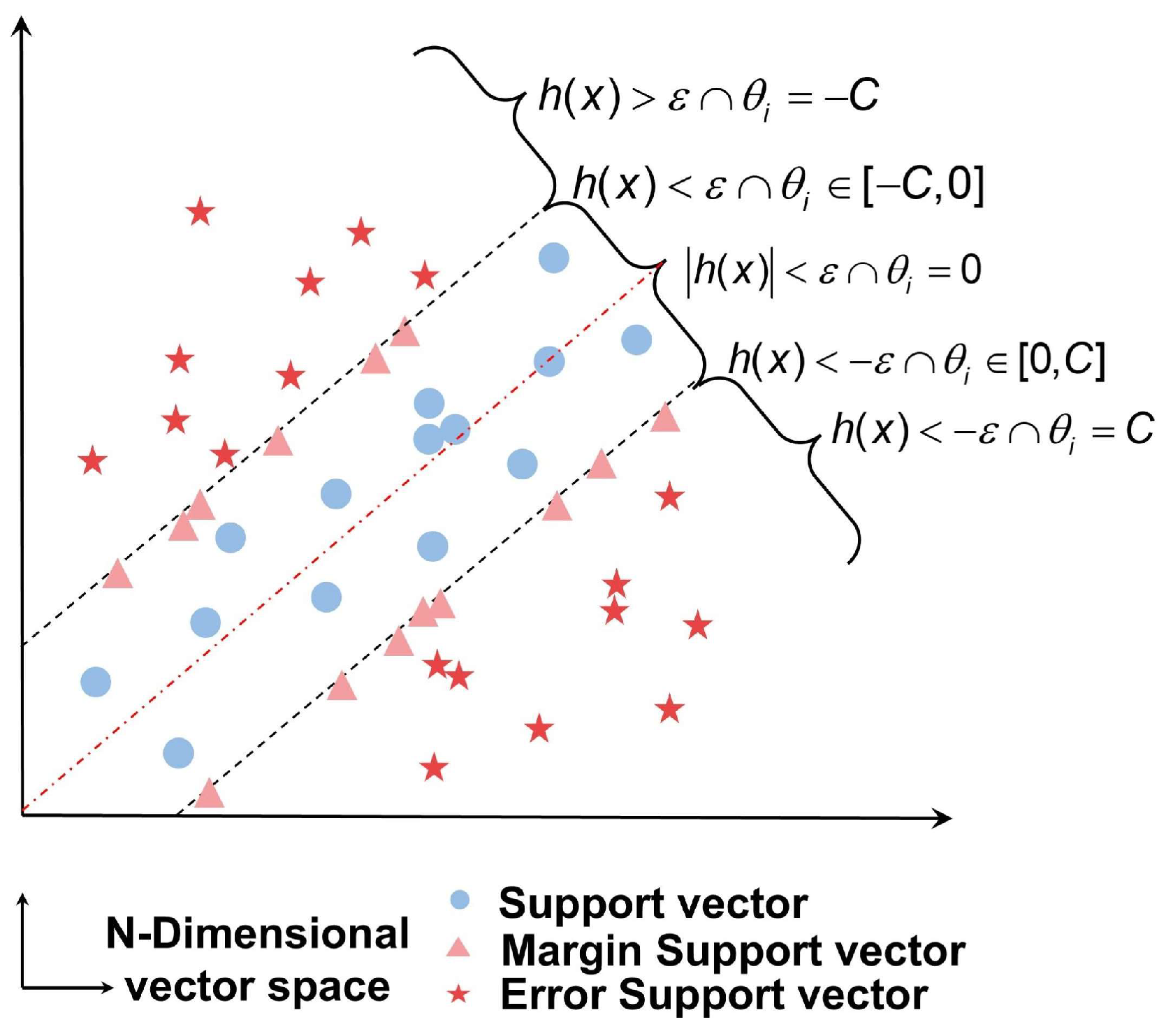
2.3.1. KKT Condition Examination for New Samples
2.3.2. Selective Elimination Strategy Based on Sample Similarity
2.4. Online Modeling Method for Temperature Prediction in Arch Dams Based on SSA-ISVR
3. Case Study
3.1. Project Overview
3.2. Modeling Preparation
3.3. Evaluation Metrics
4. Results and Discussion
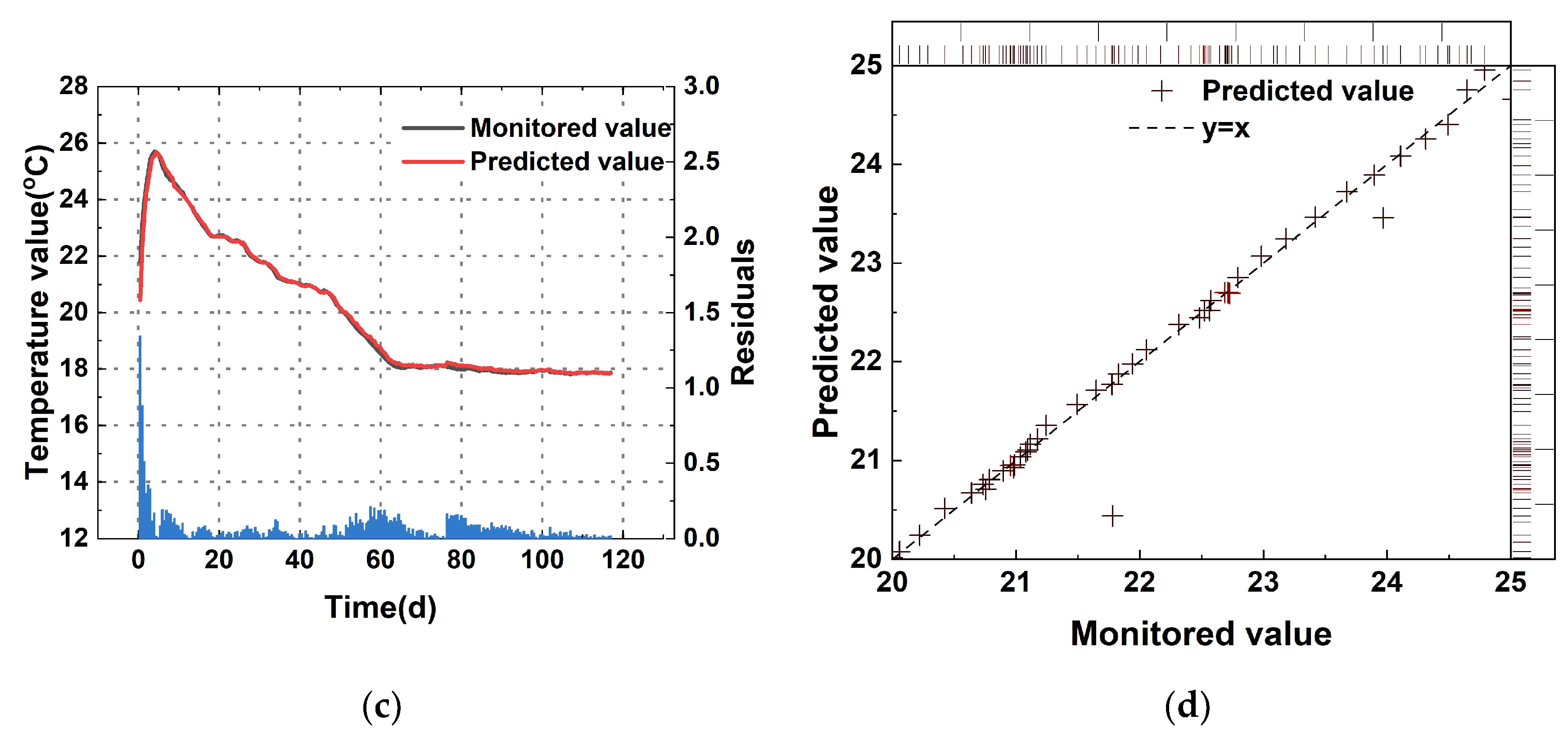
4.1. SSA-ISVR-Based Prediction Results
4.2. Comparative Analysis of Different Models
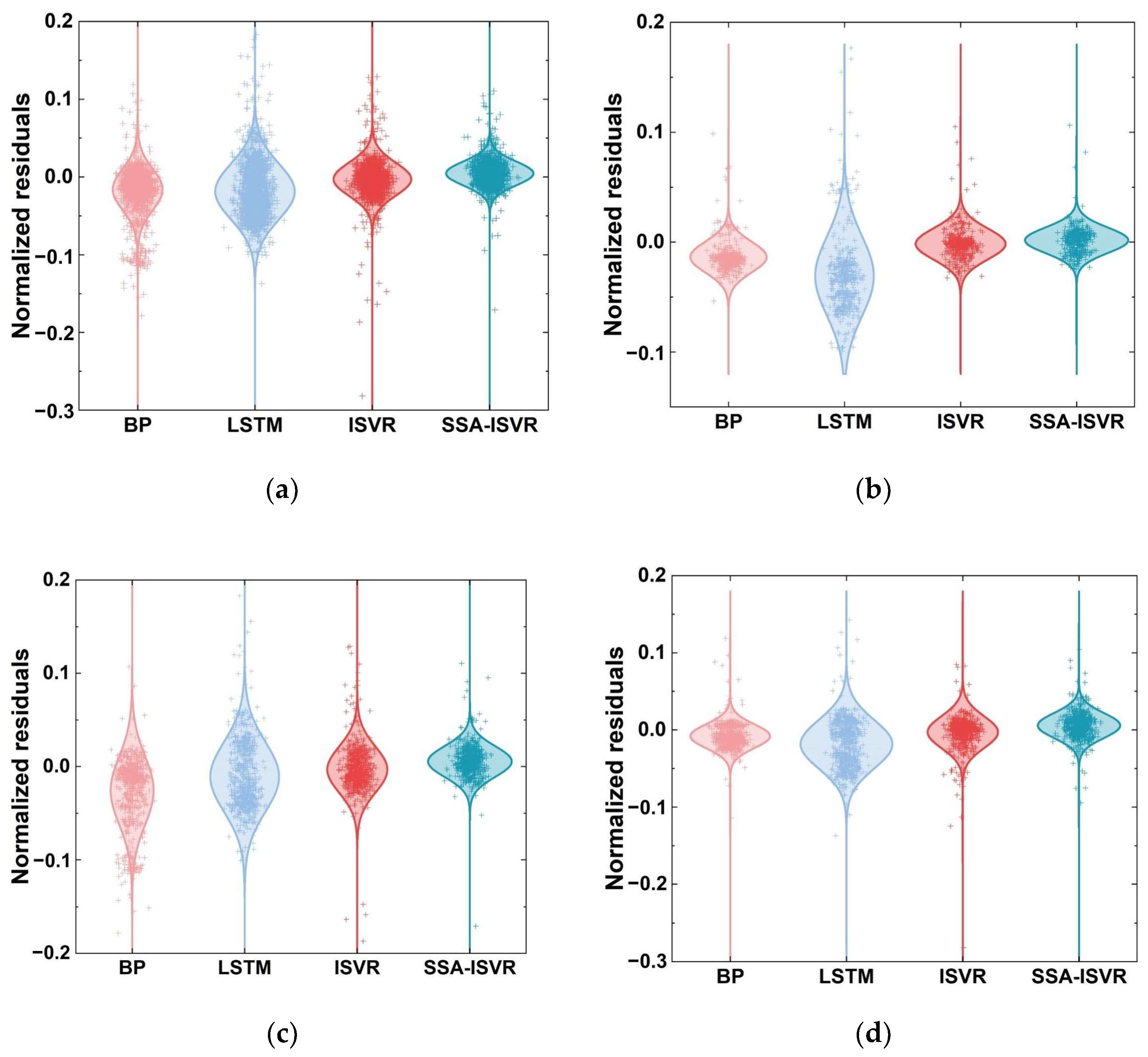
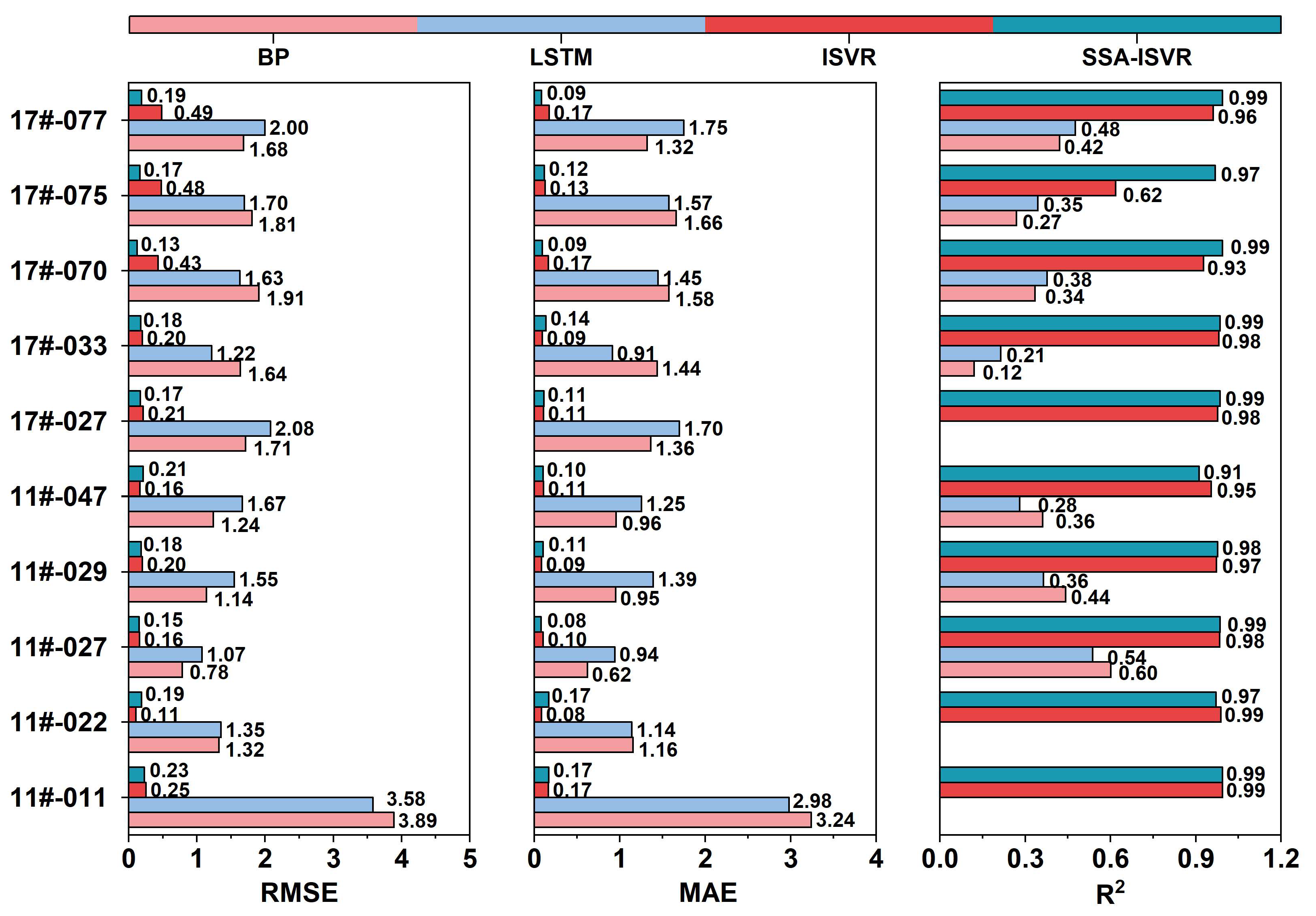
4.2.1. Stability of Prediction Performance
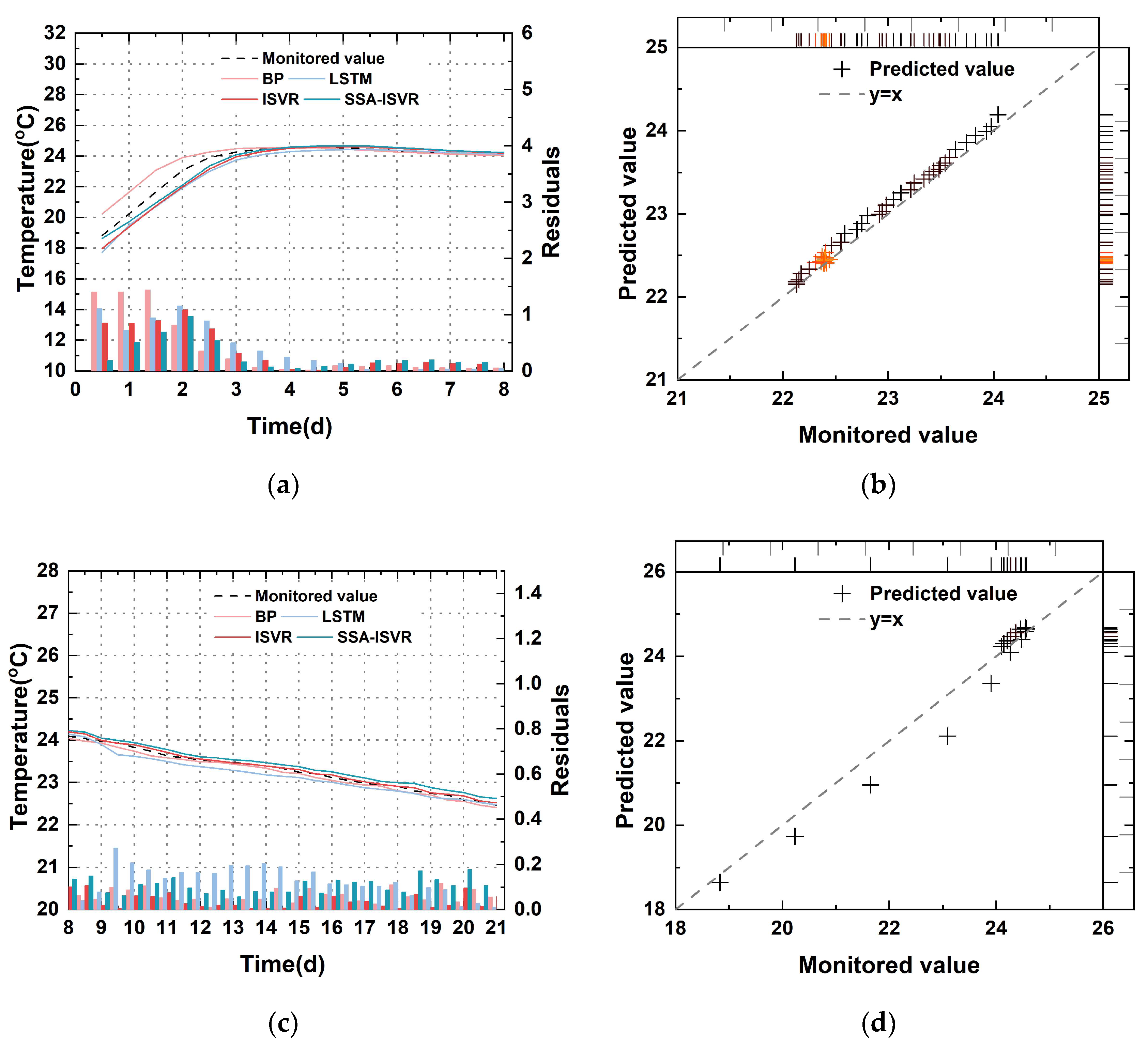
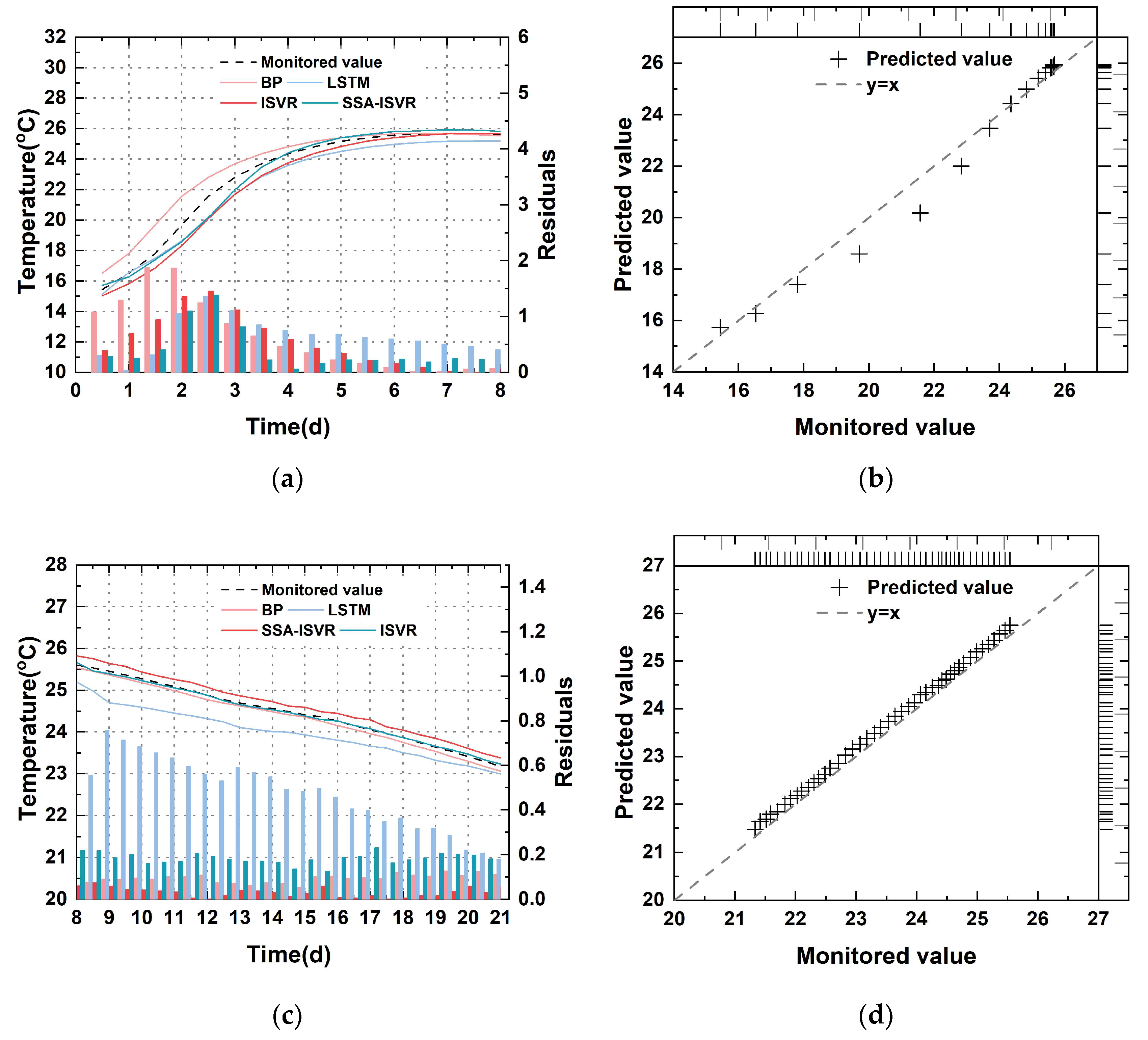
4.2.2. Comparison of Prediction Errors at Different Cooling Stages
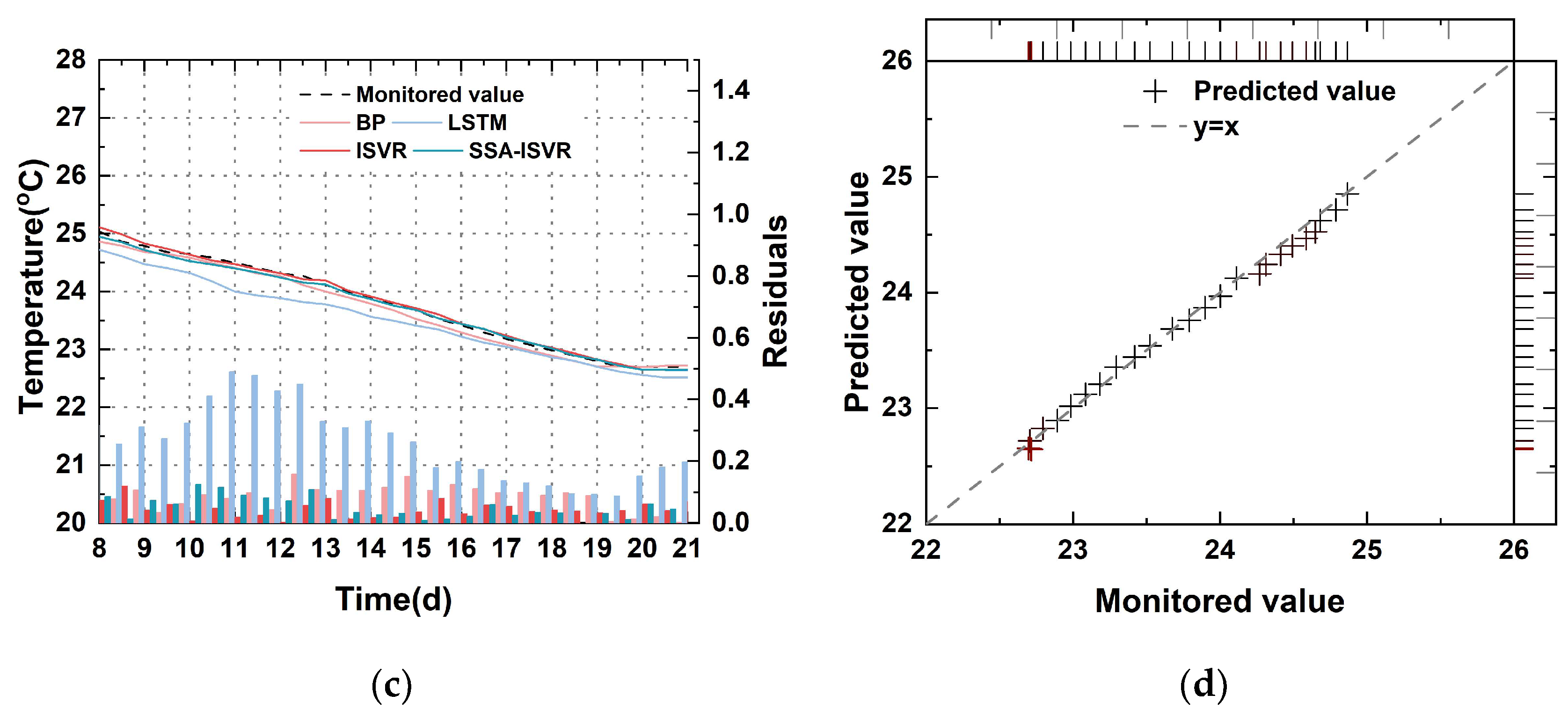
4.2.3. Evaluation of Model Generalization Using an Application Dataset
4.3. Discussion
- (1)
- The SSA optimization method was exclusively applied to the ISVR model. Although the ISVR model without SSA optimization demonstrated satisfactory performance in experiments, the efficacy of SSA optimization for other models remains to be validated.
- (2)
- While SSA parameter settings are relatively straightforward and can be informed by prior research, the methodology for selecting optimal parameters has not been thoroughly explored.
- (3)
- The impact of sample size on model performance requires additional examination. Substantial sample sizes may introduce redundancy and reduce modeling efficiency, whereas insufficient sample sizes could affect the model’s generalization capability.
5. Conclusions
- The proposed model achieved an average of 0.20 and an of 0.14 °C between predicted and measured values across multiple blocks. This result suggested that during the initial cooling phase of concrete in arch dam construction, the SSA-ISVR model provided more accurate predictions than the BP, LSTM, and ISVR models.
- Across the two cooling phases of concrete within multiple blocks, the SSA-ISVR model reduced the average by 28% and the average by 30%. This result demonstrated that the online temperature prediction model developed for arch dam construction exhibited greater generalizability than the offline models of BP and LSTM. The offline models struggled to adapt to new data patterns because of the cumulative effects of time-varying factors, which failed to decrease average prediction errors over time. In contrast, the online model was able to learn from model updates, thereby reducing prediction errors.
- Although numerical experiments demonstrated that the proposed model is a promising and effective approach for temperature prediction during concrete arch dam construction, some limitations may arise in practical applications. Given the complex construction conditions of concrete, additional features may be required to develop a temperature prediction model with higher adaptability. Future research could explore incorporating additional features to enhance the model’s learning capacity.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, P.; Ning, Z.; Shi, J.; Liu, C.; Chen, W.; Tan, Y. Study On the Gallery Structure Cracking Mechanisms and Cracking Control in Dam Construction Site. Eng. Fail. Anal. 2021, 121, 105135. [Google Scholar] [CrossRef]
- Li, M.; Lin, P.; Chen, D.; Li, Z.; Liu, K.; Tan, Y. An Ann-Based Short-Term Temperature Forecast Model for Mass Concrete Cooling Control. Tsinghua Sci. Technol. 2023, 28, 511–524. [Google Scholar] [CrossRef]
- Liu, J.; Wang, F.; Wang, X.; Hu, Z.; Liang, C. Temperature Monitoring and Cracking Risk Analysis of Corridor Top Arch of Baihetan Arch Dam During Construction Period. Eng. Fail. Anal. 2025, 167, 108903. [Google Scholar] [CrossRef]
- Nandhini, K.; Karthikeyan, J. The Early-Age Prediction of Concrete Strength Using Maturity Models: A Review. J. Build. Pathol. Rehabilit. 2021, 6, 7. [Google Scholar] [CrossRef]
- Zhu, Z.; Liu, Y.; Fan, Z.; Qiang, S.; Xie, Z.; Chen, W.; Wu, C. Improved Buried Pipe Element Method for Temperature-Field Calculation of Mass Concrete with Cooling Pipes. Eng. Comput. 2020, 37, 2619–2640. [Google Scholar] [CrossRef]
- Gao, X.; Li, Q.; Liu, Z.; Zheng, J.; Wei, K.; Tan, Y.; Yang, N.; Liu, C.; Lu, Y.; Hu, Y. Modelling the Strength and Fracture Parameters of Dam Gallery Concrete Considering Ambient Temperature and Humidity. Buildings 2022, 12, 168. [Google Scholar] [CrossRef]
- Chen, H.; Liu, Z. Temperature Control and Thermal-Induced Stress Field Analysis of Gongguoqiao Rcc Dam. J. Therm. Anal. Calorim. 2019, 135, 2019–2029. [Google Scholar] [CrossRef]
- Zhang, M.; Yao, X.; Guan, J.; Li, L. Study On Temperature Field Massive Concrete in Early Age Based On Temperature Influence Factor. Adv. Civ. Eng. 2020, 2020, 8878974. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, A.; Fan, Y.; Zhou, Y.; Chen, J.; Tan, T. Temperature Monitoring Experiment and Numerical Simulation of the Orifice Structure in an Arch Dam Considering Solar Radiation Effects. J. Civ. Struct. Health Monit. 2023, 13, 523–545. [Google Scholar] [CrossRef]
- Žvanut, P.; Turk, G.; Kryžanowski, A. Thermal Analysis of a Concrete Dam Taking Into Account Insolation, Shading, Water Level and Spillover. Appl. Sci. 2021, 11, 705. [Google Scholar] [CrossRef]
- Hu, Y.; Bao, T.; Ge, P.; Tang, F.; Zhu, Z.; Gong, J. Intelligent Inversion Analysis of Thermal Parameters for Distributed Monitoring Data. J. Build. Eng. 2023, 68, 106200. [Google Scholar] [CrossRef]
- Bo, C.; Qingyi, W.; Weinan, C.; Hao, G. Optimized Inversion Method for Thermal Parameters of Concrete Dam Under the Insulated Condition. Eng. Appl. Artif. Intell. 2023, 126, 106898. [Google Scholar] [CrossRef]
- Wang, F.; Song, R.; Yu, H.; Zhang, A.; Wang, L.; Chen, X. Thermal Parameter Inversion of Low-Heat Cement Concrete for Baihetan Arch Dam. Eng. Appl. Artif. Intell. 2024, 131, 107823. [Google Scholar] [CrossRef]
- Mata, J. Interpretation of Concrete Dam Behaviour with Artificial Neural Network and Multiple Linear Regression Models. Eng. Struct. 2011, 33, 903–910. [Google Scholar] [CrossRef]
- Ranković, V.; Grujović, N.; Divac, D.; Milivojević, N. Development of Support Vector Regression Identification Model for Prediction of Dam Structural Behaviour. Struct. Saf. 2014, 48, 33–39. [Google Scholar] [CrossRef]
- Kang, F.; Liu, J.; Li, J.; Li, S. Concrete Dam Deformation Prediction Model for Health Monitoring Based On Extreme Learning Machine. Struct. Control Health Monit. 2017, 24, e1997. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, Y.; He, X.; Huang, Y. Aasim, Rapid Prediction of the Highest Temperature of Concrete Block. Water Power 2013, 39, 46–48. [Google Scholar] [CrossRef]
- Zou, H.; Zhou, Y.; Wang, L.; Zhang, Z. Aasim, Prediction of the Maximum Temperature of the Concrete Pouring Bin of the Ultra-High Arch Dam Based On the Rbf-Bp Combined Neural Network Model. Water Resour. Power 2016, 34, 67–69. [Google Scholar] [CrossRef]
- Zhou, J.; Fan, S.; Fang, C.; Huang, Y.; Liu, F. Aasim, Prediction of the Maximum Temperature Inside the Concrete Pouring Bin Based On Random Forest Algorithm. Water Resour. Power 2024, 9, 84–87. [Google Scholar] [CrossRef]
- Wang, L.; Zhou, Y. Aasim, Application of Rbf Neural Network in the Prediction of the Maximum Temperature of the Concrete Pouring Chamber of the Extra-High Arch Dam. Water Resour. Power 2015, 33, 68–70. [Google Scholar] [CrossRef]
- Kang, F.; Li, J.; Dai, J. Prediction of Long-Term Temperature Effect in Structural Health Monitoring of Concrete Dams Using Support Vector Machines with Jaya Optimizer and Salp Swarm Algorithms. Adv. Eng. Softw. 2019, 131, 60–76. [Google Scholar] [CrossRef]
- Song, W.; Guan, T.; Ren, B.; Yu, J.; Wang, J.; Wu, B. Real-Time Construction Simulation Coupling a Concrete Temperature Field Interval Prediction Model with Optimized Hybrid-Kernel Rvm for Arch Dams. Energies 2020, 13, 4487. [Google Scholar] [CrossRef]
- Zhao, J.; Lv, Y.; Zeng, Q.; Wan, L. Online Policy Learning-Based Output-Feedback Optimal Control of Continuous-Time Systems. IEEE Trans. Circuits Syst. II Express Briefs 2024, 71, 652–656. [Google Scholar] [CrossRef]
- Fekri, M.N.; Patel, H.; Grolinger, K.; Sharma, V. Deep Learning for Load Forecasting with Smart Meter Data: Online Adaptive Recurrent Neural Network. Appl. Energ. 2021, 282, 116177. [Google Scholar] [CrossRef]
- Bayram, F.; Ahmed, B.S.; Kassler, A. From Concept Drift to Model Degradation: An Overview On Performance-Aware Drift Detectors. Knowl.-Based Syst. 2022, 245, 108632. [Google Scholar] [CrossRef]
- Malialis, K.; Panayiotou, C.G.; Polycarpou, M.M. Online Learning with Adaptive Rebalancing in Nonstationary Environments. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 4445–4459. [Google Scholar] [CrossRef]
- Wassermann, S.; Cuvelier, T.; Mulinka, P.; Casas, P. Adaptive and Reinforcement Learning Approaches for Online Network Monitoring and Analysis. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1832–1849. [Google Scholar] [CrossRef]
- Ma, J.; Theiler, J.; Perkins, S. Accurate On-Line Support Vector Regression. Neural. Comput. 2003, 15, 2683–2703. [Google Scholar] [CrossRef]
- Fan, J.; Xu, J.; Wen, X.; Sun, L.; Xiu, Y.; Zhang, Z.; Liu, T.; Zhang, D.; Wang, P.; Xing, D. The Future of Bone Regeneration: Artificial Intelligence in Biomaterials Discovery. Mater. Today Commun. 2024, 40, 109982. [Google Scholar] [CrossRef]
- Aniskin, N.; Trong, C.; Quoc, L. Influence of Size and Construction Schedule of Massive Concrete Structures On its Temperature Regime. MATEC Web Conf. 2018, 251, 02014. [Google Scholar] [CrossRef]
- Feng, W.; Wang, J.; Chen, H. A fast SVR incremental learning algorithm. J. Chin. Comput. Syst. 2015, 36, 162–166. [Google Scholar] [CrossRef]
- Li, G.; Jiang, Y.; Fan, L.; Xiao, X.; Wang, D.; Zhang, X. Constitutive Model of 25Crmo4 Steel Based On Ipso-Svr and its Application in Finite Element Simulation. Mater. Today Commun. 2023, 35, 106338. [Google Scholar]
- Xue, J.; Shen, B. A Novel Swarm Intelligence Optimization Approach: Sparrow Search Algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Fan, Y.; Zhang, Y.; Guo, B.; Luo, X.; Peng, Q.; Jin, Z. A Hybrid Sparrow Search Algorithm of the Hyperparameter Optimization in Deep Learning. Mathematics 2022, 10, 3019. [Google Scholar] [CrossRef]
- Laskov, P.; Gehl, C.; Krüger, S.; Müller, K.R.; Bennett, K.P.; Parrado-Hernández, E. Incremental Support Vector Learning: Analysis, Implementation and Applications. J. Mach. Learn. Res. 2006, 7, 1909–1936. [Google Scholar]
- Carmichael, I.; Marron, J.S. Geometric Insights Into Support Vector Machine Behavior Using the KKT Conditions. arXiv 2017, arXiv:1704.00767. [Google Scholar] [CrossRef]
- Zhou, W.; Zhang, L.; Jiao, L. Aasim, An Analysis of Svms Generalization Performance. Acta Electron. Sin. 2001, 29, 590–594. [Google Scholar] [CrossRef]
- Pan, T.; Li, S. Generalised Predictive Control for Non-Linear Process Systems Based On Lazy Learning. Int. J. Model. Identif. Control 2006, 1, 230–238. [Google Scholar] [CrossRef]
- Cheng, C.; Chiu, M. A New Data-Based Methodology for Nonlinear Process Modeling. Chem. Eng. Sci. 2004, 59, 2801–2810. [Google Scholar] [CrossRef]
- Liang, Z.; Zhao, C.; Zhou, H.; Liu, Q.; Zhou, Y. Error Correction of Temperature Measurement Data Obtained From an Embedded Bifilar Optical Fiber Network in Concrete Dams. Measurement 2019, 148, 106903. [Google Scholar] [CrossRef]
- Abbas, Z.H.; Majdi, H.S. Study of Heat of Hydration of Portland Cement Used in Iraq. Case Stud. Constr. Mat. 2017, 7, 154–162. [Google Scholar] [CrossRef]
- Zhang, Z.; Scherer, G.W.; Bauer, A. Morphology of Cementitious Material During Early Hydration. Cem. Concr. Res. 2018, 107, 85–100. [Google Scholar] [CrossRef]
- Scrivener, K.; Ouzia, A.; Juilland, P.; Kunhi Mohamed, A. Advances in Understanding Cement Hydration Mechanisms. Cem. Concr. Res. 2019, 124, 105823. [Google Scholar] [CrossRef]
- Qiang, S.; Xie, Z.; Zhong, R. A P-Version Embedded Model for Simulation of Concrete Temperature Fields with Cooling Pipes. Water Sci. Eng. 2015, 8, 248–256. [Google Scholar] [CrossRef]
- Pouya, M.R.; Sohrabi-Gilani, M.; Ghaemian, M. Thermal Analysis of Rcc Dams During Construction Considering Different Ambient Boundary Conditions at the Upstream and Downstream Faces. J. Civ. Struct. Health Monit. 2022, 12, 487–500. [Google Scholar] [CrossRef]
- Han, S.; Qubo, C.; Meng, H. Parameter Selection in SVM with RBF Kernel Function; World Automation Congress: Puerto Vallarta, Mexico, 2012. [Google Scholar]
- Achirul Nanda, M.; Boro Seminar, K.; Nandika, D.; Maddu, A. A Comparison Study of Kernel Functions in the Support Vector Machine and its Application for Termite Detection. Information 2018, 9, 5. [Google Scholar] [CrossRef]
- Liu, D.; Zhang, W.; Tang, Y.; Jian, Y. Prediction of Hydration Heat of Mass Concrete Based On the SVR Model. IEEE Access 2021, 9, 62935–62945. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | Statistics | |||||
|---|---|---|---|---|---|---|
| Training Datasets | Test Datasets | |||||
| Average Value | Standard Deviation | Median | Average Value | Standard Deviation | Median | |
| Concrete age (d) | 59.75 | 34.64 | 59.75 | 59.72 | 34.63 | 59.50 |
| Initial temperature (°C) | 20.85 | 1.96 | 20.90 | 20.77 | 2.02 | 20.90 |
| Cooling inlet water temperature (°C) | 14.60 | 5.46 | 14.35 | 14.10 | 5.62 | 13.94 |
| Cooling water flow rate (L/min) | 6.24 | 8.85 | 6.13 | 6.36 | 8.88 | 6.41 |
| Ambient temperature (°C) | 22.97 | 5.87 | 23.27 | 22.93 | 5.89 | 23.25 |
| Concrete grade | 36.66 | 2.68 | 35.00 | 36.94 | 2.70 | 35.00 |
| Height of the block (m) | 2.95 | 0.26 | 3.00 | 3.01 | 0.55 | 3.00 |
| Intermittent time of the block (d) | 13.02 | 5.73 | 12.35 | 12.54 | 5.40 | 12.10 |
| Heat dissipation area of the block (m2) | 254.59 | 521.36 | 0.00 | 239.87 | 502.47 | 0.00 |
| Item | β = 0 | β = 0.1 | β = 0.2 | β = 0.3 | β = 0.4 | β = 0.5 | β = 0.6 | β = 0.7 | β = 0.8 | β = 0.9 | β = 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | 0.263 | 0.262 | 0.263 | 0.28 | 0.269 | 0.269 | 0.27 | 0.272 | 0.269 | 0.275 | 0.27 |
| MAE | 0.176 | 0.174 | 0.175 | 0.183 | 0.179 | 0.178 | 0.178 | 0.181 | 0.178 | 0.182 | 0.186 |
| Model | Hidden Layers | Neurons/Units | Activation Function | Optimizer | Learning Rate | Iterations/Epochs | Other Settings |
|---|---|---|---|---|---|---|---|
| BP | 1 | 100 | Hyperbolic tangent function (Tanh) | Adam | 0.01 | 1000 | Training function: Levenberg–Marquardt; early stopping: error < 1 × 10−4 or validation fail > 20 |
| LSTM | 1 (LSTM layer) | 200 | Rectified linear unit (ReLU) | Adam | 0.01 (initial) | 100 | Input steps: 5; output steps: 1; regularization: 0.01; LR decay every 30 epochs by 0.2 |
| ISVR | – | – | RBF kernel | – | – | – | c and γ via grid search: c ∈ [1, 20] and γ ∈ [0.01, 10]; 5-fold CV |
| SSA-ISVR | – | – | RBF kernel | SSA | – | 20 (SSA iterations) | c ∈ [1, 20] and γ ∈ [0.01, 10]; population size: 100; fitness: CV MAE |
| Monitoring Point | Offline Training Samples | Online Testing Samples | ||||
|---|---|---|---|---|---|---|
| RMSE | MAE | R2 | RMSE | MAE | R2 | |
| 7#-026 | 0.175 | 0.082 | 0.996 | 0.123 | 0.077 | 0.996 |
| 7#-030 | 0.155 | 0.093 | 0.998 | 0.112 | 0.065 | 0.987 |
| 11#-001 | 0.217 | 0.104 | 0.990 | 0.221 | 0.139 | 0.989 |
| 11#-012 | 0.213 | 0.099 | 0.989 | 0.184 | 0.112 | 0.995 |
| 17#-078 | 0.195 | 0.082 | 0.992 | 0.170 | 0.100 | 0.995 |
| 17#-079 | 0.183 | 0.071 | 0.997 | 0.221 | 0.090 | 0.991 |
| Statistical Value | Models | Total Test Set | Monitoring Point in 7 | Monitoring Point in 11 | Monitoring Point in 17 |
|---|---|---|---|---|---|
| Mean | BP | 0.016 | 0.013 | 0.026 | 0.008 |
| LSTM | 0.019 | 0.031 | 0.011 | 0.018 | |
| ISVR | 0.005 | 0.002 | 0.003 | 0.004 | |
| SSA-ISVR | 0.003 | 0.002 | 0.005 | 0.004 | |
| Standard deviation | BP | 0.026 | 0.014 | 0.036 | 0.016 |
| LSTM | 0.036 | 0.036 | 0.037 | 0.031 | |
| ISVR | 0.021 | 0.014 | 0.025 | 0.021 | |
| SSA-ISVR | 0.015 | 0.012 | 0.016 | 0.016 |
| Train Sample Set | Algorithm | Training | ||
|---|---|---|---|---|
| RMSE | MAE | R2 | ||
| 0–120 days | BP | 0.137 | 0.070 | 0.995 |
| LSTM | 0.231 | 0.139 | 0.985 | |
| ISVR | 0.161 | 0.109 | 0.990 | |
| SSA-ISVR | 0.189 | 0.080 | 0.994 | |
| Test Sample Set | Algorithm | Test | ||
|---|---|---|---|---|
| RMSE | MAE | R2 | ||
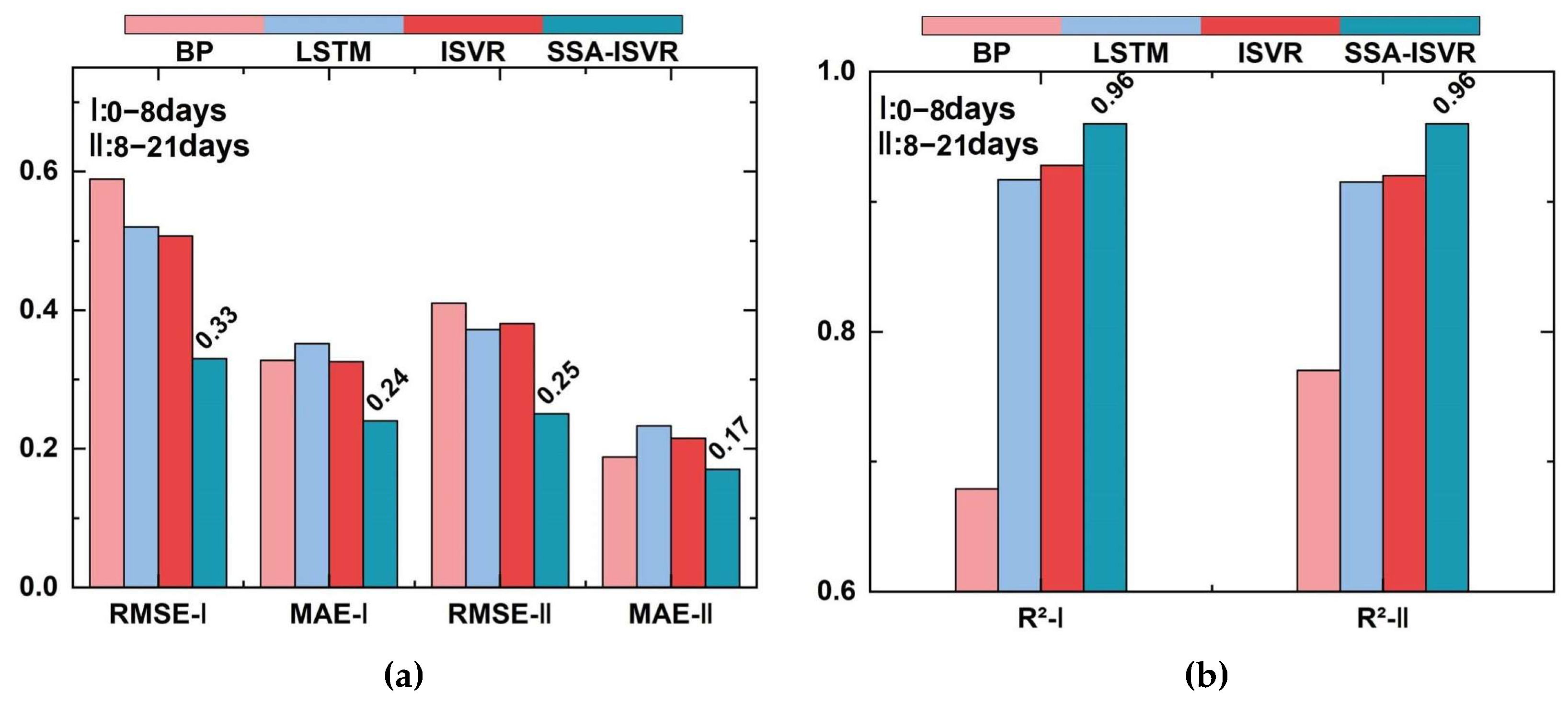
| 0–8 days | BP | 0.589 | 0.328 | 0.779 |
| LSTM | 0.520 | 0.352 | 0.917 | |
| ISVR | 0.507 | 0.326 | 0.928 | |
| SSA-ISVR | 0.339 | 0.241 | 0.960 | |
| 8–21 days | BP | 0.410 | 0.188 | 0.870 |
| LSTM | 0.372 | 0.233 | 0.915 | |
| ISVR | 0.381 | 0.215 | 0.920 | |
| SSA-ISVR | 0.248 | 0.173 | 0.958 | |
| Test Sample Set | Algorithm | Test | ||
|---|---|---|---|---|
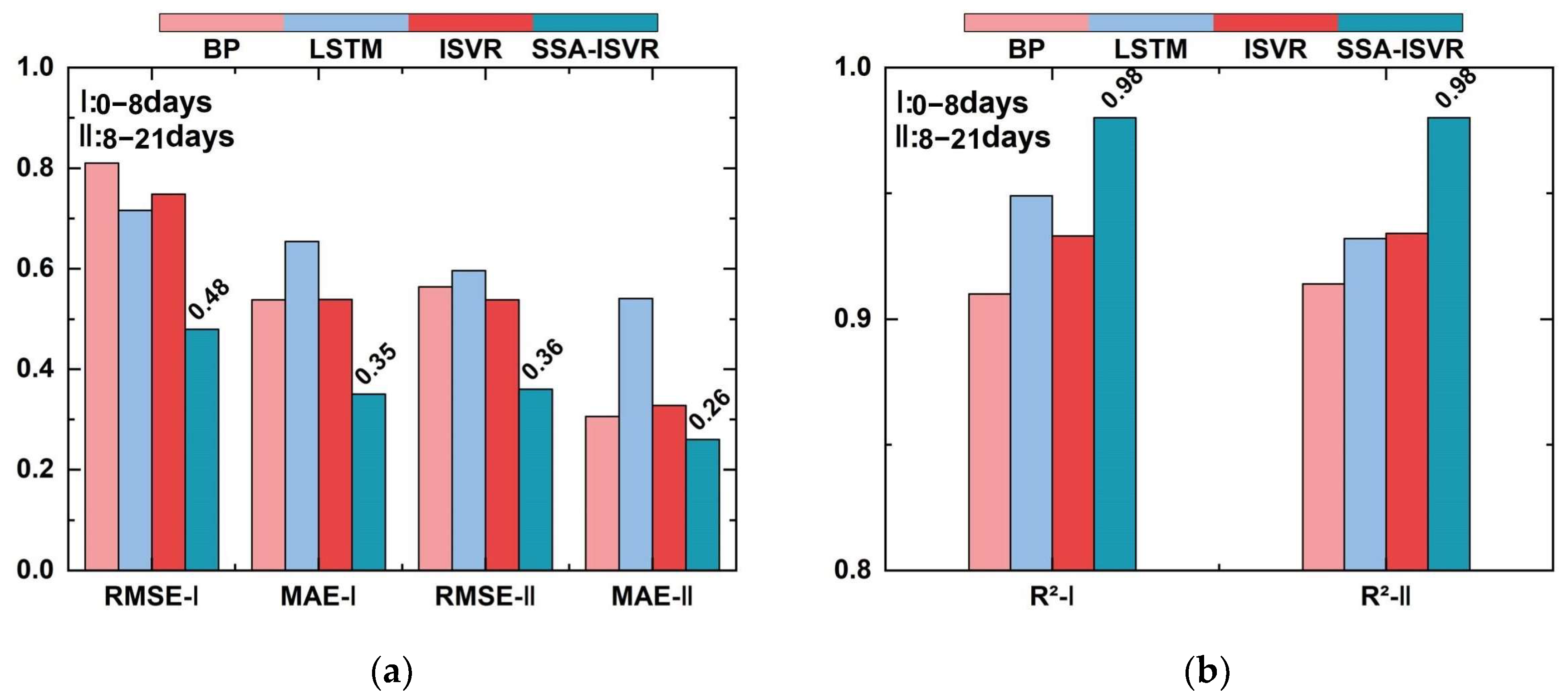
| RMSE | MAE | R2 | ||
| 0–8 days | BP | 0.810 | 0.538 | 0.910 |
| LSTM | 0.716 | 0.654 | 0.949 | |
| ISVR | 0.748 | 0.539 | 0.933 | |
| SSA-ISVR | 0.486 | 0.353 | 0.981 | |
| 8–21 days | BP | 0.564 | 0.306 | 0.914 |
| LSTM | 0.596 | 0.541 | 0.932 | |
| ISVR | 0.538 | 0.328 | 0.934 | |
| SSA-ISVR | 0.361 | 0.263 | 0.980 | |
| Test Sample Set | Algorithm | Test | ||
|---|---|---|---|---|
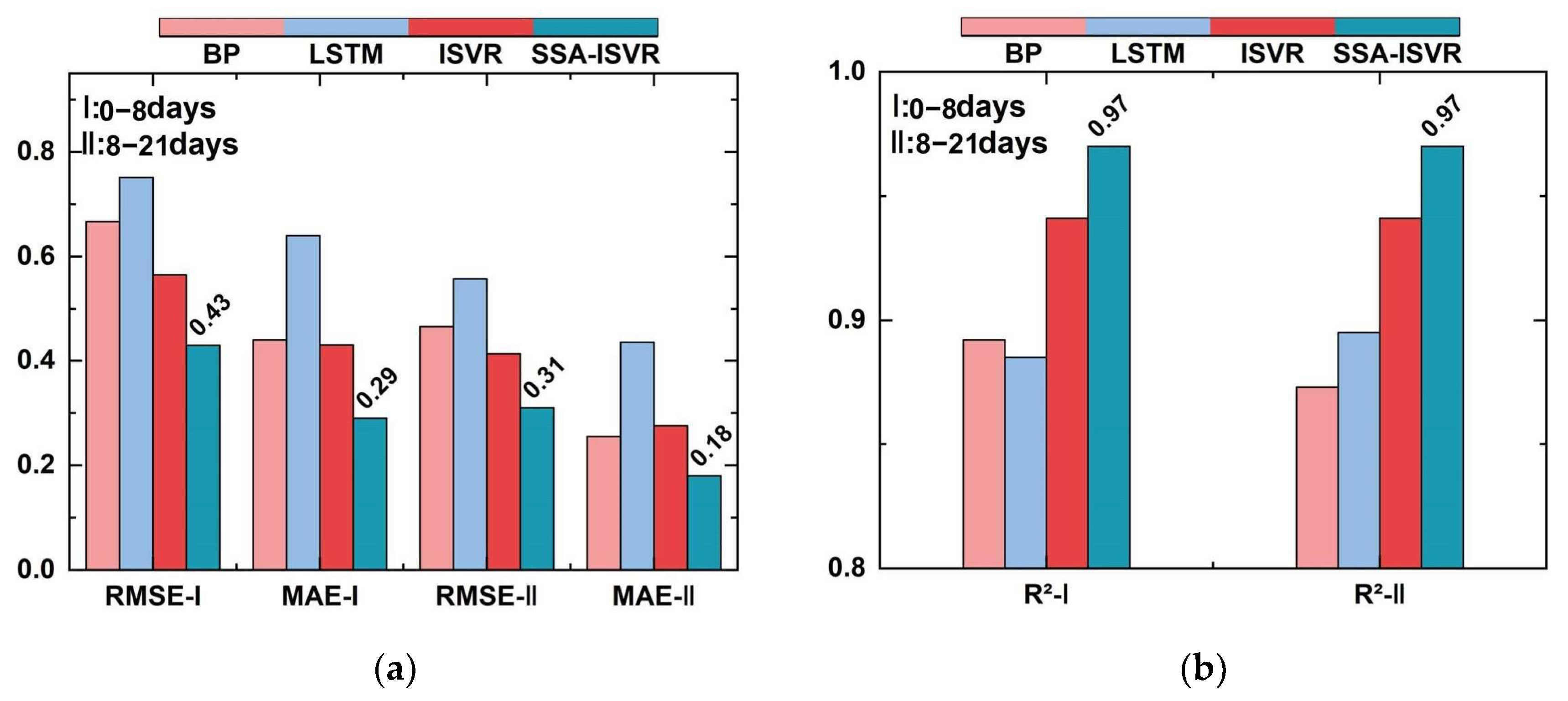
| RMSE | MAE | R2 | ||
| 0–8 days | BP | 0.667 | 0.440 | 0.873 |
| LSTM | 0.751 | 0.640 | 0.895 | |
| ISVR | 0.565 | 0.431 | 0.941 | |
| SSA-ISVR | 0.435 | 0.298 | 0.965 | |
| 8–21 days | BP | 0.466 | 0.255 | 0.892 |
| LSTM | 0.557 | 0.436 | 0.885 | |
| ISVR | 0.414 | 0.276 | 0.941 | |
| SSA-ISVR | 0.307 | 0.179 | 0.966 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, Y.; Deng, Y.; Wang, F.; Zhao, C.; Zhou, H.; Liang, Z.; Lei, L. Online Prediction of Concrete Temperature During the Construction of an Arch Dam Based on a Sparrow Search Algorithm–Incremental Support Vector Regression Model. Appl. Sci. 2025, 15, 5053. https://doi.org/10.3390/app15095053
Zhou Y, Deng Y, Wang F, Zhao C, Zhou H, Liang Z, Lei L. Online Prediction of Concrete Temperature During the Construction of an Arch Dam Based on a Sparrow Search Algorithm–Incremental Support Vector Regression Model. Applied Sciences. 2025; 15(9):5053. https://doi.org/10.3390/app15095053
Chicago/Turabian StyleZhou, Yihong, Yu Deng, Fang Wang, Chunju Zhao, Huawei Zhou, Zhipeng Liang, and Lei Lei. 2025. "Online Prediction of Concrete Temperature During the Construction of an Arch Dam Based on a Sparrow Search Algorithm–Incremental Support Vector Regression Model" Applied Sciences 15, no. 9: 5053. https://doi.org/10.3390/app15095053
APA StyleZhou, Y., Deng, Y., Wang, F., Zhao, C., Zhou, H., Liang, Z., & Lei, L. (2025). Online Prediction of Concrete Temperature During the Construction of an Arch Dam Based on a Sparrow Search Algorithm–Incremental Support Vector Regression Model. Applied Sciences, 15(9), 5053. https://doi.org/10.3390/app15095053