1. Introduction
Soft fusion of classifiers [
1,
2,
3,
4,
5] consists in combining the individual scores assigned to each class by a set of classifiers, to obtain a single score for each of the classes involved. The combination or fusion of the individual scores is performed with the hope that there is a certain complementarity of the different classifiers that allows improving the estimation of the correct class. Soft fusion of classifiers is a late fusion, which presents significant advantages with respect to the early fusion of features [
6,
7,
8,
9,
10]. It does not suffer from the problem of increased dimensionality; it allows weighted combination according to the quality of each classifier and it simplifies the problems of synchronization in case different modalities are to be fused. On the other hand, the so-called hard or decision fusion [
2,
11] is also a late fusion in which the decisions made by the individual classifiers are combined to make a final decision. While allowing very simple combination rules (for example, majority voting), hard fusion entails a loss of information that prevents the full exploitation of the complementarity between the individual classifiers.
Soft fusion of classifiers can be part of complex information fusion systems, such as multimodality fusion [
12,
13,
14,
15], sensory data fusion [
16,
17], or image fusion [
18,
19]. Although soft fusion is considered a consolidated procedure, it presents certain controversies. For example, if we combine a good classifier with weak classifiers, will we improve or worsen the performance of the good classifier? Or, more generally, what level of improvement can be expected after the fusion, based on certain properties of the individual classifiers? These and other similar questions have been attempted to be answered through essentially experimental studies in specific models and/or applications [
20,
21,
22,
23,
24,
25,
26]. Thus, the generalization of the conclusions to environments other than those used in the experiments is questionable. In short, there is a significant lack of theoretical foundations that can only be reached through mathematical developments. This is a problem that usually appears in the field of machine learning, since mathematical analysis can be very complex and it is tempting to directly carry out experimental verifications, given the current high availability of data and computational resources.
The main objective of this work is to make analytical contributions toward a better understanding of the soft fusion of classifiers. These contributions are, however, contrasted with the real data from a biomedical application. We focused on linear fusion and the two-class problem, as it is the most analytically tractable environment and leads to closed-form solutions. In any case, it must be taken into account that linear fusion marks a lower bound on the performance that could eventually be achieved through non-linear solutions [
27]. On the other hand, the two-class problem is a significant starting point for the extension to the multi-class problem [
28], which can be the subject of further work. Therefore, the conclusions may be of general interest.
Regarding the optimal linear combiner that we propose, it presents a novelty with respect to other similar approaches: the cost function is expressed in terms of the mean square error (MSE) of the estimation of the discrete variable that defines the classes, which is decomposed as the sum of the conditional MSEs for each class. Thus, we show that the MSE after fusion can be expressed in terms of the individual MSEs. The latter facilitates the determination of the parameters that influence the potential improvement of the fusion with respect to the best individual classifier. Furthermore, we consider exponential models for the class-conditional probability densities to establish the relationship between the classifier’s error probability and the MSE of the class estimate. This allows us to predict the reduction in the post-fusion error probability relative to that of the best classifier. These theoretical findings are contrasted in a biosignal application for the detection of arousals during sleep from EEG signals. The results obtained are reasonably consistent with the theoretical conclusions.
2. The Optimal Linear Combiner
Let us call
to the score assigned by the individual classifier
to class
. Considering
as a the posterior probability of
, the score assigned to
should be
. Soft fusion of classifiers consists of generating a score,
, assigned to class
(and so
to class
) by combining the scores
, respectively, provided by
individual classifiers, as indicated in
Figure 1.
We then make an estimation approach. The fused score,
, can be interpreted as an estimate of the binary random variable,
, from the “observations”
. It is
when the true class is
and
when the true class is
. Conditional to
,
should have values close to 1, and conditional to
, it should be close to 0. It is well-known that the optimal estimate of
minimizing the
MSE is the conditional mean
, which is, in general, a complex non-linear function, not expressible in close form. Therefore, we consider the optimal linear combination of scores. On the other hand, it is quite important to relate the
MSE of the estimate
with the
MSE’s of the individual estimates
. This facilitates the analysis of the expected improvement due to the fusion, which is the essential objective of this work. Thus, given the set of coefficients, we can write
but, we can express the
MSE of the estimate
as
where
, respectively, are the prior, the conditional variance, and the conditional bias corresponding to class
. Let us define the vectors
, so that
. We can compute the conditional variances and bias as follows:
where
and
are, respectively, the correlation and covariance matrices of the score vector conditional to
, and where we assumed
. The latter is a regularization condition to allow for a non-trivial solution in the following and avoid an anomalous increase in bias in the fused score. Considering (3) in (2):
where
We next obtain the coefficients that minimize
under the constraint
, where
is defined as a
D-dimensional vector of 1. Notice that
; this is a sufficient condition to ensure that
. We do not explicitly impose in the following
, since this would prevent reaching a close-form solution. Therefore, eventually, some fused scores can be out of the interval range (0,1). This is not critical as we finally must make a decision by comparing
with a threshold in the interval (0,1) so we can simply round down to 1, in case
, and round up to 0, in case
, thus not affecting the final decision. We used the method of Lagrange multipliers, i.e.,
The corresponding linear least-mean-square-error (
LLMSE) solution thus obtained is (to ease the notation we simply indicate
instead of
)
Notice that the
MSE corresponding to every individual classifier can be written similar to (2). They are the entries to the main diagonal of
, i.e.,
So, in conclusion we derived the expression of the LLMSE estimator in such a way that , and that the provided MSE is expressed in terms of the matrix, , whose main diagonal entries are the MSEs provided by the individual classifiers. As we will see in the next section, all this will allow us to analyze the expected improvements due to the fusion of classifiers.
3. The Improvement Factor
For notation convenience, let us consider that
so that
. The improvement in terms of
MSE can be computed by comparing
with the
MSE provided by the best of all the individual classifiers. So, let us define the
MSE improvement factor
. It can be demonstrated by reduction ad absurdum that
: if
was smaller than 1, then there would be a solution to (6), namely
providing a mean square error
, but by definition,
is the minimum achievable mean square error. Therefore, the first conclusion is that the optimal linear fusion of classifiers, as previously defined, will be at least as good (in the
MSE sense) as the best of the individual classifiers. Furthermore, the specific value of
depends exclusively on
. Hence, we can obtain sets of scores from previously trained individual classifiers, so that we can use (5) to obtain a sample estimate,
, from sample estimates of the covariance matrices, the bias vectors, and the priors:
. Then,
can be estimated from (7).
With the intention of achieving a better understanding of the essential elements that affect , we now consider some simple yet relevant models, by considering simplified forms of .
3.1. Fusion of Equally Operated Classifiers (EOCs)
Let us consider the case where all individual classifiers have equal variances, equal pairwise covariances, and equal bias. We call this situation “equally operated classifiers” (EOCs). Although, in practice, this may not strictly be the case, it is representative of what might be expected when all classifiers have a similar individual performance and similar dependence on each other. More formally, this corresponds to
where
is the covariance coefficient. For simplicity, we consider the same models for both classes, i.e.,
, so that
. Then, considering (5) and that
, matrix
can be written in the form:
Let us define
, where the rank of
is 1 and
is nonsingular. We can apply Miller’s lemma to compute the inverse:
From (6) and (12), we can write:
Finally, considering that, in this case,
, we may write the expression of the improvement factor as:
Notice that
, as it should be. For
and
, the maximum reduction is achieved if the individual scores are uncorrelated
which in turn reaches its maximum value of
, if
. Thus, bias is a limiting factor for the reduction in the
MSE. Actually, we demonstrate below that, in EOCs, it is
, so from (3), the fused score,
, has the same bias,
, as the individual scores,
. Therefore, the fusion improvement is essentially due to the reduction in the variance. Other interesting conclusions can be derived from (14). For example, if
, that is, when the scores are fully correlated, the set of individual classifiers actually behaves like a single classifier. Equation (14) is also consistent when fusion is not implemented, i.e.,
.
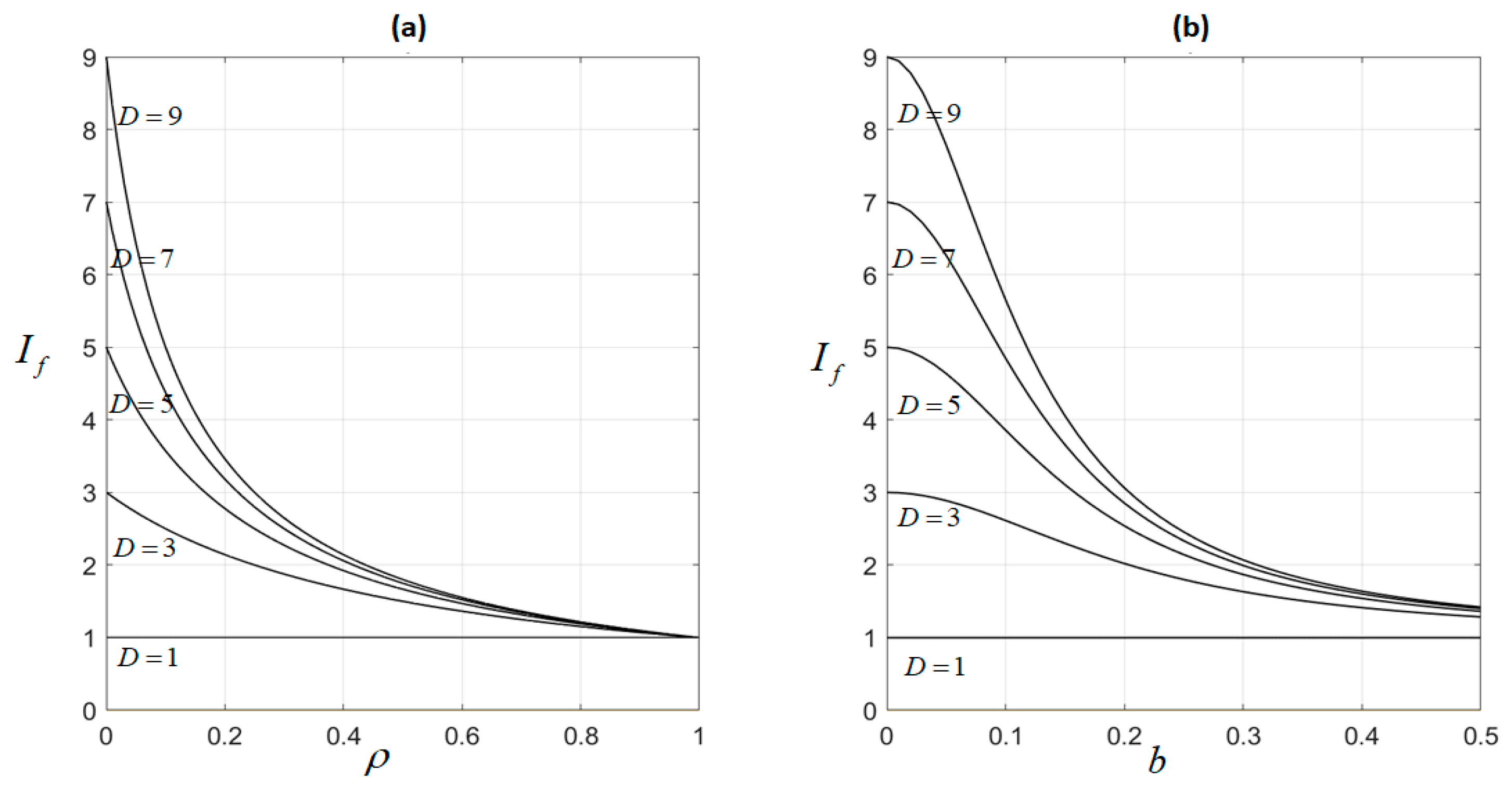
We showed that, in the EOC case, the parameters affecting the improvement factor,
, are the number of classifiers,
; the pairwise correlation,
; and the bias,
. This is illustrated in
Figure 2. Thus, in
Figure 2a, we show
as a function of
for different values of
; bias
was assumed to be 0. We see that
increases with
, but decreases with
from a maximum value of
for
to a minimum value of
for
. Similarly, in
Figure 2b, we show
as a function of
for different values of
; correlation
was assumed to be 0. Again,
increases with
, but, as expected, decreases for an increasing bias.
Let us finally compute the optimum coefficient vector,
, corresponding to the EOCs.
Thus, as expected, the mean of the scores is the LLMSE solution in the case of EOCs, always achieving an improvement factor of .
3.2. Fusion of Non-Equally Operated Classifiers (NEOCs)
Notice that, in the case of individual classifiers with disparate performances, it is reasonable to consider that the scores they provide are uncorrelated. This simplifies an analysis that would otherwise be intractable. Furthermore, as for the EOCs, we assume for simplicity that the covariance–bias model is the same for both classes; then:
Let us use Miller’s lemma again to calculate the inverse of
:
This is a complicated expression due to the arbitrary combinations of bias and variance in each individual classifier. However, we can impose some simplification to gain insights into the expected improvement. Thus, we may consider that all the individual scores have the same bias,
. Then, we can write:
where,
. Considering that
,
. If
, we have a very unbalanced scenario; then,
, i.e., if the best classifier is “much better” than the rest, little improvement can be expected from the fusion. In the opposite case, we have a totally balanced situation if
, and then
. Moreover,
reaches its maximum
, which consistently coincides with (15) (this is actually the EOC case with uncorrelated classifiers). In general, every classifier contributes
to increase
. Let us define the unbalanced factor
such that
, being
in the totally balanced case (
), and
for the very unbalanced case (
).
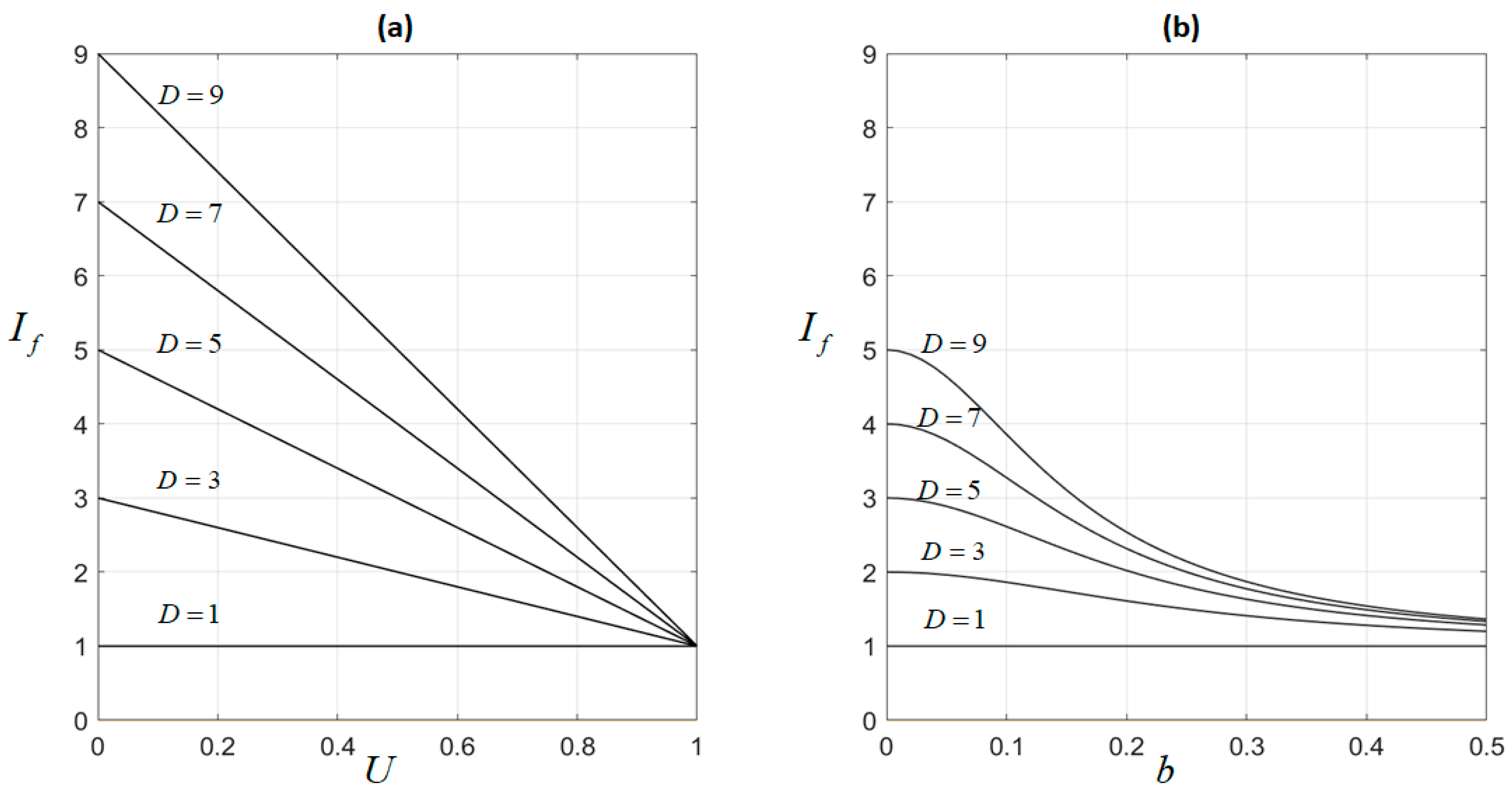
We showed that, in NEOCs, the parameters affecting the improvement factor,
, are the number of classifiers,
; the unbalance factor,
; and the bias,
. This is illustrated in
Figure 3. Thus, in
Figure 3a, we show
as a function of
for different values of
; bias was assumed to be 0. According to (21), this implies that
, explaining the decreasing straight line varying from a maximum value of
for
to a the minimum value of
for
. Similarly, in
Figure 3b, we show
as a function of
for different values of
; the unbalance factor
was assumed to be
. Again,
decreases for the increasing bias. Moreover, notice that
Figure 2b and
Figure 3b show similar curves, but in the first case,
(all classifiers show an equal performance), while
is assumed in the second case; then,
suffers a certain degradation, reaching the maximum value of
for
.
Let us finally compute the optimum coefficient vector,
, corresponding to the NEOCs. Thus:
We see that the optimum linear combiner is the vector , which gives more relevance to the classifiers having a smaller variance, minus the linear transformation of this vector, which depends on the bias contributions. Actually, .
4. From Mean Square Error to Probability of Error
Given a score,
, we have to decide between
and
. Interpreting
as the posterior probability of
, we implement the MAP test:
Then, the performance of the classifier can be evaluated by the probability of error,
. Obviously, the lower the
, the lower
should be. However, this is not demonstrable in a general case, as both the
and
are quite different integrals of the class-conditional probability density functions (pdfs), namely:
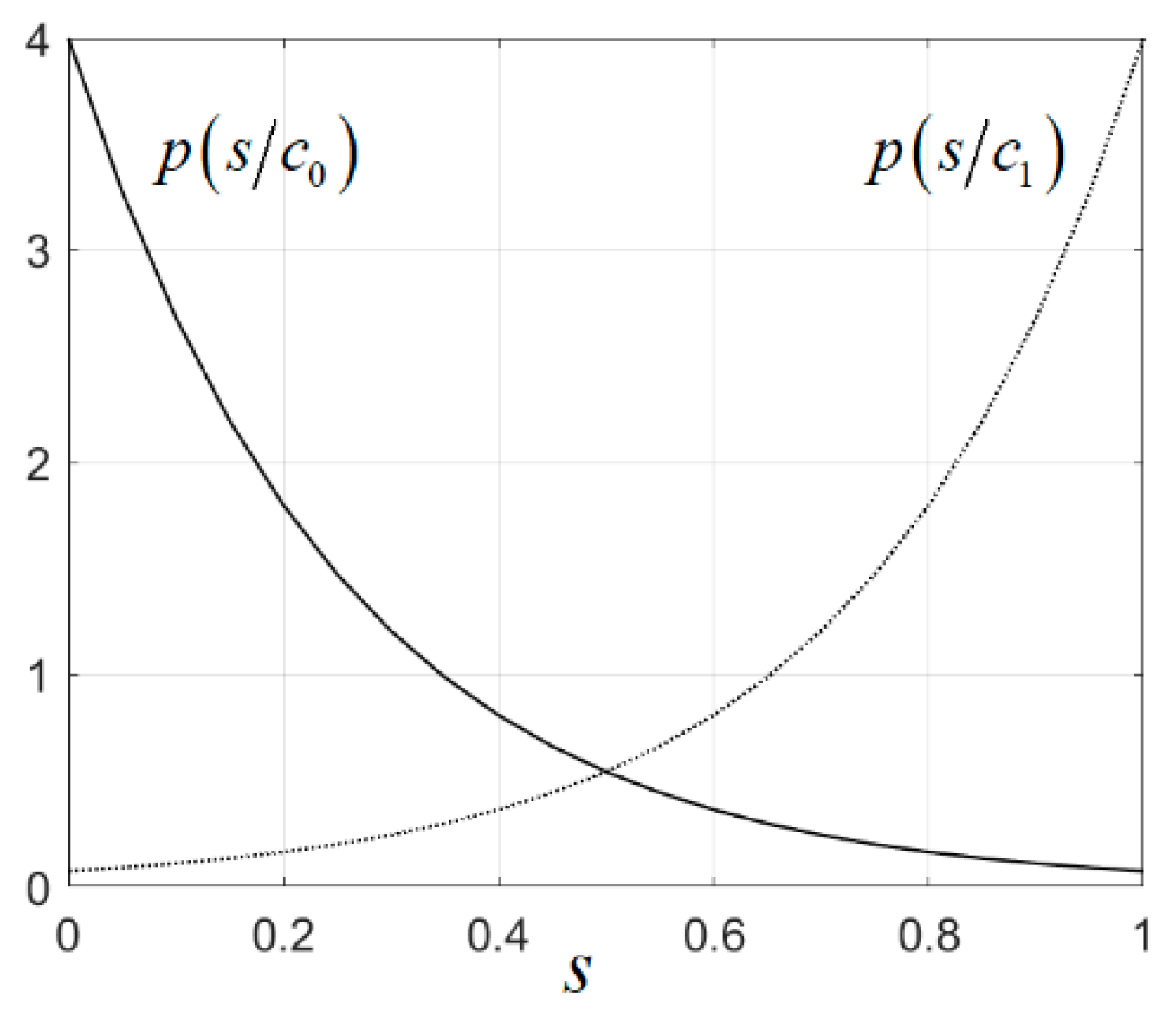
For this reason, we now assume a simple but representative model of the conditional pdfs. Let us consider that
and
are exponential pdfs in the interval
, i.e.,
where
is the unit step function. In (25), we assumed that
and
are large enough so that
, and so the exponentials are appropriate pdfs for scores. We show in
Figure 4 two exponential class-conditional pdfs for
.
We can express
is (24) as the combination of the probability of false-positives,
(type I error), and the probability of false negatives,
(type II error), and considering (23) and the exponential models (25), we have:
In general, as we did in (2) for the fused score, we can express the
MSE as the combination of the
MSEs conditional to every possible value of the random variable,
.
Solving for
and
in (27) and substituting in (26), we arrive at:
Thus, in (28), we see the definite impact that the minimization of the
MSE has on the minimization of the probability of error. Hence, it is of great interest to relate the improvement factor previously defined with the expected improvement of
with respect to
. This is straigthforward in the case that
:
But, in general, we need to define a separate improvement factor for every type of error:
, so that
Let us show some illustrative examples for the above. We consider, for simplicity, the case
. Let us define the theoretical accuracy
. Using (29), we represent in
Figure 5a the post-fusion accuracy,
, as a function of the accuracy,
, of the best classifier for different values of
. The significant increase in accuracy with the increase in
is notable. Thus, for example, a value of
increases to
for
. From the previous analysis, we know that 3 uncorrelated and unbiased classifiers would be enough to provide such an improvement factor. Furthermore, we represent in
Figure 5b the accuracy,
, as a function of
for different values of
. Once again, the significant accuracy improvement that can be achieved with improvement factors that are not excessively high is notable. This is especially true for weak classifiers that provide relatively low accuracy.
5. Real Data Experiments
In this section, we consider some experiments with real data. This involves the automatic classification of sleep stages based on the information provided by different biosignals (polysomnograms). This classification is usually performed manually by a medical expert, resulting in a slow and tedious procedure. In particular, we consider the detection of very-short periods of wakefulness [
29,
30] (also called arousals) as their frequency is related to the presence of apnea and epilepsy. The objective is by no means to present the most-precise method for solving this complex problem, among the myriad of options and variants available. Rather, it is to verify in a real-life context how the fusion of several classifiers achieves results consistent with the theory outlined above. The data were obtained from the public database Physionet [
31]. Ten patients were considered. Every patient was monitored during sleep, thus obtaining the corresponding polysomnogram. In this experiment, we considered the electroencephalograms (EEGs). Then, 8 EEG features were obtained in non-overlapping intervals of 30 sec (epochs) from every EEG recording. The number of epochs varied for every patient, ranging from 749 (6 h and 14 min) to 925 (7 h and 42 min). The 8 features were: Powers in the frequency bands delta (0–4 Hz), theta (5–7 Hz), alpha (8–12 Hz), sigma (13–15 Hz), and beta (16–30 Hz), and 3 Hjorth parameters: activity, mobility, and complexity. These features are routinely used in the analysis of EEG signals [
32,
33].
As we were interested in the detection of arousals, a two-class problem was considered, where class 1 corresponded to arousal and class 0 corresponded to any of the other possible sleep stage. This is in concordance with the two-class scenario assumed in the previous theoretical analysis.
Five classifiers were considered: Gaussian Bayes, Gaussian Naïve Bayes, Nearest Mean, Linear Discriminant, and Logistic Regression.
Table 1 indicates the equations corresponding to the score computation in every method, as well as the estimated parameters during training.
The classifiers were separately trained for every patient using the first half of the respective EEG recordings. Then, the second half was used for testing. The scores of all patients were grouped by classes. Thus, a total number of 6706 scores of class 0 and 1708 of class 1 were generated by every classifier. Despite this imbalanced scenario, we assumed that in all the experiments, in order to not harm the detection of arousals, which was a priority in this particular context.
Table 2 shows the samples’ estimates of the score bias and variance for every class and every method, according to the definitions of (2) and (3). We can see that class 1 exhibits a significantly higher bias and variance than class 0 in all the five methods. The corresponding
MSE and the accuracy are also indicated in
Table 2 and used to rank the methods from “the best” (top) to the “worst” (bottom). The last row of
Table 2 shows the statistics corresponding to the scores of the optimal linear combiner (6). Matrix
was estimated from the scores of the training set, using sample estimates in (5) for the covariance and bias matrices. Notice that, as expected, the bias of the fused scores does not show a reduction with respect to the bias of the individual classifiers. However, the variance is reduced, this effect being the main reason from the
MSE decrease and corresponding accuracy increase achieved by the fusion of classifiers. Certainly, the improvement is modest due in part to the high correlation among the scores of the 5 individual classifiers, as indicated by the correlation coefficient matrices included at the bottom of
Table 2. Furthermore, significant bias, especially in class 1, is also an issue for obtaining greater improvements. In any case, these real data results are in concordance with the expectation of the theoretical analysis.
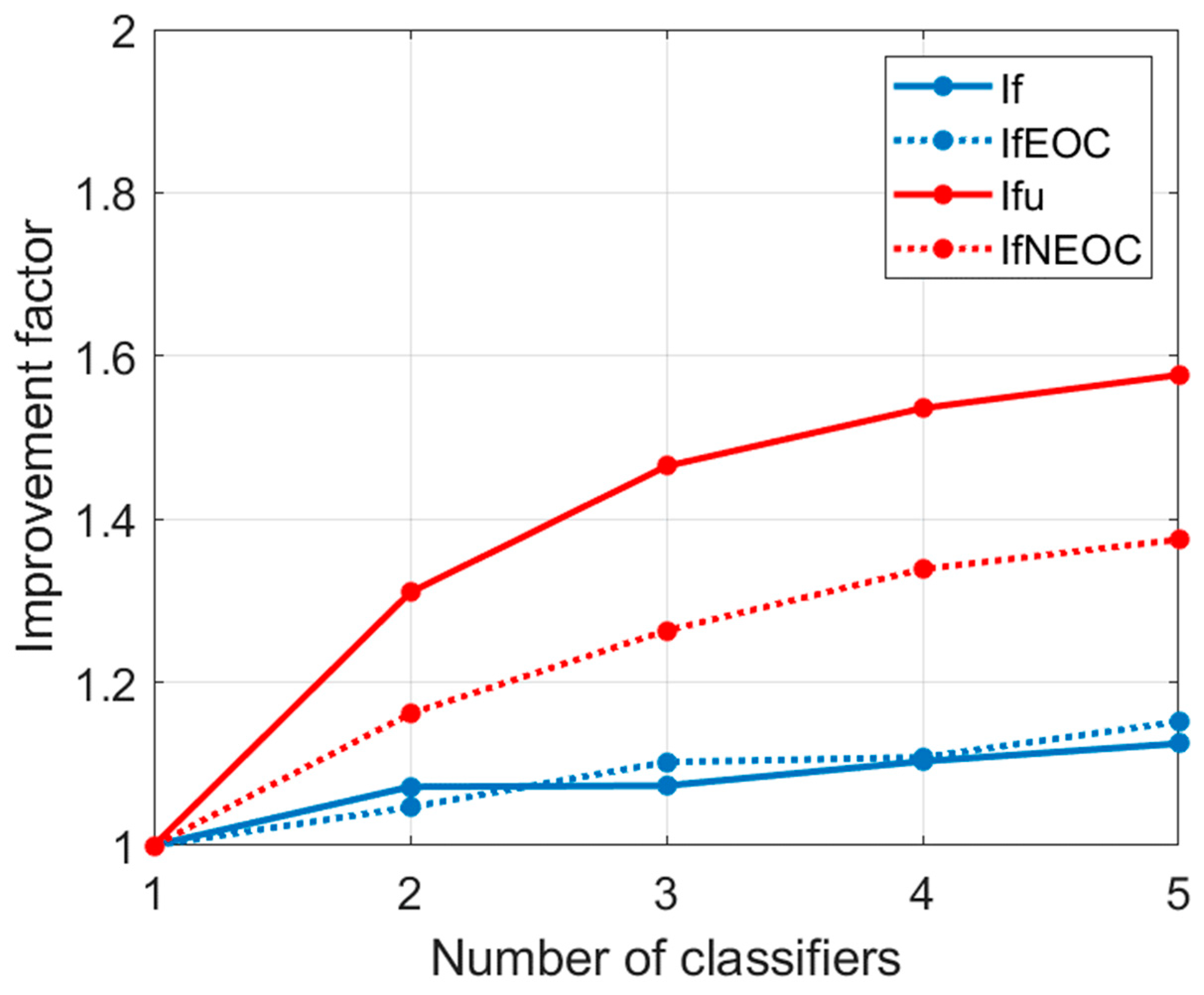
With the intention of reinforcing this perception, we show in
Figure 6 (solid blue) the variation in the improvement factor with the number of fused classifiers. Starting from
with the Nearest Mean, which is the best individual classifier according to
Table 2, we progressively incorporate a new classifier following the order of
Table 2. We can see that
increases with
as predicted by the theory, but shifts rather slowly due to the high correlation and large bias. We also represent in
Figure 6 (blue dot) the improvement factor of the EOC case computed from (14) for every
, where
, and
are estimated as:
where
,
, and
are obtained from the results of
Table 2. Thus, the Frobenius norms,
, of the correlation coefficient and the bias (constant entries) matrices of the EOC model, respectively, equate the Frobenios norms of the corresponding (non-constant entries) real-data matrices. In essence, we define an EOC model that “resembles” as much as possible the actual real-data model.
Figure 6 suggests that the EOC model, in spite of its simplicity, can provide a reasonably approximation of the actual
value.
We conducted another experiment, where the scores of each classifier are much more uncorrelated than in the previous experiment. To simulate high decorrelation, the inputs to the different classifiers in the interval under test are randomly selected (sampling with replacement) from all the available feature vectors of the training set that belong to the true class of that interval. In this way, the inputs to the different classifiers in each test interval belong to the same class, but are generally different, producing a high level of decorrelation between the scores obtained from them. This procedure serves to simulate decorrelation, but is not practical since the class being tested must be known in advance. In a practical situation, decorrelation must be obtained through appropriate training, for example, bagging-type techniques [
34], in which the same classifier is trained with different subsets of instances obtained from an original set. The hard decisions of the differently trained classifiers are combined to obtain a final decision. More generally, in classifier fusion, each classifier can be trained on different subsets of instances to induce some level of score uncorrelation. Another scenario where the scores can be uncorrelated is in late-multimodal fusion [
9], where the input of each individual classifier corresponds to a different modality.
We show in
Table 3 the same type of information shown in
Table 2. Notice that the statistics of the individual classifiers are quite similar to those in
Table 2, however the post-fusion
MSE has been significantly reduced (mainly because of the variance reduction), and the accuracy has improved by 7% with respect to the best classifier. Notice the low level of correlation (especially in class 0), as indicated by the correlation coefficient matrices included at the bottom of
Table 3.
The comparative impact of uncorrelation can be better appreciated in
Figure 6, where we show (solid red) the variation in the improvement factor in the case of uncorrelation,
, with the number of fused classifiers. Notice the significant increase in the improvement factor with respect to the correlated case (
). We also represent in
Figure 6 (red dot) the improvement factor,
, of the NEOC case computed from (21) for every
, where
;
as well as
are computed as in (31).
shows a similar evolution to
, but with some underestimation. Notice that
corresponds to the actual variance of the Linear classifier, which is the minimum variance among all the 5 classifiers, as deduced from
Table 2. However, the
value considered to compute
is that corresponding to the Nearest Mean, which is the minimum
MSE among all the 5 classifiers, as deduced from
Table 2. This probably means facing an additional problem to achieve a good fit of the NEOC model to the actual model, because in the NEOC model, the bias is assumed to be the same for all classifiers, and then both
and
correspond to the same classifier. In any case, notice that
is still far from 5, the maximum achievable value if all the classifiers are unbaised. This is evidence of the significant limitation imposed by bias in the fusion of classifiers. Another limitation to achieving maximum improvement in the NEOC model was the unbalance factor
. In our case,
has a value between 0.5 and 0.6 for all values of
, which is between the perfectly balanced case (
) and the totally unbalanced case (
).
Finally, we show in
Figure 7 the variation in estimated accuracy with the number of classifiers for the correlated (blue solid) and the uncorrelated (red solid) cases. Similar to
, the accuracy slowly increases with
in the correlated case. And, similar to
, the increase is more significant in the uncorrelated case. We also show in
Figure 7 (blue dot and red dot) the theoretical accuracies predicted by Equation (30), assuming
, namely:
where
and
are the respective actual probabilities of errors type I and type II of the best classifiers in the correlated case. And similarly, with respect to
and
.
We can see the good fitting between the theoretical prediction and the actually computed accuracies. This suggests that the exponential model assumed to deduce (30) is appropriate for the fused scores and for the scores of the best classifier. This can be corroborated if we look at
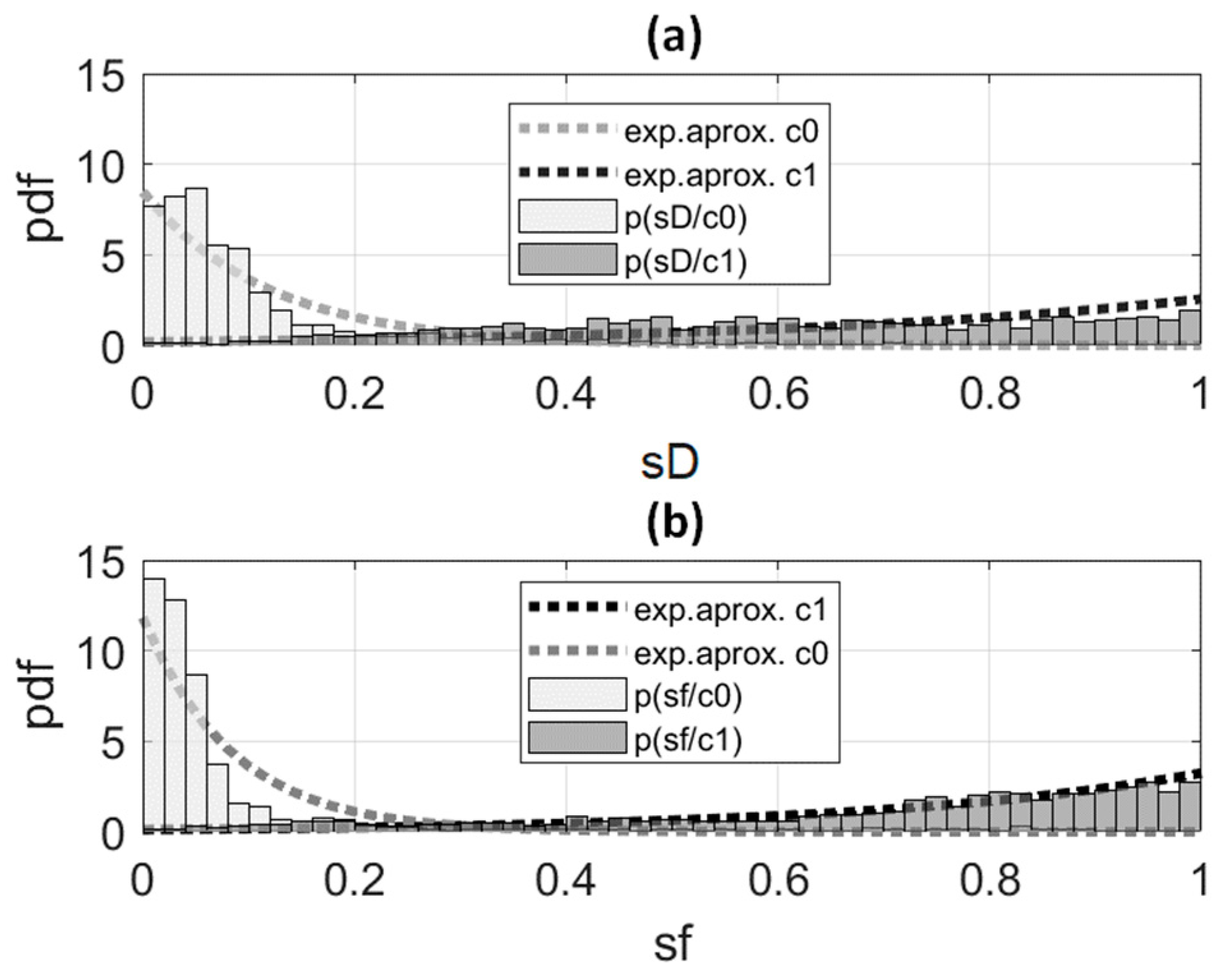
Figure 8, which shows histograms normalized to represent the non-parametric estimates of pdfs. We show in
Figure 8a the histograms corresponding to the pdf estimates of the best classifiers
(left) and
(right). Furthermore, we show in
Figure 8b the histograms corresponding to the pdf estimates of the fused scores
(left) and
(right). The exponential approximations are superimposed. Every exponential approximation was made from the ML estimates of the corresponding parameter, i.e.,
, where
is the sample mean of the scores.
In order to gain greater confidence, we performed some additional experiments. Firstly, we take into account the imbalance scenario. Thus, we conducted various experiments using either the oversampling of the least-abundant class or undersampling of the most-abundant class. For oversampling, we used the generative network-based GANSO [
35,
36], which demonstrated its superiority over the classic SMOTE method. To subsample, we simply removed instances of the most-abundant class until we reached the training size of the least-abundant one. The results do not differ significantly from those shown in
Table 2 and
Table 3. On the other hand, with the intention of gaining statistical consistency, we repeated the previous experiments 100 times, obtaining the mean values and standard deviations of all the parameters shown in
Table 2 and
Table 3. In each repetition, a different partition of the training and testing sets is considered (always at 50 percent). The mean values are similar to the data in
Table 2 and
Table 3. The standard deviations never exceed 2% of the mean values. We also performed a significance test on the accuracies obtained by the fusion, characterizing the distribution of the null hypothesis with the 100 accuracy values obtained with the best of the individual classifiers. In all cases, the
p-value is less than 0.05, so the null hypothesis is rejected, and we can consider that the accuracy values from the fusion are statistically significant. In conclusion, the results in
Table 2 and
Table 3 are sufficiently illustrative for the purpose of reinforcing the theoretical analysis (the focus of this research), with some experimental verification.
6. Discussion and Conclusions
The main objective of this work is to contribute, through mathematical analysis, to a better understanding of the soft fusion of classifiers. To perform this analysis, a combiner is proposed that provides the LLMSE estimator of the binary random variable associated with the two-class problem. The LLMSE thus obtained is expressed in terms of the properties of the individual classifiers, particularly their MSEs. All this leads to the definition of an improvement factor, which is the ratio of the MSE corresponding to the best classifier (the one with the minimum MSE) to the MSE provided by the fused score. Two simplified, yet relevant, models (EOC and NEOC) are considered to determine the key parameters affecting the expected improvement due to fusion. All in all, we concluded that those key parameters are the number of individual classifiers, the pairwise correlation among the individual scores, the bias, and the unbalance among the individual variances. In summary, we can say that it is interesting to fuse the largest number of classifiers, which preferably provide scores that are uncorrelated, unbiased, and with similar variances.
Ultimately, the classifier probability of error (or the accuracy) is the most important figure of merit. Therefore, we related the improvement in MSE to the expected accuracy improvement. To do so, we considered exponential models for the class-conditional pdfs. Although these are specific models, a clear connection between the MSE of the class estimation and the classifier performance was demonstrated.
The real data experiments showed consistency with the theoretical analysis, although the actual score models were different from the assumed in both EOC and NEOC models. Regarding accuracy, we verified the good fitting between the theoretical predictions and the actual data. This suggests that the score pdf exponential models are appropriate in this case.
Both the theoretical analysis and the experimental results encourage expanding this work in several respects. First, more general models than EOC and NEOC could better fit different real-world data scenarios. Second, it would be of great interest to seek methods capable of providing unbiased and uncorrelated scores. Specifically, the severe limitation on improvement imposed by bias suggests the merit of further investigation into this problem. The extension of the analysis to the multiclass problem and to unsupervised or semi-supervised scenarios [
37,
38] will be of undoubted interest. Additionally, other non-Bayesian fusion approaches, such as those based on the Dempster–Shafer theory, should be explored [
39].







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}