
Feature Enhancement Network for Infrared Small Target Detection in Complex Backgrounds Based on Multi-Scale Attention Mechanism

Abstract
1. Introduction
- (1)
- Comparative research is conducted to evaluate the amalgamation of multi-scale feature maps in the FPN and PAN against the newly introduced iAFF module for feature merging. Findings confirm that our suggested network, through the consolidation of diverse contextual data across channel dimensions, is capable of highlighting both extensive targets with worldwide distribution and minor targets with localized distribution. This method enhances the network’s capacity to identify and sense objects amidst significant scale fluctuations.
- (2)
- After amalgamating features from various scales, it is proposed that the OAAM enhances the interconnectivity among feature channels dynamically. Furthermore, we integrate the Dynamic Head’s scale and spatial focus, employing adaptable convolutions to concentrate on target shapes, thereby tackling local occlusion and the disappearance of 119 object characteristics, plus the disappearance of characteristics of objects.
- (3)
- We select the NWD as the loss function for regression analysis at the edges of smaller objects. Furthermore, we evaluate the impact of employing the IoU, GIoU, CIoU, and NWD as loss functions for localization in infrared small target bounding box regression. The findings show that the NWD loss mechanism markedly diminishes incorrect alerts and overlooked detections stemming from difficulties in pinpointing and identifying small infrared targets in congested environments. The enhancement bolsters the detection model’s overall resilience.
- (4)
- Utilizing a long-wave infrared camera, we capture images of drones in various situations and over various distances (100–1200 m), resulting in the formation of a comprehensive infrared target dataset called IRMT-UAV. This dataset covers a wide variety of application scenarios, including those with highly cluttered backgrounds and local occlusion between objects and their surroundings. The targets in the dataset vary from bright, medium-sized objects at close range to dim, small objects at extended distances. The varied nature of this dataset bolsters its resilience and flexibility, rendering it ideal for the training and assessment of object detection algorithms.
2. Related Work
3. Methodology
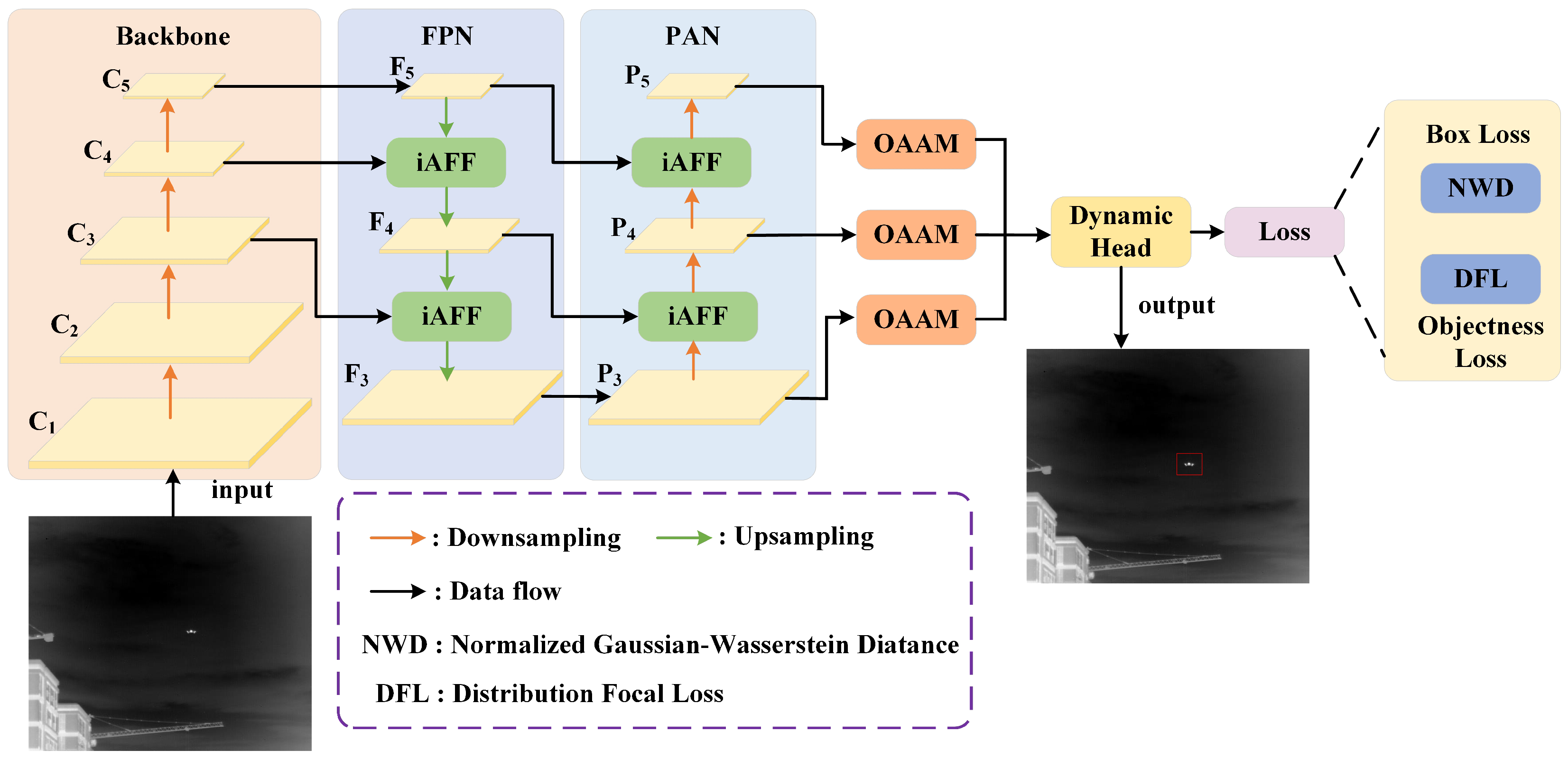
3.1. Overall Architecture
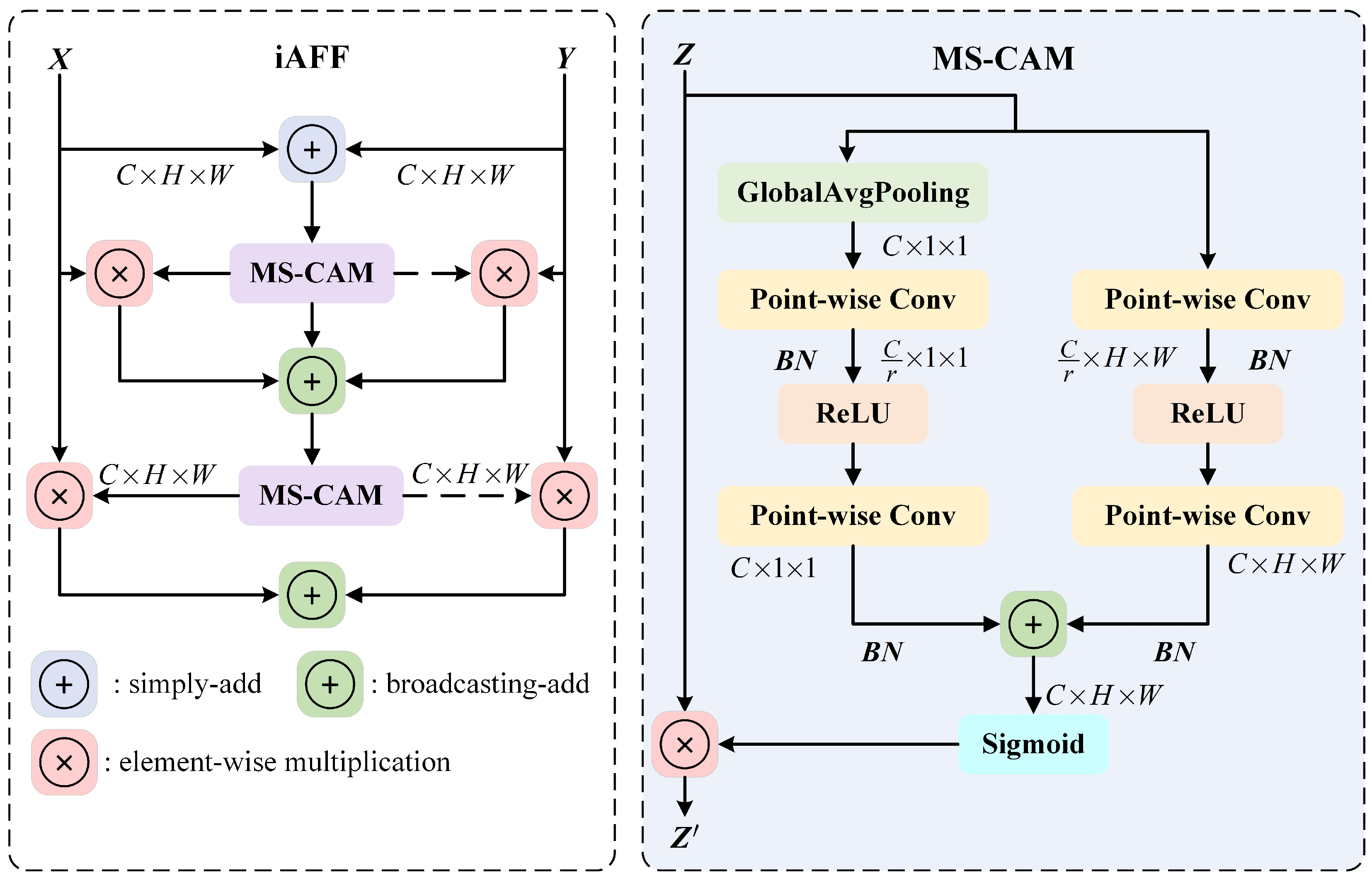
3.2. Iterative Attentional Feature Fusion
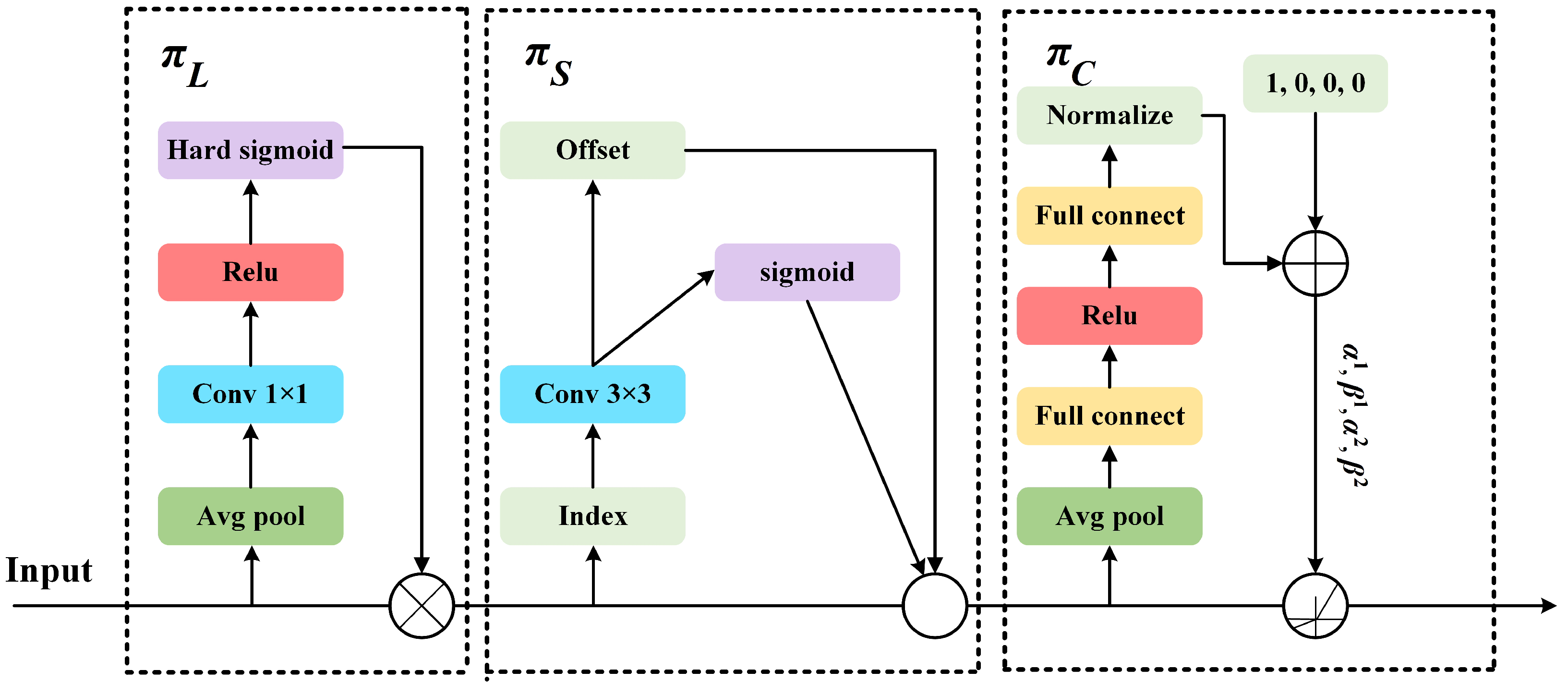
3.3. Occlusion-Aware Attention Module
3.4. Dynamic Head
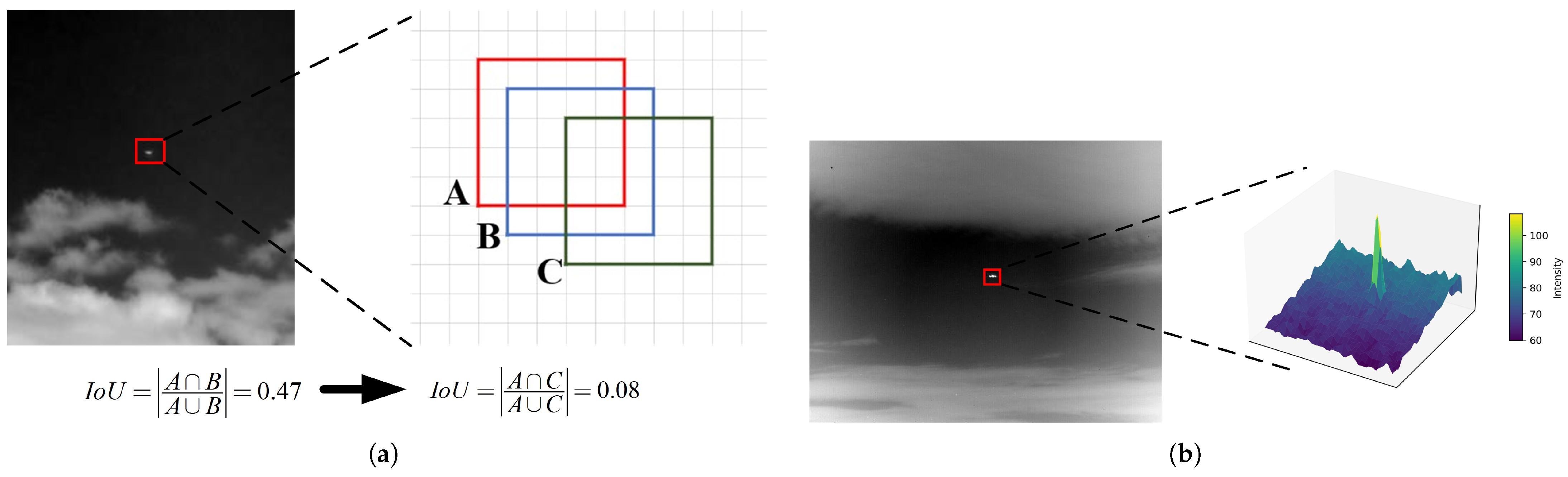
3.5. Normalized Wasserstein–Gaussian Distance
4. Experiments and Analysis
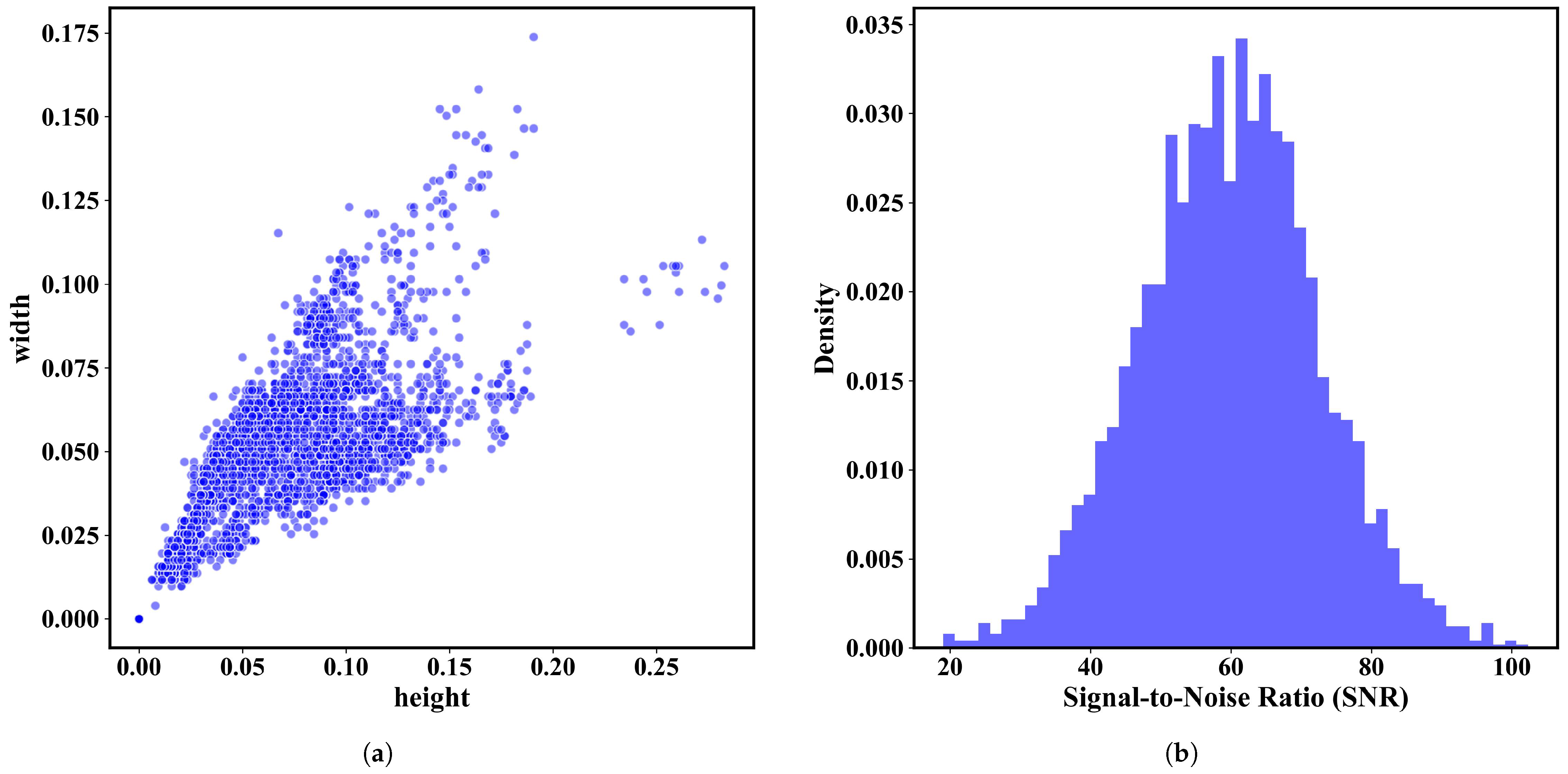
4.1. Dataset and Evaluation Metrics
4.2. Experiment Setup
4.3. Comparison with Other Methods
4.3.1. Quantitative Results
4.3.2. Visual Results
4.4. Ablation Experiments
4.4.1. The Impact of NWD on Network
4.4.2. The Impact of iAFF on the Network
4.4.3. The Impact of the OAAM and Dy-Head on the Network
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| FPN | Feature Pyramid Network |
| PAN | Path Aggregation Network |
| iAFF | Iterative Attentional Feature Fusion |
| OAAM | Occlusion-Aware Attention Module |
| NWD | Normalized Wasserstein–Gaussian Distance |
| MS-CAM | Multi-Scale Channel Attention Mechanism |
References
- Wang, K.; Du, S.; Liu, C.; Cao, Z. Interior attention-aware network for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5002013. [Google Scholar] [CrossRef]
- Han, J.; Moradi, S.; Faramarzi, I.; Zhang, H.; Zhao, Q.; Zhang, X.; Li, N. Infrared small target detection based on the weighted strengthened local contrast measure. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1670–1674. [Google Scholar] [CrossRef]
- Sun, Y.; Yang, J.; An, W. Infrared dim and small target detection via multiple subspace learning and spatial-temporal patch-tensor model. IEEE Trans. Geosci. Remote Sens. 2020, 59, 3737–3752. [Google Scholar] [CrossRef]
- Li, R.; Shen, Y. YOLOSR-IST: A deep learning method for small target detection in infrared remote sensing images based on super-resolution and YOLO. Signal Process. 2023, 208, 108962. [Google Scholar] [CrossRef]
- Xu, S.; Zheng, S.; Xu, W.; Xu, R.; Wang, C.; Zhang, J.; Teng, X.; Li, A.; Guo, L. Hcf-net: Hierarchical context fusion network for infrared small object detection. In Proceedings of the 2024 IEEE International Conference on Multimedia and Expo (ICME), Niagara Falls, ON, Canada, 15–19 July 2024; pp. 1–6. [Google Scholar]
- Yang, J.; Liu, S.; Wu, J.; Su, X.; Hai, N.; Huang, X. Pinwheel-shaped Convolution and Scale-based Dynamic Loss for Infrared Small Target Detection. arXiv 2024, arXiv:2412.16986. [Google Scholar] [CrossRef]
- Zhao, M.; Li, W.; Li, L.; Hu, J.; Ma, P.; Tao, R. Single-frame infrared small-target detection: A survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 87–119. [Google Scholar] [CrossRef]
- Qian, X.; Zhang, N.; Wang, W. Smooth giou loss for oriented object detection in remote sensing images. Remote Sens. 2023, 15, 1259. [Google Scholar] [CrossRef]
- Wang, M.; Fu, B.; Fan, J.; Wang, Y.; Zhang, L.; Xia, C. Sweet potato leaf detection in a natural scene based on faster R-CNN with a visual attention mechanism and DIoU-NMS. Ecol. Inf. 2023, 73, 101931. [Google Scholar] [CrossRef]
- Liu, X.-B.; Yang, X.-Z.; Yang, C.; Zhang, S.-T. Object detection method based on CIoU improved bounding box loss function. Chin. J. Liq. Cryst. Displays 2023, 38, 656–665. [Google Scholar] [CrossRef]
- Deshpande, S.D.; Er, M.H.; Venkateswarlu, R.; Chan, P. Max-mean and max-median filters for detection of small targets. In Proceedings of the Signal and Data Processing of Small Targets 1999, Denver, CO, USA, 4 October 1999; Volume 3809, pp. 74–83. [Google Scholar]
- Rivest, J.F.; Fortin, R. Detection of dim targets in digital infrared imagery by morphological image processing. Opt. Eng. 1996, 35, 1886–1893. [Google Scholar] [CrossRef]
- Han, J.; Ma, Y.; Zhou, B.; Fan, F.; Liang, K.; Fang, Y. A robust infrared small target detection algorithm based on human visual system. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2168–2172. [Google Scholar]
- Han, J.; Liang, K.; Zhou, B.; Zhu, X.; Zhao, J.; Zhao, L. Infrared small target detection utilizing the multiscale relative local contrast measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, L.; Zhang, T.; Cao, S.; Peng, Z. Infrared small target detection via non-convex rank approximation minimization joint l 2, 1 norm. Remote Sens. 2018, 10, 1821. [Google Scholar] [CrossRef]
- Gao, C.; Meng, D.; Yang, Y.; Wang, Y.; Zhou, X.; Hauptmann, A.G. Infrared patch-image model for small target detection in a single image. IEEE Trans. Image Process. 2013, 22, 4996–5009. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, L.; Wang, L. Miss detection vs. false alarm: Adversarial learning for small object segmentation in infrared images. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8509–8518. [Google Scholar]
- Dai, Y.; Wu, Y.; Zhou, F.; Barnard, K. Asymmetric contextual modulation for infrared small target detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 950–959. [Google Scholar]
- Hou, Q.; Wang, Z.; Tan, F.; Zhao, Y.; Zheng, H.; Zhang, W. RISTDnet: Robust infrared small target detection network. IEEE Geosci. Remote Sens. Lett. 2021, 19, 7000805. [Google Scholar] [CrossRef]
- Chen, G.; Wang, W.; Tan, S. Irstformer: A hierarchical vision transformer for infrared small target detection. Remote Sens. 2022, 14, 3258. [Google Scholar] [CrossRef]
- Dai, Y.; Li, X.; Zhou, F.; Qian, Y.; Chen, Y.; Yang, J. One-stage cascade refinement networks for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5000917. [Google Scholar] [CrossRef]
- Yao, S.; Zhu, Q.; Zhang, T.; Cui, W.; Yan, P. Infrared image small-target detection based on improved FCOS and spatio-temporal features. Electronics 2022, 11, 933. [Google Scholar] [CrossRef]
- Li, R.; An, W.; Xiao, C.; Li, B.; Wang, Y.; Li, M.; Guo, Y. Direction-coded temporal U-shape module for multiframe infrared small target detection. IEEE Trans. Neural Netw. Learn. Syst. 2023, 36, 555–568. [Google Scholar] [CrossRef]
- Ying, X.; Liu, L.; Wang, Y.; Li, R.; Chen, N.; Lin, Z.; Sheng, W.; Zhou, S. Mapping degeneration meets label evolution: Learning infrared small target detection with single point supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 15528–15538. [Google Scholar]
- Sun, H.; Bai, J.; Yang, F.; Bai, X. Receptive-field and direction induced attention network for infrared dim small target detection with a large-scale dataset IRDST. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5000513. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Chanussot, J. UIU-Net: U-Net in U-Net for infrared small object detection. IEEE Trans. Image Process. 2022, 32, 364–376. [Google Scholar] [CrossRef] [PubMed]
- Xu, R.; Wang, C.; Zhang, J.; Xu, S.; Meng, W.; Zhang, X. RSSFormer: Foreground saliency enhancement for remote sensing land-cover segmentation. IEEE Trans. Image Process. 2023, 32, 1052–1064. [Google Scholar] [CrossRef]
- Ju, M.; Luo, J.; Liu, G.; Luo, H. ISTDet: An efficient end-to-end neural network for infrared small target detection. Infrared Phys. Technol. 2021, 114, 103659. [Google Scholar] [CrossRef]
- Du, J.; Lu, H.; Zhang, L.; Hu, M.; Chen, S.; Deng, Y.; Shen, X.; Zhang, Y. A spatial-temporal feature-based detection framework for infrared dim small target. IEEE Trans. Geosci. Remote Sens. 2021, 60, 3000412. [Google Scholar] [CrossRef]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.M.; Yang, J.; Li, X. Large selective kernel network for remote sensing object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–3 October 2023; pp. 16794–16805. [Google Scholar]
- Gong, Y.; Yu, X.; Ding, Y.; Peng, X.; Zhao, J.; Han, Z. Effective fusion factor in FPN for tiny object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 1160–1168. [Google Scholar]
- Hu, M.; Li, Y.; Fang, L.; Wang, S. A2-FPN: Attention aggregation based feature pyramid network for instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15343–15352. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional feature fusion. In Proceedings of the IEEE/CVF winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3560–3569. [Google Scholar]
- Sunkara, R.; Luo, T. YOGA: Deep object detection in the wild with lightweight feature learning and multiscale attention. Pattern Recognit. 2023, 139, 109451. [Google Scholar] [CrossRef]
- Zhang, K.; Wang, W.; Lv, Z.; Feng, J.; Li, H.; Zhang, C. LKDPNet: Large-Kernel Depthwise-Pointwise convolution neural network in estimating coal ash content via data augmentation. Appl. Soft Comput. 2023, 144, 110471. [Google Scholar] [CrossRef]
- Yu, Z.; Huang, H.; Chen, W.; Su, Y.; Liu, Y.; Wang, X. Yolo-facev2: A scale and occlusion aware face detector. Pattern Recognit. 2024, 155, 110714. [Google Scholar] [CrossRef]
- Schuler, J.P.S.; Romani, S.; Abdel-Nasser, M.; Rashwan, H.; Puig, D. Grouped pointwise convolutions reduce parameters in convolutional neural networks. Mendel 2022, 28, 23–31. [Google Scholar] [CrossRef]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Chen, F.; Wu, F.; Xu, J.; Gao, G.; Ge, Q.; Jing, X.Y. Adaptive deformable convolutional network. Neurocomputing 2021, 453, 853–864. [Google Scholar] [CrossRef]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Zhang, M.; Zhang, R.; Yang, Y.; Bai, H.; Zhang, J.; Guo, J. ISNet: Shape matters for infrared small target detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18– 24 June 2022; pp. 877–886. [Google Scholar]
- Yang, B.; Zhang, X.; Zhang, J.; Luo, J.; Zhou, M.; Pi, Y. EFLNet: Enhancing feature learning network for infrared small target detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5906511. [Google Scholar] [CrossRef]
- Li, B.; Xiao, C.; Wang, L.; Wang, Y.; Lin, Z.; Li, M.; An, W.; Guo, Y. Dense nested attention network for infrared small target detection. IEEE Trans. Image Process. 2022, 32, 1745–1758. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mathematical Models Based | Deep Learning Based | |
|---|---|---|
| Box regression | MMF [11] | MDvsFA [17] |
| MIP [12] | ACM [18] | |
| IRHVS [13] | ISTDNet [19] | |
| RLCM [14] | IRSTFormer [20] | |
| NRAM [15] | OCRNet [21] | |
| IPM [16] | FCOS [22] | |
| Segmentation | – | IFEA [23] |
| DTUNet [24] | ||
| MDLE [25] | ||
| RDANet [26] | ||
| FSENet [27] |
| Hyperparameters | Value |
|---|---|
| Learning Rate | 0.001 |
| Momentum | 0.937 |
| Epochs | 300 |
| Batch Size | 64 |
| Image Size | 640 × 640 |
| Optimizer | SGD |
| Weight Decay | 0.0005 |
| Patience | 100 |
| Work | 16 |
| Pretrained | False |
| Warmup Epochs | 3 |
| Warmup Momentum | 0.8 |
| Warmup Bias Learning Rate | 0.1 |
| Method | IRMT-UAV | IRSTD-1k | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | mAP50 | Precision | Recall | mAP50 | |
| MDvsFA | 60.8% | 50.7% | 59.7% | 55.0% | 48.3% | 47.5% |
| YOLOSR-IST | 56.8% | 68.4% | 41.5% | 41.5% | 47.0% | 44.1% |
| ACM | 76.5% | 75.2% | 74.7% | 67.9% | 60.5% | 64.0% |
| ISNet | 82.0% | 84.7% | 83.4% | 71.8% | 64.1% | 65.8% |
| ALCNet | 84.8% | 78.0% | 81.3% | 83.9% | 65.6% | 72.9% |
| EFLNet | 88.2% | 84.7% | 86.8% | 85.4% | 70.8% | 73.8% |
| DNANet | 89.1% | 85.2% | 87.9% | 84.3% | 72.1% | 74.4% |
| Ours | 92.8% | 89.5% | 91.7% | 86.7% | 74.0% | 75.8% |
| Backbone | iAFF | OAAM | Dy-Head | NWD | Precision | Recall | mAP50 |
|---|---|---|---|---|---|---|---|
| YOLOv11m | ✗ | ✗ | ✗ | ✗ | 81.9% | 69.5% | 74.4% |
| ✓ | ✗ | ✗ | ✗ | 88.7% | 74.5% | 82.3% | |
| ✓ | ✓ | ✗ | ✗ | 89.7% | 82.3% | 84.5% | |
| ✓ | ✓ | ✓ | ✗ | 91.3% | 88.1% | 85.6% | |
| ✓ | ✓ | ✓ | ✓ | 92.8% | 89.5% | 91.7% | |
| YOLOv8m | ✗ | ✗ | ✗ | ✗ | 79.5% | 68.2% | 73.7% |
| ✓ | ✗ | ✗ | ✗ | 86.1% | 74.1% | 81.9% | |
| ✓ | ✓ | ✗ | ✗ | 87.3% | 80.9% | 83.7% | |
| ✓ | ✓ | ✓ | ✗ | 88.6% | 82.8% | 84.9% | |
| ✓ | ✓ | ✓ | ✓ | 91.7% | 87.4% | 89.5% | |
| RetinaNet | ✗ | ✗ | ✗ | ✗ | 78.4% | 67.8% | 72.6% |
| ✓ | ✗ | ✗ | ✗ | 84.3% | 76.3% | 78.9% | |
| ✓ | ✓ | ✗ | ✗ | 85.9% | 78.7% | 80.6% | |
| ✓ | ✓ | ✓ | ✗ | 86.3% | 80.5% | 81.4% | |
| ✓ | ✓ | ✓ | ✓ | 90.1% | 87.4% | 88.9% |
| Loss | IRMT-UAV | IRSTD-1k | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | mAP50 | Precision | Recall | mAP50 | |
| IoU | 87.8% | 86.4% | 87.2% | 86.3% | 83.7% | 85.4% |
| GIoU | 87.9% | 86.3% | 88.3% | 86.7% | 84.2% | 85.9% |
| DIoU | 88.9% | 87.2% | 89.3% | 87.9% | 85.3% | 86.2% |
| CIoU | 90.1% | 88.4% | 89.1% | 88.4% | 85.2% | 86.9% |
| NWD | 92.8% | 89.5% | 91.7% | 90.3% | 89.1% | 88.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Du, W.; Liu, Y.; Zhou, N.; Li, Z. Feature Enhancement Network for Infrared Small Target Detection in Complex Backgrounds Based on Multi-Scale Attention Mechanism. Appl. Sci. 2025, 15, 4966. https://doi.org/10.3390/app15094966
Zhang S, Du W, Liu Y, Zhou N, Li Z. Feature Enhancement Network for Infrared Small Target Detection in Complex Backgrounds Based on Multi-Scale Attention Mechanism. Applied Sciences. 2025; 15(9):4966. https://doi.org/10.3390/app15094966
Chicago/Turabian StyleZhang, Sen, Weilin Du, Yuan Liu, Ni Zhou, and Zheng Li. 2025. "Feature Enhancement Network for Infrared Small Target Detection in Complex Backgrounds Based on Multi-Scale Attention Mechanism" Applied Sciences 15, no. 9: 4966. https://doi.org/10.3390/app15094966
APA StyleZhang, S., Du, W., Liu, Y., Zhou, N., & Li, Z. (2025). Feature Enhancement Network for Infrared Small Target Detection in Complex Backgrounds Based on Multi-Scale Attention Mechanism. Applied Sciences, 15(9), 4966. https://doi.org/10.3390/app15094966