
An Adaptive Task Traffic Shaping Method for Highly Concurrent Geographic Information System Services with Limited Resources


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
2.1. The Classical Token Bucket Algorithm
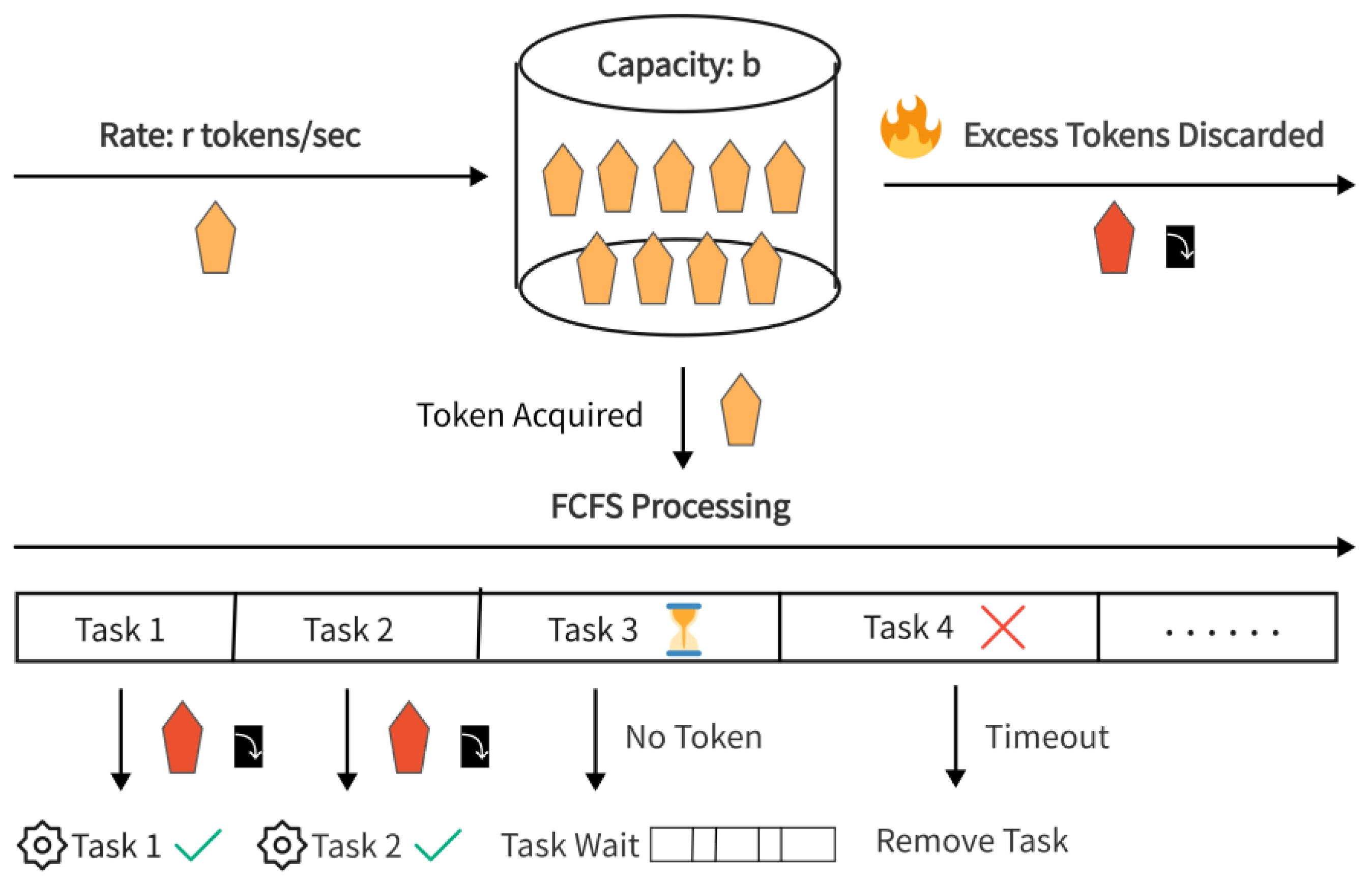
- The client sends requests, and each request forms a task on the server. All tasks form a queue, and they are processed according to FCFS (First-Come, First-Served) [25].
- A token bucket with a capacity of b tokens is set up, and tokens are provided at a rate of r tokens per second. If the bucket is full, excess tokens are discarded.
- Each arriving task must obtain a token from the bucket before it can be sent. After the task is sent, the token is removed from the bucket.
- The server receives and processes the tasks which obtain tokens. If no token-holding tasks are waiting in the queue or if the waiting time exceeds a predefined timeout, the tasks are dropped.
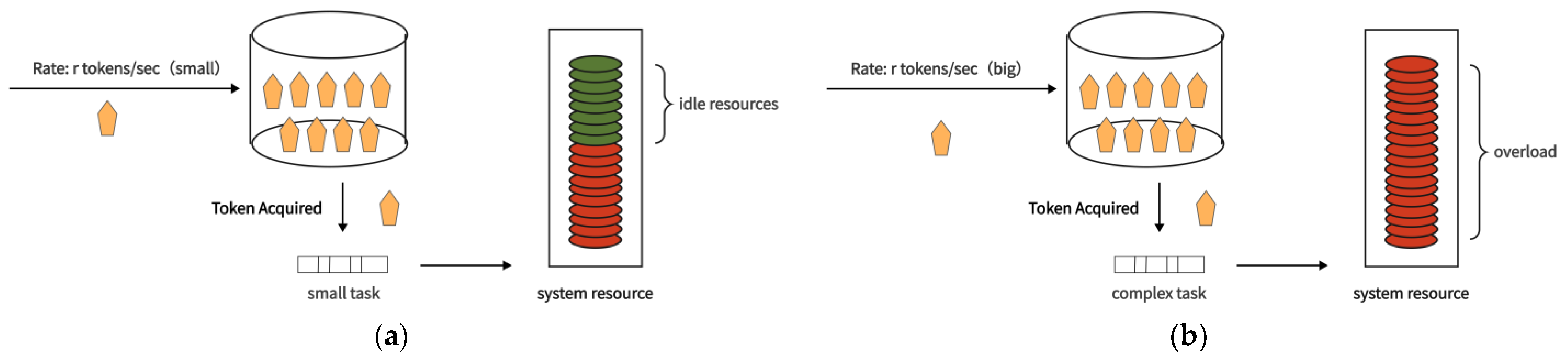
- When the task is relatively simple, the single task occupies fewer system resources, and it is appropriate to set a larger r value at this time to improve the system resource utilization and the average processing rate of the total task.
- When the task is more complex, the single task occupies more system resources; at this time, it is appropriate to set a smaller r value to improve the processing rate of the single task and the average processing rate of the total task.
2.2. Existing Single-Server Highly Concurrent Task Traffic-Shaping Methods
2.3. Shortcomings of Existing Methods
- When the requested task is simpler (i.e., occupies fewer system resources) and the current token bucket rate is less than the actual system processing capacity, the utilization of system resources is lower, increasing the average processing delay of the task volume and the service rate is lower.
- When the requested task is more complex (i.e., occupies more system resources) and the current token bucket rate is greater than the system’s actual processing capacity, the system responds to more tasks and there is task blocking, which likewise increases the average processing delay and lowers the service rate.
3. Adaptive Task Traffic-Shaping Algorithm
3.1. Task Request Queueing Theory Model
3.2. Adaptive Traffic Shaping Based on Resource Loading
3.2.1. Calculation of Single-Server Resource Load
- When all fall within the same interval of [0, 0.35], [0.35, 0.75], or [0.75, 1], it is assumed that the impact of the three indicators on the system load is consistent. In this case, the weights can be assigned by sorting the current actual values of the indicators and giving corresponding weights. Based on extensive experiments, the paper proposes the following set of weight values: {0.5, 0.3, 0.2}.
- When one indicator falls within the [0.35, 0.75] range and the other two indicators fall within the [0, 0.35] range, it is assumed that the indicator within the [0.35, 0.75] range has a greater impact on the system load, so its weight should be higher. The other two indicators can be sorted according to their actual values and assigned corresponding weights. Based on extensive experiments, the paper proposes the following set of weight values: {0.7, 0.2, 0.1}.
- When two indicators fall within the [0.35, 0.75] range and one indicator falls within the [0, 0.35] range, it is assumed that the two indicators within the [0.35, 0.75] range have a greater impact on the system load, so their weights should be higher. In this case, the indicators can be sorted according to their actual values and assigned corresponding weights. Based on extensive experiments, the paper proposes the following set of weight values: {0.5, 0.4, 0.1}.
- When one indicator falls within the [0.75, 1] range and the other two indicators fall within the [0, 0.75] range, it is assumed that this indicator is the current system bottleneck and its weight should be very high. Based on extensive experiments, the paper proposes the following set of weight values: {0.9, 0.07, 0.03}.
- When two indicators fall within the [0.75, 1] range and one indicator falls within the [0, 0.75] range, it is assumed that these two indicators are the current system bottleneck and their weights should be very high. In this case, the indicators can be sorted according to their actual values and assigned corresponding weights. Based on extensive experiments, the paper proposes the following set of weight values: {0.5, 0.47, 0.03}.
3.2.2. Adaptive Traffic Shaping Based on Resource Load
4. Experiments and Analysis
4.1. Experimental Data and Experimental Environment
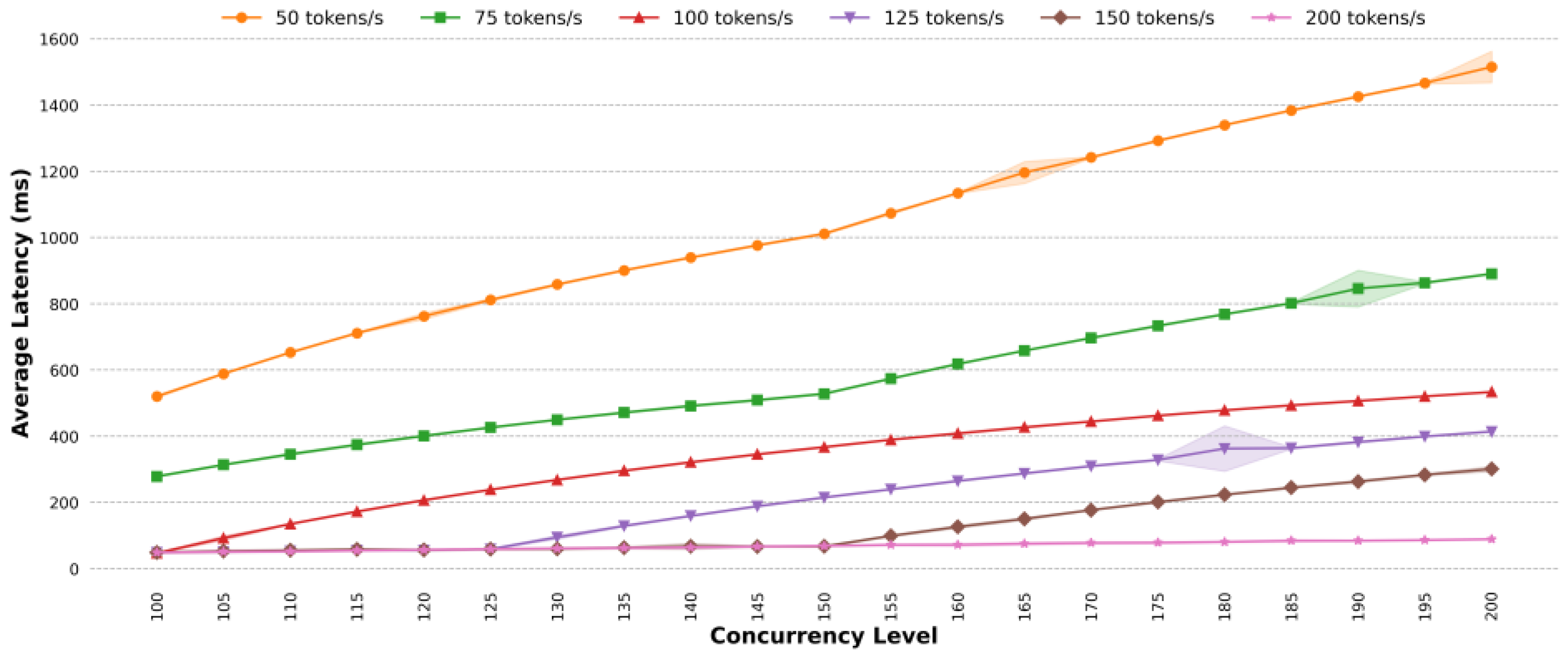
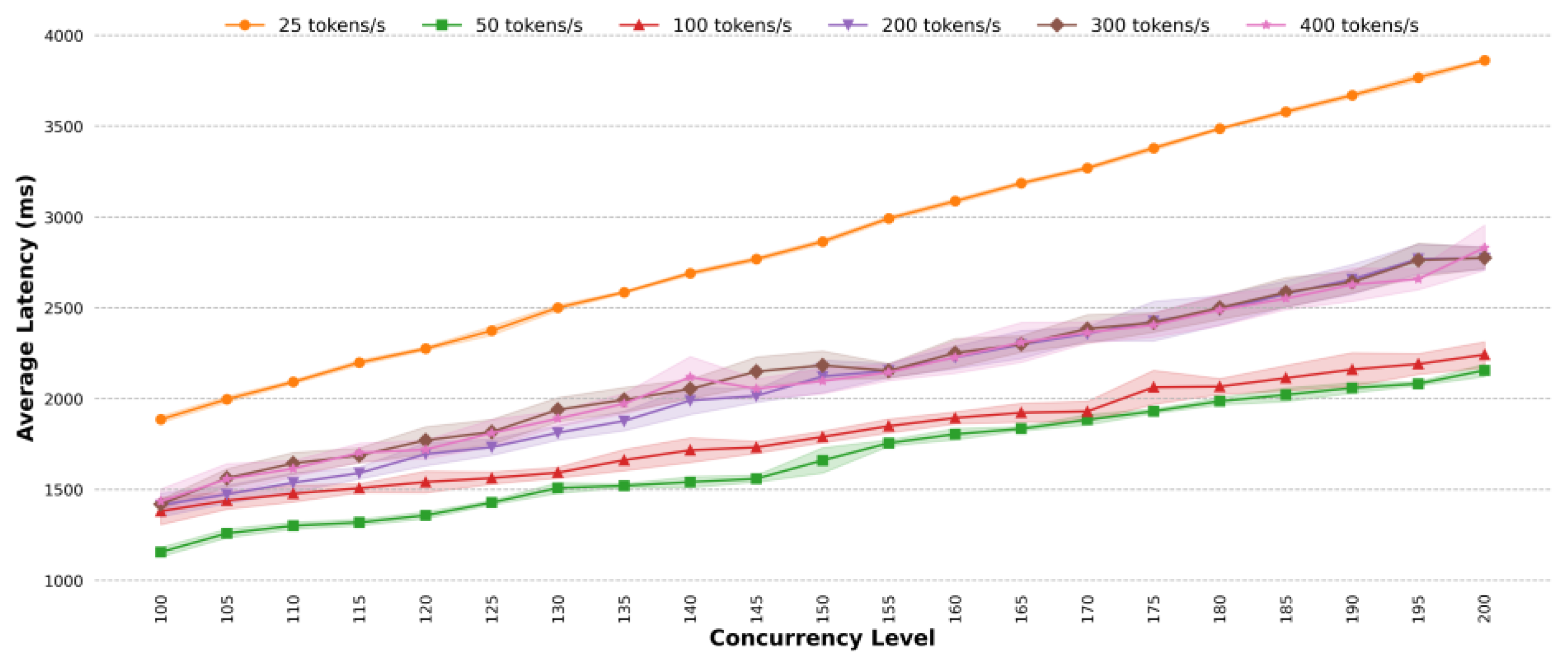
4.2. Optimal Token Fill Rate Detection
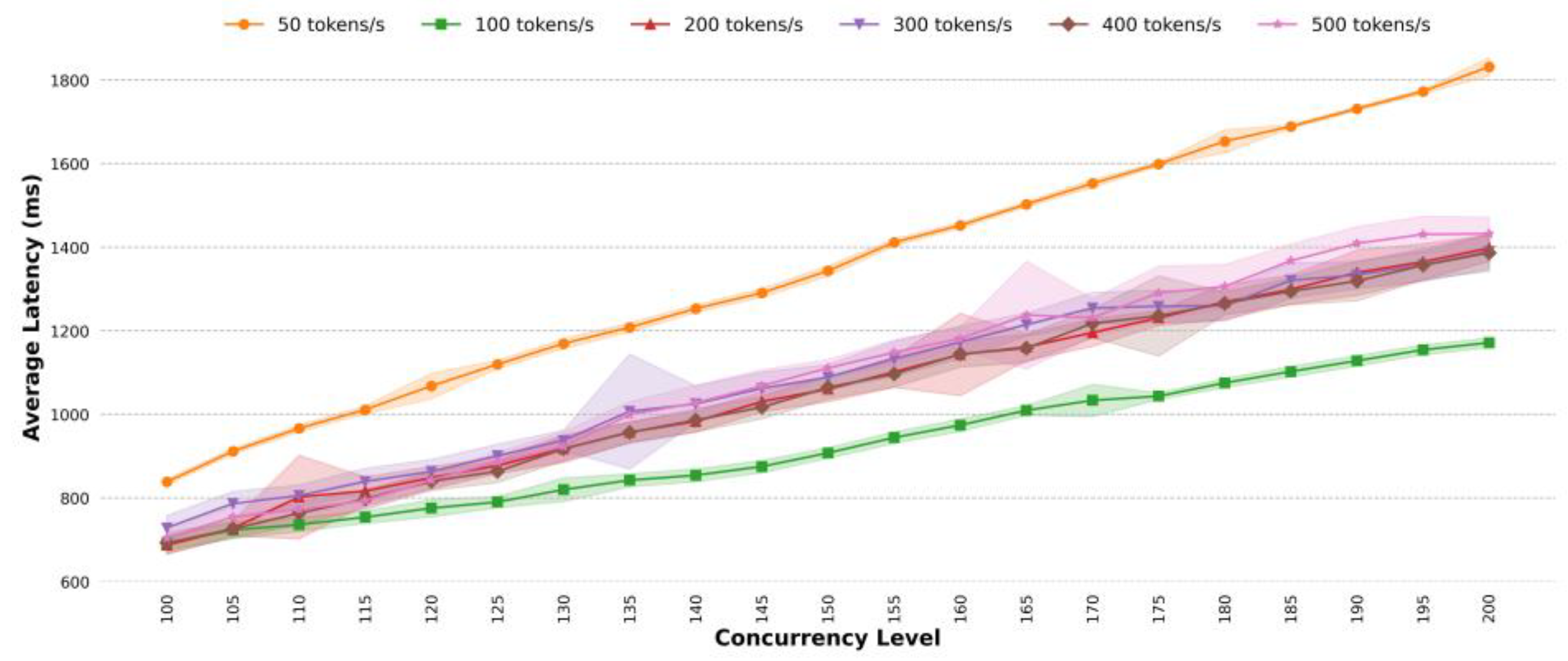
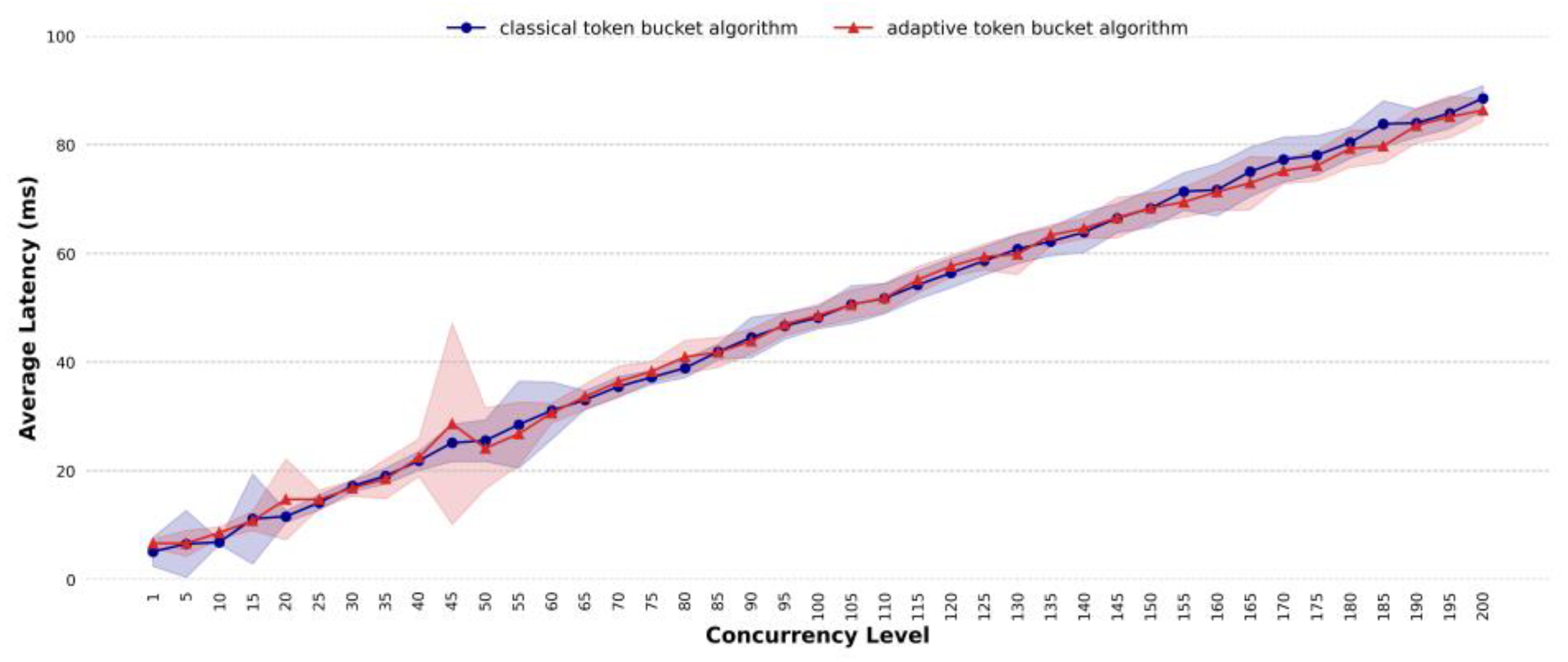
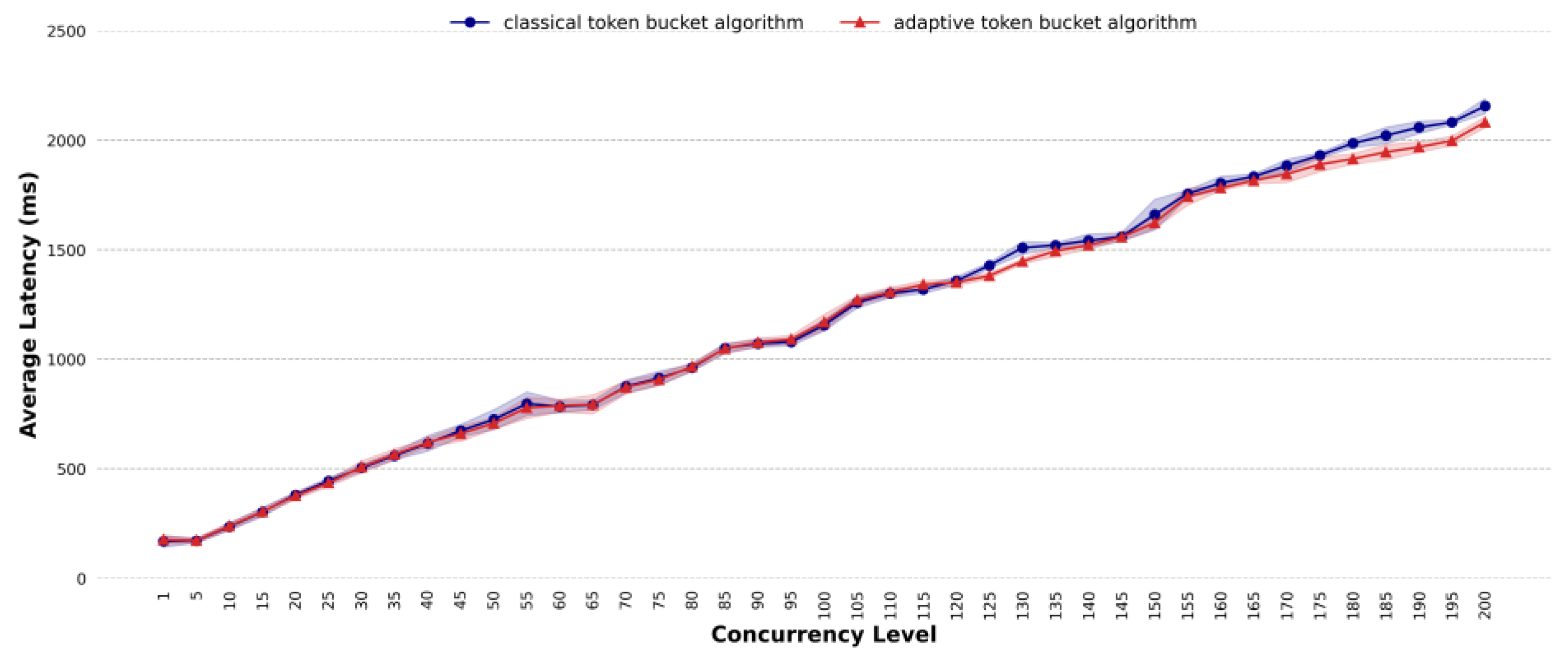
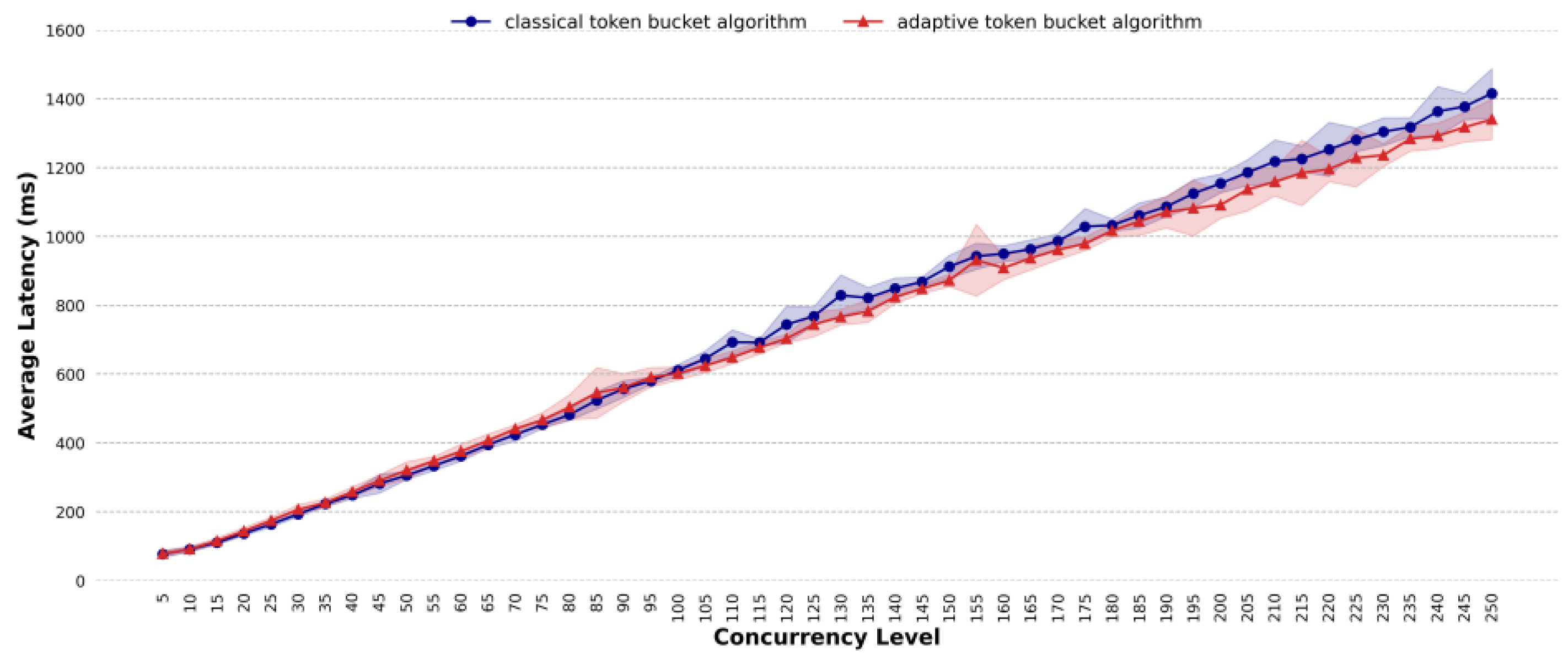
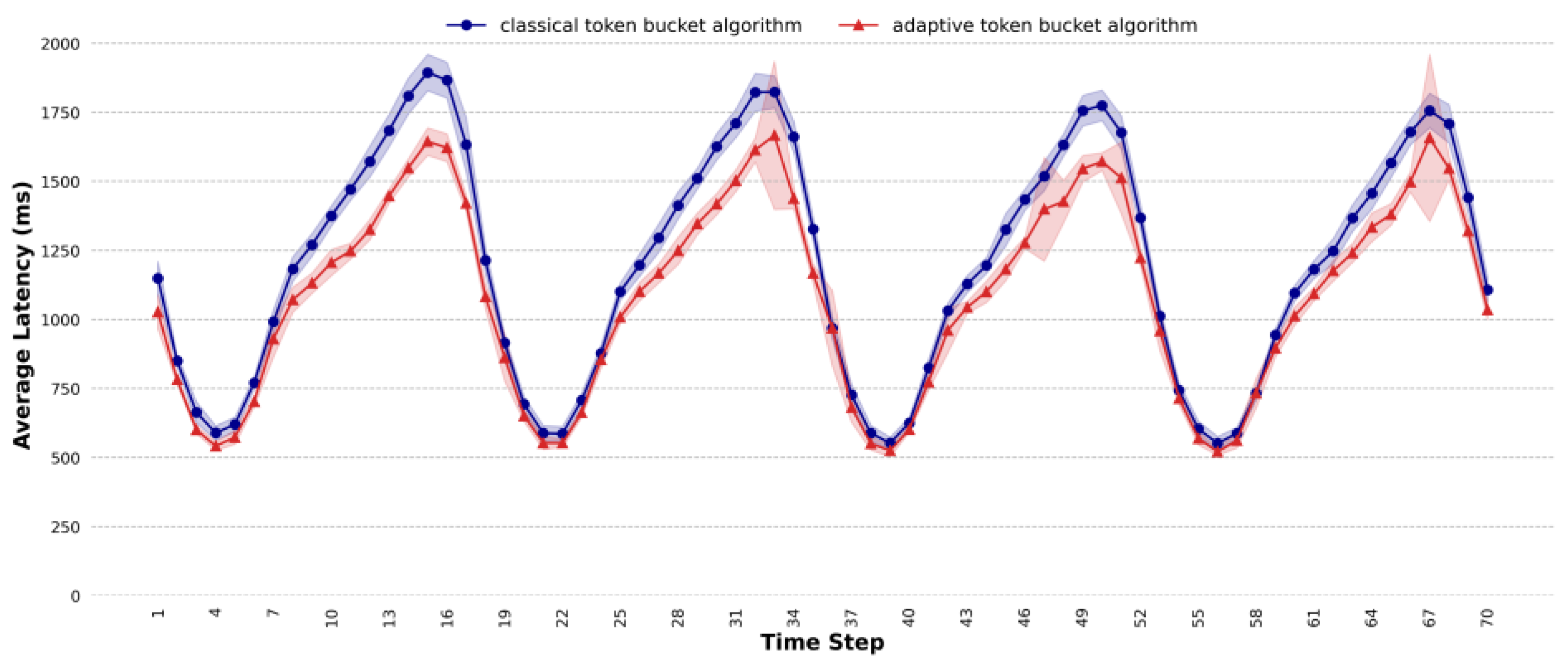
4.3. Comparative Analysis of Average Latency
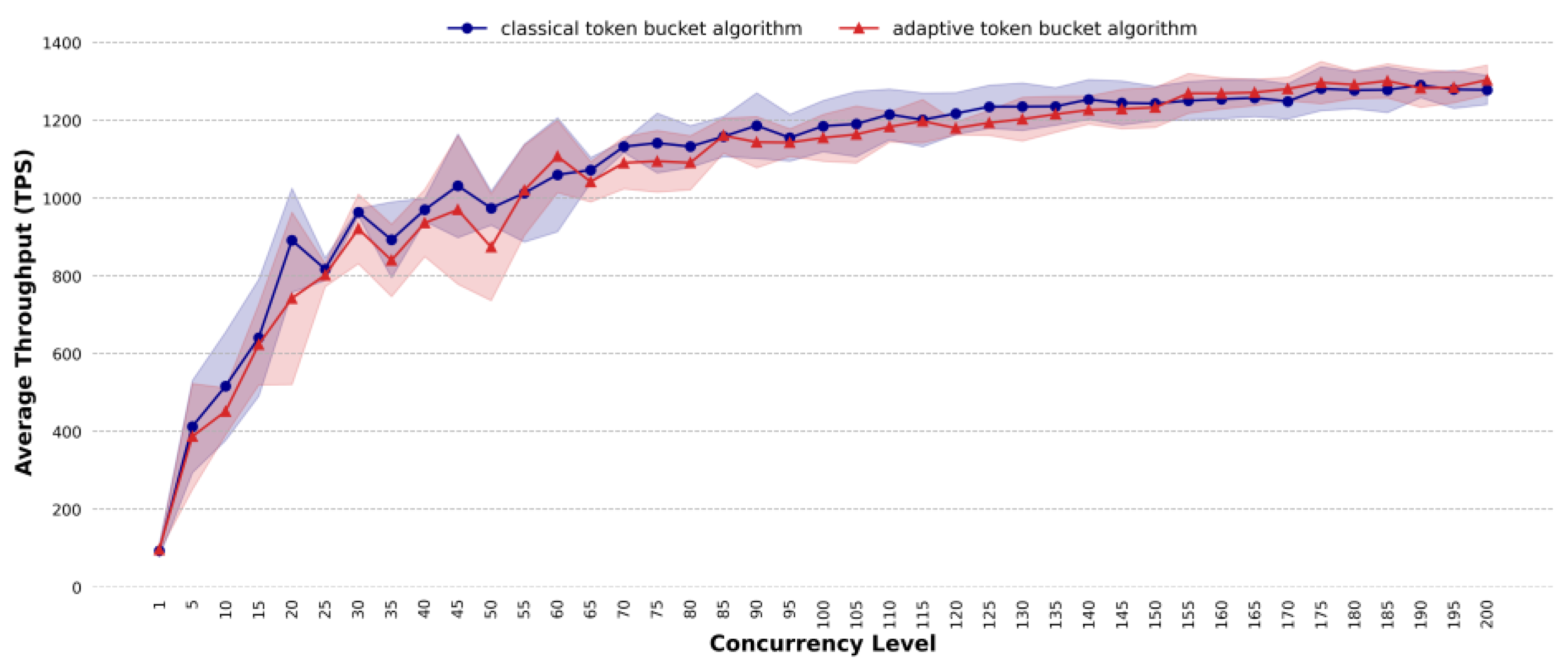
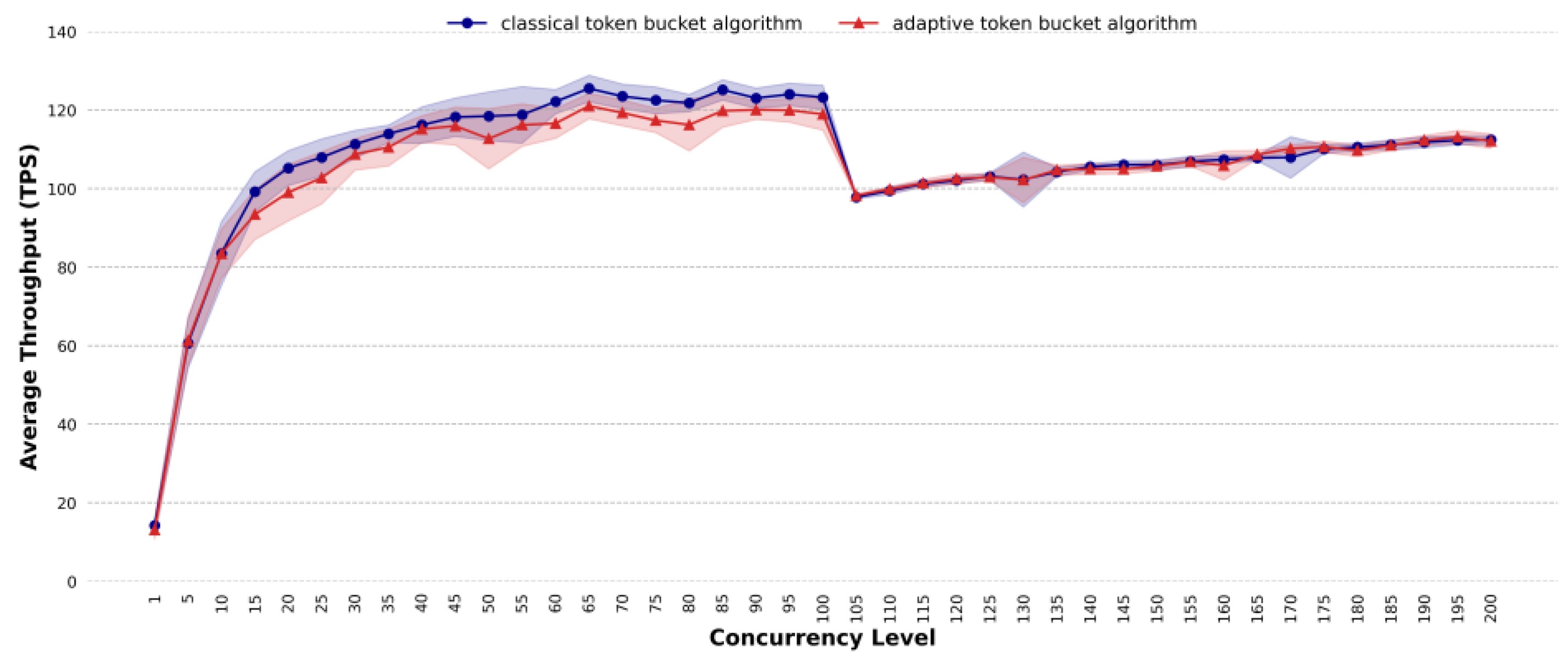
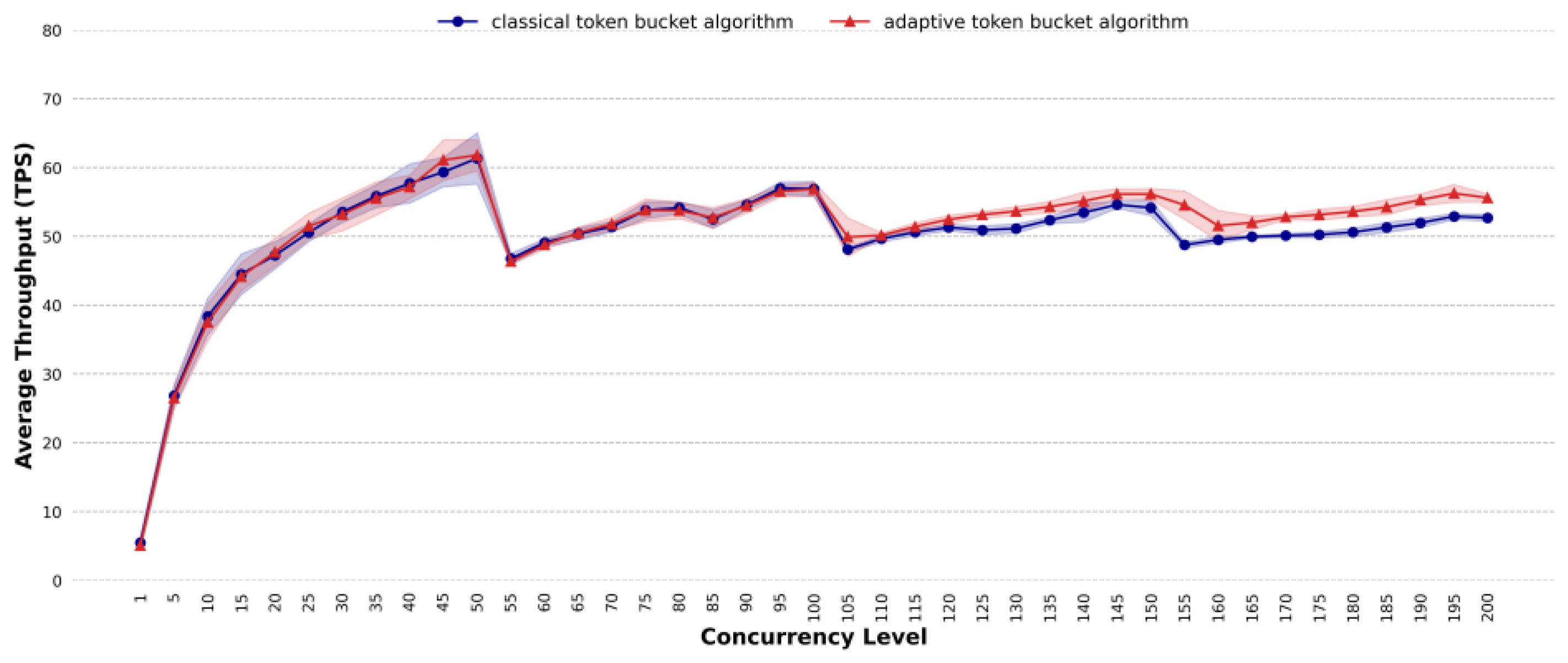
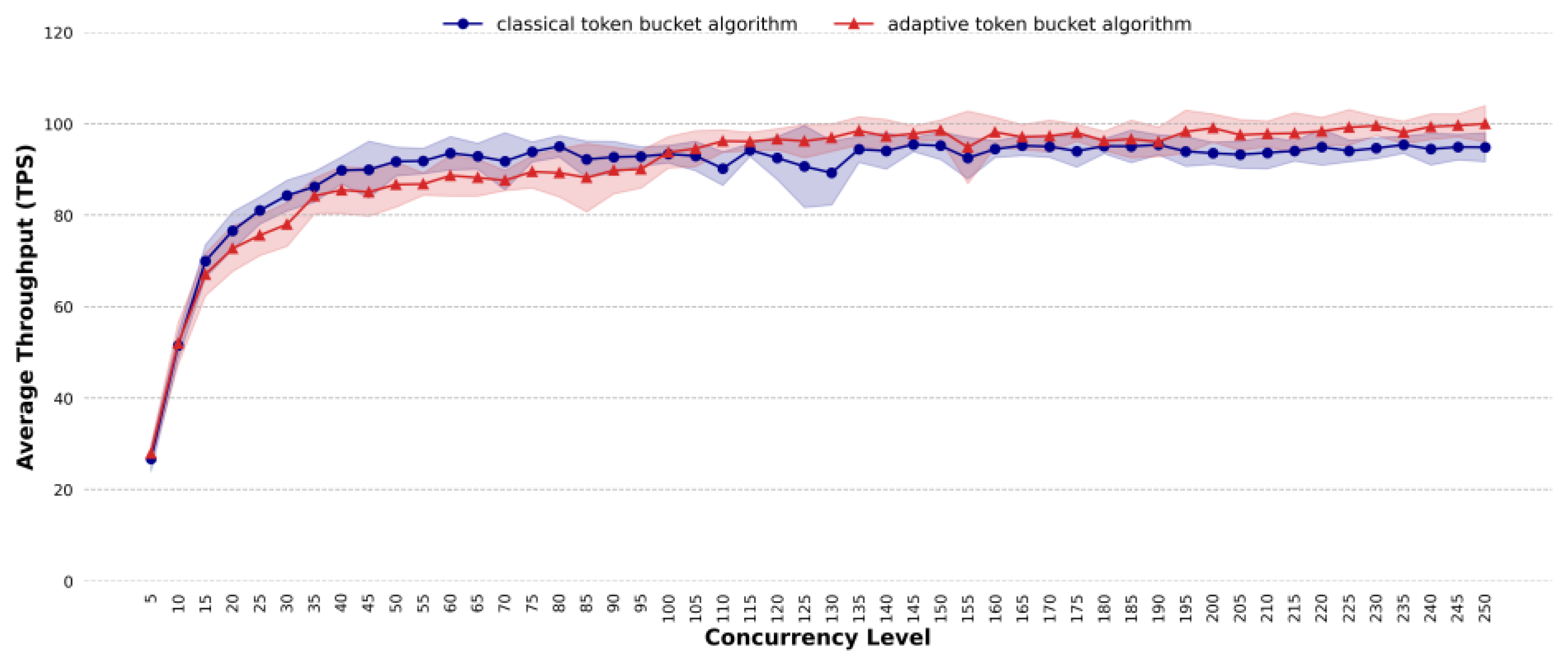
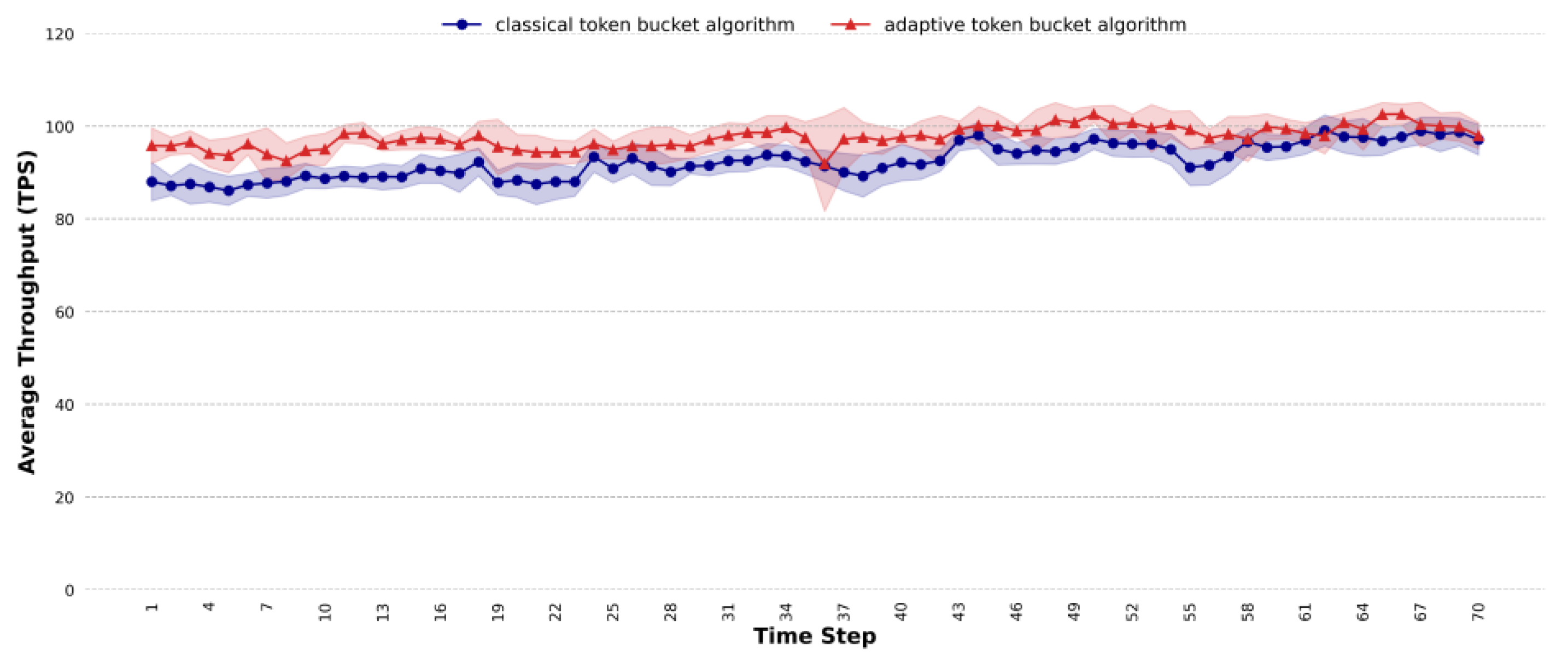
4.4. Comparative Analysis of Throughput
5. Discussion
5.1. Advantages of Adaptive Task Traffic-Shaping Algorithm
- Hardware Resource Constraints: Single-server computational capabilities are restricted by the hardware specifications of a single machine (e.g., CPU, memory, storage), leading to performance bottlenecks under high concurrency.
- Task Queueing and Resource Contention: Under high concurrency, single servers process requests sequentially, causing task queueing. Simultaneously, multiple concurrent tasks compete for limited resources (e.g., CPU cycles, memory bandwidth, disk I/O), significantly increasing response times and failing to meet real-time requirements.
- Inefficient Resource Utilization: Single-server systems may experience resource under-utilization due to static resource allocation strategies, even during periods of high task demand. This results from the inability to dynamically adjust resource distribution based on real-time workloads, wasting available computational capacity.
5.2. Application Prospects
5.3. Limitation
- The proposed method only considers three indicators, namely, CPU usage, memory occupancy, and the ratio of the number of links to the used resources; in the actual running environment, the calculation of system load is more complicated and it also needs to take into account the use of disks, the number of current processes, and so on. The next step of the research needs to detect a more reasonable calculation method for the system load.
- In this paper, when calculating single-server highly concurrent task requests, only the token fill rate is adjusted adaptively, but the capacity setting of the token bucket is not discussed. The impact of token bucket capacity on task processing efficiency needs to be discussed systematically in the future.
- Currently, the method in this paper is designed for non-priority task requests, and for multiple mixed task requests, the method in this paper needs to be further improved according to the priority of the task or QoS.
6. Conclusions
- Existing methods use a fixed token fill rate for traffic shaping, but the optimal rate is difficult to determine. The proposed method adapts the token fill rate based on system load. In terms of average latency, for different task scenarios, under highly concurrent conditions, the average latency of the proposed method is almost lower than that of the classic token bucket algorithm with the optimal rate; the proposed method can effectively reduce the average latency. For simple task scenarios, when the concurrency is 185, the average latency of the classic token bucket algorithm is 1.37 times that of the proposed method. For general task scenarios, when the concurrency exceeds 150, the average latency of the proposed method is roughly the same as that of the classic token bucket algorithm. For complex task scenarios, when the concurrency exceeds 120, the average latency of the classic token bucket algorithm is higher than that of the proposed method, with a maximum difference of 1.05 times. For mixed task scenarios, at a concurrency level of 130, the classic token bucket algorithm’s average latency is 1.08 times that of the proposed method. For dynamic traffic scenarios, the proposed method reduces the average latency by approximately 9.56%.
- In terms of average throughput, the proposed method can improve the processing efficiency under highly concurrent and dynamic traffic conditions, especially in complex task scenarios, mixed task scenarios and dynamic traffic scenarios. For complex task scenarios, when the concurrency reaches 155, the average throughput of the proposed method exceeds that of the classic token bucket algorithm, with the maximum improvement reaching 6 TPS. For mixed task scenarios, at a concurrency level of 130, the proposed method shows an average throughput that is 8 TPS higher than that of the classic token bucket algorithm. For dynamic traffic scenarios, the average throughput of the proposed method is 5.57% higher than that of the classic token bucket algorithm.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| QoS | Quality of Service |
| FCFS | First-Come, First-Served |
| TPS | Transactions Per Second |
| GIS | Geographic Information System |
| HMM | Hidden Markov Model |
| PQTBA | Priority Queue Token Bucket Algorithm |
| HTB | Hierarchical Token Bucket |
| TBDB | Token Bucket-based Dynamic Batching |
| MBS | Maximum Batch Size |
References
- Wang, S.; Zhong, Y.; Wang, E. An integrated GIS platform architecture for spatiotemporal big data. Future Gener. Comput. Syst. 2019, 94, 160–172. [Google Scholar] [CrossRef]
- Hasan, R.; Kapoor, A.; Singh, R.; Yadav, B.K. A state-of-the-art review on the quantitative and qualitative assessment of water resources using google earth engine. Environ. Monit. Assess. 2024, 196, 1266. [Google Scholar] [CrossRef]
- Zerouali, B.; Santos, C.A.G.; do Nascimento, T.V.M.; Silva, R.M.D. A cloud-integrated GIS for forest cover loss and land use change monitoring using statistical methods and geospatial technology over northern Algeria. J. Environ. Manag. 2023, 341, 118029. [Google Scholar] [CrossRef]
- Dhaini, A.; Ho, P.-H.; Jiang, X. QoS Control for Guaranteed Service Bundles Over Fiber-Wireless (FiWi) Broadband Access Networks. J. Light. Technol. 2011, 29, 1500–1513. [Google Scholar] [CrossRef]
- Kokkonis, G.; Psannis, K.; Roumeliotis, M. Network Adaptive Flow Control Algorithm for Haptic Data Over the Internet–NAFCAH; Springer: Berlin/Heidelberg, Germany, 2015; Volume 388. [Google Scholar]
- Chen, X.; Leung, K.C.; Lam, A.Y.S. Leaky bucket-inspired power output smoothing with load-adaptive algorithm. In Proceedings of the 2017 IEEE International Conference on Communications (ICC), Paris, France, 21–25 May 2017; pp. 1–6. [Google Scholar]
- Chang, Y.; Liu, Q.; Jia, X. A Data Rate and Concurrency Balanced Approach for Broadcast in Wireless Mesh Networks. IEEE Trans. Wirel. Commun. 2014, 13, 3556–3566. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, F.; Yang, Z.; Chen, C.; Tian, X.; Guan, X. Routing and scheduling co-design for holistic software-defined deterministic network. Fundam. Res. 2024, 4, 25–34. [Google Scholar] [CrossRef]
- Liu, X.; Xu, C.; Zeng, P.; Yu, H. A deep reinforcement learning algorithm for heterogeneous industrial tasks with high concurrent computing offloading. J. Comput. Sci. China 2021, 44, 2367–2381. [Google Scholar] [CrossRef]
- Shenker, S.; Partridge, C.; Guérin, R. Specification of Guaranteed Quality of Service. RFC 1997, 2212, 1–20. [Google Scholar]
- Gao, F.; Lu, W.; Gan, L.; Xu, C. A ConvNets-based approach for capturing the heterogeneity of spatial domain in parallel geoprocessing. Int. J. Digit. Earth 2024, 17, 2398066. [Google Scholar] [CrossRef]
- Lamti, L.; Afifi, H. The fair shaper: An efficient mechanism for Internet bandwidth share over ATM in a multitasks OS. In Proceedings of the 1998 IEEE ATM Workshop Proceedings. ‘Meeting the Challenges of Deploying the Global Broadband Network Infrastructure’ (Cat. No.98EX164), Fairfax, VA, USA, 26–29 May 1998; pp. 56–64. [Google Scholar]
- Koutsakis, P. Dynamic versus Static Traffic Policing: A New Approach for Videoconference Traffic over Wireless Cellular Networks. IEEE Trans. Mob. Comput. 2009, 8, 1153–1166. [Google Scholar] [CrossRef]
- Cavalca, U.; Mesquita, C.M.; Pereira, A.M.; Carrano, E.G. A computational intelligence based approach for computer network traffic shaping. In Proceedings of the 2013 IEEE Congress on Evolutionary Computation, Cancun, Mexico, 20–23 June 2013; pp. 2680–2686. [Google Scholar]
- Kale, M.R.; Labhane, S.; Manu, S.E.; Mehta, P.; Amudha, A.; Gupta, A. Scalable and Efficient Real-Time Data Processing in Cloud-Based Manufacturing Systems. In Proceedings of the 2024 15th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kamand, India, 24–28 June 2024; pp. 1–5. [Google Scholar]
- Sedighi, H.; Gehberger, D.; Ebrahimzadeh, A.; Wuhib, F.; Glitho, R.H. Efficient Dynamic Resource Management for Spatial Multitasking GPUs. IEEE Trans. Cloud Comput. 2024, 13, 99–117. [Google Scholar] [CrossRef]
- Turner, J. New directions in communications (or which way to the information age?). IEEE Commun. Mag. 1986, 24, 8–15. [Google Scholar] [CrossRef]
- Shenker, S.; Wroclawski, J. General Characterization Parameters for Integrated Service Network Elements. RFC 1997, 2215, 1–16. [Google Scholar]
- Rabie, S. A Differentiated Service Two-Rate, Three-Color Marker with Efficient Handling of in-Profile Traffic. 2005. Available online: https://www.rfc-editor.org/rfc/rfc4115 (accessed on 1 July 2005).
- Lee, C.H.; Kim, Y.T. QoS-aware hierarchical token bucket (QHTB) queuing disciplines for QoS-guaranteed Diffserv provisioning with optimized bandwidth utilization and priority-based preemption. In Proceedings of the International Conference on Information Networking 2013 (ICOIN), Bangkok, Thailand, 28–30 January 2013; pp. 351–358. [Google Scholar]
- Jiang, L.; Lu, K.; Huang, H.; Chen, Y. BCube-based Data Center Network Simulation Using NS3. J. Softw. Guide China 2020, 19, 190–194. [Google Scholar]
- Yuan, Y.; Liu, Z.Y.; Xiang, H.K.; Ding, Z.F. Traffic Survey System Based on GPS, GPRS and GIS. Adv. Mater. Res. 2011, 328–330, 989–997. [Google Scholar] [CrossRef]
- Ali, A.; Hutchison, D.; Angelov, P.; Smith, P. Towards an autonomous resilience strategy the implementation of a self evolving rate limiter. In Proceedings of the 2013 13th UK Workshop on Computational Intelligence (UKCI), Guildford, UK, 9–11 September 2013; pp. 299–304. [Google Scholar]
- Peng, Y.; Liu, Q.; Varman, P. Scalable QoS for Distributed Storage Clusters using Dynamic Token Allocation. In Proceedings of the 2019 35th Symposium on Mass Storage Systems and Technologies (MSST), Santa Clara, CA, USA, 20–24 May 2019; pp. 14–27. [Google Scholar]
- Zhao, W.; Stankovic, J.A. Performance analysis of FCFS and improved FCFS scheduling algorithms for dynamic real-time computer systems. In Proceedings of the 1989 Real-Time Systems Symposium, Santa Monica, CA, USA, 5–7 December 1989; pp. 156–165. [Google Scholar]
- Ardhana, V.Y.P.; Mulyodiputro, M.D. Analisis Quality of Service (QoS) Jaringan Internet Universitas Menggunakan Metode Hierarchical Token Bucket (HTB). J. Inform. Manag. Inf. Technol. 2023, 3, 70–76. [Google Scholar]
- Anitha, P.; Vimala, H.S.; Shreyas, J. PQTBA: Priority Queue based Token Bucket Algorithm for congestion control in IoT network. In Proceedings of the 2023 IEEE 8th International Conference for Convergence in Technology (I2CT), Lonavla, India, 7–9 April 2023; pp. 1–6. [Google Scholar]
- Mat Nawi, N.A.; Yusof, R. Simulation of Token Bucket Algorithm for Network Traffic Performance. J. Adv. Comput. Technol. Appl. 2020, 2, 21–28. [Google Scholar]
- Gao, H.; Qiu, B.; Wang, Y.; Yu, S.; Xu, Y.; Wang, X. TBDB: Token bucket-based dynamic batching for resource scheduling supporting neural network inference in intelligent consumer electronics. IEEE Trans. Consum. Electron. 2023, 70, 1134–1144. [Google Scholar] [CrossRef]
- AlQahtani, S.A. An efficient resource allocation to improve QoS of 5G slicing networks using general processor sharing-based scheduling algorithm. Int. J. Commun. Syst. 2019, 33, e4250. [Google Scholar] [CrossRef]
- Bonald, T.; Comte, C. Balanced fair resource sharing in computer clusters. Perform. Eval. 2017, 116, 70–83. [Google Scholar] [CrossRef]
- Guan, Q.; Xu, X. Impact of Channel Memory on the Data Freshness. IEEE Commun. Lett. 2023, 27, 80–84. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Q.; Luo, Y.; Liu, X.; Liang, J. An adaptive task scheduling algorithm for 3-D target imaging in radar network. EURASIP J. Adv. Signal Process. 2022, 2022, 34. [Google Scholar] [CrossRef]
- Rong, J.; Liu, F.; Miao, Y.; Zhu, H.; Wu, C. Adaptive Task Scheduling Algorithm for Multifunction Integrated System with Joint Radar–Communications Waveform. Electronics 2023, 12, 1560. [Google Scholar] [CrossRef]
- Maqbool, A.; Usmani, Z.u.A.; Afzal, F.; Razia, A. Disaster Mitigation in Urban Pakistan Using Agent Based Modeling with GIS. ISPRS Int. J. Geo-Inf. 2020, 9, 203. [Google Scholar] [CrossRef]
- Abdelkader, Y.; Ibrahim, S. Measures of Performance in the M/M/1/N Queue via the Methods of Order Statistics. Life Sci. J. 2012, 9, 945–953. [Google Scholar]
- Fiorini, P.M. Analyzing the Busy Period of the M/M/1 Queue via Order Statistics and Record Values. In Proceedings of the 2021 11th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), Cracow, Poland, 22–25 September 2021; Volume 1, pp. 217–224. [Google Scholar]
- Vijay, R.; Sree, T.R. Resource Scheduling and Load Balancing Algorithms in Cloud Computing. Procedia Comput. Sci. 2023, 230, 326–336. [Google Scholar] [CrossRef]
- Daid, R.; Kumar, Y.; Hu, Y.-C.; Chen, W.-L. An effective scheduling in data centres for efficient CPU usage and service level agreement fulfilment using machine learning. Connect. Sci. 2021, 33, 954–974. [Google Scholar] [CrossRef]
- Yoon, K.; Jeong, E.; Kang, W.; Ha, S. Memory Usage Estimation for Dataflow-Model-Based Software Development Methodology. IEEE Des. Test 2024, 41, 60–69. [Google Scholar] [CrossRef]
- Ma, C.; Chi, Y. Evaluation Test and Improvement of Load Balancing Algorithms of Nginx. IEEE Access 2022, 10, 14311–14324. [Google Scholar] [CrossRef]
- Shahid, M.A.; Alam, M.M.; Su’ud, M.M. Performance Evaluation of Load-Balancing Algorithms with Different Service Broker Policies for Cloud Computing. Appl. Sci. 2023, 13, 1586. [Google Scholar] [CrossRef]
- Li, C.; Zheng, J.; Okamura, H.; Dohi, T. Performance Evaluation of a Cloud Datacenter Using CPU Utilization Data. Mathematics 2023, 11, 513. [Google Scholar] [CrossRef]
- Boryło, P.; Chołda, P.; Domżał, J.; Jaglarz, P.; Jurkiewicz, P.; Rzepka, M.; Rzym, G.; Wójcik, R. SDNRoute: Proactive routing optimization in Software Defined Networks. Comput. Commun. 2024, 225, 250–278. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Z.; Zhou, H.; Wang, Z.; Wu, P.; Ma, Z. An Adaptive Task Traffic Shaping Method for Highly Concurrent Geographic Information System Services with Limited Resources. Appl. Sci. 2025, 15, 4932. https://doi.org/10.3390/app15094932
Wu Z, Zhou H, Wang Z, Wu P, Ma Z. An Adaptive Task Traffic Shaping Method for Highly Concurrent Geographic Information System Services with Limited Resources. Applied Sciences. 2025; 15(9):4932. https://doi.org/10.3390/app15094932
Chicago/Turabian StyleWu, Zheng, Hongyun Zhou, Zezhao Wang, Pengda Wu, and Zhaoting Ma. 2025. "An Adaptive Task Traffic Shaping Method for Highly Concurrent Geographic Information System Services with Limited Resources" Applied Sciences 15, no. 9: 4932. https://doi.org/10.3390/app15094932
APA StyleWu, Z., Zhou, H., Wang, Z., Wu, P., & Ma, Z. (2025). An Adaptive Task Traffic Shaping Method for Highly Concurrent Geographic Information System Services with Limited Resources. Applied Sciences, 15(9), 4932. https://doi.org/10.3390/app15094932