1. Introduction
The revolutionary progress of artificial intelligence technology is driving the paradigm shift of the software engineering discipline from “labor-intensive” to “intelligence-driven”. Although the continuous evolution of agile development in the current software development model has broken through the linear constraints of the traditional waterfall model [
1], the modern software development process faces systemic challenges such as dynamic evolution of requirements, generalization of application scenarios, and isomerization of project roles, which promote the deep penetration of artificial intelligence technology into the whole process of the software development life cycle. At present, technology integration has gone beyond the tool-assisted stage and entered a new era of process reconstruction and paradigm innovation [
2,
3].
Traditional methods based on statistical machine learning and deep learning in the field of software engineering often focus on specific problems in a single software development link, resulting in insufficient generalization ability of the model and difficulty in adapting to the increasing demand for intelligence in the current field of software engineering. Taking the software requirements stage as an example, early studies use deep learning models for requirements classification and feature extraction, which cannot achieve higher-level intelligent processing such as intelligent extraction and summary of requirements elements, modeling of requirements dependencies, and conflict detection. Similarly, in the phase of software operation and maintenance, traditional quality assurance methods rely on manually designed test cases and scripted regression testing, which not only face the challenge of insufficient test coverage, but also suffer from high maintenance costs.
The emergence of large language models (LLM) provides a new technical paradigm for solving the above problems. With its powerful knowledge reasoning ability and context understanding ability, the LLM can be widely used in the whole life cycle of software engineering. Through the training and optimization of the model domain adaptation, the LLM can significantly improve the intelligence level of its domain, and then realize the intelligent analysis of requirements elements, and promote the software quality assurance into a new stage of cognitive intelligence, such as automatically generating test cases, identifying defect patterns of code, etc. This cognitive intelligence method based on LLM not only breaks through the limitations of traditional methods in generalization ability, but also brings a new intelligent solution to software engineering practice. However, there are still several key challenges in the existing technologies. Firstly, it is difficult to dynamically integrate various stages in the software engineering life cycle. Secondly, there is insufficient intelligent support for cross-stage collaborative development. Finally, there is still a cognitive limitation on the value mining of development behavior data, which fails to make full use of behavioral information at each stage of the software life cycle.
In order to solve the above problems, inspired by the MoE model, this paper proposes the HCDMB model. The input data of this model deeply integrates multi-dimensional behavioral information in the whole life cycle of software development. The MoE model is combined to dynamically select the different LLMs of experts, and then a dynamic adaptive intelligent collaboration system is constructed, and the output data are intelligent decision-making suggestions provided according to user behavior, which aims to build a new paradigm for the research of artificial intelligence technology, such as LLM in the field of software engineering.
Specifically, the core innovation of the proposed model is reflected in the following two dimensions:
Firstly, multi-dimensional behavioral information collection and processing: Through the collection of cross-modal software development process behaviors and the modeling of feature extraction, the fragmentation problem of traditional single-dimensional behavior analysis is effectively solved. Secondly, context-aware expert routing mechanism: A gated routing network is constructed based on a large language, and different expert cluster sub-models are selected and activated according to the users’ multi-dimensional behavioral information and user intentions. Secondly, reinforcement learning is combined to optimize the routing gate network model, and appropriate expert models are selected based on the users’ intentions and related behavioral information to achieve accurate matching between task context and expert capabilities.
The remainder of this paper is organized as follows:
Section 2 conducts a literature review on the application of artificial intelligence technology in the field of software engineering and the MoE method.
Section 3 presents the proposed HCDMB model, including the architecture design, multi-dimensional behavioral information processing, and the construction of the MoE model with a dynamic routing mechanism based on reinforcement learning from human feedback.
Section 4 details the results, covering the experimental configurations, system implementation, and performance evaluations against baseline approaches.
Section 5 discusses the limitations of the existing methods and proposes future optimization directions and application scenarios. Finally,
Section 6 summarizes this work, discusses the contributions and limitations of the study, and outlines potential future research directions.
2. Literature Review
At present, the research of artificial intelligence technology in the field of software engineering is making significant progress. This section systematically combs the application status of artificial intelligence technology in the field of software engineering, and further analyzes the challenges faced by the existing methods. In view of the above challenges, the advantages of the MoE model and its application in the engineering field are introduced and explored.
2.1. Research on Artificial Intelligence Technology in the Field of Software Engineering
AI-enabled software engineering (AISE) has entered the peak of practical application [
4]. The application of AI in software engineering is primarily reflected in three core dimensions: requirements engineering, development paradigms, and quality assurance systems. To be specific, it is manifested as follows:
(1) Semantic deconstruction in requirements engineering. Requirements engineering focuses on constructing functional and non-functional specifications for target systems [
5,
6]. Early research predominantly centered on model-based classification, for example, Abbas et al. [
7] conducted semantic classification of requirement texts based on the Bi-LSTM model, and Marcacini et al. [
8] utilized the pre-trained language BERT model [
9] to automatically extract requirement features from user comments. With the development of large language models (LLMs), exemplified by GPT [
10] and Qwen-VL [
11], the demand engineering approach enters a new paradigm: Automated extraction and formalization of requirement elements through semantic correlation analysis, context-aware dynamic generation of requirement documentation, and knowledge graph-enhanced dependency modeling and conflict detection [
12,
13,
14].
(2) Cognitive reconfiguration and knowledge transfer in development paradigms: The traditional development model uses a linear process to promote the progress of each development stage, which exposes defects such as response delay and experience dependence when facing complex system development [
15]. Prior improvements focused narrowly on automating isolated development tasks, Azeem et al. [
16] proposed the detection of code anomalies based on machine learning methods, and Sun et al. [
17] used Sentent-BERT’s recommended code API. The advent of LLMs has fundamentally redefined the technical ecosystem of intelligent development, demonstrating robust capabilities in code generation and autocompletion (e.g., GitHub Copilot [
18]), defect pattern recognition (e.g., DeepDebug [
19]), and semantic code comprehension [
20]. The use of LLMs effectively solves the fragmentation problem of the traditional tool chain, and realizes the systematic precipitation and reuse of development experience.
(3) Intelligent evolution of quality assurance systems. Conventional approaches, constrained by manually designed test cases and scripted regression testing, struggle with inadequate coverage and exponentially rising maintenance costs [
21,
22]. Current optimizations target isolated techniques, for example, Jones et al. [
23] applied a genetic algorithm to automatically generate test datasets, and Zhu et al. [
24] generated test cases based on diffusion model. LLMs propel quality assurance into a cognitive intelligence era: Wang et al. [
25] use LLMs to implement defect pattern detection and suggestions; reinforcement learning [
26] integrated frameworks optimize test data generation through code path coverage reward functions, simultaneously enhancing coverage [
27]. This intelligent evolution establishes a novel technical paradigm for quality assurance in continuous delivery scenarios.
The current software development landscape is plagued by fragmented technology integration and isolated toolchains, impeding the transformation of localized task optimization into overall efficiency gains. AI–human interaction remains fragmented both vertically and horizontally, with a lack of dynamic coupling across roles and a deficiency in mutual interpretability and trust between human expertise and AI logic. Additionally, behavioral data from development processes are siloed and underutilized, lacking cross-project knowledge fusion and robust decision support, especially in large-scale distributed systems.
2.2. Application of Mixture of Experts
In response to the above-mentioned systematic contradictions, Jacobs et al. [
28] proposed the MoE model, providing an innovative solution for constructing an intelligent software engineering system. Its core mechanism consists of two key components: the expert routing decision layer based on the gating network and the expert sub-model cluster oriented to domain features. The sparsely gated MoE architecture proposed by Google [
29], which employs a sparse activation mechanism, lays the foundation for large-scale engineering applications.
The MoE method has high computational efficiency and scalability. MoE enables dynamic resource allocation via conditional computation, achieving exponential parameter scaling (e.g., trillion-parameter models like Switch Transformer [
30]). Furthermore, MoE has the capabilities of domain adaptation and task decoupling. It uses multidimensional features to compute expert weights and map tasks to experts. In software engineering, this allows the creation of diverse expert clusters: language-specific compilers, phase-aware controllers for workflows (requirements analysis, code generation, test verification), and cross-role behavior modelers (developer intent recognition, tester pattern mining, requirement tracing). Zhou et al. [
31] proposed that the dynamic routing mechanism could solve the capacity bottleneck of the traditional single model architecture in complex task scenarios.
At the level of engineering practice, MoE technology has shown significant application value. For example, Deepseek-v3 [
32], GPT-4 [
33] and other large models have adopted MoE architecture. This approach can be applied throughout the software development lifecycle: activating requirements experts for specifications in the analysis phase, domain-specific models (e.g., SQL optimization or concurrent programming experts) in the development phase, and quality assurance experts in testing. This dynamic scheduling breaks traditional tool-chain constraints and creates a knowledge enhancement loop through continuous expert experience accumulation.
3. Materials and Methods
This section elaborates the research model of HCDMB. Firstly, the three-level hierarchical architecture design of the system is introduced, including the input layer, the mixed expert (MoE) core layer and the output layer. Secondly, the collection and processing methods of multi-dimensional behavioral information are described in detail, including the development behavior track, collaborative interaction record, feature extraction and semantic embedding of product application data. Then, a dynamic routing mechanism based on the MoE model is proposed to optimize the routing gate network through RLHF, so as to achieve accurate matching between task context and expert capability. In addition, an expert model optimization method based on RAG and few-shot context learning is introduced, which significantly improves the reasoning efficiency and knowledge transfer ability of the system in complex scenarios. Finally, the context-aware reasoning support for the expert model is provided by constructing the project knowledge base and the multi-way recall strategy. As an outcome of the research, we wish to offer a new model and describe that we have developed under the term hybrid collaborative development model based on multi-dimensional behavioral information (HCDMB).
3.1. Design of Research Method’s Framework
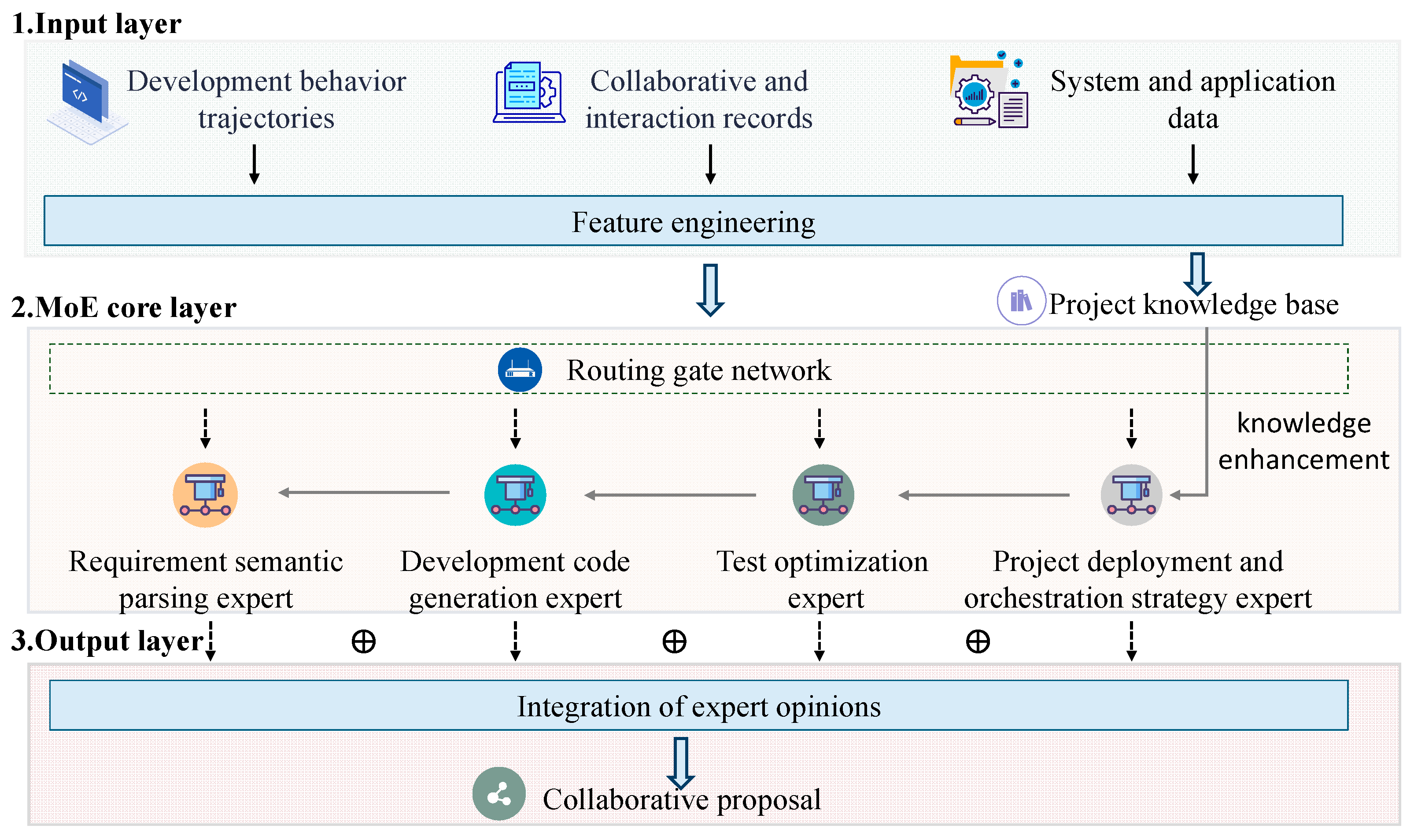
The HCDMB model adopts a hierarchical and progressive three-level architecture design, which is composed of an input layer, MoE core layer and output layer (as shown in
Figure 1).
The input layer mainly realizes the dual functions of multi-dimensional software development behavior data processing and user intention recognition. By integrating multi-source heterogeneous data acquisition pipelines, the behavior data in the whole life cycle of software development are feature extraction and engineering processing. Specifically, the data sources include development behavior trajectories, collaborative and interaction records, system and application data. The feature engineering methods adopted are as follows: for unstructured text data (such as requirements documents, code development, etc.), the embedding models based on BAAI General Embedding (BGE) [
34] and CodeBERT [
35] are used to encode semantic vectors to build project knowledge bases. For temporal behavior characteristics (such as code submission frequency, test coverage, etc.), key information is extracted and summarized as descriptive text as supplementary knowledge. The input layer is the input data of the model by associating the user’s intention with its multi-dimensional behavioral information.
The core layer of the MoE constructs an expert collaborative decision-making system, which includes an expert model group and a routing gate network. The expert model group constructed by this method is configured with four domain specialization modules: requirements semantic parsing expert based on Deepseek v3, development code generation expert based on CodeGeeX4 [
36], test optimization expert based on CodeGeeX4, and project deployment and orchestration strategy expert based on Deepseek v3. In the inference stage, each expert model accesses the project knowledge base through the retrieval augmented generation (RAG) method [
37], and retrieves the knowledge information related to users’ behavior data and intentions in the knowledge base as the context information input to each expert model to enhance and constrain the answers of the model. The routing gate network uses the Deepseek model as the base model, and uses the dynamic routing algorithm to realize the task decomposition and selection of expert models based on user intention and related behavioral information. For example, when high-frequency code commits are identified to be associated with test failures, the gated network will improve the decision weights of the test optimization experts, project deployment and orchestration experts, and trigger the collaborative response of automated test-case generation and team communication suggestions. At the same time, reinforcement learning from human feedback (RLHF) [
38] is used to fine-tune the routing gate network and improve its effectiveness.
The output layer fuses the expert opinions of the MoE core layer by constructing an analysis model and generates operational schemes, such as developing process optimization suggestions. The dynamic resource allocation scheme includes the strategic scheduling of computing resources (GPU instance allocation) and human resources (developer task-load balancing), as well as intelligent auxiliary output, covering code autocompletion, fault location and requirements tracking functions.
3.2. Implementation of Key Technologies
This section mainly discusses the key technologies in the model architecture shown in
Figure 1, and introduces the data sources of the input layer and the corresponding feature engineering methods. Furthermore, based on the data processed by feature engineering, the project knowledge base and hybrid retrieval method are further constructed to improve the answering ability of the expert model. In addition, for the MoE core layer, this section further introduces the optimization of the routing gate network model by constructing a fine-tuning dataset and the DPO-based method, and the optimization of the expert model by using the few-shot context learning method and the constructed item knowledge base.
3.2.1. Input Layer
The input layer constructs the collection and processing method of multi-dimensional behavioral information data, and realizes the feature extraction and intention association analysis of behavior data in the whole software development life cycle. The data acquisition module covers three types of core data sources: development behavior track, such as Git logs, development process code, etc.; collaborative interaction records, such as requirements documents, interface documentation, etc.; systems and applications data, such as code, system test records, etc. By associating the behavioral development information of different personnel, it provides data support for subsequent personalized services.
In the feature engineering processing part, the feature processing pipeline is constructed according to different types of data. For unstructured text data (submission comments, requirements documents, etc.), after extracting the text content, the key information in the text content is extracted with the help of a large language model through regular expressions; the BGE model is used to obtain the vectorized embedding representation of the text. In addition, the structured coding information, such as development code and test cases, is encoded by vector embedding through CodeBERT. Finally, based on the knowledge base constructed by the above information, the correlation retrieval of multi-dimensional behavioral information is carried out by combining user intention, and the more important input information is selected to participate in the subsequent process, so as to reduce the interference of redundant information in the expert model.
3.2.2. Construction of the Project Knowledge Base
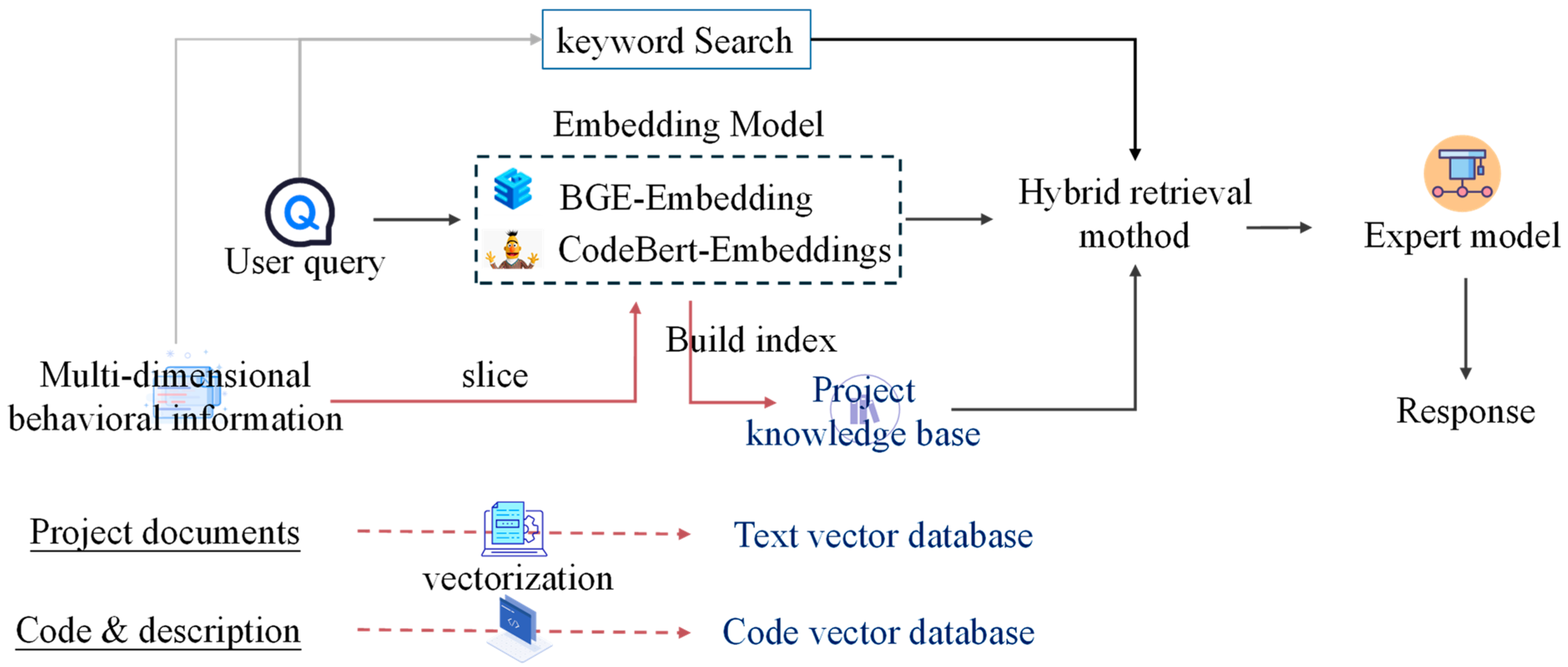
In order to support the context-aware reasoning of the expert model and the hallucination of answer results, we built a knowledge base based on the collected data. The construction process is shown in
Figure 2, where the input data of the knowledge base comes from multi-dimensional behavioral information, such as project documents, codes and related description information. After slicing the input data, the segmented data are vectorized through different embedding models, and then the project knowledge base is built by constructing an index mechanism. When the user query is received, the hybrid retrieval method is used to calculate the similarity between the vectors obtained after the user query input into the embedding model and the vectors in the project knowledge base, and the retrieval results based on keyword search are input into the expert model as candidate results as information supplements to support the expert model to generate more accurate responses.
Specifically, based on the BGE embedding model, the knowledge document is sliced into blocks and vectorized, and stored in the text vector database. At the same time, the function description of the developed code is extracted and the code’s semantic knowledge base is constructed. The embedded representation of the code slice is generated based on CodeBERT and stored in the code vector database. In the retrieval stage, a hybrid retrieval approach is constructed [
39]. By designing a multi-way recall strategy, that is, semantic retrieval by calculating the cosine similarity between the user query (user intention) and the text or code vector (Equation (1)). Given the query vector
, the semantic similarity with the vector
in the knowledge base is calculated to support the demand for deep semantic retrieval. And keyword retrieval is based on the BM25 algorithm [
40] to support the retrieval needs of ambiguous query semantics (Equation (2)). These two kinds of methods can complement each other’s shortcomings, and then return the retrieved candidate information based on the retrieval fusion module (Equation (4)), where the semantic retrieval threshold is set to 0.75, according to practical application experience and the actual use effect to balance the recall rate and accuracy. Finally, the retrieved information participates in the reasoning of the expert model to obtain together the corresponding model.
where
is the query input;
is the relevance score between the current query
and the knowledge document
.
is the ith word in
, and
is the frequency of
in
.
is its corresponding length;
is the average length of different documents.
and
are adjustable parameters and are usually set to 1.2 and 0.75, respectively, referring to the default parameters of related research [
41] and ElasticSearch implementation.
is the inverse document frequency corresponding to
(Equation (3)).
where
is the number of documents;
is the number of documents containing
.
3.2.3. MoE Routing Gate Networks Optimization
Aiming at the problem of static preference deviation in traditional MoE routing gate networks, this paper proposes a dynamic routing mechanism driven by RLHF. The input datum of this method is Query, and the output data are the expert model of route selection and the description template of Task. According to the above information, the Task information is parsed and passed to the corresponding expert model. In order to construct a route selection model in line with human preferences, this method collects several responses generated by the routing gate network model and constructs , where is the preferred response output selected by the user, and is the non-preferred response selected by the user. The MoE routing gate network is optimized by manually constructing training labels to improve the effectiveness of its expert selection.
Specifically, according to the answers generated by different expert models in different scenarios, by sampling multiple model output descriptions, the relevant professionals are coordinated to select the output path of the model. For example, for the requirements analysis expert model, the requirements analysts prefer to select the task description generated by the routing gate network. And the output of other non-preferred models is used as the reject part of the expert model fine-tuning the dataset construction. Finally, a total of 2000 data samples are constructed to fine-tune the model in each scenario.
For the fine-tuning process of the routing gate network model, specifically, considering the computing resources of the system, direct preference optimization (DPO) [
42] and QLoRa [
43] algorithms are used to realize the pre-training of this model. The dataset is from multiple responses generated by the routing gate network model, and the generated responses are evaluated by manual labeling. Please refer to
Appendix A for details of prompt templates and data samples. Its training process is shown in
Figure 3, specifically as follows:
(1) Define the policy model and the reference model. The core goal of the policy model is to directly adjust the model parameters by comparing the preference feedback of different policy outputs (such as positive and negative samples selected by users), so that the generated results are more in line with human expectations. The reference model is the given pre-trained model, which is used to provide stability guarantees during the optimization process. The core goal is to constrain the update direction of the policy model to avoid deviating too far from the original distribution and prevent overfitting or performance degradation.
(2) For a given prompt, compute the probabilities of the two routing gate network models for positive and negative samples, where the positive sample is the human-selected response and the negative sample is the rejected response.
(3) Referring to the DPO loss function (Equation (5)) proposed by Rafailov et al. [
42], by calculating the difference in the probability of generating content between the policy model and the reference model, the policy model is penalized for the decrease in the probability of positive samples and the increase in the probability of negative samples, and the model is trained by minimizing the DPO loss.
where
is the sigmoid function;
is the
;
is user-selected response preference data;
is the user’s choice of poor response data;
is the policy model;
is the reference model;
represents the cumulative probability of the current policy model generating a good response given the input
;
represents the cumulative probability of the current reference model generating a good response given the input
.
For the update strategy of model parameters, in Equation (6) is the implicit reward function of the DPO method. Intuitively, the gradient optimization of the loss function increases the possibility of the pre-trained model responding to preference , and reduces the possibility of non-preference . Further, by combining QLoRa and DPO, the performance of the routing gate network model is optimized through parametric efficient fine-tuning. QLoRa algorithm is used to compress the structured parameters of the routing gate network model, and the original high-dimensional parameter space is projected to the low-rank subspace through low-rank matrix decomposition. This algorithm converts the full-parameter fine-tuning task into learnable low-rank adapter optimization, significantly reducing the scale of tunable parameters while maintaining the model’s representational power.
The directional fine-tuning of routing a gated network is implemented by combining the DPO algorithm. Compared with the traditional RLHF paradigm, DPO restructures the preference learning problem into a classification task and directly optimizes the policy network parameters based on paired preference data, effectively avoiding the computational bottleneck in the training stage of the reward model. This end-to-end optimization approach not only reduces the video memory footprint, but also improves the stability of policy updates through the implicit reward modeling mechanism.
3.2.4. Expert Models with Few-Shot Contextual Learning
In the construction process of the expert model group, considering the limited computing resources on the server side, the background knowledge of the model is enhanced by carrying out upsampling context learning for each expert model. At the same time, the chain of thought (CoT) [
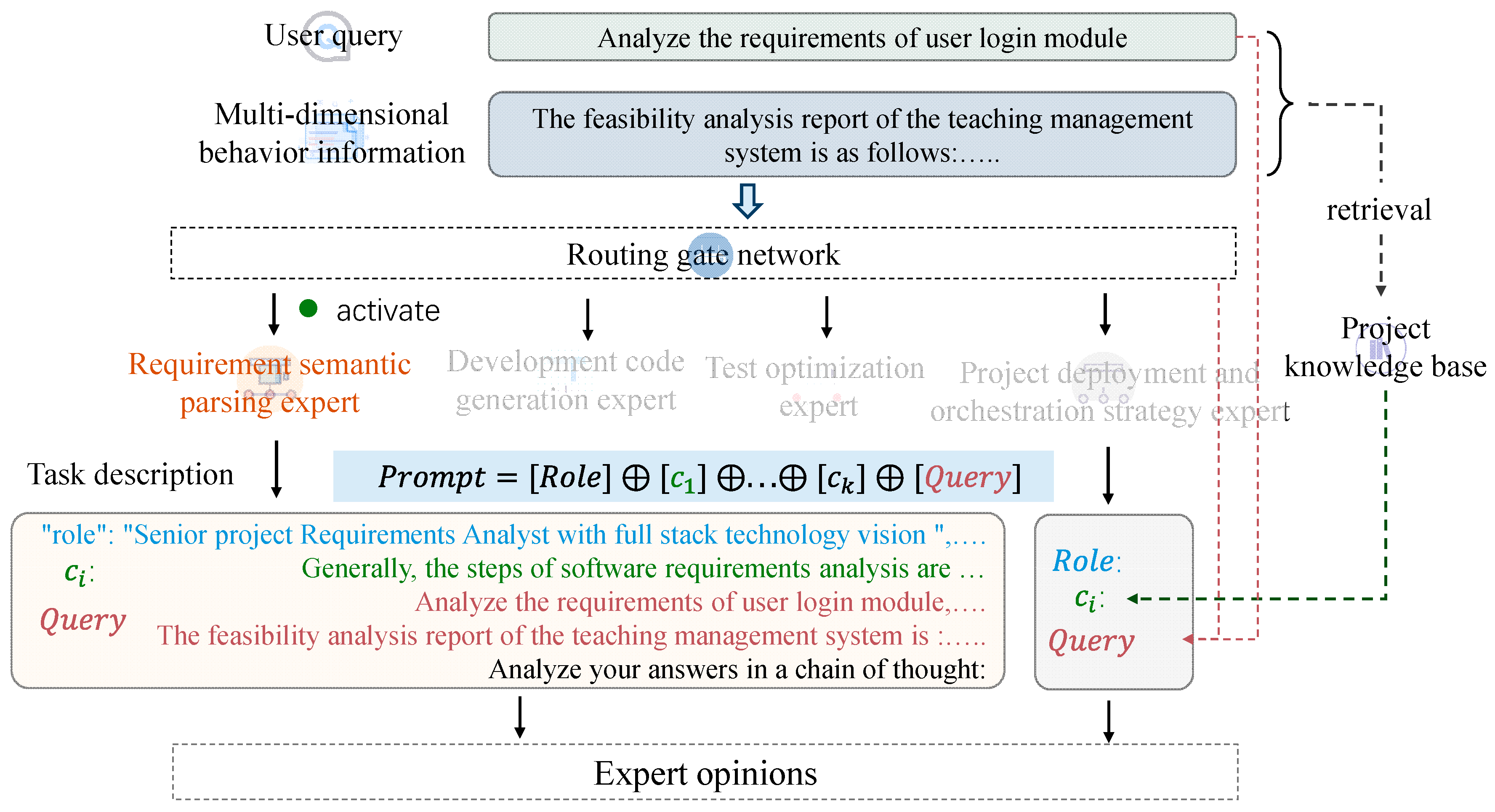
44] is used to guide the model to reason, so as to further achieve the balance between computational efficiency and reasoning quality. As shown in
Figure 4, in the model inference phase, the problem-solving process is decomposed into an interpretable chain process of knowledge retrieval → logical derivation → decision generation. Specifically, when given a sequence of correlated behaviors
, the routing gate network first activates the relevant expert model, and triggers the following process in the expert model by generating the task description and transmitting the corresponding user intention:
Firstly, the problem is decomposed, different expert models are triggered according to the input data, and the task description of the response is generated. For example, the requirements analysis task could be described as: original requirements analysis → business rule mapping → architecture impact assessment → use case modeling. Secondly, by retrieving Top-K relevant knowledge
to extract the logical reasoning path in the solution for knowledge injection. After retrieving the relevant outcomes from the knowledge base, it is further injected into the lifting template, and few-shot context learning [
45] is used for the LLM to achieve efficient model optimization without parameter training. Specifically, by constructing a structured prompt template (Equation (7)), including task description, retrieved relevant knowledge, user intention, etc., the task instructions are constructed through the above templates, and the displayed requirements of the expert model are divided into logical reasoning and answering. See
Appendix A.2 for detailed prompt template settings.
Few-shot context learning is used to guide the optimization of the expert model, which has the following advantages: first, it can optimize the output of the model without parameter update. Compared with the traditional fine-tuning that needs to update millions of parameters, context learning only needs to adjust the example selection strategy in the prompt template, which greatly reduces the consumption of computing resources. Secondly, it can integrate dynamic knowledge, inject domain knowledge through a real-time retrieval mechanism, avoid solidifying vertical domain data to model parameters, and greatly improve the effectiveness of a single expert model. Finally, it has strong interpretability, and the visual reasoning path and retrieval basis of the thinking chain form a double explanation mechanism.
4. Results
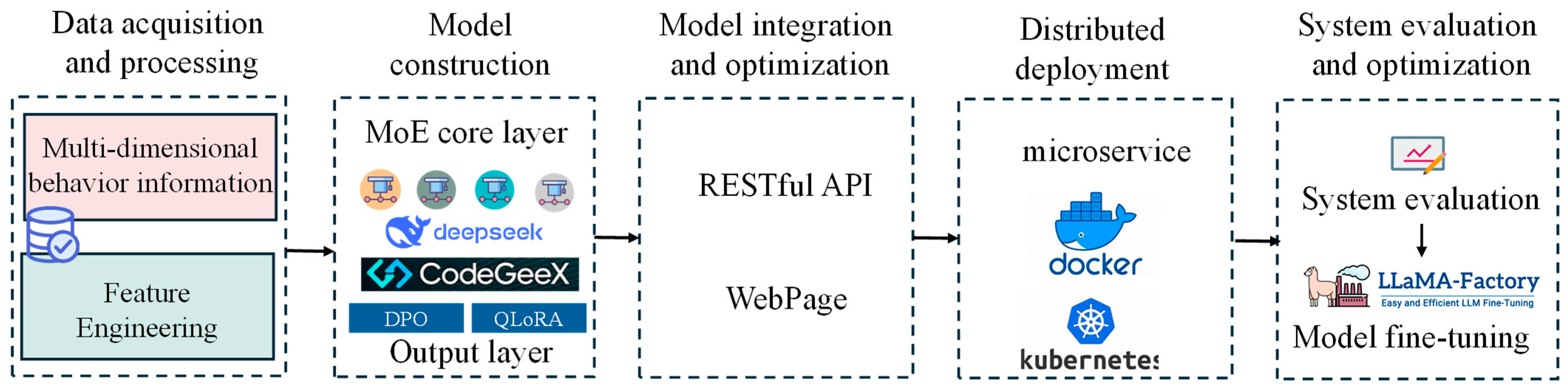
The HCDMB model proposed in this study covers a complete, closed-loop system of data acquisition and processing, model construction, model integration and optimization, distributed deployment, system evaluation and optimization, and carries out technical verification in the form of system services. Refer to
Appendix B for related model versions and system hardware descriptions. Based on the related methods mentioned above, by encapsulating the methods to provide services for project personnel, this chapter will discuss the implementation details in the actual system construction. As shown in
Figure 5, the following will describe the services of each stage of the system.
(1) Data acquisition and processing
At the level of data collection and processing, the system realizes the structural integration of behavioral information through the multi-dimensional data processing engine. For the developer behavior data, the semantic correlation mapping between user ID and operation log is established, and the multi-dimensional user portrait supporting personalized service is constructed by establishing the differentiated behavior characteristics of different functional roles. In the aspect of project document processing, the deep learning-based OCR framework (PaddleOCR) [
46] was used to realize the semantic parsing of PDF documents, and the standardized document storage format (JSON/Markdown) was formed by combining the layout reconstruction algorithm and the regularization text cleaning mechanism. For unstructured behavioral information, based on the results of feature extraction, the summary generation service of the large model is used to extract and summarize the key information, which effectively reduces the redundancy of knowledge. The construction flow for feature engineering is described in
Section 2.
(2) Model construction
In terms of model construction, the system constructed an MoE system based on domain adaptation and on two kinds of large models, CodeGeex and Deepseek, deployed in the cloud. CodeGeex provided code-related services as the base model of code generation and the test-case generation expert model. Due to its excellent reasoning ability, Deepseek can be used as the base model of the expert model for requirements analysis, project scheduling strategy generation, and the opinion summary of each model. In order to support the context-aware reasoning and role differentiation of the expert model, a few-shot context learning paradigm is designed to retrieve and enhance the chain of thinking, and a cross-project knowledge base system is constructed. The knowledge information comes from the relevant milestone document development information and the project development code in the software development process, and guidance services are provided for the model based on this prior knowledge. The above models are deployed in different servers and provide corresponding services for the system through API requests. In addition, for the MoE gating model, a dynamic routing mechanism driven by RLHF was proposed by using the model with the strong reasoning ability of Deepseek. By collecting a number of responses generated by dynamic routes, we will construct the following data: {‘ prompt ‘:‘ ‘, ‘chosen’: ‘ ‘, ‘reject’: ‘ ‘}, where prompt is the user’s intention and related behavioral information, chosen generates a response for the model that the user prefers, and reject is the model response that the user does not prefer. DPO and QLoRa algorithms are used to implement the supervised fine-tuning of the routing gate LLM. To support its selection of expert models that conform to human intuition and provide contextual information, this model is deployed as an independent service.
(3) Model integration and optimization
In the process of model integration and optimization, a two-way interactive interface is designed to meet the needs of human–machine collaboration. A RESTful API interface based on the Flask framework supports the integration of automated workflows. The second is to provide services for users through visual interface, which is developed based on the framework of Open WebUI (Ollama WebUI). Specifically, the process of system integration is as follows: Firstly, the user calls the interactive interface, and the system obtains the relevant behavior trajectory from the database through the user ID, and retrieves the relevant information through the vector representation through the data processing method. Based on the user’s intention and its recent behavior trajectory, the decision service of the MoE layer is called, and then a number of appropriate expert models are selected based on the relevant context information and decision suggestions are generated. At the same time, the decision path is visualized to provide users with the interpretability of human–machine collaboration. Users are encouraged to rate the current decision opinions to support the subsequent continuous optimization of the system.
(4) Distributed deployment
In terms of distributed deployment, the system adopts cloud-native architecture to realize elastic resource scheduling, and each expert model is encapsulated as a docker microservice and managed by a Kubernetes container orchestration platform. The dynamic scaling algorithm encapsulates each expert model as an independent microservice according to the real-time load, and its replica number is dynamically adjusted according to the real-time load: when the gating network detects the peak code generation request, the code generation expert instance is automatically expanded. The expert model and the routing gate network model were deployed independently to provide portable services for the optimization and replacement of subsequent models.
(5) System evaluation and optimization
In order to verify the performance of the subsequent system in use, a multi-dimensional evaluation system is established, and the evaluation system of the party is constructed from multiple angles such as data and roles, which will be further incorporated into the evaluation system of the system and optimized for targeted methods. As shown in
Table 1, it is evaluated by calculating the selection accuracy of the routing gate network model, the variance analysis of model inference, the user adoption rate and the system response delay, at the same time, the Lamma Factory framework will be used to supervise fine-tuning of each expert model based on the collected data and evaluation indicators in the future.
5. Discussion
The HCDMB model proposed in this paper aims to build a dynamic adaptive intelligent cooperative system by deeply integrating multi-dimensional behavioral information in the software development lifecycle. The core innovation of this framework method is embodied in three technical dimensions: multi-dimensional behavioral information fusion, dynamic expert routing mechanism, and continuously evolving learning system. By designing a cross-modal software development behavior feature encoder, modeling and representation of development behavior, management behavior and quality assurance behavior are realized. At the same time, a gated decision network is innovatively constructed, and intelligent model selection is implemented in the expert cluster according to relevant information in the project process, so as to achieve accurate matching between task context and expert ability. In addition, a reinforcement learning method based on human feedback is used to optimize the context-aware routing mechanism.
However, due to the small number of samples of manually annotated datasets in the development process, this study only fine-tuned the gated network model of the core layer of MoE, instead of optimizing each expert model, and only guided the output of the model by means of context learning with a few samples. However, in the face of complex tasks in some specific fields, the generalization ability and adaptability of the model still need to be improved. Therefore, relevant project data will be further collected in the future to further explore more efficient fine-tuning strategies, such as introducing more prior knowledge or adopting more refined parameter adjustment methods, in order to improve the performance of the model in different fields.
Specifically, efficient fine-tuning strategies with partial parameters are used to solve domain adaptability problems. Selecting an expert model that is pre-trained on a general software engineering dataset (such as the GitHub open source project), and then fine-tune the parameters of the vertical domain data efficiently through transfer learning, using LoRA technology to achieve rapid adaptation of private data from different enterprises. This strategy can effectively reduce the computational resources required to fine-tune the new domain while maintaining the generalization ability of the model.
Moreover, the method proposed in this paper only constructs four expert models, which has obvious limitations for the coverage of complex tasks. In order to meet the needs of multi-dimensional collaboration in complex projects, a hierarchical expert cluster architecture is proposed: the existing core expert model is retained in the base layer; adding experts in other vertical fields such as architecture design, performance optimization, and security audit at the extension layer; the expert registration mechanism based on docker container is established in the dynamic extension layer, allowing third-party models to access the system through standardized interfaces.
Finally, the method in this paper has made a certain exploration of human–machine collaboration and interpretability, but in order to better promote the collaboration between human developers and AI systems, further research can be carried out to enhance the interpretability and interactivity of the system in the future. For example, by developing a more intuitive visual interface that allows developers to more clearly understand the decision-making process and basis of the model, or designing a more natural language interaction that allows developers to more easily communicate and collaborate with the system.
Facing the future, the model (HCDMB) proposed, based on this paper, has a wide range of application scenarios. In the application scenario dimension, it could extend to emerging fields such as intelligent operation and maintenance, and build an intelligent ecosystem covering the whole life cycle of software. The direction of model optimization, exploring the dynamic construction mechanism of expert cluster based on neural architecture search, will further improve the adaptive ability of the system. At the same time, the establishment of a multi-dimensional behavioral data federation learning system in the development process will provide new ideas for cross-organization knowledge sharing and privacy protection.
This research is not only a technical breakthrough attempt in the field of software engineering, but also an important exploration of the evolution of human–machine collaborative paradigm. At present, artificial intelligence technology has profoundly changed the form of software development; how to build an intelligent collaborative system with both efficiency and flexibility, and how to realize the complementary advantages of human creativity and machine computing power are still scientific propositions that need to be continuously tackled. The HCDMB model provides a feasible way to solve these problems, and its subsequent development will promote the software engineering discipline to a higher level of intelligence, and lay a solid foundation for building a software ecosystem of independent evolution.
6. Conclusions
The deep integration of artificial intelligence technology and software engineering is reshaping the paradigm system of modern software development. In this paper, a hybrid collaborative development model based on multi-dimensional behavioral information is proposed to solve the problems of the traditional development model, such as the low efficiency of cross-stage collaboration, fragmentation of the intelligent tool chain and imperfect man–machine collaboration mechanisms. This model realizes the organic integration of human intelligence and machine intelligence in the whole life cycle of software development by building a dynamic and adaptive intelligent cooperation system, and provides an innovative solution to the modern software engineering challenges with dynamic demands and diversified scenarios.
The core contribution of this study is to construct an innovative framework of multi-dimensional behavioral feature fusion and dynamic expert collaboration. By integrating multi-dimensional characteristics of development behavior trajectories, collaborative interaction records, and product application data, it breaks through the limitations of traditional single-dimensional analysis. At the level of architecture design, the proposed three-level hierarchical model realizes the closed-loop optimization from data acquisition to decision execution, in which the dynamic routing mechanism, which is based on reinforcement learning and human feedback, effectively balances the domain specialization and task adaptability of the expert model. In addition, retrieval enhances the progressive learning system with the decoupling of thought chain and parameters, which significantly improves the reasoning efficiency and knowledge transfer ability of the system in complex scenarios.
From the perspective of technology evolution, this study provides important methodological enlightenment for the intelligent transformation of software engineering. Firstly, the introduction of the MoE model breaks through the rigid constraints of traditional tool chain, and realizes the flexible reconfiguration of the development process through a dynamic scheduling mechanism. Secondly, the in-depth mining of multi-dimensional behavior characteristics reveals the inherent law of the development process, which lays a theoretical foundation for the construction of a data-driven decision support system. Finally, the bidirectional explanation mechanism of human–machine collaboration effectively bridges the logical gap between domain knowledge and AI decision-making, and provides a technical path for building a trusted intelligent auxiliary system. These innovations mark an important shift in the software engineering collaborative paradigm from experience-driven to data-driven, and from manual coordination to autonomous evolution.
However, due to the realistic conditions, there are still some directions that need to be further explored. At the data level, due to the limitations of sample size and domain coverage, the generalization ability of the current system in specific vertical fields still needs to be improved. In terms of model architecture, the balance between scalability and the task-decoupling efficiency of expert clusters has not been established. In engineering practice, the contradiction between calculation cost and the real-time requirement of dynamic routing mechanisms still needs to be further optimized by hardware acceleration schemes.
In the future, we will further optimize the above directions based on user experience. Specifically, we will carry out targeted optimizations in combination with the evaluation indicators in
Table 1 (such as increasing user adoption rate and system response latency, etc.). In addition, a dataset will be further constructed based on the collected user behavioral information to optimize and fine-tune the expert model, enabling it to incorporate more knowledge in the field of software engineering. At the same time, expert models in other stages of the software development process, such as feasibility analysis experts and outline design experts, will also be added, and more intelligent solutions will be designed for the collaborative interaction of each expert model.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}