

Generative Adversarial Network-Based Lightweight High-Dynamic-Range Image Reconstruction Model




Abstract
1. Introduction
- Optimization of the HDR-GAN architecture using depthwise separable convolution, significantly reducing computational cost while maintaining high-quality HDR reconstruction.
- Thorough quantitative and qualitative evaluation of the proposed model, demonstrating the efficiency and effectiveness of the optimization on multiple datasets.
- Extensive comparative experiments with other methods, showing the ability of the proposed model to handle motion and alignment challenges in multi-exposure HDR reconstruction, while achieving a balance between performance and computational efficiency.
2. Related Work
2.1. Traditional Methods
2.2. Deep Learning Methods
3. Methods
3.1. Depthwise Separable Convolution
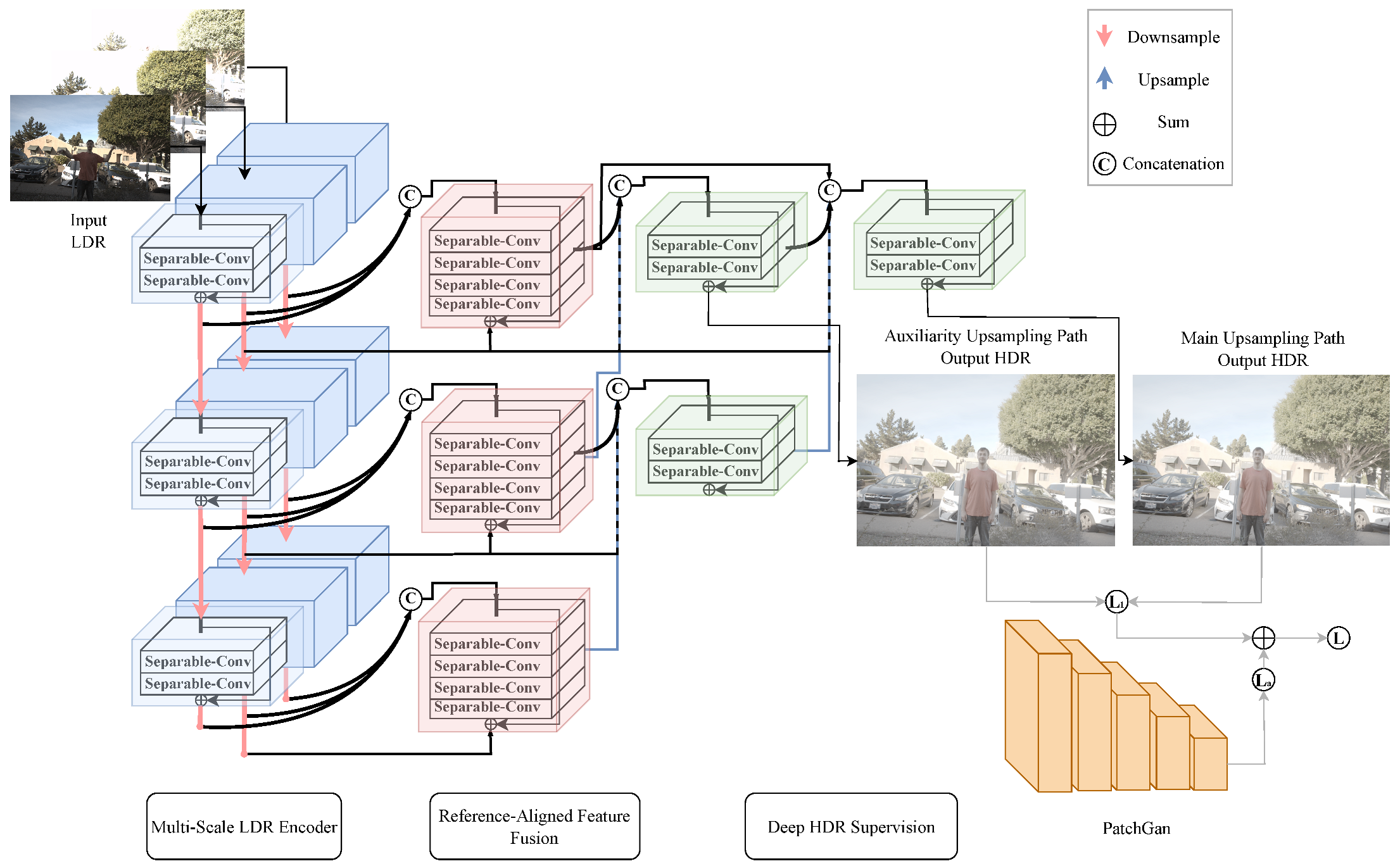
3.2. Proposed Model Generator
3.3. Discriminator of the Proposed Model
4. Experiments
4.1. Implementation Details
4.2. Dataset
4.3. Evaluation Metrics
4.4. Quantitative Results
4.5. Qualitative Results
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Johnson, A.K. High dynamic range imaging—A review. Int. J. Image Process. (IJIP) 2015, 9, 198. [Google Scholar]
- Seetzen, H.; Heidrich, W.; Stuerzlinger, W.; Ward, G.; Whitehead, L.; Trentacoste, M.; Ghosh, A.; Vorozcovs, A. High dynamic range display systems. In Seminal Graphics Papers: Pushing the Boundaries; Association for Computing Machinery: New York, NY, USA, 2023; Volume 2, pp. 39–47. [Google Scholar]
- Wang, L.; Yoon, K.J. Deep learning for hdr imaging: State-of-the-art and future trends. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 8874–8895. [Google Scholar] [CrossRef] [PubMed]
- Tiwari, G.; Rani, P. A review on high-dynamic-range imaging with its technique. Int. J. Signal Process. Image Process. Pattern Recognit. 2015, 8, 93–100. [Google Scholar] [CrossRef]
- Boitard, R.; Pourazad, M.T.; Nasiopoulos, P.; Slevinsky, J. Demystifying high-dynamic-range technology: A new evolution in digital media. IEEE Consum. Electron. Mag. 2015, 4, 72–86. [Google Scholar] [CrossRef]
- Xu, F.; Liu, J.; Song, Y.; Sun, H.; Wang, X. Multi-exposure image fusion techniques: A comprehensive review. Remote Sens. 2022, 14, 771. [Google Scholar] [CrossRef]
- Debevec, P.E.; Malik, J. Recovering high dynamic range radiance maps from photographs. In Seminal Graphics Papers: Pushing the Boundaries; Association for Computing Machinery: New York, NY, USA, 2023; Volume 2, pp. 643–652. [Google Scholar]
- Prabhakar, K.R.; Agrawal, S.; Singh, D.K.; Ashwath, B.; Babu, R.V. Towards practical and efficient high-resolution HDR deghosting with CNN. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXI 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 497–513. [Google Scholar]
- Hu, J.; Gallo, O.; Pulli, K.; Sun, X. HDR deghosting: How to deal with saturation? In Proceedings of the IEEE Conference on coMputer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1163–1170. [Google Scholar]
- Kalantari, N.K.; Ramamoorthi, R. Deep High Dynamic Range Imaging of Dynamic Scenes. ACM Trans. Graph. (Proc. SIGGRAPH 2017) 2017, 36, 144. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; NIPS: Cambridge, MA, USA, 2014. NIPS’14. Volume 2, pp. 2672–2680. [Google Scholar]
- Raipurkar, P.; Pal, R.; Raman, S. HDR-cGAN: Single LDR to HDR image translation using conditional GAN. In Proceedings of the Twelfth Indian Conference on Computer Vision, Graphics and Image Processing, Virtual Event, 20–22 December 2021. [Google Scholar]
- Wang, C.; Serrano, A.; Pan, X.; Chen, B.; Seidel, H.P.; Theobalt, C.; Myszkowski, K.; Leimkuehler, T. GlowGAN: Unsupervised Learning of HDR Images from LDR Images in the Wild. arXiv 2023, arXiv:2211.12352. [Google Scholar]
- Xu, H.; Ma, J.; Zhang, X.P. MEF-GAN: Multi-Exposure Image Fusion via Generative Adversarial Networks. IEEE Trans. Image Process. 2020, 29, 7203–7216. [Google Scholar] [CrossRef]
- Li, R.; Wang, C.; Wang, J.; Liu, G.; Zhang, H.Y.; Zeng, B.; Liu, S. Uphdr-gan: Generative adversarial network for high dynamic range imaging with unpaired data. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7532–7546. [Google Scholar] [CrossRef]
- Niu, Y.; Wu, J.; Liu, W.; Guo, W.; Lau, R.W. Hdr-gan: Hdr image reconstruction from multi-exposed ldr images with large motions. IEEE Trans. Image Process. 2021, 30, 3885–3896. [Google Scholar] [CrossRef]
- Chakraborty, T.; KS, U.R.; Naik, S.M.; Panja, M.; Manvitha, B. Ten years of generative adversarial nets (GANs): A survey of the state-of-the-art. Mach. Learn. Sci. Technol. 2024, 5, 011001. [Google Scholar] [CrossRef]
- Tel, S.; Heyrman, B.; Ginhac, D. Cen-hdr: Computationally efficient neural network for real-time high dynamic range imaging. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 378–394. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Howard, A.G. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- V, A.; Kiran, A.G. SynthNet: A skip connected depthwise separable neural network for Novel View Synthesis of solid objects. Results Eng. 2022, 13, 100383. [Google Scholar] [CrossRef]
- Krishnan, K.S.; Krishnan, K.S. SwiftSRGAN-Rethinking super-resolution for efficient and real-time inference. In Proceedings of the 2021 International Conference on Intelligent Cybernetics Technology & Applications (ICICyTA), Bandung, Indonesia, 1–2 December 2021; pp. 46–51. [Google Scholar]
- Chen, C.; Deng, X.; Yu, Z.; Wu, Z. Fabric defect detection using a one-class classification based on depthwise separable convolution autoencoder. J. Physics Conf. Ser. 2023, 2562, 012053. [Google Scholar] [CrossRef]
- Guo, Z.; Wang, J.; Chen, S.; Kang, Y. A Lightweight Stereo Matching Neural Network Based on Depthwise Separable Convolution. In Proceedings of the 2023 IEEE International Conference on Integrated Circuits, Technologies and Applications (ICTA), Hefei, China, 27–29 October 2023; pp. 122–123. [Google Scholar]
- Nemoto, H.; Korshunov, P.; Hanhart, P.; Ebrahimi, T. Visual attention in LDR and HDR images. In Proceedings of the 9th International Workshop on Video Processing and Quality Metrics for Consumer Electronics (VPQM), Chandler, AZ, USA, 5–6 February 2015. [Google Scholar]
- Sen, P.; Kalantari, N.K.; Yaesoubi, M.; Darabi, S.; Goldman, D.B.; Shechtman, E. Robust patch-based hdr reconstruction of dynamic scenes. ACM Trans. Graph. 2012, 31, 203. [Google Scholar] [CrossRef]
- Tursun, O.T.; Akyüz, A.O.; Erdem, A.; Erdem, E. An objective deghosting quality metric for HDR images. In Computer Graphics Forum; Wiley Online Library: Hoboken, NJ, USA, 2016; Volume 35, pp. 139–152. [Google Scholar]
- Tel, S.; Wu, Z.; Zhang, Y.; Heyrman, B.; Demonceaux, C.; Timofte, R.; Ginhac, D. Alignment-free HDR Deghosting with Semantics Consistent Transformer. In Proceedings of the ICCV, Paris, France, 1–6 October 2023. [Google Scholar]
- Kirk, K.; Andersen, H.J. Noise Characterization of Weighting Schemes for Combination of Multiple Exposures. In Proceedings of the BMVC, Edinburgh, UK, 4–7 September 2006; Volume 3, pp. 1129–1138. [Google Scholar]
- Granados, M.; Ajdin, B.; Wand, M.; Theobalt, C.; Seidel, H.P.; Lensch, H.P. Optimal HDR reconstruction with linear digital cameras. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 215–222. [Google Scholar]
- Khan, E.A.; Akyuz, A.O.; Reinhard, E. Ghost removal in high dynamic range images. In Proceedings of the 2006 International Conference on Image Processing, Las Vegas, NA, USA, 26–29 June 2006; pp. 2005–2008. [Google Scholar]
- Raman, S.; Chaudhuri, S. Reconstruction of high contrast images for dynamic scenes. Vis. Comput. 2011, 27, 1099–1114. [Google Scholar] [CrossRef]
- Tomaszewska, A.; Mantiuk, R. Image Registration for Multi-Exposure High Dynamic Range Image Acquisition; Vaclav Skala-UNION Agency: Plzen, Czech Republic, 2007. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Cai, J.; Gu, S.; Zhang, L. Learning a deep single image contrast enhancer from multi-exposure images. IEEE Trans. Image Process. 2018, 27, 2049–2062. [Google Scholar] [CrossRef]
- Fairchild, M.D. The HDR photographic survey. In Proceedings of the Color and Imaging Conference, Albuquerque, NM, USA, 5–9 November 2007; Society of Imaging Science and Technology: Springfield, VA, USA, 2007; Volume 15, pp. 233–238. [Google Scholar]
- Kaiser, L.; Gomez, A.N.; Chollet, F. Depthwise Separable Convolutions for Neural Machine Translation. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Guo, Y.; Li, Y.; Wang, L.; Rosing, T. Depthwise convolution is all you need for learning multiple visual domains. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8368–8375. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Park, S.W.; Kwon, J. Sphere generative adversarial network based on geometric moment matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4292–4301. [Google Scholar]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Sara, U.; Akter, M.; Uddin, M.S. Image quality assessment through FSIM, SSIM, MSE and PSNR—a comparative study. J. Comput. Commun. 2019, 7, 8–18. [Google Scholar] [CrossRef]
- Lavoué, G.; Mantiuk, R. Quality Assessment in Computer Graphics. In Visual Signal Quality Assessment: Quality of Experience (QoE); Deng, C., Ma, L., Lin, W., Ngan, K.N., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 243–286. [Google Scholar] [CrossRef]
- Mantiuk, R.; Kim, K.J.; Rempel, A.G.; Heidrich, W. HDR-VDP-2: A calibrated visual metric for visibility and quality predictions in all luminance conditions. In Proceedings of the ACM SIGGRAPH, Hong Kong, China, 12–15 December 2011. [Google Scholar] [CrossRef]
- Narwaria, M.; Mantiuk, R.K.; Da Silva, M.P.; Le Callet, P. HDR-VDP-2.2: A calibrated method for objective quality prediction of high-dynamic range and standard images. J. Electron. Imaging 2015, 24, 010501. [Google Scholar] [CrossRef]
- Mantiuk, R.K.; Hammou, D.; Hanji, P. HDR-VDP-3: A multi-metric for predicting image differences, quality and contrast distortions in high dynamic range and regular content. arXiv 2023, arXiv:2304.13625. [Google Scholar]
- Zhang, L.; Zhang, L.; Bovik, A.C. A Feature-Enriched Completely Blind Image Quality Evaluator. IEEE Trans. Image Process. 2015, 24, 2579–2591. [Google Scholar] [CrossRef]
- Lopez-Cabrejos, J.; Paixão, T.; Alvarez, A.B.; Luque, D.B. An Efficient and Low-Complexity Transformer-Based Deep Learning Framework for High-Dynamic-Range Image Reconstruction. Sensors 2025, 25, 1497. [Google Scholar] [CrossRef] [PubMed]




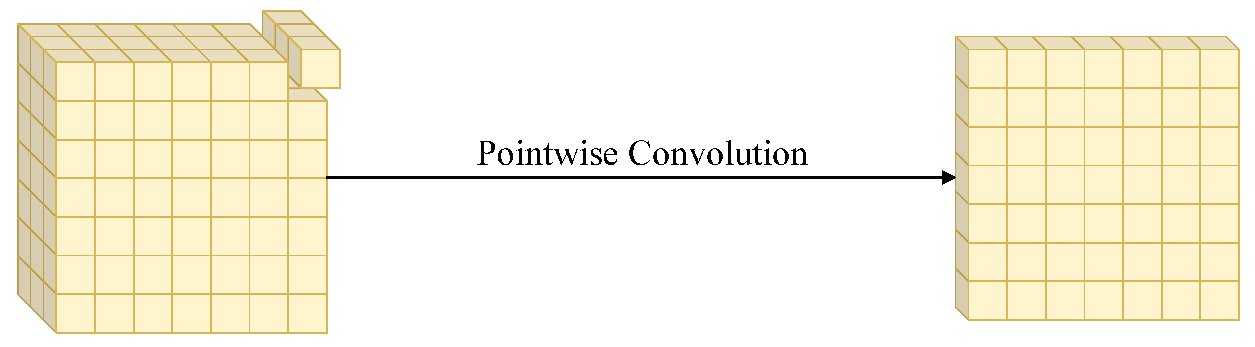





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | PSNR- ↑ | SSIM- ↑ | FLOPs(T) ↓ | N° of Parameters (M) ↓ | Size (MB) ↓ | Inference Time (s) ↓ | GPU Memory (GB) |
|---|---|---|---|---|---|---|---|
| Patch-Based | 40.80 | 0.9808 | - | - | - | - | - |
| DHDRNet | 42.67 | 0.9888 | - | 0.383 | - | - | - |
| HDR-GAN | 43.92 | 0.9905 | 1.455 | 2.557 | 10.9 | 0.19 | 8.3 |
| Lopez-Cabrejos | 44.10 | 0.9924 | 0.440 | 0.29 | 7.9 | 2.19 | 11.6 |
| Proposed Model | 43.51 | 0.9917 | 0.232 | 0.364 | 1.45 | 0.15 | 4.5 |
| Model | PSNR-l | SSIM-l | PSNR- | SSIM- | HDR-VDP2 | HDR-VDP3 |
|---|---|---|---|---|---|---|
| Patch-Based | 38.11 | 0.9721 | 40.47 | 0.9775 | 59.38 | - |
| DHDRNet | 41.23 | 0.9846 | 41.83 | 0.9832 | 65.05 | - |
| HDR-GAN | 41.57 | 0.9865 | 43.20 | 0.9913 | 65.45 | 9.32 * |
| Lopez-Cabrejos | 42.07 | 0.9886 | - | - | 67.79 | - |
| Proposed Model | 40.88 | 0.9887 | 43.17 | 0.9902 | 65.32 | 9.24 |
| Image | Resolution | HDR-GAN | Proposed Model |
|---|---|---|---|
| 001 | 1500 × 1000 | 20.54 | 20.83 |
| 002 | 1500 × 1000 | 20.44 | 20.07 |
| 003 | 1500 × 1000 | 21.70 | 21.57 |
| 004 | 1500 × 1000 | 22.64 | 22.92 |
| 005 | 1500 × 1000 | 16.39 | 16.31 |
| 006 | 1500 × 1000 | 19.60 | 19.27 |
| 007 | 1500 × 1000 | 21.35 | 21.51 |
| 008 | 1500 × 1000 | 18.69 | 18.95 |
| 009 | 1500 × 1000 | 21.89 | 22.37 |
| 010 | 1500 × 1000 | 19.56 | 19.47 |
| People Talking | 1500 × 1000 | 18.31 | 17.76 |
| Lady Sitting | 1500 × 1000 | 21.09 | 21.40 |
| Man Standing | 1500 × 1000 | 19.51 | 19.40 |
| People Standing | 1500 × 1000 | 16.36 | 16.51 |
| Barbeque Day | 1500 × 1000 | 22.91 | 22.65 |
| Average | — | 20.07 | 20.07 |
| Image | Resolution | HDR-GAN | Proposed Model |
|---|---|---|---|
| C06 | 5472 × 3648 | 24.88 | 25.06 |
| C07 | 5472 × 3648 | 25.25 | 25.93 |
| C08 * | 3632 × 2288 | 18.74 | 18.28 |
| C10 | 5472 × 3648 | 21.37 | 20.34 |
| C12 | 5472 × 3648 | 25.43 | 22.94 |
| C16 | 5472 × 3648 | 23.11 | 28.46 |
| C18 | 5472 × 3648 | 20.38 | 22.81 |
| C19 * | 6000 × 3455 | 22.29 | 22.57 |
| C20 * | 5528 × 3536 | 27.03 | 27.26 |
| C23 * | 6000 × 3580 | 20.28 | 20.98 |
| C25 * | 6000 × 3740 | 18.06 | 19.11 |
| C31 | 5472 × 3648 | 18.73 | 19.69 |
| C34 | 5472 × 3648 | 20.38 | 20.86 |
| Average | — | 22.00 | 24.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferreti, G.d.S.; Paixão, T.; Alvarez, A.B. Generative Adversarial Network-Based Lightweight High-Dynamic-Range Image Reconstruction Model. Appl. Sci. 2025, 15, 4801. https://doi.org/10.3390/app15094801
Ferreti GdS, Paixão T, Alvarez AB. Generative Adversarial Network-Based Lightweight High-Dynamic-Range Image Reconstruction Model. Applied Sciences. 2025; 15(9):4801. https://doi.org/10.3390/app15094801
Chicago/Turabian StyleFerreti, Gustavo de Souza, Thuanne Paixão, and Ana Beatriz Alvarez. 2025. "Generative Adversarial Network-Based Lightweight High-Dynamic-Range Image Reconstruction Model" Applied Sciences 15, no. 9: 4801. https://doi.org/10.3390/app15094801
APA StyleFerreti, G. d. S., Paixão, T., & Alvarez, A. B. (2025). Generative Adversarial Network-Based Lightweight High-Dynamic-Range Image Reconstruction Model. Applied Sciences, 15(9), 4801. https://doi.org/10.3390/app15094801