Abstract
Image dehazing remains a critical yet challenging task in computer vision. While the existing dehazing methods have achieved notable progress, they still struggle to effectively eliminate dense haze in scenes while maintaining consistent illumination between dehazed regions and their surroundings. To address these challenges, we propose a novel image dehazing framework named HarmoDehazeDiffusion. Our model first acquires a depth map of an input image and then integrates these depth cues with hazy images to guide the diffusion denoising process. To simultaneously tackle dense haze removal and illumination consistency, we innovatively incorporate a multi-scale feature extraction strategy, coupled with an adaptive spatial fusion mechanism. Extensive experiments conducted on multiple public benchmarks demonstrate that HarmoDehazeDiffusion achieves a state-of-the-art performance. Quantitative and qualitative evaluations reveal our method’s superior capability to remove haze while preserving natural consistency in the illumination compared to that of the existing approaches, particularly in challenging dense haze scenarios.
1. Introduction
As part of computer vision tasks, haze removal plays a paramount role in image enhancement by recovering obscured textures and color from degraded visual information. This imperative arises as hazy images significantly degrade the visual information crucial for vision tasks, adversely impacting their accuracy. Nevertheless, even experienced image restorers find it extremely difficult to manually restore hazy images to a satisfactory level. Evidently, the automatic recovery of hazy images without any human intervention is a highly challenging task.
The existing haze removal methods can primarily be categorized into two directions: traditional prior-based dehazing methods and learning-based dehazing methods. The traditional prior-based dehazing methods have played a significant role in the early stages of dehazing research. These methods typically start from image features such as texture and gradient to restore the texture and color information for hazy regions in images. Although these methods can achieve certain effects, they still have significant technical limitations. This is because these methods are often based on researchers’ prior knowledge and fixed algorithms are designed for dehazing. However, in real life, the types of haze are diverse, and it is difficult for researchers to design a prior-based algorithm that can cover many complex hazy scenes. Therefore, directly applying the traditional prior-based algorithms to hazy images often leads to incomplete haze removal and the generation of visually incoherent artifacts.
Recent dehazing algorithms have predominantly adopted learning-based approaches to address the dehazing challenge. Despite some of the success achieved by these solutions, they have generally failed to consider a crucial aspect: the dense regions of haze in images. Dense regions of haze are characterized by complete blurring of their inherent textures and the alteration of their original illumination. This implies that restoring these regions requires a method that simultaneously integrates features from different parts of the image to construct the texture of these dense regions of haze and harmonizes the illumination of dense haze regions with that of the surrounding areas by leveraging the overall lighting information for the image.
Based on an analysis of the existing limitations, we propose a network framework called HarmoDehazeDiffusion, which incorporates depth information and considers both long-range features and spatial features to tackle the texture and illumination consistency issues in dense haze regions. Given the inseparable relationship between dense haze and depth, our method continuously introduces depth information during the network’s iterative denoising process to enhance the network’s perception of depth. Subsequently, to counteract the localized homogeneity of dense haze, our multi-scale feature extraction layer captures the non-local dependencies via dilated convolutions, enabling coherent texture reconstruction. Finally, we employ a spatial fusion strategy that integrates shallow texture features with deep semantic features. A learnable fusion gate dynamically combines these features, thereby ensuring harmonious illumination between the restored dense haze regions and the surrounding areas.
Our primary contributions are summarized as follows:
- We propose a dehazing model based on a diffusion model, named HarmoDehazeDiffusion. By introducing a novel Depth Fusion Diffusion Model, the network achieves a satisfactory dehazing performance even when dealing with dense haze images.
- We present a new spatial feature fusion module that enables the network to integrate multi-level information, thereby maintaining overall consistency in the illumination in the dehazed results. Additionally, we propose an improved multi-scale feature extraction structure that allows the network to reconstruct the texture of the dense haze regions by leveraging long-range features.
- Extensive experiments conducted on the publicly available SOTS-indoor, SOTS-outdoor, and Haze4K datasets demonstrate that our proposed HarmoDehazeDiffusion method outperforms the current state-of-the-art dehazing methods in its dehazing performance.
2. Related Work
In recent years, we have witnessed significant advancements in single-image dehazing. The existing methods can be broadly categorized into two types: physics-based methods and deep-learning-based methods.
Physics-based methods rely on atmospheric scattering models [1] and handcrafted priors, focusing on filtering haze-free images using statistical analyses or observations. Examples include the Dark Channel Prior (DCP) [2], Color Lines Prior [3], Color Attenuation Prior [4], Sparse Gradient Prior [5], Maximum Reflectance Prior [6], and Non-Local Prior [7]. For example, the DCP [2] identifies the dark channel prior to modeling the characteristics of haze-free images. This is based on the assumption that in natural scenes without haze, the local minimum intensity values across the RGB channels will be nearly zero. However, handcrafted priors mainly come from empirical observations and cannot accurately characterize the haze formation process.
In contrast to physics-based methods, deep-learning-based methods employ convolutional neural networks (CNNs) to learn image priors [8,9,10,11,12,13] from hazy to clear images [12,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28]. For example, Peng et al. [8] generate restored images by reformulating an atmospheric scattering model. Guo et al. [14] introduce Transformers into image dehazing, combining the global modeling capability of Transformers with the local representation power of CNNs. FSDGN [18] reveals the relationship between haze degradation and frequency characteristics, jointly exploring information from the frequency and spatial domains for image dehazing. Wu et al. [28] proposed a paradigm for real image dehazing from the perspective of synthesizing more realistic hazy data and introducing more robust priors into the network. Zheng et al. [27] proposed a curriculum contrastive regularization approach, leveraging the dehazing results from other existing methods to provide better lower bound constraints.
Despite the remarkable progress achieved by these methods, they still suffer from content and color information loss in scenarios with dense haze. The main reason for this is that hazy images contain limited original information under challenging conditions, hindering these methods’ ability to map the information effectively.
Recently, DDPMs (Denoising Diffusion Probabilistic Models) [29,30] have garnered significant attention due to their powerful generative capabilities. A DDPM can generate high-quality images both unconditionally [31,32,33] and conditionally [34,35,36], demonstrating exceptional performance in the field of image synthesis. Leveraging its unique advantages, the diffusion model has been widely applied to various visual tasks, including image dehazing, super-resolution restoration, and image generation. Through its step-by-step denoising process, it can produce highly detailed and realistic images, bringing new breakthroughs to the field of computer vision. However, the DDPM does not consider the physical characteristics of the dehazing task, which limits its ability to complete information. For instance, the significant differences in the distribution between images with dense haze and clear images make it challenging for the DDPM to adapt to images with varying levels of haze density. Additionally, although the encoder–decoder-based denoising network architecture has demonstrated strong capabilities in diffusion models, the inherent single-scale feature extraction and limited spatial information fusion methods still lead to issues such as the insufficient utilization of the long-range features and inconsistent overall illumination in the generated results. Specifically, the traditional methods use sliding windows for global feature extraction and rely on skip connections for hierarchical feature concatenation. This design flaw results in two critical problems: first, the fixed receptive field in feature extraction weakens the model’s ability to model the long-range contextual relationships; second, the lack of dynamic coordination between shallow detail information and deep overall illumination features affects the collaborative generation of fine-grained textures and the overall illumination.
To address these issues, we propose a depth-guided multi-scale feature spatial fusion network named HarmoDehazeDiffusion. The network first estimates the depth of the input image using an existing open-source depth estimation network [37] and uses this depth information to guide the denoising process. Subsequently, by constructing a hierarchical progressive interaction architecture between the deep and shallow features and incorporating multi-scale feature extraction layers, it achieves dynamic adaptive fusion of the cross-scale features. This network enhances the overall consistency of illumination while preserving the integrity of the local details, thereby improving the semantic coherence and spatial rationality of the diffusion model in complex scenes. Experiments show that this design not only enhances the depth perception through depth guidance but also effectively mitigates issues such as blurring of details and the illumination inconsistency caused by fragmented scale information.
3. The Method
In this section, we introduce HarmoDehazeDiffusion, a haze removal model based on a conditional diffusion model, as shown in Figure 1. HarmoDehazeDiffusion involves proposing a novel Depth Fusion Diffusion Model (DFDM), which incorporates image depth information to robustly remove haze even from images with significant variations in depth. Additionally, we propose a multi-scale feature spatial fusion network to replace the traditional U-Net denoising network in the diffusion model. This network constructs a hierarchical progressive interaction architecture between the deep and shallow features, along with multi-scale feature extraction layers, to achieve dynamic adaptive fusion of the cross-scale features.
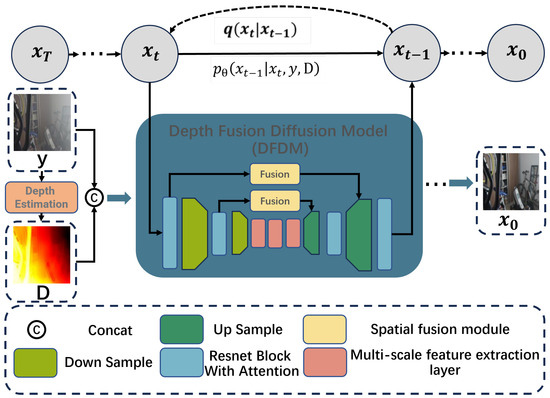
Figure 1.
Overview of the proposed HarmoDehazeDiffusion. Our model first uses a pre-trained depth estimation model to predict the depth map of the input image. Then, we concatenate the depth map with the original image to guide the denoising process of the Depth Fusion Diffusion Model. In the diffusion model, we enhance the network’s ability to perceive long-range features using a multi-scale feature extraction layer and use a spatial fusion module to fuse the shallow texture information and deep lighting information. Finally, an RGB haze-free image is obtained.
3.1. The Depth Fusion Diffusion Model
When the camera’s position is fixed, the concentration and depth of haze in specific regions of an image are closely related. Therefore, depth information is crucial for haze removal. Based on this observation, unlike previous image dehazing works [38] that have used depth estimation to augment the dataset, we propose a Depth Fusion Diffusion Model (DFDM) to incorporate a depth map as a conditional guide for the step-by-step denoising process of the diffusion model to enhance the network’s perception of image depth.
The conditional diffusion model [34,35,36] learns a conditional reverse process (|y) without modifying the diffusion process q(|) for , such that the sampled image has high fidelity to the data distribution conditioned on y. During training, we sample (, y, D) ∼ q(x, y) from a data distribution (e.g., the haze-free image x, the hazy image y, and the depth map D). Our training approach is outlined in Algorithm 1. We learn the depth-aware reverse process
We can marginalize the Gaussian diffusion process and directly sample the intermediate term from the haze-free image via , , and , where is the noise schedule. It has the same dimensionality as . The denoising network takes the hazy image y, the intermediate variable , the depth map D, and the time step t as its input, predicting the noise map as follows:
Following [31], the diffusion objective function is
It is noteworthy that we avoided directly applying a depth estimation method [37] to hazy images for depth prediction. This strategic decision stems from the limitation of atmospheric scattering in hazy conditions causing detail degradation and texture loss, which would lead to some deviations in the estimations when applying depth estimation algorithms not specifically trained on such degraded scenarios. To address this critical challenge, we implemented a data refinement strategy: First, we utilized the method [37] to estimate depth maps from the corresponding haze-free images in the dataset. Subsequently, we constructed training pairs by combining these estimated depth maps with their original hazy counterparts. This synthesized dataset was then employed to fine-tune the depth estimation model through transfer learning, enabling it to adaptively learn the latent relationship between haze-affected visual patterns and their underlying depth information.
| Algorithm 1: Depth Fusion Diffusion Model. | |||
| Input: The hazy image y, the non-hazy image x, and the depth map D | |||
| 1 | while not converged do | ||
| 2 | |||
| 3 | ) | ||
| 4 | |||
| 5 | Perform gradient descent steps on | ||
| 6 | end | ||
| 7 | return | ||
3.2. Spatial Feature Fusion
Deep feature representations, typically extracted using deep layers of neural networks, contain rich semantic information, which enables them to effectively identify the overall illumination conditions in an image. However, due to the high abstraction and low resolution of feature maps, the boundary information for deep features is often not well preserved. In contrast, more detailed information is retained for shallow features and can accurately capture the edges and texture features of objects. Nevertheless, their limited receptive fields and inclusion of a large amount of irrelevant background information pose challenges. Therefore, a common strategy is to integrate feature information from different depths to fuse the overall information on illumination and texture details. However, simple fusion methods often fail to effectively distinguish between the two, leading to issues such as blurred boundaries or background interference.
To address the aforementioned issues, our spatial feature fusion module employs a cross-depth attention mechanism, leveraging deep feature representations to guide low-level feature representations for joint context modeling and perception. Specifically, the module first performs global context encoding on the deep feature representations to extract their semantic information and generates spatial weight maps through an attention mechanism. These weight maps are then multiplied pixel-wise with the low-level feature representations. In this way, the module significantly combines the overall illumination characteristics of the deep features with the detailed texture features of the shallow layers, thereby enhancing the accuracy of the texture and spatial representation. Experiments show that after introducing this module, the performance of the dehazing model in complex scenes is significantly improved, particularly in terms of the clarity of boundaries and the overall consistency of illumination.
As shown in Figure 2, our proposed spatial feature fusion can be divided into two key stages: (1) the branch feature extraction stage and (2) the high-level and low-level information attention fusion stage. In the first stage, considering the significant differences between the low-level features and high-level features in terms of the semantic information and spatial details, we adopt a branch feature extraction strategy. Specifically, for the low-level features , which contain rich spatial details and edge information, we design a low-level branch convolutional structure: first, we use convolutional kernels with sizes of 3 and 5 to extract the features from the image, then align these two feature maps to obtain the fused low-level local features, and finally perform feature reorganization and dimensionality reduction using 1 × 1 convolutions. These combined features effectively preserve the key information on the details of the image. For the high-level features , which already possess strong semantic expression capabilities, our method only uses 1 × 1 convolutional layers for the feature transformation to enhance their semantic information while maintaining the level of feature abstraction. Through this differentiated processing approach, the shunt processing in the first stage can be represented as follows:
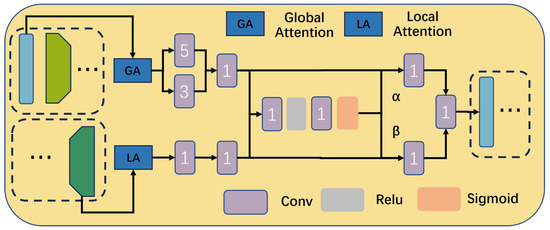
Figure 2.
Overview of the proposed spatial feature fusion.
In the second stage, we propose an innovative nonlinear fusion strategy aiming to achieve deep interactions and complementarity in the information between the low-level features and high-level features . Specifically, this stage begins with the initial fusion of the outputs and from the previous stage: the initial fused features are generated through element-wise summation, as shown below:
This addition operation preserves the core information of both features while providing a foundation for subsequent nonlinear transformations. Subsequently, to enhance the feature representation capabilities further, we design a nonlinear mapping module. This module can capture the complex dependencies between and . Through this approach, we not only allow interactions between the information of the features but also adaptively adjust the weights of the contributions of the low-level detail features and the high-level overall illumination features, thereby generating more discriminative fused features. Next, the resulting features are passed into a bottleneck module. Thus, we obtain the fusion weights and as follows:
It is worth noting that the weight values range between 0 and 1, which enables the network to calibrate the shallow features and deep features better. Finally, the final output is obtained through linear combination of the weights, which can be described as follows:
where ⊗ denotes element-wise multiplication. Through the aforementioned adaptive fusion process, the final feature map is rich in both detailed and semantic information.
3.3. Multi-Scale Feature Extraction
As shown in Figure 3, in addition to spatial features, we also introduce multi-scale feature extraction layers to replace the traditional bottleneck layers in the denoising U-Net network of the diffusion model.
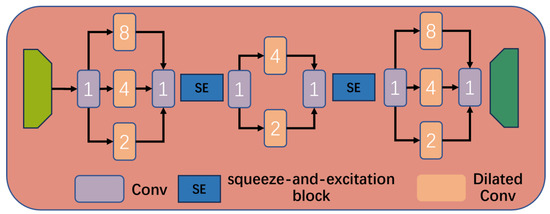
Figure 3.
Overview of the proposed multi-scale feature extraction.
Specifically, to address the limitation of the traditional U-Net, which typically uses plain convolutional layers or bottleneck layers between the encoder and the decoder, resulting in a limited performance in capturing long-range contextual information, our proposed multi-level dilated layer expands the receptive field by leveraging dilated convolutions with different dilation rates, thereby capturing contextual information at various distances in the image. The multi-level dilated layer first employs three dilated convolutional layers with dilation rates of 2, 4, and 8, respectively. These dilated convolutional layers can progressively enlarge the receptive field while maintaining the resolution of the feature maps, thus capturing multi-scale features from the image contexts.
Next, the features extracted from these three dilated layers, along with the global features, are fed into a squeeze-and-excitation block [39]. The squeeze-and-excitation block adaptively learns the importance of different channels in the feature map through a channel attention mechanism, further enhancing the discriminative power of the features. Specifically, the squeeze-and-excitation block first performs global average pooling on the input features, compressing the spatial dimensions of each channel and thereby capturing the global information for each channel. This step not only reduces the computational complexity but also effectively mitigates overfitting. Subsequently, channel weights are generated through two fully connected layers and a nonlinear activation function. Finally, channel-wise feature enhancement is achieved by multiplying the generated channel weights with the original features. This mechanism adaptively adjusts the contribution of each channel based on the requirements of the task, allowing the network to focus more on task-critical feature channels, thereby significantly improving the overall performance of the model.
4. Experiments
4.1. The Experimental Setup
Our HarmoDehazeDiffusion was implemented in PyTorch 1.7.0. In our experiments, we trained our network on an NVIDIA GeForce GTX 3090Ti. The training epoch was set as 1000. We used the Adam optimizer, with the momentum as (0.9, 0.999). The initial learning rate was 3 × . Following [34], we used the Kaiming initialization technique [40] to initialize the weights of the proposed model and used a 0.9999 Exponential Moving Average (EMA) for all of our experiments. We used 1000 diffusion steps T and a noise schedule linearly increasing from 0.0001 to 0.02 for training and 25 steps for inference.
Benchmark datasets. Experiments were conducted on the RESIDE [41], Haze-4K [42], and Dense Haze [43] datasets to validate our method. RESIDE, with its diverse data sources and image content, is subdivided into ITS (an Indoor Training Set), OTS (an Outdoor Training Set), and SOTS (a Synthetic Objective Testing Set). The Haze4K dataset, a synthetic dataset, includes 4000 paired images from both indoor and outdoor scenes. Dense Haze is a high-quality, real-world dataset that includes 55 pairs of images with and without haze.
Metrics. To verify the effectiveness of our method, we evaluated the image dehazing performance of each method using two metrics, which were the PSNR ↑ and SSIM ↑. Here, ↑ indicates that a higher value is better.
4.2. Comparison with the State of the Art
We compared the results of HarmoDehazeDiffusion with those of eight state-of-the-art methods: DehazeFormer [15], FFA-Net [22], MSBDN [16], DEA-Net [44], UDN [45], Dehamer [14], Grid [46], and the FCDM [47]. To ensure fairness in the experiments, we used the same training data and input sizes for all methods during training. In the evaluation phase, we quantitatively assessed the dehazing performance using the Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity (SSIM). The PSNR measures the pixel-level difference between the dehazed image and the real clear image, while SSIM evaluates image quality in terms of structure, brightness, and contrast.
We summarize the quantitative results of all of the methods on the test dataset in Table 1. The results show that our proposed HarmoDehazeDiffusion method outperforms the other learning-based competing methods in both its PSNR and SSIM values. This advantage can be attributed to the fact that the other baseline methods do not adequately consider the specificity of regions of dense haze, leading to their poor performance in complex haze scenarios. For example, these methods do not effectively utilize depth information and long-range features when processing scenes containing dense haze, making it difficult to reconstruct the texture of these areas. In contrast, HarmoDehazeDiffusion introduces depth information into the gradual denoising process and uses multi-scale feature extraction to combine the depth information and long-range features at each step of the network, resulting in stronger robustness when dealing with complex hazy scenes. Moreover, the spatial feature fusion of HarmoDehazeDiffusion effectively combines the shallow texture features with deep lighting features, avoiding the issue of the texture features of regions of dense haze being restored but the lighting in these regions appearing inconsistent with that in the surroundings. In short, our method employs multiple strategies to effectively address texture restoration in dense hazy regions and harmony in the lighting between these regions and their surroundings.

Table 1.
Quantitative evaluation of our method and other image dehazing methods.
From Figure 4, it can be seen that outdoor scenes have significant depth variations, where the depth information plays a crucial role in processing these scenes, as it directly affects the model’s understanding of the scene’s structure and modeling of the haze distribution. Specifically, although the FCDM method can remove most of the haze from the image, its dehazing results are still not ideal. Visual comparisons show that the FCDM often fails to fully restore clear details in dense hazy regions, resulting in images that remain blurry. Additionally, while the Grid method improves the dehazing effect, it distorts the scene’s original colors, causing noticeable color bias issues in the dehazed images, such as an unnatural color in areas of sky. Similarly, the DehazeFormer method, while it improves the dehazing effect to some extent, exhibits the significant loss of texture details in complex scenes, such as the texture of building surfaces or the details of tree branches and leaves becoming blurred. The main reason for the poor performance of these methods is that they ignore the depth information in the image and do not fully consider the differences in the haze distribution across different depth regions.

Figure 4.
Comparison of dehazing effects on images with significant changes in depth (outdoor).
In the indoor scene illustrated in Figure 5, while the variation in depth is less pronounced, it imposes more stringent requirements on the texture details and color consistency of the scene. Although methods such as the FCDM, Grid, and DehazeFormer can effectively remove haze, the FCDM suffers from inadequate color coordination, Grid exhibits color distortions due to its inability to perceive hierarchical information, and DehazeFormer demonstrates a suboptimal dehazing performance in high-luminance regions of images.

Figure 5.
Comparison of dehazing effects on images with small changes in depth (indoor).
In the real-world scene shown in Figure 6 (the quantitative results are summarized in Table 2), since the dataset is directly derived from the real world, it provides richer visual information and more accurately reflects the performance of the algorithms in practical environments. The results show that the FCDM, Grid, and DehazeFormer methods each have certain limitations. The FCDM method is prone to color distortions due to its insufficient ability to perceive the features, which leads to biased estimations of the atmospheric light. Grid, on the other hand, suffers from artifacts in the edge regions because it fails to effectively integrate the texture features. As for DehazeFormer, it performs poorly in dense and non-uniform haze conditions with complex visual information.

Figure 6.
Comparison of dehazing effects on real images.
Table 2.
Quantitative results for real images.
In contrast, our proposed HarmoDehazeDiffusion method, through the introduction of a depth-aware mechanism, spatial feature fusion, and multi-scale feature extraction, can more accurately capture various information in the scene and adaptively process the haze removal based on the characteristics of the haze distribution in different regions. This enables our method to effectively avoid color distortion issues in the results, such as preserving the natural color transitions in areas of sky while restoring the detail information for distant views. Additionally, HarmoDehazeDiffusion maintains a balance between the texture details and lighting consistency better, resulting in detailed and harmonious outcomes. These improvements are not only reflected in the quantitative metrics but are also fully validated by the visual comparisons, further demonstrating the superiority and robustness of our method in handling complex hazy scenes.
Although our method has achieved some positive results, it cannot reach an optimized real-time elimination speed due to the various computational strategies in its design. Specifically, we processed a 256 × 256 image on a 3090 Ti, with a processing time of 0.256 s and occupying 1547 MB of graphic memory.
4.3. An Ablation Study
To verify the effectiveness of each component of our method, we designed a series of variants:
- Ours w/o depth: The original model without depth maps;
- Ours w/o multi-scale FE: The model with depth maps but without multi-scale feature extraction;
- Ours w/o spatial fusion: The model with depth maps and multi-scale feature extraction but without spatial fusion;
- Ours: The complete model with depth maps, spatial fusion, and multi-scale feature extraction.
We trained these variants using the same training data and evaluated their performance on the test dataset. The evaluation results are shown in Table 3. The results indicate that our model w/o depth performs poorly in dehazing due to the lack of critical information. Our model w/o multi-scale FE, with the assistance of depth information, provides more natural results in regions with significant depth variations. However, due to the lack of long-range context and spatial fusion strategies, the network exhibits issues while handling dense haze, with poor texture recovery and lighting that is inconsistent with the surrounding regions. Our model w/o spatial fusion restores the textures in hazy regions better but still suffers with inconsistent lighting in the surrounding areas. In contrast, our complete model delivers more realistic and natural results when handling various complex and extreme scenarios.
Table 3.
Quantitative results of the ablation study.
5. Conclusions
In this paper, we innovatively propose the HarmoDenzeDiffusion framework specifically designed for haze elimination in dense hazy scenes. The proposed method first utilizes a depth map to gradually guide the denoising process of the diffusion model. Subsequently, we combine multi-scale feature extraction with a spatial fusion module to effectively solve the problems of the loss of long-distance features and the lighting consistency between dehazed areas and the surrounding areas in haze removal. Extensive experimental verification has shown that our solution is effective and superior in scenarios with dense haze, particularly demonstrating unique advantages in maintaining overall consistency in the lighting. The limitation of our method is its slow inference speed. Overall, our research proposes a novel approach to considering dehazing tasks from the perspective of overall consistency in image lighting, which can prevent the dehazing results from becoming mottled. In the future, we will consider streamlining the network architecture to achieve real-time video dehazing.
Author Contributions
Conceptualization: J.Y. Methodology: J.Y. and S.D. Software: J.Y. and S.D. Validation: J.Y., S.D., L.Y. and H.Y. Formal analysis: J.Y. Investigation: J.Y. Resources: J.Y. Data curation: J.Y. Writing—original draft preparation: J.Y. Writing—review and editing: J.Y., S.D., L.Y. and H.Y. Visualization: J.Y. Supervision: L.Y. Project administration: H.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are from public datasets. These data were derived from the following resources available in the public domain: SOTS (DOI: 10.1109/TIP.2018.2867951), https://sites.google.com/view/reside-dehaze-datasets [41], and Haze4K (DOI: 10.48550/arXiv.2108.02934), https://github.com/liuye123321/DMT-Net [42].
Conflicts of Interest
The authors declare no conflicts of interest.
References
- McCartney, E.J. Optics of the Atmosphere: Scattering by Molecules and Particles; Wiley: New York, NY, USA, 1976. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar] [PubMed]
- Fattal, R. Dehazing using color-lines. ACM Trans. Graph. (TOG) 2014, 34, 1–14. [Google Scholar] [CrossRef]
- Zhu, Q.; Mai, J.; Shao, L. Single image dehazing using color attenuation prior. In Proceedings of the BMVC, Nottingham, UK, 1–5 September 2014; Volume 4, pp. 1674–1682. [Google Scholar]
- Chen, C.; Do, M.N.; Wang, J. Robust image and video dehazing with visual artifact suppression via gradient residual minimization. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 576–591. [Google Scholar]
- Zhang, J.; Cao, Y.; Fang, S.; Kang, Y.; Wen Chen, C. Fast haze removal for nighttime image using maximum reflectance prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7418–7426. [Google Scholar]
- Berman, D.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1674–1682. [Google Scholar]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. Aod-net: All-in-one dehazing network. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4770–4778. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. Dehazenet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single image dehazing via multi-scale convolutional neural networks. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 154–169. [Google Scholar]
- Zhang, H.; Patel, V.M. Densely connected pyramid dehazing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3194–3203. [Google Scholar]
- Liu, R.; Fan, X.; Hou, M.; Jiang, Z.; Luo, Z.; Zhang, L. Learning aggregated transmission propagation networks for haze removal and beyond. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 2973–2986. [Google Scholar] [CrossRef]
- Liu, Y.; Pan, J.; Ren, J.; Su, Z. Learning deep priors for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2492–2500. [Google Scholar]
- Guo, C.L.; Yan, Q.; Anwar, S.; Cong, R.; Ren, W.; Li, C. Image dehazing transformer with transmission-aware 3D position embedding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5812–5820. [Google Scholar]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Wu, H.; Qu, Y.; Lin, S.; Zhou, J.; Qiao, R.; Zhang, Z.; Xie, Y.; Ma, L. Contrastive learning for compact single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10551–10560. [Google Scholar]
- Yu, H.; Zheng, N.; Zhou, M.; Huang, J.; Xiao, Z.; Zhao, F. Frequency and spatial dual guidance for image dehazing. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 181–198. [Google Scholar]
- Li, C.Y.; Guo, J.C.; Cong, R.M.; Pang, Y.W.; Wang, B. Underwater image enhancement by dehazing with minimum information loss and histogram distribution prior. IEEE Trans. Image Process. 2016, 25, 5664–5677. [Google Scholar] [CrossRef] [PubMed]
- Ren, W.; Ma, L.; Zhang, J.; Pan, J.; Cao, X.; Liu, W.; Yang, M.H. Gated fusion network for single image dehazing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3253–3261. [Google Scholar]
- Deng, Q.; Huang, Z.; Tsai, C.C.; Lin, C.W. Hardgan: A haze-aware representation distillation gan for single image dehazing. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 722–738. [Google Scholar]
- Qin, X.; Wang, Z.; Bai, Y.; Xie, X.; Jia, H. FFA-Net: Feature fusion attention network for single image dehazing. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11908–11915. [Google Scholar]
- Yu, H.; Huang, J.; Liu, Y.; Zhu, Q.; Zhou, M.; Zhao, F. Source-free domain adaptation for real-world image dehazing. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 6645–6654. [Google Scholar]
- Liu, H.; Wu, Z.; Li, L.; Salehkalaibar, S.; Chen, J.; Wang, K. Towards multi-domain single image dehazing via test-time training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5831–5840. [Google Scholar]
- Zhou, Y.; Chen, Z.; Li, P.; Song, H.; Chen, C.P.; Sheng, B. FSAD-Net: Feedback spatial attention dehazing network. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 7719–7733. [Google Scholar] [CrossRef] [PubMed]
- Fan, G.; Gan, M.; Fan, B.; Chen, C.P. Multiscale cross-connected dehazing network with scene depth fusion. IEEE Trans. Neural Netw. Learn. Syst. 2022, 35, 1598–1612. [Google Scholar] [CrossRef] [PubMed]
- Zheng, Y.; Zhan, J.; He, S.; Dong, J.; Du, Y. Curricular contrastive regularization for physics-aware single image dehazing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 5785–5794. [Google Scholar]
- Wu, R.Q.; Duan, Z.P.; Guo, C.L.; Chai, Z.; Li, C. Ridcp: Revitalizing real image dehazing via high-quality codebook priors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 22282–22291. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, PMLR, Lille, France, 7–9 July 2015; pp. 2256–2265. [Google Scholar]
- Song, Y.; Ermon, S. Generative modeling by estimating gradients of the data distribution. Adv. Neural Inf. Process. Syst. 2019, 32, 11918–11930. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Nichol, A.Q.; Dhariwal, P. Improved denoising diffusion probabilistic models. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8162–8171. [Google Scholar]
- Dhariwal, P.; Nichol, A. Diffusion models beat gans on image synthesis. Adv. Neural Inf. Process. Syst. 2021, 34, 8780–8794. [Google Scholar]
- Saharia, C.; Ho, J.; Chan, W.; Salimans, T.; Fleet, D.J.; Norouzi, M. Image super-resolution via iterative refinement. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 4713–4726. [Google Scholar] [CrossRef] [PubMed]
- Whang, J.; Delbracio, M.; Talebi, H.; Saharia, C.; Dimakis, A.G.; Milanfar, P. Deblurring via stochastic refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16293–16303. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Piccinelli, L.; Yang, Y.H.; Sakaridis, C.; Segu, M.; Li, S.; Van Gool, L.; Yu, F. UniDepth: Universal monocular metric depth estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 10106–10116. [Google Scholar]
- Yang, Y.; Wang, C.; Liu, R.; Zhang, L.; Guo, X.; Tao, D. Self-augmented unpaired image dehazing via density and depth decomposition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2037–2046. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Zhu, L.; Pei, S.; Fu, H.; Qin, J.; Zhang, Q.; Wan, L.; Feng, W. From synthetic to real: Image dehazing collaborating with unlabeled real data. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 50–58. [Google Scholar]
- Ancuti, C.O.; Ancuti, C.; Sbert, M.; Timofte, R. Dense-haze: A benchmark for image dehazing with dense-haze and haze-free images. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 1014–1018. [Google Scholar]
- Chen, Z.; He, Z.; Lu, Z.M. DEA-Net: Single image dehazing based on detail-enhanced convolution and content-guided attention. IEEE Trans. Image Process. 2024, 33, 1002–1015. [Google Scholar] [CrossRef]
- Hong, M.; Liu, J.; Li, C.; Qu, Y. Uncertainty-driven dehazing network. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 906–913. [Google Scholar]
- Song, Y.; He, Z.; Qian, H.; Du, X. Vision transformers for single image dehazing. IEEE Trans. Image Process. 2023, 32, 1927–1941. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wu, S.; Yuan, Z.; Tong, Q.; Xu, K. Frequency compensated diffusion model for real-scene dehazing. Neural Netw. 2024, 175, 106281. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).