3.1. Cold Item Recommendation
The cold item recommendation problem that we are trying to solve is defined as follows. Users in a user set U and items in an item set I make interactions such as clicks and ratings. Items in I are classified into one of the two mutually non-intersected subsets: warm item set and cold item set . Regardless of their subset, each item i has its side information embedding . The interactions are represented as two rating matrices, and , whose elements indicate interactions between users and warm items and between users and cold items, respectively. Each user and warm item has its own collaborative embedding and , which is calculated by a base CF method by using as the training data.
Our goal is, for a given and cold item set , to calculate an ordered list of k cold items that maximizes the prediction accuracy about u’s interaction in . To calculate , we can only use , and of cold items as input. In the training, we exploit the information from and , collaborative embeddings of users and warm items, , and of all items.
3.2. Preliminary: Diffusion Model
DM generates realistic data that satisfy a given condition (requirement, e.g., generate an image from its description represented by text embedding) from pure Gaussian noise. DM consists of a forward process that adds noise to the original data and a backward process that generates the original data from noise.
Forward Process: In the forward process, Gaussian noises are added
T times to given original data
to obtain a noised data sequence
,
, …,
. Noised data
at timestep
t are sampled from
using Equation (
1).
where
, I, and
indicate Gaussian distribution, the identity matrix, and noise scale at timestep
t, respectively.
increases as timestep
t increases. It can be learned from the data, but generally a predefined fixed scheduler is used such as the linear scheduler [
27], or cosine scheduler [
55], or sigmoid scheduler [
56]. We adopted the linear scheduler represented in Equation (
2), due to its empirical stability [
33,
38] and implementation simplicity.
where
,
, and the maximum timestep
T are hyperparameters. Following the proposal by Ho et al. [
27], we set
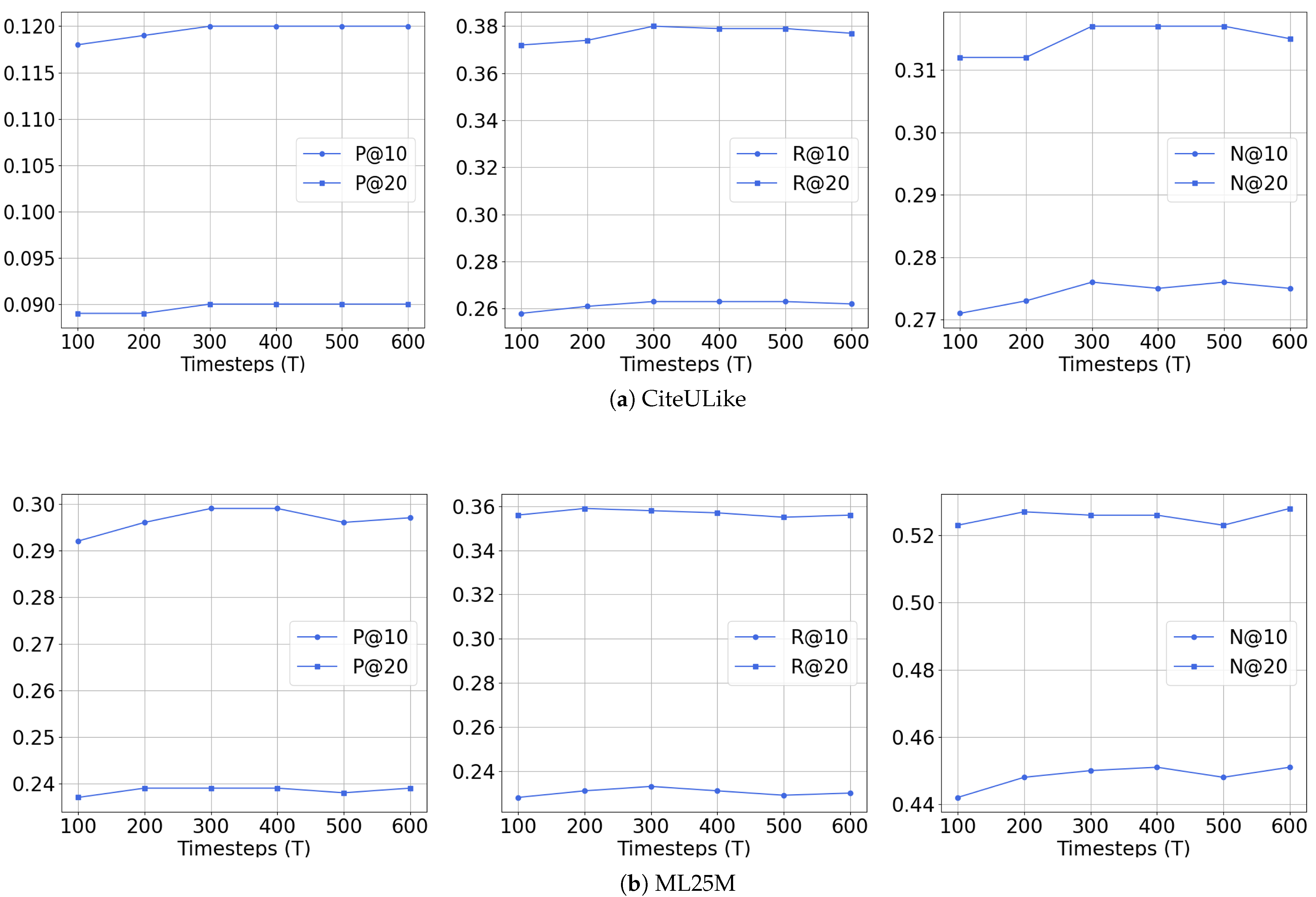
. The optimal values for
and
T will be evaluated in
Section 5.
As shown in Equation (
1), sampling
depends on its previous
only, and when Gaussian noises are applied, we can assume
is sampled from
by the single noise addition represented in Equations (
3) and (
4) [
46].
Since increases as t increases, and decrease. As a result, the information in decreases, but the noise increases as t increases. At the last time step T, converges to pure Gaussian noise.
Backward Process: The backward process of DM is a denoising process. From
, the fully noised data at the final timestep, the noise is removed step by step to recover
. The ground-truth denoising step, which is derived by using Bayes’ rule, is represented in Equations (
5)–(
7).
Unfortunately, we do not know the original data
at the inference time. Therefore, instead of using
, we train and adopt a
-predictor which predicts
from
and
t by using neural networks. In addition, because we want to control DM’s denoising (generation) direction, the predictor also takes the generation condition
c as an input. As a result,
in Equation (
6) is replaced by
-predictor
and generates a new equation, Equation (
8). The final denoising sample follows Equation (
9).
Training: DM training is equivalent to training
. Because the goal of
is to predict
, the objective function is designed to minimize the prediction error. We follow Ho et al.’s proposal [
27], Equation (
10), which not only reduces computational cost but also assigns greater importance to predictions made from noisier inputs, i.e., the more challenging cases.
where
represents the vector norm.
Algorithm 1 shows the DM training details. For a given data point and its condition c, an arbitrary timestep t is uniformly sampled between 1 and T, and the gradient of the objective function is calculated for the predictor training.
| Algorithm 1 DM Train |
Input: Dataset X with assigned conditions to its elements, maximum timestep T
Output: Trained model parameter - 1:
Initialize with random values - 2:
while is not converged do - 3:
Randomly sample a batch - 4:
for all do - 5:
Sample - 6:
Sample (Equation ( 3)) - 7:
Calculate loss using Equation ( 10) - 8:
Update using gradient descent with - 9:
end for - 10:
end while
|
Inference: Algorithm 2 shows DM’s inference procedure details. DM takes a given pure Gaussian noise and condition pair and performs denoising for each timestep to generate the data satisfying the condition. The reparameterization trick [
57] is adopted for sampling.
| Algorithm 2 DM Inference |
Input: Condition c, maximum timestep T
- 1:
- 2:
for
t←T to 1
do - 3:
- 4:
if t == 1 then - 5:
- 6:
end if - 7:
( : Equation ( 8), : The square root of Equation ( 7)) - 8:
end for - 9:
return
|
3.2.1. Overview of the Proposed Method
We first describe the overview of the proposed method and then explain the details in the following subsections.
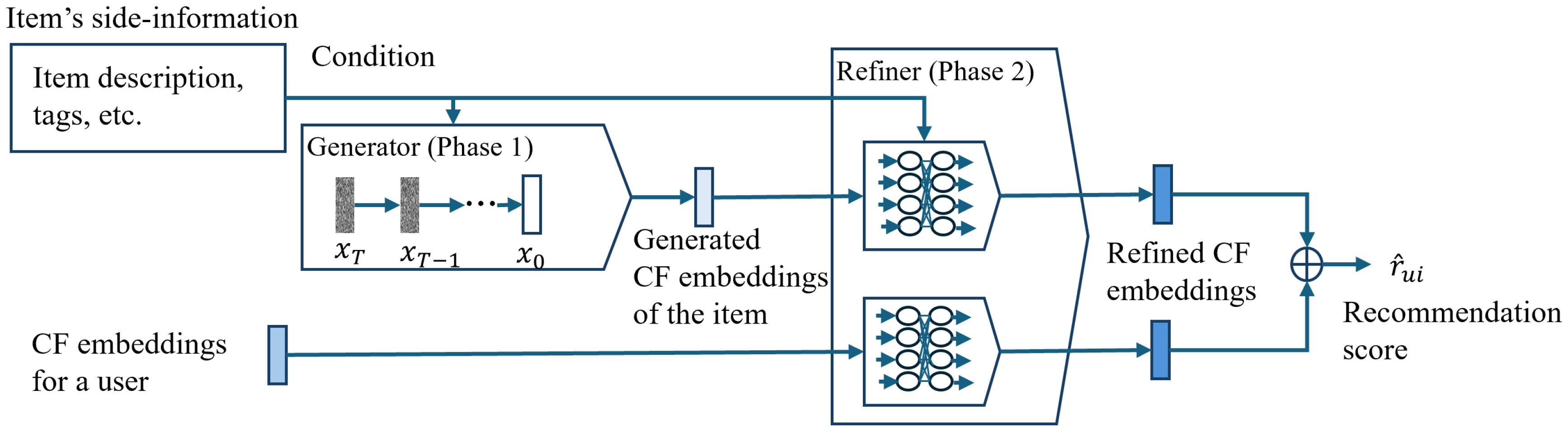
Figure 1 shows the two-phase recommendation of the proposed method. In the first phase, the DM-based generator generates collaborative embeddings of cold items using their side information as input. Then, the generated collaborative embeddings of cold items and the collaborative embeddings of users calculated by the base recommender are fed into the refiner to calculate more accurate recommendations for each user. The generated embeddings contain some errors that originated from information deficiency. For instance, coarse-grained side information of the cold items is given as the generation condition, and valuable user-side information, the ground-truth collaborative embeddings of users, is not considered. We employed the refiner to correct the error in the generated collaborative embeddings by the DM-based generator.
We train the DM-based generator first and then train the refiner using the trained generator. Although we adopted the refiner, it is worth noting that we can directly use the collaborative embeddings of cold items generated by the DM-based generator to calculate recommendation scores just by applying dot products with user collaborative embeddings.
3.2.2. DM-Based Generator
The DM-based generator is a DM that generates collaborative embeddings of cold items from their side information as its generation condition. Therefore, in the training, we assigned and to the original data and c in Algorithm 1, respectively.
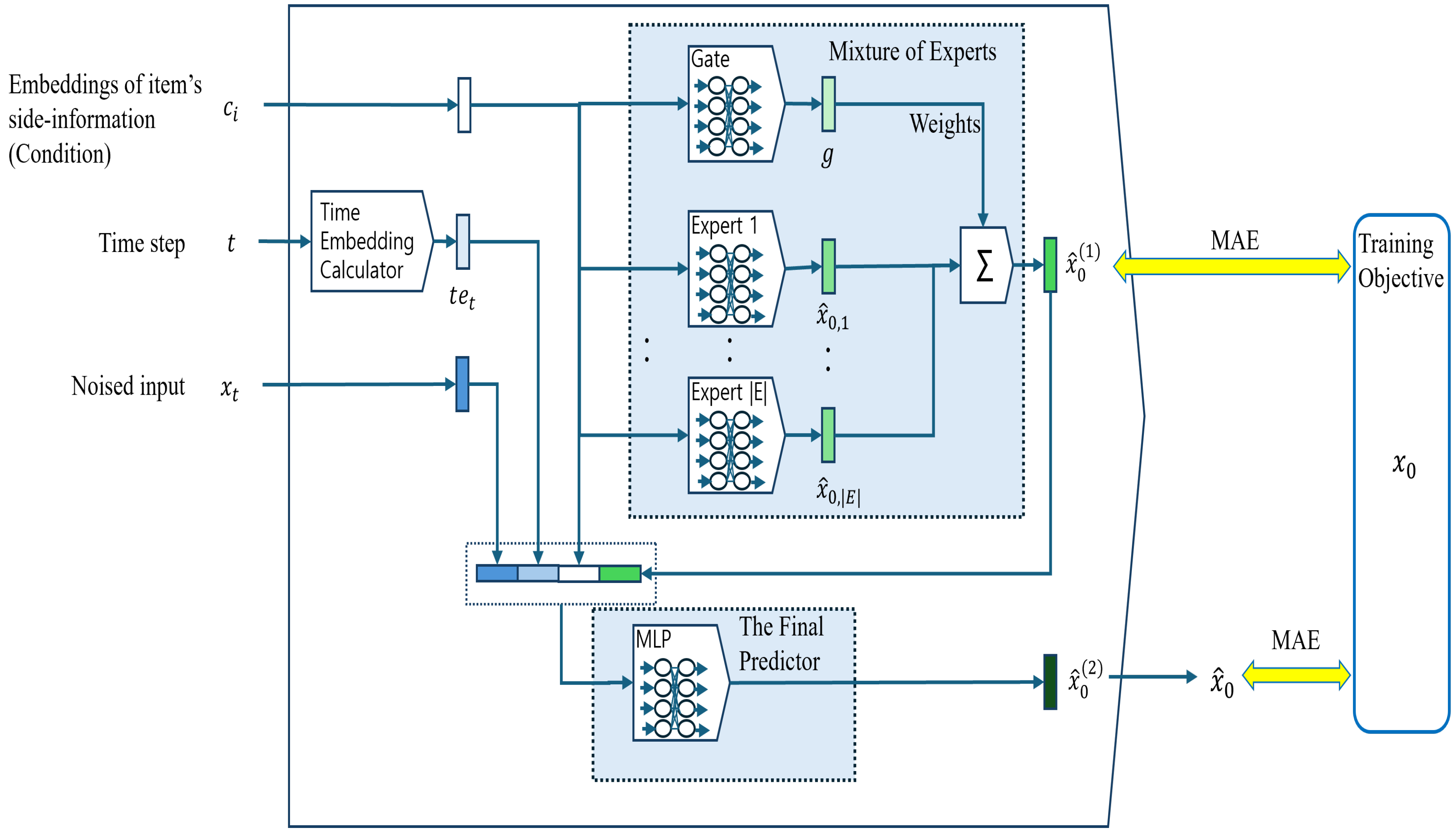
Network architecture: For the
-predictor
in Equation (
8), instead of simple MLPs used in previous works [
33,
38], we added a guideline predictor consisting of a Mixture-of-Experts network (MoE) [
58] to handle complex collaborative embedding distributions more effectively and adapt to diverse patterns with limited information on items’ side information. As shown in
Figure 2, side information
is given to the MoE to generate the first prediction of collaborative embedding
; then, with the inputs of DM,
is fed into the MLP as additional information to predict
, the collaborative embedding of cold item
.
The MoE network consists of the gate network represented in Equation (
11) and multiple experts
that have the same network structure described in Equation (
12), but different parameters are learned from each other.
where
indicates the gate vector whose elements represent the weights assigned to individual experts’ output.
,
, and
indicate the gate network’s weight matrix, bias, and the sigmoid activation function, respectively.
where
and
represent the weight matrix and bias of individual expert
e. We chose a single-layer linear transformation without an activation function as the expert network because our pre-experiments showed that the configuration mentioned above shows better performance than more complicated non-linear networks, which is also supported by other works [
20,
59].
The first prediction
for
is calculated by the weighted sum of the experts’ outputs, as represented in Equation (
13).
where
and
represent the value of the
i-th element of
g and the hyperbolic tangent activation function, respectively.
With
,
,
, and the time step embedding [
60]
, which is related to time step
t, are concatenated and passed to the three-layer MLP to calculate the final prediction
for
. The network structure of the MLP is represented in Equations (
14)–(
16).
where
and
represent the weight matrix and bias of the first layer of the MLP.
indicates the swish activation function [
61].
where
and
represent the weight matrix and bias of the
l-th layer of the MLP. The only difference in the network structure between the second and third layers is the existence of the activation function. We attached a linear transformation layer as the third layer because the value of collaborative embeddings does not indicate the probability, and we do not have concrete prior knowledge about its range.
Training: The quality of
is important because the MLP that calculates the final prediction exploits the prediction of the MoE as its prediction guide. To improve the prediction accuracy of
, we adopted the objective function in Equation (
17) instead of Equation (
10) in Algorithm 1.
where
indicates the L1-norm. Instead of MSE, we adopted MAE because the scale of the element of the embedding vector that we want to predict is small, and MAE forces the model to reduce small prediction errors. We give the fixed weight to each error in Equation (
17) to keep the model simple because our pre-experiments achieved the best performance with the configuration.
Inference: We can generate the collaborative embedding of the cold item by calculating in Algorithm 2 with as the input condition c.
3.3. Second-Phase Refiner
The refiner’s purpose in the second phase is to reduce the error that may be caused by the lack of user-side information or coarse side information of cold items by adjusting the ground-truth user collaborative embeddings and the generated item collaborative embeddings to predict more accurate user–item interactions.
Figure 3 shows the architecture of the refiner (Refiner). The ground-truth user collaborative embeddings
, generated item collaborative embeddings
, and items’ side information
are given. With the information provided, the Refiner calculates the recommendation score
which is proportional to the probability of interaction between user
u and item
i by calculating Equation (
18) with the refined user vector
and item vector
. The Refiner adopts two sub-networks: one for users and one for items. The user-side sub-network that calculates
is represented in Equation (
19).
where
, and
represent weights and biases of the first and second layer, respectively.
indicates the batch normalization [
62].
The item-side sub-network comprises the two layers represented in Equations (
20) and (
21).
where
and
, and
represent weights and biases of the first and second layers, respectively. At the inference time,
indicates the predicted collaborative embedding of the cold item calculated by the DM-based generator. We designed each of the two layers as a collaborative embedding refiner, which refines
based on the side information
and the output of the previous layer as guidelines.
Training: To train the Refiner, we use the interaction information
that is used to train the base recommender and the ground-truth item collaborative embeddings
calculated by the base recommender. For each positive interaction of user
u whose value of
is one, five negative user–item interactions whose value of
is zero are sampled. The sets of positive and negative interactions are joined to create the training dataset
. With
, the Refiner is trained to minimize the objective function represented in Equation (
22). The details of the training procedure are found in Algorithm 3.
| Algorithm 3 Refiner Train |
Input: Dataset , the sets of ground-truth user, item, generated item collaborative embeddings, and items’ side information: , , , and
Output: Trained model parameter
- 1:
Initialize with random values - 2:
while is not converged do - 3:
Randomly sample a batch - 4:
for all do - 5:
Extract , , , and from , , , and , respectively - 6:
Calculate and by using Equations ( 19)–( 21). - 7:
Calculate by using Equation ( 18) with and - 8:
Calculate loss by using Equation ( 22) - 9:
Update using gradient descent with - 10:
end for - 11:
end while
|
When we calculate
, following the ideas of Wang et al. [
20] and Volkovs et al. [
19], input
for the item-side sub-network represented in Equations (
20) and (
21) is sampled by Equation (
23). By allowing the network access to the ground-truth and generated embeddings alternately for the given side information, we expect the model to more accurately guess the ground-truth embeddings based on the generated embedding under the given side information.
Inference: The Refiner calculates refined user embeddings
from users’ ground-truth collaborative embeddings. Similarly, refined item embeddings
are calculated with the generated collaborative embeddings and side information of cold items as input. Once calculated, we can store the two kinds of embeddings in the system. For an arbitrary user
u and cold item
i pair, we can calculate
by using Equation (
18) with
and
. The ordered recommendation list of
k-items for user
u,
, is calculated by sorting the top
k items that have the highest
scores in descending order.







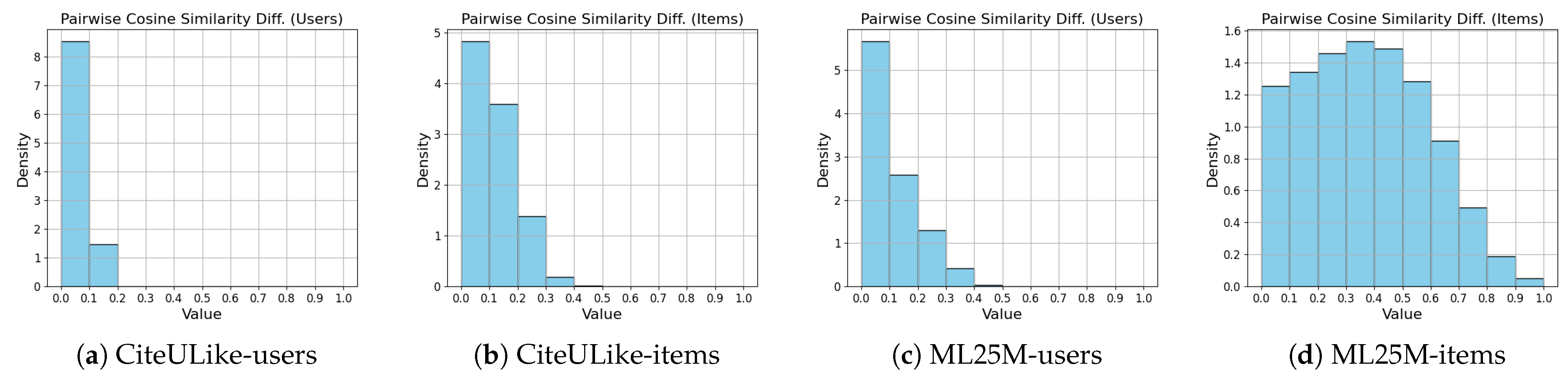
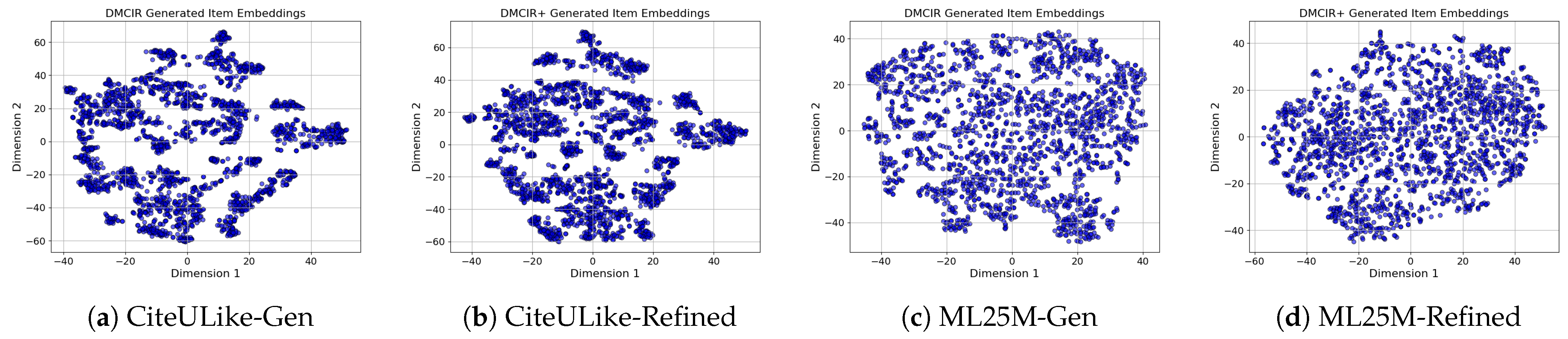

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}