1. Introduction
With the advancement of high-performance computing, the Internet of Things, and artificial intelligence technologies, robotic arms have been widely applied in areas such as automated production, urban security and services, and space exploration, continuously progressing toward the intelligent objectives of self-learning and self-regulation [
1]. In most cases, robots can effectively avoid the static obstacles present in various environments. Nevertheless, the utilized algorithms exhibit insufficient adaptability to dynamically changing obstacles, making it challenging to quickly and accurately avoid them [
2]. Probability sampling-based motion planning algorithms such as Rapid Random Tree (RRT) can swiftly search high-dimensional spaces; however, their limited environmental exploration ability leads to poor performance in handling dynamic obstacles and complex tasks. Therefore, in this context, finding the right training algorithm is important [
3,
4]. A combination of the Artificial Potential Field (APF) algorithm with numerical methods based on the Jacobian matrix has been employed to address obstacle avoidance-based path-planning in unknown environments [
5].
However, due to the aforementioned limitations of traditional algorithms in dynamic environments, academic circles are paying more and more attention to the development of reinforcement learning-based approaches [
6].
The rapid advancements in deep learning and computational capabilities have made deep reinforcement learning a reality, which is progressively being employed in domains such as gaming, robot navigation, and industrial production [
7]. DeepMind has developed models such as AlphaZero based on Deep Reinforcement Learning (DRL) [
8], which defeated world-class chess players in competitions, demonstrating that this technology can achieve a superhuman performance in complex environments. To address the challenges of non-Markovian tasks in multi-agent systems, one study proposed a synchronized decentralized training paradigm based on GR(1) specifications [
9]. By decomposing the synthesized GR(1) strategies into individual reward structures, this approach guides the multi-agent reinforcement learning (MARL) process, thereby effectively preserving the safety and liveness properties of the system. DRL has made significant strides not only in academia, but also in industry. For instance, IBM’s artificial intelligence system Watson employs deep reinforcement learning techniques to assist doctors in diagnosing cancer. Furthermore, in areas such as inverted pendulum control and unmanned surface vehicle control [
10], DRL is considered one of the most promising cutting-edge artificial intelligence technologies.
Reinforcement learning has similarly garnered the interest of experts and scholars in the field of robotics, demonstrating exceptional performance in path-planning within complex environments in scenarios characterized by a lack of prior knowledge. For example, Liu et al. [
11] innovatively integrated digital twin technology with DRL and proposed a multitasking training approach based on the twin synchro-control (TSC) scheme to enhance the control performance of humanoid robot arms. A data acquisition system was developed to collect human joint angle data, which served as a prior knowledge input for DRL, thereby optimizing the reward function of the deep deterministic policy gradient (DDPG) algorithm and improving the learning stability and convergence speed. This approach was successfully applied in the humanoid robot BHR-6, enabling it to perform tasks that are challenging to train using existing methods. Sun et al. [
12] proposed an end-to-end navigation strategy based on causal reinforcement learning, which is learned directly from the data, bypassing the traditional mapping and planning steps, thereby improving the responsiveness of drones in obstacle avoidance and navigation tasks. To address the issue of local minima in robotic arm collision avoidance using Artificial Potential Field (APF), a study proposed a method that integrates APF with deep reinforcement learning (DRL) and improves Hindsight Experience Replay (HER) into HER-CA to enhance training efficiency [
13]. Wang et al. [
14] proposes a decision reconstruction network integrated into the SAC algorithm. This network dynamically reconfigures network layers to enable cross-layer information exchange, effectively mitigating gradient conflicts and addressing the optimization challenges caused by parameter-sharing in robotic multi-task reinforcement learning. Yadav et al. [
15] examined regularization-based methods like synaptic intelligence for sequential learning in offline RL, finding they reduce learning time and mitigate forgetting but offer limited knowledge transfer. The study proposed a deep reinforcement learning-based coverage path planning approach, using actor–critic methods to train mobile robots for exploration and full coverage [
16]. Zhao et al. [
17] introduced the Efficient Progressive Policy Enhancement (EPPE) framework, which integrates sparse and process rewards to improve DRL training efficiency and global optimality in path-planning.
Zhong et al. [
18] have used a welding robot path-planning method based on the DDPG algorithm to solve the path-planning problem in a high-dimensional continuous state and action space. Cao et al. [
19] proposed a multi-agent reinforcement learning approach for square shaft-hole assembly. The method designs a reward function based on the Decoupled Multi-Agent Deep Deterministic Policy Gradient (DMDDPG) algorithm and models the first three and last three joints of the robotic arm as a multi-agent system. Liu et al. [
20] proposed DRL-based path planning method incorporates a safety verification mechanism to achieve collision-free trajectories. However, it still has limitations such as fixed end-effector orientation and the requirement for a smaller threshold in trajectory merging. Wang Y. et al. [
21] introduced a method to control a mobile robotic arm to perform door-opening operations based on an improved Proximal Policy Optimization (PPO) algorithm. Wu et al. [
22] achieved the requirements of online trajectory-planning by training a strategy consisting of a feedforward neural network in the simulation environment. Lindner et al. [
23] employed the DDPG algorithm to optimize the static obstacle-avoidance performance of robotic arms; however, they did not extend their approach to dynamic obstacle environments. To address high-dimensional path-planning challenges, Prianto et al. [
24] proposed a path-planning algorithm based on the Soft Actor–Critic (SAC) framework, utilizing configuration space augmentation to manage the complex configuration spaces associated with multi-arm systems. They also incorporated the Hindsight Experience Replay (HER) technique to enhance the sampling efficiency, enabling the real-time and rapid generation of any end-to-end shortest path. Singla et al. [
25] combined recurrent neural networks with temporal attention processes and deep reinforcement learning, allowing agents to remember important contextual data in order to prevent collisions. However, the extensive operational space of robotic arms makes it challenging to quickly obtain successful samples, causing DRL algorithms to expend significant time on ineffective exploration and resulting in slow convergence rates. To mitigate this issue, researchers have proposed leveraging “expert guidance” to accelerate the convergence of DRL algorithms. Xu et al. [
26] developed a strategy for axis–hole assembly problems guided by impedance control algorithms assisted by the DDPG for the correction of trajectories. Rahmatizadeh et al. [
27] used a deep neural network controller based on a Long Short-Term Memory (LSTM) network to generate trajectories. At the same time, a mixture density network (MDN) was used to calculate the error signal to adapt to multimodal demonstration data. Through imitation learning, the robotic arms were able to reasonably plan paths to complete the picking and placing of objects. Chen et al. [
28] designed a comprehensive reward function that combines dynamic obstacle avoidance and target proximity, which was integrated with the priority experience replay (PER) approach to improve the utilization of samples, finally allowing for the realization of real-time path-planning. Li et al. [
29] integrated the APF and DDPG algorithms, using approximate poses derived from the APF algorithm as expert guidance. They implemented a phased approach to obstacle-avoidance trajectory planning, where the DDPG algorithm dominated training during the obstacle-avoidance phase and the approximate poses from APF guided DDPG training during the target-planning phase. Additionally, they proposed a guiding mechanism to connect the control outputs of the two phases, thereby efficiently training a policy model tailored to address the research problem at hand.
However, trajectory-planning approaches for robotic arms based on DRL methods still encounter challenges in achieving convergence and conducting efficient explorations, particularly within unstructured work environments that feature both dynamic and static obstacles. The core issue lies in managing a substantial amount of failed explorations and sparse rewards, which result in training failure and make it difficult to learn effective strategies.
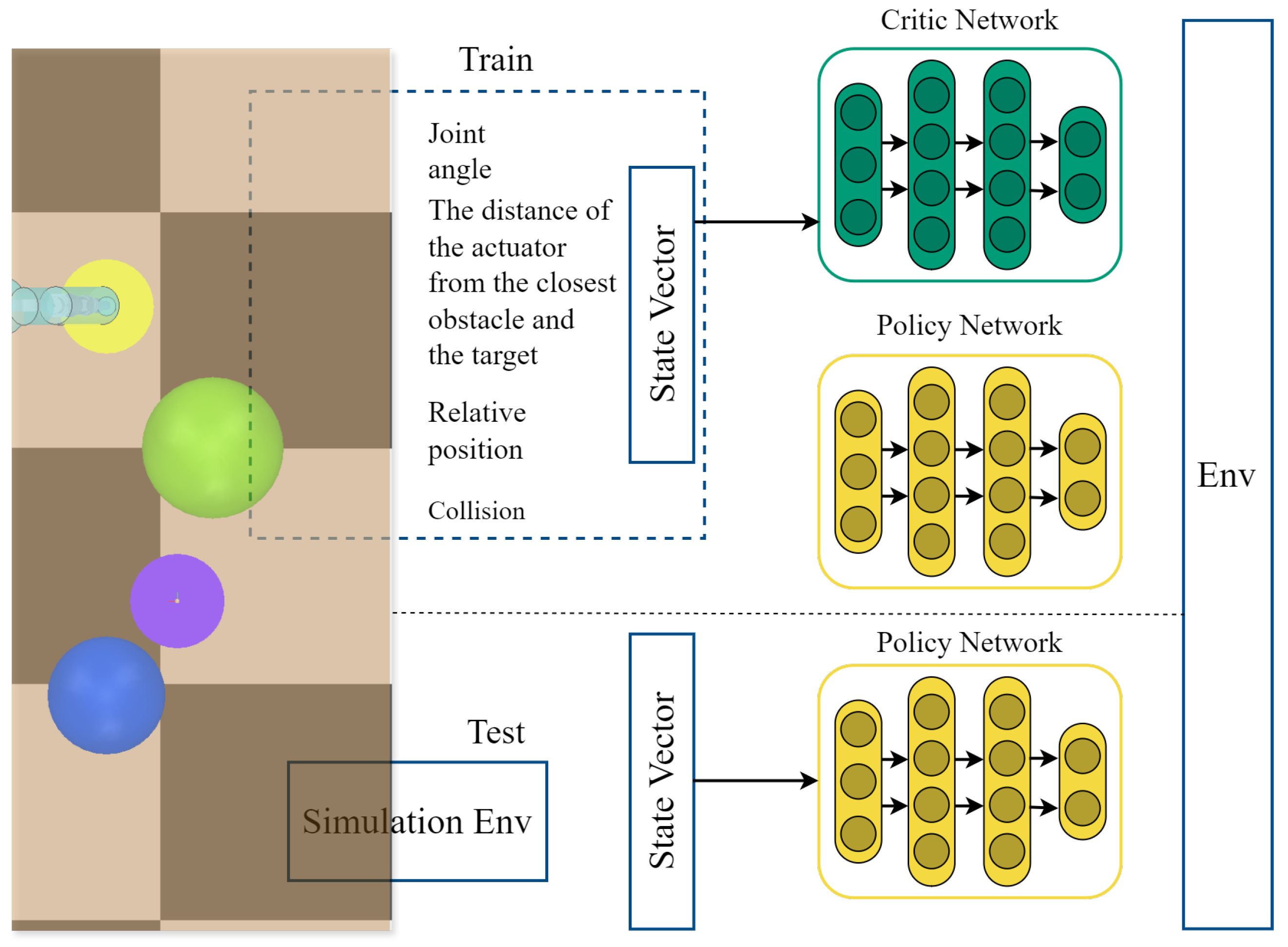
In order to solve the problem in which robot arms face difficulties in avoiding obstacles and reaching the target point in environments characterized by dynamic obstacles, we propose a new path-planning method based on reinforcement learning. Through designing a dynamic exploration guidance mechanism and an adaptive obstacle avoidance reward function, we optimize the robotic arm’s performance in terms of path-planning. The overall environmental structure is illustrated in
Figure 1. During the training process, the policy network receives the state vector as input and outputs the selected action; the critic network receives the state vector and action as input and outputs a value function that evaluates the expected reward or value of selecting the action in the state. During the testing process, the state vector obtained from the simulation environment is input into the policy network to obtain the selected action. This study implements a path planning strategy that ensures that the robotic arm remains stable during learning, and evaluates the effectiveness of this strategy in environments featuring dynamic obstacles.
3. Method
The state space and action space for the dynamic obstacle-avoidance path-planning of robotic arms are explained in detail in this section. We also list the adaptive reward function and the dynamic exploration guidance mechanism. As illustrated in
Figure 3, in order to use the MDP to solve the robotic arm path-planning problem discussed in this research, we must specify the interaction process between the algorithm and the simulation environment.
3.1. State Space
In a real working environment, the state information can be vast (and even infinite), making it impractical to enumerate all possible states. Therefore, in practical applications, key features are usually extracted for representation, in order to reduce the computational complexity and improve learning efficiency. In DRL, state information is not only important for the agent to perceive the environment, but also directly affects its decision-making process and the evaluation of long-term rewards. As such, reasonable state design can significantly improve the convergence, convergence speed, and final performance of the algorithm.
This study aims to train an agent to autonomously control the joint motion of a six-axis robot arm, while avoiding collisions and getting as close as possible to a specified target. The state space
can be represented by Equation (
5):
where
denotes the joint angles of the end effector;
represents the Cartesian position of the end effector’s reference coordinate system relative to the target coordinate system; the scalar
indicates the Euclidean distance between the end effector and the origin of the target coordinate system; and
is the shortest Euclidean distance between the end effector and the two types of obstacles. The final component—collision, which can be obtained via the CoppeliaSim API function—is a Boolean value that indicates whether the manipulator has collided with any environmental obstacles.
3.2. Action Space
The agent in the environment is a 6-DOF welding robot arm. For the motion control of the robot arm, the control strategy of the agent adopts the velocity control method, using the joint velocity as the control input, in order to achieve the real-time adjustment and trajectory optimization of the robot arm in the continuous action space. This method can dynamically adjust the angular velocity of each joint according to the current state, such that the robot arm moves along the optimal trajectory to minimize the distance between the end effector and the target position. Therefore, the action space is defined as follows:
In this context, denotes the target angular velocity of each servo motor–driven rotational joint within its allowable range. The dimension of the action space is 6.
3.3. Reward Signal
To address the issue of sparse rewards in DRL-based trajectory-planning for robotic arms within dynamic environments, this study introduces an adaptive reward function that seamlessly integrates existing reward mechanisms with energy function constraints, drawing on the principles of artificial potential field methods and energy functions. This adaptive function facilitates a smooth transition between the two reward mechanisms and carries out dynamic adjustments according to the distance between the end effector and the obstacle to ensure that the path-planning result is both safe and efficient:
Specifically,
is designed such that, when the end effector is sufficiently distant from obstacles,
serves as the dominant factor; when the distance between the end effector and an obstacle falls below the critical distance
, the energy function takes precedence.
can be expressed as follows:
where
It is evident that the
function yields a smooth transition from 0 to 1: when
is large,
approaches 1; meanwhile, when
is small, it approaches 0. Here,
serves as a tuning parameter that adjusts the smoothness of the reward mechanism.
is designed to prompt the robotic arm to accomplish the task, which mainly includes the following aspects:
The first term on the right-hand side of Equation (
11) is designed to guide the end effector toward a specific target position. It is defined based on the difference in the end effector–-target distance between the current step and the previous step:
In robotic arm path-planning tasks, we do not necessarily expect the end-effector to reach the designated location in a single step every time; instead, a gradual approach strategy is adopted. Specifically, the end effector is controlled to move incrementally at each step, gradually closing in on the target position. In designing the reward feedback, the distance between the end effector’s current position and the target point is introduced as a key parameter. Compared with relying solely on a one-step Euclidean distance, this reward function may slow down the movement process, yet it effectively reduces control complexity and meets the path-planning objective under higher-precision requirements.
Furthermore, in path-planning, precision and efficiency often impose mutual constraints. To enhance the reward mechanism’s effectiveness, when the current state nears boundary conditions (e.g., when the distance to the target point is relatively small), each slight movement in the correct direction should receive a stronger positive reward. This approach guides the robotic arm to gradually refine its path, ultimately achieving high-precision control of the target position.
The second term,
, is the obstacle avoidance reward function designed to guide the robotic arm in evading obstacles:
Here, represents the smallest gap between the robotic arm and obstacles, and denotes the decay rate of the reward function.
The third term,
, is the termination reward function, primarily designed to reward the achievement of the target and collisions with obstacles:
Considering the complexity of dynamic environments, the likelihood of collisions during the initial phases of training is substantially higher than that of reaching the target. Consequently, the reward for successfully attaining the target should be several times greater than the penalty imposed for collisions, and the reward is set to zero when the target is not achieved.
3.4. Dynamic Exploration Guidance Mechanism
There are two main challenges regarding path-planning in dynamic obstacle avoidance tasks: one is the need to avoid collisions with obstacles, and the other is the need to successfully reach the specified target point. However, it is very complicated to deduce the relationship between the state space and the action space from the perspective of the agent. This is because the state space is usually large and continuous, especially in a dynamic environment, and the agent must not only deal with the current state, but also predict and react to possible changes. In order to learn how to choose the appropriate action from the current state, the agent usually requires a large number of training iterations and calculations. This process may involve billions of training rounds and calculations, which is very time-consuming and computationally intensive for real-world applications. Therefore, in order to solve this problem, a better approach is to transform the infinite state space into a finite state space. Specifically, by limiting the range of states, the originally very large or continuous state space can be simplified into a finite set.
Consequently, it is difficult to directly start training the robot path-planning model using reinforcement learning algorithms. By restricting the state space, the agent can focus on exploring only those states that are relevant to the path-planning task, which is crucial for ensuring efficient convergence and learning. This approach excludes irrelevant and extraneous states, thereby simplifying the agent’s decision-making process. Rather than being overwhelmed by an unlimited and irrelevant state space, the agent concentrates on pertinent states, resulting in more effective decision making and faster learning. Therefore, implementing dynamic policy selection enables quicker convergence during training. Through the combination of a guiding term with stochastically sampled actions that include exploration noise from deep reinforcement learning algorithms, the selected action is dynamically integrated. Due to the presence of obstacles in the working environment, relying solely on the velocity output
generated by the inverse kinematics (IK) module is insufficient to achieve effective obstacle avoidance. To address this limitation, this paper incorporates an additional action term at produced by a deep reinforcement learning (DRL) policy network. This action serves as a compensatory component to the IK output, guiding the manipulator to avoid obstacles while maintaining goal-directed motion. The resulting hybrid action formulation is given by
where
denotes the time step duration. This formulation enables the manipulator to adaptively adjust its trajectory in response to environmental constraints while efficiently progressing toward the target. We introduced the dynamic scale factor to adjust the proportion of dynamic exploration guidance mechanism:
In addition, when operating a robotic arm manually, the speed of operation slows down as the arm approaches the target point to maintain accuracy. Similarly, in robotic arm control, the movement step size should gradually decrease to ensure a certain level of precision. Therefore, the agent’s joint angles are controlled as follows:
In this context, rate is a dynamic scaling factor that increases rapidly during the initial phase and slows its growth in the later stages; Current_episode and Max_episode denote the current and maximum number of training episodes, respectively, and
refers to a randomly sampled action augmented with exploration noise. The training workflow incorporating the dynamic exploration guidance strategy is illustrated in
Figure 4.
By dynamically adjusting the scaling factor, the initial phase of training significantly increases the probability of the robotic arm obtaining positive samples, effectively preventing the waste of training resources caused by ineffective exploration and alleviating the issue of sparse rewards in the early stages. As the number of training iterations increases, the scaling factor gradually grows, diminishing the influence of inverse kinematics, while the proportion of randomly sampled actions markedly rises, resulting in greater randomness in the robotic arm’s action selection. Building on the sufficient number of positive samples obtained from the preliminary training, the model achieves efficient convergence optimization, progressively mastering the ability to realize path-planning in dynamic obstacle-avoidance environments.
5. Discussion
In this study, we proposed a reinforcement learning (RL)-based path-planning approach for a robotic manipulator in dynamic obstacle-avoidance tasks, integrating inverse kinematics (IK) with a dynamic exploration guidance mechanism. Path-planning under dynamic conditions involves two fundamental challenges: collision-free navigation around obstacles and successful arrival at designated targets. Due to the large and continuous nature of the state space in dynamic environments, traditional reinforcement learning approaches often require significant computational resources and extensive training iterations to deduce the state-action relationships effectively.
To overcome these challenges, we introduced a novel hybrid action formulation that combines the deterministic velocity output from an IK module with an adaptive compensatory action generated by a deep reinforcement learning (DRL) policy network. Specifically, this compensatory action dynamically guides the manipulator to effectively avoid obstacles while maintaining goal-directed motion. Furthermore, our method incorporates a dynamic scaling factor to adaptively modulate exploration intensity. This scaling factor rapidly increases at the early training stages, promoting effective exploration and preventing inefficient exploration, and gradually slows down in later stages to refine the manipulator’s movements and decision-making precision. Additionally, the designed adaptive reward mechanism derived from an energy function further supports effective policy training by improving the exploration–exploitation balance.
The effectiveness of our proposed method was clearly demonstrated through rigorous comparisons with traditional DRL algorithms. The experimental results indicate that our improved SAC algorithm achieved an average success rate of 86.65%, significantly higher than the 75.25% success rate of traditional SAC. Likewise, our improved DDPG method reached a success rate of 80.56%, markedly surpassing the traditional DDPG’s 71.33%. Moreover, the improved algorithms exhibited considerably lower reward and step variances, implying more stable and robust performance. Specifically, the improved SAC and DDPG recorded reward variances of 4.1266 and 6.6281, respectively, compared to their traditional counterparts (8.4654 and 11.8709). Step variances also decreased significantly from 20.55 to 8.27 (SAC) and from 27.57 to 11.90 (DDPG).
The superior performance of the proposed approach compared to traditional methods can be attributed primarily to the underlying strategy of transforming an infinite or extensive state space into a manageable finite subset. Traditional reinforcement learning methods often suffer from inefficient convergence due to their exhaustive exploration of irrelevant states, which contributes to higher variance and reduced success rates. In contrast, our dynamic exploration guidance, combined with adaptive reward-shaping and IK-based policy refinement, significantly narrows the exploration scope. This targeted approach not only accelerates convergence but also ensures more informed and precise decision-making, substantially enhancing the robot’s real-time path-planning capabilities.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}