
BEVCorner: Enhancing Bird’s-Eye View Object Detection with Monocular Features via Depth Fusion



Abstract
1. Introduction
- We introduce a novel framework, BEVCorner, designed for BEV object detection. It integrates BEV features and monocular features using a depth fusion module.
- We explore four fusion techniques—direct replacement, weighted fusion, region-of-interest refinement, and hard combine—to balance the strengths of monocular and BEV depth estimation.
- Through extensive experiments on the NuScenes [3] dataset, we demonstrate BEVCorner’s potential, achieving a 53.21% NDS when leveraging ground-truth depth supervision. While our baseline result of 38.72% NDS lags behind BEVDepth due to challenges in monocular pipeline alignment, our upper-bound analysis highlights the promise of camera-only fusion for resource-constrained scenarios.
2. Related Work
2.1. Monocular 3D Object Detection
2.2. Multi-View 3D Object Detection
2.3. Fusion Techniques in 3D Object Detection
2.4. Depth Estimation in 3D Object Detection
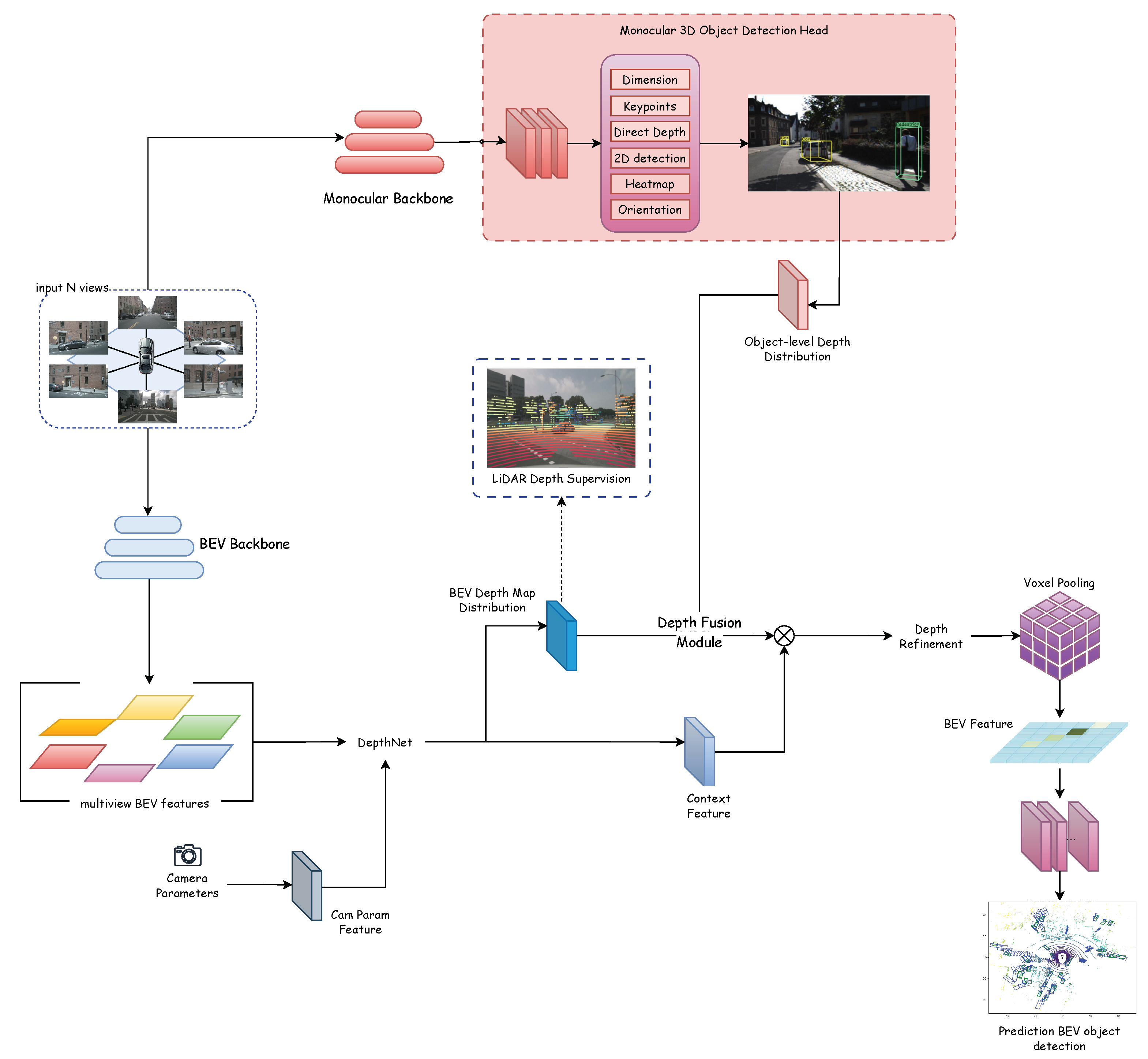
3. BEVCorner
3.1. Baseline and Motivation
3.2. Overall Architecture
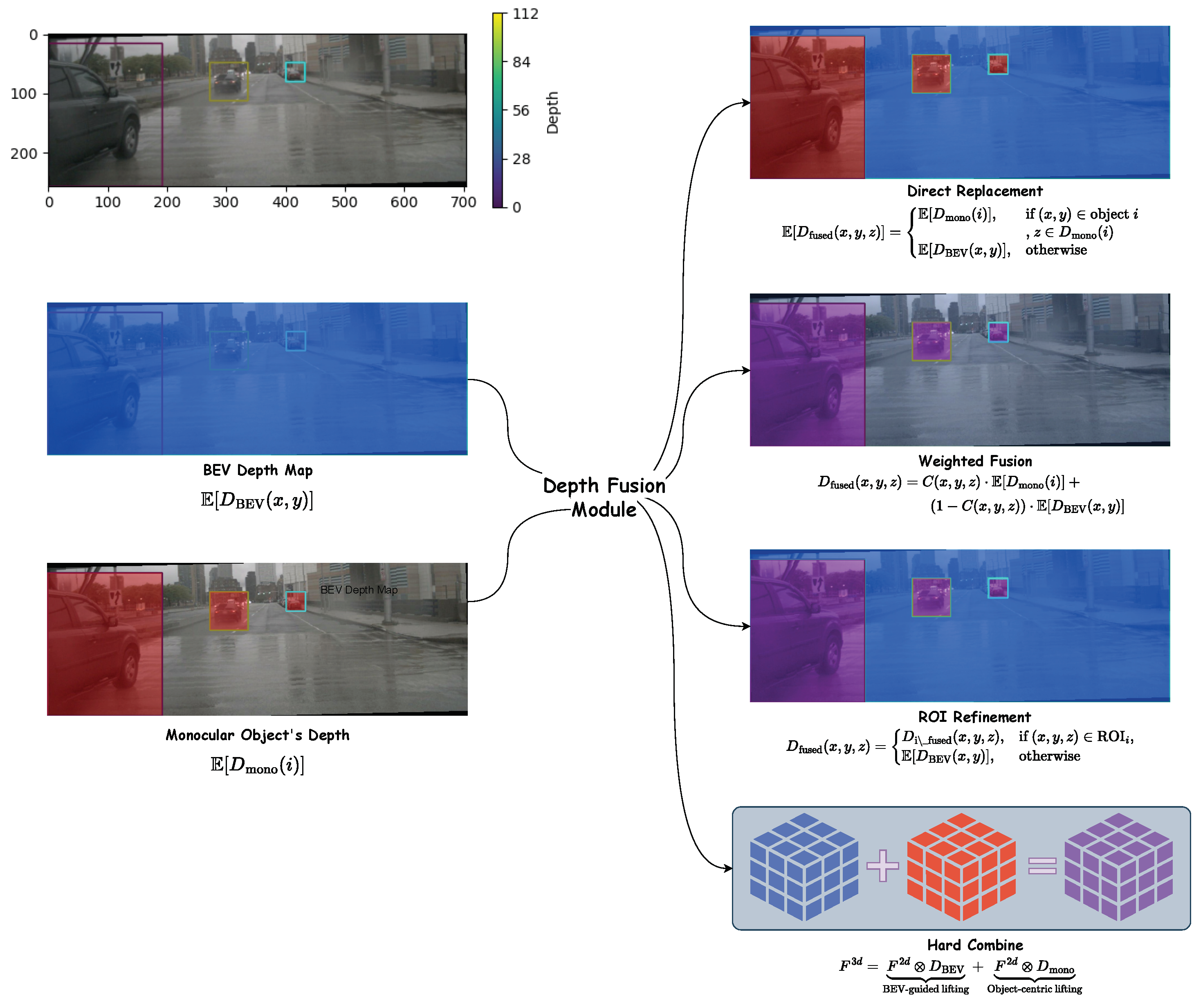
3.3. Depth Fusion Module
- Depth map ( from multi-view LiDAR supervision of BEVDepth): A base layer that provides a soft depth distribution over each pixel, or the overall depth estimate for the entire scene.
- Object Depth ( from monocular image of MonoFlex): Provides accurate, object-specific depth estimates.
- Direct Replacement
- Weighted Fusion
- Region-of-Interest Refinement
- Hard Combine
4. Experiments
4.1. Experimental Setup
4.1.1. Dataset and Metrics
4.1.2. Implementation Details
4.1.3. Training Protocol
4.1.4. Loss Calculation
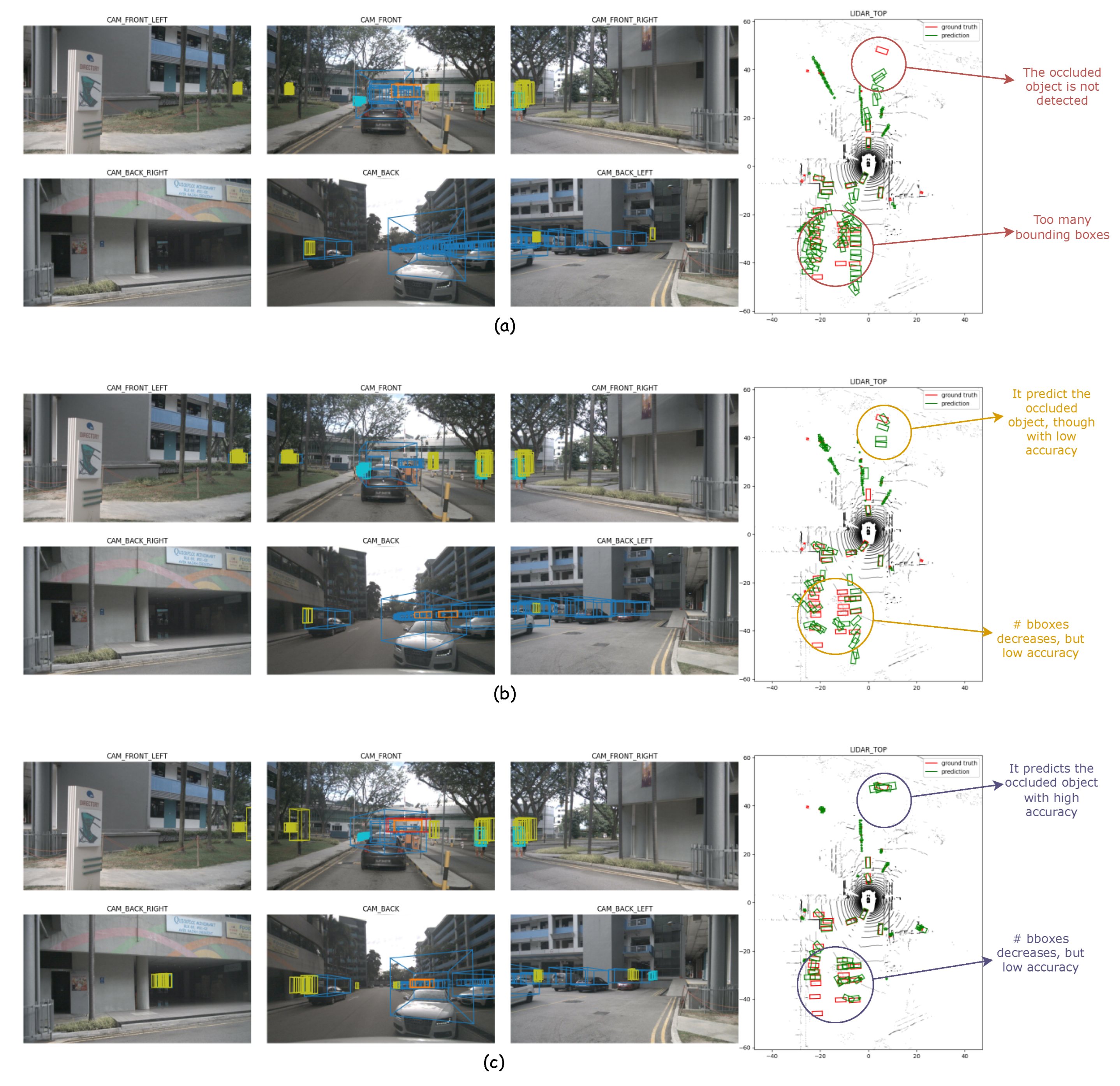
4.2. Ablation Study
4.2.1. Depth Fusion Module
4.2.2. Upper Bound Performance Estimation
4.2.3. Predictive Capacity of Object Orientation Model
4.2.4. Runtime and Efficiency
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, Y.; Lu, J.; Zhou, J. Objects are different: Flexible monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3289–3298. [Google Scholar]
- Li, Y.; Ge, Z.; Yu, G.; Yang, J.; Wang, Z.; Shi, Y.; Sun, J.; Li, Z. Bevdepth: Acquisition of reliable depth for multi-view 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1477–1485. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11621–11631. [Google Scholar]
- Luo, S.; Dai, H.; Shao, L.; Ding, Y. M3dssd: Monocular 3d single stage object detector. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 6145–6154. [Google Scholar]
- Huang, K.C.; Wu, T.H.; Su, H.T.; Hsu, W.H. Monodtr: Monocular 3d object detection with depth-aware transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 4012–4021. [Google Scholar]
- Brazil, G.; Liu, X. M3d-rpn: Monocular 3d region proposal network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9287–9296. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Roh, M.C.; Lee, J.y. Refining faster-RCNN for accurate object detection. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 514–517. [Google Scholar]
- Li, Z.; Gao, Y.; Hong, Q.; Du, Y.; Serikawa, S.; Zhang, L. Keypoint3D: Keypoint-based and Anchor-Free 3D object detection for Autonomous driving with Monocular Vision. Remote Sens. 2023, 15, 1210. [Google Scholar] [CrossRef]
- Guan, H.; Song, C.; Zhang, Z.; Tan, T. MonoPoly: A practical monocular 3D object detector. Pattern Recognit. 2022, 132, 108967. [Google Scholar] [CrossRef]
- Chen, W.; Zhao, J.; Zhao, W.L.; Wu, S.Y. Shape-aware monocular 3D object detection. IEEE Trans. Intell. Transp. Syst. 2023, 24, 6416–6424. [Google Scholar] [CrossRef]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Wang, T.; Xinge, Z.; Pang, J.; Lin, D. Probabilistic and geometric depth: Detecting objects in perspective. In Proceedings of the Conference on Robot Learning, PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 1475–1485. [Google Scholar]
- Liu, Z.; Wu, Z.; Tóth, R. Smoke: Single-stage monocular 3d object detection via keypoint estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 996–997. [Google Scholar]
- Wang, T.; Zhu, X.; Pang, J.; Lin, D. Fcos3d: Fully convolutional one-stage monocular 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 1–17 October 2021; pp. 913–922. [Google Scholar]
- Ku, J.; Pon, A.D.; Waslander, S.L. Monocular 3d object detection leveraging accurate proposals and shape reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11867–11876. [Google Scholar]
- Chen, Y.; Tai, L.; Sun, K.; Li, M. Monopair: Monocular 3d object detection using pairwise spatial relationships. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 12093–12102. [Google Scholar]
- Simonelli, A.; Bulo, S.R.; Porzi, L.; Ricci, E.; Kontschieder, P. Towards generalization across depth for monocular 3d object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 767–782. [Google Scholar]
- Yan, L.; Yan, P.; Xiong, S.; Xiang, X.; Tan, Y. Monocd: Monocular 3d object detection with complementary depths. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 10248–10257. [Google Scholar]
- Weng, X.; Kitani, K. Monocular 3d object detection with pseudo-lidar point cloud. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Tao, C.; Cao, J.; Wang, C.; Zhang, Z.; Gao, Z. Pseudo-mono for monocular 3d object detection in autonomous driving. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3962–3975. [Google Scholar]
- Li, Y.; Bao, H.; Ge, Z.; Yang, J.; Sun, J.; Li, Z. Bevstereo: Enhancing depth estimation in multi-view 3d object detection with temporal stereo. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 1486–1494. [Google Scholar]
- Li, Z.; Wang, W.; Li, H.; Xie, E.; Sima, C.; Lu, T.; Yu, Q.; Dai, J. Bevformer: Learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers. In Proceedings of the Computer Vision—ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–18. [Google Scholar]
- Liu, F.; Huang, T.; Zhang, Q.; Yao, H.; Zhang, C.; Wan, F.; Ye, Q.; Zhou, Y. Ray denoising: Depth-aware hard negative sampling for multi-view 3d object detection. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 200–217. [Google Scholar]
- Wang, Z.; Huang, Z.; Gao, Y.; Wang, N.; Liu, S. Mv2dfusion: Leveraging modality-specific object semantics for multi-modal 3d detection. arXiv 2024, arXiv:2408.05945. [Google Scholar]
- Wang, S.; Liu, Y.; Wang, T.; Li, Y.; Zhang, X. Exploring object-centric temporal modeling for efficient multi-view 3d object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 3621–3631. [Google Scholar]
- Huang, J.; Huang, G.; Zhu, Z.; Ye, Y.; Du, D. Bevdet: High-performance multi-camera 3d object detection in bird-eye-view. arXiv 2021, arXiv:2112.11790. [Google Scholar]
- Huang, J.; Huang, G. Bevdet4d: Exploit temporal cues in multi-camera 3d object detection. arXiv 2022, arXiv:2203.17054. [Google Scholar]
- Yang, C.; Chen, Y.; Tian, H.; Tao, C.; Zhu, X.; Zhang, Z.; Huang, G.; Li, H.; Qiao, Y.; Lu, L.; et al. Bevformer v2: Adapting modern image backbones to bird’s-eye-view recognition via perspective supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 17830–17839. [Google Scholar]
- Liu, H.; Teng, Y.; Lu, T.; Wang, H.; Wang, L. Sparsebev: High-performance sparse 3d object detection from multi-camera videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 18580–18590. [Google Scholar]
- Lin, X.; Lin, T.; Pei, Z.; Huang, L.; Su, Z. Sparse4d: Multi-view 3d object detection with sparse spatial-temporal fusion. arXiv 2022, arXiv:2211.10581. [Google Scholar]
- Wang, Y.; Guizilini, V.C.; Zhang, T.; Wang, Y.; Zhao, H.; Solomon, J. Detr3d: 3d object detection from multi-view images via 3d-to-2d queries. In Proceedings of the Conference on Robot Learning PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 180–191. [Google Scholar]
- Zhang, H.; Liang, L.; Zeng, P.; Song, X.; Wang, Z. SparseLIF: High-performance sparse LiDAR-camera fusion for 3D object detection. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 109–128. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. Bevfusion: Multi-task multi-sensor fusion with unified bird’s-eye view representation. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2774–2781. [Google Scholar]
- Cai, H.; Zhang, Z.; Zhou, Z.; Li, Z.; Ding, W.; Zhao, J. Bevfusion4d: Learning lidar-camera fusion under bird’s-eye-view via cross-modality guidance and temporal aggregation. arXiv 2023, arXiv:2303.17099. [Google Scholar]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4604–4612. [Google Scholar]
- Xu, D.; Anguelov, D.; Jain, A. Pointfusion: Deep sensor fusion for 3d bounding box estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 244–253. [Google Scholar]
- Pang, S.; Morris, D.; Radha, H. CLOCs: Camera-LiDAR object candidates fusion for 3D object detection. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, Nevada, USA, 25–29 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10386–10393. [Google Scholar]
- Shin, K.; Kwon, Y.P.; Tomizuka, M. Roarnet: A robust 3d object detection based on region approximation refinement. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 2510–2515. [Google Scholar]
- Wang, Z.; Jia, K. Frustum convnet: Sliding frustums to aggregate local point-wise features for amodal 3d object detection. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1742–1749. [Google Scholar]
- Yang, Z.; Sun, Y.; Liu, S.; Shen, X.; Jia, J. Ipod: Intensive point-based object detector for point cloud. arXiv 2018, arXiv:1812.05276. [Google Scholar]
- Chen, Z.; Hu, B.J.; Luo, C.; Chen, G.; Zhu, H. Dense projection fusion for 3D object detection. Sci. Rep. 2024, 14, 23492. [Google Scholar] [CrossRef] [PubMed]
- Mouawad, I.; Brasch, N.; Manhardt, F.; Tombari, F.; Odone, F. View-to-Label: Multi-View Consistency for Self-Supervised 3D Object Detection. arXiv 2023, arXiv:2305.17972. [Google Scholar] [CrossRef]
- Lian, Q.; Xu, Y.; Yao, W.; Chen, Y.; Zhang, T. Semi-supervised monocular 3d object detection by multi-view consistency. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 715–731. [Google Scholar]
- Cetinkaya, B.; Kalkan, S.; Akbas, E. Does depth estimation help object detection? Image Vis. Comput. 2022, 122, 104427. [Google Scholar] [CrossRef]
- Liu, Y. Scalable Vision-Based 3D Object Detection and Monocular Depth Estimation for Autonomous Driving. Ph.D. Thesis, Hong Kong University of Science and Technology (Hong Kong), Hong Kong, China, 2024. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? the kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 3354–3361. [Google Scholar]
- Yu, F.; Wang, D.; Shelhamer, E.; Darrell, T. Deep layer aggregation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2403–2412. [Google Scholar]
- Ma, X.; Zhang, Y.; Xu, D.; Zhou, D.; Yi, S.; Li, H.; Ouyang, W. Delving into localization errors for monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4721–4730. [Google Scholar]
- Liu, X.; Xue, N.; Wu, T. Learning auxiliary monocular contexts helps monocular 3d object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 36, pp. 1810–1818. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Aspects | BEV Object Detection | Monocular Object Detection |
|---|---|---|
| Input Data | Typically uses LiDAR point clouds or fused multi-sensor data (e.g., LiDAR + camera). | Uses a single RGB camera image. |
| Depth Information | Directly available from LiDAR or depth sensors, providing accurate 3D spatial information. | Inferred from 2D images using monocular depth estimation, which may be less accurate. |
| Strengths |
✓ Precise depth and spatial data improve object positioning in 3D space. ✓ Objects appear at consistent scales in BEV maps. ✓ Ideal for tasks needing spatial awareness, like path planning. |
✓ Rich Semantic Information, e.g., detailed visual features (e.g., texture, color) to enhance classification. ✓ Requires only a single camera, lowering hardware costs. |
| Weaknesses |
- LiDAR data can miss distant or small objects due to sparsity. - Processing point clouds or BEV maps requires significant resources. |
- Struggles with accurate 3D localization due to inferred depth. - Occluded objects in the image plane are hard to detect. - Objects at different distances vary in size, complicating detection. - Performance drops in poor conditions (e.g., rain, darkness). |
| Typical Applications | Autonomous driving (e.g., obstacle detection, path planning), robotics (e.g., navigation in structured environments). | Surveillance and security, consumer electronics (e.g., smartphones, AR/VR), and low-cost autonomous systems. |
| Computational Cost | High, due to multi-cameras and processing large point clouds or multi-sensor fusion. | Lower, though depth estimation can increase complexity. |
| Configuration | mAP(%) ↑ | mATE ↓ | mASE ↓ | mAOE ↓ | mAVE ↓ | mAAE ↓ | NDS(%) ↑ |
|---|---|---|---|---|---|---|---|
| Baseline: BEVDepth [2] | |||||||
| Vanilla: non EMA + non CBGS + 1 key | 33.13 | 0.7009 | 0.2796 | 0.536 | 0.5533 | 0.2273 | 43.59 |
| BEVCorner (Ours) | |||||||
| direct_replacement (fixed) | 20.68 | 0.8725 | 0.2945 | 0.6675 | 0.8654 | 0.2516 | 30.83 |
| weighted_fusion (fixed) | 16.68 | 0.9176 | 0.3451 | 0.8296 | 1.2502 | 0.3679 | 23.74 |
| weighted_fusion (geometry) | 27.64 | 0.7372 | 0.2938 | 0.5690 | 0.6631 | 0.2465 | 38.72 |
| weighted_fusion (learned) | 21.87 | 0.8340 | 0.2930 | 0.6437 | 0.8314 | 0.2424 | 32.49 |
| roi_refinement (fixed) | 20.77 | 0.8652 | 0.2930 | 0.6594 | 0.8249 | 0.2420 | 31.54 |
| roi_refinement (geometry) | 26.65 | 0.7525 | 0.2930 | 0.5798 | 0.6975 | 0.2560 | 37.53 |
| roi_refinement (learned) | 22.67 | 0.8247 | 0.2914 | 0.6255 | 0.7853 | 0.2531 | 33.54 |
| hard_combine (fixed) | 23.32 | 0.7369 | 0.2945 | 0.5780 | 0.7504 | 0.2391 | 35.67 |
| Object | AP (%) ↑ | ATE ↓ | ASE ↓ | AOE ↓ | AVE ↓ | AAE ↓ |
|---|---|---|---|---|---|---|
| car | 0.385 | 0.599 | 0.170 | 0.262 | 0.909 | 0.252 |
| truck | 0.178 | 0.787 | 0.228 | 0.285 | 0.756 | 0.241 |
| bus | 0.322 | 0.714 | 0.227 | 0.190 | 1.259 | 0.320 |
| trailer | 0.117 | 1.111 | 0.270 | 0.560 | 0.478 | 0.189 |
| construction_vehicle | 0.031 | 1.090 | 0.542 | 1.144 | 0.133 | 0.390 |
| pedestrian | 0.272 | 0.755 | 0.299 | 0.985 | 0.622 | 0.325 |
| motorcycle | 0.295 | 0.643 | 0.272 | 0.715 | 0.838 | 0.246 |
| bicycle | 0.291 | 0.550 | 0.275 | 0.719 | 0.310 | 0.010 |
| traffic_cone | 0.429 | 0.545 | 0.368 | nan | nan | nan |
| barrier | 0.443 | 0.578 | 0.285 | 0.261 | nan | nan |
| Configuration | mAP (%) ↑ | mATE ↓ | mASE ↓ | mAOE ↓ | mAVE ↓ | mAAE ↓ | NDS(%) ↑ |
|---|---|---|---|---|---|---|---|
| Baseline: BEVDepth [2] | |||||||
| Vanilla: non EMA + non CBGS + 1 key | 33.13 | 0.7009 | 0.2796 | 0.536 | 0.5533 | 0.2273 | 43.59 |
| BEVCorner (Ours) | |||||||
| direct_replacement (fixed) | 55.79 | 0.4461 | 0.295 | 0.7014 | 0.8257 | 0.2566 | 52.65 |
| weighted_fusion (fixed) | 54.84 | 0.4705 | 0.3035 | 0.8963 | 1.079 | 0.2971 | 47.75 |
| weighted_fusion (geometry) | 43.11 | 0.5622 | 0.2972 | 0.6121 | 0.6978 | 0.2484 | 47.38 |
| weighted_fusion (learned) | 55.84 | 0.4466 | 0.2935 | 0.6796 | 0.8 | 0.2561 | 53.16 |
| roi_refinement (fixed) | 55.81 | 0.4463 | 0.2947 | 0.691 | 0.7998 | 0.259 | 53 |
| roi_refinement (geometry) | 45.88 | 0.536 | 0.2952 | 0.6245 | 0.7284 | 0.2625 | 48.47 |
| roi_refinement (learned) | 55.07 +21.94 | 0.45 −0.25 |
0.2919 +0.01 |
0.6627 +0.13 |
0.7727 +0.22 |
0.2561 +0.03 | 53.21 +9.62 |
| hard_combine (fixed) | 23.32 | 0.737 | 0.2945 | 0.578 | 0.7504 | 0.2391 | 35.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nathania, J.; Liu, Q.; Li, Z.; Liu, L.; Gao, Y. BEVCorner: Enhancing Bird’s-Eye View Object Detection with Monocular Features via Depth Fusion. Appl. Sci. 2025, 15, 3896. https://doi.org/10.3390/app15073896
Nathania J, Liu Q, Li Z, Liu L, Gao Y. BEVCorner: Enhancing Bird’s-Eye View Object Detection with Monocular Features via Depth Fusion. Applied Sciences. 2025; 15(7):3896. https://doi.org/10.3390/app15073896
Chicago/Turabian StyleNathania, Jesslyn, Qiyuan Liu, Zhiheng Li, Liming Liu, and Yipeng Gao. 2025. "BEVCorner: Enhancing Bird’s-Eye View Object Detection with Monocular Features via Depth Fusion" Applied Sciences 15, no. 7: 3896. https://doi.org/10.3390/app15073896
APA StyleNathania, J., Liu, Q., Li, Z., Liu, L., & Gao, Y. (2025). BEVCorner: Enhancing Bird’s-Eye View Object Detection with Monocular Features via Depth Fusion. Applied Sciences, 15(7), 3896. https://doi.org/10.3390/app15073896