

Does the Grammatical Structure of Prompts Influence the Responses of Generative Artificial Intelligence? An Exploratory Analysis in Spanish

 , , , and
, , , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Data Collection
2.2. Validation of the Evaluation Instrument
2.3. Procedure
- Introduction and Consent:
- Students were welcomed, and the study context and objectives were explained.
- Participants read an informed consent form, and those who agreed to participate provided their consent.
- Questionnaire Administration:
- The questionnaire was administered via Google Forms, allowing for efficient and anonymous data collection.
- Students completed the questionnaire using their personal devices (mobile phones or tablets) in the classroom, ensuring consistent technological conditions.
- The questionnaire included the following sections:
- Demographics: Collected data such as age, gender, educational institution, university program, year of study, and prior experience with ChatGPT to contextualize responses.
- Case Analysis: Presented a common scenario for all participants: preparing for a job interview in their field of study.
- Situation: You have a job interview for an internship at a company in your field of study. You need to be prepared for the possible questions you will be asked and how to answer them effectively.
- Instructions: Use ChatGPT to generate examples of common job interview questions and tips on how to answer them.
- Satisfaction Assessment: Measured the level of satisfaction with the responses generated by ChatGPT.
- Prompt Interaction:
- Students wrote their prompt in the questionnaire, copied it into the free version of ChatGPT (3.5), and pasted the AI’s response back into the form.
- Students evaluated their satisfaction with the response:
- If satisfied, the test concluded.
- If dissatisfied, they rewrote the prompt (up to a maximum of 7 iterations) until they were satisfied.
- Ethical Considerations:
- Participation was voluntary, with students free to withdraw at any time without consequences.
- Anonymity and confidentiality were guaranteed, with all data used exclusively for academic purposes.
- Data Analysis:
- After data collection, responses were analyzed using the Content Assessment Instrument, validated by expert judgment.
- A linguist with expertise in morphosyntax evaluated each response individually, and the results were tabulated for further analysis.
2.4. Data Analysis
3. Results
3.1. Subjective Judgment of the Prompt Written According to the Instructions for the Activity
3.2. Subjective Judgment of the Quality of the Response Given by the LLM
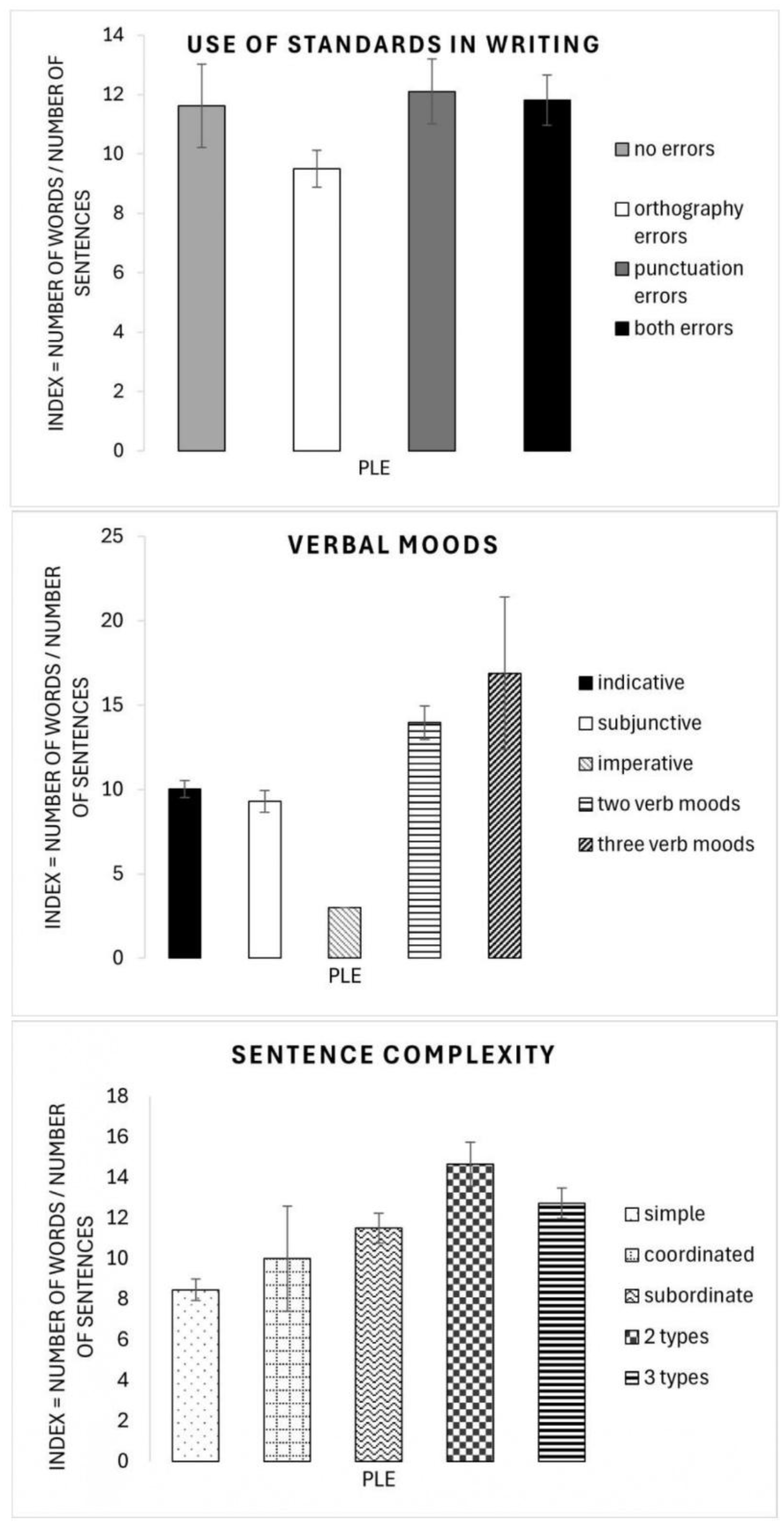
3.3. The Length of the Utterances of the Prompt
4. Discussion
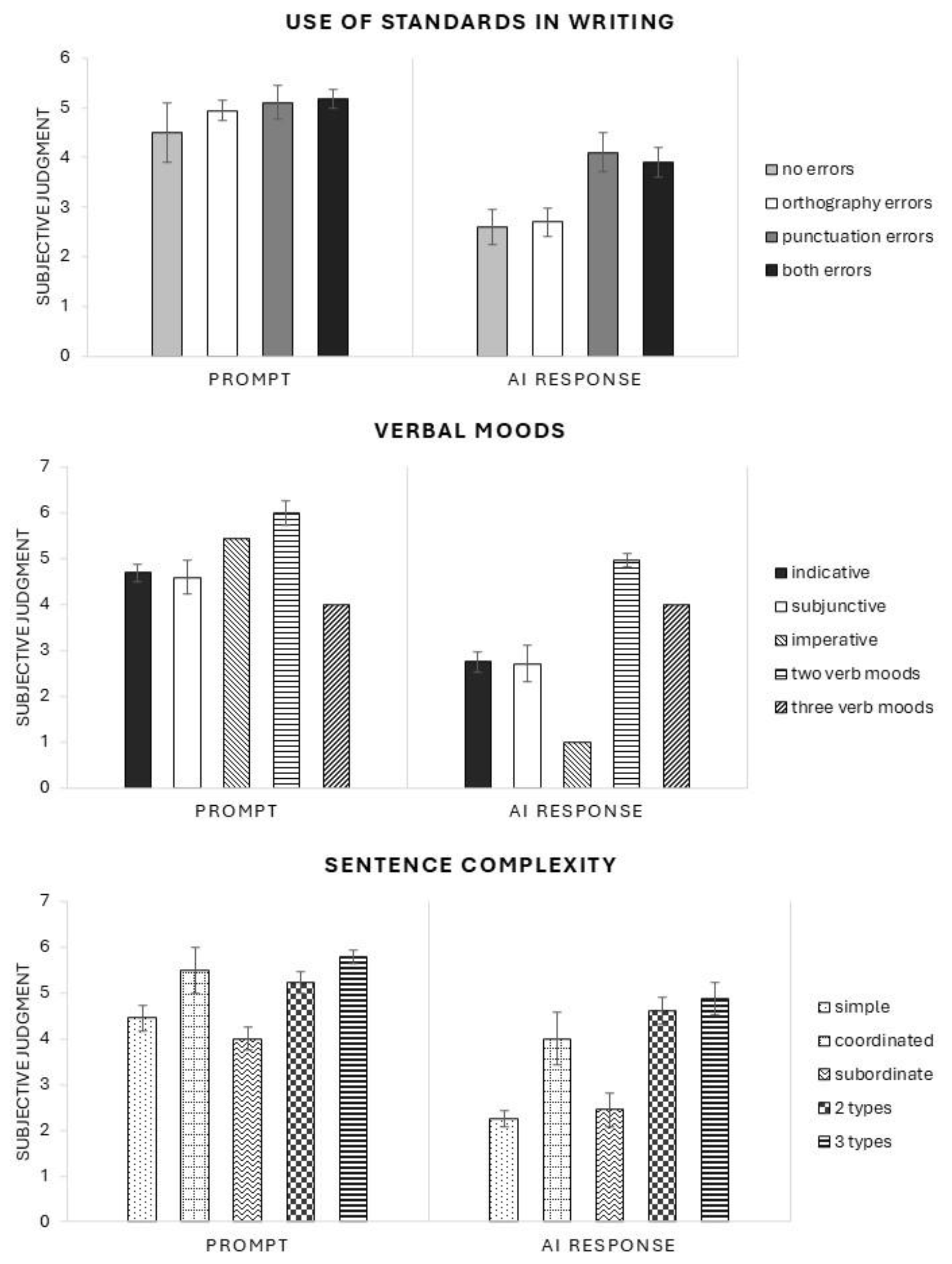
4.1. Punctuation and Orthography
4.2. Verbal Moods
4.3. Sentence Complexity
4.4. Implications for How to Objectively Evaluate a Prompt Written by an Adult
4.5. Implications of This Work in the Field of Higher Education
5. Conclusions
6. Limitations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| d | Mean | V | Vo = 0.50 | Lower | Upper | Vo = 0.70 | Decision | |
|---|---|---|---|---|---|---|---|---|
| A1 The student’s prompt demonstrates that they were able to follow the instructions given in the activity. | S | 3.75 | 0.92 | ✓ | 0.6461 | 0.9851 | ✕ | Reassess sufficiency |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 3.25 | 0.75 | ✕ | 0.4677 | 0.9111 | ✕ | Rewrite | |
| A2 The answer given by the AI is satisfactory according to the given prompt. | S | 3.75 | 0.92 | ✓ | 0.6461 | 0.9851 | ✕ | Revise sufficiency |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 3.00 | 0.67 | ✕ | 0.3906 | 0.8619 | ✕ | Rewrite | |
| B1 Record the number of words used in the question posed to the AI. | S | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| B2 Record the number of sentences used in the wording of the question posed to the AI. | S | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C1 There are orthographical errors in the wording of the prompt. | S | 2.25 | 0.42 | ✕ | 0.1933 | 0.6805 | ✕ | Insufficiency |
| R | 3.50 | 0.83 | ✓ | 0.552 | 0.953 | ✕ | Revise Relevance | |
| C | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C2 There are punctuation errors in the wording of the prompt. | S | 3.25 | 0.75 | ✕ | 0.4677 | 0.9111 | ✕ | Insufficiency |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C3 Students comply with colloquialisms and politeness in the writing of the prompt. | S | 2.75 | 0.58 | ✕ | 0.3195 | 0.8067 | ✕ | Insufficiency |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 3.75 | 0.92 | ✓ | 0.6461 | 0.9851 | ✕ | Revise writing | |
| D1 The indicative mode is present in the wording of the prompt. | S | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 3.00 | 0.67 | ✕ | 0.3906 | 0.8619 | ✕ | Rewrite | |
| D2 The subjunctive mood is present in the wording of the prompt. | S | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 3.00 | 0.67 | ✕ | 0.3906 | 0.8619 | ✕ | Rewrite | |
| D3 The imperative mood is present in the wording of the prompt. | S | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 3.00 | 0.67 | ✕ | 0.3906 | 0.8619 | ✕ | Rewrite | |
| D4 There are dual combinations of verb moods, i.e., at least two types in the wording of the prompt. | S | 3.25 | 0.75 | ✕ | 0.4677 | 0.9111 | ✕ | Insufficiency |
| R | 3.25 | 0.75 | ✕ | 0.4677 | 0.9111 | ✕ | Irrelevant | |
| C | 3.00 | 0.67 | ✕ | 0.3906 | 0.8619 | ✕ | Rewrite | |
| D5 The prompt uses three types of combined verb moods. | S | 3.25 | 0.75 | ✕ | 0.4677 | 0.9111 | ✕ | Insufficiency |
| R | 3.25 | 0.75 | ✕ | 0.4677 | 0.9111 | ✕ | Irrelevant | |
| C | 3.00 | 0.67 | ✕ | 0.3906 | 0.8619 | ✕ | Rewrite | |
| E1 There is a simple sentence in the wording of the prompt. | S | 3.75 | 0.92 | ✓ | 0.6461 | 1.0000 | ✕ | Revise sufficiency |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 3.25 | 0.75 | ✕ | 0.4677 | 0.9111 | ✕ | Rewrite | |
| E2 There is a coordinated sentence in the wording of the prompt. | S | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 3.25 | 0.75 | ✕ | 0.4677 | 0.9111 | ✕ | Rewrite | |
| E3 There is a subordinate sentence in the wording of the prompt. | S | 3.50 | 0.83 | ✓ | 0.552 | 0.953 | ✕ | Revise sufficiency |
| R | 3.50 | 0.83 | ✓ | 0.552 | 0.953 | ✕ | Revise relevance | |
| C | 3.25 | 0.75 | ✕ | 0.4677 | 0.9111 | ✕ | Rewrite | |
| E4 There are dual combinations of sentence types. | S | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | |
| R | 4.00 | 1.00 | ✓ | 0.7575 | 1.0000 | ✓ | ||
| C | 3.75 | 0.92 | ✓ | 0.6461 | 0.9851 | ✕ | Revise writing | |
| E5 Three types of combined sentences are used in the prompt. | S | 3.50 | 0.83 | ✓ | 0.552 | 0.953 | ✕ | Revise sufficiency |
| R | 3.50 | 0.83 | ✓ | 0.552 | 0.953 | ✕ | Revise relevance | |
| C | 3.00 | 0.67 | ✕ | 0.3906 | 0.8619 | ✕ | Rewrite |
References
- Roumeliotis, K.I.; Tselikas, N.D. ChatGPT and Open-AI Models: A Preliminary Review. Future Internet 2023, 15, 192. [Google Scholar] [CrossRef]
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.-B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A Family of Highly Capable Multimodal Models. arXiv 2024, arXiv:2312.11805. [Google Scholar]
- Wermelinger, M. Using GitHub Copilot to Solve Simple Programming Problems. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1, Toronto, ON, Canada, 15–18 March 2023; pp. 172–178. [Google Scholar]
- Perplexity. Perplexity AI. 2025. Available online: https://www.perplexity.ai (accessed on 7 January 2025).
- Anthropic. Claude. 2024. Available online: https://anthropic.com (accessed on 27 March 2025).
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual Instruction Tuning. Adv. Neural Inf. Process. Syst. 2023, 36, 34892–34916. [Google Scholar]
- Bryant, C.; Yuan, Z.; Qorib, M.R.; Cao, H.; Ng, H.T.; Briscoe, T. Grammatical Error Correction: A Survey of the State of the Art. Comput. Linguist. 2023, 49, 643–701. [Google Scholar] [CrossRef]
- Singh, A.; Singh, N.; Vatsal, S. Robustness of LLMs to Perturbations in Text. arXiv 2024, arXiv:2407.08989. [Google Scholar]
- Chen, B.; Zhang, Z.; Langrené, N.; Zhu, S. Unleashing the potential of prompt engineering in Large Language Models: A comprehensive review. arXiv 2024, arXiv:2310.14735. [Google Scholar]
- Srivastava, A.; Rastogi, A.; Rao, A.; Shoeb, A.A.M.; Abid, A.; Fisch, A.; Brown, A.R.; Santoro, A.; Gupta, A.; Garriga-Alonso, A.; et al. Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models. arXiv 2023, arXiv:2206.04615. [Google Scholar]
- Ortiz-Garces, I.; Govea, J.; Andrade, R.O.; Villegas-Ch, W. Optimizing Chatbot Effectiveness through Advanced Syntactic Analysis: A Comprehensive Study in Natural Language Processing. Appl. Sci. 2024, 14, 1737. [Google Scholar] [CrossRef]
- Salem, A.C.; Gale, R.C.; Fleegle, M.; Fergadiotis, G.; Bedrick, S. Automating Intended Target Identification for Paraphasias in Discourse Using a Large Language Model. J. Speech Lang. Hear. Res. 2023, 66, 4949–4966. [Google Scholar] [CrossRef]
- Lu, H.; Liu, T.; Cong, R.; Yang, J.; Gan, Q.; Fang, W.; Wu, X. QAIE: LLM-based Quantity Augmentation and Information Enhancement for few-shot Aspect-Based Sentiment Analysis. Inf. Process. Manag. 2025, 62, 103917. [Google Scholar] [CrossRef]
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding. arXiv 2021, arXiv:2009.03300. [Google Scholar]
- Hendrycks, D.; Burns, C.; Kadavath, S.; Arora, A.; Basart, S.; Tang, E.; Song, D.; Steinhardt, J. Measuring Mathematical Problem Solving with the MATH Dataset. arXiv 2021, arXiv:2103.03874. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.d.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Shi, F.; Suzgun, M.; Freitag, M.; Wang, X.; Srivats, S.; Vosoughi, S.; Chung, H.W.; Tay, Y.; Ruder, S.; Zhou, D.; et al. Language Models are Multilingual Chain-of-Thought Reasoners. arXiv 2022, arXiv:2210.03057. [Google Scholar]
- Fang, T.; Yang, S.; Lan, K.; Wong, D.F.; Hu, J.; Chao, L.S.; Zhang, Y. Is ChatGPT a Highly Fluent Grammatical Error Correction System? A Comprehensive Evaluation. arXiv 2023, arXiv:2304.01746. [Google Scholar]
- Hadi, M.U.; Tashi, Q.A.; Qureshi, R.; Shah, A.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; et al. A Survey on Large Language Models: Applications, Challenges, Limitations, and Practical Usage. TechRxiv 2023. [Google Scholar] [CrossRef]
- Mialon, G.; Dessì, R.; Lomeli, M.; Nalmpantis, C.; Pasunuru, R.; Raileanu, R.; Rozière, B.; Schick, T.; Dwivedi-Yu, J.; Celikyilmaz, A.; et al. Augmented Language Models: A Survey. arXiv 2023, arXiv:2302.07842. [Google Scholar] [CrossRef]
- Chan, C.K.Y.; Hu, W. Students’ voices on generative AI: Perceptions, benefits, and challenges in higher education. Int. J. Educ. Technol. High. Educ. 2023, 20, 43. [Google Scholar] [CrossRef]
- Overono, A.L.; Ditta, A.S. The Rise of Artificial Intelligence: A Clarion Call for Higher Education to Redefine Learning and Reimagine Assessment. Coll. Teach. 2023, 73, 123–126. [Google Scholar] [CrossRef]
- Saúde, S.; Barros, J.P.; Almeida, I. Impacts of Generative Artificial Intelligence in Higher Education: Research Trends and Students’ Perceptions. Soc. Sci. 2024, 13, 410. [Google Scholar] [CrossRef]
- Etikan, I. Comparison of Convenience Sampling and Purposive Sampling. Am. J. Theor. Appl. Stat. 2016, 5, 1–4. [Google Scholar] [CrossRef]
- Aiken, L. Three coefficients for analyzing the reliability and validity of ratings. Educ. Psychol. Meas. 1985, 45, 131–142. [Google Scholar] [CrossRef]
- Penfield, R.D.; Giacobbi, P.R., Jr. Applying a Score Confidence Interval to Aiken’s Item Content-Relevance Index. Meas. Phys. Educ. Exerc. Sci. 2004, 8, 213–225. [Google Scholar] [CrossRef]
- Johnson, D.; Goodman, R.; Patrinely, J.; Stone, C.; Zimmerman, E.; Donald, R.; Chang, S.; Berkowitz, S.; Finn, A.; Jahangir, E.; et al. Assessing the Accuracy and Reliability of AI-Generated Medical Responses: An Evaluation of the Chat-GPT Model. Res. Sq. 2023, rs.3.rs-2566942. [Google Scholar] [CrossRef]
- Molena, K.F.; Macedo, A.P.; Ijaz, A.; Carvalho, F.K.; Gallo, M.J.D.; Wanderley Garcia De Paula E Silva, F.; De Rossi, A.; Mezzomo, L.A.; Mugayar, L.R.F.; Queiroz, A.M. Assessing the Accuracy, Completeness, and Reliability of Artificial Intelligence-Generated Responses in Dentistry: A Pilot Study Evaluating the ChatGPT Model. Cureus 2024, 16, e65658. [Google Scholar] [CrossRef]
- Knoth, N.; Tolzin, A.; Janson, A.; Leimeister, J.M. AI literacy and its implications for prompt engineering strategies. Comput. Educ. Artif. Intell. 2024, 6, 100225. [Google Scholar] [CrossRef]
- White, J.; Hays, S.; Fu, Q.; Spencer-Smith, J.; Schmidt, D.C. ChatGPT Prompt Patterns for Improving Code Quality, Refactoring, Requirements Elicitation, and Software Design. arXiv 2024, arXiv:2303.07839. [Google Scholar]
- Pavelko, S.L.; Price, L.R.; Owens, R.E., Jr. Revisiting reliability: Using Sampling Utterances and Grammatical Analysis Revised (SUGAR) to compare 25-and 50-utterance language samples. Lang. Speech Hear. Serv. Sch. 2020, 51, 778–794. [Google Scholar] [CrossRef]
- Pavez, M. Presentación del Índice de Desarrollo del Lenguaje “Promedio de Longitud de los Enunciados” (PLE); Universidad de Chile: Santiago, Chile, 2002; Available online: https://www.u-cursos.cl/medicina/2010/2/FOMORES22/1/material_docente/bajar?id_material=303509 (accessed on 27 March 2025).
- Soler, M.C.; Murillo, E.; Nieva, S.; Rodríguez, J.; Mendez-Cabezas, C.; Rujas, I. Verbal and More: Multimodality in Adults’ and Toddlers’ Spontaneous Repetitions. Lang. Learn. Dev. 2023, 19, 16–33. [Google Scholar] [CrossRef]
- Torrego, L.G. Ortografía de uso Español Actual; Ediciones SM España: Madrid, España, 2015. [Google Scholar]
- Gjenero, A. Uso del Modo Subjuntivo para Expresar Deseos. Bachelor’s Thesis, University of Zagreb, Zagreb, Croatia, 2024. [Google Scholar]
- Muñoz De La Virgen, C. Adquisición del modo subjuntivo: Una propuesta didáctica. Didáctica Leng. Lit. 2024, 36, 127–144. [Google Scholar] [CrossRef]
- Vyčítalová, B.L. El Subjuntivo y el Indicativo: La Importancia de una Preparación Previa del Estudiante. Master’s Thesis, Filozofická Fakulta Ústav Románských Jazyků a Literatur, Masarykova Univerzita, Brno, Czech Republic, 2024. [Google Scholar]
- Brown, A.V.; Paz, Y.B.; Brown, E.K. El Léxico-Gramática del Español: Una Aproximación Mediante la Lingüística de Corpus; Routledge: London, UK, 2021. [Google Scholar]
- Radford, A. Analysing English Sentence Structure: An Intermediate Course in Syntax; Cambridge University Press: Cambridge, UK, 2023. [Google Scholar]
- Fleischman, S.; Bybee, J.L. Modality in Grammar and Discourse; John Benjamins B.V.: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Silva-Corvalán, C. Language Contact and Change: Spanish in Los Angeles; Oxford University Press: Oxford, UK, 1994. [Google Scholar]
- Pallant, J. SPSS Survival Manual: A Step by Step Guide to Data Analysis Using IBM SPSS; Routledge: London, UK, 2020. [Google Scholar] [CrossRef]
- Holmes, W. The Unintended Consequences of Artificial Intelligence and Education; Education International: Brussels, Belgium, 2023. [Google Scholar]
- Miao, F.; Holmes, W.; Huang, R.; Zhang, H. AI and Education: A Guidance for Policymakers; UNESCO Publishing: Paris, France, 2021. [Google Scholar]
- Heston, T.; Khun, C. Prompt Engineering in Medical Education. Int. Med. Educ. 2023, 2, 198–205. [Google Scholar] [CrossRef]
- Meskó, B. Prompt Engineering as an Important Emerging Skill for Medical Professionals: Tutorial. J. Med. Internet Res. 2023, 25, e50638. [Google Scholar] [CrossRef] [PubMed]
- Schulhoff, S.; Ilie, M.; Balepur, N.; Kahadze, K.; Liu, A.; Si, C.; Li, Y.; Gupta, A.; Han, H.; Schulhoff, S.; et al. The Prompt Report: A Systematic Survey of Prompting Techniques. arXiv 2024, arXiv:2406.06608. [Google Scholar]
| Dependent Variable Measured | Indicator | Scale |
|---|---|---|
| A1. The subjective judgment of the written prompt according to the instruction for the activity proposed by the evaluators (mean prompt) | The prompt written by the participant is evidence that they were able to follow the instructions given in the activity. | 1 not achieved |
| 2 more non achieved than achieved | ||
| 3 Approximately equal achieved and non-achieved | ||
| 4 more achieved than non-achieved | ||
| 5 nearly all achieved | ||
| 6 achieved | ||
| A2. The subjective judgment of the quality of the response given by the LLM | The answer given by the AI is satisfactory according to the prompt written by the participant. | 1 not achieved |
| 2 more non achieved than achieved | ||
| 3 Approximately equal achieved and non-achieved | ||
| 4 more achieved than non-achieved | ||
| 5 nearly all achieved | ||
| 6 achieved | ||
| B. Length of the utterances | Number of words used in the wording of the prompt posed to the AI. | Index: Number of words/Number of utterances |
| Number of sentences used in the wording of the prompt posed to the AI. |
| Independent Variable Measured | Indicator | Alternatives |
|---|---|---|
| C. Use of standards in writing (form). | No orthography or punctuation errors. | 1 |
| Orthography errors in the writing of the prompt. | 2 | |
| Punctuation errors in the writing of the prompt. | 3 | |
| Both types of errors in the writing of the prompt. | 4 | |
| D. Verbal moods or attitudes of the speaker: Use of indicative, subjunctive, and imperative moods. | In prompt writing, indicative moods are identified. | 1 |
| In prompt writing, subjunctive moods are identified. | 2 | |
| In prompt writing, imperative moods are identified. | 3 | |
| In the prompt, both types of verbal moods are identified. | 4 | |
| In the prompt, the three types of verbal moods are identified. | 5 | |
| E. Sentence complexity in the prompt: This determines the type(s) of sentences the participant used in writing the prompt. | In prompt writing, only simple sentences are identified. | 1 |
| In prompt writing, only coordinate sentences are identified. | 2 | |
| In prompt writing, only subordinate sentences are identified. | 3 | |
| In prompt writing, two types of sentences are identified. | 4 | |
| In prompt writing, the three types of sentences are identified. | 5 |
| Independent Variable | Conditions | Mean (SD) | Median (Range) |
|---|---|---|---|
| Use of standards in writing χ2 (3) = 2.64, p = 0.451 | No orthography or punctuation errors | 4.5 (1.69) | 4.5 (1–6) |
| Orthography errors in the writing of the prompt | 4.9 (0.87) | 5 (3–6) | |
| Punctuation errors in the writing of the prompt | 5.1 (1.45) | 6 (2–6) | |
| Both types of errors in the writing of the prompt | 5.1 (0.91) | 5 (3–6) | |
| Verbal moods or attitudes of the speaker χ2 (3) = 9.71, p = 0.021 | Use of indicative mood | 4.6 (1.34) | 5 (1–6) |
| Use of subjunctive mood | 4.6 (0.89) | 4 (4–6) | |
| Use of imperative mood | 0 | 0 | |
| Use of two verb moods | 5.4 (0.768) | 6 (4–6) | |
| Use of three verb moods | 6 (0.00) | 6 (6–6) | |
| Sentence complexity χ2 (4) = 21.6, p < 0.001 | Use of simple sentence | 4.4 (1.23) | 5 (4–6) |
| Use of coordinated sentences | 5.5 (0.707) | 4 (1–6) | |
| Use of subordinate clauses | 4 (0.632) | 6 (2–5) | |
| Use of two types of sentences | 5.2 (1.14) | 6 (5–6) | |
| Use three types of sentences | 5.79 (0.579) | 6 (2–6) |
| Independent Variable | Conditions | Mean (SD) | Median (Range) |
|---|---|---|---|
| Use of standards in writing χ2 (3) = 14.41, p = 0.002 | No orthography or punctuation errors | 2.6 (1.53) | 2 (1–6) |
| Orthography errors in the writing of the prompt | 2.74 (1.54) | 3 (1–6) | |
| Punctuation errors in the writing of the prompt | 4.14 (1.82) | 5 (1–6) | |
| Both types of errors in the writing of the prompt | 3.9 (1.68) | 4 (1–6) | |
| Verbal moods or attitudes of the speaker χ2 (4) = 31.5, p < 0.001 | Use of indicative mood | 2.75 (1.5) | 2 (1–6) |
| Use of subjunctive mood | 2.71 (0.9) | 3 (1–4) | |
| Use of imperative mood | 1 (--) | 1 (1–1) | |
| Use of two verb moods | 4.96 (1.3) | 5 (1–6) | |
| Use of three verb moods | 4 (2.6) | 5 (1–6) | |
| Sentence complexity χ2 (4) = 44.7, p < 0.001 | Use of simple sentence | 2.2 (1.1) | 2 (1–6) |
| Use of coordinated sentences | 4 (1) | 4 (3–5) | |
| Use of subordinate clauses | 2.4 (1.21) | 2 (1–4) | |
| Use of two types of sentences | 4.6 (1.52) | 5 (1–6) | |
| Use three types of sentences | 4.8 (1.4) | 5 (1–6) |
| Independent Variable | Conditions | Mean (SD) | Median (Range) |
|---|---|---|---|
| Use of standards in writing χ2 (3) = 6.87, p = 0.079 | No orthography or punctuation errors | 11 (6.29) | 11 (3–35) |
| Orthography errors in the writing of the prompt | 9.5 (3.43) | 9 (4–17) | |
| Punctuation errors in the writing of the prompt | 11.69 (5.25) | 11.5 (3–24) | |
| Both types of errors in the writing of the prompt | 11.81 (4.73) | 11.5 (5–24) | |
| Verbal moods or attitudes of the speaker χ2 (4) = 39.8, p < 0.001 | Use of indicative mode | 10 (4.9) | 9 (3–24) |
| Use of subjunctive mood | 9.29 (1.70) | 9 (8–13) | |
| Use of imperative mood | 3 (-) | 3 (3–3) | |
| Use of two verb moods | 13.96 (5.19) | 13. (8–35) | |
| Use of three verb moods | 16.89 (7.83) | 16.8 (9–24) | |
| Sentence complexity χ2 (4) = 22.5, p < 0.001 | Use of simple sentence | 8.46 (3.58) | 8 (3–24) |
| Use of coordinated sentences | 10 (4.50) | 10 (5.5–14) | |
| Use of subordinate clauses | 11.5 (2.48) | 11 (9–16) | |
| Use of two types of sentences | 14.66 (5.70) | 13.2 (6–35) | |
| Use three types of sentences | 12.72 (2.91) | 12.3 (8–17) |
| EFA Exploratory Factor Analysis | PCA Principal Component Analysis | |||||
|---|---|---|---|---|---|---|
| Factor | KMO = 0.65 | 1 a | Uniqueness | % of variance | Eigenvalues b | |
| Length of the utterances | 0.615 | 0.65 | 0.776 | 0.397 | 63.9 | 1.91 |
| Verbal moods | 0.614 | 0.68 | 0.776 | 0.398 | 20.9 | 0.62 |
| Sentence complexity | 0.815 | 0.62 | 0.844 | 0.287 | 15.2 | 0.45 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Viveros-Muñoz, R.; Carrasco-Sáez, J.; Contreras-Saavedra, C.; San-Martín-Quiroga, S.; Contreras-Saavedra, C.E. Does the Grammatical Structure of Prompts Influence the Responses of Generative Artificial Intelligence? An Exploratory Analysis in Spanish. Appl. Sci. 2025, 15, 3882. https://doi.org/10.3390/app15073882
Viveros-Muñoz R, Carrasco-Sáez J, Contreras-Saavedra C, San-Martín-Quiroga S, Contreras-Saavedra CE. Does the Grammatical Structure of Prompts Influence the Responses of Generative Artificial Intelligence? An Exploratory Analysis in Spanish. Applied Sciences. 2025; 15(7):3882. https://doi.org/10.3390/app15073882
Chicago/Turabian StyleViveros-Muñoz, Rhoddy, José Carrasco-Sáez, Carolina Contreras-Saavedra, Sheny San-Martín-Quiroga, and Carla E. Contreras-Saavedra. 2025. "Does the Grammatical Structure of Prompts Influence the Responses of Generative Artificial Intelligence? An Exploratory Analysis in Spanish" Applied Sciences 15, no. 7: 3882. https://doi.org/10.3390/app15073882
APA StyleViveros-Muñoz, R., Carrasco-Sáez, J., Contreras-Saavedra, C., San-Martín-Quiroga, S., & Contreras-Saavedra, C. E. (2025). Does the Grammatical Structure of Prompts Influence the Responses of Generative Artificial Intelligence? An Exploratory Analysis in Spanish. Applied Sciences, 15(7), 3882. https://doi.org/10.3390/app15073882