1. Introduction
The rise in generative artificial intelligence (GenAI) marks one of the most transformative technological shifts in recent decades, reshaping how individuals learn, communicate, and solve problems. Its rapid proliferation underscores the need to reassess the skills required for citizens to interact effectively with these advanced tools. This new scenario began when the company OpenAI (San Francisco, CA, USA) launched ChatGPT (version 3.5) in 2022. However, other tech giants such as Google (Mountain View, CA, USA), Microsoft (Redmond, WA, USA), and Meta (Menlo Park, CA, USA) already have their own GenAI platforms, widely accessible to people around the world.
The rapid development of artificial intelligence (AI) has brought notable changes to various fields, particularly education. Within this context, ChatGPT has gained prominence due to its advanced conversational capabilities and its potential to enhance teaching and learning processes. As a chatbot powered by AI, ChatGPT can offer tailored and interactive assistance to students by addressing complex queries, providing feedback on academic tasks, and facilitating open-ended dialog. Thanks to its flexibility and practical applications, this tool holds the potential to reshape traditional models of higher education [
1].
These advancements are referred to as large language models (LLMs), which are trained on vast volumes of text to process and generate natural language. They are considered part of the field of natural language processing (NLP), which enables models to ’understand,’ generate, and analyze human language. This represents a significant advantage, as it allows users to interact with LLMs using natural language rather than code, removing the need for programming skills to effectively engage with them.
Typically, the process of interacting with a GenAI involves a user providing information in various formats, such as text or audio, through a prompt. The GenAI then processes the input using a large language model and generates an output, also in multiple formats. The user does not know how the GenAI analyzes their input to transform and generate the output. Therefore, the only way to interact with the GenAI is by using the prompt.
Various authors [
2,
3] point out that managing the use of prompts is a skill that can be acquired and improved by following certain rules to enhance the richness of grammatical information provided in the input, incorporating context, roles, output formats, and other aspects. In this context, concepts such as prompt engineering, prompt strategies, and prompt techniques have been emerging. However, distinguishing between strategies and techniques is not straightforward, as they sometimes share the same names or are grouped into a generic category.
On the other hand, considering that the use of prompts in the context of GenAI is relatively new, it is not yet clear which strategies or techniques yield the best results in the quality of responses provided by GenAI. Educational communities are beginning to explore how these technologies can be integrated. Nonetheless, the lack of time and resources makes it difficult to develop a road map that facilitates their systematic integration and measures the real impact of GenAI on the teaching-learning process. Students are also facing the challenge of interacting with GenAI, requiring them to develop new skills, such as effective prompt design. These skills are not always intuitive and require strong guidance and support to leverage the use of GenAI in a critical and ethical manner.
In summary, the arrival of GenAI is redefining the concept of digital literacy, shifting from basic technology skills to the ability to communicate effectively with complex artificial intelligence systems. This shift implies a transformation in educational programs, emphasizing proper interaction with these tools while addressing risks such as technological dependence and the lack of critical thinking skills.
Although several studies have analyzed and classified prompt techniques [
2,
3,
4,
5,
6,
7], little is still known about the specific strategies employed by students to leverage the opportunities brought by GenAI. While the potential of GenAI in education is widely acknowledged, further research is needed to understand how students interact with these tools, particularly in Spanish, given that most LLMs are primarily trained in English.
Understanding how higher education students interact with GenAI is a critical first step in developing strategies to support their effective use of these tools. This exploratory study examines the prompting techniques employed by the students while working with the free version of ChatGPT (version 3.5). By analyzing both circumstantial and request-based techniques, the research identifies emergent dimensions of prompt strategies and provides a comprehensive characterization of the simple and complex strategies utilized in prompt construction. These techniques are particularly relevant as they influence the quality and effectiveness of interactions with GenAI, particularly in Spanish—a language that poses distinct grammatical and contextual challenges for LLMs. Furthermore, the study explores the relationship between the types of techniques employed and the quality of the responses generated. Beyond assessing whether students fully understand the techniques they apply, the research examines how the interaction and interrelation of these techniques, grouped into emergent strategies, impact the outputs produced by GenAI. By offering a deeper understanding of students’ prompting behaviors, the findings contribute to a foundational framework for designing educational interventions that promote critical, ethical, and effective engagement with LLMs in non-English-speaking contexts.
Despite the growing integration of generative AI tools like ChatGPT in academic settings, there remains limited understanding of how students interact with these systems—particularly in non-English contexts. Most of the research on prompt engineering and AI literacy has focused on English-speaking users, often overlooking the linguistic and cognitive challenges faced by Spanish-speaking students. Moreover, there is a lack of pedagogical frameworks to guide students in crafting effective prompts and critically evaluating AI responses. This study was motivated by the need to explore these gaps and contribute empirical evidence to support the development of culturally and linguistically appropriate AI literacy programs in higher education.
To achieve this purpose, the study was guided by the following research questions:
(1) What prompting strategies do higher education students use when interacting with ChatGPT in Spanish? (2) How do the types of techniques used in prompt formulation relate to the perceived quality of the AI-generated responses? (3) What patterns of simple and complex prompting strategies emerge from students’ interactions, and how might these inform future AI literacy initiatives?
2. Related Work
The emergence of GenAI has sparked a wave of innovation across various sectors, transforming how people and organizations coexist with technology. This accelerated development is challenging organizations to understand how these tools could bring competitive advantages. However, the implications of the massive adoption of GenAI are still underexplored, especially in the education sector, where the challenges are even more complex due to its structured nature and occasionally rigid curricula.
In this context, the pathways for integrating these new technologies may depend on the level of digital maturity within educational communities, particularly regarding their capacity to incorporate and innovate with digital tools in academic, cultural, and knowledge management processes, ultimately generating a significant impact on their external environment. Consequently, implementation proposals may range from comprehensive initiatives that encompass the entire community to smaller, informal practices based on trial and error. An important difference between artificial intelligence (AI) before GenAI and GenAI itself lies in the fact that, with the latter, we do not necessarily know where the data used to train and operate its models comes from. Therefore, the most critical way to interact with GenAI is through the prompt.
Nonetheless, the integration of ChatGPT into higher education is influenced by a range of elements that determine its acceptance and actual usage among both students and faculty members [
4,
5,
6,
7]. Gaining insight into these elements is crucial for harnessing the full potential of ChatGPT and facilitating its effective incorporation into academic settings. Empirical research has explored multiple dimensions related to ChatGPT’s adoption, such as its technological features, users’ attitudes and experiences, institutional frameworks, and the broader educational landscape.
Considering the above, in the last two years, various investigations have been conducted to build a knowledge base that enables understanding and analyzing the interactions between users and prompts. Within this emerging field, concepts such as prompts, prompt strategies, prompt techniques, and prompt engineering have emerged.
In the domain of LLMs, a prompt refers to an input provided by a user to a GenAI model to guide and trigger a specific output. Typically, the prompt consists of a piece of text used to communicate with LLMs. It can take the form of a question, a statement, a set of instructions, or any other input that serves as the basis for the model’s response [
8,
9,
10,
11].
A prompt also functions as a translational bridge between human communication and the computational abilities of LLMs. It consists of natural language instructions that operate as an intermediary language, translating human intentions into machine-readable tasks. Beyond basic directives, prompts establish a contextual framework for the interaction, signaling the relevance of certain elements and delineating the structure and content expected in the model’s output [
12].
Understanding the elements of a prompt and their importance is crucial for effective interactions with GenAI. These elements include the following, according to Giray [
13]: (1) a task or specific instruction that guides the model’s behavior toward the desired results; (2) external contextual information that provides the model with additional knowledge, helping it generate more accurate and relevant outputs; (3) the input data or question that the user wants the model to process and respond to; and (4) specifications regarding the type or format of the desired output. These elements serve as a foundation for designing effective prompts that maximize the capabilities of GenAI models.
Building upon this foundational understanding of prompt components, it becomes essential to explore how these elements can be intentionally combined and optimized through the practice of prompt engineering.
Prompt engineering is the strategic process of designing inputs (prompts) that guide LLMs to generate specific, relevant outputs. It is akin to providing the right questions or commands to ensure that the desired answers are obtained. Prompt engineers leverage the predictive capabilities and extensive training data of AI models and combine them with the nuances of human communication to strategically influence model behavior without the need for task-specific training [
14,
15]. Effective prompt engineering tactically employs the various best practices of prompt design as needed to maximize the performance of LLMs, making them more accurate and relevant for specific tasks. It involves not just the creation of prompts but also their testing and refinement based on feedback and desired outcomes.
Similarly, Eager and Brunton [
16] provided guidance on producing instructional text to enhance the development of high-quality outputs from LLMs in higher education. To facilitate the process of prompt engineering, they recommend including six key components in written prompts: (a) verb, (b) focus, (c) context, (d) focus and condition, (e) alignment, and (f) constraints and limitations. These categories offer a structured lens for designing effective prompts in educational settings and align with broader efforts to foster AI literacy.
As LLMs are increasingly used for more complex tasks, the process of prompt engineering tends to involve assembling multiple prompts in creative and layered ways. Due to the models’ sensitivity to natural language input, slight adjustments in wording, sentence construction, or contextual cues can significantly alter the resulting outputs [
17,
18].
A prompt technique is a framework that describes how to construct a single prompt, multiple prompts, or a dynamic sequence of interconnected prompts. It can incorporate features such as conditional or branching logic, parallelism, or other architectural considerations to structure a cohesive group of prompts. These techniques may be implemented either manually or through automation, depending on the complexity of the task and the desired level of precision [
19].
Among these techniques, two of the most significant are the following: (a) few-shot learning, which involves instructing an LLMs to learn a new task using only a few examples. This approach facilitates spontaneous task delegation and improves model performance [
20]. (b) Zero-shot learning, which prompts LLMs to perform tasks without any prior examples. This technique can be further enhanced by fine-tuning the instructions and incorporating reinforcement learning with human feedback [
21,
22].
Prompt engineering is an iterative process that involves designing, refining, and optimizing input prompts to effectively convey the user’s intent to a language model like ChatGPT. This practice often includes modifying or adjusting the prompting technique to improve the quality of the responses. Proper prompt engineering is essential for obtaining accurate, relevant, and coherent outputs, making it a critical skill for users seeking to maximize the potential of GenAI.
As language models continue to advance, mastering prompt engineering has become increasingly important across a wide range of applications [
3,
23]. Haugsbaken and Hagelia [
2] suggest that prompts can vary in their levels of complexity, identifying four distinct levels: (a) basic prompting, (b) prompt reviewing, (c) prompt planning, and (d) prompt scaffolding. (a) Basic prompting: This practice is associated with educational promptization and focuses primarily on input interactions with AI language models. It reflects a student’s ability to engage with chatbots in a basic manner, using a ’programming approach’ to generate a variety of content or responses, ranging from simple to complex. (b) Prompt reviewing: This level involves an emphasis on the output aspect of input-output engagements. It entails critically examining and refining the outputs provided by AI models to better align them with the intended objectives of the interaction. (c) Prompt planning: At this level, prompting evolves into a more complex and recursive process. Students construct a series of interconnected prompts designed to structure a learning process. This approach moves beyond generic communication with AI models, focusing on creating tailored and purposeful interactions that support specific learning goals.
Various studies are being conducted to understand and classify prompt techniques, as well as to evaluate their effectiveness. Schulhoff et al. [
3], using the PRISMA methodology for a systematic review, proposed an ontological taxonomy of text-based prompting techniques. This taxonomy includes 58 techniques distributed across six major categories: (a) zero-shot, (b) few-shot, (c) thought-generation, (d) ensembling, (e) self-criticism, and (f) decomposition.
Giray [
13] proposes five prompting techniques: (a) instructive prompt, (b) system prompt, (c) question–answer prompt, (d) contextual prompt, and (e) mixed prompt. An instructive prompt allows the user to employ a guide to direct their writing toward a specific task. A system prompt provides a starting point or context to help users build their content effectively. A question–answer prompt facilitates the structuring of inputs around specific research questions. A contextual prompt offers additional background or details within the prompt to help users focus on particular aspects of their response. Finally, a mixed prompt combines multiple elements, enabling users to construct their inputs in a comprehensive and understandable manner.
Sawalha, Taj, and Shoufan [
24] conducted a study to investigate how undergraduate students used ChatGPT for problem-solving, the prompting strategies they developed, the relationship between these strategies and the model’s response accuracy, the presence of individual prompting tendencies, and the influence of gender in this context. The study involved 56 senior students enrolled in the course. The findings revealed that students predominantly employed three types of prompting strategies: single copy-and-paste prompting (SCP), single reformulated prompting (SRP), and multiple-question prompting (MQP). ChatGPT’s response accuracy using SRP and MQP was significantly higher than with SCP, with effect sizes of −0.94 and −0.69, respectively.
Recent advancements in prompt engineering have led to the development of diverse techniques aimed at optimizing interactions with conversational LLMs. Fagbohun and Harrison [
25] proposed a comprehensive and interdisciplinary framework that categorizes these prompting techniques into seven conceptual groups: logical and sequential processing, contextual understanding and memory, specificity and targeting, meta-cognition and self-reflection, directional and feedback, multimodal and cross-disciplinary, and creative and generative. Each category encompasses a set of strategies tailored to specific interaction goals, such as reasoning through complex problems, eliciting reflective responses, or generating creative content. This taxonomy offers a roadmap for practitioners and educators to select the most appropriate prompting strategies based on their pedagogical objectives or domain-specific applications.
According to Sawalha et al. [
24], although there is a growing body of research on GenAI prompts, most studies have focused on their use by researchers rather than by students. Few authors have explored how students interact with GenAI tools such as ChatGPT, highlighting a significant gap in understanding student-specific behaviors and strategies in this context.
In this regard, Knoth et al. [
22] examined how AI literacy among higher education students influences their interactions with LLMs. For this study, the author defined AI literacy as “a set of competencies that enables individuals to critically evaluate AI technologies, communicate and collaborate effectively with AI, and use AI as a tool online, at home, and in the workplace” [
26] (p. 2). The study involved a sample of 45 students aged between 19 and 35 years. The findings revealed that higher-quality prompt engineering skills significantly predict the quality of LLM outputs, highlighting prompt engineering as an essential skill for the goal-directed use of generative AI tools. Furthermore, the study showed that certain aspects of AI literacy play a crucial role in improving prompt engineering quality and enabling targeted adaptation of LLMs within educational contexts.
Building upon the findings from related works, which highlight the existence of a wide range of techniques for prompt construction, this study proposes a synthesized framework comprising two groups of techniques: circumstantial and request-based. Circumstantial techniques are defined as those that provide context and structure to the prompt, forming a foundational layer to guide the interaction. For this study, 10 circumstantial techniques were identified and defined (see
Table 1). On the other hand, request-based techniques refer to those explicitly used to articulate the query or task to the LLMs. The 11 request-based techniques proposed in this framework are detailed in
Table 2. This categorization serves as a practical synthesis of the existing body of knowledge, offering a structured approach that can be applied to analyze the work produced by students, as further elaborated in the methodology and results sections.
Building upon the findings from related works, we developed a 21-item checklist through a three-step process grounded in a functional classification of prompt engineering techniques. First, an exploratory review of academic and technical literature was conducted to identify common prompting techniques relevant to educational contexts. From this review, 21 techniques were consolidated based on frequency, conceptual clarity, and applicability in higher education.
In the second step, a functional analysis grouped these techniques into two overarching categories based on their communicative role: (i) circumstantial techniques (n = 10), which provide structural or contextual cues for shaping the model’s response; and (ii) request-based techniques (n = 11), which explicitly articulate the action or task expected from the LLM. Each technique was clearly defined and illustrated with an example (see
Table 1 and
Table 2), forming a practical and pedagogically oriented framework for analyzing prompt construction.
This classification informed the design of the 21-item binary checklist used in the study, enabling a systematic analysis of student-generated prompts. The application of this framework is further elaborated in the methodology and results sections.
While this study centers on the functional structuring of prompts, the impact of grammatical and syntactic features on LLM outputs has been explored in detail in a recent publication by Viveros-Muñoz et al. [
27], which specifically examines these linguistic aspects.
To better situate this study within existing educational paradigms, it is important to consider how current theories of AI literacy and digital competence frame user interaction with generative AI. Ng [
28] defines AI literacy as a multidimensional construct that includes not only technical knowledge but also cognitive and ethical understanding, allowing users to make informed decisions about the use of AI. This concept aligns with recent calls to develop AI literacy programs that empower students to question, interpret, and strategically engage with AI systems in educational settings.
In parallel, the Digital Competence Framework for Citizens (DigComp 2.2), developed by the European Commission, outlines five competence areas. Of particular relevance are “Digital Content Creation”, which emphasizes the ability to produce and adapt digital content critically and responsibly, and “Problem Solving”, which highlights the importance of identifying needs and responding through appropriate digital tools [
29]. These frameworks offer a conceptual foundation for understanding the competencies required for meaningful engagement with AI-based technologies in education.
Although this study does not directly assess these frameworks, it builds on their principles by exploring how students formulate and refine prompts, interpret AI responses, and evaluate their usefulness—processes that implicitly involve digital content creation, problem-solving, and critical thinking.
5. Discussion
This study aimed to explore the relationship between prompting techniques written in Spanish and the responses generated by a large language model (LLMs), specifically ChatGPT (free version 3.5), as employed by higher education students. Additionally, the study examined how these techniques clustered into emergent strategies and assessed their overall impact on ChatGPT’s output quality.
To achieve this purpose, the present research aimed to fulfill the following three key objectives: (i) to identify the emerging prompt strategies employed by higher education students; (ii) to examine the relationship between the types of techniques used to formulate prompts and the quality of the responses generated by the large language model (LLM); and (iii) to describe both simple and complex strategies observed in students’ prompt-writing processes.
From the literature review, we preliminarily proposed two categories of techniques: circumstantial and request-based. Circumstantial techniques were defined as those that provide context and structure to the prompt, forming a foundational layer that guides the interaction. Conversely, request-based techniques refer to those explicitly designed to articulate the query or task directed to the LLMs. For this study, 10 circumstantial techniques and 11 request-based techniques were identified and defined (see
Table 1 and
Table 2). This categorization served as a practical synthesis of existing research, offering a structured framework that was applied to analyze the students’ prompt-writing practice.
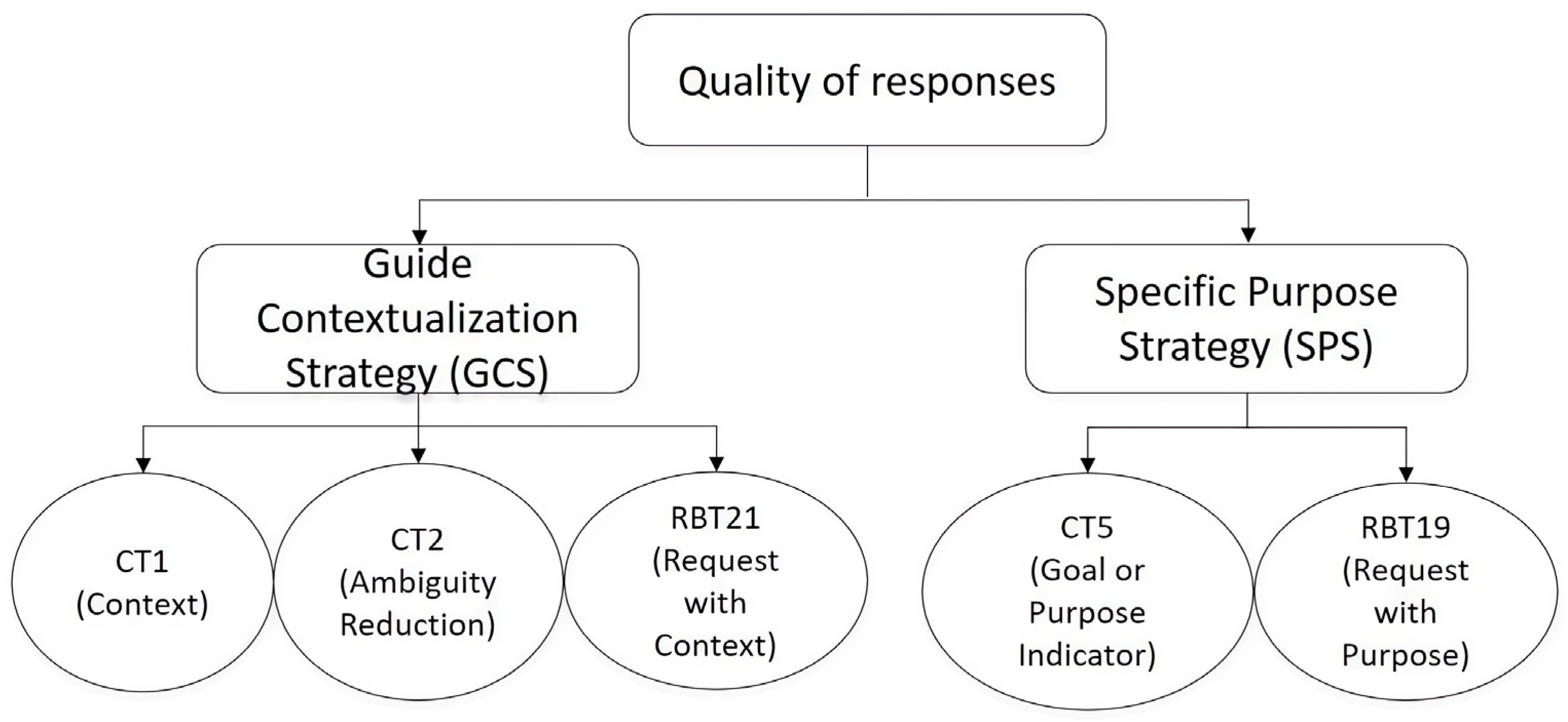
The key contribution of this study lies in the evidence it provides regarding the impact of prompt engineering strategies on the quality of responses generated by ChatGPT in Spanish. Two emergent strategies were identified, each clustering distinct prompt engineering techniques systematically identified in this research: (i) Guide Contextualization Strategy (GCS) and (ii) Specific Purpose Strategy (SPS). The GCS clusters techniques that focus on providing an informative framework to structure the language model’s response generation, ensuring that the AI operates within a well-defined context. In contrast, the SPS group’s techniques aimed at directing the model’s output by explicitly stating the underlying purpose of the request, thereby shaping the AI’s response toward a specific goal. The characteristics and distinctions of each strategy are detailed in the following sections.
Three techniques were clustered into the group of contextual strategies (GCS). The linear regression analysis revealed that CT1 (Context), CT2 (Ambiguity Reduction), and RBT21 (Request with Context) had a significant effect on the quality of responses generated by the model, F (1, 67) = 17.7, p < 0.001, R2 = 0.209, β = 0.457. These findings indicate that incorporating contextual information into prompts enhances the accuracy and relevance of the generated outputs.
Although the R
2 value of 0.209 may appear modest, it aligns with the medium effect size threshold proposed by Cohen [
31], who defined values of 0.02, 0.15, and 0.35 as small, medium, and large, respectively. In the context of educational and behavioral research, such effect sizes are considered meaningful, particularly when dealing with complex phenomena influenced by multiple factors. Therefore, the conclusion that incorporating contextual information into prompts enhances the accuracy and relevance of the generated outputs remains valid, as it is supported by a statistically significant and practically relevant association.
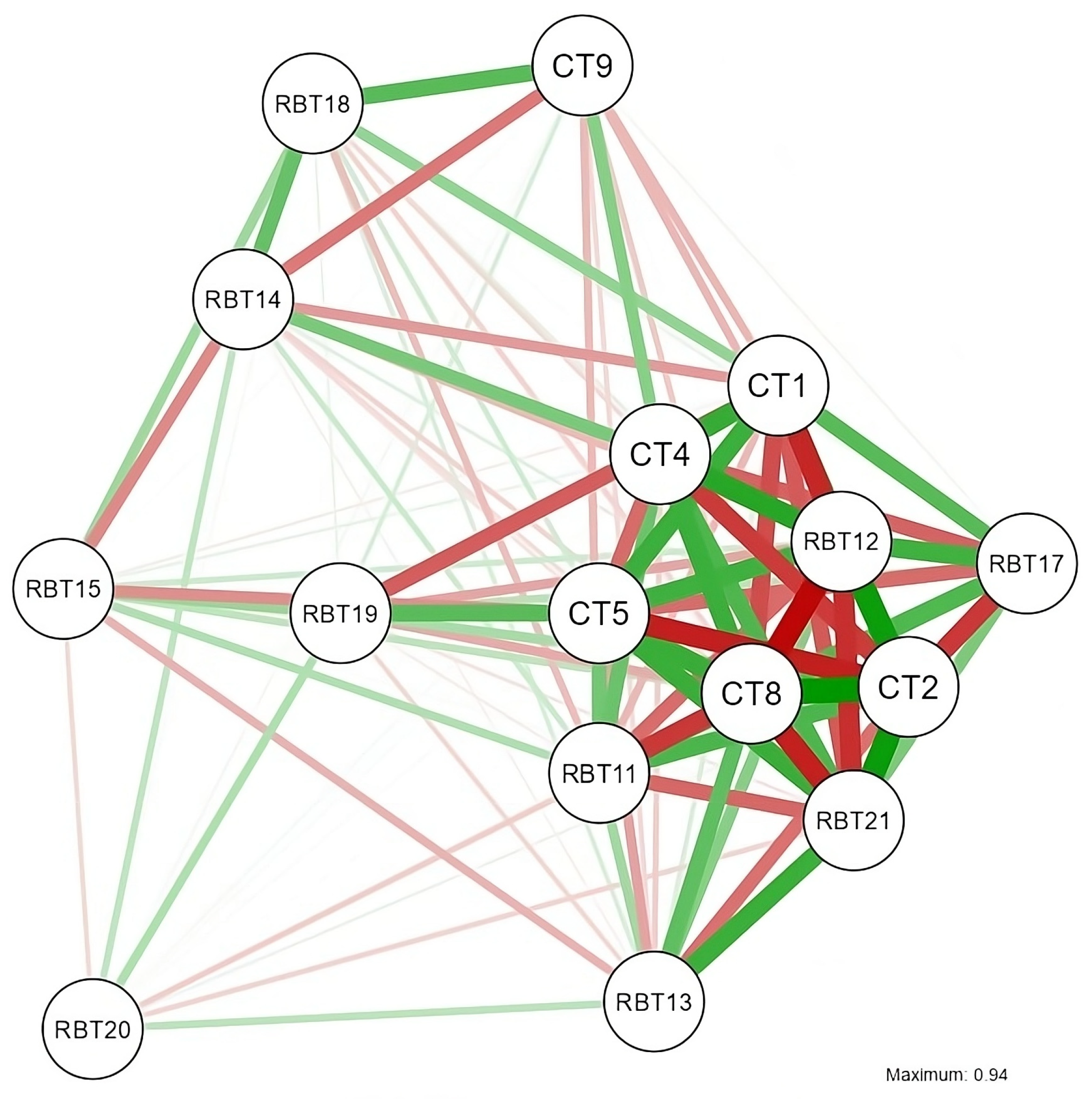
In addition, the analysis of tetrachoric correlations revealed a strong association between CT1 (Context) and CT2 (Ambiguity Reduction), rt = 0.933, suggesting that these techniques are frequently employed together. CT1 also demonstrated positive correlations with CT5 (Goal or Purpose Indicator), rt = 0.680, and RBT21 (Request with Context), rt = 0.801, indicating that students who apply contextual strategies tend to incorporate elements that clarify the purpose of their prompts.
In contrast, RBT14 (Open-Ended Question Request) showed strong negative correlations with CT1, rt = −0.842, and CT2, rt = −0.866, suggesting that this technique may reduce the likelihood of using clearly contextualized prompting strategies. A possible interpretation is that, in some cases, when students formulate entirely open-ended questions without anchoring them to specific topics or goals, they may overlook key contextual elements needed to guide the generative model effectively. This could result in prompts that lack precision or relevance, potentially affecting the quality and specificity of the AI-generated responses. These findings underscore the importance of fostering a balance between openness and contextual framing in the development of prompt engineering skills.
These findings are consistent with previous research that has identified the use of contextual information as a crucial factor in generating more accurate responses from LLMs. For example, Eager and Brunton [
16] highlight the importance of providing a clear and structured context to optimize interactions with LLMs. In this sense, the clarity and specificity of prompts are presented as key factors in obtaining more accurate outputs. Nonetheless, while previous studies have examined these strategies in expert-designed environments, our research focused on the spontaneous interactions between students and ChatGPT, offering a closer perspective on the real-world use of these tools in higher education contexts.
On the other hand, the SPS (Strategies with Purpose Specification) cluster grouped two techniques: CT5 (Goal or Purpose Indicator) and RBT19 (Request with Purpose), both of which demonstrated a significant association with response quality, F (1, 67) = 8.58, p = 0.005, R2 = 0.114, β = 0.337. However, the observed effect was smaller than that of the GCS cluster, suggesting that while explicitly articulating the intended purpose in prompts can improve interactions with generative AI, its effective implementation may require a higher level of linguistic proficiency and a deeper understanding of LLMs’ operational principles.
These results are consistent with the systematic review conducted by Lee and Palmer [
37], who emphasize the importance of users clearly defining their objectives when interacting with AI to maximize effectiveness. Nonetheless, their study revealed that students encounter difficulties in implementing these strategies, suggesting the need for more specialized training in prompt engineering.
Building on this discussion,
Figure 3 presents a synthesis of the findings from this study, summarizing the relationships between the identified strategies and their impact on response quality.
The findings of this study indicate that the techniques grouped within GCS and SPE align with certain prompt engineering strategies documented in the literature. In particular, the techniques classified under GCS share multiple characteristics with the few-shot prompting strategy [
21,
38,
39]. According to Walter [
40], incorporating examples and contextual information within a prompt can significantly enhance the quality of responses generated by LLMs. Additionally, Henrickson and Meroño-Peñuela [
41] highlight that prompts enriched with prior contextual information are more likely to generate meaningful responses. This observation aligns with the findings of this study, particularly regarding the impact of CT1 (context) and CT2 (ambiguity reduction) on response accuracy. These results suggest that providing a clear contextual framework is a crucial factor in interactions with AI models—an insight that has been consistently identified in few-shot learning research.
Conversely, the techniques grouped under SPS align with strategies that emphasize the explicit formulation of purpose within the prompt. Previous studies have indicated that clearly defining the user’s objectives can enhance interactions with LLMs [
16]. In particular, Lee and Palmer [
37] stress the importance of users establishing well-defined objectives when interacting with AI models. However, their findings also suggest that students struggle to implement these strategies effectively without prior AI literacy in prompt engineering. This observation is consistent with the results of the present study, where SPE demonstrated a weaker effect on response quality compared to GCS, reinforcing the notion that explicit purpose formulation alone may be insufficient without a deeper understanding of how LLMs function.
Furthermore, the literature has identified persona prompting as an effective technique for enhancing interactions with LLMs [
11,
42]. Although this technique was not explicitly analyzed in the present study, its potential relationship with RBT21 (request with context) warrants further investigation. This is because RBT21, like persona prompting, incorporates a contextual framework in the formulation of requests, making it similar to the role personalization characteristic of persona prompting.
In summary, the findings of this study provide evidence on the importance of contextualization and clear objective definition in the formulation of prompts in Spanish. These results align with previous research on few-shot prompting, persona prompting, and strategies for structuring objectives in interactions with GenAI. However, while many of these studies have been conducted in controlled environments with expert AI users, this research focused on the spontaneous interactions of higher education students with ChatGPT, offering a more authentic perspective on its real-world use in academic settings.
While this study focuses on the functional aspects of prompt construction—specifically the use of circumstantial and request-based techniques—it is also important to recognize that linguistic features, such as sentence complexity and grammatical mood, significantly influence LLM behavior. These language-level dimensions were addressed in a recent study conducted by our team, which examined how variations in grammatical structure affect the perceived quality of AI-generated responses in Spanish-language prompts [
27].
Implications of This Work in the Field of Higher Education
The results of this study have significant implications for the development of AI literacy programs in education. As Holmes [
43] suggests, it is essential to recognize that the relationship between AI and education is more complex than might initially appear, with misunderstandings often stemming from a lack of comprehensive research [
44].
AI literacy encompasses not only technical knowledge but also the ability to engage effectively with the ethical and societal implications of AI technology. In contemporary classrooms, AI literacy must complement traditional learning approaches, equipping students with essential skills to critically assess, interact with, and leverage AI across various aspects of their lives. As an emerging field with immense potential, AI literacy also faces the challenge of early adoption. The difficulty lies not only in imparting technical proficiency but also in fostering a comprehensive understanding of AI’s broader impact—whether social, psychological, or economic [
40].
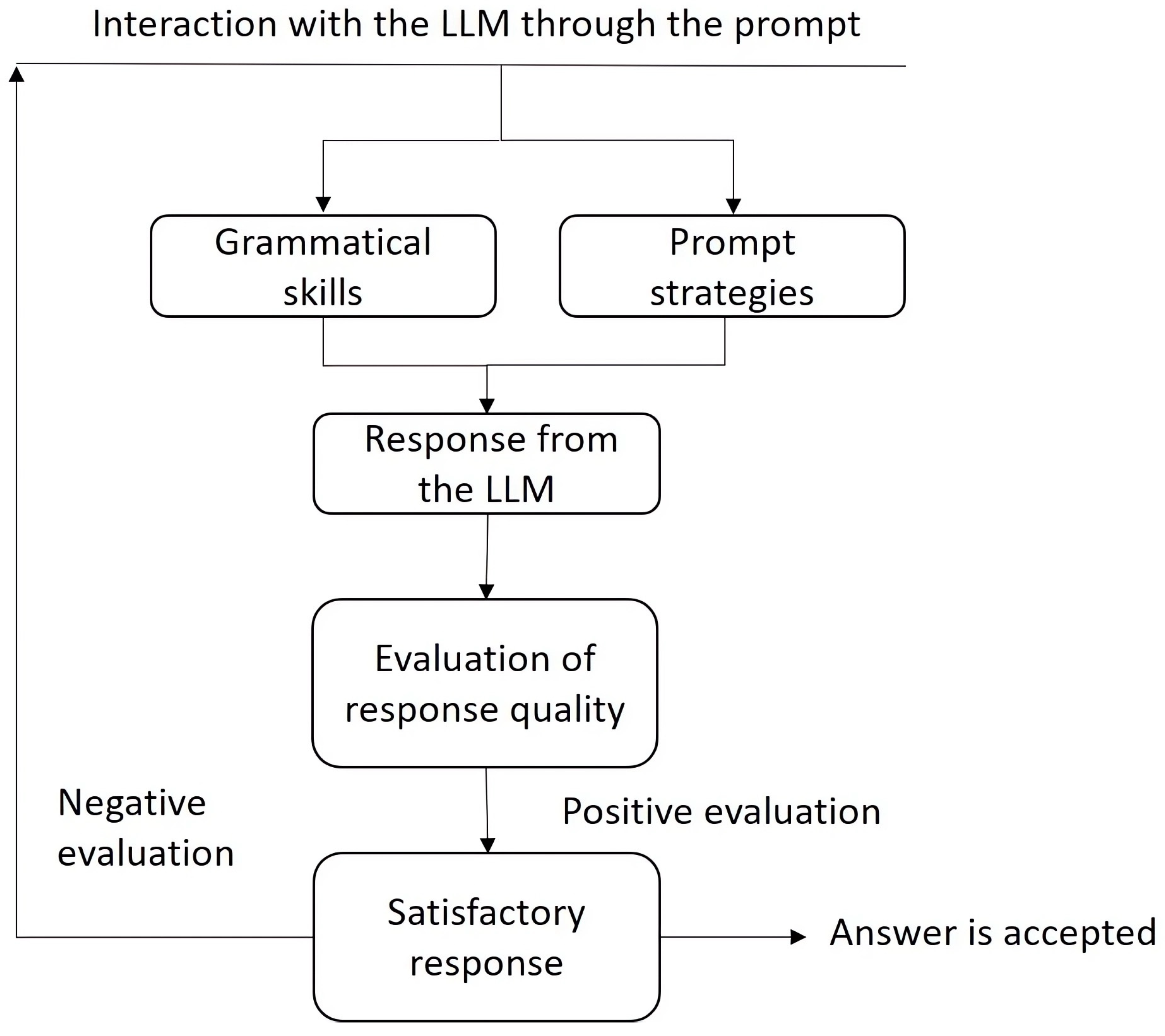
Figure 4 presents a methodological framework for structuring interactions with large LLMs through prompts. This framework illustrates the iterative nature of the process, where students formulate prompts using their grammatical skills and prompt engineering strategies, receive responses from the LLM, and evaluate the quality of those responses. If the output is satisfactory, it is accepted; if not, the process restarts with a reformulation of the prompt.
The diagram highlights two foundational components that shape the initial interaction: grammatical skills and prompt strategies. Grammatical performance—particularly in verb selection and syntactic structure—plays a critical role in the clarity and precision of the prompt.
For instance, the use of the subjunctive mood in Spanish, which introduces complexity absent in English, can affect how the model interprets and generates responses [
27]. Similarly, compound or subordinate sentence structures can be associated with both the semantic richness and processing of user inputs. As Bozkurt and Sharma [
45] note, subtle linguistic variations can significantly impact the relevance of AI-generated content.
Prompt strategies refer to the techniques employed to guide the model toward the intended outcome. These include contextualization, goal setting, and structured formulation. A prompt serves as an input to a generative AI model, guiding the nature and quality of its output [
9,
10]. As described by Schulhoff et al. [
3], well-crafted prompts can improve the coherence, depth, and factual accuracy of LLM outputs. However, as recent studies show, these strategies are still not widely understood by students and require explicit training within AI literacy programs [
46,
47,
48].
The evaluation phase is essential for determining whether the output meets the user’s expectations. This involves critical thinking, the ability to contrast sources, and ethical awareness regarding intellectual property, bias, and reliability [
40]. The cyclical nature of the model recognizes that achieving a satisfactory response often requires multiple iterations and refined prompt constructions, reinforcing the importance of deliberate interaction design.
This iterative process also reflects how users in higher education evaluate AI-generated outputs based on a web of interconnected factors, including trust, privacy, and security. While some studies identify trust as a decisive factor in adoption [
49], others report it as less influential [
6], suggesting that privacy and security concerns may mediate or moderate its effect. In this educational context, a systems-thinking perspective is essential to grasp how students’ decisions to adopt and engage with GenAI tools are shaped by multiple, interrelated influences [
50].
The findings of this study could have meaningful pedagogical implications, particularly for informing the design of educational interventions aimed at supporting novice users in their interactions with GenAI. The proposed framework might serve as a basis for training programs that foster the development of key competencies—such as grammatical precision, effective use of prompting strategies, and critical evaluation of responses. Educators could design scaffolded learning experiences that guide students in the iterative refinement of prompts, encourage experimentation with different prompt types, and promote reflective assessment of AI outputs. Incorporating these elements into AI literacy curricula might contribute to bridging the gap between basic usage and meaningful, responsible engagement with generative AI tools.
It is important to note that, as an exploratory study, the findings should be interpreted as preliminary and hypothesis-generating. Further empirical research, including longitudinal and cross-cultural studies, is necessary to validate and extend the proposed framework.
6. Conclusions
This exploratory study provides evidence on the impact of prompt engineering strategies on the quality of responses generated by ChatGPT (free version 3.5) in Spanish. Analyzing the techniques used by 102 higher education students, two emergent strategies were identified: the Guide Contextualization Strategy (GCS) and the Specific Purpose Strategy (SPS). The first strategy emphasizes the use of contextual information to guide response generation, while the second focuses on the explicit formulation of the request’s purpose.
The results indicate that GCS is more strongly associated with response quality, reinforcing the importance of providing a clear contextual framework to enhance the precision and relevance of interactions with GenAI models. On the other hand, the lower impact of SPS suggests that simply stating the purpose of a request is insufficient unless students also possess a deeper understanding of how LLMs function. This highlights a potential gap in AI literacy, where users may struggle to translate well-defined objectives into effective prompt formulations.
These findings align with prior research on few-shot prompting, persona prompting, and structured objective-setting strategies in interactions with GenAI. However, a key distinction of this study lies in its focus on spontaneous student interactions with ChatGPT, as opposed to controlled environments led by AI experts. This methodological approach offers a closer approximation to the real world.
AI usage in higher education, capturing how students naturally engage with LLMs in academic settings. The results suggest that, while context-driven strategies align with established prompting techniques, students may require additional support to refine their use of structured request-based approaches.
From an educational perspective, these findings reinforce the importance of developing AI digital literacy programs that extend beyond technical knowledge of GenAI models and equip students with effective prompt engineering strategies. The methodological framework proposed in this study, encompassing four key dimensions—grammatical skills; prompt strategies; response from the LLM; and evaluation of response quality—serves as a foundation for future initiatives aimed at fostering critical and effective engagement with GenAI in Spanish-speaking contexts.
As an exploratory study, this research underscores the need for further investigation into the relationship between GenAI and prompt engineering performance, considering factors such as language proficiency, users’ disciplinary backgrounds, and the impact of AI digital literacy programs. Additionally, future research should examine how these strategies manifest across different languages and educational settings and assess the effectiveness of interventions designed to enhance students’ AI interaction skills. Given the preliminary nature of our findings, we emphasize the importance of replicating this study in broader and more diverse educational contexts to validate the results and explore their applicability at scale. Ultimately, these insights contribute to a growing understanding of how learners engage with AI in academic contexts, reinforcing the need for tailored educational strategies that bridge the gap between technological advancement and pedagogical practice.



 ,
, 

{kind=link}
{kind=link}
{kind=link}
{kind=link}