
RHS-YOLOv8: A Lightweight Underwater Small Object Detection Algorithm Based on Improved YOLOv8


Abstract
Featured Application
Abstract
1. Introduction
- A new Ref-Dilated block is redesigned to replace the original bottleneck block in the C2f module of YOLOv8 [32], which combines the multi-scale receptive field of the cavity convolution and the strong feature extraction capability of RefConv, so as to satisfy the detection model’s feature extraction and multi-scale feature fusion capability, and the computation amount is greatly reduced.
- A new fusion module, the Hybrid Bridge Feature Pyramid Network (HBFPN), is designed to be added to the neck to fuse the deep features with the high-level features as well as the current layer, so that the fusion module with a lightweight setup efficiently improves the model’s characterization and reduces the probability of missed detection.
- The ELA attention mechanism is added to the backbone network to ensure accurate location information of the region of interest, which improves the overall performance of the model with only a minimal increase in computation. Additionally, the use of Involution convolution blocks in the backbone network enables lightweight embedding into the representation learning paradigm, which enhances the visual recognition capability of the model.
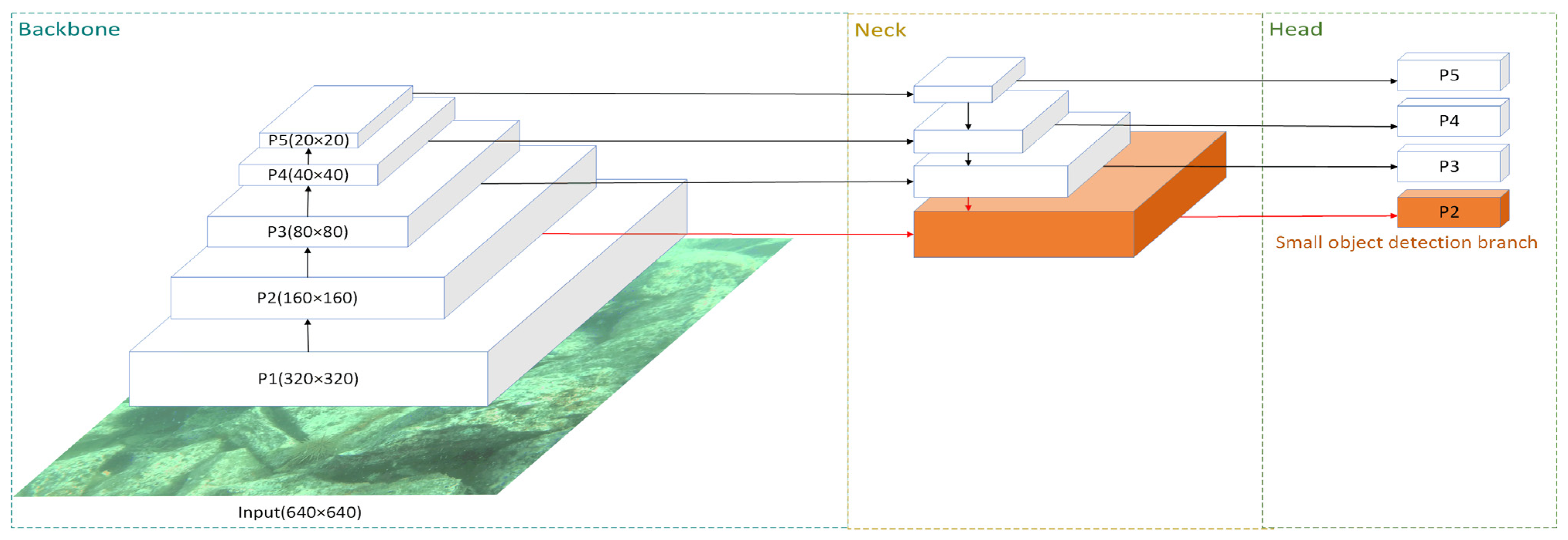
- Adding a small object detection branch to part of the low feature layer improves the accuracy of small object detection and does not lead to the loss of detection accuracy for medium and large objects.
2. Methodology
2.1. Object Detection Algorithm
2.2. Ref-Dilated Convolutional Block
2.3. Hybrid Bridge Feature Pyramid Network Fusion Block
2.4. Efficient Localization Attention
2.5. Involution
2.6. Small Object Detection Branch
3. Experiments
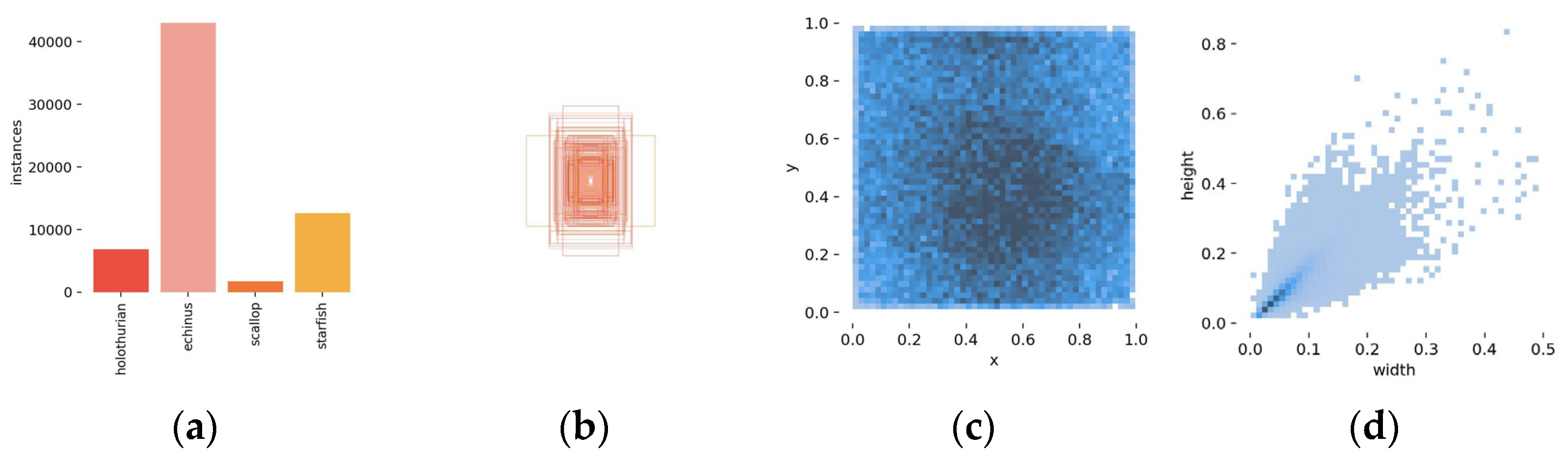
3.1. Underwater Object Detection Dataset
3.2. Experimental Configuration and Environment
3.3. Evaluation Metrics
4. Analysis and Discussion of Experimental Results
4.1. Ablation Experiments on the DUO Dataset
4.2. Comparison of Experimental Results on the DUO Dataset
4.3. Validation Experiments on the RUOD Dataset
4.4. Visualization and Analysis
5. Discussion
6. Conclusions
- Dataset enhancement: expanding sample diversity, particularly for small objects and complex underwater environments, and incorporating data from varied sea conditions (depth, visibility, and lighting) to improve robustness.
- Image preprocessing: integrating underwater-specific enhancement techniques (e.g., CLAHE and color correction based on optical physics models) to address image quality challenges.
- Deployment optimization: accelerating model inference via tools like TensorRT or ONNX Runtime, and enabling cross-platform compatibility (GPU/ARM architectures) for real-time applications in resource-constrained underwater devices.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lee, D.; Kim, G.; Kim, D.; Myung, H.; Choi, H.T. Vision-based object detection and tracking for autonomous navigation of underwater robots. Ocean Eng. 2012, 48, 59–68. [Google Scholar] [CrossRef]
- Xu, S.; Zhang, M.; Song, W.; Mei, H.; He, Q.; Liotta, A. A systematic review and analysis of deep learning-based underwater object detection. Neurocomputing 2023, 527, 204–232. [Google Scholar] [CrossRef]
- Ødegård, Ø.; Mogstad, A.A.; Johnsen, G.; Sørensen, A.J.; Ludvigsen, M. Underwater hyperspectral imaging: A new tool for marine archaeology. Appl. Opt. 2018, 57, 3214–3223. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Liu, Y.; Zhao, Z.; Liu, J.; Yang, X.; Sun, C.; Chen, S.; Li, B.; Zhou, C. Real-time detection of uneaten feed pellets in underwater images for aquaculture using an improved YOLO-V4 network. Comput. Electron. Agric. 2021, 185, 106135. [Google Scholar]
- Cho, S.H.; Jung, H.K.; Lee, H.; Rim, H.; Lee, S.K. Real-time underwater object detection based on DC resistivity method. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6833–6842. [Google Scholar] [CrossRef]
- Mosk, A.P.; Lagendijk, A.; Lerosey, G.; Fink, M. Controlling waves in space and time for imaging and focusing in complex media. Nat. Photonics 2012, 6, 283–292. [Google Scholar] [CrossRef]
- Chiang, J.Y.; Chen, Y.C. Underwater image enhancement by wavelength compensation and dehazing. IEEE Trans. Image Process. 2011, 21, 1756–1769. [Google Scholar]
- Lucieer, V.; Hill, N.A.; Barrett, N.S.; Nichol, S. Do marine substrates ‘look’ and ‘sound’ the same? Supervised classification of multibeam acoustic data using autonomous underwater vehicle images. Estuar. Coast. Shelf Sci. 2013, 117, 94–106. [Google Scholar] [CrossRef]
- Ho, M.; El-Borgi, S.; Patil, D.; Song, G. Inspection and monitoring systems subsea pipelines: A review paper. Struct. Health Monit. 2020, 19, 606–645. [Google Scholar] [CrossRef]
- Kim, D.; Lee, D.; Myung, H.; Choi, H.T. Object detection and tracking for autonomous underwater robots using weighted template matching. In Proceedings of the 2012 Oceans-Yeosu, Yeosu, Republic of Korea, 21–24 May 2012; pp. 1–5. [Google Scholar]
- Saini, A.; Biswas, M. Object detection in underwater image by detecting edges using adaptive thresholding. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 628–632. [Google Scholar]
- Priyadharsini, R.; Sharmila, T.S. Object detection in underwater acoustic images using edge based segmentation method. Procedia Comput. Sci. 2019, 165, 759–765. [Google Scholar] [CrossRef]
- Hu, J.; Jiang, Q.; Cong, R.; Gao, W.; Shao, F. Two-branch deep neural network for underwater image enhancement in HSV color space. IEEE Signal Process. Lett. 2021, 28, 2152–2156. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 2015, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Afif, M.; Ayachi, R.; Said, Y.; Pissaloux, E.; Atri, M. An evaluation of retinanet on indoor object detection for blind and visually impaired persons assistance navigation. Neural Process. Lett. 2020, 51, 2265–2279. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Du, L.; Li, L.; Wei, D.; Mao, J. Saliency-guided single shot multibox detector for object detection in SAR images. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3366–3376. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wu, W.; Liu, H.; Li, L.; Long, Y.; Wang, X.; Wang, Z.; Li, J.; Chang, Y. Application of local fully Convolutional Neural Network combined with YOLO v5 algorithm in small object detection of remote sensing image. PLoS ONE 2021, 16, e0259283. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision 2017, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Lei, F.; Tang, F.; Li, S. Underwater target detection algorithm based on improved YOLOv5. J. Mar. Sci. Eng. 2022, 10, 310. [Google Scholar] [CrossRef]
- Yan, J.; Zhou, Z.; Zhou, D.; Su, B.; Xuanyuan, Z.; Tang, J.; Lai, Y.; Chen, J.; Liang, W. Underwater object detection algorithm based on attention mechanism and cross-stage partial fast spatial pyramidal pooling. Front. Mar. Sci. 2022, 9, 1056300. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, M.; Wang, Z.; Song, W.; Zhao, D.; Zhao, H. Efficient Small-Object Detection in Underwater Images Using the Enhanced YOLOv8 Network. Appl. Sci. 2024, 14, 1095. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2023, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck transformers for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 19–25 June 2021; pp. 16519–16529. [Google Scholar]
- Ultralytics. Track and Count Objects Using YOLOv8. Roboflow. Available online: https://blog.roboflow.com/yolov8-tracking-and-counting/#object-detection-with-yolov8 (accessed on 24 May 2024).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Yu, F. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Cai, Z.; Ding, X.; Shen, Q.; Cao, X. Refconv: Re-parameterized refocusing convolution for powerful convnets. arXiv 2023, arXiv:2310.10563. [Google Scholar]
- Wang, C.Y.; Yeh, I.H.; Liao, H.Y.M. Yolov9: Learning what you want to learn using programmable gradient information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Liu, W.; Lu, H.; Fu, H.; Cao, Z. Learning to upsample by learning to sample. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2023, Paris, France, 2–3 October 2023; pp. 6027–6037. [Google Scholar]
- Xu, W.; Wan, Y. ELA: Efficient Local Attention for Deep Convolutional Neural Networks. arXiv 2024, arXiv:2403.01123, 2024. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wu, Y.; He, K. Group normalization. In Proceedings of the European Conference on Computer Vision 2018, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the inherence of convolution for visual recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 19–25 June 2021; pp. 12321–12330. [Google Scholar]
- Liu, C.; Li, H.; Wang, S.; Zhu, M.; Wang, D.; Fan, X.; Wang, Z. A dataset and benchmark of underwater object detection for robot picking. In Proceedings of the 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Fu, C.; Liu, R.; Fan, X.; Chen, P.; Fu, H.; Yuan, W.; Zhu, M.; Luo, Z. Rethinking general underwater object detection: Datasets, challenges, and solutions. Neurocomputing 2023, 517, 243–256. [Google Scholar] [CrossRef]
- Guo, Q.; Wang, Y.; Zhang, Y.; Qin, H.; Qi, H.; Jiang, Y. AWF-YOLO: Enhanced Underwater Object Detection with Adaptive Weighted Feature Pyramid Network. Complex Eng. Syst. 2023, 3, 16. [Google Scholar] [CrossRef]
- Zhao, Y.; Sun, F.; Wu, X. FEB-YOLOv8: A multi-scale lightweight detection model for underwater object detection. PLoS ONE 2024, 19, e0311173. [Google Scholar] [CrossRef]
- Feng, J.; Jin, T. CEH-YOLO: A composite enhanced YOLO-based model for underwater object detection. Ecol. Inform. 2024, 82, 102758. [Google Scholar] [CrossRef]
- Chen, J.; Er, M.J. Dynamic YOLO for small underwater object detection. Artif. Intell. Rev. 2024, 57, 1–23. [Google Scholar] [CrossRef]
- Yang, C.; Xiang, J.; Li, X.; Xie, Y. FishDet-YOLO: Enhanced underwater fish detection with richer gradient flow and long-range dependency capture through Mamba-C2f. Electronics 2024, 13, 3780. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | Version or Model |
|---|---|
| Operating system | Ubuntu 20.04.3 |
| CUDA version | 11.3 |
| CPU | Intel(R) Xeon(R) Gold 6330 |
| GPU | NVIDIA GeForce 3090(24G) |
| Python version | Python 3.9 |
| Deep learning framework | PyTorch-1.13.1 |
| Models | GFLOPs | P | R | mAP@ 0.5 | mAP@ 0.5:0.95 |
|---|---|---|---|---|---|
| YOLOv8s | 28.4 | 0.852 | 0.769 | 0.85 | 0.661 |
| YOLOv8m | 78.7 | 0.855 | 0.792 | 0.867 | 0.69 |
| YOLOv8l | 164.8 | 0.891 | 0.772 | 0.866 | 0.696 |
| YOLOv8s + Ref-Dilated | 23.9 | 0.872 | 0.78 | 0.864 | 0.68 |
| YOLOv8m + Ref-Dilated | 59.7 | 0.86 | 0.806 | 0.874 | 0.701 |
| YOLOv8l + Ref-Dilated | 117.5 | 0.867 | 0.801 | 0.877 | 0.706 |
| YOLOv8s + Ref-Dilated + Involution | 23.9 | 0.861 | 0.785 | 0.866 | 0.68 |
| YOLOv8m + Ref-Dilated + Involution | 59.7 | 0.858 | 0.807 | 0.876 | 0.702 |
| YOLOv8l + Ref-Dilated + Involution | 117.5 | 0.859 | 0.818 | 0.882 | 0.713 |
| YOLOv8s + Ref-Dilated + Involution + SOB | 26.53 | 0.861 | 0.78 | 0.868 | 0.69 |
| YOLOv8m + Ref-Dilated + Involution + SOB | 71.63 | 0.857 | 0.782 | 0.877 | 0.703 |
| YOLOv8l + Ref-Dilated + Involution + SOB | 146.5 | 0.858 | 0.806 | 0.884 | 0.716 |
| YOLOv8s + Ref-Dilated + Involution + SOB + HBFPN | 31.7 | 0.873 | 0.78 | 0.871 | 0.69 |
| YOLOv8m + Ref-Dilated + Involution + SOB + HBFPN | 76.1 | 0.871 | 0.801 | 0.879 | 0.705 |
| YOLOv8l + Ref-Dilated + Involution + SOB + HBFPN | 148.4 | 0.861 | 0.826 | 0.886 | 0.725 |
| YOLOv8s + Ref-Dilated + Involution + SOB + HBFPN + CA | 31.7 | 0.863 | 0.783 | 0.869 | 0.677 |
| YOLOv8m + Ref-Dilated + Involution + SOB + HBFPN + CA | 76.1 | 0.858 | 0.805 | 0.877 | 0.702 |
| YOLOv8l + Ref-Dilated + Involution + SOB + HBFPN + CA | 148.4 | 0.842 | 0.826 | 0.885 | 0.712 |
| YOLOv8s + Ref-Dilated + Involution + SOB + HBFPN + ELA | 31.7 | 0.873 | 0.78 | 0.871 | 0.69 |
| YOLOv8m + Ref-Dilated + Involution + SOB + HBFPN + ELA | 76.1 | 0.872 | 0.802 | 0.879 | 0.706 |
| YOLOv8l + Ref-Dilated + Involution + SOB + HBFPN + ELA | 148.4 | 0.863 | 0.827 | 0.888 | 0.726 |
| Models | mAP@0.5 | mAP@0.5:0.95 | FPS |
|---|---|---|---|
| SSD | 0.796 | 0.505 | 22 |
| Faster R-CNN | 0.744 | 0.393 | 8 |
| YOLOv3 | 0.716 | 0.403 | 69 |
| YOLOv4 | 0.767 | 0.439 | 52 |
| YOLOv5s | 0.845 | 0.634 | 45 |
| YOLOv5m | 0.846 | 0.663 | - |
| YOLOv5l | 0.848 | 0.664 | - |
| YOLOv7-tiny | 0.814 | 0.573 | 105 |
| YOLOv8s | 0.85 | 0.661 | 138 |
| YOLOv8m | 0.867 | 0.69 | 127 |
| YOLOv8l | 0.866 | 0.696 | 113 |
| YOLOv10n | 0.819 | 0.617 | 112 |
| AWF-YOLOv8 [45] | 0.778 | 0.701 | 53 |
| FEB-YOLOv8 [46] | 0.829 | 0.632 | 116 |
| CEH-YOLO [47] | 0.884 | 0.712 | 156 |
| Dynamic YOLO [48] | 0.867 | 0.681 | - |
| FishDet-YOLO [49] | 0.888 | 0.694 | 143 |
| RHS-YOLOv8s (ours) | 0.871 | 0.69 | 169 |
| RHS-YOLOv8m (ours) | 0.879 | 0.706 | 152 |
| RHS-YOLOv8l (ours) | 0.888 | 0.726 | 146 |
| Models | GFLOPs | P | R | mAP@0.5 | FPS |
|---|---|---|---|---|---|
| Faster R-CNN | 119.0 | 0.722 | 0.686 | 0.653 | 38 |
| RetinaNet | 74.6 | 0.693 | 0.653 | 0.639 | 113 |
| YOLOv5s | 16.4 | 0.835 | 0.772 | 0.810 | 161 |
| YOLOv5m | 50.3 | 0.859 | 0.819 | 0.816 | 129 |
| YOLOv5l | 114.1 | 0.863 | 0.822 | 0.825 | 107 |
| YOLOv7-tiny | 13.1 | 0.842 | 0.795 | 0.793 | 178 |
| YOLOv8s | 32.5 | 0.848 | 0.784 | 0.846 | 158 |
| YOLOv8m | 78.7 | 0.857 | 0.806 | 0.860 | 120 |
| YOLOv8l | 164.9 | 0.862 | 0.817 | 0.871 | 85 |
| RHS-YOLOv8s (ours) | 31.8 | 0.852 | 0.791 | 0.862 | 161 |
| RHS-YOLOv8m (ours) | 76.1 | 0.860 | 0.821 | 0.881 | 123 |
| RHS-YOLOv8l (ours) | 148.5 | 0.866 | 0.822 | 0.885 | 94 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Y.; Tao, J.; Wu, W.; Yuan, D.; Hou, S. RHS-YOLOv8: A Lightweight Underwater Small Object Detection Algorithm Based on Improved YOLOv8. Appl. Sci. 2025, 15, 3778. https://doi.org/10.3390/app15073778
Wei Y, Tao J, Wu W, Yuan D, Hou S. RHS-YOLOv8: A Lightweight Underwater Small Object Detection Algorithm Based on Improved YOLOv8. Applied Sciences. 2025; 15(7):3778. https://doi.org/10.3390/app15073778
Chicago/Turabian StyleWei, Yifan, Jun Tao, Wenjun Wu, Donghua Yuan, and Shunzhi Hou. 2025. "RHS-YOLOv8: A Lightweight Underwater Small Object Detection Algorithm Based on Improved YOLOv8" Applied Sciences 15, no. 7: 3778. https://doi.org/10.3390/app15073778
APA StyleWei, Y., Tao, J., Wu, W., Yuan, D., & Hou, S. (2025). RHS-YOLOv8: A Lightweight Underwater Small Object Detection Algorithm Based on Improved YOLOv8. Applied Sciences, 15(7), 3778. https://doi.org/10.3390/app15073778