1. Introduction
Autonomous driving technology is evolving rapidly, and it is advancing beyond the tasks of perception and decision-making to include the capability to generate descriptive captions for driving environment scenes, which would enhance both the interpretability and understanding of complex traffic scenarios.
A critical aspect of this advancement is the captioning of driving environment scenes, which involves generating textual descriptions of dashcam-recorded driving environments. This capability can enhance safety, improve human interpretability of autonomous driving scenarios, and support decision-making. Recent research in this domain has primarily focused on three key areas: vision–language modeling, autonomous driving datasets, and driving environment scene captioning. Vision–language modeling techniques involve the integration of vision and language models, such as bootstrapping language–image pre-training (BLIP-2) [
1], contrastive language–image pre-training (CLIP) [
2], and large language and vision assistant (LLaVA) [
3], to enhance the understanding of visual scenes. Autonomous driving datasets, such as the Large-scale Diverse Driving Video Database (BDD-100K) [
4], Karlsruhe Institute of Technology dataset (KITTI) [
5], and nuScenes dataset [
6], provide extensive labeled data for training machine learning models in real-world driving environments. BDD-100K is one of the largest autonomous driving datasets, containing 100,000 video clips with annotations for object detection, lane detection, drivable areas, and weather conditions, and it is highly suitable for diverse urban and highway driving scenarios. Similarly, KITTI, a widely used dataset, offers stereo images, light detection and ranging (LiDAR) point clouds, and ground truth annotations for various perception tasks, including object detection, optical flow estimation, and scene segmentation, with a strong focus on high-resolution sensor data for 3D perception. In contrast, nuScenes is a multi-sensor dataset that integrates camera, LiDAR, radar, and global positioning system (GPS) inputs along with detailed 3D bounding box annotations to provide a comprehensive understanding of complex urban driving environments, including traffic participants, weather conditions, and scene dynamics. Furthermore, transformer-based models for driving environment scene captioning have been extensively studied to improve the textual representation of driving environments.
Despite the remarkable progress of vision–language models in general-purpose image captioning, these models often underperform when applied to dashcam footage collected in real-world driving environments. Dashcam images present unique challenges, such as rapid motion, occlusion, low-light conditions, and highly structured yet dynamic scenes involving roads, vehicles, and pedestrians. Existing models, primarily trained on generic web-scale datasets, lack the ability to capture these road-specific contextual cues, resulting in inaccurate or overly generic captions. Consequently, the direct application of pre-trained vision–language models to dashcam scenes has proven to be unreliable for safety-critical autonomous driving systems. This highlights the urgent need for domain-specific optimization strategies that go beyond conventional fine-tuning involving parameter-efficient techniques, structural adaptation modules (e.g., LoRA), and objective function designs tailored to driving environments to ensure the model effectively learns from structured, context-rich road scenes under diverse environmental conditions.
Despite advances in the development of vision–language models and autonomous driving datasets, there are several key challenges that hinder the accurate captioning of driving environment scenes. Vision–language models do not work well with structured label datasets, which makes it difficult to generate scene captions. This issue can be divided into three specific challenges.
First, in most autonomous driving datasets, textual labeling is insufficient, as the primary focus is on structured labels for object detection, segmentation, and trajectory prediction. Autonomous driving datasets are not designed for natural language modeling, and traditional datasets, such as BDD-100K, involve object-centric annotations that do not adequately provide the sequential structure required for generating coherent scene labeling. Without additional data generation processes, these datasets cannot be directly utilized for training vision–language models. Insufficient labeling of driving environment scenes renders the direct application of vision–language models directly to road environments difficult.
Second, pre-trained vision–language models struggle with domain adaptation in road environments. Models such as BLIP-2 and CLIP are trained on generic web-scale scene-text pairs and cannot accurately interpret road-specific factors such as lane markings, traffic signs, and dynamic objects. Their performance in structured driving scenarios is worse than that in the case of general scene contexts. Pre-trained models cannot generalize road-specific factors. Vision–language models, such as BLIP-2, are trained on large-scale general-purpose datasets and struggle to accurately capture domain-specific features in road environments. Lane structures and vehicle interactions are often misrepresented or overlooked in generated captions. Thus, there is a need for domain-specific data generation and fine-tuning of the generated data.
Third, traditional scene captioning models focus on isolated objects rather than the dynamics of the scene, resulting in a loss of contextual information. Traditional methods describe individual objects without integrating the relationships between different traffic factors. Traditional models are incapable of generating captions that include information on vehicle interactions, pedestrian movement, and environmental conditions.
Fourth, there is a lack of extensive experimentation on optimizing vision–language models for structured road environments in the field of autonomous driving. While vision–language models have demonstrated strong performance in general-purpose applications, research on their adaptation to autonomous driving scenarios remains limited. Existing studies primarily focus on object-level perception rather than integrating sequential and contextual road scene information. The absence of systematic optimization techniques tailored to driving environments hinders the deployment of vision–language models in real-world autonomous systems. Without dedicated experimental validation, the effectiveness of vision–language models in structured driving datasets remains uncertain.
We propose an optimization method based on BLIP-2 as domain adaptation to enhance the captioning of driving environment scenes in autonomous driving environments. Our method comprises two main steps: generating a caption dataset in natural language from structured dataset labels and optimizing a Q-Former module with low-rank adaptation (LoRA) [
7] for domain adaptation.
First, we introduce a data preprocessing pipeline that generates a new caption dataset by transforming structured labels from datasets such as BDD-100K into natural language captions. We apply template-based transformations and utilize a large language model (LLM) to convert object labels formatted in JSON into well-formed, human-readable captions that are suitable for training vision–language models.
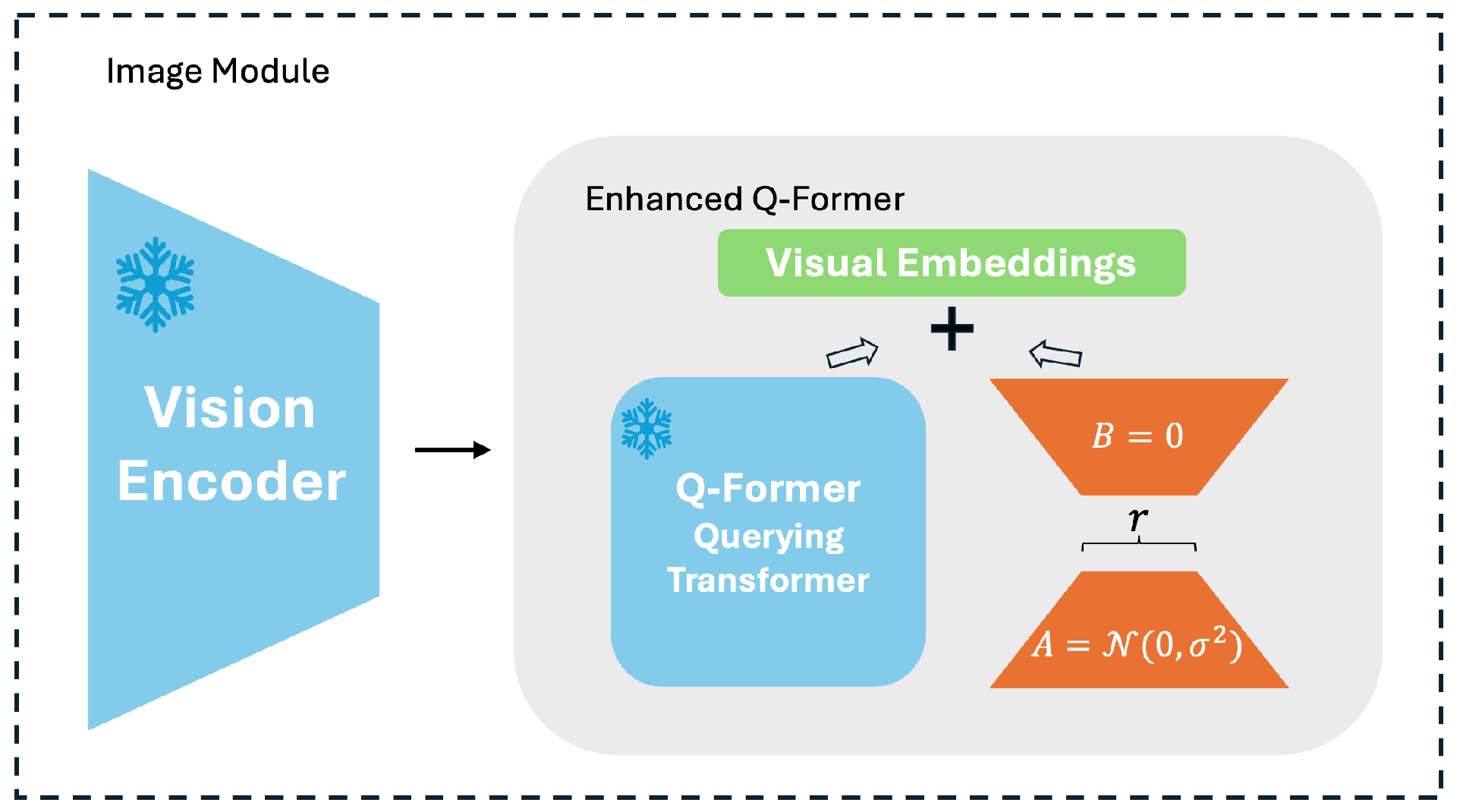
Second, as shown in
Figure 1, we fine-tune BLIP-2 by optimizing the Q-Former module while freezing the vision encoder and language model. Q-Former is a transformer-based query encoder that bridges the vision encoder and the language model and thereby facilitates effective cross-modal learning. However, BLIP-2 struggles with road-specific factors, such as traffic signals, road signs, lane markings, and vehicle interactions, since it is trained on generic web data that lack domain-specific annotations. To enhance domain adaptation, we apply LoRA to selectively update key attention layers within Q-Former, thereby improving efficiency while retaining domain-specific knowledge.
Third, to address the lack of extensive experimentation in optimizing vision–language models for autonomous driving, we propose a domain-specific adaptation of BLIP-2 using LoRA to improve caption generation for driving environment scenes. While existing vision–language models are primarily trained on general-purpose datasets, they lack adaptation techniques specifically designed for structured autonomous driving datasets. To bridge this gap, we apply LoRA to fine-tune the Q-Former module, selectively updating key attention layers while freezing the vision encoder and language model. This approach enables BLIP-2 to effectively capture road-specific contextual information, such as lane structures, traffic signals, and vehicle interactions, and generate more accurate and coherent natural language captions. By leveraging LoRA, we achieve parameter-efficient optimization that enhances BLIP-2’s ability to generate structured and contextually rich captions for autonomous driving environments while maintaining computational efficiency.
Our method effectively enhances BLIP-2’s capability to generate accurate and contextually rich captions for driving environment scenes. The generated caption dataset improves the model’s understanding of road-specific factors, while the optimized Q-Former facilitates better adaptation to autonomous driving environments. These improvements can contribute to the development of more interpretable and robust vision–language models, ultimately supporting safer and more efficient autonomous driving systems. The main contributions of this study are as follows.
We propose an optimized Q-Former module for BLIP-2 to enhance its understanding of structured driving environment scenes while freezing the vision encoder and the LLM to improve efficiency. By applying LoRA to the main attention layers, we propose efficient and targeted adaptation specific to road environments; consequently, the model can recognize lane structures, traffic signals, and dynamic interactions more accurately.
We introduce an optimized prompting strategy that incorporates important contextual factors such as weather conditions, traffic signals, and vehicles into the input format. This method ensures that the generated captions are more contextually relevant and globally consistent, and the captions can provide a more comprehensive scene understanding than simple object captions.
We describe a combination of structured dataset transformation, optimized BLIP-2 adaptation, and a structured input prompting method to significantly improve the accuracy, consistency, and contextual perception of driving environment scene captions. This advancement can improve the human interpretability of autonomous driving models and support safer and more transparent decision-making processes in real-world driving scenarios.
We describe a new data preprocessing pipeline to transform structured labels in autonomous driving datasets (e.g., BDD-100K). By using template-based transformation and an LLM, we seamlessly integrate structured driving data into vision language model training, thereby addressing the problem of sparse labels in existing datasets.
We achieve significant improvements in both performance and efficiency through our optimization strategy. The BLEU-4 score of enhanced BLIP-2 increases from 0.0117 (baseline BLIP-2) to 0.1609 (), while the SPICE score improves from 0.1002 to 0.4642. Additionally, by leveraging LoRA-based optimization, we update only 0.1022% of the model parameters, demonstrating a highly efficient solution for domain adaptation.
We provide a detailed comparative analysis against existing captioning methods, including traditional optimization strategies and prior BLIP-2 implementations. Our results show that LoRA-based optimization significantly enhances model adaptability to structured driving environments while reducing computational overhead, making it more suitable for real-world deployment in autonomous systems.
This paper provides a link between structured autonomous driving datasets and advanced vision–language models. The proposed method can facilitate the generation of more accurate and contextually enhanced scene captions, which would improve the overall reliability of autonomous systems.
2. Related Work
In VLM, scenes and natural languages are combined to generate responses, and such models play an important role in autonomous driving environments. Traditional VLM research can be categorized into three types: learning from large datasets, using multimodal models, and applying these techniques to autonomous driving scenarios.
2.1. Multimodal Models for VLM
VLM models that use multimodal learning effectively involve the integration of image and text information to generate accurate responses. Transformer-based architectures, such as MCAN [
8], LXMERT [
9], and UNITER [
10], have shown high performance since they process visual and textual features together.
Recently, pre-trained VLM such as CLIP [
2] and Flamingo [
11] have been increasingly proposed for VLM tasks, highlighting the advantages of large-scale pre-training in enhancing scene–text understanding. Specifically, domain-adaptive models such as LLaVA have shown promise in autonomous driving scenarios where scene-specific reasoning is required.
Knowledge-based VLM methods have also been investigated to improve reasoning in autonomous driving applications. These methods incorporate external knowledge sources such as traffic rules, road regulations, and driving policies to provide more accurate and contextually relevant responses.
Knowledge-enhanced VLM frameworks, integrating structured knowledge graphs [
12], can help refine model predictions and ensure that the generated responses match the real-world driving environment. This method improves the reliability and interpretability of VLM systems in autonomous driving applications, which can, in turn, facilitate the use of both visual and textual inputs by vehicles to make more accurate and safer decisions.
This paper proposes a data preprocessing pipeline that can be used to convert structured autonomous driving datasets into natural language captions. Furthermore, it fine-tunes BLIP-2’s Q-Former module based on LoRA to enhance domain adaptation performance specific to road environments, and it develops an optimized prompting strategy to generate consistent scene captions that reflect contextual information; such captions can improve the interpretability and safety of autonomous driving systems.
2.2. VLM Research in Autonomous Driving Scenarios
VLM research related to autonomous driving has been focused on enhancing vehicle situational perception and human–machine interaction. Recent researchers have used datasets such as BDD-QA to perform VLM tasks related to situations that occur while driving.
Additionally, methods for making VLM models capable of identifying and interpreting driving situations on the basis of road signs, distances between vehicles, and traffic signals have been proposed. In particular, studies have investigated the use of retrieval-augmented generation for knowledge (RAG) [
13] to optimize general VLM models for autonomous driving environments through domain adaptation techniques.
2.3. Virtual Environment-Based Autonomous Driving Simulation
Virtual-environment-based techniques have been widely employed to train sensor-based autonomous driving models, owing to their efficiency. However, ensuring high similarity between the simulated environment and the real-world counterpart is crucial for the applicability of such models to actual autonomous vehicles. While advancements in hardware and three-dimensional graphics engine technology have facilitated the creation of realistic virtual driving environments, real-world scenarios remain challenging to fully replicate. To address this issue, a study proposed a scenario simulation and modeling framework to maximize the diversity of driving scenarios encountered in a virtual environment; a dedicated simulator was used to evaluate the framework’s effectiveness [
14].
2.4. Scene Detection in Autonomous Driving Scenarios
In autonomous driving, scene detection is important for detecting dynamic environments, ensuring safety, and making real-time driving decisions. Traditional scene detection methods involve object detection, semantic segmentation, and instance segmentation for recognizing road structures, obstacles, and traffic participants.
Deep learning-based approaches, especially CNN and transformer-based architectures, have significantly improved scene detection accuracy. Models such as faster DGCB-Net [
15] have been widely used to detect objects and to segment scenes in autonomous driving datasets such as the KITTI and nuScenes datasets. However, these models often struggle with generalization in unseen driving scenarios due to variations in weather, lighting, and occlusions.
Recent advancements in VLM have led to their being endowed with multimodal scene understanding, where textual descriptions complement visual features to enhance detection and interpretation. Methods based on large-scale pre-trained VLM, such as BLIP-2 and LLaVA, have been developed to generate natural language scene descriptions that provide contextual insights beyond mere object recognition. Using such methods, autonomous systems can identify relationships between objects, predict potential hazards, and enhance decision-making.
In addition, self-supervised learning approaches have been proposed to improve scene detection in complex driving conditions. Contrastive learning techniques, such as those used in SimCLR [
16], can enable models to learn robust feature representations from large-scale unlabeled datasets. With these techniques, the scene detection performance can be improved by leveraging diverse driving environments and conditions.
This paper proposes the integration of VLM-based contextual scene descriptions and optimizes BLIP-2’s Q-Former module for enhancing scene detection in autonomous driving, and it discusses its adaptation for real-world road environments. By optimizing prompting strategies and employing domain-specific pre-training, we aim to improve the model’s capability to generate structured scene descriptions that could enhance interpretability and situational awareness in autonomous driving scenarios.
3. BLIP-2 Optimization Efficiently Using LoRA
The proposed method includes two steps to generate intuitive and contextually rich scene captions in autonomous driving environments. These steps can improve an autonomous system’s capability to accurately interpret road conditions and respond to various driving scenarios. We propose an effective caption-generation method for autonomous driving by utilizing a data-generation process and optimizing the Q-Former module.
3.1. Data Generation
The proposed method develops a new dataset using the BDD-100K dataset to enhance the accuracy of understanding and predicting vehicle behavior in autonomous driving situations [
4]. Due to the scarcity of suitable scene–caption pair datasets for autonomous driving, we select BDD-100K, which includes approximately 60,000 samples providing diverse road traffic information.
From annotations provided in the BDD-100K dataset, essential road traffic information such as scene
, time of day
, weather
, detected object
O, and traffic light color
are extracted to initially create raw natural language captions
. This information is formatted through a predefined template as follows:
These sentences are then refined by utilizing a language model such as GPT-4o, resulting in the final caption dataset c used for fine-tuning:
During the data generation process, questions such as “Describe the current road conditions including weather, time of day, and visible objects (road, vehicles, traffic lights) along with their counts” are used to generate complete natural language sentences, effectively addressing data scarcity and supporting the creation of captions suitable for autonomous driving scenarios. The structured input information used for raw caption generation, including the scene type, weather, and object details, is summarized in
Table 1, while
Figure 2 presents an example of how these raw captions are refined into final, human-like descriptions.
This transformation ensures that the generated captions are more contextually rich and readable to humans, allowing vision–language models to better understand and describe complex road environments.
3.2. Q-Former Optimization for Domain Adaptation
BLIP-2 [
1] integrates a vision encoder and an LLM, effectively bridging the gap between vision and language, thus excelling at scene captioning. However, simultaneously training both components requires significant computational resources and time. BLIP-2 overcomes this by using a specialized module, Q-Former, efficiently transferring visual features from the vision encoder to the LLM. Q-Former acts as a query transformer, selectively extracting and encoding the most relevant visual information for optimizing the language generation process.
Inspired by recent work such as LoraHub [
17], which demonstrates that dynamic low-rank adaptation enables effective cross-task generalization while optimizing only a small subset of parameters, we adopt a similar parameter-efficient strategy. By applying LoRA selectively to the attention layers within the Q-Former, we achieve efficient domain adaptation without optimizing the entire BLIP-2 architecture. This method aligns with our goal of maintaining the pre-trained knowledge of the vision encoder and language model while enabling lightweight yet effective adaptation to structured autonomous driving environments.
As shown in
Figure 3, the driving environment scene (
) is converted into vectorized visual features
through a vision transformer (ViT) [
18]-based vision encoder. The process of generating the refined learned queries
by passing the queries
through self-attention utilizing LoRA-efficiently fine-tuned Q, K, and V matrices can be summarized as follows.
Here, inside the self-attention mechanism, we incorporate low-rank adaptation (LoRA) by applying low-rank matrices to the query (
Q) and key (
K) matrices. The self-attention mechanism enhanced with LoRA is defined as follows:
Here, X represents the input features that are passed into the self-attention mechanism. In the Q-Former architecture, X corresponds to the learned queries (), which are trainable embeddings designed to interact with visual features extracted by the ViT. denotes the dimension of the key vectors. It is included to stabilize the variance of the dot product between Q and K. Without this scaling factor, the resulting values could become excessively large, leading to unstable gradients during training. Dividing by ensures that the variance of the values inside the softmax function remain balanced, improving the stability and convergence of the model. and are the down-projection matrices. and are the up-projection matrices. The rank of the low-rank matrices, r, satisfies .
By incorporating LoRA, the original weight matrices and are kept frozen, and only the low-rank matrices and are updated during training. This significantly reduces the number of trainable parameters while preserving the model’s performance.
The LoRA-enhanced self-attention mechanism improves parameter efficiency and enables effective domain adaptation in the Q-Former module of BLIP-2. By focusing exclusively on low-rank updates, our method achieves efficient adaptation while retaining the pre-trained knowledge of the original model.
Subsequently, these refined queries
and visual features
undergo cross-attention:
Next, the input text is refined via self-attention using LoRA-efficiently fine-tuned Q, K, and V matrices in the same manner as Equation (
4) to obtain
:
These two outputs, and , are entered together into the LLM decoder. Finally, the LLM decoder generates a contextually rich caption ().
The proposed method contributes to enhanced environmental understanding, situational awareness, and decision-making capabilities for autonomous vehicles.
Owing to the integration of LoRA and Q-Former, our method significantly enhances the generation efficiency and accuracy of contextually rich captions for driving environments. By selectively optimizing the self-attention layers, the model is able to focus more effectively on road-specific cues while minimizing computational overhead. This parameter-efficient strategy is all about efficiency. Ultimately, our method enables autonomous vehicles to interpret their surroundings more effectively, leading to improved situational awareness and decision-making.
4. Experiment
In real-world applications such as translation systems that require both short response times and high accuracy, BLIP-2 offers a cost-effective solution. The high efficiency results from the integration of LoRA technology and the Q-Former module, which enables the model to handle complex vision–language tasks while minimizing the computational load. The use of pre-trained VLM has been widely studied [
10,
11,
19], and BLIP-2 stands out owing to its frozen image encoders and low computational costs.
Owing to the combination of LoRA technology and the Q-Former module, both the efficiency and performance of BLIP-2 were significantly enhanced. This model is particularly suitable for highly resource-intensive applications, and it can provide outstanding results while reducing the computational cost [
20,
21]. Q-Former selectively processes only the most relevant information, while LoRA reduces the number of trainable parameters, decreasing the overall computational demand. Consequently, BLIP-2 can perform a wide range of vision-language tasks quickly and effectively, making it highly suitable for resource-limited environments [
13,
22].
The rank values and scaling factors for LoRA were selected to represent a diverse range of low-rank configurations, balancing model capacity and computational efficiency. These configurations were based on empirical practices in recent literature on LoRA-based vision–language models and were chosen to reflect low, medium, and high adaptation strengths. While a full hyperparameter search was not conducted due to resource limitations, the selected settings were sufficient to reveal meaningful performance trends. Future work may incorporate a more systematic hyperparameter tuning strategy for further refinement.
To validate these configurations, we assessed their impact on captioning performance. Increasing r and a led to consistent improvements, particularly in capturing structured elements like lane markings and traffic signals, enhancing contextual understanding in driving environments.
To establish performance benchmarks, we evaluated multiple models, as shown in
Table 2. BLIP-2 was used as a baseline without any additional fine-tuning. The LLaVA model [
3] was used for comparison purposes to assess how well the BLIP-2 performed relative to an established multimodal benchmark.
Table 2 shows that LoRA-enhanced BLIP-2 significantly outperformed both baseline models. BLEU-4 improved 2-fold, and SPICE increased nearly 1.5-fold, indicating better fluency and semantic understanding in driving scenes.
To evaluate the scene captioning performance in diverse driving environments, we employed a large-scale dataset consisting of 69,864 image–caption pairs, each paired with detailed human-annotated captions. The dataset spans a wide range of real-world driving conditions, supporting effective domain adaptation and comprehensive assessment of model performance. As illustrated in
Table 3, the dataset encompasses various scenes, weather conditions, times of day, and detected objects, providing a rich context for evaluating vision–language models in complex driving scenarios.
This diverse and richly annotated dataset enables the robust evaluation of caption generation across various lighting conditions, weather scenarios, and traffic densities, reflecting the complexity and contextual richness of real-world driving environment scenes.
Although this study primarily reports aggregate performance across the entire dataset, the dataset itself includes a wide range of challenging environmental conditions, such as night-time, rainy, snowy, and foggy scenes, which are known to be critical for the reliability of autonomous systems. This diversity enables future work to conduct a stratified evaluation to analyze model robustness under specific safety-critical scenarios. Incorporating such fine-grained analysis remains an important direction for improving the interpretability and reliability of vision–language models in real-world driving applications.
To quantitatively assess the captioning quality of each model, we employed three widely used evaluation metrics: CIDEr [
22], BLEU [
23], and SPICE [
24]. These metrics capture different aspects of the generated captions, including lexical accuracy, fluency, informativeness, and semantic relevance.
CIDEr measures the consensus between a generated caption and a set of reference captions using TF–IDF (term frequency–inverse document frequency)-weighted n-gram similarity. It emphasizes how similar the generated caption is to what a human would write for the same image.
where
is the candidate caption,
is the set of reference captions, and
is the cosine similarity between TF–IDF vectors of n-grams.
BLEU is a precision-based metric that measures the overlap of n-grams between the candidate and reference captions. BLEU-n (e.g., BLEU-1 to BLEU-4) reflects precision at different n-gram levels.
where
is the precision of n-grams,
is the weight (typically uniform), and BP is a brevity penalty to penalize short candidates.
SPICE evaluates the semantic content of captions by parsing them into scene graphs and comparing their objects, attributes, and relationships. It computes an F-score based on matching semantic tuples between the candidate and reference.
SPICE is particularly useful for assessing how well the generated caption captures the meaning and structure of the scene.
As evident in
Table 2, both baseline models BLIP-2 and LLaVA exhibited low SPICE, BLEU and CIDEr scores, which indicated that these models had limited capability in generating contextually rich captions for driving environment scenes. The BLEU-4 score for BLIP-2 remained at 0.0117, and LLaVA performed even worse (0.0075), which indicated poor fluency and coherence of the generated captions. Similarly, the SPICE score, which is used for evaluating the semantic structure and relevance, was only 0.1002 for BLIP-2 and 0.0637 for LLaVA, further highlighting their incapability to adapt to driving environments.
The BLEU score trends in
Figure 4 show a clear upward trajectory as LoRA configurations improve. The fine-tuned enhanced BLIP-2 consistently outperformed the baseline BLIP-2, with superior fluency and lexical diversity of driving environment scene captions. Notably, as the LoRA rank (
r) and scaling factor (
a) increased, the BLEU-4 score improved, with the highest setting (r = 32, a = 64) having a score of 0.1609; this score was approximately 14 times that of the baseline BLIP-2.
Enhanced BLIP-2, fine-tuned with LoRA, showed substantial improvements across all evaluation metrics. For instance, BLEU-4 scores improved significantly, reaching 0.1318 with r = 8 and a = 16, and the score further increased to 0.1609 with r = 32 and a = 64. Similarly, CIDEr scores showed a clear upward trend, increasing from 0.0340 (BLIP-2) to 0.2458 (enhanced BLIP-2, r = 32, a = 64). Clearly, fine-tuning resulted in the model generating driving environment scene captions that were closer to human descriptions. The SPICE score also saw a major boost, peaking at 0.4642, confirming the improved semantic consistency in driving environment scene captions.
The improvements in CIDEr and SPICE scores, apparent in
Figure 5, further show the effectiveness of LoRA-based fine-tuning for domain adaptation. The CIDEr score, which indicates the informativeness of captions, increased from 0.0340 (BLIP-2) to 0.2458 (enhanced BLIP-2, r = 32, a = 64). This suggests that fine-tuned models can produce captions that better capture the details of complex driving environments. Similarly, the SPICE score, which measures semantic correctness and scene understanding, shows a consistent rise, peaking at 0.4642, indicating that models fine-tuned using LoRA generated more contextually relevant captions and showed improved scene comprehension.
These results indicate that LoRA-based fine-tuning effectively enhanced the driving environment scene captioning performance of BLIP-2, improving both linguistic accuracy and contextual relevance. The model with the highest performance (enhanced BLIP-2, r = 32, and a = 64) showed substantial improvements over the baselines, which pointed to the effectiveness of domain-adaptive optimization.
Figure 6 presents the results of experiments conducted under a fixed configuration of
and
, focusing on the impact of different dropout rates on model performance. The comparison highlights how varying the dropout value influences the effectiveness of LoRA-based optimization across BLEU-4, SPICE, and CIDEr metrics.
To determine the optimal dropout rate for LoRA-based optimization, we conducted experiments with three different values: 0.08, 0.05, and 0.02. As shown in
Table 4, the configuration with dropout = 0.02 consistently achieved the highest scores across all evaluation metrics. This suggests that a lower dropout rate enhances the model’s ability to generate fluent and semantically accurate captions while maintaining training stability. Based on these results, we selected 0.02 as the final dropout setting in our optimization strategy.
For the training setup, the parameters were carefully chosen to optimize the model performance. The learning rate was set to
, and the weight decay was set to
to prevent overfitting [
25]. Both the training and testing phases were conducted with a batch size of 64. LoRA was configured with specific settings to enhance model responsiveness and efficiency:
and
, dropout was maintained at 0.02, and the bias was set to “none”. These settings were intended to ensure that the model operated efficiently and the model exploited low-rank matrices to enhance its learning capability.
In terms of parameter efficiency, the total number of trainable parameters in our model was 3,831,808, while the entire model consisted of 3,748,511,744 parameters. This corresponds to a trainable parameter ratio of 0.1022, demonstrating that only a small fraction of the total parameters were updated during training. By employing LoRA-based optimization, we achieved parameter-efficient fine-tuning, significantly reducing computational overhead while preserving the pre-trained knowledge of the model. This further supports the effectiveness of domain-adaptive fine-tuning, as demonstrated by the improvements in CIDEr and SPICE scores.
I conducted the computational experiments using a cloud server equipped with an NVIDIA A100 GPU with 40 GB of VRAM. This setup ensured that the large-scale dataset was processed efficiently, maximizing the throughput and minimizing training durations. The reduced computational demand resulting from LoRA-based fine-tuning further contributed to faster training cycles, making the method highly scalable for real-world autonomous driving applications.
5. Discussion
As our experimental results showed, optimizing the Q-Former module of BLIP-2 with a LoRA technique significantly enhanced the model’s domain adaptation in autonomous driving environments. Specifically, the proposed method improved structured dataset transformation, domain-specific adaptation based on LoRA, and contextual input prompting techniques, resulting in higher scene captioning performance.
First, structured dataset transformation was achieved through a template-based data preprocessing pipeline, which effectively converted structured dataset labels (e.g., BDD-100K) into natural language labels [
6]. This transformation facilitated the use of structured driving datasets for training VLMs and helped overcome the textual annotation problem that has been a limiting factor in traditional autonomous driving datasets [
5]. Consequently, the model learned a better and more contextually aware scene representation, which improved the quality and informativeness of the generated captions.
Second, LoRA-based domain-specific adaptation significantly improved the model’s capability to recognize road environment factors such as lane markings, traffic signals, and vehicle interactions. These factors are often misunderstood or misinterpreted by pre-trained VLM. Fine-tuning the Q-Former module with LoRA improved the generalization problem of pre-trained models while reducing computational costs. Experimental results showed that LoRA enhanced the retrieval and captioning performance while maintaining efficiency and feasibility for autonomous driving applications.
Third, context-aware input prompting was optimized to include critical driving contexts, including weather conditions, traffic signals, and vehicle interactions, in the captioning process [
8]. The effective structuring of the input prompts using our method resulted in captions that were more contextually relevant, globally coherent, and semantically rich. This method helped overcome a major limitation of traditional captioning models for driving environment scenes, which often produced object-centric descriptions without considering scene dynamics [
9].
Overall, our method achieved state-of-the-art performance, as indicated by BLEU, CIDEr, and SPICE scores, and it showed significant improvements in the scene captioning accuracy and contextual relevance compared with the baseline models. These results showed the effectiveness of our method in enhancing the interpretability, contextual perception, and domain adaptation of VLMs for autonomous driving environments.
Despite the notable improvements achieved with our proposed method, several limitations remain, indicating the scope for further enhancement. A major limitation was the dependence on structured data availability. Our method involves the use of structured datasets such as BDD-100K for training, which might not be readily available for all autonomous driving domains. The requirement of labeled datasets restricted the applicability of our method to environments where annotated data were scarce or unavailable.
To address this issue, future research should explore the integration of unsupervised or self-supervised learning techniques. Such integration can allow the model to learn from unlabeled data and thereby enhance its generalizability across diverse autonomous driving datasets. Another key challenge is real-time performance and latency considerations. While the use of LoRA effectively reduced the computational overhead, the real-time use of the model in autonomous vehicles would require additional optimization to meet latency constraints. Ensuring low-latency inference is important for real-world applications, especially in dynamic driving environments where rapid decision-making is necessary. Future research should explore techniques such as model compression and quantization along with edge-device deployment strategies to improve the inference speed while maintaining high accuracy. These optimizations would enhance the feasibility of our method for real-time autonomous driving systems, making it more adaptable to resource-constrained environments.
6. Conclusions
We propose an optimized method for generating accurate captions of driving scenes in autonomous driving environments, emphasizing structured dataset transformation, efficient BLIP-2 adaptation through LoRA, and refined input prompting techniques. Our approach significantly improves domain adaptation, contextual relevance, and interpretability, addressing critical performance limitations inherent in traditional vision–language models (VLMs) for autonomous driving.
Our experimental results demonstrate that strategically optimizing only the Q-Former module using LoRA substantially enhances the model’s ability to accurately interpret critical road-specific features such as lane structures, traffic signals, and dynamic vehicle interactions, all while maintaining exceptional computational efficiency. This targeted optimization not only conserves computational resources but also ensures the feasibility of deploying our model in resource-constrained autonomous driving systems.
Moreover, our structured dataset transformation approach effectively integrates structured autonomous driving datasets into vision–language learning frameworks, optimizing dataset utilization and overcoming limitations associated with insufficient textual annotations commonly encountered in standard datasets. Additionally, our carefully optimized, context-aware prompting strategy explicitly incorporates environmental variables, such as weather conditions and traffic dynamics, thereby generating more coherent, informative, and contextually relevant captions.
Overall, our method achieves superior captioning accuracy, enhanced contextual perception, and significantly improved computational efficiency, contributing directly to safer, more transparent, and legally compliant autonomous driving technologies. These optimizations lay a robust foundation for further innovations in vision–language modeling that can effectively bridge structured driving data with sophisticated scene understanding.
However, several optimization challenges remain, presenting valuable directions for future research. The dependency on structured datasets highlights the importance of exploring optimization strategies involving unsupervised or self-supervised learning to broaden model generalizability. While LoRA provides considerable computational efficiency improvements, achieving true real-time capabilities necessitates additional optimization efforts, such as advanced model compression techniques and strategic edge-device deployments.
Future optimization could also include integrating temporal context through video-based models, significantly improving scene continuity and long-term situational awareness. Moreover, optimizing legal compliance and decision-making reliability through integration with rule-based traffic law knowledge graphs presents another promising research avenue. Finally, human-in-the-loop optimization strategies may further enhance model interpretability, adaptability, and continuous improvement in realistic driving conditions.
Beyond the current scope, our model’s performance and efficiency can be further optimized for video-based and multimodal data integration by employing advanced parameter-efficient tuning techniques like LoRA, ensuring broader applicability and enhanced real-world performance.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}