

Neural Architecture Search for Generative Adversarial Networks: A Comprehensive Review and Critical Analysis


Abstract
:1. Introduction
1.1. Background
1.2. Motivation
1.3. Objectives
2. Related Studies
2.1. Overview of NAS-GAN Reviews
2.2. Other NAS Reviews with GAN Sections
2.3. Identified Gaps in the Literature
3. Research Methodology
3.1. Study Objectives and Research Questions
- RQ1: What NAS approaches are applied to GANs in the literature?
- –
- To address this question, we identified the approaches present in the literature, highlighting both their benefits and limitations. By systematically reviewing existing methods, we were able to provide a comprehensive analysis that underscores the strengths of each approach while also acknowledging potential drawbacks and areas for improvement.
- RQ2: What are the key search spaces explored in NAS-GAN?
- –
- To address this research question, we examined the search spaces utilized in the studied approaches, exploring their applications and additional relevant aspects. This investigation provided insights into how different search spaces are leveraged within the context of the approaches, highlighting their effectiveness and areas for potential enhancement.
- RQ3: What evaluation methods are used to assess the found architecture?
- –
- To address this research question, we identified the metrics employed to evaluate NAS-GAN approaches and assessed their applicability. This analysis provided a detailed overview of the evaluation criteria used in the studies, examining their effectiveness in measuring the performance and suitability of the NAS-GAN approaches in various contexts.
- RQ4: What are the gaps in the research on NAS in GANs?
- –
- To address this research question, we studied and analyzed the relevant literature, providing a comprehensive review of existing studies and identifying areas for future research. This approach allowed us to suggest potential directions for future work based on the gaps and limitations identified in the current body of knowledge.
3.2. Search Strategy
- In Google Scholar, IEEE, ACM, and Springer: (“Generative Adversarial Network” OR “GAN*”) AND (“Architecture” OR “Architectural”) AND (“Search” OR “Optimization”) AND (“Reinforcement Learning” OR “Policy” OR “Evolutionary” OR “Evolutionary Algorithm*” OR “Genetic Algorithm*” OR “Differential” OR “Gradient-based”)
- In Arxiv and Science Direct (we changed the search string because of limitations in their search tool): (“Generative Adversarial Network” OR “GAN”) AND (“Architecture” OR “Architectural”) AND (“Search” OR “Optimization”) AND (“Reinforcement Learning” OR “Policy” OR “Evolutionary” OR “Evolutionary Algorithm” OR “Genetic Algorithm” OR “Differential” OR “Gradient-based”).
3.3. Study Selection and Quality Assessment
- 1.
- Initial selection: We searched each database mentioned in Section 3.2. We first chose studies based on their titles.
- 2.
- Filtering studies: To find the most relevant studies from our initial collection, we used our quality assessment criteria. We also looked at the abstract, introduction, and conclusion of each study to filter them further.
- 3.
- Merging: After filtering, we had a group of studies relevant to our research. Some were duplicates because of overlaps in database results. We combined all the studies into one set, removing duplicates.
- 4.
- Snowballing: To find more related studies and make sure we didn’t miss anything, we used backward and forward snowballing. Backward snowballing means looking at a study’s reference list to find new papers [20]. Forward snowballing means finding new papers that cite the study we’re looking at [20]. These processes helped us add new papers we didn’t find in our first search.
- 5.
- Final Decision: After adding the new studies from snowballing, we filtered our set of studies one more time to get our final group of relevant studies.
- 1.
- Inclusion Criteria:
- (a)
- Studies must be written in English.
- (b)
- Studies must focus primarily on architecture search for GANs, providing clear details on the NAS techniques employed.
- (c)
- Only peer-reviewed articles, conference papers, and reputable preprints with sufficient methodological detail were considered.
- 2.
- Exclusion Criteria:
- (a)
- Studies that focus primarily on topics other than architecture search (e.g., hyperparameter tuning, latent space exploration, or unrelated GAN applications) were excluded.
- (b)
- Studies lacking sufficient technical detail or methodological transparency regarding the NAS process were not considered.
- (c)
- Duplicate studies identified across different databases were removed.
3.4. Limitation on Research Methodology
3.5. Data Extraction and Synthesis
- RQ1:
- –
- Search Strategy: This criterion examines the techniques and approaches employed in the solutions presented by relevant studies. These may include, but are not limited to RL, EA, and other methodologies prevalent in the existing literature.
- –
- Search Type: This criterion identifies if the search strategy searches for both generator and discriminator networks, or if it only searches for a generator network.
- –
- Performance Assessment Strategy: This criterion examines how the search strategy estimates its current performance to guide the search.
- –
- GPU Cost: This criterion identifies the search speed of the solutions presented by relevant studies based on its GPU usage.
- –
- Advantages: This criterion examines the positive outcomes and potential merits associated with each methodological approach discussed in the existing literature.
- –
- Disadvantages: This criterion identifies and analyzes any constraints, shortcomings, or negative aspects (where applicable) of the investigated approach.
- RQ2:
- –
- Search Space: This criterion examines the type of search space used to encode the network component in the solutions presented by relevant studies. These may include, but are not limited to, Cell-based or Entire/Chain-Structured and other methodologies prevalent in the existing literature.
- RQ3:
- –
- Evaluation Metrics: This criterion examines evaluation measurements used to evaluate the performance of the solution presented by the relevant studies.
- –
- Dataset: This criterion identifies the datasets used in the solution presented by relevant studies.
- –
- Supported Generation Type: This criterion identifies the types of generation tasks that are supported by the solution approaches. These may include, unconditional image generation, conditional images generation or both.
4. Results and Discussion
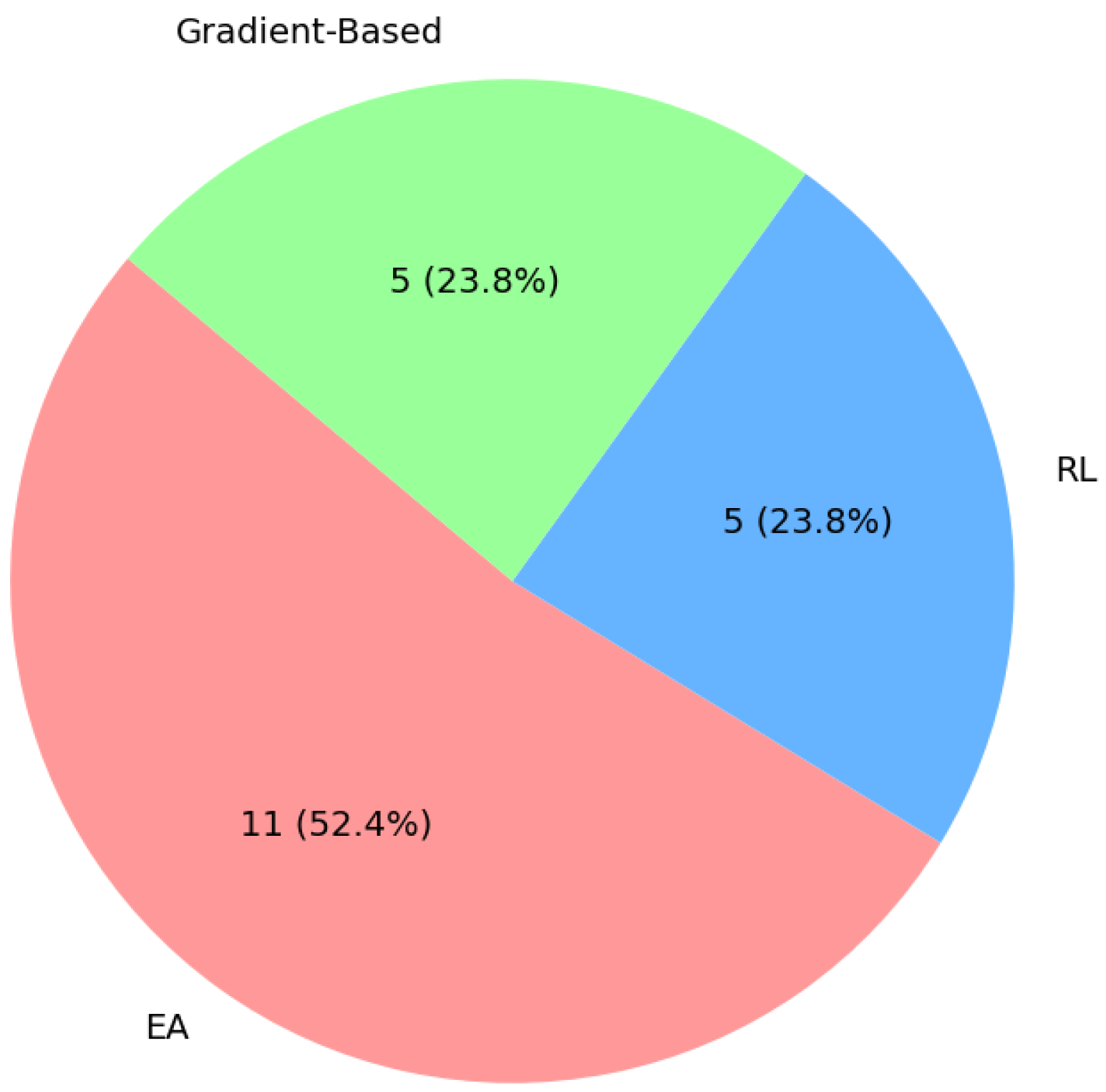
4.1. RQ1: What NAS Approaches Are Applied to GANs in the Literature?
4.1.1. Evolutionary Algorithms Approaches
4.1.2. Reinforcement Learning Approaches
- On-Policy Search
- Off-Policy Search
4.1.3. Gradient-Based Approaches
4.2. RQ2: What Are the Key Search Spaces Explored in NAS-GAN?
4.2.1. Entire/Chain-Structure Space
4.2.2. Cell-Based Space
4.3. RQ3: What Evaluation Methods Are Used to Assess the Found Architecture?
4.3.1. Evaluation Metrics
- Inception Score (IS): IS [43] attempts to measure image realism and diversity using a pre-trained InceptionV3 network [44], calculating scores based on predicted class probability distributions. However, IS has critical flaws: it lacks direct comparison to training data, can miss mode collapse, and introduces ImageNet biases. Its non-intuitive nature hinders meaningful interpretation of score differences. Despite these limitations, IS remains widely used, highlighting the need for more robust evaluation metrics.Our review of representitive works (e.g., [12,14,22]) shows IS scores vary slightly across methods, with NAS approaches demonstrating more consistent high-quality images. Notably, the state-of-the-art IS on this benchmark comes from EWSGAN, an evolutionary method. While this highlights the potential of evolutionary approaches, it also underscores the success of NAS methods in consistently achieving high IS scores. Given IS’s vulnerability to adversarial examples and other shortcomings, it should be used cautiously and always supplemented with additional evaluation metrics for a comprehensive assessment of generative models.
- Fréchet Inception Distance (FID): FID [45] improves on IS by comparing generated and real image statistics using InceptionV3 features, calculating the Fréchet distance between feature distributions. While considered more robust than IS and better correlated with human judgment, FID’s limitations include assuming Gaussian distributions, relying on a potentially biased pre-trained network, and possibly overlooking certain aspects of image quality or diversity. Despite these drawbacks, FID remains widely used for evaluating generative models.Analysis of reported scores from major NAS-GAN approaches [12,14,29] reveals significant variation across methods, with NAS approaches consistently outperforming manual methods. AdversarialNAS, EAGAN, and EWSGAN demonstrate impressive scores across datasets, suggesting NAS’s effectiveness in generating high-quality images. This data indicates that automated searches often find more optimal architectures than human designers. Recent work using EA algorithms has achieved state-of-the-art results, though the longevity of this trend remains uncertain. However, these findings warrant further investigation into the factors contributing to NAS’s success and potential limitations of current evaluation metrics.
- Computational Efficiency: NAS-GAN needs to improve efficiency and performance while managing computational resources. Search time, measured in GPU Days, is critical in NAS as it explores architecture space to identify promising GAN structures [46]. To address computational challenges, researchers have developed several strategies. Weight sharing reduces parameters and computational load, used in [14,30,31].Adaptive mechanisms and progressive growing dynamically adjust network complexity, as seen in AGAN [34]. Evolutionary algorithms iteratively improve GAN architectures, adopted by (e.g., [30,36,40]). Multi-objective optimization balances performance and computational cost, implemented by [28,32]. Ensemble methods use multiple discriminators for improved diversity and efficiency, utilized by E-GAN. Coevolutionary algorithms evolve Generators and Discriminators simultaneously, employed by Lipizzaner and COEGAN. Lastly, multi-stage training gradually increases model complexity, an approach adopted by Mustangs.
- Model Size: Model size is a critical yet complex factor in NAS for GANs, requiring a delicate balance between performance and efficiency. While NAS algorithms often incorporate size constraints, this approach has significant limitations. The focus on smaller models, though advantageous for memory usage and speed, can lead to oversimplification of trade-offs, bias towards suboptimal architectures, and difficulty in accurately assessing the impact on performance. Moreover, it risks overlooking larger innovative architectures with unique benefits [47].Reviewed methods address model size differently. Some, like EAGAN and AutoGAN, explicitly use parameter count as an optimization criterion or reportable metric. Others, such as AdversarialNAS and NSGA-II DCGAN, dynamically adjust size during training or use multi-objective optimization. Methods like E-GAN and Lipizzaner focus on pruning and efficiency. However, not all approaches prioritize or report size metrics, with some like AGAN and E2GAN emphasizing performance over explicit size considerations.A more holistic approach to architecture optimization is necessary, considering factors beyond just size, such as interpretability, robustness, and adaptability. This comprehensive view could yield more balanced and effective GAN architectures, avoiding the pitfalls of overly simplistic size-based optimizations while still maintaining efficiency.
- Mode Collapse Resistance: Mode collapse is a common failure mode in GANs where the generator produces a limited variety of outputs, failing to capture the full diversity of the target distribution. In the context of NAS, architectures should be evaluated on their resistance to mode collapse [48]. This can be assessed through diversity metrics applied to generated samples, or by analyzing the distribution of generated outputs in feature space. A good NAS solution for GANs should prioritize architectures that maintain output diversity while still producing high-quality samples.
- Convergence Stability: GAN training instability, characterized by mode collapse and oscillating losses, remains a significant challenge. Convergence stability in NAS for GANs is crucial, measured by consistent performance across multiple initializations [49]. In the reviewed literature, multiple solutions have been developed to address this issue, such as adaptive training techniques used by AGAN. Some methods focus on balancing Generator and Discriminator performance used in NSGA-II DCGAN, while Mustangs employs multi-agent systems or co-evolutionary algorithms COEGAN, Lipizzaner that continuously measure stability. Advanced techniques like alpha-divergence minimization used by alphaGAN and EWSGAN’s Wasserstein distance optimization have also been explored. Despite these diverse approaches, the field lacks a comprehensive comparison of their effectiveness, and the trade-offs between stability, performance, and computational cost remain unclear. Moreover, the reliance on existing evaluation metrics may not fully capture the nuances of convergence stability, suggesting a need for more robust assessment methods.
- Sample Quality: While automated metrics like IS and FID are valuable, they don’t always align perfectly with human perception. Therefore, subjective evaluation of generated images by human raters remains an important aspect of GAN assessment [50]. This typically involves showing raters a mix of real and generated images and asking them to judge qualities such as realism, coherence, and aesthetic appeal. For NAS in GANs, this human evaluation can be used as a final validation step for top-performing architectures. However, it’s important to note that human evaluation is time-consuming and can be subject to biases, so it’s often used in conjunction with automated metrics rather than as the sole evaluation criterion. All presented work conducted sample quality check in their experiments.
4.3.2. Datasets
4.3.3. Supported Generation Type
4.4. RQ4: What Are the Gaps in the Research on NAS in GANs?
- Current NAS for GANs systems primarily focus on automated architecture generation for both Generator and Discriminator networks or exclusively for Generator networks. However, an approach that concentrates on searching for superior Discriminator networks has yet to be introduced. This represents a significant opportunity for future research to explore dedicated Discriminator architecture search methods, which could lead to enhanced overall GAN performance.
- Another significant gap is the reliance on CIFAR-10 and STL-10 datasets for evaluating GAN architecture performance. While these datasets allow for direct comparisons, they limit the generalizability of the findings. Very few systems have used datasets like CelebA and LSUN for validation. Therefore, future research should aim to conduct performance evaluations on a larger variety of image datasets, including CelebA, LSUN, and COCO, to provide a more comprehensive assessment of GAN performance.
- Most existing NAS-GANs systems have been developed for unconditional image generation tasks. To broaden the scope and impact of NAS for GANs, future work should also focus on other types of image generation, such as conditional image generation and image-to-image translation tasks. This expansion would not only enhance the versatility of GANs but also potentially uncover new applications and benefits of NAS in different image generation contexts.
- There is also a need for more robust evaluation metrics beyond just the Inception Score and FID. While these metrics are commonly used, they may not capture all aspects of GAN performance. Future research should develop and incorporate new metrics that can provide a more holistic evaluation of GAN quality, including aspects like diversity, fidelity, and realism.
- Another area that requires more exploration is the interpretability and explainability of the generated GAN architectures. Understanding why certain architectures perform better than others can provide valuable insights and guide future design improvements. Research efforts should aim to develop techniques that enhance the interpretability of NAS-generated GAN architectures.
- A further aspect that warrants deeper exploration is the integration of NAS with emerging AI paradigms, such as self-supervised learning, which could significantly enhance the robustness and generalizability of GANs.
- Another domain that calls for more research is the environmental and computational costs associated with NAS processes, promoting the development of more energy-efficient and sustainable AI models.
- There is also a need to investigate the impact of NAS on GANs in other domains beyond image generation, such as natural language processing or time-series data, which could open new avenues for GAN applications.
- Additionally, the application of NAS techniques to transformer architectures within GANs remains unexplored. Given the success of transformers in various machine learning tasks, exploring NAS for transformer-based GAN architectures could lead to significant advancements. This presents a promising research direction that could leverage the strengths of transformers for improved GAN performance.
4.5. Practical Applications of NAS in GANs
4.5.1. Medical Imaging and Synthetic Data Generation
4.5.2. Data Augmentation for Limited Datasets
4.5.3. Anomaly Detection
4.5.4. Creative Content Generation
4.6. Ethical and Environmental Considerations
5. Implications of the Study
5.1. Key Findings
- Current NAS for GANs systems primarily focus on automated architecture generation for both Generator and Discriminator networks or exclusively for Generator networks. However, an approach that concentrates on searching for superior Discriminator networks has yet to be introduced. Dedicated Discriminator architecture search methods could lead to enhanced overall GAN performance.
- The reliance on CIFAR-10 and STL-10 datasets for evaluating GAN architectures limits the generalizability of findings. While these datasets enable direct comparisons, they are insufficient for evaluating performance across diverse applications. Broader dataset evaluations, including CelebA, LSUN, and COCO, are necessary.
- Most existing NAS-GAN systems are limited to unconditional image generation tasks. Expanding research to other types of image generation, such as conditional image generation and image-to-image translation, would broaden the scope and impact of NAS in GAN applications.
5.2. Opportunities for Improving and Expanding Applications of NAS-GANs
- Current evaluation metrics, such as IS and FID, may not capture all aspects of GAN performance. Developing new metrics to assess diversity, fidelity, and realism can provide a more holistic evaluation framework.
- There is a pressing need to improve the interpretability and explainability of generated GAN architectures. Understanding why specific architectures perform better can guide future designs and enable practical applications.
- Integrating NAS with AI paradigms, such as self-supervised learning, could enhance the robustness and generalizability of GANs.
- Addressing the environmental and computational costs of NAS processes is crucial. Developing energy-efficient and sustainable AI models will make NAS-GAN methods more accessible and scalable.
- Beyond image generation, NAS-GAN techniques have potential in other domains, such as natural language processing and time-series data. Researching these applications could unlock new opportunities for GANs.
- The application of NAS techniques to transformer-based GAN architectures remains unexplored. Given the success of transformers in various machine learning tasks, incorporating NAS into transformer-based GANs could significantly advance the field.
6. Threats to Validity
7. Conclusions
- The superiority of evolutionary algorithms and gradient-based methods in certain contexts for NAS-GAN.
- The importance of robust evaluation metrics beyond traditional scores like IS and FID.
- The need for diverse datasets in assessing GAN performance, beyond the commonly used CIFAR-10 and STL-10.
- The potential for exploring dedicated Discriminator architecture search methods.
- The opportunity to expand NAS-GAN research into conditional image generation and other domains beyond image generation.
Funding
Acknowledgments
Conflicts of Interest
References
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Souza, L.A.; Passos, L.A.; Mendel, R.; Ebigbo, A.; Probst, A.; Messmann, H.; Palm, C.; Papa, J.P. Fine-tuning Generative Adversarial Networks using Metaheuristics. In Proceedings of the Bildverarbeitung für die Medizin 2021, Regensburg, Germany, 7–9 March 2021; Springer: Wiesbaden, Germany, 2021; pp. 205–210. [Google Scholar]
- Abd Elaziz, M.; Dahou, A.; Abualigah, L.; Yu, L.; Alshinwan, M.; Khasawneh, A.M.; Lu, S. Advanced metaheuristic optimization techniques in applications of deep neural networks: A review. Neural Comput. Appl. 2021, 33, 14079–14099. [Google Scholar] [CrossRef]
- Apostolopoulos, I.; Papathanasiou, N.; Apostolopoulos, D.; Panayiotakis, G. Applications of Generative Adversarial Networks (GANs) in Positron Emission Tomography (PET) imaging: A review. Eur. J. Nucl. Med. Mol. Imaging 2022, 49, 3717–3739. [Google Scholar] [CrossRef] [PubMed]
- Xia, X.; Pan, X.; Li, N.; He, X.; Ma, L.; Zhang, X.; Ding, N. GAN-based anomaly detection: A review. Neurocomputing 2022, 493, 497–535. [Google Scholar] [CrossRef]
- Kocasari, U.; Dirik, A.; Tiftikci, M.; Yanardag, P. StyleMC: Multi-channel based fast text-guided image generation and manipulation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–7 January 2022; pp. 895–904. [Google Scholar]
- Mosolova, A.V.; Fomin, V.V.; Bondarenko, I.Y. Text augmentation for neural networks. In Proceedings of the CEUR Workshop Proceedings, Moscow, Russia, 5–7 July 2018; Volume 2268, pp. 104–109. [Google Scholar]
- Talbi, E.G. Optimization of deep neural networks: A survey and unified taxonomy. arXiv 2020, arXiv:2006.05597. [Google Scholar]
- Thanh-Tung, H.; Tran, T. Catastrophic forgetting and mode collapse in GANs. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–10. [Google Scholar]
- Elsken, T.; Metzen, J.H.; Hutter, F. Neural architecture search: A survey. J. Mach. Learn. Res. 2019, 20, 1–21. [Google Scholar]
- He, X.; Zhao, K.; Chu, X. AutoML: A survey of the state-of-the-art. Knowl.-Based Syst. 2021, 212, 106622. [Google Scholar]
- Gong, X.; Chang, S.; Jiang, Y.; Wang, Z. AutoGAN: Neural architecture search for generative adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3224–3234. [Google Scholar]
- Costa, V.; Lourenço, N.; Correia, J.; Machado, P. COEGAN: Evaluating the coevolution effect in generative adversarial networks. In Proceedings of the Genetic and Evolutionary Computation Conference, Prague, Czech Republic, 13–17 July 2019; pp. 374–382. [Google Scholar]
- Tian, Y.; Shen, L.; Su, G.; Li, Z.; Liu, W. AlphaGAN: Fully differentiable architecture search for generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6752–6766. [Google Scholar] [CrossRef]
- Ganepola, V.V.V.; Wirasingha, T. Automating generative adversarial networks using neural architecture search: A review. In Proceedings of the 2021 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 5–7 March 2021; pp. 577–582. [Google Scholar]
- Buthgamumudalige, V.U.; Wirasingha, T. Neural Architecture Search for Generative Adversarial Networks: A Review. In Proceedings of the 2021 10th International Conference on Information and Automation for Sustainability (ICIAfS), Negambo, Sri Lanka, 11–13 August 2021; pp. 246–251. [Google Scholar]
- Wang, Y.; Zhang, Q.; Wang, G.G.; Cheng, H. The application of evolutionary computation in generative adversarial networks (GANs): A systematic literature survey. Artif. Intell. Rev. 2024, 57, 182. [Google Scholar] [CrossRef]
- Kang, J.-S.; Kang, J.; Kim, J.-J.; Jeon, K.-W.; Chung, H.-J.; Park, B.-H. Neural Architecture Search Survey: A Computer Vision Perspective. Sensors 2023, 23, 1713. [Google Scholar] [CrossRef]
- White, C.; Safari, M.; Sukthanker, R.; Ru, B.; Elsken, T.; Zela, A.; Dey, D.; Hutter, F. Neural architecture search: Insights from 1000 papers. arXiv 2023, arXiv:2301.08727. [Google Scholar]
- Kitchenham, B. Procedures for Performing Systematic Reviews; Technical report; Keele University: Newcastle, UK, 2004. [Google Scholar]
- Talbi, E.G. Metaheuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 74. [Google Scholar]
- Wang, C.; Xu, C.; Yao, X.; Tao, D. Evolutionary generative adversarial networks. IEEE Trans. Evol. Comput. 2019, 23, 921–934. [Google Scholar] [CrossRef]
- Al-Dujaili, A.; Schmiedlechner, T.; Hemberg, E.; O’Reilly, U.M. Towards distributed coevolutionary GANs. arXiv 2018, arXiv:1807.08194. [Google Scholar]
- Toutouh, J.; Hemberg, E.; O’Reilly, U.M. Spatial Evolutionary Generative Adversarial Networks. In Proceedings of the Genetic and Evolutionary Computation Conference, Prague, Czech Republic, 13–17 July 2019; pp. 472–480. [Google Scholar]
- Garciarena, U.; Santana, R.; Mendiburu, A. Evolved GANs for generating pareto set approximations. In Proceedings of the Genetic and Evolutionary Computation Conference, GECCO ’18, Kyoto, Japan, 15–19 July 2018; pp. 434–441. [Google Scholar] [CrossRef]
- Lu, Y.; Kakillioglu, B.; Velipasalar, S. Autonomously and simultaneously refining deep neural network parameters by a bi-generative adversarial network aided genetic algorithm. arXiv 2018, arXiv:1809.10244. [Google Scholar]
- Wu, Z.; Song, S.; Khosla, A.; Yu, F.; Zhang, L.; Tang, X.; Xiao, J. 3D ShapeNets: A deep representation for volumetric shapes. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1912–1920. [Google Scholar] [CrossRef]
- Du, L.; Cui, Z.; Wang, L.; Ma, J. Structure tuning method on deep convolutional generative adversarial network with nondominated sorting genetic algorithm II. Concurr. Comput. Pract. Exp. 2020, 32, e5688. [Google Scholar] [CrossRef]
- Lin, Q.; Fang, Z.; Chen, Y.; Tan, K.C.; Li, Y. Evolutionary Architectural Search for Generative Adversarial Networks. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 6, 783–794. [Google Scholar] [CrossRef]
- Ying, G.; He, X.; Gao, B.; Han, B.; Chu, X. EAGAN: Efficient two-stage evolutionary architecture search for GANs. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 37–53. [Google Scholar]
- Xue, Y.; Tong, W.; Neri, F.; Chen, P.; Luo, T.; Zhen, L.; Wang, X. Evolutionary Architecture Search for Generative Adversarial Networks Based on Weight Sharing. IEEE Trans. Evol. Comput. 2024, 28, 653–667. [Google Scholar] [CrossRef]
- Kobayashi, M.; Nagao, T. A Multi-Objective Architecture Search for Generative Adversarial Networks. In Proceedings of the 2020 Genetic and Evolutionary Computation Conference Companion, Cancún, Mexico, 8–12 July 2020; pp. 133–134. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Wang, H.; Huan, J. AGAN: Towards automated design of generative adversarial networks. arXiv 2019, arXiv:1906.11080. [Google Scholar]
- Zhou, P.; Xie, L.; Ni, B.; Tian, Q. Searching Towards Class-Aware Generators for Conditional Generative Adversarial Networks. IEEE Signal Process. Lett. 2022, 29, 1669–1673. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, Q.; Huang, Z.; Li, W.; Dai, D.; Yang, M.; Wang, J.; Fink, O. Off-policy reinforcement learning for efficient and effective gan architecture search. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 175–192. [Google Scholar]
- Li, W.; Wen, S.; Shi, K.; Yang, Y.; Huang, T. Neural Architecture Search With a Lightweight Transformer for Text-to-Image Synthesis. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1567–1576. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Gao, C.; Chen, Y.; Liu, S.; Tan, Z.; Yan, S. AdversarialNAS: Adversarial Neural Architecture Search for GANs. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 5679–5688. [Google Scholar]
- Doveh, S.; Giryes, R. DEGAS: Differentiable efficient generator search. Neural Comput. Appl. 2021, 33, 17173–17184. [Google Scholar] [CrossRef]
- Li, M.; Lin, J.; Ding, Y.; Liu, Z.; Zhu, J.Y.; Han, S. GAN Compression: Efficient Architectures for Interactive Conditional GANs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Xue, Y.; Chen, K.; Neri, F. Differentiable Architecture Search with Attention Mechanisms for Generative Adversarial Networks. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 3141–3151. [Google Scholar] [CrossRef]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4780–4789. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Srivastava, A.; Valkov, L.; Russell, C.; Gutmann, M.U.; Sutton, C. Veegan: Reducing mode collapse in gans using implicit variational learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Mescheder, L.; Geiger, A.; Nowozin, S. Which training methods for GANs do actually converge? In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 3481–3490. [Google Scholar]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Deng, L. The MNIST Database of Handwritten Digit Images for Machine Learning Research [Best of the Web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Krizhevsky, A. Learning Multiple Layers of Features from Tiny Images; Technical report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Ahmed, H.S. Uncover This Tech Term: Generative Adversarial Networks. Korean J. Radiol. 2024, 25, 493–498. [Google Scholar] [CrossRef]
- Tanaka, F.H.K.D.S.; Aranha, C. Data augmentation using GANs. arXiv 2019, arXiv:1904.09135. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4217–4228. [Google Scholar] [CrossRef]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2018, arXiv:1710.10196. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
| Review Paper | Year | Scope | Limitations | This Review’s Improvements |
|---|---|---|---|---|
| Ganepola & Wirasingha [15] | 2021 | Image generation, GAN compression; analysis of RL, EA, and gradient-based strategies | Focuses on pre-2021 works, with limited detail on mutation/operator design | Extends coverage to 2021–2025 with additional technical insights |
| Buthgamumudalige & Wirasingha [16] | 2021 | Transferability, supervised learning in NAS-GAN; evaluates IS and FID on CIFAR-10, STL-10 | Limited dataset diversity and minimal discussion of evolutionary operators | Expands evaluation to diverse datasets (CelebA, LSUN) and provides deeper operator-level analysis |
| Kang et al. [18] | 2023 | NAS in computer vision tasks | Superficial NAS-GAN coverage | Provides in-depth NAS-GAN analysis |
| White et al. [19] | 2023 | Broad NAS survey (1000+ papers) | Minimal focus on GANs | Emphasizes GAN-specific techniques |
| Wang et al. [17] | 2024 | EC in GANs: architecture search, parameter tuning, loss function adaptation, and synchronization strategies | Broad scope reduces NAS-specific depth; less focus on discrete architecture search | Goes beyond traditional EC-based methods, offering a holistic technical perspective and comprehensive analysis of diverse approaches. |
| This Review | 2025 | Comprehensive NAS-GAN analysis | N/A | Synthesizes 2021–2025 works, addressing reproducibility, dataset diversity, and technical gaps |
| Aspect | Ganepola & Wirasingha (2021) [15] | Buthgamumudalige & Wirasingha (2021) [16] | This Review |
|---|---|---|---|
| Search Strategies | EA, RL, Gradient-based | RL, Gradient-based | EA, RL, Gradient-based |
| Datasets | CIFAR-10, STL-10 | CIFAR-10, STL-10 | CIFAR-10, STL-10, CelebA, LSUN, MNIST |
| Evaluation Metrics | IS, FID, GPU days, Search space | IS, FID | IS, FID, Search spcae, Computational Cost |
| Limitations Addressed | Focus on early NAS-GANs | Limited evaluation criteria | Metric reliability, Reproducibility, Discriminator NAS gaps |
| Novel Contributions | Initial NAS-GAN taxonomy | Multi-criteria analysis | Analysis of recent NAS-GAN works, dataset diversity |
| Method | Search Strategy | Searched Network | Architecture Modification Technique | Optimization Objective | GPU Type | GPU Days | Search Space Type | Search Space Size |
|---|---|---|---|---|---|---|---|---|
| AutoGAN | RL | G Only | RNN Controller | IS | 2080Ti | 2 | Cell | |
| AGAN | RL | G and D | RNN Controller | IS | Titan-X | 1200 | Cell | |
| MN-NAS | RL | G Only | MDP | IS | 1080Ti | - | Cell | |
| E2GAN | RL | G Only | MDP | IS & FID | 2080Ti | 0.3 | Cell | - |
| T2IGAN | RL | G Only | MDP | IS & FID | V100 | 0.42 | Cell | |
| AdversarialNAS | Gradient | G and D | - | GAN objective | 2 X 2080Ti | 1 | Cell | |
| DEGAS | Gradient | G Only | - | Reconstruction loss | Titan-X | 4 | Chain | |
| GAN Compression | Gradient | G Only | - | GAN Objective + reconstruction loss | 2080Ti | - | Cell | |
| alphaGAN | Gradient | G Only | - | Duality Gap Loss & GAN Objective | Tesla P40 | 0.15 | Cell | |
| DAMGAN | Gradient | G Only | Dual-Attention Mechanisms | GAN objective | 3090 | 0.09 | Cell | - |
| EvoGAN | EA | G and D | Mutation | Custom | NA | - | Hybrid | - |
| Bi-GAN | EA | G Only | Mutation & Continuous Refinement | Accuracy | NA | - | Hybrid | - |
| NSGA-II DCGAN | EA | G Only | Crossover & Mutation | Custom | - | - | Chain | - |
| E-GAN | EA | G and D | Mutation | Custom | 1080TI | 1.25 | - | - |
| Lipizzaner | EA | G and D | Mutation | GAN objective | - | - | Cell | - |
| Mustangs | EA | G and D | Mutation | GAN objective | - | - | Cell | - |
| COEGAN | EA | G and D | Mutation | FID & Discriminator loss | - | - | Chain | - |
| EAGAN | EA | G and D | Crossover & Mutation | IS - FID | NA | 1.2 | Cell | |
| EAS-GAN | EA | G Only | Mutation | Custom | 3090 | 1 | Cell | - |
| EWSGAN | EA | G Only | Crossover & Mutation | IS - FID | 2080Ti | 1 | Cell | |
| NSGA-II with CGP | EA | G and D | Crossover & Mutation | IS & FID | - | - | CPG | - |
| Method | MNIST (FID ↓ *) | CelebA (FID ↓ *) |
|---|---|---|
| COEGAN [13] | 43.0 ± 4.0 | - |
| E-GAN [22] | 466.1 | - |
| Lip-BCE [23] | 48.96 | 36.25 |
| Lip-MSE [23] | 371.6 | 158.7 |
| Lip-HEU [23] | 52.53 | 37.87 |
| Mustangs † [24] | 42.24 | 36.15 |
| Method | Search Strategy | CIFAR-10 | STL-10 | ||
|---|---|---|---|---|---|
| IS ↑ * | FID ↓ ** | IS ↑ * | FID ↓ ** | ||
| AutoGAN [12] | RL | 8.55 ± 0.10 | 12.42 | 9.23 ± 0.08 | 31.01 |
| AGAN [34] | RL | 8.29 ± 0.09 | 30.50 | 9.23 ± 0.08 | 52.72 |
| E2GAN [36] | RL | 8.51 ± 0.13 | 11.26 | 9.51 ± 0.09 | 25.35 |
| AdversarialNAS [39] | Gradient | 8.74 ± 0.07 | 10.87 | 9.63 ± 0.19 | 26.98 |
| DEGAS [40] | Gradient | 8.37 ± 0.08 | 12.01 | 9.71 ± 0.11 | 28.76 |
| alphaGAN [14] | Gradient | 8.98 ± 0.09 | 10.35 | 10.12 ± 0.13 | 22.43 |
| DAMGAN [42] | Gradient | 8.99 ± 0.08 | 10.27 | 10.35 ± 0.14 | 22.18 |
| E-GAN [22] | EA | 6.9 ± 0.09 | - | - | - |
| EAGAN [30] | EA | 8.81 ± 0.10 | 9.91 | 10.44 ± 0.08 | 22.18 |
| EAS-GAN [29] | EA | 7.45 ± 0.08 | 33.2 | - | 38.84 |
| EWSGAN † [31] | EA | 8.99 ± 0.11 | 9.09 | 10.51 ± 0.13 | 21.89 |
| NSGA-II with CGP [32] | EA | 8.89 ± 0.01 | 16.6 | 10.3 ± 0.01 | 26.3 |
| Method | IS ↑ * | FID ↓ ** |
|---|---|---|
| AGAN | 8.82 ± 0.09 | 23.8 |
| DEGAS | 8.85 ± 0.07 | 9.83 |
| NSGA-II with CGP | 9.22 ± 0.05 | 7.24 ± 0.08 |
| Method | Dataset | Generation Type | IS ↑ * | FID ↓ ** |
|---|---|---|---|---|
| Mustangs | MNIST | Unsupervised | - | 42.24 |
| Mustangs | CelebA | Unsupervised | - | 36.15 |
| EWSGAN | CIFAR-10 | Unsupervised | 8.99 | 9.09 |
| EWSGAN | STL-10 | Unsupervised | 10.51 | 21.89 |
| NSGA-II with CGP | STL-10 | Supervised | 9.22 | 7.24 |
| T2IGAN | CIFAR-100 | Conditional | 8.65 | 14.10 |
| GAN Compression | Horse ↔ Zebra | Conditional | 8.95 | 14.20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, A.; Ahmed, M. Neural Architecture Search for Generative Adversarial Networks: A Comprehensive Review and Critical Analysis. Appl. Sci. 2025, 15, 3623. https://doi.org/10.3390/app15073623
Alotaibi A, Ahmed M. Neural Architecture Search for Generative Adversarial Networks: A Comprehensive Review and Critical Analysis. Applied Sciences. 2025; 15(7):3623. https://doi.org/10.3390/app15073623
Chicago/Turabian StyleAlotaibi, Abrar, and Moataz Ahmed. 2025. "Neural Architecture Search for Generative Adversarial Networks: A Comprehensive Review and Critical Analysis" Applied Sciences 15, no. 7: 3623. https://doi.org/10.3390/app15073623
APA StyleAlotaibi, A., & Ahmed, M. (2025). Neural Architecture Search for Generative Adversarial Networks: A Comprehensive Review and Critical Analysis. Applied Sciences, 15(7), 3623. https://doi.org/10.3390/app15073623