
The Teleoperation of Robot Arms by Interacting with an Object’s Digital Twin in a Mixed Reality Environment


Abstract
1. Introduction
2. Materials and Methods
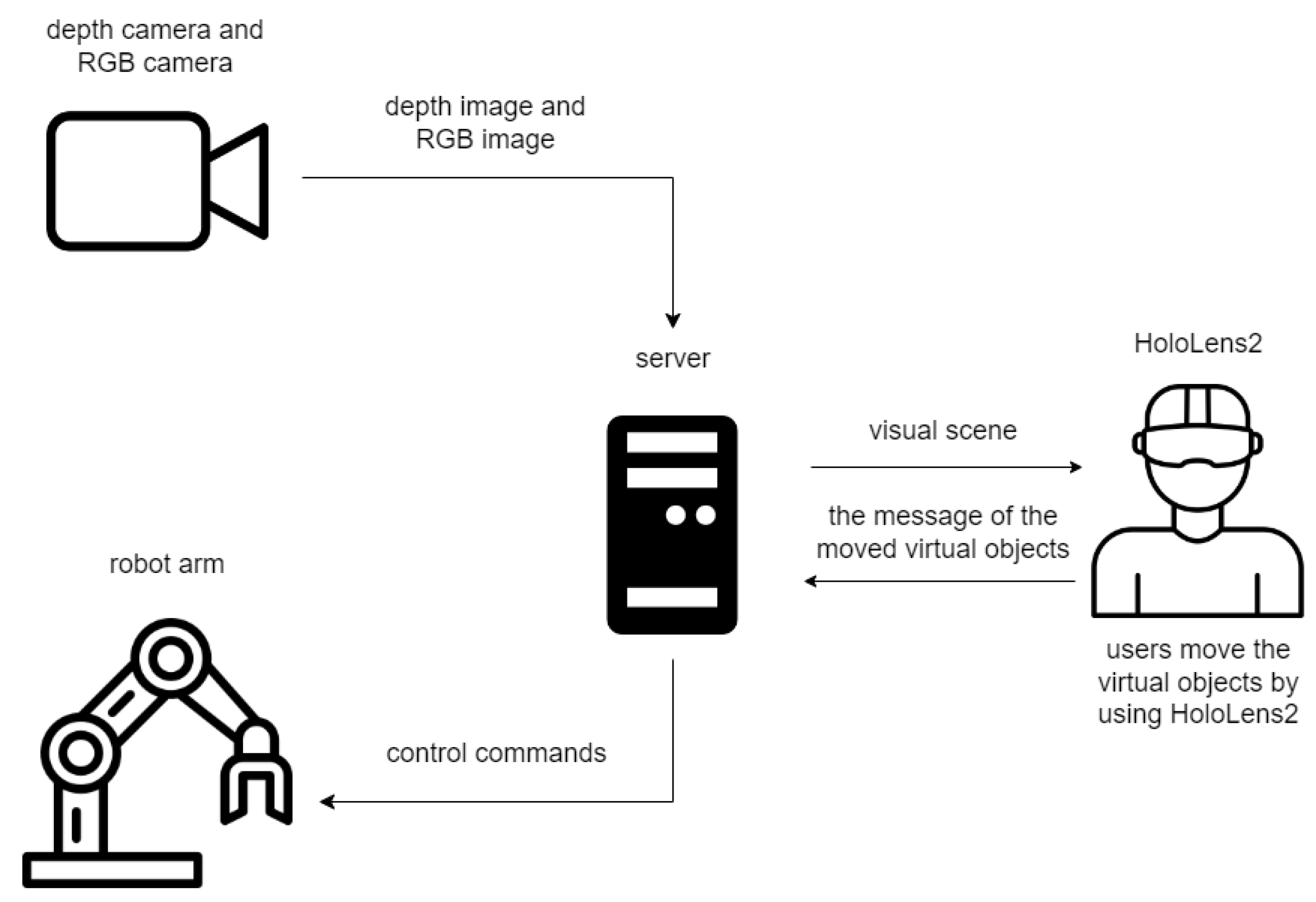
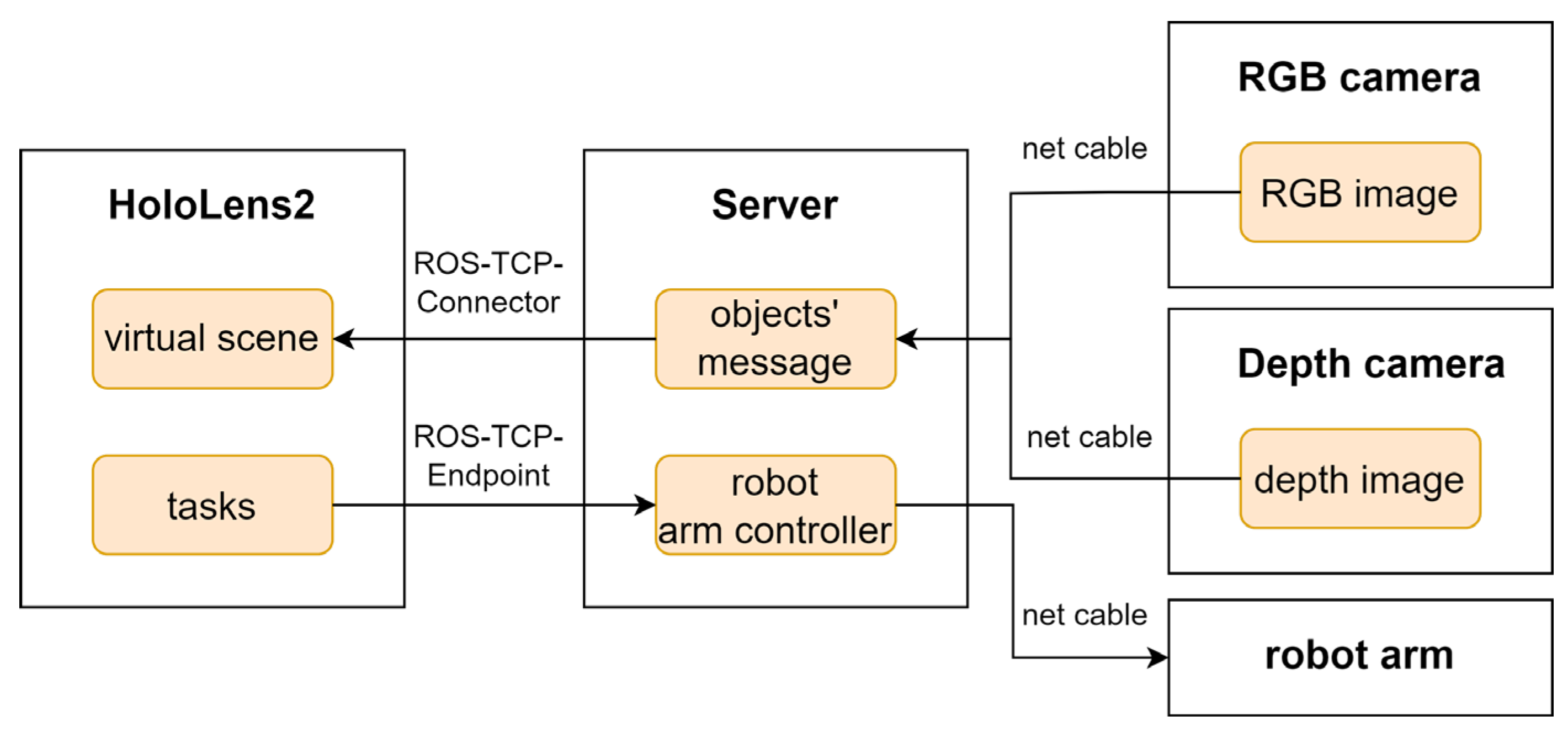
2.1. System Architecture
2.2. The Communication Between Server and MR Device
2.3. The Location of Objects
2.3.1. Aligning RGB Image and Depth Image
2.3.2. Coordinates of Transformation Between ROS and Unity
2.4. The Generation of the Virtual Scene
| Algorithm 1: ROS Subscriber |
| ; |
| 1: while 1 do |
| 5: end while |
| Algorithm 2: ROS Publisher |
| ; |
| ; |
| do |
| 2: |
| 3: then 4: |
| 5: |
| 6: |
| 7: |
| 8: end if |
| 9: end for |
2.5. Experiment
2.5.1. Participants
2.5.2. Experiment Setup
2.5.3. Measurements
3. Results
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Manuel, M.P.; Faied, M.; Krishnan, M. A LoRa-Based Disaster Management System for Search and Rescue Mission. IEEE Internet Things J. 2024, 11, 34024–34034. [Google Scholar] [CrossRef]
- Zhang, Y.; Song, Z.; Yu, J.; Cao, B.; Wang, L. A novel pose estimation method for robot threaded assembly pre-alignment based on binocular vision. Robot. Comput. Integr. Manuf. 2025, 93, 102939. [Google Scholar] [CrossRef]
- Koreis, J. Human–robot vs. human–manual teams: Understanding the dynamics of experience and performance variability in picker-to-parts order picking. Comput. Ind. Eng. 2025, 200, 110750. [Google Scholar] [CrossRef]
- Wang, F.; Li, C.; Niu, S.; Wang, P.; Wu, H.; Li, B. Design and Analysis of a Spherical Robot with Rolling and Jumping Modes for Deep Space Exploration. Machines 2022, 10, 126. [Google Scholar] [CrossRef]
- Yuan, S.; Chen, R.; Zang, L.; Wang, A.; Fan, N.; Du, P.; Xi, Y.; Wang, T. Development of a software system for surgical robots based on multimodal image fusion: Study protocol. Front. Surg. 2024, 11, 1389244. [Google Scholar] [CrossRef]
- Cooper, R.A.; Smolinski, G.; Candiotti, J.L.; Satpute, S.; Grindle, G.G.; Sparling, T.L.; Nordstrom, M.J.; Yuan, X.; Symsack, A.; Dae Lee, C.; et al. Current State, Needs, and Opportunities for Wearable Robots in Military Medical Rehabilitation and Force Protection. Actuators 2024, 13, 236. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Wang, R.; Wang, S.; Wang, Y.; Zheng, G.; Tan, M. Residual Reinforcement Learning for Motion Control of a Bionic Exploration Robot—RoboDact. IEEE Trans. Instrum. Meas. 2023, 72, 7504313. [Google Scholar] [CrossRef]
- Dubois, A.; Gadde, L.E. The construction industry as a loosely coupled system: Implications for productivity and innovation. Constr. Manag. Econ. 2002, 20, 621–631. [Google Scholar] [CrossRef]
- Cai, S.; Ma, Z.; Skibniewski, M.J.; Bao, S. Construction automation and robotics for high-rise buildings over the past decades: A comprehensive review. Adv. Eng. Inform. 2019, 42, 100989. [Google Scholar] [CrossRef]
- Su, Y.-P.; Chen, X.-Q.; Zhou, C.; Pearson, L.H.; Pretty, C.G.; Chase, J.G. Integrating Virtual, Mixed, and Augmented Reality into Remote Robotic Applications: A Brief Review of Extended Reality-Enhanced Robotic Systems for Intuitive Telemanipulation and Telemanufacturing Tasks in Hazardous Conditions. Appl. Sci. 2023, 13, 12129. [Google Scholar] [CrossRef]
- Truong, D.Q.; Truong, B.N.M.; Trung, N.T.; Nahian, S.A.; Ahn, K.K. Force reflecting joystick control for applications to bilateral teleoperation in construction machinery. Int. J. Precis. Eng. Manuf. 2017, 18, 301–315. [Google Scholar] [CrossRef]
- Dinh, T.Q.; Yoon, J.I.; Marco, J.; Jennings, P.A.; Ahn, K.K.; Ha, C.J. Sensorless force feedback joystick control for teleoperation of construction equipment. Int. J. Precis. Eng. Manuf. 2017, 18, 955–969. [Google Scholar] [CrossRef]
- Vu, M.H.; Na, U.J. A New 6-DOF Haptic Device for Teleoperation of 6-DOF Serial Robots. IEEE Trans. Instrum. Meas. 2011, 60, 3510–3523. [Google Scholar] [CrossRef]
- Labonte, D.; Boissy, P.; Michaud, F. Comparative Analysis of 3-D Robot Teleoperation Interfaces With Novice Users. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2010, 40, 1331–1342. [Google Scholar] [CrossRef]
- Solanes, J.E.; Muñoz, A.; Gracia, L.; Martí, A.; Girbés-Juan, V.; Tornero, J. Teleoperation of industrial robot manipulators based on augmented reality. Int. J. Adv. Manuf. Technol. 2020, 111, 1077–1097. [Google Scholar] [CrossRef]
- Caterino, M.; Rinaldi, M.; Di Pasquale, V.; Greco, A.; Miranda, S.; Macchiaroli, R. A Human Error Analysis in Human–Robot Interaction Contexts: Evidence from an Empirical Study. Machines 2023, 11, 670. [Google Scholar] [CrossRef]
- Paes, D.; Feng, Z.; Mander, S.; Datoussaid, S.; Descamps, T.; Rahouti, A.; Lovreglio, R. Video see-through augmented reality fire safety training: A comparison with virtual reality and video training. Saf. Sci. 2025, 184, 106714. [Google Scholar] [CrossRef]
- Madani, S.; Sayadi, A.; Turcotte, R.; Cecere, R.; Aoude, A.; Hooshiar, A. A universal calibration framework for mixed-reality assisted surgery. Comput. Methods Programs Biomed. 2025, 259, 108470. [Google Scholar] [CrossRef]
- Zhang, T.; Cui, Y.; Fang, W. Integrative human and object aware online progress observation for human-centric augmented reality assembly. Adv. Eng. Inform. 2025, 64, 103081. [Google Scholar] [CrossRef]
- Zhang, C.; Lin, C.; Leng, Y.; Fu, Z.; Cheng, Y.; Fu, C. An Effective Head-Based HRI for 6D Robotic Grasping Using Mixed Reality. IEEE Robot. Autom. Lett. 2023, 8, 2796–2803. [Google Scholar] [CrossRef]
- Gadre, S.Y.; Rosen, E.; Chien, G.; Phillips, E.; Tellex, S.; Konidaris, G. End-User Robot Programming Using Mixed Reality. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 2707–2713. [Google Scholar] [CrossRef]
- Rivera-Pinto, A.; Kildal, J.; Lazkano, E. Toward Programming a Collaborative Robot by Interacting with Its Digital Twin in a Mixed Reality Environment. Int. J. Hum. Comput. Interact. 2023, 40, 4745–4757. [Google Scholar] [CrossRef]
- Cruz Ulloa, C.; Domínguez, D.; Del Cerro, J.; Barrientos, A. A Mixed-Reality Tele-Operation Method for High-Level Control of a Legged-Manipulator Robot. Sensors 2022, 22, 8146. [Google Scholar] [CrossRef] [PubMed]
- DePauw, C.G.; Univerisity, B.R.; Lehigh, A.W.; Miller, M.; Stoytchev, A. An Effective and Intuitive Control Interface for Remote Robot Teleoperation with Complete Haptic Feedback. In Proceedings of the Emerging Technologies Conference-ETC, San Diego, CA, USA, 3–6 March 2008. [Google Scholar]
- Girbés-Juan, V.; Schettino, V.; Demiris, Y.; Tornero, J. Haptic and Visual Feedback Assistance for Dual-Arm Robot Teleoperation in Surface Conditioning Tasks. IEEE Trans. Haptics 2021, 14, 44–56. [Google Scholar] [CrossRef]
- Chen, F.; Gao, B.; Selvaggio, M.; Li, Z.; Caldwell, D.; Kershaw, K.; Masi, A.; Castro, M.D.; Losito, R. A framework of teleoperated and stereo vision guided mobile manipulation for industrial automation. In Proceedings of the 2016 IEEE International Conference on Mechatronics and Automation, Harbin, China, 7–10 August 2016; pp. 1641–1648. [Google Scholar] [CrossRef]
- McHenry, N.; Spencer, J.; Zhong, P.; Cox, J.; Amiscaray, M.; Wong, K.C.; Chamitoff, G. Predictive XR Telepresence for Robotic Operations in Space. In Proceedings of the 2021 IEEE Aerospace Conference (50100), Big Sky, MT, USA, 6–13 March 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Smolyanskiy, N.; González-Franco, M. Stereoscopic First Person View System for Drone Navigation. Front. Robot. AI 2017, 4, 11. [Google Scholar] [CrossRef]
- Rosen, E.; Whitney, D.; Phillips, E.; Chien, G.; Tompkin, J.; Konidaris, G.; Tellex, S. Communicating and controlling robot arm motion intent through mixed-reality head-mounted displays. Int. J. Robot. Res. 2019, 38, 1513–1526. [Google Scholar] [CrossRef]
- Su, Y.; Chen, X.; Zhou, T.; Pretty, C.; Chase, G. Mixed reality-integrated 3D/2D vision mapping for intuitive teleoperation of mobile manipulator. Robot. Comput. Integr. Manuf. 2022, 77, 102332. [Google Scholar] [CrossRef]
- Pace, F.D.; Gorjup, G.; Bai, H.; Sanna, A.; Liarokapis, M.; Billinghurst, M. Assessing the Suitability and Effectiveness of Mixed Reality Interfaces for Accurate Robot Teleoperation. In Proceedings of the 26th ACM Symposium on Virtual Reality Software and Technology, Virtual Event, Canada, 1–4 November 2020; p. 45. [Google Scholar] [CrossRef]
- Zhou, T.; Zhu, Q.; Du, J. Intuitive robot teleoperation for civil engineering operations with virtual reality and deep learning scene reconstruction. Adv. Eng. Inform. 2020, 46, 101170. [Google Scholar] [CrossRef]
- Sun, D.; Kiselev, A.; Liao, Q.; Stoyanov, T.; Loutfi, A. A New Mixed-Reality-Based Teleoperation System for Telepresence and Maneuverability Enhancement. IEEE Trans. Hum. Mach. Syst. 2020, 50, 55–67. [Google Scholar] [CrossRef]
- Nakamura, K.; Tohashi, K.; Funayama, Y.; Harasawa, H.; Ogawa, J. Dual-arm robot teleoperation support with the virtual world. Artif. Life Robot. 2020, 25, 286–293. [Google Scholar] [CrossRef]
- Naceri, A.; Mazzanti, D.; Bimbo, J.; Tefera, Y.T.; Prattichizzo, D.; Caldwell, D.G.; Mattos, L.S.; Deshpande, N. The Vicarios Virtual Reality Interface for Remote Robotic Teleoperation. J. Intell. Robot. Syst. 2021, 101, 80. [Google Scholar] [CrossRef]
- Sun, Q.; Chen, W.; Chao, J.; Lin, W.; Xu, Z.; Cao, R. Smart Task Assistance in Mixed Reality for Astronauts. Sensors 2023, 23, 4344. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measure | Explain |
|---|---|
| Mental Demand | How mentally demanding was the task? |
| Physical Demand | How physically demanding was the task? |
| Temporal Demand | How hurried or rushed was the pace of the task? |
| Performance | How successful were you in accomplishing what you were asked to do? |
| Effort | How hard did you have to work to accomplish your level of performance? |
| Frustration | How insecure, discouraged, irritated, stressed, and annoyed were you? |
| Number | Explain |
|---|---|
| 1 | I thought that I would like to use this system frequently |
| 2 | I found the system unnecessarily complex |
| 3 | I thought the system was easy to use |
| 4 | I thought that I would need the support of a technical person to be able to use this system |
| 5 | I found the various functions in this system were well integrated |
| 6 | I thought that there was too much inconsistency in this system |
| 7 | I would imagine that most people would learn to use this system very quickly |
| 8 | I found the system very cumbersome to use |
| 9 | I felt very confident using the system |
| 10 | I needed to learn a lot of things before I could get going with this system |
| Measure | Traditional Method | Our Method | t | p | ||
|---|---|---|---|---|---|---|
| Mean | Std. Dev | Mean | Std. Dev | |||
| Mental Demand | 45.50 | 13.50 | 18.67 | 12.91 | 7.737 | <0.001 |
| Physical Demand | 27.00 | 12.42 | 17.50 | 7.274 | 3.554 | <0.001 |
| Temporal Demand | 38.50 | 14.67 | 21.17 | 13.64 | 4.659 | <0.001 |
| Performance | 37.50 | 15.85 | 20.83 | 11.84 | 4.537 | <0.001 |
| Effort | 48.33 | 19.72 | 26.57 | 18.28 | 4.359 | <0.001 |
| Frustration | 27.83 | 13.89 | 21.10 | 20.82 | 1.449 | 0.154 |
| Learnability | 53.75 | 17.12 | 75.83 | 17.95 | −4.794 | <0.001 |
| Usability | 65.63 | 16.44 | 82.19 | 10.95 | −4.516 | <0.001 |
| Total score | 63.25 | 13.94 | 80.92 | 9.475 | −5.645 | <0.001 |
| Measure | MR-3DPC | Our Method |
|---|---|---|
| Mental Demand | 47.8 | 18.7 |
| Physical Demand | 41.3 | 17.5 |
| Temporal Demand | 47.73 | 21.2 |
| Performance | 50.33 | 20.8 |
| Effort | 49.67 | 26.6 |
| Frustration | 41.73 | 21.1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Zhao, B.; Li, Q. The Teleoperation of Robot Arms by Interacting with an Object’s Digital Twin in a Mixed Reality Environment. Appl. Sci. 2025, 15, 3549. https://doi.org/10.3390/app15073549
Wu Y, Zhao B, Li Q. The Teleoperation of Robot Arms by Interacting with an Object’s Digital Twin in a Mixed Reality Environment. Applied Sciences. 2025; 15(7):3549. https://doi.org/10.3390/app15073549
Chicago/Turabian StyleWu, Yan, Bin Zhao, and Qi Li. 2025. "The Teleoperation of Robot Arms by Interacting with an Object’s Digital Twin in a Mixed Reality Environment" Applied Sciences 15, no. 7: 3549. https://doi.org/10.3390/app15073549
APA StyleWu, Y., Zhao, B., & Li, Q. (2025). The Teleoperation of Robot Arms by Interacting with an Object’s Digital Twin in a Mixed Reality Environment. Applied Sciences, 15(7), 3549. https://doi.org/10.3390/app15073549