
WaveConv-sLSTM-KET: A Novel Framework for the Multi-Task Analysis of Oil Spill Fluorescence Spectra


Abstract
1. Introduction
2. Materials and Methods
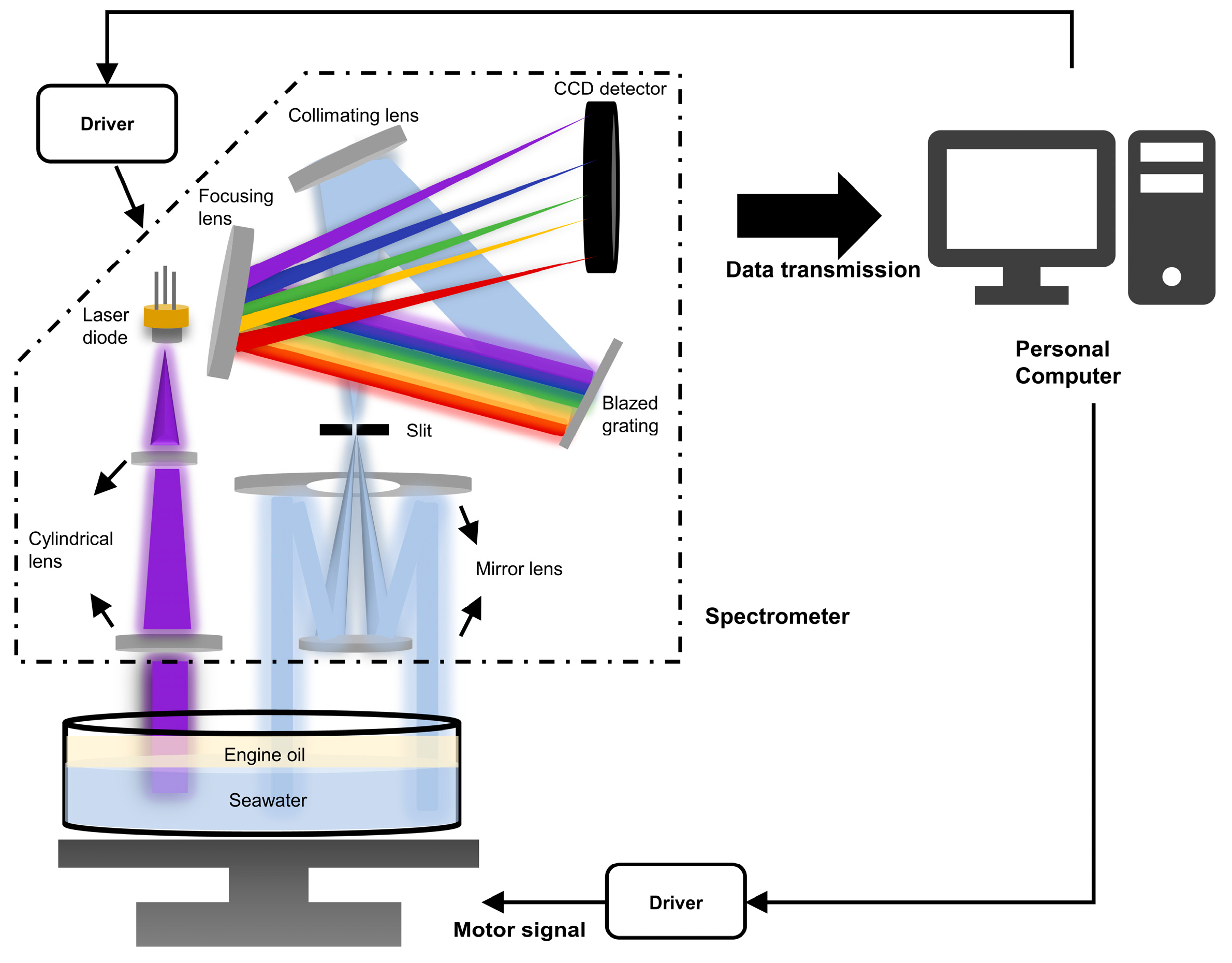
2.1. Experimental Scheme and Data Acquisition
2.2. Spectra Preprocessing and Augmentation Methods
2.3. Multi-Task Spectral Analysis Framework
2.3.1. Wavelet Transform CNN Block
2.3.2. Scalar Long Short-Term Memory Block
2.3.3. Kolmogorov–Arnold Network-Enhanced Transformer Block
2.3.4. Training Parameters and Strategy
2.4. Model Evaluation Methods
2.4.1. Evaluation Metrics
2.4.2. Model Comparison
3. Results and Discussion
3.1. Spectral Analysis
3.2. Model Training Process
3.3. Model Performance Evaluation
3.3.1. Classification Performance
3.3.2. Regression Performance
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lira, A.L.O.; Craveiro, N.; da Silva, F.F.; Rosa Filho, J.S. Effects of contact with crude oil and its ingestion by the symbiotic polychaete Branchiosyllis living in sponges (Cinachyrella sp.) following the 2019 oil spill on the tropical coast of Brazil. Sci. Total Environ. 2021, 801, 149655. [Google Scholar] [CrossRef] [PubMed]
- Lourenco, R.A.; Combi, T.; Alexandre, M.D.R.; Sasaki, S.T.; Zanardi-Lamardo, E.; Yogui, G.T. Mysterious oil spill along Brazil’s northeast and southeast seaboard (2019–2020): Trying to find answers and filling data gaps. Mar. Pollut. Bull. 2020, 156, 111219. [Google Scholar] [CrossRef] [PubMed]
- Oliveira, L.G.; Araújo, K.C.; Barreto, M.C.; Bastos, M.E.P.A.; Lemos, S.G.; Fragoso, W.D. Applications of chemometrics in oil spill studies. Microchem. J. 2021, 166, 106216. [Google Scholar] [CrossRef]
- Mohammadiun, S.; Hu, G.; Gharahbagh, A.A.; Li, J.; Hewage, K.; Sadiq, R. Intelligent computational techniques in marine oil spill management: A critical review. J. Hazard. Mater. 2021, 419, 126425. [Google Scholar] [CrossRef] [PubMed]
- Ajadi, O.A.; Meyer, F.J.; Tello, M.; Ruello, G. Oil Spill Detection in Synthetic Aperture Radar Images Using Lipschitz-Regularity and Multiscale Techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2389–2405. [Google Scholar] [CrossRef]
- Kim, D.; Jung, H.S. Mapping Oil Spills from Dual-Polarized SAR Images Using an Artificial Neural Network: Application to Oil Spill in the Kerch Strait in November 2007. Sensors 2018, 18, 2237. [Google Scholar] [CrossRef]
- Gibril, M.B.A.; Kalantar, B.; Al-Ruzouq, R.; Ueda, N.; Saeidi, V.; Shanableh, A.; Mansor, S.; Shafri, H.Z.M. Mapping Heterogeneous Urban Landscapes from the Fusion of Digital Surface Model and Unmanned Aerial Vehicle-Based Images Using Adaptive Multiscale Image Segmentation and Classification. Remote Sens. 2020, 12, 1081. [Google Scholar] [CrossRef]
- Li, Y.; Yu, Q.; Xie, M.; Zhang, Z.; Ma, Z.; Cao, K. Identifying Oil Spill Types Based on Remotely Sensed Reflectance Spectra and Multiple Machine Learning Algorithms. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 9071–9078. [Google Scholar] [CrossRef]
- De Kerf, T.; Gladines, J.; Sels, S.; Vanlanduit, S. Oil Spill Detection Using Machine Learning and Infrared Images. Remote Sens. 2020, 12, 4090. [Google Scholar] [CrossRef]
- Salisbury, J.W.; D’Aria, D.M.; Sabins, F.F. Thermal infrared remote sensing of crude oil slicks. Remote Sens. Environ. 1993, 45, 225–231. [Google Scholar] [CrossRef]
- Yu, H.; Li, Y.; Du, W.; Yang, M.; Peng, X.; Wang, X.; Long, J. A Novel Interpretable Ensemble Learning Method for NIR-Based Rapid Characterization of Petroleum Products. IEEE Trans. Instrum. Meas. 2023, 72, 2523211. [Google Scholar] [CrossRef]
- Zhang, S.; Yuan, Y.; Wang, Z.; Wei, S.; Zhang, X.; Zhang, T.; Song, X.; Zou, Y.; Wang, J.; Chen, F.; et al. A novel deep learning model for spectral analysis: Lightweight ResNet-CNN with adaptive feature compression for oil spill type identification. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2025, 329, 125626. [Google Scholar] [CrossRef]
- Sun, L.; Zhang, Y.; Ouyang, C.; Yin, S.; Ren, X.; Fu, S. A portable UAV-based laser-induced fluorescence lidar system for oil pollution and aquatic environment monitoring. Opt. Commun. 2023, 527, 128914. [Google Scholar] [CrossRef]
- Xie, M.; Xie, L.; Li, Y.; Han, B. Oil species identification based on fluorescence excitation-emission matrix and transformer-based deep learning. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2023, 302, 123059. [Google Scholar] [CrossRef] [PubMed]
- Brown, C.E. Laser Fluorosensors. In Oil Spill Science and Technology; Gulf Professional Publishing: Houston, TX, USA, 2011; pp. 171–184. [Google Scholar]
- Brown, C.E.; Fingas, M.F. Review of the development of laser fluorosensors for oil spill application. Mar. Pollut. Bull. 2003, 47, 477–484. [Google Scholar] [CrossRef]
- Okparanma, R.N.; Mouazen, A.M. Determination of Total Petroleum Hydrocarbon (TPH) and Polycyclic Aromatic Hydrocarbon (PAH) in Soils: A Review of Spectroscopic and Nonspectroscopic Techniques. Appl. Spectrosc. Rev. 2013, 48, 458–486. [Google Scholar] [CrossRef]
- Hou, Y.; Li, Y.; Liu, Y.; Li, G.; Zhang, Z. Effects of polycyclic aromatic hydrocarbons on the UV-induced fluorescence spectra of crude oil films on the sea surface. Mar. Pollut. Bull. 2019, 146, 977–984. [Google Scholar] [CrossRef]
- Chen, X.; Hu, Y.; Li, X.; Kong, D.; Guo, M. Fast dentification of overlapping fluorescence spectra of oil species based on LDA and two-dimensional convolutional neural network. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2025, 324, 124979. [Google Scholar] [CrossRef]
- Visser, H. Teledetection of the thickness of oil films on polluted water based on the oil fluorescence properties. Appl. Opt. 1979, 18, 1746–1749. [Google Scholar] [CrossRef]
- Hoge, F.E.; Swift, R.N. Oil film thickness measurement using airborne laser-induced water Raman backscatter. Appl. Opt. 1980, 19, 3269–3281. [Google Scholar] [CrossRef]
- Cui, Y.; Kong, D.; Ma, Q.; Xie, B.; Zhang, X.; Kong, D.; Kong, L. Algorithm research on inversion thickness of oil spill on the sea surface using Raman scattering and fluorescence signal. Spectrosc. Spectr. Anal. 2022, 42, 104–109. [Google Scholar]
- Zhang, X.; Kong, D.; Cui, Y.; Zhong, M.; Kong, D.; Kong, L. An Evaluation Algorithm for Thick Oil Film on Sea Surface Based on Fluorescence Signal. IEEE Sens. J. 2023, 23, 9727–9738. [Google Scholar] [CrossRef]
- Yin, S.; Sun, F.; Liu, W.; Bi, Z.; Liu, Q.; Tian, Z. Remote Identification of Oil Films on Water via Laser-Induced Fluorescence LiDAR. IEEE Sens. J. 2023, 23, 13671–13679. [Google Scholar] [CrossRef]
- Yin, S.; Cui, Z.; Bi, Z.; Li, H.; Liu, W.; Tian, Z. Wide-Range Thickness Determination of Oil Films on Water Based on the Ratio of Laser-Induced Fluorescence to Raman. IEEE Trans. Instrum. Meas. 2022, 71, 7008011. [Google Scholar] [CrossRef]
- Zhang, S.; Yuan, Y.; Wang, Z.; Li, J. The application of laser-induced fluorescence in oil spill detection. Environ. Sci. Pollut. Res. Int. 2024, 31, 23462–23481. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Li, Y.; Xie, M. Oil Species Identification Based on the Fluorescence Spectroscopic Analysis Using the Excitation-Emission Matrix and Transfer Learning. Water Air Soil Pollut. 2024, 235, 642. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, Y.; Kong, D. Application of 3D fluorescence spectroscopy and a convolutional neural network for oil emulsion species identification. Measurement 2024, 237, 115177. [Google Scholar] [CrossRef]
- Chen, Y.; Yang, R.; Zhao, N.; Zhu, W.; Huang, Y.; Zhang, R.; Chen, X.; Liu, J.; Liu, W.; Zuo, Z. Concentration Quantification of Oil Samples by Three-Dimensional Concentration-Emission Matrix (CEM) Spectroscopy. Appl. Sci. 2020, 10, 315. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, P.; Zhao, Y.; Li, X.; Kong, D. Application of excitation-emission matrix fluorescence spectroscopy and chemometrics for quantitative analysis of emulsified oil concentration. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2025, 328, 125423. [Google Scholar] [CrossRef]
- Fingas, M. The Challenges of Remotely Measuring Oil Slick Thickness. Remote Sens. 2018, 10, 319. [Google Scholar] [CrossRef]
- McCabe, G.P. Principal Variables. Technometrics 1984, 26, 137–144. [Google Scholar] [CrossRef]
- Höskuldsson, A. PLS regression methods. J. Chemom. 1988, 2, 211–228. [Google Scholar] [CrossRef]
- Xie, M.; Xu, Q.; Li, Y. Deep or Shallow? A Comparative Analysis on the Oil Species Identification Based on Excitation-Emission Matrix and Multiple Machine Learning Algorithms. J. Fluoresc. 2024, 34, 2907–2915. [Google Scholar] [CrossRef] [PubMed]
- Yang, Y.; Sun, R.; Li, H.; Qin, Y.; Zhang, Q.; Lv, P.; Pan, Q. Lightweight deep learning algorithm for real-time wheat flour quality detection via NIR spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2025, 330, 125653. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.B.; Wang, Z.D.; Liu, X.H.; Zengb, N.Y.; Liu, Y.R.; Alsaadi, F.E. A survey of deep neural network architectures and their applications. Neurocomputing 2017, 234, 11–26. [Google Scholar] [CrossRef]
- Temitope Yekeen, S.; Balogun, A.-L. Advances in Remote Sensing Technology, Machine Learning and Deep Learning for Marine Oil Spill Detection, Prediction and Vulnerability Assessment. Remote Sens. 2020, 12, 3416. [Google Scholar] [CrossRef]
- Xie, M.; Xu, Q.; Xie, L.; Li, Y.; Han, B. Establishment and optimization of the three-band fluorometric indices for oil species identification: Implications on the optimal excitation wavelengths and the detection band combinations. Anal. Chim. Acta 2023, 1280, 341871. [Google Scholar] [CrossRef]
- Liu, X.N.; Qiao, S.D.; Ma, Y.F. Highly sensitive methane detection based on light-induced thermoelastic spectroscopy with a 2.33 μm diode laser and adaptive Savitzky-Golay filtering. Opt. Express 2022, 30, 1304–1313. [Google Scholar] [CrossRef]
- Bi, Y.M.; Yuan, K.L.; Xiao, W.Q.; Wu, J.Z.; Shi, C.Y.; Xia, J.; Chu, G.H.; Zhang, G.X.; Zhou, G.J. A local pre-processing method for near-infrared spectra, combined with spectral segmentation and standard normal variate transformation. Anal. Chim. Acta 2016, 909, 30–40. [Google Scholar] [CrossRef]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet Convolutions for Large Receptive Fields. In Computer Vision—ECCV 2024; Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G., Eds.; Springer Nature: Cham, Switzerland, 2025; pp. 363–380. [Google Scholar]
- Beck, M.; Pöppel, K.; Spanring, M.; Auer, A.; Prudnikova, O.; Kopp, M.; Klambauer, G.; Brandstetter, J.; Hochreiter, S. xLSTM: Extended Long Short-Term Memory. arXiv 2024, arXiv:2405.04517. [Google Scholar]
- Vaswani, A. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, Z.; Wang, Y.; Vaidya, S.; Ruehle, F.; Halverson, J.; Soljačić, M.; Hou, T.Y.; Tegmark, M. Kan: Kolmogorov-arnold networks. arXiv 2024, arXiv:2404.19756. [Google Scholar]
- Pekel, E. Deep Learning Approach to Technician Routing and Scheduling Problem. Adcaij-Adv. Distrib. Comput. Artif. Intell. J. 2022, 11, 191–206. [Google Scholar] [CrossRef]
- Merlemis, N.; Drakaki, E.; Zekou, E.; Ninos, G.; Kesidis, A.L. Laser induced fluorescence and machine learning: A novel approach to microplastic identification. Appl. Phys. B 2024, 130, 168. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Range/Values | Optimal Solution |
|---|---|---|
| Learning rate | [1 × 10−5, 1 × 10−3] | 6.922 × 10−5 |
| Batch size | [32, 64, 128, 256, 512] | 32 |
| Kernel sizes | [3, 19] | [19, 5, 17] |
| Strides | [1, 5] | [3, 5, 5] |
| Number of layers (LSTMs) | [2, 5] | 3 |
| Transformer dropout rate | [0.1, 0.5] | 0.5 |
| Transformer blocks | [2, 5] | 4 |
| Attention heads | [2, 4, 8, 16] | 4 |
| Embedding dimension | [64, 128, 256, 512] | 64 |
| Dense dimension | [64, 128, 256, 512] | 256 |
| Model | Accuracy (Train) | Recall (Train) | Precision (Train) | F1 Score (Train) | Accuracy (Test) | Recall (Test) | Precision (Test) | F1 Score (Test) |
|---|---|---|---|---|---|---|---|---|
| Hybrid framework | 99.98% | 99.99% | 99.98% | 0.9998 | 99.76% | 99.76% | 99.73% | 0.9975 |
| Transformer | 99.96% | 99.97% | 99.97% | 0.9997 | 99.52% | 99.53% | 99.5% | 0.9951 |
| SVM | 89.83% | 89.82% | 89.85% | 0.8972 | 92.62% | 92.16% | 92.42% | 0.9223 |
| KNN | 87.52% | 87.46% | 88.56% | 0.8733 | 93.81% | 93.68% | 94.08% | 0.9351 |
| Methods | Raw | SG | SG + SNV | Normalization | ||||
|---|---|---|---|---|---|---|---|---|
| Hybrid Framework | Accuracy | 99.76% | Accuracy | 99.82% | Accuracy | 99.76% | Accuracy | 99.82% |
| Recall | 99.76% | Recall | 99.81% | Recall | 99.75% | Recall | 99.81% | |
| Precision | 99.73% | Precision | 99.79% | Precision | 99.74% | Precision | 99.79% | |
| F1 score | 0.9975 | F1 score | 0.9980 | F1 score | 0.9974 | F1 score | 0.9980 | |
| Transformer | Accuracy | 99.52% | Accuracy | 99.88% | Accuracy | 99.52% | Accuracy | 99.88% |
| Recall | 99.53% | Recall | 99.88% | Recall | 99.53% | Recall | 99.88% | |
| Precision | 99.50% | Precision | 99.87% | Precision | 99.52% | Precision | 99.87% | |
| F1 score | 0.9951 | F1 score | 0.9987 | F1 score | 0.9952 | F1 score | 0.9987 | |
| SVC | Accuracy | 92.62% | Accuracy | 92.5% | Accuracy | 97.26% | Accuracy | 92.74% |
| Recall | 92.16% | Recall | 92.02% | Recall | 97.13% | Recall | 92.31% | |
| Precision | 92.42% | Precision | 92.32% | Precision | 97.10% | Precision | 92.60% | |
| F1 score | 0.9223 | F1 score | 0.9210 | F1 score | 0.9711 | F1 score | 0.9237 | |
| KNN | Accuracy | 93.81% | Accuracy | 93.93% | Accuracy | 93.69% | Accuracy | 93.81% |
| Recall | 93.68% | Recall | 93.82% | Recall | 93.46% | Recall | 93.68% | |
| Precision | 94.08% | Precision | 94.09% | Precision | 93.75% | Precision | 93.93% | |
| F1 score | 0.9351 | F1 score | 0.9363 | F1 score | 0.9342 | F1 score | 0.9351 | |
| Model | MAE | RMSE | R2 | RPD |
|---|---|---|---|---|
| Hybrid framework | 0.0068 | 0.0212 | 0.9806 | 7.1876 |
| Transformer | 0.0266 | 0.0375 | 0.9392 | 4.0542 |
| SVM | 0.4000 | 0.5420 | 0.7028 | 1.8343 |
| LR | 0.5446 | 0.6639 | 0.5541 | 1.4976 |
| Methods | Raw | SG | SG + SNV | Normalization | ||||
|---|---|---|---|---|---|---|---|---|
| Hybrid Framework | MAE | 0.0068 | MAE | 0.0090 | MAE | 0.0075 | MAE | 0.0076 |
| RMSE | 0.0212 | RMSE | 0.0241 | RMSE | 0.0229 | RMSE | 0.0209 | |
| R2 | 0.9806 | R2 | 0.9750 | R2 | 0.9774 | R2 | 0.9810 | |
| RPD | 7.1876 | RPD | 6.3188 | RPD | 6.6544 | RPD | 7.2614 | |
| Transformer | MAE | 0.0266 | MAE | 0.0250 | MAE | 0.0241 | MAE | 0.0251 |
| RMSE | 0.0375 | RMSE | 0.0349 | RMSE | 0.0358 | RMSE | 0.0355 | |
| R2 | 0.9392 | R2 | 0.9473 | R2 | 0.9446 | R2 | 0.9455 | |
| RPD | 4.0542 | RPD | 4.3567 | RPD | 4.2505 | RPD | 4.2816 | |
| SVC | MAE | 0.4000 | MAE | 0.4059 | MAE | 0.4264 | MAE | 0.4058 |
| RMSE | 0.542 | RMSE | 0.5490 | RMSE | 0.5679 | RMSE | 0.5499 | |
| R2 | 0.7028 | R2 | 0.6962 | R2 | 0.6737 | R2 | 0.694 | |
| RPD | 1.8343 | RPD | 1.8109 | RPD | 1.7507 | RPD | 1.8079 | |
| LR | MAE | 0.5446 | MAE | 0.5446 | MAE | 0.5498 | MAE | 0.5459 |
| RMSE | 0.6639 | RMSE | 0.6639 | RMSE | 0.6754 | RMSE | 0.6661 | |
| R2 | 0.5541 | R2 | 0.5541 | R2 | 0.5385 | R2 | 0.5511 | |
| RPD | 1.4976 | RPD | 1.4976 | RPD | 1.472 | RPD | 1.4925 | |
| Model | SNR (dB) | Accuracy | Precision | Recall | F1 Score | MAE | RMSE | R2 | RPD |
|---|---|---|---|---|---|---|---|---|---|
| Hybrid Framework | GT | 0.9976 | 0.9973 | 0.9976 | 0.9975 | 0.0068 | 0.0212 | 0.9806 | 7.1876 |
| 15 | 0.8357 | 0.8475 | 0.8397 | 0.8402 | 0.0365 | 0.0651 | 0.8166 | 2.3353 | |
| 20 | 0.9405 | 0.9427 | 0.9435 | 0.9428 | 0.0256 | 0.0489 | 0.8965 | 3.1079 | |
| 25 | 0.9786 | 0.9797 | 0.9801 | 0.9799 | 0.0161 | 0.0343 | 0.9492 | 4.4371 | |
| 30 | 0.9952 | 0.9949 | 0.9954 | 0.9951 | 0.0081 | 0.0234 | 0.9763 | 6.5 | |
| Transformer | GT | 0.9952 | 0.995 | 0.9953 | 0.9951 | 0.0266 | 0.0375 | 0.9392 | 4.0542 |
| 15 | 0.5488 | 0.5734 | 0.5472 | 0.5387 | 0.1105 | 0.1431 | 0.1141 | 1.0625 | |
| 20 | 0.7417 | 0.7544 | 0.7443 | 0.7409 | 0.0852 | 0.1144 | 0.4345 | 1.3298 | |
| 25 | 0.9202 | 0.9212 | 0.9225 | 0.9212 | 0.0567 | 0.0797 | 0.7251 | 1.9072 | |
| 30 | 0.9714 | 0.9721 | 0.9719 | 0.9719 | 0.0387 | 0.0541 | 0.8736 | 2.8124 |
| Method | Accuracy | R2 | RPD | Iteration | Noise Sensitivity | Parameter |
|---|---|---|---|---|---|---|
| Hybrid Framework | 99.76% | 0.9806 | 7.1876 | 400 | 16.48% | 4.57 M |
| Transformer | 99.52% | 0.9392 | 4.0542 | 1000 | 66.34% | 16.79 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, S.; Li, M.; Li, J. WaveConv-sLSTM-KET: A Novel Framework for the Multi-Task Analysis of Oil Spill Fluorescence Spectra. Appl. Sci. 2025, 15, 3177. https://doi.org/10.3390/app15063177
Zhang S, Li M, Li J. WaveConv-sLSTM-KET: A Novel Framework for the Multi-Task Analysis of Oil Spill Fluorescence Spectra. Applied Sciences. 2025; 15(6):3177. https://doi.org/10.3390/app15063177
Chicago/Turabian StyleZhang, Shubo, Menghan Li, and Jing Li. 2025. "WaveConv-sLSTM-KET: A Novel Framework for the Multi-Task Analysis of Oil Spill Fluorescence Spectra" Applied Sciences 15, no. 6: 3177. https://doi.org/10.3390/app15063177
APA StyleZhang, S., Li, M., & Li, J. (2025). WaveConv-sLSTM-KET: A Novel Framework for the Multi-Task Analysis of Oil Spill Fluorescence Spectra. Applied Sciences, 15(6), 3177. https://doi.org/10.3390/app15063177