
Quantitative Analysis of Risk Coupling Effects in Highway Accidents: A Focus on Primary and Secondary Accidents


Abstract
1. Introduction
2. Related Works
2.1. Risk Factor Identification
2.2. Risk Coupling Analysis
3. Methods
3.1. Data Collection and Preprocessing
3.2. Framework
3.3. Risk Factor Extraction
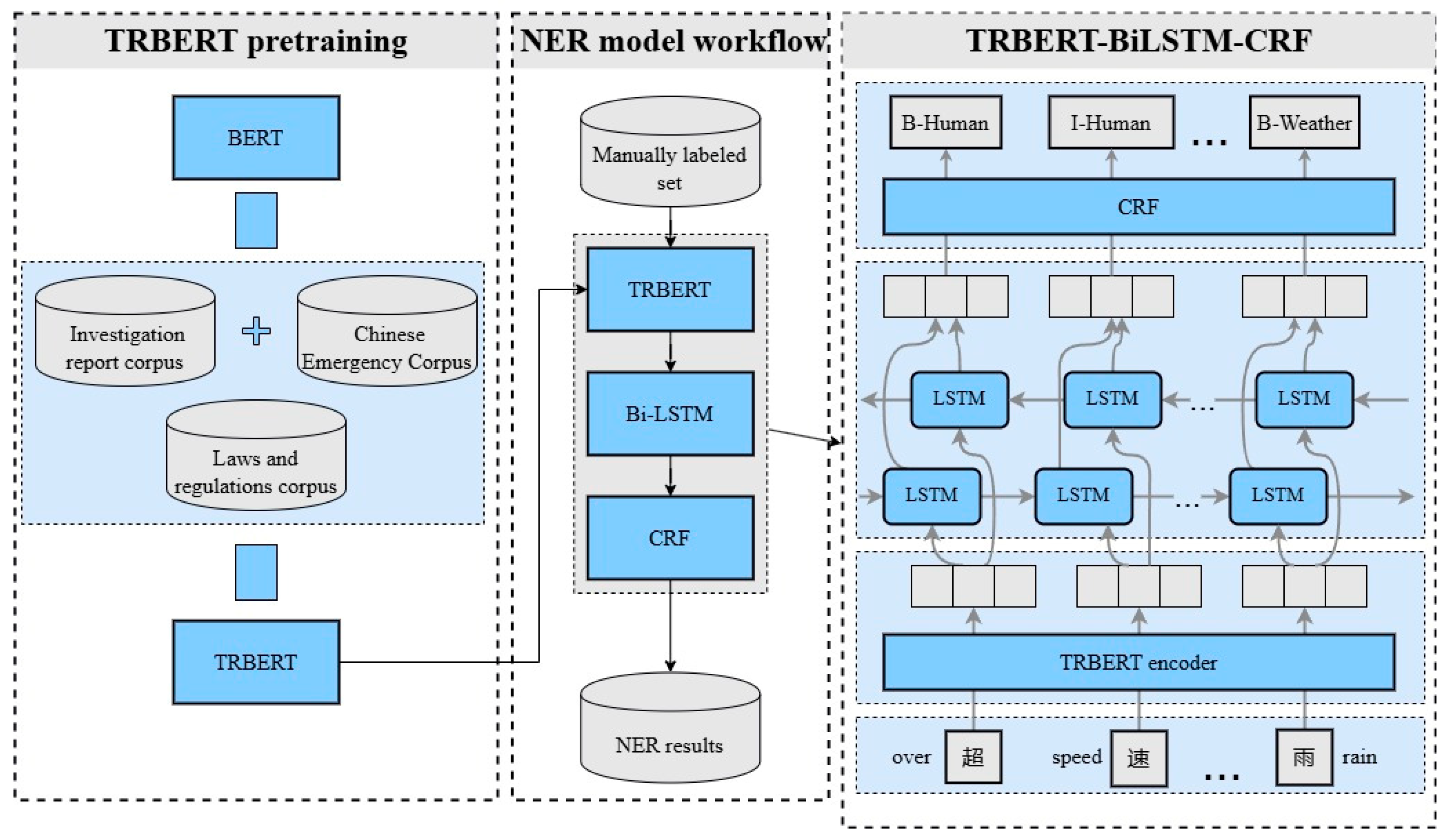
3.3.1. TRBERT Pretraining
3.3.2. TRBERT-BiLSTM-CRF
3.3.3. Entity Alignment
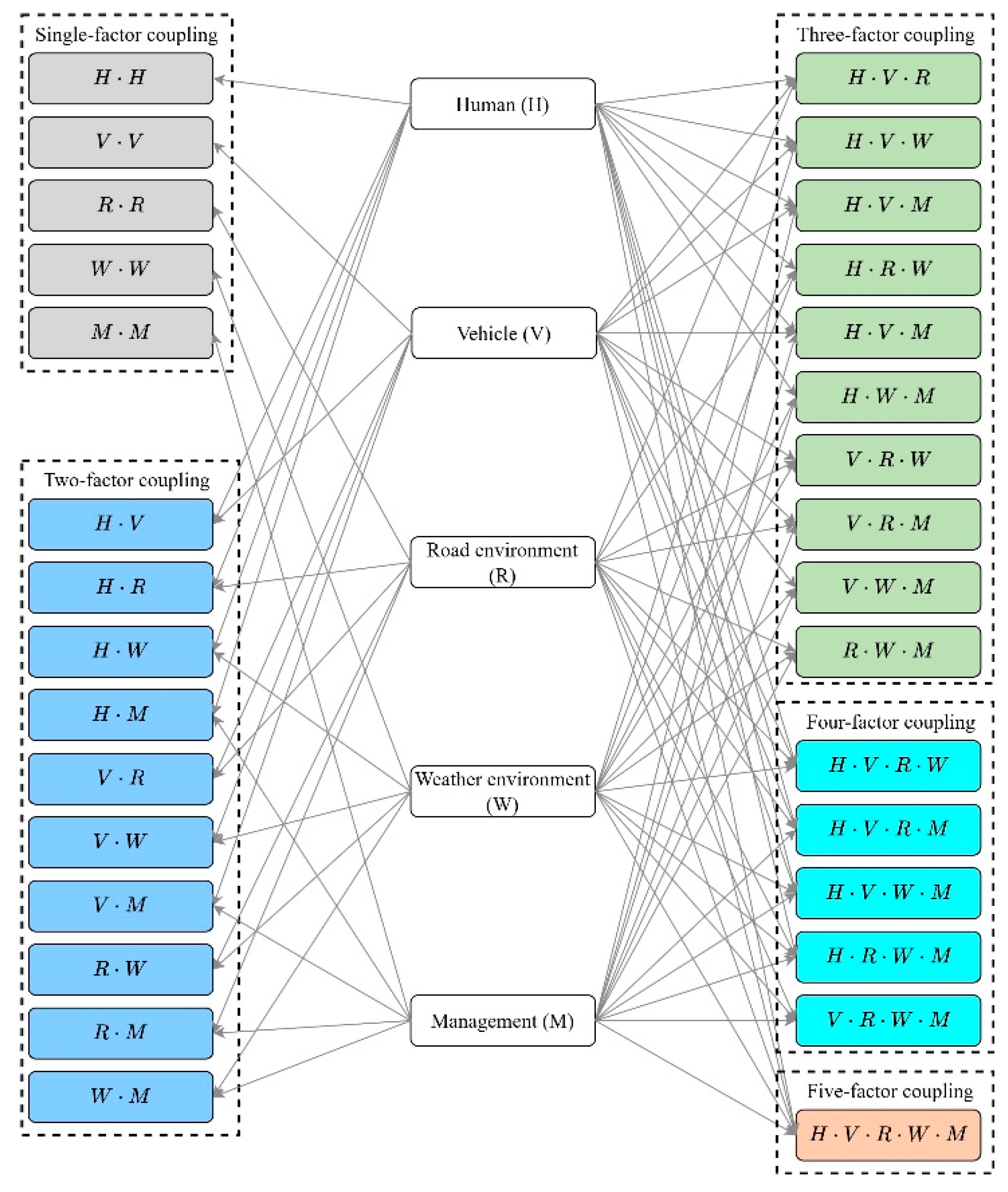
3.4. Risk Factor Coupling Analysis
3.4.1. N-K Model
3.4.2. Wilcoxon Signed-Rank Test
- H0: There is no significant difference in the risk coupling values between PA and SA;
- H1: There is a significant difference in the risk coupling values between PA and SA.
4. Results
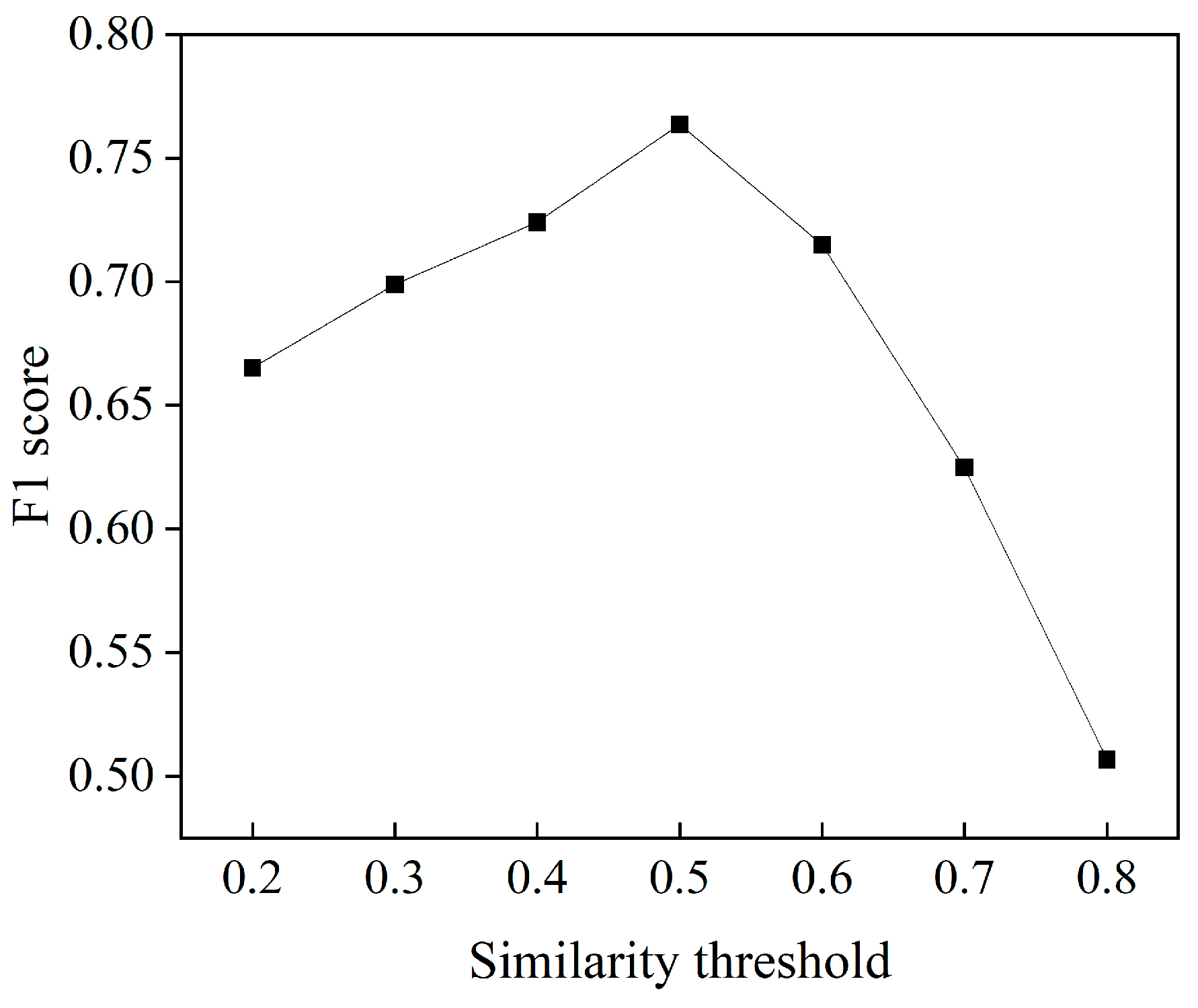
4.1. Performance of the Risk Factor Identification Model
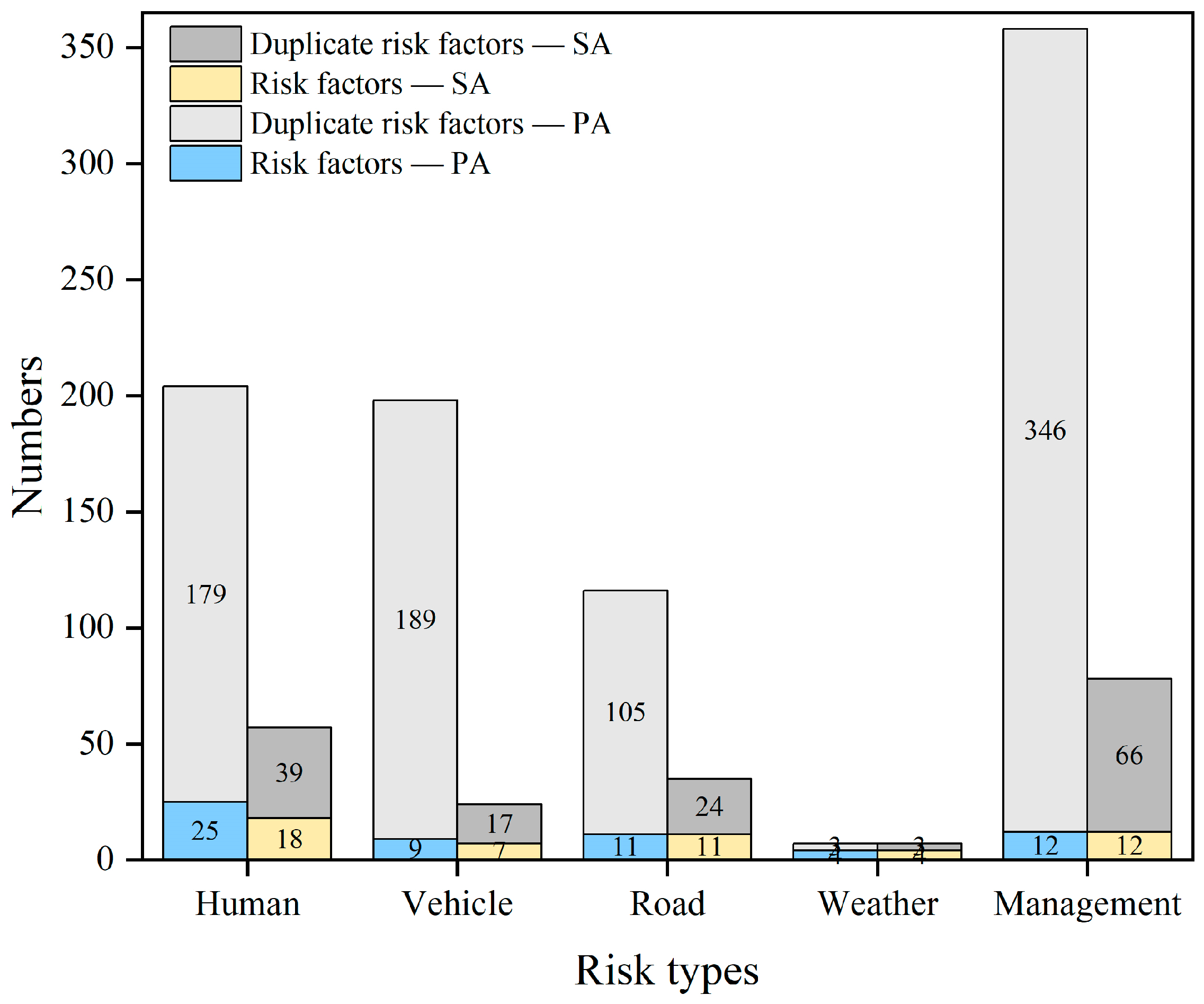
4.2. Risk Factor Extraction
4.3. Risk Type Mapping and Counting
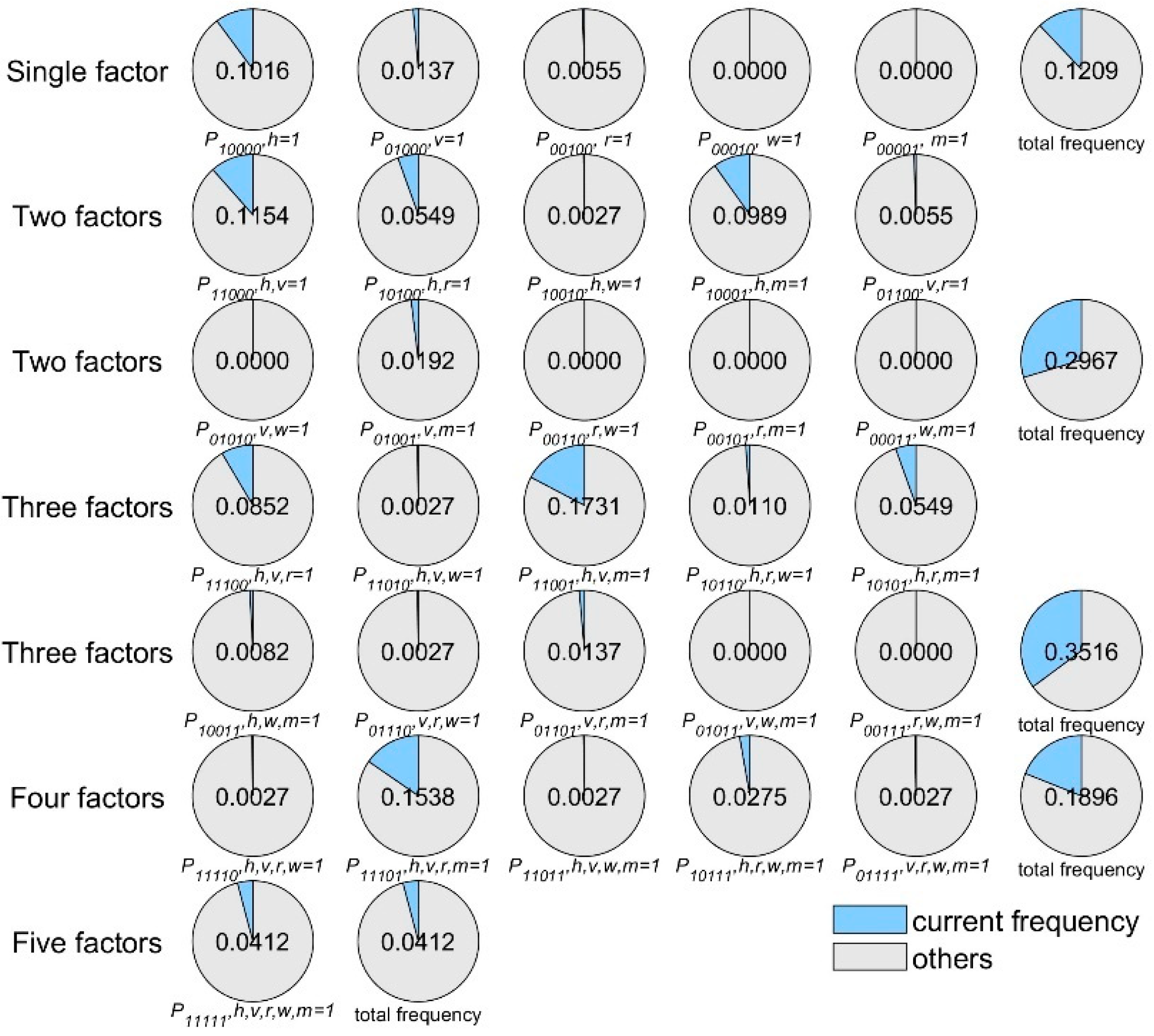
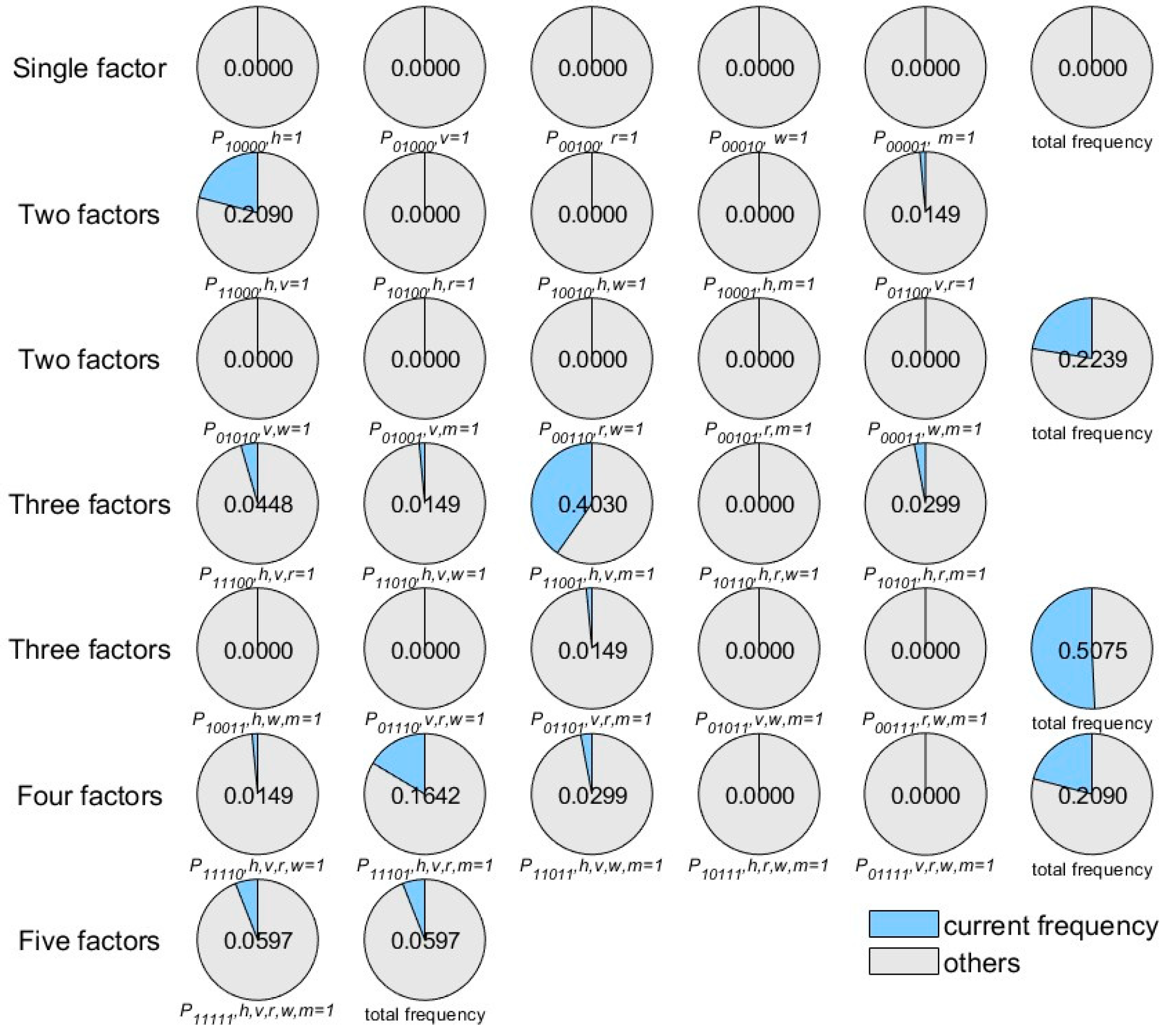
4.4. Risk Coupling Probability Calculation
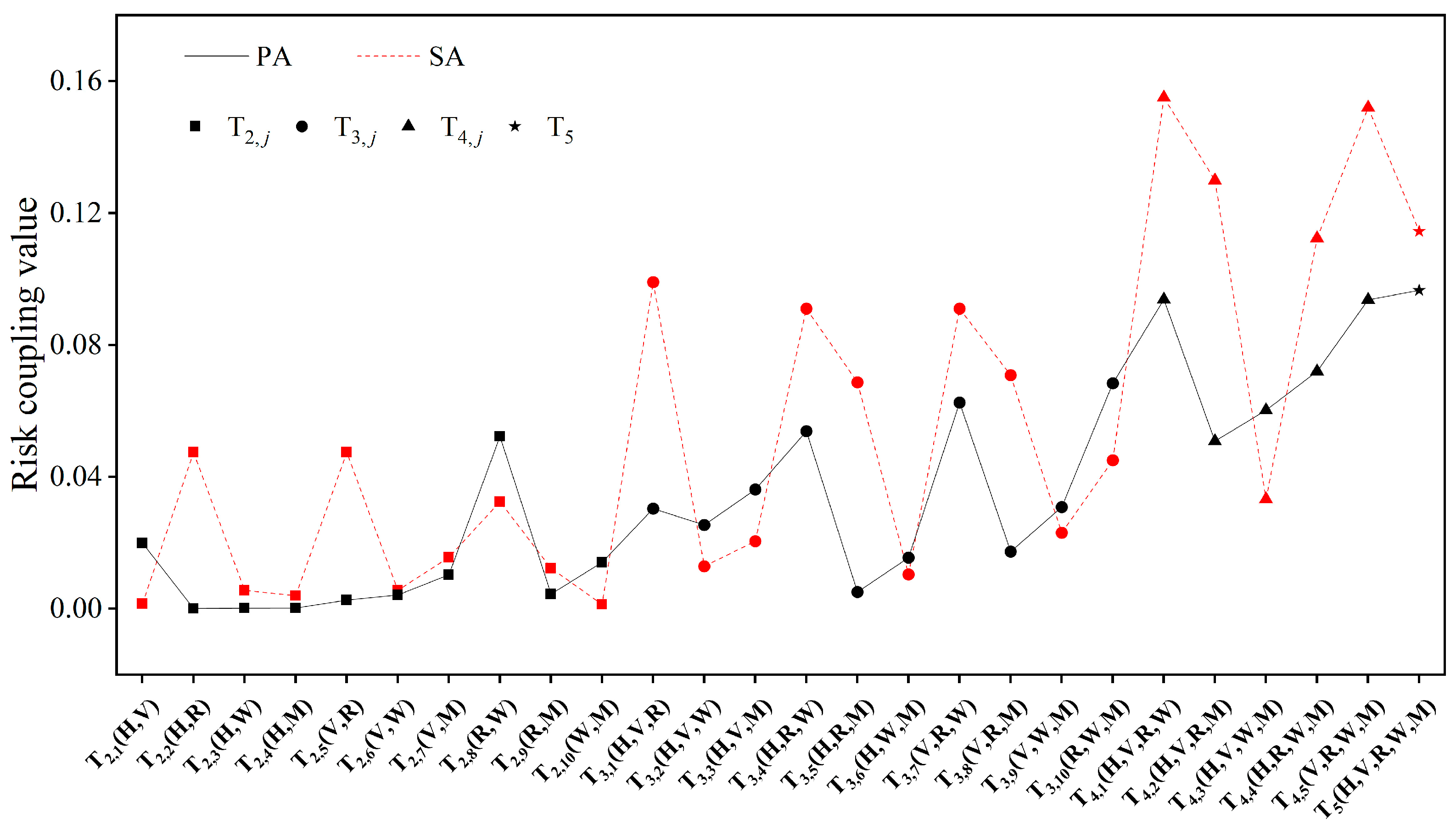
4.5. Risk Coupling Value Generation
4.6. Risk Coupling Value Test in the Two Accident Categories
5. Discussion
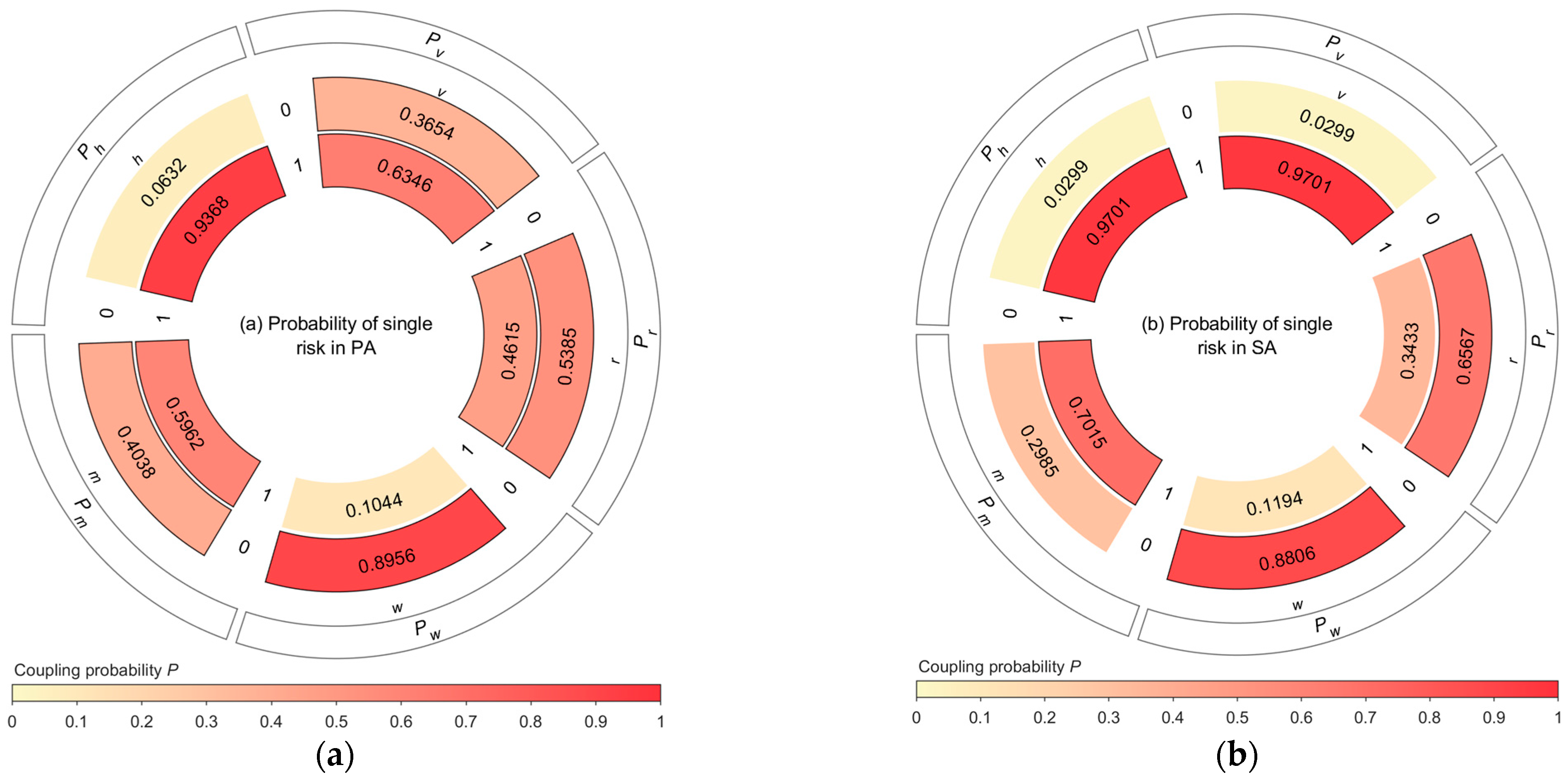
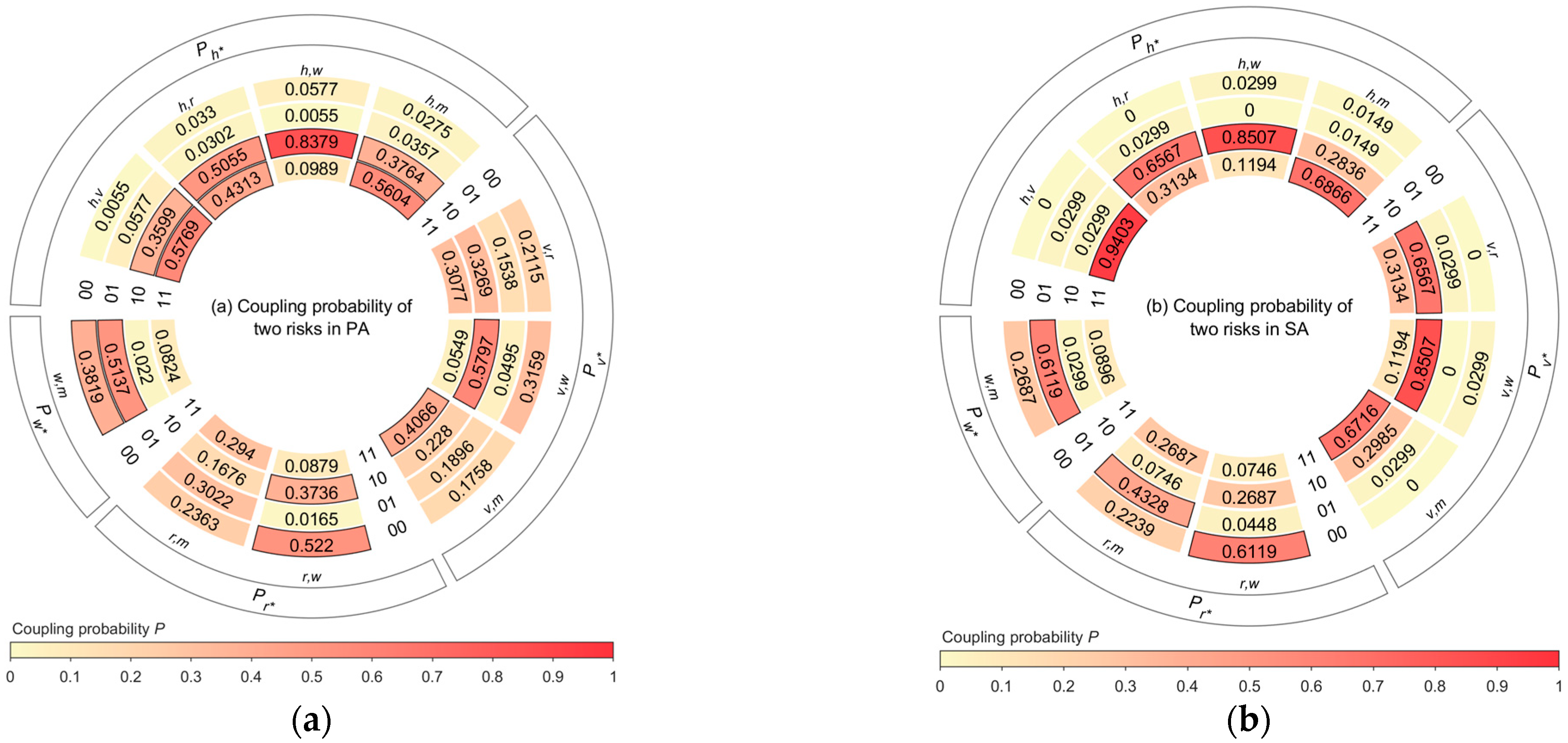
5.1. Risk Coupling Value Comparison in the Two Accident Categories
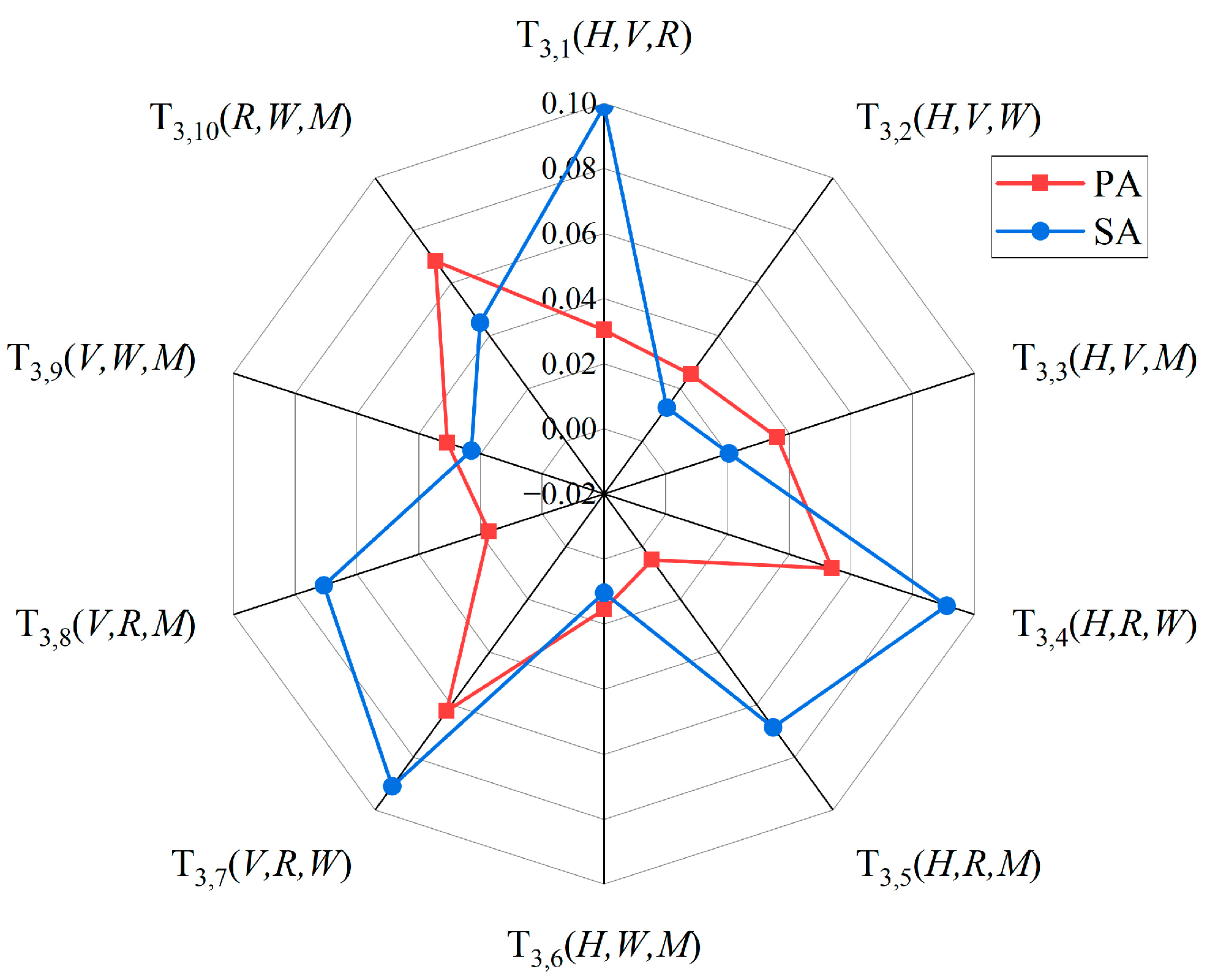
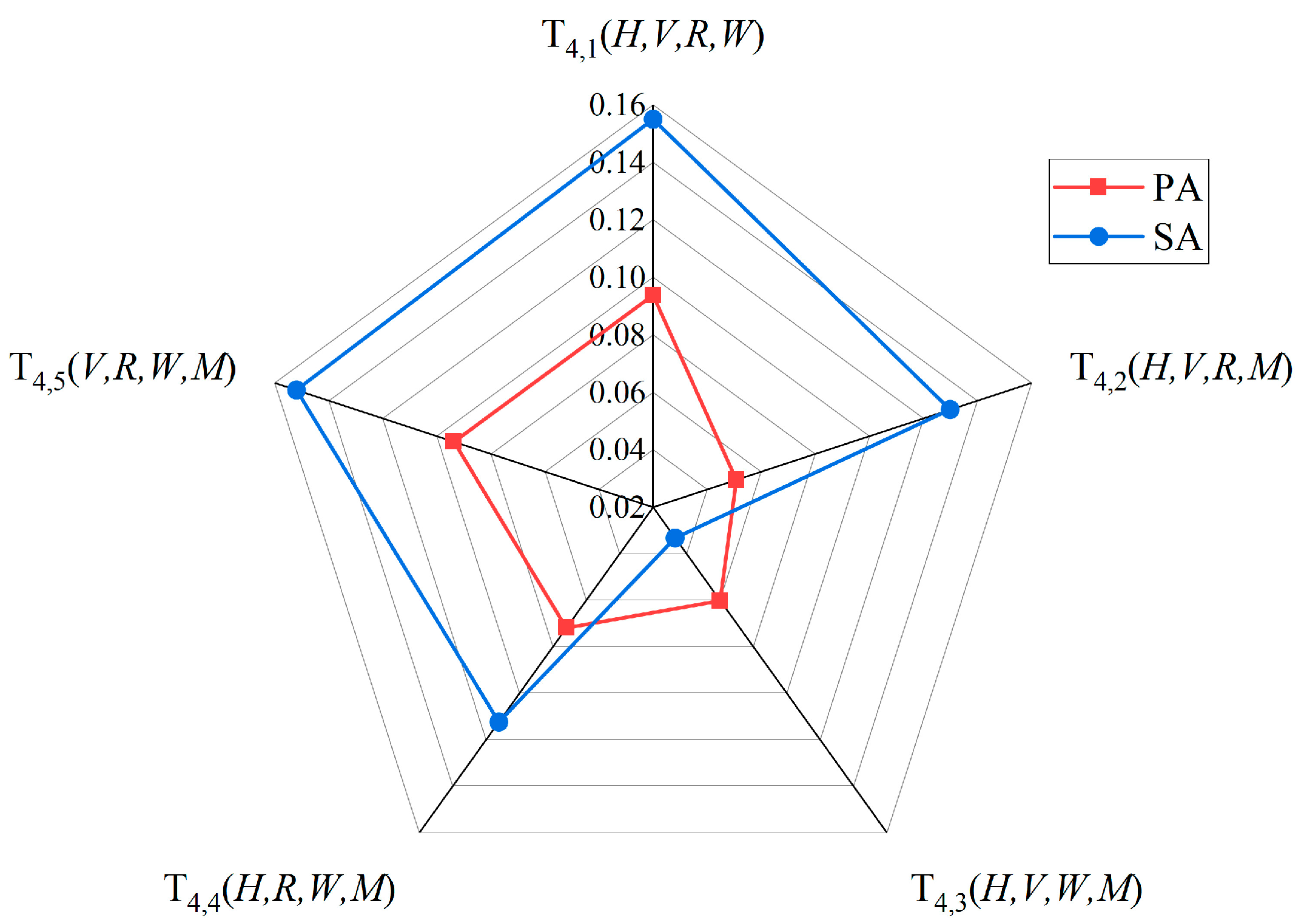
5.2. Risk Coupling Value Ranking in the Two Accident Categories
- In PA, the top five risk coupling scenarios were , , , , and ;
- In SA, the top five risk coupling scenarios were , , , , and .
- In PA, the top five risk coupling scenarios were , , , , and ;
- In SA, the top five risk coupling scenarios were , , , , and .
- In PA, the top three risk coupling scenarios were , , and ;
- In SA, the top three risk coupling scenarios were , , and .
5.3. Accident Prevention Suggestions
5.4. Limitations and Future Work
6. Conclusions
- The risk coupling values increased with the number of risk coupling types in both ACs. However, this was not absolute, as the coupling values for the five risk coupling types in SA were lower than those for the four risk coupling types, suggesting that the occurrence of SA may be more dependent on specific risk types;
- The risk coupling values in SA were generally higher than in PA, indicating that more complex accident scenarios led to an increase in risk coupling values. This can be attributed to the cumulative coupling of new risk factors with initial risk factors and the complex evolving scenarios in SA;
- There was a significant difference in the risk coupling values between PA and SA. The coupling of objective factors (e.g., adverse environmental conditions) is more likely to lead to PA and is easier to prevent. In contrast, the interaction between subjective (e.g., vehicle) and objective factors (e.g., road conditions) is more likely to result in SA, reflecting greater randomness and being harder to prevent.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Risk Factor | Risk Type | No. | Risk Factor | Risk Type |
|---|---|---|---|---|---|
| 1 | Speeding | Human | 14 | Driving without a license | Human |
| 2 | Fatigue driving | Human | 15 | Drunk driving | Human |
| 3 | Distracted driving | Human | 16 | Illegal operations | Human |
| 4 | Lack of attention | Human | 17 | Carelessness | Human |
| 5 | Improper overtaking | Human | 18 | Overconfidence | Human |
| 6 | Illegal U-turn | Human | 19 | Improper operation | Human |
| 7 | Failure to follow lane rules | Human | 20 | Lack of safety awareness | Human |
| 8 | Illegal lane change | Human | 21 | Failing to place warning signs properly | Human |
| 9 | Driving below minimum speed | Human | 22 | Negligence in observation | Human |
| 10 | Driving in the opposite direction | Human | 23 | Failure to maintain safe distance | Human |
| 11 | Failure to wear a seatbelt | Human | 24 | Failure to use lights properly | Human |
| 12 | Illegal reversing | Human | 25 | Improper parking | Human |
| 13 | Driving a vehicle not permitted by license | Human | |||
| 26 | Noncompliant vehicle specifications | Vehicle | 31 | Decreased braking performance | Vehicle |
| 27 | Carrying flammable or explosive goods | Vehicle | 32 | Illegal modifications | Vehicle |
| 28 | Seat detachment | Vehicle | 33 | Overloading or oversize load | Vehicle |
| 29 | Improper cargo securing | Vehicle | 34 | Missing or unclear reflective markings | Vehicle |
| 30 | Tire blowout | Vehicle | |||
| 35 | Downhill | Road | 41 | Missing or unclear road signs and markings | Road |
| 36 | Uphill | Road | 42 | Failure to install required safety facilities | Road |
| 37 | Curved roads | Road | 43 | Road congestion | Road |
| 38 | Road debris | Road | 44 | Poor visibility | Road |
| 39 | Slippery road surface | Road | 45 | Nighttime | Road |
| 40 | Icy road surface | Road | |||
| 46 | Rainy | Weather | 48 | Foggy | Weather |
| 47 | Snowy | Weather | 49 | Low visibility | Weather |
| 50 | Failure to implement safety responsibility | Management | 56 | Inadequate risk analysis and assessment | Management |
| 51 | Negligence in safety management | Management | 57 | Ineffective overload control | Management |
| 52 | Lack of supervision | Management | 58 | Noncompliance with emergency plans | Management |
| 53 | Insufficient education and training | Management | 59 | Ineffective dynamic monitoring | Management |
| 54 | Unscientific allocation of police resources | Management | 60 | Insufficient hazard identification and remediation | Management |
| 55 | Insufficient perception equipment | Management | 61 | Insufficient traffic safety campaigns | Management |
| No. | Risk Factor | Risk Type | No. | Risk Factor | Risk Type |
|---|---|---|---|---|---|
| 1 | Speeding | Human | 10 | Improper operation | Human |
| 2 | Fatigue driving | Human | 11 | Lack of safety awareness | Human |
| 3 | Distracted driving | Human | 12 | Failing to place warning signs properly | Human |
| 4 | Lack of attention | Human | 13 | Negligence in observation | Human |
| 5 | Improper overtaking | Human | 14 | Failure to maintain safe distance | Human |
| 6 | Illegal U-turn | Human | 15 | Failure to use lights properly | Human |
| 7 | Failure to follow lane rules | Human | 16 | Failure to report in time | Human |
| 8 | Failure to wear a seatbelt | Human | 17 | Improper handling | Human |
| 9 | Driving a vehicle not permitted by license | Human | 18 | Failure to evacuate people properly | Human |
| 19 | Noncompliant vehicle specifications | Vehicle | 23 | Abnormal parking | Vehicle |
| 20 | Carrying flammable or explosive goods | Vehicle | 24 | Tire combustion | Vehicle |
| 21 | Overloading or oversize load | Vehicle | 25 | Hazardous material leakage | Vehicle |
| 22 | Missing or unclear reflective markings | Vehicle | |||
| 26 | Downhill | Road | 30 | Icy road surface | Road |
| 27 | Curved roads | Road | 31 | Road congestion | Road |
| 28 | Road debris | Road | 32 | Nighttime | Road |
| 29 | Slippery road surface | Road | |||
| 33 | Rainy | Weather | 35 | Foggy | Weather |
| 34 | Snowy | Weather | 36 | Low visibility | Weather |
| 37 | Failure to implement safety responsibility | Management | 42 | Noncompliance with emergency plans | Management |
| 38 | Negligence in safety management | Management | 43 | Ineffective dynamic monitoring | Management |
| 39 | Lack of supervision | Management | 44 | Insufficient hazard identification and remediation | Management |
| 40 | Insufficient education and training | Management | 45 | Ineffective patrols | Management |
| 41 | Unscientific allocation of police resources | Management |
References
- Híjar, M.; Carrillo, C.; Flores, M.; Anaya, R.; Lopez, V. Risk Factors in Highway Traffic Accidents: A Case Control Study. Accid. Anal. Prev. 2000, 32, 703–709. [Google Scholar] [CrossRef]
- Li, L.; Tan, E.; Gao, P.; Jin, Y. Enhancing Concurrent Emergency Response: Joint Scheduling of Emergency Vehicles on Freeways with Tailored Heuristic. Appl. Sci. 2024, 14, 7433. [Google Scholar] [CrossRef]
- Guo, J.; Luo, C.; Ma, K. Risk Coupling Analysis of Road Transportation Accidents of Hazardous Materials in Complicated Maritime Environment. Reliab. Eng. Syst. Saf. 2023, 229, 108891. [Google Scholar] [CrossRef]
- Yang, H.; Wang, Z.; Xie, K.; Ozbay, K.; Imprialou, M. Methodological Evolution and Frontiers of Identifying, Modeling and Preventing Secondary Crashes on Highways. Accid. Anal. Prev. 2018, 117, 40–54. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Liu, B.; Fu, T.; Liu, S.; Stipancic, J. Modeling When and Where a Secondary Accident Occurs. Accid. Anal. Prev. 2019, 130, 160–166. [Google Scholar] [CrossRef]
- Fan, D.; Lo, C.K.Y.; Zhou, Y. Sustainability Risk in Supply Bases: The Role of Complexity and Coupling. Transp. Res. Part E Logist. Transp. Rev. 2021, 145, 102175. [Google Scholar] [CrossRef]
- Fan, C.; Montewka, J.; Bolbot, V.; Zhang, Y.; Qiu, Y.; Hu, S. Towards an Analysis Framework for Operational Risk Coupling Mode: A Case from MASS Navigating in Restricted Waters. Reliab. Eng. Syst. Saf. 2024, 248, 110176. [Google Scholar] [CrossRef]
- Rasmussen, J. Risk Management in a Dynamic Society: A Modelling Problem. Saf. Sci. 1997, 27, 183–213. [Google Scholar] [CrossRef]
- Shappell, S.A.; Wiegmann, D.A. Applying Reason: The Human Factors Analysis and Classification System (HFACS). Hum. Factors Aerosp. Saf. 2001, 1, 59–86. [Google Scholar]
- Leveson, N. A New Accident Model for Engineering Safer Systems. Saf. Sci. 2004, 42, 237–270. [Google Scholar] [CrossRef]
- Dong, C.; Zhang, Y.; Wang, Z.; Liu, J.; Zhang, J. The Hybrid Systems Method Integrating STAMP and HFACS for the Causal Analysis of the Road Traffic Accident. Ergonomics 2024, 67, 971–994. [Google Scholar] [CrossRef] [PubMed]
- Li, K.; Wang, S. A Network Accident Causation Model for Monitoring Railway Safety. Saf. Sci. 2018, 109, 398–402. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, T.; Bai, Q.; Shao, W.; Wang, Q. New Systems-Based Method to Conduct Analysis of Road Traffic Accidents. Transp. Res. Part F Traffic Psychol. Behav. 2018, 54, 96–109. [Google Scholar] [CrossRef]
- Stanton, N.A.; Box, E.; Butler, M.; Dale, M.; Tomlinson, E.-M.; Stanton, M. Using Actor Maps and AcciMaps for Road Safety Investigations: Development of Taxonomies and Meta-Analyses. Saf. Sci. 2023, 158, 105975. [Google Scholar] [CrossRef]
- Hossain, A.; Sun, X.; Alam, S.; Das, S.; Sheykhfard, A. Crash Contributing Factors and Patterns Associated with Fatal Truck-Involved Crashes in Bangladesh: Findings from the Text Mining Approach. Transp. Res. Rec. 2024, 2678, 706–725. [Google Scholar] [CrossRef]
- Xu, P.; Wang, Q.; Ye, Y.; Wong, S.C.; Zhou, H. Text as Data: Narrative Mining of Non-Collision Injury Incidents on Public Buses by Structural Topic Modeling. Travel Behav. Soc. 2025, 39, 100981. [Google Scholar] [CrossRef]
- Xiong, M.; Wang, H.; Che, C.; Sun, M. Application of Text Mining and Coupling Theory to Depth Cognition of Aviation Safety Risk. Reliab. Eng. Syst. Saf. 2024, 245, 110032. [Google Scholar] [CrossRef]
- Goldberg, D.M. Characterizing Accident Narratives with Word Embeddings: Improving Accuracy, Richness, and Generalizability. J. Saf. Res. 2022, 80, 441–455. [Google Scholar] [CrossRef]
- Goh, Y.M.; Ubeynarayana, C.U. Construction Accident Narrative Classification: An Evaluation of Text Mining Techniques. Accid. Anal. Prev. 2017, 108, 122–130. [Google Scholar] [CrossRef]
- Hughes, P.; Shipp, D.; Figueres-Esteban, M.; van Gulijk, C. From Free-Text to Structured Safety Management: Introduction of a Semi-Automated Classification Method of Railway Hazard Reports to Elements on a Bow-Tie Diagram. Saf. Sci. 2018, 110, 11–19. [Google Scholar] [CrossRef]
- Kutela, B.; Dzinyela, R.; Haule, H.; Sheykhfard, A.; Msechu, K. Leveraging Autonomous Vehicles Crash Narratives to Understand the Patterns of Parking-Related Crashes. Traffic Saf. Res. 2023, 4, e000033. [Google Scholar] [CrossRef]
- Ma, Z.; Chen, Z.-S. Mining Construction Accident Reports via Unsupervised NLP and Accimap for Systemic Risk Analysis. Autom. Constr. 2024, 161, 105343. [Google Scholar] [CrossRef]
- Singh, K.; Maiti, J.; Dhalmahapatra, K. Chain of Events Model for Safety Management: Data Analytics Approach. Saf. Sci. 2019, 118, 568–582. [Google Scholar] [CrossRef]
- Dzinyela, R.; Dadashova, B.; Westfall, G.; Das, S.; Silvestri-Dobrovolny, C.; Adanu, E.K.; Lord, D. Analysis of Motorcyclists Crash Severity Using Cluster Correspondence and Hierarchical Binary Logit Models. Multimodal Transp. 2025, 4, 100197. [Google Scholar] [CrossRef]
- Das, S.; Dzinyela, R.; Liu, J.; Dadashova, B.; Silvestri-Dobrovolny, C. Understanding Patterns of Factor Influences in Motorcycle Crashes with Fixed Objects. J. Transp. Saf. Secur. 2024, 1–27. [Google Scholar] [CrossRef]
- Zhu, Y.; Liao, H.; Huang, D. Using Text Mining and Multilevel Association Rules to Process and Analyze Incident Reports in China. Accid. Anal. Prev. 2023, 191, 107224. [Google Scholar] [CrossRef] [PubMed]
- Xu, N.; Ma, L.; Liu, Q.; Wang, L.; Deng, Y. An Improved Text Mining Approach to Extract Safety Risk Factors from Construction Accident Reports. Saf. Sci. 2021, 138, 105216. [Google Scholar] [CrossRef]
- Shen, J.; Liu, S.; Zhang, J. Using Text Mining and Bayesian Network to Identify Key Risk Factors for Safety Accidents in Metro Construction. J. Constr. Eng. Manag. 2024, 150, 04024052. [Google Scholar] [CrossRef]
- Ahadh, A.; Binish, G.V.; Srinivasan, R. Text Mining of Accident Reports Using Semi-Supervised Keyword Extraction and Topic Modeling. Process Saf. Environ. Prot. 2021, 155, 455–465. [Google Scholar] [CrossRef]
- Zhong, B.; Pan, X.; Love, P.E.D.; Sun, J.; Tao, C. Hazard Analysis: A Deep Learning and Text Mining Framework for Accident Prevention. Adv. Eng. Inform. 2020, 46, 101152. [Google Scholar] [CrossRef]
- Pan, X.; Zhong, B.; Wang, Y.; Shen, L. Identification of Accident-Injury Type and Bodypart Factors from Construction Accident Reports: A Graph-Based Deep Learning Framework. Adv. Eng. Inform. 2022, 54, 101752. [Google Scholar] [CrossRef]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef]
- Xiong, M.; Wang, H.; Wong, Y.D.; Hou, Z. Enhancing Aviation Safety and Mitigating Accidents: A Study on Aviation Safety Hazard Identification. Adv. Eng. Inform. 2024, 62, 102732. [Google Scholar] [CrossRef]
- Liu, D.; Cheng, L. MAKG: A Maritime Accident Knowledge Graph for Intelligent Accident Analysis and Management. Ocean Eng. 2024, 312, 119280. [Google Scholar] [CrossRef]
- Wu, Q.; Yao, P.; Zhu, H.; Zhu, W.; Wu, Y.; Li, L. A Deep Learning Approach to Recognizing Fine-Grained Expressway Location Reference from Unstructured Texts in Chinese. Int. J. Geogr. Inf. Sci. 2024, 38, 654–674. [Google Scholar] [CrossRef]
- Liu, C.; Yang, S. A Text Mining-Based Approach for Understanding Chinese Railway Incidents Caused by Electromagnetic Interference. Eng. Appl. Artif. Intell. 2023, 117, 105598. [Google Scholar] [CrossRef]
- Kwon, S.; Ko, Y.; Seo, J. Effective Vector Representation for the Korean Named-Entity Recognition. Pattern Recognit. Lett. 2019, 117, 52–57. [Google Scholar] [CrossRef]
- Liu, C.; Yang, S. Using Text Mining to Establish Knowledge Graph from Accident/Incident Reports in Risk Assessment. Expert Syst. Appl. 2022, 207, 117991. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding 2019. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019. [Google Scholar]
- Cai, B.; Tian, S.; Yu, L.; Long, J.; Zhou, T.; Wang, B. ATBBC: Named Entity Recognition in Emergency Domains Based on Joint BERT-BILSTM-CRF Adversarial Training. J. Intell. Fuzzy Syst. 2024, 46, 4063–4076. [Google Scholar] [CrossRef]
- Luo, F.; Liu, T. Analysis of Coupled Risk of Air Traffic Safety Based on N-K Model. J. Wuhan Univ. Technol. (Inf. Manag. Eng.) 2011, 33, 267–270. [Google Scholar]
- Liu, Z.; Ma, Q.; Cai, B.; Shi, X.; Zheng, C.; Liu, Y. Risk Coupling Analysis of Subsea Blowout Accidents Based on Dynamic Bayesian Network and NK Model. Reliab. Eng. Syst. Saf. 2022, 218, 108160. [Google Scholar] [CrossRef]
- Ren, C.; Yang, M. Risk Assessment of Hazmat Road Transportation Accidents before, during, and after the Accident Using Bayesian Network. Process Saf. Environ. Prot. 2024, 190, 760–779. [Google Scholar] [CrossRef]
- Fa, H.; Shuai, B.; Yang, Z.; Niu, Y.; Huang, W. Mining the Accident Causes of Railway Dangerous Goods Transportation: A Logistics-DT-TFP Based Approach. Accid. Anal. Prev. 2024, 195, 107421. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.D.; Liu, J.; Wang, W.Q.; Zhou, H.W.; Wang, X.D.; Lu, F.; Wan, L.T.; Teng, L.Y.; Zhao, H. Integration of the BBN-NK-Boltzmann Model of Tunnel Fire Network Scenarios with Coupled Forward and Reverse Rendition Analysis. Reliab. Eng. Syst. Saf. 2023, 240, 109546. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, Y. Research on Coupling Mechanism of Intelligent Ship Navigation Risk Factors Based on N-K Model. J. Mar. Sci. Technol. 2023, 28, 195–207. [Google Scholar] [CrossRef]
- Hu, L.; Xue, Y.; Zhao, X.; Lyu, Y.; Lei, G.; Liu, F.; Zhang, C. Study on the Coupling Effect of Road Traffic Risk Causes under Different Driving Ages. Saf. Environ. Eng. 2023, 30, 1–9. [Google Scholar] [CrossRef]
- Hu, L.; Yu, H.E.; Zhi, H.; Ruijie, Z.; Chen, C.; Bing, L. Multi-Dimensional Coupling Study on Traffic Accident Risk of Highway in Mountainous Areas. China Saf. Sci. J. 2024, 34, 17–27. [Google Scholar] [CrossRef]
- Jia, C.; Shi, Y.; Yang, Q.; Zhang, Y. Entity Enhanced BERT Pre-Training for Chinese NER. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 6384–6396. [Google Scholar]
- Zhang, S.; Zheng, D.; Hu, X.; Yang, M. Bidirectional Long Short-Term Memory Networks for Relation Classification. In Proceedings of the 29th Pacific Asia Conference on Language, Information and Computation, Shanghai, China, 30 October–1 November 2015; pp. 73–78. [Google Scholar]
- Sutton, C.; McCallum, A. An Introduction to Conditional Random Fields. Found. Trends Mach. Learn. 2012, 4, 267–373. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging 2015. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Xue, Y.; Liu, Y.; Zhang, T. Research on Formation Mechanism of Coupled Disaster Risk. J. Nat. Disasters 2013, 22, 44–50. [Google Scholar] [CrossRef]
- Pan, F.Q.; Zhang, Y.; Yang, J.S.; Zhang, L.X.; Chen, X.F.; Yang, X.X. Risk Coupling Evaluation of Undersea Tunnel Traffic Accident Based on Catastrophe Theory. Adv. Transp. Stud. 2022, 58, 179–196. [Google Scholar]
- Kauffman, S.A.; Weinberger, E.D. The NK Model of Rugged Fitness Landscapes and Its Application to Maturation of the Immune Response. J. Theor. Biol. 1989, 141, 211–245. [Google Scholar] [CrossRef] [PubMed]
- Hu, L.; Xue, G.; Li, L.; Wang, M. Analysis of Coupling of Highway Traffic Risks in Geological and Meteorological Environment of Plateau Regions. China J. Highw. Transp. 2018, 31, 110–119. [Google Scholar] [CrossRef]
- Meng, X.; Li, H.; Zhang, W.; Zhou, X.-Y.; Yang, X. Analyzing Ship Collision Accidents in China: A Framework Based on the N-K Model and Bayesian Networks. Ocean Eng. 2024, 309, 118619. [Google Scholar] [CrossRef]
- Ganco, M. NK Model as a Representation of Innovative Search. Res. Policy 2017, 46, 1783–1800. [Google Scholar] [CrossRef]
- Woolson, R.F. Wilcoxon Signed-Rank Test. In Encyclopedia of Biostatistics; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2005; ISBN 978-0-470-01181-2. [Google Scholar]
- Luo, L.; Yang, Z.; Yang, P.; Zhang, Y.; Wang, L.; Lin, H.; Wang, J. An Attention-Based BiLSTM-CRF Approach to Document-Level Chemical Named Entity Recognition. Bioinformatics 2018, 34, 1381–1388. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Zhang, L. Drilling Risk Named Entity Recognition Based on RoBERTa-BiLSTM-CRF. In Proceedings of the Third International Conference on Machine Vision, Automatic Identification, and Detection (MVAID 2024), Kunming, China, 16 August 2024; SPIE: Kunming, China; Volume 13230, pp. 246–251. [Google Scholar]
- Zhang, H.; Geng, H. A Methodology to Identify and Assess High-Risk Causes for Electrical Personal Accidents Based on Directed Weighted CN. Reliab. Eng. Syst. Saf. 2023, 231, 109027. [Google Scholar] [CrossRef]
- Yao, J.; Zhang, B.; Wang, D.; Lei, D.; Tong, R. Risk Coupling Analysis under Accident Scenario Evolution: A Methodological Construct and Application. Risk Anal. 2024, 44, 1482–1497. [Google Scholar] [CrossRef]
- Qiao, W. Analysis and Measurement of Multifactor Risk in Underground Coal Mine Accidents Based on Coupling Theory. Reliab. Eng. Syst. Saf. 2021, 208, 107433. [Google Scholar] [CrossRef]




| Data Sources | Data Description | No. Sentences | Size (MB) |
|---|---|---|---|
| Accident investigation reports | Text of case reports on traffic accidents issued by the China MEM and the relevant emergency management departments of various provinces and cities. | 584,654 | 536 |
| Chinese Emergency Corpus (CEC) | CEC is built by the Data Semantic Laboratory at Shanghai University. This corpus is divided into five categories—earthquake, fire, traffic accident, terrorist attack, and intoxication of food. We extracted the text related to traffic accidents from this corpus. | 14,149 | 6 |
| Laws and regulations | Text of Chinese road traffic law and regulation documents. | 10,018 | 4 |
| Hyperparameter | Tuning Range | Selected Value |
|---|---|---|
| Learning rate | 1 × 10−5, 3 × 10−5, 5 × 10−5 | 3 × 10−5 |
| Batch size | 8, 16 | 8 |
| Training epoch | 10, 20, 30 | 20 |
| Dropout rate | 0.2, 0.4, 0.6 | 0.2 |
| Max length | 128, 256,512 | 256 |
| Model | |||
|---|---|---|---|
| BiLSTM-CRF | 0.7430 | 0.7717 | 0.7570 |
| RoBERTa-BiLSTM-CRF | 0.8420 | 0.8490 | 0.8455 |
| BERT-BiLSTM-CRF | 0.8416 | 0.8508 | 0.8462 |
| TRBERT-BiLSTM-CRF | 0.9100 | 0.9464 | 0.9278 |
| Entity Category | ||||
|---|---|---|---|---|
| HUMAN | 0.8833 | 0.9298 | 0.9060 | 114 |
| VEHICLE | 0.8846 | 0.9388 | 0.9109 | 49 |
| ROAD | 0.9310 | 0.9643 | 0.9474 | 28 |
| WEATHER | 1.0000 | 1.0000 | 1.0000 | 6 |
| MANAGEMENT | 0.8511 | 0.8989 | 0.8743 | 89 |
| 0.8803 | 0.9266 | 0.9029 | 286 | |
| 0.9100 | 0.9464 | 0.9278 | 286 | |
| 0.8806 | 0.9266 | 0.9030 | 286 |
| Rank | Coupling Scenario | Coupling Value | Coupling Scenario | Coupling Value |
|---|---|---|---|---|
| PA | SA | |||
| 1 | 0.096555 | 0.155031 | ||
| 2 | 0.093765 | 0.151980 | ||
| 3 | 0.093676 | 0.129920 | ||
| 24 | 0.000196 | 0.003938 | ||
| 25 | 0.000165 | 0.001474 | ||
| 26 | 0.000052 | 0.001270 | ||
| Group | AC | Q1 | Medium | Q3 | Statistic | Z | p-Value | Hypothesis Accepted |
|---|---|---|---|---|---|---|---|---|
| PA-SA | PA | 0.0049 | 0.0279 | 0.0966 | 90.0 | −2.1588 | 0.0292 | H1 |
| SA | 0.0118 | 0.0391 | 0.0930 |
| AC | Key Risk Types | Risk Factors | Prevention and Control Measures | Investigation Suggestions |
|---|---|---|---|---|
| PA | Management | Negligence in safety management, lack of supervision, insufficient education and training, insufficient perception equipment, ineffective dynamic monitoring, insufficient hazard identification and remediation, etc. | Strengthen dynamic monitoring of key vehicles, regularly check safety training and education records, conduct regular safety hazard inspections and rectifications, and strengthen traffic safety publicity through various channels such as online platforms and offline activities. Focus on providing safety training for drivers of operational vehicles. | After PA, focus on investigating the driver, the operating management unit of the accident vehicle, and the supervising unit. |
| Weather | Rainy, snowy, foggy, low visibility. | Traffic operators can use third-party platforms to push adverse weather alerts and should also strengthen signal guidance. When necessary, control measures such as speed limits and temporary road closures should be implemented. | After PA, collect and analyze information such as rainfall, snowfall, and visibility for the accident location, with particular focus on agglomerate fog in mountainous areas. | |
| Vehicle | Noncompliant vehicle specifications, illegal modifications, overloading or oversize load, missing or unclear reflective markings, etc. | Regularly inspect and maintain the vehicle’s driving system, braking system, lighting system, safety system, and facilities to eliminate safety hazards. Strengthen the work on controlling overloaded vehicles. | After PA, the vehicle specifications should be checked for defects and faults, with particular attention given to any overloading or weight limit violations. | |
| SA | Road | Downhill, curved roads, road debris, slippery road surfaces, road congestion, nighttime, etc. | Strengthen accident information reminders upstream of unfavorable road conditions. Implement remote traffic flow diversion and speed limit measures when necessary. Warnings at the scene of the accident should be strengthened at night. | After SA, the road design and layout should be checked for any design defects, with a focus on the road conditions and traffic conditions at the time of SA. |
| Vehicle | Noncompliant vehicle specifications, illegal modifications, overloading or oversize load, missing or unclear reflective markings, etc. | The vehicles involved in PA should be moved to the hard shoulder as soon as possible, and signal guidance should be provided upstream of the accident area. The cargo should be promptly verified to determine whether it contains flammable or explosive materials. | After SA, the accident vehicle specifications should be checked for defects and faults and whether the vehicle is loaded with flammable and explosive goods. Attention should be paid to whether there is abnormal parking behavior after the occurrence of PA. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, P.; Chen, N.; Li, L.; Du, J.; Jin, Y. Quantitative Analysis of Risk Coupling Effects in Highway Accidents: A Focus on Primary and Secondary Accidents. Appl. Sci. 2025, 15, 3114. https://doi.org/10.3390/app15063114
Gao P, Chen N, Li L, Du J, Jin Y. Quantitative Analysis of Risk Coupling Effects in Highway Accidents: A Focus on Primary and Secondary Accidents. Applied Sciences. 2025; 15(6):3114. https://doi.org/10.3390/app15063114
Chicago/Turabian StyleGao, Peng, Nan Chen, Linwei Li, Jiashui Du, and Yinli Jin. 2025. "Quantitative Analysis of Risk Coupling Effects in Highway Accidents: A Focus on Primary and Secondary Accidents" Applied Sciences 15, no. 6: 3114. https://doi.org/10.3390/app15063114
APA StyleGao, P., Chen, N., Li, L., Du, J., & Jin, Y. (2025). Quantitative Analysis of Risk Coupling Effects in Highway Accidents: A Focus on Primary and Secondary Accidents. Applied Sciences, 15(6), 3114. https://doi.org/10.3390/app15063114