
Automated Coronary Artery Identification in CT Angiography: A Deep Learning Approach Using Bounding Boxes

Abstract
1. Introduction
- We propose an annotation method that defines bounding boxes for major coronary arteries (RCA, LCA-LAD, and LCA-CX) in cross-sectional CCTA slices, enabling systematic and reproducible labeling.
- We develop and evaluate a deep learning pipeline using object detection techniques, integrating conventional metrics (e.g., Average Precision) with novel criteria (e.g., localization error) to capture the distinct ways detection failures manifest.
- We provide a comprehensive framework that highlights the most significant sources of detection error, offering insights into potential improvements in automated CCTA preprocessing. This framework can be further extended to advanced visualization strategies or 3D reconstructions, promoting more standardized and reliable coronary vessel identification.
Related Work
2. Materials and Methods
2.1. Subjects
2.2. Hardware
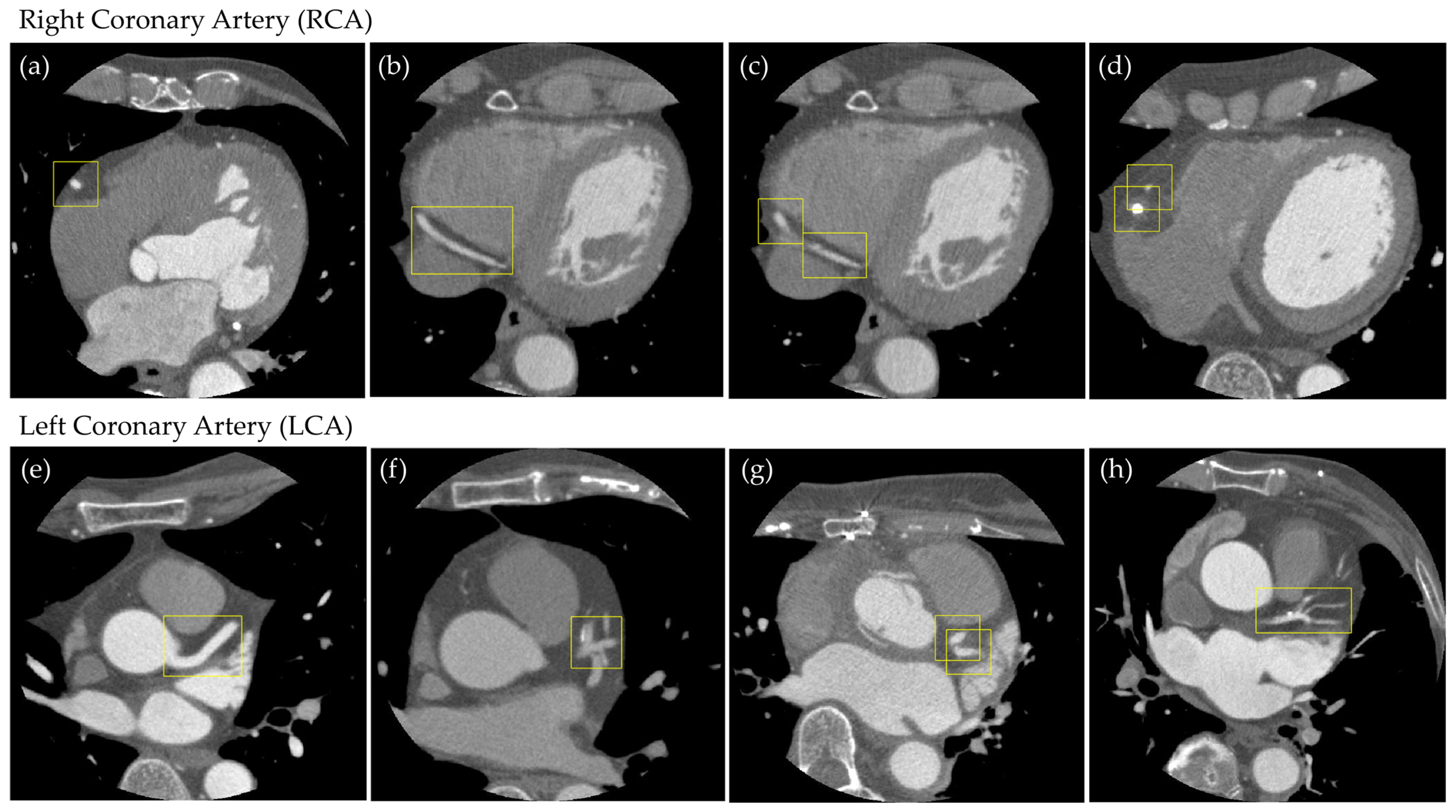
2.3. Supervised Data Creation
Object Detection
2.4. Evaluation Methods
2.4.1. Object Detection
2.4.2. Evaluation of Detection Accuracy Using Additional Metrics
3. Results
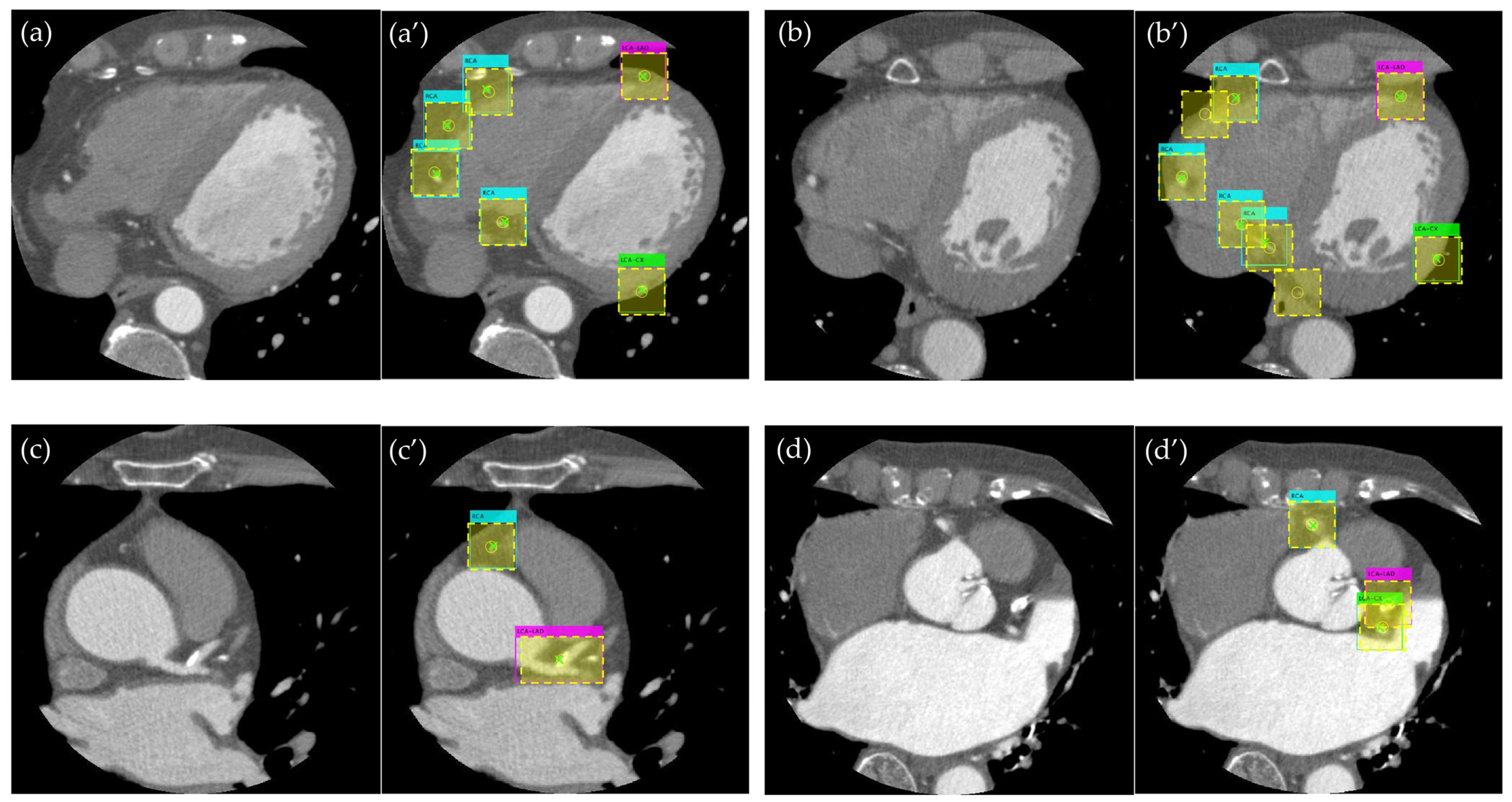
3.1. Evaluation of the Object Detection Model
3.2. Evaluation of Detection Accuracy Using Additional Metrics
3.2.1. IoU Above Threshold Rates
3.2.2. DSC Above Threshold Rates
3.2.3. Mean Absolute Error (MAE)
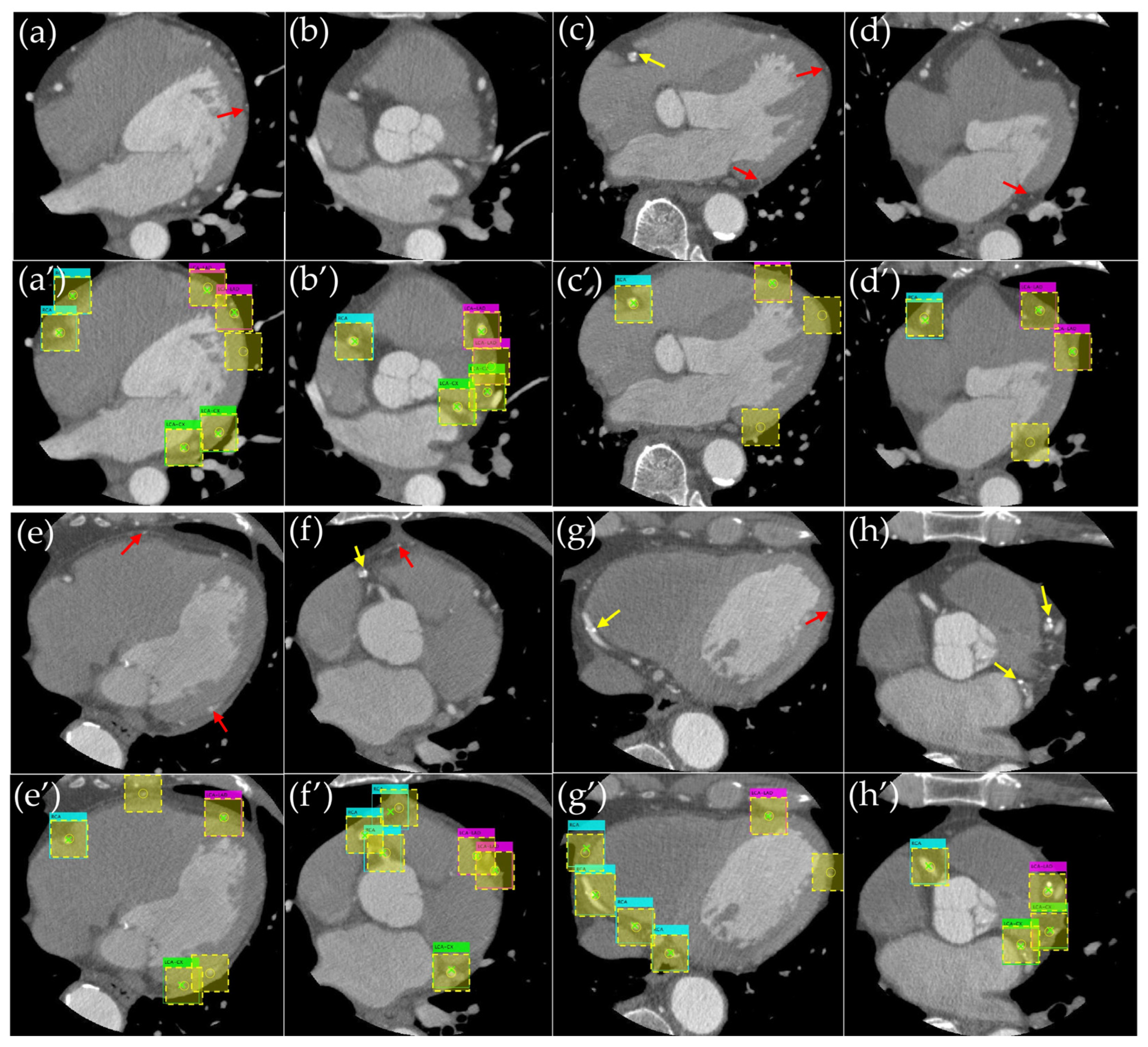
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| IHD | Ischemic Heart Disease |
| CAD | Coronary Artery Disease |
| CCTA | Coronary Computed Tomography Angiography |
| MIP | Maximum Intensity Projection |
| CPR | Curved Planar Reformation |
| CNN | Convolutional Neural Network |
| ECG | Electrocardiogram |
| ROI | Region of Interest |
| RCA | Right Coronary Artery |
| LCA-LAD | Left Coronary Artery–Left Anterior Descending |
| LCA-CX | Left Coronary Artery–Circumflex |
| LMT | Left Main Trunk |
| IoU | Intersection over Union |
| DSC | Dice Similarity Coefficient |
| MAE | Mean Absolute Error |
| AP | Average Precision |
| SGDM | Stochastic Gradient Descent with Momentum |
| CPR | Curved Planar Reformations |
| CT | Computed Tomography |
| MRI | Magnetic Resonance Imaging |
| X-ray | X-ray Imaging |
References
- Tsao, C.W.; Aday, A.W.; Almarzooq, Z.I.; Anderson, C.A.M.; Arora, P.; Avery, C.L.; Baker-Smith, C.M.; Beaton, A.Z.; Boehme, A.K.; Buxton, A.E.; et al. Heart Disease and Stroke Statistics—2023 Update: A Report from the American Heart Association. Circulation 2023, 147, E93–E621. [Google Scholar] [CrossRef]
- Neumann, F.J.; Sechtem, U.; Banning, A.P.; Bonaros, N.; Bueno, H.; Bugiardini, R.; Chieffo, A.; Crea, F.; Czerny, M.; Delgado, V.; et al. 2019 ESC Guidelines for the Diagnosis and Management of Chronic Coronary Syndromes. Eur. Heart J. 2020, 41, 407–477. [Google Scholar] [CrossRef]
- Yamaguchi, M.; Hoshino, M.; Sugiyama, T.; Kanaji, Y.; Nagamine, T.; Misawa, T.; Hada, M.; Araki, M.; Hamaya, R.; Usui, E.; et al. Association of Near-Infrared Spectroscopy-Defined Lipid Rich Plaque with Lesion Morphology and Peri-Coronary Inflammation on Computed Tomography Angiography. Atherosclerosis 2022, 346, 109–116. [Google Scholar] [CrossRef] [PubMed]
- Tonet, E.; Amantea, V.; Lapolla, D.; Assabbi, P.; Boccadoro, A.; Berloni, M.L.; Micillo, M.; Marchini, F.; Chiarello, S.; Cossu, A.; et al. Cardiac Computed Tomography in Monitoring Revascularization. J. Clin. Med. 2023, 12, 7104. [Google Scholar] [CrossRef] [PubMed]
- Vecsey-Nagy, M.; Jermendy, Á.L.; Kolossváry, M.; Vattay, B.; Boussoussou, M.; Suhai, F.I.; Panajotu, A.; Csőre, J.; Borzsák, S.; Fontanini, D.M.; et al. Heart Rate-Dependent Degree of Motion Artifacts in Coronary CT Angiography Acquired by a Novel Purpose-Built Cardiac CT Scanner. J. Clin. Med. 2022, 11, 4336. [Google Scholar] [CrossRef] [PubMed]
- Prokop, M.; Shin, H.O.; Schanz, A.; Schaefer-Prokop, C.M. Use of Maximum Intensity Projections in CT Angiography: A Basic Review. Radiographics 1997, 17, 433–451. [Google Scholar] [CrossRef] [PubMed]
- Karlo, C.A.; Leschka, S.; Stolzmann, P.; Glaser-Gallion, N.; Wildermuth, S.; Alkadhi, H. A Systematic Approach for Analysis, Interpretation, and Reporting of Coronary CTA Studies. Insights Imaging 2012, 3, 215–228. [Google Scholar] [CrossRef]
- Manabe, K.; Asami, Y.; Yamada, T.; Sugimori, H. Improvement in the Convolutional Neural Network for Computed Tomography Images. Appl. Sci. 2021, 11, 1505. [Google Scholar] [CrossRef]
- Ichikawa, S.; Itadani, H.; Sugimori, H. Toward Automatic Reformation at the Orbitomeatal Line in Head Computed Tomography Using Object Detection Algorithm. Phys. Eng. Sci. Med. 2022, 45, 835–845. [Google Scholar] [CrossRef]
- Asami, Y.; Yoshimura, T.; Manabe, K.; Yamada, T.; Sugimori, H. Development of Detection and Volumetric Methods for the Triceps of the Lower Leg Using Magnetic Resonance Images with Deep Learning. Appl. Sci. 2021, 11, 12006. [Google Scholar] [CrossRef]
- Inomata, S.; Yoshimura, T.; Tang, M.; Ichikawa, S.; Sugimori, H. Estimation of Left and Right Ventricular Ejection Fractions from Cine-MRI Using 3D-CNN. Sensors 2023, 23, 6580. [Google Scholar] [CrossRef]
- Yoshimura, T.; Nishioka, K.; Hashimoto, T.; Mori, T.; Kogame, S.; Seki, K.; Sugimori, H.; Yamashina, H.; Nomura, Y.; Kato, F.; et al. Prostatic Urinary Tract Visualization with Super-Resolution Deep Learning Models. PLoS ONE 2023, 18, e0280076. [Google Scholar] [CrossRef] [PubMed]
- Usui, K.; Yoshimura, T.; Ichikawa, S.; Sugimori, H. Development of Chest X-Ray Image Evaluation Software Using the Deep Learning Techniques. Appl. Sci. 2023, 13, 6695. [Google Scholar] [CrossRef]
- Zhang, Y.; Gorriz, J.M.; Dong, Z. Deep Learning in Medical Image Analysis. J. Imaging 2021, 7, 74. [Google Scholar] [CrossRef] [PubMed]
- Reza-Soltani, S.; Fakhare Alam, L.; Debellotte, O.; Monga, T.S.; Coyalkar, V.R.; Tarnate, V.C.A.; Ozoalor, C.U.; Allam, S.R.; Afzal, M.; Shah, G.K.; et al. The Role of Artificial Intelligence and Machine Learning in Cardiovascular Imaging and Diagnosis. Cureus 2024, 16, e68472. [Google Scholar] [CrossRef] [PubMed]
- Serruys, P.W.; Kotoku, N.; Nørgaard, B.; Garg, S.; Nieman, K.; Dweck, M.; Bax, J.; Knuuti, J.; Narula, J.; Perera, D.; et al. Computed Tomographic Angiography in Coronary Artery Disease. EuroIntervention 2023, 18, E1307–E1327. [Google Scholar] [CrossRef]
- Mansoor, C.M.M.; Chettri, S.K.; Naleer, H.M.M. Development of an Efficient Novel Method for Coronary Artery Disease Prediction Using Machine Learning and Deep Learning Techniques. Technol. Health Care 2024, 32, 4545–4569. [Google Scholar] [CrossRef]
- Jafari, M.; Shoeibi, A.; Khodatars, M.; Ghassemi, N.; Moridian, P.; Alizadehsani, R.; Khosravi, A.; Ling, S.H.; Delfan, N.; Zhang, Y.D.; et al. Automated Diagnosis of Cardiovascular Diseases from Cardiac Magnetic Resonance Imaging Using Deep Learning Models: A Review. Comput. Biol. Med. 2023, 160, 106998. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Lücke, C.; Foldyna, B.; Andres, C.; Boehmer-Lasthaus, S.; Grothoff, M.; Nitzsche, S.; Gutberlet, M.; Lehmkuhl, L. Post-Processing in Cardiovascular Computed Tomography: Performance of a Client Server Solution versus a Stand-Alone Solution. RoFo 2014, 186, 1111–1121. [Google Scholar] [CrossRef] [PubMed]
- Merkow, J.; Marsden, A.; Kriegman, D.; Tu, Z. Dense Volume-to-Volume Vascular Boundary Detection. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2016; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; Volume 9902, pp. 371–379. [Google Scholar] [CrossRef]
- Lee, M.C.H.; Petersen, K.; Pawlowski, N.; Glocker, B.; Schaap, M. TeTrIS: Template Transformer Networks for Image Segmentation with Shape Priors. IEEE Trans. Med. Imaging 2019, 38, 2596–2606. [Google Scholar] [CrossRef]
- Yao, H.; Williamson, C.; Soroushmehr, R.; Gryak, J.; Najarian, K. Hematoma Segmentation Using Dilated Convolutional Neural Network. In Proceedings of the 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Honolulu, HI, USA, 18–21 July 2018; pp. 5902–5905. [Google Scholar] [CrossRef]
- Zreik, M.; Lessmann, N.; van Hamersvelt, R.W.; Wolterink, J.M.; Voskuil, M.; Viergever, M.A.; Leiner, T.; Išgum, I. Deep Learning Analysis of the Myocardium in Coronary CT Angiography for Identification of Patients with Functionally Significant Coronary Artery Stenosis. Med. Image Anal. 2018, 44, 72–85. [Google Scholar] [CrossRef]
- Wolterink, J.M.; van Hamersvelt, R.W.; Viergever, M.A.; Leiner, T.; Išgum, I. Coronary Artery Centerline Extraction in Cardiac CT Angiography Using a CNN-Based Orientation Classifier. Med. Image Anal. 2019, 51, 46–60. [Google Scholar] [CrossRef] [PubMed]
- Dey, D.; Schuhbaeck, A.; Min, J.K.; Berman, D.S.; Achenbach, S. Non-Invasive Measurement of Coronary Plaque from Coronary CT Angiography and Its Clinical Implications. Expert Rev. Cardiovasc. Ther. 2013, 11, 1067–1077. [Google Scholar] [CrossRef] [PubMed]
- Leipsic, J.; Abbara, S.; Achenbach, S.; Cury, R.; Earls, J.P.; Mancini, G.B.J.; Nieman, K.; Pontone, G.; Raff, G.L. SCCT Guidelines for the Interpretation and Reporting of Coronary CT Angiography: A Report of the Society of Cardiovascular Computed Tomography Guidelines Committee. J. Cardiovasc. Comput. Tomogr. 2014, 8, 342–358. [Google Scholar] [CrossRef]
- Yang, G.; Kitslaar, P.; Frenay, M.; Broersen, A.; Boogers, M.J.; Bax, J.J.; Reiber, J.H.C.; Dijkstra, J. Automatic Centerline Extraction of Coronary Arteries in Coronary Computed Tomographic Angiography. Int. J. Cardiovasc. Imaging 2012, 28, 921–933. [Google Scholar] [CrossRef] [PubMed]
- Lesage, D.; Angelini, E.D.; Bloch, I.; Funka-Lea, G. A Review of 3D Vessel Lumen Segmentation Techniques: Models, Features and Extraction Schemes. Med. Image Anal. 2009, 13, 819–845. [Google Scholar] [CrossRef]
- Wolterink, J.M.; Leiner, T.; de Vos, B.D.; van Hamersvelt, R.W.; Viergever, M.A.; Išgum, I. Automatic Coronary Artery Calcium Scoring in Cardiac CT Angiography Using Paired Convolutional Neural Networks. Med. Image Anal. 2016, 34, 123–136. [Google Scholar] [CrossRef]
- Jawaid, M.M.; Rajani, R.; Liatsis, P.; Reyes-Aldasoro, C.C.; Slabaugh, G. A Hybrid Energy Model for Region Based Curve Evolution—Application to CTA Coronary Segmentation. Comput. Methods Programs Biomed. 2017, 144, 189–202. [Google Scholar] [CrossRef]
- Mangla, A.; Oliveros, E.; Williams, K.A.S.; Kalra, D.K. Cardiac Imaging in the Diagnosis of Coronary Artery Disease. Curr. Probl. Cardiol. 2017, 42, 316–366. [Google Scholar] [CrossRef]
- Wolterink, J.M.; Leiner, T.; Takx, R.A.P.; Viergever, M.A.; Išgum, I. Automatic Coronary Calcium Scoring in Non-Contrast-Enhanced ECG-Triggered Cardiac CT with Ambiguity Detection. IEEE Trans. Med. Imaging 2015, 34, 1867–1878. [Google Scholar] [CrossRef] [PubMed]
- Kirişli, H.A.; Schaap, M.; Metz, C.T.; Dharampal, A.S.; Meijboom, W.B.; Papadopoulou, S.L.; Dedic, A.; Nieman, K.; de Graaf, M.A.; Meijs, M.F.L.; et al. Standardized Evaluation Framework for Evaluating Coronary Artery Stenosis Detection, Stenosis Quantification and Lumen Segmentation Algorithms in Computed Tomography Angiography. Med. Image Anal. 2013, 17, 859–876. [Google Scholar] [CrossRef] [PubMed]
- Price, W.N.; Cohen, I.G. Privacy in the Age of Medical Big Data. Nat. Med. 2019, 25, 37–43. [Google Scholar] [CrossRef] [PubMed]
- Rudin, C. Stop Explaining Black Box Machine Learning Models for High Stakes Decisions and Use Interpretable Models Instead. Nat. Mach. Intell. 2019, 1, 206–215. [Google Scholar] [CrossRef]
- van Assen, M.; De Cecco, C.N.; Eid, M.; von Knebel Doeberitz, P.; Scarabello, M.; Lavra, F.; Bauer, M.J.; Mastrodicasa, D.; Duguay, T.M.; Zaki, B.; et al. Prognostic Value of CT Myocardial Perfusion Imaging and CT-Derived Fractional Flow Reserve for Major Adverse Cardiac Events in Patients with Coronary Artery Disease. J. Cardiovasc. Comput. Tomogr. 2019, 13, 26–33. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| RCA | LCA-LAD | LCA-CX | |
|---|---|---|---|
| fold1 | 0.71 | 0.67 | 0.63 |
| fold2 | 0.72 | 0.62 | 0.61 |
| fold3 | 0.70 | 0.70 | 0.64 |
| fold4 | 0.72 | 0.78 | 0.57 |
| fold5 | 0.68 | 0.72 | 0.62 |
| mean | 0.71 | 0.70 | 0.61 |
| IoU Above Threshold Rates | |||
|---|---|---|---|
| RCA | LCA-LAD | LCA-CX | |
| fold1 | 77.5 | 76.7 | 76.7 |
| fold2 | 76.3 | 77.2 | 73.6 |
| fold3 | 82.0 | 83.1 | 74.8 |
| fold4 | 78.9 | 84.2 | 64.2 |
| fold5 | 71.3 | 75.2 | 66.4 |
| mean | 77.2 | 79.3 | 71.1 |
| DSC Above Threshold Rates | |||
|---|---|---|---|
| RCA | LCA-LAD | LCA-CX | |
| fold1 | 79.8 | 78.8 | 80.4 |
| fold2 | 77.8 | 80.0 | 76.6 |
| fold3 | 84.0 | 85.0 | 77.0 |
| fold4 | 80.5 | 85.5 | 66.1 |
| fold5 | 73.1 | 76.0 | 68.9 |
| mean | 79.0 | 81.1 | 73.8 |
| MAE [mm] | |||
|---|---|---|---|
| RCA | LCA-LAD | LCA-CX | |
| fold1 | 13.1 | 10.1 | 4.6 |
| fold2 | 15.7 | 13.4 | 5.4 |
| fold3 | 13.9 | 9.4 | 7.9 |
| fold4 | 18.3 | 12.2 | 6.8 |
| fold5 | 17.2 | 7.5 | 4.5 |
| mean | 15.6 | 10.5 | 5.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sakamoto, M.; Yoshimura, T.; Sugimori, H. Automated Coronary Artery Identification in CT Angiography: A Deep Learning Approach Using Bounding Boxes. Appl. Sci. 2025, 15, 3113. https://doi.org/10.3390/app15063113
Sakamoto M, Yoshimura T, Sugimori H. Automated Coronary Artery Identification in CT Angiography: A Deep Learning Approach Using Bounding Boxes. Applied Sciences. 2025; 15(6):3113. https://doi.org/10.3390/app15063113
Chicago/Turabian StyleSakamoto, Marin, Takaaki Yoshimura, and Hiroyuki Sugimori. 2025. "Automated Coronary Artery Identification in CT Angiography: A Deep Learning Approach Using Bounding Boxes" Applied Sciences 15, no. 6: 3113. https://doi.org/10.3390/app15063113
APA StyleSakamoto, M., Yoshimura, T., & Sugimori, H. (2025). Automated Coronary Artery Identification in CT Angiography: A Deep Learning Approach Using Bounding Boxes. Applied Sciences, 15(6), 3113. https://doi.org/10.3390/app15063113