
Enhanced Privacy-Preserving Architecture for Fundus Disease Diagnosis with Federated Learning



Abstract
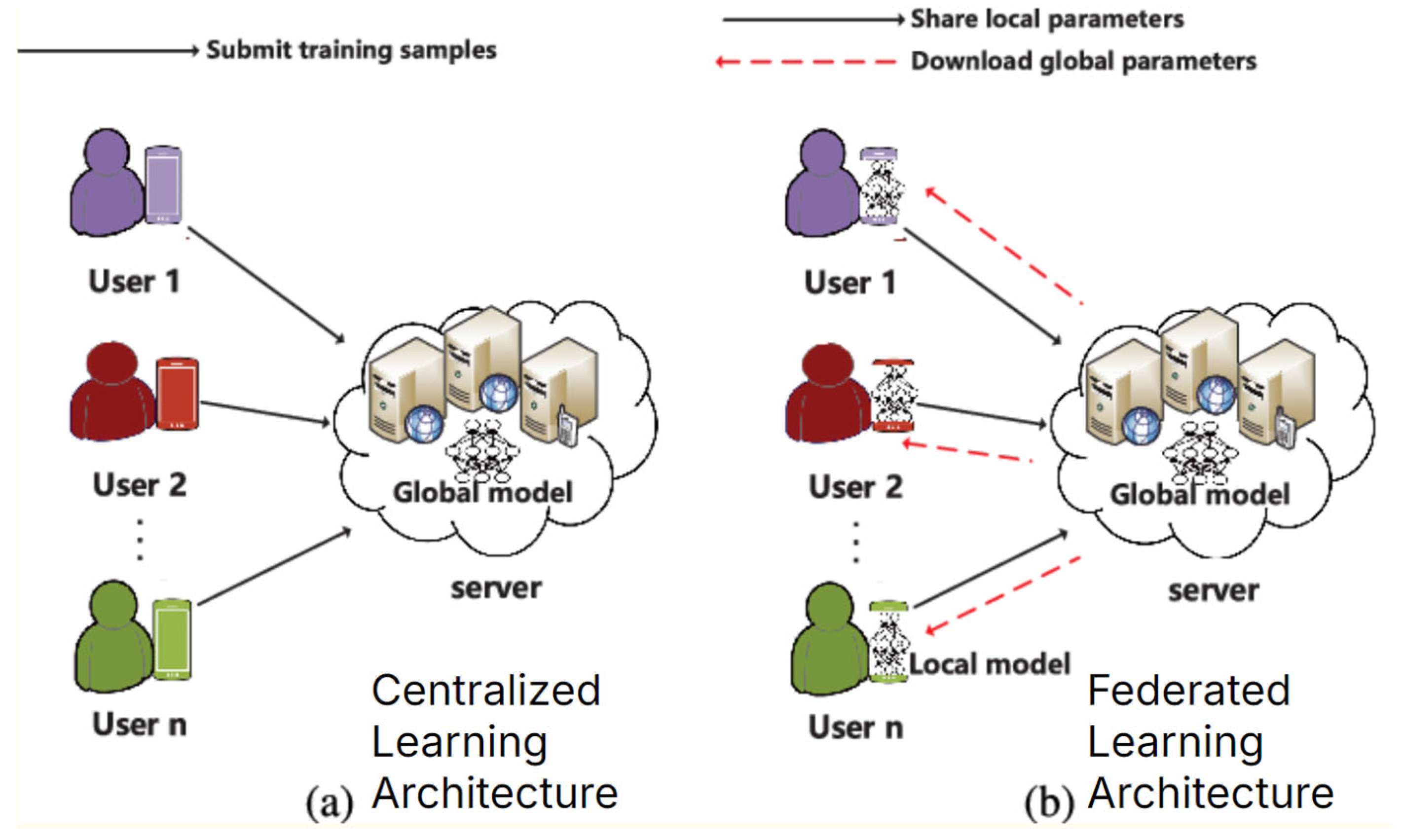
1. Introduction
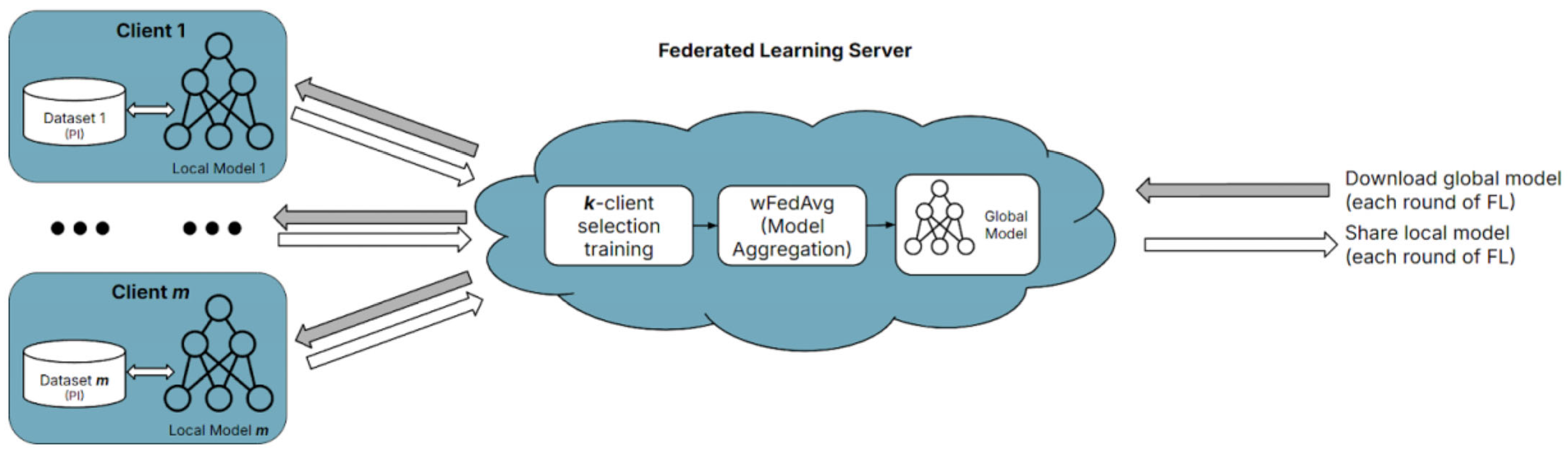
- FL trains local models on each user’s data and aggregates models together to create a global model (the global model is created based on combining model weights, instead of combining datasets, which violates data privacy regulations).
- This ensures privacy when training models through techniques such as differential privacy.
- FL often adds random noise (varying fluctuations to model weights during training) to datasets to prevent backtracking and reverse engineering of the models to reveal sensitive information about any individual patient used in the data (often using the differential privacy method) [16].
- Computing power can become distributed at scale and reduce bandwidth requirements (computations for training are split across the different clients participating in FL instead of just a singular centralized server).
2. Related Work
3. Methodology
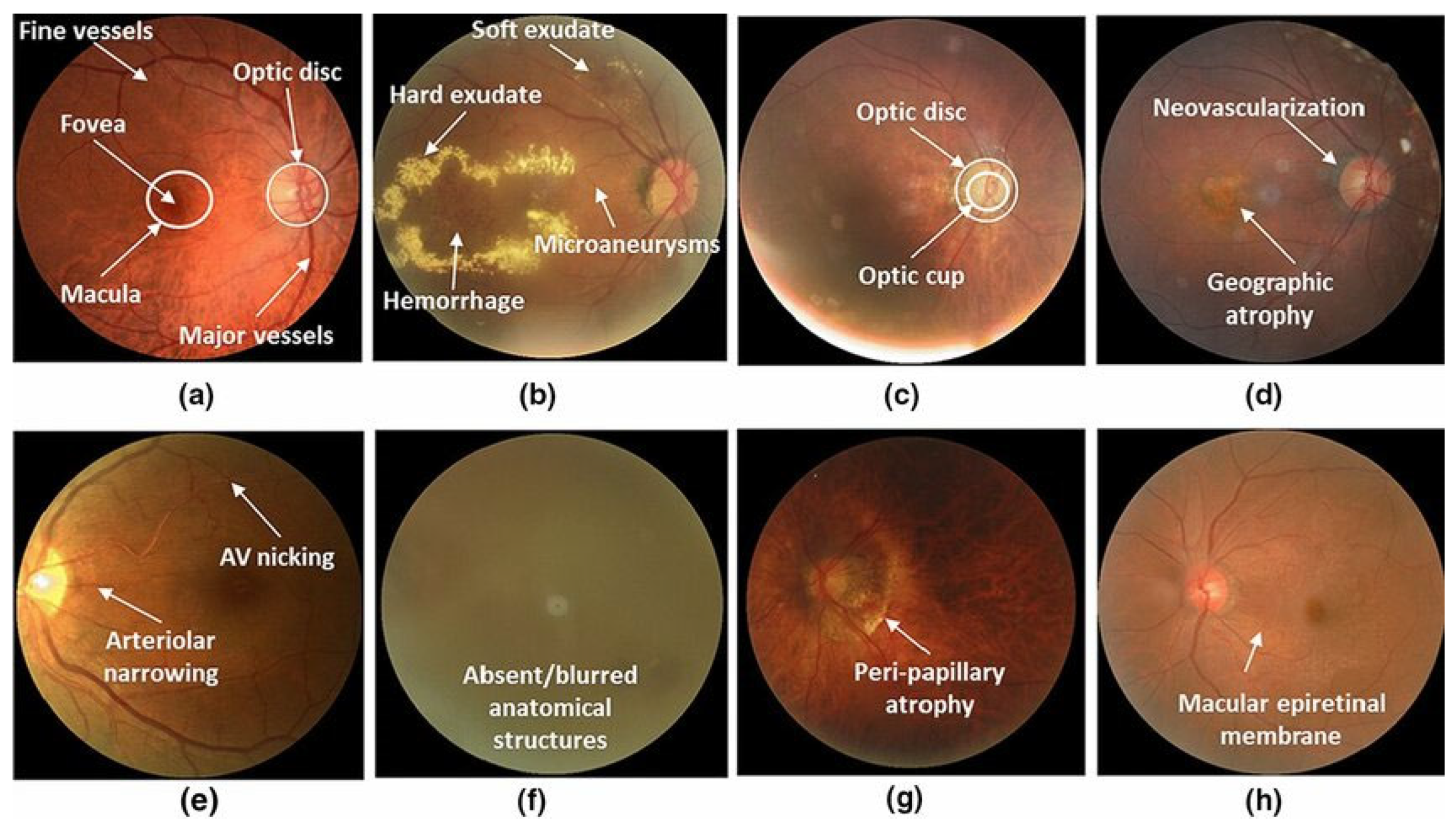
3.1. Project Dataset
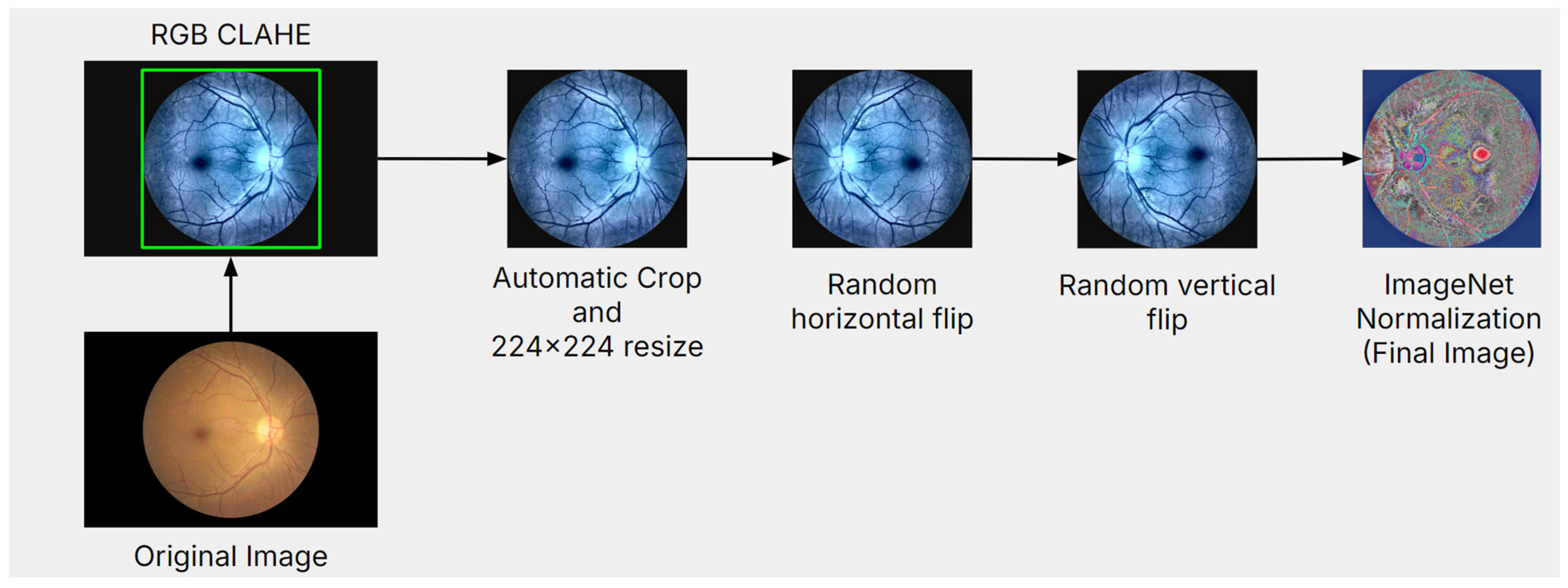
3.2. Data Preprocessing
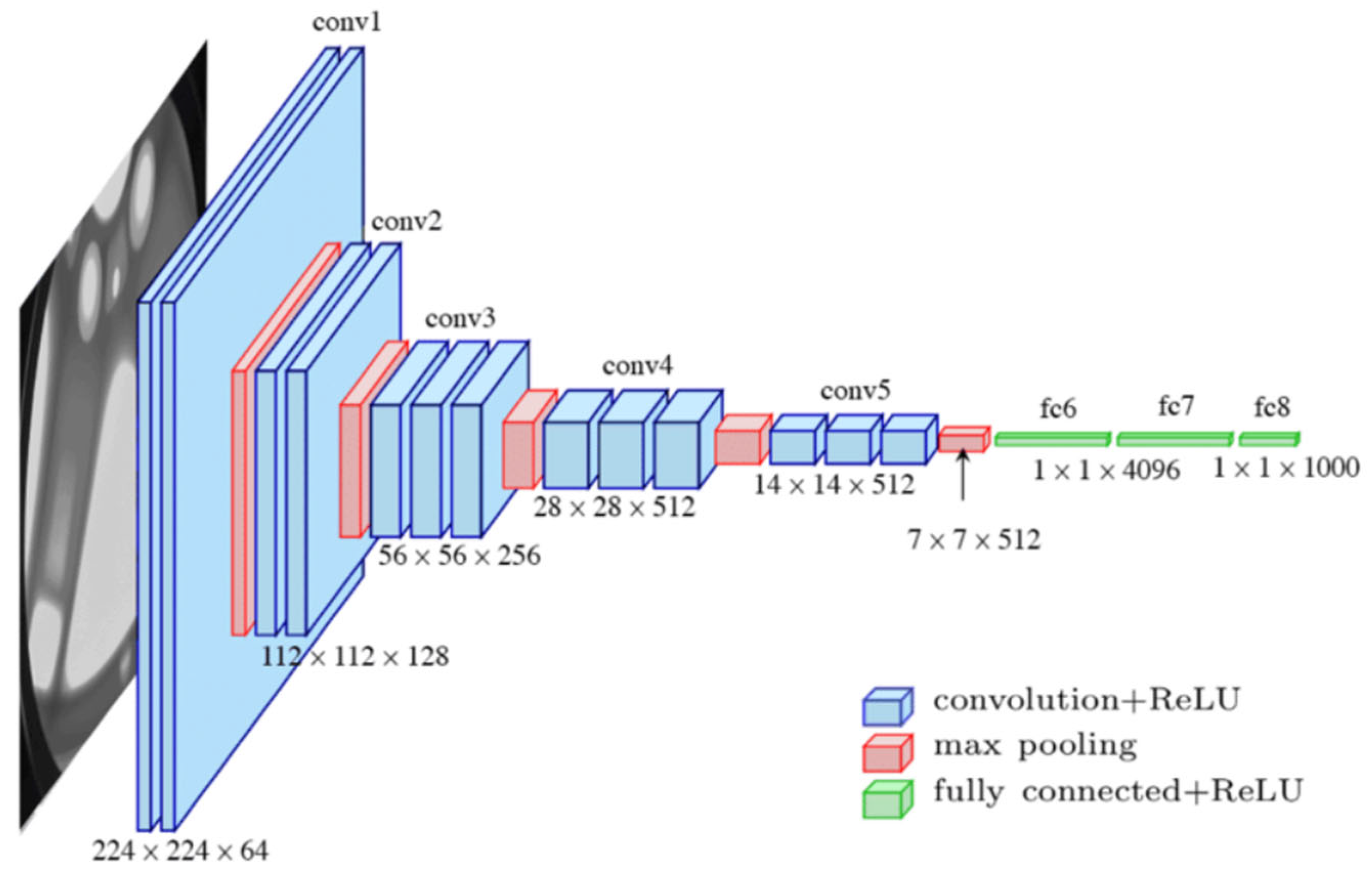
3.3. Transfer Learning and CNN Architectures
3.4. Model Training and Experimental Setup
3.5. Proposed DataWeightedFed Approach
3.5.1. Hypothesis
3.5.2. Proof
- (a)
- Client Selection:
- (b)
- Local Training for Selected Clients: each selected client i ∈ St updates its local model by minimizing its local loss function over n epochs:
- (c)
- Global Aggregation: the global model Gt is updated as a weighted average of the local models:
- (a)
- FedAvg Formula:
- (b)
- Weighted FedAvg (wFedAvg) Formula:
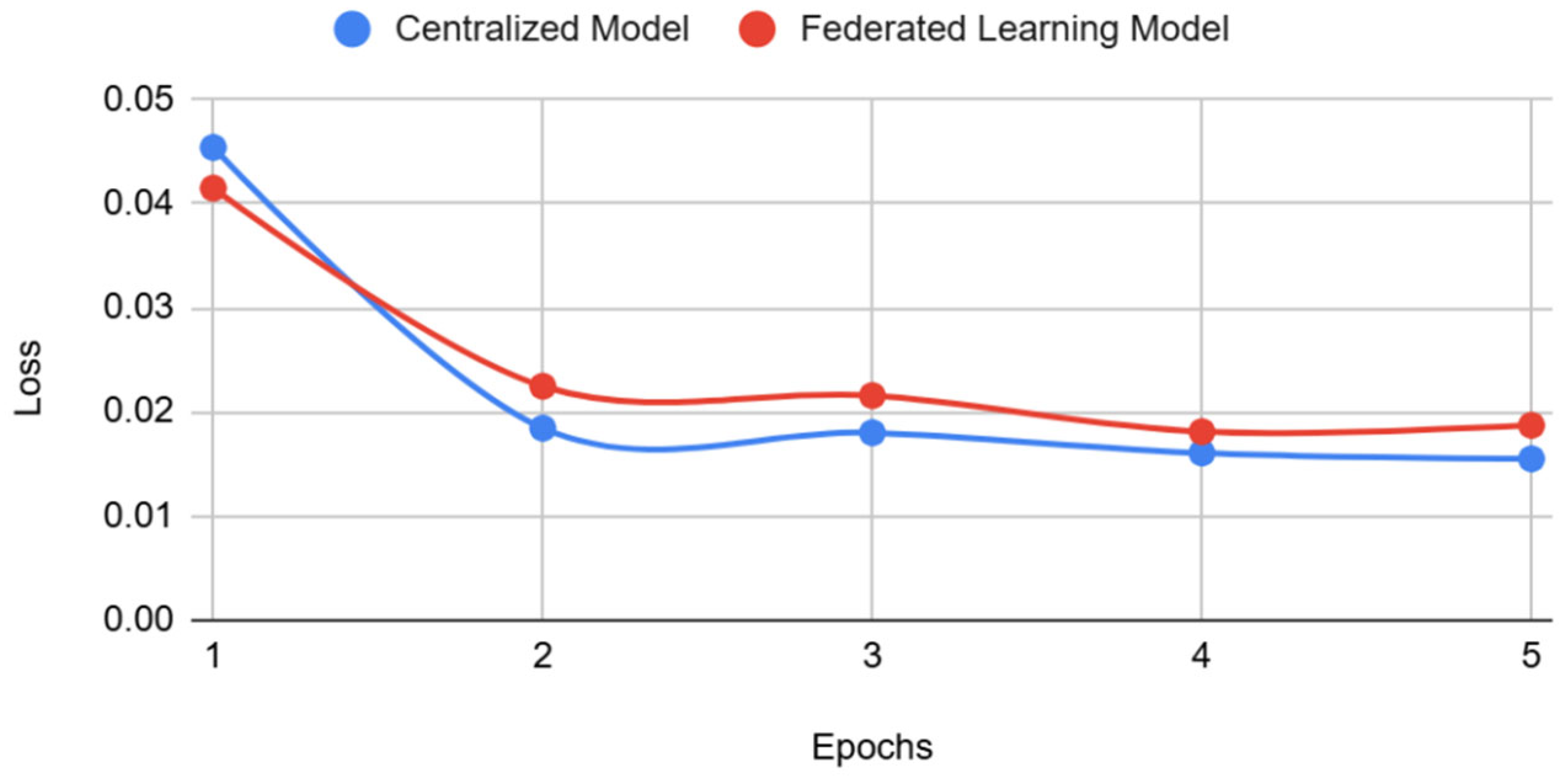
4. Results
Statistical Significance of Model Performance
5. Discussion
6. Conclusions
7. Study Limitations and Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AMD | Age-related Macular Degeneration |
| CL | Centralized Learning |
| CLAHE | Contrast Limited Adaptive Histogram Equalization |
| CNN | Convolutional Neural Network |
| DL | Deep Learning |
| FL | Federated Learning |
| GDPR | General Data Protection Regulation |
| HIPAA | Health Insurance Portability and Accountability Act |
| ML | Machine Learning |
| non-IID | non-Independent and Identically Distributed |
| ODIR | Ocular Disease Intelligent Recognition |
| PI | Personal Information |
| PIPEDA | Personal Information Protection and Electronic Documents Act |
| PPT | Privacy-Preserving Technique |
| TL | Transfer Learning |
References
- Alowais, S.A.; Alghamdi, S.S.; Alsuhebany, N.; Alqahtani, T.; Alshaya, A.I.; Almohareb, S.N.; Aldairem, A.; Alrashed, M.; Saleh, K.B.; Badreldin, H.A.; et al. Revolutionizing healthcare: The role of artificial intelligence in clinical practice. BMC Med. Educ. 2023, 23, 689. [Google Scholar] [CrossRef] [PubMed]
- Salem, H.; Negm, K.R.; Shams, M.Y.; Elzeki, O.M. Recognition of ocular disease based optimized VGG-net models. In Medical Informatics and Bioimaging Using Artificial Intelligence: Challenges, Issues, Innovations and Recent Developments; Springer International Publishing: Cham, Switzerland, 2021; pp. 93–111. [Google Scholar]
- Abdalla, H.B.; Kumar, Y.; Marchena, J.; Guzman, S.; Gheisari, M.; Awlla, A.; Cheraghy, M. The Future of AI in the Face of Data Scarcity. CMC-Comput. Mater. Contin. 2025; submitted. ISSN 1546-2226. [Google Scholar]
- Drainakis, G.; Pantazopoulos, P.; Katsaros, K.V.; Sourlas, V.; Amditis, A.; Kaklamani, D.I. From centralized to Federated Learning: Exploring performance and end-to-end resource consumption. Comput. Networks. 2023, 225, 109657. [Google Scholar] [CrossRef]
- Adjerid, I.; Acquisti, A.; Telang, R.; Padman, R.; Adler-Milstein, J. The impact of privacy regulation and technology incentives: The case of health information exchanges. Manag. Sci. 2016, 62, 1042–1063. [Google Scholar] [CrossRef]
- Summary of the HIPAA Privacy Rule. Available online: https://www.hhs.gov/hipaa/for-professionals/privacy/laws-regulations/index.html (accessed on 9 September 2024).
- General Data Protection Regulation. Available online: https://gdpr-info.eu/ (accessed on 9 September 2024).
- Personal Information Protection and Electronic Documents Act. Available online: https://laws-lois.justice.gc.ca/eng/acts/P-8.6/ (accessed on 9 September 2024).
- Nugroho, K. Comparative Analysis of Federated and Centralized Learning Systems in Predicting Cellular Downlink Throughput Using CNN. IEEE Access 2025, 13, 22745–22763. [Google Scholar] [CrossRef]
- AbdulRahman, S.; Tout, H.; Ould-Slimane, H.; Mourad, A.; Talhi, C.; Guizani, M. A survey on federated learning: The journey from centralized to distributed on-site learning and beyond. IEEE Internet Things J. 2020, 8, 5476–5497. [Google Scholar] [CrossRef]
- Xu, G.; Li, H.; Liu, S.; Yang, K.; Lin, X. VerifyNet: Secure and verifiable federated learning. IEEE Trans. Inf. Forensics Secur. 2019, 15, 911–926. [Google Scholar] [CrossRef]
- Liu, J.C.; Goetz, J.; Sen, S.; Tewari, A. Learning from others without sacrificing privacy: Simulation comparing centralized and federated machine learning on mobile health data. JMIR mHealth uHealth 2021, 9, e23728. [Google Scholar] [CrossRef]
- Liu, T.; Wang, H.; Ma, M. Federated Learning with Efficient Aggregation via Markov Decision Process in Edge Networks. Mathematics 2024, 12, 920. [Google Scholar] [CrossRef]
- Zhang, T.; Gao, L.; He, C.; Zhang, M.; Krishnamachari, B.; Avestimehr, A.S. Federated learning for the internet of things: Applications, challenges, and opportunities. IEEE Internet Things Mag. 2022, 5, 24–29. [Google Scholar] [CrossRef]
- Bogdanova, A.; Attoh-Okine, N.; Sakurai, T. Risk and advantages of federated learning for health care data collaboration. ASCE-ASME J. Risk Uncertain. Eng. Syst. Part A Civ. Eng. 2020, 6, 04020031. [Google Scholar] [CrossRef]
- El Ouadrhiri, A.; Abdelhadi, A. Differential privacy for deep and federated learning: A survey. IEEE Access 2022, 10, 22359–22380. [Google Scholar] [CrossRef]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Velpula, V.K.; Sharma, L.D. Multi-stage glaucoma classification using pre-trained convolutional neural networks and voting-based classifier fusion. Front. Physiol. 2023, 14, 1175881. [Google Scholar] [CrossRef] [PubMed]
- Sigit, R.; Triyana, E.; Rochmad, M. Cataract detection using single layer perceptron based on smartphone. In Proceedings of the 2019 3rd International Conference on Informatics and Computational Sciences (ICICoS), Semarang, Indonesia, 29–30 October 2019; pp. 1–6. [Google Scholar]
- Saqib, S.M.; Iqbal, M.; Asghar, M.Z.; Mazhar, T.; Almogren, A.; Rehman, A.U.; Hamam, H. Cataract and glaucoma detection based on Transfer Learning using MobileNet. Heliyon 2024, 10, e36759. [Google Scholar] [CrossRef]
- Liu, B.; Lv, N.; Guo, Y.; Li, Y. Recent advances on federated learning: A systematic survey. Neurocomputing 2024, 597, 128019. [Google Scholar] [CrossRef]
- Wen, J.; Zhang, Z.; Lan, Y.; Cui, Z.; Cai, J.; Zhang, W. A survey on federated learning: Challenges and applications. Int. J. Mach. Learn. Cybern. 2023, 14, 513–535. [Google Scholar] [CrossRef]
- Islam, M.; Reza, M.T.; Kaosar, M.; Parvez, M.Z. Effectiveness of federated learning and CNN ensemble architectures for identifying brain tumors using MRI images. Neural Process. Lett. 2023, 55, 3779–3809. [Google Scholar] [CrossRef]
- Li, W.; Milletarì, F.; Xu, D.; Rieke, N.; Hancox, J.; Zhu, W.; Baust, M.; Cheng, Y.; Ourselin, S.; Cardoso, M.J.; et al. Privacy-preserving federated brain tumour segmentation. In Proceedings of the Machine Learning in Medical Imaging: 10th International Workshop, MLMI 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, 13 October 2019; Springer International Publishing: Cham, Switzerland, 2019. Proceedings 10. pp. 133–141. [Google Scholar]
- Zargar, H.H.; Zargar, S.H.; Mehri, R.; Tajidini, F. Using VGG16 Algorithms for classification of lung cancer in CT scans Image. arXiv 2023, arXiv:2305.18367. [Google Scholar]
- Chea, N.; Nam, Y. Classification of Fundus Images Based on Deep Learning for Detecting Eye Diseases. Comput. Mater. Contin. 2021, 67, 411–426. [Google Scholar] [CrossRef]
- Khan, A.A.; Alsubai, S.; Wechtaisong, C.; Almadhor, A.; Kryvinska, N.; Al Hejaili, A.; Mohammad, U.G. CD-FL: Cataract Images Based Disease Detection Using Federated Learning. Comput. Syst. Sci. Eng. 2023, 47, 1733–1750. [Google Scholar] [CrossRef]
- Yang, X.L.; Yi, S.L. Multi-classification of fundus diseases based on DSRA-CNN. Biomed. Signal Process. Control. 2022, 77, 103763. [Google Scholar]
- Choi, J.Y.; Yoo, T.K.; Seo, J.G.; Kwak, J.; Um, T.T.; Rim, T.H. Multi-categorical deep learning neural network to classify retinal images: A pilot study employing small database. PLoS ONE. 2017, 12, e0187336. [Google Scholar] [CrossRef] [PubMed]
- Li, N.; Li, T.; Hu, C.; Wang, K.; Kang, H. A benchmark of ocular disease intelligent recognition: One shot for multi-disease detection. In Proceedings of the Benchmarking, Measuring, and Optimizing: Third BenchCouncil International Symposium, Bench 2020, Virtual Event, 15–16 November 2020; Springer International Publishing: Cham, Switzerland, 2021. Revised Selected Papers 3. pp. 177–193. [Google Scholar]
- Kamiran, F.; Calders, T. Data preprocessing techniques for classification without discrimination. Knowl. Inf. Syst. 2011, 33, 1–33. [Google Scholar] [CrossRef]
- Shijie, J.; Ping, W.; Peiyi, J.; Siping, H. Research on data augmentation for image classification based on convolution neural networks. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 4165–4170. [Google Scholar]
- Hitam, M.S.; Awalludin, E.A.; Yussof, W.N.J.H.W.; Bachok, Z. Mixture contrast limited adaptive histogram equalization for underwater image enhancement. In Proceedings of the 2013 International Conference on Computer Applications Technology (ICCAT), Sousse, Tunisia, 20–22 January 2013; pp. 1–5. [Google Scholar]
- Hosna, A.; Merry, E.; Gyalmo, J.; Alom, Z.; Aung, Z.; Azim, M.A. Transfer learning: A friendly introduction. J. Big Data 2022, 9, 102. [Google Scholar] [CrossRef]
- Karen, S. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Mansour, A.B.; Carenini, G.; Duplessis, A.; Naccache, D. Federated learning aggregation: New robust algorithms with guarantees. In Proceedings of the 2022 21st IEEE International Conference on Machine Learning and Applications (ICMLA), Nassau, Bahamas, 12–14 December 2022; pp. 721–726. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Year | Ref. | Methodology | Strengths | Weaknesses |
|---|---|---|---|---|---|
| Velpula et al. | (2023) | [18] | CL with voting ensemble of ResNet50, VGG-19, AlexNet, DNS201, IncRes | High accuracy (85.43%) | Lacks privacy-preserving techniques (PPTs), not applicable in real-world privacy-restricted environments |
| Sigit et al. | (2019) | [19] | CL using a single layer perceptron model | Practical approach using smartphones, good accuracy (85%) | Limited complexity, lacks generalizability, no FL support |
| Saqib et al. | (2024) | [20] | CL and TL with MobileNetV1 and V2 | High accuracy (89%) with TL | Models designed for smaller datasets, not scalable to large real-world scenarios |
| Islam et al. | (2023) | [23] | FL with CNN ensemble architectures for brain tumor classification | Demonstrates FL’s effectiveness in medical imaging | Accuracy reduction compared to non-FL methods (from 96.68% to 91.05%) |
| Li et al. | (2019) | [24] | FL for brain tumor segmentation with privacy protection | Analyzes trade-offs between accuracy and privacy in FL | Increased differential privacy noise lowers model performance |
| Zargar et al. | (2023) | [25] | CL using VGG-16 for lung cancer classification | High sensitivity (92.08%) and accuracy (91%) | Lacks PPT, limited to single neural network architecture |
| Chea and Nam | (2021) | [26] | Deep learning (DL) with CNN for fundus image classification | Effective in detecting multiple eye diseases | Does not incorporate PPT, potential overfitting due to limited dataset |
| Khan et al. | (2023) | [27] | FL for cataract disease detection using CNN | Preserves data privacy, demonstrates FL’s applicability in medical imaging | Reduction in accuracy compared to centralized methods, requires robust communication infrastructure |
| Yang et al. | (2022) | [28] | Centralized DL using a multi-categorical neural network for retinal image classification | Demonstrated feasibility of classifying multiple retinal diseases with a small dataset | Limited by small sample size, potential overfitting, lacks PPT |
| Choi et al. | (2022) | [29] | Centralized DL using CNNs for medical image analysis | Achieved high accuracy in detecting specific medical conditions | Requires large, labeled datasets, lacks PPT, potential generalization issues |
| Ref. | Learning | Model(s) | Accuracy | Reduction |
|---|---|---|---|---|
| [18] | CL | Voting Ensemble of ResNet50, VGG-19, AlexNet, DNS201, IncRes | 85.43% | 0.64% |
| [19] | CL | Single Layer Perceptron Model | 85.00% | 0.14% |
| [20] | CL, TL | MobileNetV1, MobileNetV2 | 89.00% | 4.62% |
| Ours | CL | VGG-19 | 86.63% | 2.02% |
| Ours | FL | VGG-19 (with wFedAvg and k-client selection training) | 84.88% | 1.85% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, R.; Kumar, Y.; Kruger, D. Enhanced Privacy-Preserving Architecture for Fundus Disease Diagnosis with Federated Learning. Appl. Sci. 2025, 15, 3004. https://doi.org/10.3390/app15063004
Jiang R, Kumar Y, Kruger D. Enhanced Privacy-Preserving Architecture for Fundus Disease Diagnosis with Federated Learning. Applied Sciences. 2025; 15(6):3004. https://doi.org/10.3390/app15063004
Chicago/Turabian StyleJiang, Raymond, Yulia Kumar, and Dov Kruger. 2025. "Enhanced Privacy-Preserving Architecture for Fundus Disease Diagnosis with Federated Learning" Applied Sciences 15, no. 6: 3004. https://doi.org/10.3390/app15063004
APA StyleJiang, R., Kumar, Y., & Kruger, D. (2025). Enhanced Privacy-Preserving Architecture for Fundus Disease Diagnosis with Federated Learning. Applied Sciences, 15(6), 3004. https://doi.org/10.3390/app15063004