
A New Ensemble Strategy Based on Surprisingly Popular Algorithm and Classifier Prediction Confidence


Abstract
1. Introduction
- Designing an ensemble strategy that integrates classification confidence with surprise popularity;
- Proposing a prior regression method based on classification confidence and defining posteriors using confidence metrics;
- Validating the algorithm on public datasets, with experimental results demonstrating superior performance over conventional ensemble methods. Our research highlights the potential of this approach and provides new directions for future studies and applications in ensemble learning.
2. Related Work
2.1. Development of Ensemble Learning
2.2. Applications of Ensemble Learning
3. Methodology
3.1. Problem Definition
3.2. Bayesian Truth Serum
- The participant’s own answer to the question.
- The participant’s prediction of how others will answer the question.
- Collect answer: Participants answer a question and provide a probability distribution of how likely they think others will choose each option.
- Calculate prior probability: Calculate the prior probability for each answer option, typically the average distribution of responses provided by all participants.
- III.
- Calculate posterior probability: Calculate each participant’s posterior probability based on their report and the prior probability.
- IV.
- Scoring Mechanism: Calculate a score based on each participant’s posterior probability and their provided confidence; a higher score indicates that their answer is more likely to be close to the truth.
3.3. Confidence Truth Serum
3.3.1. Algorithm Overview
3.3.2. Ensemble Strategy
- (1)
- According to the explanation of the Bayesian Truth Serum algorithm in Section 3.2, we need to calculate the prior probability P and posterior probability Q for each answer option (i.e., the classification result for each sample).
- (2)
- It can be seen that the process of calculating the “surprising” degree of label 1 in the above binary classification task essentially assumes the answer to be 1, which is conceptually similar to hypothesis testing. Similarly, we can assume the answer to be 0 during the algorithm’s calculation process to obtain the corresponding ensemble result. In fact, the above process of calculating the prior and posterior probabilities for label 1 or label 0 does not affect the final classification result. Taking the construction of a multiple linear regression model as an example, we provide a brief proof under the extreme case where confidence is equal to 1:
3.4. Confidence Truth Serum with Single Regression (CTS-SR)
3.5. Analysis
4. Experiment
4.1. Experimental Setup
4.2. Experimental Results
4.2.1. Experiment 1: Comparison with Baseline Algorithms
4.2.2. Experiment 2: Comparison with Single Classifiers
4.2.3. Experiment 3: Friedman–Nemenyi Test
- (1)
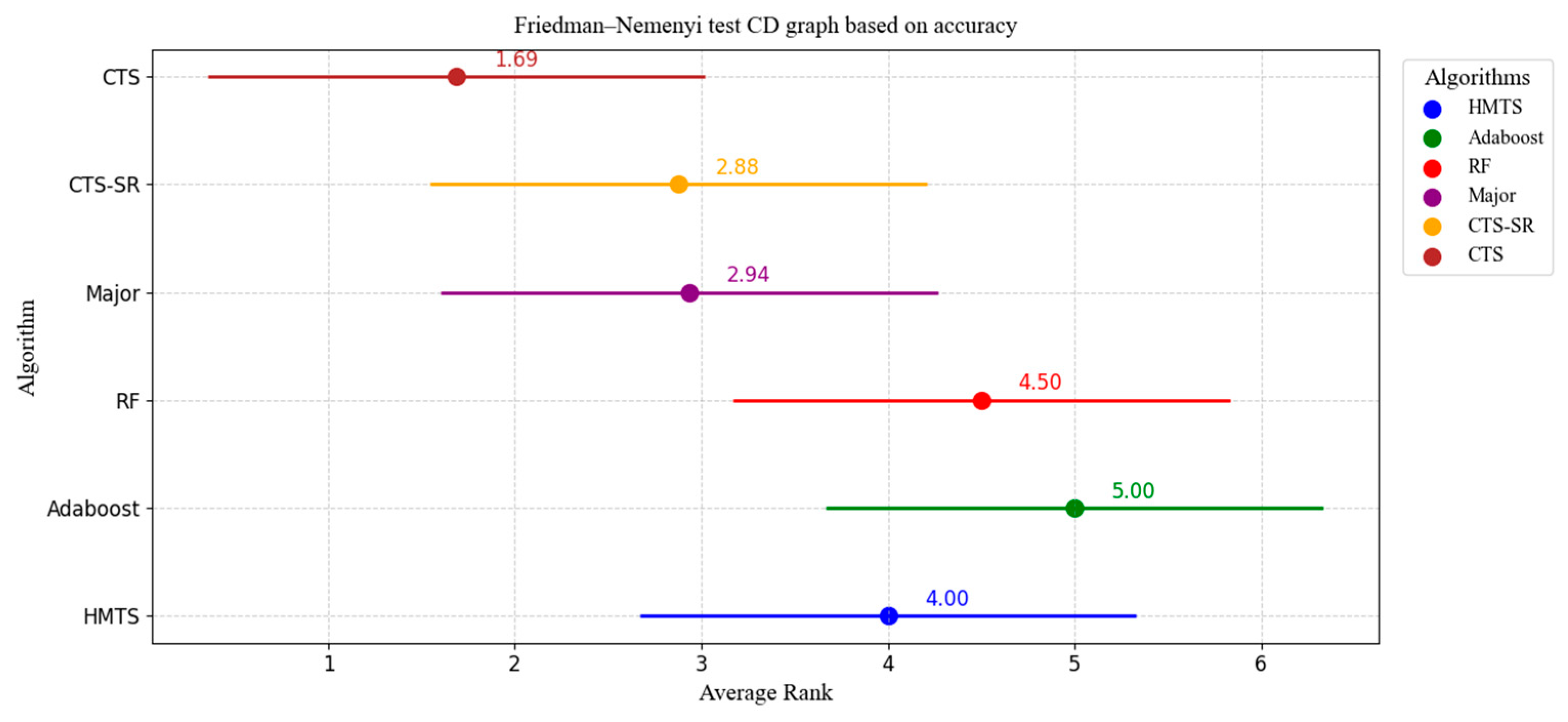
- Friedman–Nemenyi Test Based on Accuracy
- (2)
- Friedman–Nemenyi Test Based on F1 score
4.2.4. Experiment 4: Calculation and Analysis of Correlation Coefficient
4.2.5. Experiment 5: Data Analysis
5. Conclusions
- (1)
- Enhancing feature representation capability: It can capture the uncertainty information of sample classifications under different classifiers, enriching the representation of sample features.
- (2)
- Improving the model’s robustness: Introducing classification confidence increases model diversity, reduces the risk of overfitting, and enhances robustness.
- (3)
- Boosting prediction performance: Classification confidence reflects the consistency of samples under different classifiers. By integrating this information, samples can be predicted more accurately.
6. Limitations and Future Work
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Polikar, R. Ensemble based systems in decision making. IEEE Circuits Syst. Mag. 2006, 6, 21–45. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble Methods in Machine Learning. In Proceedings of the International Workshop on Multiple Classifier Systems, Cagliari, Italy, 21–23 June 2000. [Google Scholar] [CrossRef]
- Ganaie, M.A.; Hu, M.; Malik, A.K.; Tanveer, M.; Suganthan, P.N. Ensemble deep learning: A review. Eng. Appl. Artif. Intell. 2022, 115, 105151. [Google Scholar] [CrossRef]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Ho, T.K.; Hull, J.J.; Srihari, S.N. Decision Combination in Multiple Classifiers Systems. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 66–75. [Google Scholar]
- Prelec, D. A Bayesian Truth Serum for Subjective Data. Science 2004, 306, 462–466. [Google Scholar] [CrossRef] [PubMed]
- Prelec, D.; Seung, H.S.; Mccoy, J. A solution to the single-question crowd wisdom problem. Nature 2017, 541, 532–535. [Google Scholar] [CrossRef] [PubMed]
- Luo, T.; Liu, Y. Machine truth serum: A surprisingly popular approach to improving ensemble methods. Mach. Learn. 2022, 112, 789–815. [Google Scholar] [CrossRef]
- Mccoy, J.; Prelec, D. A Bayesian Hierarchical Model of Crowd Wisdom Based on Predicting Opinions of Others. Manag. Sci. 2023, 70, 5931–5948. [Google Scholar] [CrossRef]
- Hosseini, H.; Mandal, D.; Shah, N.; Shi, K. Surprisingly Popular Voting Recovers Rankings, Surprisingly! In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–27 August 2021. [Google Scholar] [CrossRef]
- Schapire, R.E.; Singer, Y. Improved Boosting Algorithms Using Confidence-rated Predictions. Mach. Learn. 1999, 37, 297–336. [Google Scholar] [CrossRef]
- Dietterich, T.G. An Experimental Comparison of Three Methods for Constructing Ensembles of Decision Trees: Bagging, Boosting, and Randomization. Mach. Learn. 2000, 40, 139–157. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD’16), San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T. LightGBM: A Highly Efficient Gradient Boosting Decision Tree. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Webb, G.I.; Zheng, Z. Multistrategy Ensemble Learning: Reducing Error by Combining Ensemble Learning Techniques. IEEE Trans. Knowl. Data Eng. 2004, 16, 981–991. [Google Scholar] [CrossRef]
- Zhang, D.; Jiao, L.; Bai, X.; Wang, S.; Hou, B. A robust semi-supervised SVM via ensemble learning. Appl. Soft Comput. 2018, 65, 632–643. [Google Scholar] [CrossRef]
- Yu, Z.; Wang, D.; You, J.; Wong, H.-S.; Wu, S.; Zhang, J.; Han, G. Progressive Subspace Ensemble Learning. Pattern Recognit. 2016, 60, 692–705. [Google Scholar] [CrossRef]
- Svargiv, M.; Masoumi, B.; Keyvanpour, M.R. A new ensemble learning method based on learning automata. J. Ambient. Intell. Humaniz. Comput. 2020, 13, 3467–3482. [Google Scholar] [CrossRef]
- Phama, K.; Kim, D.; Park, S.; Choi, H. Ensemble learning-based classification models for slope stability analysis. Catena 2021, 196, 104886. [Google Scholar] [CrossRef]
- Gutierrez-Espinoza, L.; Abri, F.; Namin, A.S.; Jones, K.S.; Sears, D.R.W. Ensemble Learning for Detecting Fake Reviews. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020. [Google Scholar] [CrossRef]
- Yang, X.; Xu, Y.; Quan, Y.; Ji, H. Image Denoising via Sequential Ensemble Learning. IEEE Trans. Image Process. 2020, 29, 5038–5049. [Google Scholar] [CrossRef] [PubMed]
- Wang, T.; Zhang, Z.; Jing, X.; Zhang, L. Multiple Kernel Ensemble Learning for Softwaredefect prediction. Autom. Softw. Eng. 2016, 23, 569–590. [Google Scholar] [CrossRef]
- An, N.; Ding, H.; Yang, J.; Au, R.; Ang, T.F.A. Deep ensemble learning for Alzheimer’s disease classification. J. Biomed. Inform. 2020, 105, 103411. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Model | Dataset | Learning Paradigms |
|---|---|---|---|---|
| MTS, HMTS, DMTS [8] | 2023 | Perceptron, LR, RF, SVM, MLP. | UCI Repository. | Supervised, semi-supervised. |
| Decision-tree algorithm C4.5 [12] | 2000 | Randomization, bagging, and boosting. | UCI Repository. | Supervised. |
| XGBoost [13] | 2016 | Tree boosting, C4.5, randomization, sparsity-aware algorithm, weighted quantile sketch. | Allstate, Higgs Boson, Yahoo! LTRC, Criteo. | Supervised. |
| LightGBM [14] | 2017 | GOSS, EFB. | Allstate Insurance Claim, Flight Delay, LETOR, KDD10, KDD12. | Supervised. |
| Multistrategy Ensemble Learning [15] | 2004 | Bagging, wagging, boosting, SASC. | UCI Repository. | Supervised. |
| EnsembleS3VM [16] | 2018 | SVM, LapSVM, S3VMs, S4VMs. | UCI Repository, PolSAR. | Semi-supervised. |
| PSEL [17] | 2016 | Decision tree. | UCI Repository, alizadeh—2000—v1, armstrong—2002—v1 and other 16 cancer datasets. | Supervised. |
| LAbEL [18] | 2020 | SVM, random forest, naïve Bayes, logistic regression. | Heart disease dataset, Breast cancer Wisconsin (Diagnostic) dataset, Yelp, Abalone dataset, Gender voice. | Supervised. |
| Our Study | 2025 | Gbt, LR, RF, SVM, MLP. | UCI Repository, musk, magazine. | Supervised. |
| Methods | Field | Year | Model | Dataset | Learning Paradigms |
|---|---|---|---|---|---|
| Parallel learning, Sequential learning [19] | Slope stability | 2021 | Homogeneous ensemble: DT, SVM, ANN, KNN. Heterogeneous ensemble: KNN, SVM, SGD, GP, QDA, GNB, DT, ANN. | 153 slope cases. | Supervised. |
| Bagging, AdaBoost [20] | Fake Reviews | 2020 | DT, RF, SVM, XGBT, MLP. | Restaurant Dataset. | Supervised. |
| Sequential learning [21] | Image Denoising | 2020 | Local base denoiser, Nonlocal base denoiser. | 400 cropped images of size 180 × 180 from the Berkeley segmentation dataset, BSD68. | Supervised. |
| MKEL [22] | Software defect prediction | 2016 | SVM. | Datasets from NASA MDP. | Supervised. |
| DELearning [23] | Alzheimer’s disease classification | 2020 | Bayes Network, naïve Bayes, J48 and so on, DBN, RBM. | UDS. | Supervised. |
| Datasets | # of Instances | # of Features | Numeric Type | Description of Content |
|---|---|---|---|---|
| Australian | 690 | 14 | Integer, Float | Credit card applicant information. |
| German | 1000 | 24 | Integer | Credit history characteristics. |
| spam | 4601 | 57 | Integer, Float | Content characteristics of the emails. |
| biodeg | 1055 | 41 | Integer, Float | Chemical characteristics of the substances. |
| magazine | 2374 | 10 | Double | Comments of magazine in Amazon. |
| all-beauty | 508 | 768 | Double | Characters of Beauty products. |
| musk | 476 | 166 | Integer | Structural characteristics of the molecules. |
| Hilly | 1212 | 100 | Double | Characteristics of the terrain. |
| Accuracy (%) | CTS | CTS-SR | Major | RF | AdaBoost | HMTS |
|---|---|---|---|---|---|---|
| Australian | 86.95 | 87.24 | 86.95 | 84.92 | 88.69 | 83.18 |
| German | 75.6 | 74.2 | 74.8 | 71.4 | 72.6 | 72.2 |
| spam | 94.08 | 89.56 | 93.61 | 92.95 | 90.83 | 92.78 |
| biodeg | 85.98 | 87.12 | 86.36 | 83.52 | 81.25 | 84.84 |
| magazine | 81.04 | 80.53 | 80.28 | 78.60 | 75.82 | 77.84 |
| all-beauty | 85.82 | 86.61 | 85.43 | 82.67 | 81.10 | 85.03 |
| musk | 84.13 | 81.43 | 80.83 | 80.23 | 75.44 | 83.53 |
| Hilly | 55.94 | 50.82 | 51.65 | 54.62 | 48.18 | 55.11 |
| F1 Score (%) | CTS | CTS-SR | Major | RF | AdaBoost | HMTS |
|---|---|---|---|---|---|---|
| Australian | 84.94 | 85.23 | 84.84 | 82.31 | 86.59 | 79.16 |
| German | 49.58 | 37.07 | 46.15 | 45.69 | 42.67 | 48.52 |
| spam | 92.08 | 84.99 | 91.71 | 90.96 | 88.24 | 92.07 |
| biodeg | 79.89 | 80.34 | 79.77 | 75.63 | 74.01 | 78.60 |
| magazine | 87.32 | 82.65 | 87.28 | 85.63 | 84.39 | 84.64 |
| all-beauty | 82.52 | 82.52 | 82.46 | 78.43 | 75.75 | 80.80 |
| musk | 81.27 | 76.69 | 76.74 | 75.73 | 73.02 | 80.96 |
| Hilly | 59.48 | 57.53 | 65.03 | 56.69 | 64.23 | 57.63 |
| Accuracy (%) | CTS | CTS-SR | DT | LightGBM | MLP | SVM |
|---|---|---|---|---|---|---|
| Australian | 86.95 | 87.24 | 82.60 | 85.79 | 81.73 | 86.66 |
| German | 75.6 | 74.2 | 67.2 | 73.6 | 68.2 | 74.0 |
| spam | 94.08 | 89.56 | 89.48 | 90.65 | 93.69 | 92.13 |
| biodeg | 85.98 | 87.12 | 79.16 | 84.84 | 85.60 | 86.93 |
| magazine | 81.04 | 80.53 | 73.79 | 76.49 | 80.87 | 80.62 |
| all-beauty | 85.82 | 86.61 | 72.83 | 84.25 | 83.46 | 86.61 |
| musk | 84.13 | 81.43 | 69.46 | 75.74 | 78.74 | 79.64 |
| Hilly | 55.94 | 50.82 | 54.78 | 53.46 | 50.19 | 49.17 |
| F1 Score (%) | CTS | CTS-SR | DT | LightGBM | MLP | SVM |
|---|---|---|---|---|---|---|
| Australian | 84.94 | 85.23 | 80.00 | 82.63 | 78.70 | 84.86 |
| German | 49.58 | 37.07 | 37.95 | 49.78 | 46.37 | 44.91 |
| spam | 92.08 | 84.99 | 86.76 | 93.51 | 91.95 | 89.69 |
| biodeg | 79.89 | 80.34 | 68.64 | 79.66 | 77.26 | 80.22 |
| magazine | 87.32 | 82.65 | 82.58 | 87.38 | 87.75 | 87.39 |
| all-beauty | 82.52 | 82.52 | 73.97 | 80.78 | 79.41 | 83.16 |
| musk | 81.27 | 76.69 | 62.63 | 72.40 | 75.17 | 73.64 |
| Hilly | 59.48 | 57.53 | 58.29 | 57.88 | 63.17 | 63.24 |
| Datasets | # of Recovery/# of Test | Proportion |
|---|---|---|
| Australian | 3/345 | 0.9% |
| German | 12/500 | 2.4% |
| spam | 36/2301 | 1.6% |
| biodeg | 10/528 | 1.9% |
| magazine | 33/1187 | 2.8% |
| all-beauty | 5/254 | 2.0% |
| musk | 19/334 | 5.7% |
| Hilly | 84/606 | 13.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shi, H.; Yuan, Z.; Zhang, Y.; Zhang, H.; Wang, X. A New Ensemble Strategy Based on Surprisingly Popular Algorithm and Classifier Prediction Confidence. Appl. Sci. 2025, 15, 3003. https://doi.org/10.3390/app15063003
Shi H, Yuan Z, Zhang Y, Zhang H, Wang X. A New Ensemble Strategy Based on Surprisingly Popular Algorithm and Classifier Prediction Confidence. Applied Sciences. 2025; 15(6):3003. https://doi.org/10.3390/app15063003
Chicago/Turabian StyleShi, Haochen, Zirui Yuan, Yankai Zhang, Haoran Zhang, and Xiujuan Wang. 2025. "A New Ensemble Strategy Based on Surprisingly Popular Algorithm and Classifier Prediction Confidence" Applied Sciences 15, no. 6: 3003. https://doi.org/10.3390/app15063003
APA StyleShi, H., Yuan, Z., Zhang, Y., Zhang, H., & Wang, X. (2025). A New Ensemble Strategy Based on Surprisingly Popular Algorithm and Classifier Prediction Confidence. Applied Sciences, 15(6), 3003. https://doi.org/10.3390/app15063003