

A Machine Learning Framework for Student Retention Policy Development: A Case Study

Abstract
1. Introduction
- RQ1.
- What main personal and educational factors in the student information system may be used to predict whether a student will drop out?
- RQ2.
- Which machine learning (ML) classifiers are suitable for dropout prediction using the limited data from the registration systems?
- RQ3.
- How can the predictions be used to develop proactive policies for student retention?
2. Literature Review
3. Methodology
3.1. Data Collection and Dataset Description
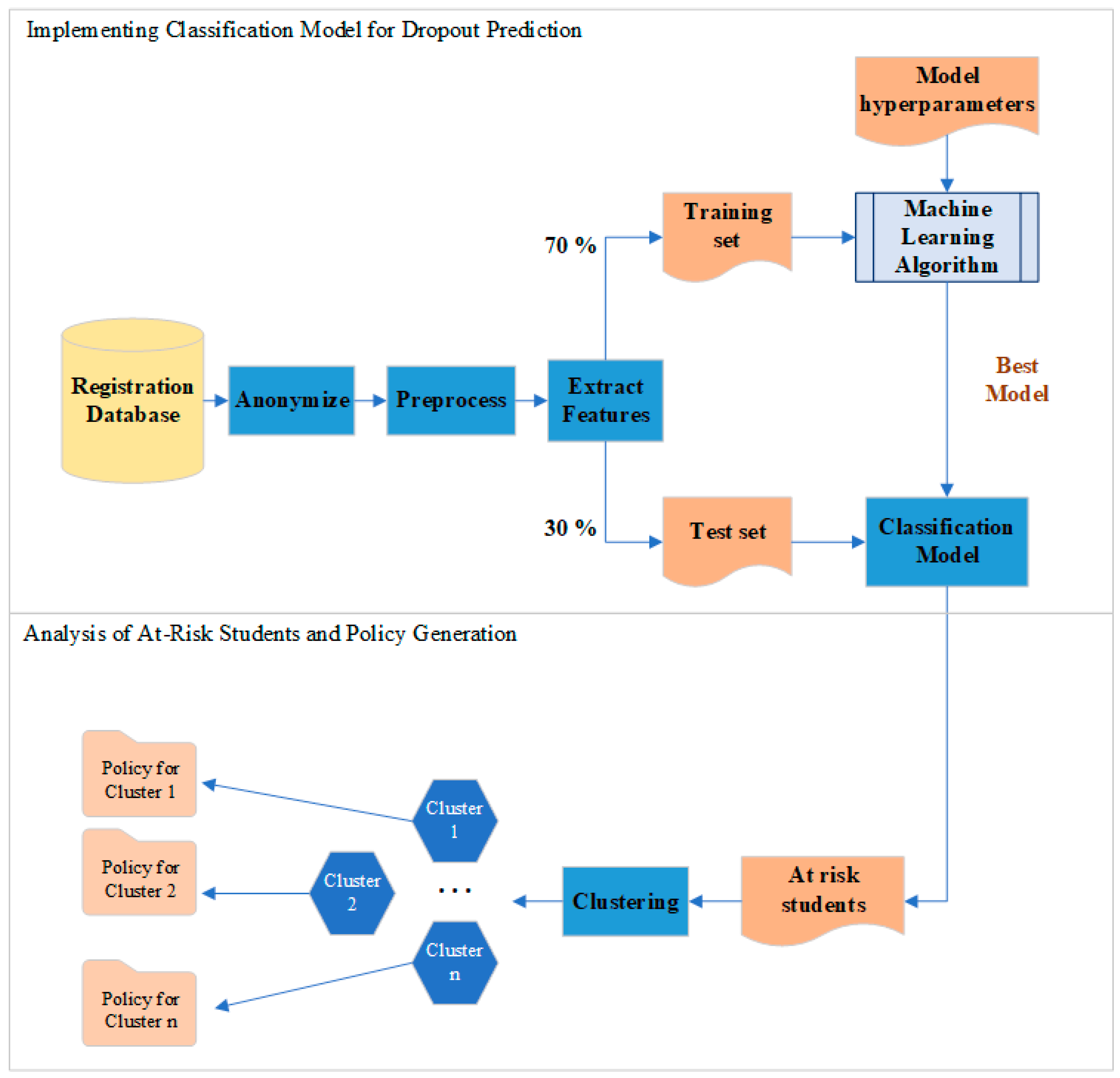
3.2. Proposed Framework
3.2.1. Data Pre-Processing and Feature Extraction
3.2.2. Machine Learning Models Used
- Support Vector Classifier (SVC) is a model designed especially for binary classification problems. It is a statistical learning method that can handle both linear and nonlinear problems by constructing a line or hyperplane to separate the data into different classes. Kernel tricks such as radial basis function (RBF) are used to map the data into higher dimensional spaces to allow the classification of nonlinear data using hyperplanes [14,20].
- K-Nearest Neighbors (KNN) is a lazy algorithm that determines the class of a sample by assigning a given sample to the class that is most frequently represented among its “K” nearest data points based on a similarity measure. This approach relies on the principle that similar data points tend to be close to each other in the feature space [21].
- Random Forest (RF) is an ensemble learning algorithm that enhances predictive performance by combining the outputs of multiple decision trees. Each tree in the Random Forest is trained on a random subset of the data, and the final prediction is determined by aggregating the predictions of all individual trees. Ensemble methods aim to produce a more robust and superior model by combining several weak learners [20].
- The Categorical Boosting (CatBoost) algorithm model is effective in classification problems. CatBoost uses categorical variant-specific variations of gradient boosting algorithms to improve the handling and use of categorical variables. Categorical variables are variables that have non-numeric values that represent class labels in classification problems [22].
- Multi-layer Perceptron (MLP) is a fully connected feedforward Artificial Neural Network class. MLP creates a model for classifying data using multi-layer neural networks [11].
- The Naïve Bayes (NB) algorithm is based on Bayes’ theorem and the assumption of independence between features. NB is a probability-based model that is effective in classification problems [12].
- Logistic Regression (LR) is a statistical model used to explain or predict a dependent variable (usually a categorical or binary variable) by a set of independent variables. LR is used to estimate the probability distribution of the dependent variable [23].
- Classification and Regression Trees (CART) is a machine learning algorithm used for classification and regression tasks. The purpose of this algorithm is to give the piecewise constant estimator of a classifier or a regression function from the training sample of observations. This algorithm creates branches and leaves by splitting the dataset to create decision trees. It is based on binary tree-structured partitions and a penalized criterion that allows some “good” tree-structured estimators to be selected from a large collection of trees [24].
- The clustering (K-means) algorithm applies a simple and straightforward approach to divide a particular dataset into a specified number of clusters [41]. The aim is to form the clusters so that inter-cluster similarities between the members of a cluster are maximized. At the same time, each cluster is expected to be dissimilar to all other clusters; that is, the intra-cluster similarities are minimized.
- The Decision Tree (DT) algorithm is a supervised learning algorithm used frequently for classification problems [42]. The decision tree method creates a model in the form of a tree structure consisting of a root, inner nodes that are decision or feature nodes, and leaf nodes that represent the target class. The root and inner nodes contain predicates, i.e., they are labeled with a question. Branches leaving these nodes indicate possible answers to the predicate. Thus, each decision node represents a prediction for the solution of the problem [43].
3.2.3. Evaluation Measures
4. Experimental Results and Discussion
4.1. Feature Analysis of the Dataset
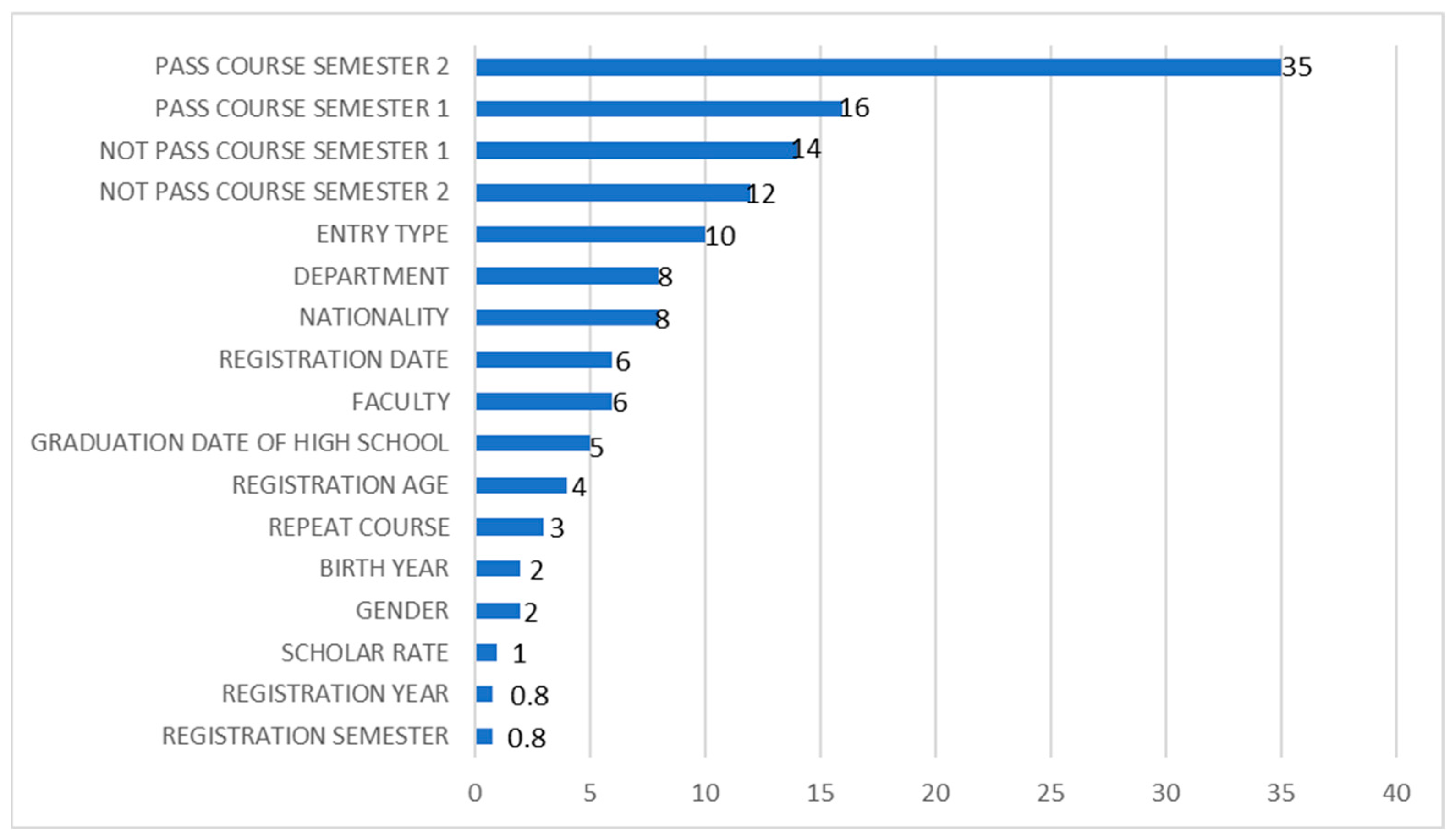
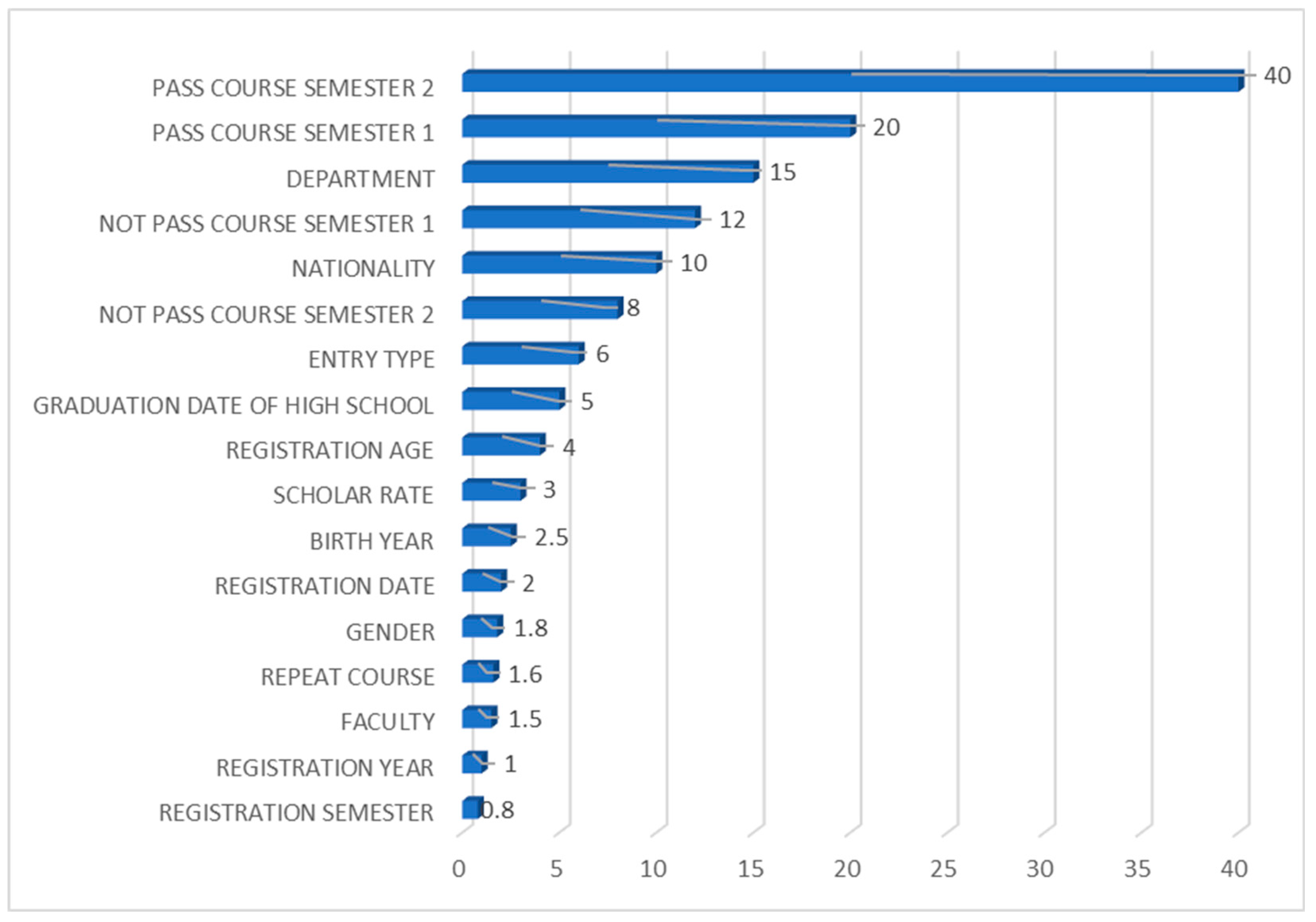
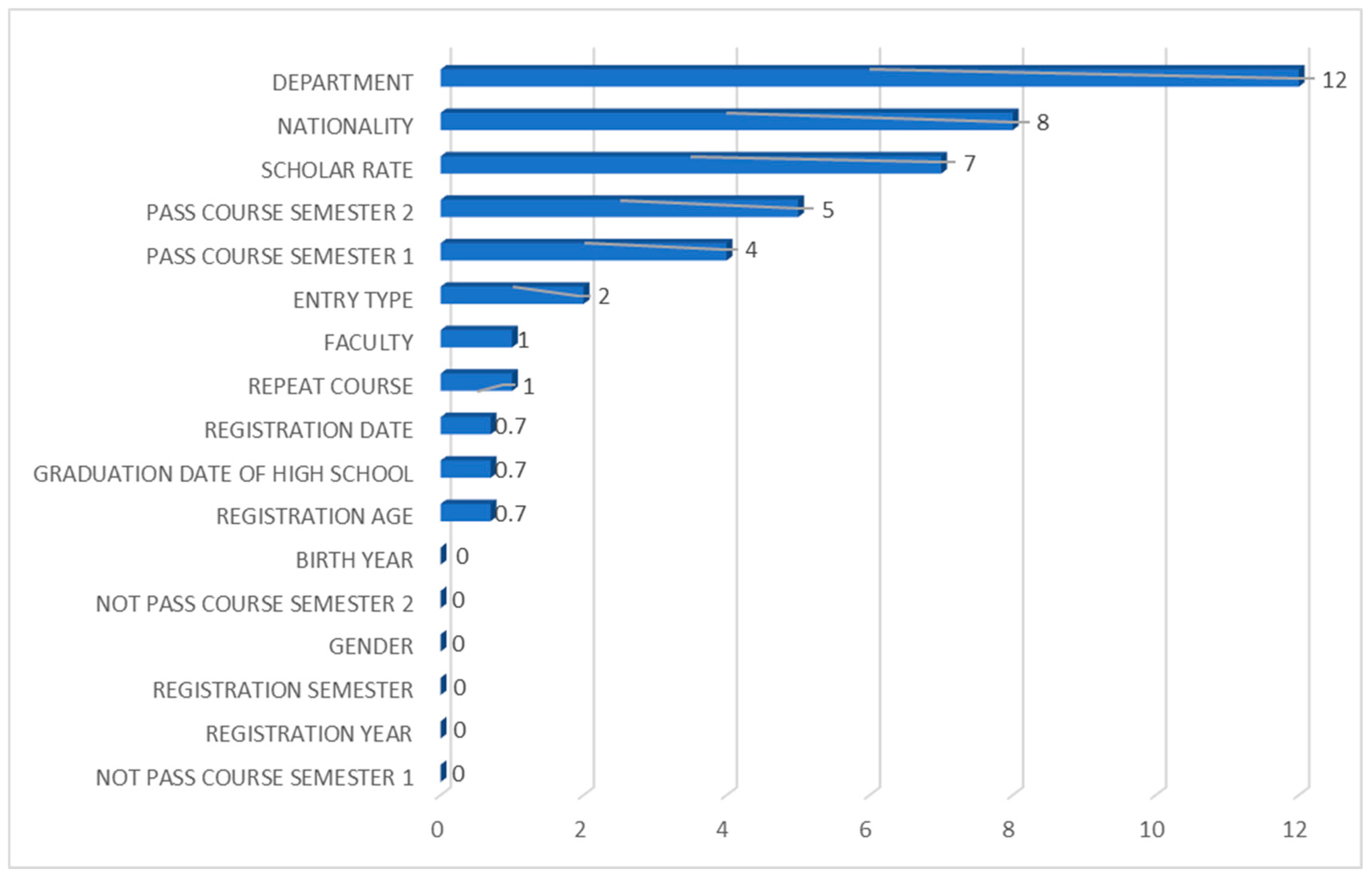
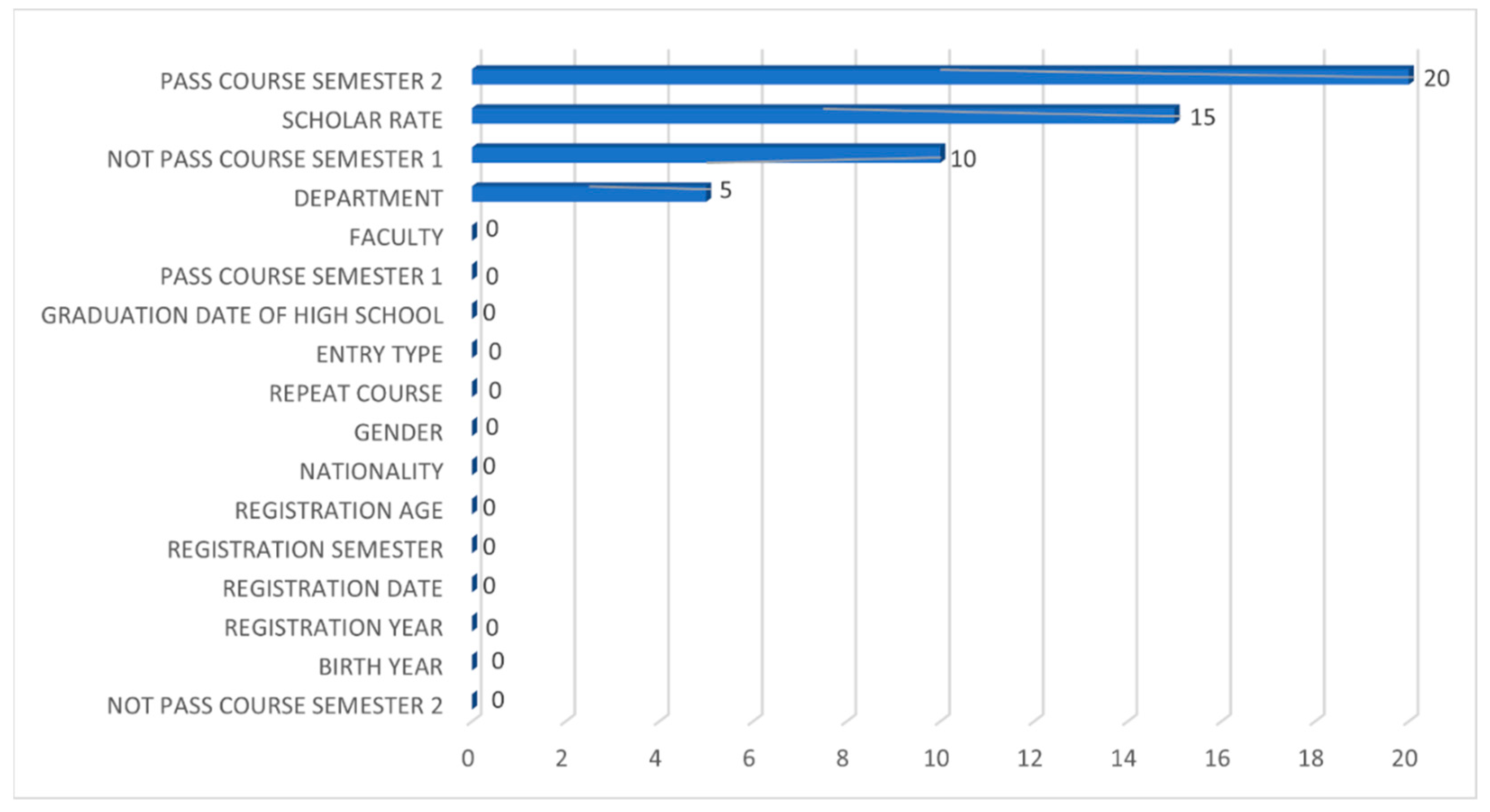
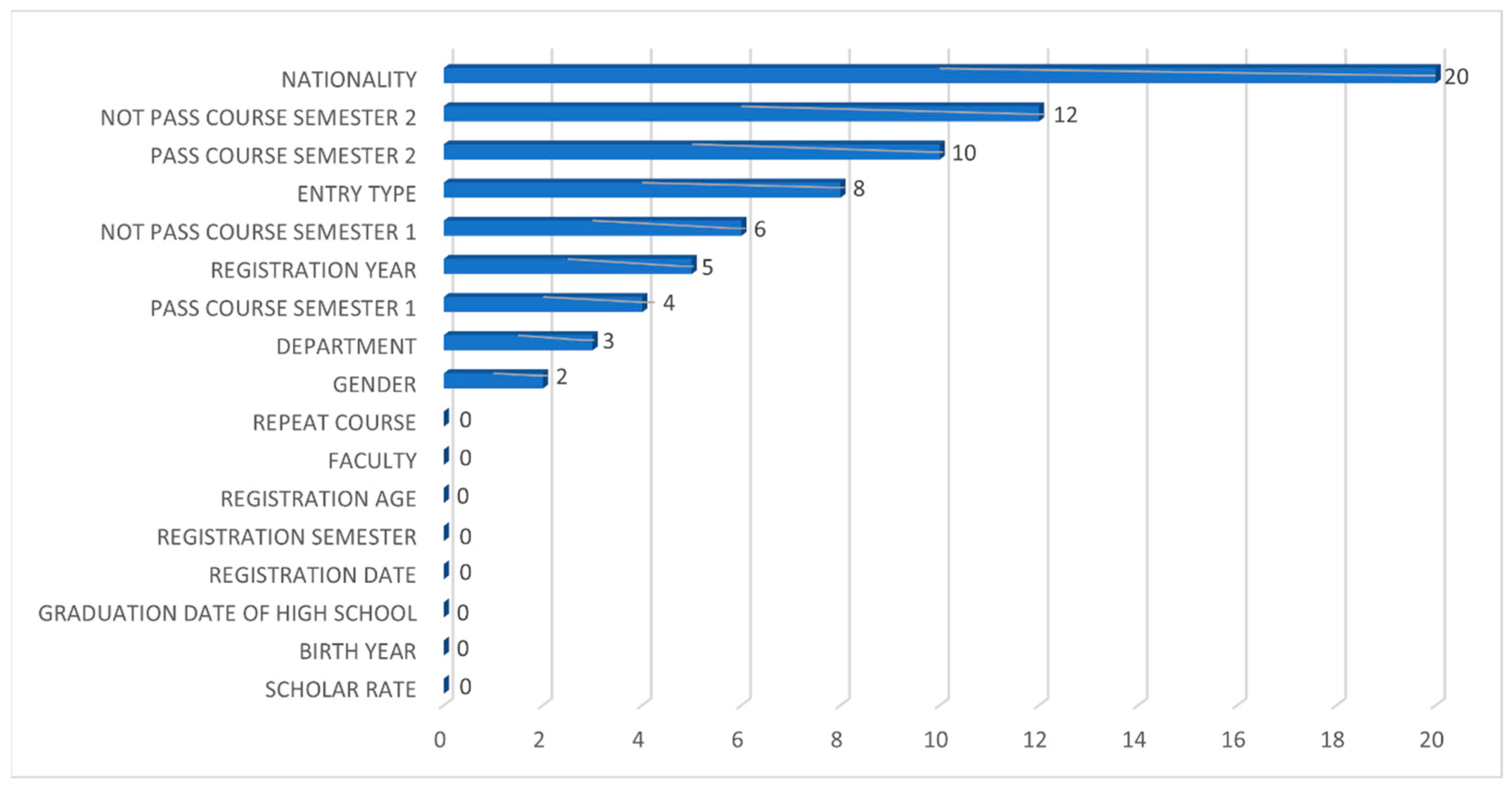
4.1.1. Feature Importance Analysis for the Random Forest Classifier
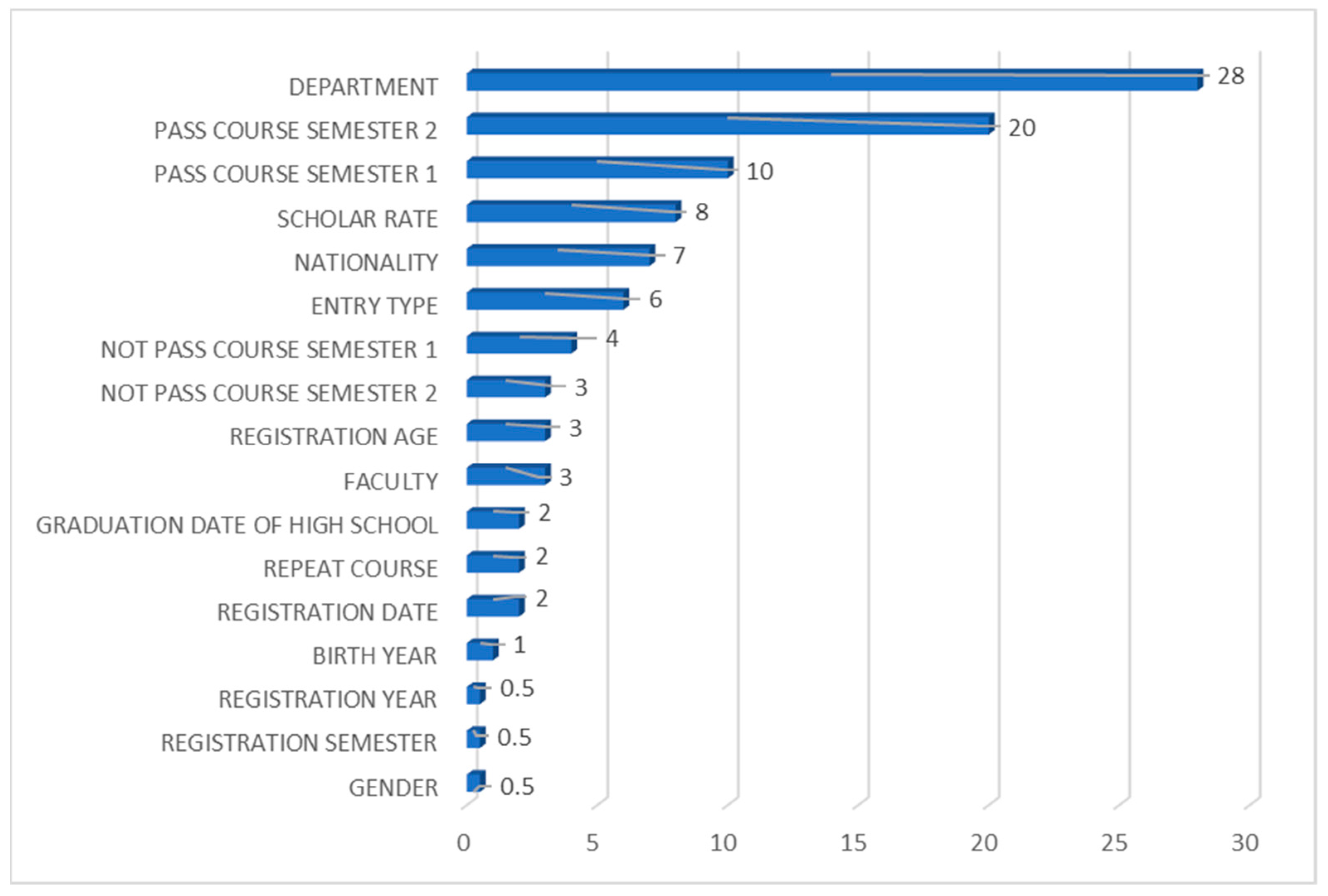
4.1.2. Feature Importance Analysis for the Support Vector Classifier
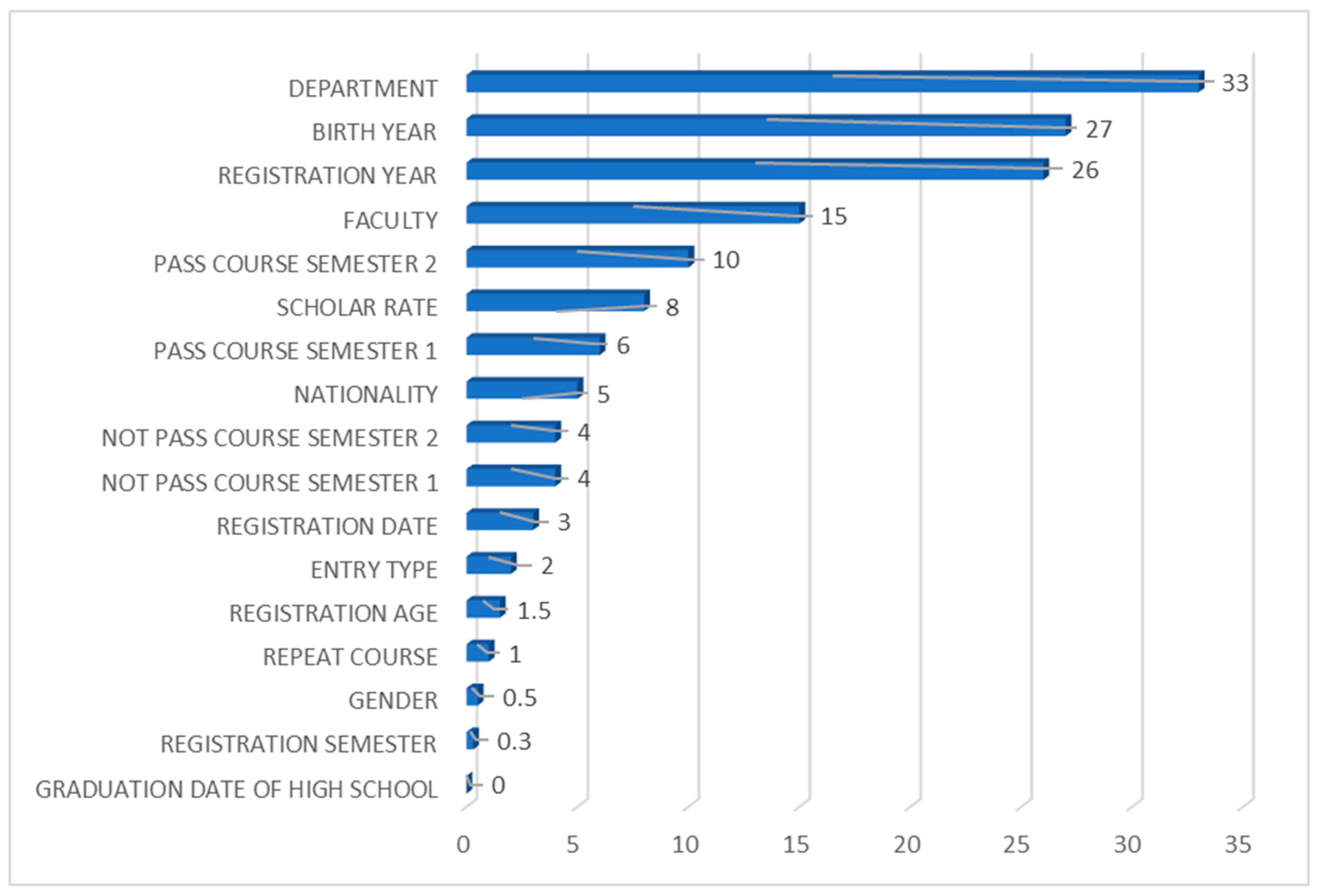
4.1.3. Feature Importance Analysis for the Logistic Regression Classifier
4.1.4. Feature Importance Analysis for the Categorical Boosting Classifier
4.1.5. Feature Importance Analysis for the K-Nearest Neighbors Classifier
4.1.6. Feature Importance Analysis for the Artificial Neural Network Classifier
4.1.7. Feature Importance Analysis for Naïve Bayes Classifier
4.1.8. Feature Importance Analysis for the Classification and Regression Trees Classifier
4.1.9. Feature Importance Analysis Across All Classifiers
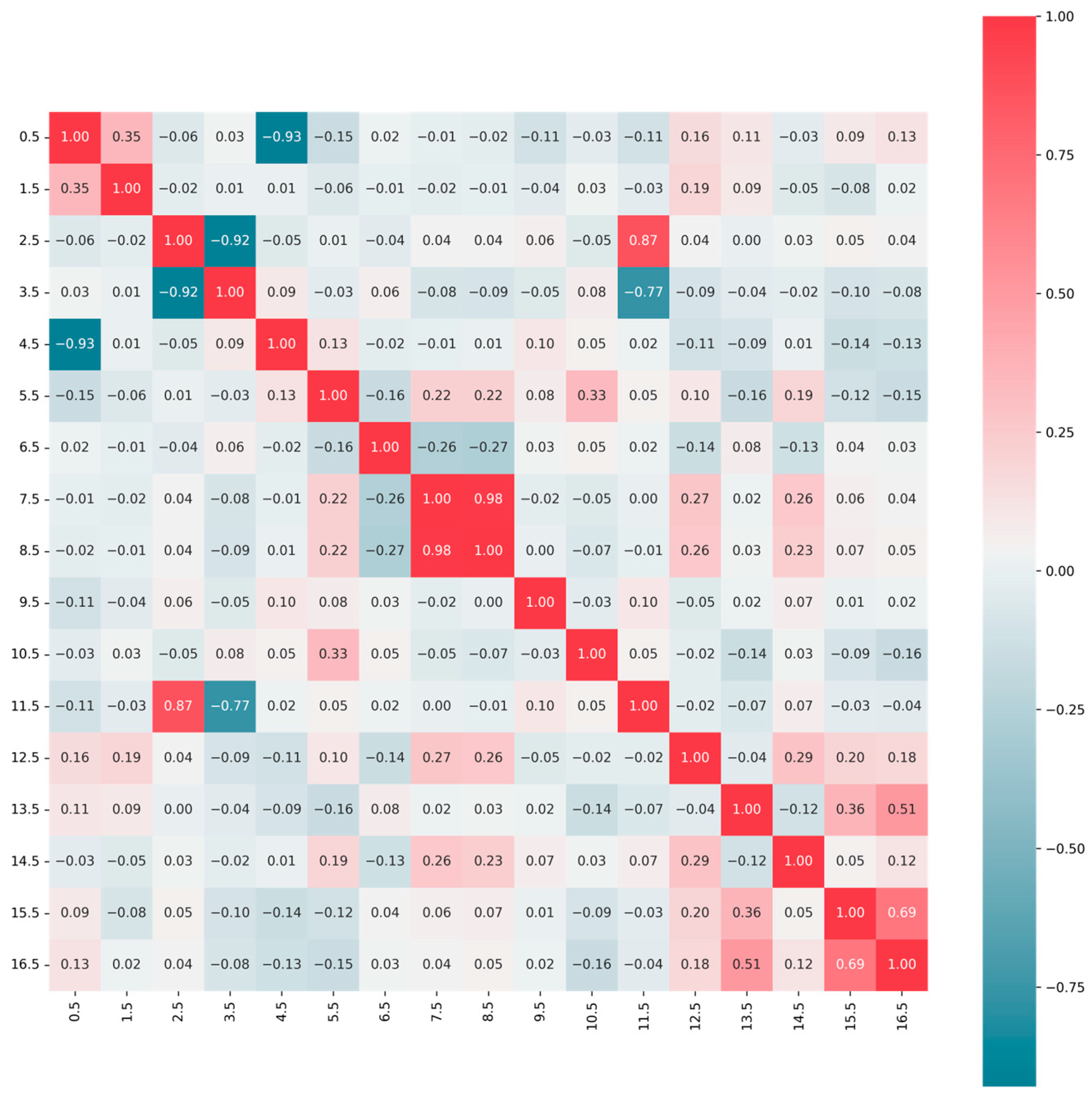
4.1.10. Correlation Analysis of Features
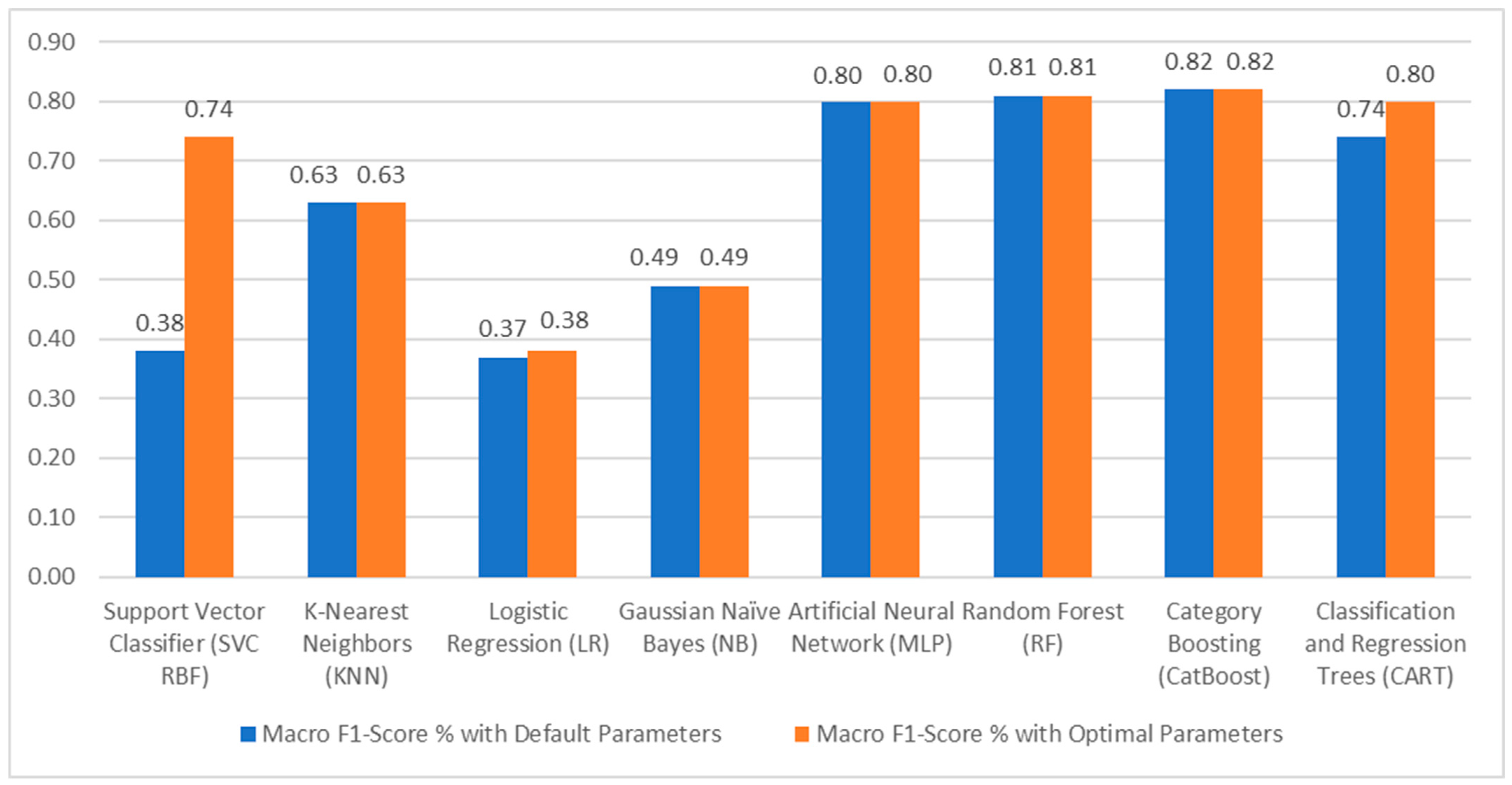
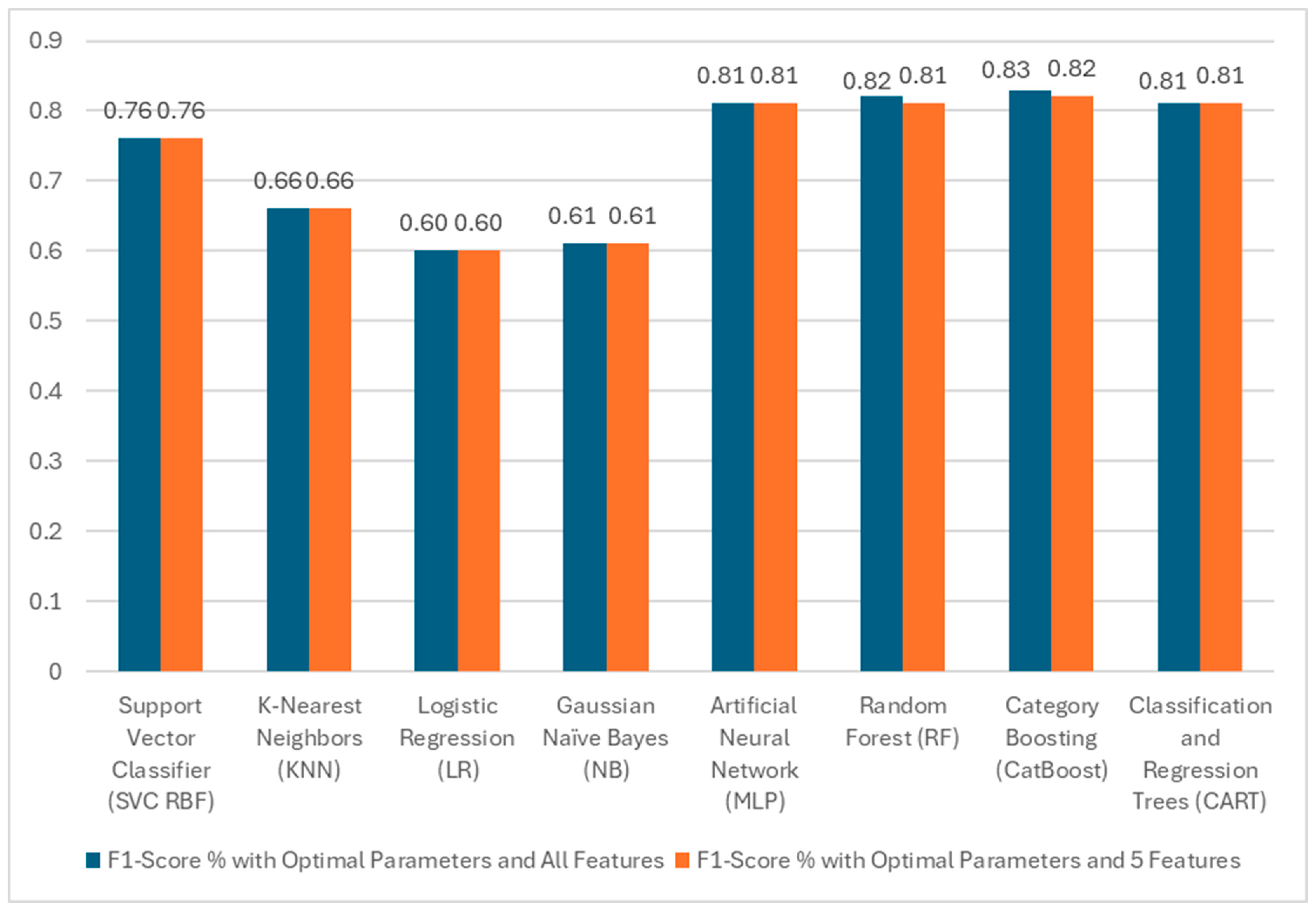
4.2. Dropout Prediction Using Machine Learning Algorithms
4.3. Using Prediction Results to Enhance Student Retention Policies
4.3.1. Visualization of Results by the HEI
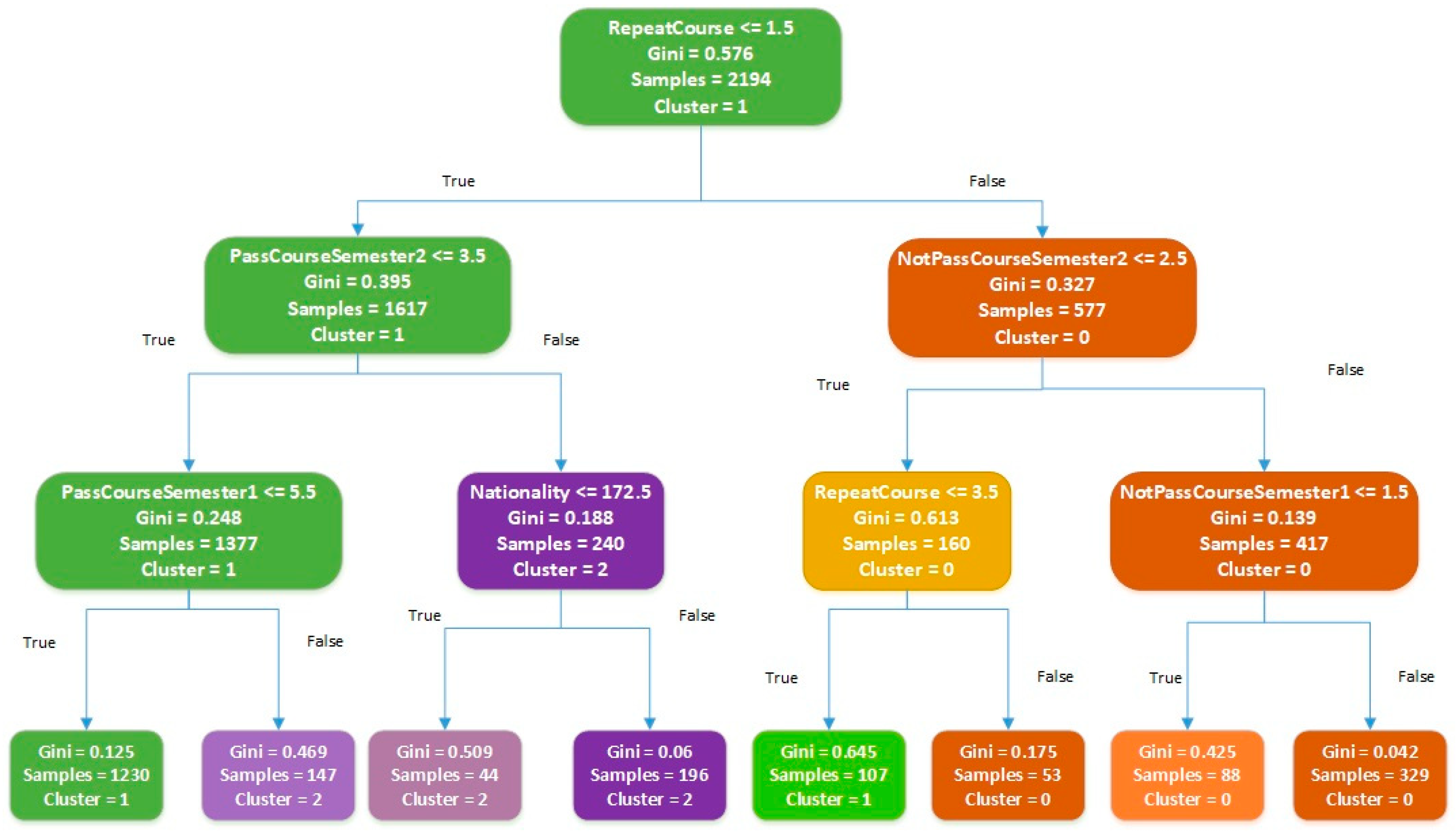
4.3.2. Example Scenario: Using Clustering and Decision Trees for Student Retention
- Cluster 0: Students with consistent challenges
- Retention Policy
- Cluster 1: Students with moderate or declining performance
- Retention Policy
- Cluster 2: Relatively more successful students
- Retention Policy
4.4. Comparison with Existing Systems
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Del Bonifro, F.; Gabbrielli, M.; Lisanti, G.; Zingaro, S.P. Student Dropout Prediction. In Artificial Intelligence in Education. AIED 2020. Lecture Notes in Computer Science; Bittencourt, I., Cukurova, M., Muldner, K., Luckin, R., Millán, E., Eds.; Springer: Cham, Switzerland, 2020; Volume 12163, pp. 124–135. [Google Scholar] [CrossRef]
- Larsen, M.S.; Kornbeck, K.P.; Kristensen, R.; Larsen, M.R.; Sommersel, H.B. Dropout Phenomena at Universities: What Is Dropout? Why Does Dropout Occur? What Can Be Done by the Universities to Prevent or Reduce it? Danish Clearinghouse for Educational Research, Aarhus University: 2013; Report No. 15. Available online: https://pure.au.dk/ws/portalfiles/portal/55033432/Evidence_on_dropout_from_universities_technical_report_May_2013_1_.pdf (accessed on 10 January 2025).
- Jadrić, M.; Garača, Ž.; Čukušić, M. Student Dropout Analysis with Application of Data Mining Methods. Manag. J. Contemp. Manag. Issues 2010, 15, 31–46. Available online: https://hrcak.srce.hr/file/81744 (accessed on 10 January 2025).
- OECD. Education at a Glance 2022; OECD Publishing: Paris, France, 2023; Available online: https://www.oecd.org/en/publications/education-at-a-glance-2022_3197152b-en.html (accessed on 20 February 2025).
- Talamás-Carvajal, J.A.; Ceballos, H.G. A stacking ensemble machine learning method for early identification of students at risk of dropout. Educ. Inf. Technol. 2023, 28, 12169–12189. [Google Scholar] [CrossRef]
- Liu, H.; Chen, X.; Zhao, F. Learning behavior feature fused deep learning network model for MOOC dropout prediction. Educ. Inf. Technol. 2024, 29, 3257–3278. [Google Scholar] [CrossRef]
- Selim, K.S.; Rezk, S.S. On predicting school dropouts in Egypt: A machine learning approach. Educ. Inf. Technol. 2023, 28, 9235–9266. [Google Scholar] [CrossRef]
- Rodríguez, P.; Villanueva, A.; Dombrovskaia, L.; Valenzuela, J.P. A methodology to design, develop, and evaluate machine learning models for predicting dropout in school systems: The case of Chile. Educ. Inf. Technol. 2023, 28, 10103–10149. [Google Scholar] [CrossRef]
- Takács, R.; Kárász, J.T.; Takács, S.; Horváth, Z.; Oláh, A. Applying the Rasch model to analyze the effectiveness of education reform in order to decrease computer science students’ dropout. Humanit. Soc. Sci. Commun. 2021, 8, 1–8. [Google Scholar] [CrossRef]
- Takács, R.; Takács, S.; Kárász, J.T.; Oláh, A.; Horváth, Z. The impact of the first wave of COVID-19 on students’ attainment, analysed by IRT modelling method. Humanit. Soc. Sci. Commun. 2023, 10, 127. [Google Scholar] [CrossRef]
- Wang, Z.; Zhu, C.; Ying, Z.; Zhang, Y.; Wang, B.; Jin, X.; Yang, H. Design and implementation of early warning system based on educational big data. In Proceedings of the International Conference on Systems and Informatics, Nanjing, China, 10–12 November 2018; Volume 5, pp. 549–553. [Google Scholar] [CrossRef]
- Kabathova, J.; Drlik, M. Towards Predicting Students’ Dropout in University Courses Using Different Machine Learning Techniques. Appl. Sci. 2021, 11, 3130. [Google Scholar] [CrossRef]
- Singh, H.; Kaur, B.; Sharma, A.; Singh, A. Framework for suggesting corrective actions to help students intended at risk of low performance based on experimental study of college students using explainable machine learning model. Educ. Inf. Technol. 2024, 29, 7997–8034. [Google Scholar] [CrossRef]
- Hassan, M.A.; Muse, A.H.; Nadarajah, S. Predicting student dropout rates using supervised machine learning: Insights from the 2022 National Education Accessibility Survey in Somaliland. Appl. Sci. 2024, 14, 7593. [Google Scholar] [CrossRef]
- Cho, C.H.; Yu, Y.W.; Kim, H.G. A study on dropout prediction for university students using machine learning. Appl. Sci. 2023, 13, 12004. [Google Scholar] [CrossRef]
- Mduma, N. Data balancing techniques for predicting student dropout using machine learning. Data 2023, 8, 49. [Google Scholar] [CrossRef]
- Villegas-Ch, W.; Govea, J.; Revelo-Tapia, S. Improving student retention in institutions of higher education through machine learning: A sustainable approach. Sustainability 2023, 15, 14512. [Google Scholar] [CrossRef]
- Kok, C.L.; Ho, C.K.; Chen, L.; Koh, Y.Y.; Tian, B. A novel predictive modeling for student attrition utilizing machine learning and sustainable big data analytics. Appl. Sci. 2024, 14, 9633. [Google Scholar] [CrossRef]
- Vieira, P.M.; Rodrigues, F. An automated approach for binary classification on imbalanced data. Knowl. Inf. Syst. 2024, 66, 2747–2767. [Google Scholar] [CrossRef]
- Ahmad, G.N.; Shafiullah, S.; Fatima, H.; Abbas, M.; Rahman, O.; Imdadullah, I.; Alqahtani, M.S. Mixed Machine Learning Approach for Efficient Prediction of Human Heart Disease by Identifying the Numerical and Categorical Features. Appl. Sci. 2022, 12, 7449. [Google Scholar] [CrossRef]
- Navamani, J.M.A.; Kannammal, A. Predicting performance of schools by applying data mining techniques on public examination results. Res. J. Appl. Sci. Eng. Technol. 2015, 9, 262–271. [Google Scholar] [CrossRef]
- Prokhorenkova, L.; Gusev, G.; Vorobev, A.; Dorogush, A.V.; Gulin, A. CatBoost: Unbiased boosting with categorical features. Advances in Neural Information Processing Systems 31 (NeurIPS 2018). In Proceedings of the 31st Conference on Neural Information Processing Systems (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018. Available online: https://proceedings.neurips.cc/paper/2018/hash/14491b756b3a51daac41c24863285549-Abstract.html (accessed on 10 January 2025).
- Pan, C.; Poddar, A.; Mukherjee, R.; Ray, A.K. Impact of categorical and numerical features in ensemble machine learning frameworks for heart disease prediction. Biomed. Signal Process. Control 2022, 76, 103666. [Google Scholar] [CrossRef]
- Gey, S.; Nedelec, E. Model Selection for CART Regression Trees. IEEE Trans. Inf. Theory 2005, 51, 658–670. [Google Scholar] [CrossRef]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V. A training algorithm for optimal margin classifiers. In Proceedings of the COLT ‘92: Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2001. [Google Scholar]
- Hosmer, D.W.; Lemeshow, S. Applied Logistic Regression; Wiley-Interscience: New York, NY, USA, 2000. [Google Scholar]
- Menard, S. Applied Logistic Regression Analysis, 2nd ed.; SAGE Publications: Thousand Oaks, CA, USA, 2002. [Google Scholar]
- Rish, I. An empirical study of the naive Bayes classifier. In Proceedings of the IJCAI 2001 Workshop on Empirical Methods in Artificial Intelligence, Seattle, WA, USA, 4–10 August 2001; Volume 3, No. 22, pp. 41–46. [Google Scholar]
- Zhang, H. The optimality of Naïve Bayes. In Proceedings of the Seventeenth International FLAIRS Conference, Sandestin Beach, FL, USA, 19–21 May 2024; pp. 562–567. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Louppe, G. Understanding random forests: From theory to practice. arXiv 2014, arXiv:1407.7502. [Google Scholar]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; CRC Press: New York, NY, USA, 1984. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: New York, NY, USA, 2009. [Google Scholar]
- Kodinariya, T.M.; Makwana, P.R. Review on Determining Number of Clusters in K-Means Clustering. Int. J. 2013, 1, 90–95. Available online: https://www.researchgate.net/publication/313554124_Review_on_Determining_of_Cluster_in_K-means_Clustering (accessed on 10 January 2025).
- Sharma, D.; Kumar, N. A review on machine learning algorithms, tasks and applications. Int. J. Adv. Res. Comput. Eng. Technol. 2017, 6, 1548–1552. Available online: https://www.researchgate.net/publication/320609700_A_Review_on_Machine_Learning_Algorithms_Tasks_and_Applications (accessed on 10 January 2025).
- Sharma, H.; Kumar, S. A survey on decision tree algorithms of classification in data mining. Int. J. Sci. Res. 2016, 5, 2094–2097. Available online: https://www.researchgate.net/publication/324941161_A_Survey_on_Decision_Tree_Algorithms_of_Classification_in_Data_Mining (accessed on 10 January 2025).
- Križanić, S. Educational Data Mining Using Cluster Analysis and Decision Tree Technique: A Case Study. Int. J. Eng. Bus. Manag. 2020, 12, 1847979020908675. [Google Scholar] [CrossRef]
- Tang, H. Person-centered analysis of self-regulated learner profiles in MOOCs: A cultural perspective. Educ. Technol. Res. Dev. 2021, 69, 1247–1269. [Google Scholar] [CrossRef]
- Mohd Hashim, M.H.; Tasir, Z. An e-learning environment embedded with sign language videos: Research into its usability and the academic performance and learning patterns of deaf students. Educ. Technol. Res. Dev. 2020, 68, 2873–2911. [Google Scholar] [CrossRef]
- Hoca, S.; Dimililer, N. Comparative Analysis of Pre- and Post-COVID-19 Student Dropout Patterns Using Clustering: A Case Study. In Proceedings of the 15th International Congress on Social Sciences, Humanities, and Education, Istanbul, Turkey, 9–10 December 2023; pp. 492–499. [Google Scholar]
- Tuero, E.; Bernardo, A.B.; Blanco, E.; Vázquez-Merino, D. University dropout and transfer intention: What is the influence of resilience and social adaptation on the two types of dropout? J. Coll. Stud. Retent. Res. Theory Pract. 2024, 15210251241268812. [Google Scholar] [CrossRef]
- Ramirez-Levine, R.; Rennar-Potacco, D.; Sharma, V.; Chen, P.Z. The longitudinal retention of STEM students through a multifaceted mentoring and tutoring program. Mentor. Tutoring Partn. Learn. 2024, 1, 20. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Graduates | Number of Dropouts | Total | Imbalance Ratio |
|---|---|---|---|
| 12,453 | 8521 | 20,974 | 1.5 |
| Feature | Description | Category |
|---|---|---|
| BirthYear | Birth year of the student | Demographic |
| Gender | The biological sex of the student | Demographic |
| GraduateDateHighSchool | Year and month of the high school graduation date | Demographic |
| Nationality | Student’s nationality | Demographic |
| RegistrationAge | Student’s age at registration year | Demographic |
| Department | The department where the student is enrolled | Enrolment |
| EntryType | The admission type (university entrance exam, international exams, etc.) of the student | Enrolment |
| Faculty | The faculty where the student is enrolled | Enrolment |
| RegistrationDate | Year and month of the registration date | Enrolment |
| RegistrationSemester | Shows the intake semester (fall or spring) | Enrolment |
| RegistrationYear | The academic year in which a student enrolls typically begins in September of one year and ends in June of the following year | Enrolment |
| ScholarRate | The scholarship percentage of the student | Enrolment |
| NotPass_Course_Semester1 | Number of courses the student did not pass at the end of the first semester | Academic performance |
| NotPass_Course_Semester2 | Number of courses the student did not pass at the end of the second semester | Academic performance |
| Pass_Course_Semester2 | Number of courses the student passed at the end of the second semester | Academic performance |
| Pass_Course_Semester1 | Number of courses the student passed at the end of the first semester | Academic performance |
| Repeat_Course | Number of courses the student repeated | Academic performance |
| ML Algorithm | Pros | Cons |
|---|---|---|
| Support Vector Classifier (SVC) | Powerful for high-dimensional data and works well with small to medium-sized datasets [26]. | Computationally expensive for large datasets, requiring alternative approaches like linear SVMs or deep learning [27]. |
| K-Nearest Neighbors (KNN) | Simple, effective for small datasets, and adaptable to various data distributions [28]. | Expensive and slow for large datasets, making it impractical in big data applications [29]. |
| Logistic Regression (LR) | Simple, interpretable, and efficient for linear problems [30]. | Struggles with complex, nonlinear relationships and high-dimensional data [31]. |
| Gaussian Naïve Bayes (NB) | Efficient, works well with small datasets, and is effective in high-dimensional spaces [32]. | The assumption of feature independence is often unrealistic, leading to poor performance when features are correlated [33]. |
| Artificial Neural Network (MLP) | Excels at capturing complex nonlinear relationships, making them ideal for tasks like image recognition and NLP [34]. | Require high computational power and are prone to overfitting without proper regularization [35]. |
| Random Forest (RF) | Highly accurate, robust to overfitting, and works well with diverse datasets [36]. | Expensive and difficult to interpret, especially with many trees [37]. |
| Categorical Boosting (CatBoost) | Excels at handling categorical data efficiently and reduces overfitting, making it ideal for tabular datasets with many categorical features [22]. | Expensive and slower compared to simpler models, especially for large datasets [38]. |
| Classification and Regression Trees (CART) | Easy to interpret and useful for decision-making in domains requiring transparency [39]. | Prone to overfitting unless pruning or ensemble methods are applied [40]. |
| Models | Accuracy | Precision | Recall | Dropout F1 | Grad F1 | Macro F1 | Weighted F1 |
|---|---|---|---|---|---|---|---|
| Support Vector Classifier (SVC) | 0.60 | 0.50 | 0.50 | 0.0 | 0.75 | 0.38 | 0.45 |
| K-Nearest Neighbors (KNN) | 0.66 | 0.64 | 0.63 | 0.54 | 0.73 | 0.63 | 0.65 |
| Logistic Regression (LR) | 0.59 | 0.30 | 0.50 | 0.0 | 0.75 | 0.37 | 0.44 |
| Gaussian Naïve Bayes (NB) | 0.61 | 0.58 | 0.53 | 0.23 | 0.74 | 0.49 | 0.54 |
| Artificial Neural Network (MLP) | 0.81 | 0.81 | 0.79 | 0.74 | 0.85 | 0.80 | 0.81 |
| Random Forest (RF) | 0.82 | 0.81 | 0.80 | 0.76 | 0.85 | 0.81 | 0.82 |
| Categorical Boosting (CatBoost) | 0.83 | 0.83 | 0.81 | 0.78 | 0.86 | 0.82 | 0.83 |
| Classification and Regression Trees (CART) | 0.75 | 0.74 | 0.75 | 0.70 | 0.79 | 0.74 | 0.75 |
| Models | Accuracy | Precision | Recall | Dropout F1 | Grad F1 | Macro F1 | Weighted F1 |
|---|---|---|---|---|---|---|---|
| Support Vector Classifier (SVC) | ↑0.76 | ↑0.75 | ↑0.74 | 0.67 | 0.81 | ↑0.74 | 0.75 |
| K-Nearest Neighbors (KNN) | 0.66 | 0.64 | 0.63 | 0.54 | 0.73 | 0.63 | 0.65 |
| Logistic Regression (LR) | ↑0.60 | 0.30 | 0.50 | 0.0 | 0.75 | ↑0.38 | 0.45 |
| Gaussian Naïve Bayes (NB) | 0.61 | 0.58 | 0.53 | 0.23 | 0.74 | 0.49 | 0.54 |
| Artificial Neural Network (MLP) | 0.81 | ↑0.81 | ↓0.79 | 0.75 | 0.85 | 0.80 | 0.81 |
| Random Forest (RF) | 0.82 | ↑0.82 | 0.80 | 0.76 | 0.86 | 0.81 | 0.82 |
| Categorical Boosting (CatBoost) | 0.83 | 0.83 | 0.81 | 0.77 | 0.87 | 0.82 | 0.83 |
| Classification and Regression Trees (CART) | ↑0.81 | ↑0.81 | ↑0.80 | 0.75 | 0.85 | ↑0.80 | 0.81 |
| Models | Accuracy | Precision | Recall | Dropout F1 | Grad F1 | Macro F1 | Weighted F1 |
|---|---|---|---|---|---|---|---|
| Support Vector Classifier (SVC) | 0.76 | 0.76 | 0.74 | 0.68 | 0.81 | 0.75 | 0.76 |
| K-Nearest Neighbors (KNN) | 0.66 | 0.64 | 0.63 | 0.54 | 0.72 | 0.63 | 0.65 |
| Logistic Regression (LR) | 0.60 | 0.30 | 0.50 | 0.0 | 1.0 | 0.38 | 0.45 |
| Gaussian Naïve Bayes (NB) | 0.61 | 0.58 | 0.52 | 0.17 | 0.74 | 0.46 | 0.52 |
| Artificial Neural Network (MLP) | 0.81 | 0.81 | 0.79 | 0.75 | 0.85 | 0.80 | 0.81 |
| Random Forest (RF) | 0.81 | 0.80 | 0.78 | 0.74 | 0.85 | 0.79 | 0.80 |
| Categorical Boosting (CatBoost) | 0.82 | 0.82 | 0.80 | 0.76 | 0.86 | 0.81 | 0.82 |
| Classification and Regression Trees (CART) | 0.81 | 0.80 | 0.79 | 0.75 | 0.85 | 0.80 | 0.81 |
| Cluster | Key Characteristics | Recommended Intervention |
|---|---|---|
| Cluster 0: Consistent Challenges | Repeating and failing many courses | Personalized tutoring, academic counseling |
| Cluster 1: Moderate Struggles | Some failures, declining performance | Early-warning alerts, faculty mentorship |
| Cluster 2: High-Achievers at Risk | Good grades but possibly disengaged | Peer mentoring, social integration programs |
| Study | Dataset Size | ML Models Used | Best Performing Model | Features Used |
|---|---|---|---|---|
| Our Case Study | 20,974 students (1 university, multiple departments) | CatBoost, RF, MLP, SVM, LR, KNNs, NB, CARTs | F1-score: 82% | Demographics, enrolment, academic performance |
| [5] | University data (various features) 63,912 students | Stacking Classifier, AdaBoost, XGBoost, KNNs, DT, LR | Accuracy: 88.41% | First-semester academic performance, demographic data |
| [11] | University dataset 1712 students | DT, MLP, NB | Accuracy: 86% and above | Academic, library usage |
| [12] | Course level data from e-learning system (261 students) 2016–2020 | NB, RF, MLP, LR, SVM, DT | F1-score: 91% | Course access, assignments, tests |
| [13] | University dataset (multiple departments) 669 students | XGBoost, LightGBM, RF, MLP, SVM, Extra Trees | Accuracy: 96.5% | Academic, personal, family, psychology, assessments |
| [15] | Academic information system of Sahmyook University 20,050 students between 2010 and 2022 | LR, DT, RF, SVM, DNN, LightGBM | F1-score: 84% | Demographic, book loan information, scholarship information, counsel information, extra course information, academic status information, grade information |
| [17] | 500 students from the 2021 academic year | MLP, SVM, KNNs, Gradient Boosting, RF, LR | F1-score: 82% | Student demographics, academic data, attendance data, and socioeconomic variables |
| [18] | Private university in Malaysia 197 students between 2006 and 2011 | LR | F1-score: 81% | Demographics, academic records, and surveys for gathering information about student’s socioeconomic background and psychological factors |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hoca, S.; Dimililer, N. A Machine Learning Framework for Student Retention Policy Development: A Case Study. Appl. Sci. 2025, 15, 2989. https://doi.org/10.3390/app15062989
Hoca S, Dimililer N. A Machine Learning Framework for Student Retention Policy Development: A Case Study. Applied Sciences. 2025; 15(6):2989. https://doi.org/10.3390/app15062989
Chicago/Turabian StyleHoca, Sidika, and Nazife Dimililer. 2025. "A Machine Learning Framework for Student Retention Policy Development: A Case Study" Applied Sciences 15, no. 6: 2989. https://doi.org/10.3390/app15062989
APA StyleHoca, S., & Dimililer, N. (2025). A Machine Learning Framework for Student Retention Policy Development: A Case Study. Applied Sciences, 15(6), 2989. https://doi.org/10.3390/app15062989