
Generative Adversarial Network Based on Self-Attention Mechanism for Automatic Page Layout Generation

Abstract
1. Introduction
2. Methods
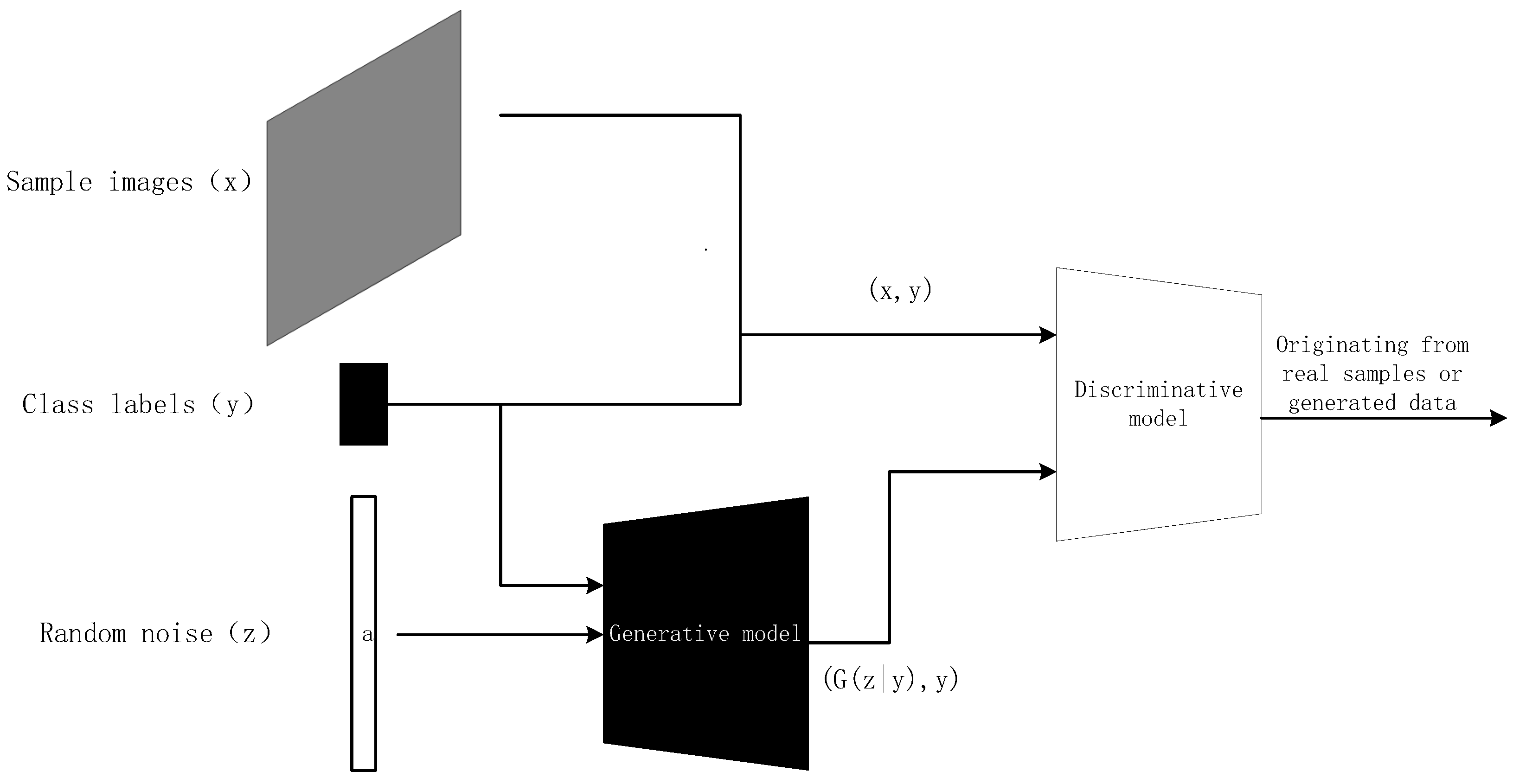
2.1. Generative Adversarial Networks
2.1.1. The Theory of Generative Adversarial Networks (GANs)
2.1.2. The Principle of Generative Adversarial Networks (GANs)
| Algorithm 1 GAN Training Algorithm |
|
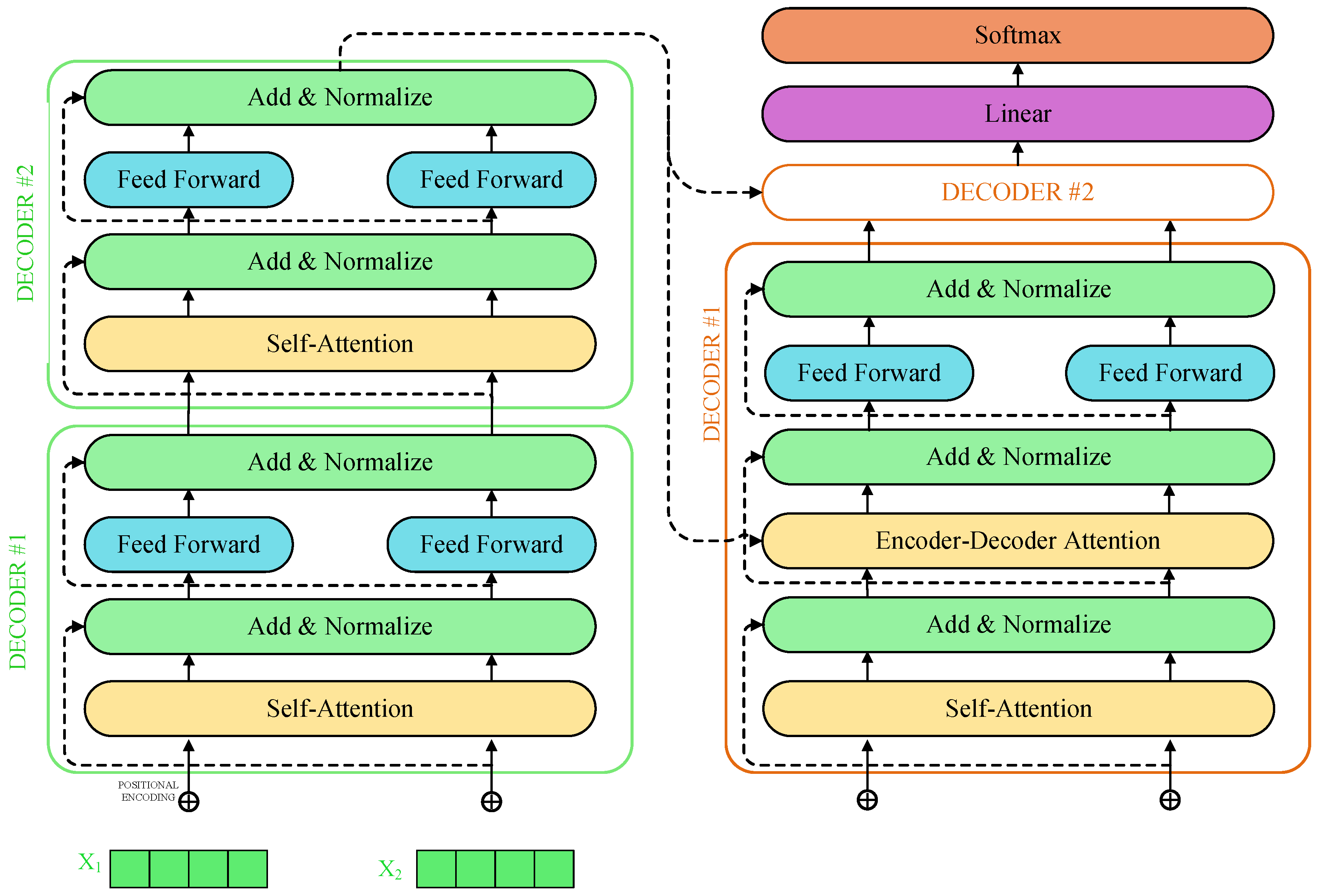
2.2. Transformer
2.3. TGAN
2.3.1. TGAN Principle
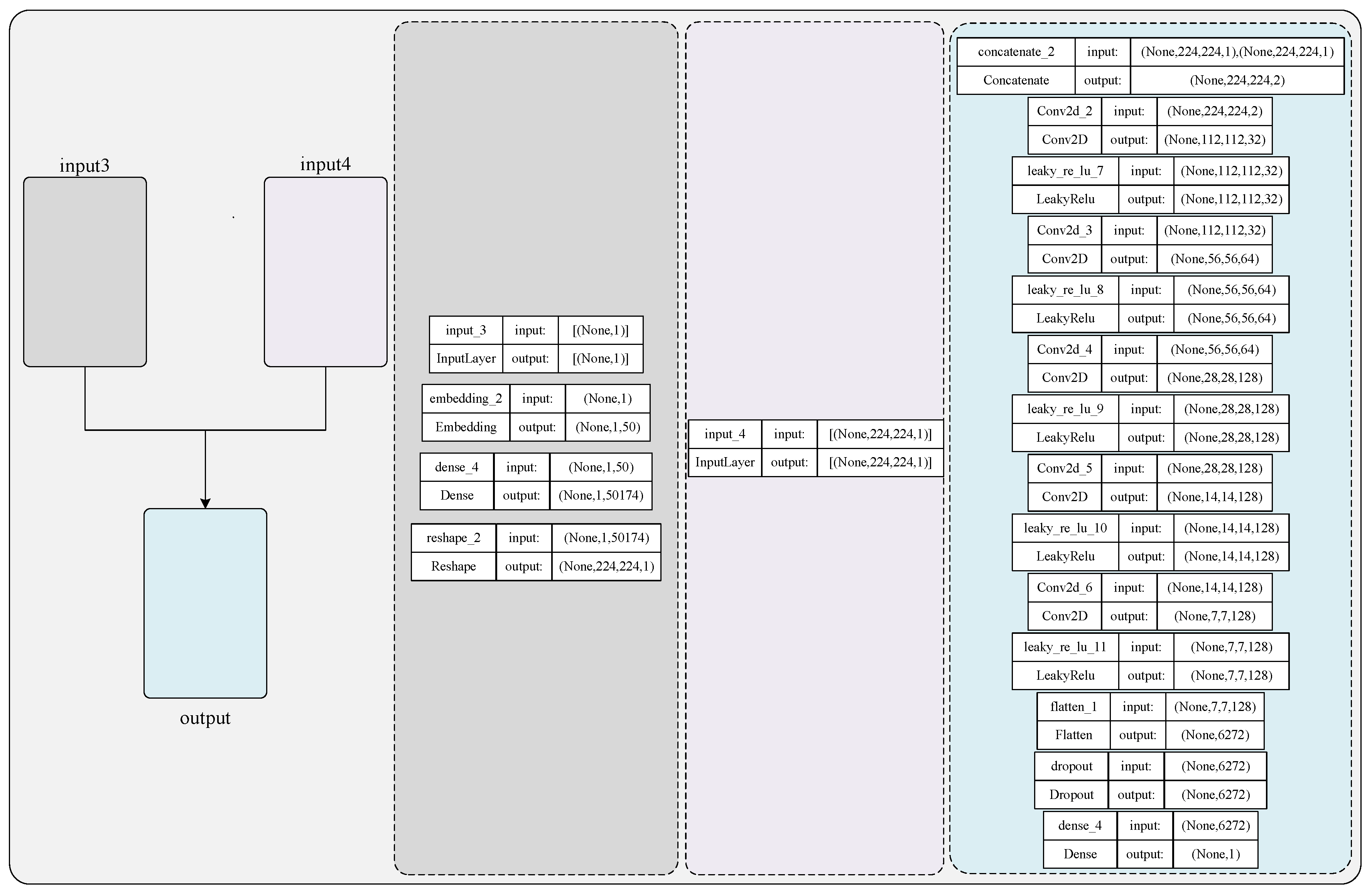
2.3.2. Generator
2.3.3. Discriminator
2.4. Integrated Layout Optimization
- is the standard adversarial loss from Equation (1).
- is a balancing coefficient (set to 0.8 through grid search).
- denotes the six energy terms defined in Section 3.4.2.
- are adaptive weights updated every 5 epochs based on validation performance.
| Algorithm 2 Integrated Training Process. |
3. Experiment
3.1. Dataset
- To address the issue of varying real sizes across all page layouts, all real data were standardized to a size of 224 × 224 pixels.
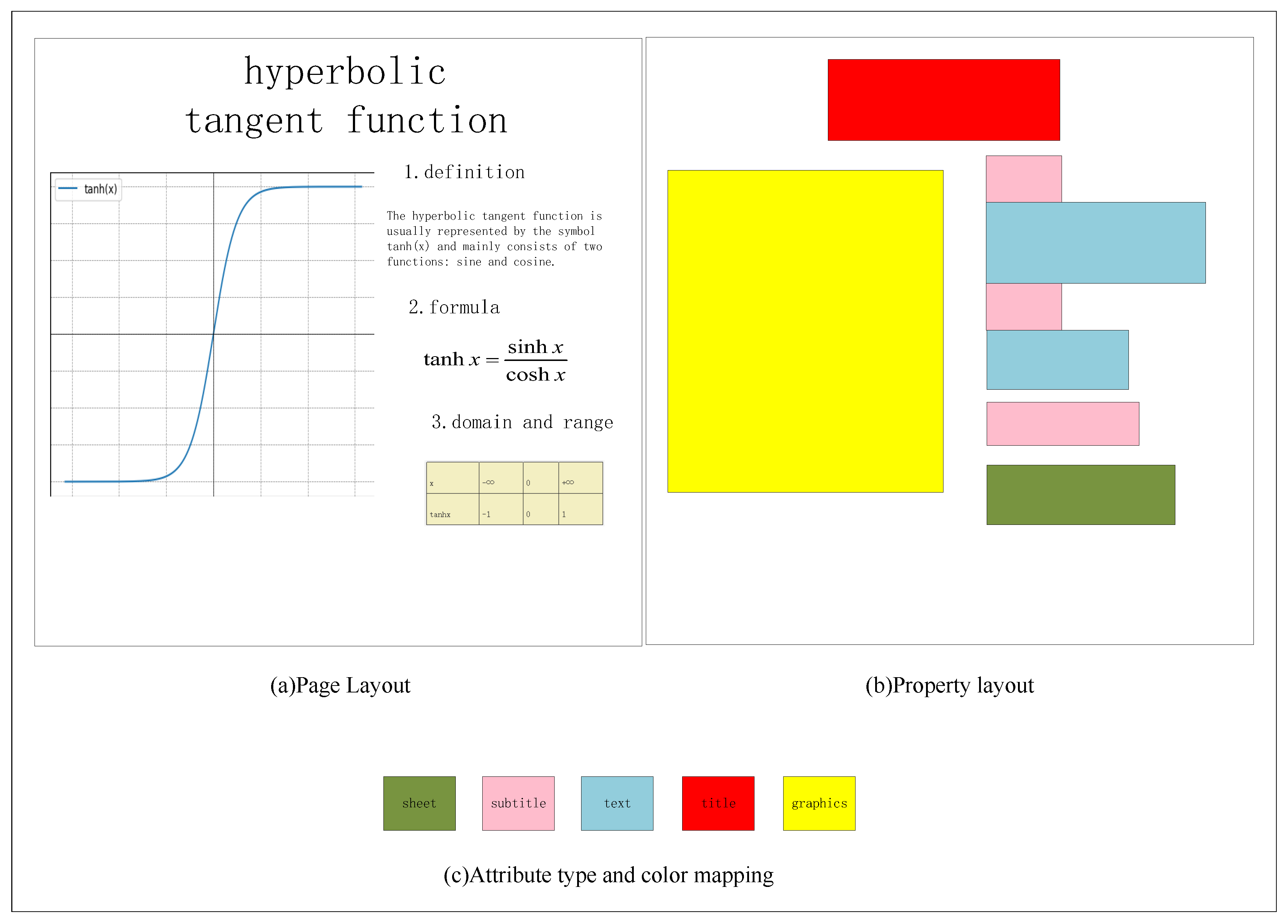
- Elements within page layouts, such as titles, subtitles, tables, graphics, and text, were abstracted into differently colored boxes to disregard internal content, text, images, formats, and other factors that could influence the model’s overall page layout generation.
3.2. Data Augmentation and Pre-Training
- Geometric Augmentation: random scaling (0.8–1.2×), rotation (±15°), and translation (±10% of layout width/height) to simulate diverse design scenarios.
- Element-wise Augmentation: random permutation of element types (e.g., swapping text and image positions) and perturbation of bounding box coordinates (±5 pixels).
- Pre-training: the Transformer module was pre-trained on the RICO dataset [38] (72k mobile UI layouts) to learn general layout patterns, followed by fine-tuning on our domain-specific data.
3.3. Experimental Considerations Detail
3.4. Evaluating Indicator
3.4.1. Subjective Scoring
- Rationality of object placement: Whether the object positions look aesthetically pleasing, whether objects are aligned with each other, and whether objects are within safe locations on the page. Aligning objects enhances the visual understanding of their relationship for readers and contributes to the overall aesthetic and orderly appearance of the layout.
- Readability of text: whether there is overlap between text and images that affects readability.
3.4.2. Objective Scoring
- AlignmentAlignment is crucial for design, especially in limited space where efficient information transmission and aesthetically pleasing organization are prioritized. The first consideration in this context is the alignment of various elements. This paper defines six possible alignment types: Left, X-center, Right, Top, Y-center, and Bottom. Before defining the alignment energy term, an analysis phase is executed, marking all aligned objects and alignment groups.A simple heuristic algorithm is employed to compute the alignment of object bounding boxes. Initially, the difference between the edges or center positions of the bounding boxes must be smaller than a threshold:where a is the alignment type and represents the distance between two objects i and j, depending on the alignment type used for the bounding boxes of the objects. For example, if a = Left, then Left measures the difference between the left edges of the bounding boxes of two objects. The threshold is set to =0.065, allowing slightly misaligned objects to still be marked as aligned. Secondly, if an object is positioned between other objects, the objects may not align:where is the number of objects between i and j. Next, the alignment indicator is defined. The alignment indicator variable between objects i and j, denoted as , is a combination of the terms mentioned above:In each axis, two objects typically align with only a single type. The minimum alignment distance is set to 1, while the other two are set to 0. However, if all types are perfectly aligned (= 0 for all types), then all three indicators are set to 1.Next, the aligned group is defined as a set of connected aligned objects. If objects i and k are aligned and objects k and j are aligned with the same type, then i and j are set to be aligned, i.e., .Finally, the alignment energy term is defined, measuring the proportion of objects aligned with a specific alignment type. Larger alignment groups are encouraged, as they result in simpler designs and greater uniformity between objects. The alignment energy term measures the score of pairs of objects aligned with type a:where n is the number of objects and indicates whether objects i and j are aligned according to type a. Different alignment types define separate energy terms. indicates whether i is a text object aligned internally within type a. Each feature is transformed by , which is a smooth step function defined by the following formula. The parameter controls the smoothness of the step, with larger values making the energy more sensitive to smaller changes.
- BalanceThe term “balance” refers to the equal distribution of weight on a page, indicating symmetry or asymmetry in terms of color, size, shape, and texture. This paper primarily focuses on the symmetry of object sizes on the page. The overall balance is measured using a binary mapping (along the axis flip) of text or graphic objects. For x-axis symmetry, the balance energy term is defined as:where represents a binary variable indicating whether pixel p belongs to the class and denotes the symmetric counterpart of pixel p along the x-axis in the image G. A similar balance energy term is defined for y-axis symmetry, where represents the y-axis symmetric term.
- White spaceIn graphic design, white space is the foundation of readability and aesthetics. The distance between objects is closely related to their correlation; the closer the objects are, the more likely they are to be associated with each other. White space also influences the overall design style, and many modern designs incorporate significant empty spaces. However, excessive white space between objects can distract the reader’s attention. The blank space should ideally constitute around half of the total page area. The energy term for white space is defined as follows:where is a binary variable indicating whether the pixel p is covered by an object and w and h are the width and height of the entire page, respectively.
- ScaleThe scale of an object determines its usability and style. Objects must be large enough for visibility but not too large, as it can lead to a cluttered and unattractive design. Objects in the layout can be broadly categorized into text and graphics. The size of text objects is defined as follows:where represents the height of the text object, represents the number of lines in the text object, is the scaling parameter, and normalization is performed with respect to the page height h. In this paper, = 1 is used uniformly. Using smaller values, such as = 0.4, will increase the size of text objects. The size of graphic objects is defined as follows:where and represent the width and height of the bounding box of the graphic object and w and h are the width and height of the page. The scale energy term for text objects is defined as:where is the number of text objects. The scale energy term EgraphicSize for graphic objects is defined similarly to EtextSize.
- OverlapOverlap between objects is common in many designs, but some overlaps can impact information retrieval. Three types of overlaps are defined, including overlap between text objects, overlap between graphic and text objects, and overlap between graphic objects. Separate energy terms are defined for each overlap type and summed over overlapping pixels p. The overlap energy term between text objects is defined as:where represents the pixels overlapped between text objects. EgraphicTextOverlap and EgraphicGraphicOverlap are similarly defined for overlap between text and graphic objects and overlap between graphic objects, respectively.
- BoundaryThe ability to control the extension of objects beyond the boundaries is achieved by calculating the portion of objects that exceeds the boundaries. Two separate energy terms, namely, the graphic boundary energy term and the text boundary energy term, are defined for this purpose. The graphic boundary energy term is defined as follows:where represents the sum of all pixels in object i and represents the sum of pixels in object i that are within the page boundaries. The definition of the text boundary energy term is similar to that of the graphic boundary energy term. By defining energy terms for alignment, balance, white space, scale, overlap, and boundary separately, it is possible to provide an objective evaluation of the presentation layout based on its detailed aspects. The range of values for each energy term is [0,1]. All energy terms are weighted equally with = 1/6, measuring the overall quality of the layout. The closer the weighted sum of energy terms is to 0, the better the layout quality.
3.5. Training Process
3.5.1. Data Preparation
3.5.2. Hyperparameter Tuning
3.5.3. Model Training and Optimization
3.5.4. Model Evaluation Strategies
3.6. Ablation Experiment Result Analysis
- Standard GAN: basic GAN without Transformer or conditioning.
- TGAN w/o Self-Attention: remove self-attention modules.
- TGAN w/o Conditioning: remove conditional inputs (labels).
- Fixed-Weight: TGAN with fixed weights.
- Adaptive-Weight (Full): Our complete model with dynamic .
- Self-attention impact: Removing self-attention (TGAN w/o SA) degrades alignment by 23.6% (0.89→0.68) and increases overlap by 257% (0.07→0.25), confirming its critical role in modeling spatial dependencies.
- Conditioning necessity: disabling conditional inputs (TGAN w/o Cond) reduces balance by 16.5% (0.85→0.71), indicating that label guidance stabilizes layout semantics.
- Adaptive-Weight superiority: Adaptive-Weight outperforms Fixed-Weight in all metrics (e.g., +8.5% alignment), demonstrating the necessity for dynamic constraint balancing.
- Standard GAN limitation: the basic GAN achieves the lowest scores, proving that vanilla architectures struggle with layout generation.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Alignment | Overlap | Balance | White Space | Boundary | Scale |
|---|---|---|---|---|---|---|
| Standard GAN | 0.62 | 0.31 | 0.58 | 0.61 | 0.72 | 0.65 |
| TGAN w/o Self-Attention | 0.68 | 0.25 | 0.63 | 0.66 | 0.78 | 0.70 |
| TGAN w/o Conditioning | 0.74 | 0.19 | 0.71 | 0.70 | 0.82 | 0.75 |
| Fixed-Weight | 0.82 | 0.12 | 0.78 | 0.75 | 0.87 | 0.81 |
| Adaptive-Weight (Full) | 0.89 | 0.07 | 0.85 | 0.82 | 0.93 | 0.88 |
3.7. Comparison Experiment Result Analysis
- Results generated by the TGAN exhibit better alignment and fewer instances of overlap, facilitating more efficient information conveyance.
- TGAN layouts adhere to topological constraints among objects, arranging elements with constraints in a logical manner on the page, making the relationships between elements clear and maximizing their expressive potential.
3.8. Quantitative Metrics and User Study
3.8.1. Quantitative Evaluation of Generation Quality
- Fréchet Inception Distance (FID): This measures the similarity between the distribution of generated samples and real data. A lower FID indicates better generation quality. We use a pre-trained Inception-v3 model to extract feature vectors from layout images and compute the Fréchet distance between their means and covariances.
- Inception Score (IS): This evaluates the diversity and semantic consistency of generated samples. A higher IS indicates more reasonable results. This score is calculated based on the entropy of the class prediction distribution from Inception-v3.
3.8.2. User Preference Study
- Aesthetics: visual appeal and style consistency (1–5 scale).
- Functionality: element alignment and readability (1–5 scale).
- Overall preference: percentage of participants selecting the method as “best layout”.
- The TGAN achieves significantly higher scores in both aesthetics and functionality (4.5 vs. 3.4) compared to the LayoutGAN.
- A total of 78% of participants selected the TGAN as the preferred method, demonstrating strong alignment with human design intuition.
- Qualitative feedback highlights the TGAN’s superior performance in handling complex element relationships (e.g., “Text–image alignment feels natural”).
| Method | Aesthetics | Functionality | Preference (%) |
|---|---|---|---|
| LayoutGAN | 3.1 ± 0.4 | 3.4 ± 0.3 | 13% |
| Deep Layout | 3.6 ± 0.3 | 3.8 ± 0.2 | 9% |
| TGAN (Ours) | 4.3 ± 0.2 | 4.5 ± 0.3 | 78% |
3.9. Performance Evaluation
4. Summary
- The dataset neglects the impact of internal elements and text on the overall layout. While the dataset used in this study provides a comprehensive representation of page layouts, it has certain limitations that may impact the results. Specifically, the dataset abstracts elements such as titles, subtitles, tables, graphics, and text into colored boxes, disregarding the internal content, text, images, and formats. This abstraction simplifies the problem but also omits critical information that could influence the overall layout quality. For instance, the relationships between text and images, such as how text wraps around images or how images are positioned relative to text blocks, are not captured in the dataset. These relationships are essential for creating visually appealing and functional layouts. Additionally, the dataset does not include information about the content of the text, such as font size, font type, and color, which can significantly affect readability and aesthetics.To enhance the quality of the algorithm, future work should consider incorporating more detailed information about internal elements into the dataset. This could include the following: Text and image relationships: including information about how text and images interact, such as text wrapping, image captions, and the spatial relationships between text blocks and images. Text content: Adding details about font size, font type, color, and other text attributes to better capture the visual and functional aspects of text in layouts. Image content: Including metadata about images, such as their aspect ratio, color palette, and content type (e.g., photograph, illustration, chart), to help the model understand how different types of images should be placed in a layout.By incorporating these additional details, the dataset can provide a more comprehensive representation of page layouts, allowing the algorithm to learn more nuanced and context-aware layout generation strategies. This would lead to higher-quality and more realistic layout results.In future work, as software and hardware continue to evolve, there is an opportunity to enhance the dataset, further optimize the network, and improve the accuracy and performance of page layout.
- This paper only scratches the surface of graphic design layout styles in automatic layout for presentations. It optimizes only the position and proportions of objects, without considering the influence of color and background. The classification of layout objects in the paper is relatively coarse, including only five categories: background, title, subtitle, text, and graphics. This approach has certain limitations. In future work, additional types of elements should be incorporated, and further subdivisions can be applied to the existing five categories for a more comprehensive treatment.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, T.; Zhao, Z.; Xia, M.; Huang, J.; Weng, L.; Hu, K.; Lin, H.; Zhao, W. FTA-Net: Frequency-Temporal-Aware Network for Remote Sensing Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 3448–3460. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, K.; Liao, X.; Qian, Y.; Wang, Q.; Yuan, Z.; Heng, P.A. Channel-Unet: A spatial channel-wise convolutional neural network for liver and tumors segmentation. Front. Genet. 2019, 10, 1110. [Google Scholar] [CrossRef] [PubMed]
- Zhan, Z.; Ren, H.; Xia, M.; Lin, H.; Wang, X.; Li, X. AMFNet: Attention-Guided Multi-Scale Fusion Network for Bi-Temporal Change Detection in Remote Sensing Images. Remote Sens. 2024, 16, 1765. [Google Scholar] [CrossRef]
- Wang, Z.; Gu, G.; Xia, M.; Weng, L.; Hu, K. Bitemporal Attention Sharing Network for Remote Sensing Image Change Detection. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10368–10379. [Google Scholar] [CrossRef]
- Shi, Y.; Shang, M.; Qi, Z. A conditional deep framework for automatic layout generation. IEEE Access 2022, 10, 86092–86100. [Google Scholar] [CrossRef]
- Gupta, K.; Lazarow, J.; Achille, A.; Davis, L.S.; Mahadevan, V.; Shrivastava, A. Layouttransformer: Layout generation and completion with self-attention. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1004–1014. [Google Scholar]
- Arroyo, D.M.; Postels, J.; Tombari, F. Variational transformer networks for layout generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 10–17 October 2021; pp. 13642–13652. [Google Scholar]
- Cheng, C.Y.; Huang, F.; Li, G.; Li, Y. Play: Parametrically conditioned layout generation using latent diffusion. arXiv 2023, arXiv:2301.11529. [Google Scholar]
- Akkem, Y.; Biswas, S.K.; Varanasi, A. A comprehensive review of synthetic data generation in smart farming by using variational autoencoder and generative adversarial network. Eng. Appl. Artif. Intell. 2024, 131, 107881. [Google Scholar] [CrossRef]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative adversarial network: An overview of theory and applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Pei, L.; Sun, Z.; Xiao, L.; Li, W.; Sun, J.; Zhang, H. Virtual generation of pavement crack images based on improved deep convolutional generative adversarial network. Eng. Appl. Artif. Intell. 2021, 104, 104376. [Google Scholar] [CrossRef]
- Odena, A. Semi-supervised learning with generative adversarial networks. arXiv 2016, arXiv:1606.01583. [Google Scholar]
- Sajun, A.R.; Zualkernan, I. Survey on implementations of generative adversarial networks for semi-supervised learning. Appl. Sci. 2022, 12, 1718. [Google Scholar] [CrossRef]
- Yang, H.; Hu, Y.; He, S.; Xu, T.; Yuan, J.; Gu, X. Applying Conditional Generative Adversarial Networks for Imaging Diagnosis. In Proceedings of the 2024 IEEE 6th International Conference on Power, Intelligent Computing and Systems (ICPICS), Shenyang, China, 26–28 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1717–1722. [Google Scholar]
- Yang, Y.; Liu, J.; Huang, S.; Wan, W.; Wen, W.; Guan, J. Infrared and visible image fusion via texture conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4771–4783. [Google Scholar] [CrossRef]
- Denton, E.L.; Chintala, S.; Fergus, R. Deep generative image models usinga laplacian pyramid of adversarial networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1486–1494. [Google Scholar]
- Yin, H.; Xiao, J. Laplacian pyramid generative adversarial network for infrared and visible image fusion. IEEE Signal Process. Lett. 2022, 29, 1988–1992. [Google Scholar] [CrossRef]
- Berthelot, D.; Schumm, T.; Metz, L. Began: Boundary equilibrium generative adversarial networks. arXiv 2017, arXiv:1703.10717. [Google Scholar]
- Zhou, Y.; Chen, Z.; Shen, H.; Zheng, X.; Zhao, R.; Duan, X. A refined equilibrium generative adversarial network for retinal vessel segmentation. Neurocomputing 2021, 437, 118–130. [Google Scholar] [CrossRef]
- Cortes, C.; Lawarence, N.; Lee, D.; Sugiyama, M.; Garnett, R. Advances in neural information processing systems 28. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neural Inf. Process. Syst. 2017, 30, 5769–5779. [Google Scholar]
- Ngasa, E.E.; Jang, M.A.; Tarimo, S.A.; Woo, J.; Shin, H.B. Diffusion-based Wasserstein generative adversarial network for blood cell image augmentation. Eng. Appl. Artif. Intell. 2024, 133, 108221. [Google Scholar] [CrossRef]
- Nowozin, S.; Cseke, B.; Tomioka, R. f-gan: Training generative neural samplers using variational divergence minimization. Adv. Neural Inf. Process. Syst. 2016, 29, 271–279. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.; Wang, Z.; Paul Smolley, S. Least squares generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2794–2802. [Google Scholar]
- Shi, Y.; Shang, M.; Qi, Z. Intelligent layout generation based on deep generative models: A comprehensive survey. Inf. Fusion 2023, 100, 101940. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, T.; Li, H.; Zhang, S.; Wang, X.; Huang, X.; Metaxas, D.N. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5907–5915. [Google Scholar]
- Xu, T.; Zhang, P.; Huang, Q.; Zhang, H.; Gan, Z.; Huang, X.; He, X. Attngan: Fine-grained text to image generation with attentional generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 1316–1324. [Google Scholar]
- Chai, S.; Zhuang, L.; Yan, F. Layoutdm: Transformer-based diffusion model for layout generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 18349–18358. [Google Scholar]
- Jiang, F.; Ma, J.; Webster, C.J.; Li, X.; Gan, V.J. Building layout generation using site-embedded GAN model. Autom. Constr. 2023, 151, 104888. [Google Scholar] [CrossRef]
- Chen, L.; Jing, Q.; Zhou, Y.; Li, Z.; Shi, L.; Sun, L. Element-conditioned GAN for graphic layout generation. Neurocomputing 2024, 591, 127730. [Google Scholar] [CrossRef]
- Banerjee, R.H.; Rajagopal, A.; Jha, N.; Patro, A.; Rajan, A. Let AI clothe you: Diversified fashion generation. In Proceedings of the Computer Vision—ACCV 2018 Workshops: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers 14. Springer: Berlin/Heidelberg, Germany, 2019; pp. 75–87. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Han, K.; Xiao, A.; Wu, E.; Guo, J.; Xu, C.; Wang, Y. Transformer in transformer. Adv. Neural Inf. Process. Syst. 2021, 34, 15908–15919. [Google Scholar]
- Jiang, S.; Lin, H.; Ren, H.; Hu, Z.; Weng, L.; Xia, M. MDANet: A High-Resolution City Change Detection Network Based on Difference and Attention Mechanisms under Multi-Scale Feature Fusion. Remote Sens. 2024, 16, 1387. [Google Scholar] [CrossRef]
- Zhao, W.; Xia, M.; Weng, L.; Hu, K.; Lin, H.; Zhang, Y.; Liu, Z. SPNet: Dual-Branch Network with Spatial Supplementary Information for Building and Water Segmentation of Remote Sensing Images. Remote Sens. 2024, 16, 3161. [Google Scholar] [CrossRef]
- Deka, B.; Huang, Z.; Franzen, C.; Hibschman, J.; Afergan, D.; Li, Y.; Nichols, J.; Kumar, R. Rico: A mobile app dataset for building data-driven design applications. In Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology, Québec City, QC, Canada, 22–25 October 2017; pp. 845–854. [Google Scholar]




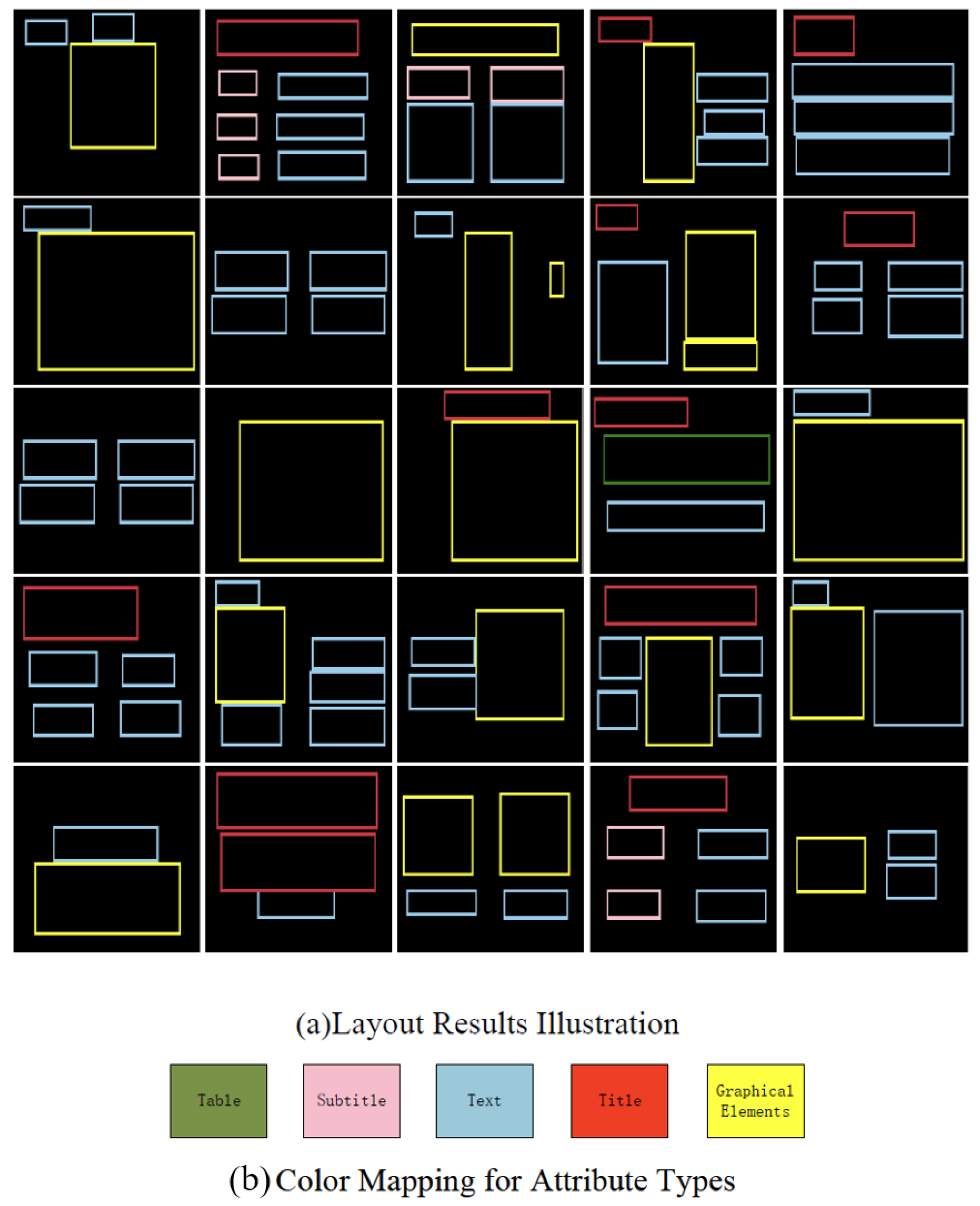
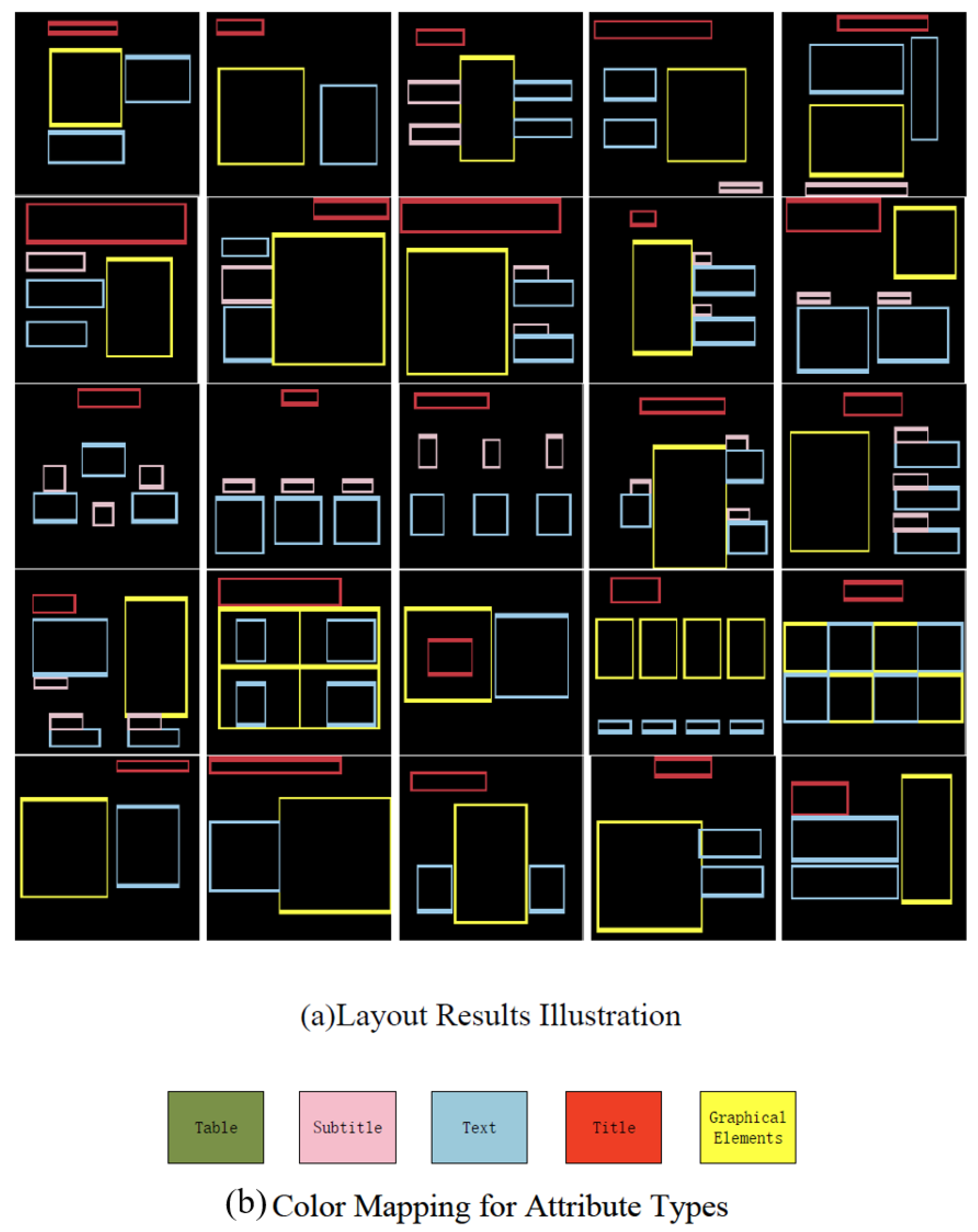
| Method | Samples | Subjective Score | Objective Score | ||
|---|---|---|---|---|---|
| Mean | Variance | Mean | Variance | ||
| GAN | 200 | 7.992 | 0.503 | 0.078 | 0.0032 |
| GAN | 400 | 7.876 | 0.521 | 0.065 | 0.0035 |
| GAN | 600 | 8.105 | 0.417 | 0.053 | 0.0029 |
| LayoutTransformer | 200 | 7.983 | 0.497 | 0.076 | 0.0034 |
| LayoutTransformer | 600 | 8.173 | 0.421 | 0.057 | 0.0031 |
| VTN | 600 | 8.123 | 0.412 | 0.060 | 0.0032 |
| L-CGAN | 600 | 7.674 | 0.501 | 0.064 | 0.0031 |
| PLAY | 600 | 8.207 | 0.445 | 0.059 | 0.0030 |
| TGAN (Ours) | 200 | 8.45 | 0.38 | 0.048 | 0.0023 |
| TGAN (Ours) | 400 | 8.52 | 0.36 | 0.045 | 0.0020 |
| TGAN (Ours) | 600 | 8.60 | 0.35 | 0.042 | 0.0018 |
| Method | FID | IS |
|---|---|---|
| LayoutGAN | 32.7 | 8.2 |
| Deep Layout | 28.5 | 8.9 |
| VTN | 25.1 | 9.3 |
| PLAY | 21.8 | 9.6 |
| TGAN (Ours) | 18.3 | 10.1 |
| Model | Params (M) | FLOPs (G) | Training Time (h) |
|---|---|---|---|
| GAN (Baseline) | 12.5 | 4.2 | 48 |
| LayoutTransformer | 68.3 | 23.7 | 120 |
| VTN | 45.8 | 18.5 | 96 |
| L-CGAN | 28.6 | 9.8 | 72 |
| PLAY | 34.2 | 14.3 | 84 |
| TGAN (Ours) | 53.1 | 16.9 | 90 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, P.; Liu, X.; Weng, L.; Liu, Z. Generative Adversarial Network Based on Self-Attention Mechanism for Automatic Page Layout Generation. Appl. Sci. 2025, 15, 2852. https://doi.org/10.3390/app15052852
Sun P, Liu X, Weng L, Liu Z. Generative Adversarial Network Based on Self-Attention Mechanism for Automatic Page Layout Generation. Applied Sciences. 2025; 15(5):2852. https://doi.org/10.3390/app15052852
Chicago/Turabian StyleSun, Peng, Xiaomei Liu, Liguo Weng, and Ziheng Liu. 2025. "Generative Adversarial Network Based on Self-Attention Mechanism for Automatic Page Layout Generation" Applied Sciences 15, no. 5: 2852. https://doi.org/10.3390/app15052852
APA StyleSun, P., Liu, X., Weng, L., & Liu, Z. (2025). Generative Adversarial Network Based on Self-Attention Mechanism for Automatic Page Layout Generation. Applied Sciences, 15(5), 2852. https://doi.org/10.3390/app15052852