
Evaluating LLMs for Automated Scoring in Formative Assessments




Abstract
1. Introduction
- RQ1: Are LLM-generated grades as reliable as human evaluations? H0: There is no significant difference between the two.
- RQ2: Can open-source LLMs achieve scoring accuracy comparable to premium models? H0: There is no significant scoring difference between the models.
2. Materials and Methods
2.1. Development of the Platform
2.2. Experimental Design
2.3. Evaluation and Analysis
3. Results
3.1. Scoring Performance
3.2. Question Type Analysis
3.3. Similarity Between LLM and Human Evaluator
3.4. Comparative Analysis of LLM Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

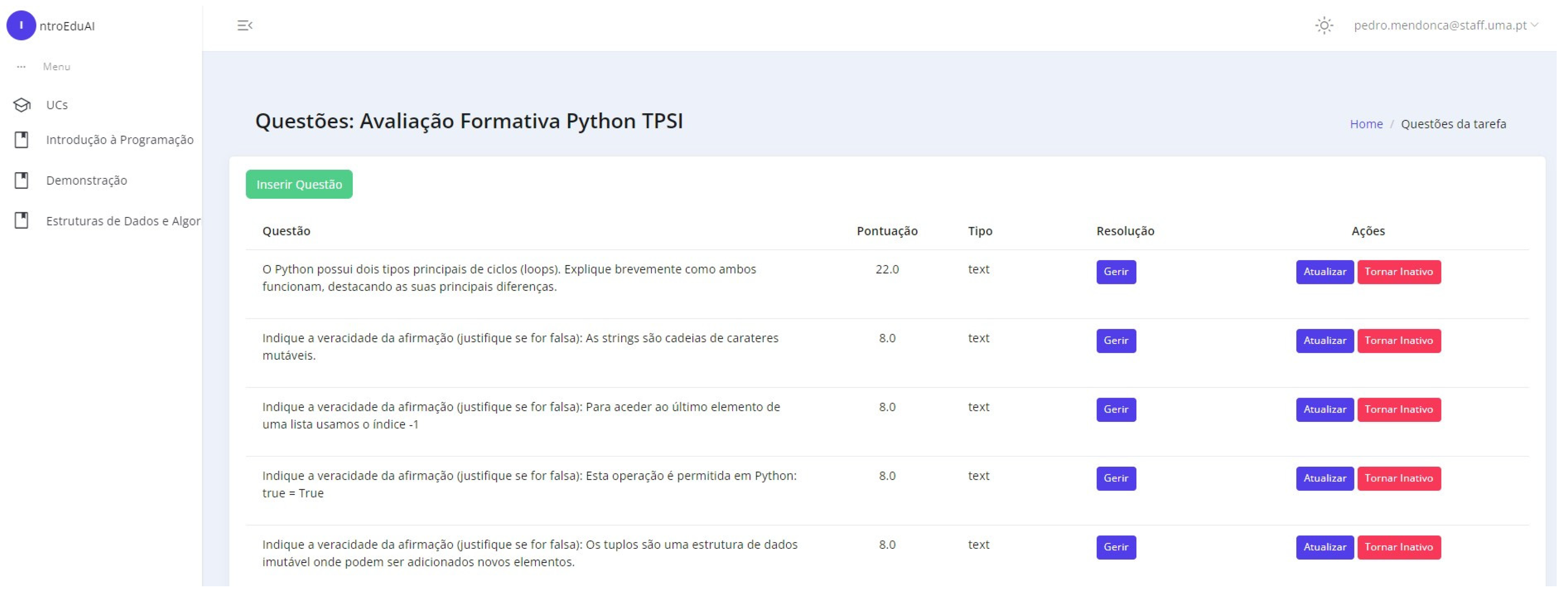
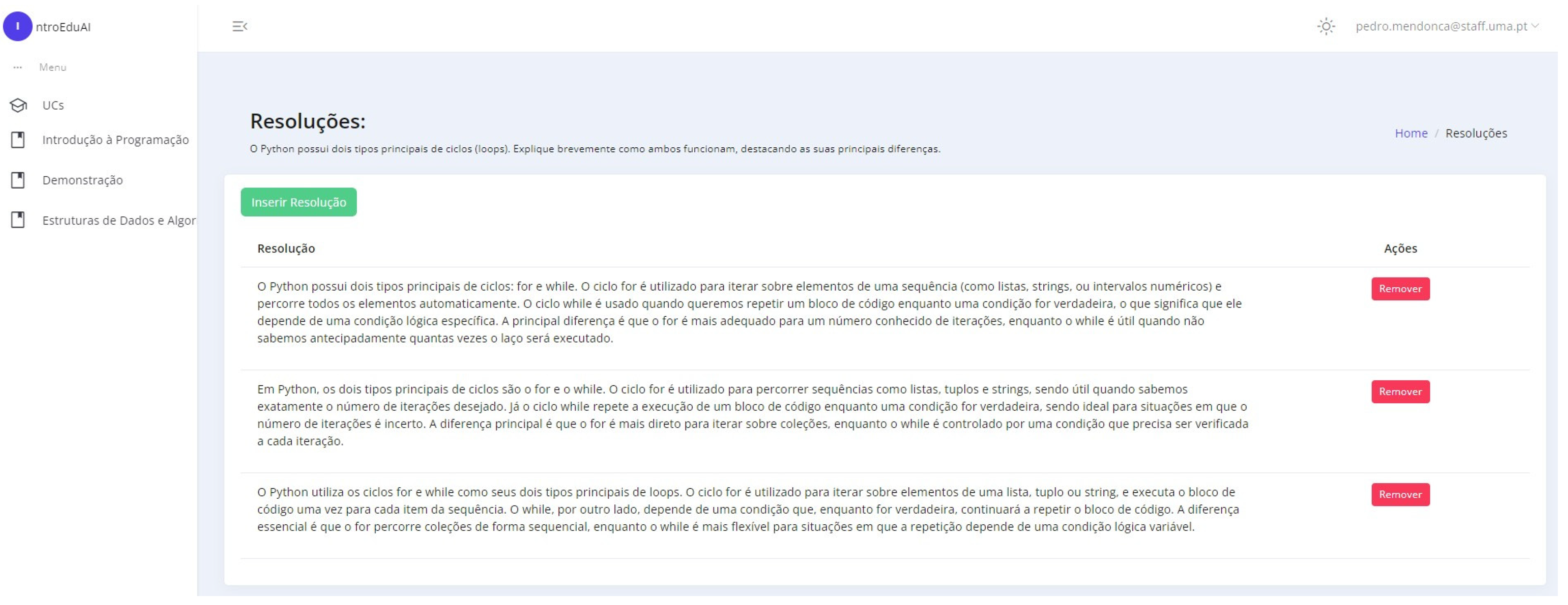

Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Question | Solution Example | Criteria |
|---|---|---|---|
| 2 | Python has two main types of loops. Briefly explain how each of them works, highlighting their main differences. | Python has two main types of loops: for and while. The for loop is used to iterate over elements of a sequence (such as lists, strings, or numeric ranges) and automatically traverses all elements. The while loop is used when we want to repeat a block of code while a condition is true, which means it depends on a specific logical condition. The main difference is that the for loop is more suitable for a known number of iterations, while the while loop is useful when we do not know in advance how many times the loop will execute. | Identification of Loop Types (Total: 6 points) Explanation of the Functioning of the for Loop (Total: 7 points) Explanation of the Functioning of the while Loop (Total: 7 points) Clarity and Coherence in the Comparison between for and while (Total: 2 points) |
| 3 | Determine the truth of the statement (justify if false): Strings are mutable sequences of characters. | False. Strings in Python are immutable, meaning that we cannot alter their individual characters after creation. | Indication of True or False (3 points) Justification of the Answer (Total: 5 points) |
| 4 | Determine the truth of the statement (justify if false): To access the last element of a list, we use the index −1. | True | Indication of True or False (8 points) |
| 9 | Determine the truth of the statement (justify if false): This operation is permitted in Python: true = True | True | Indication of True or False (8 points) |
| 10 | Determine the truth of the statement (justify if false): Tuples are an immutable data structure where new elements can be added. | False, because tuples are immutable, which means we cannot add new elements after their creation. | Indication of True or False (3 points) Justification for the False Answer:
|
| 11 | Determine the truth of the statement (justify if false): Comments are extremely important in programming, as they help document the code. | True | Indication of True or False (8 points) |
| 12 | You intend to store the contacts (telephone, email, address) of the students in the TPSI course. Indicate and justify which type(s) of data structures you would use to perform this operation. | I would use a list of composite data structures, such as dictionaries, where each dictionary would represent a contact. Within each dictionary, I would use the keys telephone, email, and address to store each student’s information, as this allows me to easily associate each piece of information with its respective key. | Identification of the Main Structure (5 points) Explanation of Using Dictionaries as a Complementary Structure (12 points) Justification of the Combination of List + Dictionary (8 points) |
| ID | Question | Solution Example | Criteria |
|---|---|---|---|
| 13 | Implement a function called insertValidNIF that repeatedly reads a user’s NIF and validates it according to the criteria below:
| def insertValidNIF(): while True: try: nif = int(input(“Insert your NIF: “)) if len(str(nif)) != 9: raise ValueError break except ValueError: print(“Invalid NIF. Please insert a valid NIF.”) return nif | Definition of the insertValidNIF Function (3 points) Use of a while Loop for Repeated Validation (7 points) Reading the NIF Value (3 points) Verification and Handling of Errors for Different Types (6 points) Length Verification (6 points) Error Message for Invalid NIF (5 points) Return of the Valid NIF (3 points) Clarity and Coherence in the Comparison between for and while (Total: 2 points) |
| 14 | Create a Python program that performs the following operations:
Telefone: 291223322 Email: joao_aspacheco@sapo.pt
| def adicionarContacto(): id = int(input(“ID: “)) nome = input(“Nome: “) telefone = int(input(“Telefone: “)) email = input(“Email: “) localidade = input(“Localidade: “) return {“id”: id, “nome”: nome, “telefone”: telefone, “email”: email, “localidade”: localidade} def listarContactos(): print(“Lista de Contactos:”) for contacto in listaContactos: print(f”ID: {contacto[’id’]} - Nome: {contacto[’nome’]} / {contacto[’localidade’]}\nTelefone: {contacto[’telefone’]}, Email: {contacto[’email’]}”) listaContactos = []listaContactos.append(adicionarContacto()) listarContactos() | Initialization of the Empty List (5 points)Creation of the adicionarContacto() Function:
|
| Criterion | Sub-Criterion | Description | Points |
|---|---|---|---|
| Identification of Main Structure | Mentioning lists as main structure for contact information | 5 | |
| Mentioning inappropriate structure (dictionaries, tuples, sets) | 0 | ||
| Explanation of Dictionaries as Complementary Structure | Explanation of Key-Value Pairs | Explaining dictionaries store contact details as key-value pairs | 6 |
| Partial/ambiguous explanation | 3 to 5 | ||
| Incorrect/missing explanation | 0 | ||
| Clarity in Attribute Association | Justifying dictionaries enable clear data association with specific keys | 6 | |
| Partial/ambiguous explanation | 3 to 5 | ||
| Incorrect/missing explanation | 0 | ||
| Justification of Combining List + Dictionary | Flexibility and Organization of Contacts | Explaining list of dictionaries allows dynamic contact addition | 4 |
| Partial explanation | 2 to 3 | ||
| Incorrect/missing explanation | 0 | ||
| Ease of Search and Manipulation | Indicating that this combination allows efficient search, access, and modification of information for each student, using keys to retrieve specific fields and indices to access each student in the list | 4 | |
| Partial explanation | 2 to 3 | ||
| Incorrect/missing explanation | 0 |
References
- Fagbohun, O.; Iduwe, N.P.; Abdullahi, M.; Ifaturoti, A.; Nwanna, O.M. Beyond Traditional Assessment: Exploring the Impact of Large Language Models on Grading Practices. J. Artifical Intell. Mach. Learn. Data Sci. 2024, 2, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Bond, M.; Khosravi, H.; De Laat, M.; Bergdahl, N.; Negrea, V.; Oxley, E.; Pham, P.; Chong, S.W.; Siemens, G. A Meta Systematic Review of Artificial Intelligence in Higher Education: A Call for Increased Ethics, Collaboration, and Rigour. Int. J. Educ. Technol. High. Educ. 2024, 21, 4. [Google Scholar] [CrossRef]
- Automatic Assessment of Text-Based Responses in Post-Secondary Education: A Systematic Review. Comput. Educ. Artif. Intell. 2024, 6, 100206. [CrossRef]
- The Emergent Role of Artificial Intelligence, Natural Learning Processing, and Large Language Models in Higher Education and Research. Res. Social. Adm. Pharm. 2023, 19, 1236–1242. [CrossRef]
- Henkel, O.; Hills, L.; Roberts, B.; McGrane, J. Can LLMs Grade Open Response Reading Comprehension Questions? An Empirical Study Using the ROARs Dataset. Int. J. Artif. Intell. Educ. 2024. [Google Scholar] [CrossRef]
- Liu, M.; M’Hiri, F. Beyond Traditional Teaching: Large Language Models as Simulated Teaching Assistants in Computer Science. In Proceedings of the 55th ACM Technical Symposium on Computer Science Education V. 1, Portland, OR, USA, 20–23 March 2024; pp. 743–749. [Google Scholar]
- Kooli, C.; Yusuf, N. Transforming Educational Assessment: Insights Into the Use of ChatGPT and Large Language Models in Grading. Int. J. Hum.–Comput. Interact. 2025, 41, 1–12. [Google Scholar] [CrossRef]
- Kosar, T.; Ostojić, D.; Liu, Y.D.; Mernik, M. Computer Science Education in ChatGPT Era: Experiences from an Experiment in a Programming Course for Novice Programmers. Mathematics 2024, 12, 629. [Google Scholar] [CrossRef]
- Cooper, G. Examining Science Education in ChatGPT: An Exploratory Study of Generative Artificial Intelligence. J. Sci. Educ. Technol. 2023, 32, 444–452. [Google Scholar] [CrossRef]
- Zhai, X. ChatGPT User Experience: Implications for Education 2022. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4312418 (accessed on 2 March 2025).
- Dorfner, F.J.; Jürgensen, L.; Donle, L.; Mohamad, F.A.; Bodenmann, T.R.; Cleveland, M.C.; Busch, F.; Adams, L.C.; Sato, J.; Schultz, T.; et al. Is Open-Source There Yet? A Comparative Study on Commercial and Open-Source LLMs in Their Ability to Label Chest X-Ray Reports. arXiv 2024, arXiv:2402.12298. [Google Scholar]
- Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Garcia Valencia, O.A.; Cheungpasitporn, W. Integrating Retrieval-Augmented Generation with Large Language Models in Nephrology: Advancing Practical Applications. Medicina 2024, 60, 445. [Google Scholar] [CrossRef]
- Gao, Y.; Xiong, Y.; Gao, X.; Jia, K.; Pan, J.; Bi, Y.; Dai, Y.; Sun, J.; Wang, M.; Wang, H. Retrieval-Augmented Generation for Large Language Models: A Survey. arXiv 2023. [Google Scholar] [CrossRef]
- Fung, S.C.E.; Wong, M.F.; Tan, C.W. Automatic Feedback Generation on K-12 Students’ Data Science Education by Prompting Cloud-Based Large Language Models. In Proceedings of the Eleventh ACM Conference on Learning @ Scale, Atlanta, GA, USA, 18–20 July 2024; pp. 255–258. [Google Scholar]
- Posedaru, B.-S.; Pantelimon, F.-V.; Dulgheru, M.-N.; Georgescu, T.-M. Artificial Intelligence Text Processing Using Retrieval-Augmented Generation: Applications in Business and Education Fields. Proc. Int. Conf. Bus. Excell. 2024, 18, 209–222. [Google Scholar] [CrossRef]
- Carpenter, D.; Min, W.; Lee, S.; Ozogul, G.; Zheng, X.; Lester, J. Assessing Student Explanations with Large Language Models Using Fine-Tuning and Few-Shot Learning. In Proceedings of the 19th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2024); Kochmar, E., Bexte, M., Burstein, J., Horbach, A., Laarmann-Quante, R., Tack, A., Yaneva, V., Yuan, Z., Eds.; Association for Computational Linguistics: Mexico City, Mexico, 2024; pp. 403–413. [Google Scholar]
- (PDF) Generative Language Models with Retrieval Augmented Generation for Automated Short Answer Scoring. Available online: https://www.researchgate.net/publication/382944163_Generative_Language_Models_with_Retrieval_Augmented_Generation_for_Automated_Short_Answer_Scoring (accessed on 19 January 2025).
- Cohn, C.; Hutchins, N.; Le, T.; Biswas, G. A Chain-of-Thought Prompting Approach with LLMs for Evaluating Students’ Formative Assessment Responses in Science. Proc. AAAI Conf. Artif. Intell. 2024, 38, 23182–23190. [Google Scholar] [CrossRef]
- Wong, E. Comparative Analysis of Open Source and Proprietary Large Language Models: Performance and Accessibility. Adv. Comput. Sci. 2024, 7, 1–7. [Google Scholar]
- Wang, Y.; Wang, M.; Manzoor, M.A.; Liu, F.; Georgiev, G.N.; Das, R.J.; Nakov, P. Factuality of Large Language Models: A Survey. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Miami, FL, USA, 12–16 November 2024; pp. 19519–19529. [Google Scholar]
- Jury, B.; Lorusso, A.; Leinonen, J.; Denny, P.; Luxton-Reilly, A. Evaluating LLM-Generated Worked Examples in an Introductory Programming Course. In Proceedings of the 26th Australasian Computing Education Conference, Sydney, NSW, Australia, 29 January–2 February 2024; pp. 77–86. [Google Scholar]
- Fay, M.P.; Proschan, M.A. Wilcoxon-Mann-Whitney or t-Test? On Assumptions for Hypothesis Tests and Multiple Interpretations of Decision Rules. Stat. Surv. 2010, 4, 1–39. [Google Scholar] [CrossRef]
- Lakens, D. Equivalence Tests: A Practical Primer for t Tests, Correlations, and Meta-Analyses. Social. Psychol. Personal. Sci. 2017, 8, 355–362. [Google Scholar] [CrossRef] [PubMed]
- Lakens, D.; McLatchie, N.; Isager, P.M.; Scheel, A.M.; Dienes, Z. Improving Inferences About Null Effects with Bayes Factors and Equivalence Tests. J. Gerontol. Ser. B 2020, 75, 45–57. [Google Scholar] [CrossRef]
- Fine-Tuning ChatGPT for Automatic Scoring. Comput. Educ. Artif. Intell. 2024, 6, 100210. [CrossRef]
- Henkel, O.; Hills, L.; Boxer, A.; Roberts, B.; Levonian, Z. Can Large Language Models Make the Grade? An Empirical Study Evaluating LLMs Ability To Mark Short Answer Questions in K-12 Education. In Proceedings of the Eleventh ACM Conference on Learning @ Scale, Atlanta, GA, USA, 18–20 July 2024; pp. 300–304. [Google Scholar]
- Mansour, W.A.; Albatarni, S.; Eltanbouly, S.; Elsayed, T. Can Large Language Models Automatically Score Proficiency of Written Essays? In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Orino, Italia, 20–25 May 2024; pp. 2777–2786. [Google Scholar]
- Chang, L.-H.; Ginter, F. Automatic Short Answer Grading for Finnish with ChatGPT. Proc. AAAI Conf. Artif. Intell. 2024, 38, 23173–23181. [Google Scholar] [CrossRef]
- Grévisse, C. LLM-Based Automatic Short Answer Grading in Undergraduate Medical Education. BMC Med. Educ. 2024, 24, 1060. [Google Scholar] [CrossRef]
- Song, Y.; Zhu, Q.; Wang, H.; Zheng, Q. Automated Essay Scoring and Revising Based on Open-Source Large Language Models. IEEE Trans. Learn. Technol. 2024, 17, 1920–1930. [Google Scholar] [CrossRef]
- DeepSeek-AI; Guo, D.; Yang, D.; Zhang, H.; Song, J.; Zhang, R.; Xu, R.; Zhu, Q.; Ma, S.; Wang, P.; et al. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning. arXiv 2025. [Google Scholar] [CrossRef]


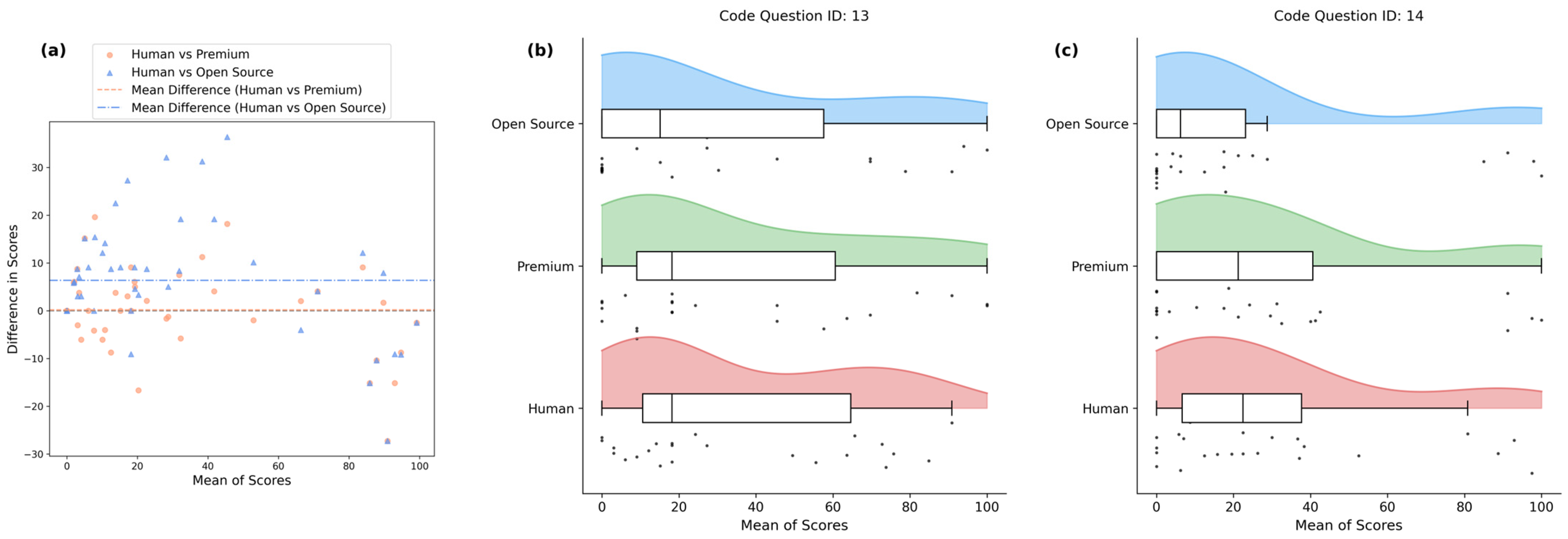
| Question ID | Type | Human | Open Source LLM | Premium LLM | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Min | Max | Mean | SD | Min | Max | Mean | SD | Min | Max | Mean | SD | ||
| 2 | Short-text | 0.00 | 86.36 | 40.97 | 23.41 | 0.00 | 90.91 | 40.91 | 24.97 | 0.00 | 100.00 | 55.01 | 26.55 |
| 3 | Short-text | 0.00 | 100.00 | 37.14 | 42.95 | 0.00 | 100.00 | 36.41 | 42.34 | 0.00 | 100.00 | 34.60 | 40.31 |
| 4 | Short-text | 0.00 | 100.00 | 82.25 | 37.78 | 0.00 | 100.00 | 82.61 | 37.90 | 0.00 | 100.00 | 82.61 | 37.90 |
| 9 | Short-text | 0.00 | 100.00 | 91.30 | 28.18 | 0.00 | 100.00 | 91.30 | 28.18 | 0.00 | 100.00 | 91.30 | 28.18 |
| 10 | Short-text | 0.00 | 100.00 | 60.69 | 31.59 | 0.00 | 100.00 | 64.13 | 36.36 | 0.00 | 100.00 | 68.48 | 35.59 |
| 11 | Short-text | 0.00 | 100.00 | 92.75 | 23.99 | 0.00 | 100.00 | 95.65 | 20.39 | 0.00 | 100.00 | 91.30 | 28.18 |
| 12 | Short-text | 0.00 | 62.67 | 19.59 | 15.49 | 0.00 | 73.33 | 14.15 | 17.39 | 0.00 | 84.00 | 34.72 | 26.09 |
| 13 | Code | 0.00 | 90.91 | 34.83 | 30.19 | 0.00 | 100.00 | 29.38 | 35.06 | 0.00 | 100.00 | 34.91 | 33.49 |
| 14 | Code | 0.00 | 97.50 | 30.51 | 30.70 | 0.00 | 100.00 | 23.26 | 33.49 | 0.00 | 100.00 | 30.11 | 33.06 |
| Question Type | Evaluator | SD | Var |
|---|---|---|---|
| Short-Answer | Teacher | 4.438 | 74.843 |
| Open Source LLM | 1.197 | 12.670 | |
| Premium LLM | 0.873 | 6.540 | |
| Code | Teacher | 6.350 | 83.566 |
| Open Source LLM | 1.020 | 4.207 | |
| Premium LLM | 0.710 | 3.874 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mendonça, P.C.; Quintal, F.; Mendonça, F. Evaluating LLMs for Automated Scoring in Formative Assessments. Appl. Sci. 2025, 15, 2787. https://doi.org/10.3390/app15052787
Mendonça PC, Quintal F, Mendonça F. Evaluating LLMs for Automated Scoring in Formative Assessments. Applied Sciences. 2025; 15(5):2787. https://doi.org/10.3390/app15052787
Chicago/Turabian StyleMendonça, Pedro C., Filipe Quintal, and Fábio Mendonça. 2025. "Evaluating LLMs for Automated Scoring in Formative Assessments" Applied Sciences 15, no. 5: 2787. https://doi.org/10.3390/app15052787
APA StyleMendonça, P. C., Quintal, F., & Mendonça, F. (2025). Evaluating LLMs for Automated Scoring in Formative Assessments. Applied Sciences, 15(5), 2787. https://doi.org/10.3390/app15052787