
Increasing the Accessibility of Causal Domain Knowledge via Causal Information Extraction Methods: A Case Study in the Semiconductor Manufacturing Industry




Abstract
1. Introduction
- How effective are existing causal information extraction methods on different types of industrial documents?
- What is the effect of text representation learning on the overall performance of causal information extraction in industrial settings?
- Extending causal information extraction methods to industrial documents, increasing the availability of causal domain knowledge for downstream tasks in the industry.
- Providing guidance for practitioners working in different industries with similar types of documents. This guidance includes summarizing causal relation annotation guidelines in natural language, providing examples of these annotations from semiconductor manufacturing, and emphasizing the importance of inter-annotator agreements (IAA) to ensure annotation quality and clarity.
- Addressing data consistency issues commonly found in semi-structured documents, like the merged cells in FMEA documents.
- Contributing to the body of research that highlights the effect of representation learning on downstream tasks.
2. Related Work
2.1. Causal Information Extraction Applications
2.2. Causal Information Extraction Methods
- Efficient generalizability achieving broad applicability of the method with limited manual work, such as creating new knowledge bases for domain-specific patterns.
- The ability to acquire useful vectorized representations of the text that enables the training of different methods for causal information extraction.
- Having consistently and sufficiently annotated data sets with clear annotation guidelines that mitigate the different interpretations of causal information described in text.
- A representation that allows the system to manage the complexity associated with the description of causal relationships, such as nested or enchained causal relations.
3. Methods
- Text extraction from different document formats (the input extraction step in Figure 1): This step involves extracting a textual representation of the information contained in the different documents. This textual representation can be analyzed and used to develop causal information extraction methods. This step is elaborated in Section 3.1.
- Structured data representation (the Sentence annotation step in Figure 1): This step involves representing the information contained in texts extracted from different industrial documents in a structured format (i.e., a set of named entities and relations between these entities) that can be easily used for downstream tasks such as risk assessment, data analysis, etc. This step is outlined in Section 3.2.
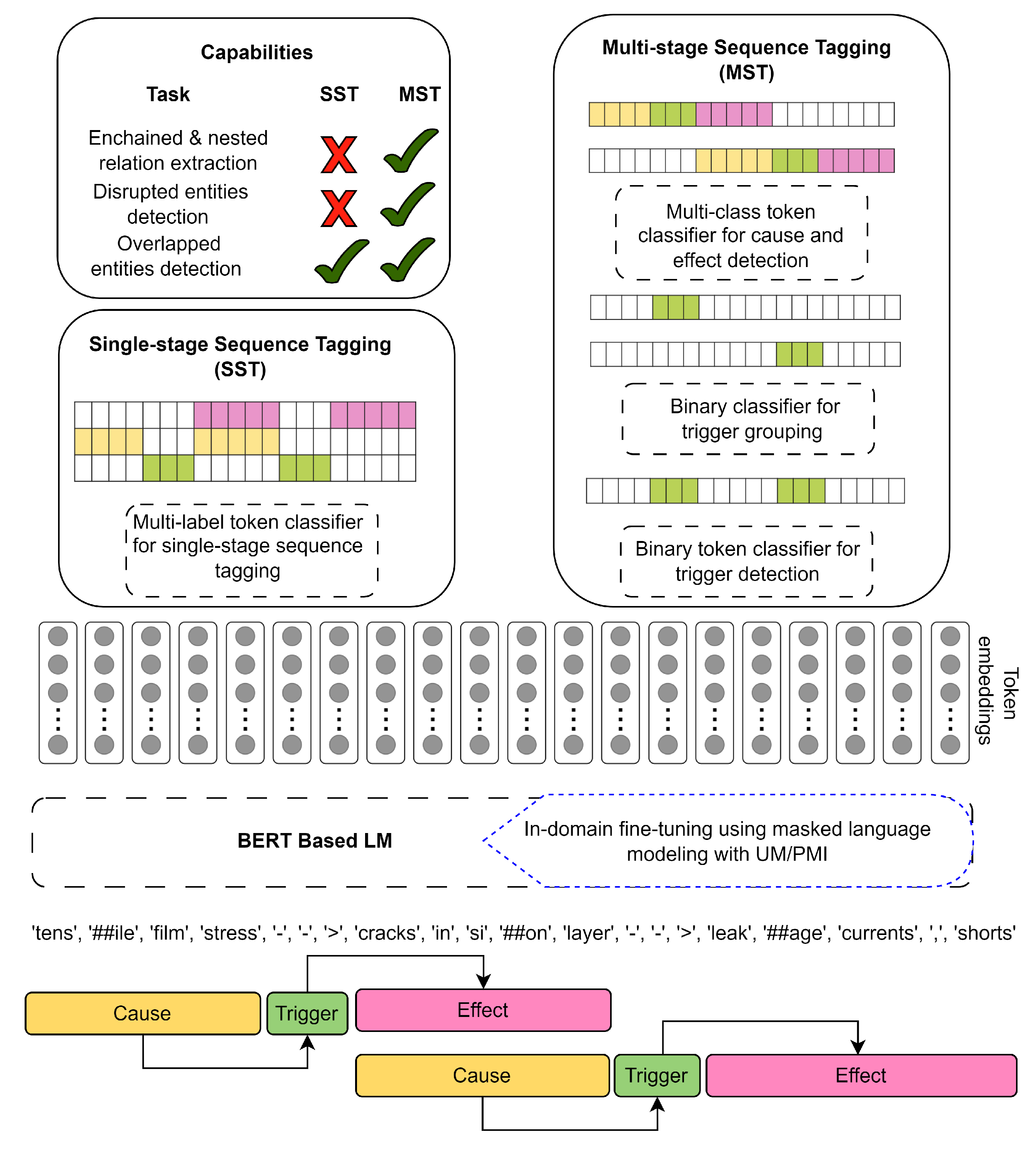
- Automated causal information extraction from text (the Model training step in Figure 1): This step involves extracting a meaningful vectorized text representation, leveraging this representation to develop causal information extraction methods that transfer the information contained in the text to a set of named entities and relations between these entities. Namely, we propose two approaches: the first one based on SST, and the second one based on MST. This step is elaborated in Section 3.3.
3.1. Text Extraction from Different Document Formats
3.2. Structured Data Representation of Causal Information
- Causal relations are only annotated on text level, which corresponds to a single FMEA cell or a text box recognized by the OCR in the case of a presentation slides. Relations between entities that belong to different texts are disregarded.
- Two entities—either two effects or two causes—are annotated as a single entity if they are linked to the same cause or effect [30]. Example: Die chipping/crackEffect due toTrigger dicing process condition/parameters and the wafer condition in kerf areaCause.
- Causal relations can be chained [30]. The effect of a cause can be the cause of another effect. Example: Due toTriggera wrong implantation doseCause, the compensation was destroyedEffect Cause, and thereforeTrigger, the lot was disregardedEffect. In the example, the entity “the compensation was destroyed” is the effect of “a wrong implementation dose” and the cause of “the lot was disregarded”.
- Nested relations are allowed. There can be causal relations inside an entity (cause or effect). Example: Foreign material or residue does not cause failure at wafer testEffect due toTrigger thin isolation, inhibiting leakage currentCause. In the example, “thin isolation, inhibiting leakage current” is the cause of the first part of the sentence, but within this cause, there is another causal relation, since “Thin isolation” is the inhibitory cause of “leakage current”. In this case, we annotate the cause as well as the entities and the relations within the cause.
- Entities can be interrupted by other entities. Interrupted entities are annotated as one entity, excluding the part that belongs to another entity. Example: Due to a wrong implantation dose, the compensation was destroyedCause, and the lot wasEffect thusTrigger disregardedEffect.
- Entities are only annotated if there is a complete causal relation with a cause, an effect, and a trigger.
- Causal relations without an explicit trigger are disregarded [29].
- Lexical causatives are disregarded [28,29]. Example: Electrical and mechanical stress at application environment is cracking the isolation layer between defect and conductive line. Sentences with transitive verbs like “to crack” are not considered causal, even though one could argue that, in the example, the action of cracking is the cause for the crack. Such relations are disregarded since the entities and the trigger cannot be clearly separated.
- Hypothetical and assumed causal relations are annotated. Example: Scratches at Wafer BSEffect, most probably due toTrigger particlesCause.
- Future causal relations are considered. Example: Sentences like “X will lead to Y” are annotated.
- Relative pronouns are annotated as part of the cause or effect. Example: There is a QMP regarding edge damage whichCause could causeTrigger the flying diesEffect.
3.3. Automated Causal Information Extraction from Text
3.4. Evaluation Methodology
4. Experiments and Results
5. Discussion
Limitations and Opportunities
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Avg | Average |
| FMEA | Failure Mode and Effects Analysis |
| IAA | Inter-Annotator Agreement |
| MST | Multi-Stage Sequence Tagging |
| NER | Named Entity Recognition |
| PMI | Point-Wise Mutual Information masking |
| SST | Single-Stage Sequence Tagging |
| UM | Uniform Masking |
References
- Hu, Y.; Zhang, X.; Ngai, E.; Cai, R.; Liu, M. Software project risk analysis using Bayesian networks with causality constraints. Decis. Support Syst. 2013, 56, 439–449. [Google Scholar] [CrossRef]
- Saha, A.; Hoi, S.C. Mining root cause knowledge from cloud service incident investigations for AIOps. In Proceedings of the 44th International Conference on Software Engineering: Software Engineering in Practice, Pittsburgh, PA, USA, 25–27 May 2022; pp. 197–206. [Google Scholar]
- Anand, S.S.; Bell, D.A.; Hughes, J.G. The role of domain knowledge in data mining. In Proceedings of the Fourth International Conference on Information and Knowledge Management, Baltimore, MD, USA, 28 November–2 December 1995; pp. 37–43. [Google Scholar]
- Razouk, H.; Kern, R. Improving the consistency of the Failure Mode Effect Analysis (FMEA) documents in semiconductor manufacturing. Appl. Sci. 2022, 12, 1840. [Google Scholar] [CrossRef]
- Hayama, T.; Nanba, H.; Kunifuji, S. Structure extraction from presentation slide information. In Proceedings of the PRICAI 2008: Trends in Artificial Intelligence: 10th Pacific Rim International Conference on Artificial Intelligence, Hanoi, Vietnam, 15–19 December 2008; Proceedings 10. Springer: Berlin/Heidelberg, Germany, 2008; pp. 678–687. [Google Scholar]
- Girju, R. Automatic detection of causal relations for question answering. In Proceedings of the ACL 2003 Workshop on Multilingual Summarization and Question Answering, Sapporo, Japan, 8–10 July 2003; pp. 76–83. [Google Scholar]
- Yang, J.; Han, S.C.; Poon, J. A survey on extraction of causal relations from natural language text. Knowl. Inf. Syst. 2022, 64, 1161–1186. [Google Scholar] [CrossRef]
- Gärber, D. Causal Relationship Extraction from Historical Texts using BERT. Master’s Thesis, Graz University of Technology, Graz, Austria, 2022. [Google Scholar]
- Gopalakrishnan, S.; Chen, V.Z.; Dou, W.; Hahn-Powell, G.; Nedunuri, S.; Zadrozny, W. Text to Causal Knowledge Graph: A Framework to Synthesize Knowledge from Unstructured Business Texts into Causal Graphs. Information 2023, 14, 367. [Google Scholar] [CrossRef]
- Saha, A.; Ni, J.; Hassanzadeh, O.; Gittens, A.; Srinivas, K.; Yener, B. SPOCK at FinCausal 2022: Causal Information Extraction Using Span-Based and Sequence Tagging Models. In Proceedings of the 4th Financial Narrative Processing Workshop@ LREC2022, Marseille, France, 24 June 2022; pp. 108–111. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef]
- Richie, R.; Grover, S.; Tsui, F.R. Inter-annotator agreement is not the ceiling of machine learning performance: Evidence from a comprehensive set of simulations. In Proceedings of the 21st Workshop on Biomedical Language Processing, Dublin, Ireland, 26 May 2022; pp. 275–284. [Google Scholar]
- Razouk, H.; Liu, X.L.; Kern, R. Improving FMEA Comprehensibility via Common-Sense Knowledge Graph Completion Techniques. IEEE Access 2023, 11, 127974–127986. [Google Scholar] [CrossRef]
- Reklos, I.; Meroño-Peñuela, A. Medicause: Causal relation modelling and extraction from medical publications. In Proceedings of the 1st International Workshop on Knowledge Graph Generation From Text co-located with 19th Extended Semantic Conference (ESWC 2022), Hersonissos, Greece, 30 May 2022; Volume 3184, pp. 1–18. [Google Scholar]
- Seol, J.W.; Jo, S.H.; Yi, W.; Choi, J.; Lee, K.S. A Problem-Action Relation Extraction Based on Causality Patterns of Clinical Events in Discharge Summaries. In Proceedings of the 23rd ACM International Conference on Conference on Information and Knowledge Management, Shanghai, China, 3–7 November 2014; pp. 1971–1974. [Google Scholar]
- Negi, K.; Pavuri, A.; Patel, L.; Jain, C. A novel method for drug-adverse event extraction using machine learning. Inform. Med. Unlocked 2019, 17, 100190. [Google Scholar] [CrossRef]
- Aerts, W.; Zhang, S. Management’s causal reasoning on performance and earnings management. Eur. Manag. J. 2014, 32, 770–783. [Google Scholar] [CrossRef]
- Nam, K.; Seong, N. Financial news-based stock movement prediction using causality analysis of influence in the Korean stock market. Decis. Support Syst. 2019, 117, 100–112. [Google Scholar] [CrossRef]
- Kong, M.; Li, R.; Wang, J.; Li, X.; Jin, S.; Xie, W.; Hou, M.; Cao, C. Cftnet: A Robust Credit Card Fraud Detection Model Enhanced by Counterfactual Data Augmentation. Neural Comput. Appl. 2024, 36, 8607–8623. [Google Scholar] [CrossRef]
- Tang, Y.; Xiong, J.J.; Luo, Y.; Zhang, Y.C. How do the global stock markets Influence one another? Evidence from finance big data and granger causality directed network. Int. J. Electron. Commer. 2019, 23, 85–109. [Google Scholar] [CrossRef]
- Ravivanpong, P.; Riedel, T.; Stock, P. Towards Extracting Causal Graph Structures from TradeData and Smart Financial Portfolio Risk Management. In Proceedings of the EDBT/ICDT Workshops, Edinburgh, UK, 29 March 2022. [Google Scholar]
- Mariko, D.; Abi Akl, H.; Trottier, K.; El-Haj, M. The financial causality extraction shared task (FinCausal 2022). In Proceedings of the 4th Financial Narrative Processing Workshop@ LREC2022, Marseille, France, 24 June 2022; pp. 105–107. [Google Scholar]
- Safont-Andreu, A.; Burmer, C.; Schekotihin, K. Using Ontologies in Failure Analysis. In Proceedings of the ISTFA 2021 ASM International, Phoenix, AZ, USA, 31 October–4 November 2021; pp. 23–28. [Google Scholar]
- Yuan, X.; Chen, K.; Zuo, W.; Zhang, Y. TC-GAT: Graph Attention Network for Temporal Causality Discovery. arXiv 2023, arXiv:2304.10706. [Google Scholar]
- Glymour, C.; Zhang, K.; Spirtes, P. Review of causal discovery methods based on graphical models. Front. Genet. 2019, 10, 524. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.L.; Yu, L.C.; Chang, P.C. Detecting causality from online psychiatric texts using inter-sentential language patterns. BMC Med. Inform. Decis. Mak. 2012, 12, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Akkasi, A.; Moens, M.F. Causal relationship extraction from biomedical text using deep neural models: A comprehensive survey. J. Biomed. Inform. 2021, 119, 103820. [Google Scholar] [CrossRef]
- Dunietz, J.; Levin, L.; Carbonell, J. Annotating Causal Language Using Corpus Lexicography of Constructions. In Proceedings of the 9th Linguistic Annotation Workshop, Denver, CO, USA, 5 June 2015; pp. 188–196. [Google Scholar] [CrossRef]
- Dunietz, J.; Levin, L.; Carbonell, J. The BECauSE Corpus 2.0: Annotating Causality and Overlapping Relations. In Proceedings of the 11th Linguistic Annotation Workshop, Valencia, Spain, 3 April 2017; pp. 95–104. [Google Scholar] [CrossRef]
- Mariko, D.; Labidurie, E.; Ozturk, Y.; Akl, H.A.; de Mazancourt, H. Data Processing and Annotation Schemes for FinCausal Shared Task. arXiv 2020, arXiv:2012.02498. [Google Scholar]
- Liu, X.L.; Salhofer, E.; Andreu, A.S.; Kern, R. S2ORC-SemiCause: Annotating and Analysing Causality in the Semiconductor Domain; River Publishers: Aalborg, Denmark, 2022. [Google Scholar]
- Khetan, V.; Ramnani, R.; Anand, M.; Sengupta, S.; Fano, A.E. Causal BERT: Language models for causality detection between events expressed in text. arXiv 2020, arXiv:2012.05453. [Google Scholar]
- Lee, J.; Pham, L.H.; Uzuner, O. Mnlp at fincausal2022: Nested ner with a generative model. In Proceedings of the 4th Financial Narrative Processing Workshop@ LREC2022, Marseille, France, 24 June 2022; pp. 135–138. [Google Scholar]
- Khetan, V.; Rizvi, M.I.H.; Huber, J.; Bartusiak, P.; Sacaleanu, B.; Fano, A. MIMICause: Representation and automatic extraction of causal relation types from clinical notes. arXiv 2021, arXiv:2110.07090. [Google Scholar]
- Levine, Y.; Lenz, B.; Lieber, O.; Abend, O.; Leyton-Brown, K.; Tennenholtz, M.; Shoham, Y. Pmi-masking: Principled masking of correlated spans. arXiv 2020, arXiv:2010.01825. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Walker, N.; Trewartha, A.; Huo, H.; Lee, S.; Cruse, K.; Dagdelen, J.; Dunn, A.; Persson, K.; Ceder, G.; Jain, A. The Impact of Domain-Specific Pre-Training on Named Entity Recognition Tasks in Materials Science. Patterns 2021, 3, 100488. [Google Scholar] [CrossRef]
- Tosone, D. Improving FMEA consistency in semiconductor manufacturing through text classification. Master’s Thesis, University of Udine, Alpen-Adria-Universität Klagenfurt, Klagenfurt, Austria, 2022. [Google Scholar]
- Mindee. docTR: Document Text Recognition. 2021. Available online: https://github.com/mindee/doctr (accessed on 1 March 2023).
- Stenetorp, P.; Pyysalo, S.; Topić, G.; Ohta, T.; Ananiadou, S.; Tsujii, J. brat: A Web-based Tool for NLP-Assisted Text Annotation. In Proceedings of the Demonstrations Session at EACL 2012, Avignon, France, 23–27 April 2012. [Google Scholar]
- Niess, G.; Razouk, H.; Mandic, S.; Kern, R. Addressing Hallucination in Causal Q&A: The Efficacy of Fine-tuning over Prompting in LLMs. In Proceedings of the Joint Workshop of the 9th Financial Technology and Natural Language Processing (FinNLP), The 6th Financial Narrative Processing (FNP), and the 1st Workshop on Large Language Models for Finance and Legal (LLMFinLegal), Abu Dhabi, United Arab Emirates, 19–20 January 2025; pp. 253–258. [Google Scholar]
- Riaz, M.; Girju, R. Another look at causality: Discovering scenario-specific contingency relationships with no supervision. In Proceedings of the 2010 IEEE Fourth International Conference on Semantic Computing, Pittsburgh, PA, USA, 22–24 September 2010; pp. 361–368. [Google Scholar]


{kind=link}
{kind=link}
| Annotation | Data Set | Micro Avg | Macro Avg | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FMEA | Slides | FMEA and Slides | FMEA and Slides | |||||||||
| Trigger | 94 | 94 | 8 | 93 | 93 | 3 | 94 | 94 | 5 | 94 | 94 | 6 |
| Cause | 87 | 90 | 23 | 84 | 85 | 9 | 87 | 88 | 14 | 86 | 88 | 16 |
| Effect | 86 | 88 | 16 | 67 | 68 | 6 | 81 | 83 | 10 | 76 | 78 | 11 |
| Macro Avg | 89 | 91 | 16 | 81 | 82 | 6 | 87 | 88 | 10 | 85 | 86 | 11 |
| Model | Annotation | Test Data Set | Micro Avg | Macro Avg | |||||
|---|---|---|---|---|---|---|---|---|---|
| FMEA | Slides | FMEA and Slides | FMEA and Slides | ||||||
| SST | MST | SST | MST | SST | MST | SST | MST | ||
| BERT | Trigger | 98 ± 1 | 98 ± 2 | 75 ± 4 | 81 ± 2 | 86 ± 2 | 89 ± 2 | 86 ± 2 | 90 ± 2 |
| Cause | 88 ± 2 | 88 ± 4 | 61 ± 3 | 62 ± 6 | 74 ± 2 | 73 ± 5 | 74 ± 2 | 75 ± 5 | |
| Effect | 74 ± 9 | 85 ± 6 | 61 ± 6 | 58 ± 2 | 67 ± 7 | 69 ± 3 | 68 ± 8 | 72 ± 4 | |
| Macro Avg | 87 ± 4 | 90 ± 4 | 66 ± 4 | 67 ± 3 | 76 ± 4 | 77 ± 3 | 76 ± 4 | 79 ± 4 | |
| Trigger Grouping | - | 96 ± 3 | - | 97 ± 4 | - | 96 ± 4 | - | 96 ± 4 | |
| BERT UM | Trigger | 99 ± 1 | 98 ± 1 | 81 ± 4 | 81 ± 3 | 89 ± 2 | 89 ± 1 | 90 ± 2 | 90 ± 2 |
| Cause | 92 ± 5 | 87 ± 7 | 63 ± 6 | 57 ± 6 | 76 ± 4 | 71 ± 4 | 78 ± 6 | 72 ± 6 | |
| Effect | 90 ± 4 | 89 ± 3 | 67 ± 6 | 57 ± 4 | 76 ± 4 | 70 ± 2 | 78 ± 5 | 73 ± 4 | |
| Macro Avg | 94 ± 3 | 91 ± 4 | 70 ± 5 | 65 ± 4 | 80 ± 3 | 77 ± 2 | 82 ± 4 | 78 ± 4 | |
| Trigger Grouping | - | 98 ± 3 | - | 100 ± 0 | - | 99 ± 1 | - | 99 ± 2 | |
| BERT PMI | Trigger | 99 ± 1 | 99 ± 1 | 79 ± 3 | 82 ± 4 | 89 ± 2 | 90 ± 2 | 89 ± 2 | 90 ± 2 |
| Cause | 89 ± 5 | 90 ± 3 | 65 ± 3 | 64 ± 6 | 76 ± 3 | 75 ± 4 | 77 ± 4 | 77 ± 4 | |
| Effect | 88 ± 7 | 91 ± 5 | 71 ± 4 | 59 ± 2 | 78 ± 5 | 73 ± 2 | 80 ± 6 | 75 ± 4 | |
| Macro Avg | 92 ± 4 | 93 ± 3 | 72 ± 3 | 68 ± 4 | 81 ± 3 | 79 ± 3 | 82 ± 4 | 81 ± 3 | |
| Trigger Grouping | - | 98 ± 1 | - | 100 ± 1 | - | 99 ± 0 | - | 99 ± 1 | |
| MatBERT | Trigger | 97 ± 2 | 98 ± 1 | 76 ± 3 | 80 ± 4 | 86 ± 2 | 89 ± 2 | 86 ± 2 | 89 ± 2 |
| Cause | 87 ± 3 | 89 ± 2 | 64 ± 17 | 66 ± 7 | 75 ± 8 | 75 ± 3 | 76 ± 10 | 78 ± 5 | |
| Effect | 82 ± 8 | 93 ± 4 | 60 ± 10 | 64 ± 5 | 71 ± 9 | 79 ± 2 | 71 ± 9 | 78 ± 4 | |
| Macro Avg | 89 ± 4 | 93 ± 2 | 67 ± 10 | 70 ± 5 | 77 ± 6 | 81 ± 2 | 78 ± 7 | 82 ± 4 | |
| Trigger Grouping | - | 95 ± 4 | - | 98 ± 3 | - | 96 ± 2 | - | 96 ± 4 | |
| MatBERT UM | Trigger | 97 ± 2 | 97 ± 1 | 78 ± 4 | 81 ± 4 | 87 ± 3 | 88 ± 2 | 88 ± 3 | 89 ± 2 |
| Cause | 88 ± 4 | 86 ± 8 | 66 ± 11 | 69 ± 6 | 76 ± 5 | 76 ± 3 | 77 ± 8 | 77 ± 7 | |
| Effect | 84 ± 9 | 89 ± 4 | 69 ± 6 | 63 ± 8 | 77 ± 6 | 75 ± 3 | 76 ± 6 | 76 ± 6 | |
| Macro Avg | 90 ± 4 | 91 ± 4 | 71 ± 7 | 71 ± 6 | 80 ± 5 | 80 ± 3 | 80 ± 6 | 81 ± 5 | |
| Trigger Grouping | - | 96 ± 2 | - | 98 ± 2 | - | 97 ± 2 | - | 97 ± 2 | |
| MatBERT PMI | Trigger | 96 ± 1 | 98 ± 1 | 76 ± 5 | 82 ± 4 | 86 ± 3 | 90 ± 2 | 86 ± 3 | 90 ± 2 |
| Cause | 83 ± 8 | 88 ± 4 | 67 ± 7 | 65 ± 4 | 74 ± 1 | 75 ± 3 | 75 ± 8 | 76 ± 4 | |
| Effect | 86 ± 10 | 94 ± 3 | 65 ± 10 | 72 ± 6 | 76 ± 10 | 82 ± 4 | 76 ± 10 | 83 ± 4 | |
| Macro Avg | 88 ± 6 | 93 ± 3 | 69 ± 7 | 73 ± 5 | 79 ± 5 | 82 ± 3 | 79 ± 7 | 83 ± 3 | |
| Trigger Grouping | - | 93 ± 4 | - | 98 ± 2 | - | 96 ± 2 | - | 96 ± 3 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Razouk, H.; Benischke, L.; Gärber, D.; Kern, R. Increasing the Accessibility of Causal Domain Knowledge via Causal Information Extraction Methods: A Case Study in the Semiconductor Manufacturing Industry. Appl. Sci. 2025, 15, 2573. https://doi.org/10.3390/app15052573
Razouk H, Benischke L, Gärber D, Kern R. Increasing the Accessibility of Causal Domain Knowledge via Causal Information Extraction Methods: A Case Study in the Semiconductor Manufacturing Industry. Applied Sciences. 2025; 15(5):2573. https://doi.org/10.3390/app15052573
Chicago/Turabian StyleRazouk, Houssam, Leonie Benischke, Daniel Gärber, and Roman Kern. 2025. "Increasing the Accessibility of Causal Domain Knowledge via Causal Information Extraction Methods: A Case Study in the Semiconductor Manufacturing Industry" Applied Sciences 15, no. 5: 2573. https://doi.org/10.3390/app15052573
APA StyleRazouk, H., Benischke, L., Gärber, D., & Kern, R. (2025). Increasing the Accessibility of Causal Domain Knowledge via Causal Information Extraction Methods: A Case Study in the Semiconductor Manufacturing Industry. Applied Sciences, 15(5), 2573. https://doi.org/10.3390/app15052573