
Meta-Data-Guided Robust Deep Neural Network Classification with Noisy Label




Abstract
1. Introduction
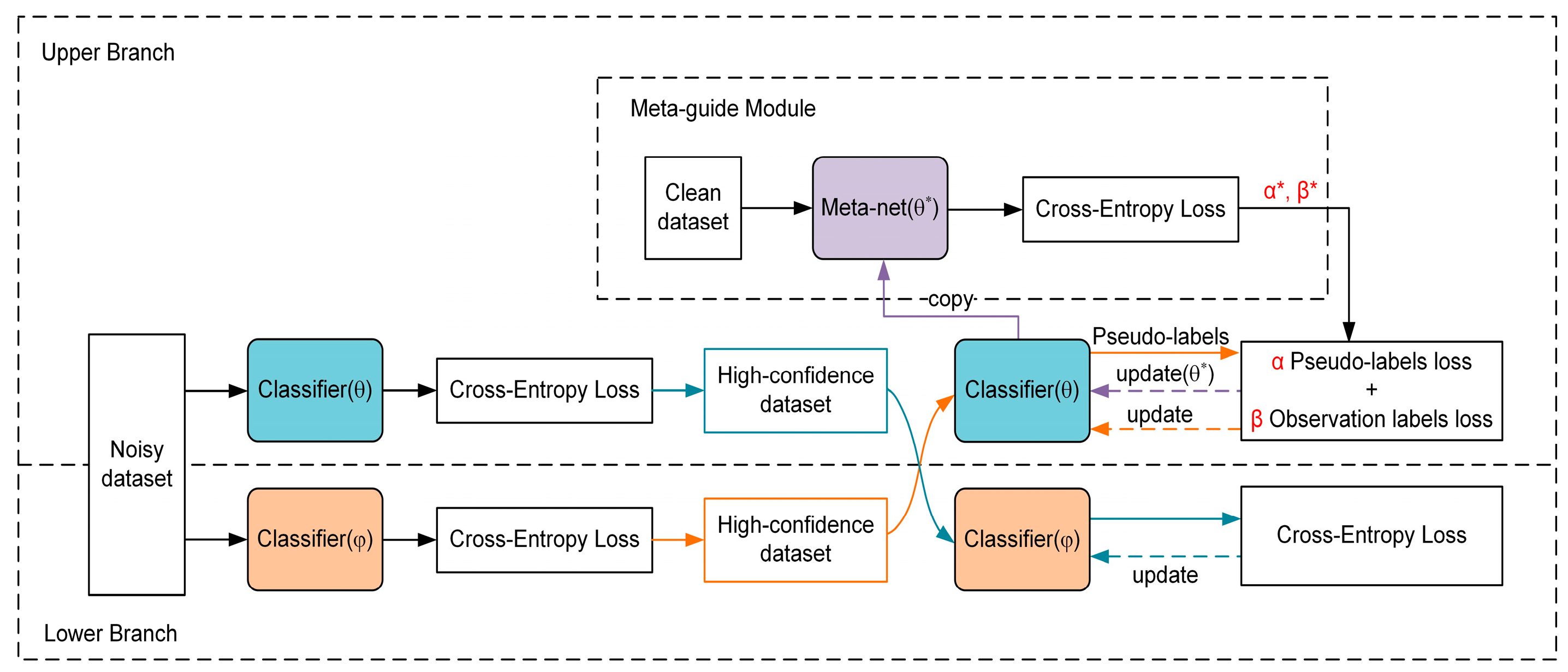
- We propose a cross dual-branch classifier framework enhanced with meta-learning to guide each other and achieve adaptive sample relabeling, CoNet-MS. CoNet-MS can improve the accuracy of classifiers by cross-guiding dual-branch and reweighting labels with the meta-guided module on the upper branch. Two classifier networks with divergent initialization can facilitate learning complementary features to filter distinct errors from noisy labels. Following the small-loss principle [13] where DNNs prioritize clean samples, each branch treats low-loss samples as high-confidence pseudo-clean ones. Cross-filtering high-confidence samples can alleviate error accumulation and mitigate overfitting to noisy labels. The meta-guided module in the upper branch further diversifies the dual branches, enhancing framework robustness.
- Furthermore, the innovative meta-net module in the upper branch dynamically adjusts the weights of the output of the observed and pseudo-label by the upper classifier in the loss function, using part of the clean dataset. In brief, the clean data information is implicitly utilized to guide the pseudo-labeling correction of the samples instead of participating directly in training.
- We experimentally demonstrate that the proposed meta-learning enhanced cross-dual network framework, CoNet-MS can improve the robustness of the model to label noise. Specifically, CoNet-MS achieves significant performance improvements compared to L2B. In addition, we also provide a comprehensive comparison with state-of-the-art (SOTA) techniques [9,10,11], and the result shows that our method has superior performance, highlighting the advantages of CoNet-MS in the field of meta-learning and LNLs.
2. Related Works
3. The Proposed CoNet-MS Framework and Its Main Modules
3.1. Problem Statement
3.2. The Overall Framework of CoNet-MS
3.3. Cross Dual-Branch Classifier Network Architecture
3.4. Meta-Guided Module: Reweighting Losses Between the Pseudo-Label and the Observed Label in Upper Branch
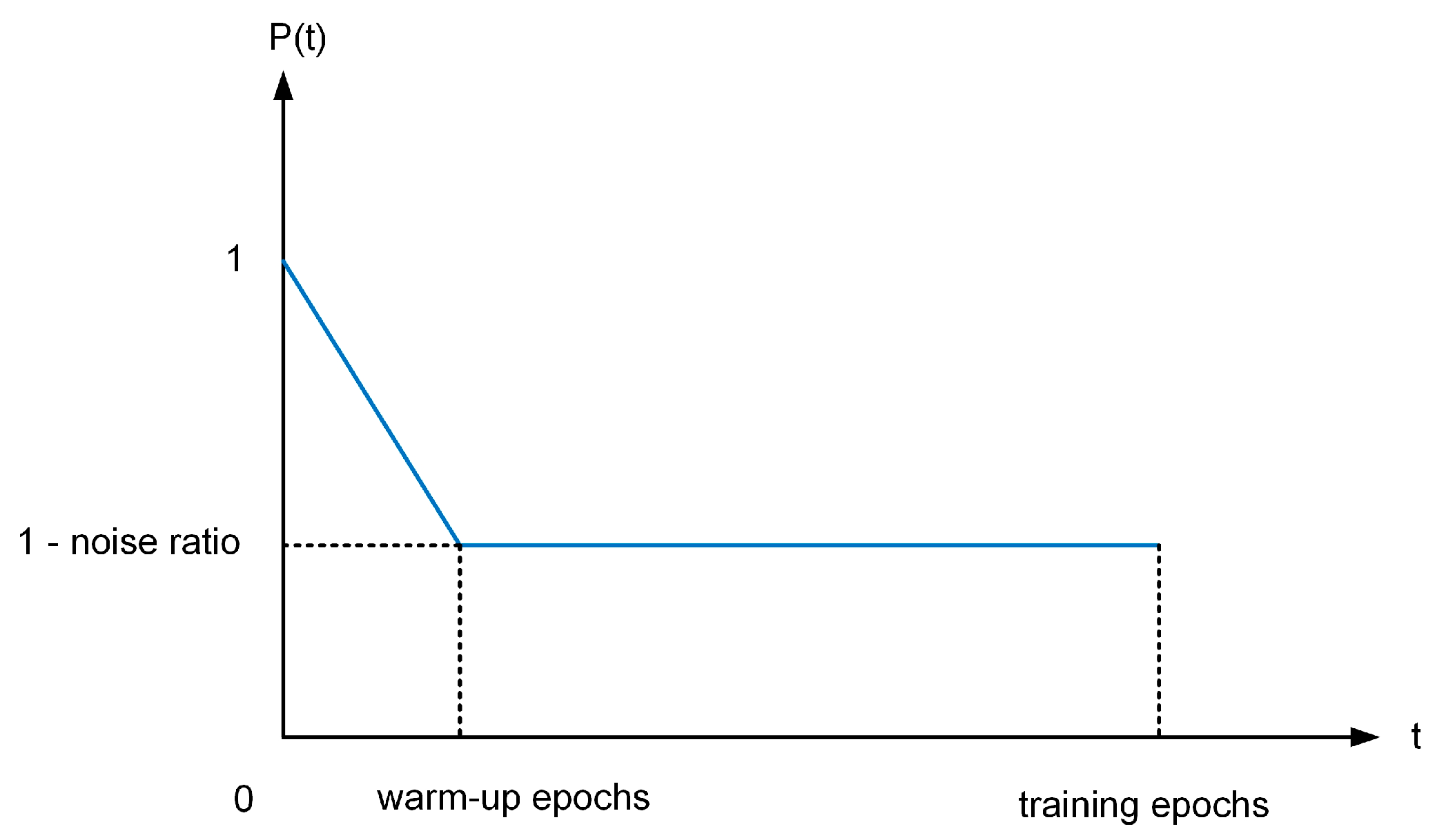
3.5. Training Pseudo-Codes
| Algorithm 1 CoNet-MS |
| 1: Input: |
| 2: Output: |
| 3: for to do |
| 4: SampleMiniBatch |
| 5: SampleMiniBatch |
| 6: for each sample in do 7: 8: Initialize learnable weights 9: Compute Meta-net parameters by Equation (7) 10: Update Hyperparameters by Equation (9)–(11) 11: Obtain by Equation (4) 12: Obtain by Equation (5) 13: end for 14: Update by Equation (12) 15: Update by Equation (13) 16: end for |
4. Experiments
4.1. Experimental Datasets
4.2. Baselines
- Conventional cross entropy: Training a classifier neural network directly with noisy data as the most basic and lowest-bound comparison to visualize the effect of noisy labels on classification performance.
- Co-teaching [9]: Simultaneously training two classifier networks. Based on the small-loss principle, each network guides the other network to filter out the noisy data during training to reduce the influence of noisy samples.
- MetaLabelNet [10]: Alternatively training a meta-network using meta-data and letting the meta-network generate pseudo-labels for training samples to guide the updating of a classifier.
- L2B [11]: Using meta-data to reweight loss function weights, adjust sample influence and implicitly correct labels.
4.3. Evaluation Metrics
- TP (true positive): the number of samples that are actually positive and predicted to be positive;
- FP (false positive): the number of samples that are actually negative but predicted to be positive;
- FN (false negative): the number of samples that are actually positive but predicted to be negative;
- TN (true negative): the number of samples that are actually negative and predicted to be negative.
4.4. Experimental Settings
4.5. Performance Evaluation
Comparison with the State-of-the-Art Methods
- Firstly, CoNet-MS shows the best classification performance under many different noise rates among all schemes, which fully demonstrates the superiority and robustness of our proposed scheme.
- L2B achieves the second-best test accuracy under all noise scenarios by adjusting the loss weights by meta-learning to counteract noisy labels. However, it is not sufficient to reduce the influence of noisy samples in the loss function, and there is a gap between the pseudo-label assigned to the samples and the ground-truth label. Our scheme makes the following improvement: introducing a dual-network sample filtering mechanism to discard samples with lower confidence and retain more valuable samples at each update. Empirically, compared to L2B, our scheme CoNet-MS achieves better classification accuracy at different noise rates, with a improvement in test accuracy under the scenario of high noise rate (), demonstrating the high robustness of our scheme to high-ratio noise.
- Although MetaLabelNet uses part of clean data, i.e., meta-data for the relabeling of training samples, the meta-network is only trained on clean datasets and may overfit to these data and lead to the biased soft label for other training samples, which may affect the classifier performance. To solve this problem, CoNet-MS utilizes the meta-net to reweight the loss value between the pseudo-label and the observed label of the training sample while filtering samples through the cross dual-branch structure. As a result, the classification accuracy of the final model is improved by nearly compared to the former in the case of an 80% noise rate.
- The co-teaching method utilizes the “small loss” principle to filter out samples with high confidence and achieves good noise immunity by filtering potentially noisy samples from two networks with different parameters. However, simply using small loss to select training samples may result in leftover noise labels, and even worse, we cannot use the abundant samples with noisy labels, which may negatively affect the model. To address this issue, CoNet-MS proposed implicitly realizes the discarding of noisy samples by dynamically weighting the loss function to reduce the impact of lower confidence samples when updating the network. In addition, CoNet-MS also performs label estimation, which further improves the accuracy of the model by correcting the sample labels.
- Unlike L2B, which relies solely on meta-weights, CoNet-MS further reduces confirmation bias by cross-validating pseudo-labels between two networks, leading to a 0.47% accuracy gain over L2B.
- Compared to co-teaching (73.85%), our method shows stronger resilience to high noise ratios, indicating that meta-learning enhances the precision of the sample selection of co-teaching.
- First of all, under the imbalanced dataset, CoNet-MS outperforms all baseline methods in both noise types. Specifically, under uniform noise, CoNet-MS achieves the highest accuracy of 74.23%, which is a 1.82% improvement compared to L2B. Meanwhile, with a pair-flipping noise rate of 40%, our scheme still achieves the best performance, i.e., 69.75% accuracy, but improves by only 0.51% relative to L2B, reflecting the particular challenges caused by the noise between similar classes in an imbalanced dataset, which should be thoroughly investigated in future work.
- Secondly, compared with results in Table 3 and Table 4, that is, the test accuracy of uniform and pair-flipping noises on the balanced dataset, i.e., CIFAR-10, the results in Table 5 and Table 6 are generally smaller than those in Table 3 and Table 4. It is well known that an imbalanced training dataset will have a negative effect on classification accuracy, even in a training dataset with fully clean labels.
- As shown in Table 5, under uniform noise, our method achieves the Macro F1 of 0.7234, surpassing co-teaching and L2B. This indicates that CoNet-MS not only improves overall accuracy but also better balances precision and recall across imbalanced classes. For pair-flipping noise (Table 6), CoNet-MS attains the Macro F1 of 0.6734, marginally exceeding L2B. The smaller Macro F1 gap (0.0076) compared to the uniform noise scenario (0.0136) aligns with the observed accuracy trend. Specifically, the noise-induced confusion between semantically close classes likely degrades both precision (false positives) and recall (false negatives), thereby limiting Macro F1 gains.
4.6. Ablation Study
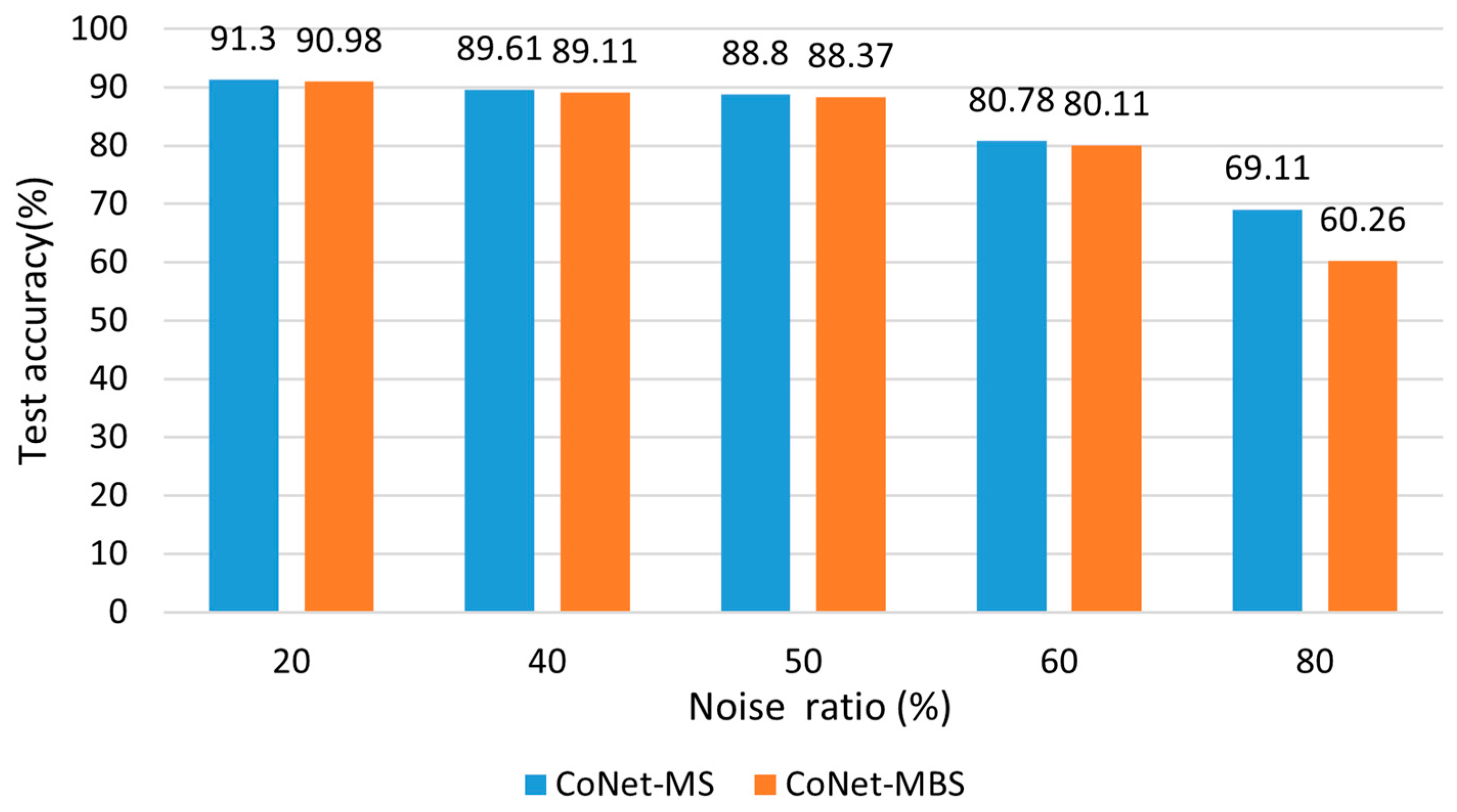
4.6.1. Comparison with Asymmetric CoNet-MS and Symmetric Variant CoNet-MBS
- The test accuracy of CoNet-MS outperforms CoNet-MBS at all noise rates. A key idea of a dual-branch classifier network to filter out samples is to utilize the difference in learning capabilities between the two networks for mutual supervision to reduce labeling noise. If two networks simultaneously use the same strategy to adjust the weights, they may interfere with the sample selection process and produce redundant and erroneous sample judgments, thus reducing the selection of valid samples, which in turn affects the model performance. In contrast, if only one network performs meta-learning weight adjustment, that network is better able to utilize its features without being disturbed by another network’s adjustment.
- At low noise rates (e.g., to ), the performance of the two models is very close, while at a high noise rate of , the performance of the CoNet-MS model improves by almost over CoNet-MBS. This is because two networks with simultaneous weight adjustments may lead to overly complex fitting of the model to the training data, especially at high noise rates, which is more likely to result in overfitting, thus reducing the model’s ability to generalize to unseen data.
4.6.2. Comparison of the Outputs of the Upper- and Lower-Branch Classifiers
- The test accuracy of CoNet-MS is the highest at all noise rates. This illustrates that the upper and lower-branch classifiers learn different features and patterns from the data, and when their predictions are averaged, they can combine this complementary information to provide more comprehensive and accurate predictions.
- In addition, Figure 5 shows that the lower classifier has higher test accuracy than the upper classifier at all noise rates. This may be due to the fact that the upper branch is embedded with a meta-guided module, which makes the high-confidence samples of its classifier more reliable. By exchanging high-confidence samples through the dual network, the lower branch receives reliable samples from the upper branch, which improves the accuracy of the lower classifier.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, H.; Kim, M.; Park, D.; Shin, Y.; Lee, J.G. Learning from noisy labels with deep neural networks: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 8135–8153. [Google Scholar] [CrossRef]
- Algan, G.; Ulusoy, I. Image classification with deep learning in the presence of noisy labels: A survey. Knowl.-Based Syst. 2021, 215, 106771. [Google Scholar] [CrossRef]
- Liu, S.; Niles-Weed, J.; Razavian, N.; Fernandez-Granda, C. Early-learning regularization prevents memorization of noisy labels. Adv. Neural Inf. Process. Syst. 2020, 33, 20331–20342. [Google Scholar]
- Yao, Y.; Sun, Z.; Zhang, C.; Shen, F.; Wu, Q.; Zhang, J.; Tang, Z. Jo-src: A contrastive approach for combating noisy labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 5192–5201. [Google Scholar]
- Dgani, Y.; Greenspan, H.; Goldberger, J. Training a neural network based on unreliable human annotation of medical images. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 39–42. [Google Scholar]
- Cheng, J.; Liu, T.; Ramamohanarao, K.; Tao, D. Learning with bounded instance and label-dependent label noise. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 13–18 July 2020; pp. 1789–1799. [Google Scholar]
- Jiang, L.; Zhou, Z.; Leung, T.; Li, L.-J.; Fei-Fei, L. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 2304–2313. [Google Scholar]
- Arpit, D.; Jastrzkebski, S.; Ballas, N.; Krueger, D.; Bengio, E.; Kanwal, M.S.; Maharaj, T.; Fischer, A.; Courville, A.; Bengio, Y.; et al. A closer look at memorization in deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 233–242. [Google Scholar]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. Adv. Neural Inf. Process. Syst. 2018, 31, 8536–8546. [Google Scholar]
- Algan, G.; Ulusoy, I. Metalabelnet: Learning to generate soft-labels from noisy-labels. IEEE Trans. Image Process. 2022, 31, 4352–4362. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Li, X.; Liu, F.; Wei, Q.; Chen, X.; Yu, L.; Xie, C.; Lungren, M.P.; Xing, L. L2B: Learning to Bootstrap Robust Models for Combating Label Noise. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 23523–23533. [Google Scholar]
- Algan, G.; Ulusoy, I. Meta soft label generation for noisy labels. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 7142–7148. [Google Scholar]
- Li, M.; Soltanolkotabi, M.; Oymak, S. Gradient descent with early stopping is provably robust to label noise for overparameterized neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Online Conference, 26–28 August 2020; pp. 4313–4324. [Google Scholar]
- Xia, X.; Liu, T.; Wang, N.; Han, B.; Gong, C.; Niu, G.; Sugiyama, M. Are anchor points really indispensable in label-noise learning? Adv. Neural Inf. Process. Syst. 2019, 32, 6835–6846. [Google Scholar]
- Ghosh, A.; Kumar, H.; Sastry, P.S. Robust loss functions under label noise for deep neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Wang, X.; Hua, Y.; Kodirov, E.; Clifton, D.A.; Robertson, N.M. IMAE for noise-robust learning: Mean absolute error does not treat examples equally and gradient magnitude’s variance matters. arXiv 2019, arXiv:1903.12141. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. Adv. Neural Inf. Process. Syst. 2018, 32, 8792–8802. [Google Scholar]
- Wang, Y.; Ma, X.; Chen, Z.; Luo, Y.; Yi, J.; Bailey, J. Symmetric cross entropy for robust learning with noisy labels. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 322–330. [Google Scholar]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Zhang, B.; Li, Y.; Tu, Y.; Peng, J.; Wang, Y.; Wu, C.; Xiao, Y.; Zhao, C. Learning from noisy labels with coarse-to-fine sample credibility modeling. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2022; pp. 21–38. [Google Scholar]
- Li, J.; Socher, R.; Hoi, S.C. Dividemix: Learning with noisy labels as semi-supervised learning. arXiv 2020, arXiv:2002.07394. [Google Scholar]
- Ghosh, A.; Lan, A. Contrastive learning improves model robustness under label noise. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 2703–2708. [Google Scholar]
- Karim, N.; Rizve, M.N.; Rahnavard, N.; Mian, A.; Shah, M. Unicon: Combating label noise through uniform selection and contrastive learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 9676–9686. [Google Scholar]
- Li, J.; Xiong, C.; Hoi, S.C. Learning from noisy data with robust representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9485–9494. [Google Scholar]
- Tanaka, D.; Ikami, D.; Yamasaki, T.; Aizawa, K. Joint optimization framework for learning with noisy labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5552–5560. [Google Scholar]
- Shen, Y.; Sanghavi, S. Learning with bad training data via iterative trimmed loss minimization. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 5739–5748. [Google Scholar]
- Yu, X.; Han, B.; Yao, J.; Niu, G.; Tsang, I.; Sugiyama, M. How does disagreement help generalization against label corruption? In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7164–7173. [Google Scholar]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14 June 2009; pp. 41–48. [Google Scholar]
- Han, B.; Tsang, I.W.; Chen, L.; Celina, P.Y.; Fung, S.-F. Progressive stochastic learning for noisy labels. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 5136–5148. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Wong, Y.; Zhao, Q.; Kankanhalli, M.S. Learning to learn from noisy labeled data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5051–5059. [Google Scholar]
- Zhang, Z.; Zhang, H.; Arik, S.O.; Lee, H.; Pfister, T. Distilling effective supervision from severe label noise. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9294–9303. [Google Scholar]
- Zheng, G.; Awadallah, A.H.; Dumais, S. Meta label correction for noisy label learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Conference, 2–9 February 2021; Volume 35, pp. 11053–11061. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Reed, S.; Lee, H.; Anguelov, D.; Szegedy, C.; Erhan, D.; Rabinovich, A. Training deep neural networks on noisy labels with bootstrapping. arXiv 2014, arXiv:1412.6596. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| The number of samples in the training set | |
| The number of samples in the clean validation set | |
| The batch size of training set | |
| The batch size of clean validation set | |
| Cross-entropy loss function | |
| Pseudo-label of the sample | |
| The number of classes in dataset | |
| ) | |
| The high-confidence proportion of samples in the -th epoch | |
| The weight loss of the pseudo-label for | |
| The high-confidence dataset selected by | |
| The high-confidence dataset selected by | |
| Parameters of the meta-net | |
| Parameters of the upper-branch classifier in the -th epoch | |
| Component | Computational Complexity |
|---|---|
| Cross dual-branch classifier network architecture | |
| Meta-guided module |
| Noise Ratio (%) | 20 | 40 | 50 | 60 | 80 |
|---|---|---|---|---|---|
| Conventional Cross Entropy | 82.86 | 77.84 | 72.06 | 67.62 | 40.02 |
| Co-teaching [9] | 85.88 | 81.02 | 75.84 | 70.28 | 43.88 |
| MetaLabelNet [10] | 83.42 | 77.74 | 75.32 | 71.2 | 49.98 |
| L2B [11] | 89.44 | 87.86 | 85.99 | 77.99 | 66.09 |
| Ours (CoNet-MS) | 91.3 | 89.61 | 88.80 | 80.78 | 69.11 |
| Noise Ratio (%) | 40 |
|---|---|
| Conventional Cross Entropy | 73.24 |
| Co-teaching [9] | 73.85 |
| MetaLabelNet [10] | 84.66 |
| L2B [11] | 87.96 |
| Ours (CoNet-MS) | 88.43 |
| Method | Accuracy (%) | Macro F1 |
|---|---|---|
| Conventional Cross Entropy | 70.47 | 0.6852 |
| Co-teaching [9] | 73.43 | 0.7123 |
| L2B [11] | 72.41 | 0.7098 |
| Ours (CoNet-MS) | 74.23 | 0.7234 |
| Method | Accuracy (%) | Macro F1 |
|---|---|---|
| Conventional Cross Entropy | 62.90 | 0.5918 |
| Co-teaching [9] | 67.49 | 0.6375 |
| L2B [11] | 69.24 | 0.6658 |
| Ours (CoNet-MS) | 69.75 | 0.6734 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, J.; Wang, Y.; Shi, A.; Ma, J.; Jin, Q. Meta-Data-Guided Robust Deep Neural Network Classification with Noisy Label. Appl. Sci. 2025, 15, 2080. https://doi.org/10.3390/app15042080
Lu J, Wang Y, Shi A, Ma J, Jin Q. Meta-Data-Guided Robust Deep Neural Network Classification with Noisy Label. Applied Sciences. 2025; 15(4):2080. https://doi.org/10.3390/app15042080
Chicago/Turabian StyleLu, Jie, Yufeng Wang, Aiju Shi, Jianhua Ma, and Qun Jin. 2025. "Meta-Data-Guided Robust Deep Neural Network Classification with Noisy Label" Applied Sciences 15, no. 4: 2080. https://doi.org/10.3390/app15042080
APA StyleLu, J., Wang, Y., Shi, A., Ma, J., & Jin, Q. (2025). Meta-Data-Guided Robust Deep Neural Network Classification with Noisy Label. Applied Sciences, 15(4), 2080. https://doi.org/10.3390/app15042080