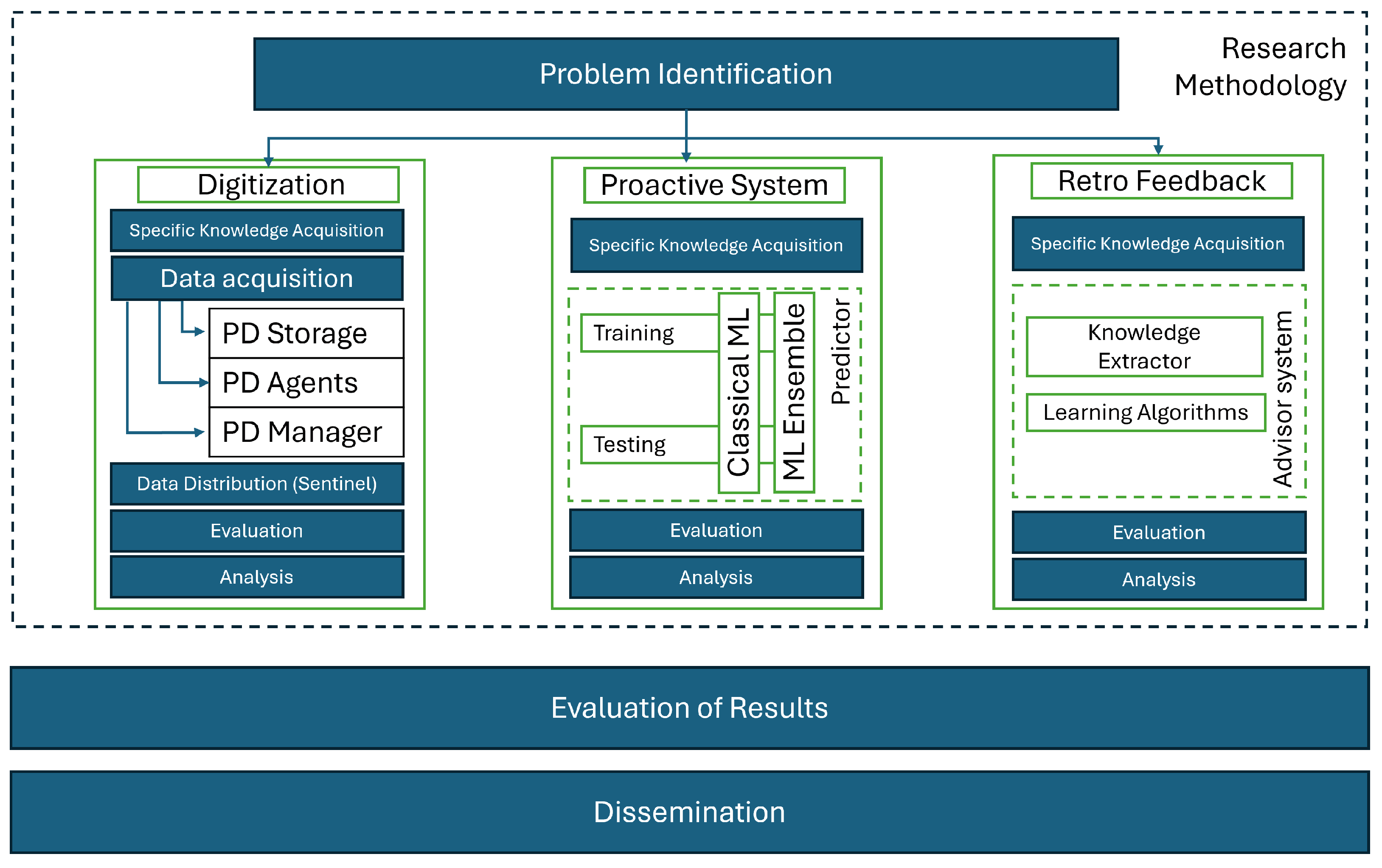
Consequently, after applying the aforementioned methodology and the main goals described by Boscher et al., the global proposed solution is defined as a System of Systems (SoS) comprising an agent-based data gathering architecture for creating a complete manufacturing process digital twin. This system focuses on detecting anomalies through predictions and, finally, an advisory system to redirect the process to normality.
2.1. Digitization and Manufacturing Process Representation
As defined in [
23], a system is a collection of interconnected elements that, when combined, produce results unattainable by the elements operating independently. These elements can be complex and large in scale, consisting of sub-elements working together to achieve a common objective.
The concept of a system of systems refers to a scenario in which the constituent elements are themselves collaborative systems, each exhibiting the characteristic of operational independence. In particular, each individual system can achieve a functional purpose independently, without relying on its involvement in the broader system of systems. Furthermore, each system maintains managerial autonomy, meaning it is managed and evolves to fulfill its own goals rather than those of the overarching system [
24]. As discussed by [
25,
26], these attributes distinguish a system of systems from large monolithic systems. Fields such as enterprise architecture and service-oriented architecture address systems with these defining features, enabling the development of such solutions.
The architecture of a system is critical to its success in meeting the objectives of its stakeholders [
27]. In this case, it is defined as the collection of structures necessary to understand the system, including its components, the relationships between these components, and their properties.
In light of this explanation, the general sub-challenge addressed in this research is to create different individual systems for data collection to build the digital representation of the process. Each system can operate independently and solve the acquisition problem within its own area or domain. Moreover, all of these modules are designed with the necessary communication capabilities to interact and carry out their specific tasks toward achieving the final objective: the optimization of the production process as a whole.
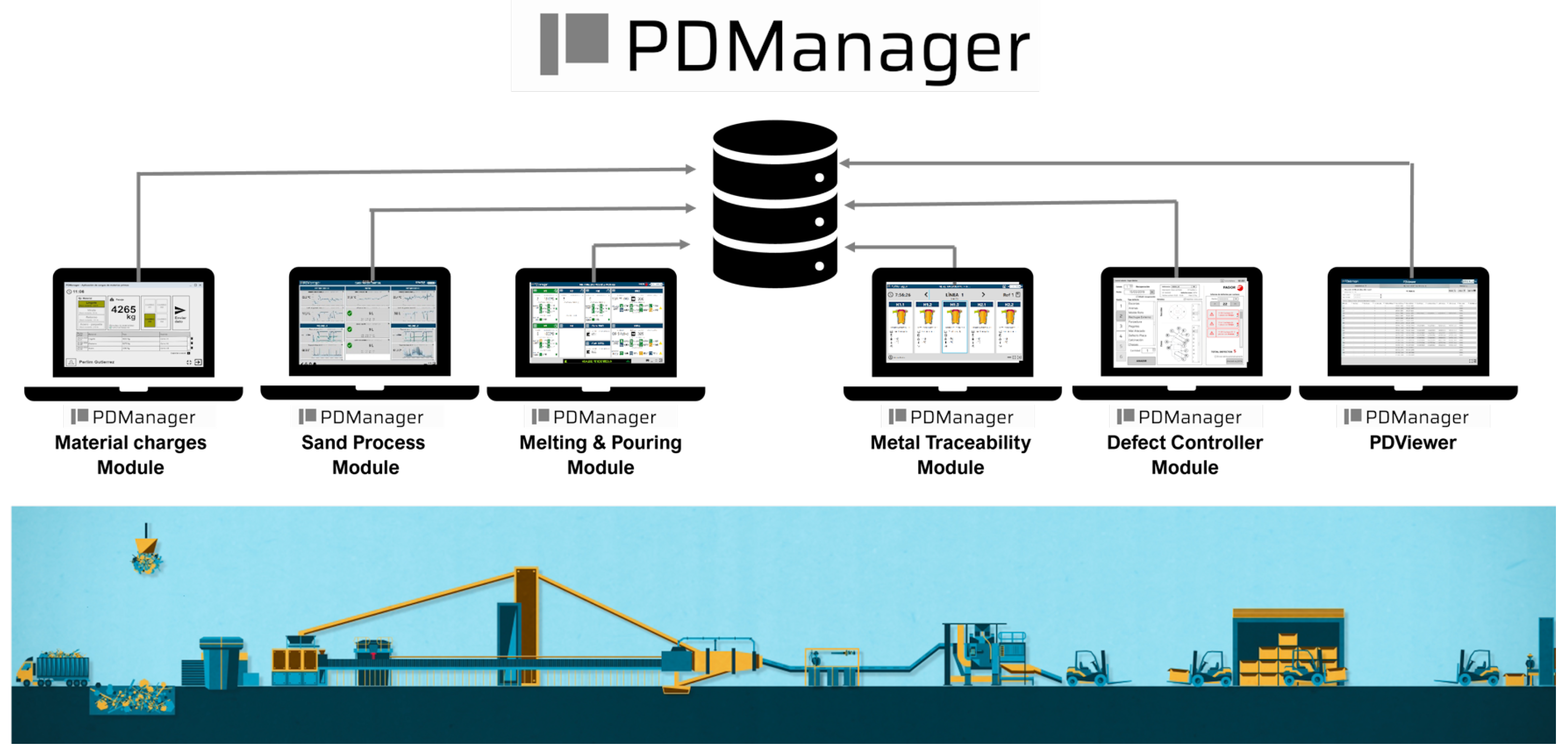
To carry out this data gathering process, the Production Data Manager tool, PDManager, developed by the Azterlan Research Center is used (for more information, please visit
https://www.azterlan.es/en/kh/pdmanager, accessed on 20 January 2025). Specifically, PDManager is a real-time production control system designed to guarantee digitization, traceability, and the orderly storage of key parameters in a centralized database for the manufacturing process of cast components.
This system is composed of three root elements:
PDStorage: A centralized relational database where all the gathered data are correlated, keeping the production history. In addition to being used for monitoring and recording information in real time, it can be employed for knowledge generation and predictive model creation based on these provided data. This kind of storage system and its capability to centralize data and information is discussed in the literature [
28,
29].
PDAgents: Small software artifacts created as services that focus on the specific task of interacting with third-party entities (i.e., other databases, files, or even machinery), extracting the necessary data from the production process itself. Krivic et al showed in [
30] how these developments can create the needed data flowing ecosystem for IoT management. The creation of this type of micro-service is the axis of a more complex software architecture that can also help in other domains like smart agriculture [
31].
PDManager modules: The PDManager system has different modules (some of which can be seen in
Figure 2) that, first, allow the operator to interact with and monitor the area where they are located and, second, provide a tool to perform manual correlation of data when automatic correlation is not possible.
Regarding the process explanation given in
Section 1, to address the aforementioned management process, data must be extracted from the entire manufacturing process. The deployment of PDManager focuses on implementing different modules that manage the following process areas: (i) primary coatings, (ii) secondary coatings, (iii) melting, and (iv) final inspections.
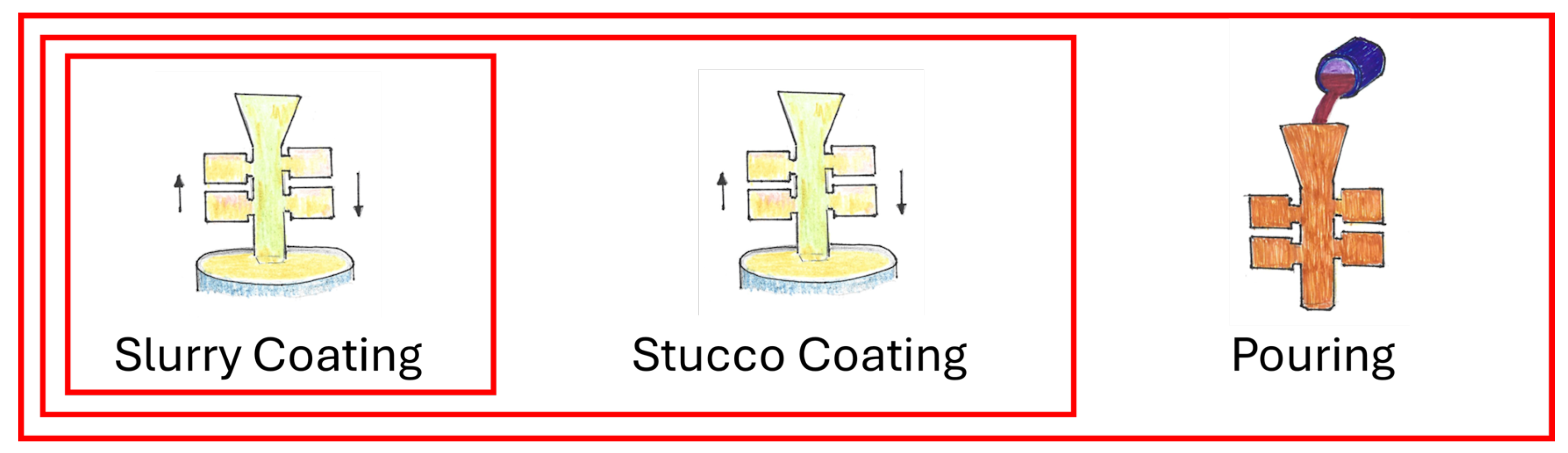
Specifically, the first stage of data aggregation relates to the coating process. In detail, the primary coating is the phase where the first layer of wax is applied to the model. Its primary purpose is to create the model’s surface. To achieve this, a liquid suspension, also known as slurry, is used. The slurry consists of a fine ceramic material and a binder with high heat resistance and good adhesion. Subsequently, the secondary coating involves applying additional layers on top of the primary layer. Its main function is to provide mechanical strength and structural stability to the mold. Therefore, coarser sand is used together with a colloidal silica binder.
The addition of each coating, which will eventually be converted into a shell mold, is of great importance. For primary and secondary coatings, the data to be captured are the environmental data for the room, which are obtained from a third-party platform provided by EKIOM
TM company from Paris, France (
https://www.ekiom.net/, accessed on 20 January 2025). EKIOM
TM records temperature and humidity data with different sensors placed in the primary and secondary areas. In addition, slurry data are extracted from the pre-existing Factory Win platform deployed in the foundry. This information is supplied by a
MicrosoftTM ExcelTM file located in the coatings laboratory. This document compiles data related to slurry analyses carried out periodically through rigorous internal procedures in the foundry. More specifically, the variables include density, temperature, SiO
2 percentage, and others.
These parameters are critical because if the environmental data are not correct, the mold layers will not dry under optimal conditions, causing mold breaks. Furthermore, if the slurry creation is incorrect, it will cause poor adhesion between layers, which may also cause mold breakages.
Then, in the melting area, the controlled data include the chemical composition of the alloy, the temperature of the furnace, and other variables related to the casting. At this stage, the data flow in two different ways. On the one hand, some data are manually digitized through the PDManager Melting and Pouring module. On the other hand, several pieces of data are stored in the Factory Win platform and are automatically detected and extracted from it. Specifically, composition data are measured via spark spectrometry analysis performed in the chemical laboratory, while the rest of the data are generated by various sensors connected to the corresponding equipment.
For the last area, the final inspection, the gathered information pertains to the quality results of the manufactured castings. The data focus on the occurrence of shrinkages and mechanical properties, such as elongation, which are analyzed in this research. For this last data extraction process, information about inclusions is obtained from PDManager, which is connected to Factory Win and continuously updated with results from fluorescent particle tests performed on all created parts. This process is carried out by qualified technicians who determine the number of pores/inclusions in each part. Additionally, elongation data for castings are provided. For this purpose, representative standard specimens from the manufacturing order are machined and later tested to obtain the final mechanical properties, which are then digitized via PDManager.
Once the data are extracted and stored in the appropriate repository, they should be utilized to improve the day-to-day process. Thus, they will be used to represent the production process, delivering the right information to the right people at the right time. The most effective way to achieve the goal of data distribution is by implementing an observer/observable pattern [
32], which is based on the subscriber/publisher paradigm [
33].
During the past decade, communication schemes have been redesigned and reimplemented with the aim of integrating data from several heterogeneous data sources. Moreover, the introduction of certain standards (for instance, the IEC 61850 standard for substation automation [
34]), which defines a data model oriented toward objects and functions, allows for modeling all the devices of a system by categorizing them according to their functionalities. This technology also enables their integration into a high-speed peer-to-peer communication network through standardization. However, further improvements were needed to establish an open and standardized working environment. The solution was the creation of a real-time publisher/subscriber communication model, as demonstrated in [
35]. In fact, this type of communication is widely used and well documented in books and research papers such as the following: [
33,
36,
37,
38].
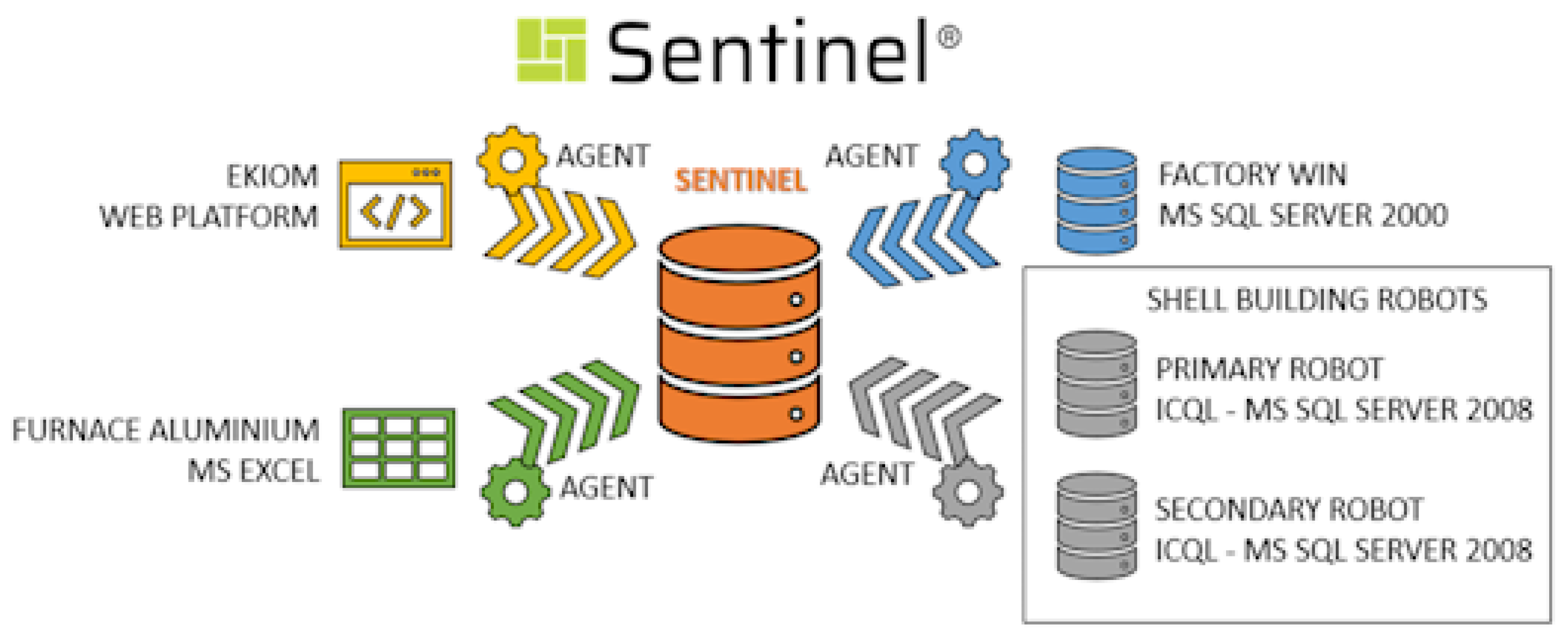
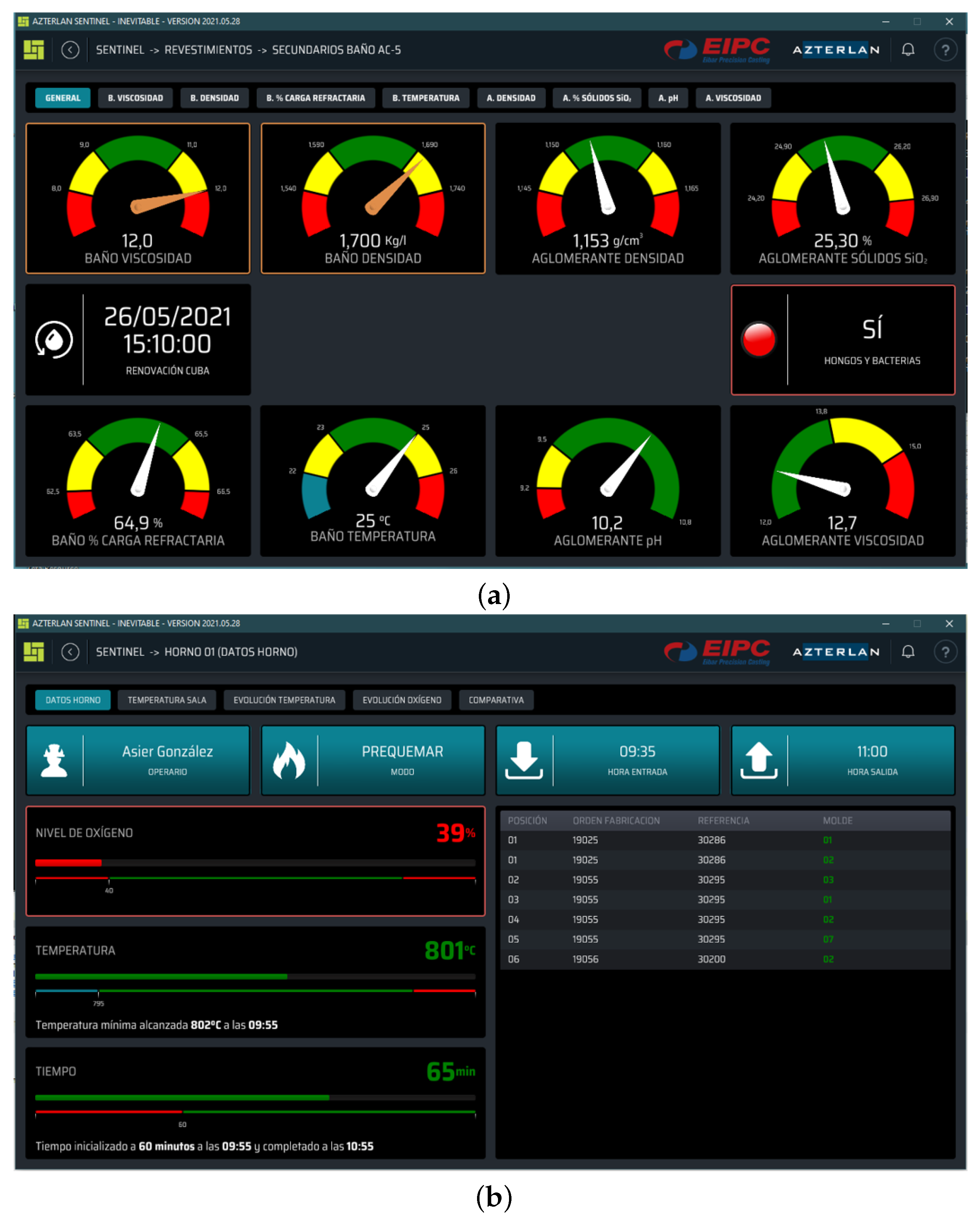
In a effort to combine this communication and data distribution technologies, Azterlan developed Sentinel (for more information about Sentinel, please visit
https://www.azterlan.es/en/kh/sentinel-predictive-control, accessed on 20 January 2025). It is an integral system for data distribution and process monitoring, as well as anomaly detection, digital representations of the process, alert communication, and a tool for incorporating and utilizing different Artificial Intelligence (AI) models. Despite all the features available in the Sentinel system (illustrated in
Figure 3), at this stage of development, Sentinel is focused solely on distributing, displaying, and presenting the gathered information. Hence, for now, we define Sentinel as a software system for automated and real-time data distribution. Sentinel displays key information and alerts to the people and locations where they are most useful. It allows for the deployment of dashboards or control panels designed according to user needs. These control panels can be implemented as static displays (on-site) or with navigation capabilities across different levels of information depth (e.g., process managers, laboratory, quality department, maintenance, and management, among others).
In order to define and design the data distribution, as well as the visualization methods in Sentinel, the following aspects have been analyzed:
KPI identification: Firstly, the work team determines the key process indicators that are valuable for the day-to-day work and the management of the process. In this way, the different areas that can be included and the different data that can be employed are studied here.
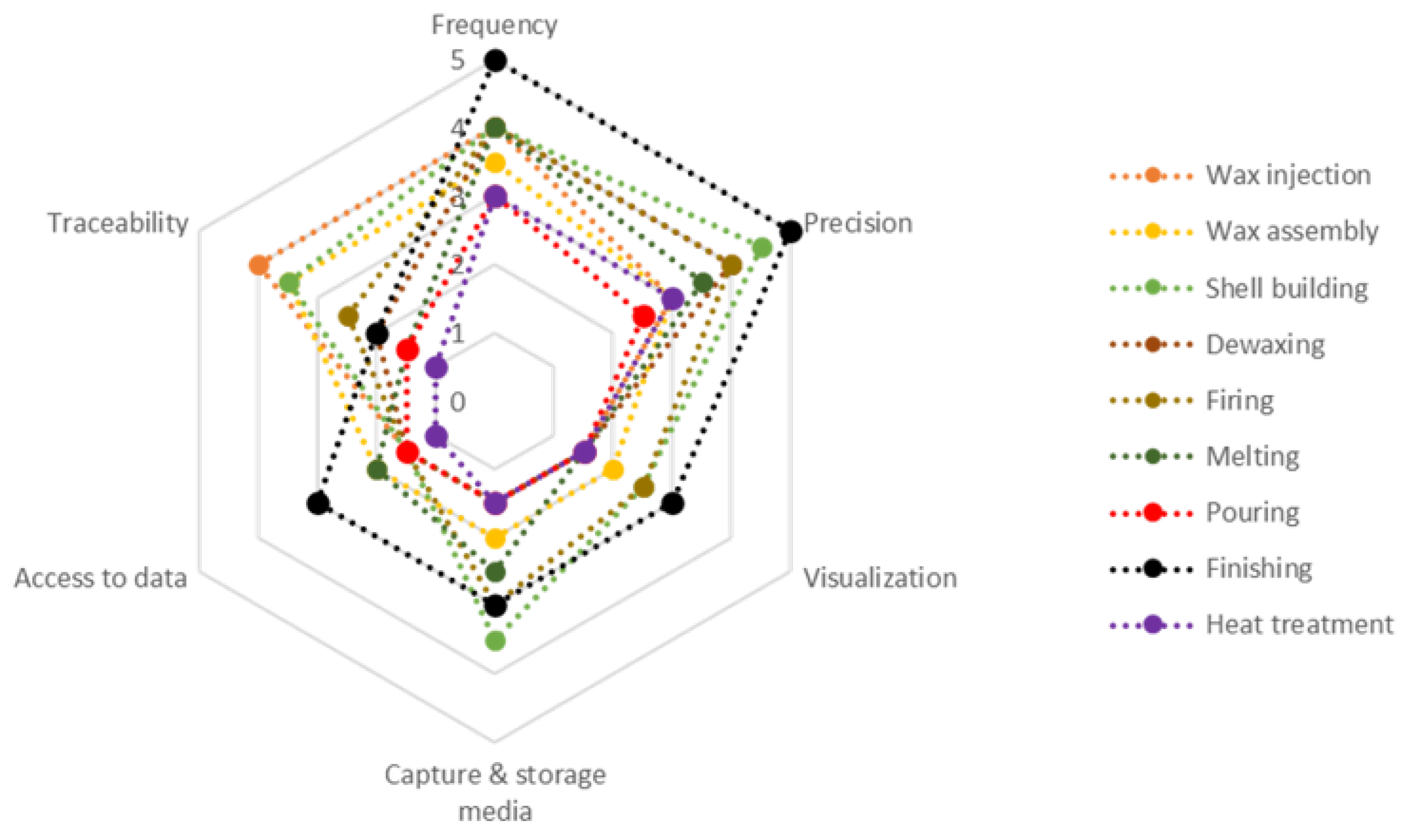
KPI analysis: Once the interests and possibilities were listed, we developed an analysis addressing all key stages of the process. To achieve this, six different variables were compared using the Likert scale [
39] and combined in a Star Plot. The variables used are: (i) frequency, (ii) accuracy of the available information, (iii) visualization or its necessity, (iv) capture and storage media, (v) possibility of data access, and (vi) traceability.
KPI Priority. After the previously conducted study, a filtering process is developed based on the priority of working on these indicators. This analysis is performed using a scatterplot.
Data distribution location. As the final task, the appropriate location for each visualization is determined.
In the end, the management of all input sources was performed, as shown in
Figure 4. Four different PDManager capture agents were developed to integrate these data sources. Subsequently, all the information was centralized in a single database, allowing Sentinel to utilize it for data distribution and visualization in this specific use case.
2.2. Creation of a Proactive System Based on Predictions
Thanks to the work defined and described in
Section 2.1, we now have all relevant process information available. This information flows in real time through our capture and storage system. Hence, all the described data serve as the raw input necessary to create an intelligent process management system. The collected data enable the digital representation of the process using advanced techniques. In fact, these data allow us to develop a proactive intelligent system that anticipates potential problems in the process. Its creation will be carried out through what is known as a digital twin.
More accurately, the concept of a digital twin [
40] refers to the creation of a virtual and intangible representation based on real data. Its objective is to replicate a physical or real situation. In our case, it focuses on representing the investment casting manufacturing process. The main contribution of a digital twin is to decouple the physical world from the virtual one, enabling analysis of how the process operates and subsequently preventing unexpected deviations in both virtual and real representations.
For our use case, the digital twin must facilitate process improvements aimed at defect reduction, energy efficiency, and time-to-market reduction. To achieve these objectives, the digital twin must operate under three clear axioms, as well defined in [
41]:
Proactivity: The system must be able to anticipate adverse situations. In fact, the digital twin makes use of the digital world through simulations and artificial intelligence. Thus, it will be able to determine the possible state of the production process in the near future (i.e., a temporary state ).
Adjustment: The management of the virtual environment must always work within a specific configuration. This means that the digital twin must meet the requirements of the manufacturing process. In other words, none of the tests or simulations that are developed will break the rules that govern the physical representation of the process.
Business intelligence: The twin will even serve as a knowledge management tool. Specifically, it is a repository of business intelligence that encompasses everything needed to manage all the tasks associated with the actual process. By utilizing the digital twin and providing it with this repository, business knowledge will remain within the company, preventing the much-feared knowledge leakage.
For a digital twin to work, it must apply the same methodology that a doctor does. This methodology is called “diagnosis”, and its basic steps are as follows [
22]:
- (i)
Observation: The digital twin is based on observation, which serves as the foundation for the digital representation of the real world. Observation focuses on extracting raw data, as previously explained and defined. This observation is essential because it enables the identification of operational patterns, trends, and other aspects that will be used in subsequent tasks. It is important to note that without observation—in other words, without a data capture process—developing this type of technology would not be possible.
- (ii)
Evaluation: Making use of the knowledge already loaded into the twin, as well as the data that are being produced in real time, our system develops a process known as “evaluation”. This process performs different simulations based on the current real situation it receives through “observation”. Subsequently, the further operations required to adjust and optimize the process will depend on the evaluations or predictions obtained in this stage.
- (iii)
Decision making: The previous processes, by themselves, do not add value. That is why a correction or adjustment of the monitored activity is needed. Thus, taking into account the results of the observation and evaluation steps, solver algorithms find the appropriate fit for the purpose of the twin. Afterwards, the system proceeds to communicate the results or actions that must be put into practice [
42]. Sometimes, they are sent to humans (M2H–machine to human communication), and other times, they are sent to machines via M2M (machine to machine).
In order to generate a tool capable of representing the reality of the manufacturing process, specifically, the production of molds and parts flowing in the investment casting workflow, it is necessary to be able to represent the flow of these molds in the lost wax casting process and the events that occur in it. In this case, the data obtained from the primary coating, secondary coating, melting, and inspection areas will be transformed into a sequence of enqueued elements that are sequentially characterized in each stage and digitally represented as a FIFO queue.
Hence, our digital twin was formally defined as a queue Q of z discrete molds, where V is the sum of molds ( for primary coating and previous molds, from primary coating to secondary coating, M from secondary coating to melting, and I for final inspections). Some variables will not be informed until the mold arrives at the specific stage where that data are gathered. In the end, the entire representation is defined as . For our use case, , and when the full set of molds is ready, they are all moved together to the next step, pushing them forward in the sequence.
In order to reproduce the current situation of the process, the digital twin must be able to model the movements of the molds, as explained before. In this way, it performs event-based management of the system, detecting when a group of molds reaches a new sequential step, represented by each red square in
Figure 5. In fact, the digital twin operates under the following events:
The first event occurs when a set of molds is being generated in the primary coating stage. To detect this, the digital twin is subscribed to the PDManager storage database. During the coating process, the system collects data until the last coating has dried and the robot moves the mold to the next stage. When the full set of molds is completed, the digital twin receives this event from the database and triggers a series of tasks to digitally generate the process state, update the digital twin, perform the associated calculations, and finally, move these molds to the next step.
The second event is triggered when the secondary coating is applied. The digital twin is again subscribed to the storage, and the event is fired to indicate that some work must be performed. This second event functions similarly to the previous one but pertains to the creation of the final mold. Again, when all molds are created, the digital representation is updated, and all calculations are executed. Finally, the entire set of molds is promoted to the next stage.
The last detected event occurs when the casting is finally created. This means that the final event is fired when the metal is poured into the mold. Again, the system operates in batches of molds. The subscription to the PDManager database triggers the management process for this step. At that moment, the digital twin receives the information about the creation of the castings, and all of them are moved to the final steps. These last steps are not monitored in this research, though they could be incorporated in future developments. Nevertheless, after the completion of the castings, the quality of each casting is measured, and these data are gathered for the prediction methods. While this is not a step for the digital twin, it is crucial for anticipating the behavior of each casting concerning mechanical properties and the appearance of porosity.
Due to these events and the data gathering process, the digital twin is able to characterize each mold. At this moment, the mold
has the set of variables
that can now be sent to the machine learning models, which will attempt to predict the state the part will reach when the final inspection is carried out. In the same way that the system manages the events, the predictions will also be triggered at every grouping step illustrated in
Figure 5.
In order to develop the aforementioned predictions and considering that we have extracted all the manufacturing process results, as well as the recorded results in both prediction objectives, the best approach is the employment of supervised learning. Specifically, this is a type of machine learning where models are trained using labeled data. The labeled data include the corresponding correct output. This learning is performed using statistical classifiers to categorize data based on patterns in the labeled examples. These classifiers learn from the labeled data to make predictions on new and unseen data. The process relies on statistical methods to model the relationship between input features and target labels.
To make future predictions and to properly evaluate the machine learning models for the prediction of both aforementioned objectives, we applied the following methodology.
Cross validation: In order to obtain a proper representation of the data, we must use as much available information as possible. For this purpose, K-fold cross validation is usually used in machine learning experiments [
43]. In our experiments, we performed a K-fold cross validation with
. In this approach, our dataset was split into 10 sets of learning (66% of the total dataset) and testing (34% of the total data).
Teaching the model: For each fold, we performed the learning phase of each algorithm using the corresponding training dataset, applying different parameters or learning algorithms depending on the model. Due to the lack of knowledge about the performance of this type of prediction in the investment casting process and considering that this research is in an initial stage, we decided to use classical machine learning models to validate whether the methodology could be useful. More accurately, we used the following models:
- −
Classical statistical classifiers: This type of classifier has been widely used in machine learning due to its simplicity, interpretability, and effectiveness with relatively small datasets [
44]. One of the key advantages of these classifiers is that they are computationally efficient and easy to implement. Although newer machine learning models, such as deep learning approaches, have gained popularity, classical statistical classifiers remain valuable for their reliability and ease of use in many practical applications [
45,
46,
47,
48,
49]. Specifically, we conducted our research by evaluating the following classical algorithms:
- ∗
Bayesian networks: For Bayesian networks, we used different structural learning algorithms, including K2 [
50], hill climber [
51], and Tree Augmented Naïve (TAN) [
52]. Moreover, we also performed experiments with a naïve Bayes classifier.
- ∗
K-nearest neighbor: For K-nearest neighbor [
53], we performed experiments with
,
,
,
,
, and
.
- ∗
Artificial neural networks: We used a three-layer Multilayer Perceptron (MLP) [
54] taught using a back-propagation algorithm.
- ∗
Support vector machines: We performed our experiments with a polynomial kernel [
55], a normalized polynomial kernel [
56], a Pearson VII function-based universal kernel [
57], and a radial basis function (RBF)-based kernel [
58].
- ∗
Decision trees: We performed experiments with the C4.5 algorithm [
59] and random forest [
60], an ensemble of randomly constructed decision trees. In particular, we tested the random forest with a variable number of random trees
N, from
to
in increments of 50.
- ∗
Voted perceptron: This algorithm, described in [
61], is an extension of the basic perceptron algorithm that improves classification performance by combining multiple perceptron models. It was selected because it helps improve accuracy and robustness compared to standard perceptrons.
- −
Combined machine learning classifiers: Classifiers by themselves are able to obtain good results, but we cannot ensure that a specific classifier is perfectly suitable for the prediction of every objective in the investment casting process. To solve this problem, several studies have combined classifiers [
62]. These techniques seek to obtain a better classification decision despite incorporating a higher degree of complexity into the process. From a statistical point of view [
63], assuming a labeled dataset
Z and
n as the number of different classifiers with relatively good performance in making predictions for
Z, we can select one of them to solve classification problems. However, there is a risk of not choosing the correct one. Therefore, the safest option is to use all of them and take an average of their outputs. The resulting classifier is not necessarily better but reduces the risk induced by using inappropriate classifiers. From a computational point of view [
62], some supervised machine learning algorithms, in their learning phase, generate models based on local maximum solutions. Thus, an aggregation of classifiers is much closer to the optimal classifier than only one of them. Similarly, the casting process itself can be categorized as linear or nonlinear. By using these combination methods, we are capable of designing a collective intelligence system for classification which incorporates both linear and nonlinear classifiers. The combination methods we used to develop the experiments are detailed below.
- ∗
By vote: Using democratic voting to classify elements is one of the oldest strategies for decision making. Extending electoral theory, other methods can allow for combinations of classifiers [
64]. Specifically, we tested (i) the majority voting rule, (ii) the product rule, (iii) the average rule, (iv) the max rule, and (v) the min rule.
- ∗
Grading: The base classifiers are all the classifiers that we want to combine through the grading method [
65], and these were evaluated using k-fold cross validation to ensure that each of the instances was employed for the learning phase of each classifier. Therefore, the classification step is as follows: [
65]. First, each base classifier makes a prediction for the instance to be classified. Second, meta-classifiers qualify the result obtained by the base classifiers for the instance being classified. Finally, the classification is derived using only the positive results. Conflicts (i.e., multiple classifiers with different predictions achieving a correct result) can be solved using the vote method or by employing the estimated confidence of the base classifier. For this research, the classifiers used in the grading method are naïve Bayes, a Bayesian network taught with the TAN algorithm and, finally, kNN with
k ranging from 1 to 5.
- ∗
Stacking: The stacking method [
66] is another approach to combining classifiers that aims to improve the ensemble based on the cross-validation method. For the classification process, first, we carry out a query to the classifiers in level 0 (original classifiers). Second, once we obtain the answer from all of them, we apply the transformations of
k numbers that produce the input dataset for level 1 (this is the result transformation step). Third, level 1 classifiers derive the solution. Finally, the response is transformed back into the level 0 space to provide the final result. The whole process is known as
stacked generalization and can be further enhanced by adding multiple stacking levels. Again, and to enable comparisons of this method with grading, the classifiers used are naïve Bayes, a Bayesian network taught with the TAN algorithm and, finally, kNN with
k ranging from 1 to 5.
- ∗
Multi scheme: This is a meta-classification method implemented by Weka [
67] which allows for the combination of classifiers in a simple manner. This method employs a combination rule based on the results obtained via cross validation and the error rate measured as the mean square error from several classifiers.
Testing the model: For each fold, first, we measured the accuracy of the model; in other words, how well the classifier performs in terms of correctly classified instances. Moreover, we also evaluated the error rate between the predicted value set X and the real value set Y (both having the size of the testing dataset m) with mean absolute error (MAE) (shown in Equation (
1)).
Similarly, we used Root Mean Square Error (RMSE) (shown in Equation (
2)).
Finally, we also tested each model measuring the Area Under the ROC Curve (AUC) [
68]. This ranges from 0 to 1, where 0.5 indicates random guessing and 1.0 indicates perfect classification. Higher AUC values indicate better model performance.
2.3. Retro-Feedback for Controlling and Adjusting the Manufacturing Parameters
With all the development carried out in this research, we have created an ex ante method to foresee several defects or characteristics in the investment casting manufacturing process. Throughout this research, several topics of discussion have emerged, and we have worked to address them. In particular, by using the classifiers as a stand-alone solution, (i) we cannot be completely sure that the selected classifier is the best one to generalize the manufacturing process, (ii) the learning algorithms employed for creating some of the machine learning classifiers only find a local maximum; hence, the final result is not optimal, and (iii) by using a single classifier, we should generate a classifier close to the process’s nature (linear or non-linear). Hence, we solved all these problems by developing and testing several methods to combine heterogeneous classifiers, as explained in
Section 2.2. This new approach was safer because we used all the classifiers instead of selecting just one, allowing us to approximate their behavior to the optimal one.
Nevertheless, although we were able to detect the problems using an ex ante method, we were not able to modify the plant parameters to solve them online. In fact, predicting the near-future situation without the ability to address it will only provide us with the knowledge that we are producing faulty parts before they are evaluated. We will continue to face all the problems associated with these deviations, even though we are aware of their existence. Therefore, as the final part of the digital twin—and also the main component of the system—an advisory system for adjusting the process has been designed to close the loop.
The observation or data extraction process, along with its output tags, has allowed us to work on deriving the knowledge embedded in the data itself. This research has focused on creating an action recommender aimed at maintaining the system within the desired area, defined as standard or normal production. Thus, when the previously explained predictors detect an anomaly, the advisory system will begin working to find a way to redirect the process and prevent the occurrence of that problem.
In this way, to build this system, the knowledge was extracted in two different manners. On the one hand, we extract it from process engineers. This is a manual task that incorporates the gathered expert knowledge into the final system. On the other hand, some patterns were extracted as associative rules using the Tertius [
69] algorithm. The module responsible for evaluation and recommendation generation will be aware of the current state of the process (information obtained from the observation of the digital twin), the predicted state the production will reach (predictions or simulations generated by the digital twin), and finally, the set points and limits within which the process must operate (provided by engineers). Once these data have been unified, the process will be automatically redirected to prevent the detected problem or deviation.
Sometimes, the recommendation system will focus on increasing or decreasing the working range of one or more variables. At other times, it will determine that it is better to start producing within new ranges, adjusting the limits of that variable to a new optimal production zone. This system aims to modify control ranges that have become obsolete or to discover new manufacturing trends that optimize the process, reduce scrap, and, consequently, increase productivity.
The generated adjustments in primary and secondary coatings affect the acceptance and control ranges of immersion baths and climatic conditions. Keep in mind that modifications will be made to variables that allow for actionable changes and can be adjusted with small additions. In cases of major modifications, the bath would need to be completely changed, which will not be applied in the current batch but will be considered for the next production. Optimizations in the melting area directly affect changes or adjustments to the chemical composition of the melt to ultimately achieve an optimized metal for casting.
In summary, the recommendation system takes the data for each recorded variable (those defined during the information gathering process detailed earlier) and evaluates them by combining the predictions of the classification models with the working ranges extracted through the learning that the system itself has developed for each variable. In this way, depending on the evolution of the recorded data concerning the output variables (specifically, porosity defects and the mechanical property of elongation), it provides recommendations. These recommendations focus on which variables should be adjusted and the direction of adjustment, whether increasing or decreasing their values. The system is supported by a concise expert system based on process knowledge, which is continuously adapted using the normality ranges detected during process data generation.



 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}