1. Introduction
A person’s voice is a behavioral characteristic used for identification and authentication. It is often termed a “voiceprint”, owing to its variability in response to the speaker’s pronunciation, intonation, and speech patterns. These vocal characteristics change throughout a person’s life, owing to anatomical and physiological factors, making the human voice a reliable indicator of age [
1]. Age, a significant personal attribute and valuable signal, has garnered attention in various fields, including biometrics and computer vision [
2].
Recognizing a speaker’s age from their voice has applications across multiple domains, including commercial services, forensic investigations, and healthcare. For instance, in commercial services, call-center systems can be designed to identify a caller’s age and match them with the most suitable agent. Additionally, by recognizing a customer’s age and sex, services can be enhanced through more targeted advertising and marketing strategies [
3]. In forensic investigations for crimes such as kidnapping and blackmail, estimating the age of a speaker from voice recordings can assist in identifying the perpetrator [
4]. In healthcare, voice analysis can be used to estimate a person’s vocal age compared to their physical age. However, estimating a speaker’s age from short-term utterances remains challenging and interest in addressing this issue has recently increased.
Early research on speaker age estimation set the foundation for modern approaches. Bahari, McLaren [
5] applied an i-vector-based method, demonstrating the feasibility of automated solutions. Subsequently, OSMAN, Büyük [
6] examined the effects of utterance length and the number of frames on least-squares support-vector regression models, highlighting how speech duration and feature granularity affect predictive accuracy. At around the same time, A Badr and K Abdul-Hassan [
7] introduced a bidirectional gated recurrent neural network (G-RNN) approach that leveraged various features—such as Mel-frequency cepstral coefficients (MFCCs), spectral subband centroids (SSCs), linear-predictive coefficients (LPCs), and formants—to capture the frequency-sensitive elements of speech. Li, Han [
8] further advanced these techniques by demonstrating how acoustic and prosodic feature fusion can bolster model performance.
As deep-learning techniques gained momentum, Avikal, Sharma [
9] used linear-prediction cepstral coefficients (LPCCs) and Gaussian mixture models (GMMs) to group ages in five-year increments between 5 and 50. Focusing specifically on Korean speech, So, You [
10] proposed a deep artificial neural network trained on MFCCs, achieving notable accuracy gains for men in their 20s, 30s, and 50s, as well as for women in their 20s, 40s, and 50s. Further refinements emerged through transformer-based architectures and self-supervised methods, as seen in the work of Gupta, Truong [
11] and Burkhardt, Wagner [
12], both of which reported enhanced predictive accuracy via bi-encoder transformer models and robust speech representations.
The most recent wave of research has explored specialized convolutional neural networks (CNNs) and attention mechanisms. Tursunov, Mustaqeem [
3] introduced a CNN with a multi-attention module (MAM) on speech spectrograms generated via short-time Fourier transform (STFT), showing that accurate age classification is possible, even across multiple languages and varying age brackets. Truong, Anh [
13] compared seven self-supervised learning (SSL) models for joint age estimation and gender classification on the TIMIT corpus and demonstrated that an attention-based prediction model outperformed wav2vec 2.0 in both clean and 5dB signal-to-noisy conditions, achieving more robust and accurate speech representations. However, several studies, including those of Grzybowska and Kacprzak [
1] and Kalluri, Vijayasenan [
14], emphasize that domain-specific adaptations—particularly the integration of diverse feature sets—are crucial for capturing the full breadth of language- and culture-specific vocal nuances.
However, these studies have several limitations that create significant practical challenges. First, studies using non-Korean datasets cannot be directly applied to Korean speakers because of language-specific vocal characteristics. The unique features of Korean speech, such as pitch patterns and consonant tensing, significantly affect age-related voice characteristics, leading to poor performance when models trained on other languages are used. Second, the few existing studies on Korean speech either lack comprehensive age coverage or use broad and imprecise age categories that limit practical applications. This makes it difficult to provide accurate age-specific services, such as precise content recommendations or customer-service matching.
Finally, most studies have relied on single-feature extraction methods or limited model architectures, potentially missing important vocal characteristics specific to Korean speakers. This approach fails to capture the complex interactions between various acoustic features unique to Korean age-related speech patterns, resulting in suboptimal real-world performance.
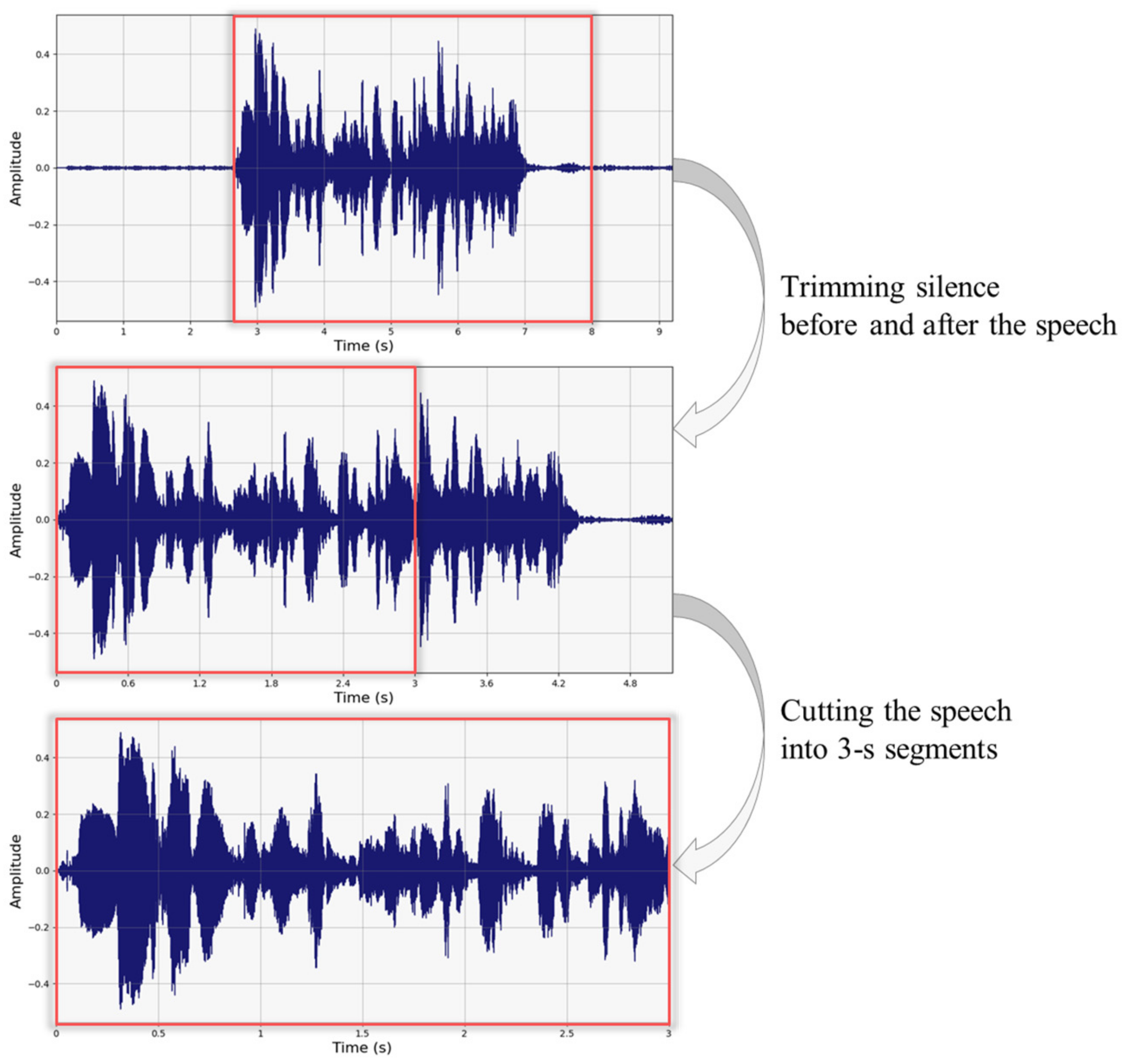
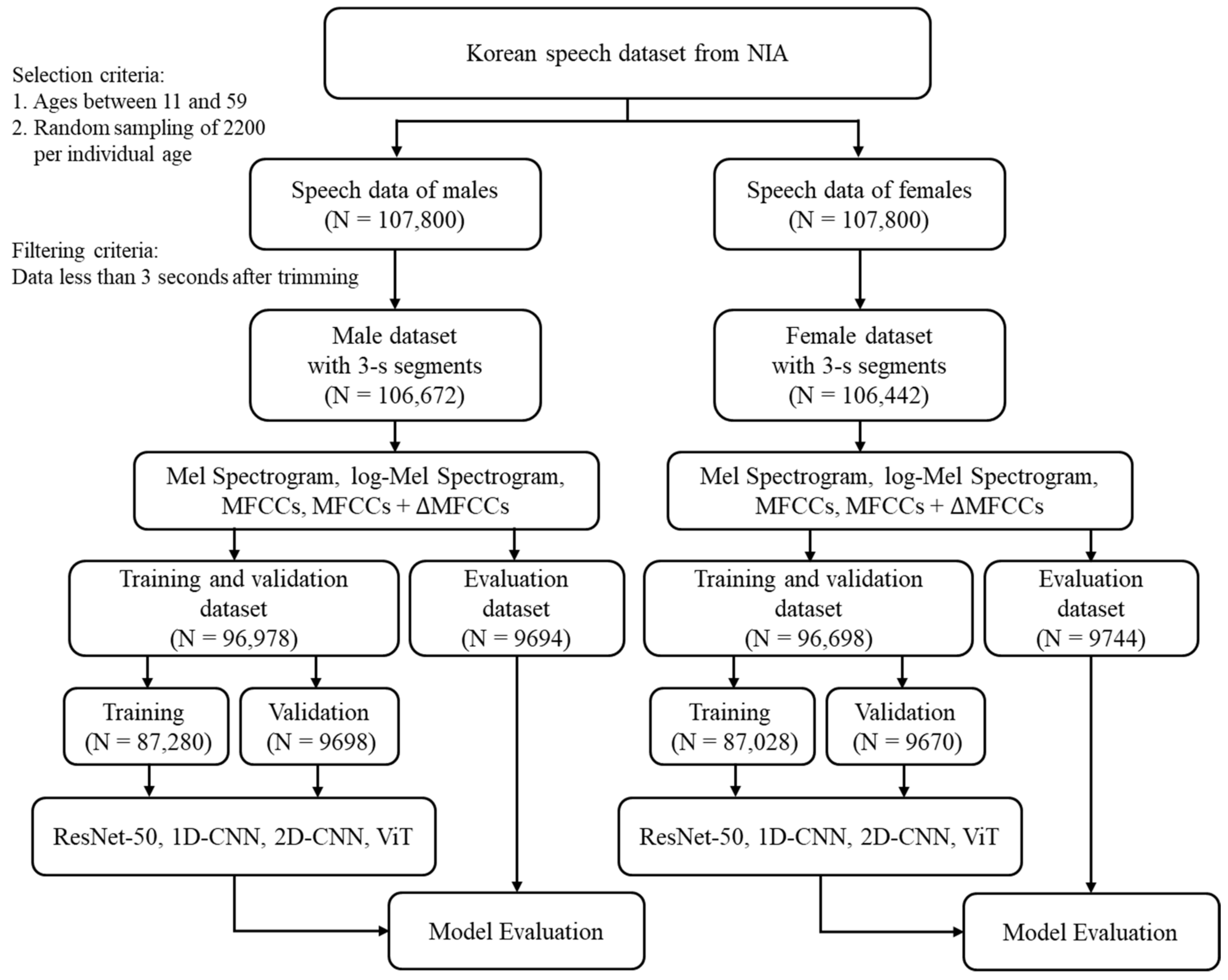
To address these limitations, this study proposes a comprehensive framework that is specifically designed to overcome each challenge. For a robust analysis of Korean speech characteristics, we utilized a large-scale dataset, comprising approximately 2200 speech samples per age, collected from various regions of Korea to ensure a balanced representation across different dialects and speaking styles. To enable precise age-specific services, we implemented fine-grained classification in five-year increments across the ages of 11–59, resulting in 10 distinct age groups.
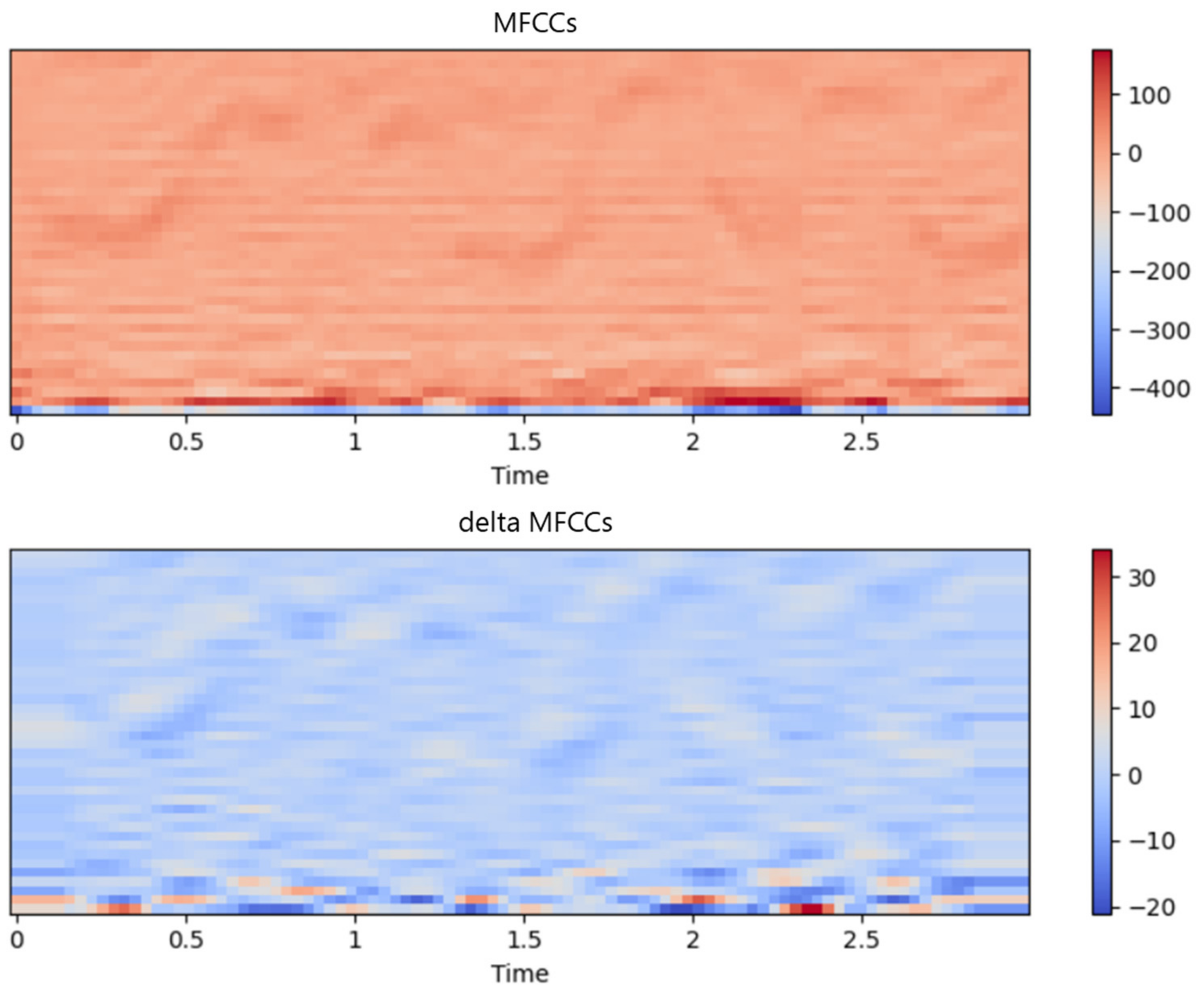
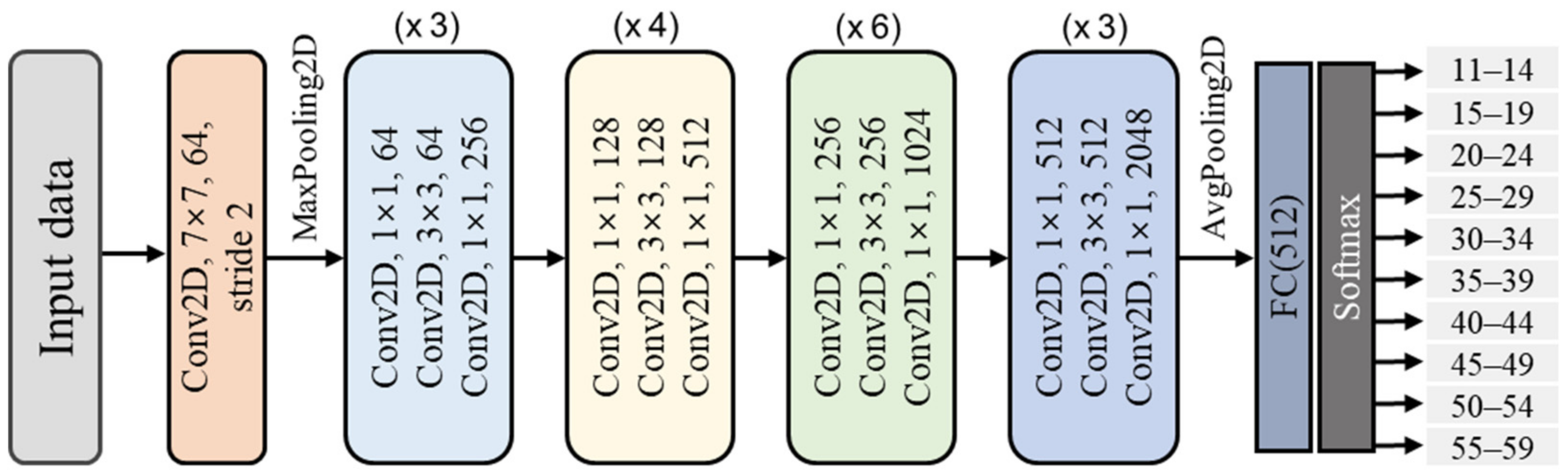
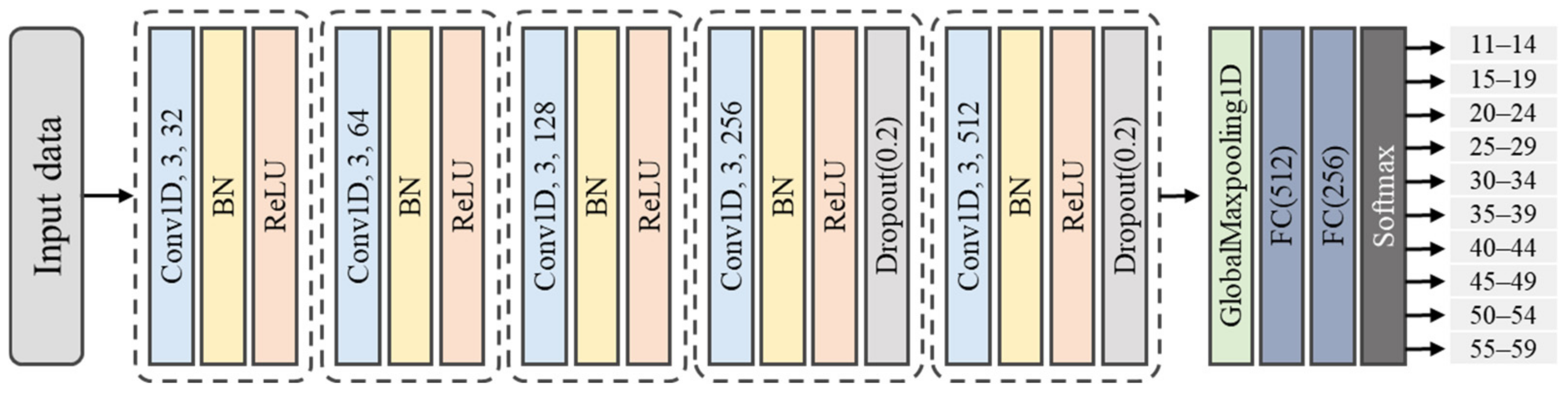
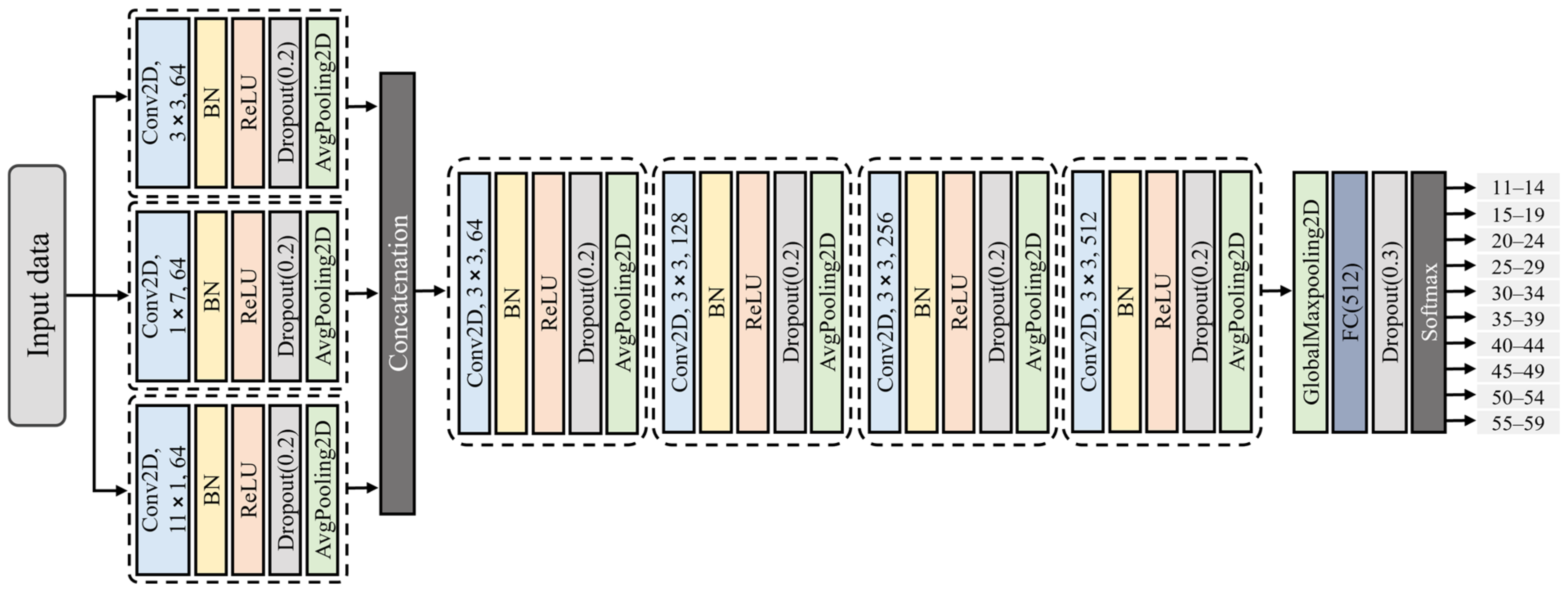
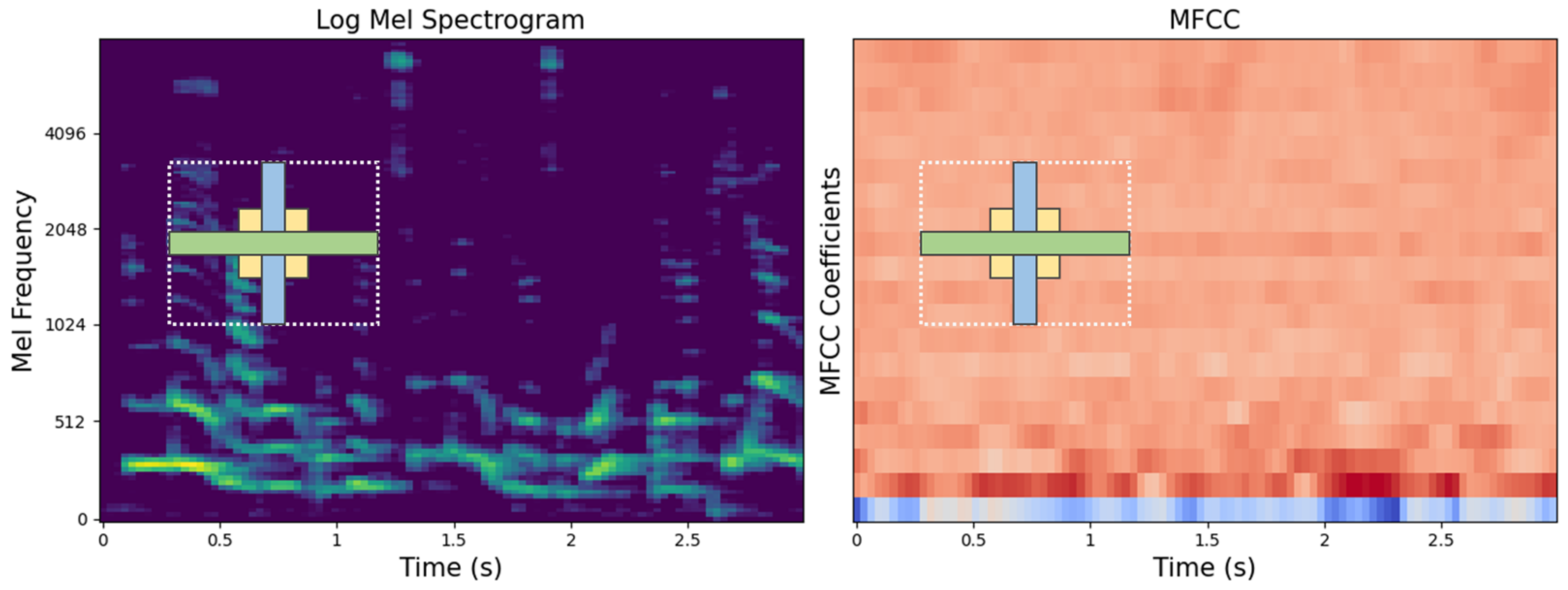
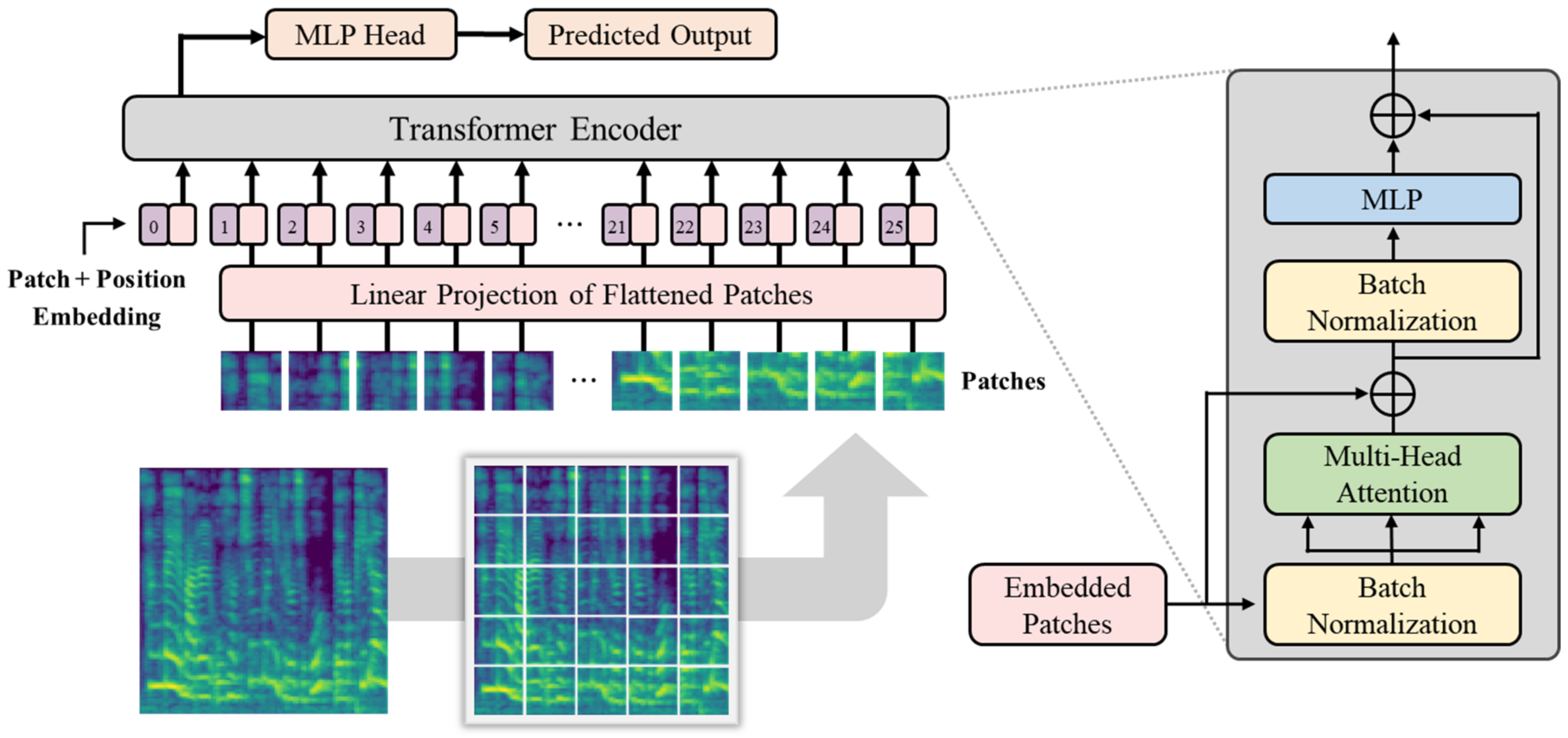
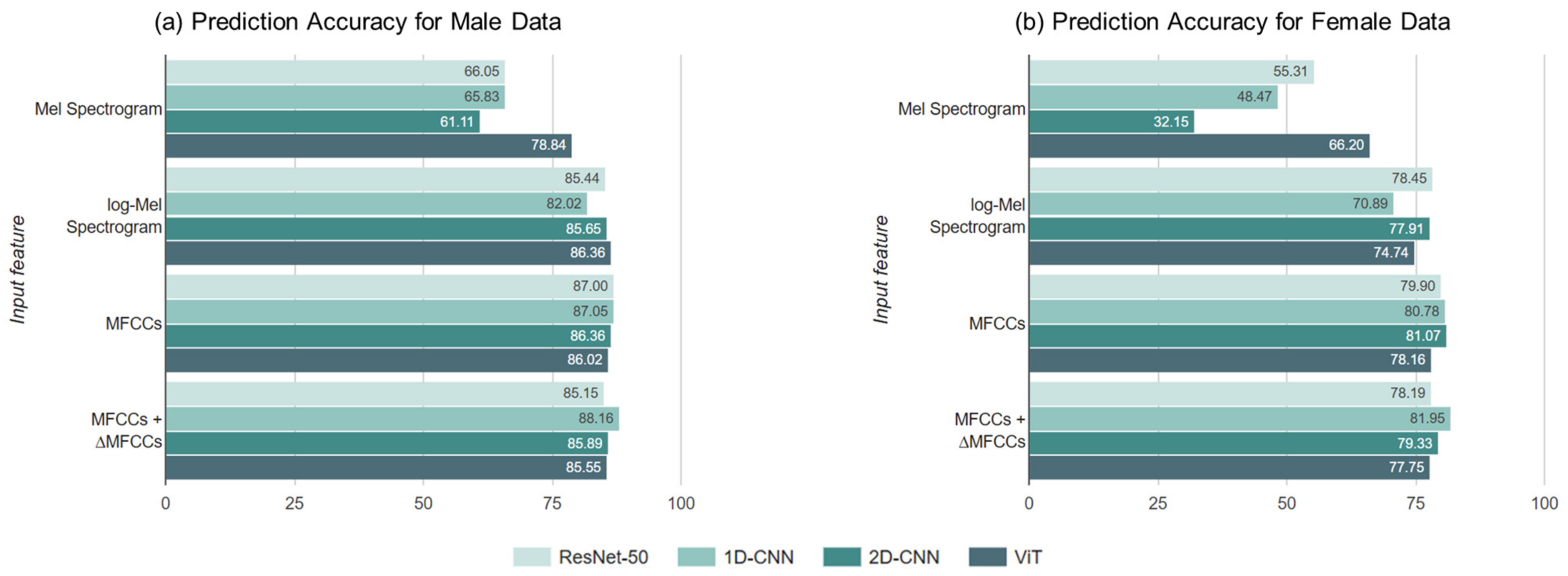
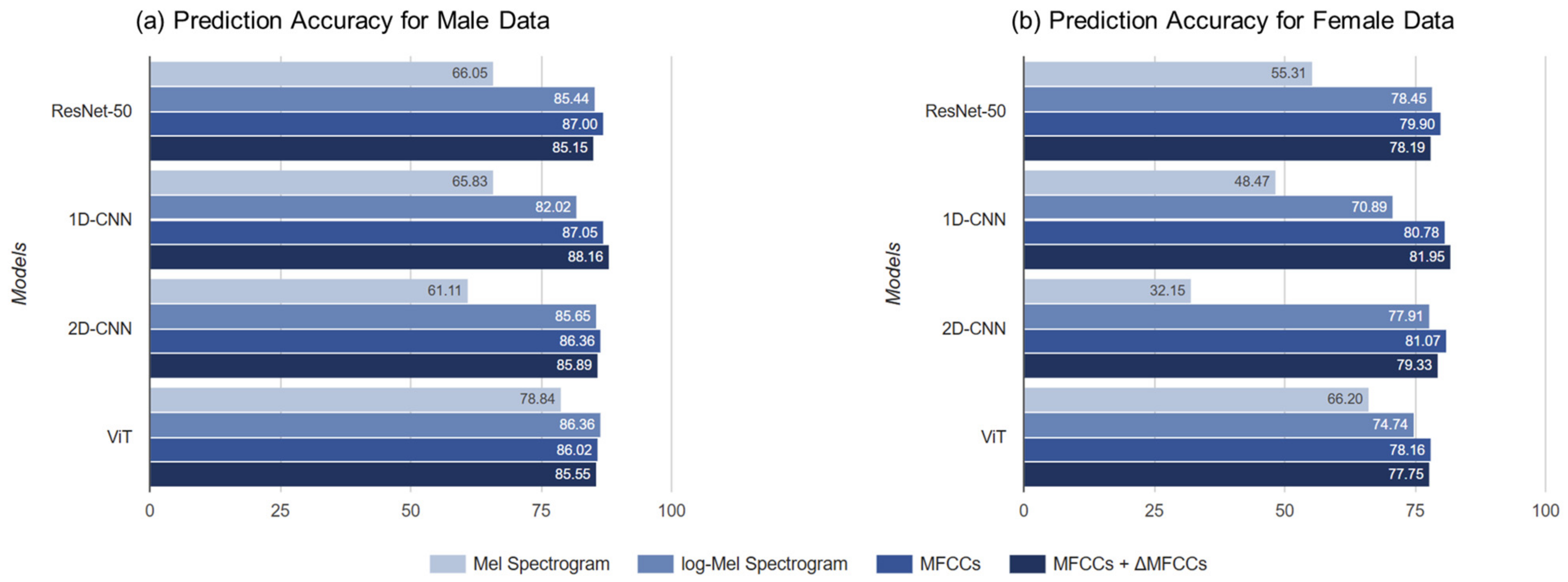
To capture various age-related voice characteristics, we employed complementary feature-extraction methods (Mel spectrogram and log-Mel spectrogram for frequency-domain analysis, MFCCs and ΔMFCCs for temporal dynamics) and analyzed the characteristics using various deep-learning architectures (ResNet-50, 1D-CNN, 2D-CNN, and a vision transformer). Notably, we trained all models from scratch rather than using pre-trained models because existing pre-trained models optimized for general speech or other languages may not effectively capture unique Korean phonological characteristics [
15,
16].
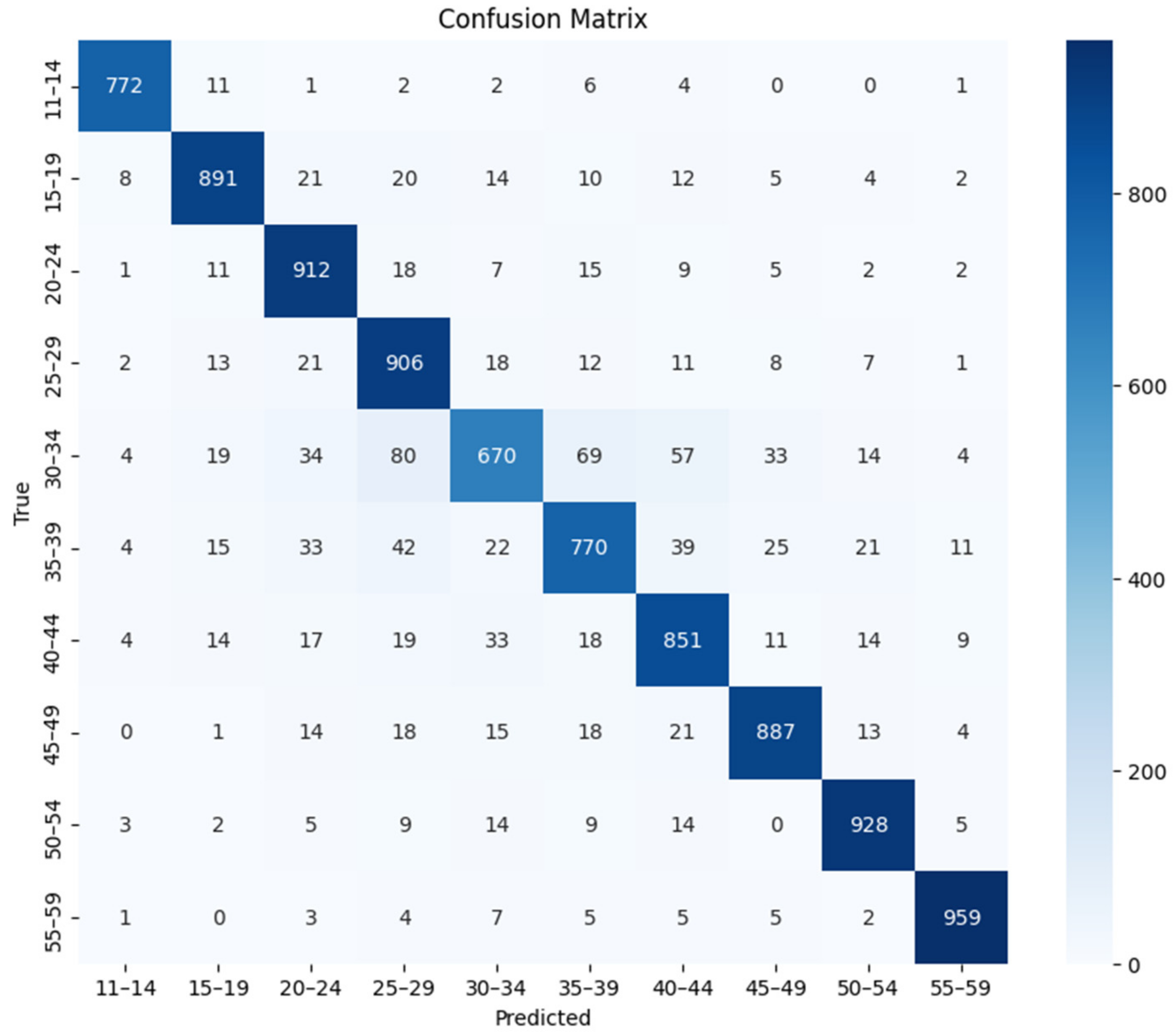
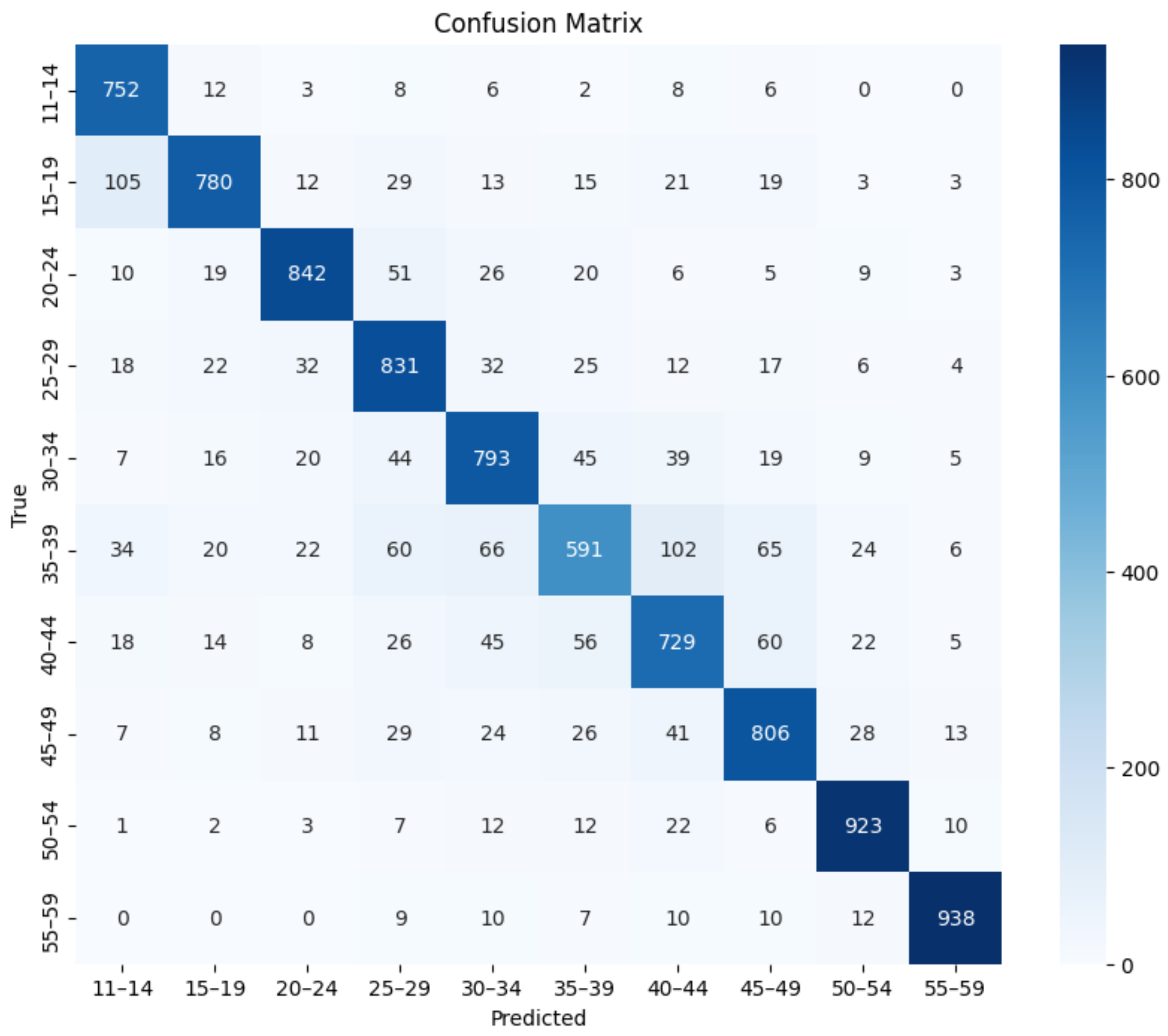
This study makes three major contributions to existing literature. First, we established an effective framework for Korean speech-based age prediction by systematically evaluating various combinations of voice features and deep-learning models. Our experiments showed that the combination of MFCCs + ΔMFCCs features with a 1D-CNN architecture achieves the best performance for both sexes. Second, we demonstrated superior classification accuracy (88.16% for males and 81.95% for females), while using more detailed age groups than in previous studies, enabling more precise age-sensitive applications, such as personalized customer-service matching. Finally, through a detailed performance analysis, we identified specific challenges in age prediction, particularly in distinguishing voices in the 30–39 age range, providing crucial insights for future research in Korean speech processing.
The remainder of this paper is organized as follows:
Section 2 describes the dataset, data preprocessing, and feature-extraction methods used in this study.
Section 3 provides an overview of the neural network architectures employed in the experiments.
Section 4 presents the evaluation metrics, detailed results, and comparative analyses for age prediction using voice features and neural networks.
Section 5 concludes the paper with a summary and suggestions for future research.
5. Conclusions
In this study, four different speech feature extraction methods and four neural network architectures were employed to predict the ages of Korean male and female speakers aged between their teens and 50s, with the goal of identifying the optimal age-prediction combination specific to Korean speech. While many studies have explored predicting age from speech, few have focused on Korean speech, and most either lack specific age ranges or do not segment the data into distinct age groups. To address these limitations, this study used a large Korean dataset to predict ten segmented age groups.
The speech features used were the Mel spectrogram, log-Mel spectrogram, MFCCs, and MFCCs + ΔMFCCs, while the deep learning models comprised ResNet-50, 1D-CNN, 2D-CNN, and ViT. Among the four speech features, the model that achieved the highest average accuracy was ViT. For all combinations, the age prediction performance for males surpassed that for females. For both males and females, the highest accuracy was obtained when MFCCs + ΔMFCCs was trained on 1D-CNN, with accuracies of 88.16% and 81.95%, respectively. This combination represented the optimal pairing of speech features and models specialized for the Korean speech dataset presented in this study.
While this study employed established deep learning architectures, there remains significant potential for developing novel architectures that are specifically optimized for speech age prediction. Future research could focus on specialized attention mechanisms that more effectively capture age-specific vocal characteristics. Furthermore, exploring hybrid architectures that integrate the strengths of CNNs and transformers may enhance model performance, whereas investigating self-supervised learning approaches could leverage unlabeled speech data more efficiently. For female speakers, further analysis is recommended to identify the underlying factors that make distinguishing voices of those in their late 30s from those in their early 40s more challenging. The model could also be extended to perform multitask learning, allowing simultaneous recognition of age, emotions, place of origin, and other characteristics.
Nevertheless, our current framework achieves state-of-the-art performance for fine-grained Korean speech age prediction while maintaining practical applicability, demonstrating significant improvements over existing approaches. The achievement of 88.16% accuracy across ten distinct age groups represents a substantial advance in the field, particularly given the challenging nature of distinguishing between narrowly separated age ranges. The results of this study can be applied to personalized services designed for Korean speech or services sensitive to narrow age ranges. The model trained on the optimal combination demonstrated strong performance in predicting 10 segmented age groups by using short speech samples. This suggests the feasibility of automated age prediction for large, unspecified populations with potential applications in various fields. Although applying speech data from different languages or cultural backgrounds may not guarantee the same level of performance, the preprocessing techniques and framework presented in this study offer a valuable reference for the development of more advanced models and applications in speech recognition and age prediction. Looking ahead, this approach presents promising potential to further improve automated speech systems across diverse linguistic and cultural contexts. Nonetheless, several open issues remain, such as further investigating age-related changes beyond the 50s, addressing the scarcity of high-quality labeled data in other dialects and languages, and exploring advanced techniques (e.g., self-supervised or domain-adaptive methods) to enhance model robustness. These directions could pave the way for more inclusive and accurate age prediction systems, extending the applicability of this research to a broader demographic scope and a wider range of linguistic and cultural environments.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}