
Enhanced Conformer-Based Speech Recognition via Model Fusion and Adaptive Decoding with Dynamic Rescoring


Abstract
1. Introduction
2. Related Work
2.1. Research Process
2.2. Research Difficulties
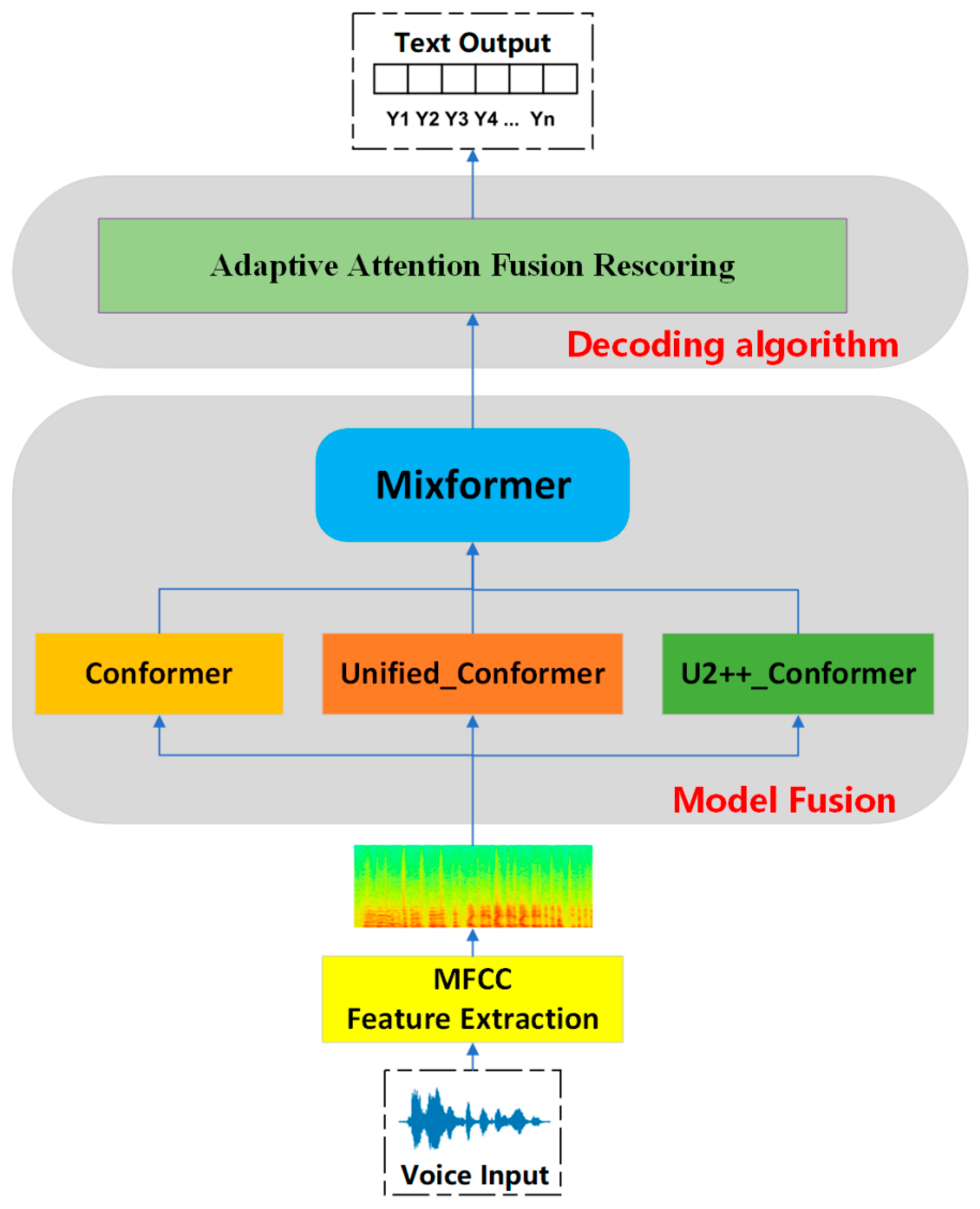
2.3. Proposed Method
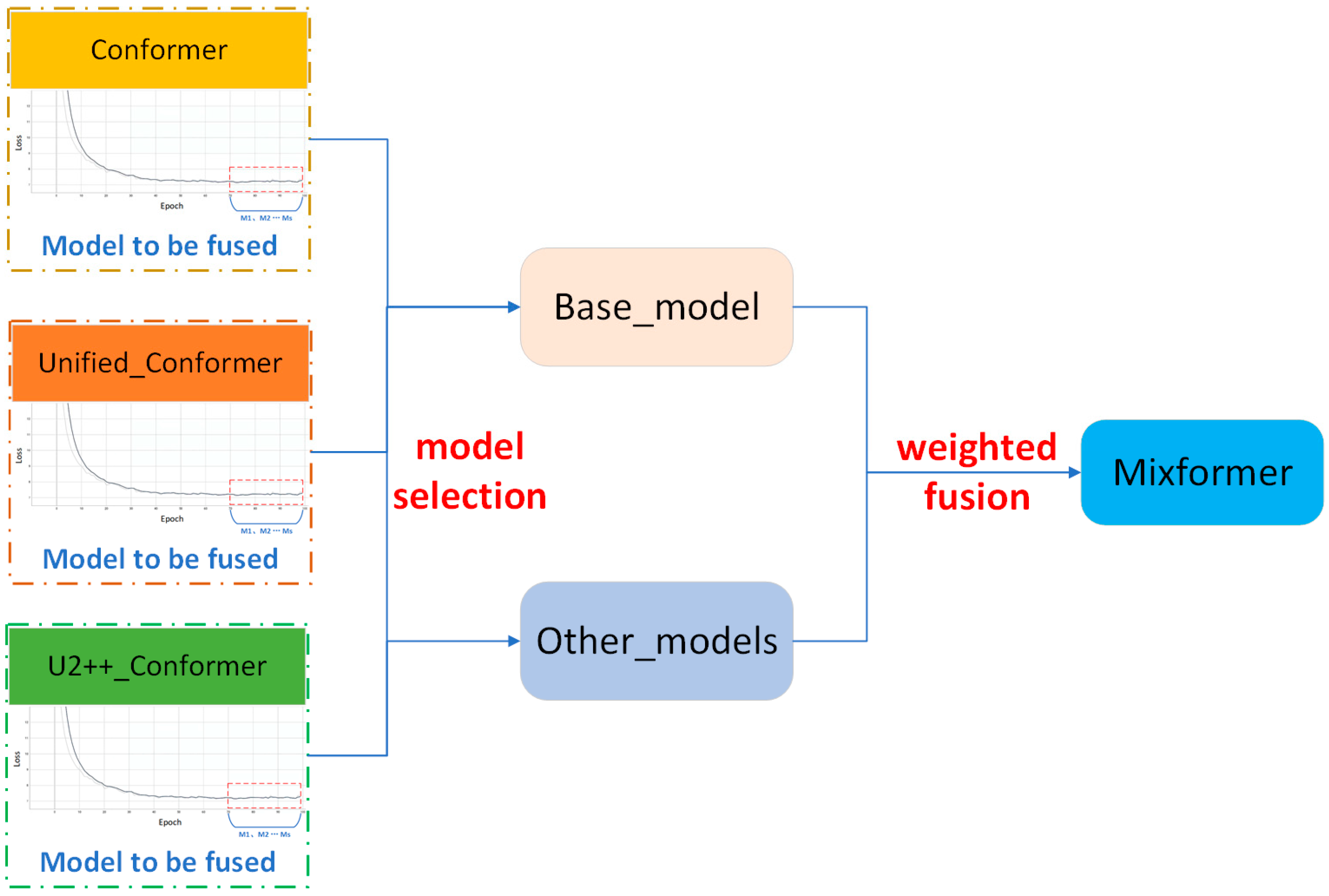
- Model Architecture: The study adopts the advanced Conformer architecture and conducts preliminary experiments with three variant structures. A model weight fusion method is proposed, where during the convergence phase of training, the models’ weights are organically fused based on loss values. This approach addresses two key aspects: first, smoothing and reducing the sensitivity of specific training iterations to noise in the data, thereby preventing overfitting during training; second, combining the different strengths of the three networks to improve overall recognition accuracy.
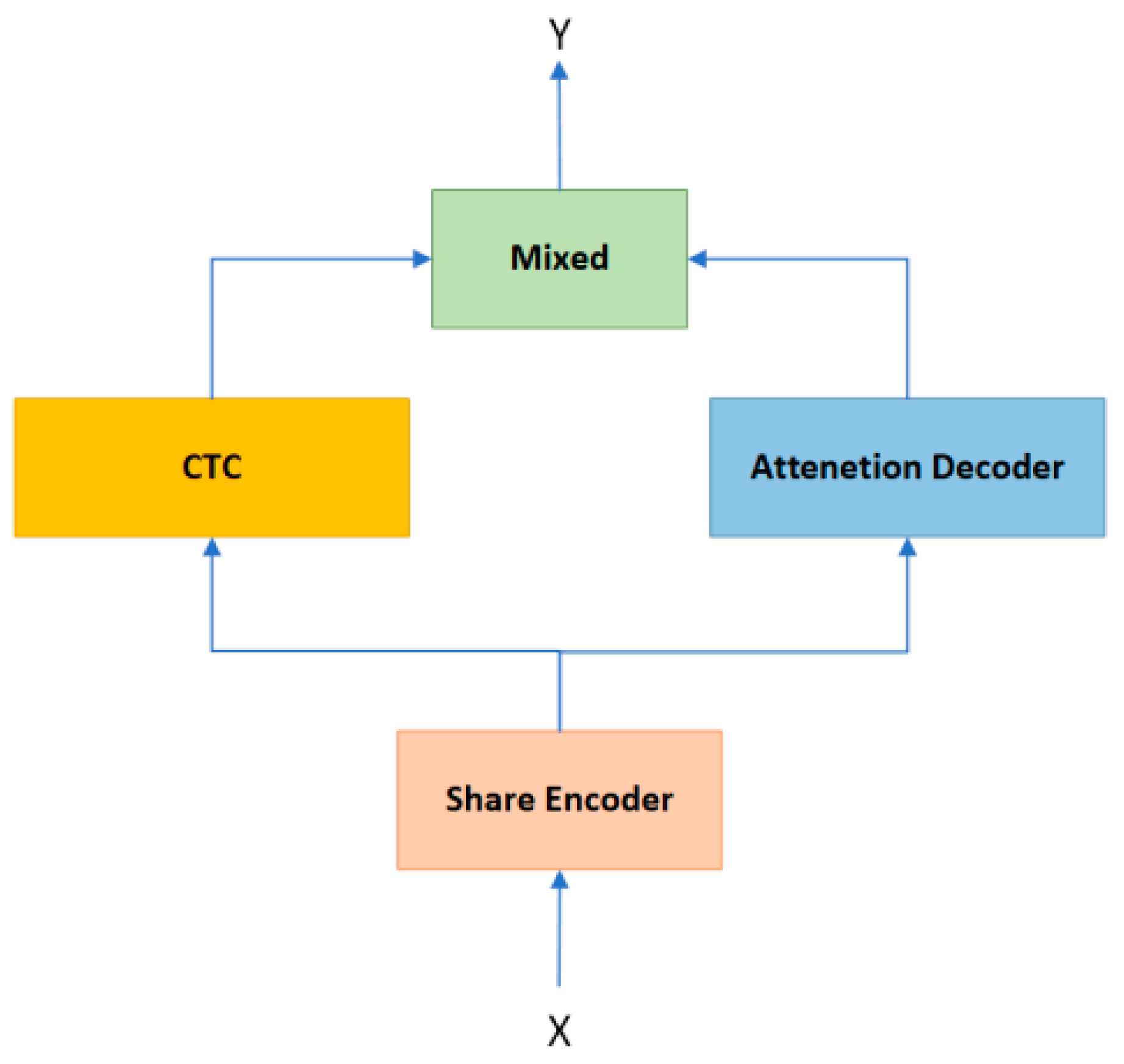
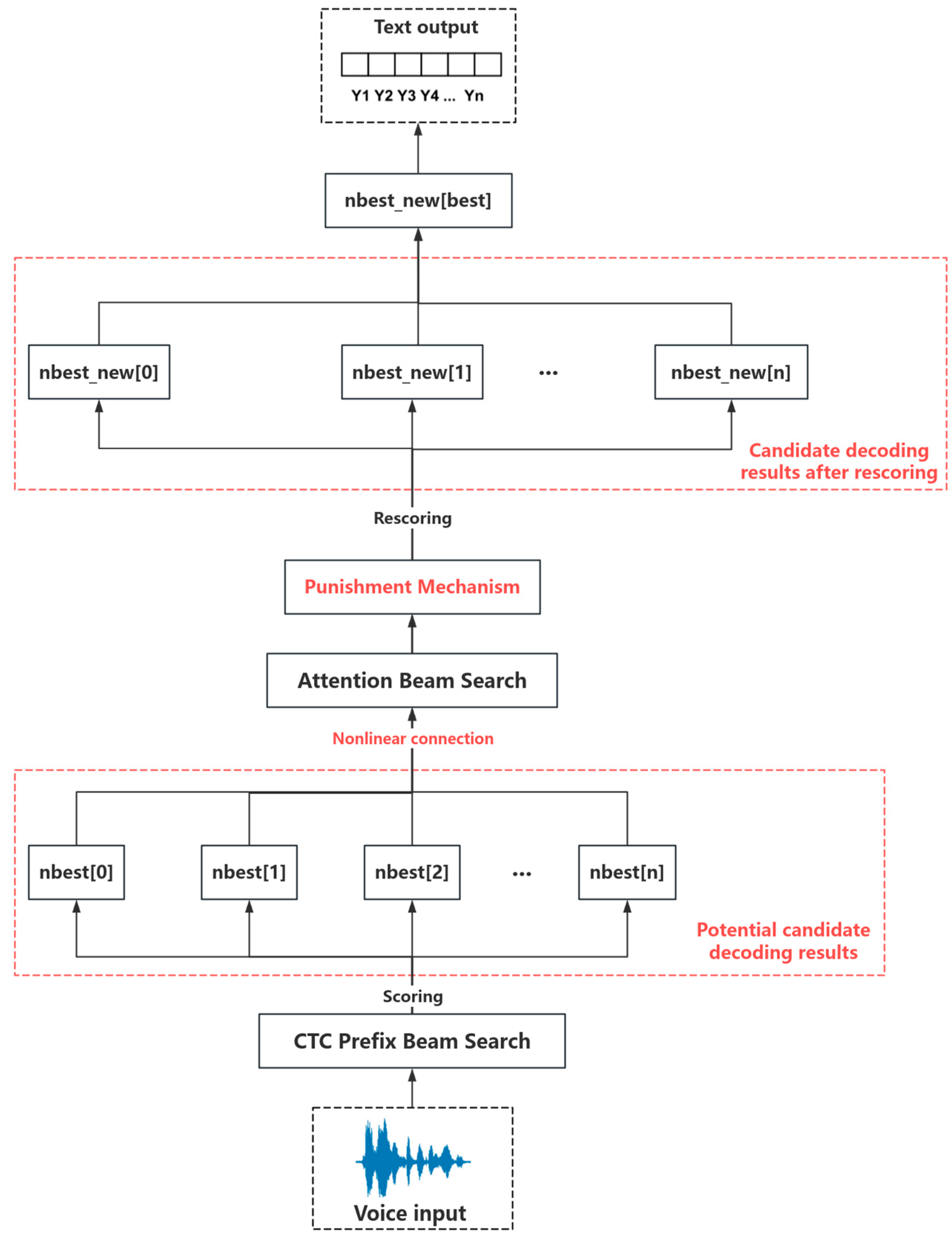
- Decoding Algorithm: A new decoding algorithm, “Dynamic Adaptive Decoding”, is introduced. This method connects CTC and attention mechanisms using nonlinear functions to form a hybrid decoding approach. It optimizes the output by dynamically evaluating and selecting the superior results from both decoding methods, leading to more accurate speech recognition. Additionally, a penalty mechanism is introduced to regulate the reliance on a single decoding method by adjusting penalty coefficients, thereby enhancing the robustness of the decoding process.
3. Materials and Methods
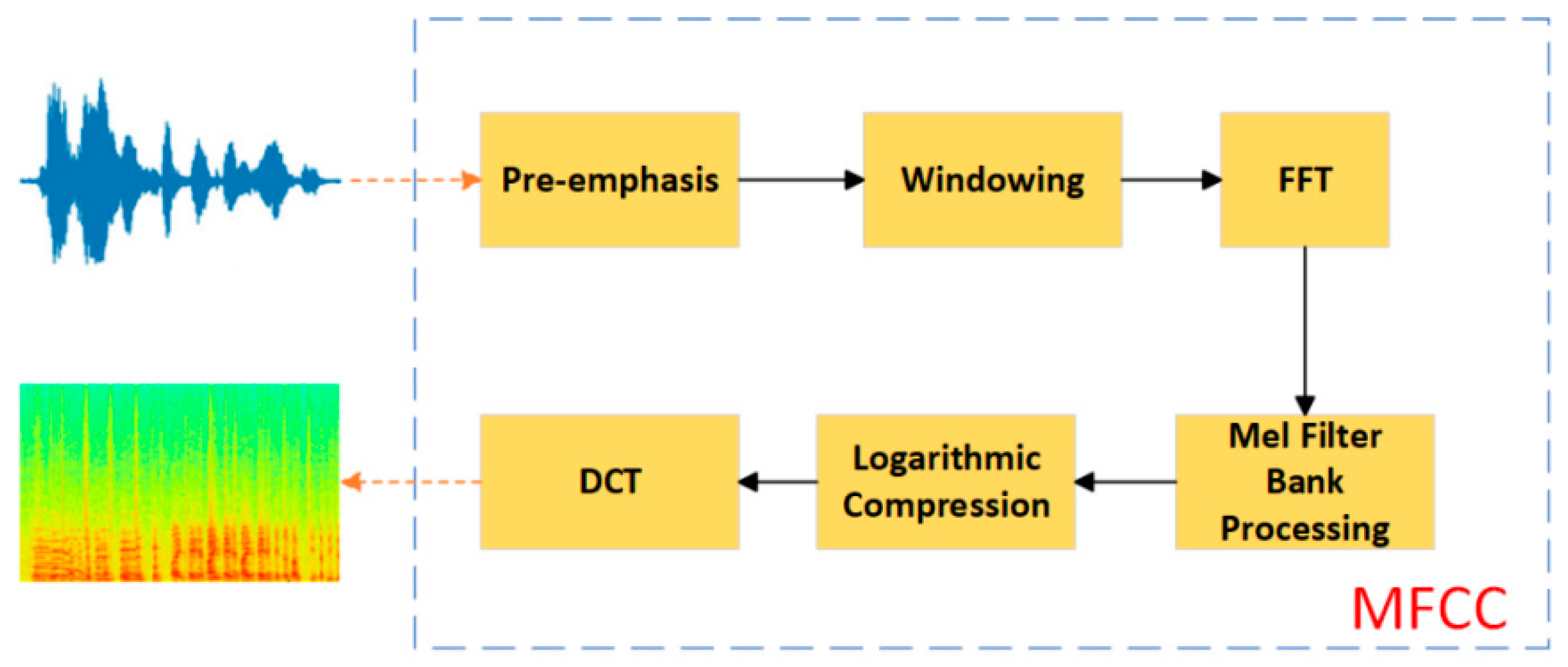
3.1. Fundamental Theory
3.2. Model Fusion
| Algorithm 1 Weighted Average Prediction |
| Require: ε: A small constant to prevent division by zero 1: Initialize Weighted_Sum as an empty dictionary 2: Initialize Total_Weight as an empty dictionary 3: for each model Mi in set of models M do 4: Compute weight Wi = 1/(Loss of Mi + ε) 5: for each parameter k in the intersection of keys in base model Mb and Mi do 6: If k is not in Weighted_Sum 7: Initialize Weighted_Sum[k] = 0 8: Initialize Total_Weight[k] = 0 9: Weighted_Sum[k] += Wi * value of parameter k in Mi 10: Total_Weight[k] += Wi 11: end for 12: for each parameter k in Weighted_Sum do 13: Y_weighted[k] = Weighted_Sum[k]/Total_Weight[k] 14: end for 15: Return Y_weighted |
3.3. Decoding Algorithms
4. Experiments
4.1. Experimental Setup
4.2. Dataset Base
4.3. Performance Metrics
5. Results
5.1. Basic Experiment
5.2. Model Fusion Experiment
5.3. Decoding Algorithm Improvement Experiment
5.4. Ablation Experiment
6. Conclusions
7. Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Precedence Research. Available online: https://www.marketresearch.com/IMARC-v3797/Voice-Speech-Recognition-Technology-Deployment-36766503/ (accessed on 12 November 2024).
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.-R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Huang, W.; Chiu, C.-C.; Pang, R. Transformer in action: A comparative study of transformer-based acoustic models for large-scale speech recognition applications. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6778–6782. [Google Scholar] [CrossRef]
- Liu, Q.F.; Gao, J.Q.; Wan, G.S. The Research Development and Challenge of Automatic Speech Recognition. Data Comput. Dev. Front. 2019, 2, 26–36. [Google Scholar] [CrossRef]
- Al-Radhi, M.S.; Csapó, T.G.; Zainkó, C.; Németh, G. Continuous wavelet vocoder-based decomposition of parametric speech waveform synthesis. Proc. Interspeech 2021, 2021, 2212–2216. [Google Scholar] [CrossRef]
- Jelinek, F. Statistical Methods for Speech Recognition; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Seltzer, M.L.; Yu, D.; Wang, Y. An investigation of deep neural networks for noise robust speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013; pp. 7398–7402. [Google Scholar]
- Ghaffarzadegan, S.; Bořil, H.; Hansen, J.H.L. Deep neural network training for whispered speech recognition using small databases and generative model sampling. Int. J. Speech Technol. 2017, 20, 1063–1075. [Google Scholar] [CrossRef]
- Chauhan, M.S.; Mishra, R.; Patel, M.I. Speech recognition and separation system using deep learning. In Proceedings of the 2021 International Conference on Innovative Computing, Intelligent Communication and Smart Electrical Systems (ICSES), Coimbatore, India, 25–26 August 2021; pp. 1–5. [Google Scholar]
- Wang, P. Research and design of smart home speech recognition system based on deep learning. In Proceedings of the 2020 International Conference on Computer Vision, Image and Deep Learning (CVIDL), Chongqing, China, 11–13 December 2020; pp. 218–221. [Google Scholar]
- Vetráb, M.; Gosztolya, G. Using hybrid HMM/DNN embedding extractor models in computational paralinguistic tasks. In Proceedings of the 2023 International Conference on Acoustic Sensors and Their Applications, Budapest, Hungary, 2–4 October 2023; p. 5208. [Google Scholar]
- Zhi, T.; Shi, Y.; Du, W.; Li, G.; Wang, D. M2ASR-MONGO: A free Mongolian speech database and accompanied baselines. In Proceedings of the 2021 24th Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), Kuala Lumpur, Malaysia, 1–3 December 2021; pp. 140–145. [Google Scholar]
- Liu, K.; Wei, J.; Zou, J.; Wang, P.; Yang, Y.; Shen, H.T. Improving Pre-trained Model-based Speech Emotion Recognition from a Low-level Speech Feature Perspective. IEEE Trans. Multimed. 2024, 26, 10623–10636. [Google Scholar] [CrossRef]
- Karita, S.; Chen, N.; Hayashi, T. A comparative study on transformer vs. RNN in speech applications. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), Sentosa, Singapore, 14–18 December 2019; pp. 449–456. [Google Scholar]
- Miao, H.; Cheng, G.; Gao, C.; Zhang, P.; Yan, Y. Transformer-based online CTC/Attention end-to-end speech recognition architecture. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6084–6088. [Google Scholar] [CrossRef]
- Tanaka, K.; Kameoka, H.; Kaneko, T. ATTS2s-VC: Sequence-to-sequence voice conversion with attention and context preservation mechanisms. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6805–6809. [Google Scholar] [CrossRef]
- Wang, Y.; Shi, Y.; Zhang, F. Weak-attention suppression for transformer-based speech recognition. arXiv 2005, arXiv:2005.09137. [Google Scholar]
- Gulati, A.; Qin, J.; Chiu, C.C.; Parmar, N.; Zhang, Y.; Yu, J.; Han, W.; Wang, S.; Zhang, Z.; Wu, Y.; et al. Conformer: Convolution-augmented transformer for speech recognition. arXiv 2005, arXiv:2005.08100. [Google Scholar]
- Liu, M.; Wei, Y. An improvement to conformer-based model for high-accuracy speech feature extraction and learning. Entropy 2022, 24, 866. [Google Scholar] [CrossRef]
- Zhong, G.; Song, H.; Wang, R.; Sun, L.; Liu, D.; Pan, J.; Fang, X.; Du, J.; Zhang, J.; Dai, L. External text-based data augmentation for low-resource speech recognition in the constrained condition of OpenASR21 challenge. In Proceedings of the Interspeech 2022, Incheon, Republic of Korea, 18–22 September 2022; pp. 4860–4864. [Google Scholar]
- Chen, H.; Du, J.; Dai, Y. Audio-visual speech recognition in MISP2021 challenge: Dataset release and deep analysis. In Proceedings of the Annual Conference of the International Speech Communication Association, Brno, Czech Republic, 30 August–3 September 2022; pp. 1766–1770. [Google Scholar]
- Li, J.; Fang, X.; Chu, F. Acoustic feature shuffling network for text-independent speaker verification. In Proceedings of the INTERSPEECH 2022, Brno, Czech Republic, 30 August–3 September 2022; pp. 4790–4794. [Google Scholar]
- Nakatani, T. Improving transformer-based end-to-end speech recognition with connectionist temporal classification and language model integration. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 1896–1900. [Google Scholar]
- Wu, X. Deep sparse conformer for speech recognition. arXiv 2022, arXiv:2209.00260. [Google Scholar]
- Kim, J.; Lee, J. Generalizing RNN-transducer to out-domain audio via sparse self-attention layers. arXiv 2021, arXiv:2108.10752. [Google Scholar]
- Burchi, M.; Timofte, R. Audio-visual efficient conformer for robust speech recognition. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 7–10 March 2023; pp. 2258–2267. [Google Scholar]
- Shi, Y.; Chang, S. Exploring the potentials of conformer for end-to-end speech recognition. IEEE Trans. Acoust. Speech Signal Process. 2021, 34, 566–578. [Google Scholar]
- Wang, T.; Deng, J.; Geng, M.; Ye, Z.; Hu, S.; Wang, Y.; Cui, M.; Jin, Z.; Liu, X.; Meng, H. Conformer-based elderly speech recognition system for Alzheimer’s disease detection. arXiv 2022, arXiv:2206.13232. [Google Scholar]
- Liu, H.; Chen, Z.; Shi, W. Robust Audio-Visual Mandarin Speech Recognition Based on Adaptive Decision Fusion and Tone Features. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 1381–1385. [Google Scholar] [CrossRef]
- Kakuba, S.; Poulose, A.; Han, D.S. Deep Learning Approaches for Bimodal Speech Emotion Recognition: Advancements, Challenges, and a Multi-Learning Model. IEEE Access 2023, 11, 113769–113789. [Google Scholar] [CrossRef]
- Zhang, X.; Ma, Z.; Liu, Z.; Zhu, F.; Wang, C. Research status and prospects of transformer in speech recognition tasks. J. Comput. Sci. Explor. 2021, 15, 1578–1594. [Google Scholar]
- Si, D.; Yun, C. Practical sharpness-aware minimization cannot converge all the way to optima. Adv. Neural Inf. Process. Syst. 2024, 36, 26190–26228. [Google Scholar]
- Shamir, O. Employing No Regret Learners for Pure Exploration in Linear Bandits. Presented at NeurIPS 2020. Available online: https://opt-ml.org/ (accessed on 15 April 2024).
- Zheng, Z.J. Deep Learning Optimization Techniques. Available online: https://0809zheng.github.io/ (accessed on 15 April 2024).
- Hanif, M.K.; Zimmermann, K.H. Accelerating Viterbi algorithm on graphics processing units. Computing 2017, 99, 1105–1123. [Google Scholar] [CrossRef]
- Wang, D.; Wang, X.; Lv, S. An overview of end-to-end automatic speech recognition. Symmetry 2019, 11, 1018. [Google Scholar] [CrossRef]
- Ren, Z.; Yolwas, N.; Slamu, W.; Cao, R.; Wang, H. Improving hybrid CTC/attention architecture for agglutinative language speech recognition. Sensors 2022, 22, 7319. [Google Scholar] [CrossRef]
- Zhang, Y. Research on end-to-end speech recognition based on convolutional neural networks. Ph.D. Thesis, Beijing Jiaotong University, Beijing, China, 2021. [Google Scholar] [CrossRef]
- Xie, X. Research and system construction of end-to-end speech recognition models. Ph.D. Thesis, Jiangnan University, Wuxi, China, 2022. [Google Scholar] [CrossRef]
- Mukhamadiyev, A.; Khujayarov, I.; Djuraev, O. Automatic speech recognition method based on deep learning approaches for Uzbek language. Sensors 2022, 22, 3683. [Google Scholar] [CrossRef]
- Li, J.; Duan, Z.; Li, S. ESAformer: Enhanced self-attention for automatic speech recognition. IEEE Signal Process. Lett. 2024, 31, 471–475. [Google Scholar] [CrossRef]
- Yao, Z.; Guo, L.; Yang, X. Zipformer: A faster and better encoder for automatic speech recognition. arXiv 2023, arXiv:2310.11230. [Google Scholar]
- Tian, Z.; Yi, J.; Tao, J. Hybrid autoregressive and non-autoregressive transformer models for speech recognition. IEEE Signal Process. Lett. 2022, 29, 762–766. [Google Scholar] [CrossRef]
- Yi, C.; Zhou, S.; Xu, B. Efficiently fusing pretrained acoustic and linguistic encoders for low-resource speech recognition. IEEE Signal Process. Lett. 2021, 28, 788–792. [Google Scholar] [CrossRef]
- Andrusenko, A.; Nasretdinov, R.; Romanenko, A. UConv-Conformer: High Reduction of Input Sequence Length for End-to-End Speech Recognition. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Composition | Conformer | Unified_Conformer | U2++_Conformer |
|---|---|---|---|
| Encoder Params | Output Dim: 256 | Output Dim: 256 | Output Dim: 256 |
| Number of Blocks: 12 | Number of Blocks: 12 | Number of Blocks: 12 | |
| Activation: Swish | Activation: Swish | Activation: Swish | |
| Decoder Params | Number of Blocks: 6 | Number of Blocks: 6 | Number of Blocks: 3 |
| Model Params | CTC Weight: 0.3 | CTC Weight: 0.3 | CTC Weight: 0.3 |
| LSM Weight: 0.1 | LSM Weight: 0.1 | LSM Weight: 0.1 | |
| Reverse Weight: None | Reverse Weight: None | Reverse Weight: 0.3 | |
| Dataset Params | Max Length: 2000 | Max Length: 2000 | Max Length: 40960 |
| Min Length: 50 | Min Length: 50 | Min Length: 0 | |
| Batch Size: 12 | Batch Size: 12 | Batch Size: 12 | |
| Max Training Epochs | 100 | 100 | 100 |
| Optimizer Params | Learning Rate: 0.004 | Learning Rate: 0.001 | Learning Rate: 0.001 |
| Layer Name | Output Size | Input Size/Patch Size, Stride |
|---|---|---|
| Input | 80-d | 1000 × 80 |
| Conv2D (input layer) | 250 × 20 × 256 | 80 × T, 4 × 4, stride 2 (time and freq) |
| Positional encoding | 250 × 256 | 250 × 256 |
| Conformer block × 12 | 250 × 256 | 250 × 256 |
| Feed-forward layer | 250 × 256 | 250 × 256 |
| Self-attention layer | 250 × 256 | 250 × 256 |
| CNN module | 250 × 256 | 250 × 256 |
| Fully connected layer | 5002-d | 250 × 256 |
| Output | 5002-d | 250 × 5002 |
| Dataset | Subset | Audio Duration(h) | Word | Sampling Rate | Format |
|---|---|---|---|---|---|
| Training set | train-clean-100 | 100 | 5,185,647 | 16 kHz | flac |
| train-clean-360 | 360 | 18,668,330 | |||
| train-clean-500 | 500 | 25,928,235 | |||
| Validation set | dev-clean | 5.4 | 53,167 | ||
| dev-other | 5.3 | 52,183 | |||
| Test set | dev-other | 5.4 | 53,958 | ||
| test-other | 5.1 | 50,961 | |||
| Total | 981.2 | 49,992,481 | |||
| Method | Decoding Algorithm | WER(%) | |||
|---|---|---|---|---|---|
| Dev-Clean | Dev-Other | Test-Clean | Test-Other | ||
| Conformer (Arithmetic mean) | attention | 7.10% | 16.30% | 7.23% | 16.75% |
| ctc_greedy_search | 8.83% | 18.46% | 9.19% | 18.77% | |
| ctc_prefix_beam_search | 8.70% | 18.39% | 9.06% | 18.73% | |
| Unified_Conformer (Arithmetic mean) | attention | 4.55% | 10.12% | 4.93% | 10.31% |
| ctc_greedy_search | 4.68% | 12.05% | 4.88% | 12.16% | |
| ctc_prefix_beam_search | 4.63% | 12.03% | 4.84% | 12.09% | |
| U2++_Conformer (Arithmetic mean) | attention | 4.41% | 10.59% | 4.87% | 10.83% |
| ctc_greedy_search | 5.08% | 12.38% | 5.26% | 12.59% | |
| ctc_prefix_beam_search | 5.03% | 12.34% | 5.20% | 12.48% | |
| Method | Decoding Algorithm | WER(%) | |||
|---|---|---|---|---|---|
| Dev-Clean | Dev-Other | Test-Clean | Test-Other | ||
| Conformer (Arithmetic mean) | attention | 7.10% | 16.30% | 7.23% | 16.75% |
| ctc_greedy_search | 8.83% | 18.46% | 9.19% | 18.77% | |
| ctc_prefix_beam_search | 8.70% | 18.39% | 9.06% | 18.73% | |
| Conformer (weighted mean) | attention | 7.00% | 16.26% | 7.18% | 16.72% |
| ctc_greedy_search | 8.83% | 18.41% | 9.16% | 18.74% | |
| ctc_prefix_beam_search | 8.69% | 18.35% | 9.06% | 18.69% | |
| Method | Decoding Algorithm | WER(%) | |||
|---|---|---|---|---|---|
| Dev-Clean | Dev-Other | Test-Clean | Test-Other | ||
| Unified_Conformer (Arithmetic mean) | attention | 4.55% | 10.12% | 4.93% | 10.31% |
| ctc_greedy_search | 4.68% | 12.05% | 4.88% | 12.16% | |
| ctc_prefix_beam_search | 4.63% | 12.03% | 4.84% | 12.09% | |
| Unified_Conformer (weighted mean) | attention | 4.56% | 10.12% | 4.93% | 10.32% |
| ctc_greedy_search | 4.67% | 12.05% | 4.87% | 12.17% | |
| ctc_prefix_beam_search | 4.63% | 12.02% | 4.83% | 12.10% | |
| Method | Decoding Algorithm | WER(%) | |||
|---|---|---|---|---|---|
| Dev-Clean | Dev-Other | Test-Clean | Test-Other | ||
| U2++_Conformer (Arithmetic mean) | attention | 4.41% | 10.59% | 4.87% | 10.83% |
| ctc_greedy_search | 5.08% | 12.38% | 5.26% | 12.59% | |
| ctc_prefix_beam_search | 5.03% | 12.34% | 5.20% | 12.48% | |
| U2++_Conformer (weighted mean) | attention | 4.39% | 10.54% | 4.81% | 10.79% |
| ctc_greedy_search | 5.05% | 12.37% | 5.27% | 12.60% | |
| ctc_prefix_beam_search | 5.01% | 12.32% | 5.20% | 12.47% | |
| Method | Decoding Algorithm | WER(%) | |||
|---|---|---|---|---|---|
| Dev-Clean | Dev-Other | Test-Clean | Test-Other | ||
| Mixformer | attention | 4.60% | 10.12% | 4.91% | 10.22% |
| ctc_greedy_search | 4.58% | 11.85% | 4.85% | 12.06% | |
| ctc_prefix_beam_search | 4.54% | 11.83% | 4.83% | 11.97% | |
| Method | Decoding Algorithm | WER(%) | |||
|---|---|---|---|---|---|
| Dev-Clean | Dev-Other | Test-Clean | Test-Other | ||
| Conformer | adaptive attention fusion rescoring | 5.17% | 12.35% | 5.43% | 12.36% |
| Unified_Conformer | adaptive attention fusion rescoring | 4.35% | 10.02% | 4.73% | 10.13% |
| U2++_Conformer | adaptive attention fusion rescoring | 4.14% | 10.20% | 4.42% | 10.08% |
| Method | Decoding Algorithm | WER(%) | |||
|---|---|---|---|---|---|
| Dev-Clean | Dev-Other | Test-Clean | Test-Other | ||
| Conformer | attention | 7.00% | 16.26% | 7.18% | 16.72% |
| ctc_greedy_search | 8.83% | 18.41% | 9.16% | 18.74% | |
| ctc_prefix_beam_search | 8.69% | 18.35% | 9.06% | 18.69% | |
| adaptive attention fusion rescoring | 5.17% | 12.35% | 5.43% | 12.36% | |
| Unified_Conformer | attention | 4.56% | 10.12% | 4.93% | 10.32% |
| ctc_greedy_search | 4.67% | 12.05% | 4.87% | 12.17% | |
| ctc_prefix_beam_search | 4.63% | 12.02% | 4.83% | 12.10% | |
| adaptive attention fusion rescoring | 4.35% | 10.02% | 4.73% | 10.13% | |
| U2++_Conformer | attention | 4.39% | 10.54% | 4.81% | 10.79% |
| ctc_greedy_search | 5.05% | 12.37% | 5.27% | 12.60% | |
| ctc_prefix_beam_search | 5.01% | 12.32% | 5.20% | 12.47% | |
| adaptive attention fusion rescoring | 4.14% | 10.20% | 4.42% | 10.08% | |
| Method | Decoding Algorithm | WER(%) | |||
|---|---|---|---|---|---|
| Dev-Clean | Dev-Other | Test-Clean | Test-Other | ||
| Conformer | attention | 7.00% | 16.26% | 7.18% | 16.72% |
| ctc_greedy_search | 8.83% | 18.41% | 9.16% | 18.74% | |
| ctc_prefix_beam_search | 8.69% | 18.35% | 9.06% | 18.69% | |
| Unified_Conformer | attention | 4.56% | 10.12% | 4.93% | 10.32% |
| ctc_greedy_search | 4.67% | 12.05% | 4.87% | 12.17% | |
| ctc_prefix_beam_search | 4.63% | 12.02% | 4.83% | 12.10% | |
| U2++_Conformer | attention | 4.39% | 10.54% | 4.81% | 10.79% |
| ctc_greedy_search | 5.05% | 12.37% | 5.27% | 12.60% | |
| ctc_prefix_beam_search | 5.01% | 12.32% | 5.20% | 12.47% | |
| Mixformer | attention | 4.60% | 10.12% | 4.91% | 10.22% |
| ctc_greedy_search | 4.58% | 11.85% | 4.85% | 12.06% | |
| ctc_prefix_beam_search | 4.54% | 11.83% | 4.83% | 11.97% | |
| Conformer | adaptive attention fusion rescoring | 5.17% | 12.35% | 5.43% | 12.36% |
| Unified_Conformer | adaptive attention fusion rescoring | 4.35% | 10.02% | 4.73% | 10.13% |
| U2++_Conformer | adaptive attention fusion rescoring | 4.14% | 10.20% | 4.42% | 10.08% |
| Mixformer | adaptive attention fusion rescoring | 3.92% | 8.94% | 4.07% | 9.31% |
| Method | WER(%) | |||
|---|---|---|---|---|
| Dev-Clean | Dev-Other | Test-Clean | Test-Other | |
| DeepSpeech | 4.71% | 12.6% | 4.80% | 13.0% |
| Kaldi | 4.63% | 12.1% | 4.81% | 12.7% |
| HuBERT | 3.93% | 9.35% | 4.08% | 10.5% |
| Wav2Vec 2.0 | 3.95% | 9.25% | 4.10% | 9.82% |
| Mixformer (Our method) | 3.92% | 8.94% | 4.07% | 9.31% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Geng, J.; Jia, D.; He, Z.; Wu, N.; Li, Z. Enhanced Conformer-Based Speech Recognition via Model Fusion and Adaptive Decoding with Dynamic Rescoring. Appl. Sci. 2024, 14, 11583. https://doi.org/10.3390/app142411583
Geng J, Jia D, He Z, Wu N, Li Z. Enhanced Conformer-Based Speech Recognition via Model Fusion and Adaptive Decoding with Dynamic Rescoring. Applied Sciences. 2024; 14(24):11583. https://doi.org/10.3390/app142411583
Chicago/Turabian StyleGeng, Junhao, Dongyao Jia, Zihao He, Nengkai Wu, and Ziqi Li. 2024. "Enhanced Conformer-Based Speech Recognition via Model Fusion and Adaptive Decoding with Dynamic Rescoring" Applied Sciences 14, no. 24: 11583. https://doi.org/10.3390/app142411583
APA StyleGeng, J., Jia, D., He, Z., Wu, N., & Li, Z. (2024). Enhanced Conformer-Based Speech Recognition via Model Fusion and Adaptive Decoding with Dynamic Rescoring. Applied Sciences, 14(24), 11583. https://doi.org/10.3390/app142411583