5.6. Experimental Results
(1) Quality evaluation of voice conversion
The primary goals of the voice conversion (VC) task are to transform the speaker’s timbre while preserving the original linguistic content and maximize the naturalness and intelligibility of the generated speech. To this end, we evaluated the proposed method on the speech test set by using both subjective and objective metrics. Subjective evaluation was conducted based on Mean Opinion Score (MOS) tests, while objective performance was quantified by using the Mel Cepstral Distortion (MCD) and Word Error Rate (WER). This combination provided a comprehensive assessment of the effectiveness of different voice conversion approaches.
As shown in
Table 1, the proposed MPFM-VC algorithm achieved the highest scores among the evaluated methods in terms of naturalness (MOS), audio fidelity (MCD), and speech clarity (WER). Compared with existing models, MPFM-VC exhibited relatively consistent performance across multiple evaluation metrics, suggesting improved robustness under varying data conditions.
In particular, MPFM-VC showed an 11.57% increase in MOS compared to Free-VC, which may reflect better handling of speech continuity and prosodic variation while reducing artifacts commonly associated with end-to-end VITS-based frameworks. Compared with diffusion-based models such as Diff-VC and DDDM-VC, MPFM-VC reported lower MCD and WER values, indicating that it may better preserve semantic content and enhance the intelligibility of the converted speech. Furthermore, compared to Voiceflow-VC, a recent baseline based on rectified flow matching, MPFM-VC achieved marginal improvements across all three evaluation metrics. Although Voiceflow-VC already produces competitive results in terms of synthesis quality and efficiency, the inclusion of multi-dimensional feature modeling and content perturbation in MPFM-VC may contribute to enhanced spectral accuracy and prosodic consistency, which could lead to improved intelligibility and speaker similarity.
Overall, these results suggest that the proposed architectural components in MPFM-VC—particularly the integration of auxiliary acoustic features and robustness-aware training strategies—may enhance the model’s adaptability to various acoustic conditions and speaker characteristics.
(2) Timbre similarity evaluation of voice conversion
The goal of speaker similarity evaluation is to assess a voice conversion method’s ability to preserve the timbre consistency of the target speaker. In this study, we adopted two metrics for analysis: Similarity MOS (SMOS) and Speaker Embedding Cosine Similarity (SECS).
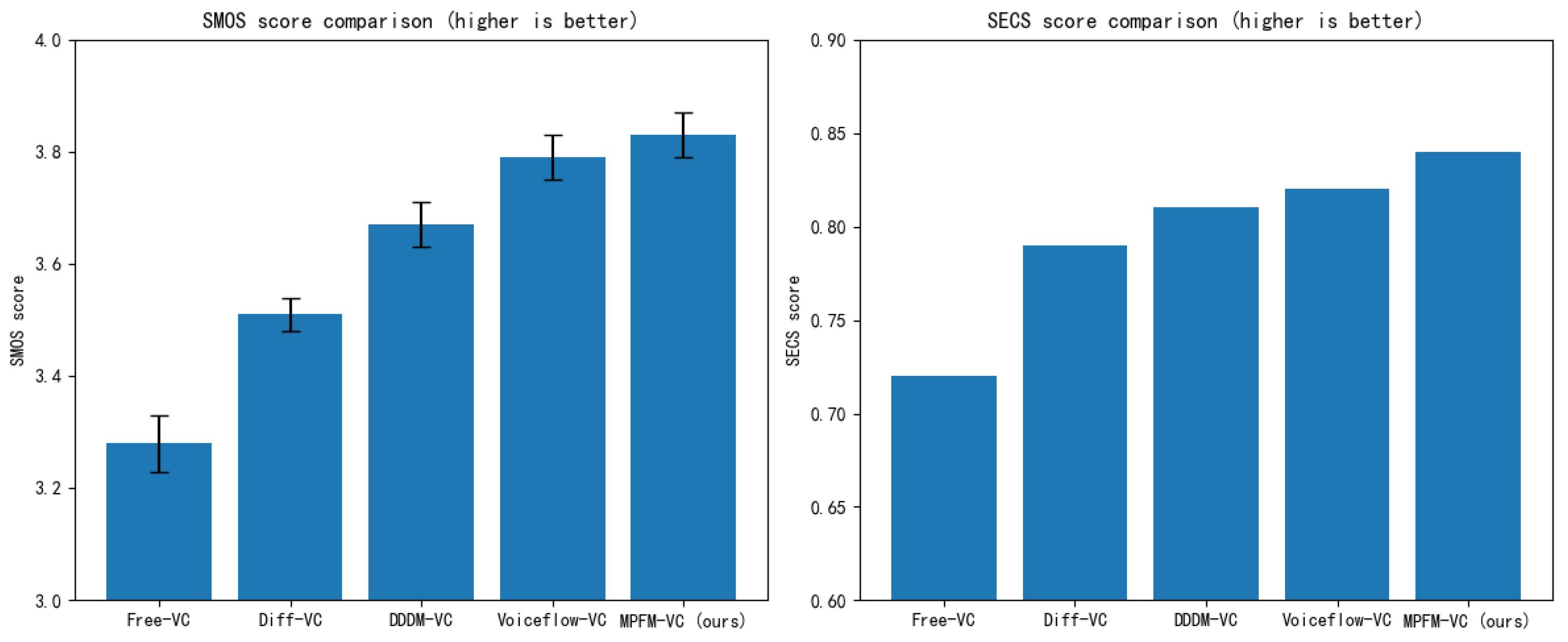
As shown in
Table 2 and
Figure 8, MPFM-VC exhibited relatively high speaker consistency in the speaker similarity evaluation task, achieving the highest SMOS (3.83) and SECS (0.84) scores. This suggests that MPFM-VC may better preserve the timbral characteristics of the target speaker during conversion. Compared with Free-VC, MPFM-VC enhanced the model’s adaptability to target speaker embeddings through multi-dimensional feature perception modeling, thereby improving post-conversion timbre similarity. Although Diff-VC benefited from diffusion-based generation, which improved overall audio quality to some extent, it failed to sufficiently disentangle speaker identity features, resulting in residual characteristics from the source speaker in the converted speech. While DDDM-VC introduced feature disentanglement mechanisms that improved speaker similarity, it still fell short compared with MPFM-VC. MPFM-VC showed slightly improved results over Voiceflow-VC by incorporating adversarial training tailored to speaker embeddings, which more effectively suppressed residual speaker leakage and refined speaker identity alignment.
These findings suggest that the combination of flow-based modeling and speaker-guided adversarial training in MPFM-VC may support improved speaker similarity while maintaining acceptable naturalness and synthesis stability in voice conversion tasks.
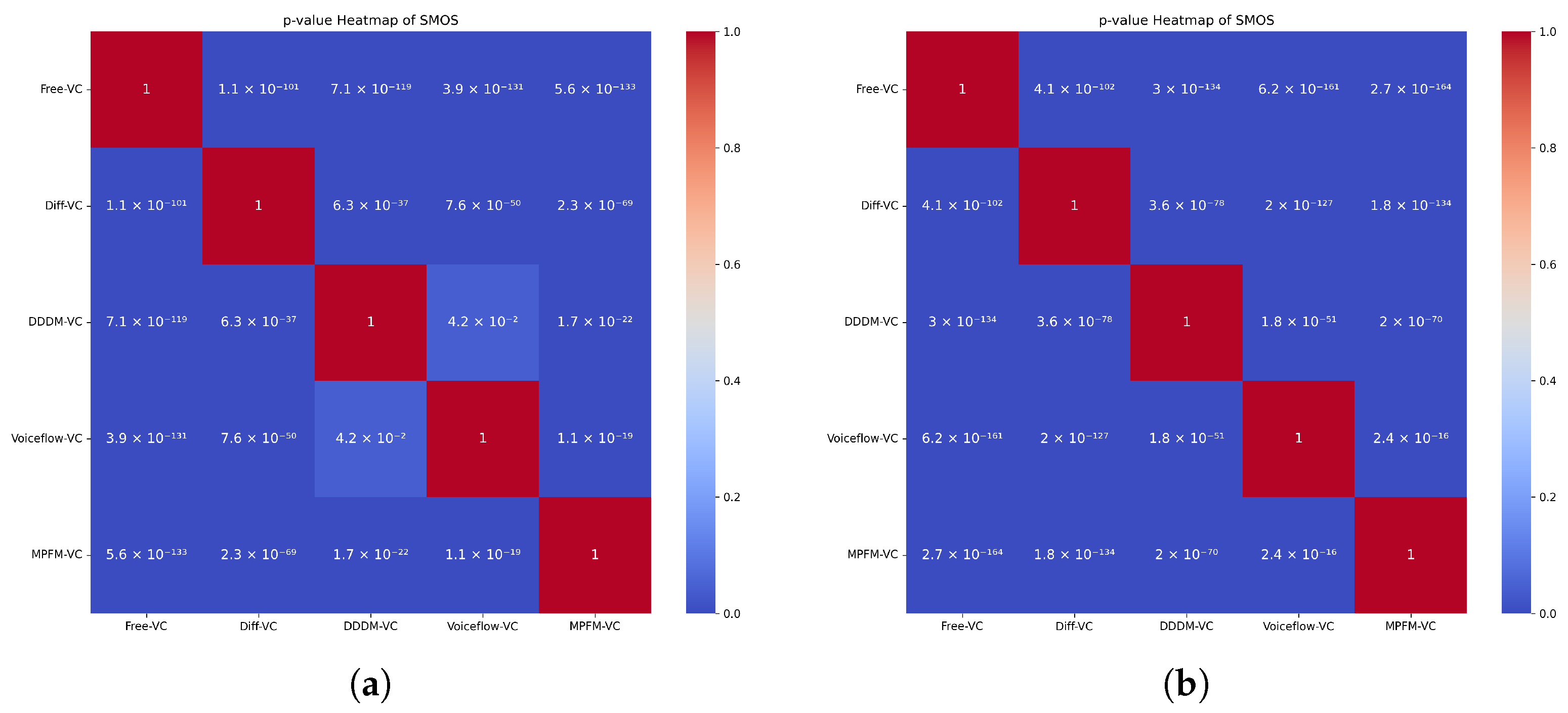
(3) Student’st-test of voice conversion
To validate the reliability of the subjective evaluation results, we conducted two-sample Student’s t-tests between each pair of evaluated systems for both MOS and SMOS metrics. In the p-value heatmaps, lower (blue) values indicate stronger statistical significance.
As shown in
Figure 9, for MOS, our proposed method MPFM-VC exhibited statistically significant improvements (
p < 0.05) over all baseline models, including Free-VC, Diff-VC, DDDM-VC, and Voiceflow-VC. The p-values were all extremely small (e.g., 2.3 ×
between MPFM-VC and DDDM-VC), confirming that the perceived improvements in naturalness were not due to chance.
Similarly, for SMOS, MPFM-VC also achieved statistically significant differences against all other systems, with p-values often smaller than 1 × . This reinforces the claim that our method provides more consistent and perceptually closer timbre to the target speaker than competing approaches.
Notably, even between Voiceflow-VC and other strong baselines like DDDM-VC, the differences were statistically significant, which highlighted the effectiveness of flow-matching-based methods in general. However, MPFM-VC still surpassed Voiceflow-VC with clear statistical confidence. These results demonstrated that the performance gains observed in MOS and SMOS were both consistent and statistically significant, further supporting the effectiveness of our proposed multi-dimensional perception flow-matching strategy.
(4) Quality evaluation of singing voice conversion
In the context of voice conversion, singing voice conversion is generally more challenging than standard speech conversion due to its inherently richer pitch variations, timbre stability, and prosodic complexity. We adopted the same set of evaluation metrics used in speech conversion to comprehensively evaluate the performance of different models on the singing voice conversion task, including the subjective Mean Opinion Score (MOS) and objective indicators such as Mel Cepstral Distortion (MCD) and the Word Error Rate (WER).
As shown in
Table 3, MPFM-VC achieved strong results on the singing voice conversion task, with a MOS of 4.12, an MCD of 6.32, and a WER of 4.86%. Through multi-dimensional feature perception modeling, MPFM-VC adapted to melodic variations and pitch fluctuations typically found in singing voices, producing outputs that exhibited improved fluency and preserve audio clarity. Compared with Free-VC, MPFM-VC achieved slightly better naturalness scores, possibly due to its use of flow matching, which may enhance dynamic feature modeling. Diffusion-based methods like Diff-VC and DDDM-VC tended to introduce some degree of over-smoothing, which may affect fine acoustic detail retention. Voiceflow-VC, as a recent flow-matching approach, achieved competitive performance (MOS: 3.93, WER: 5.56%), showing effective modeling of singing voices. However, MPFM-VC reported consistently higher scores across all metrics, potentially due to the integration of multi-dimensional conditioning and perturbation training.
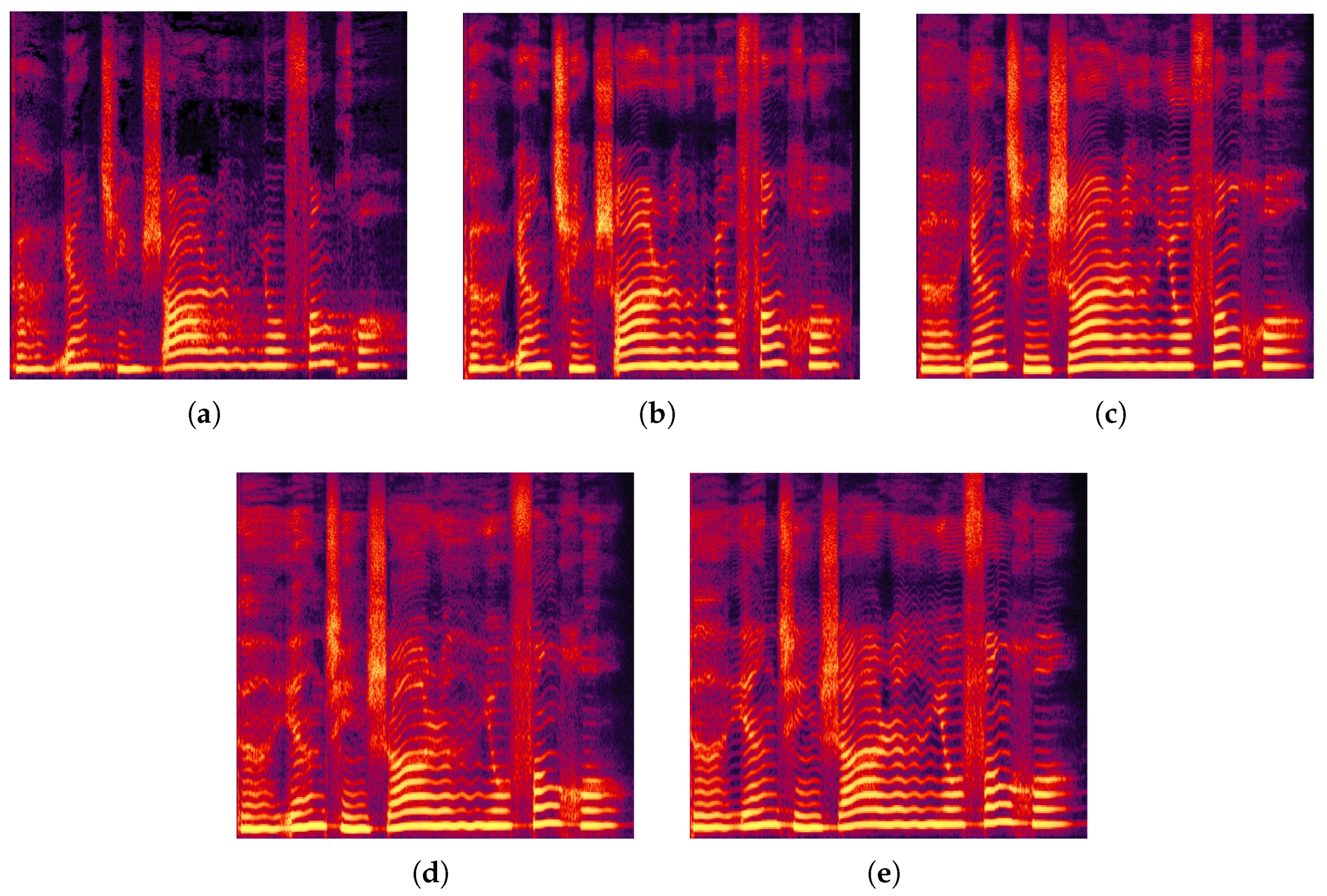
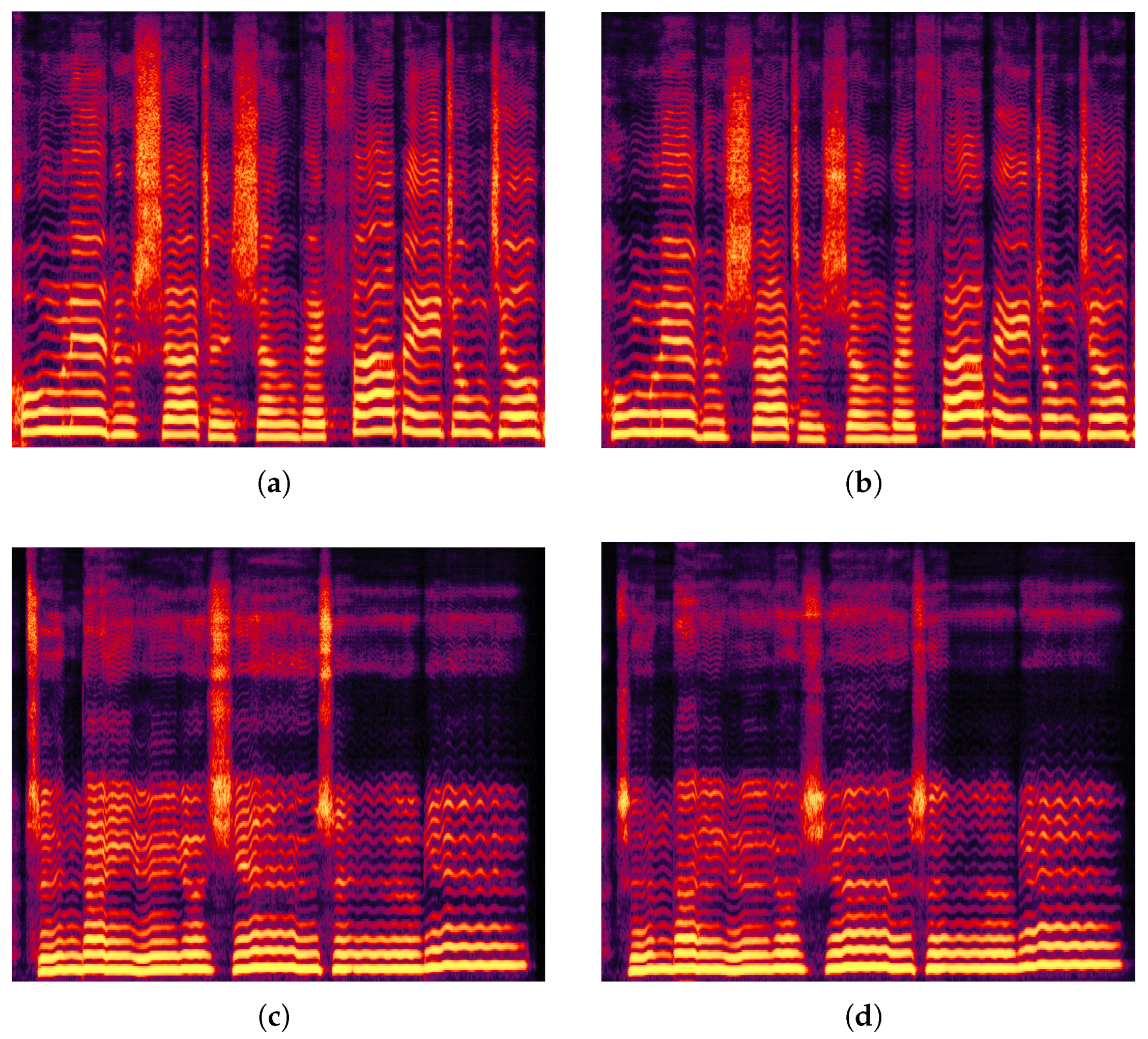
Additionally, we randomly selected a singing voice segment for spectrogram comparison, as shown in
Figure 10. The spectrogram generated by MPFM-VC appeared sharper and more structured, which may be attributed to the multi-dimensional perception network that enabled a more accurate reconstruction of detailed features such as vibrato and articulation. Voiceflow-VC also showed strong performance in maintaining temporal and spectral structure, outperforming Free-VC and diffusion-based models in some aspects. However, it captured slightly fewer high-frequency harmonics and transient variations compared to MPFM-VC, which may be important for expressive singing voice synthesis. These findings support the potential of the proposed method in producing perceptually improved results in singing voice conversion.
(5) Timbre similarity evaluation of singing voice conversion
Timbre similarity in singing voices is a critical metric for evaluating a model’s ability to preserve the target singer’s vocal identity during conversion. Compared with normal speech, singing involves more complex pitch variations, formant structures, prosodic patterns, and timbre continuity, which pose additional challenges for accurate speaker similarity modeling. In this study, we performed a comprehensive evaluation by using both subjective SMOS (Similarity MOS) and objective SECS (Speaker Embedding Cosine Similarity) to assess the effectiveness of different methods in capturing and preserving timbral consistency in singing voice conversion.
As shown in
Table 4 and
Figure 11, MPFM-VC achieved superior performance in singing voice timbre similarity evaluation. It achieved higher scores in both SMOS (3.79) and SECS (0.81) than the compared baselines, suggesting improved preservation of the target singer’s timbral identity. In singing voice conversion, Free-VC and Diff-VC showed limitations in disentangling content and speaker representations, which may result in timbre mismatches with the target voice. Although the diffusion-based DDDM-VC model partially solved this issue, it continued to exhibit timbre smoothing effects, which may reduce the perceptual uniqueness of the generated singing voices. Voiceflow-VC showed improved timbre consistency over these baselines and achieved competitive SMOS and SECS scores. However, it achieved slightly lower scores than MPFM-VC, especially in cases requiring preservation of fine speaker-specific details during dynamic singing phrases.
In contrast, MPFM-VC incorporated an adversarial speaker disentanglement strategy, which helped reduce residual source speaker cues and contributed to improved alignment with the target singer’s timbre. Additionally, MPFM-VC enabled the fine-grained modeling of timbral variation with a multi-dimensional feature-aware flow-matching mechanism, potentially supporting more stable and consistent timbre rendering throughout the conversion process.
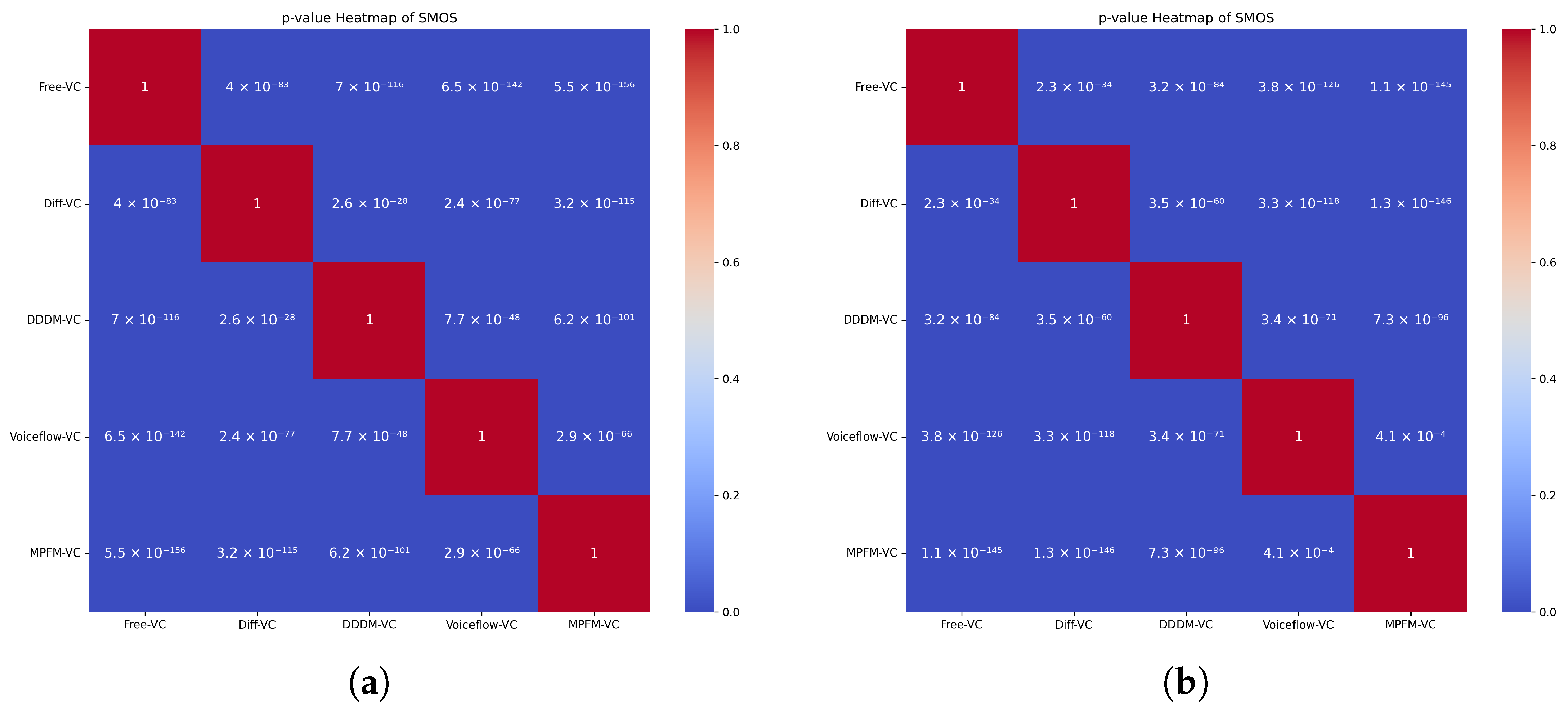
(6) Student’s t-test of singing voice conversion
To further validate the significance of our model’s performance in the singing voice conversion task, we conducted pairwise Student’s t-tests on subjective evaluation metrics (MOS and SMOS). As shown in
Figure 12, most p-values were significantly below 0.05, indicating that the differences in perceived speech quality and timbre similarity between MPFM-VC and other baselines were statistically significant. Notably, MPFM-VC consistently achieved statistically better results over all compared methods in both metrics.
(7) Robustness Evaluation under Low-Quality Conditions
In real-world applications, voice conversion systems must exhibit robustness to low-quality input data in order to maintain reliable performance under adverse conditions such as background noise, limited recording hardware, or unclear articulation by the speaker. To assess this capability, we additionally collected a set of 30 low-quality speech samples that incorporated common noise-related challenges, including mumbling, background reverberation, ambient noise, signal clipping, and low-bitrate encoding.
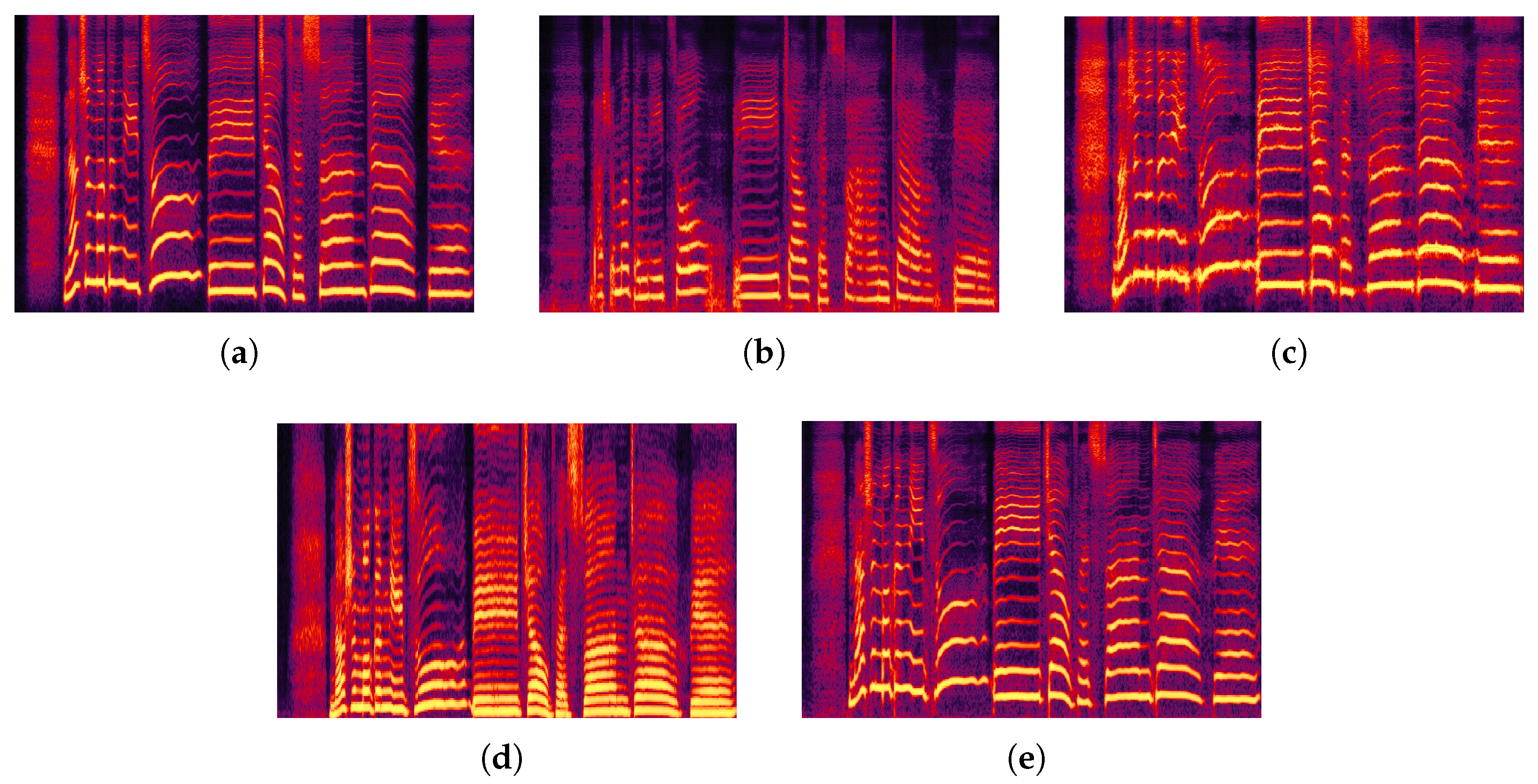
As shown in
Table 5 and the spectrograms in
Figure 13, MPFM-VC maintained stable performance even under low-quality speech conditions. The generated spectrograms retained clear structural patterns, suggesting preserved synthesis quality despite degraded inputs, whereas other systems showed more degradation in terms of naturalness and timbre consistency.
Diffusion-based models, such as Diff-VC and DDDM-VC, exhibited reduced performance under noise perturbation. Their spectrograms appeared blurred, and metrics such as MCD and WER indicated degradation. For instance, Diff-VC resulted in the highest WER (35.20%) and MCD (8.85), pointing to its sensitivity to noisy inputs. Voiceflow-VC, using rectified flow matching, showed relatively better robustness compared to diffusion-based baselines, achieving higher MOS (3.12) and SMOS (3.34) than Free-VC and DDDM-VC. However, its performance remained slightly lower than that of MPFM-VC in terms of intelligibility and timbre similarity.
MPFM-VC achieved the highest scores across all evaluation metrics—including WER (15.37%), MCD (6.89), SMOS (3.53), and SECS (0.73). These results suggest that multi-dimensional feature modeling and content perturbation strategies may enhance resilience to noisy conditions and support more consistent and intelligible voice conversion in practical scenarios.
It is worth noting that although Free-VC showed relatively weaker performance in previous experiments, it still performed more reliably than diffusion-based architectures under low-quality speech conditions. Its generated spectrograms exhibited limited blurring, which may suggest some noise tolerance associated with the end-to-end variational autoencoder (VAE)-based modeling approach. However, its SECS score remained notably lower than that of MPFM-VC, suggesting possible challenges in preserving accurate timbre.
Voiceflow-VC, which leverages rectified flow matching for generation, showed improved robustness compared to diffusion-based models such as Diff-VC and DDDM-VC. It achieved competitive intelligibility and timbre similarity scores, and its spectrograms appeared more consistent under noise. Nevertheless, its overall performance was slightly lower than MPFM-VC, particularly in preserving speaker-specific features during more complex singing phrases, as reflected in the SECS and WER scores.
MPFM-VC maintained relatively high speech quality and speaker similarity under low-quality input conditions. It yielded the highest scores across the reported evaluation metrics—including MOS, MCD, WER, and SMOS—and its spectrograms retained structural clarity. This outcome may be related to the integration of multi-dimensional feature-aware flow matching, which enables more detailed modeling of speech under varying noise conditions. Additionally, the content perturbation-based training augmentation may improve the model’s robustness to missing or degraded input features, and the adversarial training on speaker embeddings may contribute to better timbre preservation under noisy conditions.
5.7. Ablation Experiments
(1) Prosodic feature verification in multi-dimensional perception network
In this study, we refined the existing Classifier-Free Guidance (CFG) inference strategy, as shown in Equation (
7), by increasing the weight of prosodic features in the MDPN. This adjustment enabled a more effective analysis of the impact of prosody on the generated speech through spectrogram-based evaluations.
We set the weight of the prosodic matrix in the prosody-based CFG to 0.5 to compare its effect with the version without prosody CFG. As illustrated in the
Figure 14, we randomly selected two pairs of singing samples for a more intuitive comparison. In the versions with prosody CFG, the high-frequency regions appeared more enriched, indicating a greater vocal openness and increased vocal brightness. Additionally, the spectrogram showed brighter formant structures for each syllable, suggesting that the prosody CFG enhanced the emphasis and articulation of stressed syllables.
(2) Content perturbation-based training enhancement method
In the voice conversion task, the content perturbation-based training augmentation strategy was designed to improve model generalization by introducing controlled perturbations to content representations during training. That approach aimed to reduce inference-time artifacts such as unexpected noise and improve the overall stability of the converted speech. To validate the effectiveness of this method, we conducted an ablation study by removing the content perturbation mechanism and observing its impact on speech conversion performance. In addition, we also applied the methods of two related works to our MPFM-VC as the baseline. SpecAugment [
51] randomly adds a mask to the input mel spectrogram, and Maskcyclegan-VC [
52] uses a filling in frames (FIF) method to mask the mel spectrogram, which is similar to the method in this paper. The difference lies in that it enhances the spectrum, while the method in this paper enhances the content representation. A test set consisting of 100 out-of-distribution audio samples with varying durations was used to simulate real-world scenarios under complex conditions. The following evaluation metrics were determined: MOS, MCD, WER, SMOS, SECS, and the frequency of plosive artifacts per 10 s in converted speech (Badcase).
As shown in
Table 6, the content perturbation-based training augmentation appeared to contribute to improved stability and robustness in the voice conversion model. When this component was removed, the Badcase rate increased noticeably (from 0.39 to 1.52 per 10 s), suggesting a higher occurrence of artifacts such as plosive noise or interruptions in more acoustically challenging cases. Additionally, MCD and WER both rose slightly, which may indicate reduced fidelity and intelligibility.
Interestingly, the MOS improved slightly in the absence of perturbation, possibly due to better in-domain fitting, though this came at the cost of generalization across longer or mismatched utterances. Meanwhile, the SMOS and SECS remained largely stable, implying that the perturbation strategy primarily contributed to robustness rather than timbre consistency.
Compared to the traditional SpecAugment method, which yielded inferior results likely due to random masking, the proposed strategy offered more structured perturbation. Similarly, the FIF approach from MaskCycleGAN-VC also enhanced robustness, though it resulted in slight reductions in MOS and MCD. Nevertheless, FIF performed comparably to our approach in content preservation and timbre similarity under certain conditions.
Overall, the results suggest that the content perturbation strategy provides meaningful improvements in stability and generalization, particularly under noisy or out-of-domain scenarios, and can be a valuable addition for real-world voice conversion systems.
(3) Adversarial training mechanism based on voiceprint
In the voice conversion task, the strategy of adversarial training on speaker embeddings was designed to enhance the timbre similarity to the target speaker while suppressing residual speaker identity information from the source speaker. This ensured that the converted speech better matched the target speaker’s voice without compromising the overall speech quality.
To evaluate the effectiveness of that strategy, we conducted an ablation study by removing the adversarial training module and comparing its impact on timbre similarity and overall speech quality in the converted outputs. Moreover, we incorporated the conditioning strategy from Voicebox [
36] into our baseline model MPFM-VC. The method involved using the mel spectrogram of a target speaker as a prompt, which was injected into each perceptual block to enhance speaker similarity.
As shown in
Table 7, the speaker adversarial training module appeared to contribute substantially to timbre matching in the voice conversion task. When this component was removed, both SMOS and SECS scores decreased—from 3.83 to 3.62 and from 0.84 to 0.73, respectively—suggesting reduced alignment with the target speaker’s timbre and an increase in residual characteristics from the source speaker.
In contrast, the MOS and MCD metrics remained largely unchanged, indicating that the adversarial mechanism had a limited impact on overall audio quality. Interestingly, WER showed a slight improvement, which may reflect enhanced intelligibility. However, this change could be associated with a loss of timbre specificity, as the model could default to producing more neutral or averaged vocal characteristics.
While higher speaker similarity could be achieved with Voicebox-based methods, they relied on the mel spectrogram of a reference utterance, which might introduce unrelated acoustic information and affect both quality and intelligibility.
Overall, adversarial training helped improve timbre consistency by suppressing residual speaker identity cues in the content representation. While some perceptual quality scores improved when this component was omitted, these gains came at the expense of precise speaker identity transfer. Therefore, in practical applications, adversarial training remains essential to achieving high-quality voice conversion, ensuring that the generated speech is not only intelligible but also accurately timbre-matched to the intended target speaker.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}