

Context Is King: Large Language Models’ Interpretability in Divergent Knowledge Scenarios

 , , , and
, , , and
Abstract
1. Introduction
- The introduction of the Context-Driven Divergent Knowledge Evaluation (CDK-E) methodology along with the Divergent Knowledge Dataset (DKD), a novel methodology and dataset for evaluating the interpretability of LLMs in context-specific scenarios that diverge from the model’s inherent knowledge.
- The presentation of empirical results demonstrating the effectiveness of contextual information in achieving interpretability and explainability.
- The provision of analysis and discussion for the integration of LLMs, focusing on improving interpretability and enhancing the understanding of their decision-making processes, along with a framework for future research in explainable AI (XAI).
2. Related Work
2.1. Context-Based Interaction Techniques
- Few-shot Prompting: In this technique, a few examples are provided to the model as part of the prompt. This approach enables in-context learning to help the model understand the desired output format and the type of responses expected [31].
- Chain-of-Thought Prompting: Chain-of-thought (CoT) prompting encourages the model to break down complex problems into smaller manageable steps [32]. By prompting the model to “think aloud” and generate intermediate reasoning steps, users can improve the model’s ability to handle tasks that require logical reasoning and multi-step problem solving. This technique enhances the transparency and interpretability of the model’s decision-making process.
- Retrieval-Augmented Generation: One of the most popular techniques nowadays due to its ability to connect LLMs with external information sources, Retrieval-Augmented Generation (RAG) [33] combines the LLMs’ understanding and generation capabilities with external information retrieval. These retrieval mechanisms fetch relevant and up-to-date information from external sources, enabling LLMs to access an authoritative knowledge base beyond their training data before generating a response. RAG enhances the already powerful capabilities of LLMs by integrating specific domain knowledge or an organization’s internal knowledge base, all without the need for model retraining. It is a cost-effective approach that addresses the limitation of knowledge cutoffs, ensuring that outcomes are relevant, accurate, and useful in various contexts.
- Prompt Chaining: This technique breaks down complex tasks requiring iterative processing or multi-step reasoning into smaller manageable tasks. By connecting multiple prompts in a sequence, each building on the previous one, prompt chaining guides the model through a series of steps. This approach helps to improve the reliability, performance, and understanding of LLMs’ interactions, resulting in more accurate and comprehensive responses.
- ReAct: ReAct (synergizing reasoning and acting) explores the use of LLMs to generate both reasoning traces and task-specific actions in an interleaved manner [34]. By prompting the model to not only reason through a problem but also suggest specific actions, the system can induce, track, and update action plans while handling exceptions. Additionally, ReAct enables the model to integrate external sources such as knowledge bases or environments to inform its actions.
2.2. Explainable AI and Interpretability in Large Language Models
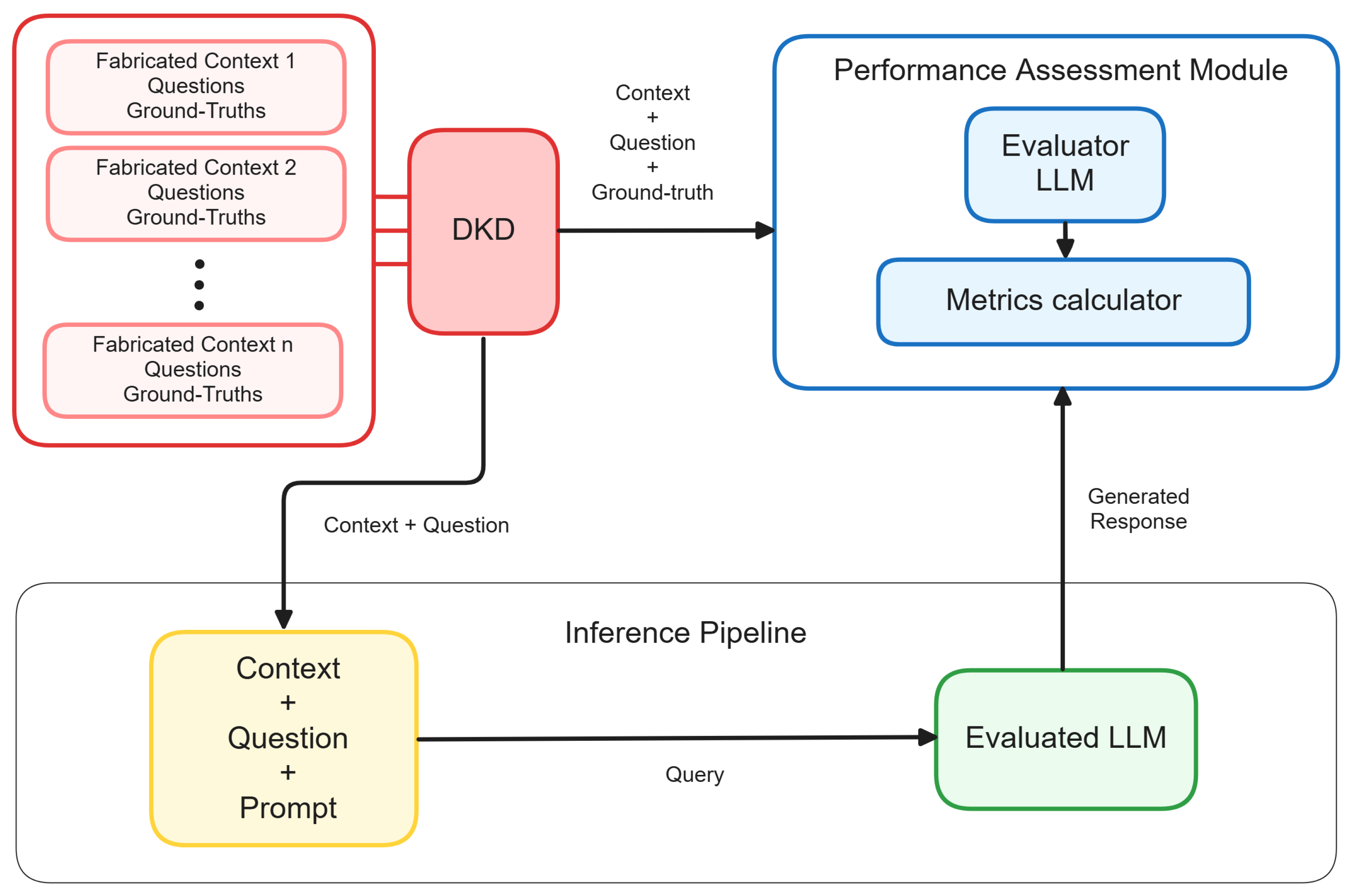
3. CDK-E: Context-Driven Divergent Knowledge Evaluation
- Biases and Hallucinations: By using divergent contexts, CDK-E enhances the detection of hallucinations and biases in LLM responses as these issues become more apparent when the model is exposed to information that conflicts with its internal knowledge.
- Contextual Misalignment: By evaluating LLM outputs against the provided context, CDK-E helps to identify any misalignment between generated and ground-truths.
- Scalability: The model-independent pipeline, combined with prompt engineering, enables scalable and flexible evaluation across various models and datasets.
3.1. DKD: Divergent Knowledge Dataset
3.1.1. Divergent Context Fabrication
3.1.2. Question Design
3.1.3. Validation and Annotation
3.2. Performance Assessment Module
3.2.1. Answer Semantic Similarity
- A represents the embeddings (vectorized form) of the generated answer.
- B represents the embeddings (vectorized form) of the ground-truth answer.
- and are the components of vectors A and B, respectively.
- n is the number of dimensions in the vector space.
3.2.2. Answer Correctness
- (true positive) represents the number of facts or statements that are present in both the ground-truth and the generated answer.
- (false positive) represents the number of facts or statements that are present in the generated answer but not in the ground-truth.
- (false negative) represents the number of facts or statements that are present in the ground-truth but not in the generated answer.
3.2.3. LLM-Score-Based Metrics for Accuracy and Completeness
- Accuracy (Acc): Assesses if the LLM-generated answer reflects the factual information presented, calculated by prompting “Does the LLM-generated answer correctly reflect the facts presented in the ground-truth?”.
- Completeness (Cm): Evaluates if the answer includes all key points by prompting “Does the LLM-generated answer cover all key points mentioned in the ground-truth?”.
3.2.4. LLM Answer Validation
4. Experimental Setup
4.1. Configuration and Creation of DKD
4.2. Evaluated Models and Configuration
- GPT-3.5 Turbo [2]: An enhanced version of GPT-3, known for its improved performance and efficiency in generating human-like text. It has 175 billion parameters and is trained on a diverse range of internet text. Inference for GPT-3.5 Turbo was conducted using the OpenAI API.
- GPT-4o [56]: The latest iteration in the GPT series, featuring even more parameters and fine-tuned capabilities. GPT-4o offers superior accuracy and a deeper understanding of context compared to its predecessors. Inference for GPT-4o was conducted using the OpenAI API.
- Llama 3 (70B) [57]: Developed by Meta, this model features 70 billion parameters and is designed for large-scale language tasks. Llama 3 demonstrates state-of-the-art performance on a wide range of industry benchmarks and includes new capabilities such as improved reasoning and code generation. Inference for Llama 3 was conducted using AWS Bedrock.
- Mixtral 8x7B [58]: Developed by Mistral AI, this is a Sparse Mixture-of-Experts (SMoE) model that utilizes only 12.9 billion active parameters out of a total of 46.7 billion. It is designed for efficiency and performance, with strong capabilities in multiple languages and coding tasks. Inference for Mixtral was conducted using AWS Bedrock. It is the smallest model we are testing, aiming to determine if our interpretability thesis holds with less powerful models.
4.3. Contextual Prompt Injection, Evaluator LLMs, and Metric Configuration
5. Results and Discussion
5.1. Empirical Results
5.2. Detailed Response Analysis
- Hallucinations errors: These occur when models generate information that is entirely unrelated to the provided context or divergent knowledge. Those models with inferior performance, especially Mixtral 8x7B, exhibited a relatively high frequency of hallucination errors. For example, in response to a question about a fictional historical event, Mixtral 8x7B introduced unrelated historical facts not included in the prompt, likely drawing from its internal knowledge base.
- Context misalignment: This type of error occurs when models fail to use the divergent context correctly even though relevant information is available. This is the most common error and occurs mainly when the answer to the question is not explicitly found in the divergent context but the model needs to assimilate some of that knowledge to achieve an indirect answer. For example, when a question involves calculating a celebrity’s age based on an altered date of birth, the model may default to its internal knowledge instead of processing the divergent information. Such cases highlight opportunities for improvement, particularly through refined prompting techniques. Approaches like chain-of-thought [32], task decomposition, and sequential reasoning could be employed to guide the model’s focus toward divergent information more effectively. These methods are increasingly utilized in the most advanced models, such as OpenAI’s GPT-o1 series, and show promise in enhancing alignment with context-specific knowledge.
- Verbose and extraneous information: Predominantly found in the GPT models, this error involves providing overly detailed or verbose responses that include information not directly relevant to the question. For instance, when asked about a simple fictional fact, GPT-3.5 added unnecessary background information, diluting the focus of the answer. On the other hand, Llama 3 and Mixtral 8x7B were more concise in their responses, sometimes to the point of omitting important information.
5.3. Correlations Between Metrics
5.4. Discussion
5.4.1. Implications for Future Research
5.4.2. Challenges and Limitations
6. Conclusions
- Extended Datasets: Expanding the DKD to include more diverse and complex contexts, thereby increasing the robustness of the evaluation framework.
- Advanced Metrics: Developing and integrating new metrics that capture additional dimensions of explainable AI, such as causal inference and user interpretability.
- Interactive Interpretability: Exploring interactive approaches where users can engage with LLMs to understand and refine their responses, enhancing the transparency and usability of AI systems.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Acc | Accuracy |
| AWS | Amazon Web Service |
| AC | Answer Correctness |
| ASS | Answer Semantic Similarity |
| API | Application Programming Interface |
| AI | Artificial Intelligence |
| BERT | Bidirectional Encoder Representations from Transformers |
| CoT | Chain of Thought |
| Cm | Completeness |
| CDK-E | Context-Driven Divergent Knowledge Evaluation |
| DKD | Divergent Knowledge Dataset |
| XAI | Explainable Artificial Intelligence |
| FC | Factual Correctness |
| GPT | Generative Pre-trained Transformer |
| LLM | Large Language Model |
| LAV | LLM Answer Validation |
| LIMEs | Local Interpretable Model-agnostic Explanations |
| RAG | Retrieval-Augmented Generation |
| RAGAS | Retrieval-Augmented Generation Assessment |
| ReAct | Reasoning and Acting |
| SHAPs | Shapley Additive Explanations |
Appendix A. Prompt Utilized in CDK-E
Appendix A.1. Prompt Utilized for the Development of the Fabricated Context of the Dataset
Appendix A.2. Prompt Utilized for the Creation of Contextual Questions
Appendix A.3. Prompt Utilized for CDK-E Inference with OpenAI API
Appendix A.4. Prompt Utilized for CDK-E Inference with AWS Bedrock API for Llama 3
Appendix A.5. Prompt Utilized for CDK-E Inference with AWS Bedrock API for Mixtral 8x7B
Appendix A.6. Prompt Utilized for LLM-Based Accuracy and Completeness
Appendix A.7. Prompt Utilized for LLM Answer Validation
Appendix B. DKD Details

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Name | Topic | Characters | Tokens |
|---|---|---|---|---|
| 1 | Agatha Christie | Literature | 7375 | 1605 |
| 2 | Al Capone | History | 8002 | 1817 |
| 3 | Artificial Intelligence | Science/Tech | 6726 | 1220 |
| 4 | Christopher Columbus | History | 7975 | 1747 |
| 5 | Cryptography RSA | Science/Tech | 7895 | 1585 |
| 6 | Deep Learning | Science/Tech | 7348 | 1392 |
| 7 | DeepL Translator | Science/Tech | 5780 | 1194 |
| 8 | Doctor Who | Movies/Television | 8113 | 1698 |
| 9 | Elon Musk | Science/Tech | 7983 | 1696 |
| 10 | Fahrenheit 451 | Literature | 6963 | 1469 |
| 11 | FIFA World Cup | Sports | 8014 | 1635 |
| 12 | French Revolution | History | 7520 | 1544 |
| 13 | Friends | Movies/Television | 7899 | 1740 |
| 14 | Gabriel García Márquez | Literature | 7867 | 1779 |
| 15 | Google PageRank Algorithm | Science/Tech | 7665 | 1339 |
| 16 | Gravity | Maths/Physics | 7715 | 1538 |
| 17 | Greek Mythology | History | 6867 | 1375 |
| 18 | Harry Potter | Literature | 7888 | 1715 |
| 19 | Hogwarts | Fiction | 7839 | 1583 |
| 20 | Isaac Asimov | Literature | 7983 | 1790 |
| 21 | James Bond | Movies/Television | 7233 | 1607 |
| 22 | Jane Austen | Literature | 7913 | 1720 |
| 23 | Jules Verne | Literature | 7358 | 1738 |
| 24 | J.R.R. Tolkien | Literature | 7964 | 1774 |
| 25 | Llama (animal) | Other | 8000 | 1887 |
| 26 | Machine Learning | Science/Tech | 6257 | 1139 |
| 27 | Madrid Football Club | Sports | 7991 | 1844 |
| 28 | Mad Max | Movies/Television | 7997 | 1714 |
| 29 | Mars (planet) | Maths/Physics | 6855 | 1562 |
| 30 | Michael Jackson | Movies/Television | 8006 | 1821 |
| 31 | Miguel Delibes | Literature | 7910 | 1861 |
| 32 | Nicolas Flamel | History | 7336 | 1783 |
| 33 | Philip K. Dick | Literature | 7917 | 1750 |
| 34 | Problem P versus NP | Science/Tech | 7919 | 1751 |
| 35 | Pyramids of Guimar | History | 8025 | 1735 |
| 36 | Pythagoras | Maths/Physics | 7946 | 1840 |
| 37 | Rebecca Yarros | Literature | 4231 | 1117 |
| 38 | Russian Revolution | History | 7157 | 1443 |
| 39 | Sherlock Holmes | Literature | 7868 | 1616 |
| 40 | Spider Man | Fiction | 8022 | 1618 |
| 41 | Star Trek | Movies/Television | 7380 | 1500 |
| 42 | Stephen King | Literature | 8033 | 1761 |
| 43 | Telenovela | Literature | 7326 | 1673 |
| 44 | Theory of Relativity | Maths/Physics | 8018 | 1587 |
| 45 | The Lord of the Rings | Literature | 7980 | 1909 |
| 46 | Thomas Mann | Literature | 7628 | 1668 |
| 47 | Thomas More | History | 7832 | 1721 |
| 48 | Tony Hawk | Sports | 7990 | 1840 |
| 49 | Traditionalism | History | 7595 | 1610 |
| 50 | Winnie the Pooh | Literature | 7508 | 1668 |
Appendix C. Complete Results
| LAV | Acc | Cm | ASS | AC | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | 3.5 | 4o | Ll3 | Mx | 3.5 | 4o | Ll3 | Mx | 3.5 | 4o | Ll3 | Mx | 3.5 | 4o | Ll3 | Mx | 3.5 | 4o | Ll3 | Mx |
| 1 | 100 | 100 | 100 | 80 | 97.5 | 98.8 | 98.8 | 75 | 88.8 | 95 | 62.5 | 67.5 | 94.5 | 98.2 | 86 | 90.1 | 70.2 | 87.9 | 48.4 | 67 |
| 2 | 95.2 | 100 | 100 | 90.5 | 94 | 96.4 | 96.4 | 86.9 | 91.7 | 96.4 | 64.3 | 86.9 | 96 | 98.5 | 84.5 | 94.2 | 78.3 | 84.6 | 41.4 | 78.2 |
| 3 | 95 | 85 | 65 | 65 | 87.5 | 80 | 67.5 | 56.2 | 87.5 | 77.5 | 57.5 | 56.2 | 93 | 93.1 | 87.9 | 88.4 | 70.4 | 56.2 | 48.6 | 52.2 |
| 4 | 95 | 95 | 95 | 95 | 95 | 92.5 | 92.5 | 90 | 90.5 | 93.8 | 66.8 | 86.2 | 95.3 | 97.6 | 86.8 | 89.1 | 71.9 | 80.6 | 42.9 | 59.7 |
| 5 | 100 | 100 | 90.5 | 81 | 98.8 | 96.4 | 95.2 | 81 | 92.9 | 95.2 | 64.3 | 81 | 94.5 | 97.5 | 88.4 | 93.5 | 74.7 | 83.9 | 61.3 | 74.2 |
| 6 | 100 | 100 | 100 | 100 | 96.4 | 96.4 | 94 | 90.5 | 98.8 | 92.9 | 64.3 | 77.4 | 96.9 | 97.6 | 85.1 | 91 | 79.5 | 82.8 | 42.1 | 63.1 |
| 7 | 80 | 95 | 80 | 80 | 85 | 87.5 | 75 | 75 | 78.8 | 90 | 53.8 | 63.7 | 95.9 | 98.1 | 86.7 | 92.1 | 72.3 | 82 | 49.5 | 60.9 |
| 8 | 100 | 100 | 95.2 | 66.7 | 95.2 | 95.2 | 91.7 | 66.7 | 85.7 | 91.7 | 54.8 | 51.2 | 94.2 | 97.7 | 87.2 | 89.5 | 65.6 | 87.2 | 50.4 | 43.2 |
| 9 | 90.5 | 100 | 100 | 85.7 | 91.7 | 92.9 | 98.8 | 81 | 88.1 | 94 | 64.3 | 78.6 | 95.8 | 97 | 87.5 | 90.8 | 76.7 | 81 | 53.1 | 67.4 |
| 10 | 90 | 90 | 95 | 75 | 86.2 | 85 | 85 | 71.2 | 90 | 81.2 | 61.3 | 72.5 | 95.1 | 96.7 | 87.7 | 92.2 | 71.9 | 73.7 | 49.1 | 55.2 |
| 11 | 81 | 90.5 | 95.2 | 81 | 83.3 | 88.1 | 91.7 | 77.4 | 92.9 | 97.6 | 54.8 | 89.3 | 95.4 | 98.4 | 85 | 94.4 | 65.8 | 85.7 | 46.2 | 71.8 |
| 12 | 100 | 95 | 90 | 95 | 98.8 | 93.8 | 88.8 | 95 | 97.5 | 93.8 | 63.7 | 88.8 | 99.4 | 98.6 | 88.1 | 95.3 | 90.5 | 88.4 | 60.8 | 82 |
| 13 | 100 | 100 | 95 | 90 | 92.5 | 100 | 90 | 90 | 92.5 | 98.8 | 65 | 88.8 | 97.1 | 97 | 85.5 | 91.6 | 92 | 89.8 | 47 | 74.7 |
| 14 | 95 | 100 | 100 | 70 | 92.5 | 96.2 | 95 | 71.2 | 95 | 98.8 | 62.5 | 72.5 | 94.9 | 97.7 | 87.7 | 90.3 | 69.1 | 86.9 | 52.3 | 63.5 |
| 15 | 100 | 100 | 90 | 70 | 95 | 82.5 | 82.5 | 73.8 | 95 | 90 | 65 | 71.2 | 97.7 | 97.1 | 90 | 92.3 | 78.9 | 79.9 | 61.7 | 60.2 |
| 16 | 95 | 85 | 90 | 80 | 90 | 85 | 80 | 75 | 86.2 | 77.5 | 55 | 72.5 | 95.3 | 95.1 | 89.5 | 92.7 | 69 | 70.7 | 60.5 | 67.5 |
| 17 | 95 | 95 | 85 | 90 | 87.5 | 91.2 | 81.2 | 87.5 | 82.5 | 82.5 | 65 | 76.2 | 91.8 | 91.5 | 92.5 | 89.3 | 66.4 | 68 | 70.9 | 60.8 |
| 18 | 95.2 | 100 | 100 | 90.5 | 91.7 | 98.8 | 97.6 | 86.9 | 91.7 | 98.8 | 60.7 | 81 | 96.2 | 98.7 | 88.7 | 92.6 | 87.7 | 91.1 | 50.5 | 63.2 |
| 19 | 95.2 | 95.2 | 95.2 | 90.5 | 91.7 | 94 | 86.9 | 82.1 | 91.7 | 92.9 | 63.1 | 76.2 | 95.8 | 97.6 | 89.3 | 93.3 | 76 | 83.9 | 63.4 | 75.3 |
| 20 | 90 | 100 | 100 | 85 | 95 | 93.8 | 88.8 | 86.2 | 92 | 90 | 56.2 | 77.5 | 95.4 | 97.3 | 84.7 | 93.9 | 68 | 77.2 | 54.1 | 71.3 |
| 21 | 100 | 100 | 95 | 80 | 97.5 | 98.8 | 91.2 | 81.2 | 96.2 | 91.2 | 53.8 | 75 | 96.4 | 96 | 85.6 | 90.8 | 80.3 | 74.6 | 46.2 | 54.2 |
| 22 | 100 | 100 | 90 | 100 | 93.8 | 98.8 | 88.8 | 91.2 | 95 | 91.2 | 61.3 | 87.5 | 96.4 | 96.6 | 86.9 | 93.2 | 73.3 | 81.6 | 45.7 | 71.1 |
| 23 | 85 | 95 | 85 | 80 | 90 | 93.8 | 85 | 81.2 | 85 | 92.5 | 57.5 | 80 | 96.4 | 97.6 | 85.2 | 92.2 | 70.3 | 72.1 | 50.9 | 58.4 |
| 24 | 100 | 100 | 100 | 80 | 100 | 98.8 | 97.5 | 80 | 95 | 98.8 | 71.2 | 86.2 | 96.1 | 99.1 | 86.3 | 94.5 | 82.9 | 90.6 | 62.6 | 77.1 |
| 25 | 95 | 100 | 90 | 75 | 91.2 | 96.2 | 83.8 | 76.2 | 92.5 | 96.2 | 66.2 | 73.8 | 95.5 | 96.4 | 86.1 | 92.3 | 70.8 | 85.4 | 49.7 | 54.6 |
| 26 | 95 | 95 | 100 | 90 | 95 | 95 | 97.5 | 88.8 | 87.5 | 98.8 | 71.2 | 85 | 93.6 | 95.5 | 90 | 91.5 | 72.5 | 82.2 | 55 | 75 |
| 27 | 90 | 90 | 95 | 90 | 87.5 | 88.8 | 90 | 83.8 | 91.2 | 82.5 | 58.8 | 77.5 | 97.7 | 96 | 84.9 | 94.2 | 85.9 | 83 | 51.2 | 76.1 |
| 28 | 95.2 | 100 | 85.7 | 81 | 91.7 | 89.3 | 85.7 | 82.1 | 91.7 | 86.9 | 53.6 | 81 | 95.4 | 95.4 | 90.4 | 91.9 | 76.6 | 73.7 | 51.8 | 62.7 |
| 29 | 95 | 100 | 85 | 90 | 91.2 | 96.2 | 83.8 | 88.8 | 87.5 | 93.8 | 70 | 85 | 95 | 96.3 | 88.2 | 93.3 | 74.2 | 75.7 | 67.3 | 81.9 |
| 30 | 90 | 100 | 100 | 75 | 90 | 98.8 | 93.8 | 72.5 | 87.5 | 93.8 | 65 | 66.2 | 95.5 | 97.3 | 85.1 | 91 | 78.1 | 84.3 | 61.9 | 61 |
| 31 | 95 | 100 | 90 | 90 | 97.5 | 96.2 | 88.8 | 93.8 | 96.2 | 96.2 | 62.5 | 81.2 | 95.1 | 97.8 | 84.6 | 88.7 | 78.3 | 87.6 | 45.4 | 64 |
| 32 | 95 | 90 | 90 | 90 | 91.2 | 88.8 | 83.8 | 87.5 | 90 | 92.5 | 70 | 83.8 | 96.2 | 98 | 86.6 | 90.9 | 79.8 | 87.5 | 49.2 | 62.8 |
| 33 | 100 | 95 | 90 | 85 | 95 | 93.8 | 87.5 | 82.5 | 93.8 | 88.8 | 63.7 | 77.5 | 94.3 | 95.3 | 85.9 | 91.4 | 75.6 | 64.8 | 32.9 | 65.6 |
| 34 | 85 | 95 | 90 | 75 | 82.5 | 91.2 | 78.8 | 77.5 | 83.8 | 80 | 53.8 | 72.5 | 96.7 | 96.4 | 87.8 | 93.3 | 76.9 | 77.5 | 37.6 | 70.4 |
| 35 | 95 | 100 | 100 | 100 | 92.5 | 93.8 | 97.5 | 95 | 93.8 | 90 | 71.2 | 86.2 | 97.1 | 96.6 | 90.4 | 93.8 | 83.7 | 85.7 | 60.9 | 74.3 |
| 36 | 95 | 100 | 90 | 75 | 93.8 | 95 | 87.5 | 75 | 88.8 | 96.2 | 63.7 | 73.8 | 94.1 | 97.3 | 86.8 | 92 | 82.3 | 84.8 | 59.8 | 57.2 |
| 37 | 94.7 | 94.7 | 94.7 | 100 | 93.4 | 94.7 | 93.4 | 96.1 | 89.5 | 97.4 | 59.2 | 76.3 | 94.3 | 98.7 | 85.8 | 89.7 | 81.7 | 86.4 | 44.5 | 63.9 |
| 38 | 85.7 | 81 | 81 | 81 | 84.5 | 85.7 | 82.1 | 85.7 | 85.7 | 86.9 | 59.5 | 85.7 | 98 | 98 | 87.1 | 95.1 | 82 | 79 | 65.8 | 76.4 |
| 39 | 95 | 95 | 95 | 85 | 96.2 | 92.5 | 91.2 | 82.5 | 96.2 | 92.5 | 71.2 | 77.5 | 96.2 | 97.1 | 88.6 | 91.8 | 77.4 | 79.4 | 66.1 | 66.6 |
| 40 | 85 | 100 | 90 | 80 | 81.2 | 98.8 | 86.2 | 80 | 76.2 | 97.5 | 61.3 | 67.5 | 94.4 | 97.3 | 87.4 | 90.3 | 72.5 | 80 | 45.2 | 54.7 |
| 41 | 80 | 100 | 100 | 80 | 80 | 90 | 90 | 86.2 | 78.8 | 90 | 58.8 | 88.8 | 94.9 | 98.4 | 87.2 | 94.3 | 72.5 | 81.3 | 38.5 | 68.1 |
| 42 | 100 | 100 | 85 | 90 | 95 | 97.5 | 83.8 | 86.2 | 91.2 | 92.5 | 63.7 | 80 | 95.6 | 96.3 | 89.5 | 92.2 | 75.2 | 71.4 | 52.9 | 62.3 |
| 43 | 100 | 100 | 100 | 75 | 92.5 | 97.5 | 91.2 | 73.8 | 92.5 | 88.8 | 65 | 58.8 | 95.5 | 95.8 | 90.7 | 90.8 | 66 | 73.3 | 53.5 | 48.9 |
| 44 | 90.5 | 76.2 | 70 | 71.4 | 84.5 | 73.8 | 68.8 | 64.3 | 82.1 | 69 | 53.8 | 60.7 | 95.4 | 96.5 | 87.8 | 93.2 | 71.9 | 73.9 | 49.5 | 60.8 |
| 45 | 100 | 100 | 100 | 90 | 95 | 91.2 | 92.5 | 80 | 90 | 83.8 | 62.5 | 78.8 | 97 | 95.5 | 87.8 | 93.2 | 79 | 76.2 | 51.7 | 62.8 |
| 46 | 90 | 100 | 100 | 95 | 91.2 | 92.5 | 90 | 86.2 | 90 | 91.2 | 63.7 | 83.8 | 95.4 | 97.4 | 87.8 | 93.4 | 77 | 81.3 | 50.1 | 74.8 |
| 47 | 95 | 100 | 95 | 90 | 96.2 | 98.8 | 93.8 | 87.5 | 90 | 100 | 65 | 90 | 94.1 | 97 | 86.3 | 93 | 72 | 91.3 | 46.6 | 68.9 |
| 48 | 95.2 | 100 | 95.2 | 100 | 96.4 | 92.9 | 91.7 | 96.4 | 95.2 | 91.7 | 56 | 79.8 | 97.2 | 98.8 | 83.7 | 89.3 | 75.4 | 83.5 | 39 | 63.4 |
| 49 | 100 | 100 | 100 | 90 | 98.8 | 93.8 | 92.5 | 95 | 97.5 | 95 | 75 | 85 | 97.8 | 98.2 | 90.5 | 94.8 | 86.1 | 84.1 | 74.5 | 71.6 |
| 50 | 95 | 100 | 95 | 95 | 92.5 | 96.2 | 92.5 | 87.5 | 96.2 | 98.8 | 61.3 | 86.2 | 95.9 | 97.1 | 85.9 | 93.5 | 80 | 87.5 | 51.7 | 80 |
| 94.2 | 96.6 | 92.8 | 84.8 | 92.1 | 93.1 | 88.8 | 82.4 | 90.3 | 91.4 | 62.3 | 77.7 | 95.7 | 97.1 | 87.3 | 92.1 | 76.1 | 80.8 | 52.2 | 66 | |
| LAV | Acc | Cm | ASS | AC | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ID | 3.5 | 4o | Ll3 | Mx | 3.5 | 4o | Ll3 | Mx | 3.5 | 4o | Ll3 | Mx | 3.5 | 4o | Ll3 | Mx | 3.5 | 4o | Ll3 | Mx |
| 1 | 100 | 100 | 100 | 85 | 100 | 100 | 97.5 | 82.5 | 98.8 | 100 | 93.8 | 81.2 | 94.5 | 98.2 | 86 | 90.1 | 93.8 | 98.1 | 88.6 | 80.3 |
| 2 | 95.2 | 100 | 95.2 | 90.5 | 92.9 | 98.8 | 96.4 | 90.5 | 92.9 | 98.8 | 94 | 90.5 | 96 | 98.5 | 84.5 | 94.2 | 89.5 | 91.2 | 83 | 84.6 |
| 3 | 95 | 95 | 75 | 90 | 86.2 | 83.8 | 71.2 | 77.5 | 88.8 | 87.5 | 68.8 | 78.8 | 93 | 93.1 | 87.9 | 88.4 | 83.6 | 79.3 | 72.5 | 70.2 |
| 4 | 100 | 95 | 100 | 100 | 97.5 | 95 | 96.2 | 96.2 | 96.2 | 95 | 97.5 | 95 | 95.3 | 97.6 | 86.8 | 89.1 | 87.9 | 93.5 | 77 | 82.7 |
| 5 | 100 | 100 | 100 | 100 | 97.6 | 98.8 | 97.6 | 94 | 97.6 | 98.8 | 94 | 97.6 | 94.5 | 97.5 | 88.4 | 93.5 | 83 | 90.9 | 83.3 | 75.8 |
| 6 | 100 | 100 | 100 | 100 | 97.6 | 98.8 | 95.2 | 96.4 | 97.6 | 97.6 | 92.9 | 95.2 | 96.9 | 97.6 | 85.1 | 91 | 88.9 | 92 | 81.3 | 88.1 |
| 7 | 85 | 100 | 95 | 90 | 82.5 | 96.2 | 86.2 | 80 | 82.5 | 97.5 | 81.2 | 83.8 | 95.9 | 98.1 | 86.7 | 92.1 | 82.7 | 86.5 | 74.6 | 74.4 |
| 8 | 100 | 100 | 95.2 | 71.4 | 96.4 | 97.6 | 94 | 72.6 | 96.4 | 96.4 | 88.1 | 71.4 | 94.2 | 97.7 | 87.2 | 89.5 | 92.4 | 92.3 | 83.8 | 68 |
| 9 | 100 | 100 | 100 | 90.5 | 95.2 | 97.6 | 98.8 | 90.5 | 95.2 | 96.4 | 95.2 | 92.9 | 95.8 | 97 | 87.5 | 90.8 | 90.7 | 89.5 | 93.8 | 86.4 |
| 10 | 90 | 90 | 95 | 85 | 90 | 91.2 | 91.2 | 82.5 | 88.8 | 91.2 | 88.8 | 85 | 95.1 | 96.7 | 87.7 | 92.2 | 85 | 84 | 79.4 | 69 |
| 11 | 81 | 85.7 | 90.5 | 81 | 86.9 | 89.3 | 90.5 | 85.7 | 88.1 | 89.3 | 85.7 | 89.3 | 95.7 | 98.4 | 85 | 94.4 | 83.1 | 89.2 | 86.8 | 80.9 |
| 12 | 100 | 95 | 90 | 95 | 100 | 95 | 88.8 | 95 | 98.8 | 95 | 87.5 | 95 | 99.4 | 98.6 | 88.1 | 95.3 | 96.7 | 94.5 | 87 | 93.8 |
| 13 | 95 | 90 | 85 | 90 | 95 | 90 | 82.5 | 88.8 | 95 | 90 | 80 | 88.8 | 97.1 | 97 | 85.5 | 91.6 | 87.9 | 85.5 | 77.6 | 84.7 |
| 14 | 95 | 100 | 100 | 85 | 98.8 | 100 | 98.8 | 90 | 100 | 100 | 97.5 | 91.2 | 94.9 | 97.7 | 87.7 | 90.3 | 82.4 | 86.9 | 93.2 | 77.5 |
| 15 | 90 | 95 | 90 | 95 | 87.5 | 93.8 | 83.8 | 90 | 88.8 | 93.8 | 80 | 86.2 | 97.7 | 97.1 | 90 | 92.3 | 90.8 | 87.6 | 80 | 75.1 |
| 16 | 90 | 95 | 95 | 90 | 88.8 | 91.2 | 88.8 | 88.8 | 87.5 | 91.2 | 87.5 | 87.5 | 95.3 | 95.1 | 89.5 | 92.7 | 83.5 | 82.6 | 86.1 | 77.3 |
| 17 | 100 | 100 | 95 | 100 | 92.5 | 93.8 | 90 | 92.5 | 86.2 | 93.8 | 86.2 | 88.8 | 91.8 | 91.5 | 92.5 | 89.3 | 83.8 | 79.6 | 85.6 | 78.6 |
| 18 | 95.2 | 100 | 100 | 95.2 | 94 | 98.8 | 97.6 | 92.9 | 94 | 98.8 | 94 | 92.9 | 96.2 | 98.7 | 88.7 | 92.6 | 84.8 | 95.5 | 86.9 | 82.8 |
| 19 | 95.2 | 100 | 95.2 | 90.5 | 90.5 | 95.2 | 90.5 | 86.9 | 91.7 | 94 | 85.7 | 89.3 | 95.8 | 97.6 | 89.3 | 93.3 | 82.5 | 90.9 | 76.6 | 81.5 |
| 20 | 90 | 95 | 100 | 90 | 92.5 | 93.8 | 95 | 90 | 90 | 93.8 | 91.2 | 91.2 | 95.4 | 97.3 | 84.7 | 93.9 | 89.8 | 93.2 | 79.9 | 90.7 |
| 21 | 100 | 100 | 90 | 90 | 97.5 | 100 | 91.2 | 91.2 | 97.5 | 98.8 | 87.5 | 91.2 | 96.4 | 96 | 85.6 | 90.8 | 90.6 | 91.4 | 83.8 | 77.4 |
| 22 | 95 | 95 | 95 | 95 | 90 | 95 | 90 | 92.5 | 90 | 91.2 | 88.8 | 93.8 | 96.4 | 96.6 | 86.9 | 93.2 | 82.4 | 84 | 74.9 | 88.1 |
| 23 | 90 | 100 | 85 | 90 | 91.2 | 96.2 | 85 | 88.8 | 92.5 | 98.8 | 85 | 88.8 | 96.4 | 97.6 | 85.2 | 92.2 | 81.2 | 86.1 | 69 | 79.7 |
| 24 | 100 | 100 | 100 | 90 | 100 | 100 | 97.5 | 90 | 100 | 98.8 | 96.2 | 92.5 | 96.1 | 99.1 | 86.3 | 94.5 | 84.2 | 90.5 | 75.8 | 82.5 |
| 25 | 100 | 100 | 95 | 95 | 97.5 | 98.8 | 91.2 | 86.2 | 97.5 | 98.8 | 88.8 | 88.8 | 95.5 | 96.4 | 86.1 | 92.3 | 79 | 87.5 | 75.3 | 73.6 |
| 26 | 95 | 100 | 95 | 100 | 95 | 97.5 | 93.8 | 97.5 | 93.8 | 97.5 | 93.8 | 98.8 | 93.6 | 95.5 | 90 | 91.5 | 86.3 | 85.5 | 87.9 | 79.1 |
| 27 | 95 | 80 | 90 | 80 | 95 | 88.8 | 91.2 | 86.2 | 97.5 | 88.8 | 90 | 88.8 | 97.7 | 96 | 84.9 | 94.2 | 90.3 | 89 | 88.1 | 86.6 |
| 28 | 95.2 | 95.2 | 90.5 | 95.2 | 91.7 | 94 | 89.3 | 86.9 | 95.2 | 92.9 | 84.5 | 89.3 | 95.4 | 95.4 | 90.4 | 91.9 | 82.7 | 85.1 | 78.9 | 80.5 |
| 29 | 95 | 95 | 90 | 100 | 91.2 | 93.8 | 88.8 | 92.5 | 88.8 | 93.8 | 86.2 | 91.2 | 95 | 96.3 | 88.2 | 93.3 | 90.6 | 87.1 | 82.9 | 84.4 |
| 30 | 90 | 95 | 95 | 90 | 87.5 | 95 | 88.8 | 88.8 | 85 | 93.8 | 87.5 | 88.8 | 95.5 | 97.3 | 85.1 | 91 | 86.4 | 94.7 | 93 | 82.7 |
| 31 | 100 | 100 | 90 | 100 | 96.2 | 98.8 | 90 | 96.2 | 97.5 | 97.5 | 88.8 | 96.2 | 95.1 | 97.8 | 84.6 | 88.7 | 87.9 | 91.7 | 72.4 | 87.4 |
| 32 | 95 | 95 | 90 | 95 | 93.8 | 93.8 | 86.2 | 91.2 | 92.5 | 100 | 86.2 | 91.2 | 96.2 | 98 | 86.6 | 90.9 | 91.3 | 87.5 | 87.2 | 85.6 |
| 33 | 100 | 100 | 90 | 85 | 97.5 | 96.2 | 87.5 | 86.2 | 97.5 | 96.2 | 86.2 | 87.5 | 94.3 | 95.3 | 85.9 | 91.4 | 87.8 | 79.4 | 87.7 | 82.9 |
| 34 | 90 | 95 | 90 | 85 | 85 | 87.5 | 80 | 78.8 | 87.5 | 87.5 | 77.5 | 77.5 | 96.7 | 96.4 | 87.8 | 93.3 | 83.4 | 80.4 | 75.7 | 85.2 |
| 35 | 100 | 100 | 100 | 100 | 97.5 | 96.2 | 100 | 97.5 | 97.5 | 97.5 | 97.5 | 96.2 | 97.1 | 96.6 | 90.4 | 93.8 | 86.5 | 85.7 | 80.7 | 84.5 |
| 36 | 95 | 95 | 90 | 85 | 95 | 93.8 | 87.5 | 83.8 | 93.8 | 93.8 | 85 | 83.8 | 94.1 | 97.3 | 86.8 | 92 | 81 | 86.4 | 79.8 | 73 |
| 37 | 94.7 | 100 | 94.7 | 100 | 94.7 | 98.7 | 94.7 | 98.7 | 94.7 | 100 | 94.7 | 98.7 | 94.3 | 98.7 | 85.8 | 89.7 | 79.4 | 89.7 | 74.1 | 85.6 |
| 38 | 90.5 | 95.2 | 85.7 | 95.2 | 88.1 | 91.7 | 86.9 | 90.5 | 90.5 | 91.7 | 85.7 | 90.5 | 98 | 98 | 87.1 | 95.1 | 85.7 | 88.6 | 76 | 88 |
| 39 | 95 | 95 | 95 | 90 | 98.8 | 93.8 | 95 | 87.5 | 98.8 | 95 | 96.2 | 90 | 96.2 | 97.1 | 88.6 | 91.8 | 90.6 | 88 | 84.2 | 85.9 |
| 40 | 80 | 90 | 75 | 80 | 81.2 | 90 | 78.8 | 80 | 81.2 | 90 | 76.2 | 81.2 | 94.4 | 97.3 | 87.4 | 90.3 | 81.6 | 84.9 | 85.7 | 74.2 |
| 41 | 95 | 100 | 95 | 95 | 92.5 | 100 | 91.2 | 95 | 91.2 | 98.8 | 88.8 | 97.5 | 94.9 | 98.4 | 87.2 | 94.3 | 81.2 | 89.5 | 76.8 | 75.4 |
| 42 | 100 | 100 | 85 | 95 | 97.5 | 98.8 | 85 | 95 | 95 | 97.5 | 83.8 | 92.5 | 95.6 | 96.3 | 89.5 | 92.2 | 81.3 | 89.1 | 78.6 | 82.4 |
| 43 | 95 | 100 | 95 | 85 | 95 | 95 | 91.2 | 76.2 | 96.2 | 96.2 | 88.8 | 75 | 95.5 | 95.8 | 90.7 | 90.8 | 80.4 | 77.5 | 70.3 | 74.8 |
| 44 | 95.2 | 95.2 | 71.4 | 100 | 88.1 | 88.1 | 73.8 | 90.5 | 88.1 | 86.9 | 72.6 | 91.7 | 95.4 | 96.5 | 87.4 | 93.2 | 86.1 | 82.1 | 67.9 | 75.2 |
| 45 | 100 | 95 | 95 | 90 | 98.8 | 97.5 | 93.8 | 87.5 | 92.5 | 95 | 83.8 | 90 | 97 | 95.5 | 87.8 | 93.2 | 85.9 | 85.5 | 83.8 | 76.7 |
| 46 | 95 | 100 | 100 | 95 | 92.5 | 96.2 | 95 | 88.8 | 91.2 | 96.2 | 88.8 | 86.2 | 95.4 | 97.4 | 87.8 | 93.4 | 93.9 | 91.7 | 87.5 | 81.6 |
| 47 | 90 | 95 | 90 | 85 | 91.2 | 95 | 90 | 88.8 | 91.2 | 95 | 90 | 91.2 | 94.1 | 97 | 86.3 | 93 | 88 | 90.4 | 81.6 | 81.6 |
| 48 | 100 | 100 | 95.2 | 100 | 100 | 97.6 | 94 | 97.6 | 98.8 | 97.6 | 90.5 | 96.4 | 97.2 | 98.8 | 83.7 | 89.3 | 84.9 | 94.8 | 76 | 82.8 |
| 49 | 100 | 100 | 100 | 100 | 100 | 97.5 | 97.5 | 97.5 | 98.8 | 97.5 | 95 | 98.8 | 97.8 | 98.2 | 90.5 | 94.8 | 92.5 | 92.4 | 90.9 | 86.5 |
| 50 | 100 | 100 | 95 | 95 | 97.5 | 98.8 | 91.2 | 92.5 | 98.8 | 98.8 | 88.8 | 91.2 | 95.9 | 97.1 | 85.9 | 93.5 | 90.1 | 91.2 | 85.9 | 83.8 |
| 5.2 | 96.9 | 92.9 | 91.9 | 93.6 | 95.3 | 90.5 | 89.3 | 93.3 | 95.2 | 88.1 | 89.7 | 95.7 | 97.1 | 87.3 | 92.1 | 86.3 | 88.2 | 81.4 | 81 | |
Appendix D. Cost Estimation for the Use of LLMs
- Token Usage: The number of tokens processed by each model.
- Token Cost: The cost associated with the processed tokens.
| Model Name | Model Version | Price per 1000 Input Tokens ($) | Price per 1000 Output Tokens ($) | Usage Cost ($) |
|---|---|---|---|---|
| GPT-3.5 Turbo | gpt-3.5-turbo-0125 | 0.0005 | 0.0015 | 12 |
| GPT-4-Turbo | gpt-4-turbo-2024-04-09 | 0.01 | 0.03 | 16.9 |
| GPT-4o | gpt-4o-2024-05-13 | 0.005 | 0.015 | 12.95 |
| Llama 3 (70B) | meta.llama3-70b-instruct-v1:0 | 0.00345 | 0.00455 | 16.36 |
| Mixtral 8x7b | mistral.mixtral-8x7b-instruct-v0:1 | 0.00059 | 0.00091 | 1.65 |
| Claude 3 Haiku | anthropic.claude-3-haiku-20240307-v1:0 | 0.00025 | 0.00125 | 7.32 |
| Total Cost | 67.18 | |||
References
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Burstein, J., Doran, C., Solorio, T., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2019; pp. 4171–4186. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open foundation and fine-tuned chat models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Anil, R.; Borgeaud, S.; Wu, Y.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K.; et al. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Jiang, A.Q.; Sablayrolles, A.; Mensch, A.; Bamford, C.; Chaplot, D.S.; Casas, D.d.l.; Bressand, F.; Lengyel, G.; Lample, G.; Saulnier, L.; et al. Mistral 7B. arXiv 2023, arXiv:2310.06825. [Google Scholar]
- Abdin, M.; Jacobs, S.A.; Awan, A.A.; Aneja, J.; Awadallah, A.; Awadalla, H.; Bach, N.; Bahree, A.; Bakhtiari, A.; Behl, H.; et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv 2024, arXiv:2404.14219. [Google Scholar]
- Subagja, A.D.; Ausat, A.M.A.; Sari, A.R.; Wanof, M.I.; Suherlan, S. Improving customer service quality in MSMEs through the use of ChatGPT. J. Minfo Polgan 2023, 12, 380–386. [Google Scholar] [CrossRef]
- Bao, K.; Zhang, J.; Zhang, Y.; Wang, W.; Feng, F.; He, X. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems, Singapore, 18–22 September 2023; pp. 1007–1014. [Google Scholar]
- Zhang, B.; Haddow, B.; Birch, A. Prompting large language model for machine translation: A case study. In Proceedings of the International Conference on Machine Learning. PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 41092–41110. [Google Scholar]
- Zhang, T.; Ladhak, F.; Durmus, E.; Liang, P.; McKeown, K.; Hashimoto, T.B. Benchmarking large language models for news summarization. Trans. Assoc. Comput. Linguist. 2024, 12, 39–57. [Google Scholar] [CrossRef]
- Ostendorff, M.; Rethmeier, N.; Augenstein, I.; Gipp, B.; Rehm, G. Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 11670–11688. [Google Scholar]
- Piñeiro-Martín, A.; García-Mateo, C.; Docío-Fernández, L.; López-Pérez, M.d.C. Ethical Challenges in the Development of Virtual Assistants Powered by Large Language Models. Electronics 2023, 12, 3170. [Google Scholar] [CrossRef]
- Singh, C.; Inala, J.P.; Galley, M.; Caruana, R.; Gao, J. Rethinking Interpretability in the Era of Large Language Models. arXiv 2024, arXiv:2402.01761. [Google Scholar]
- Weidinger, L.; Mellor, J.; Rauh, M.; Griffin, C.; Uesato, J.; Huang, P.S.; Cheng, M.; Glaese, M.; Balle, B.; Kasirzadeh, A.; et al. Ethical and social risks of harm from language models. arXiv 2021, arXiv:2112.04359. [Google Scholar]
- Ferrara, E. Should chatgpt be biased? challenges and risks of bias in large language models. arXiv 2023, arXiv:2304.03738. [Google Scholar]
- Abid, A.; Farooqi, M.; Zou, J. Persistent anti-muslim bias in large language models. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, Virtual, 19–21 May 2021; pp. 298–306. [Google Scholar]
- Abid, A.; Farooqi, M.; Zou, J. Large language models associate Muslims with violence. Nat. Mach. Intell. 2021, 3, 461–463. [Google Scholar] [CrossRef]
- Kaddour, J.; Harris, J.; Mozes, M.; Bradley, H.; Raileanu, R.; McHardy, R. Challenges and applications of large language models. arXiv 2023, arXiv:2307.10169. [Google Scholar]
- Harrer, S. Attention is not all you need: The complicated case of ethically using large language models in healthcare and medicine. EBioMedicine 2023, 90, 104512. [Google Scholar] [CrossRef] [PubMed]
- Perlman, A.M. The implications of ChatGPT for legal services and society. SSRN 2022, 4294197. [Google Scholar] [CrossRef]
- Sok, S.; Heng, K. ChatGPT for education and research: A review of benefits and risks. SSRN 2023, 4378735. [Google Scholar]
- Fu, D.; Li, X.; Wen, L.; Dou, M.; Cai, P.; Shi, B.; Qiao, Y. Drive like a human: Rethinking autonomous driving with large language models. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 910–919. [Google Scholar]
- Du, M.; Liu, N.; Hu, X. Techniques for interpretable machine learning. Commun. ACM 2019, 63, 68–77. [Google Scholar] [CrossRef]
- Arrieta, A.B.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; García, S.; Gil-López, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Došilović, F.K.; Brčić, M.; Hlupić, N. Explainable artificial intelligence: A survey. In Proceedings of the 2018 41st International convention on information and communication technology, electronics and microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 0210–0215. [Google Scholar]
- Shuster, K.; Poff, S.; Chen, M.; Kiela, D.; Weston, J. Retrieval Augmentation Reduces Hallucination in Conversation. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2021, Punta Cana, Dominican Republic, 16–20 November 2021; pp. 3784–3803. [Google Scholar]
- Hadi, M.U.; Qureshi, R.; Shah, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; Mirjalili, S.; Shah, M. Large language models: A comprehensive survey of its applications, challenges, limitations, and future prospects. Authorea Preprints 2023. [Google Scholar]
- Mungoli, N. Exploring the Synergy of Prompt Engineering and Reinforcement Learning for Enhanced Control and Responsiveness in Chat GPT. J. Electr. Electron. Eng. 2023, 2, 201–205. [Google Scholar]
- Kojima, T.; Gu, S.S.; Reid, M.; Matsuo, Y.; Iwasawa, Y. Large language models are zero-shot reasoners. Adv. Neural Inf. Process. Syst. 2022, 35, 22199–22213. [Google Scholar]
- Min, S.; Lyu, X.; Holtzman, A.; Artetxe, M.; Lewis, M.; Hajishirzi, H.; Zettlemoyer, L. Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 11048–11064. [Google Scholar]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- Lewis, P.; Perez, E.; Piktus, A.; Petroni, F.; Karpukhin, V.; Goyal, N.; Küttler, H.; Lewis, M.; Yih, W.t.; Rocktäschel, T.; et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 2020, 33, 9459–9474. [Google Scholar]
- Yao, S.; Zhao, J.; Yu, D.; Du, N.; Shafran, I.; Narasimhan, K.; Cao, Y. ReAct: Synergizing Reasoning and Acting in Language Models. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023; pp. 190–213. [Google Scholar]
- Wang, X.; Wei, J.; Schuurmans, D.; Le, Q.; Chi, E.; Narang, S.; Chowdhery, A.; Zhou, D. Self-consistency improves chain of thought reasoning in language models. arXiv 2022, arXiv:2203.11171. [Google Scholar]
- Diao, S.; Wang, P.; Lin, Y.; Zhang, T. Active prompting with chain-of-thought for large language models. arXiv 2023, arXiv:2302.12246. [Google Scholar]
- Li, Z.; Peng, B.; He, P.; Galley, M.; Gao, J.; Yan, X. Guiding large language models via directional stimulus prompting. Adv. Neural Inf. Process. Syst. 2024, 36, 62630–62656. [Google Scholar]
- Shinn, N.; Cassano, F.; Gopinath, A.; Narasimhan, K.; Yao, S. Reflexion: Language agents with verbal reinforcement learning. Adv. Neural Inf. Process. Syst. 2024, 36, 8634–8652. [Google Scholar]
- Liu, Z.; Yu, X.; Fang, Y.; Zhang, X. Graphprompt: Unifying pre-training and downstream tasks for graph neural networks. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 417–428. [Google Scholar]
- Zhang, Z.; Zhang, A.; Li, M.; Zhao, H.; Karypis, G.; Smola, A. Multimodal chain-of-thought reasoning in language models. arXiv 2023, arXiv:2302.00923. [Google Scholar]
- Shi, F.; Chen, X.; Misra, K.; Scales, N.; Dohan, D.; Chi, E.H.; Schärli, N.; Zhou, D. Large language models can be easily distracted by irrelevant context. In Proceedings of the International Conference on Machine Learning. PMLR, Edmonton, AB, Canada, 30 June–3 July 2023; pp. 31210–31227. [Google Scholar]
- Yoo, K.M.; Kim, J.; Kim, H.J.; Cho, H.; Jo, H.; Lee, S.W.; Lee, S.g.; Kim, T. Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 2422–2437. [Google Scholar]
- Zhao, H.; Yang, F.; Lakkaraju, H.; Du, M. Opening the black box of large language models: Two views on holistic interpretability. arXiv 2024, arXiv:2402.10688. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Zhao, H.; Chen, H.; Yang, F.; Liu, N.; Deng, H.; Cai, H.; Wang, S.; Yin, D.; Du, M. Explainability for large language models: A survey. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–38. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Chen, H.; Covert, I.C.; Lundberg, S.M.; Lee, S.I. Algorithms to estimate Shapley value feature attributions. Nat. Mach. Intell. 2023, 5, 590–601. [Google Scholar] [CrossRef]
- Al-Najjar, H.A.; Pradhan, B.; Beydoun, G.; Sarkar, R.; Park, H.J.; Alamri, A. A novel method using explainable artificial intelligence (XAI)-based Shapley Additive Explanations for spatial landslide prediction using Time-Series SAR dataset. Gondwana Res. 2023, 123, 107–124. [Google Scholar] [CrossRef]
- Ross, A.; Marasović, A.; Peters, M.E. Explaining NLP Models via Minimal Contrastive Editing (MiCE). In Proceedings of the Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Online, 1–6 August 2021; pp. 3840–3852. [Google Scholar]
- Wu, X.; Zhao, H.; Zhu, Y.; Shi, Y.; Yang, F.; Liu, T.; Zhai, X.; Yao, W.; Li, J.; Du, M.; et al. Usable XAI: 10 strategies towards exploiting explainability in the LLM era. arXiv 2024, arXiv:2403.08946. [Google Scholar]
- Wei Jie, Y.; Satapathy, R.; Goh, R.; Cambria, E. How Interpretable are Reasoning Explanations from Prompting Large Language Models? In Proceedings of the Findings of the Association for Computational Linguistics: NAACL 2024, Mexico City, Mexico, 16–21 June 2024; Duh, K., Gomez, H., Bethard, S., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2024; pp. 2148–2164. [Google Scholar] [CrossRef]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Chen, J.; Lin, H.; Han, X.; Sun, L. Benchmarking large language models in retrieval-augmented generation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; pp. 17754–17762. [Google Scholar]
- Ram, O.; Levine, Y.; Dalmedigos, I.; Muhlgay, D.; Shashua, A.; Leyton-Brown, K.; Shoham, Y. In-context retrieval-augmented language models. Trans. Assoc. Comput. Linguist. 2023, 11, 1316–1331. [Google Scholar] [CrossRef]
- Es, S.; James, J.; Espinosa Anke, L.; Schockaert, S. RAGAs: Automated Evaluation of Retrieval Augmented Generation. In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: System Demonstrations, St. Julian’s, Malta, 21–22 March 2024; Aletras, N., De Clercq, O., Eds.; Association for Computational Linguistics: Kerrville, TX, USA, 2024; pp. 150–158. [Google Scholar]
- OpenAI. GPT-4o: A Model That Can Reason Across Audio, Vision, and Text in Real Time. 2024. Available online: https://openai.com/index/hello-gpt-4o/ (accessed on 31 October 2024).
- Meta. Introducing Meta Llama 3: The Most Capable Openly Available LLM to Date. Meta, 18 April 2024. Available online: https://ai.meta.com/blog/meta-llama-3/ (accessed on 23 January 2025).
- Mistral AI. Mixtral of Experts: A High Quality Sparse Mixture-of-Experts. 2023. Available online: https://mistral.ai/news/mixtral-8x22b/ (accessed on 23 January 2025).
- Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; Anadkat, S.; et al. Gpt-4 technical report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Anthropic. The Claude 3 Model Family: Opus, Sonnet, Haiku. 2023. Available online: https://www-cdn.anthropic.com/de8ba9b01c9ab7cbabf5c33b80b7bbc618857627/Model_Card_Claude_3.pdf (accessed on 31 October 2024).
- Industrial PhD information by Galician Innovation Agency. Available online: https://www.xunta.gal/dog/Publicados/2021/20211005/AnuncioG0596-270921-0001_gl.html (accessed on 23 January 2025).




| Score | Description |
|---|---|
| 0.0 | Completely incorrect or irrelevant answer. |
| 0.25 | Partially correct answer, but largely incomplete or includes irrelevant information. |
| 0.5 | Somewhat correct answer that covers some key points but may miss others or include irrelevant details. |
| 0.75 | Mostly correct answer covering most key points with minor omissions or irrelevant details. |
| 1.0 | Completely correct answer covering all key points accurately and concisely. |
| Model | LAV | Acc | Cm | ASS | AC | ||||
|---|---|---|---|---|---|---|---|---|---|
| - | |||||||||
| GPT-3.5 Turbo | 94.2 | 95.2 | 92.1 | 93.6 | 90.3 | 93.3 | 95.7 | 76.1 | 86.3 |
| GPT-4o | 96.6 | 96.9 | 93.1 | 95.3 | 91.4 | 95.2 | 97.1 | 80.8 | 88.2 |
| Llama 3—70B | 92.8 | 92.9 | 88.8 | 90.5 | 62.3 | 88.1 | 87.3 | 52.2 | 81.4 |
| Mixtral 8x7B | 84.8 | 91.9 | 82.4 | 89.3 | 77.7 | 89.7 | 92.1 | 66.0 | 81.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Piñeiro-Martín, A.; Santos-Criado, F.-J.; García-Mateo, C.; Docío-Fernández, L.; López-Pérez, M.d.C. Context Is King: Large Language Models’ Interpretability in Divergent Knowledge Scenarios. Appl. Sci. 2025, 15, 1192. https://doi.org/10.3390/app15031192
Piñeiro-Martín A, Santos-Criado F-J, García-Mateo C, Docío-Fernández L, López-Pérez MdC. Context Is King: Large Language Models’ Interpretability in Divergent Knowledge Scenarios. Applied Sciences. 2025; 15(3):1192. https://doi.org/10.3390/app15031192
Chicago/Turabian StylePiñeiro-Martín, Andrés, Francisco-Javier Santos-Criado, Carmen García-Mateo, Laura Docío-Fernández, and María del Carmen López-Pérez. 2025. "Context Is King: Large Language Models’ Interpretability in Divergent Knowledge Scenarios" Applied Sciences 15, no. 3: 1192. https://doi.org/10.3390/app15031192
APA StylePiñeiro-Martín, A., Santos-Criado, F.-J., García-Mateo, C., Docío-Fernández, L., & López-Pérez, M. d. C. (2025). Context Is King: Large Language Models’ Interpretability in Divergent Knowledge Scenarios. Applied Sciences, 15(3), 1192. https://doi.org/10.3390/app15031192