Abstract
Stance detection identifies the attitude or stance toward specific targets and has a wide range of applications across various domains. Implicit mention of the target makes it difficult to establish connections between the target and the text. Existing approaches focus on integrating external knowledge but overlook the complex associations and stance information within it, which is crucial for maintaining reasoning consistency. To solve this problem, we propose a logical stance detection framework based on the principle of stance transitivity. Our framework achieves stance reasoning by leveraging symbolic and natural language reasoning. Specifically, we extract a list of targets related to the specific target from unlabeled data and use LLMs to construct a target-stance graph. This allows us to examine complicated interactions between targets and integrate stance information across related targets. We conducted massive experiments to validate the effectiveness of our proposed method. The experimental results indicate that our framework significantly improves the performance of stance detection tasks, offering a robust solution to the challenges posed by implicit targets.
1. Introduction
Stance detection aims to identify the attitude or stance (e.g., support, oppose, or neutral) towards a specific target, such as an entity, a topic, or a claim [1]. This task has garnered significant attention from researchers due to its broad applications across various fields, including fake news detection [2], rumor detection [3], fact-checking [4], hate speech detection [5], election prediction [6,7], user feedback, political views, etc.
In stance detection tasks, identifying stance is relatively straightforward when the target is explicitly mentioned within the text. However, in real-world communication scenarios, individuals often avoid making direct assessments of the controversial target. Instead, they may comment on other entities or events closely related to the target as an indirect and implicit way to convey stance, driven by motivations such as risk avoidance, social politeness, or attitude probing. For example, as shown in Figure 1, the text in example 1 explicitly mentioned the target “Tax Policy” and expressed a clear Against stance. In contrast, the text in example 2 made no direct mention of the target “Climate Change.” The “Favor” stance towards this implicit target is transmitted through a chain of entities that are logically and ideologically connected between the mentioned entities (“fossil fuel”, “renewable energy”) and the broader concept of climate change. The indirect expression toward the implicit target poses significant challenges for stance detection.

Figure 1.
Two examples of stance classification. The stance in Example 1 is obtained directly, while the stance in Example 2 is determined through inference.
To address the problem of implicit targets, existing studies have exploited external knowledge to compensate for the distance between the text and the specified target [8,9,10,11,12]. These methods primarily focus on obtaining accurate and relevant knowledge between documents and topics. However, there are two limitations. (1) Neglects complex associations. They overlook complex knowledge relationships, particularly when targets are not directly related but are connected through intermediate objects. (2) They also fail to consider the importance of stance information. These methods neglect the stance information inherent in the associated knowledge, resulting in a lack of logical coherence in the detection processes.
In this paper, we propose a novel framework called Logical Stance Detection with target-stance graph (LSD) to achieve implicit target stance detection. We implement a complete stance reasoning process to achieve implicit target stance detection, inspired by cognitive research on how humans perform stance reasoning processes [13]. Stance reasoning process involves the following steps: (S1) identifying the explicit targets from text, (S2) judging the stance towards the explicit targets, (S3) judging the relationship between the explicit target and the specific target, and (S4) judging the stance toward the specific target. We align S1 and S2 as Open Target Stance Detection (OTSD) [14] to obtain explicit target-stance pairs for all texts. Then, we construct a target-stance graph to uncover complex relationships between explicit and specified targets. In the final step, we leverage the transitivity of the stance to derive the stance result through logical reasoning. Stance transitivity refers to the propagation of stances among three entities according to specific rules. Considering the probability of stance and the potential for logical defects, we propose a hybrid approach that combines symbolic and natural language reasoning. This approach leverages a chain-of-thought methodology to enhance stance reasoning. By integrating symbolic logic with the flexibility and context awareness of Natural Language Processing (NLP), we address the uncertainties and ambiguities inherent in the expression of stance. In summary, our contributions to this work are as follows:
- We achieve the stance reasoning process by extracting open target-stance pairs and the stance between target pairs.
- We take advantage of the transitivity of stance to transform stance reasoning into a more credible and interpretable logical reasoning process.
- Extensive experimental results on three datasets demonstrate that our proposed framework significantly outperforms existing methods. Further analysis shows that our method has the potential to apply to the implicit target scenarios.
2. Related Works
In this section, we thoroughly review two existing approaches to implicit target stance detection: external knowledge and stance reasoning. In addition, we introduce the concept of stance transitivity between target pairs, which plays a crucial role in propagating stance information and improving the logical coherence of the detection process.
2.1. External Knowledge
Stance on social networks is often expressed implicitly without directly mentioning targets, preventing it from being directly revealed in the text and increasing the difficulty of detection. Some studies have employed external knowledge to establish connections between entities present in the text and the specific target [8,9,10]. Yang et al. [3] first extract topics related to the target from a large-scale corpus and then obtain tweet representations about different topics. Some studies use the large language models’ (LLMs) chain of thought (COT) method to establish the connection between text and target [11,12]. Wang et al. [15] propose a method to generate diverse experts using training data, enabling LLMs to produce detailed and contextually rich background knowledge.
2.2. Stance Reasoning
Existing studies have explored diverse reasoning approaches to enhance the accuracy and interpretability of stance acquisition. Huang et al. [16] address implicit stance expression by employing a BiLSTM-based implicit stance reasoning module. It fails to emphasize the “implicit” focus and still trains classification models by blindly combining text and targets. Yuan et al. [13] propose a subtask-based approach to simplify the complex reasoning process into two steps: determining whether the text contains the target and then performing stance detection, but both tasks are simple classification tasks. Liu et al. [17] proposed an extended stance triangle framework that characterizes the relationship between explicit and implicit objects. For explicit object extraction, they collect all noun phrases in the constituency tree, then manually annotate both the relationship between objects and subjects and the text’s stance toward explicit targets.
Since the advent of large language models (LLMs), relevant work has begun to rely on LLMs to obtain intermediate reasoning evidence for stance reasoning. Taranukhin et al. [18] leveraged chain-of-thought in-context learning to generate explicit reasoning steps. Zheng et al. [19] uses LLMs to perform four-dimensional reasoning: direct evidence matching, semantic analysis, linguistic pattern recognition, and logical inference. Dai et al. [20] introduce the First-Order Logic Aggregated Reasoning (FOLAR) framework, which generates first-order logic (FOL) rules from text via chain-of-thought prompting, uses a Logic Tensor Network (LTN) to encode these rules, and adopts a Multi-Decision Fusion mechanism to aggregate LTN outputs for final stance acquisition.
2.3. Stance Transitivity
From the perspective of interactive linguistics, stance transitivity is conceptualized through a triangle framework involving one cognizing subject and two attitudinal objects [17]. This framework emphasizes the dynamic, interactive, and social nature of stance expression. The transitive nature of stance can be explained by Heider’s balance theory, which posits a universal human need for balance and harmony. This theory is typically formalized as the P-O-X triadic model, as shown in Figure 2. Here, P denotes the cognitive subject, while O and X are two attitudinal objects within a unit. The subject P’s evaluations of O and X carry emotional charges of liking/disliking or support/oppose, and these attitudes typically align. For instance, liking a person leads to appreciating their work, and disliking them fosters disapproval of their friends. Thus, cognitive balance is achieved when all three relationships are positive (i.e., “+”), or when only two relationships are negative (i.e., “−”). Stance transitivity thus refers to the propagation of evaluative judgments across three entities (e.g., a speaker, an event, and a viewpoint). Extending the finding that stance is expressed both between speakers and toward targets [21]. Given three targets (t1, t2, t3), the stance of (t1, t2), and the stance of (t2, t3), the polarity of the stance of (t1, t3) can be inferred.
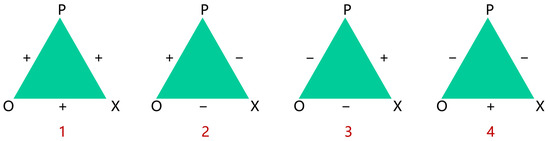
Figure 2.
The equilibrium state of Heider’s balance theory. The triangle’s three vertices represent the cognitive subject P in the cognitive system or unit, another object or individual O that has a relationship with the subject, and other related objects X.
3. Method
In this section, we detail our proposed Logical Stance Detection (LSD) framework with a target-stance graph based on stance transitivity. As illustrated in Figure 3, LSD comprises three core modules: (1) target-stance graph construction, which structures discrete targets and stances into a unified representation; (2) text-to-target relationship acquisition, which establishes connections between textual content and implicit target; and (3) a logical stance reasoning process that exploits stance transitivity to infer the final stance.
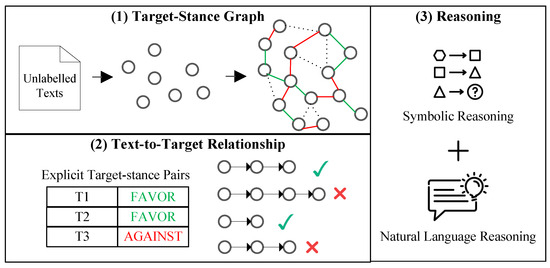
Figure 3.
Overview of our framework for stance detection.
3.1. Task Description
Given a text x and a target t, stance detection aims to discern the stance polarity expressed by x towards t. This work addresses the more challenging scenario of implicit target stance detection, where the target t is not explicitly mentioned in the text x, or where there is no direct semantic relationship to the text. Models must infer stance despite this absence of explicit cues.
3.2. Target-Stance Graph Construction
To further derive the relationship between targets, we construct a Target-Stance Graph where nodes represent distinct targets and edges encode stance relationships. Unlike prior research, we leverage stance information to characterize the relationships between targets instead of relying solely on semantic relationships or textual content. Stance values are quantized as opposition (), neutral/no relation (0), or support (1). Nodes correspond to explicit targets extracted from unlabeled text via prompt-based methods. Each target node represents a specific target and aggregates contextual representations from its occurrences across multiple unlabeled contexts . The node embedding is computed as the average of contextualized BERT embeddings for all tokens comprising the target mentions:
where denotes the set of all tokens constituting mentions of the target throughout the corpus.
Edge construction employs In-Context Learning (ICL) to determine stance relationships. For each ordered pair , we prompt: “Assuming there is a user X that supports , what would X’s stance be on ?” This approach leverages the model’s pretrained knowledge to infer stance consistency. We categorize relationships into: (1) Definite, absolute stance transmission (e.g., “All vaccine supporters oppose disease spread”). (2) High-probability, statistically likely stance transmission (e.g., “Vaccine supporters typically favor public health funding”). These stance expressions serve as edge attributes, with generated textual expressions providing explanatory semantics. The stance value is assigned as:
The adjacency matrix is defined by , capturing directed stance relationships between targets. H represents the size of nodes.
3.3. Text-to-Target Relationship Acquisition
To establish the relationship between input text x and a specific target t, we implement a two-stage framework: (1) the stance relationships between the text and explicit targets mentioned in x, which is called the open-target stance detection task [14], and (2) the stance relationships between explicit targets and specific implicit targets through graph mediation.
Initially, we utilize ICL to derive explicit targets and their associated stances from the text x. We employ a direct prompt method that combines target generation and stance detection into a single step. However, unlike previous work, we explicitly account for the diversity of targets within a single text. Our method handles more complex scenarios where multiple stances are expressed toward different targets simultaneously. We conducted a screening process to remove targets that lacked practical significance, such as single-character tokens (e.g., “A”, “1”) and stop words. Additionally, we use lexical normalization to standardize the representation of the targets to ensure consistency across the datasets. Ultimately, we retained a total of 6633 valid targets across both datasets. This careful curation enhances the quality and utility of the data, ensuring the effectiveness of subsequent stance detection tasks. The prompt is as follows.
Analyze the following tweet, generate the target for this tweet, and determine its stance towards the generated target. The target follows the following rules:
The target stance pair can be more than one. The output format should be: “<target1>: <stance1>, <target2>: <stance2>”. |
Second, we get the stance relationships between explicit targets and specific implicit targets through graph-mediated for specific and implicit target ,
where is the target-stance adjacency matrix, and propagates stance information through graph connectivity paths between and .
We employ a depth-limited Depth-First Search (DFS) to exhaustively explore all possible paths between entities up to a maximum of N hops. This exploration returns a set of candidate paths. This strategy is chosen over Breadth-First Search (BFS) because our objective is not to determine a single shortest path but to capture a comprehensive set of semantically meaningful reasoning paths for subsequent analysis. DFS is easier to implement and takes up less space, but it still takes the same amount of time. This choice ensures efficient path discovery, enabling the system to handle large-scale target-stance graphs without compromising performance. We convert paths into textual representations based on their attributes. All discovered paths are then converted into textual representations for further processing.
This approach provides a structured and computationally efficient method for identifying the relationships between targets, which is essential for accurate and logical stance reasoning in the next phase of the framework.
3.4. Logical Stance Reasoning
After establishing the relationship between text and implicit target, logical reasoning is employed to infer the stance of the text toward a specific target. Logical reasoning proceeds from known premises to derive conclusions that are necessary or highly probable. The most powerful and precise way to implement such reasoning is through symbolic formalization. The transitivity of stance offers a structural basis for this form of inference and allows its rigorous representation using symbolic rules [20,22]. Here, we introduce symbolic reasoning with ICL. As stance detection is a natural language processing task, we also incorporate natural language reasoning to compensate for the limitations of purely symbolic approaches. It enhances robustness by validating results from symbolic reasoning and capturing nuanced contextual expressions. A reasoning example is shown in Appendix A.
Symbolic Reasoning. We first translate existing context into a symbolic representation using ICL. Each sample includes three parts: the content of the tweet, the explicit target-stance pairs obtained, and the stance relationship from the explicit target to the specific target obtained in Section 3.3. The results of the translation are shown in Figure 4. The tweet content and the target-stance pairs are formalized as facts. The stance relationships among targets are expressed as logical rules. The problem statement indicates that this tweet supports a specific target, and the task is to determine whether this support is true, false, or unknown. We reiterate the relevant predicates, domain-specific rules and facts from the previous translation. Through symbolic reasoning based on known premises, we attempt to derive valid conclusions. Additionally, we introduce a new symbol, “”, to represent high-probability implications of the form “if A, then it is likely that B.” For instance, the statement “if a text supports abortion, then it is likely to support atheism” can be formally expressed as . In the real world, the associations between stances exhibit differences in transfer strength. Some associations possess strong certainty, approaching determinism, while others are probabilistic in nature, their validity often highly dependent on specific contexts. For instance, the relationship between “god” and “atheism” is definitive and certain. However, a relationship like the one between “abortion” and “atheism” is not absolute. “if a text does not support abortion, then it does not support atheism” is not a guaranteed rule. The majority of those who oppose abortion have religious beliefs and oppose atheism. By introducing this symbol, we are able to explicitly characterize transfer relationships that are possible but not necessarily certain, thereby effectively enhancing the expressive capacity of stance reasoning in uncertain environments. Specifically, when multiple symbolic paths lead to conflicting conclusions, inferences derived from paths containing certain, deterministic rules (denoted by “→”) are given precedence over those from paths containing probabilistic rules (denoted by “”).

Figure 4.
The translation process in symbolic reasoning part.
Natural Language Reasoning. However, symbolic reasoning may fail to yield definitive conclusions due to a lack of logical pathways or may produce contradictions across multiple inference paths. To overcome these limitations, the proposed method further incorporates a deep semantic analysis of the original tweet content. This analysis serves as a critical verification step by examining elements such as hashtags, word choice, rhetorical devices, and emotional tone to identify evidence indicative of stance. Finally, a conclusive answer is derived for the query statement.
Decision. It is important to emphasize that the final conclusion does not rely on a single mode of reasoning. We have formally defined a decision rule to resolve disagreements between symbolicreasoning (SR) and neural language reasoning (NLR), and it operates as follows: (1) If SR provides a clear inference and NLR does not strongly contradict it, the symbolic result is adopted. (2) If SR has multiple conflicting inferences, or if NLR provides strong contradictory evidence, the NLR result is prioritized. (3) If SR cannot infer a result and NLR provides evidence, the NLR result is used. (4) If both SR and NLR are inconclusive, the final output is Unknown. This structured rule ensures a principled and transparent integration of both reasoning modalities.
The symbolic framework ensures rigor and consistency in the logical process, while semantic and contextual analysis often supplies decisive evidence to resolve ambiguities. This structured reasoning process effectively combines formal rules with a deep understanding of the subtleties of language, which leads to reliable conclusions and shows that the method can handle real-world uncertainties. A logical sequence of steps ensures an accurate inference throughout the entire process. The structured reasoning processes are as follows.
| Execution: Let’s execute the plan step by step, applying first-order logic inference rules and logical operators to determine the truth value of the statement. Step 1: Identify the Goal Step 2: Define the Relevant Rules and Predicates Step 3: Review the Given Facts Step 4: Analyze the Rules Step 5: Apply the Rules to the Given Facts Step 6: Determine if the Statement Can Be Inferred Step 7: Evaluate the Content of the Tweet Step 8: Conclude the result **Final answer: true|false|unknown** |
4. Experimental Setup
4.1. Experimental Dataset
Sem16 The SemEval-2016 Task 6 dataset [1] comprises six predefined targets: Atheism (AT), Climate Change is a Real Concern (CC), Feminist Movement (FM), Hillary Clinton (HC), Legalization of Abortion (LA), and Donald Trump (DT). Each instance is classified into one of three stance categories: Favor, Against, or None.
COVID-19-Stance [23] includes four predefined targets: “Wearing a Face Mask”, “Anthony S. Fauci, M.D.”, “Keeping Schools Closed”, and “Stay at Home Orders”. Each instance is classified into one of three stance categories: Favor, Against, or None.
ArgMin [24] consists of eight topics (e.g., abortion, cloning, death penalty, etc.) derived from various sources such as news articles, editorials, blogs, debate forums, and encyclopedias. The text has been preprocessed using Stanford CoreNLP. Each sentence is labeled with one of three types of labels: NoArgument, Argument_against, or Argument_for. To enhance the model’s understanding of these labels, we have transformed them into three simplified categories: against, none, and favor.
The detailed statistics are shown in Table 1.

Table 1.
Statistics of our utilized datasets.
4.2. Experimental Implementation
Implementation Details. In this paper, we conduct experiments with LLaMA3.1-70B-Instruct as LLMs (https://huggingface.co/meta-llama/Llama-3.1-70B-Instruct, accessed on 29 September 2024). Due to resource limitations, we deployed the AWQ version of Llama 3.1-70B locally using VLLM, with GPU memory utilization set to 0.88 across two A100 80 GB GPUs. For the multi-hop reasoning stage, the number of hops k was set to 3. The decoding temperature was set to 0.5 to balance diversity and determinism. We ran the method four times and reported the average score for our method.
Evaluation Metric. For Sem16, following previous works [1], we use the score as the average of the macro F1 score on the labels `favor’ and `against’ as the metric for evaluation and comparison. For COVID-19-Stance dataset and ArgMin dataset, we adopt the macro F1 score, defined as the average F1 score across all labels, to evaluate model performance [23].
4.3. Comparison Models
In this study, we conducted comparative experiments with several notable methods. These methods primarily focus on stance detection from two perspectives: one being model-based and the other using the large language model. The selected baselines are enumerated as follows:
Model-based methods mainly leverage the relationship between texts and targets, such as BERT [25], BERTweet [26], DeBERTa [27], JointCL [28], VTCG [29], SEGP [30], GDA-CL [31], SSCL [32] and TTS [33].
LLM-based methods mainly obtain extra knowledge by using LLMs, including EDDA [34], COLA [35] and DQA [36], the latter of which employs direct question answering. Notably, both EDDA and COLA originally utilized ChatGPT-3.5-turbo in their respective studies.
We initially extracted the experimental results from the original publications to identify the best performance metrics for each model. In cases where outcomes were not reported, we performed replication studies. For methodologies involving large language models, LLaMA3.1-70B was utilized as the substitute architecture.
5. Results
5.1. Main Results
The overall performance of our approach compared to baseline methods is summarized in Table 2 for the Sem16 dataset and the COVID-19 dataset. We observe that the proposed LSD method consistently outperforms all baselines on most targets, thereby demonstrating its strong generalization capability to unseen targets in a transductive setting. Specifically, LSD advanced performance with an average macro-F1 score of 71.9 across Sem16 and COVID-19-Stance datasets. For the Sem16 dataset, its average performance is outstanding, and for the COVID-19-Stance dataset, it achieves an impressive average of 74.3. In the Sem16 dataset, our framework achieved significant improvements over the best baselines: 3.5% in AT (74.3 vs. 70.8) and 5.7% in CC. In the COVID-19 dataset, our framework showed notable improvements of 1.6% in mask (77.6 vs. 76.0), 8.5% in Fauci (78.5 vs. 70.0), and 81.9% in school (69.3 vs. 38.1) compared to the best baseline. These improvements demonstrate that our framework is particularly effective at addressing implicit targets, especially when specific targets are complex. For instance, in targets such as “keep school closed”, where the underlying stances may not be explicitly stated, our framework excels by capturing nuanced relationships and reasoning through the data. This capability allows it to outperform baseline methods in scenarios requiring deeper understanding and inference. Conversely, our framework has yet to show significant improvement for specific targets that are relatively simple and directly expressed, such as specific individuals or objects. In these cases, users express their opinions clearly and straightforwardly, reducing the need for complex reasoning. As a result, simpler models achieve good results without the additional complexity introduced by our framework. In short, our framework excels in situations where the target is complex and implicit, leveraging advanced logical reasoning to capture nuanced relationships and infer stances effectively. Additionally, it handles direct and simple expressions competently, ensuring robust performance across a variety of targets.
Table 2.
Comparison of different methods on Sem16 and COVID-19-Stance datasets for Stance Detection. Best results in bold, second-best underlined. The results with ♮, ♯, ℸ, ‡, and † are retrieved from Liang et al. [28], Li and Yuan [31], Zou et al. [32], Ding et al. [34], and Lan et al. [35], respectively. The * mark refers to a p-value < 0.05. The detailed p-values and mean ± standard deviation are reported in Appendix B.
Additionally, while baselines (e.g., EDDA, COLA) exhibit varying performances across different targets (e.g., COLA has relatively low scores on “keep school closed”), and showing sensitivity to specific target domains, our approach (LSD) demonstrates robust generalizability. It achieves relatively high F1 scores across multiple targets, such as exceeding 70% on most targets of both datasets and having an average score of 74.3 on the COVID-19-Stance dataset, with scores like 78.3 on Fauci.
In addition, we conducted experiments on the ArgMin dataset and found that our method achieved the best overall performance in the stance detection task, with an average F1-score of 72.4%, as shown in Table 3. Specifically, LSD attained the highest F1-scores in six out of the eight topics (AB, GC, ML, MW, NE, SU), demonstrating substantial improvements particularly in the AB and GC targets compared to previous best-performing methods. Although COLA performed best in the CL and DP categories, LSD closely followed with excellent results of 76.8% and 68.6%, respectively. These results fully validate the effectiveness and robustness of the LSD method.
Table 3.
Comparison of different methods on ArgMin dataset for Stance Detection. Best results in bold, second-best underlined.
5.2. Ablation Study
In order to investigate the effectiveness of each component, we conduct ablation studies on our model, and the results are reported in Table 4. Firstly, to explore the role of the target-stance graph in Section 3.3, we set k to 1 to remove the influence of multi-hop relations, denoted as “”. Next, in order to explore the role of symbolic reasoning in Section 3.4, we concatenated known context as input and informed LLM of the rules for stance propagation, allowing LLM to answer directly without using symbolic reasoning, denoted as “”. Through , it is found that after multi-hop relations are removed, the results on both datasets have declined. For example, the AT category drops from 74.3 to 70.0, and the CC category drops from 71.2 to 51.2 on Sem16. The mask category drops from 77.6 to 67.7, and the Fauci category drops from 78.3 to 54.6 on COVID-19. It demonstrates the critical importance of the multi-hop relationships module to our framework, and the target-stance graph plays a crucial role in capturing the relationships between entities, especially for more complex targets.
Table 4.
Results of the ablation study.
Through , we found that the experimental results decreased significantly without logical stance reasoning. The F1 scores generally decrease across all categories when symbolic reasoning is removed. For example, the AT category drops from 74.3 to 65.3, and the CC category drops from 71.2 to 48.2. The school category drops dramatically from 69.3 to 19.8, indicating that symbolic reasoning is particularly important for this category. The decline was more pronounced due to increased noise, which the framework cannot effectively manage without logical reasoning. It demonstrates the critical importance of the reasoning module to our framework. The LSD framework, including both the target-stance graph and logical reasoning, achieves the highest performance across all categories. It indicates that the combination of these two components is synergistic, with component complementing the other to improve overall model performance.
5.3. Impact of the Values of k
To investigate the impact of the hop count of the target path on the results, we analyzed the hyperparameter k between 0–3 using DQA model and our LSD on LLaMA3.1-70B, as shown in Table 5 and Table 6. In the process of obtaining relationships, the number of hops k as a hyperparameter affects the effectiveness. Since four-hop paths are nearly absent, we limit the value of k to a maximum of 3. We use the F1 score as an evaluation metric. The F1 score provides a balanced measure of precision and recall, allowing us to assess how well the framework captures and transmits positional information across multiple hops.
Table 5.
Results with the hyperparameter k between 0–3 using the DQA method on LLaMA3.1-70B.
Table 6.
Results with the hyperparameter k between 1–3 using our framework LSD on LLaMA3.1-70B. When , there is no need for reasoning.
In Table 5, as the value of k increases, the F1 scores generally show an upward trend. This indicates that a higher hop count allows the model to understand the relationships between entities better, thereby improving prediction accuracy. However, for some categories like HC, LA, and DT, there is a slight decline in F1 scores when . This might be due to the introduction of additional noise or irrelevant information with too many hops, leading to a slight degradation in performance. Table 6 illustrates the performance of our LSD framework across different values of k. Notably, even starting from , LSD generally outperforms the DQA model, and at , the improvement is particularly significant in many categories. For instance, in the AT category, the F1 score reaches 74.3, which is much higher than the DQA model’s 62.8. This suggests that the LSD framework is more efficient in handling multi-hop paths, capturing complex relationships while maintaining lower noise levels.
In contrast, the performance on the COVID-19 dataset is relatively stable, particularly for categories like mask, Fauci, school, and home. In Table 5, it does not show significant improvements from to , suggesting that short paths are sufficient for most of the valuable information in DAQ method. As k increases, F1 scores typically rise initially before leveling off or slightly declining. This reflects the dual impact of multi-hop paths: they help the model capture richer contextual information, improving accuracy, but too many hops can introduce noise or irrelevant details, potentially degrading performance. In Table 6, LSD demonstrates strong generalization across different k values, particularly at , where it achieves high F1 scores in multiple categories. This suggests that LSD can handle both simple single-hop relationships and more complex multi-hop interactions, making it highly adaptable.
While the DQA model performs well at and , its performance gains are limited at in some categories, and it shows a decline. This may indicate that the DQA model has limitations in effectively utilizing complex multi-hop paths, failing to leverage the full potential of the additional information. Although higher hop counts can boost performance, not all tasks require the maximum number of hops. Therefore, selecting an appropriate k value is critical in practical applications, balancing the need for sufficient information with the risk of introducing noise.
6. Conclusions
In this paper, we propose a Logical Stance Detection with Stance Transitivity (LSD) framework, obtaining the relationship between text and specific targets through the target-stance graph and using stance transitivity for logical reasoning to obtain stance. We evaluate its performance under a transductive learning setting for stance detection towards unseen targets on three benchmark datasets. The experimental results demonstrate significant performance improvement and validate the efficacy of the LSD framework in leveraging stance transitivity for logical inference. Specifically, when addressing complex and implicit targets, the framework performs better than baseline models. It achieves advanced results, proving its strong capability to handle scenarios requiring deep logical inference by accurately capturing nuanced semantic relationships inherent in such targets. While reasoning generally contributes to performance improvement, experimental results reveal a critical insight: not all inference tasks necessitate complex reasoning mechanisms. Excessive reasoning (i.e., over-reasoning) tends to introduce extraneous noise into the inference process, which may undermine task performance. Consequently, balancing acquiring sufficient information to support accurate inference and avoiding redundant complexity remains a key challenge for applying advanced reasoning frameworks.
Our future work will evolve along three directions to advance the LSD framework. First, we plan to develop an integrated adaptive reasoning engine that dynamically selects the most efficient inference pathways and intelligently decides when to employ complex transitivity versus simpler strategies based on task demands. Second, to enhance practicality and reduce reliance on large language models, we will fine-tune specialised small models for specific stance-taking tasks. Lastly, extending the framework’s scope remains a key priority. We will rigorously evaluate its performance on long-form speech structures and diversify its linguistic capabilities by testing across multiple languages, thereby assessing its robustness and generalizability.
7. Limitations
The LSD framework crucially relies on the presence of diverse targets in domain-specific, unlabeled text to construct high-quality target-stance graphs. The effectiveness of transitive stance reasoning depends on the sufficient quantity and diversity of targets in the unlabeled in-domain data. Only with ample distinct targets can the framework capture comprehensive inter-target stance relationships, thereby establishing a foundation for accurate graph construction. This strong domain dependence leads to limited cross-domain generalization.
Current evaluations of the framework are constrained by the characteristics of existing public stance datasets, which primarily consist of short texts such as social media comments. To address this gap, future work will focus on constructing a stance detection dataset comprising longer and more complex texts. This will enable a comprehensive assessment of the framework’s adaptability to long-text scenarios and provide a more robust benchmark for future methodological improvements.
Author Contributions
Conceptualization, Y.C. and X.M.; methodology, Y.C. and X.C.; validation, Y.C.; formal analysis, Y.C. and X.M.; investigation, Y.C.; writing—original draft preparation, Y.C.; writing—review and editing, Y.C. and X.M.; project administration, B.L. and H.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The code repository is available at: https://github.com/winwin-17/lsd (accessed on 29 September 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. A Reasoning Example
Target: Legalization Of Abortion
Text: I get several requests with petitions to save whales but never to stop the slaughter of babies in the wombs of mothers. #abortion. #SemST
Facts:
Tweet(Tweet1, “I get several requests with petitions to save whales but never to stop the slaughter of babies in the wombs of mothers. #abortion. #SemST”)
Supports(Tweet1,WhaleSlaughter, false) ::: Tweet1 doesn’t support whale slaughter.
Supports(Tweet1,Abortion, false) ::: Tweet1 doesn’t support abortion.
Rules:
Supports($x, WhaleSlaughter, false) Supports($x, AnimalRights, true) ::: If it oppses whale slaughter, then it is likely to support the Animal Rights.
Supports($x, AnimalRights, true) Supports($x, LegalizationOfAbortion, true) ::: If it supports animal rights, then it is likely to support the legalization of abortion.
Supports($x, Anbortion, true) ↔ Supports($x, LegalizationOfAbortion, true) ::: All those who support abortion support Legalization of Abortion.
Query: Supports(Tweet1, LegalizationOfAbortion, True) ::: The tweet supports Legalization Of Abortion.
Execution: Let’s execute the plan step by step, applying first-order logic inference rules and logical operators to determine the truth value of the statement “SupportsAtheism(Tweet1, True)”.
Step 1: Apply the Rules to the Given Facts
From Supports(Tweet1, Abortion, false) and the rule Supports($x, Anbortion, false) ↔ Supports($x, LegalizationOfAbortion, false):
Using Modus Ponens Supports($x, Anbortion, false) ↔ Supports($x, LegalizationOfAbortion, false). Therefore, **Supports(Tweet1, LegalizationOfAbortion, False)**.
Step 2: Determine if the Statement Can Be Inferred
From both rule and the given facts, we can conclusively determine **Supports(Tweet1, LegalizationOfAbortion, False)**.
Step 3: Evaluate the Content of the Tweet
The tweet mentions ”#abortion” in a context that suggests a comparison or contrast with saving whales, but it explicitly states it doesn’t support abortion.
Step 4: Conclude the result
Therefore, the statement **Supports(Tweet1, LegalizationOfAbortion, true)** remains false.
**Final answer: false**
Appendix B. Detailed Experimental Statistical Analysis
The detailed p-values and mean ± standard deviation are reported as follows.
Table A1.
Performance Statistics (Mean ± SD and p-values) on the Sem16 dataset.
Table A1.
Performance Statistics (Mean ± SD and p-values) on the Sem16 dataset.
| Methods | Sem16 | |||||
|---|---|---|---|---|---|---|
| AT | CC | FM | HC | LA | DT | |
| COLA-LLaMA3 | 33.1 ± 0.4 | 61.9 ± 4.4 | 63.9 ± 0.5 | 73.4 ± 1.3 | 61.8 ± 0.5 | 56.7 ± 0.2 |
| LSD-LLaMA3 | 74.3 ± 3.3 | 71.2 ± 0.8 | 67.8 ± 3.3 | 78.4 ± 1.2 | 64.2 ± 0.8 | 61.3 ± 0.8 |
| p-value | 0.0001 | 0.0229 | 0.1153 | 0.0011 | 0.0168 | 0.0014 |
Table A2.
Performance Statistics (Mean ± SD and p-values) on the COVID-19-Stance dataset.
Table A2.
Performance Statistics (Mean ± SD and p-values) on the COVID-19-Stance dataset.
| Methods | COVID-19 | |||
|---|---|---|---|---|
| Mask | Fauci | School | Home | |
| COLA-LLaMA3 | 71.0 ± 0.8 | 53.5 ± 0.8 | 38.1 ± 2.4 | 68.0 ± 1.2 |
| LSD-LLaMA3 | 77.6 ± 0.6 | 78.3 ± 2.5 | 69.3 ± 2.2 | 72.0 ± 1.8 |
| p-value | 0.0012 | 0.0004 | 0.0004 | 0.0066 |
References
- Mohammad, S.M.; Sobhani, P.; Kiritchenko, S. Stance and Sentiment in Tweets. arXiv 2016, arXiv:1605.01655. [Google Scholar] [CrossRef]
- Bhatt, G.; Sharma, A.; Sharma, S.; Nagpal, A.; Raman, B.; Mittal, A. Combining Neural, Statistical and External Features for Fake News Stance Identification. In Proceedings of the Web Conference 2018—WWW ’18, Lyon, France, 23–27 April 2018; pp. 1353–1357. [Google Scholar] [CrossRef]
- Yang, R.; Ma, J.; Lin, H.; Gao, W. A Weakly Supervised Propagation Model for Rumor Verification and Stance Detection with Multiple Instance Learning. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’22, Madrid, Spain, 11–15 July 2022; pp. 1761–1772. [Google Scholar] [CrossRef]
- Zhang, F.; Liu, J.; Xie, J.; Zhang, Q.; Xu, Y.; Zha, Z.J. ESCNet: Entity-enhanced and Stance Checking Network for Multi-modal Fact-Checking. In Proceedings of the 2024 ACM on Web Conference, Singapore, 13–17 May 2024; pp. 2429–2440. [Google Scholar] [CrossRef]
- Grimminger, L.; Klinger, R. Hate Towards the Political Opponent: A Twitter Corpus Study of the 2020 US Elections on the Basis of Offensive Speech and Stance Detection. In Proceedings of the 11th Workshop on Computational Approaches to Subjectivity, Sentiment and Social Media Analysis, Virtual, 19 April 2021; pp. 171–180. [Google Scholar]
- Müller, A.; Riedl, J.; Drews, W. Real-Time Stance Detection and Issue Analysis of the 2021 German Federal Election Campaign on Twitter. In Proceedings of the International Conference on Electronic Government, Linköping, Sweden, 6–8 September 2022; pp. 125–146. [Google Scholar] [CrossRef]
- Zhang, H.; Kwak, H.; Gao, W.; An, J. Wearing Masks Implies Refuting Trump?: Towards Target-specific User Stance Prediction across Events in COVID-19 and US Election 2020. In Proceedings of the 15th ACM Web Science Conference 2023, Austin, TX, USA, 30 April–1 May 2023; pp. 23–32. [Google Scholar] [CrossRef]
- Luo, Y.; Liu, Z.; Shi, Y.; Li, S.Z.; Zhang, Y. Exploiting Sentiment and Common Sense for Zero-shot Stance Detection. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 7112–7123. [Google Scholar]
- Zhu, Q.; Liang, B.; Sun, J.; Du, J.; Zhou, L.; Xu, R. Enhancing Zero-Shot Stance Detection via Targeted Background Knowledge. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval—SIGIR ’22, Madrid, Spain, 11–15 July 2022; pp. 2070–2075. [Google Scholar] [CrossRef]
- Liu, R.; Lin, Z.; Tan, Y.; Wang, W. Enhancing Zero-shot and Few-shot Stance Detection with Commonsense Knowledge Graph. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021; Zong, C., Xia, F., Li, W., Navigli, R., Eds.; Association for Computational Linguistics: New York, NY, USA, 2021; pp. 3152–3157. [Google Scholar] [CrossRef]
- Gatto, J.; Sharif, O.; Preum, S.M. Chain-of-Thought Embeddings for Stance Detection on Social Media. arXiv 2023, arXiv:2310.19750. [Google Scholar] [CrossRef]
- Zhang, B.; Ding, D.; Jing, L.; Huang, H. A Logically Consistent Chain-of-Thought Approach for Stance Detection. arXiv 2023, arXiv:2312.16054. [Google Scholar] [CrossRef]
- Yuan, J.; Zhao, Y.; Lu, Y.; Qin, B. SSR: Utilizing Simplified Stance Reasoning Process for Robust Stance Detection. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 6846–6858. [Google Scholar]
- Akash, A.U.; Fahmy, A.; Trabelsi, A. Can Large Language Models Address Open-Target Stance Detection? In Findings of the Association for Computational Linguistics: ACL 2025; Association for Computational Linguistics: New York, NY, USA, 2025; pp. 971–985. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Cheng, S.; Li, P.; Liu, Y. DEEM: Dynamic Experienced Expert Modeling for Stance Detection. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; pp. 4530–4541. [Google Scholar]
- Huang, T.; Cui, Z.; Du, C.; Chiang, C.E. CL-ISR: A Contrastive Learning and Implicit Stance Reasoning Framework for Misleading Text Detection on Social Media. arXiv 2025, arXiv:2506.05107. [Google Scholar] [CrossRef]
- Liu, Z.; Yap, Y.K.; Chieu, H.L.; Chen, N. Guiding Computational Stance Detection with Expanded Stance Triangle Framework. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 3987–4001. [Google Scholar] [CrossRef]
- Taranukhin, M.; Shwartz, V.; Milios, E. Stance Reasoner: Zero-Shot Stance Detection on Social Media with Explicit Reasoning. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; pp. 15257–15272. [Google Scholar]
- Zheng, Y.; Liu, X.; Wu, P.; Pan, L. CRAVE: A Conflicting Reasoning Approach for Explainable Claim Verification Using LLMs. arXiv 2025, arXiv:2504.14905. [Google Scholar] [CrossRef]
- Dai, G.; Liao, J.; Zhao, S.; Fu, X.; Peng, X.; Huang, H.; Zhang, B. Large Language Model Enhanced Logic Tensor Network for Stance Detection. Neural Netw. 2025, 183, 106956. [Google Scholar] [CrossRef] [PubMed]
- Wen, H.; Hovy, E.; Hauptmann, A. Transitive Consistency Constrained Learning for Entity-to-Entity Stance Detection. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; pp. 1467–1480. [Google Scholar] [CrossRef]
- Xu, J.; Fei, H.; Pan, L.; Liu, Q.; Lee, M.L.; Hsu, W. Faithful Logical Reasoning via Symbolic Chain-of-Thought. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; pp. 13326–13365. [Google Scholar] [CrossRef]
- Glandt, K.; Khanal, S.; Li, Y.; Caragea, D.; Caragea, C. Stance Detection in COVID-19 Tweets. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Bangkok, Thailand, 1–6 August 2021; pp. 1596–1611. [Google Scholar] [CrossRef]
- Stab, C.; Miller, T.; Schiller, B.; Rai, P.; Gurevych, I. Cross-topic Argument Mining from Heterogeneous Sources. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3664–3674. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Nguyen, D.Q.; Vu, T.; Tuan Nguyen, A. BERTweet: A pre-trained language model for English Tweets. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Virtual, 16–20 November 2020; pp. 9–14. [Google Scholar] [CrossRef]
- He, P.; Gao, J.; Chen, W. DeBERTaV3: Improving DeBERTa using ELECTRA-Style Pre-Training with Gradient-Disentangled Embedding Sharing. In Proceedings of the The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Liang, B.; Zhu, Q.; Li, X.; Yang, M.; Gui, L.; He, Y.; Xu, R. JointCL: A Joint Contrastive Learning Framework for Zero-Shot Stance Detection. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 81–91. [Google Scholar] [CrossRef]
- Wen, H.; Hauptmann, A. Zero-Shot and Few-Shot Stance Detection on Varied Topics via Conditional Generation. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 1491–1499. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, Y.; Liu, Y.; Zhang, W.; Hu, S. SEGP: Stance-Emotion Joint Data Augmentation with Gradual Prompt-Tuning for Stance Detection. In Proceedings of the 22nd International Conference on Computational Science, London, UK, 21–23 June 2022; pp. 577–590. [Google Scholar]
- Li, Y.; Yuan, J. Generative Data Augmentation with Contrastive Learning for Zero-Shot Stance Detection. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 6985–6995. [Google Scholar] [CrossRef]
- Zou, J.; Zhao, X.; Xie, F.; Zhou, B.; Zhang, Z.; Tian, L. Zero-Shot Stance Detection via Sentiment-Stance Contrastive Learning. In Proceedings of the 2022 IEEE 34th International Conference on Tools with Artificial Intelligence (ICTAI), Macao, China, 31 October–2 November 2022; pp. 251–258. [Google Scholar] [CrossRef]
- Li, Y.; Zhao, C.; Caragea, C. TTS: A Target-based Teacher-Student Framework for Zero-Shot Stance Detection. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 1500–1509. [Google Scholar] [CrossRef]
- Ding, D.; Dong, L.; Huang, Z.; Xu, G.; Huang, X.; Liu, B.; Jing, L.; Zhang, B. EDDA: An Encoder-Decoder Data Augmentation Framework for Zero-Shot Stance Detection. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; pp. 5484–5494. [Google Scholar]
- Lan, X.; Gao, C.; Jin, D.; Li, Y. Stance Detection with Collaborative Role-Infused LLM-Based Agents. Proc. Int. AAAI Conf. Web Soc. Media 2024, 18, 891–903. [Google Scholar] [CrossRef]
- Zhang, B.; Fu, X.; Ding, D.; Huang, H.; Li, Y.; Jing, L. Investigating Chain-of-thought with ChatGPT for Stance Detection on Social Media. arXiv 2023, arXiv:2304.03087. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).