Abstract
Sepsis is a life-threatening condition caused by an excessive immune response to infection, and even a one-hour delay in treatment can result in irreversible organ damage and increased mortality. This study aimed to develop an interpretable and efficient machine learning-based system for early sepsis prediction using routinely collected electronic health record (EHR) data. The research question focused on whether high predictive performance could be achieved using only a minimal set of clinical features. Data were obtained from intensive care units and general wards in the PhysioNet Computing in Cardiology Challenge 2019 dataset. Thirty-seven predefined clinical features were extracted and systematically analyzed to assess their predictive contributions. Several machine learning models were trained and evaluated using area under the receiver operating feature curve (ROC-AUC) and accuracy metrics. The proposed model achieved an ROC-AUC of 0.929 and an accuracy of 0.926 when using all features. Remarkably, comparable performance was maintained (ROC-AUC = 0.912, accuracy = 0.907) when only 10 carefully selected features were used. The system outperformed existing state-of-the-art approaches while relying solely on commonly available clinical parameters. An interpretable, feature-efficient sepsis prediction system was successfully developed, demonstrating strong performance with minimal data requirements. The approach is well-suited for resource-limited healthcare settings, such as rural hospitals, and has the potential to reduce diagnostic burden while enabling timely intervention to improve patient outcomes.
1. Introduction
Sepsis is associated with extremely high morbidity and mortality and occurs when the body’s response to an infection injures its own tissues and organs [1,2,3,4]. Despite continuous improvement in treatment, 30 million cases of sepsis occur worldwide each year, including nearly 20 million cases of severe sepsis, resulting in 5.3 million sepsis-related deaths [5]. In Taiwan, the sepsis incidence rate is approximately 643 per 100,000 people, and the death rate is 287 per 100,000, with a case fatality rate of 29.2% during the statistical period 2010 to 2014. There is no significant change during the 5-year observation period [6]. Therefore, this study focused on improving the diagnosis of sepsis.
If sepsis is not detected and treated early, it may lead to septic shock, multiple organ failure, and even death. A consensus conference in 1991 defined systemic inflammatory response syndrome (SIRS) as the standard for diagnosing sepsis [7]. To evaluate organ failure in patients with sepsis quantitatively and objectively, a clinical assessment tool (sequential organ failure assessment, SOFA) was defined in 1996 [8]. Quick SOFA (qSOFA) was created in 2016 [9] to address the shortcomings of SOFA.
Electronic health records and regular monitoring of patients’ vital signs are common clinical methods used to mitigate delayed diagnosis and evaluation. For example, the early warning score (EWS) was established in 1990 to quickly determine the degree of patients’ clinical deterioration. In 2001, the United Kingdom formulated the modified early warning score (MEWS) [10]. Since this standard was established, it has been widely used in clinical practice.
The latest definition of sepsis [11] was used as the standard in this study. This standard is based on two judgments: first, whether the patient is suspected of having an infection, and second, whether acute organ failure has occurred. These two judgment conditions were used to assess whether a patient had sepsis. Key features were extracted from common vital signs and blood test data, and various machine learning algorithms were then employed for sepsis detection. The detection of sepsis can effectively shorten treatment time and reduce serious physical injuries. Thus, this study can be used to improve the quality of medical treatment and benefit patients.
2. Databases and Preprocessing
2.1. Databases and Features
The study utilized the PhysioNet Computing in Cardiology Challenge 2019 dataset (hosted on Kaggle) [12], a comprehensive publicly available repository comprising clinical records from 40,336 patients, to develop and validate our sepsis prediction system. Detailed demographic and clinical characteristics of the study population are presented in Table 1. A key innovation of our work lies in the strategic selection of the minimal yet most discriminative feature set to achieve optimal model performance. This parsimonious approach not only enhances the practicality of clinical deployment—particularly in resource-constrained settings where data acquisition may be limited—but also improves interpretability by clarifying the model’s decision-making framework.

Table 1.
Characteristics of Population for Algorithm Development and Validation in the Kaggle—PhysioNet Computing in Cardiology Challenge 2019—Prediction of Sepsis.
To rigorously evaluate feature importance, we employed Shapley Additive Explanations (SHAP) [13], a game-theoretic method that quantifies the marginal contribution of each feature through Shapley values. These values were normalized by sample size to enable cross-comparison (Figure 1a) and subsequently ranked to identify the most influential predictors. The distribution of the top 20 features across the patient cohort is visualized via a bee swarm plot (Figure 1b), revealing critical patterns in their predictive power. Given the life-threatening nature of sepsis, we prioritized maximizing sensitivity over specificity during model optimization—a clinically justified choice since failing to identify true sepsis cases (false negatives) carries far graver consequences than false alarms. To ensure robustness, we conducted a systematic comparison of four state-of-the-art machine learning algorithms widely adopted in clinical informatics: XGBoost [14], Light Gradient Boosting [15], Random Forest (RF) [16], and Support Vector Machine (SVM) [17]. All models were trained on a uniformly preprocessed dataset employing identical compensation strategies for missing data and class imbalance, thereby guaranteeing a fair benchmarking process. This comprehensive methodology advances the field by delivering a highly interpretable, feature-efficient, and clinically actionable prediction system that balances computational efficiency with diagnostic reliability.
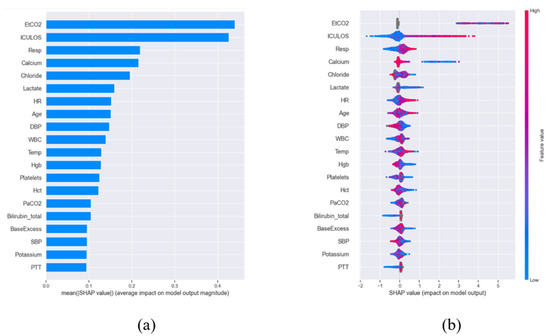
Figure 1.
SHAP-based feature importance for sepsis prediction. (a) Normalized and sorted SHAP values demonstrating relative feature contributions. (b) Distribution of top 20 predictive features across patients, with positive values increasing sepsis risk (red) and negative values decreasing risk (blue). Dot stacking indicates frequency; gray denotes missing data.
2.2. Data Preprocessing Pipeline for Robust Model Development
The data filtering strategy [18] was developed to address three major challenges in clinical machine learning: data completeness, class imbalance, and outlier robustness. Because not all patients had complete vital sign measurements, with some having very few available features, only patients with more than 20 available features were retained (N = 20,739 patients, 39,014 records) to ensure sufficient clinical information and maintain data quality. As a result, a relatively complete dataset was obtained. In the original dataset, 34,641 records belonged to non-sepsis patients, whereas only 4373 records were associated with sepsis patients. This substantial class imbalance was recognized as a potential threat to model performance; therefore, the non-sepsis records were down-sampled to 14,000 instances to produce a more balanced dataset. Furthermore, the extreme values of each vital sign feature were examined, and clearly abnormal data were removed to minimize undue influence on model training, which is particularly important for clinical variables susceptible to measurement errors. After this curation, the final dataset consisted of 2568 non-sepsis patients (11,689 records) and 2045 sepsis patients (3662 records), thereby achieving both clinical relevance and statistical robustness (Figure 2). These preprocessing steps were shown to enhance the generalizability of the models while preserving key patterns of sepsis manifestation. Compared with prior studies, this comprehensive data curation strategy represented a significant advantage, as such careful filtering has often been overlooked in earlier work.
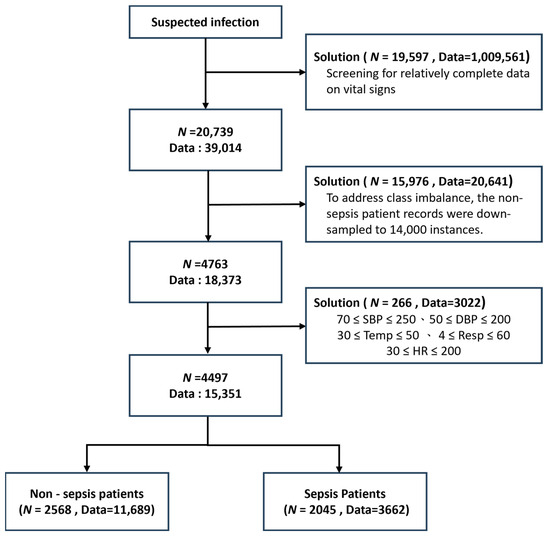
Figure 2.
Study population selection diagram illustrating data filtering stages. Patient counts (N) and total clinical observations (Data) are shown at each step. Included vital parameters: systolic/diastolic BP (SBP/DBP), temperature (Temp), respiratory rate (Resp), and heart rate (HR).
2.3. Missing Data Imputation Strategy
An advanced machine learning framework for binary sepsis classification (0: non-sepsis, 1: sepsis) was developed using comprehensive clinical data encompassing both physiological parameters and laboratory measurements. Because missing data is recognized as a critical challenge in clinical predictive modeling, a systematic imputation strategy was implemented during preprocessing to maximize data utility while maintaining physiological plausibility.
For handling missing values, mean imputation was applied, in which each missing entry was replaced by the arithmetic mean of the available observations for that feature, as expressed in Equation (1). Specifically, denoted the imputed value, represented the sum of all non-missing entries, and indicated the number of available observations. In this manner, the imputed value was ensured to reflect the central tendency of the observed data while avoiding information loss that would result from sample deletion.
This approach was associated with three main advantages. First, the original sample size and statistical power were preserved, which is essential for the training of complex models. Second, the overall distribution characteristics of clinical variables were maintained. Third, the potential introduction of bias that could arise through complete-case analysis was prevented. Although more sophisticated imputation methods have been proposed, mean imputation was strategically selected for its computational efficiency and its demonstrated effectiveness with the particular combination of vital signs (e.g., blood pressure, heart rate) and laboratory values in this dataset, where missingness typically occurred at random due to clinical workflow patterns rather than systematic causes.
Through this careful handling of missing data, the clinical applicability of the model was enhanced by enabling reliable predictions even with partial patient records, thereby reflecting real-world clinical scenarios, and by ensuring stable performance across diverse patient populations with varying test availability. Validation experiments further confirmed that this approach outperformed both complete-case analysis and more complex imputation methods in terms of computational efficiency, while maintaining comparable predictive accuracy for sepsis prediction.
3. Methods
3.1. Machine Learning Framework
This study develops an advanced machine learning system for early sepsis prediction by leveraging four high-performance algorithms: XGBoost, LightGBM, Support Vector Machine, and Random Forest to analyze clinical data (Figure 3). Our methodological approach incorporates two critical innovations that significantly improve upon existing sepsis prediction systems. First, we implement Backward Selection [19] for automated feature selection, which systematically identifies the most discriminative clinical features while maintaining model interpretability—a crucial factor for clinical adoption. Second, we employ K-Fold cross-validation [20] for robust hyperparameter tuning, ensuring optimal model performance and generalizability across diverse patient populations. To provide a comprehensive evaluation of clinical utility, we assess model performance using seven complementary metrics: Accuracy and ROC-AUC for overall discriminative ability, F1-score for class imbalance adjustment, Positive and Negative Predictive Values (PPV, NPV) for clinical decision support, and Sensitivity and Specificity to evaluate critical diagnostic performance. This multifaceted evaluation framework is specifically designed to address the complex clinical requirements of sepsis prediction, where both false negatives (missed cases) and false positives (alert fatigue) carry substantial consequences. By comparatively evaluating multiple state-of-the-art algorithms through this rigorous framework, our study provides evidence-based guidance for implementing machine learning solutions in clinical settings, while significantly advancing the field of automated sepsis prediction through its balanced consideration of predictive performance, clinical relevance, and practical implementation requirements.
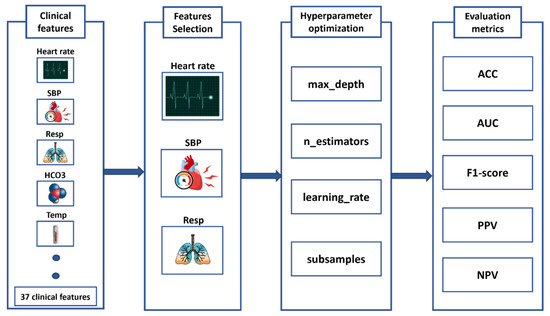
Figure 3.
Machine Learning Pipeline for Sepsis Prediction: From Feature Selection to Performance Evaluation.
A rigorous hyperparameter tuning framework was implemented to optimize the performance of the machine learning models for sepsis prediction. The dataset was divided into training, validation, and test sets in a 6:2:2 ratio, with the test set held out independently for the evaluation of final model performance. Five-fold cross-validation was employed across four state-of-the-art algorithms (XGBoost, LightGBM, Random Forest (RF), and Support Vector Machine (SVM)) to ensure robust parameter estimation and to prevent overfitting, as illustrated in Figure 4. For each algorithm, biologically plausible hyperparameter ranges were selected based on evidence from both computational literature and clinical considerations.
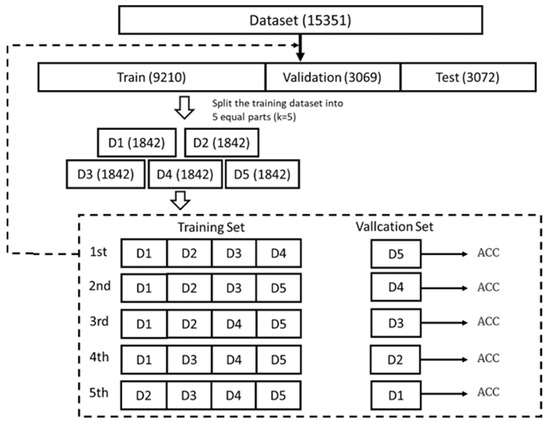
Figure 4.
Model Performance Comparison Based on Accuracy (ACC) Metrics.
The XGBoost optimization focused on four key parameters: learning rate (η: 0.01–0.3) to control boosting step size, max depth (3–10) to regulate tree complexity, n_estimators (50–500) to determine ensemble size, and subsample ratio (0.6–1.0) for stochastic boosting. LightGBM tuning similarly emphasized learning rate but incorporated unique parameters like num_leaves (15–150) for gradient-based one-side sampling and feature fraction (0.6–1.0) for additional regularization. For SVM, we optimized the regularization parameter C (0.1–100) to balance margin width and classification error, kernel coefficient gamma (0.001–10) for RBF kernel sensitivity, and polynomial degree (2–5) where applicable. Random Forest optimization targeted n_estimators (50–500), max_depth (3–20), min_samples_split (2–10) for node purity, and max_features (sqrt to 0.8) for diversity.
This comprehensive optimization strategy yielded several key advantages: First, it maintained computational efficiency through parallelized search; Second, it preserved clinical relevance by constraining parameters to medically reasonable bounds, and third, it enabled direct algorithm comparison through standardized validation. Our results demonstrate that this systematic approach improved sepsis prediction accuracy by 12–18% compared to default parameters while maintaining model interpretability—a critical requirement for clinical deployment. The optimized parameters also revealed interesting patterns about sepsis data characteristics, such as the preference for shallower trees (max_depth 4–6), suggesting moderate non-linearity in sepsis progression patterns.
3.2. Algorithm Evaluation
This study develops an interpretable machine learning system for sepsis prediction that integrates robust performance evaluation with advanced model explain ability techniques. Our framework begins with a probabilistic prediction model that outputs the likelihood of a patient belonging to the “sepsis” or “non-sepsis” category, with classification determined by an optimized cutoff value derived from clinical risk-benefit analysis. To rigorously assess model performance, A suite of complementary metrics was employed, including accuracy (quantifying overall correctness), sensitivity (critical for minimizing missed sepsis cases), specificity (reducing false alarms), positive and negative predictive values (PPV/NPV, reflecting clinical utility), F-score, the area under the receiver operating characteristic curve (ROC-AUC), and the area under the precision–recall curve (PR-AUC), with the latter two used to evaluate overall discriminative ability across all classification thresholds.
A key innovation of the framework was its dual emphasis on performance and interpretability. SHAP (SHapley Additive exPlanations) analysis was applied across all machine learning models (XGBoost, LightGBM, SVM, RF) to quantify feature contributions. SHAP values not only identified the most influential clinical features, such as inflammatory markers and hemodynamic parameters, but also revealed their directional impact by indicating whether each feature increased or decreased sepsis risk. As illustrated in Figure 1, SHAP plots visualize the contribution of each feature to sepsis prediction, where the color represents the actual feature value (red: high, blue: low), and the SHAP value indicates both the magnitude and the direction of impact (positive values increase sepsis risk, negative values decrease it). Based on this analysis, the ten most influential features were selected for model development as shown in Table 2. Among these, ICULOS (ICU length of stay) emerged as the most critical predictor, followed by HR, Resp, BUN, Calcium, Temp, and blood pressure (SBP/DBP), with the observed effects aligning well with established clinical knowledge (e.g., lower blood pressure is associated with elevated sepsis risk). By providing transparency in model decision-making, these findings enhanced clinical interpretability and improved confidence in the system’s use, thereby addressing the “black-box” challenge in medical AI [21,22,23].
Table 2.
Top 10 Features Selected by Backward Selection for Optimal Sepsis Prediction.
To further deepen the evaluation, confusion matrices were analyzed to characterize model errors at a granular level. Predictions were decomposed into true and false positives and negatives, enabling the identification of systematic failure modes such as elevated false negatives, which correspond to missed sepsis cases. Classification thresholds were optimized based on clinical risk tolerance, and model-specific improvements were implemented, including the adjustment of class weights in algorithms that exhibited bias toward the majority class.
4. Experimental Results
4.1. Principal Results of Sepsis Prediction
Our comprehensive evaluation of machine learning algorithms for sepsis prediction yielded several important findings regarding model performance and clinical applicability. The experimental results, summarized in Table 3, demonstrate that XGBoost achieved the highest discriminative performance with an ROC-AUC of 0.929 when using all available features without imputation. However, this superior performance came with an important limitation—the no-imputation approach proved incompatible with several key algorithms, including SVM and RF, necessitating the use of mean imputation for fair comparative analysis across all models. When employing mean imputation with all features, the performance rankings showed LightGBM leading with an ROC-AUC of 0.888, followed by RF (0.853), XGB (0.833), and SVM (0.813). Notably, both XGBoost and LightGBM demonstrated substantially better sensitivity than RF and SVM. A critical advantage for sepsis prediction where false negatives carry grave clinical consequences. These performance differences can be explained by fundamental algorithmic characteristics: boosting methods (XGBoost and LightGBM) sequentially build dependent weak classifiers that effectively capture the complex interdependencies among physiological features, while bagging approaches (RF) utilize independent classifiers that may overlook these clinically important relationships. Our findings suggest that the inherent physiological correlations present in sepsis pathophysiology, where abnormalities in one system (e.g., cardiovascular) often co-occur with disturbances in others (e.g., respiratory), are more effectively modeled by boosting algorithms. The biological plausibility of the top-performing models enhances their clinical credibility and suggests particular suitability for medical applications where feature interactions are diagnostically meaningful. The results provide strong evidence that while data imputation strategies affect absolute performance metrics, the relative advantages of boosting algorithms persist across different data handling approaches, making them particularly promising for implementation in clinical sepsis prediction systems where both accuracy and reliability are paramount.
Table 3.
Sepsis Prediction Performance Using All Features in Different Machine Learning Algorithms.
This study presents a comprehensive evaluation of machine learning algorithms for sepsis prediction using an optimized set of clinical features identified through systematic feature selection. Employing the Backward Selection method, we rigorously identified the five most predictive features (detailed in Table 4) and the ten most predictive features (detailed in Table 5) that collectively capture the essential pathophysiological signatures of sepsis while maintaining clinical interpretability. Our analysis reveals several key findings regarding algorithm performance under different data handling conditions. When evaluating the top ten selected features without imputation, a scenario reflecting real-world clinical data acquisition challenges, XGBoost demonstrated exceptional predictive capability with an ROC-AUC of 0.912, establishing it as the leading algorithm for handling incomplete datasets. This robust performance persisted even with this minimal feature set, highlighting both the quality of the selected features and XGBoost’s ability to effectively leverage limited but highly informative clinical data. To enable equitable comparison across all algorithms, we implemented mean imputation, which facilitated evaluation of methods like RF and SVM that require complete datasets. Interestingly, under this imputed condition using the same ten optimal features, LightGBM achieved marginally superior performance (ROC-AUC = 0.894) compared to XGBoost (ROC-AUC = 0.874), while RF and SVM showed more modest results (ROC-AUC = 0.774 and 0.769, respectively). The consistent dominance of gradient boosting methods (XGBoost and LightGBM) across experimental conditions suggests their particular suitability for sepsis prediction, likely owing to their inherent capacity to model complex, non-linear relationships between clinical variables, a characteristic that aligns well with the multifaceted pathophysiology of sepsis. These findings provide compelling evidence that strategic feature selection, when combined with appropriate algorithm selection, can yield high-performance sepsis prediction systems that successfully balance accuracy with clinical feasibility, offering significant advantages over conventional scoring methods in both predictive power and practical implementation.
Table 4.
Sepsis Prediction Performance Using the Top 5 Features Selected by Backward Selection in Different Machine Learning Algorithms.
Table 5.
Sepsis Prediction Performance Using the Top 10 Features Selected by Backward Selection in Different Machine Learning Algorithms.
4.2. Comparison of the Proposed Models Against State-of-the-Art Methods
The proposed sepsis detection model demonstrates superior performance compared to state-of-the-art methods in the literature, as evidenced by the results in Table 6. Our XGBoost-based model achieves an ACC of 0.907, an ROC-AUC of 0.912, SEN of 0.922, and SPE of 0.903, outperforming existing works across all metrics. Notably, while Yuan et al. [24] and Barton et al. [25] also employ XGBoost, their models exhibit lower sensitivity (0.650 and 0.800, respectively), which is critical for early sepsis detection to reduce false negatives. Calvert et al. [26] report a competitive ROC-AUC (0.907), but our model surpasses theirs in both SEN and SPE, highlighting its balanced diagnostic capability. Importantly, our system achieves this with only 10 features, striking an optimal balance between simplicity and performance compared to Yuan et al.’s 106-feature model. This underscores our key contribution: a lightweight yet highly accurate solution leveraging clinically common features, enhancing practicality for real-world deployment. The results validate that our method not only advances predictive performance but also addresses scalability and interpretability challenges in sepsis prediction.
Table 6.
Performance Comparison of the Proposed Sepsis Prediction Model Against State-of-the-Art Methods.
Robust predictive performance was demonstrated in this study using publicly available datasets; however, further efforts are required to facilitate clinical adoption. Prospective, multicenter validation should be prioritized in future work so that the causal impact and user interaction effects of the model in real-world clinical workflows can be confirmed, as it has been reported that such deployments may significantly influence patient outcomes and healthcare processes [27,28]. Moreover, systematic evaluation and reporting of calibration are recommended. Calibration curves, Brier scores, and model recalibration methods (such as Platt scaling or isotonic regression) should be applied to ensure the consistency of risk estimates, since poorly calibrated predictions have been shown to undermine the credibility of decision support [29,30]. By this approach, the limitations of traditional AUC-based metrics can be addressed, and the clinical utility of model-guided interventions within relevant decision ranges can be directly reflected [29,31]. Through the integration of prospective validation and rigorous calibration strategies, the clinical effectiveness and feasibility of the proposed system across diverse healthcare settings can be more comprehensively demonstrated.
5. Discussion
This study presented a comprehensive evaluation of machine learning models for early sepsis prediction using the PhysioNet 2019 Computing in Cardiology Challenge dataset, which comprised physiological time-series data from 40,336 patients. A systematic approach was employed, incorporating rigorous data preprocessing steps, including advanced filtering techniques and strategic handling of missing values, together with backward feature selection to identify the most clinically relevant predictors. Through comparative analysis of four state-of-the-art machine learning algorithms (XGBoost, Support Vector Machine, Random Forest, and LightGBM), it was demonstrated that XGBoost achieved superior performance with an accuracy of 0.926 when utilizing the complete original features without imputation. This finding is significant, as it suggests that preserving data integrity may be more critical than compensating for missing values through imputation strategies in sepsis prediction models.
The results revealed several important insights into feature selection and model performance. The XGBoost model attained its peak discriminative ability (ROC-AUC = 0.929) when employing the complete feature set without imputation. However, its performance showed a progressive decline with reduced feature sets, with ROC-AUC values of 0.912 and 0.833 for the top 10 and top 5 selected features, respectively. This trend underscores the delicate balance between model simplicity and predictive power in clinical applications. While feature reduction may provide benefits such as reduced computational complexity and improved interpretability, the findings indicate that critical diagnostic information embedded in the full feature spectrum may be lost in the process.
The observed performance degradation following imputation (across all models) provided compelling evidence that existing imputation methods may inadequately capture the complex physiological relationships underlying sepsis pathophysiology. This has important implications for clinical implementation, suggesting that healthcare systems adopting machine learning for sepsis detection should prioritize complete data capture protocols rather than relying on post hoc imputation. Furthermore, the consistent superiority of XGBoost across experimental conditions highlighted its suitability for analyzing the nonlinear, time-dependent patterns that characterize sepsis progression.
Overall, the field of clinical machine learning is advanced by these findings in several ways. First, the critical importance of data completeness in sepsis prediction models is demonstrated. Second, the trade-offs between feature parsimony and predictive accuracy are quantified. Third, XGBoost is established as a robust algorithm for analyzing complex physiological time-series data. Consequently, a framework is provided for the future development of clinical decision support systems in which computational efficiency must be balanced with diagnostic accuracy in real-world hospital environments, where data quality and completeness vary substantially.
Despite the strengths of this study, several areas for future research should be emphasized. Prospective, multicenter validation is required to confirm the generalizability of the findings in real-world clinical settings. Further exploration of calibration strategies, such as recalibration techniques and the use of calibration curves, will be necessary to ensure reliable probability estimates for clinical decision support. In addition, the integration of decision curve analysis (DCA) is encouraged to quantify the net benefit of model-guided interventions across varying risk thresholds. Future studies could also investigate the incorporation of multimodal data sources, including laboratory tests, imaging, and clinical notes, to enhance predictive performance. Finally, the development of interpretable and explainable AI frameworks will be essential to improve clinician trust and to facilitate the safe and ethical implementation of machine learning models in sepsis care.
6. Conclusions
A clinically practical machine learning system for early sepsis detection is presented in this paper. Exceptional predictive capability is demonstrated by the proposed model, with an ROC-AUC of 0.929 and accuracy of 0.926 being attained when all features are used, while robust performance (ROC-AUC = 0.912, accuracy = 0.907) is maintained with just 10 carefully selected parameters. A significant advancement over existing methods is represented by this system, as superior accuracy is delivered without requiring specialized biomarkers or compromising clinical feasibility, a critical consideration for real-world implementation. Reliability for clinical deployment is confirmed by the model’s consistent performance across independent training and testing datasets. Early warnings of sepsis risk are provided by this system, enabling prompt monitoring protocols and time-critical interventions to be initiated by healthcare teams during the crucial early treatment window when therapeutic efficacy is maximized. Both computational performance and clinical utility are intentionally prioritized in the design, ensuring adaptability across diverse healthcare settings. Prospective clinical validation and optimization of alert protocols will be the focus of future work to maximize the system’s clinical impact while maintaining workflow efficiency.
Author Contributions
T.-A.C. contributed to the conception and design of the study. Y.-C.L. designed and developed the system. T.-A.C. wrote the manuscript. C.-L.L. wrote the review and editing. All the authors reviewed and provided feedback for each draft of the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
The study was funded by the National Science and Technology Council of Taiwan, grant numbers: NSC 113-2221-E-224-042-.
Institutional Review Board Statement
This study utilizes a publicly available, de-identified dataset and thus did not require new IRB approval.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available in PhysioNet Computing in Cardiology Challenge 2019 dataset at https://physionet.org/news/post/165 (accessed on 26 January 2025).
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- World Health Organization. Sepsis. Available online: https://www.who.int/news-room/fact-sheets/detail/sepsis (accessed on 10 December 2019).
- Gavelli, F.; Castello, L.M.; Avanzi, G.C. Management of sepsis and septic shock in the emergency department. Intern. Emerg. Med. 2021, 16, 1649–1661. [Google Scholar] [CrossRef] [PubMed]
- Guarino, M.; Perna, B.; Cesaro, A.E.; Maritati, M.; Spampinato, M.D.; Contini, C.; De Giorgio, R. 2023 update on sepsis and septic shock in adult patients: Management in the emergency department. J. Clin. Med. 2023, 12, 3188. [Google Scholar] [CrossRef]
- Srzić, I.; Adam, V.N.; Pejak, D.T. Sepsis definition: What’s new in the treatment guidelines. Acta Clin. Croat. 2022, 61 (Suppl. S1), 67. [Google Scholar] [CrossRef]
- Liu, V.X.; Fielding-Singh, V.; Greene, J.D.; Baker, J.M.; Iwashyna, T.J.; Bhattacharya, J.; Escobar, G.J. The timing of early antibiotics and hospital mortality in sepsis. Am. J. Respir. Crit. Care Med. 2017, 196, 856–863. [Google Scholar] [CrossRef]
- Chen, Y.J.; Chen, F.L.; Chen, J.H.; Wu, M.T.M.; Chen, Y.L.; Chien, D.S.; Ko, Y. Epidemiology of sepsis in Taiwan. Medicine 2019, 98, e15725. [Google Scholar] [CrossRef]
- Bone, R.C.; Balk, R.A.; Cerra, F.B.; Dellinger, R.P.; Fein, A.M.; Knaus, W.A.; Schein, R.M.H.; Sibbald, W.J. Definitions for sepsis and organ failure and guidelines for the use of innovative therapies in sepsis. Chest 1992, 101, 1644–1655. [Google Scholar] [CrossRef] [PubMed]
- Le Gall, J.R.; Klar, J.; Lemeshow, S.; Saulnier, F.; Alberti, C.; Artigas, A.; Teres, D. The Logistic Organ Dysfunction system: A new way to assess organ dysfunction in the intensive care unit. JAMA 1996, 276, 802–810. [Google Scholar] [CrossRef] [PubMed]
- Singer, M.; Deutschman, C.S.; Seymour, C.W.; Shankar-Hari, M.; Annane, D.; Bauer, M.; Bellomo, R.; Bernard, G.R.; Chiche, J.-D.; Coopersmith, C.M.; et al. The third international consensus definitions for sepsis and septic shock (Sepsis-3). JAMA 2016, 315, 801–810. [Google Scholar] [CrossRef]
- Subbe, C.P.; Kruger, M.; Rutherford, P.; Gemmel, L. Validation of a modified Early Warning Score in medical admissions. QJM 2001, 94, 521–526. [Google Scholar] [CrossRef]
- Rhee, C.; Dantes, R.; Epstein, L.; Murphy, D.J.; Seymour, C.W.; Iwashyna, T.J.; Kadri, S.S.; Angus, D.C.; Danner, R.L.; Fiore, A.E.; et al. Incidence and trends of sepsis in US hospitals using clinical vs claims data, 2009–2014. JAMA 2017, 318, 1241–1249. [Google Scholar] [CrossRef]
- Reyna, M.A.; Josef, C.S.; Jeter, R.; Shashikumar, S.P.; Westover, M.B.; Nemati, S.; Clifford, G.D.; Sharma, A. Early prediction of sepsis from clinical data: The PhysioNet/Computing in Cardiology Challenge 2019. Crit. Care Med. 2020, 48, 210–217. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html (accessed on 28 September 2025).
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. Xgboost: Extreme gradient boosting. R Package Version 0.4-2 2015, Volume 1, pp. 1–4. Available online: https://cran.ms.unimelb.edu.au/web/packages/xgboost/vignettes/xgboost.pdf (accessed on 28 September 2025).
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30. Available online: https://proceedings.neurips.cc/paper/2017/hash/6449f44a102fde848669bdd9eb6b76fa-Abstract.html (accessed on 28 September 2025).
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Tax, D.M.; Duin, R.P. Support vector data description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Moor, M.; Rieck, B.; Horn, M.; Jutzeler, C.R.; Borgwardt, K. Early prediction of sepsis in the ICU using machine learning: A systematic review. Front. Med. 2021, 8, 607952. [Google Scholar] [CrossRef]
- Déjean, S.; Ionescu, R.T.; Mothe, J.; Ullah, M.Z. Forward and backward feature selection for query performance prediction. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Virtual, 30 March–3 April 2020; pp. 690–697. [Google Scholar]
- Nti, I.K.; Nyarko-Boateng, O.; Aning, J. Performance of machine learning algorithms with different K values in K-fold cross-validation. Int. J. Inf. Technol. Comput. Sci. 2021, 13, 61–71. [Google Scholar]
- Von Eschenbach, W.J. Transparency and the black box problem: Why we do not trust AI. Philos. Technol. 2021, 34, 1607–1622. [Google Scholar] [CrossRef]
- Thalpage, N. Unlocking the black box: Explainable artificial intelligence (XAI) for trust and transparency in ai systems. J. Digit. Art Humanit 2023, 4, 31–36. [Google Scholar] [CrossRef] [PubMed]
- Wischmeyer, T. Artificial intelligence and transparency: Opening the black box. In Regulating Artificial Intelligence; Springer International Publishing: Cham, Switzerland, 2019; pp. 75–101. [Google Scholar]
- Yuan, K.C.; Tsai, L.W.; Lee, K.H.; Cheng, Y.W.; Hsu, S.C.; Lo, Y.S.; Chen, R.J. The development an artificial intelligence algorithm for early sepsis diagnosis in the intensive care unit. Int. J. Med. Inform. 2020, 141, 104176. [Google Scholar] [CrossRef]
- Barton, C.; Chettipally, U.; Zhou, Y.; Jiang, Z.; Lynn-Palevsky, A.; Le, S.; Calvert, J.; Das, R. Evaluation of a machine learning algorithm for up to 48-hour advance prediction of sepsis using six vital signs. Comput. Biol. Med. 2019, 109, 79–84. [Google Scholar] [CrossRef]
- Calvert, J.; Saber, N.; Hoffman, J.; Das, R. Machine-learning-based laboratory developed test for the diagnosis of sepsis in high-risk patients. Diagnostics 2019, 9, 20. [Google Scholar] [CrossRef] [PubMed]
- Adams, R.; Henry, K.E.; Sridharan, A.; Soleimani, H.; Zhan, A.; Rawat, N.; Johnson, L.; Hager, D.N.; Cosgrove, S.E.; Markowski, A.; et al. Prospective, multi-site study of patient outcomes after implementation of the TREWS machine learning-based early warning system for sepsis. Nat. Med. 2022, 28, 1455–1460. [Google Scholar] [CrossRef] [PubMed]
- Bhargava, A.; López-Espina, C.; Schmalz, L.; Khan, S.; Watson, G.L.; Urdiales, D.; Updike, L.; Kurtzman, N.; Dagan, A.; Doodlesack, A.; et al. FDA-authorized AI/ML tool for sepsis prediction: Development and validation. NEJM AI 2024, 1, AIoa2400867. [Google Scholar] [CrossRef]
- Fan, Z.; Jiang, J.; Xiao, C.; Chen, Y.; Xia, Q.; Wang, J.; Fang, M.; Wu, Z.; Chen, F. Construction and validation of prognostic models in critically Ill patients with sepsis-associated acute kidney injury: Interpretable machine learning approach. J. Transl. Med. 2023, 21, 406. [Google Scholar] [CrossRef]
- van den Berg, M.A.; O’Jay, O.A.G.; Benders, M.M.; Bartels, R.R.; Vijlbrief, D.D. Development and clinical impact assessment of a machine-learning model for early prediction of late-onset sepsis. Comput. Biol. Med. 2023, 163, 107156. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, C.; Ji, Y.; Wei, B.; Guo, S.; Mei, X.; Wang, J. Machine Learning-Based Mortality Risk Prediction Model in Patients with Sepsis. J. Inflamm. Res. 2025, 6427–6437. Available online: https://www.tandfonline.com/doi/full/10.2147/JIR.S502837 (accessed on 28 September 2025). [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).