Abstract
Multimodal Sentiment Analysis (MSA) aims to predict subjective human emotions by leveraging multimodal information. However, existing research inadequately utilizes explicit sentiment semantic information at the lexical level in text and overlooks noise interference from non-dominant modalities, such as irrelevant movements in visual modalities and background noise in audio modalities. To address this issue, we propose a multimodal sentiment analysis model based on knowledge enhancement and text-guided learning (MMKT). The model constructs a sentiment knowledge graph for the textual modality using the SenticNet knowledge base. This graph directly annotates word-level sentiment polarity, strengthening the model’s understanding of emotional vocabulary. Furthermore, global sentiment knowledge features are generated through graph embedding computations to enhance the multimodal fusion process. Simultaneously, a dynamic text-guided learning approach is introduced, which dynamically leverages multi-scale textual features to actively suppress redundant or conflicting information in visual and audio modalities, thereby generating purer cross-modal representations. Finally, concatenated textual features, cross-modal features, and knowledge features are utilized for sentiment prediction. Experimental results on the CMU-MOSEI and Twitter2019 dataset demonstrate the superior performance of the MMKT model.
1. Introduction
Over the past decade, the rapid development of the Internet has generated vast amounts of online comments. Analyzing sentiments in these comments is of great significance for social stability and development [1]. To address this need, sentiment analysis technology has emerged. Sentiment analysis, also known as opinion analysis or opinion mining, constitutes an important research direction in the field of Natural Language Processing (NLP). It aims to automatically extract and analyze emotions and viewpoints from text [1,2,3]. Sentiment analysis is essential for the advancement of artificial intelligence [3]. Over the years, sentiment analysis has emerged as an actively explored domain within affective computing [4,5,6].
Historically, textual data has predominantly served as the primary medium for expressing ideas, thereby establishing the textual modality as the dominant component within multimodal data frameworks. Its pivotal role in identifying latent affective dimensions remains undisputed. Although text-based sentiment analysis has achieved remarkable success, contemporary opinion-driven data dissemination is undergoing a structural transformation—expressive formats combining images and text, along with video-based content, are progressively supplanting traditional textual forms as the mainstream. Consequently, monomodal text-based sentiment analysis can no longer adequately address the complexities of internet-based multimodal environments. Taking e-commerce reviews as an example, when users provide textual feedback, they typically attach multiple images as supplementary evidence to substantiate personal viewpoints, thus enhancing review credibility. These images generally maintain close correlations with textual content, delivering critical supplemental information for sentiment analysis tasks—assisting in pinpointing sentiment-bearing words and amplifying emotional expression. In video content analysis scenarios, temporally synchronized text, visual frames, and audio form a three-dimensional information matrix. Modalities collectively construct a comprehensive sentiment expression map through temporal feature correlations, interpreting the holistic emotional state from complementary perspectives [7].
Current research commonly overlooks explicit sentiment semantic information embedded at the lexical level in textual modalities. For instance, in the sentence “This filthy restaurant looks truly irritating”, words like “filthy” and “irritating” explicitly convey negative sentiment. Conversely, multimodal tweets with hashtags like “#GoodWeather” and “#GoodMood” exhibit distinctly positive emotional tendencies due to the core word “good”. Beyond adjectives, certain nouns (e.g., smile) and verbs (e.g., like) also carry explicit affective connotations. These sentiment-bearing lexicons serve as semantic anchors for cross-modal fusion, effectively guiding the integration process in sentiment analysis models.
Additionally, several studies and corresponding ablation experiments [8,9,10] further demonstrate that different modalities contribute disproportionately to sentiment recognition, with the textual modality demonstrating particular predominance. interference from emotion-irrelevant factors in non-dominant modalities—such as extraneous facial movements in visual streams or background noise contamination in audio signals—may induce semantic divergence across multimodal sources. Such interference substantially constrains the performance of multimodal sentiment analysis systems.
Building upon these challenges, we propose a Multimodal Sentiment Analysis Model Based on Knowledge-Enhanced and Text-guided Learning (MMKT). The model incorporates lexical sentiment semantics into multimodal fusion while actively suppressing redundant or conflicting information in visual and audio modalities through its dynamic text-guided learning approach. This achieves robustness enhancement in complex scenarios and elevates multimodal sentiment analysis performance.
The main contributions of this work are summarized as follows:
- Employing Transformer layers to project initial features of textual, audio, and visual modalities into low-dimensional spaces, filtering redundant information.
- Constructing a sentiment knowledge graph for the textual modality using the SenticNet knowledge base, which directly annotates word-level sentiment polarity to provide explicit sentiment labels. This strengthens the model’s understanding of emotional vocabulary while generating global sentiment knowledge features through graph embedding computations, thereby enhancing multimodal fusion.
- Introducing a dynamic text-guided learning approach that leverages multi-scale textual features to actively suppress redundant or conflicting information in visual and audio modalities, producing refined cross-modal representations.
- Our experimental results on the CMU-MOSEI and Twitter2019 datasets demonstrate that the MMKT model outperforms baseline methods in multimodal sentiment analysis tasks while validating the efficacy of its constituent modules.
2. Related Works
2.1. Multimodal Sentiment Analysis
Existing multimodal sentiment analysis research predominantly focuses on the design and optimization of modality fusion strategies, aiming to enhance the robustness and accuracy of sentiment discrimination by mining semantic complementarity through cross-modal feature interaction. Zadeh et al. [11] pioneered the construction of the MOSI dataset in their study, characterized by annotating sentiment polarity labels for utterances within video clips, thereby establishing a benchmark platform for multimodal sentiment analysis. However, the MOSI dataset’s limited scale (only 2199 clips) and coarse-grained labeling constrain model generalizability. To address this, Zadeh et al. [12] further introduced the MOSEI dataset, expanding its scale to 23,453 video clips with fine-grained sentiment intensity annotations. They concurrently proposed a dynamic fusion graph network to reveal cross-modal complementary mechanisms through interpretable modality interaction modeling, advancing novel methodologies for multimodal fusion theory.
To strengthen contextual modeling capabilities, Poria et al. [13] developed a hierarchical multimodal sentiment analysis framework that constructs layered feature representations using contextual relationships among intra-video utterances, achieving efficient sentiment classification. Shenoy et al. [14] designed the Multilogue-Net model for conversational scenarios, capturing temporal dependencies of modal elements across dialogue turns via context-aware modules while parsing individual differences in emotional expression through speaker identity encoders. Williams et al. [15] presented an early fusion strategy based on feature alignment, which temporally synchronizes textual, audio, and visual features before direct concatenation, followed by temporal dependency modeling via LSTM or CNN architectures.
Zadeh et al. [16] proposed an innovative Tensor Fusion Network (TFN) that expands unimodal feature vectors into multidimensional tensors. Hazarika et al. [8] designed a multi-objective optimization framework employing joint constraints of distribution similarity, orthogonal loss, reconstruction loss, and task prediction loss to achieve learning of both modality-invariant and modality-specific representations. Tsai et al. [17] introduced an unaligned cross-modal attention mechanism based on Transformer architecture, where modality features are fed into encoders to dynamically capture semantic correlations in asynchronous modalities through cross-attention.
To better capture inter-modal correlations for constructing efficient joint feature representations, Xu et al. [18] designed a bidirectional multi-level attention mechanism for multimodal sentiment analysis, whereby text-visual dual-path attention drives feature alignment and complementarity across modalities. Harish et al. [19] subsequently extended this approach, proposing a hierarchical attention fusion architecture for tri-modal (text-image-audio) scenarios. This framework leverages attention mechanisms to perform fusion at both feature-level and decision-level, empirically confirming the technical advantages of multi-layer fusion for multimodal modeling.
2.2. Transformer
Transformer, introduced by Vaswani et al. [20] as an attention-based building block for machine translation, learns contextual relationships between tokens by aggregating sequence-wide information. This architecture demonstrates exceptional modeling capabilities across diverse tasks—including natural language processing, speech processing, and computer vision [21,22,23,24]. Within Multimodal Sentiment Analysis (MSA), the technique has been extensively adopted for multimodal fusion, representation learning, and feature extraction [25,26,27].
3. Methodology
3.1. Task Definition
Multimodal Sentiment Analysis (MSA) aims to analyze human emotions by leveraging multimodal data from datasets. Each video sample in the dataset comprises three components: textual, audio, and visual information. Initially, pretrained models and tools—BERT-Base for text, LibROSA0.9.2 for audio, and OpenFace2.0 for vision—extract precomputed initial feature sequences for each modality. These sequences are represented as , where denotes textual, audio, and visual modalities, respectively, and indicates the feature dimensionality of each modality. Its primary workflow is illustrated in Figure 1.
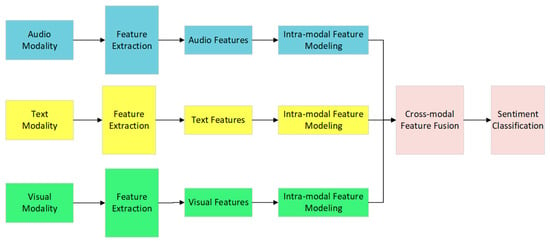
Figure 1.
Overall workflow architecture of Multimodal Sentiment Analysis tasks.
3.2. Overall Architecture
The architecture of the proposed model is illustrated in Figure 2. First, Transformer layers are employed to project initial features of textual, audio, and visual modalities into low-dimensional spaces, filtering redundant information. Subsequently, a dynamic text-guided mechanism leverages multi-scale textual features (low, medium, high) to direct cross-modal attention computation, suppressing interference from emotion-irrelevant information in visual and audio modalities while enhancing emotion-related associations. Next, a sentiment graph is constructed based on the SenticNet knowledge base, linking textual vocabulary with external sentiment nodes (polarity, intensity) to generate global sentiment features through graph embedding. Finally, concatenated textual features, cross-modal features, and knowledge features undergo dynamic weighting via an attention mechanism to emphasize critical information before sentiment prediction.
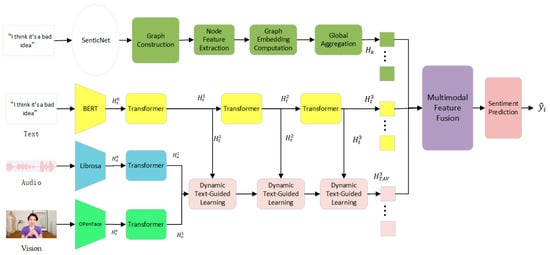
Figure 2.
The overall architecture of the MMKT model.
3.3. Multimodal Embedding
For multimodal inputs , this study employs three Transformer layers to standardize feature representations within each modality. The process begins by randomly initializing low−dimensional tokens , for each modality. Subsequently, Transformers embed core modality information into these tokens, as formalized in equation:
where represents the unified features for each modality , with dimensions , and denote the modality-specific feature extractor and its parameters, respectively, and indicates the concatenation operation.
In the experiments, and were set to 8 and 128, respectively. By migrating core modal information to the initialized low-dimensional tokens, human-emotion-irrelevant redundant information could be effectively reduced, thereby achieving higher computational efficiency with fewer parameters in subsequent tasks.
3.4. Dynamic Text-Guided Learning
Visual and audio modalities often contain emotion-irrelevant noise such as background illumination variations, irrelevant body movements, and environmental sounds. Direct fusion may mislead the model. Therefore, this paper proposes a dynamic text-guided learning approach. It extracts multi-scale textual features and dynamically learns cross-modal features from visual and audio modalities under the guidance of these textual features, enabling finer-grained cross-modal correlation capture. The specific structure is illustrated in Figure 3.
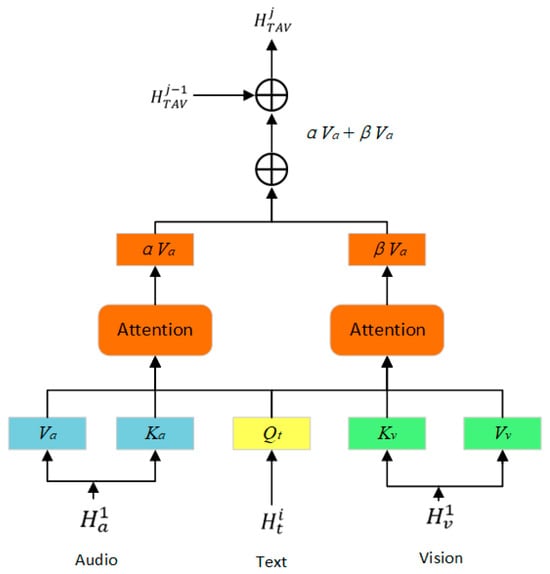
Figure 3.
Dynamic Text-Guided Learning Module Architecture.
We define the feature as the low-scale textual representation. Building upon this, mid-scale and high-scale textual features are further learned through two Transformer layers. Unlike the previous phase, these Transformer layers directly model the textual features:
where denotes the mid-scale and high-scale, respectively, represents the linguistic features at different scales with dimensions , and denote the Transformer layer for learning the i-th level linguistic features and its parameters, correspondingly.
Based on the multi-scale textual features , a cross-modal feature is first initialized. Subsequently, this cross-modal feature is iteratively updated by computing relationships between textual features and audio/visual modalities. Specifically, the extracted serves as the query vector, while acts as the key vector to compute the similarity matrix between textual and audio features:
where denotes the weight normalization operation, and are learnable parameters, and represents the dimension of each attention head.
Similarly, denotes the similarity matrix between textual and visual features:
where is a learnable parameter.
This attention mechanism calculates similarity matrices () that identify which regions of the audio and visual sequences are most relevant to the linguistic context. For instance, when the text contains the word “laughing,” the mechanism assigns higher weights to visual frames showing smiles and audio segments containing laughter, while actively suppressing irrelevant information (e.g., background noise in audio, unrelated movements in video).
Subsequently, the cross-modal feature is iteratively updated by a weighted sum of the previous state and the attended audio and visual features. This process ensures the final fused representation is dynamically sculpted by the textual context:
where denotes the current fusion iteration index, represents the output feature of the corresponding layer, and and are learnable parameters.
In essence, text does not merely fuse with audio and video; it guides and refines them. This addresses the limitation of prior work that treats modalities as separate entities and fuses them statically.
3.5. External Sentiment Knowledge Introduction
The External Sentiment Knowledge Introduction module aims to enhance the fusion process by generating additional sentiment-aware representations through graph embedding methods based on the external SenticNet knowledge base.
3.5.1. Knowledge Graph Definition and Construction
We define the sentiment knowledge graph as
where V is the sentiment node set comprising text word nodes and external knowledge nodes, E denotes the edge set where eij = (vi, vj) represents the connection between nodes vi and vj, H signifies the node feature set, and A denotes the n × n adjacency matrix with n being the total number of nodes.
Additionally, N(v) is defined as the neighbor set of node v, formally expressed as
During the construction of the sentiment knowledge graph, considering the coverage limitations of the SenticNet knowledge base, raw text undergoes filtering to retain only valid tokens composed of alphanumeric characters while removing irrelevant symbols. It should be noted that since SenticNet annotates sentiment-related vocabulary, typically only a small subset of words in each sentence match affective attributes in the knowledge base. Consequently, graph nodes are partitioned into two distinct sets: V1 denotes lexical nodes from the original text, while V2 represents external sentiment attribute nodes derived from SenticNet, containing polarity and intensity information. These collectively constitute the complete node set V. Feature vectors H for all nodes are derived from the same pre-trained BERT model that processes the raw text modality, where hi corresponds to the feature vector of node vi. This means we are not adding entirely new representational machinery but are instead repurposing and structuring the deeply contextualized features we already compute. This minimizes the risk of introducing incoherent or ungrounded representations.
In the edge construction phase, to avoid redundant intra-class connections, edges are exclusively permitted between V1 and V2 nodes, while connections within V1 or V2 are omitted. Thus, the adjacency matrix A is given by the following equation:
where denotes the weight of edge proportional to the co-occurrence frequency of and . The co-occurrence probability for each node is obtained by the following equation:
Subsequently, the Positive Pointwise Mutual Information () matrix is computed to quantify co-occurrence relationships between sentiment nodes:
where denotes the co-occurrence frequency of nodes and during random walks, we employs the matrix to initialize the weights of the edges.
3.5.2. Graph Embedding Computation
To achieve a global sentiment knowledge representation dependent on each node in the graph, the sentiment features of individual nodes must first be updated. For node in graph G, a binary multiplication operation is performed between its edge weights and node features to aggregate information from its neighboring nodes . This design choice ensures that the most salient sentiment signal from a node’s neighborhood dominates the feature update, making the model more resilient to missing or weak connections:
Subsequently, the resulting sentiment feature of node is obtained by the following equation:
where is a learnable parameter (default value: 0) that dynamically controls the blend between the node’s original feature (from BERT) and the aggregated feature from its neighbors (influenced by SenticNet). The model can learn to down-weight the external knowledge contribution if it is noisy or conflicting for a specific context.
After aggregating the sentiment features of all nodes, the global sentiment knowledge representation is generated:
where is the readout function for graph , and here a global averaging operation across all nodes is performed.
3.6. Multimodal Feature Fusion
First, the textual features , cross-modal features , and the global sentiment knowledge representation enhanced by external knowledge—obtained through the aforementioned process—are concatenated to form a multimodal joint representation:
where denotes the vector concatenation operation.
Subsequently, the attention weight matrix is computed:
where and are learnable parameters. The Sigmoid function ensures the weight values reside within [0, 1] to mitigate interference from extreme values.
After obtaining the importance of each feature through the above equation, the concatenated features are multiplied by the attention weight matrix. This amplifies the influence of critical features while suppressing redundant or noisy information, yielding the final multimodal fused features:
3.7. Sentiment Prediction
After feeding the final multimodal fused features into a fully connected layer, the function is applied to predict the sentiment polarity probability distribution for each sample:
where is the joint representation after multimodal fusion, and denotes the fully connected layer.
For the CMU-MOSEI dataset, the model is trained using an L1 loss function with L2 regularization introduced to prevent overfitting:
where is the ground-truth label, is the predicted value, denotes the L2 regularization coefficient, represents the learnable parameters, and is the size of the training set.
For the Twitter2019 dataset, the Asymmetric Loss (ASL) function is employed to mitigate severe class imbalance between positive and negative samples:
where the terms and are defined as follows:
where and are the focal parameters for positive and negative samples, set to 0 and 4, respectively, and is the hyperparameter for modulating negative sample loss, set to 0.1.
4. Experiments
4.1. Datasets and Evaluation Metrics
We conduct experiments on the CMU-MOSEI dataset [12] and the Twitter2019 dataset [28]. CMU-MOSEI is the largest video-level English dataset in multimodal sentiment analysis research and one of the most widely used datasets. It comprises 23,453 utterance segments extracted from 3228 videos, covering 1000 distinct speakers and 250 high-frequency online video topics. Table 1 details the dataset specifications. The videos were crawled from YouTube and segmented into utterances, with each segment manually annotated for sentiment intensity on a scale ranging from −3 (strongly negative) to 3 (strongly positive) to quantify relative emotional strength. The dataset includes annotations for six basic discrete emotions: happiness, sadness, anger, disgust, fear, and surprise. Segments with sentiment polarity >0 are labeled as positive, while those <0 are labeled as negative. Figure 4 presents representative samples from the CMU-MOSEI dataset.

Table 1.
Experimental multimodal sentiment dataset details.
Figure 4.
Sample Visualization from CMU-MOSEI Dataset.
Twitter2019 is a multimodal sarcasm detection dataset constructed from the Twitter platform, comprising 24,635 tweet samples. Each tweet includes both text and its corresponding image, with detailed dataset splits provided in Table 1. During data preprocessing, noise unrelated to sentiment analysis—such as web links prefixed with “www.”, hashtags (“#”), and user mentions (“@”)—was removed from tweet content. These elements could mislead subsequent models in sentiment polarity judgment. Consequently, data entries beginning with “www”, “#”, or “@” were systematically filtered. For example, the original tweet “@Jack I’m so happy today #happy #travel” was cleaned to “I’m so happy today”. This preprocessing eliminates sentiment-irrelevant redundancy in the text, thereby enhancing the model’s ability to capture core semantic features.
For the two distinct datasets, this paper performs classification and regression tasks, respectively. For classification tasks, Accuracy, Recall (R), and F1-score are adopted as primary metrics; for regression tasks, Mean Absolute Error (MAE) and Pearson Correlation Coefficient (Corr) are selected as evaluation metrics. With the exception of MAE—where lower values indicate better performance—higher values are desirable for all other metrics.
4.2. Experimental Settings
The model was trained on a computing platform equipped with a GeForce RTX 3090 GPU, running the Windows 10 operating system. Implementation was based on the Python3.7 programming language and PyTorch1.9.0 deep learning framework. Additional experimental parameters are specified in Table 2.
Table 2.
Experimental parameter settings for the MMKT model.
4.3. Comparative Experiments
To comprehensively validate the performance of the proposed MMKT model, this paper compares it against the following state-of-the-art methods in Multimodal Sentiment Analysis (MSA):
- Baseline Models on CMU-MOSEI Dataset:
TFN [16]: Models intra-modal (unimodal) and inter-modal (bimodal/trimodal) dynamics via a three-fold Cartesian product, enabling end-to-end multimodal fusion.
LMF [29]: An improved version of TFN that employs low-rank tensor factorization to mitigate exponential computational complexity growth in high-dimensional tensors, enhancing fusion efficiency.
MFM [30]: Decomposes multimodal representations into two independent factors: cross-modally shared discriminative factors and modality-specific generative factors, optimized via joint generative-discriminative objectives.
ICCN [31]: Learns cross-modal correlations through Deep Canonical Correlation Analysis (DCCA), combining high-quality text features from deep models with non-text features to generate fused embeddings.
MulT [17]: Centers on directional cross-modal attention, modeling interactions across unaligned multimodal sequences at different timesteps while capturing long-range dependencies.
MISA [8]: Projects modalities into two subspaces: a modality-invariant subspace for learning shared information and reducing modality gaps, and a modality-specific subspace preserving unique features.
MAG-BERT [9]: Integrates multimodal non-linguistic data during fine-tuning of BERT-like pretrained language models, generating feature-shifted embeddings for text representations via a Multimodal Adaptation Gate (MAG).
Self-MM [32]: Generates self-supervised unimodal signals to jointly train multimodal and unimodal auxiliary tasks, learning inter-modal consistency and disparity.
MMIM [33]: Preserves task-critical information via hierarchical mutual information (MI) maximization—computing MI between cross-modal unimodal inputs and between multimodal fused embeddings and unimodal inputs.
TCMCL [34]: A Text-Centric Multimodal Contrastive Learning (TCMCL) framework for sentiment analysis is proposed, which centers around textual content and incorporates a cross-modal textual enhancement module based on a Siamese network architecture. This module enhances text features through audio and visual conditions, respectively, thereby extending non-textual affective cues.
TCHFN [35]: Through the design of the Cross-modal Reinforced Transformer (CRT), cross-modal enhancement of target modalities is achieved. With text as the core, it facilitates a refined fusion process. Additionally, Text-Centric Contrastive Learning (TCCL) is employed to align non-text modalities with the text modality, emphasizing the central role of text in the fusion process.
- Baseline Models on Twitter2019 Dataset:
HPM [28]: Treats text features, image features, and image attributes as three independent modalities, fusing them via a Bi-LSTM architecture. As the first deep learning-based fusion model in multimodal sarcasm detection, HPM outperforms traditional feature concatenation.
D&R Net [36]: Models cross-modal contrast and semantic associations via a dual-network structure: the Decomposition Network extracts inter-modal commonality (e.g., sentiment consistency) and disparity (e.g., sarcastic contradiction); the Relation Network constructs contextual semantic relationships for fine-grained understanding.
IIMI-MMSD [37]: Built on BERT, it captures cross-modal incongruity (e.g., text-image emotional conflict) via cross-modal attention and models intra-textual semantic contradictions (e.g., ironic expressions) through co-attention mechanisms, significantly enhancing fine-grained reasoning.
Experimental results on CMU-MOSEI are presented in Table 3, while results on Twitter2019 are shown in Table 4.
Table 3.
Results of comparative experiment on the CMU-MOSEI dataset.
Table 4.
Results of comparative experiment on the Twitter2019 dataset.
Experimental results on the CMU-MOSEI dataset (Table 3) demonstrate that the MMKT model proposed in this paper significantly outperforms existing baseline methods in overall performance. Specifically, Comparative experiments with two text-centric models (TCMCL and TCHFN) further solidify the contribution of the MMKT model within the existing literature on text-centered models. And compared to other baseline models, it achieves improvements of 1.39% in binary classification accuracy (Acc-2) and 1.68% in weighted F1 score, showcasing the model’s strong competitiveness in multimodal sentiment analysis tasks.
Sarcasm is often expressed through contrasts between literal meaning and actual intent, such as using positive words to convey negative emotions. Single modalities often struggle to capture complete sarcastic information; only by fully integrating features from other modalities can accurate judgments be made. Experimental results on the Twitter2019 dataset (Table 4) further indicate that the MMKT model also excels in multimodal sarcasm detection tasks, achieving improvements of 2.08% in accuracy (Accuracy) and 2.13% in F1 score. Compared to the IIMI-MMSD model, MMKT—by combining BERT’s powerful text representation with externally introduced emotional knowledge—achieves breakthroughs even with reduced reliance on visual auxiliary modules, providing an efficient solution for modeling multimodal semantic conflicts.
4.4. Ablation Study
To investigate the contribution of each module in the MMKT model, we conducted a series of ablation studies on the CMU-MOSEI dataset. By progressively removing components—including dynamic text-guided learning (MMKT-T, replaced with feature concatenation), external sentiment knowledge introduction (MMKT-K), and their combination (MMKT-KT)—we quantitatively analyzed their impact on model performance. The experimental results are presented in Table 5 below.
Table 5.
Ablation study of the MMKT model on the CMU-MOSEI dataset.
The ablation results indicate that removing any sub-module leads to decreased accuracy in multimodal sentiment prediction. Specifically, eliminating either the dynamic text-guided learning component or the external sentiment knowledge integration module causes significant degradation across all evaluation metrics. The simultaneous removal of both components (MMKT-KT) results in even more pronounced performance deterioration. This demonstrates that both the construction of the sentiment knowledge graph and the dynamic guidance of textual features over auxiliary modalities provide indispensable contributions to model performance enhancement, facilitating subsequent feature fusion and prediction.
To further investigate the impact of individual modalities within the MMKT framework, we conducted additional experiments on the CMU-MOSEI dataset comparing performance across: text-only (T), text-audio (T + A), and text-visual (T + V) bimodal configurations. These comparisons reveal the model’s analytical efficacy under different modality combinations, with results summarized in Table 6.
Table 6.
Modality ablation study of the MMKT model on the CMU-MOSEI dataset.
The ablation results demonstrate that the model maintains relatively high performance even after removing visual and auditory modality inputs. This indicates that the architecture does not heavily rely on any single modality and can degrade gracefully—an essential trait for handling real-world situations where certain modalities may be missing or corrupted. This also implies that for Multimodal Sentiment Analysis (MSA) tasks, priority should be given to eliminating non-affective noise in auxiliary modalities—such as background acoustic interference or irrelevant visual objects—to enhance information quality and utilization efficiency. Such optimization is critical for maximizing the contribution of auxiliary modalities to overall performance.
5. Conclusions
This study proposes the MMKT model for multimodal sentiment analysis based on knowledge enhancement and text-guided learning. The model employs three Transformer layers to migrate core modal information into initialized low-dimensional tokens, reducing redundancy unrelated to human affect across modalities. Leveraging a dynamic text-guided learning approach, it actively suppresses noise contamination and conflicting information in visual and audio modalities through multi-scale textual feature guidance, thereby minimizing potential semantic discrepancies between multimodal sources. We construct a sentiment knowledge graph for the textual modality using the SenticNet knowledge base. This graph provides explicit sentiment labels at the lexical level, thereby addressing a common limitation in existing methods that neglect such fine-grained affective semantics. Global sentiment knowledge features are subsequently generated via graph embedding computation. Attention mechanisms are then applied to fuse feature information, amplifying the influence of critical elements. Finally, the fused multimodal features are fed into fully connected layers for sentiment prediction.
Comparative experiments on the CMU-MOSEI and Twitter2019 datasets demonstrate the superior performance of MMKT in multimodal sentiment analysis. Ablation studies further validate the effectiveness of the model’s innovative components. In summary, MMKT provides a robust and effective solution for MSA by strategically leveraging textual guidance and external knowledge. This also indicates its potential for real-world application in the future.
6. Discussion
In today’s digital era, e-commerce and social media platforms are saturated with multimodal data, particularly image-text hybrid content as the most prevalent form. Such data proliferates across mainstream social platforms, and conducting sentiment analysis on these visual-textual composites enables intelligent decision-making across multiple domains: Government agencies can leverage sentiment analysis to monitor online public opinion in real-time, identifying potential social risks; Healthcare institutions may develop mental health risk assessment frameworks by integrating visual-textual affective features; Enterprises can optimize product design and marketing strategies through user sentiment profiling, achieving targeted market responses.
Our proposed MMKT model has demonstrated effectiveness in multimodal sentiment analysis tasks. However, it may encounter additional challenges such as cross-cultural affective disparities and low-quality user-generated content (UGC) in more complex real-world deployment scenarios. In future work, we will test the MMKT model on various noisy social media datasets. This will involve curating data from platforms such as Twitter and Weibo, which inherently contain challenging real-world conditions, including irregular syntax, diverse noise patterns in visual/audio modalities, and cultural variations in expression. Through these experiments, we aim to further validate and enhance the robustness of MMKT, particularly its capability to handle cross-modal semantic conflicts and noise interference.
Author Contributions
Conceptualization, C.S. and Y.Z.; methodology, C.S.; software, C.S.; validation, C.S.; formal analysis, C.S. and Y.Z.; investigation, C.S.; resources, C.S.; data curation, C.S.; writing—original draft preparation, C.S.; writing—review and editing, C.S. and Y.Z.; visualization, C.S.; supervision, Y.Z.; project administration, Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in the study are included in the article: further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl.-Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Chaturvedi, I.; Cambria, E.; Welsch, R.E.; Herrera, F. Distinguishing between facts and opinions for sentiment analysis: Survey and challenges. Inf. Fusion 2018, 44, 65–77. [Google Scholar] [CrossRef]
- Liu, B.; Zhang, L. A survey of opinion mining and sentiment analysis. In Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 415–463. [Google Scholar]
- Teijeiro-Mosquera, L.; Biel, J.I.; Alba-Castro, J.L.; Gatica-Perez, D. What your face vlogs about: Expressions of emotion and big-five traits impressions in youtube. IEEE Trans. Affect Comput. 2015, 6, 193–205. [Google Scholar] [CrossRef]
- Cambria, E. Affective computing and sentiment analysis. IEEE Intell. Syst. 2016, 31, 102–107. [Google Scholar] [CrossRef]
- Cambria, E.; Poria, S.; Gelbukh, A.; Nacional, I.P.; Thelwall, M. Sentiment analysis is a big suitcase. IEEE Intell. Syst. 2017, 32, 74–80. [Google Scholar] [CrossRef]
- Li, H.; Xu, H. Video-based Sentiment Analysis with hvnLBP-TOP Feature and Bi-LSTM. In Proceedings of the 33rd AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9963–9964. [Google Scholar]
- Hazarika, D.; Zimmermann, R.; Poria, S. MISA: Modality-invariant and specific representations for multimodal sentiment analysis. In Proceedings of the 28th ACM International Conference on Multimedia, Association for Computing Machinery, New York, NY, USA, 12–16 October 2020; pp. 1122–1131. [Google Scholar]
- Rahman, W.; Hasan, M.K.; Lee, S.; Zadeh, A.; Mao, C.; Morency, L.; Hoque, E. Integrating multimodal information in large pretrained transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 2359–2369. [Google Scholar]
- Guo, J.; Tang, J.; Dai, W.; Ding, Y.; Kong, W. Dynamically adjust word representations using unaligned multimodal information. In Proceedings of the 30th ACM International Conference on Multimedia, Association for Computing Machinery, New York, NY, USA, 10–14 October 2022; pp. 3394–3402. [Google Scholar]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Mosi: Multimodal corpus of sentiment intensity and subjectivity analysis in online opinion videos. arXiv 2016, arXiv:1606.06259. [Google Scholar] [CrossRef]
- Zadeh, A.; Zellers, R.; Pincus, E.; Morency, L.P. Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intell. Syst. 2016, 31, 82–88. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Hazarika, D.; Majumder, N.; Zadeh, A.; Morency, L.-P. Context-dependent sentiment analysis in user-generated videos. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 873–883. [Google Scholar]
- Shenoy, A.; Sardana, A. Multilogue-Net: A Context Aware RNN for Multi-modal Emotion Detection and Sentiment Analysis in Conversation. arXiv 2020, arXiv:2002.08267. [Google Scholar]
- Williams, J.; Kleinegesse, S.; Comanescu, R.; Radu, O. Recognizing emotions in video using multimodal dnn feature fusion. In Proceedings of the Grand Challenge and Workshop on Human Multimodal Language, Melbourne, Australia, 20 July 2018; pp. 11–19. [Google Scholar]
- Zadeh, A.; Chen, M.; Poria, S.; Cambria, E.; Morency, L.-P. Tensor Fusion Network for Multimodal Sentiment Analysis. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; pp. 1103–1114. [Google Scholar]
- Tsai, Y.H.H.; Bai, S.; Liang, P.P.; Kolter, J.Z.; Morency, L.P.; Salakhutdinov, R. Multimodal Transformer for unaligned multimodal language sequences. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 6549–6558. [Google Scholar]
- Xu, J.; Huang, F.; Zhang, X.; Wang, S.; Li, Z.; He, Y. Visual-textual sentiment classification with bi-directional multilevel attention networks. Knowl.-Based Syst. 2019, 178, 61–73. [Google Scholar] [CrossRef]
- Harish, A.B.; Sadat, F. Trimodal Attention Module for Multimodal Sentiment Analysis (Student Abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13803–13804. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Kenton, L.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MI, USA, 2 June 2019; pp. 4171–4186. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the 16th European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Volume 12346, pp. 213–229. [Google Scholar]
- Chen, W.; Xing, X.; Xu, X.; Pang, J.; Du, L. Speechformer: A hierarchical efffcient framework incorporating the characteristics of speech. arXiv 2022, arXiv:2203.03812. [Google Scholar]
- Liu, Y.; Wang, W.; Feng, C.; Zhang, H.; Chen, Z.; Zhan, Y. Expression snippet transformer for robust video-based facial expression recognition. Pattern Recognit. 2023, 138, 109368. [Google Scholar] [CrossRef]
- Huang, J.; Tao, J.; Liu, B.; Lian, Z.; Niu, M. Multimodal transformer fusion for continuous emotion recognition. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing(ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3507–3511. [Google Scholar]
- Liu, Y.; Zhang, H.; Zhan, Y.; Chen, Z.; Yin, G.; Wei, L.; Chen, Z. Noise-resistant multimodal transformer for emotion recognition. arXiv 2023, arXiv:2305.02814. [Google Scholar] [CrossRef]
- Yuan, Z.; Li, W.; Xu, H.; Yu, W. Transformer-based feature reconstruction network for robust multimodal sentiment analysis. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4400–4407. [Google Scholar]
- Cai, Y.; Cai, H.; Wan, X. Multi-Modal Sarcasm Detection in Twitter with Hierarchical Fusion Model. In Proceedings of the 57th annual meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; Volume 4, pp. 2506–2515. [Google Scholar]
- Liu, Z.; Shen, Y.; Lakshminarasimhan, V.B.; Liang, P.P.; Zadeh, A.; Morency, L.P. Efficient Low-rank Multimodal Fusion with Modality-Specific Factors. arXiv 2018, arXiv:1806.00064. [Google Scholar]
- Tsai, Y.H.H.; Liang, P.P.; Zadeh, A.; Morency, L.P.; Salakhutdinov, R. Learning Factorized Multimodal Representations. arXiv 2018, arXiv:1806.06176. [Google Scholar]
- Sun, Z.; Sarma, P.; Sethares, W.; Liang, Y. Learning Relationships between Text, Audio, and Video via Deep Canonical Correlation for Multimodal Language Analysis. In Proceedings of the National Conference on Artificial Intelligence. Association for the Advancement of Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020; Volume 34, pp. 8992–8999. [Google Scholar]
- Yu, W.; Xu, H.; Yuan, Z.; Wu, J. Learning Modality-Specific Representations with Self-Supervised Multi-Task Learning for Multimodal Sentiment Analysis. arXiv 2021, arXiv:2102.04830. [Google Scholar] [CrossRef]
- Han, W.; Chen, H.; Poria, S. Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis. arXiv 2021, arXiv:2109.00412. [Google Scholar] [CrossRef]
- Peng, H.; Gu, X.; Li, J.; Wang, Z.; Xu, H. Text-Centric Multimodal Contrastive Learning for Sentiment Analysis. Electronics 2024, 13, 1149. [Google Scholar] [CrossRef]
- Hou, J.; Omar, N.; Tiun, S.; Saad, S.; He, Q. TCHFN: Multimodal sentiment analysis based on text-centric hierarchical fusion network. Knowl.-Based Syst. 2024, 300, 112220. [Google Scholar] [CrossRef]
- Xu, N.; Zeng, Z.; Mao, W. Reasoning with Multimodal Sarcastic Tweets via Modeling Cross-Modality Contrast and Semantic Association. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 3777–3786. [Google Scholar]
- Pan, H.; Lin, Z.; Fu, P.; Qi, Y.; Wang, W. Modeling Intra and Inter-modality Incongruity for Multi-Modal Sarcasm Detection. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; pp. 1383–1392. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).