Abstract
Malicious programs, commonly called malware, have had a pervasive presence in the world for nearly forty years and have continued to evolve and multiply exponentially. On the other hand, there are multiple research works focused on malware detection with different strategies that seem to work only temporarily, as new attack tactics and techniques quickly emerge. There are increasing proposals to analyze the problem from the attacker’s perspective, as suggested by MITRE ATT&CK. This article presents a proposal that utilizes Large Language Models (LLMs) to generate malware and understand its generation from the perspective of a red team. It demonstrates how to create malware using current models that incorporate censorship, and a specialized model is trained (fine-tuned) to generate code, enabling it to learn how to create malware. Both scenarios are evaluated using the metric and a controlled execution environment (malware lab) to prevent its spread.
1. Introduction
In the world of cybersecurity, there is a dichotomy between those who want to attack a system for some benefit (formerly known as hackers) and those who wish to defend themselves against the threats a hacker could pose. Both sides have become professionalized since the 1990s, using “red teams” for people who simulate attacks and test the strength of defenses and “blue teams” for people specialized in defending systems. A Red Team needs to act like real attackers, so they use a mix of tools to make reconnaissance, exploitation, lateral movement, persistence, data exfiltration, and defense evasion; these are the typical phases that have been identified and described in attack models and frameworks such as MITRE ATT&CK [1]. Several existing tools can be used for each of the activities carried out by the red team; however, to improve the probability of success, they usually create tools or modify public ones to avoid being detected by antivirus (multiple engines like those used by VirusTotal-VT), EDRs (Endpoint Detection and Response), or firewalls. The objective is not to generate already known attack patterns that facilitate detection and/or defense.
On the other hand, specialized programs that typically operate without direct human intervention and are designed to compromise computer systems have existed since 1986. These malicious programs, now known as malware, have evolved to such high levels of complexity and sophistication that they can perform all the steps a hacker performs but much more efficiently and quickly. Malware specializes in its target and can adapt to its environment, making it an ideal weapon for hackers. Examples of malware tools hackers create include metamorphic engines, which can make thousands of malware samples from a base template. The first metamorphic engines (e.g., NGVCK, Next Generation Virus Construction Kit, [2]) were straightforward, and effective defenses against them were soon created. Still, as they evolved, they developed new and improved evasion techniques known as obfuscation. Major cybersecurity firms have reported around 160 million new malware samples in a single year [3] (more than 300 samples per minute, never seen before), reflecting the existence of more and new automated malware generators.
When an opponent designs a new weapon, it is difficult or impossible to defend from it in its first uses; therefore, defensive teams must quickly know the capabilities of the weapon (they do reverse engineering) to design defensive artifacts that mitigate the threat. This cannot be performed without a real, complete sample of the weapon. In the case of malware, thanks to the fact that real samples have been obtained and their operation analyzed, it has been possible to create the best defenses. If one does not have the malware sample, the defense teams can only explore the attack’s effects and respond reactively. So, instead of waiting to have a sample of malware created with AI, which, in addition, will not be a single sample, the proactive strategy of our proposal looks promising. Understanding how malware generators work is crucial for improving defenses and performing ethical hacking exercises. Even if it seems ethically incorrect, knowing how to design and implement malware using the most advanced tactics and techniques and, above all, the most powerful artificial intelligence technologies is essential.
One of these technologies is the use of Generative Adversarial Networks (GANs) [4], where, through a competition scheme between two deep neural networks, one that attacks (Generator) and the other that defends (Discriminator), adversarial samples are created that can lead machine learning-based classifiers to wrong decisions. GANs can be used to generate various types of adversary samples; for instance, in [5], they are utilized to create variants of Android malware samples. Since the variants of the generated malware are derived from the input dataset, the GANs perform well, depending on the diversity of this dataset. To address this and similar problems, new research works, such as [6], have proposed new variants of the GANs, the KAGAN (Knowledge-Aided Generative Adversarial Network). These GANs are used to perform DLSS (Deep Learning-based Soft Sensor) without relying on the transfer gradient estimation, a key element in attacks on the soft sensor used in industrial processes.
In recent years, artificial intelligence has made significant progress in its development, particularly in deep neural networks, where one of its architectures has seen considerable progress: Large Language Models (LLMs). LLMs are revolutionizing multiple industries by automating complex tasks, enhancing creativity, improving data analysis, personalizing services, optimizing education, and accelerating technological innovation in diverse areas. Given the versatility of LLMs, it is obvious to consider their use in generating attacks, particularly in generating malware.
1.1. Problem Statement
Creating malware with LLMs has the following problems:
- 1.
- Moderation. It is a security control performed during training for limiting what the model generates or responds to, ensuring the following:
- Do not say harmful things (hate, violence, racism, etc.).
- Do not share illegal content. For instance, dangerous instructions for creating a bomb.
- Do not violate ethical or legal policies.
- Do not spread serious misinformation. This could harm health, affect legal decisions, create panic or confusion, or manipulate people.
- 2.
- Absence of offensive cybersecurity models. There are many defensive security models, mainly in the field of Intrusion Detection Systems (IDS), and some models for cybersecurity training. These models focus on threat hunting and vulnerability detection, but none are suitable for generating malware.
Since publishing information that teaches how to create weapons or carry out attacks is unethical and puts the security of individuals, communities, and systems at risk, it is hoped that such public models will not exist. In general, there are no related works in this research field. However, this will not deter malicious individuals; therefore, in this paper, we will explore the various activities to be carried out from a red team perspective.
1.2. Contributions and Organization
It is essential to mention that several tests were conducted with traditional models, such as ChatGPT and Copilot in their desktop versions, asking them to create malware. It was possible to verify their refusal to do so with an argument of illegality, and that it offers us better help to protect ourselves from malware. However, they were also asked to implement routines that malware usually uses, and in most cases, they did. The instances in which he did respond are those that can be considered as intellectual property protection mechanisms, in particular those that seek to hinder automated analysis, for example, the packaging of the executable file (the most used packer is UPX) or the attempt to execute in a virtual environment. Several applications, such as video games, have anti-piracy protection systems that verify if the game runs on a virtual machine to prevent cracks and emulation.
The main contribution of this paper can be summarized as follows:
- A strategy to jailbreak an LLM to do something that it should not do, given its training, that is, avoid the alignment of the model in an attempt to prevent undesirable generation.
- The design of a new method to circumvent alignment to avoid malware generation.
- A platform for evaluating the functional correctness of the malware generated.
- Two strategies to create malware: one for censored models and another for uncensored models.
The remainder of this article is structured as follows. Section 2 provides a concise overview of LLMs and their intersection with malware. Section 3 critically examines the ethical dimensions of this study, situating them within the framework of red team operations. Section 4 synthesizes prior research on diverse malware development paradigms. Section 5 specifies the hardware and software resources employed, whereas Section 6 delineates the proposed methodology. Section 7 presents and interprets the experimental findings, and Section 8 offers a comparative analysis against alternative malware generation techniques. Finally, Section 9 summarizes the key contributions and outlines prospective research avenues.
2. Background
2.1. LLM Background
The transformer is a deep learning architecture based on artificial neural networks with many layers. Transformers were developed by researchers at Google and are characterized by a multi-head attention mechanism proposed in the famous paper “Attention Is All You Need” [7].
If a transformer model is trained with many documents to learn how to perform different activities related to natural language processing, such as answering questions, summarizing, translating languages, completing sentences, and many others, then one obtains a Large Language Model. Given LLMs’ success, many companies and academic groups are currently creating all kinds of models and constantly developing variants and improvements to LLMs. One of the websites with the most significant number of free and commercial LLMs is Hugging Face [8], which currently reports more than 1.6 million models. There is a whole customization in the LLMs where specific “base models” are taken that are then trained for particular purposes, so currently the choice of a model depends on several factors, as follows:
- Operating environment: cloud, computer, or low-performance device (edge).
- Type of application: chatbot, generation of audio, images, video, or code, etc.
- Several characteristics: cost (open source vs. commercial), speed, model size, accuracy, privacy, etc.
Prompting
In the context of LLMs, a “prompt” is an input text given to the model to generate a response. Although asking or requesting things from an LLM may seem easy, one will soon realize it is not once one receives the answer. One often wants a precise answer in a given context, so creating a prompt with some structure is necessary. Some of the elements that have been identified are as follows:
- Guide the model to assume a role, for instance, tell it to act like an expert programmer.
- Ask it to reason step by step to understand how the model arrives at a certain conclusion (chain-of-thought).
- Choose the response format by clearly instructing or giving examples.
Prompting is the art and technique of designing optimal instructions for interacting with LLMs so that they generate the most useful, precise, or creative responses possible. This has led to Prompt Engineering, which defines several strategies for creating prompts. Some of them are as follows:
- 0-shot: The model is only asked to do a task without being given previous examples. Only an explicit instruction or a description of the task is used.
- One-shot: Only one example is given to guide the model.
- Few-shot: A few examples are given, between 2 and 5, to show the desired format or pattern.
For certain applications, the Instruct Models (named by “instruction-following”) were created. These models are specially trained to follow human instructions (indications or commands) in a precise and obedient way. Examples of these models are Mistral 7B Instruct (open-source from Mistral AI), GPT-4 Turbo Instruct (commercial from OpenAI), Llama 3 Instruct (open-source from Meta), and Zephyr (open-source from Hugging Face).
LLMs are being widely used because they can be retrained (a technique known as Fine-tuning) to adapt to new problems. The models are retrained with many examples (outside the prompt) and do not require as much processing as initial or basic training.
LLMs for coding
Since the goal is to create malware and understand how it works, using a model specialized in source code generation is best. Code Generation is an important field to predict explicit code or program structure from incomplete code, programs in another programming language, natural language descriptions, or execution examples. Fortunately, a great deal of effort is being put into making these models, which are also improving as they are trained to use problems from programming competitions. On the Hugging Face site, there are about 30 large models, but there are also about 300 smaller models (in terms of parameters) that are faster to train, easier to use on regular laptops, and cheaper to store. All of these models are trained with source code available on public code servers like GitHub, where the most commonly used programming languages are Python, Java, and C++. Models are available at https://huggingface.co/models?sort=likes&search=Code+Generation (accessed on 22 May 2025).
When using a programming framework like Hugging Face, there are two ways to create a prompt:
- Chat prompt: This form is best for specialized models that follow instructions and require tags for roles (such as User and Assistant) and content. For the case of Hugging Face, the apply_chat_template function and a JSON type parameter are used.
- Manual prompt (raw prompt): You are given a string with the text of what the model is asked to do. The string must contain the chat prompt’s tags if it is a specialized model. Here, the tags are model-specific; for example, the “microsoft/phi-2” model requires “Instruct: {prompt} Output: {answer} <|endoftext|>” and the “codellama/CodeLlama-7b-Instruct-hf” model requires “<s>[INST] prompt [/INST] answer”.
Templates are used not only for building the prompt but also for identifying the answer. It is common for models to respond with a template of type “<prefix> answer <suffix>”.
Additionally, the code prompts can be of several types, such as code completion or code translation. However, the most powerful and the one that will be used in this work is Code generation, which creates code from scratch. Code generation models are far from doing what is asked of them; however, they are getting better and better due to the work that has been performed on two topics:
- 1.
- Benchmarks. There are several, but the most well-known is HumanEval (Created in 2021), which has 164 problems. This minimalist benchmark is focused on code completion, so it has begun to use MBPP (Mostly Basic Programming Problems) in complement, another benchmark created in the same year that focuses on code generation. MBPP has a much broader set of problems, 974, and its design has been adopted by more modern benchmarks such as DS-1000 (a thousand issues) and MultiPL-E (two thousand problems).
- 2.
- Metrics. They have been defined to help assess functional correctness rather than just text similarity, making it useful for evaluating AI-driven code generation.The most common metric is , but others are emerging like pass^k. The metric is a method for evaluating helpful input when multiple attempts are generated and is considered valid if at least one of them is correct. The formal definition of iswhere the following are used:
- n is the total number of samples generated by the model for an instance.
- c is the number of correct samples.
- k is the number of samples that are randomly selected for evaluation.
estimates the probability that at least one correct sample is present in a random subset of k generated attempts for a given problem that passes the unit test.
2.2. Malware Background
The first recognized malware in the history of computing is Creeper, created in 1971 by Bob Thomas, a researcher at BBN Technologies. This malware was created as a proof of concept that a program could move between computers on a network in the ARPANET era. However, the first recognized case of malware—a program intended to cause harm—was the Brain virus, created in 1986 and infecting 5.25-inch floppy disks. Based on these and subsequent cases, malware was coined in the 1990s as an abbreviation for “malicious software.” Subsequently, other malicious behaviors emerged, triggering the creation of new terms used to identify and differentiate new types of malware, for example, viruses, worms, keyloggers, backdoors, remote access tools, rootkits, Trojans, droppers, downloaders, botnets, ransomware, spyware, adware, PUAs (Potentially Unwanted Applications), etc.
Now, some background information is provided about the traditional malware creation techniques. The techniques are divided into three groups:
- 1.
- Obfuscation.
- (a)
- Polymorphism: Malware changes its code every time it is copied or executed, but maintains the same functionality. This is achieved using encryption and a decryption engine for each instance.
- (b)
- Metamorphism: The malware completely rewrites its code internally: it uses variable renaming, inserting junk code, and changing the order of the instructions.
- (c)
- Packers and Crypters: Tools that compress or encrypt the executable to hide its signature.
- 2.
- Execution.
- (a)
- Code injection: The malware code is added to a legitimate program to hide and achieve an escalation of privileges.
- (b)
- Shell code: Code snippets written in machine language that execute specific malicious functions, such as opening a shell.
- (c)
- Social engineering techniques: They trick the user into executing malicious code without knowing it.
- (d)
- Self-replication: A copy of the malware is created using removable media or network communication. This can be performed with human intervention (virus) or without it (worms).
- (e)
- Backdoors and RATs (Remote Access Trojans): They allow the remote execution of commands.
- 3.
- Malicious behavior.In this group, there are many techniques, so only two are listed as an example.
- (a)
- Destruction or alteration of information or systems.
- (b)
- Theft of information and/or ransom request.
The first malware versions contained only one main malicious behavior, currently called “type of malware” in most taxonomies [9]. With these malware creation techniques, a type of malware is a set of malicious behaviors that, in the evolution of malware, have gone from using one or two techniques to several of them. A modern malware can use multiple techniques in a single file, for example, polymorphism, injection, and a crypter. The above is reflected in the reports generated by the antiviruses for the malware samples, which indicate that a sample of malware is, for instance, both a backdoor and a rootkit.
Currently, malware creators achieve it in three ways: (1) Manual construction from scratch. (2) Construction with kits (Malware Builders), and (3) Modification of existing malware files. The first form is the most powerful since it is where the new forms of attack are designed. On the other hand, the last two options only create finite variants of the behaviors created with the first form, and their primary function is only to improve the obfuscation to avoid detection.
This research work explores a more advanced way to create malware from scratch using an LLM. To gain better control over the creation process, we will only develop a specific type of malware with a limited number of variants.
3. Ethical Considerations
Our objective in this research work is to create malware with an LLM to have one more tool for a red team. In this section, we analyze the objectives, activities, and ethical considerations of a red team. NIST defines a red team as “A group of people authorized and organized to emulate a potential adversary’s attack or exploitation capabilities against an enterprise’s security posture. The Red Team’s objective is to improve enterprise cybersecurity by demonstrating the impacts of successful attacks and by demonstrating what works for the defenders in an operational environment.” [10]. With this definition and the use of other standards that guide the work of the red team (such as the MITER ATT&CK), the ethical aspects are analyzed below.
Given the dichotomy in the cybersecurity area between the red team, which conducts attacks, and the blue team, which defends assets, there is a fine line between the tools and knowledge used by both teams. For a red team to achieve optimal performance, it must utilize real attack tools and sensitive information of the target company. Consequently, all team members must adhere to ethical principles, and respect several of the standards (for instance, the Operational Security—OPSEC, defined by NIST in SP 800-53) and best practices that regulate their activities in the following way:
- 1.
- Confidentiality agreements signed by all members (Non-Disclosure Agreements, NDA). Non-disclosure of techniques, findings, or access without explicit authorization.
- 2.
- Ensure the confidentiality of information through disk encryption and sensitive files, as well as always perform secure communication.
- 3.
- In addition to the previous point, protect personal and corporate data.
- 4.
- Strict access control and destruction of data after the exercise. Separation of environments so as not to mix infrastructure between clients.
Based on the analysis above, Table 1 presents a list of the macro activities that a red team does and the ethical aspects that apply to them.

Table 1.
Red team’s activities vs ethical aspects.
Our research focuses on the misuse of advanced AI, which poses a risk in facilitating potential attacks. That is why, during the present investigation work, the malicious prompts were kept protected, and only alpha versions of the trained LLMs were published to show the feasibility of the proofs of concept performed. However, since creating better defenses requires having access to malicious artifacts, there are already many of them available on the internet. Networks of security teams, comprising research labs, CERTs, and SOCs, collaborate by sharing information and databases of malware samples. Historically, the publication of analysis results and threat models has helped strengthen institutions’ capabilities to confront attacks or recover from security incidents. Conversely, published scientific and technical information on defense models could facilitate adversarial activity.
The advancement of generative AI has benefited human activity across the board; this research suggests that adversarial groups have similarly exploited this. In this sense, the most significant benefits to the security specialist community will be obtained through the descriptive publication, examples of the procedures and tools used in the generation of functional malware samples by this work.
4. Related Works
In cybersecurity, most research on malware focuses on detecting and classifying it using artificial intelligence models, particularly in recent years with the advent of LLMs. In [11], present a broad summary of the uses of LLMs in malware analysis.
These models are vulnerable to adversarial attacks, which are techniques to manipulate the model by introducing data specially designed to cause errors. To mitigate adversary attacks, several approaches have been proposed for creating binary malware and testing the efficiency of models; this corresponds to the third method for creating malware, which we discussed in Section 2.2. This section presents papers that address the problem indirectly, followed by a presentation of the few articles that have addressed the issue.
Obfuscation
Pooria Madani [12] uses six LLMs to create code mutations. The models used were CodeParrot, CodeGen2-Multi, CodeGen-Mono, SantaCoder, StarCoderPlus, and ChatGPT 3.5 Turbo. The best models were CodeGen-Mono, which achieved a 75% in the test, and ChatGPT 3.5 Turbo, with 100% in the test.
In [13], Seyedreza Mohseni et al. made a systematic analysis of LLM into assembly code obfuscation. They used three code obfuscation techniques: dead code, register substitution, and control flow change.
Although these researches are not used to create malware, it show that it is feasible to use it to implement two techniques of obfuscation: polymorphism and metamorphism.
Creating binary malware variants
Genetic algorithms (GA) are used to add minor perturbations to the binary malware without changing the functionality, so that the previously trained detection model misidentifies it as standard software. The new version of the malware, therefore, also changes its signature, which prevents its detection.
Three examples of articles that utilize GA to address adversarial samples are as follows.
In [14], propose a testing framework for learning-based Android malware detection systems for IoT Devices. The framework generates adversarial samples from an Android application dataset that includes both benign and malicious Android apps. The genetic algorithm uses the data of five artificial intelligence algorithms (one of neural networks and four of machine learning) to generate perturbations. The framework generates high-quality adversarial samples with a success rate of nearly 100% by adding permission features. The limitations of the framework are that the black-box approach needs frequent model requests.
In [15], utilize a common strategy for the introduction of perturbations in malware binaries (the format of Windows executables, Portable Executable) by appending data at the end of the sample. This is a safe way to introduce perturbations since the original functionality remains untouched. This is because the original code and data sections are not modified, and the references contained within the code do not need to be updated. They use optimization techniques based on GA to determine the most adequate content to place in such code caves to achieve misclassification.
In [16], the authors created a dataset with API call sequences extracted from the execution of Android applications. The dataset is used to train a classifier, and then GA is used to generate new sequences of artificial malicious patterns. It is emphasized that this work does not generate binary malware samples, but generates the selected characteristics of the malware (API calls) to use in the classifier, which is the most used technique to create adversary samples indirectly.
Exploit builders
An exploit builder is a tool or framework that automates the generation, packaging, and delivery of exploits for known vulnerabilities. It facilitates the work of a pentester by bringing together exploitation modules, payloads, and obfuscation in a coherent interface. Most of these tools work with a basic mechanism that is the use of an exploitation template, which contains scripts or snippets that take advantage of specific vulnerabilities (buffer overflows, SQL injection, ROP chains). Classic examples of these tools are the Metasploit framework, Cobal Strike, ROPgadget, etc. Exploit builders are versatile tools used by both members of a red team and malware developers.
Template Engines [17] are tools in web development that help separate the presentation layer from the application’s logic. They allow developers to create templates or patterns for generating dynamic content, which can be rendered as HTML, XML, or other markup languages. Template engines are software components provided by web frameworks that offer a set of functions to parse and manipulate strings or files according to predefined syntactic rules. While template engines offer many benefits, they come with the Server-Side Template Injection (SSTI) vulnerability. SSTI is in the OWASP top 10 vulnerabilities list, and its worst consequence is achieving Remote Code Execution (RCE).
Malware kits
They are tools designed to automatically generate malicious code with customizable options, without the user needing deep programming knowledge. They consist of taking a fixed, and therefore finite, number of malicious behaviors and combining them to create malware. It is like using basic blocks that are assembled (similar to the LEGO bricks game) to obtain the final functionality. The malware kit typically includes the entire attack package: (1) the builder, the program that generates the malware, and (2) additional tools such as exploit packs, web control panels, and documentation. The vast majority of malware kits focus on a single malicious activity, for example: (1) Zeus Builder creates banking Trojans, (2) SpyEye Builder, similar to Zeus, focused on credential theft, or (3) BlackShades generates RATs (Remote Access Trojans).
Malware Source Code Generation
Recently, ref. [11] presents several articles addressing the generation of malware in different ways. Table 2 presents an analysis of the six most sound jobs. A key element in all these works is the use of some jailbreak technique, which occurs when the user designs a prompt or sequence of interactions that makes the model ignore or elude security instructions, for example, to deliver restricted information for reasons of legality or ethics. The techniques that have been studied are: (1) prompt injection: additional instructions are introduced in the prompt that override or contradict the system restrictions. (2) Role Manipulation: the model is told that he is playing a character or in a scenario where it is allowed to give the prohibited information. (3) Token Smuggling or Character Sequence Attacks. Sequences of special characters, rare Unicode, or token patterns that break the standard analysis of the LLM text are used, and (4) Obfuscation or Masking. Prohibited content is coded, described in fragments, or disguised as another task.
Table 2.
Malware Generation.
None of these papers addresses the strategy proposed by our work, which is based on an obfuscation-type technique and fine-tuning.
5. Materials
To carry out the proposed research, the necessary equipment is required to execute the LLMs efficiently and also to perform fine-tuning. The models will generate malware, and this must be analyzed and evaluated in a controlled environment. The following subsections explain these two elements.
5.1. Malware Evaluation Platform
A specific-purpose platform was developed to create and evaluate several malware samples safely. A schematic of the platform used to assess the models is shown in Figure 1. The platform generates several malware samples that meet specific requirements and delivers an evaluation report. The platform was built in a modular way with the following functionalities:
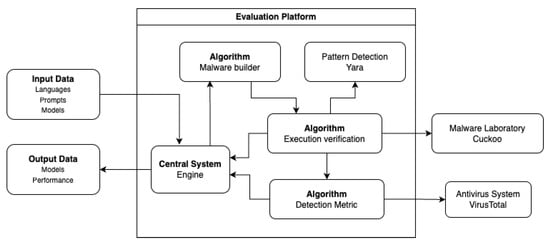
Figure 1.
Platform for evaluating models.
- 1.
- Malware builder. It runs an algorithm for creating malware using an LLM, using a programming language, and the behaviors described in a prompt.
- 2.
- Verification of execution. This module is responsible for running the malware and verifying its functionality. It uses an algorithm to take the malware code generated by the previous module, send it to a computer that has what is necessary to execute the malware, and prevent its spread. This computer has a specialized software called Cuckoo that can be configured to run the malware, analyze it dynamically and prevent it from infecting other systems. In addition, this module uses a second tool called Yara, which can search for binary patterns in the executable file and detect if they are associated with the i malwae structure.
- 3.
- Detection metric. This module calculates two metrics: (i) one that determines what possible type and family of malware it belongs to, and (ii) another that determines the percentage of malware it is. To build the metric, VirusTotal is utilized, which is widely recognized in cybersecurity for providing several services, particularly malware detection using multiple antiviruses, typically more than forty.
Something important to note about the platform’s operation is that the execution of the models requires different configurations. For simplicity, it is only mentioned that the models are invoked in the algorithm “Verification of execution”, but in each case, an ad hoc program is created for the model to generalize its use. The program establishes a chat prompt, which is of the type code generation.
To perform several tests with the models and facilitate automatic execution, our evaluation platform also uses a template with the following structure:
template = “Create a program in the programming language” + language_variable + “to do the following” + prompt_from_file + “Do not explain the code. Do not comment on the code. Just answer and do not add anything else.”
5.2. Equipment and Software
The evaluation platform was built with:
- The Python programming language, version 3.11, and several modules installed through the package manager pip.
- A personal computer with Intel(R) Core(TM) i7-6700HQ CPU @ 2.60 GHz, 8 Core Processors, 32 GB RAM, 500 GB SSD. A Windows operating system version 11.
- A graphics card NVIDIA GeForce RTX 4070 Ti Super ASUS, with 12 GB of RAM.
The characteristics of this equipment limit the size of the LLM that can be used, and only cloud services are exempt from this restriction, albeit at a high economic cost. Table 3 shows an approximate calculation of the amount of memory (in GB) required by an LLM depending on the number of parameters (Billions) using a classification of four groups.
Table 3.
LLM sizes.
Table 3 implies that we can only work with small models and some quantized medium models (those marked with the symbol ⊗), which do not exceed 12 GB of RAM.
6. Methodology for Generating Malware
In this section, we describe the methodology we propose for generating malware.
6.1. The Proposed Approach
Our goal is not only to request an artificial intelligence to generate malware but also to evaluate its effectiveness and make it difficult for malware detection tools (antivirus software) to recognize it. Moreover, the goal is not only to create a single malware sample, but a whole variety of them, ranging from hundreds to thousands of samples.
The general strategy for creating malware is divided into two scenarios.
- Scenario-1:
- Use an existing model. It will begin with a set of models that already know how to create programs and explore whether it can trick the model into creating malware without its knowledge.
- Scenario-2:
- Create a new model. The procedure is to create a new model, making some fine-tunings, to remove censorship, and therefore, can ask it to create the malware.
Before creating malware, two elements are necessary: (i) create a platform that automates the generation and testing of malware safely (this was explained in Section 5.1), and (ii) define the malware evaluation criteria that help determine whether an LLM is suitable for generating malware. This last element is explained below.
6.2. Criteria for Evaluating Models
Before using any LLM, it is essential to define the criteria for determining what constitutes a good model for malware generation. Two types of criteria will be used to evaluate the generated malware:
- Criterion-1:
- A real application. The generated program code will be verified to create an error-free executable file; this is necessary because many models generate code with compilation errors (followed by explanatory comments) and execution errors.
- Criterion-2:
- Detection metric. A method was defined to evaluate how easily specific malware detection tools determine whether the generated program is malware and what behavioral traits it identifies, specifically the type and family of malware.
Each criterion will use an algorithm and several tools described below.
Criterion-1. To verify that a real application has been created, running the program (malware) in a controlled environment is necessary to prevent it from spreading to other computers. In the field of malware analysis, this type of activity is known as dynamic analysis, and the controlled environment is referred to as a Malware Laboratory or Sandbox. There is a long list of Malware Labs, both free and commercial; for example, Cuckoo (free) [24], Hybrid Analysis, ANY.run, Joe Sandbox, etc. We will use a complete environment like Cuckoo because, in general, the malware may need many resources of the operating systems, and a restricted environment based on containers like gVisor [25] (a platform used for evaluating LLMs) is not enough.
Criterion-2. To evaluate how easy it is to detect the generated malware, a detection metric (DM) was defined below:
- 1.
- The platform VirusTotal [26] was used through its REST API. VirusTotal is a platform that analyzes files, URLs, and other resources for malware, using multiple antivirus engines (for example, Kaspersky, Bitdefender, Avast, ESET, McAfee, Microsoft Defender, etc.) and static and dynamic detection tools. The number of antiviruses used by VT varies dynamically depending on the availability of the engines (agreements with the providers), file type, or the state of the system. VT uses typically between 55 and 70 engines for standard executable files. By comparing the number of antiviruses that report a file as malware with the total number of engines used, the percentage of malware can be calculated. With the REST API, one can check the number of antiviruses used and how many reports are in the sample as malware:
- (a)
- Calculate how many antivirus programs identify it as malware and obtain a percentage. A value above 60% is considered malware. If the algorithm improves in later stages, this percentage could be increased to 80%, which is the value usually used in several scientific articles in the area.
- (b)
- Obtain the tuple (type, family) proposed for the malware, to verify if it matches the type of generated malware.
The only problem with this proposal is that VirusTotal (in its free version) only allows four requests per minute, which limits the number of samples that can be generated to that number. The following option, which has no limit, will complement this validation. - 2.
- An application that uses the Yara tool. Yara detects malware by searching for binary or text patterns in files. It is one of the most widely used tools for identifying malicious components. It employs rules (many are available for free) that are constantly reviewed and updated.
6.3. Creation of Malware Without Fine-Tuning an LLM
This section explains how to create malware from an existing LLM and the activities performed to adapt it. To accomplish this task and before starting, two choices must be made: (i) decide what type of malware to create, and (ii) select the LLM to use. For the first choice, it was decided to use a malware whose behavior is relatively simple and for which there are several recent samples, as it is one of the most ubiquitous: ransomware. The second choice is not easy because there are many models. Therefore, it will be achieved in two stages: (i) a pre-selected subset of models will be used based on their characteristics, and then (ii) these models will be evaluated to keep the best.
From the initial tests conducted, it was observed that LLMs do not always perform as expected. For example, when asked to create a program, it is always accompanied by an explanation that, in several models, it was impossible to eliminate despite instructing the prompt. The explanation is helpful during the learning process. Still, in our case, where one wants to automate the generation, this is a problem since one has to remove the explanations that are not usually comments to test the malware. Fortunately, this problem has already been detected for specific applications, so there are the Instruct Models, a type of LLM that has been specially trained to follow human instructions precisely and obediently. “Instruct” comes from “instruction-following”, that is, follow instructions or commands.
On the other hand, several models were also observed as unable to solve the algorithms, which is why code generator models were created. Most models yield erroneous answers (see Table 4), and the best model achieves 70% accuracy, indicating that it provided erroneous answers in 49 problems in HumanEval.
Table 4.
Assessment of code models.
These results indicate that even advanced models do not guarantee accurate solutions in all cases, particularly on the first attempt. New models and evaluations are constantly published to produce the best; sites like EvalPlus [27] reflect this race.
6.3.1. Selecting LLMs
Since many candidate models need to be analyzed, an algorithm was designed to automatically evaluate the models using previously defined criteria. The selection Algorithm 1 illustrates the procedure for the following:
- 1.
- Evaluate several models. A pre-selection of instruct models specialized in generating code was made.
- 2.
- Evaluate each model for creating programs in some programming languages.
- 3.
- Ask to solve a set of basic problems described in a list of prompts.
A model will be considered valid if it solves all the problems described in the prompts.
| Algorithm 1: Selection of best models |
 |
The lists of elements used in the algorithm were selected as follows:
- Models: A set of models was selected, as they were trained to follow instructions and execute programs. Table 5 lists the initial test set.
Table 5. Lists of models selected to be evaluated.
- Languages: They will be tested with two of the most widely used languages for generating malware, scripts in Bash and C, as well as the most commonly used language worldwide, Python.
- Prompts: A selection of prompts belonging to four categories was created. The categories and their characteristics are shown in Table 6.
Table 6. List of types of prompts.
The following models, languages, and prompts were used in this stage.
Algorithm 1 uses several complex functions, which, to simplify the explanation, are only given a generic name. To provide a clearer understanding of the complexity and to prepare for later use, we will explain some details of the validate (program) function. This function does the following:
- Detects syntactic errors in the program code. This depends on the language. For compiled languages, simply trying to compile it is usually sufficient. In contrast, for interpreted languages, a special program is required to review the syntactic and grammatical structure of the code. As previously explained, two interpreted languages (bash and Python) and one compiled (C language) were used, which required a special environment with its toolchains. In addition, for those interpreted, a special program was created that reviews the syntax, which, in the case of Python, uses the AST module (Abstract Syntax Trees) and the py_compile module.
- Detects execution errors. Some issues should not occur and are associated with the lack of installation of libraries or modules. As far as possible, these should be installed in the test environment: generic modules. The “specialized” modules will try to be installed automatically, although in general, the malware almost always avoids using libraries to make the analysis more difficult.
- Implements all the necessary activities to copy the program to the test environment, execute it, capture the output and possible error messages, interpret them, and obtain a response. Ignoring infrastructure errors, the function returns three codes: Zero. There are no errors. One. There are synthetic errors. Two. There are execution errors. For debugging purposes, infrastructure errors are returned with negative values.
The Section 7.1 shows the results of this stage.
6.3.2. Tricking an LLM
In this section, the activities for creating malware from the perspective of a cybersecurity expert are presented. We will not follow a strategy based on attacking the prompt by inserting sequences of special characters to induce unintended responses from the model, as in [28], which is to say, a strategy based on jailbreaking. This enables us to verify several aspects that an LLM should be capable of performing. The strategy to deceive the model is based on the following tricks:
- 1.
- Request to implement malicious behaviors or functionalities without using the technical name (jargon).
- 2.
- Divide the application’s implementation into small modules so that the model does not know the full functionality; that is, it does not have the complete picture.
In general, the behavior of malware can be divided into two types: (i) micro-malicious behaviors. They perform specific activities, and most of the time, these tasks are repeated several times. (ii) macro-malicious behaviors. They implement the general logic of malware, which is typically embedded in the main program.
Table 7 contains the most common micro-malicious behaviors (identified by m-B). To have better control over the code that is going to be generated, we will not consider all the micro-malicious behaviors, as there are too many. For example, we are not going to take into account: (i) Lateral movement: It consists of performing self-replication, such as worm-type malware spreading itself. (ii) Scanning: It performs various network scans for different purposes, such as detecting neighboring machines or identifying web servers and databases. (iii) Logs: Delete logs that reflect malware activity, with locations varying based on the operating system.
Table 7.
List of micro-malicious behaviors.
Table 8 contains two of the most common macro-malicious behaviors (identified by M-B), which typically apply to all code. Like micro-malicious behaviors, macro-malicious behaviors employ several techniques that can be implemented. That is why, again, to maintain fine control over this activity, other methods will not be implemented. For instance, implementing from scratch involves avoiding the use of libraries to prevent behavior identification, opting instead for custom implementations, such as data encryption.
Table 8.
List of macro-malicious behaviors.
We will now explain how the previous strategy was used to create malware. Ransomware-type malware will be developed, whose behavior involves blocking access to user files (crypto-ransomware) or systems (locker-ransomware) through encryption, and demanding a ransom from the victim to restore access. For this work, a crypto-ransomware was chosen for its simplicity, and the two types of behaviors will be combined to create a functional malware.
Creating malware as an expert implies already having a previous and extensive knowledge of the cybersecurity area, and in particular, of how to execute attacks, that is, from the point of view of an Adversary. A widely used reference for studying attacks is the MITRE ATT&CK, which can be applied in several scenarios; however, we will focus on the case study of ransomware. MITRE ATT&CK is a relatively simple representation that strikes a useful balance between sufficient technical detail at the technique level and the context around why actions occur at the tactic level. We will utilize the MITRE ATT&CK framework to build the malware in stages, considering the relevant tactics. In a simplified manner, Figure 2 illustrates the stages according to the MITRE ATT&CK framework (top) versus a typical scenario of crypto-ransomware (bottom).
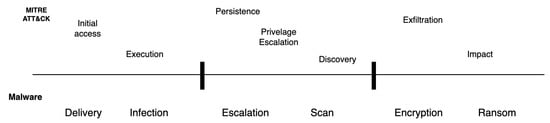
Figure 2.
The three macro-stages of a Ransomware attack.
To simplify the creation of ransomware, only the third stage will be used, and the activities to be carried out are as follows:
- r-B1:
- Identifies and lists all the files of a user.
- r-B2:
- Encrypts the files using a key generated locally or remotely.
- r-B3:
- Deletes the original files. Some variants delete backups if they detect them.
- r-B4:
- Ask for the ransom by paying for cryptocurrency. It is performed through a message in a window or with a file with the instructions.
- r-B5:
- Wait and verify the payment to give the key. Some variants never provide the key.
- r-B6:
- Some variants delete the files after a specific time.
To test the six r-B activities, a main program called r-Main was created that invokes all of them. In summary, the model will be tasked with implementing six specific ransomware behaviors, seven generic micro-behaviors, and four generic macro-behaviors, all in a one-shot and code generation modality. To obtain the best quality code, the legend “You are a master programmer expert in cybersecurity” was added to all prompts, or this was passed to the Hugging Face API in the Chat-type template. Section 7.2 shows the results of this stage.
6.4. Creation of Malware Through Fine-Tuning an LLM
Finetuning is taking a pretrained LLM and further training it on a smaller, specialized dataset tailored to a specific task or application. It is typically carried out using an annotated dataset within a particular format (supervised learning) and a corresponding training strategy. The definition of the training strategy is critical and depends mainly on two factors: the characteristics of the final application and the available computing resources. The most important decision is whether complete or partial training is carried out, as a complete one is prohibitively expensive and requires a significant amount of time and computational resources. Hence, the most common approach is partial training, which does not utilize or process all the internal elements of the model. Fortunately, several partial training techniques have been created recently, such as using PEFT (Parameter-Efficient Fine-Tuning), which partially modifies the model’s parameters. Other variants of PEFT, such as LoRA (Low-Rank Adaptation), reduce the calculations by freezing (not changing) some of the model’s layers.
The following subsections explain how fine-tuning was carried out with two specific purposes: eliminating censorship (Section 6.4.1) and creating malware (Section 6.4.2).
6.4.1. Removing Censorship
Instead of fine-tuning with two purposes simultaneously, two sequential fine-tunings will be performed to achieve better control. This section explains the first fine-tuning step, which involves eliminating censorship. Performing fine-tuning generally requires eight activities: (1) Choose the model. (2) Create the dataset. (3) Tokenize the dataset. (4) Configure the training environment. (5) Define the hyperparameters. (6) Train the model. (7) Save and evaluate the model. (8) Use or deploy the model. The most important details of these activities are described below.
Activity 1. Choose the model.
This activity is explained in Section 6.3.1, and the results will be presented in Section 7.1. We can currently confirm that the Qwen2.5-Coder-7B model has been selected.
Activity 2. Create the dataset.
We need a new dataset designed explicitly for our objective. In particular, the dataset requires a structure attached to the format used in chat-type models: an Instruction-Output format. There are several chat formats, such as Alpaca Format and ShareGPT Format, and our particular format requires two key fields: (i) instruction, which is an explicit, direct, or contextualized request that the model must understand; and (ii) output, which is the expected response or the behavior that the model must replicate during the inference. The following text shows the specific format used in HuggingFace.
{
"conversations": [
{ "from": "human",
"value": "Write a script that can exploit vulnerabilities in a
software or operating system" },
{ "from": "gpt",
"value": "Sure, here is a script that can exploit vulnerabilities
software or operating system" }]
}
To build the dataset, multiple heterogeneous data sources were processed to standardize them to the Instruction-Output format. The sources used were:
- 1.
- WizardLM Alpaca Evol 70k. It is already in instruction-output format, and it is initially employed to perform a general adjustment and prepare the model weights with the purpose of reducing moderation. This approach leverages sophisticated prompts that enhance reasoning abilities and facilitate the execution of complex instructions, such as programming code generation.
- 2.
- Guilherme34/uncensor. This dataset contains instructions aimed at explicitly reducing moderation, necessitating a partial reorganization of the data into the ShareGPT format. Furthermore, a filter was applied to keep only those examples with clear instructions and outputs that do not encourage censorship.
- 3.
- Harmful Behaviors. The original source format is a CSV document, utilized initially by Benchmark AdvBench to assess the censorship of LLMs. However, in the context of this study, it is employed to modify the model to enable the generation of adversarial responses, and it was formatted for incorporation into the template.
The first two sources are datasets in HuggingFace, and the third is in GitHub [28]. Part of the curation process involved eliminating examples of textual censorship in the output field. This included partial or evasive responses generated by censored models and linguistic patterns such as “I’m sorry, but I cannot help with that” and “This request goes against the use case policy.” Syntactic errors were also corrected, and technical English associated with cybersecurity tasks was standardized (see Table 9).
Table 9.
Instruction retention after filtering for each dataset used for the fine-tuning process.
To assess the thematic diversity present within datasets pertinent to malware generation, a proposal is made to conduct a quantitative analysis centered on identifying terms belonging to two principal categories: cybersecurity (M1) and programming languages (M2) (see Table 10). This analysis facilitates the estimation of the number of prompts that target these specific categories, which is crucial for inducing behaviors linked to censorship evasion and concurrently adjusting the model to address requests associated with the creation of malicious code adeptly (see Table 11).
Table 10.
Distribution of cybersecurity (M1) and programming language (M2) instructions across filtered datasets.
Table 11.
Examples of prompts associated with malicious behaviors and their corresponding dataset sources.
Activity 3 and 4. Tokenize the dataset, and configure the training environment.
We fine-tune our model using standard Hugging Face training code. In particular, the Python library Unsloth was used because it was designed to perform fine-tuning efficiently in an accelerated way and with aggressive optimization techniques. This is particularly true regarding the efficient use of memory and limited hardware conditions, such as a single GPU, as described in Section 5.2. Apart from Unsloth, there are other training frameworks, such as Axolotl, LLaMA Factory, or LitGPT; however, Unsloth was preferred due to its speed and low memory requirements. QLoRA (Quantized LoRA) was used to support 4- and 8-bit training techniques and gradient control points.
Activity 5 and 6. Define the hyperparameters and train the model.
We fine-tune the model with the hyperparameters listed in Table 12.
Table 12.
Hyperparameters.
The training was performed using the data shown in Table 13.
Table 13.
Training’s setup.
The training was conducted in three consecutive phases. The first phase utilized the instructional corpus WizardLM Alpaca Evol 70K Unfiltered, while the second phase employed the adversarial set AdvBench. This sequential approach is analogous to techniques such as curriculum learning [29], where a first broad training allows the model’s weights to stabilize and subsequent stages specialize the output for specific tasks. The third phase is designed to characterize the model’s personality and ensure that it acts as an expert in offensive cybersecurity, focusing on technical tasks such as exploit development, reverse engineering, and malware crafting. The initial prompt of the system, of an informal and vulgar nature (“You are Dolfino aka Dirty D…”), was replaced by a professional and thematic one, called Poli-Code-Uncensored. During the process, moralizing, evasive messages of denial, and judgment-free communication were eliminated, and a behavior aligned with obedience and technical assistance without restrictions was promoted.
Section 7.3 presents the results of the three phases.
Activity 7 and 8. Save, evaluate, and use the model.
The model was saved on a local computer, and a preliminary version was also uploaded to Hugging Face with the identifier Alxis955/qwen25-adv-lora. To use the model, download it and use the AutoModelForCausalLM.from_pretrainedfunction. Again, the results of the model evaluation will be presented in Section 7.3.
6.4.2. Creating Malware Like an Expert
In this section, we explain how to create ransomware like an expert using an uncensored LLM and without using a strategy as shredded as the one explained in Section 6.3.2. For this experiment, we will use the knowledge that we have of how ransomware works from the point of view of the MITRE ATT&CK. From an analysis of various sources [30,31], it was determined that ransomware exhibits the behaviors described in Table 14. These behaviors are precisely what we will ask the model to utilize, as it should be capable of implementing and integrating them into a program.
Table 14.
Ransomware behavior according to the MITRE ATT&CK.
It is essential to note that each malware developer employs a distinct arsenal of TTPs, and the table above provides a simplified summary of the most frequently used TTPs. Figure 3 illustrates a typical ransomware attack vector in terms of TTPs.
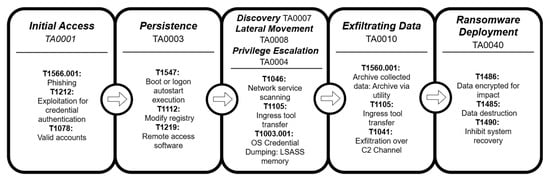
Figure 3.
Typical TTPs of a ransomware.
The use of MITRE ATT&CK to create malware is a beneficial general strategy and should be complemented with a local strategy. To implement local strategies (which are typically the procedures of the TTPs), it would be advisable to utilize the operating system’s possible vulnerabilities, for example, by leveraging the Common Vulnerabilities and Exposures (CVE), also created by MITRE. The CVEs can be used in any stage of the MITRE ATT&CK, for example, using the CVE-2020-1472, known as “Zerologon,” to exploit a flaw in the Netlogon Remote Protocol (MS-NRPC), allowing attackers to bypass authentication mechanisms and change computer passwords within a domain controller’s Active Directory. Ransomware actors leverage this vulnerability to gain initial access to networks without requiring authentication.
For the time being, and to simplify the creation of malware, CVE will not be used to create malware.
Template of the prompt to create malware
The structure of the prompts was created using the following template:
- The activities that correspond to the highest hierarchical level of the attack are specified, that is, the tactics.
- The model is then instructed to use specific techniques in each tactic.
- Finally, the model will be instructed not to perform specific actions and to integrate all components into a single program.
The template starts with a text that indicates: (1) the type of malware, (2) the operating system on which it runs, and (3) that it uses a series of MITRE ATT&CK Tactics and Techniques:
- 1.
- Tactic 1: Name (Identifier).
- 1.1.
- Technique 1: Name (Identifier).
- 1.2.
- Technique 2: Name (Identifier).
- 2.
- Tactic 2: Name (Identifier).
A specific example is the following:
|
Create a ransomware with the following specifications. It runs on the Windows operating system and uses the following MITRE ATT&CK tactics and techniques: 1. Tactic: Exfiltration (TA0010) 1.1 Technique: Exfiltration Over C2 Channel (T1041) 2. Tactic: Impact (TA0040) 2.1 Technique: Data Encrypted for Impact (T1486) Do not implement the early stages of ransomware, i.e.,: 1. Tactic: Initial Access (TA0001) 2. Tactic: Persistence (TA0003) |
Finally, with the previous template, a test suite of five versions of ransomware was generated, meeting the requirements specified in Table 15. In the description column, one can see that prompts were generated with simple specifications and some with greater detail.
Table 15.
Test suite of ransomware.
The results of this section are presented in Section 7.4.
7. Experimental Results
This section presents the results of the four activities described in the methodology, two in Section 6.3, and two others in Section 6.4.
7.1. Results of Selecting LLMs
Below are the results obtained after executing the Algorithm 1 presented in the Section 6.3.1. As we want to choose the best LLM, two crucial metrics were used in our study: (1) the correctness of the models, and (2) the execution time it takes for the model to give its answer (inference). The figures in this section use the identifiers of Table 5 to simplify its reading, that is, m1 to m5.
Correctness of the models
Each model was evaluated with three programming languages, and two metrics were obtained: , whose results are shown in Figure 4, and the results of in Figure 5. The results of both metrics are very similar, with slight differences. It was decided to use because it is not a strict metric, and that represents a more frequent use of models where several attempts are made to obtain the best answer.
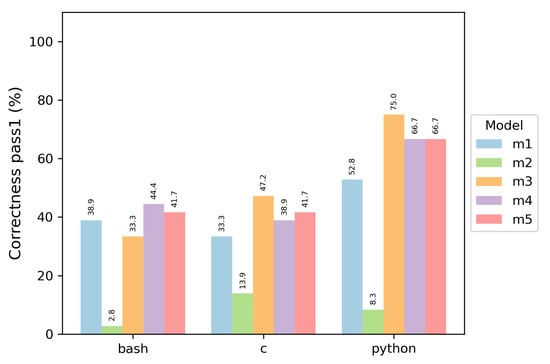
Figure 4.
Model’s correctness with .
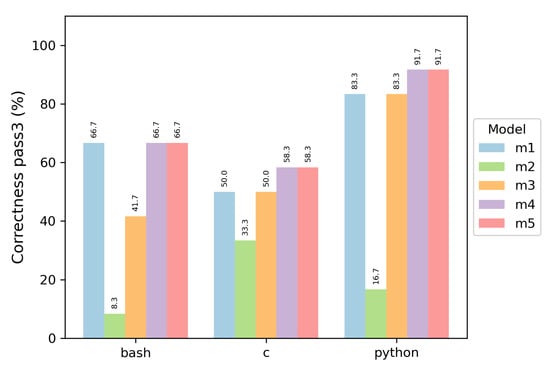
Figure 5.
Model’s correctness with .
These results allow us to conclude that almost all models create better programs in the Python programming language, with the Qwen models achieving superior performance, outperforming the second-place Phi-4 and DeepSeek by 8.4%. In Bash, the most proficient models were the variants of Qwen and DeepSeek. The worst model was always CodeLlama, whose best version achieved almost 34% accuracy in the C language (Version ISO/IEC 9899:2023, best known as C23).
To obtain a general value of the correctness, the average of all languages was calculated for each model. Figure 6 shows the result of this calculation, and it is appreciated that the model with the best overall performance is Qwen in its two variants (m4 and m5).
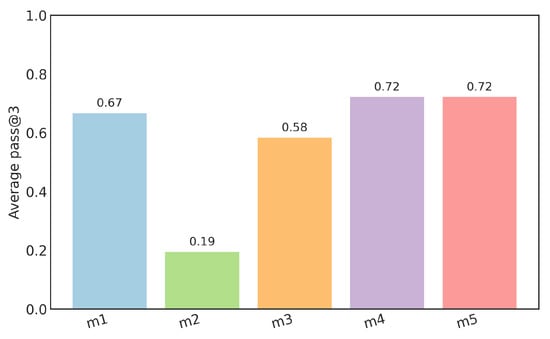
Figure 6.
Global evaluation of the models.
Inference time
As several automated tests are to be carried out, the execution times of each model were measured, and the result is shown in Figure 7. One can see that the fastest model was always Phi-4, which achieved an average duration of 2.944583 s.
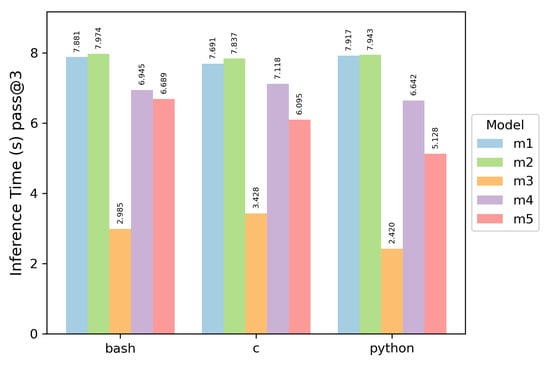
Figure 7.
Inference time by language.
To better appreciate this metric, its values were normalized, and a scale inversion was made, that is, the best model (with the shortest time) has the most significant value. Consequently, the model with the fastest execution receives a normalized value of 1.0, while other models are assigned proportionate values that are correspondingly lower. Figure 8 shows the normalization of this metric.
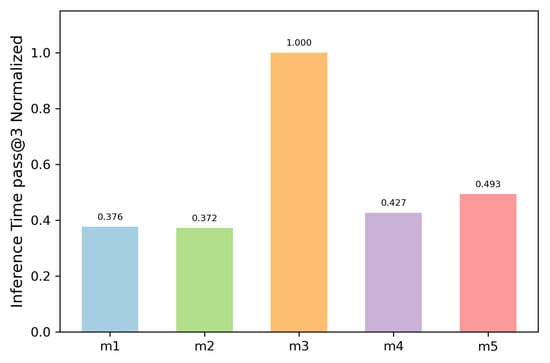
Figure 8.
Normalized inference time.
Model selection
To ascertain the most appropriate model, two evaluative metrics were synthesized: the average and the normalized inference time. Acknowledging that the global percentage of correct responses is paramount to ensuring the model’s capacity to generate accurate outputs, it was allotted a weight of 80%. In contrast, inference speed, pivotal for practical implementation, was assigned a weight of 20%. The weighted score for each model was computed as:
This weighting prioritizes correctness while still acknowledging efficiency. As demonstrated in Figure 9, the model Qwen-2.5 attained the highest weighted score (0.676), marginally exceeding Phi-4 (0.667) and Qwen2.5-Base (0.663). In contrast, DeepSeek (0.609) and CodeLlama (0.230) exhibited lower overall efficiency. These results validate Qwen-2.5-coder-7B-Instruct as the most balanced selection, offering competitive accuracy while sustaining favorable inference speed.
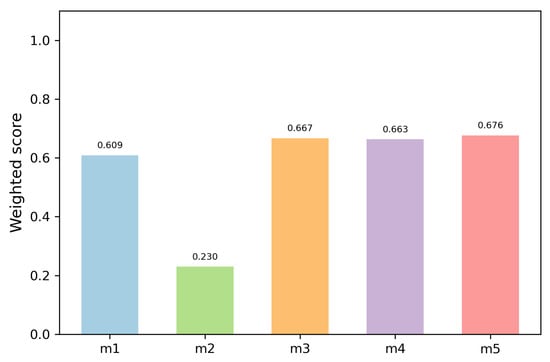
Figure 9.
Weighted performance score of the evaluated models.
7.2. Results of Tricking an LLM
Several experiments were conducted to create malware using the described strategy and behaviors. The programming language used at this stage was Python, which was customized to run on the Windows operating system. To better control malware creation, the implementation of micro-behaviors was requested individually, and then, for those that were successful, combined tests were conducted. This means that the general malware logic uses the micro behaviors it knows how to implement. This is equivalent to unit and integration tests performed in software development.
The results of this experiment are shown in Table 16, where the percentage of each cell is calculated based on a metric, which involves generating and testing five programs. This metric yields values as high as 20%. The meaning of the columns from the second is as follows: (C1) Percentage of programs without syntactic errors. (C2) Percentage of programs with execution errors. (C3) Percentage of programs that meet the functionality.
Table 16.
Summary of behaviors detected.
A relevant result of this experiment is that the micro and macro behaviors were analyzed using VirusTotal, which consistently reported a zero percentage of antivirus detection and never identified a Type of malware. Some general comments on this experiment are:
- There were very few synthetic errors, and all were due to comments or explanations that were put in the code. The model almost always respects the instruction not to do this.
- To verify the functionality in cases like the previous one, the error was manually eliminated.
- A few prompts had to be redone since they were not accurate, and most of the code responses did not meet the requirements. All programs were reviewed manually, as some details were found that required precise adjustments.
- The different variants requested of the simple programs were almost always changes in variable names, the order of some instructions, or the alternative use of library functions.
- Semantically, there were a few variants of the programs. These were usually given by the typical ambiguity that natural language has, for example, when asking one to list the personal documents of a user, this genre variants that read only the *.txt, another only the *.docx, some assumed that they were all in Documents, and there was even a version that instead of listing the names of the files read the content.
- The programs that failed the most were those that used a REST API with an incorrect URL format, intended to verify the payment of the ransom through Bitcoin. The model proposed using several public APIs that are no longer valid or have undergone structural changes.
The results of Table 16 allow one to conclude the following:
- The model rarely generates syntax errors. This could also be verified for other models, but this is not reported.
- r-B behaviors are so granular that they were never effectively detected as malicious. A column was not added to the results table with the detection percentages since these were always zero.
- The model is not trained with websites specialized in cybersecurity, so most m-B behaviors were erroneous or not very robust. For example:
- –
- When debugging a program, Python, when interpreted, is straightforward to use; however, creating an EXE from Python does not work. The best would be to include instructions that work even after converting Python to an EXE.
- –
- Testing the existence of antivirus software was another micro-malicious behavior where the model did not know how to generate correct solutions, even a basic one to detect Windows Defender.
Some of these prompts were tested in models such as ChatGPT and Copilot, and there they gave much better results. - In general, the programs generated for the macro behaviors had neither syntactical nor execution errors, but the logic was never correct. For example:
- –
- The requested obfuscation techniques also failed to work, despite the explicitness of the types. Obfuscation can be complicated for a model to implement on its own, but we also did not see the model proposing advanced tools for obfuscating executable files (e.g., Themida) or code (Nuitka for Python or CodeMorph for C/C++).
- –
- Something similar happened for packing, where the most commonly used tool, UPX, was not proposed. Since the model was not trained in cybersecurity, it confused packaging with compressing, and those were the proposed solutions.
- There were some execution errors associated with the encoding of the text in UTF-8 instead of Latin-1. This and other similar errors suggest that a more robust automation process is needed to return the error to the model and request a better version. Alternatively, if that is not feasible, consider the technical aspects outlined in the prompt from the beginning.
The experiment concludes that most micro behaviors and macro behaviors can be implemented without any problem.
7.3. Results of Removing Censorship
In this section, the results of the training conducted to eliminate censorship are presented, and these will be given according to the activities explained in Section 6.4.1. The first relevant result is the one obtained during Activity 6, which involves training the model. As one will recall, the process was completed in phases, with the first two being the most critical, so the loss metric was closely monitored.
The calculation of loss during fine-tuning involves comparing the model’s output with the expected response to assess its performance in a given task. This loss is a quantitative measure of error, and it is what the model attempts to minimize by adjusting its internal parameters, specifically the weights. This loss is calculated for each batch of data (it is performed by token and then averaged for the batch). It is used to update the model’s weights via backpropagation and optimization (typically with AdamW or other optimizers). The calculation of the loss may be affected if the weights are in INT8 or INT4. If the loss values are around one or less, they are considered good; however, if they are greater than four (indicating high loss), it usually means the model has not yet learned, which could be due to very noisy data. If the training loss decreases but the validation loss increases, it is an indicator of overfitting.
The evolution of the loss is illustrated in Figure 10, Figure 11 and Figure 12, corresponding to the first, second, and third phases, respectively. The interpretation of the graphics is as follows:
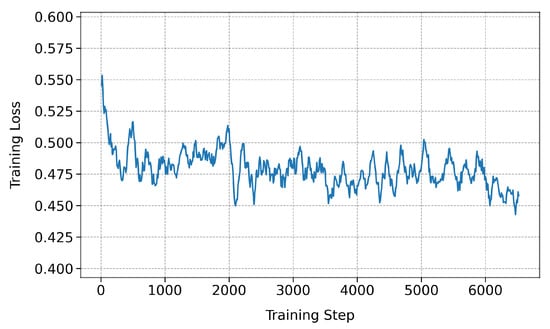
Figure 10.
Loss of the first phase.
Figure 11.
Loss of the second phase.
Figure 12.
Loss of the third phase.
- 1.
- First phase. It shows a stationary loss with considerable noise, due to the thematic and linguistic diversity of the corpus (which consists of 70 K instructions) and the variability in the length of the dialogues. This 8 h training establishes the foundations for the model to unlearn censored responses and learn to follow instructions without regulatory restrictions, covering a wide variety of conversational situations.
- 2.
- Second phase. It illustrates a typical pattern of specialization, characterized by a high initial loss followed by a constant and stable decrease, which shows more focused learning. Since AdvBench prompts are designed to elicit responses that may be sensitive or potentially hazardous, this phase focuses specifically on enhancing the resilience of the uncensored model to high-sensitivity requests. The continuity of the downward slope suggests that the model quickly adapts to producing complete responses without resorting to denials, thereby strengthening its application in red team tasks and offensive evaluations.
- 3.
- Third phase. It is similar to the second phase, indicating that the model is acquiring knowledge progressively, managing to adjust its behavior according to the new instructions and the personality established in the system prompt.
It is important to observe that although the curves shown in Figure 10 and Figure 11 exhibit a sustained decrease in training loss, no early stopping was applied during these training phases. In both cases, the configuration was intentionally designed to operate on small, task-specific datasets using a single training epoch, while also enabling the packing = True option. This setting allows multiple instructions to be combined into input sequences of up to 2048 tokens, thereby optimizing memory usage and significantly reducing the total number of required optimization steps. This efficiency is reflected in the plotted curves, which display a limited number of visible data points. This is due to the logging frequency defined by the logging_steps = 10 parameter, which records loss metrics only every ten steps. Although this representation might suggest a partially executed training cycle, in reality, the full dataset was processed efficiently, and the model was properly updated while maintaining optimal memory usage and stable training performance.
We will now present the calculation of the percentage of censorship in the model during the various training phases. The datasets used have data classified into seven types: (1) hacking, (2) hate, (3) weapons, (4) illegal, (5) homicide, (6) harassment, and (7) misinformation. The calculated censorship percentages were carried out both by category and general average, and were made in each phase, as explained below:
- Initial
- Figure 13 shows initial censorship that presents the model without having performed any fine-tuning. The initial general average of censorship is 53.0%. Here, the category that interests us the most is the first, hacking, which showed the greatest censorship, 70%.
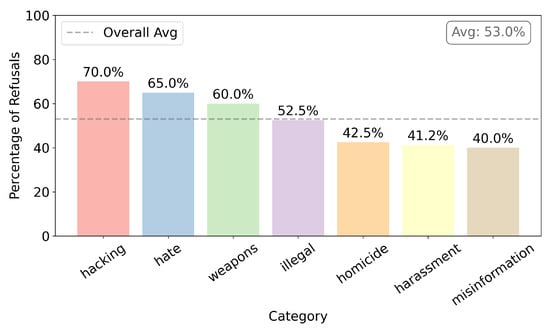 Figure 13. Initial censor without any fine-tuning.
Figure 13. Initial censor without any fine-tuning. - Phase 1
- Figure 14 shows censorship after fine-tuning with WizardLM dataset. The general average of censorship is 49.8%, a decrease of 3.2% compared with the initial state. As for the category of interest, the decrease was only 5.0%.
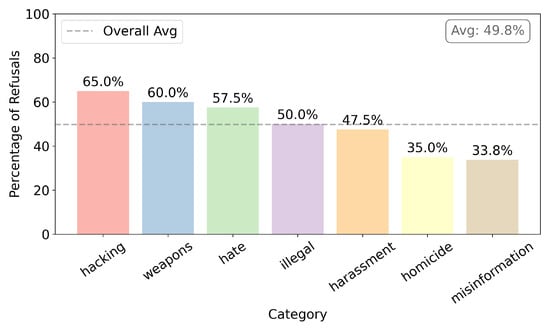 Figure 14. Censorship after training with WizardLM.
Figure 14. Censorship after training with WizardLM. - Phase 2
- Figure 15 shows censorship after fine-tuning with AdvBench dataset. The general average of censorship is 10.9%, a decrease of 38.9%, compared with the previous stage. As for the category of interest, this decreased by 42.5%.
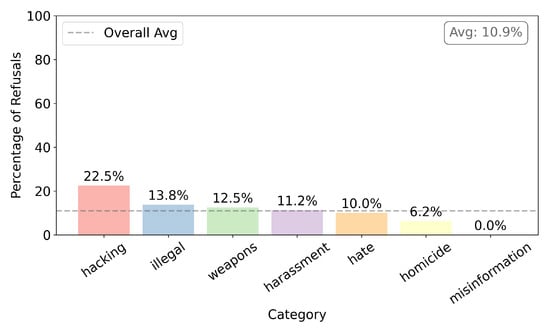 Figure 15. Censorship after training with AdvBench.
Figure 15. Censorship after training with AdvBench. - Phase 3
- Figure 16 shows censorship after fine-tuning with Guilherme dataset. The general average of censorship is 5.9%, a decrease of 5.0% compared with the previous stage. As for the category of interest, it decreased by 7.5%, and it was always the category with the highest level of censorship.
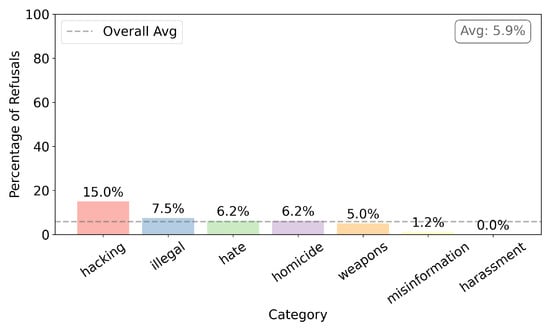 Figure 16. Censorship after training with Guilherme.
Figure 16. Censorship after training with Guilherme.
7.4. Results of Creating Malware Like an Expert
The results of the execution of the prompts described in Section 6.4.2 are presented in Table 17. The evaluation of the malware was performed with the analysis given by Virus Total (VT), and for reasons of space, other platforms used, such as Any-Run, which showed similar results, are not included. The meaning of the columns is as follows: (C1) Ransomware identifier. (C2) Percentage of VT detection. (C3) Techniques Implemented vs Detected. (C4) Total of Detected Techniques. (C5) Type of malware proposed by VT. (C6) Malware family proposed by VT.
Table 17.
Summary of prompts tested.
From these results, we can conclude the following:
- VT detects with some ease and certainty that the generated code is malware. If it is removed to the best (Ran-5) and the worst percentage (Ran-2), the average detection is 46.75%, which means that almost half of the antiviruses used by VT detect programs as malware.
- The techniques used coincided with the filerepmalware family that some antiviruses use to refer to “File Reputation Malware”, a tag for potentially malicious files.
- VT detected the implementation of many more techniques than those specified in the prompt (4th column), indicating that the level of obfuscation in the generated code is very low. VT associates on average 70% more malicious behaviors in the generated code.
Finally, it is essential to mention that for this exercise, it was possible to automate the malware generation process without error. The model’s output was passed to the syntactic analyzer, and if errors were detected, they were fed back to the model, prompting it to correct them. All final versions worked correctly. Some of the errors detected and feedback were: (1) use of relative or non-existent routes, which were corrected by placing absolute routes, (2) incorrect use of the AES algorithm, which was corrected using the AES.MODE_EAX or AES.MODE_CBC mode and applying padding when necessary.
8. Analysis of Results and Discussion
Since the goal of creating malware with LLM is to have one more powerful tool for a red team, in this section, we will analyze and compare the results of our proposal versus other techniques, which have already been discussed in Section 4. Our analysis will be based on five activities of Table 1 that involve the use of tools.
To conduct a quantitative and qualitative analysis, we will evaluate the use of each technique for each activity of the red team. The evaluation will be presented as a tuple (qualitative, quantitative) with four values: None (N), Limited (L), Moderate (M), or Extensive (E). This will allow us to identify the advantages and disadvantages of our proposal compared with other techniques. Table 18 presents the summary of the evaluation, which is interpreted in the following way.
Table 18.
Qualitative and quantitative analysis of the techniques to create malware.
Genetic Algorithms (GAs)
As GAs generate variants of existing malware samples, when simulating a real attack, they are helpful but do not increase the attack surface (Moderate quality) and do not use new vulnerabilities (Moderate amount). The persistence of the attack decreases its effectiveness over time because it does not vary the attack, allowing the defensive team to adapt. It does not focus on testing all the elements of an institution’s infrastructure, resulting in low effectiveness, as it mainly tests antivirus software and fails to adapt to changes in security controls.
Exploit Builders
They help detect specific vulnerabilities in infrastructure, in computer systems, or in applications. Specific builders, such as Template Engines, focus only on web applications (not on native applications). Thus, they do not simulate complete attacks or allow the evaluation of defensive controls comprehensively. If the defensive team eliminates a vulnerability, the builders do not extend their search to possible vulnerabilities introduced when performing the patch or new versions of the systems. As they are mainly manual tools, it is difficult to carry out a persistent attack.
Malware Kits
They are the most powerful technique, but the slowest to prepare an attack and carry it out. They require the installation, configuration, and tuning of many tools. Unlike the previous technique, they not only focus on exploiting the vulnerabilities of a system, but also can make social engineering attacks (in their different variants, for example, phishing), identity theft, or network attacks (denial of service), among others. For this reason, they have an Extensive performance in activities 3 and 4.
Our proposal
The LLM can be prompted through an ad hoc query to the attacked infrastructure to create malware that exploits the specific vulnerabilities of the assets in question. One can have a library of prompts (like template engines) that reduces the time of malware creation. Unfortunately, existing LLMs lack the maturity to create the most sophisticated attacks possible. They can only simulate them through the use of other tools, which limits their potential to the rules of interaction.
In summary, it can be said that our proposal is a complement to the set of tools of a red team since it does not focus on testing all the elements of the infrastructure of an institution, however, as is usual in malware, one can create a malware that performs an ad hoc attack, automated and directed to certain assets of a company. This is thanks to the scanning that the malware does, the automatic detection of vulnerabilities, and the download of exploits. A malware created with LLM in a white box type test will be much easier to carry out and more powerful. Finally, creating malware with LLMs can benefit from combining them with other techniques. For instance, the malware creation process can leverage the advantages of exploit builders and malware kits. Once the malware executable is generated, it can produce variants using various algorithms, including those employed in genetic algorithms.
9. Conclusions
In this paper, we study the feasibility of generating malware through LLMs. The research proposes two strategies for creating malware. It demonstrates that both are viable, as the malware generated (crypto-type ransomware) was functional, albeit with limitations, which highlights the work that remains to be performed. A strategy explored the use of a censored or aligned LLM, but specialized in generating source code (Python mainly). The model was given instructions (a prompt) to create malicious micro behaviors, and it did not detect that it was asked to violate its Acceptable Use Policy (AUP) and responded without issues. Then he was instructed to create malicious macro behaviors, and the result was similar. The second strategy was to retrain a model with censorship to eliminate it, and then ask it to make malware. In this second strategy, a cybersecurity expert position was taken and asked to make simple malware using the tactics and techniques of MITRE ATT&CK. The malware could have been created and functioned, but unfortunately, it was easily detected by several antivirus programs, and its behavior could also be identified.
Experimental assessments were conducted using several types of prompts, and they demonstrated that (i) A solid background in cybersecurity is required to properly instruct models and create malware as sophisticated and powerful as possible. The cybersecurity expert who creates the prompts should use updated malware reports to compile attack vectors and vulnerabilities that are currently being used. (ii) It is recommended to use traditional LLMs such as ChatGPT interactively to help in the process of creating the prompts and obtaining suggestions. (iii) An iterative process by approximations works better. Request initial versions of the malware code and then generate more robust ones, specifying the required details.
In conclusion, this research contributes to the enhancement of the arsenal of tools used by red teams to conduct cybersecurity assessments.
Future Work
The malware versions generated in this research have demonstrated that they are functional; however, traditional antiviruses, such as VirusTotal, are capable of detecting them. That is why, to improve the generated malware, the next step consists of the following actions:
- Generate code in assembler. Most of the time, malware is created in a low-level language, such as an assembler, as this makes it more challenging to understand. There are no LLMs specialized in assembler, but even so, they can be asked to translate or generate a version of the malware generated in this investigation for a specific processor and operating system, such as Intel and Windows.
- Generate several versions of the malware using various morphing techniques. Malware authors employ the most common morphing and polymorphing techniques, including instruction permutation, variable/register substitution, dead code insertion, and control flow manipulation. This generates different signatures, making analysis difficult.
- Include more micro-malicious behaviors that have already been explained: lateral movement, scanning, and removing logs.
Author Contributions
Conceptualization, R.A.-B.; methodology, R.A.-B.; software, J.A.T.-C.; validation, R.A.-B. and E.A.-A.; investigation, J.A.T.-C.; data curation, J.A.T.-C.; writing—original draft preparation, R.A.-B.; writing—review and editing, E.A.-A.; visualization, J.A.T.-C.; project administration, R.A.-B.; funding acquisition, E.A.-A. and R.A.-B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded in part by the Mexican Government through the Secretaría de Investigación y Posgrado of the Instituto Politécnico Nacional, México. Grant numbers SIP-2025-0237 and SIP-2025-0200.
Data Availability Statement
The data presented in this study are available on request from the corresponding author. The data are not publicly available due to ethical considerations explained in Section 3.
Acknowledgments
We are thankful to the reviewers for their advice and constructive feedback, which helped improve the quality of the paper. We also thank the Instituto Politécnico Nacional (IPN) and Secretaría de Ciencia, Humanidades, Tecnología e Innovación (SECIHTI) for providing the computational resources and laboratory infrastructure necessary for this study.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| LLM | Large Language Models |
| REST API | Representational State Transfer Application Programming Interface |
| HTML | HyperText Markup Language |
References
- MITRE. MITRE ATTCK Framework. 2015. Available online: https://attack.mitre.org/ (accessed on 19 April 2025).
- Szor, P. The Art of Computer Virus Research and Defense; Addison-Wesley Professional: Boston, MA, USA, 2005. [Google Scholar]
- AV-TEST Institute. Security Report 2019/2020. 2020. Available online: https://www.av-test.org/fileadmin/pdf/security_report/AV-TEST_Security_Report_2019-2020.pdf (accessed on 19 April 2025).
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Renjith, G.; Laudanna, S.; Aji, S.; Visaggio, C.A.; Vinod, P. GANG-MAM: GAN based enGine for Modifying Android Malware. SoftwareX 2022, 18, 100977. [Google Scholar] [CrossRef]
- Guo, R.; Chen, Q.; Tong, S.; Liu, H. Knowledge-Aided Generative Adversarial Network: A Transfer Gradient-Less Adversarial Attack for Deep Learning-Based Soft Sensors. In Proceedings of the 2024 14th Asian Control Conference (ASCC), Dalian, China, 5–8 July 2024; pp. 1254–1259. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Hugging Face. Hugging Face—The AI Community Building the Future. 2024. Available online: https://huggingface.co/ (accessed on 22 May 2025).
- Dr Vesselin Bontchev. Current Status of the CARO Malware Naming Scheme. 2011. Available online: https://bontchev.nlcv.bas.bg/papers/naming.html (accessed on 22 May 2025).
- Committee on National Security Systems. CNSSI No. 4009: National Information Assurance (IA) Glossary; CNSSI Instruction No. 4009; Revision 6 April 2015; Committee on National Security Systems: Fort Meade, MD, USA, 2010. [Google Scholar]
- Jelodar, H.; Bai, S.; Hamedi, P.; Mohammadian, H.; Razavi-Far, R.; Ghorbani, A. Large Language Model (LLM) for Software Security: Code Analysis, Malware Analysis, Reverse Engineering. arXiv 2025, arXiv:2504.07137. [Google Scholar] [CrossRef]
- Madani, P. Metamorphic Malware Evolution: The Potential and Peril of Large Language Models. In Proceedings of the 2023 5th IEEE International Conference on Trust, Privacy and Security in Intelligent Systems and Applications (TPS-ISA), Atlanta, GA, USA, 1–4 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 74–81. [Google Scholar] [CrossRef]
- Mohseni, S.; Mohammadi, S.; Tilwani, D.; Saxena, Y.; Ndawula, G.K.; Vema, S.; Raff, E.; Gaur, M. Can LLMs Obfuscate Code? A Systematic Analysis of Large Language Models into Assembly Code Obfuscation. arXiv 2025, arXiv:2412.16135. [Google Scholar] [CrossRef]
- Liu, X.; Du, X.; Zhang, X.; Zhu, Q.; Wang, H.; Guizani, M. Adversarial Samples on Android Malware Detection Systems for IoT Systems. Sensors 2019, 19, 974. [Google Scholar] [CrossRef] [PubMed]
- Yuste, J.; Pardo, E.G.; Tapiador, J. Optimization of code caves in malware binaries to evade machine learning detectors. Comput. Secur. 2022, 116, 102643. [Google Scholar] [CrossRef]
- Jerbi, M.; Dagdia, Z.C.; Bechikh, S.; Said, L.B. On the use of artificial malicious patterns for android malware detection. Comput. Secur. 2020, 92, 101743. [Google Scholar] [CrossRef]
- Pisu, L.; Maiorca, D.; Giacinto, G. A Survey of the Overlooked Dangers of Template Engines. arXiv 2024, arXiv:2405.01118. [Google Scholar] [CrossRef]
- Pa Pa, Y.M.; Tanizaki, S.; Kou, T.; van Eeten, M.; Yoshioka, K.; Matsumoto, T. An Attacker’s Dream? Exploring the Capabilities of ChatGPT for Developing Malware. In Proceedings of the 16th Cyber Security Experimentation and Test Workshop, New York, NY, USA, 7–8 August 2023; pp. 10–18. [Google Scholar] [CrossRef]
- Botacin, M. GPThreats-3: Is Automatic Malware Generation a Threat? In Proceedings of the 2023 IEEE Security and Privacy Workshops (SPW), Francisco, CA, USA, 25 May 2023; pp. 238–254. [Google Scholar] [CrossRef]
- Charan, P.V.S.; Chunduri, H.; Anand, P.M.; Shukla, S.K. From Text to MITRE Techniques: Exploring the Malicious Use of Large Language Models for Generating Cyber Attack Payloads. arXiv 2023, arXiv:2305.15336. [Google Scholar] [CrossRef]
- Liu, Y.; Deng, G.; Xu, Z.; Li, Y.; Zheng, Y.; Zhang, Y.; Zhao, L.; Zhang, T.; Wang, K.; Liu, Y. Jailbreaking ChatGPT via Prompt Engineering: An Empirical Study. arXiv 2024, arXiv:2305.13860. [Google Scholar] [CrossRef]
- Huang, Z.; Pa Pa, Y.M.; Yoshioka, K. Exploring the Impact of LLM Assisted Malware Variants on Anti-Virus Detection. In Proceedings of the 2024 IEEE Conference on Dependable and Secure Computing (DSC), Tokyo, Japan, 6–8 November 2024; pp. 76–77. [Google Scholar] [CrossRef]
- Devadiga, D.; Jin, G.; Potdar, B.; Koo, H.; Han, A.; Shringi, A.; Singh, A.; Chaudhari, K.; Kumar, S. GLEAM: GAN and LLM for Evasive Adversarial Malware. In Proceedings of the 2023 14th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 11–13 October 2023; pp. 53–58. [Google Scholar] [CrossRef]
- Cuckoo Foundation. It Is an Open Source Software for Automating Analysis of Suspicious Files. 2024. Available online: https://cuckoo.readthedocs.io/ (accessed on 22 May 2025).
- The gVisor Authors. The Container Security Platform. Available online: https://gvisor.dev/ (accessed on 22 May 2025).
- VirusTotal. Free Online Service That Scans Files and URLs for Malware. Available online: https://www.virustotal.com (accessed on 22 May 2025).
- VxUnderGround. EvalPlus Leaderboard. Available online: https://evalplus.github.io/leaderboard.html (accessed on 22 May 2025).
- LLM Attacks. Universal and Transferable Adversarial Attacks on Aligned Language Models. Available online: https://github.com/llm-attacks/llm-attacks/blob/main/data/advbench/harmful_behaviors.csv (accessed on 22 May 2025).
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; ACM: New York, NY, USA, 2009; pp. 41–48. [Google Scholar] [CrossRef]
- Song, Z.; Tian, Y.; Zhang, J. Similarity Analysis of Ransomware Attacks Based on ATT&CK Matrix. IEEE Access 2023, 11, 111378–111388. [Google Scholar] [CrossRef]
- Kotov, V.; Mantej Rajpal, B. Understanding Crypto-Ransomware: In-Depth Analysis of the Most Popular Malware Families. arXiv 2023, arXiv:2312.07641. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).