
TSINet: A Semantic and Instance Segmentation Network for 3D Tomato Plant Point Clouds


Abstract
1. Introduction
- We design a Geometry-Aware Adaptive Feature Extraction Block (GAFEB) within a shared encoder, incorporating EdgeConv, PAConv, and residual connections to enhance the extraction of local and contextual geometric features.
- A Dual Attention-Based Feature Enhancement Module (DAFEM) is introduced, combining spatial and channel attention mechanisms to model salient regions in decoder features, improving perception in structurally complex areas.
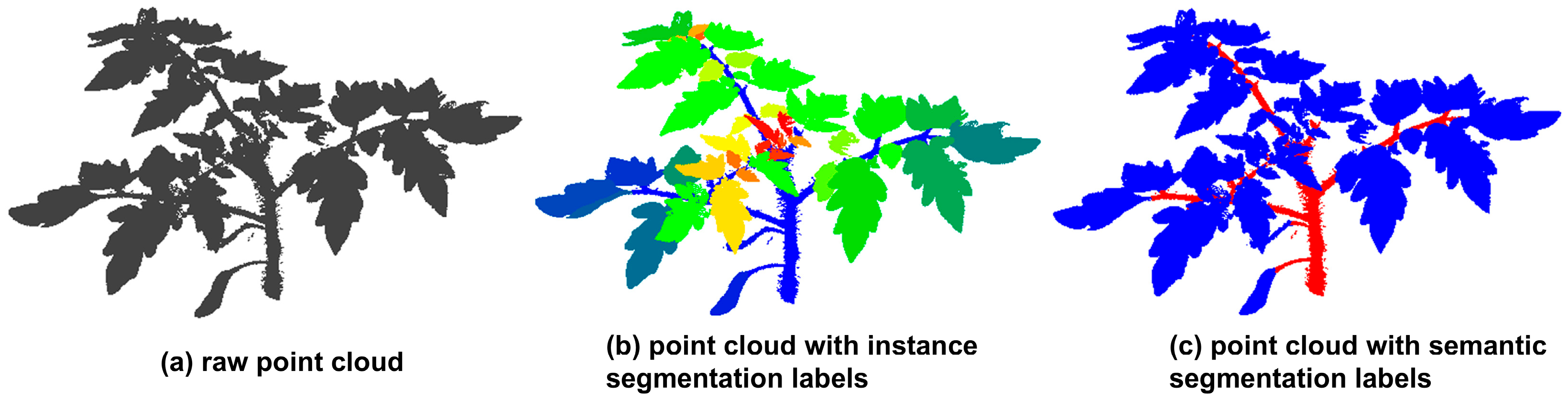
- We propose TSINet, a point-based dual-functional segmentation network tailored to tomato plants, capable of segmenting stems and leaves with precision in both semantics and instances.
2. Materials and Methods
2.1. Data Acquisition
2.2. Data Preprocessing
2.3. Network Architecture
2.3.1. Geometry-Aware Adaptive Feature Extraction Block (GAFEB)
2.3.2. Dual-Branch Feature Decoder
2.3.3. Dual Attention-Based Feature Enhancement Module (DAFEM)
2.3.4. Loss Function
3. Experimental Results and Analysis
3.1. Experimental Platform
3.2. Model Evaluating Indicator
3.3. Semantic Segmentation Results
3.4. Instance Segmentation Results
4. Discussion
4.1. Ablation Study
4.2. Cross-Species Evaluation for Model Generalization
4.3. Limitations and Future Works
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Roohanitaziani, R.; De Maagd, R.A.; Lammers, M.; Molthoff, J.; Meijer-Dekens, F.; Van Kaauwen, M.P.W.; Finkers, R.; Tikunov, Y.; Visser, R.G.F.; Bovy, A.G. Exploration of a Resequenced Tomato Core Collection for Phenotypic and Genotypic Variation in Plant Growth and Fruit Quality Traits. Genes 2020, 11, 1278. [Google Scholar] [CrossRef] [PubMed]
- Kumar, M.; Tomar, M.; Bhuyan, D.J.; Punia, S.; Grasso, S.; Sá, A.G.A.; Carciofi, B.A.M.; Arrutia, F.; Changan, S.; Radha; et al. Tomato (Solanum lycopersicum L.) Seed: A Review on Bioactives and Biomedical Activities. Biomed. Pharmacother. 2021, 142, 112018. [Google Scholar] [CrossRef] [PubMed]
- Roșca, M.; Mihalache, G.; Stoleru, V. Tomato Responses to Salinity Stress: From Morphological Traits to Genetic Changes. Front. Plant Sci. 2023, 14, 1118383. [Google Scholar] [CrossRef] [PubMed]
- Murphy, K.M.; Ludwig, E.; Gutierrez, J.; Gehan, M.A. Deep Learning in Image-Based Plant Phenotyping. Annu. Rev. Plant Biol. 2024, 75, 771–795. [Google Scholar] [CrossRef]
- Tian, K.; Li, J.; Zeng, J.; Evans, A.; Zhang, L. Segmentation of Tomato Leaf Images Based on Adaptive Clustering Number of K-Means Algorithm. Comput. Electron. Agric. 2019, 165, 104962. [Google Scholar] [CrossRef]
- Ivanovska, M.; Struc, V.; Pers, J. TomatoDIFF: On-Plant Tomato Segmentation with Denoising Diffusion Models. In Proceedings of the 18th International Conference on Machine Vision and Applications (MVA), Hamamatsu, Japan, 23–25 July 2023. [Google Scholar]
- Niu, Z.; Huang, T.; Xu, C.; Sun, X.; Taha, M.F.; He, Y.; Qiu, Z. A Novel Approach to Optimize Key Limitations of Azure Kinect DK for Efficient and Precise Leaf Area Measurement. Agriculture 2025, 15, 173. [Google Scholar] [CrossRef]
- Miao, T.; Zhu, C.; Xu, T.; Yang, T.; Li, N.; Zhou, Y.; Deng, H. Automatic Stem-Leaf Segmentation of Maize Shoots Using Three-Dimensional Point Cloud. Comput. Electron. Agric. 2021, 187, 106310. [Google Scholar] [CrossRef]
- Liang, X.; Yu, W.; Qin, L.; Wang, J.; Jia, P.; Liu, Q.; Lei, X.; Yang, M. Stem and Leaf Segmentation and Phenotypic Parameter Extraction of Tomato Seedlings Based on 3D Point. Agronomy 2025, 15, 120. [Google Scholar] [CrossRef]
- Xing, Y.; Pham, D.; Williams, H.; Smith, D.; Ahn, H.S.; Lim, J.; MacDonald, B.A.; Nejati, M. Look How They Have Grown: Non-Destructive Leaf Detection and Size Estimation of Tomato Plants for 3D Growth Monitoring. arXiv 2023. [Google Scholar] [CrossRef]
- Qiao, G.; Zhang, Z.; Niu, B.; Han, S.; Yang, E. Plant Stem and Leaf Segmentation and Phenotypic Parameter Extraction Using Neural Radiance Fields and Lightweight Point Cloud Segmentation Networks. Front. Plant Sci. 2025, 16, 1491170. [Google Scholar] [CrossRef]
- Sun, Y.; Guo, X.; Yang, H. Win-Former: Window-Based Transformer for Maize Plant Point Cloud Semantic Segmentation. Agronomy 2023, 13, 2723. [Google Scholar] [CrossRef]
- Zhang, L.; Huang, Z.; Yang, Z.; Yang, B.; Yu, S.; Zhao, S.; Zhang, X.; Li, X.; Yang, H.; Lin, Y.; et al. Tomato Stem and Leaf Segmentation and Phenotype Parameter Extraction Based on Improved Red Billed Blue Magpie Optimization Algorithm. Agriculture 2025, 15, 180. [Google Scholar] [CrossRef]
- Yan, J.; Tan, F.; Li, C.; Jin, S.; Zhang, C.; Gao, P.; Xu, W. Stem–Leaf Segmentation and Phenotypic Trait Extraction of Individual Plant Using a Precise and Efficient Point Cloud Segmentation Network. Comput. Electron. Agric. 2024, 220, 108839. [Google Scholar] [CrossRef]
- Yang, X.; Miao, T.; Tian, X.; Wang, D.; Zhao, J.; Lin, L.; Zhu, C.; Yang, T.; Xu, T. Maize Stem–Leaf Segmentation Framework Based on Deformable Point Clouds. ISPRS J. Photogramm. Remote Sens. 2024, 211, 49–66. [Google Scholar] [CrossRef]
- Hao, H.; Wu, S.; Li, Y.; Wen, W.; Fan, J.; Zhang, Y.; Zhuang, L.; Xu, L.; Li, H.; Guo, X.; et al. Automatic Acquisition, Analysis and Wilting Measurement of Cotton 3D Phenotype Based on Point Cloud. Biosyst. Eng. 2024, 239, 173–189. [Google Scholar] [CrossRef]
- Liu, Z.; Zhao, J.; Hu, Y.; Li, R.; Deng, Q.; Guan, R.; Yang, R.; Xu, Z.; Zhou, G. FACNet: A High-Precision Pumpkin Seedling Point Cloud Organ Segmentation Method. Comput. Electron. Agric. 2025, 231, 110049. [Google Scholar] [CrossRef]
- Yao, J.; Gong, Y.; Xia, Z.; Nie, P.; Xu, H.; Zhang, H.; Chen, Y.; Li, X.; Li, Z.; Li, Y. Facility of Tomato Plant Organ Segmentation and Phenotypic Trait Extraction via Deep Learning. Comput. Electron. Agric. 2025, 231, 109957. [Google Scholar] [CrossRef]
- Song, J.; Ma, B.; Xu, Y.; Yu, G.; Xiong, Y. Organ Segmentation and Phenotypic Information Extraction of Cotton Point Clouds Based on the CotSegNet Network and Machine Learning. Comput. Electron. Agric. 2025, 236, 110466. [Google Scholar] [CrossRef]
- Xie, K.; Cui, C.; Jiang, X.; Zhu, J.; Liu, J.; Du, A.; Yang, W.; Song, P.; Zhai, R. Automated 3D Segmentation of Plant Organs via the Plant-MAE: A Self-Supervised Learning Framework. Plant Phenomics 2025, 7, 100049. [Google Scholar] [CrossRef]
- Liu, F.-Y.; Geng, H.; Shang, L.-Y.; Si, C.-J.; Shen, S.-Q. A Cotton Organ Segmentation Method with Phenotypic Measurements from a Point Cloud Using a Transformer. Plant Methods 2025, 21, 37. [Google Scholar] [CrossRef]
- Dong, S.; Fan, X.; Li, X.; Liang, Y.; Zhang, M.; Yao, W.; Yang, X.; Wang, Z. Automatic 3D Plant Organ Instance Segmentation Method Based on PointNeXt and Quickshift++. Plant Phenomics 2025, 7, 100065. [Google Scholar] [CrossRef]
- Schunck, D.; Magistri, F.; Rosu, R.A.; Cornelißen, A.; Chebrolu, N.; Paulus, S.; Léon, J.; Behnke, S.; Stachniss, C.; Kuhlmann, H.; et al. Pheno4D: A Spatio-Temporal Dataset of Maize and Tomato Plant Point Clouds for Phenotyping and Advanced Plant Analysis. PLoS ONE 2021, 16, e0256340. [Google Scholar] [CrossRef] [PubMed]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. arXiv 2017, arXiv:1706.02413. [Google Scholar]
- Comaniciu, D.; Meer, P. Mean Shift: A Robust Approach toward Feature Space Analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds; ACM Transactions on Graphics (tog): New York, NY, USA, 2019. [Google Scholar]
- Xu, M.; Ding, R.; Zhao, H.; Qi, X. PAConv: Position Adaptive Convolution with Dynamic Kernel Assembling on Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Wang, X.; Liu, S.; Shen, X.; Shen, C.; Jia, J. Associatively Segmenting Instances and Semantics in Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhao, L.; Tao, W. JSNet: Joint Instance and Semantic Segmentation of 3D Point Clouds. AAAI 2020, 34, 12951–12958. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Overall | Training Set | Test Set | |
|---|---|---|---|
| Initial dataset | 77 | 61 | 15 |
| Augmented Dataset | 1540 | 1220 | 320 |
| Index | Part | PointNet [28] | PointNet++ [24] | DGCNN [26] | ASIS [29] | JSNet [30] | TSINet (Ours) |
|---|---|---|---|---|---|---|---|
| Precision (%) | Leaf | 95.35 | 97.16 | 97.35 | 97.27 | 97.34 | 97.89 |
| Stem | 96.10 | 94.99 | 95.53 | 95.19 | 95.27 | 96.10 | |
| Mean | 95.72 | 96.07 | 96.44 | 96.23 | 96.30 | 97.00 | |
| Recall (%) | Leaf | 98.85 | 98.40 | 98.57 | 98.47 | 98.49 | 98.74 |
| Stem | 85.46 | 91.32 | 91.91 | 91.67 | 91.88 | 93.59 | |
| Mean | 92.15 | 94.86 | 95.24 | 95.07 | 95.18 | 96.17 | |
| F1-score (%) | Leaf | 97.07 | 97.78 | 97.96 | 97.87 | 97.91 | 98.32 |
| Stem | 90.47 | 93.12 | 93.69 | 93.40 | 93.54 | 94.83 | |
| Mean | 93.77 | 95.45 | 95.82 | 95.63 | 95.73 | 96.57 | |
| IoU (%) | Leaf | 94.30 | 95.65 | 96.00 | 95.82 | 95.90 | 96.69 |
| Stem | 82.59 | 87.12 | 88.13 | 87.62 | 87.87 | 90.17 | |
| Mean | 88.45 | 91.39 | 92.06 | 91.72 | 91.89 | 93.43 |
| Methods | mPrec (%) | mRec (%) | mCov (%) | mWCov (%) |
|---|---|---|---|---|
| ASIS [29] | 72.20 | 67.92 | 70.92 | 74.62 |
| JSNet [30] | 74.61 | 70.04 | 72.59 | 79.12 |
| TSINet (ours) | 81.54 | 81.69 | 81.60 | 86.40 |
| Index | Group | Component | Leaf | Stem | Mean | |
|---|---|---|---|---|---|---|
| GAFEB | DAFEM | |||||
| Precision (%) | A | √ | × | 97.15 | 95.11 | 96.13 |
| B | × | √ | 96.91 | 93.63 | 95.27 | |
| C | √ | √ | 97.89 | 96.10 | 97.00 | |
| Recall (%) | A | √ | × | 98.44 | 91.29 | 94.86 |
| B | × | √ | 97.96 | 90.57 | 94.26 | |
| C | √ | √ | 98.74 | 93.59 | 96.17 | |
| F1-score (%) | A | √ | × | 97.79 | 93.16 | 95.48 |
| B | × | √ | 97.43 | 92.08 | 94.76 | |
| C | √ | √ | 98.32 | 94.83 | 96.57 | |
| IoU (%) | A | √ | × | 95.68 | 87.20 | 91.44 |
| B | × | √ | 94.99 | 85.32 | 90.16 | |
| C | √ | √ | 96.69 | 90.17 | 93.43 | |
| Index | Group | Component | Mean | |
|---|---|---|---|---|
| GAFEB | DAFEM | |||
| mPrec (%) | A | √ | × | 80.14 |
| B | × | √ | 79.86 | |
| C | √ | √ | 81.54 | |
| mRec (%) | A | √ | × | 78.43 |
| B | × | √ | 78.10 | |
| C | √ | √ | 81.69 | |
| mCov (%) | A | √ | × | 81.82 |
| B | × | √ | 79.82 | |
| C | √ | √ | 81.60 | |
| mWCov (%) | A | √ | × | 83.97 |
| B | × | √ | 82.14 | |
| C | √ | √ | 86.40 | |
| Methods | mPrec (%) | mRec (%) | mCov (%) | mWCov (%) |
|---|---|---|---|---|
| TSINet (Testing on Maize) | 58.82 | 60.04 | 62.34 | 64.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, S.; Lu, X.; Zhang, L. TSINet: A Semantic and Instance Segmentation Network for 3D Tomato Plant Point Clouds. Appl. Sci. 2025, 15, 8406. https://doi.org/10.3390/app15158406
Ma S, Lu X, Zhang L. TSINet: A Semantic and Instance Segmentation Network for 3D Tomato Plant Point Clouds. Applied Sciences. 2025; 15(15):8406. https://doi.org/10.3390/app15158406
Chicago/Turabian StyleMa, Shanshan, Xu Lu, and Liang Zhang. 2025. "TSINet: A Semantic and Instance Segmentation Network for 3D Tomato Plant Point Clouds" Applied Sciences 15, no. 15: 8406. https://doi.org/10.3390/app15158406
APA StyleMa, S., Lu, X., & Zhang, L. (2025). TSINet: A Semantic and Instance Segmentation Network for 3D Tomato Plant Point Clouds. Applied Sciences, 15(15), 8406. https://doi.org/10.3390/app15158406