1. Introduction
Currently, LLMs are being widely developed in a variety of industries, including voice recognition, natural language processing, online Q&A, computer vision, and recommendation systems. Varieties of famous applications in different fields that make extensive use of LLMs are growing [
1,
2]. The number of methods and systems for generating LLM models is increasing [
3,
4,
5,
6,
7,
8]. It requires a large amount of expensive equipment, particularly including thousands of GPUs and high-speed Ethernet routers, to develop the transmission of massive data streams during the training period of the model. Additionally, a stable scheduling system and efficient model parallelism or data parallelism framework are developed for training LLMs. The amount of training data or datasets is an important factor which determines the capability of the LLM. For example, GPT-3 [
9] has 175 billion parameters pretrained from 45 TB datasets, and PaLM [
10], similarly trained from 45 TB data, which has 540 billion parameters. For the LLM training, GPUs distribute the hyperparameters and gradient accumulations of each node, as they are essential parts of the model. To make progress, GPUs actively collaborate with each other. As we all know, purposeful training model parallel and stability issues, including failures and delays, are notoriously difficult to diagnose and optimize in large-scale systems. To achieve a good and low training time result from the LLM, it is necessary to achieve the following: carefully develop the system’s structure; determine the functionality of each node; design the structure of connections, data flows, and commands; and implement a system for monitoring and correcting errors.
Based on Kubernetes [
11], many effective systems have been developed to generate LLMs. For example, in the MegaScale training system [
12], many components have been implemented to fix problems. The instances of many issues relating to the training system structure and the training process are as follows: achieving high training efficiency and stability at scale; failures and stragglers; maximizing the overlapping communication and computation; high network performance achievements; reducing pipeline bubbles; improving training efficiency without compromising accuracy; and reducing the iteration time.
In the MegaScale, several methods, works, and algorithms have been implemented to address the above-mentioned issues [
13,
14]. These are as follows: diagnostic tools to monitor system components and events deep in the stack; identification of root causes and implementation of effective techniques to achieve fault tolerance and mitigate stragglers; realization of the sliding window attention; application of parallel transformer block; LAMB optimizer based on the pattern of each parallelism strategy custom techniques and optimized for a specific task network topology; decreasing the number of ECMP hashing conflicts; enhancing the checkpoint and recovery procedures to decrease interruptions; adjustment of congestion control configuration and retransmit timeout parameters; creating heartbeat messages that contain diverse forms of information, which aids real-time anomaly and early warning detection; developing a set of diagnostic tests that pinpoint the nodes that are causing disruptions; a software for performance analysis that records fine-grained CUDA events, generates system-wide heat maps, and traces timelines from a distributed perspective; a 3D parallel training visualization tool, which will demonstrate data dependencies between diagnostic ranks; utilizing different pipeline scheduling strategies; crafting methods to conceal the extra work involved in all off-the-critical-path operations; and fusing LayerNorm and GeLU kernels together [
15,
16].
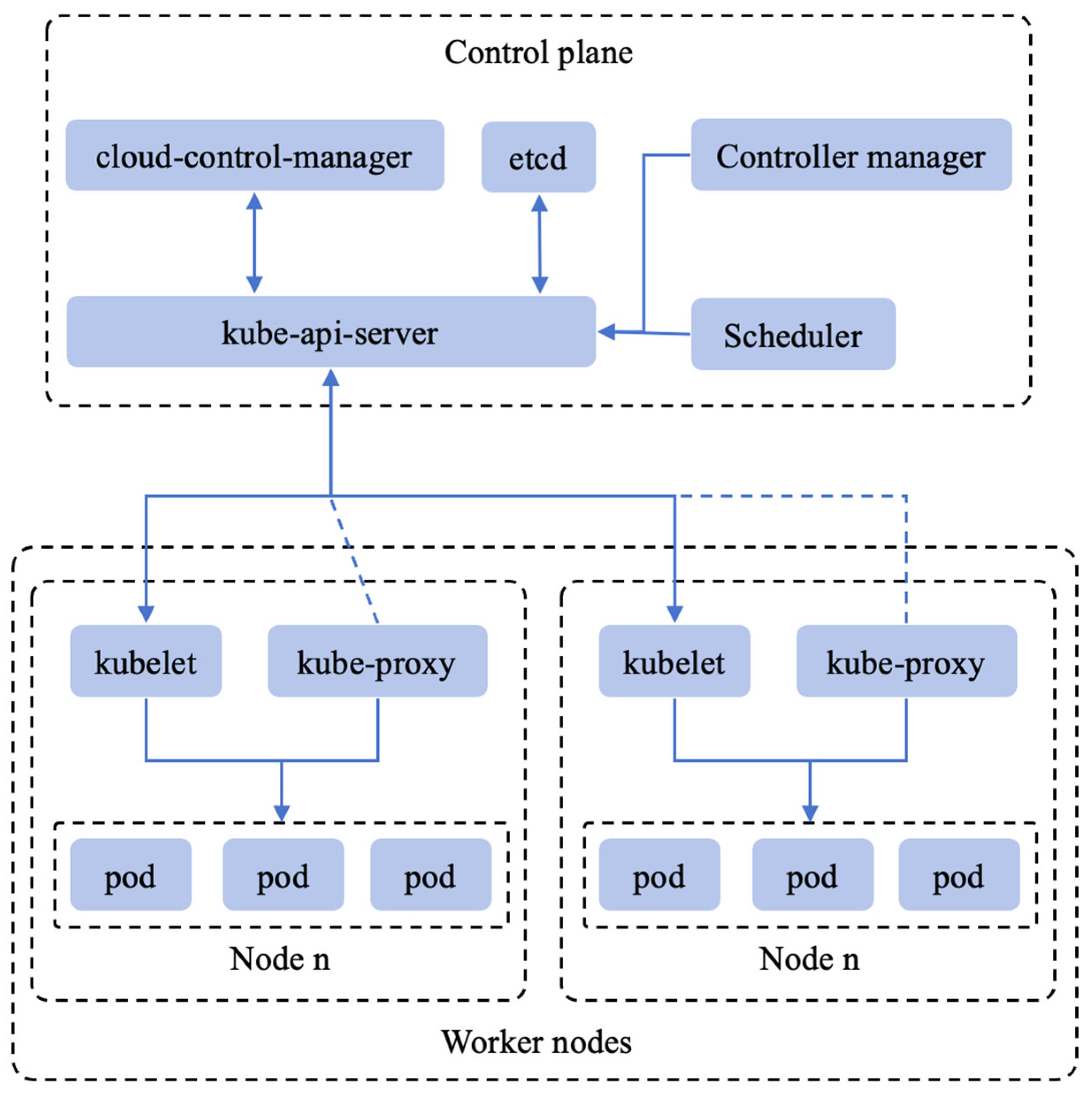
However, Kubernetes is a general-purpose orchestration platform for containerized applications. It is worth noting that Kubernetes was not originally designed for model training based on
Figure 1; therefore, it requires many third-party extensions and various programs to mitigate the influence of training LLMs. The details are as follows:
Kubernetes cannot provide advanced scheduling. The vanilla version cannot even provide a method for performing a single job on many nodes, which can lead to training LLMs with low efficiency. To improve scheduling efficiency, it is necessary to develop a complex method that takes into account Kubernetes’ massive structure.
Kubernetes cannot provide granular management of the hardware, while device plugins can offer the same function. However, designing or installing these plugins requires specialized engineering skills to offer such granular management of the hardware.
Kubernetes requires researchers to design or install additional Kubernetes operators by themselves to provide the ability to train the LLMs. The list of additional Kubernetes operators is as follows: NVIDIA GPU Operator, NVIDIA Network Operator, MPI Operator [
17], Training Operator, some solutions for shared filesystems and databases, etc.
Kubernetes requires researchers to implement etcd, monitor the network, and integrate SSL, where everything works more or less smoothly if the developer does not tinker with it.
When researchers are training LLMs on Kubernetes, the training workload must be containerized and follow the cloud-native principles. According to the description of MegaScale, it is essential to deeply transform the underlying architecture of Kubernetes and concurrently transform the distributed training programs to ensure successful cluster execution of large model workloads.
Each stage requires specialized engineering skills and expertise, contributing to the manual costs and complexity of developing LLMs. Due to the complexity of a training system based on Kubernetes, pretraining the LLM requires more time in system environment setup. Therefore, it requires a considerable number of programmers and a significant amount of time to implement numerous algorithms, which causes the process of pretraining LLM to involve a lot of manual labor costs and low actual utilization of large-scale GPU cluster computing power (occupying approximately 30% of the entire cluster lease time). The GPU cluster must remain on during this period. Although academic papers have suggested an efficient MFU with this system, the K8S-based cluster system actually incurs higher costs for training LLMs.
As shown in
Figure 2, Slurm [
18] and Kubernetes solve similar problems and offer comparable services. Both can be used for model training or other high-performance computing tasks. Slurm is extremely popular in the HPC industry [
19]. It is implemented on over half of the Top 500 supercomputers in the world and many research labs, universities, and large corporations developing HPC. Compared to Kubernetes, Slurm has a long history of running workloads for all kinds of institutions performing intense computations. While Slurm was not originally designed for LLM training, it has been adapted to current needs (for example, through support for GPU computing). Slurm’s original structure is much closer to current machine learning requirements than that of Kubernetes.
As shown in
Table 1, compared to Kubernetes, Slurm’s scheduler is smart and efficient. It is designed for supercomputers and can process on a massive scale with tens of thousands of nodes with hundreds of jobs per second. Researchers can directly implement distributed training programs on it without additional configuration. Slurm realizes the flexible management of hardware resources; it distinguishes CPU sockets, CPU cores, and hyperthreads. Additionally, it provides the ability of GPU sharding and network topology, where researchers can submit single or multiple tasks on a random node; Slurm is highly compatible with PyTorch structures, allowing researchers to submit tasks on each node. It is easy to extend and integrate some functions, for example, programming a heartbeat task to monitor the health of each node.
Therefore, this paper presents a highly efficient and simple training system implemented on 1024 GPU cluster, which employs the following methods: dynamic hybrid shared strategy for parallelling model parameters and data, employs a self-detecting, fault-tolerant distributed structure based on Slurm to maintain the health of the running GPU cluster. The main advantage of the proposed approach is the purposeful simplicity of the environment and scheduling for training an LLM, which significantly reduces manual labor costs, and relatively speeds up the training time of the LLM system.
Section 2 of this paper describes the proposed system for the training process and its distinctive details based on Slurm and FSDP.
Section 3 presents the results of implementing the designed system.
Section 4 conducts a comparative analysis of existing systems and the proposed system.
Section 5 further develops the research plan proposal and its anticipated consequences.
Section 6 provides the conclusions.
2. The Pretraining System
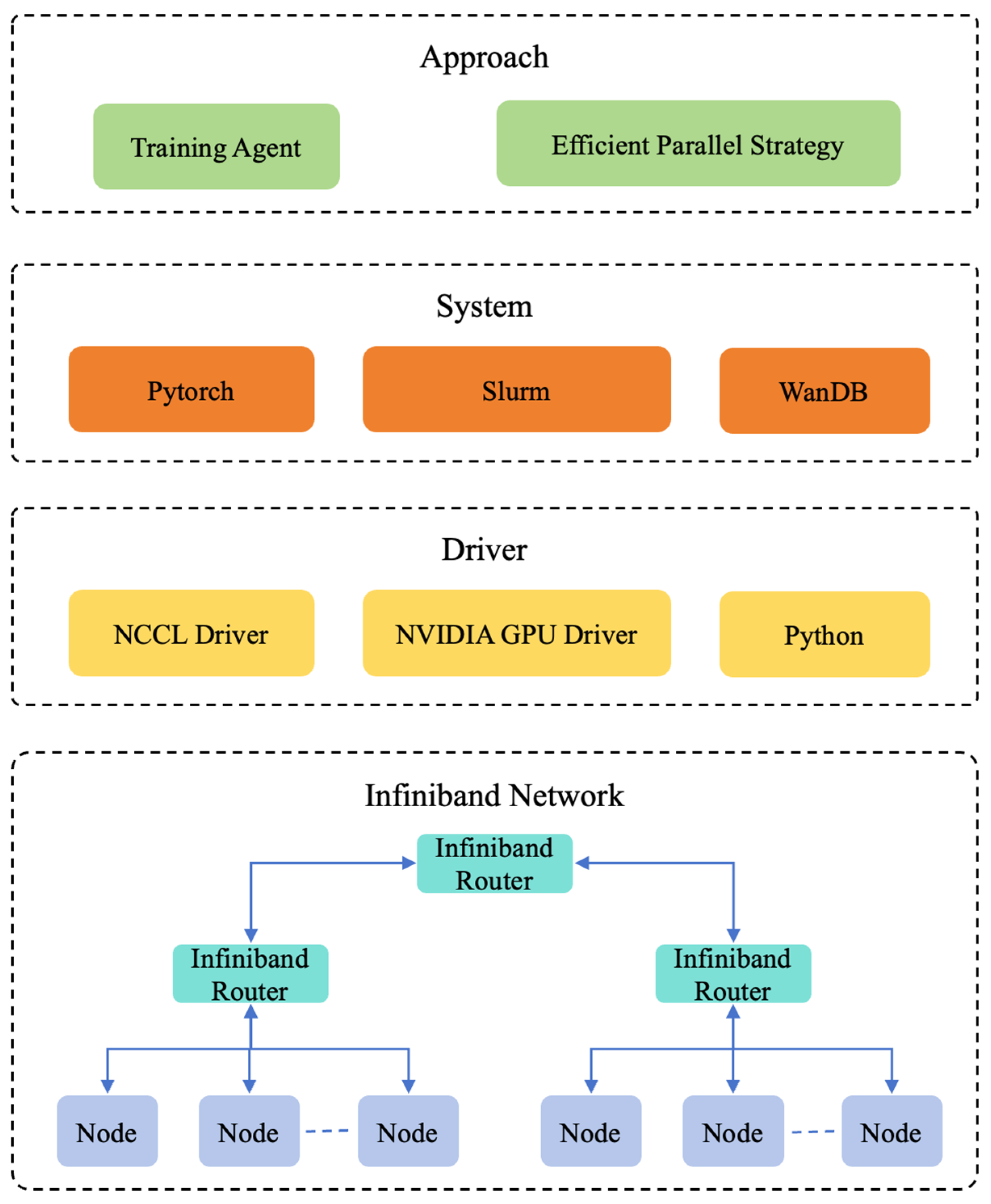
The proposed system structure is described in
Figure 1. It consists of four layers, each showcasing technical details of hardware and software. At the bottom, Node represents the real computer machine, communicating through the two-layer InfiniBand protocol [
20]. In the second layer, NCCL [
21] and NVIDIA GPU Driver, powered by NVIDIA Inc., Santa Clara, CA, USA, is implemented on the computer machine to perform GPU data exchange and parallel computing. The third layer is the basic component for our proposed system, which includes Pytorch 1.12 [
22], Slurm 21.08.8, and Wandb 0.17.4. The top layer focuses on the development approach, including optimizing the GPU distributed system and an efficient parallel strategy. In summary, our proposed system is simple and efficient, enabling rapid implementation on the GPU cluster. The details of our system are shown in
Figure 3.
2.1. The Proposed GPU Distributed System
The preparation and error time for the LLM training environment occupy approximately 30 percent of the whole training time, which, in real situations, is determined by the GPU distributed system implemented. Decreasing manual labor costs in training LLMs requires developing a simple and efficient GPU distributed system, which includes an error tolerance agent to monitor system components and events.
Based on the architecture of a classic Slurm cluster (
Figure 2), we created a robust pretraining framework for LLMs. This framework automatically detects errors, recovers quickly from the latest checkpoint, and implements error tolerance with minimal human interaction. Additionally, it has negligible influence with running LLM training processes.
2.1.1. Optimized Pretraining Framework
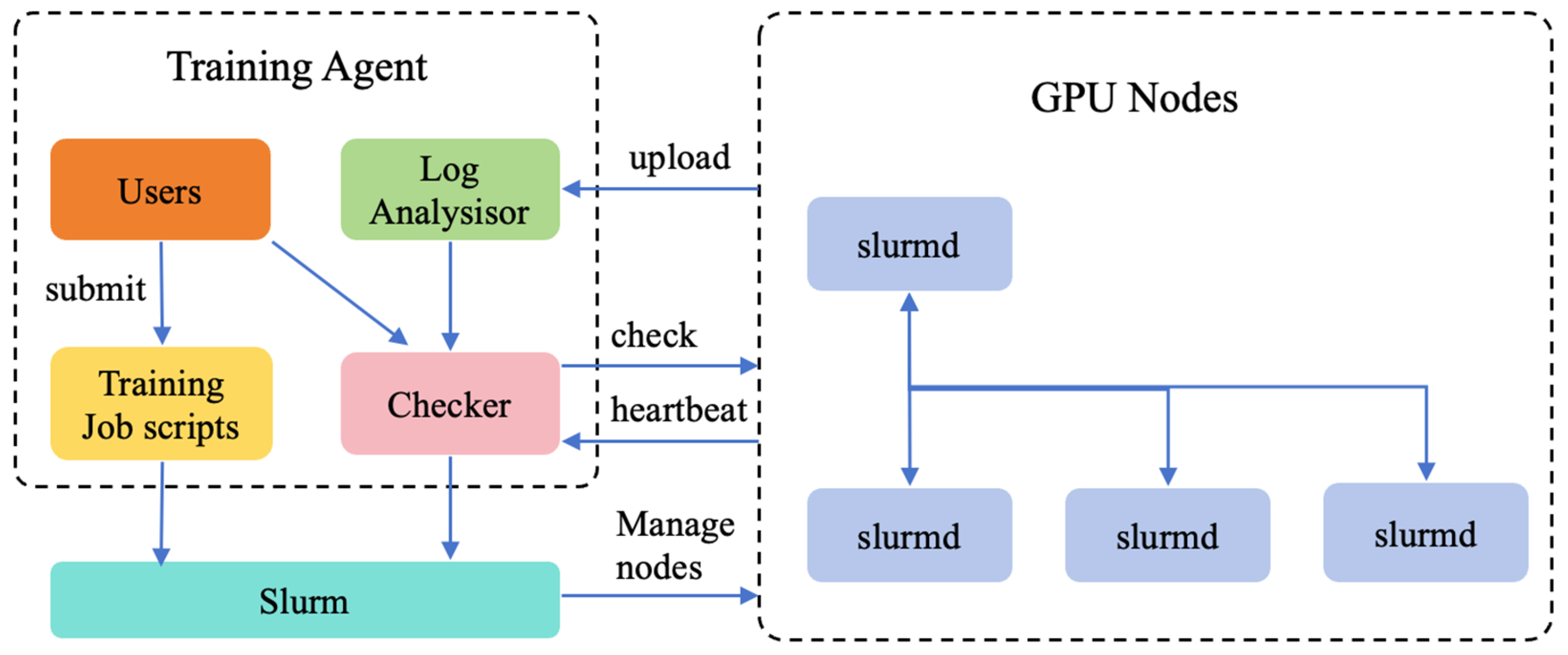
As shown in
Figure 4, the training agent process connected to a Slurm is created to distribute GPU nodes and initiate the appropriate slurmds for each node when a training job task is submitted. A slurmd can manage only one node. After completing several initialization tasks, the slurmd builds the training task on each node and a robust pretraining daemon that sends heartbeats to the training agent on a regular basis. The messages contained in these heartbeats are designed to perform real-time anomaly tests and give early warnings of problems. If an error status is detected in a specific pretraining task or if a slurmd cannot receive a heartbeat within a defined time window, the training agent initiates the error recovery process, suspends the running training job across all slurmds, and submits the script to perform a series of self-diagnostics. These diagnostic programs are designed to be lightweight yet comprehensive and can handle most general hardware and software errors. The training agent will shut down the GPU nodes by submitting its ID when faulty nodes are detected. In response to the slurmd’s message, Slurm closes the faulty GPU nodes and adds the cluster with the same numbers of good GPU nodes that were detected by our diagnostics. In addition, users can manipulate nodes through submitting scripts. When the recovery is finished, the training agent restart training from the newest checkpoint. Our work focus on developing checkpoint and restart tasks to optimize the loss of training process, which minimizes the restart time of training LLM to 10 min.
2.1.2. Message Organize and Analysis
The messages of heartbeat contain the essential information of the slurmd, such as the active state, the network traffic, and the GPU utilization. In addition, the real-time data of the pretraining process is uploaded, allowing the agent to rapidly analyze any important errors. The standard Linux output and error logs of training processes are contained. These messages will be filtered and detected on the cloud. Once the special bug and warning keywords are found, the agent will upload the current diagnostic data.
To improve the detection of pretraining robustness and stability, our work has implemented a detection system, which can reach the millisecond level. Multiple levels of detection are developed to follow different indicators. Second-level detection generally aims to monitor the sum health condition and to eliminate common configuration influences of pretraining.
2.1.3. Diagnostic Program and Running
A contradiction exists between running time and correctness of self-detect analysis. The long detection period results in adversely affecting the efficiency of training time, which can lead to high error correct rates and cause misjudgment of the health state of the machine. Based on a variety of experiments and optimizations, we have implemented a series of simple analytical tests, which can effectively handle various hardware and software bugs and errors in the period of training process.
For testing potential errors on GPU communication, the agent develops a detailed end-to-end experiment among the GPUs, to monitor whether the network bandwidth meets essential benchmarks.
2.1.4. Optimal Checkpoint and Fast Resume
The agent is required to retrieve the training by loading model weights and optimizer states from the newest checkpoint when detecting and identifying a crash machine. It is important to ensure the checkpoint is close to the pretraining state when the crash occurred, to optimize the loss of the GPU computation and the training time. By reducing the checkpoint saving interval during pretraining, we can achieve this. Additionally, this minimizes checkpoint latency, especially the time spent on the special path during pretraining process.
To perform rapid checkpoint, the agent adopts an improved two-level method. On the one hand, each node slurmd saves its states to the machine’s memory and meanwhile goes on with the pretraining process. The high NVLINK bandwidth has made it possible to minimize this task to several seconds with the improvement in Pytorch’s parallel rule [
23]. On the flip side, an online background thread periodically sends the state from the machine’s memory to a network file system (NFS [
24] in our implementation, connected with our system by Infiniband 100 Gbps protocol) for centralized maintenance. This two-level method enables rapid GPU recovery from training crashes.
2.2. Efficient Parallel Strategy
In the industry of LLMs, efficient LLM pretraining in a thousand GPU cluster is essential. As the number of model parameters and accuracy increase, the requirements of GPUs have also exploded. Realizing these scale computational needs without compromising model accuracy requires the development of dataset pipeline management, optimized parallel sharding strategies, and fast iterator computations.
2.2.1. Dataset Pipeline Management
Dataset chunking and loading are generally ignored. Furthermore, these tasks lead to a significant amount of the GPU idle time being wasted at the start of every pretraining step, because the chunking of the dataset is performed on the CPU. To improve these tasks is important for minimizing the time taken in the pretraining process.
The dataset chunk is not on the essential workflow’s path. The data chunk for the next training step can start when the GPU tasks sync gradients at the end of every step, which is performed as a background process.
After the dataset chunking, data loader workers need to be created for distributed training. Each GPU process is performed with its own data loader. The machine memory loads the chunked data before forwarding it to GPU memory. This mechanism leads workers to compete for read IO bandwidth, which can easily result in training bottlenecks. During pretraining, eight GPU workers in the one node are in the same data parallel team. Therefore, the input of each iteration is essentially the same. According to this observation, we implemented a simple and fast method: to load chunked data into a shared CPU memory, with each node having one data loader. After reading data into the shared memory, each GPU worker copied the chunked data from memory to its GPU memory. The approach reduces excess reads and, importantly, minimizes the time of data loading.
2.2.2. Dynamic Hybrid Sharding Strategy
Efficient parallel processing for the model parameters and dataset becomes paramount in the training process. As is well known, extensive model training involves significant engineering complexity.
As shown in
Figure 5, the FSDP works comprises three main parts: constructor, forward path, and backward path. Constructors have shard model parameters, and each rank keeps only its own shard. The forward path obtains the world size of the GPU cluster, calculates iterator steps of training according to the dataset, and then performs all-gather to collect all shards from all ranks to recover the full parameter in this FSDP unit, performs forward computation, and discards the parameter shards that it has just collected. Backward path performs all-gather to collect all shards from all ranks to recover the full parameter in this FSDP unit, performs backward computation, and performs reduce scatter to sync gradients and discard parameters.
Based on the above process of FSDP, it offers various alternative fragmentation strategies, which determine how your model is sharded across GPUs and machines. The strategies are as follows:
FULL_SHARD (For very large models that do not fit into a machine. The model is sharded across all GPUs on all machines. Requires a cluster with fast inter-node network).
SHARD_GRAD_OP (Slice gradient and optimizer state across workers).
NO_SHARD (Does not fragment anything; this is equivalent to DDP).
HYBRID_SHARD (For models that fit into a single machine, e.g., TinyLlama [
25] 1B-3B on an 8xA100. This will shard the model within the machine but replicates across machines. Useful to avoid slow network bottleneck between machines).
In the fragmentation strategies of FSDP, HYBRID_SHARD is performed when the work can fit the LLM model inside a single node, while it always cannot work when the model is implemented on multiple nodes. Using the HYBRID_SHARD can lead to 100% of network bandwidth occupation on multiple nodes, which can lead to cluster crashing. Then we must introduce the FULL_SHARD sharding strategy across all GPU nodes. At eight nodes and below, this paper employs the FULL_SHARD sharding strategy (one of the FSDP strategies), yielding similar results to those obtained with the Lightning-AI [
26] cluster. However, when scaling the cluster from eight nodes to 16, 32, 64, and 128 nodes, our cluster encounters several issues. For data parallel training, when the number of nodes reaches 16 or more, the data communication link becomes highly complex and lengthy, for example, due to sharing across all GPUs and the two-layer Infiniband network (
Figure 3), the communication latency between the first and the last nodes reaches about 45 min, resulting in substantial time spent splitting the LLM model into chunks in the 1024 GPU cluster. In the realm of LLM pretraining engineering, network fluctuation can lead to a longer period of training for the LLMs. The cluster crashes because of synchronizing the data timeout, which has a default timeout of 30 min.
Based on this observation, the proposed work adopts the Dynamic HYBRID_SHARD sharding strategy (combining the FULL_SHARD sharding strategy and the HYBRID_SHARD sharding strategy), which is a two-layer approach, as follows:
At the top layer, as
Figure 6 shows, the FULL_SHARD sharding strategy is used across a group of multiple nodes. For example, when our cluster scales to eight nodes and the minimum number of nodes required for the LLM model to run is four nodes. (In this work, the default number of nodes is four as a group). In each group, the method performs FULL_SHARD sharding strategy to full sharding. This leads to a reduction in the FULL_SHARD data exchange to 50%.
At the bottom layer, implement HYBRID_SHARD sharding strategy into these groups. Within each group, shard the model and then replicate it across all groups. This reduces communication volume by limiting expensive all-gathers and reduces scatters to within a node, improving performance for medium-sized models.
2.2.3. The Configuration Optimization
Our work makes various modifications and incorporates the simple optimization at the configuration level of the training process to minimize the time of the training process, without compromising accuracy.
We set the max tokens for the end of the training process, which stops training after this many tokens have been trained across all GPUs. Additionally, we adopt a parallel version of a simple formula to calculate the max iterator for the gradient updating.
where the max_tokens_per_device represents the max tokens of each node. max_tokens represents the whole tokens in this period of training LLM. world_size is the number of GPUs in the cluster. tokens_per_iter is the tokens of each iterator. micro_batch_size is the number of GPUs in each node. block_size is the length of the sequences in the training process. max_iters is the max iterator numbers in this training process. The computation of gradient updating can be performed in parallel using this method, which results in reduced computation time.
Additionally, we set the micro-batch size to eight, which is the highest possible to efficiently utilize the cluster’s GPU memory and push GPUs to 99%+ utilization. Of course, the proposed work uses the BF16 for training, which offers essentially the same prediction accuracy as a 32-bit floating-point format while significantly reducing power consumption and improving throughput with no additional time consumed.
3. Results for the Proposed System Implementation
Currently, the suggested approach is implemented in the Linux operating system version 5.15.0-94-generic-x86_64-with-glibc2.17, using the Python programming language version 3.8.11. Each executing node includes 96 CPUs and 8 GPUs, NVIDIA H100 80 GB HBM3 [
27].
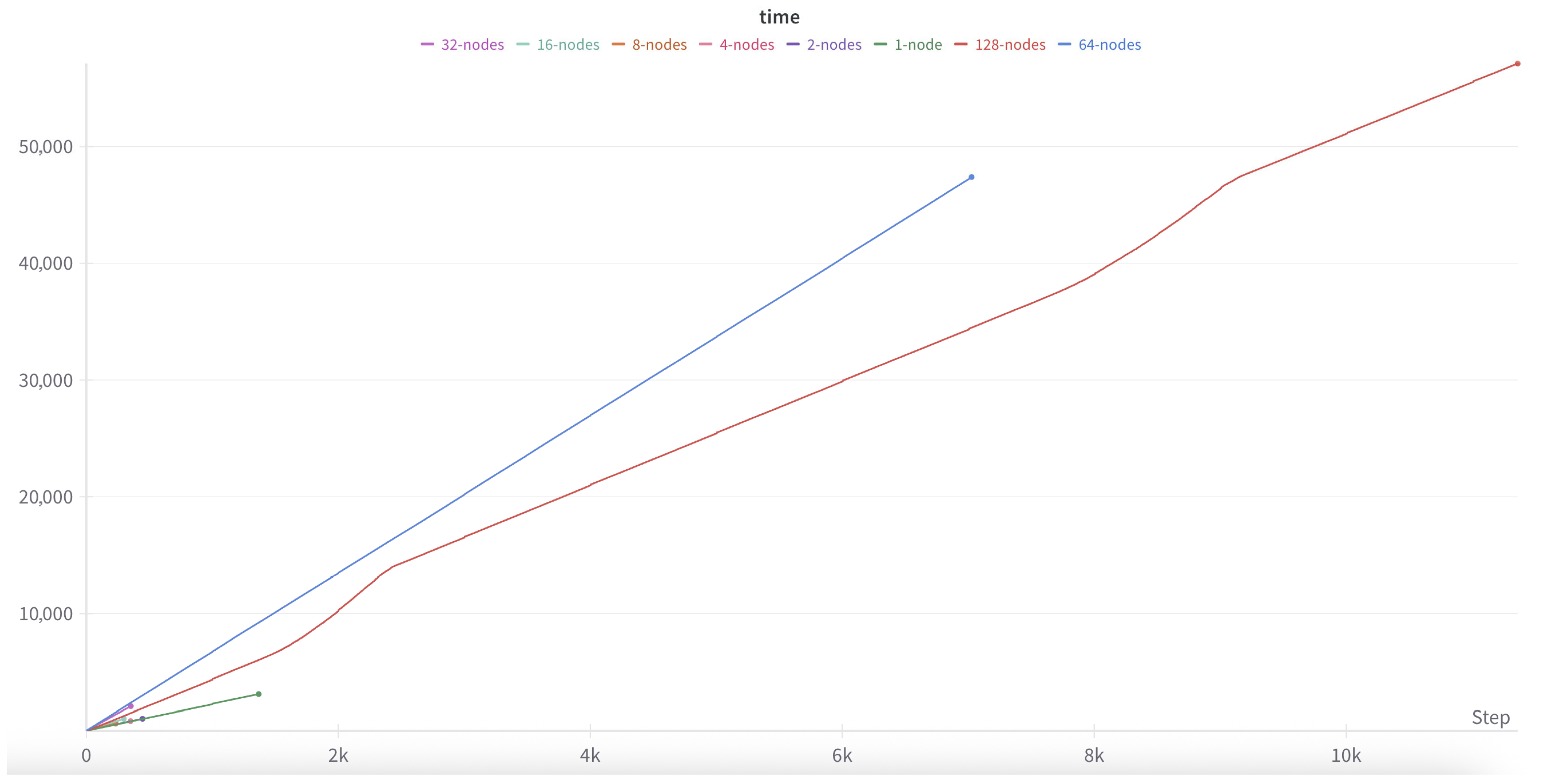
Experiments were performed with the number of executing nodes set to 16, 32, 64, and 128. Finally the work completed the whole of 128 node training process because of the expensive cost of H100. Additionally, performing 16, 32, and 64 nodes period test (every test continued to 2 days for stable remaining day’s computation) for calculating the time of the whole training process. The log of training the LLM on the present system is shown at
https://api.wandb.ai/links/jnist/v5bnkz47 (accessed on 24 July 2025). During the training, a log file is generated at each step, where the iteration numbers, step number, loss, iteration time, and remaining time are recorded.
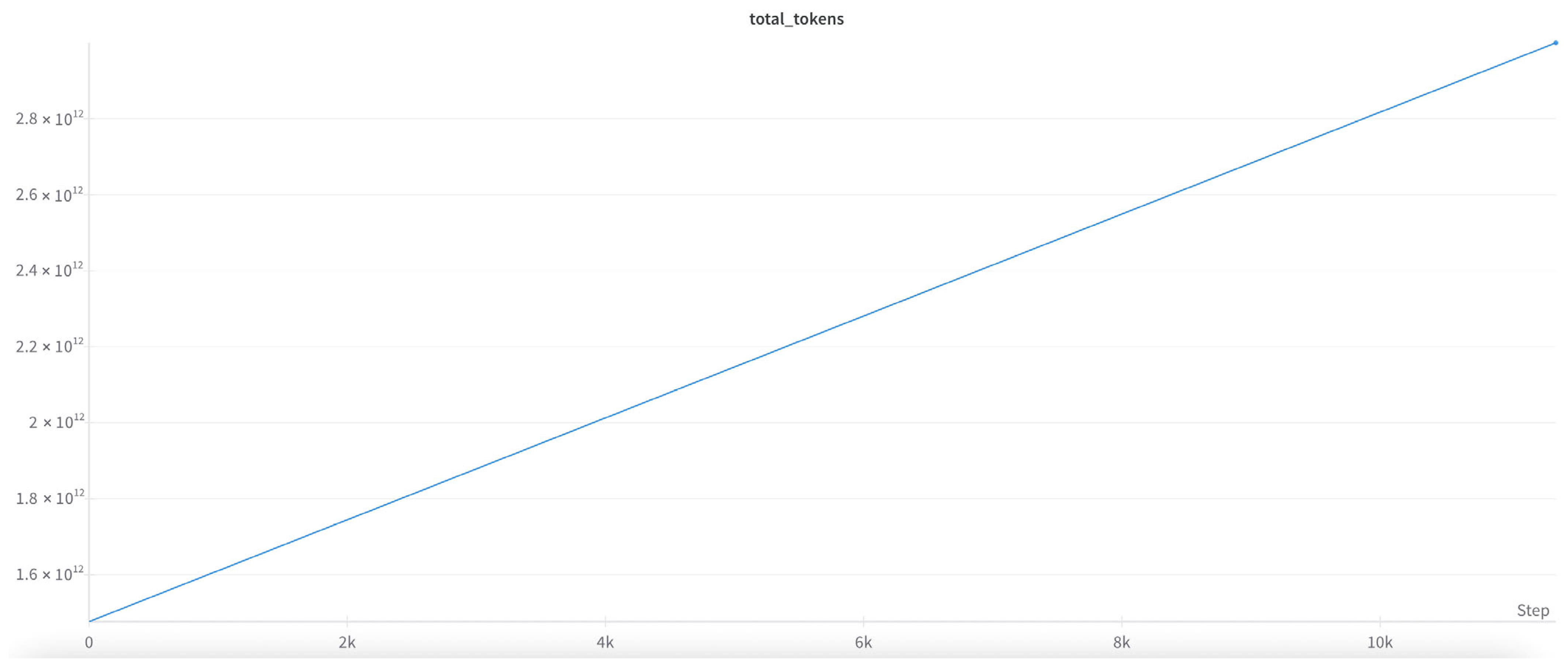
The proposed 1024 GPU cluster is tested on TinyLlama, an open-source, small language model with 1.1 billion parameters and 300 billion tokens (as shown in
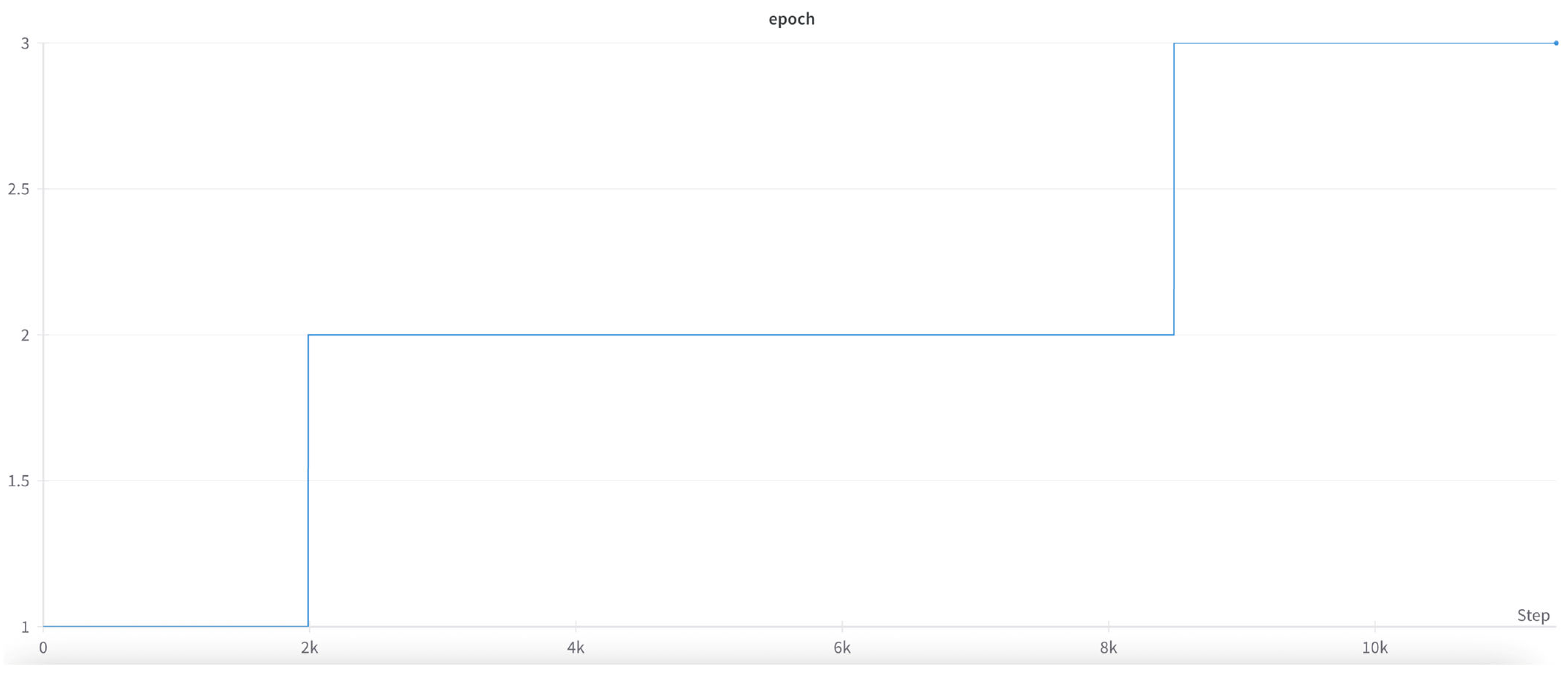
Figure 7). The whole training process includes three epochs, as shown in
Figure 8.
The system performance graphs based on various parameters can also be plotted.
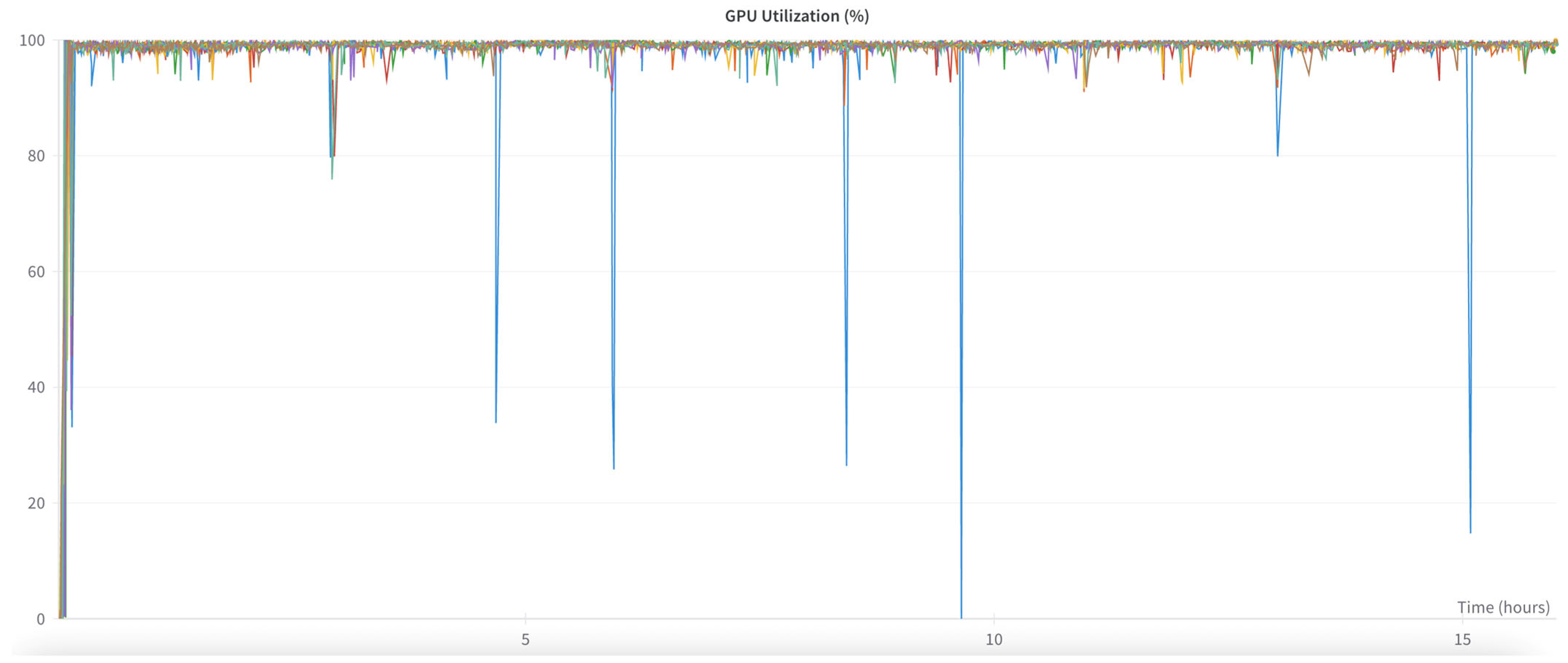
Figure 9 illustrates the degree of GPU utilization for multiple numbers of GPUs involved in training, as a function of training time.
Figure 10 illustrates the training loss and running state of the 1024-GPU SLURM system for TinyLlama. In general, two crash events occur, which are similar to those reported by the original authors of TinyLlama and Lightning-AI.
5. Discussion and Future Work
Generally, using a large-scale model pretraining platform typically requires a certain amount of time, compared to the duration of model training for platform compatibility tasks. Platforms such as MegaScale may even demand more time. Remarkably, our objective is to achieve a real experience by ensuring no code modifications or platform compatibility issues are necessary. The team in this project took less than two days to train TinyLlama directly.
In the future, our focus will be on optimizing the cluster at the low level to boost computational efficiency. The general PyTorch framework employed for one-click training, which aims to reduce actual large model training time, does not fully leverage the computational power of the H100 GPU. As indicated in
Table 1, the Model Flops Utilization (MFU) only reaches 43.8% or 38.6%. This is because TinyLlama utilizes flash-attention2, and an algorithm was optimized explicitly for A100 GPUs. Moving forward, the project team plans to integrate flash-attention3, which present three essential methods to accelerate attention on H100 GPUs (leverage the asynchrony of tensor cores and TMA to overlap overall computation and data movement through warp-specialization and interleave block-wise matmul and softmax operations, as well as block quantization and incoherent processing that leverages hardware support for FP8 low precision), with the expectation that MFU will exceed 60%.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}