1. Introduction
In recent years, virtual space technologies such as XR and the metaverse have been rapidly advancing, leading to the widespread adoption of head-mounted displays (HMDs). Among HMDs, smart glasses designed for mobile users have garnered significant attention. However, text input methods for smart glasses in mobile environments are not yet well developed, and improvements in usability and accuracy are required.
Currently, text input methods for HMDs, including smart glasses, can be broadly classified into physical keyboards, voice recognition, and virtual keyboard projection. Physical keyboards allow users to input text similarly to conventional PCs, but they are inconvenient for mobile use due to the need to carry and place them somewhere ([
1]).
Voice recognition eliminates the need for a keyboard, but it has privacy concerns and is susceptible to background noise, making it difficult to use in public spaces. Pascual et al. [
2] found that input via speech recognition is subject to noise and social acceptability, as well as privacy restrictions when entering passwords and private messages.
Due to these limitations, virtual keyboard projection has attracted attention as a promising input method for HMDs.
Virtual keyboards can be projected onto a flat surface, such as a desk, or in midair, and users can select keys using controllers, eye tracking, or hand tracking. Traditionally, controllers have been the most common input method, but they are not ideal for mobile use due to portability issues. Eye tracking requires high-precision eye trackers, which are expensive and have not yet been widely adopted. Hand tracking, on the other hand, is relatively cost-effective and has improved in accuracy, as many recent HMDs are equipped with advanced hand-tracking capabilities. However, two major challenges remain—the accuracy limitations of hand tracking and the lack of haptic feedback—both of which contribute to input errors.
Input errors caused by hand tracking occur due to discrepancies between the detected hand position and its actual location, leading to unintended key selections. Dudley et al. [
3] state that the use of a virtual keyboard in the air is challenged by the lack of haptic feedback and the inability to place part of the hand or arm on a physical plane. They also state that tracking errors and delays exacerbate these inaccuracies. One potential solution to reduce input errors is to enlarge the keys; however, in QWERTY layouts, increasing key sizes takes up more screen space and requires larger hand movements, which can lead to fatigue. Thus, alternative approaches, such as reducing the number of keys and supplementing key selection with additional gestures, are being explored.
This study proposes a new text input method called “FlickPose,” with the objectives of developing a text input method optimized for mobile environments and evaluating its effectiveness in comparison to standard methods. FlickPose is based on the flick input keyboard layout and allows users to select keys through a touch-panel method and a raycast method. Additionally, left-hand gestures are used to determine the characters to be input.
Here, the focus of this research is on smart glasses, which are devices intended for use in a mobile environment. However, currently available smart glasses do not have a hand tracker with sufficient accuracy. Therefore, this study implements the system on Meta Quest3, a VR/MR HMD as an alternative device, and incorporates a machine learning model to estimate the hand pose of the left hand, thereby improving input accuracy.
FlickPose addresses the limitations of conventional input methods and seeks to provide a more intuitive and comfortable text entry experience.
The contributions of this research are as follows:
This study introduces FlickPose, a text input system that combines right-hand key selection with left-hand pose recognition to replicate flick-style input in mobile environments for HMDs. The system is optimized for mobile use, addressing limitations of physical keyboards and voice input by offering a portable and privacy-friendly solution for on-the-go users.
- 2.
The implementation of a raycast-based touchless input mechanism to reduce input errors.
To mitigate false inputs commonly caused by a lack of haptic feedback, FlickPose implements a raycast-based input method, allowing users to select keys by pointing a ray from the wrist and confirming input with a pinch gesture. This enables accurate input while maintaining visual focus on the text entry field, improving usability in immersive AR/VR contexts.
- 3.
The development and evaluation of a high-accuracy hand pose recognition model using MLP.
A machine learning model based on a multi-layer perceptron (MLP) was developed to classify five predefined left-hand poses used for character selection. The model uses preprocessed fingertip joint data from the HMD’s hand tracking system. Experimental comparisons with Random Forest, LightGBM, and a rule-based method showed that the MLP model achieved higher accuracy, stability, and generalizability, suggesting its suitability for real-time interaction.
2. Related Work
2.1. Text Input Methods for XR Users
In recent years, however, there are also methods that use HMDs and other sensors to acquire data on the HMD user’s body and use body movements to operate XR applications when wearing an HMD. Typical body data used for manipulation when wearing an HMD include hand data and gaze data.
Since methods using controllers are generally superior to those using the hand or eye gaze in terms of accuracy, research has been conducted on new character input methods using these devices. For example, Jiang et al. [
4] proposed a method for character input by arranging keys in a circular pattern on a controller touchpad. Gugenheimer et al. [
5] and Lee et al. [
6] proposed method to operate a touch-panel on the front of the HMD. As examples of using other devices, Kim et al. [
7], Lu et al. [
8], and Chen et al. [
9] proposed methods using a smartphone for text input. On the other hand, Speicher et al. [
10] pointed out that while the method of pointing a controller at a virtual keyboard is superior in performance, it may lead to fatigue after long hours of typing. In addition, these methods are not suitable for mobile users, as the controllers need to be carried separately from the HMD when used.
As a method using gaze data, Kishi et al. [
11] proposed combining gaze and hand movements for flick input. Lu et al. [
12] compared methods for inputting text using eye gaze only, which involved inputting text using dwell, blinks, and eye movement. However, methods using eye gaze data have not gained widespread acceptance due to the high cost of devices equipped with eye trackers.
Therefore, in implementing a text input system, we use hand data from the viewpoint that data can be acquired by the HMD alone and are expected to be widely used in the future from a price standpoint. Since current smart glasses are not equipped with a hand tracker of sufficient accuracy, Meta Quest 3 will be used as the device to implement the character input system.
Meta Quest 3 analyzes images from the headset’s built-in camera to estimate the position and orientation of a total of 24 joint points on the fingers, arms, legs, and torso; by using the Oculus Integration SDK, this information can be obtained in Unity.
2.2. Hand Tracking for Typing on Virtual Keyboards
When creating a text input system utilizing hand tracking with HMDs, the typical methods of placing multiple objects such as keyboards are to project keys onto a physical object such as a desk or the user’s body, or to project virtual objects such as keys or panels into the air.
The advantages of projecting a keyboard onto a physical object are that the distance to the keys can be intuitively understood and tactile feedback can be obtained when touching the keys, making it easy to establish that they have been touched. On the other hand, a method based on the use of a physical plane or the like may become impossible to use in an environment where a flat surface such as a wall or desk is not available in the vicinity, making it necessary to take measures such as adjusting the method so that it can be even used in the air. Methods to obtain tactile feedback without using a physical plane exist; these involve touching the user’s body. Whitmire et al. [
13] proposed a method that assigns QWERTY-arranged keys to the joints of the fingers—other than the thumbs of both hands—and performs character input by touching them with the thumbs. Xu et al. [
14,
15] concentrated multiple keys on the fingertip of the index finger, enabling character input using only the thumb and index finger. As another example, Darbar et al. [
16] proposed a method of projecting a virtual keyboard onto the palm of the hand. Although methods using the user’s body can provide tactile feedback in many situations in the mobile user environment, they have the disadvantage of limiting the area on which the keyboard can be projected due to large individual differences in body size and other factors.
Methods using virtual objects allow the use of key layouts and functions that mitigate the conventional restrictions on the position or shape of the objects. Regarding the position of virtual objects, Vatavu et al. [
17] studied the shape, position, and size of menus displayed on a smart glasses screen. Pascual et al. [
2] compared placements of a virtual keyboard and found that placing it parallel to the user’s viewpoint yielded the highest performance. On the other hand, methods using virtual objects do not provide tactile feedback, and they also introduce errors in hand tracking, so there is a risk of misrecognition and false touches during key selection. These errors can be reduced to some extent by enlarging the object, but at the risk of loss of comfort. One solution to this problem is to use a method that absorbs the blurring of hand movements during key selection by inputting words in units, or to adopt an arrangement that allows text to be input using a small number of keys.
As a method to input word units, Markussen et al. [
18], Gupta et al. [
19], Dudley et al. [
3], and Wang et al. [
20] employed gestural input, in which words are estimated from the cursor’s path on the keyboard. As for reducing the number of keys, assigning keys to points other than virtual objects, such as to fingertips or hand poses, is advantageous because the effect of tactile feedback can be ignored. Wong et al. [
21] proposed a method that assigns flick input keys to the joints from the index finger to the little finger and enables input by contacting them with the thumb. Jiang et al. [
22] proposed a method of assigning keys, with six alphanumeric characters each, to the nodes of the index and middle fingers and selecting a key during the first selection and a character during the second selection. Lee et al. [
23] assigned a row of alphanumeric characters to the left and right while maintaining a hand pinch motion. Chu et al. [
24] proposed a method to select a character by arranging keys on a plane and determining the row and column in sequence by hand posing.
2.3. Dealing with Environments Where Tactile Feedback Is Not Available
Jiang et al. [
25] proposed PinchText, a one-handed text input method combining hand position and pinch motions that eliminates the need for tactile feedback. It employs a flick-based key layout where users first select a row or column and then refine their choice with a pinch motion. Words are entered by choosing from predicted candidates. However, the precise input of passwords and proper nouns remains challenging due to the lack of pinpoint character selection.
Our study builds on PinchText by implementing raycasting for touch-free character input through hand and pinch movements. While PinchText supports only four pinch variations, which is insufficient for flick-based input, our method, FlickPose, integrates left-hand poses, enabling the input of Japanese characters, symbols, and complex text such as passwords and proper nouns.
2.4. Virtual Keyboard Display Position and Touch Detection
When using virtual objects for text input, the key layout and selection method, as well as keyboard placement, are crucial. Pascual et al. [
2] compared different AR keyboard placements and fingertip visual feedback methods using a QWERTY layout and Leap Motion for hand tracking. Their study tested raycast, which connects the fingertip to the keyboard with a line; glow, which makes the fingertip glow; and both combined. They found that View Parallel, where the keyboard aligns with the user’s view, was the most preferred placement, though visual feedback showed no significant difference.
FlickPose follows a similar View Parallel placement by positioning the keyboard below the text field. However, when the text field is not front-facing, the keyboard shifts accordingly, which may disrupt usability. Adjusting the keyboard position relative to the HMD could address this but may hinder real-time text monitoring. Further studies are needed to evaluate usability in practical scenarios.
Additionally, Pascual et al. dismissed Wrist Back, where the keyboard is placed on the arm, but this approach could provide tactile feedback. Mollyn et al. [
26] proposed EgoTouch, using machine learning and an RGB camera to detect arm touches with high accuracy. If arm-based keyboards prove effective, they could reduce false inputs while offering tactile feedback. This method could also enhance FlickPose by enabling UI panel projection on the left hand, allowing hand pose switching or pressure-based input with the right hand.
3. FlickPose System
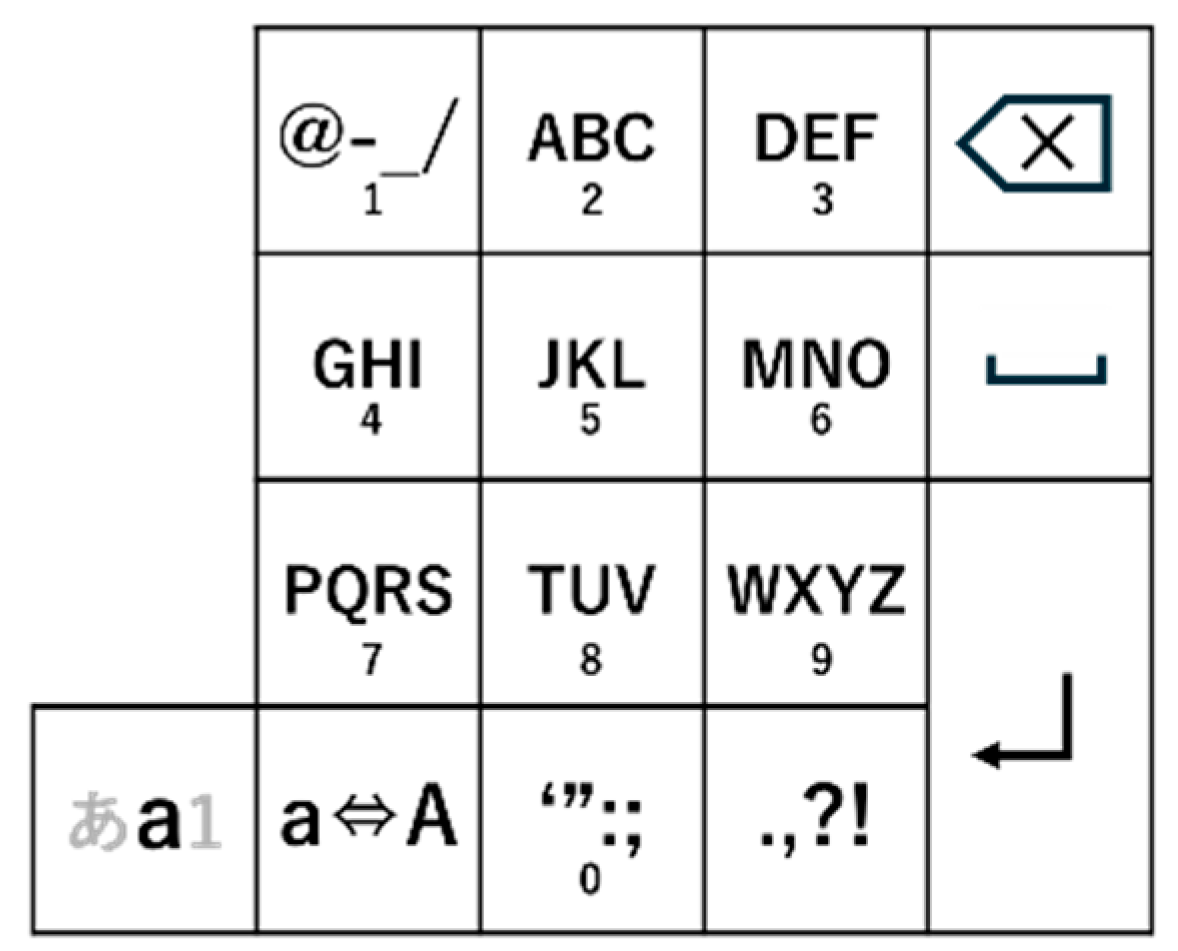
We employ a method that uses virtual objects. As for the key layout, this study implements FlickPose based on a flicking input layout with a small number of keys, as shown in
Figure 1. The lower left key represents the current mode, with representative characters for Japanese, English, and numbers.
The characters to be input by the character input system created in this study are hiragana, katakana, kanji, English characters, numbers, and symbols. To enable the input of these characters with a key layout based on flick input, the following six major functions are required.
Character input: inputting characters.
Delete: deleting the last character in the string being entered.
Character conversion: converting lowercase and muddled hiragana, and upper and lowercase alphabetical characters.
Word conversion: converting a string of hiragana characters into a string containing katakana or kanji characters.
Decision: fixing hiragana without word conversion.
Mode switch: switching between Japanese mode and alphanumeric mode.
To implement these functions, existing flick input uses the key layout shown in
Figure 1.
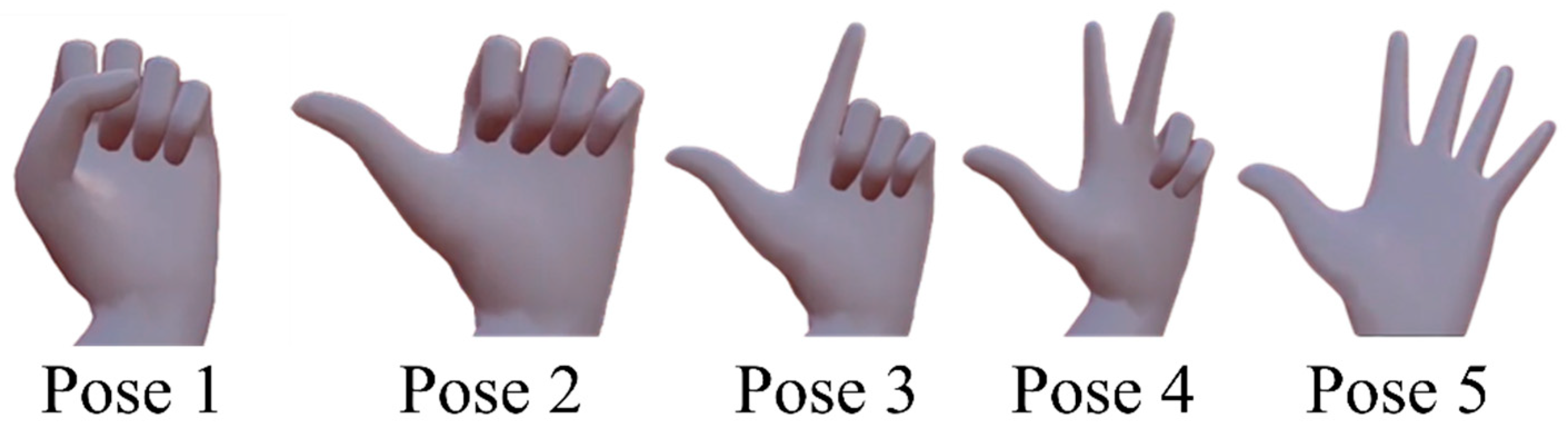
In the key layout for flick input, up to five different characters are assigned to each key for character input. After touching the key assigned to the character to be input, the user selects the character by either lifting the finger from the screen as it is or moving the finger up, down, left, or right, and then releasing it with a flick motion. However, it is difficult for users to perform an accurate flick operation in the air unless they are able to feel the finger. Therefore, instead of flick input, this system uses left-hand poses to select the character on the key; the user inputs the character corresponding to the hand pose. The hand poses used in this system are shown in
Figure 2. The hand pose determination method is explained in detail in
Section 3.
When virtual keyboards are used, they are typically placed either near the input field or in the user’s hand. Placing the keyboard near the input field raises the user’s arm, increasing physical strain. Hincapié-Ramos et al. [
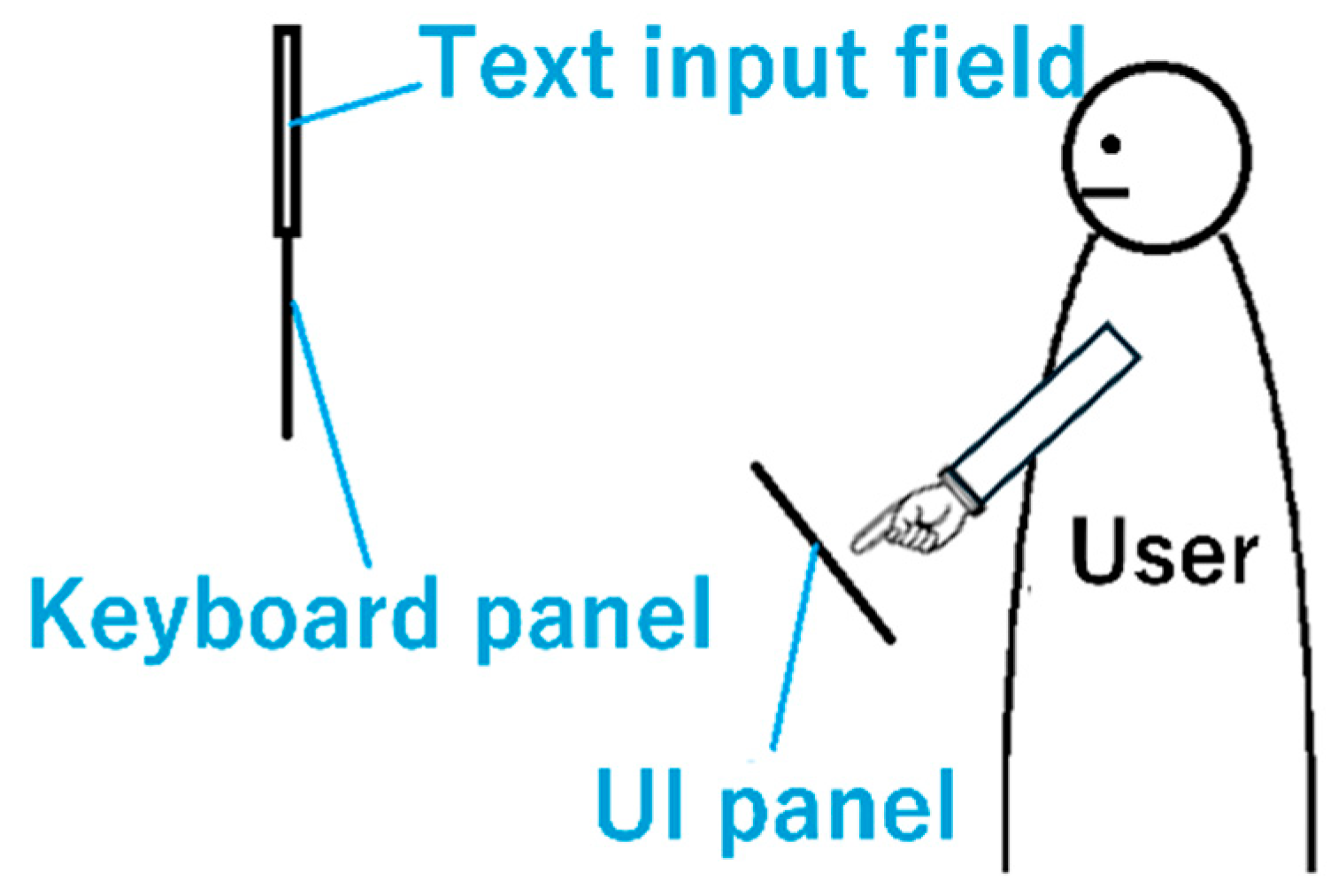
27] note that extended pointing at mid-air targets can lead to the “gorilla arm” effect, where the arm becomes fatigued. Alternatively, placing the keyboard in the user’s hand allows input using only the hand, regardless of the input field’s position, but makes it difficult to view the input field while typing. To address this, FlickPose displays a keyboard panel below the input field and an additional UI panel in the user’s hand, allowing key selection through the UI panel.
The UI panel consists of a panel with the same arrangement as the keyboard panel and a panel for all deletions, and keys can be selected by touching the panel corresponding to the key to be selected. The system also highlights the selected UI panel and its corresponding key to allow selection while checking the highlighted text input key without directly checking the UI panel.
Based on the above, this study implements FlickPose using virtual objects as shown in
Figure 3.
Figure 3 shows some Japanese characters: The character on the lower right of the Word conversion keys/panel means “Next”. The character on the Mode switch key/panel represents a typical Japanese character. The character written on the panel means “All delection”. The keyboard panel and UI panel are displayed directly below the input field and near the user’s hand, respectively. The position of virtual objects is shown in
Figure 4 when viewed from the side. In this study, each object on the keyboard panel is referred to as a key and each object that makes up the UI panel is referred to as a panel. The hand pose list is placed on the left side of the input column for confirmation of the user’s hand pose, and when the user changes the hand pose, the corresponding panel changes to red.
3.1. Text Input Methods
As mentioned above, text input in FlickPose is performed by typing keys while holding a hand pose. In this case, the key selection method is implemented in two ways: the touch-panel method and raycast method.
In the touch-panel method, as shown in
Figure 5, UI panels are placed in the air within the reach of the input system user, and the function of the keys corresponding to each panel is used by touching the UI panel with the fingertip of the index finger of the right hand and releasing it. While this method allows intuitive operation, similar to the conventional method, there is a risk of erroneous input in the air where the user cannot feel the finger. Therefore, another key selection method, the raycast method, is implemented.
In the raycast method, as shown in
Figure 6, the UI panel is placed farther back than the user’s hand can reach, and the user selects buttons by pointing a green straight line (ray) extending from the wrist to the UI panel. For the decision action after key selection, Huang et al. [
28] found that the most comfortable interaction is to touch the thumb with the fingertip of the index finger, and this study follows their lead and adopts the pinch action of the index finger of the right hand. Since raycasting allows users to select keys without directly touching the UI panel, it reduces false input caused by misjudging the distance to the keys, which is one of the drawbacks of using virtual objects.
For each character input method, all keys correspond to panels in the UI panel. To input characters, the user can select and use the panel corresponding to each button and all deletion panels in the touch-panel and raycast methods, respectively.
In this system, hiragana diacritic marks and the conversion between uppercase and lowercase English letters are handled using conversion keys. Kana-to-kanji conversion is performed using the conversion keys located in the conversion column above the character input keys. This column includes 11 keys, each corresponding to a candidate word, arranged in a 3 × 4 grid with an additional key to move to the next page. Each conversion key shows a candidate based on the unconverted portion of the input. If there are more than 12 candidates, the “next page” key allows users to view additional options. Users select the desired candidate by pressing the appropriate conversion key. The method for determining conversion candidates and the dictionary used are explained in the next subsection. Other available keys include the decision key and the delete key. The decision key confirms selected hiragana and excludes them from further conversion, while the delete key removes the last character entered.
3.2. Word Conversion
As mentioned above, FlickPose displays conversion candidates based on the untranslated portion of the input. It uses the IPA dictionary, mecab-ipadic, from NMeCab, an open-source Japanese morphological analysis engine. FlickPose extends this dictionary by adding the task-specific words not originally included. It then searches for exact matches with the untranslated string, and matching words are displayed as conversion candidates.
3.3. Adaptation to Use Environments That Involve Movement
In environments where smart glasses are used, users may walk or move during text input and then resume typing afterward. Conventional methods often fix the keyboard at its initial position, so it stays where it first displayed, even after the user moves. To continue input, users must manually recall the keyboard or reset its position, which can be inconvenient. To solve this, FlickPose includes a feature that automatically tracks the user’s movement and keeps the virtual keyboard aligned. This supports both changes in the user’s position, such as walking, and changes in body orientation.
4. Machine Learning Model to Estimate Hand Pose
4.1. Hand Pose Used for the System
As described in
Section 3, FlickPose uses hand poses to select characters to be entered. In this case, since FlickPose assigns a maximum of five different characters to each key, it is necessary to use hand data to represent at least five different characters. Therefore, hand poses, which are easier to remember and less burdensome than hand gestures, are used to replace the flick operation. Sign language comprises typical hand poses, but in this study, the hand poses shown in
Figure 2 in
Section 3 are adopted in consideration of the ease of posing, the intuitively understandable relationship between poses, and the difficulty of changing poses. If the number of fingers is increased in order, Pose 5 becomes one in which the ring finger is extended from the thumb. However, this hand pose is assumed to be used infrequently due to the large burden placed on the hand. Therefore, the pose with all fingers extended is designated as Pose 5. In Pose 1, all fingers are bent, but the thumb can be bent in several ways, such as by tucking it in or touching the side of the index finger, and both are treated like Pose 1 in this study.
4.2. Data Collection
Hand pose classification methods include rule-based and machine learning models. However, the accuracy of rule-based methods is insufficient, and it is difficult to accommodate the users’ diverse hand shapes and poses. Therefore, this study uses machine learning models to classify hand poses.
To build a machine learning model to determine the five hand poses described above, the hand data were collected.
Here, FlickPose uses right-hand key selection and left-hand hand poses to input characters, but a pattern in which the left and right hands are interchanged is also possible. However, including such a pattern would result in too many experimental comparisons, and so the role of each hand is fixed in this study. Therefore, only the hand data necessary to estimate the hand pose of the left hand is collected.
Since it was not necessary to acquire dynamic changes to determine hand poses, data on the coordinates and orientation of each joint point, as described below, were collected.
In addition to the five types of hand poses used in the system, data from other hand poses that do not belong to the five types should be collected to prevent misjudgment during hand pose switching. Then, in the implementation of the system, the current hand pose is updated when the hand pose is classified in another way.
The “other” class includes specific hand shapes that do not fall under Poses 1–5. In particular, it covers 14 patterns, such as those shown in
Figure 7, where each finger is moderately bent in a relaxed position. These poses are expected to occur frequently during typical user behavior.
Figure 8 shows the data collection scene, which includes a text display screen and a hand data collection start button. The text screen is positioned in front of the user, while the start button is located near the user’s hand and initially appears blue. To collect data, the user touches the start button with their right hand while maintaining a specific hand pose with the left hand. This records the coordinates of 24 joints and the orientation of the wrist base at intervals of 0.1 s.
Since the “other” class includes many types of hand poses, collecting an equal number of samples for each pose would result in bias toward the “other” class. To avoid this, we collected 1000 samples for Pose 1 (thumb tucked in), Pose 5 (all fingers extended except the little finger), and poses in the “other” class, while collecting 5000 samples for each of the remaining poses. The number of samples collected per person for each class is shown in
Table 1.
Finally, the data collection system was used to conduct experiments to collect hand data from the subjects. The subjects were five males between the ages of 22 and 25, and the collection was conducted after explaining the experiment had been explained and the equipment tested. In addition, all five subjects performed the experiment at the same location. The data collected were split into training, validation, and test data at a ratio of 8:1:1.
4.3. Data Preprocessing
Hand data obtained in the data collection experiment was collected while moving the hand position. Therefore, individual differences are large if the data is used as is. Therefore, we preprocess data to facilitate machine learning.
Preprocessing includes converting the coordinates of each joint point to relative coordinates based on the position and orientation of the wrist near its base and then standardizing the values in each dimension of the joint point using the following equation.
where
is the value after standardization,
is the value before standardization,
is the mean value, and
is the standard deviation.
4.4. Classification Using Neural Network
Machine learning is performed using the data obtained by preprocessing. The dataset consists of a set of three-dimensional coordinates for 24 joint points, i.e., 72-dimensional numerical data, and the total number of datapoints is 205,000 because data were collected from five persons. The training data in this study were preprocessed hand data. These were divided 8:1:1 and used as training data, validation data, and test data, respectively.
Since FlickPose aims to run in stand-alone manner, it uses Unity Barracuda version 3.0.1 (
https://docs.unity3d.com/Packages/com.unity.barracuda@1.0/manual/index.html, accessed on 23 June 2025) for the operation of the machine learning model. In addition, since the load placed on the device by the machine learning model needs to be reduced, it is necessary to choose a model that can run on the Unity Barracuda and is lightweight. Therefore, this study compares MLP, LightGBM, Random Forest, and Rule-Based methods as candidates. The models were built and tested on Google Colab using Keras with Tensorflow as the backend. Since the hand poses to be classified in this study deal with the bending and stretching of fingers with large joint changes and the number of patterns is small, the model uses the original architecture with a simple structure.
First, training is performed in a way that uses all collected joint point positions as inputs. We constructed the machine learning model of MLP [
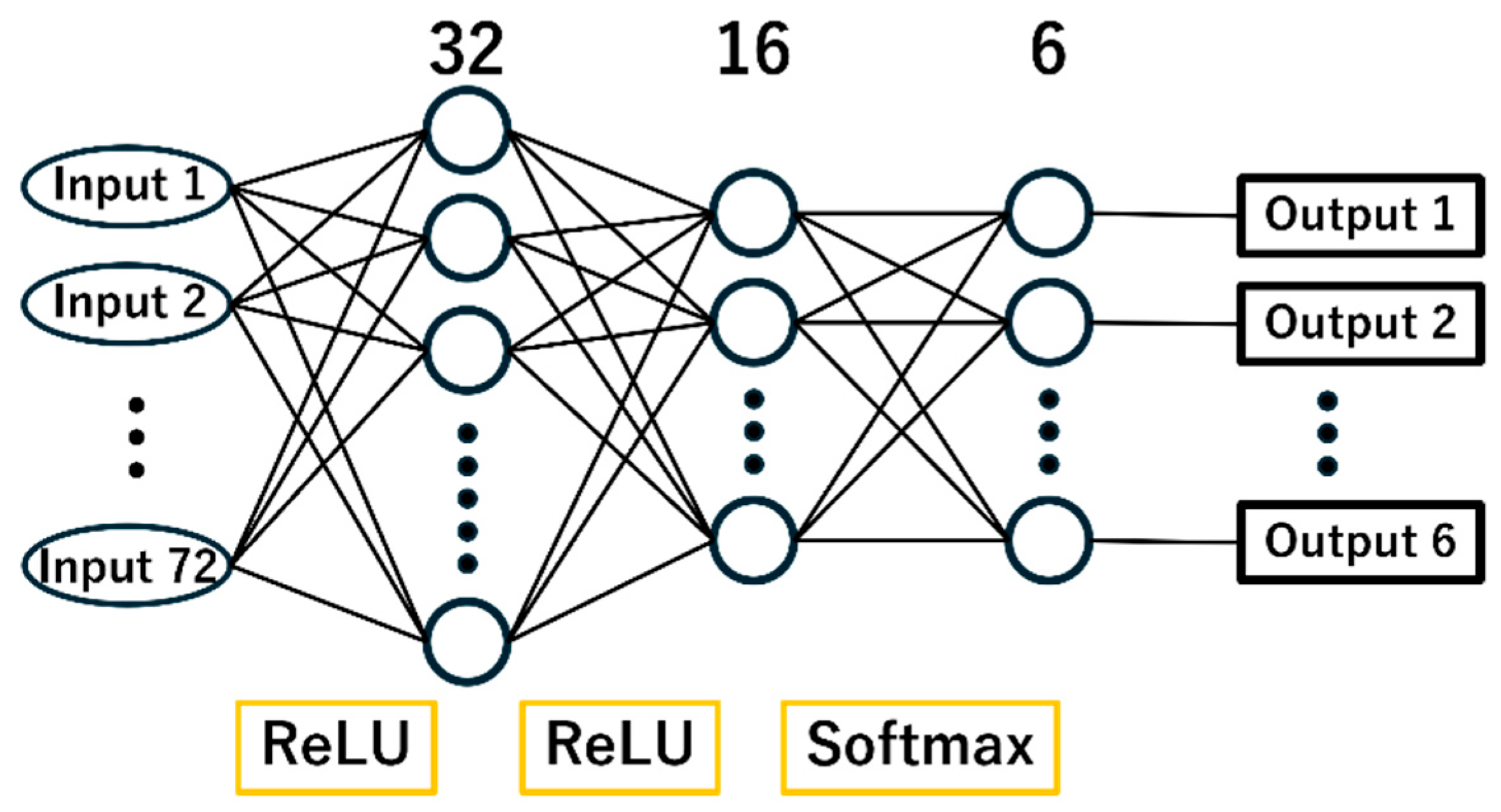
29]. The architecture of the model consists of three dense layers as shown in
Figure 9. The input of the model has 72 dimensions and outputs SoftMax values for 6 classes of poses 1-5 and Other. Note that Softmax is used as the activation function in the output layer, while ReLU is used in the other two layers. The other hyperparameters used are Adam (Adaptive Moment Estimation) for the optimizer, Sparse Categorical Crossentropy for the loss function, and accuracy for the evaluation function. The training results with the preprocessed hand data are demonstrated in
Table 2. The dataset, as mentioned above, consists of the five varieties of hand data collected, divided 8:1:1 into training data, validation data, and test data.
Note that accuracy, precision, recall, and Macro-F1 are used as evaluation indices. As shown in
Table 2, high values exceeding 0.99 were obtained for all the evaluation indices, indicating that classification with high accuracy can be expected.
Since FlickPose is intended for use in situations where text input is performed by other applications, the memory it occupies must be minimized. Therefore, we reduced the number of joint points used for inputs and conducted training with a model that uses as input a total of 15-dimensional data points from the joint points of the fingertips, which are assumed to be the most important in the estimation of the hand poses adopted in this study. The training results for this model are demonstrated in
Table 3. The dataset is the same as when the model was trained using all the joint points demonstrated in
Table 2.
Comparing the evaluations in
Table 2 and
Table 3, we see that the scores of the model with only the fingertips as input are slightly lower for each evaluation index, but the results for both models show that each value is very high, exceeding 0.99, indicating that even with only the fingertips as input, the accuracy is expected to be sufficient for character input. Therefore, in this study, only the joint point position of the fingertip was used as input to the model.
4.5. Comparison with Other Learning Models
We compare the classification performance of the constructed MLP machine learning model with other machine learning models and other hand pose classification methods. Before the comparison, we describe the Random Forest, LightGBM and rule-based architecture, which are the subjects of performance comparisons in this study.
The hyperparameters selected during the construction of the Random Forest were as follows. The number of features used for branching is selected as sqrt, which is the square root of the number of input dimensions. Since the input data for the Random Forest is 15-dimensional numerical data, as in MLP, the number of features is 3, truncated to the decimal point of the square root of 15.
Number of decision trees (n_estimators): 100
Number of features used for branching (max_features): 3
Depth of decision trees (max_depth): 5
The hyperparameters used to construct LightGBM are listed below. Given that the target of the training was a relatively simple hand pose estimation, default values were used for many of the hyperparameter values. Note that, as with MLP and Random Forest, the input for LightGBM is also 15-dimensional numerical data.
Objective function (objective): multiclass
Boosting algorithm (boosting_type): gbdt
Evaluation index (metric): multi_logloss
Learning rate (learning_rate): 0.1
Maximum number of leaves per tree (num_leaves): 31
Depth of decision tree (max_depth): 5
In the rule-based algorithm, since the same process is performed with each finger, the processing with the index finger is used as an example. Four joints of the index finger are used, starting from the fingertip, and the vectors to the adjacent joints are calculated. Next, the cosines are computed for each combination of these vectors. When the fingers are extended, the vectors point in the same direction, so the cosine value approaches 1.
Therefore, if the value obtained by multiplying all three calculated cosines is greater than a predetermined threshold value, the finger can be judged to be extended. By performing this series of processes for each finger, Poses 1–5 can be determined in the form of a combination of the bending and stretching of each finger.
Next, the classification accuracy of each method is compared. The five hand poses collected are used for the comparison, but since all methods except for the rule-based one are trained in advance, the classification accuracy of human hands not used for training is also important for the implementation scenario. Therefore, MLP, Random Forest, and LightGBM were trained five times by taking four out of five datasets and dividing them 9:1 into training and validation data, respectively, and using the remaining dataset for one person as test data. Cross-validation was then performed to find the average of the results obtained from each training.
The classification results obtained with each method are shown in
Table 4. From
Table 4, it can be seen that the accuracy is particularly high for MLP and LightGBM. Here, in a situation where a character input system is implemented, it is important to be able to maintain high accuracy even with hand data that is not included in the training data. For this reason, a comparison of the variance of the evaluation values obtained in each trial of the cross-validation is performed, and the variance in each evaluation index for MLP and LightGBM is shown in
Table 5. From
Table 5, it can be seen that LightGBM is larger in the variance of all evaluation indicators except precision, and that the variance of precision is very small. This indicates that MLP is a model with smaller variance in data precision than LightGBM. Therefore, in implementing FlickPose in this study, an MLP was used to determine the hand pose of the left hand. FlickPose uses Unity Barracuda, an official Unity package, to run the trained model in standalone fashion, without a server or other connections. Finally, source codes of the training model and the dataset are available in
Supplemental material.
5. Experiments to Evaluate Text Input System
5.1. Text Input Systems for Comparison
Evaluation experiments were conducted using three different methods: the touch-panel type and raycast type of FlickPose implemented in this study plus the virtual keyboard as standard equipment in Meta Quest 3 (hereafter referred to as the standard method).
The basic specifications of both key selection methods for FlickPose are as described in
Section 3. However, if these methods are used as they are, the position, and the size of the UI panel at hand are fixed, which may make it difficult to use depending on individual differences such as the subject’s body size. Therefore, it is necessary to adjust the UI panel for each subject. In the evaluation experiment, an optional function was installed to allow the position, size, and orientation of the UI panel to be freely changed.
In addition, as mentioned in
Section 3, FlickPose changes the characters displayed on the keyboard panel and UI panel to those corresponding to the hand pose for only the currently selected key, but there were a few people in the preliminary experiment who preferred the method in which all characters on the panel are changed. Therefore, in the evaluation experiment, the user could optionally select whether the characters changed according to the hand pose for either the currently selected key or for all keys. These optional functions can be used by starting the option mode with the option button placed near the hand, as shown in
Figure 10, and the subject can make modifications according to his/her preference during the practice period before the experimental task is started.
Figure 10 shows some Japanese characters. The character on the Option button means Option. In addition, a part of the Keyboard Panel in Japanese mode is shown in the upper right corner of
Figure 10, and a part of the UI Panel is shown in the lower right corner.
Next, the virtual keyboard of the standard method is shown in
Figure 11, and input is performed by touching the panel with a finger or pointing a hand at it and making a pinching motion. In addition, the experimental system was built in Unity as it was in FlickPose, with the same layout and size of text input fields, etc. The Japanese written in the lower center of the virtual keyboard in
Figure 11 means space.
5.2. Experimental Methods
In the experiment, each participant completed three types of character input tasks—hiragana, hiragana + alphanumeric, and hiragana + kanji—using three input methods: touch-panel, raycast, and standard. The task texts will be explained later. The same sentences were used across all methods to ensure consistent difficulty, as varying them by method or participant could affect results. To prevent participants from memorizing the task texts, each method was tested on a different day, with at least one day between sessions. Since the touch-panel and raycast methods use the same hand poses, the input methods were tested in the following order—touch-panel, standard, and then raycast—to minimize learning effects. Detailed procedures for each method are provided below.
After explaining the overall experiment, the experimenter explained how to use the text input system used in the day’s experiment.
- 2.
Practice.
The HMD was given to the subject, and after putting it on, the subject started the text input system and practiced text input. In this experiment, there was no limit on the practice time, and the subject moved on to text input when he/she had tried each function of the text input system and had become sufficiently accustomed to it. In the case of the touch-panel and raycast experiments, the UI panel and other settings were configured at this stage using the optional functions described above, and in the case of the standard method experiment, the subject tried both the QWERTY layout and the 50-character kana table before selecting one or the other.
- 3.
Text input.
Subjects input task sentences for the hiragana task, hiragana + alphanumeric task, and hiragana + kanji task. Each task was performed without a break, but there was break time between tasks, and subjects removed the HMD and took a sufficient break before moving on to the next task. Subjects also input the text in a standing position.
- 4.
Questionnaire response.
After all tasks were completed, two surveys described below were answered online.
An example of the screen during the experiment is shown in
Figure 12, where the subject enters the task text displayed above the text input field into the text input field below. The “Task sentence” and “Text being entered” sections in
Figure 12 contain the Japanese task sentence and part of the task sentence, respectively.
There are three types of tasks in the experiment: a hiragana task in which participants input task sentences in hiragana, a hiragana + alphanumeric task in which participants input task sentences in hiragana and alphanumeric characters, and a hiragana + kanji task in which participants input task sentences in hiragana and kanji.
Finally, the post-experiment questionnaire is described. In order to measure the usability of each system in this study, the System Usability Scale (SUS) questionnaire was administered after the experiment. The usability can be calculated in the form of a score out of 100 points by answering ten questions, with alternating positive and negative ones, on a 5-point scale, with 1 being “strongly disagree” and 5 being “strongly agree.” In this study, the 10 questions were translated into Japanese from the SUS questionnaire. In addition, another questionnaire was administered to identify differences in subjective evaluations of usability. The questionnaire consisted of questions about name, the frequency of HMD use, discomfort when wearing the HMD, and methods used in the day’s experiment, as well as questions about usability. The usability questions are shown in
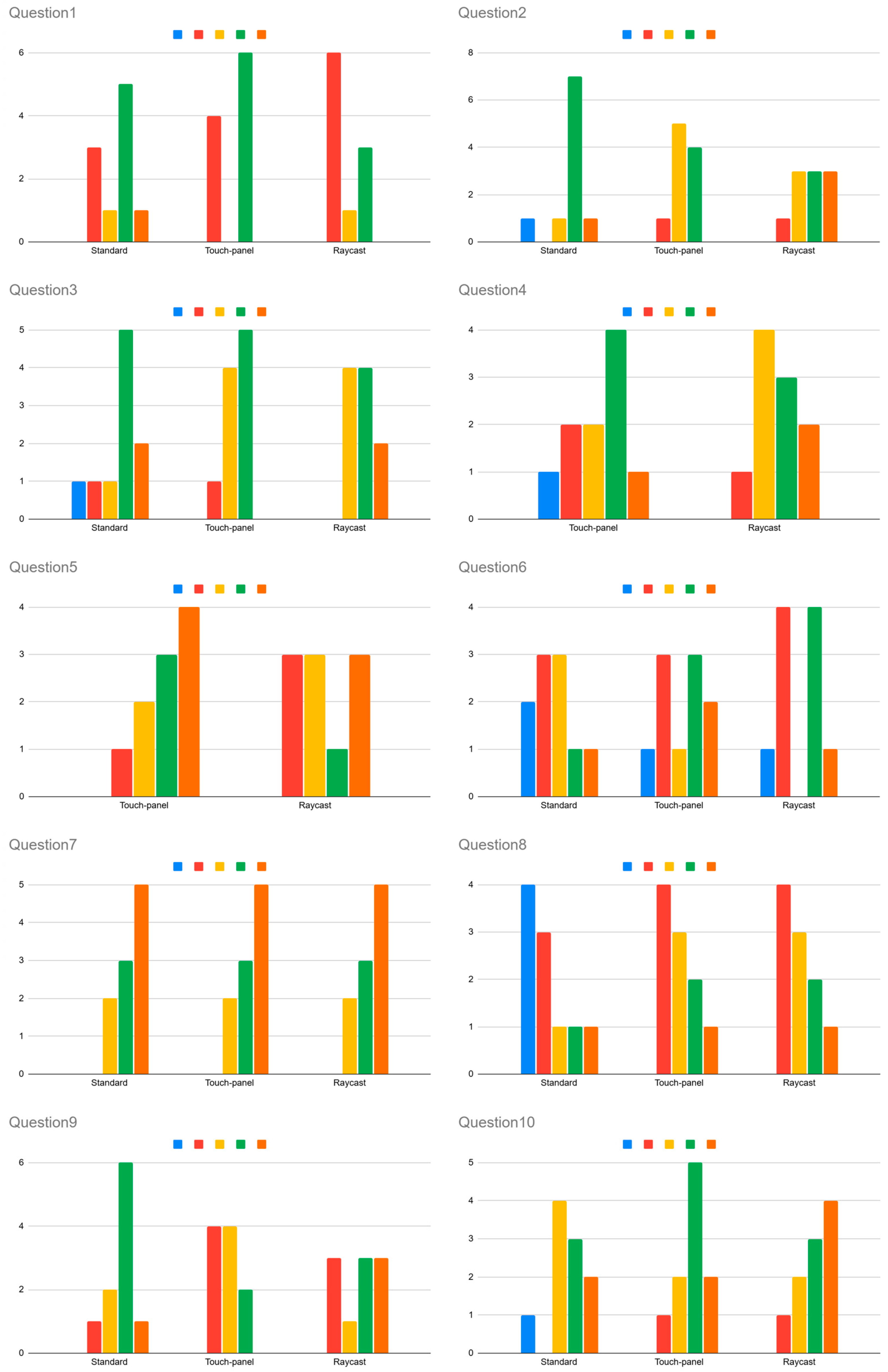
Table 6, and subjects answered each question on a 5-point scale from 1 to 5, with higher numbers for Q1 demonstrating a negative rating and higher numbers for Q2–10 demonstrating a positive rating. Note that Q4 and Q5 were answered with respect to touch-panel and raycast experiments using hand poses.
Under the above conditions, an experiment was conducted with ten adult male subjects who did not participate in the data collection experiment. As an example,
Figure 13 shows the subjects during the raycast experiment.
5.3. Participants
This study involved two types of experiments: five participants took part in the hand data collection experiment, and ten participated in the input experiment. All participants were over 18 years old, including students from our lab, and none were researchers specializing in text input for HMDs or smart glasses. Additionally, no participant took part in both experiments.
5.4. Experimental Results
First, we explain the character input speed, the number of deletions, and the number of consecutive deletions used as evaluation indices in this study. Words per minute (WPM) and characters per minute (CPM) are generally used to calculate character input speed, which represent the number of words or characters entered per minute, respectively. They can quantitatively measure the input speed of sentences composed of English letters and hiragana, but the task sentences used in this study contain alphanumeric characters and kanji characters in addition to hiragana and thus include key inputs that are not reflected in the number of characters, such as conversion keys and mode-switch keys. Therefore, in this study, the number of keystrokes required to input the task text in the shortest time was divided by the time taken to input the text to calculate the character input speed.
The number of deletions is calculated as the number of characters deleted during the input of the task sentence. In addition, when the same task sentence is being input, consecutive deletions may occur, and the maximum of those values is calculated as the number of consecutive deletions for that task sentence. For example, if a single character is deleted twice, two characters are deleted once, and three characters are deleted once during the input of a certain task sentence, the number of deletions is seven and the number of consecutive deletions is three. The reason for calculating the number of consecutive deletions is to measure the ease of checking the input field during the input process. If the user only looks at the keyboard when inputting text, even if an error occurs, the user will not be able to check the input field until it is too late, which will delay the detection of the error, and thus multiple deletions will be necessary. On the other hand, if the text input system allows the user to easily check the input field, or if the user can input text while keeping his/her eyes on the input field, the number of consecutive deletions is expected to be smaller, because the user can detect the input error at an early stage.
Next, the values for each evaluation index calculated based on the log data are described.
Table 7 shows the average values and the standard deviation of the character input speeds of the ten subjects for each task and overall. From
Table 7, the hiragana + alphanumeric task has the lowest average character input speed per task for all methods. The standard method has the highest average for all tasks at 37.26, followed by the raycast method and the touch-panel method, in that order. Comparing the average values of the standard method and the raycast method in
Table 7, it can also be seen that the difference between the average values for the hiragana task and the hiragana + alphanumeric task is smaller than the difference for the hiragana + kanji task. Regarding standard deviation, the standard method displays the smallest and the raycast method displays the largest for each task and overall.
Table 8 presents the average and standard deviation of the number of deletions per task and overall across all participants. The results show that the raycast method had the fewest deletions on average, while the standard method had the most. In all methods, the average number of deletions increased in the later tasks. The standard deviation was smallest for the touch-panel method only in the hiragana + kanji task, and smallest for the raycast method in the other tasks.
Table 9 presents the average and standard deviation of consecutive deletions for each task and overall. The results show that the raycast method had the fewest consecutive deletions on average, while the standard method had the most. Similar to
Table 8, the average number of consecutive deletions increased in the later tasks. The standard deviation was highest for the standard method across all tasks.
Finally, we will discuss the results of the post-experiment questionnaire. The average SUS scores are shown in
Table 10, with the raycast method achieving the highest score. However, the two-tailed t-test at the 0.05 significance level revealed no statistically significant differences. For the other questionnaire items, the distribution of 5-point ratings is shown in
Figure 14. In this figure, blue bars represent the number of participants who selected 1, and orange bars represent those who selected 5. Since Q4 and Q5 focus on hand posing, results for the standard method are excluded from these questions. Finally, we will discuss the questionnaire results. In Q1, over half of the participants rated the standard and touch-panel methods 4 or more, indicating higher fatigue. In contrast, for the raycast method, more than half rated it 2, suggesting lower fatigue. In Q2, 80% of participants rated the standard method 4 or higher for ease of use, while FlickPose received more moderate scores, mostly around the middle. In Q3, which evaluated screen layout usability, over 80% of participants rated all methods 3 or higher. For Q7, related to the hiragana task, all methods showed similar distributions, with 80% of participants selecting 4 or higher, indicating the task was easy to perform. However, in Q8 (hiragana + alphanumeric task), fewer than three participants rated any method 4 or higher. This matches the earlier finding that this task had the slowest input speed. In Q9 (hiragana + kanji task), over half of the participants rated both the standard and raycast methods 4 or higher. In Q10, more than half rated all methods 4 or higher, with FlickPose receiving especially favorable responses—about 70% of participants gave it high ratings.
According to the post-experiment survey, eight participants used the QWERTY layout and two used the 50-character kana table when using the standard method. In terms of VR headset usage, four participants reported using it at least once a week.
5.5. Discussion
This paper presents a novel text input method that integrates hand posing and key selection. We first designed the configurations and input functions for both the touch-screen and raycast systems. Then, we collected data to train a hand pose estimation model and developed the model accordingly. Finally, we conducted text input experiments to compare its performance and usability with the standard method. The results revealed several new insights.
The raycast method resulted in the fewest deletions across all tasks, averaging about 33.5% fewer than the standard method. Unlike the touch-panel and standard methods, the raycast method involves pointing at a key and performing a pinch gesture to input it. This approach avoids touching untactile virtual keys and allows for better control over input timing, which likely contributed to its higher accuracy.
Although the touch-panel method also requires touching keys, similar to the standard method, it showed about 13.5% fewer deletions. This may be due to the FlickPose key layout, which uses fewer and larger keys compared to the traditional QWERTY layout. Additionally, FlickPose reduces the number of key selections needed for entering Japanese words used in the tasks. These factors likely contributed to the lower deletion rate compared to the standard method.
As for the number of consecutive deletions, the raycast method has the lowest overall value. This may be because the raycast method allows users to select keys by the direction of their hands alone, regardless of the distance from their hands to the UI panel, making it easier than the other two methods to keep their eyes near the character entry field, leading to the early detection of incorrect input. In addition, as a common feature of all methods, the number of consecutive deletions in the hiragana + kanji task was the largest. This is likely due to the fact that when performing a kanji conversion, if a mistake is made in the conversion destination, it is necessary to delete the entire conversion point, which causes the continuous deletion.
Next, considering the overall evaluation indices, the standard method was the fastest in terms of character input speed on average for all tasks, and the raycast method was the best for the two deletion-related evaluation indices. As mentioned earlier, the raycast method, which does not require finger touch, is superior in terms of input accuracy, but operations unique to the XR environment, such as rays and pinches, may have hindered subjects who had no experience using HMDs from learning the system. Here, since this study was designed to be used by mobile users and it was expected that the users are regular users of HMDs, the results for those with HMD experience were also important. Therefore,
Table 11 shows the average values and the standard deviation for all tasks of text input speed, the number of deletions, and number of consecutive deletions for the four subjects who indicated that they had experience using the VR headset at least once a week.
Table 11 also shows that the raycast method achieved the best performance across all evaluation metrics for frequent HMD users. While the touch-panel method still showed slower input speed and more deletions compared to the other two methods, the differences appeared smaller than those observed in the results for all participants.
One advantage of FlickPose is that it does not rely on predicting the intended character or key. Previous studies have explored word prediction based on cursor trajectories (e.g., Markussen et al. [
18], Gupta et al. [
19], Dudley et al. [
3], and Wang et al. [
20]). PinchText, proposed by Jiang et al. [
25], uses a key sequence similar to FlickPose and predicts words from selected key patterns. These approaches primarily target English input. However, Japanese poses a challenge for prediction-based methods, as similar character sequences can have multiple meanings. To address this, our method avoids prediction and instead uses hand poses to input characters directly, while also reducing the number of keys compared to the QWERTY layout.
Another advantage of FlickPose that did not directly appear in the experimental results is the automatic tracking of the panel described in
Section 3. The standard method assumes that the user remains stationary while entering text. As a result, after moving, the user must either relaunch the system or reset the origin of the virtual space. In contrast, FlickPose automatically tracks the user’s movement, allowing continuous use in mobile environments where the user walks during input. This difference is expected to significantly affect both input time and usability in mobile scenarios.
6. Limitations and Future Work
In this study, we proposed FlickPose, a novel text input method that integrates hand posing with key selection. Experimental results suggest that it can improve performance for regular HMD users. However, several limitations and future challenges remain.
The input experiment resulted in some erroneous inputs, which are reflected in both the total and consecutive deletion counts. Identifying the causes of these errors could help improve system performance. In the text input experiment, the input logs are collected, and it is possible to see which characters are deleted. However, the causes of errors are difficult to determine because the number of patterns is very large (for example, if the key selection was correct and the hand pose was wrong, it is difficult to determine whether the subject made a hand pose mistake, the machine learning model made a mistake, or the task sentence was misread). Therefore, it is not possible to quantitatively calculate the breakdown of error causes. However, there were some issues that were pointed out by several subjects as the cause of the error.
With respect to hand pose determination, more misclassifications of Pose 1 and Pose 2 occurred than for other hand poses. Although a machine learning model was used to identify hand poses in this study, the evaluation of the training results did not show many misjudgments of Pose 1 and Pose 2. Therefore, it is believed that the main cause of misjudgment is that the subjects in the evaluation experiment had different skeletal and joint characteristics than the five subjects for whom data was collected. Therefore, it is necessary to improve the responsiveness of the model by increasing the number of people for whom data is collected. Efforts to improve the robustness of the model by increasing the dataset require further study.
Regarding hand poses, it was noted that other poses should be adopted. Specifically, it was pointed out that Pose 4 placed a heavy burden on the hands, especially the middle finger. It was also pointed out that Pose 1 should be performed with all fingers extended, because the load is smaller when fingers are extended than when fists are clenched. In our study, we employed Poses 1–5 as simpler poses than sign language and finger writing, but as subjects pointed out, there is room for improvement in hand poses. In addition, subjects were confused by the hand poses when they first started using FlickPose, but they became somewhat familiar with them during the input experiment. Considering this, the emphasis should be placed on minimizing the burden on the hand rather than forcing the hand pose to be more regular.
In addition, a mistake was made in selecting the blank key by mistake when trying to select the delete key, especially on the touch-panel type. Subjects made the mistake of pressing the blank key when they tried to touch the key directly because the blank key is directly below the delete key. This problem can be attributed in part to the lack of tactile feedback. We believe that adjusting the size of the keys according to how often they are used could be a possible countermeasure.
Since FlickPose relies on the device’s built-in hand tracker, its accuracy may decrease in environments where tracking performance is limited. This issue could be mitigated by using time-series data to estimate hand poses and correct finger misalignment. Recently, EMG-based wristbands (e.g., Mudra Band,
https://mudra-band.com/pages/mudra-band-main, accessed on 23 June 2025) have been developed, offering accurate hand recognition with less effort than traditional controllers. We believe incorporating such devices could further enhance accuracy.
Although FlickPose relies less on tactile feedback, especially in the raycast form, the lack of tactile feedback remains a challenge. To address this issue, there are previous works (Whitmire et al. [
13], Xu et al. [
14,
15]) that provide tactile feedback by touching the tips of each finger, the sides of the fingers, the arms, and other body parts. We believe that more accurate input can be achieved by referring to these studies.
A major limitation of this study is the small number of participants. The input experiment included only 10 subjects, which is not sufficient for reliable statistical analysis. To obtain more robust results, it is essential to conduct the experiment with a larger sample size. Additionally, due to difficulties in recruiting non-Japanese speakers, the study was conducted with Japanese speakers, and the task text was written in Japanese.
However, from an international perspective, it is desirable to conduct the experiment with English or other language speakers. Therefore, it is necessary to conduct input experiments with speakers of different languages as subjects.
Examining the effects of user proficiency with the system is another important area for future research. Although participants were given 10 to 20 min of practice before the input experiment, this was not enough for them to become fully proficient with the system. Therefore, there is a possibility that long-term use of the system will improve performance more. Conducting long-term experiments and analyzing the learning curve will be future work.
In this study, both FlickPose and the environment of the evaluation experiment were implemented on Unity, and so we did not check its operation with applications such as text editors. Therefore, the load on the device when FlickPose and applications are run simultaneously has not been confirmed, and in some cases, it may be difficult to use them together. Further investigation is needed to determine the load on the device when used in conjunction with other applications. In addition, regarding input experiments that assume a real environment, this study assumes mobile users and includes a function to track objects in consideration of the case where the user moves when using the system. Standard methods do not have a function to automatically follow the user, but Meta Quest 3 used in this study, for example, can display the keyboard in front of the user by resetting the reference point of the viewpoint after the user moves. Therefore, it is necessary to investigate and compare the character input speed, usability, etc., caused by the presence or absence of an automatic follow-up function by conducting experiments on tasks that require movement between inputs.
7. Concluding Remarks
This study introduces FlickPose, a text input system designed for mobile HMD users that combines right-hand key selection and left-hand hand poses. The system features a flick-style keyboard layout with a keyboard panel, a UI panel, and a hand pose list. Key selection is performed via either a touch-panel method (tapping virtual buttons) or a raycast method (pointing with a ray and pinching).
Instead of traditional flick gestures, five left-hand poses are used to select characters. The system automatically adjusts the virtual keyboard’s position based on user movement, enabling smooth input—even on the go.
A machine learning model (MLP) was developed to classify hand poses using fingertip joint data from the HMD. This model outperformed Random Forest and a rule-based method and had lower variability than LightGBM.
An evaluation with ten participants compared FlickPose (touch-panel and raycast) with the standard virtual keyboard across three input tasks. The raycast method showed the best performance among frequent HMD users, while all methods had similar usability scores.
The source codes for the machine learning model and the hand pose dataset developed in this study, along with a demonstration video, are provided in the
supplementary materials as indicated below.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}