
Smart Routing for Sustainable Supply Chain Networks: An AI and Knowledge Graph Driven Approach





Abstract
Featured Application
Abstract
1. Introduction
2. Theoretical Foundations and Research Gap
- The use of KGs or GDBs to model transport chains, product flows, LCAs, or the LCI
- The application of LLMs to automate route generation, enrich incomplete SCM or LCA data
Need for Further Investigation
3. Methodology
3.1. Conceptual Framework: Combining Generative AI with Graph-Based Optimization
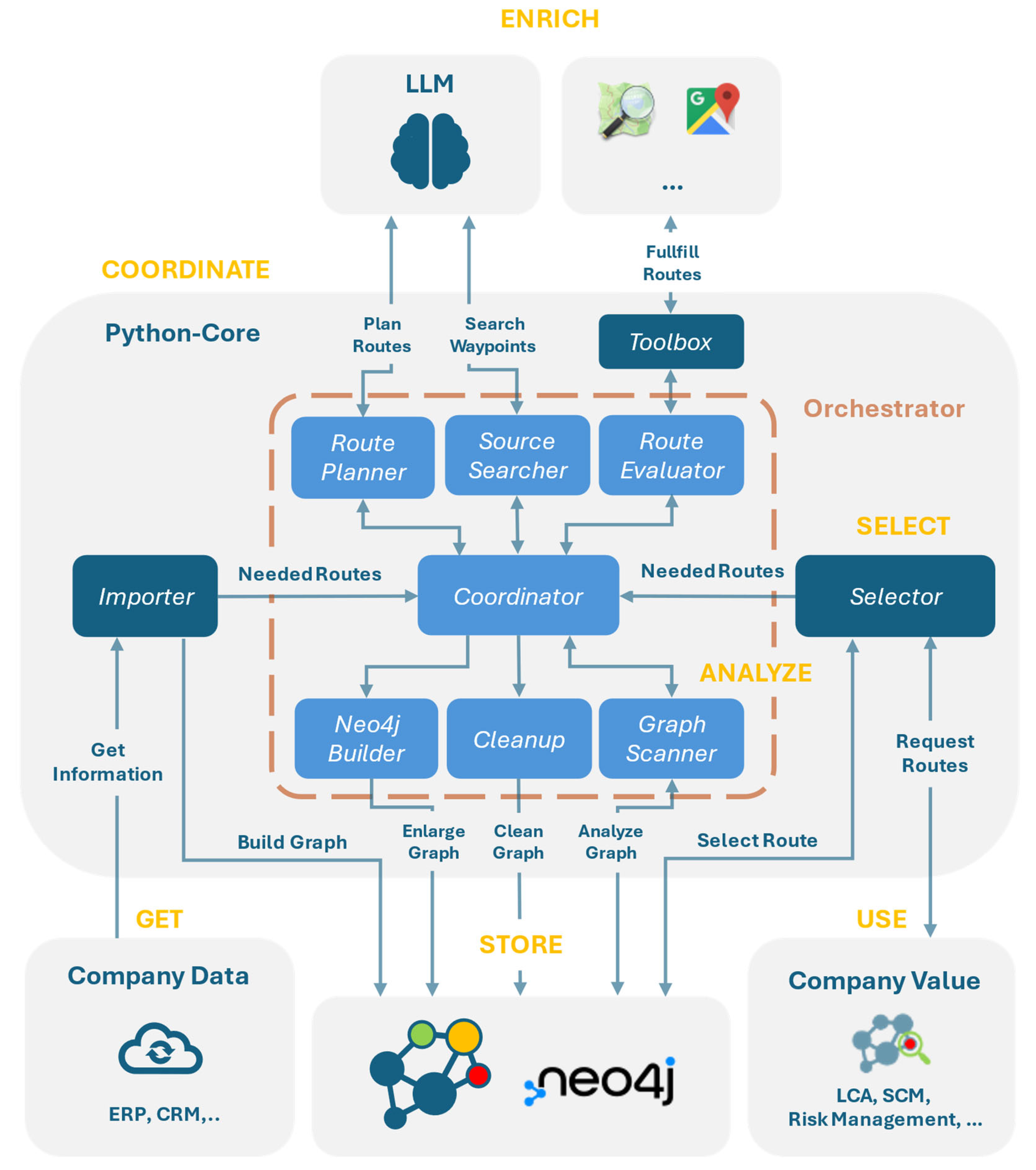
3.2. Prototype Architecture: Modular Agent-Based Design
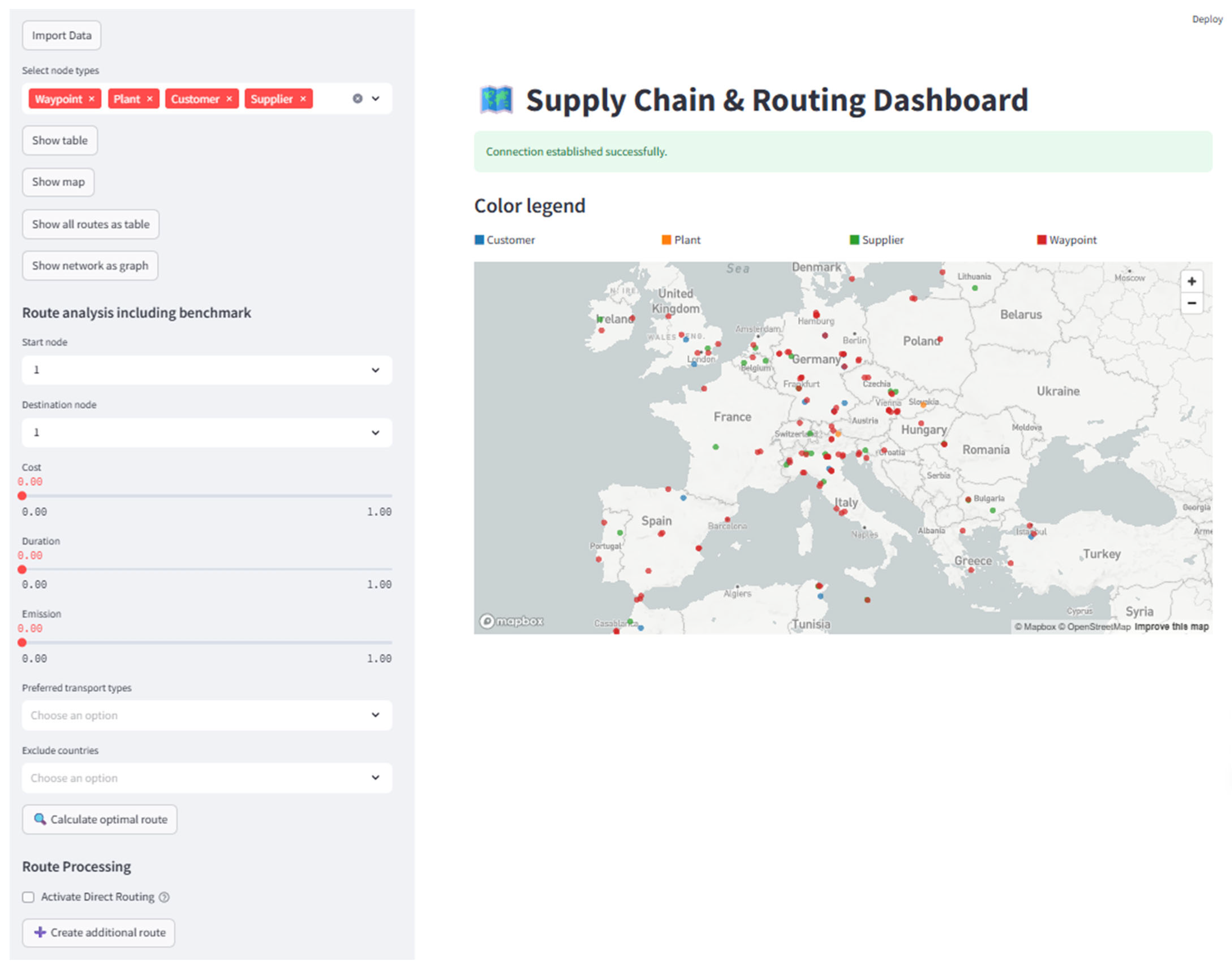
- Import data enables the mass import of nodes, relationships, and predefined routing demands. The user can trigger the full orchestration process with a single action.
- Create additional routes that allow on-demand route creation for a user-specific start–end combination, using the orchestration process.
- Visualize graph content offers both a dynamic network graph and a georeferenced map to explore entities and transport connections.
- Route analysis and benchmarking leverage the SELECT task to find the best route between two selected nodes. Users can define custom preferences (e.g., exclude nodes in specific countries, prioritize certain transport modes) and compare routing alternatives across criteria such as cost, time, and emissions.
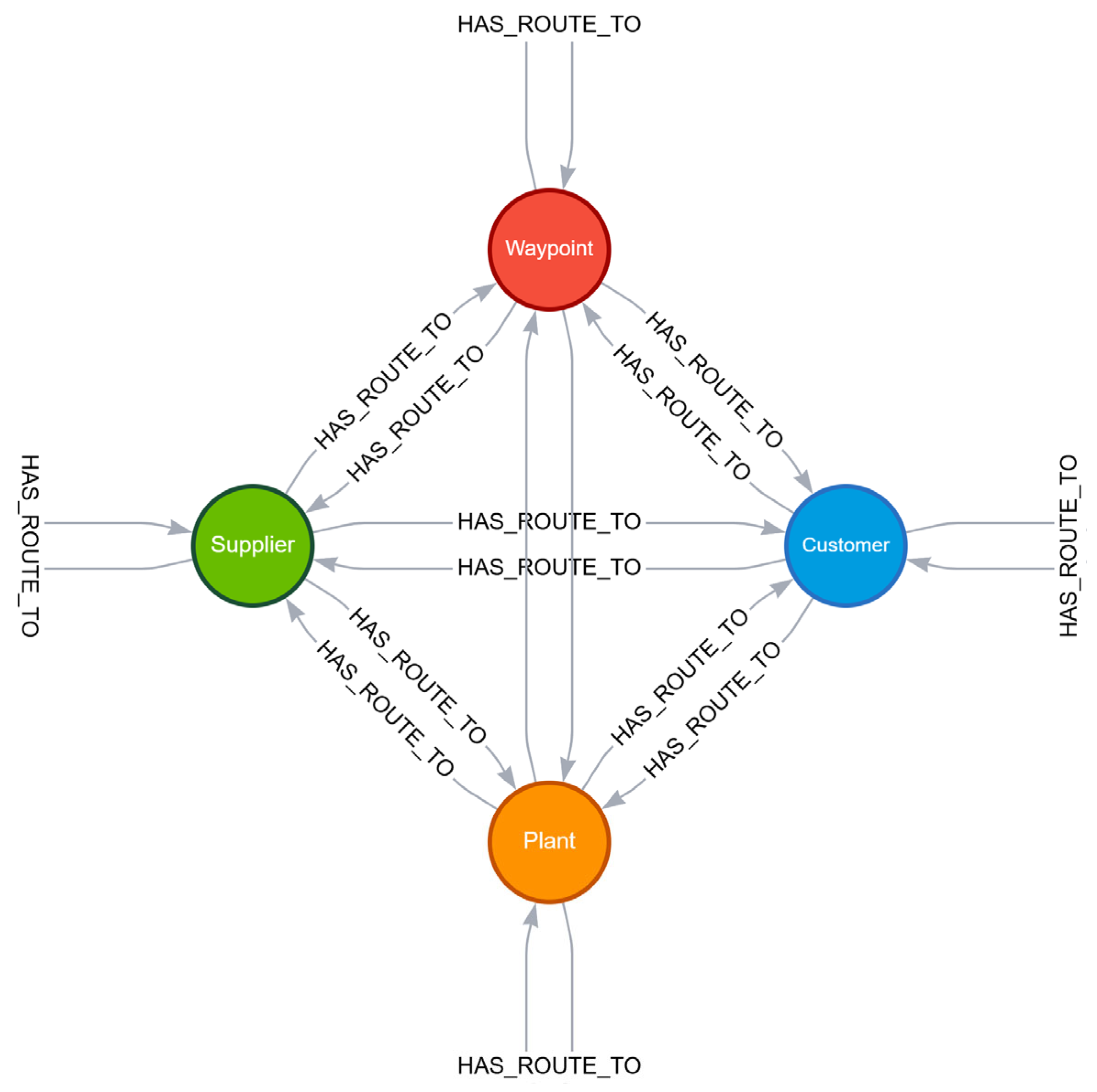
3.3. Knowledge Graph Ontology
- Nodes represent logistical entities (e.g., plants, suppliers, customers, and waypoints).
- Relationships (HAS_ROUTE_TO) represent directional transport links between these nodes, enriched with logistical and environmental metadata.
4. Use Case
4.1. Experimental Setup
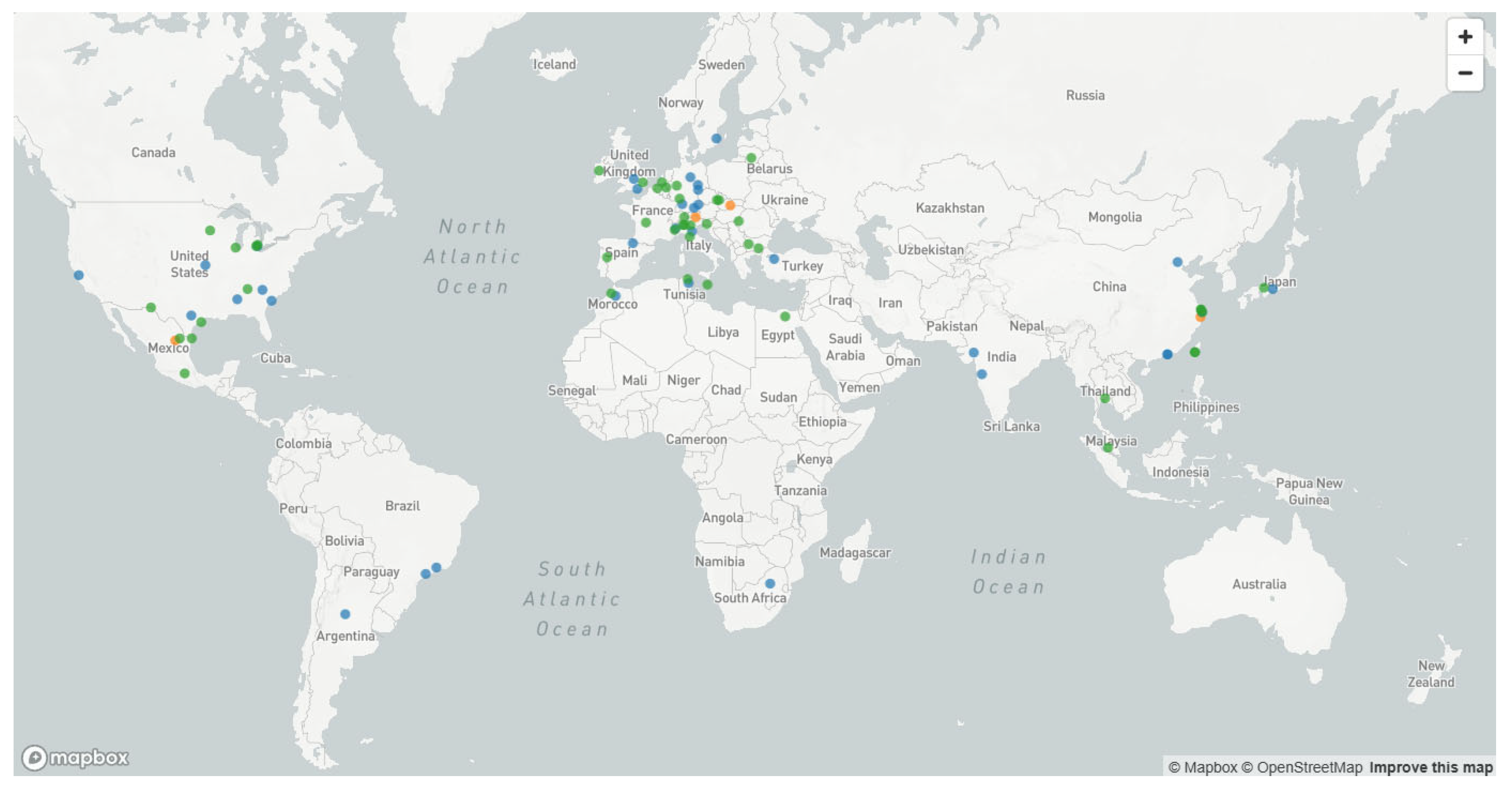
- Four production plants located in Mexico, Italy, Slovakia, and China.
- A total of 77 supply chain entities (suppliers and customers) spread across North America, Europe, Africa, and Asia, as visualized in Figure 6.
- A total of 200 needed routes representing logistical connections required for optimal supply chain operation between plants, suppliers, and customers.
- Two waypoints to give the LLM an idea of how the waypoints should look.
- Two routes to give the LLM an idea of how the routes should look.
4.2. Results and Validation
- Existence: whether the proposed logistics facility is a real, identifiable location suitable for cargo transport.
- Location accuracy: whether the coordinates place the node within a valid proximity (defined as ≤1 km) of its official location.
4.3. Observed Anomalies
- Structural anomalies: A total of six self-loop routes were identified, where the starting and ending nodes were identical (A → A). These are typically unintended and indicate either a geocoding fallback failure or incorrect source-to-destination mapping. These routes do not negatively affect subsequent graph operations.
- Mode-to-node mismatches: Several semantic mismatches between the mode and waypoint type were detected. Twelve bidirectional air routes were incorrectly initiated from locations classified as seaports. A prominent example is the case of the Port of Newark, where the generated waypoint shares coordinates with New York International Airport. While the geographic location is technically accurate due to the spatial overlap of port and airport facilities in major logistics hubs like New York, the assigned waypoint type was semantically incorrect. The LLM classified the node as a seaport, yet assigned air as the transport mode. This mismatch illustrates the need for more precise type validation logic beyond coordinate proximity alone. Additionally, two bidirectional rail routes originating from customer nodes were identified as using rail transport. Upon manual verification using Google Maps, this assignment appears valid, as the customer locations indeed have direct railway connections.
- Incorrect node reuse and name-based confusion: In 12 cases (pairs), routes were assigned between one incorrectly named and classified waypoint (e.g., “Truck Terminal Munich” was in reality “Airport of Munich”). This problem is based on incorrect localization by the LLM for road waypoints, which in the SourceSearcher later matched with the wrong location due to a proximity-based distance match.
- Planner-based correction for modality conflicts: In two notable cases (pairs), the route planner suggested the mode “River” for inland nodes (e.g., “Bratislava Seaport”). In this case, the RoutePlanner suggested the mode correctly after the SourceSearcher (LLM) recognized that Slovakia is a landlocked country and responded that no valid waypoint could be generated and changed the mode type to river.
- Location-based filtering: Another 12 routes pairs were removed due to coordinate errors, typically when the generated node could not be geolocated within a valid proximity to known transport infrastructure. These were flagged and discarded during the post-enrichment validation step.
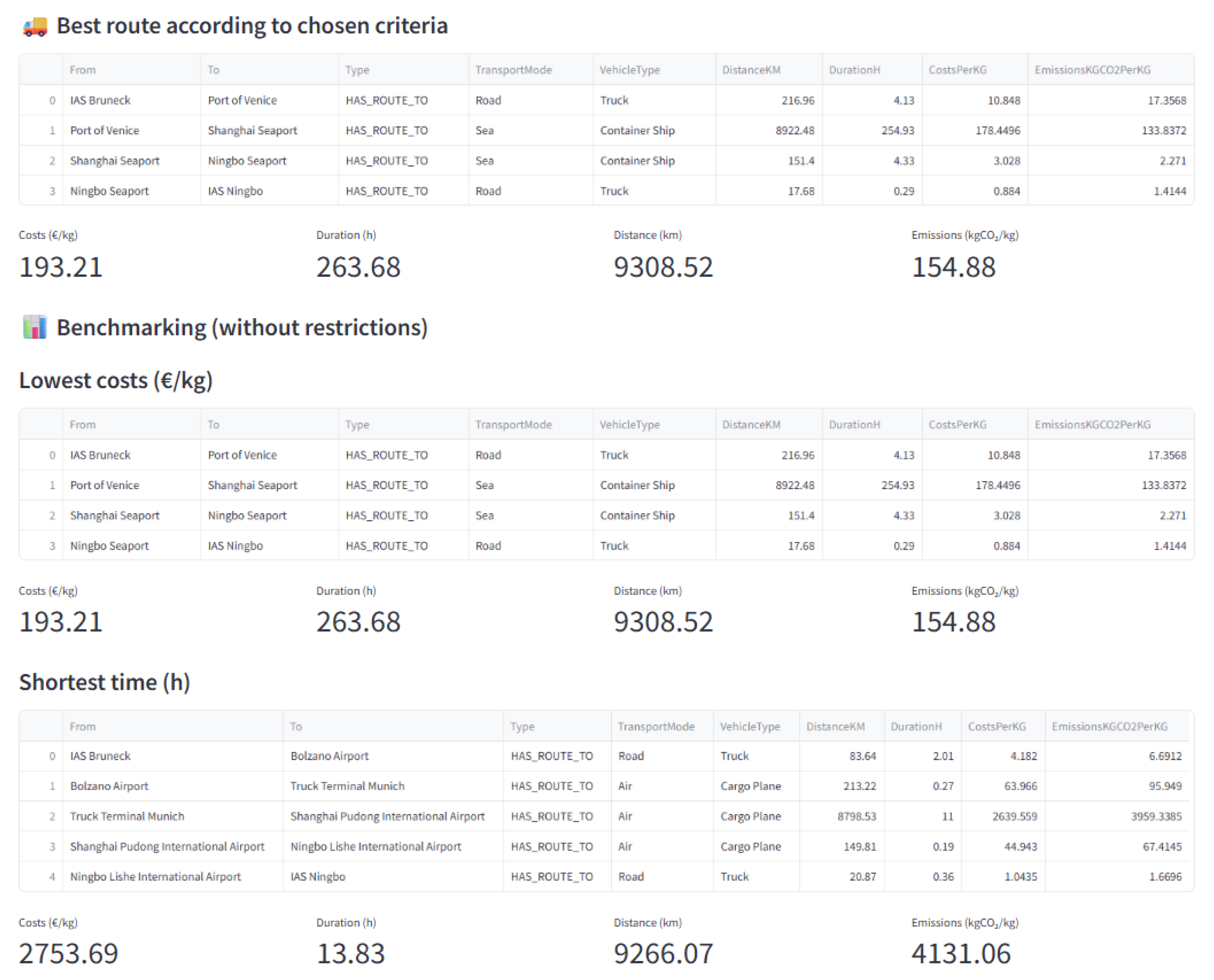
4.4. Strategic Benchmarking of Sustainability Options
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix A.1
“You are a logistics expert for global supply chains. Your task is to generate a realistic cargo goods transport route from location {start_label} to {end_label}. The route should be the most used, plausible, realistic, and feasible for cargo transport.The route may include multiple segments and intermediate waypoints, but only the following are allowed as intermediate points: Seaports (Seaport), Airports (Airport—Cargo Hub), Freight Rail Terminals (Freight Rail Hub), Truck Terminals (Truck Terminal). Other types of waypoints must not be used. The waypoints may include real places, even if they are not currently in the Neo4j database. Changing the mode is time-consuming and should be minimized. Not all of the modes must be used.Focus exclusively on cargo transport (no passenger routes). Each leg of the route must specify a transport mode (choose from: Air, Sea, Rail, Road).Do not include vehicle types—that will be handled by a separate Route Evaluator Agent.Answer format:1.<Start> → <Waypoint1>: Mode = <>,2.<Waypoint1> → <Waypoint2>: Mode = <>,…No point at the end of the last line.”
Appendix A.2
“You are a logistics and supply chain expert. Your goal is to find the realistic and true data from ONE logistics waypoint (JSON format) that would serve as an intermediate node named {end_label} located IN {city_country}.The waypoint must match the current mode {mode_current}, and be suitable for cargo logistics. Allowed types: {types}.The next leg of the route will be by mode {mode_next}, so your suggested waypoint must support a logical transition.Return the result as a JSON object with these exact fields: {properties_template}.Country must be ISO (e.g., DE, US, IT).The name should be the official name without informations in brackets ().Use plausible and official names and accurate geo data.”
References
- Adel, A. Future of Industry 5.0 in Society: Human-Centric Solutions, Challenges and Prospective Research Areas. J. Cloud Comput. 2022, 11, 40. [Google Scholar] [CrossRef]
- Spaltini, M.; Acerbi, F.; De Carolis, A.; Terzi, S.; Taisch, M. Toward a Technology Roadmapping Methodology to Enhance Sustainable and Digital Transition in Manufacturing. Prod. Manuf. Res. 2024, 12, 2298572. [Google Scholar] [CrossRef]
- Goel, A.; Masurkar, S.; Pathade, G.R. An Overview of Digital Transformation and Environmental Sustainability: Threats, Opportunities, and Solutions. Sustainability 2024, 16, 11079. [Google Scholar] [CrossRef]
- Javaid, M.; Haleem, A.; Singh, R.P.; Suman, R.; Gonzalez, E.S. Understanding the Adoption of Industry 4.0 Technologies in Improving Environmental Sustainability. Sustain. Oper. Comput. 2022, 3, 203–217. [Google Scholar] [CrossRef]
- He, B.; Bai, K.-J. Digital Twin-Based Sustainable Intelligent Manufacturing: A Review. Adv. Manuf. 2021, 9, 1–21. [Google Scholar] [CrossRef]
- European Sustainability Reporting Standards. Available online: https://finance.ec.europa.eu/news/commission-adopts-european-sustainability-reporting-standards-2023-07-31_en (accessed on 30 June 2024).
- Mazhar, M.U.; Domingues, A.R.; Yakar-Pritchard, G.; Bull, R.; Ling, K. Reaching for Net Zero: The Impact of an Innovative University-led Business Support Programme on Carbon Management Strategy and Practices of Small and Medium-sized Enterprises. Bus. Strategy Environ. 2024, 33, 6940–6960. [Google Scholar] [CrossRef]
- Afolabi, H.; Ram, R.; Hussainey, K.; Nandy, M.; Lodh, S. Exploration of Small and Medium Entities’ Actions on Sustainability Practices and Their Implications for a Greener Economy. J. Appl. Account. Res. 2023, 24, 655–681. [Google Scholar] [CrossRef]
- Zhang, Z.; Guan, D.; Wang, R.; Meng, J.; Zheng, H.; Zhu, K.; Du, H. Embodied Carbon Emissions in the Supply Chains of Multinational Enterprises. Nat. Clim. Change 2020, 10, 1096–1101. [Google Scholar] [CrossRef]
- ISO 14040:2006; Environmental Management—Life Cycle Assessment—Principles and Framework. International Organization for Standardization: Geneva, Switzerland, 2006.
- ISO 14044:2006; Environmental Management—Life Cycle Assessment—Requirements and Guidelines. International Organization for Standardization: Geneva, Switzerland, 2006.
- Rebitzer, G.; Ekvall, T.; Frischknecht, R.; Hunkeler, D.; Norris, G.; Rydberg, T.; Schmidt, W.-P.; Suh, S.; Weidema, B.P.; Pennington, D.W. Life Cycle Assessment. Environ. Int. 2004, 30, 701–720. [Google Scholar] [CrossRef]
- Hauschild, M.Z.; Rosenbaum, R.K.; Olsen, S.I. (Eds.) Life Cycle Assessment: Theory and Practice; Springer International Publishing: Cham, Switzerland, 2018; ISBN 978-3-319-56474-6. [Google Scholar]
- Market.us. Logistics 2.0: Transportation Management Software Industry to Skyrocket to USD 77.0 Billion by 2033! Global Trade Magazine. 2024. Available online: https://www.globaltrademag.com/logistics-2-0-transportation-management-software-industry-to-skyrocket-to-usd-77-0-billion-by-2033/ (accessed on 27 May 2025).
- The Complexity of Quantifying Freight Emissions|Insights & Sustainability|Climatiq. Available online: https://www.climatiq.io/blog/complexity-of-quantifying-freight-emissions (accessed on 27 May 2025).
- Kiemel, S.; Rietdorf, C.; Schutzbach, M.; Miehe, R. How to Simplify Life Cycle Assessment for Industrial Applications—A Comprehensive Review. Sustainability 2022, 14, 15704. [Google Scholar] [CrossRef]
- Felder, M.; Bataleblu, A.A.; Grünbacher, G.; Rauch, E. Development of an ERP-Integrated Direct Routing and Way-Point Routing for Increasing Automation of LCAs in Supply Chains. Procedia Comput. Sci. 2025, 253, 2674–2683. [Google Scholar] [CrossRef]
- Yurtay, Y. Carbon Footprint Management with Industry 4.0 Technologies and Erp Systems in Sustainable Manufacturing. Appl. Sci. 2025, 15, 480. [Google Scholar] [CrossRef]
- Ferrari, A.M.; Volpi, L.; Settembre-Blundo, D.; García-Muiña, F.E. Dynamic Life Cycle Assessment (LCA) Integrating Life Cycle Inventory (LCI) and Enterprise Resource Planning (ERP) in an Industry 4.0 Environment. J. Clean. Prod. 2021, 286, 125314. [Google Scholar] [CrossRef]
- Eberhardt, K.; Schwärzel, A.; Klaus Kaiser, F.; Rosenberg, S.; Schultmann, F. Leveraging Knowledge Graphs in Pharmaceutical Supply Chains: Insights into Key Drivers of Drug Shortages. Int. J. Prod. Res. 2025, 59, 1–24. [Google Scholar] [CrossRef]
- Kosasih, E.E.; Brintrup, A. Towards Trustworthy AI for Link Prediction in Supply Chain Knowledge Graph: A Neurosymbolic Reasoning Approach. Int. J. Prod. Res. 2025, 63, 2268–2290. [Google Scholar] [CrossRef]
- Saad, M.; Zhang, Y.; Tian, J.; Jia, J. A Graph Database for Life Cycle Inventory Using Neo4j. J. Clean. Prod. 2023, 393, 136344. [Google Scholar] [CrossRef]
- Wu, T.; Li, J.; Bao, J.; Liu, Q.; Jin, Z.; Gao, J. CarbonKG: Industrial Carbon Emission Knowledge Graph-Based Modeling and Application for Carbon Traceability of Complex Manufacturing Process. J. Comput. Inf. Sci. Eng. 2024, 24, 081001. [Google Scholar] [CrossRef]
- Saidi, C.; Hamani, N.; Benaissa, M.; Rolf, B.; Reggelin, T.; Lang, S. Modeling Reconfigurable Supply Chains Using Knowledge Graphs: Towards Supply Chain 5.0. Prod. Eng. Res. Devel. 2025. [Google Scholar] [CrossRef]
- Peng, T.; Gao, L.; Agbozo, R.S.K.; Xu, Y.; Svynarenko, K.; Wu, Q.; Li, C.; Tang, R. Knowledge Graph-Based Mapping and Recommendation to Automate Life Cycle Assessment. Adv. Eng. Inform. 2024, 62, 102752. [Google Scholar] [CrossRef]
- Chen, L.; Silvennoinen, H.; Wolf, C.D.; Hall, D.; Mele, T.V.; Block, P. Towards Automated Building Life Cycle Assessments: A Novel Approach Using Large Language Models and the COMPAS Framework. In Proceedings of the IASS 2024 Symposium, Zürich, Switzerland, 26–30 August 2024. [Google Scholar]
- Gu, X.; Chen, C.; Fang, Y.; Mahabir, R.; Fan, L. CECA: An Intelligent Large-Language-Model-Enabled Method for Accounting Embodied Carbon in Buildings. Build. Environ. 2025, 272, 112694. [Google Scholar] [CrossRef]
- Greif, L.; Hauck, S.; Kimmig, A.; Ovtcharova, J. A Knowledge Graph Framework to Support Life Cycle Assessment for Sustainable Decision-Making. Appl. Sci. 2024, 15, 175. [Google Scholar] [CrossRef]
- Oladeji, O.; Mousavi, S.S. Leveraging AI-Derived Data for Carbon Accounting: Information Extraction from Alternative Sources. AAAI Fall Symp. Ser. 2024, 2, 135–139. [Google Scholar] [CrossRef]
- Huang, Z.; Shi, G.; Sukhatme, G.S. Can Large Language Models Solve Robot Routing? arXiv 2024, arXiv:2403.10795. [Google Scholar]
- Kurdve, M.; Fransson, K.; Jonsson, P. Availability and Need for Climate Footprint and Resilience Data from Suppliers in Automotive Supply Chains. In Advances in Transdisciplinary Engineering; Andersson, J., Joshi, S., Malmsköld, L., Hanning, F., Eds.; IOS Press: Amsterdam, The Netherlands, 2024; ISBN 978-1-64368-510-6. [Google Scholar]
- Negri, M.; Cagno, E.; Colicchia, C. Building Sustainable and Resilient Supply Chains: A Framework and Empirical Evidence on Trade-Offs and Synergies in Implementation of Practices. Prod. Plan. Control 2024, 35, 90–113. [Google Scholar] [CrossRef]
- Daios, A.; Kladovasilakis, N.; Kelemis, A.; Kostavelis, I. AI Applications in Supply Chain Management: A Survey. Appl. Sci. 2025, 15, 2775. [Google Scholar] [CrossRef]
- Robinson, I.; Webber, J.; Eifrem, E. Graph Databases: New Opportunities for Connected Data, 2nd ed.; O’Reilly: Beijing, China; Boston, UK; Farnham, UK; Sebastopol, CA, USA; Tokyo, Japan, 2015; ISBN 978-1-4919-3089-2. [Google Scholar]
- Kotiranta, P.; Junkkari, M.; Nummenmaa, J. Performance of Graph and Relational Databases in Complex Queries. Appl. Sci. 2022, 12, 6490. [Google Scholar] [CrossRef]
- Dijkstra Single-Source Shortest Path—Neo4j Graph Data Science. Available online: https://neo4j.com/docs/graph-data-science/2.18/algorithms/dijkstra-single-source/ (accessed on 28 May 2025).
- Bayramoğlu, K.; Çelikoğlu, Ş.; Turan, İ. An Examination of the Emissions, Cost, and Time of Intermodal Transportation. Sustainability 2025, 17, 2368. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- API Reference—OpenAI API. Available online: https://platform.openai.com (accessed on 28 May 2025).
- Holtzman, A.; Buys, J.; Du, L.; Forbes, M.; Choi, Y. The Curious Case of Neural Text Degeneration. arXiv 2019, arXiv:1904.09751. [Google Scholar]
- Introducing the Model Context Protocol. Available online: https://www.anthropic.com/news/model-context-protocol (accessed on 27 May 2025).
- Hou, X.; Zhao, Y.; Wang, S.; Wang, H. Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions. arXiv 2025, arXiv:2503.23278. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors (Year) | LCA | SCM | Methodology | Technology | Application Domain |
|---|---|---|---|---|---|
| Saad et al. (2023) [22] | X | Semantic graph for LCI | GDB | LCI management | |
| Wu et al. (2024) [23] | X | X | KG-based carbon flow analysis | GDB | Carbon emission tracking in manufacturing |
| Saidi et al. (2025) [24] | X | X | KG with multicriteria decision | GDB | Supply chain reconfiguration |
| Peng et al. (2024) [25] | X | X | Automated LCA with GDB | GDB | Product LCA (electronics) |
| Chen et al. (2024) [26] | X | LLM for BIM parsing and LCA automation | LLM | Building LCA (architecture/engineering) | |
| Gu et al. (2025) [27] | X | LLM for BIM parsing and LCA automation | LLM | Embodied carbon in construction | |
| Greif et al. (2024) [28] | X | KG-based LCA with AI enrichment | GDB, LLM | Product LCA (3D printing case) | |
| Oladeji & Mousavi (2023) [29] | X | X | NLP-driven emissions graph | GDB, LLM | Supply chain carbon footprint tracking |
| Tasks | Functionality |
|---|---|
| Get | Capturing raw logistics data from ERP, MES, e.g., systems, like suppliers, plants, customers, and needed or known routes |
| Analyze | Performing network analysis to detect gaps, incomplete paths, and optimization potential |
| Coordinate | Prioritizes missing routes and orchestrates agent-based enrichment workflows |
| Enrich | Employs LLM agents and external APIs (e.g., OpenRouteService ORS, geolocation) to infer and propose new waypoints, create routes, enrich the new entities with information, and evaluate plausibility |
| Store | Integrating enriched data back into the KG model for future access and optimization |
| Select | Performing route selection, benchmarking, and optimization using Dijkstra’s algorithm from the graph data science library |
| Use | Enables downstream applications such as LCA calculation, dashboarding, and strategic planning. |
| Agent/Modules | Task | Role | Core Methode | Parameters/API |
|---|---|---|---|---|
| Coordinator Agent | COORDINATE | Manages the overall workflow in sequential phases | State machine logic | |
| GraphScanner Agent | ANALYZE | Identifies graph properties, missing and incomplete routes | Cypher queries, graph traversal | |
| RoutePlanner Agent | ENRICH | Suggests plausible multimodal cargo routes | LLM (GPT-4), custom prompt | Temperature = 0.3 |
| SourceSearcher Agent | ENRICH | Geocodes planner output, resolves or creates waypoints | LLM (GPT-4), distance, and fuzzy name matching | Temperature = 0.1 Radius = 2 km Name similarity ≥ 0.8 |
| RouteEvaluator Agent | ENRICH | Quantifies route segments Values by the chosen requested toolbox methodology | Mode-specific toolbox | OSR, static methods |
| Neo4jBuilder Agent | STORE | Writes or updates nodes and routes into Neo4j | Cypher queries | |
| Cleanup Agent | STORE | Removes incomplete data | Rule-based validation | |
| Selector | SELECT | Selects optimal routes for defined criteria | Dijkstra (Neo4j) | Custom weights, mode preferences, and country filters |
| Node Labels | Description |
|---|---|
| Plant | Manufacturing site where goods are produced |
| Supplier | Source of raw materials, components, etc. |
| Customer | Recipient of the produced goods |
| Waypoint | Logistical hub such as a seaport, airport, rail, or truck terminal |
| Property | Description | Example |
|---|---|---|
| name | Official name | Port of Hamburg |
| type | Facility classification | Seaport |
| country | ISO 2-letter country code | DE |
| city | City location | Hamburg |
| postal_code | Postal code | 20457 |
| address | Street and street Nr. | Am Standtorkai 60 |
| latitude | Latitude coordinate | 53.551086 |
| longitude | Longitude coordinate | 9.993682 |
| Property | Description | Example |
|---|---|---|
| mode | Transport type (road, sea, rail, and air) | Road |
| vehicle_type | Specific vehicle used | Truck |
| distance_km | Total distance in kilometers | 1300 km |
| duration_h | Estimated transport time | 15 h |
| emissions_kgco2_kg | CO2 emissions per kilogram transported | 140 kgCO2/kg |
| costs_e_kg | Cost per kg transported | 100 €/kg |
| availability | Status flag (0 = not available, 1 = incomplete, 2 = valid) | 2 |
| update_date | Last update timestamp | 20 May 2025 |
| source | Data source (e.g., LLM+API, ERP, manual) | Manual |
| Node Type | Total Nodes | Valid Existing | Correct Location | Valid (%) | Correct Location (%) |
|---|---|---|---|---|---|
| Airport | 61 | 61 | 61 | 100.00% | 100.00% |
| Seaport | 69 | 67 | 35 | 97.10% | 50.70% |
| Freight Rail Hub | 61 | 49 | 7 | 80.30% | 11.50% |
| Truck Terminal | 9 | 7 | 0 | 77.80% | 0.00% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Felder, M.; De Marchi, M.; Dallasega, P.; Rauch, E. Smart Routing for Sustainable Supply Chain Networks: An AI and Knowledge Graph Driven Approach. Appl. Sci. 2025, 15, 8001. https://doi.org/10.3390/app15148001
Felder M, De Marchi M, Dallasega P, Rauch E. Smart Routing for Sustainable Supply Chain Networks: An AI and Knowledge Graph Driven Approach. Applied Sciences. 2025; 15(14):8001. https://doi.org/10.3390/app15148001
Chicago/Turabian StyleFelder, Manuel, Matteo De Marchi, Patrick Dallasega, and Erwin Rauch. 2025. "Smart Routing for Sustainable Supply Chain Networks: An AI and Knowledge Graph Driven Approach" Applied Sciences 15, no. 14: 8001. https://doi.org/10.3390/app15148001
APA StyleFelder, M., De Marchi, M., Dallasega, P., & Rauch, E. (2025). Smart Routing for Sustainable Supply Chain Networks: An AI and Knowledge Graph Driven Approach. Applied Sciences, 15(14), 8001. https://doi.org/10.3390/app15148001