

Implementing an AI-Based Digital Twin Analysis System for Real-Time Decision Support in a Custom-Made Sportswear SME




Abstract
1. Introduction
2. Materials and Methods
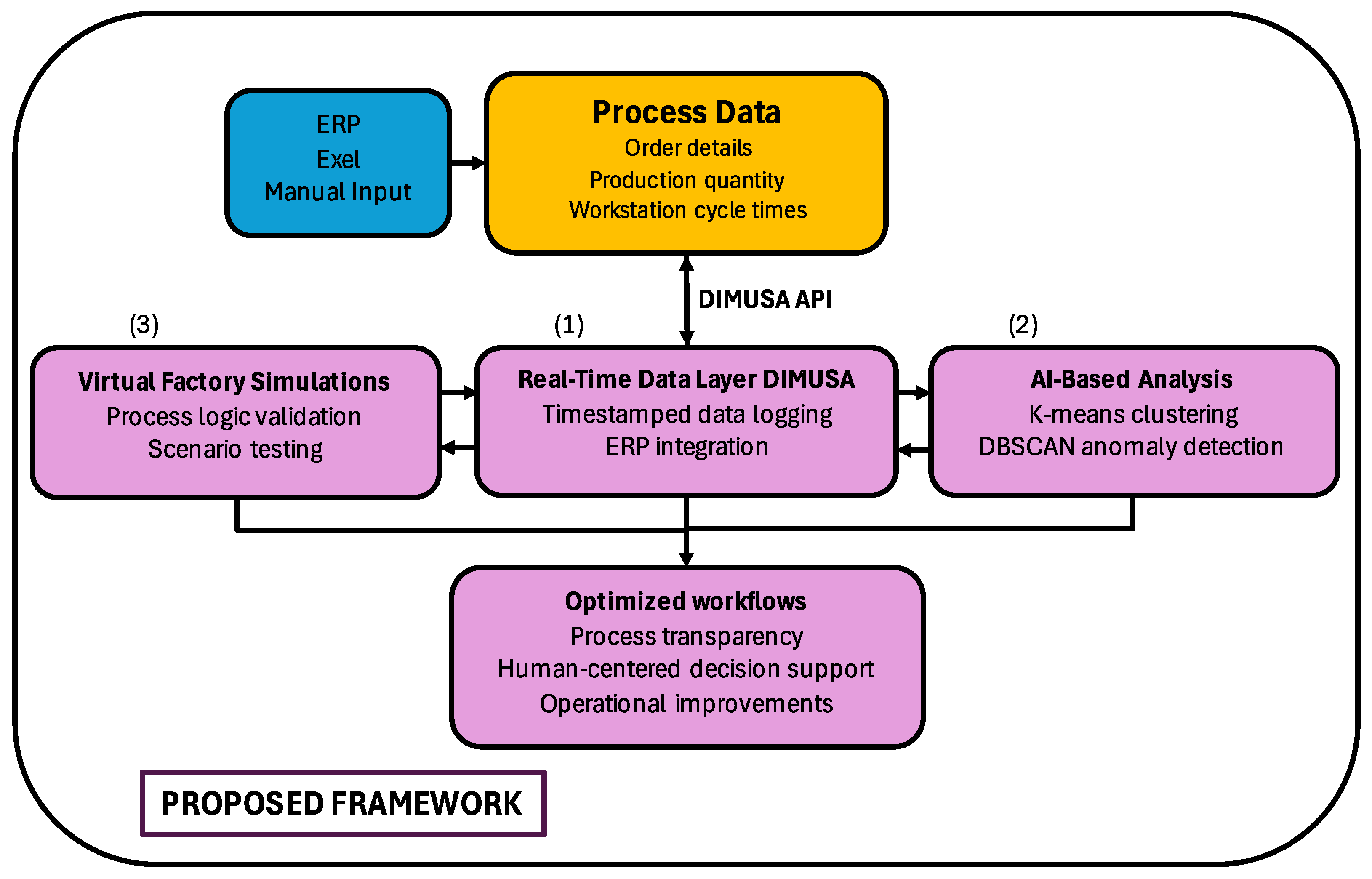
2.1. Overview of the Framework
- (1)
- real-time production data acquisition and processing,
- (2)
- cluster analysis to detect production patterns and anomalies, and
- (3)
- simulation for validating improvement scenarios and visualizing process behavior.
2.2. Production Environment Description
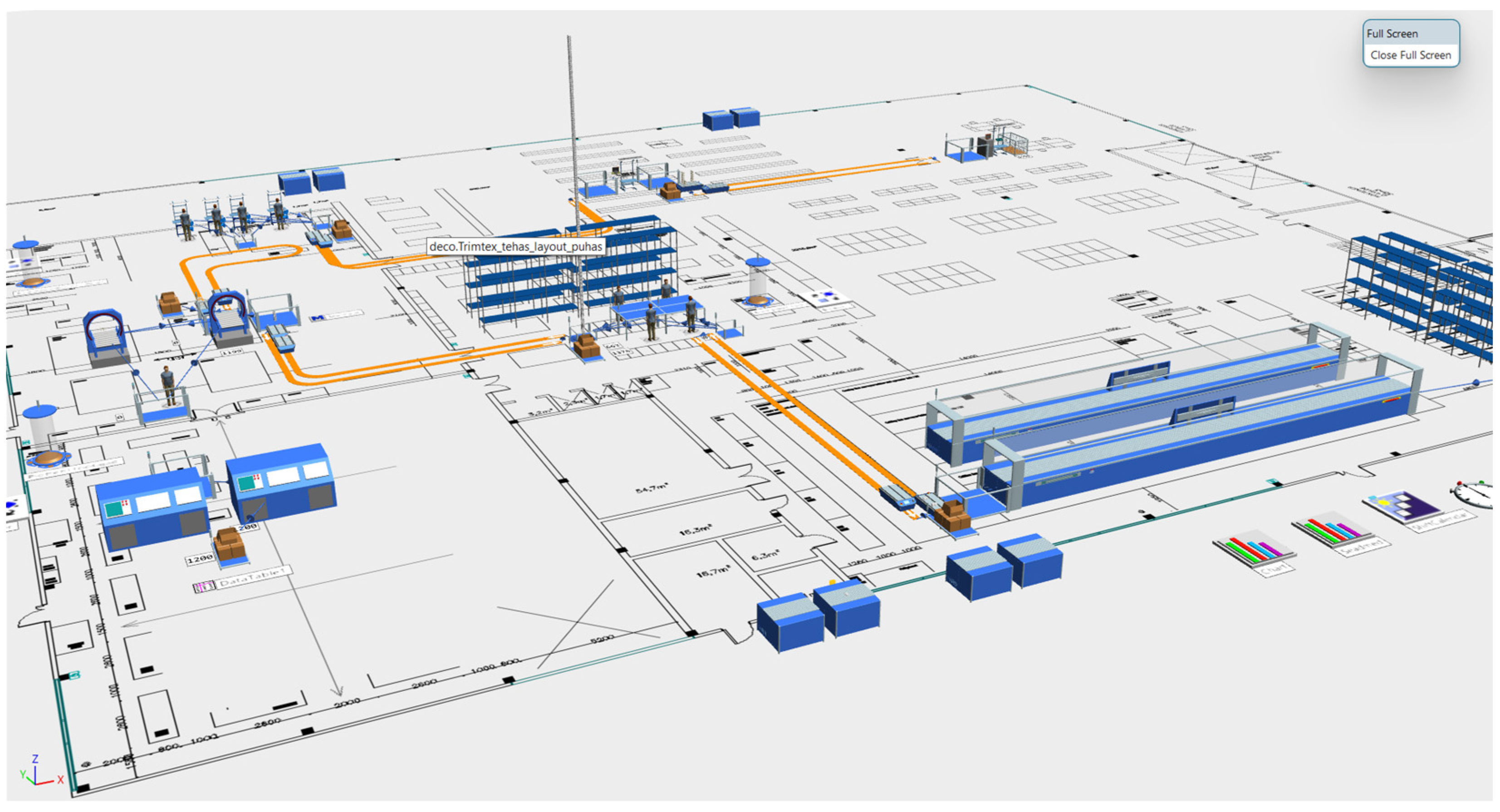
2.3. Virtual Factory Simulation
2.4. Data Acquisition and Integration
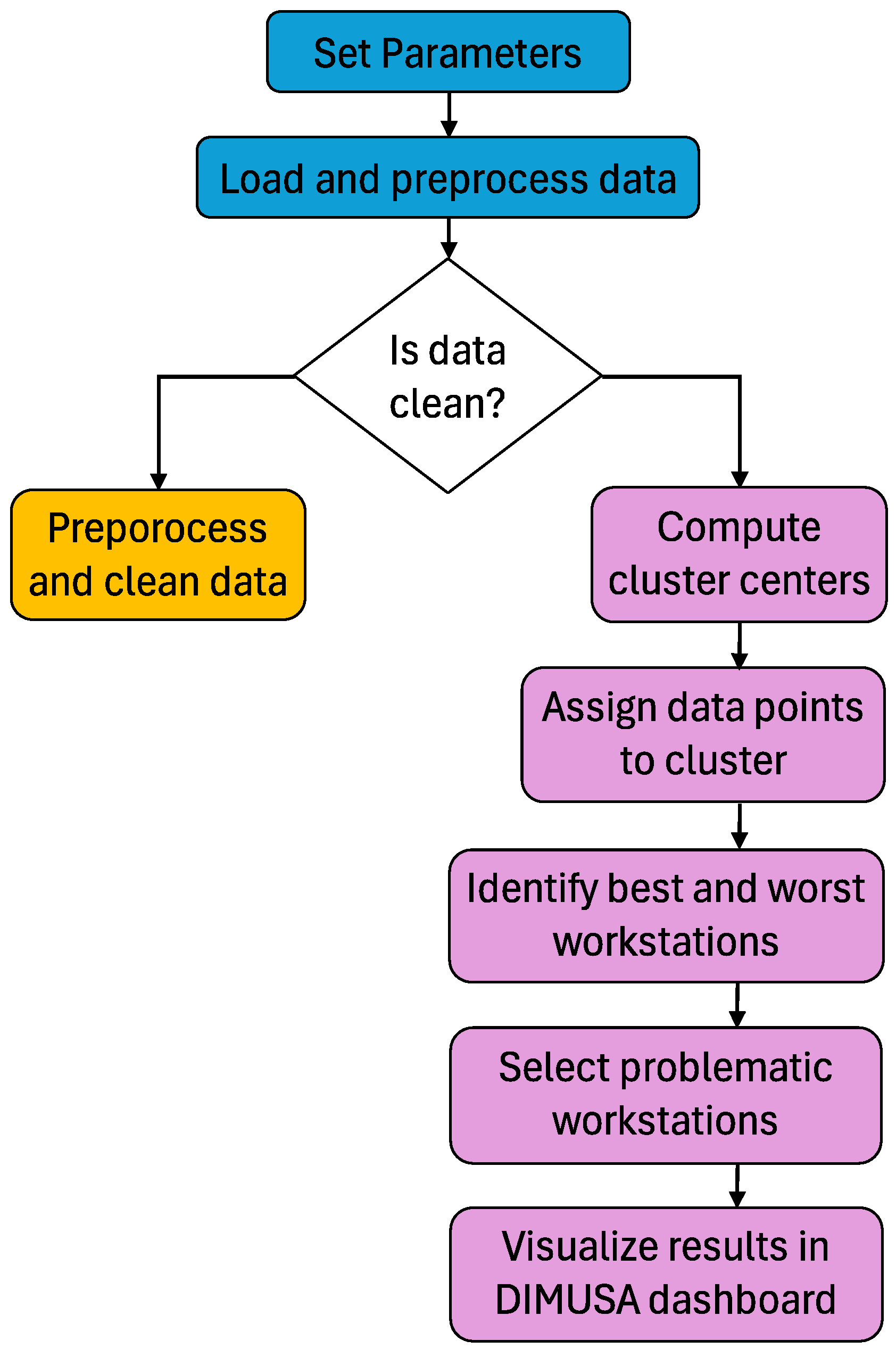
2.5. Clustering and Analysis Methods
3. Results
3.1. Production Data Characteristics
3.2. Cluster Analysis Results
3.3. Identified Bottlenecks and Insights
3.4. Simulation Validation
3.5. Impact
4. Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mchirgui, N.; Quadar, N.; Kraiem, H.; Lakhssassi, A. The Applications and Challenges of Digital Twin Technology in Smart Grids: A Comprehensive Review. Appl. Sci. 2024, 14, 10933. [Google Scholar] [CrossRef]
- Derigent, W.; Cardin, O.; Trentesaux, D. Industry 4.0: Contributions of Holonic Manufacturing Control Architectures and Future Challenges. J. Intell. Manuf. 2021, 32, 1797–1818. [Google Scholar] [CrossRef]
- Masood, T.; Sonntag, P. Industry 4.0: Adoption Challenges and Benefits for SMEs. Comput. Industry 2020, 121, 103261. [Google Scholar] [CrossRef]
- Davila-Gonzalez, S.; Martin, S. Human Digital Twin in Industry 5.0: A Holistic Approach to Worker Safety and Well-Being through Advanced AI and Emotional Analytics. Sensors 2024, 24, 655. [Google Scholar] [CrossRef] [PubMed]
- Wang, B.; Zheng, P.; Wang, L.H.; Mourtzis, D. Human-Centric Smart Manufacturing Towards Industry 5.0; Springer Nature: Berlin/Heidelberg, Germany, 2025. [Google Scholar] [CrossRef]
- Demarchi, M.; Bonello, A.; Francalanza, E.; Rauch, E. A Digital Twin for SMEs in the Context of Industry 5.0. Procedia CIRP. 2024, 126, 242–247. [Google Scholar] [CrossRef]
- Raamets, T.; Karjust, K.; Hermaste, A.; Kelpman, K. Virtual Factory Model Development for AI-Driven Optimization in Manufacturing. Proc. Est. Acad. Sci. 2025, 74, 228. [Google Scholar] [CrossRef]
- Paavel, M.; Karjust, K.; Majak, J. PLM Maturity Model Development and Implementation in SME. Procedia CIRP. 2017, 63, 651–657. [Google Scholar] [CrossRef]
- Snatkin, A.; Karjust, K.; Eiskop, T. Real Time Production Monitoring System in SME. In Proceedings of the Proceedings of the 8th International Conference od DAAAM Baltic Industrial Engineering 19–21st, Tallinn, Estonia, 19–21 April 2012; Tallinna Tehnikaülikooli Kirjastus: Tallinn, Estonia, 2012; pp. 573–578. [Google Scholar]
- Ahmed, M.; Seraj, R.; Islam, S.M.S. The K-Means Algorithm: A Comprehensive Survey and Performance Evaluation. Electron. 2020, 9, 1295. [Google Scholar] [CrossRef]
- Sundar, R.; Balaji, A.N.; Satheesh Kumar, R.M. A Review on Lean Manufacturing Implementation Techniques. Procedia Eng. 2014, 97, 1875–1885. [Google Scholar] [CrossRef]
- Daniyan, I.; Adeodu, A.; Mpofu, K.; Maladzhi, R.; Kana-Kana Katumba, M.G. Application of Lean Six Sigma Methodology Using DMAIC Approach for the Improvement of Bogie Assembly Process in the Railcar Industry. Heliyon 2022, 8, e09043. [Google Scholar] [CrossRef] [PubMed]
- de Man, J.C.; Strandhagen, J.O. Spreadsheet Application Still Dominates Enterprise Resource Planning and Advanced Planning Systems. IFAC-Pap 2018, 51, 1224–1229. [Google Scholar] [CrossRef]
- Siemens Software. Plant Simulation Software, 2025 version; Siemens AG: Munich, Germany, 2025. Available online: https://plm.sw.siemens.com/en-US/tecnomatix/plant-simulation-software/ (accessed on 2 May 2025).
- Mahmood, K.; Karjust, K.; Raamets, T. Production Intralogistics Automation Based on 3D Simulation Analysis. J. Mach. Eng. 2021, 21, 102–115. [Google Scholar] [CrossRef]
- Longo, F.; Mirabelli, G.; Solina, V.; Alberto, U.; De Paola, G.; Giordano, L.; Ziparo, M. A Simulation-Based Framework for Manufacturing Design and Resilience Assessment: A Case Study in the Wood Sector. Appl. Sci. 2022, 12, 7614. [Google Scholar] [CrossRef]
- Siderska, J. Application of Tecnomatix Plant Simulation for Modeling Production and Logistics Processes. Bus. Manag. Educ. 2016, 14, 64–73. [Google Scholar] [CrossRef]
- Ram, A.; Jalal, S.; Jalal, A.S.; Kumar, M. A Density Based Algorithm for Discovering Density Varied Clusters in Large Spatial Databases. Int. J. Comput. Appl. 2010, 3, 1–4. [Google Scholar] [CrossRef]
- Cui, J.M.; Liu, J.M.; Liao, Z.Y. Research on K-Means Clustering Algorithm and Its Implementation. In Proceedings of the 2nd International Conference on Computer Science and Electronics Engineering (ICCSEE 2013), Hangzhou, China, 22–23 March 2013; Atlantis Press: Dordrecht, The Netherlands, 2013; pp. 1804–1806. [Google Scholar] [CrossRef]
- Ahmad, A.; Dey, L. A K-Mean Clustering Algorithm for Mixed Numeric and Categorical Data. Data Knowl. Eng. 2007, 63, 503–527. [Google Scholar] [CrossRef]
- Niekurzak, M.; Lewicki, W. Optimisation of the Production Process of Ironing Refractory Products Using the OEE Indicator as Part of Innovative Solutions for Sustainable Production. Sustainability 2025, 17, 4779. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the Second International Conference on Knowledge Discovery and Data Mining (KDD’96), Oregon, Portland, 2–4 August 1996; pp. 226–331. [Google Scholar]
- MacQueen, J. Some Methods for Classification and Analysis of Multivariate Observations. In Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1967; pp. 281–297. [Google Scholar]
- Xu, R.; Wunsch, D. Survey of Clustering Algorithms. IEEE Trans. Neural Netw. 2005, 16, 645–678. [Google Scholar] [CrossRef] [PubMed]
- Thames, L.; Schaefer, D. Software-Defined Cloud Manufacturing for Industry 4.0. Procedia CIRP 2016, 52, 12–17. [Google Scholar] [CrossRef]
- Becker, T.; Chankov, S.M.; Windt, K. Synchronization Measures in Job Shop Manufacturing Environments. Procedia CIRP 2013, 7, 157–162. [Google Scholar] [CrossRef]
- Jain, S.; Lechevalier, D. Standards Based Generation of a Virtual Factory Model. In Proceedings of the 2016 Winter Simulation Conference (WSC), Washington, DC, USA, 11–14 December 2016; pp. 2762–2773. [Google Scholar] [CrossRef]
- ur Rehman, A.; Ramzan, M.B.; Shafiq, M.; Rasheed, A.; Naeem, M.S.; Savino, M.M. Productivity Improvement Through Time Study Approach: A Case Study from an Apparel Manufacturing Industry of Pakistan. Procedia Manuf. 2019, 39, 1447–1454. [Google Scholar] [CrossRef]
- Skoogh, A.; Johansson, B. A Methodology for Input Data Management in Discrete Event Simulation Projects. In Proceedings of the Winter Simulation Conference, Miami, FL, USA, 7–10 December 2008; pp. 1727–1735. [Google Scholar] [CrossRef]
- Uhlemann, T.H.J.; Lehmann, C.; Steinhilper, R. The Digital Twin: Realizing the Cyber-Physical Production System for Industry 4. Procedia CIRP 2017, 61, 335–340. [Google Scholar] [CrossRef]
- Kritzinger, W.; Karner, M.; Traar, G.; Henjes, J.; Sihn, W. Digital Twin in Manufacturing: A Categorical Literature Review and Classification. IFAC-PapersOnLine 2018, 51, 1016–1022. [Google Scholar] [CrossRef]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine Learning in Manufacturing: Advantages, Challenges, and Applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Ferreira, L.P.; Ares, E.; Peláez, G.; Marcos, M.; Araújo, M. A Methodology to Evaluate Complex Manufacturing Systems through Discrete-Event Simulation Models. Key Eng. Mater. 2012, 502, 7–12. [Google Scholar] [CrossRef]
- Matt, D.T.; Modrák, V.; Zsifkovits, H. Implementing Industry 4.0 in SMEs: Concepts, Examples and Applications; Springer Nature: Berlin/Heidelberg, Germany, 2021; pp. 1–429. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
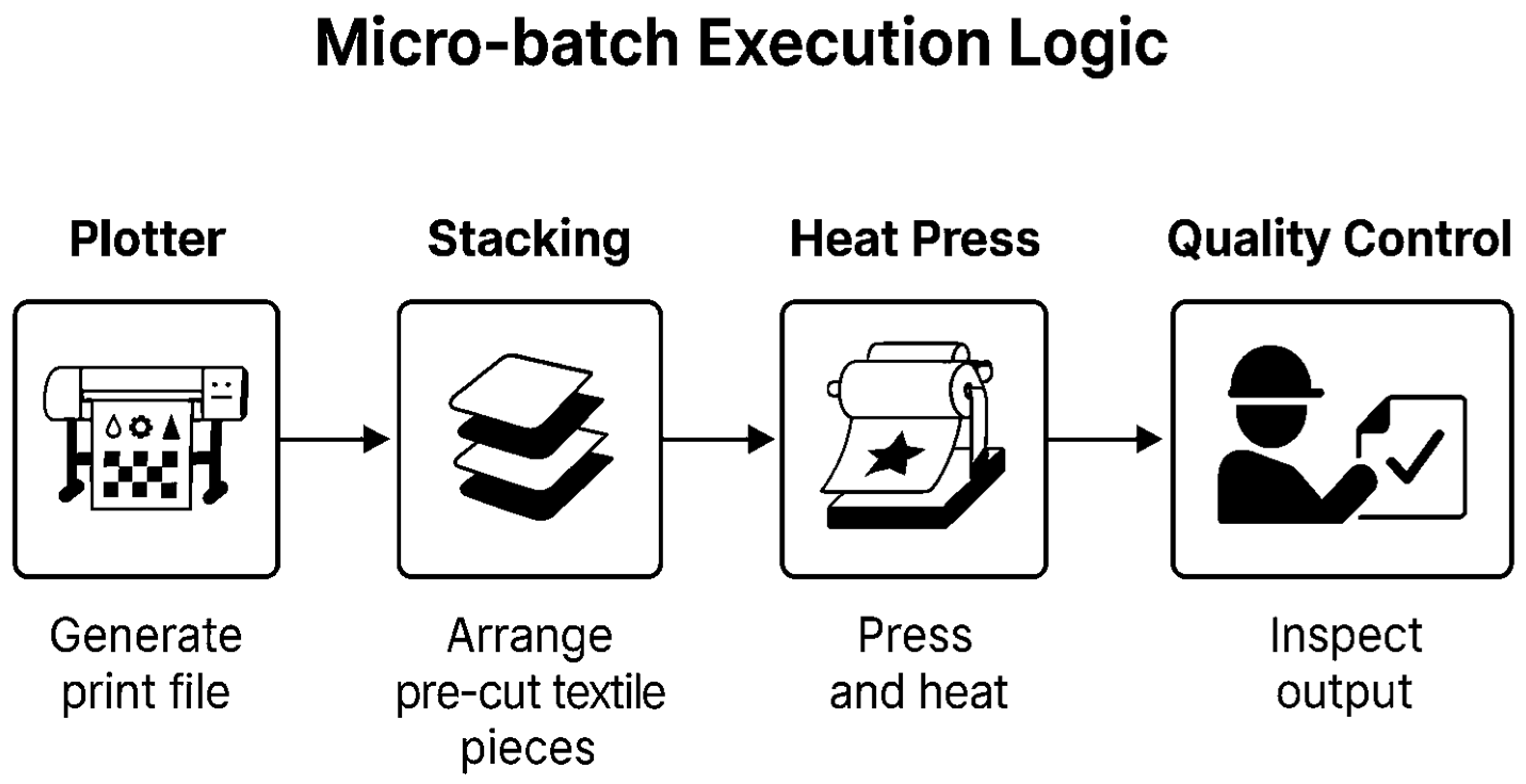
| Code | Workstation/Activity | Process Description |
|---|---|---|
| KJ-KL010 | Staging and material placement | Marking and transporting material from fabric storage |
| KJ-JL020 | Cutting | Cutting material according to the cutting order |
| KJ-VD031 | White parts preparation | Preparing white fabric parts for pressing |
| KJ-VD032 | White parts preparation | Preparing white fabric parts for pressing |
| KJ-VD033 | White parts preparation | Preparing white fabric parts for pressing |
| KJ-VD034 | White parts preparation | Preparing white fabric parts for pressing |
| KJ-PL040 | Plotter | Preparing press rollers for sublimation |
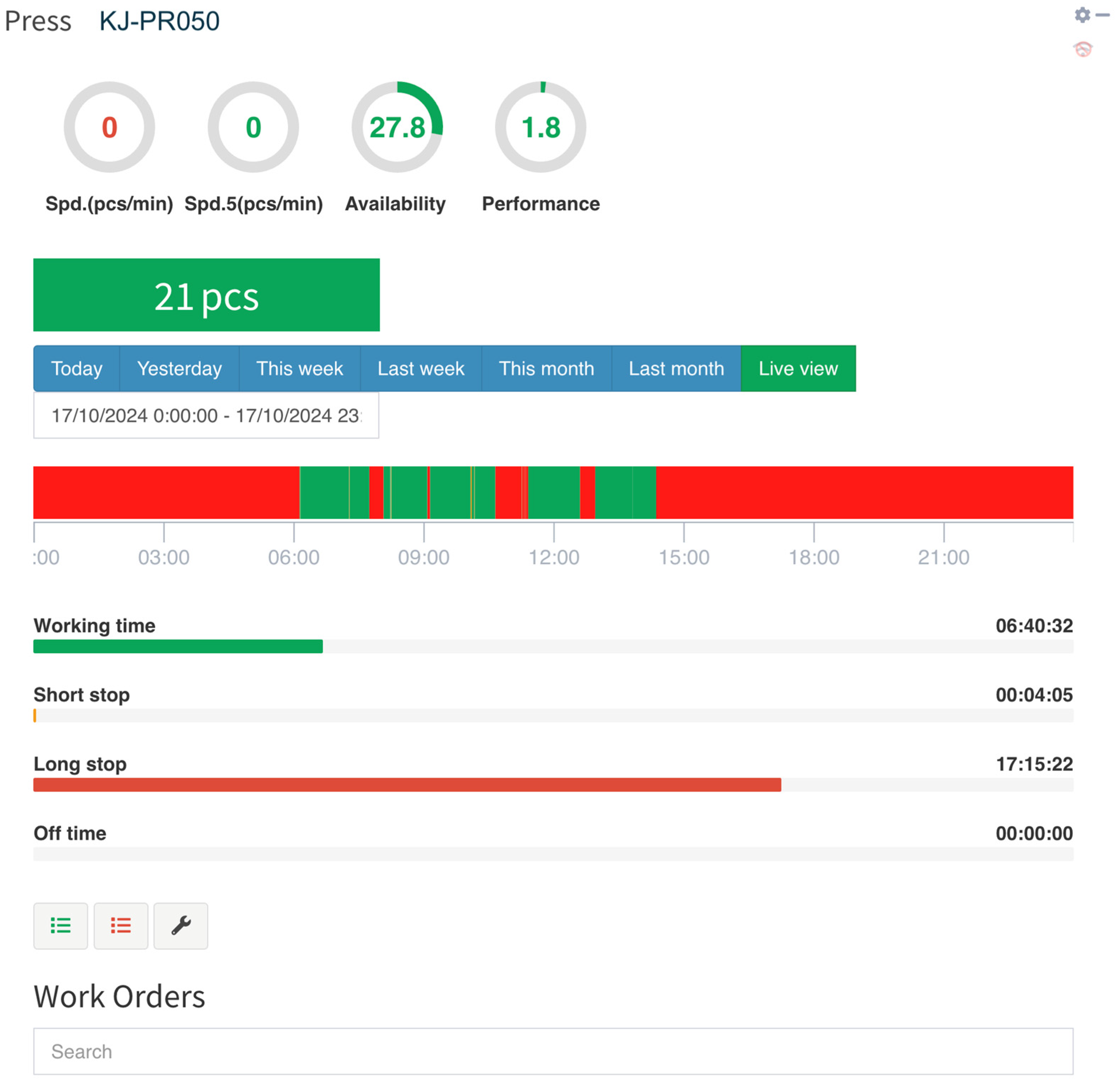
| KJ-PR050 | Pressing | Pressing visual elements onto white parts |
| KJ-KK061 | Quality control | Inspecting the quality of pressed parts |
| KJ-KK062 | Quality control | Inspecting the quality of pressed parts |
| KJ-KK063 | Quality control | Inspecting the quality of pressed parts |
| KJ-KK064 | Quality control | Inspecting the quality of pressed parts |
| KJ-OM070 | Sewing | Sewing product components |
| KJ-PA080 | Packaging | Packaging finished products |
| Date | Workstation | Availability % | Performans % | Quality % | OEE % | TEEP % | Result/pcs |
|---|---|---|---|---|---|---|---|
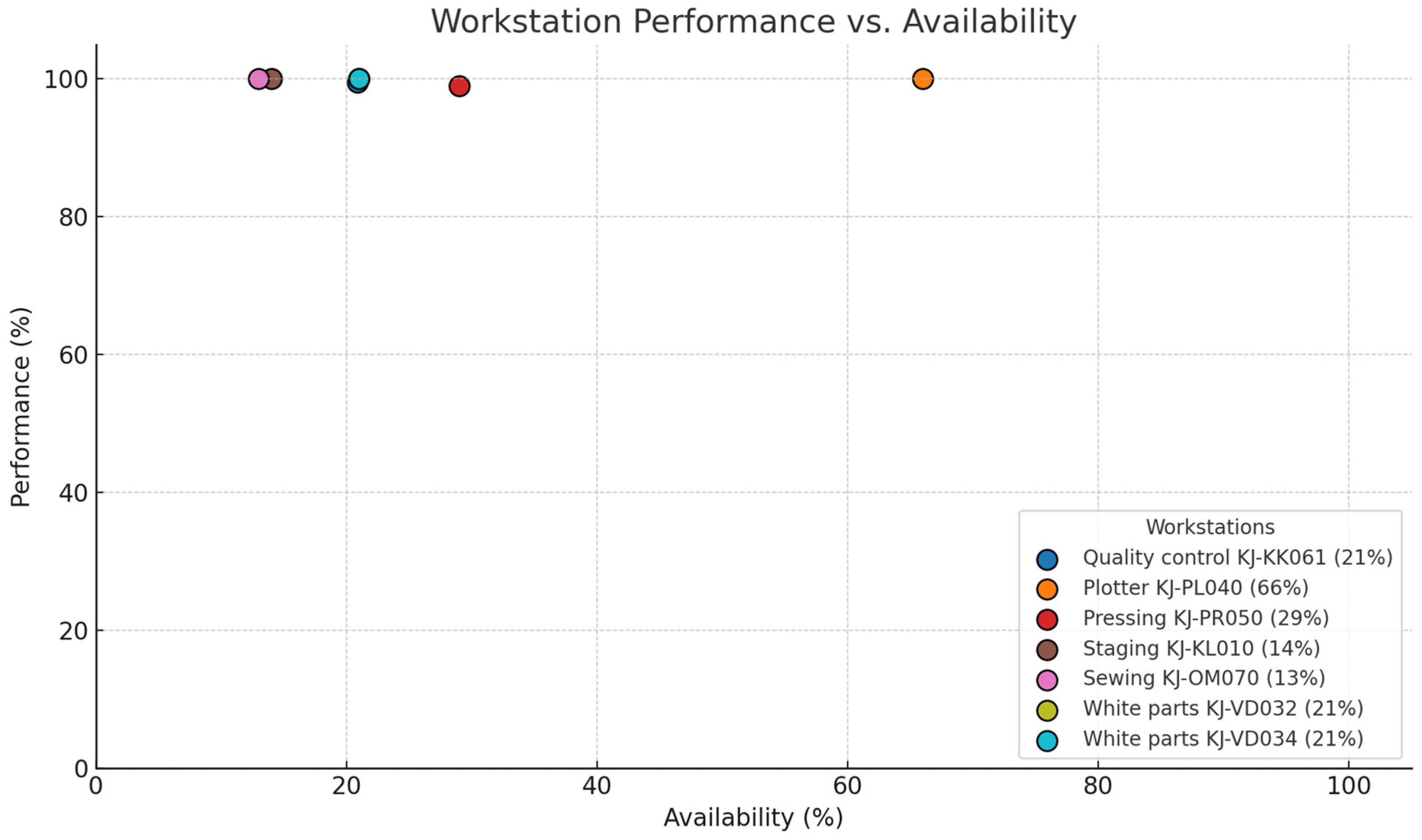
| 2024/10 | Plotter KJ-PL040 | 67% | 100% | 100% | 67% | 16% | 9200 |
| 2024/10 | Press KJ-PR050 | 29% | 100% | 100% | 29% | 7% | 9200 |
| 2024/10 | Quality control KJ-KK061 | 24% | 100% | 100% | 24% | 6% | 2300 |
| 2024/10 | White parts KJ-VD031 | 22% | 101% | 100% | 22% | 5% | 2622 |
| 2024/10 | White parts KJ-VD032 | 22% | 101% | 100% | 22% | 5% | 2622 |
| 2024/10 | White parts KJ-VD033 | 21% | 101% | 100% | 22% | 5% | 2599 |
| 2024/10 | White parts KJ-VD034 | 21% | 101% | 100% | 22% | 5% | 2599 |
| 2024/10 | Quality control KJ-KK062 | 21% | 100% | 100% | 21% | 5% | 2300 |
| 2024/10 | Quality control KJ-KK063 | 21% | 100% | 100% | 21% | 5% | 2300 |
| 2024/10 | Quality control KJ-KK064 | 21% | 100% | 100% | 21% | 5% | 2300 |
| 2024/10 | Cutting KJ-JL020 | 15% | 100% | 100% | 15% | 4% | 20,355 |
| 2024/10 | Sewing KJ-OM070 | 14% | 100% | 100% | 14% | 3% | 9200 |
| 2024/10 | Packaging KJ-PA080 | 14% | 100% | 100% | 14% | 3% | 9200 |
| Actual execution of work orders (manual input) | |||||||||||
| Code | Workstation | Actual start | Actual stop | Off | Short stop | Long Stop | Working | Quantity/m2 | |||
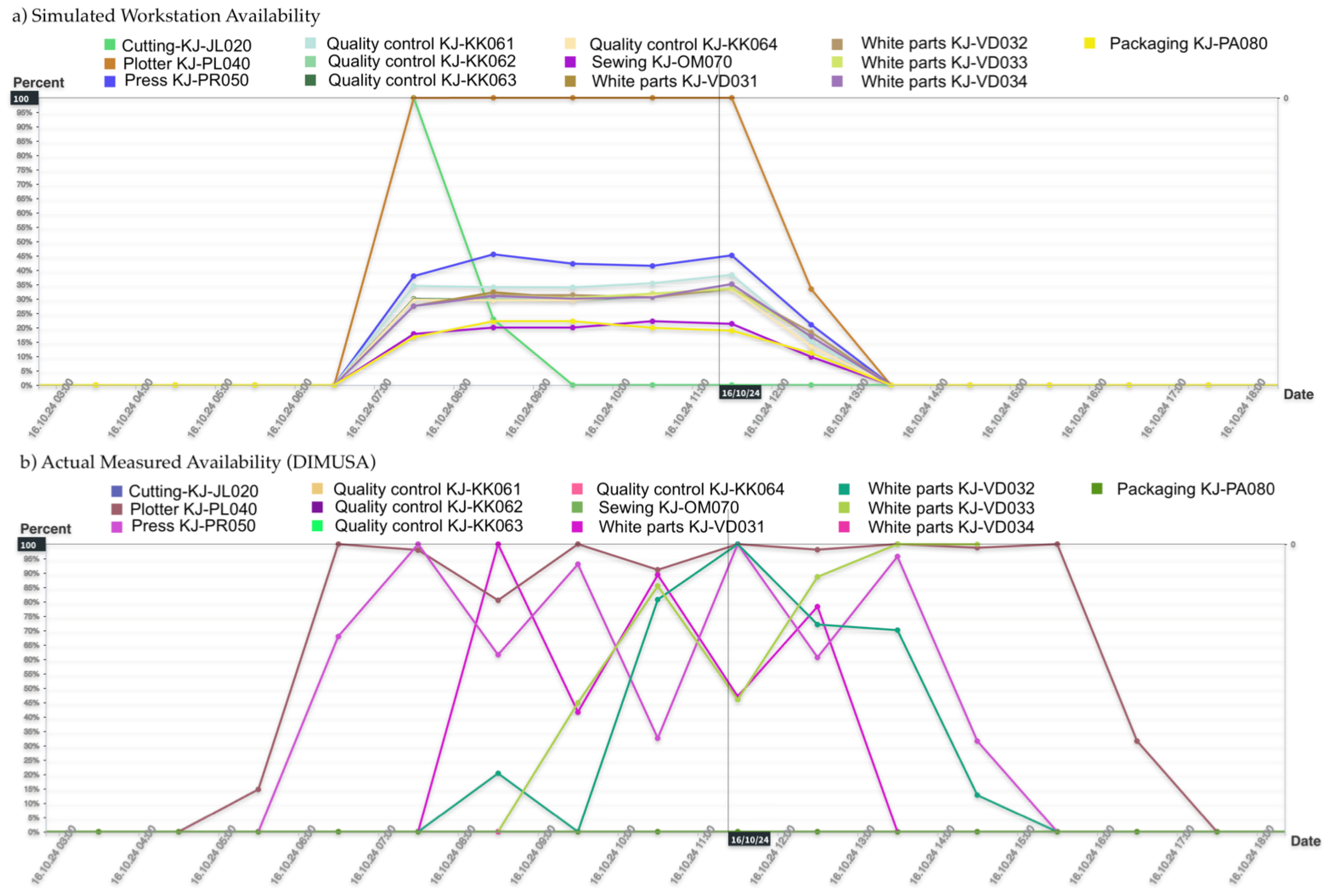
| Micro-batch-44-025-CAA | Plotter KJ-PL040 | 16/10/2024 5:56:02 | 16/10/2024 7:31:21 | 00:00:00 | 00:01:12 | 00:00:00 | 01:34:07 | 115.9 m2 | |||
| Micro-batch-44-023-CA | Plotter KJ-PL040 | 16/10/2024 7:32:18 | 16/10/2024 8:31:58 | 00:00:00 | 00:01:02 | 00:03:23 | 00:55:14 | 73.88 m2 | |||
| Micro-batch-44-034-CAA | Plotter KJ-PL040 | 16/10/2024 14:33:11 | 16/10/2024 16:23:18 | 00:00:00 | 00:00:00 | 00:05:04 | 01:45:01 | 148.58 m2 | |||
| Micro-batch-44-032-CM | Plotter KJ-PL040 | 16/10/2024 10:26:16 | 16/10/2024 12:36:55 | 00:00:00 | 00:01:08 | 00:00:20 | 02:09:09 | 164.1 m2 | |||
| Micro-batch-44-028-CK | Plotter KJ-PL040 | 16/10/2024 8:52:37 | 16/10/2024 10:21:49 | 00:00:00 | 00:00:48 | 00:00:00 | 01:28:23 | 104.03 m2 | |||
| Micro-batch-44-037-CM | Plotter KJ-PL040 | 16/10/2024 12:37:27 | 16/10/2024 14:32:58 | 00:00:00 | 00:00:44 | 00:00:00 | 01:54:46 | 169 m2 | |||
| TOTAL: | 00:00:00 | 0:04:55 | 0:08:49 | 9:46:43 | 775.49 m2 | ||||||
| Virtual factory simulation data | |||||||||||
| Shift | Workstation | Start | End | Off | Short stop | Long Stop | Working | Quantity/m2 | Availability | Performance | OEE |
| 17.10.2024 | Plotter KJ-PL040 | 16/10/2024 7:00:00 | 16/10/2024 15:00:00 | 00:00:00 | 00:00:01 | 02:39:59 | 05:20:00 | 400 | 67% | 100% | 67% |
| DIMUSA real-time data | |||||||||||
| Shift | Workstation | Start | End | Off | Short stop | Long Stop | Working | Quantity/m2 | Availability | Performance | OEE |
| 17.10.2024 | Plotter KJ-PL040 | 16/10/2024 6:00:00 | 16/10/2024 18:00:00 | 00:00:00 | 00:04:55 | 01:56:13 | 09:58:51 | 775 | 83% | 0% | 0% |
| Actual execution of work orders (manual input) | |||||||||||
| Code | Workstation | Actual start | Actual stop | Off | Short stop | Long Stop | Working | Quantity/m2 | |||
| Micro-batch-44-025-CAA | Press KJ-PR050 | 17/10/2024 11:26:31 | 17/10/2024 12:08:10 | 00:00:00 | 00:00:00 | 00:00:00 | 00:41:38 | 115.9 m2 | |||
| Micro-batch-44-023-CA | Press KJ-PR050 | 17/10/2024 12:09:23 | 17/10/2024 12:37:29 | 00:00:00 | 00:00:00 | 00:00:40 | 00:27:25 | 73.88 m2 | |||
| Micro-batch-44-020-CAA | Press KJ-PR050 | 17/10/2024 8:34:12 | 17/10/2024 9:06:07 | 00:00:00 | 00:00:00 | 00:00:34 | 00:31:20 | 91.3 m2 | |||
| Micro-batch-44-032-CM | Press KJ-PR050 | 17/10/2024 9:09:51 | 17/10/2024 10:05:54 | 00:00:00 | 00:00:28 | 00:00:00 | 00:55:34 | 164.1 m2 | |||
| Micro-batch-44-037-CM | Press KJ-PR050 | 17/10/2024 13:00:30 | 17/10/2024 13:52:52 | 00:00:00 | 00:00:00 | 00:00:00 | 00:52:22 | 169 m2 | |||
| TOTAL: | 00:00:00 | 0:00:28 | 0:01:15 | 3:28:21 | 614 m2 | ||||||
| Virtual factory simulation data | |||||||||||
| Shift | Workstation | Start | End | Off | Short stop | Long Stop | Working | Quantity/m2 | Availability | Performance | OEE |
| 17.10.2024 | Press KJ-PR050 | 17/10/2024 7:00:00 | 17/10/2024 15:00:00 | 00:00:00 | 00:00:00 | 05:40:00 | 02:20:00 | 400 | 29% | 99.9% | 29% |
| DIMUSA real—time data | |||||||||||
| Shift | Workstation | Start | End | Off | Short stop | Long Stop | Working | Quantity/m2 | Availability | Performance | OEE |
| 17.10.2024 | Press KJ-PR050 | 17/10/2024 6:00:00 | 17/10/2024 18:00:00 | 00:00:00 | 00:04:05 | 05:15:24 | 06:40:30 | 614 | 56% | 4% | 2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Raamets, T.; Karjust, K.; Majak, J.; Hermaste, A. Implementing an AI-Based Digital Twin Analysis System for Real-Time Decision Support in a Custom-Made Sportswear SME. Appl. Sci. 2025, 15, 7952. https://doi.org/10.3390/app15147952
Raamets T, Karjust K, Majak J, Hermaste A. Implementing an AI-Based Digital Twin Analysis System for Real-Time Decision Support in a Custom-Made Sportswear SME. Applied Sciences. 2025; 15(14):7952. https://doi.org/10.3390/app15147952
Chicago/Turabian StyleRaamets, Tõnis, Kristo Karjust, Jüri Majak, and Aigar Hermaste. 2025. "Implementing an AI-Based Digital Twin Analysis System for Real-Time Decision Support in a Custom-Made Sportswear SME" Applied Sciences 15, no. 14: 7952. https://doi.org/10.3390/app15147952
APA StyleRaamets, T., Karjust, K., Majak, J., & Hermaste, A. (2025). Implementing an AI-Based Digital Twin Analysis System for Real-Time Decision Support in a Custom-Made Sportswear SME. Applied Sciences, 15(14), 7952. https://doi.org/10.3390/app15147952